一文解析大语言模型量化技术
目录
一、为什么需要量化技术
1、数据规模
2、32位浮点数(FP32)
3、16位浮点数(FP16)
4、Bfloat16(BF16)
5.INT8(8位整数)和INT4(4位整数)
总结:
二、量化方法
1、对称量化:
2、非对称量化
3、量化后的计算
三、如何对神经网络量化
1、动态量化
2、静态量化
3、PyTorch代码示例
1.动态量化示例
2.静态量化示例:
四、量化感知训练
五、AWQ(激活感知权重量化)
量化就是将高精度数值转换为低精度数值,在大语言模型中,量化可以将32位浮点数转化位8位或者4位的低精度数据。在内存节省和资源开销方面推理数据方面得到不错的结果。
一、为什么需要量化技术
1、数据规模
在如今的大语言模型规模中,参数量的大小已经大到超乎想象,比如现在很火的DeepSeek-V3有671B(六千七百一十亿)的参数量、GPT-4有1760B(一万六千亿)的参数量等等。在如此大的参数量的情况之下如果运算的话那将是一个很耗时的工程了,如果参数都是32位的数据,那会异常庞大。所以我们需要用到量化的操作来降低计算工作量
2、32位浮点数(FP32)
FP32格式,每个数字都用32位(二进制,三十二个0、1)来表示,无论是超过了还是小于。这种格式将每个数分为:符号位(1位)、指数位(8位)和尾数(小数部分23位)。
计算:
比如:符号位(sign):0 指数位(exponent)10000010 尾数(mantissa):01000000000000000000000
将上面的二进制还原成十进制后:value=(-1)**0x2(130-127)x(1+0.25)=10.0
范围:约 ±1.18×10⁻³⁸ 到 ±3.4×10³⁸
3、16位浮点数(FP16)
和上面一样,这里是用十六个二进制来表示,符号位(1位)、指数位(5位)和尾数(小数部分10位)。行对于FP32,它的精度不是那么精确,可能会造成误差,但是优势在于内存减半,计算量也减少了。
计算和上面一样的公式,范围:±5.96×10⁻⁸ ~ ±6.55×10⁴
4、Bfloat16(BF16)
BF16(Bfloat16)是一种 16 位浮点数格式,符号位(1位)、指数位(8位)、尾数位(7位)由 Google Brain 团队提出,专为 深度学习训练 设计。它在保持 FP32 的数值范围的同时,牺牲部分精度以提升计算效率。相较于FP32,它牺牲了一点精度,但计算效率是16位的。
计算方法:和上面一样
范围也和FP32一样:±1.18×10⁻³⁸ ~ ±3.4×10³⁸
5.INT8(8位整数)和INT4(4位整数)
上面介绍的是小数的表示方法,下面我们来看看整数的表示方法。INT8(8-bit 整数)和 INT4(4-bit 整数)是两种低精度数值格式,主要用于 深度学习推理加速 和 边缘计算,通过牺牲精度来大幅减少内存占用和计算开销。有符号范围:INT8:-128到127,INT4:-8 到 7无符号范围:UINT8:0到255,UINT4:0 到 15
在整数里面,有一个无符号和有符号的概念,无符号(uint)就是只能表示正数,有符号数(int)可以表示正负
举个例子:以加载Llama 13B为例,以FP32加载需要52GB内存,以FP16加载需要26GB,以int8加载需要13GB,以int4加载需要6.5GB。所以我们要找到一个合适的方法来加载参数以降低计算量和减少内存使用
总结:
|
二、量化方法
总的来说因为整数运算速度大于浮点数,所以量化就是将浮点数用整数来表示,同时减少量化后模型推理的误差。
但是数据表示我们又要用到浮点数,所以我们还需要一个方式来将整数变为浮点数,所以我们引入了反量化的概念。
1、对称量化:
顾名思义,对称肯定要有对称轴,所以我们要先找到对称轴(0)。比如给我们一组数据[1.21, -1.31, 0.22, 0.83, 2.11, -1.53, 0.79, -0.54, 0.84],我们以int8为例,先找到这组数据中的绝对值最大值(2.11),在用这个最大值除以表示范围,int8的范围是-128到127,为了简化计算,我们不要-128,取-127到127,那么就是2.11/127=0.016614,这个就是缩放系数
量化:将所有的数除以上面计算得到的缩放系数就得到了量化后的数组了,[73, -79,13,50,127,-92,48,-33,51]
反量化:将所有的数乘以缩放系数,这里会有一点损失
2、非对称量化
顾名思义:非对称就是没有对称轴,也就是我们要将浮点数映射到无符号整数上,因为无符号是从0开始的,没有负数,所有没有对称轴。
缩放系数:先找到这组数据的最大值和最小值,以上面那个例子:[1.21, -1.31, 0.22, 0.83, 2.11, -1.53, 0.79, -0.54, 0.84],最大值:2.11,最小值:-1.53。然后最大值减去最小值除以范围:[2.11-(-1.53)]/255=0.0142745。
相比于上面的对称量化,这里还需要求:zero_point= - 最小值/缩放系数=-(1.53)/0.0142745=107。他的作用是将缩放后的变量进行平移,让所有的变量刚好处于0到255之间。还有一个clamp函数,这个函数的作用也是为了将变量规定在0到255之间,小于0的赋值为0大于255的赋值为255,和relu有异曲同工之妙。
量化:当上面的东西都准备好之后,我们将数据除以缩放系数加上zero_point后经过clamp函数,就得到量化后的值了[192,15,122,165,255,0,162,69,166]
反量化:将量化后的值减去zero_point乘上缩放比例,clamp函数就不用管了
总结:对比对称量化和非对称量化,对称量化:计算简单,但是精度较低;非对称量化:计算比较复杂,但是精度较高
3、量化后的计算
在计算层面上怎么体现呢,上面只是将浮点数变为了整数。
我们设原始的数据Xf和Wf,量化后的数据为Xq和Wq,根据我们上面的量化的方法,中间会有两个缩放系数Sx和Sw,那么我们的Xf*Wf就可以表示为:Xq*Sx@Wq*Sw,因为Xq*Sx是反量化,反量化后就相当于原数据。Wq*Sw同理,这样就相当于将浮点数运算变成了整数运算了。
按照这种思想,非对称量化的计算也很简单了,这里设zero_point为Zx和Zw。那么公式为:
XfWf=(Xq-Zx)*Sx@(Wq-Zw)*Sw,其实就是将反量化的公式当中原数据使用
三、如何对神经网络量化
对于神经网络,输入和参数都需要经过Normalization、激活函数,有些还有L1,L2正则化,数据范围都不大,而且数值影响会被平滑。
1、动态量化
在推理的时候的输入一般为FP32,我们将他量化为INT8,然后将权重也量化为INT8,那么推理的时候就是整数计算了,然后输出之前对数据和权重进行反量化,也就是FP32的形式输出。还有就是一般将训练好的模型权重量化为int8。
缺点:每一次推理每一层都要对输入统计量化参数,这样很耗时;每一层计算完后都转为FP32存入显存,占用显存带宽。
2、静态量化
为了解决上面动态量化的遗留问题,引入了静态量化。
1.将训练好的模型权重量化为int8,并保存量化参数(上面说到的zero_point和缩放因子)
2.校准:利用一些代表性的数据进行模型推理(无需标签),用这些数据在神经网络每一层产生的激活值估算出激活值的量化参数(ero_point和缩放因子)。这样就不用推理时每次根据实际激活值计算量化参数。
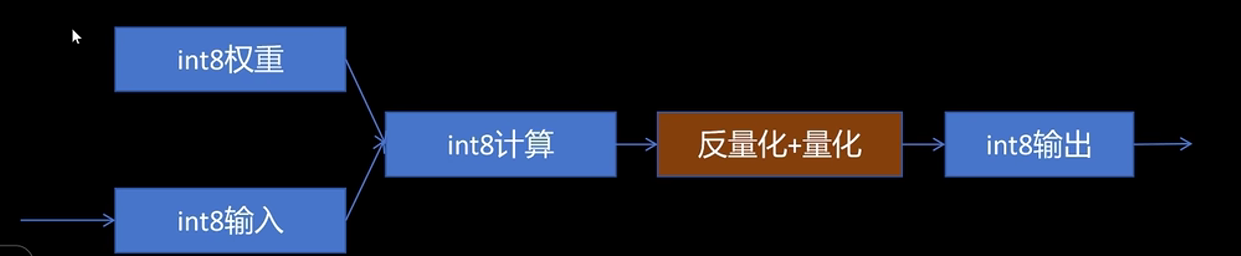
3.每一层对量化后的int8权重和int8激活值进行计算
4.在没一层输出时将结果反量化为FP32,或者直接传递INT8激活值+固定参数(减少显存占用)。同时根据校准产生的激活值量化参数,把激活值化为int8,把量化参数放入量化后的激活值中
5.将int8激活值和它的量化参数传入下一层
静态量化通过预校准固定参数,彻底解决了动态量化的实时计算瓶颈,是部署高吞吐量AI服务的首选方案。实际应用中需权衡校准数据成本和精度要求,结合硬件支持选择最优量化策略。
缺点:依赖校准数据质量(分布偏差会导致精度损失)
3、PyTorch代码示例
在PyTorch中已经有量化的API了,torch.ao.quantization类
1.动态量化示例
# PyTorch动态量化示例(权重INT8,激活动态量化)
model_int8 = torch.quantization.quantize_dynamic(model_fp32, {torch.nn.Linear}, # 仅量化指定层dtype=torch.qint8
)2.静态量化示例:
import torch
from torch.quantization import QuantStub, DeQuantStub, prepare, convert# 定义模型(插入量化/反量化节点)
class QuantizedModel(torch.nn.Module):def __init__(self, model_fp32):super().__init__()self.quant = QuantStub() # 输入量化self.model = model_fp32self.dequant = DeQuantStub() # 输出反量化def forward(self, x):x = self.quant(x)x = self.model(x)x = self.dequant(x)return x# 准备模型
model_fp32 = ... # 原始模型
model_quant = QuantizedModel(model_fp32)
model_quant.qconfig = torch.quantization.get_default_qconfig('fbgemm') # 后端配置# 校准阶段(用代表性数据)
model_prepared = torch.quantization.prepare(model_quant)
for data in calibration_data:model_prepared(data) # 统计激活值分布
model_int8 = torch.quantization.convert(model_prepared) # 转换为静态量化模型# 推理(全程INT8)
input_fp32 = torch.randn(1, 3, 224, 224)
output_fp32 = model_int8(input_fp32) # 输出自动反量化四、量化感知训练
量化感知训练(QAT)是一种在模型训练过程中模拟量化误差的方法,旨在让模型在低精度(如INT8)环境下保持高精度性能。其核心思想是通过前向传播模拟量化、反向传播保持高精度更新,使模型权重适应量化后的数值分布,从而减少最终量化部署时的精度损失。
1.加载FP32的模型参数和激活值:在前向传播时,向网络中插入模拟量化算子,将FP32权重和激活值“假装”量化为INT8(实际仍用FP32存储)。
2.量化噪声模拟:通过模拟INT8的舍入误差和截断效应,让模型在训练中学习抵抗量化带来的精度损失。
3.得到模型:训练完成后,直接导出真正的INT8量化模型(无需额外校准)。
QAT(量化感知训练)就是让模型提前适应“被压缩”的感觉,就像运动员在高原训练(模拟缺氧环境),比赛时到平原就能轻松发挥。
举个例子:就像在训练小狗握手,普通训练(对称量化): 让狗在宽敞的地方训练握手(高精度环境),QAT训练:让狗在狭窄的空间里面训练,等它习惯了,将它放在阳台等角落里它也会握手。相当于预训练。
QAT = “先苦后甜”式训练,让模型在模拟的艰苦环境(低精度)中学习,最终在真实部署时既快又准!
4.代码示例:
import torch
import torch.quantization# 1. 定义模型(插入伪量化节点)
class QATModel(torch.nn.Module):def __init__(self):super().__init__()self.quant = torch.quantization.QuantStub()self.conv = torch.nn.Conv2d(3, 64, kernel_size=3)self.dequant = torch.quantization.DeQuantStub()def forward(self, x):x = self.quant(x)x = self.conv(x)x = self.dequant(x)return x# 2. 加载预训练模型(FP32)
model_fp32 = QATModel()
model_fp32.load_state_dict(torch.load('pretrained.pth'))# 3. 配置QAT参数
model_fp32.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')# 4. 准备QAT训练
model_qat = torch.quantization.prepare_qat(model_fp32)# 5. 正常训练(模拟量化)
optimizer = torch.optim.SGD(model_qat.parameters(), lr=0.001)
for epoch in range(10):for data, target in train_loader:optimizer.zero_grad()output = model_qat(data)loss = criterion(output, target)loss.backward()optimizer.step()# 6. 导出INT8模型
model_int8 = torch.quantization.convert(model_qat)
torch.save(model_int8.state_dict(), 'quantized_model.pth')五、AWQ(激活感知权重量化)
AWQ是一种针对大型语言模型(LLMs)的训练后量化(PTQ)方法,专注于4位仅权重量化,旨在最小化推理成本的同时保持模型精度。与量化感知训练(QAT)方法不同,AWQ无需反向传播或重新训练,因此适用于大型模型的扩展。这种技术特别适合像边缘设备这样资源受限的硬件,通过有策略地保护对精度至关重要的权重来实现高效推理。
举个例子:就像图书管理,普通方法,比如上面讲到的对称量化,不管内容是否重要一股脑的全部挤在书架上。而AWQ,先检查那些是经常用到的书、重点的书,放在书架上,不重要的数据把它一股脑全丢角落里,既能节省空间,有保护了关键内容
AWQ好比一种压缩技术,像给模型减肥一样,只压缩不太重要的部分,重要的部分保存高精度,让大模型在手机平板上也能跑的很快、不卡顿。
那么什么是“经常用到的书”呢?在模型运行时,某些数字对结果的影响大就是常用的,AWQ会自动找到它们
压缩:就是将什么我们提到的:将浮点数FP32压缩成INT8,对于不重要的我们将它压缩成INT4.
代码示例:
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer# 1. 加载预训练模型
model_path = "meta-llama/Llama-2-7b"
quant_path = "llama-2-7b-awq-int4"# 2. 配置AWQ参数
quant_config = {"zero_point": True, # 使用零点量化"q_group_size": 128, # 分组量化大小"w_bit": 4, # 权重量化为INT4"version": "GEMM" # 使用矩阵乘优化
}# 3. 执行AWQ量化
model = AutoAWQForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
model.quantize(tokenizer, quant_config=quant_config)# 4. 保存量化模型
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)# 5. 加载量化模型推理
model = AutoAWQForCausalLM.from_quantized(quant_path)
inputs = tokenizer("Hello, AWQ!", return_tensors="pt")
outputs = model.generate(**inputs)相关文章:

一文解析大语言模型量化技术
目录 一、为什么需要量化技术 1、数据规模 2、32位浮点数(FP32) 3、16位浮点数(FP16) 4、Bfloat16(BF16) 5.INT8(8位整数)和INT4(4位整数) 总结&#…...

使用python实现自动化拉取压缩包并处理流程
使用python实现自动化拉取压缩包并处理流程 实现成果展示使用说明 实现成果展示 使用说明 执行./run.sh 脚本中的内容主要功能是: 1、从远程服务器上下拉制定时间更新的数据 2、将数据中的zip拷贝到指定文件夹内 3、解压后删除所有除了lcm之外的文件 4、新建一个ou…...

解构编程语言的基因密码:论数据类型如何被语言系统定义与重塑
摘要 本文从理论与实践层面系统探讨编程语言中数据类型的定义、实现与演化。通过静态与动态类型系统的差异分析,结合案例、流程图和表格,全面呈现主流语言数据类型设计特点及其对内存管理、错误防范与性能优化的影响。文章旨在为语言设计者和开发者提供…...

GRPO vs SFT:强化学习提升大模型多模态推理泛化能力的原因研究
GRPO vs SFT:强化学习提升大模型多模态推理泛化能力的原因研究 作者:吴宇斌 原文地址:https://zhuanlan.zhihu.com/p/1892362859628963761 训练目标与优化方式差异对比 监督微调(SFT)的目标: SFT使用带标注…...
助力制造企业构建高可靠智能生产网络)
从千兆到40G:飞速(FS)助力制造企业构建高可靠智能生产网络
案例亮点 部署S5850-24S2Q交换机,启用MLAG跨设备链路聚合,构建高性能冗余架构,消除单点故障风险,将网络可用性提升至99.99%,保障生产系统与全球业务连续性。采用40G光模块与US Conec MTP连接头多模跳线实现数据中心间…...
)
WHAT - 《成为技术领导者》思考题(第三章)
文章目录 涉及内容理解问题管理想法的交流保证质量 思考题思路和示例框架1. 观察一个你认为是领导者的人,列出他的行为,分类,并思考自己未采用的行为2. 观察一个不太像领导者的人,列出错过的简单机会,并反思3. 让别人注…...
 环境安装)
Go 语言入门:(一) 环境安装
一、前言 这里不同于其他人的 Go 语言入门,环境安装我向来注重配置,比如依赖包、缓存的默认目录。因为前期不弄好,后面要整理又影响这影响那的,所以就干脆写成文章,方便后期捡起。 二、安装 1. 安装包 https://go.…...

GTC2025全球流量大会:领驭科技以AI云端之力,助力中国企业出海破浪前行
在全球化与数字化浪潮下,AI技术正成为中国企业出海的重要驱动力。一方面,AI通过语言处理、数据分析等能力显著提升出海企业的运营效率与市场适应性,尤其在东南亚等新兴市场展现出"高性价比场景适配"的竞争优势;另一方面…...

013几何数学——算法备赛
几何数学 平面切分 蓝桥杯2020年省赛题 问题描述 平面上有N条直线,其中第i条直线为yAxB.请计算这些直线将平面分成了几个部分? 输入 第一行输入一个N,接下来N行输入两个整数代表Ai和Bi。 1<N<10^5. 思路分析 初始时一条直线将…...

VUE3:封装一个评论回复组件
之前用React封装的评论回复组件,里面有三个主要部分:CommentComponent作为主组件,CommentItem处理单个评论项,CommentInput负责输入框。现在需要将这些转换为Vue3的组件。 Vue3和React在状态管理上有所不同,Vue3使用r…...

DELL R740服务器闪黄灯不开机故障案例
1:DELL R740服务器 2:东莞长安客户工厂晚上十一二点电路跳闸多次,导致R740 ERP服务器无法开机。 3:故障现象为:主机能正常通电,开机按钮无通电迹象,正常情况会闪绿灯慢闪,通电一会后…...
)
记录一下QA(from deepseek)
Q1:__init__.py文件 在 Python 中,当你在一个目录下创建 __init__.py 文件时,这个目录会被视为一个 包(Package)。包的存在使得 Python 能够通过点号(.)层级式地组织模块(.py 文件)&…...

码蹄集——进制输出、求最大公约数、最小公倍数
进制乱炖 本题考查输出的进制转换,可以直接使用c里的format格式输出 #include<iostream> #include<algorithm> #include<string> using namespace std;int main() {int x;cin>>x;printf("%d %o %x %u\n",x,x,x,x);//十进制 八进…...

从技术走向管理:带来哪些角色转变与挑战
文章目录 一、从技术到管理1、从技术转到管理的优劣势(1)优势(2)劣势 2、刚转岗容易犯的几个问题3、最大的变化:不再是一个人单打独斗4、警惕:一开始不要把“人”过早的介入到“事”5、如何完成角色的转变&…...
)
C语言-指针(一)
目录 指针 内存 概念 指针变量 取地址操作符(&) 操作符“ * ” 指针变量的大小 注意 指针类型的意义 作用 void * 指针 const修饰指针变量 const放在*前 const放在*后 双重const修饰 指针的运算 1.指针 - 整数 2.指针 - 指针 3.指…...

Python面试问题
一、Python 基础 1. Python 的特点 动态类型:变量无需声明类型。解释型语言:逐行解释执行。支持多种编程范式(面向对象、函数式、过程式)。 2. 列表(List)与元组(Tuple)的区别 特…...
)
RAG工程-基于LangChain 实现 Advanced RAG(预检索优化)
Advanced RAG 概述 Advanced RAG 被誉为 RAG 的第二范式,它是在 Naive RAG 基础上发展起来的检索增强生成架构,旨在解决 Naive RAG 存在的一些问题,如召回率低、组装 prompt 时的冗余和重复以及灵活性不足等。它重点聚焦在检索增强࿰…...
循环结构程序设计习题1)
【时时三省】(C语言基础)循环结构程序设计习题1
山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 习题1 输入两个正整数m和n,求其最大公约数和最小公倍数。 解题思路: 求两个正整数 m 和 n 的最大公约数通常使用辗转相除法(欧几里得算法ÿ…...
)
[密码学实战]SDF之设备管理类函数(一)
[密码学实战]SDF之设备管理类函数(一) 一、标准解读:GM/T 0018-2023核心要求 1.1 SDF接口定位 安全边界:硬件密码设备与应用系统间的标准交互层功能范畴: #mermaid-svg-s3JXUdtH4erONmq9 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16p…...

CDGP|如何建立高效的数据治理团队?
近年来,数据治理行业迅速发展,越来越多的企业开始重视并投入大量资源来建立和完善数据治理体系。数据治理体系不仅能够帮助企业更好地管理和利用数据资源,提升数据质量和数据价值,还能够为企业带来竞争优势和可持续发展能力。 然…...

如何评价 DeepSeek 的 DeepSeek-V3 模型?
DeepSeek-V3 是由杭州 DeepSeek 公司于 2024 年 12 月 26 日发布的一款开源大语言模型,其性能和创新技术在国内外引起了广泛关注。从多个方面来看,DeepSeek-V3 的表现令人印象深刻,具体评价如下: 性能卓越 DeepSeek-V3 拥有 6710 …...

【基础篇】prometheus命令行参数详解
文章目录 本篇内容讲解命令行参数详解 本篇内容讲解 prometheus高频修改命令行参数详解 命令行参数详解 在页面的/页面上能看到所有的命令行参数,如图所示: 使用shell命令查看 # ./prometheus --help usage: prometheus [<flags>]The Promethe…...

SpringBoot实现接口防刷的5种高效方案详解
目录 前言:接口防刷的重要性 方案一:基于注解的访问频率限制 实现原理 核心代码实现 使用示例 优缺点分析 方案二:令牌桶算法实现限流 算法原理 核心实现 配置使用 适用场景分析 方案三:分布式限流(Redis …...

DeepSearch复现篇:QwQ-32B ToolCall功能初探,以Agentic RAG为例
DeepSearch复现篇:QwQ-32B ToolCall功能初探,以Agentic RAG为例 作者:CyPaul Space 原文地址:https://zhuanlan.zhihu.com/p/30289363967 全文阅读约3分钟~ 背景 今天看到 论文:Search-R1: Training LLMs to Reason …...

项目实战-贪吃蛇大作战【补档】
这其实算是一个补档,因为这个项目是我在大一完成的,但是当时没有存档的习惯,今天翻以前代码的时候翻到了,于是乎补个档,以此怀念和志同道合的网友一起做项目的日子 ₍ᐢ ›̥̥̥ ༝ ‹̥̥̥ ᐢ₎♡ 这里面我主要负责…...

power bi获取局域网内共享文件
power bi获取局域网内共享文件 需求: 数据源并不一定都是在本地,有可能在云端,也有可能在其他服务器,今天分享如果数据源在另外一台服务器,如何获取数据源的方法。 明确需求:需要通过PowerBI获取局域网中的…...

100%提升信号完整性:阻抗匹配在高速SerDes中的实践与影响
一个高速信号SerDes通道(例如PCIe、112G/224G-PAM4)包含了这些片段: 传输线连通孔(PTH or B/B via)连接器高速Cable锡球(Ball and Bump) 我们会希望所有的片段都可以有一致的阻抗,…...

第六章:Tool and LLM Integration
Chapter 6: Tool and LLM Integration 从执行流到工具集成:如何让AI“调用真实世界的技能”? 在上一章的执行流框架中,我们已经能让多个代理协作完成复杂任务。但你是否想过:如果用户要求“查询实时天气”或“打开网页搜索”&…...

prompt提示词编写技巧
为什么学习prompt编写 目的:通过prompt的编写,提升LLM输出相关性、准确性和多样性,并对模型输出的格式进行限制,满足我们的业务需求。 学过提示词工程的人:像“专业导演”,通过精准指令控制 AI 输出&#…...

Nginx配置SSL详解
文章目录 Nginx配置SSL详解1. SSL/TLS 基础知识2. 准备工作3. 获取SSL证书4. Nginx SSL配置步骤4.1 基础配置4.2 配置说明 5. 常见配置示例5.1 双向认证配置5.2 多域名SSL配置 6. 安全优化建议7. 故障排查总结参考资源下载验证的完整实例 Nginx配置SSL详解 1. SSL/TLS 基础知识…...

网络安全之红队LLM的大模型自动化越狱
前言 大型语言模型(LLMs)已成为现代机器学习的重要支柱,广泛应用于各个领域。通过对大规模数据的训练,这些模型掌握了多样化的技能,展现出强大的生成与理解能力。然而,由于训练数据中难以完全剔除有毒内容&…...
)
【技术笔记】通过Cadence Allegro创建一个PCB封装(以SOT23为例)
【技术笔记】通过Cadence Allegro创建一个PCB封装(以SOT23为例) 一、焊盘创建二、PCB封装设计三、丝印位号及标识添加 更多内容见专栏:【硬件设计遇到了不少问题】、【Cadence从原理图到PCB设计】 一、焊盘创建 首先要找到元器件的相关手册&…...

新环境注册为Jupyter 内核
1. 确认环境是否已注册为内核 在终端运行以下命令,查看所有已注册的内核: jupyter kernelspec list2. 为自定义环境注册内核 步骤 1:激活目标虚拟环境 conda activate your_env_name # 替换为你的环境名步骤 2:安装…...

[Spring] Seata详解
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

使用JDK的数据校验和Spring的自定义注解校验前端传递参数的两种方法
第一种:JDK的数据校验注解 PostMapping("/test")public String test(QueryParam param, RequestHeader(value "App_key") String App_key,RequestHeader(value "App_secret") String App_secret) throws IOException {param.setApp…...
)
JS错误处理的新方案 (不使用try-catch)
错误处理一直是JavaScript开发者需要认真对待的问题,传统的try-catch语法虽然简单直观,但在异步代码中使用时存在诸多限制。 try-catch的局限性 传统try-catch模式在现代JavaScript开发中面临的问题: 1. 异步错误捕获的缺陷 try-catch无法…...
)
前端实现商品放大镜效果(Vue3完整实现)
前端实现商品放大镜效果(Vue3完整实现) 前言 在电商类项目中,商品图片的细节展示至关重要。放大镜效果能显著提升用户体验,允许用户在不跳转页面的情况下查看高清细节。本文将基于Vue3实现一个高性能的放大镜组件,完整…...

redis未授权访问漏洞学习
一、Redis常见用途 1. Redis介绍 全称与起源: Redis全称Remote Dictionary Service(远程字典服务),最初由antirez在2009年开发,用于解决网站访问记录统计的性能问题。发展历程: 从最初仅支持列表功能的内存数据库,经过十余年发展已支持多种…...

阿里qiankun微服务搭建
主服务 chat vue3 ts vite 子服务 ppt react 18 vite 子服务 agent 主服务 npm i vite-plugin-qiankun mian.ts import ./style/base.scss import virtual:svg-icons-register import { createApp } from vue import { createPinia } from piniaimport App from ./App.vue im…...

【CodeSprint】第二章-2.1 简单模拟
第二章 2.1 简单模拟 ✏️ 关于专栏:专栏用于记录 prepare for the coding test。 1. 简单模拟 简单模拟题目不需要复杂算法,直接按照题意一步步模拟即可。 1.1 促销计算 题目描述 某百货公司为了促销,采用购物打折的优惠方法:…...

Golang实现函数默认参数
golang原生不支持默认参数 在日常开发中,我们有时候需要使用默认设置,但有时候需要提供自定义设置 结构体/类,在Java我们可以使用无参、有参构造函数来实现,在PHP中我们也可以实现(如 public function xxx($isCName false, $sec…...

【Python Web开发】03-HTTP协议
文章目录 1. HTTP协议基础1.1 请求-响应模型1.2 请求方法1.3 请求和响应结构1.4 状态码 2. Python 发送 HTTP 请求2.1 urllib库2.2 requests 库 3. Python 构建 HTTP 服务器3.1 http.server模块3.2 Flask 框架 4. HTTP 协议的安全问题5. 缓存和性能优化 HTTP(Hypert…...

提高营销活动ROI:大数据驱动的精准决策
提高营销活动ROI:大数据驱动的精准决策 大家好,我是Echo_Wish。今天我们来聊聊如何通过大数据来提高营销活动的ROI(投资回报率)。我们都知道,随着市场的日益竞争,营销的成本不断增加,如何在这片红海中脱颖而出,不仅需要精准的营销策略,还需要依靠先进的技术,尤其是大…...

前端excel导出
在数据可视化和管理日益重要的今天,前端实现 Excel 导出功能已经成为众多项目中的刚需。 一、Excel 导出的常见场景 数据报表导出:在企业管理系统、数据分析平台中,用户经常需要将系统中的数据以 Excel 表格的形式导出,便于离…...
)
pymsql(SQL注入与防SQL注入)
SQL注入: import pymysql# 创建数据库连接 返回一个对象 conn pymysql.connect(host"localhost", # MySQL服务器地址 本地地址 127.0.0.1user"root", # 用户名 (账号)password"155480", # 密码database&qu…...

基于Springboot + vue + 爬虫实现的高考志愿智能推荐系统
项目描述 本系统包含管理员和学生两个角色。 管理员角色: 个人中心管理:管理员可以管理自己的个人信息。 高校信息管理:管理员可以查询、添加或删除高校信息,并查看高校详细信息。 学生管理:管理员可以查询、添加或…...

delphi使用sqlite3
看了一下delphi调用sqlite3最新版本的调用,网上说的都很片面,也没有完整的资料了。 我自己研究了一下,分享出来。 在调用demo中,官方也给了一个demo但是功能很少,没有参考价值。 1.定义: 首先把sqlite3…...

高压开关柜局部放电信号分析系统
高压开关柜局部放电信号分析系统 - 开发笔记 1. 项目概述 这个项目是我在2025年实现的高压开关柜局部放电信号分析系统,目的是通过采集分析局部放电信号,判断设备的工作状态和潜在故障。系统包含从信号模拟生成、特征提取、到深度学习模型训练的全流程…...

ai环境conda带torch整体迁移。
conda打包好的GPU版torch环境,其实很简单,就是conda装好的torch环境env整体打包,然后到新机器上再解压到env路径。 打开搭建好的环境,找自己路径,我默认的是这个。 cd/root/anaconda3/envs/ 然后整个文件夹打包。tar -…...

电价单位解析与用电设备耗电成本计算
一、电价单位 元/kWh 的解析 定义: 元/kWh 表示每千瓦时电能的费用,即1度电的价格。例如,若电价为0.5元/kWh,则使用1千瓦的电器1小时需支付0.5元。 电价构成: 中国销售电价由四部分组成: 上网电价…...