RAG工程-基于LangChain 实现 Advanced RAG(预检索优化)
Advanced RAG 概述
Advanced RAG 被誉为 RAG 的第二范式,它是在 Naive RAG 基础上发展起来的检索增强生成架构,旨在解决 Naive RAG 存在的一些问题,如召回率低、组装 prompt 时的冗余和重复以及灵活性不足等。它重点聚焦在检索增强,通过增加 Pre - Retrieval 预检索和 Post - Retrieval 后检索阶段,以及优化索引结构和原始查询来提高被索引内容的质量。
在预检索处理优化方面,Advanced RAG 采用多种策略,如摘要索引、父子索引、假设性问题索引、元数据索引等。检索阶段会优化检索过程,主要方法包括混合检索等策略。检索后处理则使用复杂技术,如重排序、上下文压缩策略等,以确保生成的内容更准确、相关和简洁,更好地满足用户需求。
预检索优化
摘要索引
在处理大量文档时,如何快速地找到所需信息是一个常见挑战。摘要索引是一种针对大量文档的结构化索引机制,核心目标是提升信息检索效率,解决传统检索中存在的信息定位慢、精准度低、查找繁琐等问题。其本质是通过对文档内容进行提炼、结构化处理和索引构建,形成一套高效的信息检索 “导航系统”,帮助用户快速、精准地定位和获取所需信息。
在RAG 流程将文档分块后,我们可以使用大模型对每个分块内容进行总结,然后生成摘要索引。而后在检索时,我们可以根据问题找到摘要索引,再由摘要索引找到原文档;或者我们也可以直接回复用户摘要内容。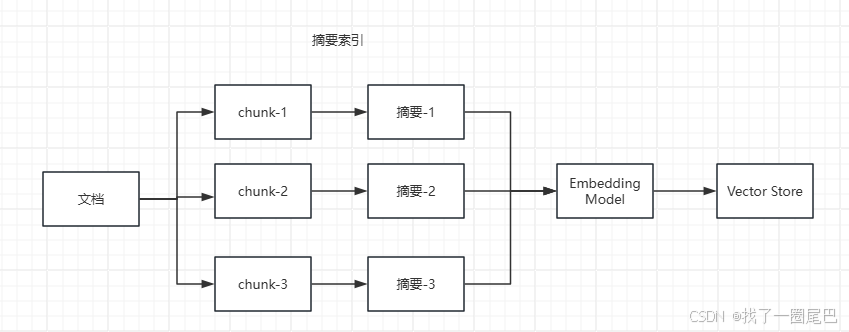
接下来,我们用一段基于Langchain 框架的代码实现摘要索引的功能:
import os
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate# 设置 OpenAI API 密钥
os.environ["OPENAI_API_KEY"] = "your_openai_api_key"def generate_summary_index(file_path):try:# 加载文档loader = TextLoader(file_path)documents = loader.load()# 文档分块text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)chunks = text_splitter.split_documents(documents)# 使用大模型生成摘要llm = ChatOpenAI(temperature=0)# 创建摘要生成链chain = ({"chunk": lambda x: x.page_content}| ChatPromptTemplate.from_template("请总结以下内容:\n\n{chunk}")| llm| StrOutputParser())# 批量生成文档摘要(最大并发数5)summaries = chain.batch(chunks, {"max_concurrency": 5})# 打印每个块的部分摘要内容for i, summary in enumerate(summaries):print(f"块 {i + 1} : {repr(summary[:50])}...")# 创建摘要索引embeddings = OpenAIEmbeddings()summary_index = FAISS.from_texts(summaries, embeddings)return summary_index, chunks, summariesexcept Exception as e:print(f"生成摘要索引时出现错误: {e}")return None, None, Nonedef retrieve_info(summary_index, texts, summaries, question):if summary_index is None:return None, Nonetry:# 根据问题检索摘要索引docs = summary_index.similarity_search(question)if docs:summary = docs[0].page_content# 根据摘要找到原文档summary_index = summaries.index(summary)original_doc = texts[summary_index]return summary, original_doc.page_contentexcept ValueError:print("未在摘要列表中找到匹配的摘要。")except Exception as e:print(f"检索信息时出现错误: {e}")return None, Noneif __name__ == "__main__":file_path = "your_text_file.txt"summary_index, texts, summaries = generate_summary_index(file_path)question = "你想要查询的问题"summary, original_content = retrieve_info(summary_index, texts, summaries, question)if summary and original_content:print("摘要内容:", summary)print("原文档内容:", original_content)else:print("未找到相关信息。")
这段代码使用了一个LangChain 框架的chain 链,封装了使用大模型对文档进行总结的流程。后续使用chain.batch()方法对文档进行总结摘要,并将最终结果保存到FAISS 向量数据库中,方便后续的检索查询使用。
父子索引
在文档检索与处理的技术链中,文档块大小的设定始终是一个关键且充满矛盾的环节。一方面,为了确保 Embedding 过程能够精准锚定文档语义内核,我们需要将文档拆解为较小的单元。这是因为,当文档块被控制在合适的较小规模时,Embedding 模型可以聚焦于单一的语义主题或逻辑片段,生成的向量表征能够更纯粹、准确地映射文档的核心含义。
但另一方面,当用户基于具体问题进行检索,期望获得详实答案时,较小的文档块却难以满足需求。因为 LLM 在生成答案时,需要依托丰富的上下文信息构建完整的逻辑链条。此时,较大的文档块凭借其承载的更多背景知识、完整的推理路径等内容,能为 LLM 提供更充分的 “弹药”,助力其输出全面且准确的回答。
在应对这组看似不可调和的矛盾时,父子索引成为了破局的有效方案。父子索引通过构建层级化的文档关联体系,将文档信息进行结构化拆解与关联。它允许我们将大文档设定为父文档,将其拆解出的较小语义单元作为子文档,父子文档既保持各自独立存储,又通过特定的标识建立紧密联系。在检索环节,若侧重于 Embedding 的精准度,可优先检索子文档,利用其精确的语义向量快速定位相关信息;当用户需要完整的上下文来获取全面答案时,则可以通过父子索引的关联关系,迅速将相关的子文档聚合,形成内容丰富的大文档块提供给 LLM。如此一来,既保证了 Embedding 对文档语义的精准捕捉,又满足了 LLM 对完整上下文的需求,巧妙化解了文档检索中关于文档块大小的矛盾困境。
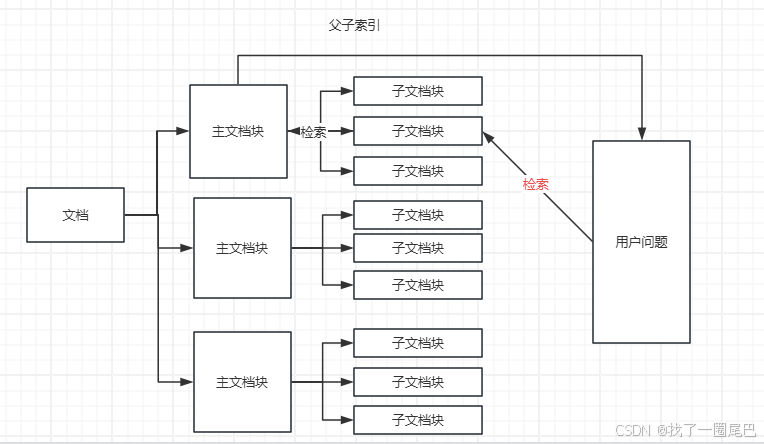
接下来,我们用一段基于Langchain 框架的代码实现父子索引的功能:
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_core.stores import InMemoryStore
from langchain.retrievers import ParentDocumentRetriever# 定义文本文件路径,需要根据实际情况修改
TXT_DOCUMENT_PATH = "your_text_file.txt"# 初始化嵌入模型
embeddings_model = HuggingFaceEmbeddings()# 数据加载
# 初始化文档加载器
loader = TextLoader(TXT_DOCUMENT_PATH, encoding='utf-8')
# 加载文档
docs = loader.load()# 分割器准备
# 创建主文档分割器
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=1024)
# 创建子文档分割器
child_splitter = RecursiveCharacterTextSplitter(chunk_size=256)# 存储准备
# 存储小块
vectorstore = Chroma(collection_name="split_parents", embedding_function=embeddings_model
)
# 创建内存存储对象,存储大块
store = InMemoryStore()# 创建检索器
# 创建父文档检索器
retriever = ParentDocumentRetriever(vectorstore=vectorstore,docstore=store,child_splitter=child_splitter,parent_splitter=parent_splitter,search_kwargs={"k": 1}
)# 添加文档到检索器
retriever.add_documents(docs)# 搜索子块
print("------------搜索子块------------------------")
try:sub_docs = vectorstore.similarity_search("介绍下DeepSeek和市场占用情况")if sub_docs:print(sub_docs[0].page_content)else:print("未找到相关子块内容。")
except Exception as e:print(f"搜索子块时出现错误: {e}")# 搜索子块,返回关联大块
print("------------搜索子块,返回关联大块------------------------")
try:retrieved_docs = retriever.invoke("介绍下DeepSeek和市场占用情况")if retrieved_docs:print(retrieved_docs[0].page_content)else:print("未找到相关大块内容。")
except Exception as e:print(f"搜索关联大块时出现错误: {e}")在这段代码中,我们使用ParentDocumentRetriever创建了一个父文档检索器,并指定了向量存储对象、文档存储对象、子文档分割器、父文档分割器和搜索参数。这样在后续的retriever.invoke方法中,我们通过这个retriever就可以实现父子索引的效果,从细粒度的文档块中检索,然后返回并获取粗粒度的文档块。
假设性问题索引
在传统RAG系统中,用户输入的查询往往是简短的问题,而待检索的文档块长度则相对较长,这种长度上的显著差异使得语义相似性计算面临挑战。当使用传统方法计算简短查询与长文档块之间的语义相似度时,由于长文档块包含大量冗余信息,极易导致语义匹配失准,从而使检索结果难以精准契合用户需求。
为有效解决这一问题,我们可以引入大语言模型(LLM)进行辅助优化。具体而言,让 LLM 针对每个文档块,基于其内容生成 N 个假设性问题。这些假设性问题能够从不同角度提炼文档块的核心语义信息,将其转化为更贴近用户实际查询形式的文本表述。随后,对这些假设性问题进行向量化处理,将其嵌入向量空间构建索引。在系统运行过程中,当接收到用户的查询时,不再直接将其与原始长文档块进行匹配,而是与假设性问题的向量索引进行相似度查询。通过这种方式,能够找到与用户查询语义最为接近的假设性问题,并将该问题对应的原始文档块提取出来,作为上下文传递给 LLM。由于假设性问题已经对文档块的关键语义进行了精准提炼,LLM 基于此接收到的上下文,能够更准确地理解用户意图,从而生成高质量、高相关性的答案。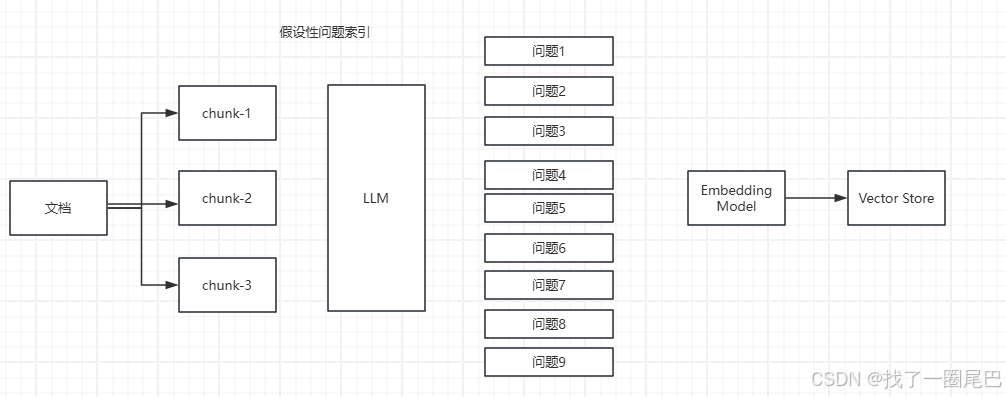
接下来,上代码。
from typing import List
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from langchain.chat_models import ChatOpenAI # 假设使用 OpenAI 模型,可按需替换
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import uuid
from langchain.vectorstores import Chroma
from langchain.retrievers import MultiVectorRetriever
from langchain_core.documents import Document
from langchain.storage import InMemoryByteStore# 定义文本文件路径,需要根据实际情况修改
TXT_DOCUMENT_PATH = "your_text_file.txt"# 初始化嵌入模型
from langchain.embeddings import HuggingFaceEmbeddings
embeddings_model = HuggingFaceEmbeddings()# 初始化大语言模型,这里使用 ChatOpenAI 作为示例,可根据需求替换
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)# 定义假设性问题模型
class HypotheticalQuestions(BaseModel):"""生成假设性问题"""questions: List[str] = Field(..., description="List of questions")# 创建提示模板
prompt = ChatPromptTemplate.from_template("""生成一个包含3个假设问题的列表,以下文档可用于回答这些问题:{doc}"""
)# 创建假设性问题链
chain = ({"doc": lambda x: x.page_content}| prompt# 将LLM输出构建为字符串列表| llm.with_structured_output(HypotheticalQuestions)# 提取问题列表| (lambda x: x.questions)
)# 数据加载
# 初始化文档加载器
loader = TextLoader(TXT_DOCUMENT_PATH, encoding='utf-8')
# 加载文档
docs = loader.load()# 分割文档(如果需要)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(docs)# 针对文档1生成假设性问题
# chain.invoke(docs[0])# 批量处理所有文档生成假设性问题(最大并行数5)
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5})
# print(hypothetical_questions)# 初始化Chroma向量数据库(存储生成的问题向量)
vectorstore = Chroma(collection_name="hypo-questions", embedding_function=embeddings_model
)
# 初始化内存存储(存储原始文档)
store = InMemoryByteStore()id_key = "doc_id" # 文档标识键名# 配置多向量检索器
retriever = MultiVectorRetriever(vectorstore=vectorstore,byte_store=store,id_key=id_key,search_kwargs={"k": 1}
)# 为每个原始文档生成唯一ID
doc_ids = [str(uuid.uuid4()) for _ in docs]# 将生成的问题转换为带元数据的文档对象
question_docs = []
for i, question_list in enumerate(hypothetical_questions):question_docs.extend([Document(page_content=s, metadata={id_key: doc_ids[i]}) for s in question_list])# 将问题文档存入向量数据库
retriever.vectorstore.add_documents(question_docs)
# 将原始文档存入字节存储(通过ID关联)
retriever.docstore.mset(list(zip(doc_ids, docs)))# 进行检索
sub_docs = retriever.vectorstore.similarity_search("deepseek受到哪些攻击?")print("==========================检索到的相似问题==========================")
if sub_docs:print(sub_docs[0].page_content)
else:print("未检索到相似问题")print("==========================自动匹配问题文档块==========================")
retrieved_docs = retriever.invoke("deepseek受到哪些攻击?")
if retrieved_docs:print(retrieved_docs[0].page_content)
else:print("未检索到匹配的文档块")这段代码的重点在于HypotheticalQuestions 结合 langchain 链的使用,将文档拆分为多个假设性问题。而后我们使用了MultiVectorRetriever多向量检索器存储了两个库,一个是向量库,用来存假设性问题,一个是内存库,用来存问题对应的文档块。
元数据索引
与传统依赖文本内容语义分析的检索方式不同,元数据索引利用预先定义的标签、属性、类别等结构化元数据信息,构建起一套轻量化、结构化的检索体系。
例如,在企业知识库场景中,文档可能包含产品手册、技术规范、市场报告等多种类型,通过为每个文档添加 “文档类型”“创建时间”“所属部门”“关键词标签” 等元数据,系统能够快速定位特定条件下的文档集合。当用户想要检索 “过去一年由研发部门创建的技术规范” 时,元数据索引可直接基于 “创建时间”“所属部门”“文档类型” 等元数据进行快速筛选,在无需深入分析文本内容语义的情况下,即可高效返回目标数据集。这种检索方式不仅大幅提升了数据检索的效率,还能有效降低计算资源消耗,尤其适用于数据集规模庞大、数据类型多样且检索需求具有明确结构化特征的场景,为 RAG 系统快速锁定相关数据、提升检索响应速度提供了有力支持 。
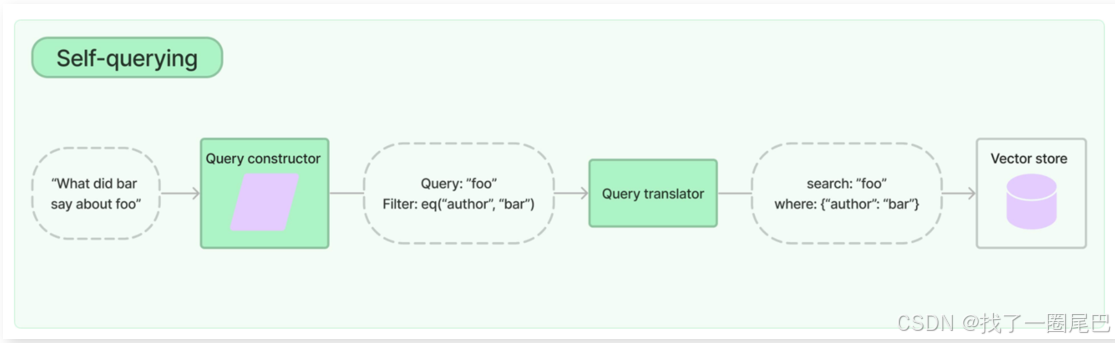
接下来,让我们写一段关于元数据索引检索的代码示例:
from langchain.schema import Document
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever# 初始化嵌入模型
embeddings_model = HuggingFaceEmbeddings()# 初始化大语言模型,这里使用 ChatOpenAI 作为示例,可根据需求替换
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)# 定义文档列表
docs = [Document(page_content="小米智能手环6",metadata={"品牌": "小米", "价格": 249, "评分": 4.6}),Document(page_content="华为FreeBuds Pro无线耳机",metadata={"品牌": "华为", "价格": 999, "评分": 4.8}),Document(page_content="小米移动电源3",metadata={"品牌": "小米", "价格": 99, "评分": 4.4}),Document(page_content="华为Mate 40 Pro智能手机",metadata={"品牌": "华为", "价格": 6999, "评分": 5.0}),Document(page_content="小米AirDots Pro蓝牙耳机",metadata={"品牌": "小米", "价格": 299, "评分": 4.5}),Document(page_content="华为智能手表GT 2",metadata={"品牌": "华为", "价格": 1288, "评分": 4.7}),Document(page_content="小米小爱音箱Play",metadata={"品牌": "小米", "价格": 169, "评分": 4.3})
]# 元数据字段定义(指导LLM如何解析查询条件)
metadata_field_info = [{"name": "品牌", "type": "string", "description": "产品的品牌名称"},{"name": "价格", "type": "integer", "description": "产品的价格"},{"name": "评分", "type": "float", "description": "产品的用户评分"},
]# 文档内容描述(指导LLM理解文档内容)
document_content_description = "电子产品的信息"# 创建向量存储
vectorstore = Chroma.from_documents(docs, embeddings_model, collection_name="self-query")# 创建自查询检索器(核心组件)
retriever = SelfQueryRetriever.from_llm(llm,vectorstore,document_content_description,metadata_field_info,
)# 示例查询
query = "查找价格低于 500 且评分高于 4.5 的小米产品"
results = retriever.get_relevant_documents(query)# 输出查询结果
print(f"查询: {query}")
for result in results:print(f"产品: {result.page_content}, 品牌: {result.metadata['品牌']}, 价格: {result.metadata['价格']}, 评分: {result.metadata['评分']}") 这段代码的核心是通过 SelfQueryRetriever.from_llm 方法创建的自查询检索器 retriever。该方法接受大语言模型 llm、向量存储 vectorstore、文档内容描述 document_content_description 和元数据字段信息 metadata_field_info 作为参数,构建出一个能够根据用户输入的自然语言查询,自动解析查询条件并在向量存储中进行检索的检索器。
为了辅助大模型进行元数据的处理转换,我们还需要一段比较标准的,可以将问题转换为元数据的提示词,像这样:
你的目标是按照以下提供的结构化请求模式,对用户的查询进行结构化处理。
请以 Markdown 代码片段的形式回复,其中包含符合以下格式的 JSON 对象:
{"query": string, // 用于与文档内容进行比较的文本字符串"filter": string // 用于筛选文档的逻辑条件语句 }注意事项:
查询字符串:应仅包含期望与文档内容匹配的文本。筛选条件中的任何条件都不应在查询字符串中出现。
逻辑条件语句:由一个或多个比较和逻辑运算语句组成。
比较语句格式:
comp(attr,val)
comp(取值为 eq、ne、gt、gte、lt、lte、contain、like、in、nin):分别表示等于、不等于、大于、大于等于、小于、小于等于、包含、模糊匹配、在、不在这些比较操作。
attr(字符串类型):要应用比较操作的属性名称。
val(字符串类型):比较时使用的值。逻辑运算语句格式:
op(statement1,statement2,…)
op(取值为 and、or、not):分别表示逻辑与、逻辑或、逻辑非运算符。
statement1,statement2, 等(可以是比较语句或逻辑运算语句):是一个或多个要应用逻辑运算的语句。运算符使用限制:确保仅使用上述列出的比较器和逻辑运算符,不要使用其他运算符。
属性引用:确保筛选器中引用的属性是数据源中实际存在的属性。
函数使用规范:确保筛选条件仅使用函数名称及其对应的属性名称(当对属性应用函数时)。
日期格式:当筛选条件涉及处理日期类型值时,仅使用 “YYYY-MM-DD” 格式。
数据类型匹配:确保筛选条件根据属性的描述进行操作,仅进行与存储数据类型相符的可行比较。
筛选条件的使用:确保仅在有需要时使用筛选条件。如果不存在需要应用的筛选条件,请将
filter的值设置为 "NO_FILTER"。
示例 1
数据来源:
{"content": "歌曲歌词","attributes": {"artist": {"type": "string","description": "歌曲艺术家的名称"},"length": {"type": "integer","description": "歌曲时长(秒)"},"genre": {"type": "string","description": "歌曲类型,可以是 \"pop\", \"rock\" 或 \"rap\""}} }用户查询:泰勒・斯威夫特或凯蒂・佩里创作的关于青少年爱情的时长少于 3 分钟的舞曲流行歌曲有哪些?
结构化请求:
{"query": "青少年爱情","filter": "and(or(eq(\"artist\", \"Taylor Swift\"), eq(\"artist\", \"Katy Perry\")), lt(\"length\", 180), eq(\"genre\", \"pop\"))" }示例 2
数据来源:
{"content": "歌曲歌词","attributes": {"artist": {"type": "string","description": "歌曲艺术家的名称"},"length": {"type": "integer","description": "歌曲时长(秒)"},"genre": {"type": "string","description": "歌曲类型,可以是 \"pop\", \"rock\" 或 \"rap\""}} }用户查询:
哪些歌曲没有在 Spotify 上发布结构化请求:
{"query": "","filter": "NO_FILTER" }示例 3
数据来源:
{"content": "电子产品的信息","attributes": {"品名": {"type": "string","description": "产品的品牌名称"},"价格": {"type": "integer","description": "产品的价格"},"评分": {"type": "float","description": "产品的用户评分"}} }用户查询:
小米价格高于200元的耳机结构化请求:
对应测试的代码片段:
# 由大模型进行提取问题的提示词from langchain.chains.query_constructor.base import get_query_constructor_prompt# 构建查询解析器(调试用)
prompt = get_query_constructor_prompt(document_content_description,metadata_field_info,
)
print(prompt.format(query="小米价格高于200元的耳机"))总结
最后,我们对本次介绍的Advanced RAG 的预检索优化方法进行小结,本次提到了四种预检索优化的方法,包括摘要索引、父子索引、假设性问题索引、元数据索引。
| 索引类型 | 适用场景 | 案例 |
|---|---|---|
| 摘要索引 | 适用于需要快速检索和生成简洁上下文的场景。 | 在新闻资讯平台中,系统需要快速从海量新闻中提取关键信息,通过摘要索引可以迅速生成简洁的上下文,帮助用户快速了解新闻的核心内容。 |
| 父子索引 | 适用于需要确保语义完整性和层次化检索的场景。 | 在法律检索系统中,用户查询法律条款时,父子索引通过分层检索精准查找相关内容,并召回对应大文档块确保上下文的完整性,避免因分块过细导致语义丢失。 |
| 假设性问题索引 | 适用于需要处理复杂查询和多样化表达的场景。 | 在药品咨询系统中,用户查询症状时可能会问:“感冒了吃什么药?”。假设性问题索引通过为每种药品生成一系列假设性问题,帮助用户更准确地检索到相关信息。 |
| 元数据索引 | 适用于需要快速筛选和分类的场景。 | 在电商推荐系统中,系统通过元数据索引快速筛选出符合用户偏好的商品信息,提高推荐效率和准确性。 |
相关文章:
)
RAG工程-基于LangChain 实现 Advanced RAG(预检索优化)
Advanced RAG 概述 Advanced RAG 被誉为 RAG 的第二范式,它是在 Naive RAG 基础上发展起来的检索增强生成架构,旨在解决 Naive RAG 存在的一些问题,如召回率低、组装 prompt 时的冗余和重复以及灵活性不足等。它重点聚焦在检索增强࿰…...
循环结构程序设计习题1)
【时时三省】(C语言基础)循环结构程序设计习题1
山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 习题1 输入两个正整数m和n,求其最大公约数和最小公倍数。 解题思路: 求两个正整数 m 和 n 的最大公约数通常使用辗转相除法(欧几里得算法ÿ…...
)
[密码学实战]SDF之设备管理类函数(一)
[密码学实战]SDF之设备管理类函数(一) 一、标准解读:GM/T 0018-2023核心要求 1.1 SDF接口定位 安全边界:硬件密码设备与应用系统间的标准交互层功能范畴: #mermaid-svg-s3JXUdtH4erONmq9 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16p…...

CDGP|如何建立高效的数据治理团队?
近年来,数据治理行业迅速发展,越来越多的企业开始重视并投入大量资源来建立和完善数据治理体系。数据治理体系不仅能够帮助企业更好地管理和利用数据资源,提升数据质量和数据价值,还能够为企业带来竞争优势和可持续发展能力。 然…...

如何评价 DeepSeek 的 DeepSeek-V3 模型?
DeepSeek-V3 是由杭州 DeepSeek 公司于 2024 年 12 月 26 日发布的一款开源大语言模型,其性能和创新技术在国内外引起了广泛关注。从多个方面来看,DeepSeek-V3 的表现令人印象深刻,具体评价如下: 性能卓越 DeepSeek-V3 拥有 6710 …...

【基础篇】prometheus命令行参数详解
文章目录 本篇内容讲解命令行参数详解 本篇内容讲解 prometheus高频修改命令行参数详解 命令行参数详解 在页面的/页面上能看到所有的命令行参数,如图所示: 使用shell命令查看 # ./prometheus --help usage: prometheus [<flags>]The Promethe…...

SpringBoot实现接口防刷的5种高效方案详解
目录 前言:接口防刷的重要性 方案一:基于注解的访问频率限制 实现原理 核心代码实现 使用示例 优缺点分析 方案二:令牌桶算法实现限流 算法原理 核心实现 配置使用 适用场景分析 方案三:分布式限流(Redis …...

DeepSearch复现篇:QwQ-32B ToolCall功能初探,以Agentic RAG为例
DeepSearch复现篇:QwQ-32B ToolCall功能初探,以Agentic RAG为例 作者:CyPaul Space 原文地址:https://zhuanlan.zhihu.com/p/30289363967 全文阅读约3分钟~ 背景 今天看到 论文:Search-R1: Training LLMs to Reason …...

项目实战-贪吃蛇大作战【补档】
这其实算是一个补档,因为这个项目是我在大一完成的,但是当时没有存档的习惯,今天翻以前代码的时候翻到了,于是乎补个档,以此怀念和志同道合的网友一起做项目的日子 ₍ᐢ ›̥̥̥ ༝ ‹̥̥̥ ᐢ₎♡ 这里面我主要负责…...

power bi获取局域网内共享文件
power bi获取局域网内共享文件 需求: 数据源并不一定都是在本地,有可能在云端,也有可能在其他服务器,今天分享如果数据源在另外一台服务器,如何获取数据源的方法。 明确需求:需要通过PowerBI获取局域网中的…...

100%提升信号完整性:阻抗匹配在高速SerDes中的实践与影响
一个高速信号SerDes通道(例如PCIe、112G/224G-PAM4)包含了这些片段: 传输线连通孔(PTH or B/B via)连接器高速Cable锡球(Ball and Bump) 我们会希望所有的片段都可以有一致的阻抗,…...

第六章:Tool and LLM Integration
Chapter 6: Tool and LLM Integration 从执行流到工具集成:如何让AI“调用真实世界的技能”? 在上一章的执行流框架中,我们已经能让多个代理协作完成复杂任务。但你是否想过:如果用户要求“查询实时天气”或“打开网页搜索”&…...

prompt提示词编写技巧
为什么学习prompt编写 目的:通过prompt的编写,提升LLM输出相关性、准确性和多样性,并对模型输出的格式进行限制,满足我们的业务需求。 学过提示词工程的人:像“专业导演”,通过精准指令控制 AI 输出&#…...

Nginx配置SSL详解
文章目录 Nginx配置SSL详解1. SSL/TLS 基础知识2. 准备工作3. 获取SSL证书4. Nginx SSL配置步骤4.1 基础配置4.2 配置说明 5. 常见配置示例5.1 双向认证配置5.2 多域名SSL配置 6. 安全优化建议7. 故障排查总结参考资源下载验证的完整实例 Nginx配置SSL详解 1. SSL/TLS 基础知识…...

网络安全之红队LLM的大模型自动化越狱
前言 大型语言模型(LLMs)已成为现代机器学习的重要支柱,广泛应用于各个领域。通过对大规模数据的训练,这些模型掌握了多样化的技能,展现出强大的生成与理解能力。然而,由于训练数据中难以完全剔除有毒内容&…...
)
【技术笔记】通过Cadence Allegro创建一个PCB封装(以SOT23为例)
【技术笔记】通过Cadence Allegro创建一个PCB封装(以SOT23为例) 一、焊盘创建二、PCB封装设计三、丝印位号及标识添加 更多内容见专栏:【硬件设计遇到了不少问题】、【Cadence从原理图到PCB设计】 一、焊盘创建 首先要找到元器件的相关手册&…...

新环境注册为Jupyter 内核
1. 确认环境是否已注册为内核 在终端运行以下命令,查看所有已注册的内核: jupyter kernelspec list2. 为自定义环境注册内核 步骤 1:激活目标虚拟环境 conda activate your_env_name # 替换为你的环境名步骤 2:安装…...

[Spring] Seata详解
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

使用JDK的数据校验和Spring的自定义注解校验前端传递参数的两种方法
第一种:JDK的数据校验注解 PostMapping("/test")public String test(QueryParam param, RequestHeader(value "App_key") String App_key,RequestHeader(value "App_secret") String App_secret) throws IOException {param.setApp…...
)
JS错误处理的新方案 (不使用try-catch)
错误处理一直是JavaScript开发者需要认真对待的问题,传统的try-catch语法虽然简单直观,但在异步代码中使用时存在诸多限制。 try-catch的局限性 传统try-catch模式在现代JavaScript开发中面临的问题: 1. 异步错误捕获的缺陷 try-catch无法…...
)
前端实现商品放大镜效果(Vue3完整实现)
前端实现商品放大镜效果(Vue3完整实现) 前言 在电商类项目中,商品图片的细节展示至关重要。放大镜效果能显著提升用户体验,允许用户在不跳转页面的情况下查看高清细节。本文将基于Vue3实现一个高性能的放大镜组件,完整…...

redis未授权访问漏洞学习
一、Redis常见用途 1. Redis介绍 全称与起源: Redis全称Remote Dictionary Service(远程字典服务),最初由antirez在2009年开发,用于解决网站访问记录统计的性能问题。发展历程: 从最初仅支持列表功能的内存数据库,经过十余年发展已支持多种…...

阿里qiankun微服务搭建
主服务 chat vue3 ts vite 子服务 ppt react 18 vite 子服务 agent 主服务 npm i vite-plugin-qiankun mian.ts import ./style/base.scss import virtual:svg-icons-register import { createApp } from vue import { createPinia } from piniaimport App from ./App.vue im…...

【CodeSprint】第二章-2.1 简单模拟
第二章 2.1 简单模拟 ✏️ 关于专栏:专栏用于记录 prepare for the coding test。 1. 简单模拟 简单模拟题目不需要复杂算法,直接按照题意一步步模拟即可。 1.1 促销计算 题目描述 某百货公司为了促销,采用购物打折的优惠方法:…...

Golang实现函数默认参数
golang原生不支持默认参数 在日常开发中,我们有时候需要使用默认设置,但有时候需要提供自定义设置 结构体/类,在Java我们可以使用无参、有参构造函数来实现,在PHP中我们也可以实现(如 public function xxx($isCName false, $sec…...

【Python Web开发】03-HTTP协议
文章目录 1. HTTP协议基础1.1 请求-响应模型1.2 请求方法1.3 请求和响应结构1.4 状态码 2. Python 发送 HTTP 请求2.1 urllib库2.2 requests 库 3. Python 构建 HTTP 服务器3.1 http.server模块3.2 Flask 框架 4. HTTP 协议的安全问题5. 缓存和性能优化 HTTP(Hypert…...

提高营销活动ROI:大数据驱动的精准决策
提高营销活动ROI:大数据驱动的精准决策 大家好,我是Echo_Wish。今天我们来聊聊如何通过大数据来提高营销活动的ROI(投资回报率)。我们都知道,随着市场的日益竞争,营销的成本不断增加,如何在这片红海中脱颖而出,不仅需要精准的营销策略,还需要依靠先进的技术,尤其是大…...

前端excel导出
在数据可视化和管理日益重要的今天,前端实现 Excel 导出功能已经成为众多项目中的刚需。 一、Excel 导出的常见场景 数据报表导出:在企业管理系统、数据分析平台中,用户经常需要将系统中的数据以 Excel 表格的形式导出,便于离…...
)
pymsql(SQL注入与防SQL注入)
SQL注入: import pymysql# 创建数据库连接 返回一个对象 conn pymysql.connect(host"localhost", # MySQL服务器地址 本地地址 127.0.0.1user"root", # 用户名 (账号)password"155480", # 密码database&qu…...

基于Springboot + vue + 爬虫实现的高考志愿智能推荐系统
项目描述 本系统包含管理员和学生两个角色。 管理员角色: 个人中心管理:管理员可以管理自己的个人信息。 高校信息管理:管理员可以查询、添加或删除高校信息,并查看高校详细信息。 学生管理:管理员可以查询、添加或…...

delphi使用sqlite3
看了一下delphi调用sqlite3最新版本的调用,网上说的都很片面,也没有完整的资料了。 我自己研究了一下,分享出来。 在调用demo中,官方也给了一个demo但是功能很少,没有参考价值。 1.定义: 首先把sqlite3…...

高压开关柜局部放电信号分析系统
高压开关柜局部放电信号分析系统 - 开发笔记 1. 项目概述 这个项目是我在2025年实现的高压开关柜局部放电信号分析系统,目的是通过采集分析局部放电信号,判断设备的工作状态和潜在故障。系统包含从信号模拟生成、特征提取、到深度学习模型训练的全流程…...

ai环境conda带torch整体迁移。
conda打包好的GPU版torch环境,其实很简单,就是conda装好的torch环境env整体打包,然后到新机器上再解压到env路径。 打开搭建好的环境,找自己路径,我默认的是这个。 cd/root/anaconda3/envs/ 然后整个文件夹打包。tar -…...

电价单位解析与用电设备耗电成本计算
一、电价单位 元/kWh 的解析 定义: 元/kWh 表示每千瓦时电能的费用,即1度电的价格。例如,若电价为0.5元/kWh,则使用1千瓦的电器1小时需支付0.5元。 电价构成: 中国销售电价由四部分组成: 上网电价…...
)
辛格迪客户案例 | 华道生物细胞治疗生产及追溯项目(CGTS)
01 华道(上海)生物医药有限公司:细胞治疗领域的创新先锋 华道(上海)生物医药有限公司(以下简称“华道生物”)是一家专注于细胞治疗技术研发与应用的创新型企业,尤其在CAR-T细胞免疫…...
(十三)——继承)
C++(初阶)(十三)——继承
继承 继承概念示例 定义格式 继承和访问方式继承方式访问方式实例 继承类模板基类和派生类之间的转换继承中的作用域隐藏规则选择题 派生类的默认成员函数默认成员函数派生类中的实现 实现一个不能被继承的类继承与友元继承与静态成员多继承及其菱形继承问题虚继承多继承指针偏…...

S09-电机运行时间
感谢粉丝网友的支持,也欢迎你们的讨论和分享。昨天我们简单讨论了一下标准功能块的重要性,仅仅是拿电机块举了一个例子,有粉丝问能否把电机运行时间做到块里面,完善一下功能呢?那是绝对当然的100%可以的啊!…...
微调技术总结)
大语言模型(LLMs)微调技术总结
文章目录 全面总结当前大语言模型(LLM)微调技术1. 引言2. 为什么需要微调?3. 微调技术分类概览4. 各种微调技术详细介绍4.1 基础微调方法4.1.1 有监督微调(Supervised Fine-Tuning, SFT)4.1.2 全参数微调(F…...

python练习:求数字的阶乘
求数字的阶乘 eg:5的阶乘 54321 """ 求数字的阶乘 eg:5的阶乘 5*4*3*2*1 """count 1 for i in range(1,6):count count * iprint(count)运行结果:...

综合练习一
背景 某银行监管系统,需要设计并实现用户登入记录功能,每个用户登入系统时,系统自动记录登入用户的账户、登入时间、登入失败成功与否信息等,普通用户只能登入登出,管理员可以登入后查看日志及分析统计信息等。 用户…...

List--链表
一、链表 1.1 什么是List? 在C语言中,我们需要使用结构体struct来进行List(链表)的实现: struct ListNode {DataType Data;//DataType是任意类型的变量定义struct ListNode* next;//指向下一个结点的指针变量 }; 与之前的vect…...

SpeedyAutoLoot
SpeedyAutoLoot自动拾取插件 SpeedyAutoLoot.lua local AutoLoot CreateFrame(Frame)SpeedyAutoLootDB SpeedyAutoLootDB or {} SpeedyAutoLootDB.global SpeedyAutoLootDB.global or {}local BACKPACK_CONTAINER BACKPACK_CONTAINER local LOOT_SLOT_CURRENCY LOOT_SLOT…...

编程日志4.23
栈的C顺序表实现 #include<iostream> #include<stdexcept> using namespace std; //模板声明,表明Stack类是一个通用的模板,可以用于存储任何类型的元素T template<typename T> //栈的声明 //Stack类的声明,表示一个栈的…...

打印所有字段
package com.volvo.midend.vehicle;import com.volvo.midend.vehicle.dto.out.vista.VistaDemoVO;import java.lang.reflect.Field;public class TestAllFiled {// 递归打印类的所有字段public static void printAllFields(Class<?> clazz, int indentLevel) {// 根据缩…...

4G FS800DTU上传图像至巴法云
目录 1 前言 2 准备工作 2.1 硬件准备 2.2 软件环境 2.3 硬件连接 3 实现方案 4 巴法云平台账号创建与设备联网配置 4.1 创建账号 4.2 进入巴法云 4.3 获取联网参数 4.4 连接巴法云 5 拍照上传至巴法云 6 ESP32-CAM程序 7 总结 1 前言 巴法云(Bemfa Cloud)是一个…...

一键叠图工具
写了个拼图小工具 供大家测试 APP安卓的 测试下载 点击下载 百度网盘: https://pan.baidu.com/s/17B5KVIMMZlOAsF7a16KNug?pwd1234 提取码: 1234 拼图步骤:选图--选择变亮或变暗--滤镜发色 在正式开始之前,我们来定义几条原则先(熟悉…...

【OSG学习笔记】Day 12: 回调机制——动态更新场景
UpdateCallback 在OpenSceneGraph(OSG)里,UpdateCallback是用来动态更新场景的关键机制。 借助UpdateCallback,你能够实现节点的动画效果,像旋转、位移等。 NodeCallback osg::NodeCallback 是一个更通用的回调类&…...

快速上手Prism WPF 工程
1、Prism 介绍 定位: Prism 是 微软推出的框架,专为构建 模块化、可维护的复合式应用程序 设计,主要支持 WPF、Xamarin.Forms、UWP 等平台。核心功能: 模块化开发:将应用拆分为独立模块,…...

Dockerfile讲解与示例汇总
容器化技术已经成为应用开发和部署的标准方式,而Docker作为其中的佼佼者,以其轻量、高效、可移植的特性,深受开发者和运维人员的喜爱。本文将从实用角度出发,分享各类常用服务的Docker部署脚本与最佳实践,希望能帮助各位在容器化之路上少走弯路。 无论你是刚接触Docker的…...
——MATLAB技巧)
MATLAB Coder代码生成(工业部署)——MATLAB技巧
MATLAB Coder是MATLAB生态中用于将算法代码转换为C/C++代码的核心工具,其生成的代码可直接部署到嵌入式硬件、工业控制器或企业级应用中,尤其在智能制造、物联网和实时控制领域具有广泛应用。 通过 MATLAB Coder,可以轻松地将 MATLAB 代码转换为高效的 C/C++ 代码,适用于嵌…...