强化学习之基于无模型的算法之时序差分法
2、时序差分法(TD)
核心思想
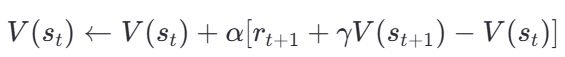
- st:当前状态;
- rt+1:从状态 stst 转移到下一状态 st+1st+1 所获得的奖励;
- γ:折扣因子,用于衡量未来奖励的重要性;
- α:学习率,控制更新的步长。
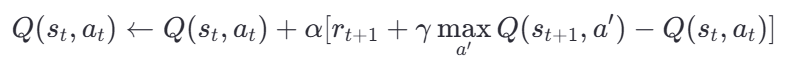
- maxa′Q(st+1,a′):在状态st+1 下所有可能动作的最大 Q 值。
算法特点
样本效率高
融合两者优点
- 不需要环境模型(类似蒙特卡罗);
- 利用贝尔曼方程进行更新(类似动态规划);
- 克服了蒙特卡罗方法中对完整 episode 的依赖,提高学习效率。
- 收敛性问题:在复杂环境中可能出现收敛慢或不收敛的问题,尤其在状态空间大或奖励稀疏时表现不佳。
- 对超参数敏感:算法性能受学习率 α、折扣因子 γ 等影响较大,需多次实验调参。
- 模型泛化能力有限:通常只能针对特定环境学习最优策略,环境变化后需重新训练。
1)TD learning of state values
核心思想
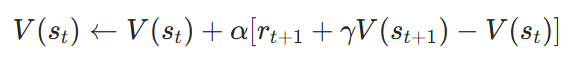
- TD Target:rt+1+γV(st+1)(基于下一状态的预估价值)。
- TD Error:δt=rt+1+γV(st+1)−V(st)(当前估计的偏差)。
2)TD learning of action values : Sarsa
核心思想
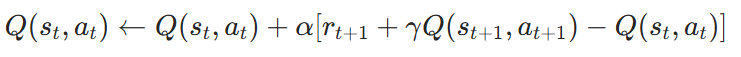
- 策略依赖:动作 at+1 由当前策略(如ε-贪婪策略)生成。
伪代码
实现代码
import time
import numpy as np
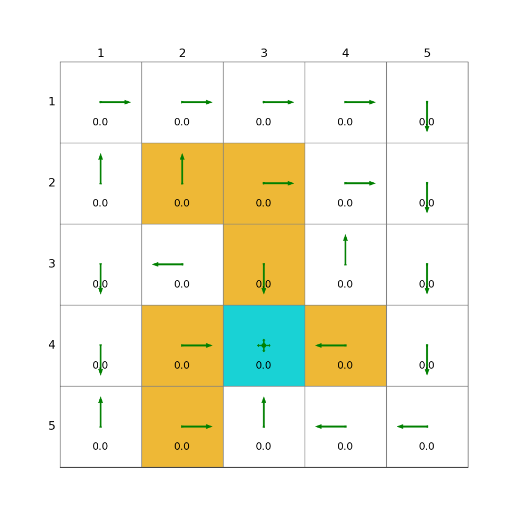
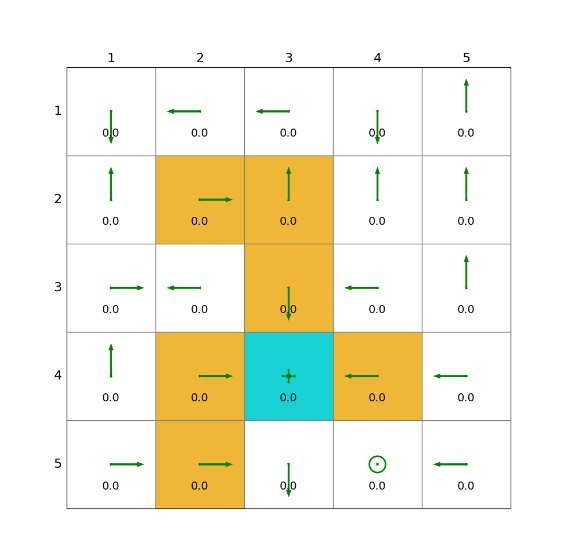
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def sarsa(self, alpha=0.1, epsilon=0.1, num_episodes=80):while num_episodes > 0:done = Falseself.env.reset()next_state = 0num_episodes -= 1total_rewards = 0episode_length = 0while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size),p=self.policy[state]) #按照当前策略选择动作_, reward, done, _, _ = self.env.step(action) #根据当前动作得到下一状态和奖励,在self.env.agent_locationepisode_length += 1total_rewards += rewardnext_state = self.env.pos2state(self.env.agent_location) #下一动作next_action = np.random.choice(np.arange(self.action_space_size),p=self.policy[next_state]) #按照当前策略选择下一动作target = reward + self.gama * self.qvalue[next_state, next_action]error = target - self.qvalue[state, action] #估计偏差self.qvalue[state, action] = self.qvalue[state, action] + alpha * error #q值更新qvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size): #策略更新if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilondef show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.sarsa()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
3)TD learning of action values: Expected Sarsa
核心思想
Expected Sarsa 也是一种用于学习动作价值函数 Q(s, a))的 TD 算法。与 Sarsa 不同的是,它在更新时考虑了下一个状态下所有可能动作的期望价值,而不是仅仅使用一个特定的动作。
算法公式:
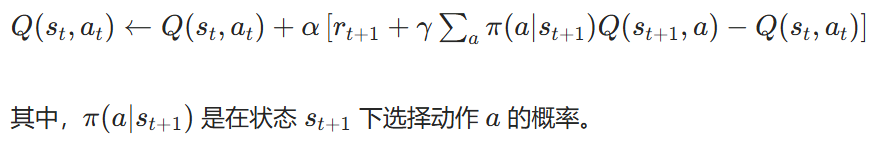
伪代码
和Sarsa类似,只是在Q 值更新时使用的是期望价值。
实现代码
import matplotlib.pyplot as plt
import numpy as np
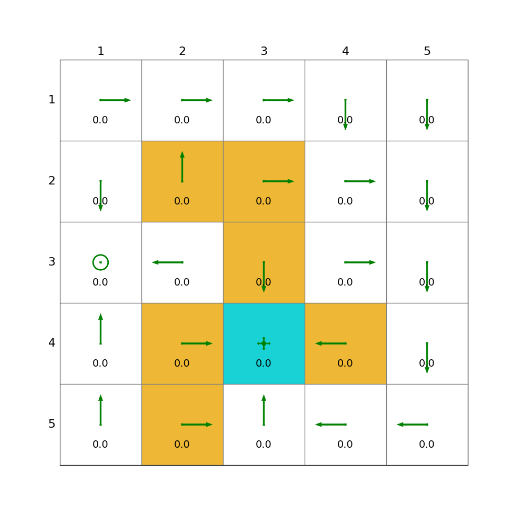
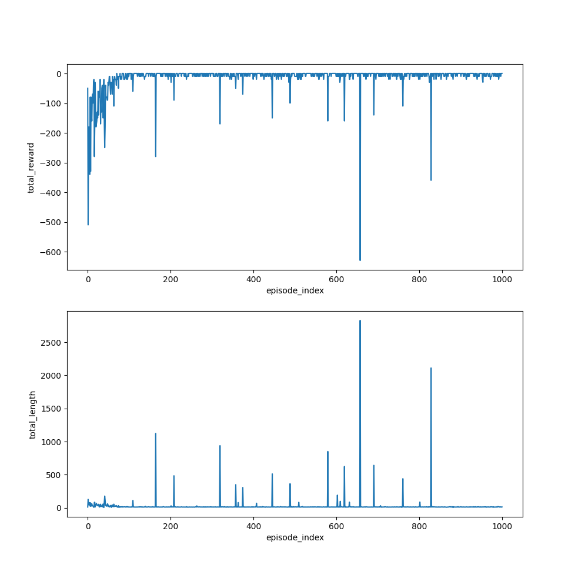
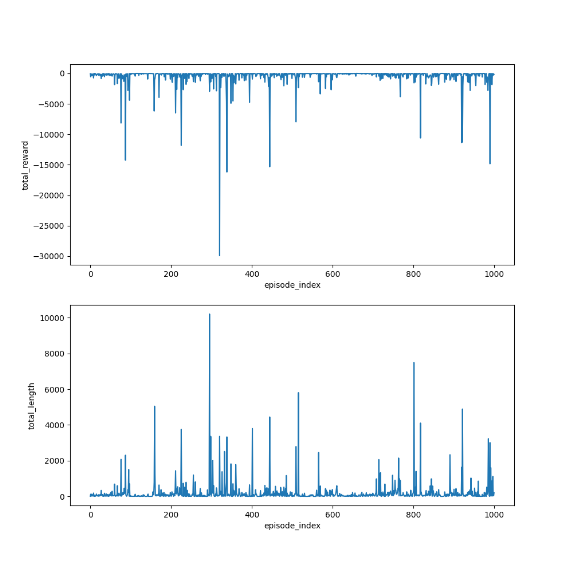
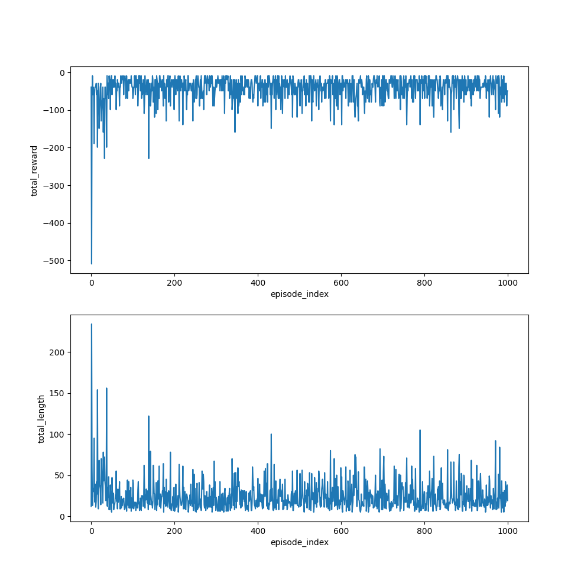
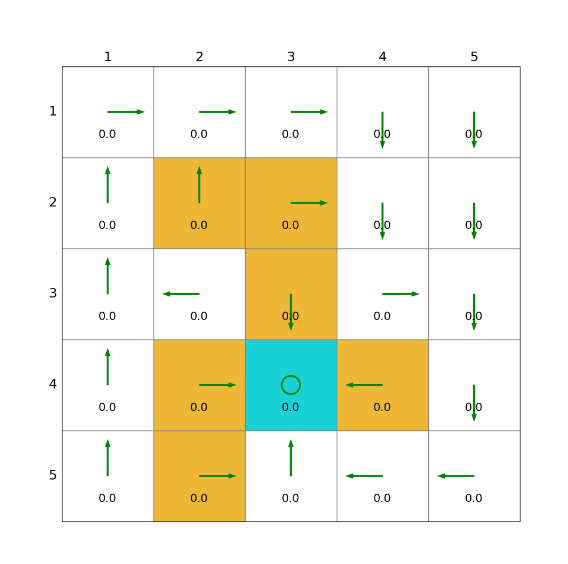
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def expected_sarsa(self, alpha=0.1, epsilon=1, num_episodes=1000):init_num = num_episodesqvalue_list = [self.qvalue, self.qvalue + 1]episode_index_list = []reward_list = []length_list = []while num_episodes > 0:if epsilon > 0.1:epsilon -= 0.01episode_index_list.append(init_num - num_episodes)done = Falseself.env.reset()next_state = 0total_rewards = 0episode_length = 0num_episodes -= 1while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size),p=self.policy[state])_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)expected_qvalue = 0episode_length += 1total_rewards += rewardfor next_action in range(self.action_space_size):expected_qvalue += self.qvalue[next_state, next_action] * self.policy[next_state, next_action]target = reward + self.gama * expected_qvalueerror = target - self.qvalue[state, action]self.qvalue[state, action] = self.qvalue[state, action] + alpha * errorqvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(episode_length)fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,xlabel='episode_index', ylabel='total_length')fig.show()def show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.expected_sarsa()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
4)TD learning of action values: n-step Sarsa
核心思想

特点
- 平衡短期和长期信息:通过调整 n 的值,可以在短期和长期奖励之间进行权衡。当 (n = 1) 时,n - step Sarsa 退化为普通的 Sarsa 算法;当 n 趋近于无穷大时,它类似于蒙特卡罗方法。
- 可以提高学习的稳定性和效率,尤其是在环境动态变化的情况下。
伪代码
实现代码
import matplotlib.pyplot as plt
import numpy as np
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def nsteps_sarsa(self, alpha=0.1, epsilon=1, num_episodes=1000, n=10):init_num = num_episodesqvalue_list = [self.qvalue.copy()]episode_index_list = []reward_list = []length_list = []while num_episodes > 0:if epsilon > 0.1:epsilon -= 0.01episode_index_list.append(init_num - num_episodes)done = Falseself.env.reset()next_state = 0total_rewards = 0episode_length = 0num_episodes -= 1# 存储轨迹信息(状态、动作、奖励)trajectory = []while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size), p=self.policy[state])_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)trajectory.append((state, action, reward))total_rewards += rewardepisode_length += 1# 计算 n-step 回报T = len(trajectory) # 轨迹长度for t in range(T):# 获取当前状态、动作、奖励state, action, reward = trajectory[t]target = 0# 计算 n-step 回报if t + n < T:# 如果轨迹足够长,计算 n-step 回报for i in range(n-1,-1,-1):next_reward_n = trajectory[t + i][2]target = target*self.gama + next_reward_nnext_state_n = trajectory[t + n][0]next_action_n = trajectory[t + n][1]q_next = self.qvalue[next_state_n, next_action_n]target = target + q_nextelse:for i in range(T-t-1,-1,-1):next_reward_n = trajectory[t + i][2]target = target * self.gama + next_reward_nnext_state_n = trajectory[T-t-1][0]next_action_n = trajectory[T-t-1][1]q_next = self.qvalue[next_state_n, next_action_n]target = target + q_next# 更新 Q 值error = target - self.qvalue[state, action]self.qvalue[state, action] += alpha * error# 更新策略qvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(episode_length)fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,xlabel='episode_index', ylabel='total_length')fig.show()def show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.nsteps_sarsa()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
5)TD learning of optimal action values: Q-learning
核心思想
Q - learning 是一种异策略(off - policy)的 TD 算法,直接学习最优动作价值函数Q*(s, a)。异策略意味着它使用一个行为策略来生成行为,而使用另一个目标策略(通常是贪心策略)来更新动作价值。
算法公式:
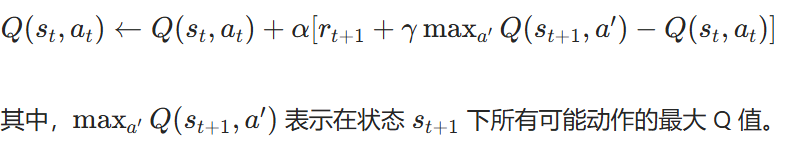
伪代码
1)在线版本的Q-learning(on-policy)
对于每一个 episode,执行以下操作:
如果当前状态st 不是目标状态,执行以下步骤:
经验收集(Collect the experience)
获取经验元组(st,at,rt+1,st+1):
具体来说,按照当前策略πt(st) 选择并执行动作at,得到奖励rt+1 和下一状态 st+1。
Q 值更新(Update q-value):按照上述公式
策略更新(Update policy):用ε 贪婪策略
2)离线版本的Q-learning(off-policy)
对于由行为策略 πb 生成的每一个 episode {s0,a0,r1,s1,a1,r2,…},执行以下操作:
对于该 episode 中的每一步t=0,1,2,…,执行以下操作:
Q 值更新(Update q-value):按照上述公式
策略更新(Update policy):用贪婪策略
实现代码
import matplotlib.pyplot as plt
import numpy as np
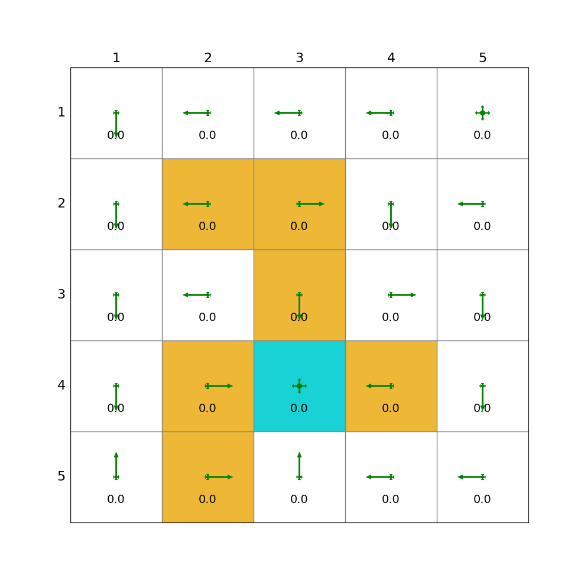
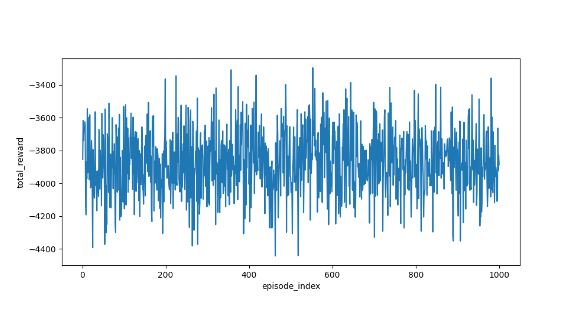
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未来奖励的衰减程度self.env = envself.action_space_size = env.action_space_size #动作空间大小self.state_space_size = env.size ** 2 #状态空间大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #奖励self.state_value = np.zeros(shape=self.state_space_size) #状态值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #动作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每个动作概率相等self.policy = self.mean_policy.copy()def q_learning_on_policy(self, alpha=0.001, epsilon=0.4, num_episodes=1000):init_num = num_episodesqvalue_list = [self.qvalue, self.qvalue + 1]episode_index_list = []reward_list = []length_list = []while num_episodes > 0:episode_index_list.append(init_num - num_episodes)done = Falseself.env.reset()next_state = 0total_rewards = 0episode_length = 0num_episodes -= 1while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size),p=self.policy[state])_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)episode_length += 1total_rewards += rewardnext_qvalue_star = self.qvalue[next_state].max()target = reward + self.gama * next_qvalue_starerror = self.qvalue[state, action] - targetself.qvalue[state, action] = self.qvalue[state, action] - alpha * errorqvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(episode_length)fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,xlabel='episode_index', ylabel='total_length')fig.show()def q_learning_off_policy(self, alpha=0.01, num_episodes=1000, episode_length=1000):qvalue_list = [self.qvalue, self.qvalue + 1]episode_index_list = []reward_list = []length_list = []init_num = num_episodeswhile num_episodes > 0:num_episodes -= 1total_rewards = 0episode_index_list.append(init_num - num_episodes)start_state = self.env.pos2state(self.env.agent_location)start_action = np.random.choice(np.arange(self.action_space_size),p=self.mean_policy[start_state])episode = self.obtain_episode(self.mean_policy.copy(), start_state=start_state, start_action=start_action,length=episode_length)for step in range(len(episode) - 1):reward = episode[step]['reward']state = episode[step]['state']action = episode[step]['action']next_state = episode[step + 1]['state']next_qvalue_star = self.qvalue[next_state].max()target = reward + self.gama * next_qvalue_starerror = self.qvalue[state, action] - targetself.qvalue[state, action] = self.qvalue[state, action] - alpha * erroraction_star = self.qvalue[state].argmax()self.policy[state] = np.zeros(self.action_space_size)self.policy[state][action_star] = 1total_rewards += rewardqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(len(episode))fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')fig.show()def obtain_episode(self, policy, start_state, start_action, length):f""":param policy: 由指定策略产生episode:param start_state: 起始state:param start_action: 起始action:param length: episode 长度:return: 一个 state,action,reward,next_state,next_action 序列"""self.env.agent_location = self.env.state2pos(start_state)episode = []next_action = start_actionnext_state = start_statewhile length > 0:length -= 1state = next_stateaction = next_action_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)next_action = np.random.choice(np.arange(len(policy[next_state])),p=policy[next_state])episode.append({"state": state, "action": action, "reward": reward, "next_state": next_state,"next_action": next_action})return episodedef show_policy(self):# 可视化策略(Policy):将智能体的策略(每次行动的方向标注为箭头)以图形化的方式渲染到环境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可视化状态价值函数(State - ValueFunction):将每个状态的价值(长期累积奖励的预期)以文本形式渲染到环境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)# solver.q_learning_on_policy()solver.q_learning_off_policy()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
1)在线版本的Q-learning
2)离线版本的Q-learning(off-policy)
相关文章:

强化学习之基于无模型的算法之时序差分法
2、时序差分法(TD) 核心思想 TD 方法通过 引导值估计来学习最优策略。它利用当前的估计值和下一个时间步的信息来更新价值函数, 这种方法被称为“引导”(bootstrapping)。而不需要像蒙特卡罗方法那样等待一个完整的 episode 结束才进行更新&…...
:连接异常)
【网络原理】TCP异常处理(二):连接异常
目录 一. 由进程崩溃引起的连接断开 二. 由关机引起的连接断开 三. 由断电引起的连接断开 四. 由网线断开引起的连接断开 一. 由进程崩溃引起的连接断开 在一般情况下,进程无论是正常结束,还是异常崩溃,都会触发回收文件资源,…...
)
[stm32] 4-1 USART(1)
文章目录 前言4-1 USARTUSART简介什么是USART?USART名字的含义?如何使用USART? USART的工作原理什么是串并转换?为什么要进行串并转换?移位寄存器串并行转换电路 USART寄存器组和完整框图 前言 本笔记内容,为本人依据…...

C++多线程与锁机制
1. 基本多线程编程 1.1 创建线程 #include <iostream> #include <thread>void thread_function() {std::cout << "Hello from thread!\n"; }int main() {std::thread t(thread_function); // 创建并启动线程t.join(); // 等待线程结束return 0; …...
:自定义传输层开发)
【MCP Node.js SDK 全栈进阶指南】高级篇(4):自定义传输层开发
引言 在MCP(Model Context Protocol)应用开发中,传输层是连接客户端与服务器的关键环节,直接影响应用的性能、可靠性和扩展性。默认的传输方式虽然能满足基本需求,但在复杂场景下,自定义传输层能够为应用提供更高的灵活性和优化空间。本文将深入探讨MCP TypeScript-SDK中…...

当向量数据库与云计算相遇:AI应用全面提速
如果将AI比作一台高速运转的机器引擎,那么数据便是它的燃料。 然而,存储数据的燃料库--传统数据库,在AI时代的效率瓶颈愈发明显,已经无法满足AI对于数据的全新需求。 因此,向量数据库近年来迅速崛起。向量数据库通过…...

【2024-NIPS-版权】Evaluating Copyright Takedown Methods for Language Models
1.背景 目前 LLMs 在训练过程中使用了大量的受版权保护数据,这些数据会导致大模型记忆并生成与训练数据相似的内容,从而引发版权问题。随着版权所有者对模型训练和部署中的版权问题提起诉讼(例如 Tremblay v. OpenAI, Inc. 和 Kadrey v. Met…...

【PyTorch动态计算图原理精讲】从入门到灵活应用
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比二、实战演示环境配置要求核心代码实现案例1:基础计算图构建案例2:条件分支动态图案例3:循环结构动态图运行结果验证三、性能对比测试方…...

阿里巴巴Qwen3发布:登顶全球开源模型之巅,混合推理模式重新定义AI效率
今天凌晨,阿里巴巴正式开源了新一代通义千问大模型Qwen3,这一举措不仅标志着国产大模型技术的又一里程碑,更以“混合推理”“极致性能”“超低成本”三大核心优势,刷新了全球开源模型的竞争格局。Qwen3在多项评测中超越DeepSeek-R…...
)
5. 配置舵机ID(具身智能机器人套件)
1. 连接舵机 waveshare驱动器板使用9-12v供电Type-C连接电脑DVG连接一个舵机 2. 使用FT SCServo Debug软件 设置串口设置波特率(默认1000000,100万)打开串口编程界面修改ID 3. 依次修改所有舵机ID 分别使用waveshare驱动板连接舵机&…...

Nacos源码—2.Nacos服务注册发现分析四
大纲 5.服务发现—服务之间的调用请求链路分析 6.服务端如何维护不健康的微服务实例 7.服务下线时涉及的处理 8.服务注册发现总结 7.服务下线时涉及的处理 (1)Nacos客户端服务下线的源码 (2)Nacos服务端处理服务下线的源码 (3)Nacos服务端发送服务变动事件给客户端的源码…...

从Windows开发迁移到信创开发的指南:国产替代背景下的技术路径与实践
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

从数据到决策:安科瑞EIoT如何让每一度电“清晰可见”?
安科瑞顾强 在能源管理迈向精细化与数字化的今天,安科瑞EIoT能源物联网平台以“数据驱动能源价值”为核心理念,融合物联网、云计算与大数据技术,打通从设备感知到云端决策的全链路闭环,助力工商业企业、园区、物业等场景实现用电…...
)
10.学习笔记-MyBatisPlus(P105-P110)
1.MyBatisPlus入门案例 (1)MyBatisPlus(简称Mp)是基于MyBatis框架基础上开发的增强型工具,目的是简化开发,提高效率。 (2)开发方式:基于MyBatis使用MyBatisPlusÿ…...

LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
TL;DR 2024 年 Meta FAIR 提出了 LayerSkip,这是一种端到端的解决方案,用于加速大语言模型(LLMs)的推理过程 Paper name LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding Paper Reading Note Paper…...

fastapi和flaskapi有什么区别
FastAPI 和 Flask 都是 Python 的 Web 框架,但设计目标和功能特性有显著差异。以下是它们的核心区别: 1. 性能与异步支持 FastAPI 基于 Starlette(高性能异步框架)和 Pydantic(数据校验库)…...

在 JMeter 中使用 BeanShell 获取 HTTP 请求体中的 JSON 数据
在 JMeter 中,您可以使用 BeanShell 处理器来获取 HTTP 请求体中的 JSON 数据。以下是几种方法: 方法一:使用前置处理器获取请求体 如果您需要在发送请求前访问请求体: 添加一个 BeanShell PreProcessor 到您的 HTTP 请求采样器…...

Go 1.25为什么要废除核心类型
关于核心类型为什么要1.25里要移除,作者Robert在博客Goodbye core types - Hello Go as we know and love it!里给了详细耐心的解答。 背景:Go 1.18 引入了泛型(generics),带来了类型参数…...

flask中的Response 如何使用?
在 Flask 中,Response 对象用于生成 HTTP 响应并返回给客户端。以下是其常见用法及示例: 1. 直接返回字符串或 HTML 视图函数返回的字符串会被自动包装为 Response 对象,默认状态码为 200,内容类型为 text/html: app…...

基于SpringAI实现简易聊天对话
简介 本文旨在记录学习和实践 Spring AI Alibaba 提供的 ChatClient 组件的过程。ChatClient 是 Spring AI 中用于与大语言模型(LLM)进行交互的高级 API,它通过流畅(Fluent)的编程接口,极大地简化了构建聊天…...

STM32单片机入门学习——第49节: [15-2] 读写内部FLASH读取芯片ID
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.29 STM32开发板学习——第49节: [15-2] 读写内部FLASH&读取芯片ID 前言开发板说…...

第14讲:科研图表的导出与排版艺术——高质量 PDF、TIFF 输出与投稿规范全攻略!
目录 📘 前言:导出,不只是“保存”! 🎯 一、你需要掌握的导出目标 🖼️ 二、TIFF / PNG 导出规范(适用于投稿) 🧲 三、PDF 矢量图导出(排版首选) 🧩 四、强烈推荐组合:showtext + Cairo 🧷 五、多个图的组合导出技巧 🧪 六、特殊投稿需求处理 �…...
)
SRIO IP调试问题记录(ready信号不拉高情况)
问题:调试过程中遇到有时写入数据后数据不发送,并且ready信号在写入一定数据后一直拉低的情况(偶发,不是每次必然出现)。buf空间设置为16时,写入15包数据,写完第16包包头后,ready信号…...
)
使用DDR4控制器实现多通道数据读写(十)
一、本章概述 本章节对目前单通道的读写功能进项测试,主要验证读写的数据是否正确,并观察该工程可以存储的最大容量。通过空满信号进行读写测试,根据ila抓取fifo和ddr4全部满的时刻,可以观察到最大容量。再通过debug逻辑可以测试读…...

从 BERT 到 GPT:Encoder 的 “全局视野” 如何喂饱 Decoder 的 “逐词纠结”
当 Encoder 学会 “左顾右盼”:Decoder 如何凭 “单向记忆” 生成丝滑文本? 目录 当 Encoder 学会 “左顾右盼”:Decoder 如何凭 “单向记忆” 生成丝滑文本?引言一、Encoder vs Decoder:核心功能与基础架构对比1.1 本…...

探寻软件稳定性的奥秘
在软件开发的广袤领域中,软件的稳定性宛如基石,支撑着整个软件系统的运行与发展。《发布!软件的设计与部署》这本书的第一部分,对软件稳定性进行了深入且全面的剖析,为软件开发人员、架构师以及相关从业者们提供了极具…...

Reverse-WP记录9
前言 之前写的,一直没发,留个记录吧,万一哪天记录掉了起码在csdn有个念想 1.easyre1 32位无壳elf文件 shiftF12进入字符串,发现一串数字,双击进入 进入main函数 int __cdecl main(int argc, const char **argv, const…...

日常开发小Tips:后端返回带颜色的字段给前端
一般来说,展示给用户的字体格式,都是由前端控制,展现给用户; 但是当要表示某些字段的数据为异常数据,或者将一些关键信息以不同颜色的形式呈现给用户时,而前端又不好判断,那么就可以由后端来控…...

partition_pdf 和chunk_by_title 的区别
from unstructured.partition.pdf import partition_pdf from unstructured.chunking.title import chunk_by_titlepartition_pdf 和 chunk_by_title 初看有点像,都在"分块",但是它们的本质完全不一样。 先看它们核心区别 partition_pdfchun…...

JAVA-使用Apache POI导出数据到Excel,并把每条数据的图片打包成zip附件项
最近项目要实现一个功能,就是在导出报表的时候 ,要把每条数据的所有图片都要打包成zip附件在excel里一起导出。 1. 添加依赖 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>…...

前端——CSS1
一,概述 CSS(Cascading Style Sheets)(级联样式表) css是一种样式表语言,为html标签修饰定义外观,分工不同 涉及:对网页的文字、背景、宽、高、布局进行修饰 分为内嵌样式表&…...

《AI大模型应知应会100篇》【精华】第40篇:长文本处理技巧:克服大模型的上下文长度限制
[精华]第40篇:长文本处理技巧:克服大模型的上下文长度限制 摘要 在大语言模型应用中处理超出其上下文窗口长度的长文本是一项挑战。本文面向初学者介绍长文本处理的常见难题,以及一系列有效策略和技巧,包括如何对文档进行合理分…...
)
开源模型应用落地-qwen模型小试-Qwen3-8B-快速体验(一)
一、前言 阿里云最新推出的 Qwen3-8B 大语言模型,作为国内首个集成“快思考”与“慢思考”能力的混合推理模型,凭借其 80 亿参数规模及 128K 超长上下文支持,正在重塑 AI 应用边界。该模型既可通过轻量化“快思考”实现低算力秒级响应,也能在复杂任务中激活深度推理模式,以…...
模型开源以及初体验)
千问3(Qwen3)模型开源以及初体验
体验地址:百炼控制台 1 千问3模型:全球最强开源大模型震撼发布 2025年4月29日,阿里巴巴正式开源了新一代通义千问模型Qwen3(简称千问3),这一里程碑式的事件标志着中国开源大模型首次登顶全球性能榜首。千问…...

对 FormCalc 语言支持较好的 PDF 编辑软件综述
FormCalc是一种专为PDF表单计算设计的脚本语言,主要应用于Adobe生态及SAP相关工具。以下是对FormCalc支持较好的主流软件及其特点: 1. Adobe LiveCycle Designer 作为FormCalc的原生开发环境,LiveCycle Designer提供最佳支持: …...

20250429-李彦宏口中的MCP:AI时代的“万能接口“
目录 一、什么是MCP? 二、为什么需要MCP? 三、MCP的工作原理 3.1 核心架构 3.2 工作流程 四、MCP的应用场景 4.1 开发者工具集成 4.2 智能助手增强 4.3 企业应用集成 4.4 典型案例 五、MCP的技术特点 5.1 标准化接口 5.2 可扩展性设计 5.…...

汽车启动原理是什么?
好的!同学们,今天我们来讨论汽车的启动原理,重点分析其中的动力来源和摩擦力作用。我会结合物理概念,用尽量直观的方式讲解。 1. 汽车为什么会动?——动力的来源 汽车发动机(内燃机或电动机)工…...

LeetCode[347]前K个高频元素
思路: 使用小顶堆,最小的元素都出去了,省的就是大,高频的元素了,所以要维护一个小顶堆,使用map存元素高频变化,map存堆里,然后输出堆的东西就行了 代码: class Solution…...

《软件测试52讲》学习笔记:如何设计一个“好的“测试用例?
引言 在软件测试领域,设计高质量的测试用例是保证软件质量的关键。本文基于茹炳晟老师在《软件测试52讲》中关于测试用例设计的讲解,结合个人学习心得,系统总结如何设计一个"好的"测试用例。 一、什么是"好的"测试用例…...

【深度学习新浪潮】ISP芯片算法技术简介及关键技术分析
ISP芯片及其功能概述 ISP(Image Signal Processor)芯片作为现代影像系统的核心组件,负责对图像传感器输出的原始信号进行后期处理。ISP的主要功能包括线性纠正、噪声去除、坏点修复、色彩校正以及白平衡调整等,这些处理步骤对于提高图像质量和视觉效果至关重要。随着科技的…...
)
QtCreator Kits构建套件报错(红色、黄色感叹号)
鼠标移动上去,查看具体报错提示。 一.VS2022Qt5.14.2(MSVC2017) 环境VS2022Qt5.14.2(MSVC2017) 错误:Compilers produce code for different ABIs:x86-windows-msvc2005-pe-64bit,x86-windows-msvc2005-pe-32bit 错误࿱…...
:全球布局,领航资管新纪元)
天能资管(SkyAi):全球布局,领航资管新纪元
在全球化浪潮汹涌澎湃的今天,资管行业的竞争已不再是单一市场或区域的较量,而是跨越国界、融合全球资源的全面竞争。天能资管(SkyAi),作为卡塔尔投资局(Qatar Investment Authority,QIA)旗下的尖端科技品牌,正以其独特的全球视野和深远的战略眼光,积极布局资管赛道,力求在全球资…...

基于PHP的宠物用品商城
有需要请加文章底部Q哦 可远程调试 基于PHP的宠物用品商城 一 介绍 宠物用品商城系统基于原生PHP开发,数据库mysql,前端bootstrap,jquery.js等。系统角色分为用户和管理员。(附带参考文档) 技术栈:phpmysqlbootstrapphpstudyvsc…...

桂链:使用Fabric的测试网络
桂链是基于Hyperledger Fabric开源区块链框架扩展开发的区块链存证平台,是桂云网络(OSG)公司旗下企业供应链、流程审批等场景数字存证软件产品,与桂花流程引擎(Osmanthus)并列为桂云网络旗下的标准与可定制…...

k8s术语master,node,namepace,LABLE
1.Master Kubernetes中的master指的是集群控制节点,每个kubernetes集群里都需要有一个Master节点来负责整个集群的管理和控制,基本上kubernetes的所有控制命令都发给它,它来负责具体的执行过程。Master节点通常会占据一个独立的服务器(高可用建议3台服务器)。 Master节点…...

香港科技大学广州|智能制造学域硕、博研究生招生可持续能源与环境学域博士招生宣讲会—四川大学专场!
香港科技大学广州|智能制造学域硕、博研究生招生&可持续能源与环境学域博士招生宣讲会—四川大学专场!!! 两个学域代表教授亲临现场,面对面答疑解惑助攻申请!可带简历现场咨询和面试! &am…...
)
【Vue】 实现TodoList案例(待办事项)
目录 组件化编码流程(通用) 1.实现静态组件:抽取组件,使用组件实现静态页面效果 2.展示动态数据: 1. 常规 HTML 属性 3.交互——从绑定事件监听开始 什么时候要用 event: 什么时候不需要用 event&am…...

Ubuntu 20.04 安装 ROS 2 Foxy Fitzroy
目录 1,安装前须知 2,安装过程 2.1,设置语言环境 2.2,设置源 2.3,安装ROS 2软件包 2.4,环境设置 2.5,测试 2.6,不想每次执行source 检验是否成功(另…...

【Unity】使用LitJson保存和读取数据的例子
LitJson 是一个轻量级的 JSON 解析和生成库,广泛应用于 .NET 环境中。 优点:轻量级,易用,性能优秀,支持LINQ和自定义对象的序列化和反序列化。 public class LitJsonTest : MonoBehaviour { // Start is called before…...
飞蛾扑火算法优化+Transformer四模型回归打包(内含MFO-Transformer-LSTM及单独模型)
飞蛾扑火算法优化Transformer四模型回归打包(内含MFO-Transformer-LSTM及单独模型) 目录 飞蛾扑火算法优化Transformer四模型回归打包(内含MFO-Transformer-LSTM及单独模型)预测效果基本介绍程序设计参考资料 预测效果 基本介绍 …...