NIPS2021 | 视觉 Transformer 的有趣特性
Intriguing Properties of Vision Transformers
- 摘要-Abstract
- 引言-Introduction
- 相关工作-Related Work
- 视觉Transformer的有趣特性-Intriguing Properties of Vision Transformers
- 视觉Transformer对遮挡具有鲁棒性吗?-Are Vision Transformers Robust to Occlusions?
- 形状与纹理:Transformer能否对两种特征同时建模?-Shape vs. Texture: Can Transformer Model Both Characteristics?
- 位置编码是否保留全局图像上下文?-Does Positional Encoding Preserve the Global Image Context?
- 视觉Transformer对对抗性和自然扰动的鲁棒性-Robustness of Vision Transformers to Adversarial and Natural Perturbations
- 视觉Transformer的有效现成标记-Effective Off-the-shelf Tokens for Vision Transformer
- 讨论和结论-Discussion and Conclusion

论文链接
GitHub链接
本文 “Intriguing Properties of Vision Transformers” 系统研究了视觉 Transformer(ViT)的特性,并与CNN对比。发现 ViT 对严重遮挡、扰动和域偏移具有高度鲁棒性;其对形状的识别能力强,纹理偏差小,经训练可实现无像素级监督的语义分割;ViT 的现成特征可组合成特征集合,在传统和少样本学习范式中表现出色。研究还探讨了位置编码等因素对 ViT 性能的影响,为后续研究提供了方向。
摘要-Abstract
Vision transformers (ViT) have demonstrated impressive performance across numerous machine vision tasks. These models are based on multi-head self-attention mechanisms that can flexibly attend to a sequence of image patches to encode contextual cues. An important question is how such flexibility (in attending image-wide context conditioned on a given patch) can facilitate handling nuisances in natural images e.g., severe occlusions, domain shifts, spatial permutations, adversarial and natural perturbations. We systematically study this question via an extensive set of experiments encompassing three ViT families and provide comparisons with a high-performing convolutional neural network (CNN). We show and analyze the following intriguing properties of ViT: (a) Transformers are highly robust to severe occlusions, perturbations and domain shifts, e.g., retain as high as 60% top-1 accuracy on ImageNet even after randomly occluding 80% of the image content. (b) The robustness towards occlusions is not due to texture bias, instead we show that ViTs are significantly less biased towards local textures, compared to CNNs. When properly trained to encode shape-based features, ViTs demonstrate shape recognition capability comparable to that of human visual system, previously unmatched in the literature. © Using ViTs to encode shape representation leads to an interesting consequence of accurate semantic segmentation without pixel-level supervision. (d) Off-the-shelf features from a single ViT model can be combined to create a feature ensemble, leading to high accuracy rates across a range of classification datasets in both traditional and few-shot learning paradigms. We show effective features of ViTs are due to flexible and dynamic receptive fields possible via self-attention mechanisms.
视觉Transformer(ViT)在众多机器视觉任务中展现出了令人瞩目的性能。这些模型基于多头自注意力机制,能够灵活地关注一系列图像patch,对上下文线索进行编码。一个重要的问题是,这种灵活性(即基于给定patch关注全图上下文)如何有助于处理自然图像中的干扰因素,例如严重遮挡、域偏移、空间排列变化、对抗性扰动和自然扰动。我们通过涵盖三个ViT系列的大量实验,系统地研究了这个问题,并与高性能卷积神经网络(CNN)进行了比较。我们展示并分析了ViT的以下有趣特性:(a)Transformer对严重遮挡、扰动和域偏移具有高度鲁棒性,例如,即使在随机遮挡ImageNet中80%的图像内容后,仍能保持高达60%的top-1准确率。(b)对遮挡的鲁棒性并非源于纹理偏差,相反,我们发现与CNN相比,ViT对局部纹理的偏差明显更小。经过适当训练以编码基于形状的特征后,ViT展现出的形状识别能力可与人类视觉系统相媲美,这在以往的文献中是前所未有的。(c)使用ViT对形状表示进行编码会产生一个有趣的结果,即无需像素级监督即可实现精确的语义分割。(d)单个ViT模型的现成特征可以组合形成特征集合,在传统和少样本学习范式下的一系列分类数据集中都能实现高准确率。我们证明了ViT的有效特征得益于通过自注意力机制实现的灵活动态感受野。
引言-Introduction
这部分内容主要阐述了研究视觉Transformer(ViT)学习表示特性的重要性,对比了其与卷积神经网络(CNN)在处理多种干扰因素和泛化能力上的差异,介绍了实验基于的模型和数据集,并说明了研究的主要发现和创新设计,具体如下:
- 研究背景与动机:ViT在机器视觉领域备受关注,研究其学习表示特性至关重要,尤其是在安全关键应用场景下,需要模型具有强大的鲁棒性和泛化能力。
- 研究内容:对比ViT与CNN在处理遮挡、分布转移、对抗和自然扰动等干扰因素,以及在不同数据分布上的泛化能力。基于ViT、DeiT和T2T三个Transformer家族,在十五个视觉数据集上展开深入分析。
- 研究发现
- 遮挡鲁棒性:与最先进的CNN相比,ViT在面对前景物体、非显著背景区域和随机补丁位置的严重遮挡时表现出更强的鲁棒性。例如,在ImageNet验证集上,DeiT在高达80%的随机遮挡下,仍能保持约60%的top-1准确率,而此时CNN准确率为零。
- 形状识别优势:在形状识别任务中,ViT表现优于CNN,且与人类视觉系统相当,对纹理的依赖程度低于CNN,这使其在处理纹理较少的数据(如绘画)时,能更好地识别物体形状。
- 综合鲁棒性:ViT在应对空间patch级排列、对抗扰动和常见自然损坏(如噪声、模糊、对比度变化和像素化伪影)等干扰因素时,表现出比CNN更好的鲁棒性。不过,专注于形状训练的ViT和CNN一样,在面对对抗攻击和常见损坏时较为脆弱。
- 特征泛化能力:ImageNet预训练模型的现成ViT特征在新领域(如少样本学习、细粒度识别、场景分类和长尾分类)中具有出色的泛化能力。
- 创新设计:提出对DeiT的架构修改,通过专用token编码形状信息,实现同一架构内对不同线索的建模,进而在无像素级监督下实现自动分割;还介绍了现成特征转移方法,利用单一架构的表示集合,结合预训练ViT获得了最先进的泛化性能。

图1:我们展示了视觉Transformer(ViT)的一些有趣特性,包括其对以下情况表现出的令人印象深刻的鲁棒性:(a)严重的遮挡;(b)分布偏移(例如,通过风格化处理去除纹理线索);(c)对抗性扰动;以及(d)补丁排列。此外,我们经过训练、专注于形状线索的视觉Transformer(ViT)模型能够在没有任何像素级监督的情况下分割前景(e)。最后,视觉Transformer(ViT)模型的现成特征比卷积神经网络(CNNs)的泛化能力更好(f)。
相关工作-Related Work
这部分内容主要回顾了与视觉Transformer(ViT)相关的研究工作,包括CNN和ViT在鲁棒性、形状与纹理学习、特征可视化与泛化等方面的研究,具体如下:
- CNN与ViT的鲁棒性研究对比:CNN在独立同分布(i.i.d)设置下表现出色,但对分布偏移(对抗噪声、常见图像损坏和域偏移)敏感。已有研究分析了ViT对对抗噪声、空间扰动等的鲁棒性,本文则重点关注ViT对patch掩蔽、局部对抗patch和常见自然损坏的鲁棒性,与其他类似研究实验设置有所不同 。
- 形状与纹理学习研究:有研究表明CNN主要利用纹理进行决策,对全局形状重视不足,而本文分析发现大的ViT模型纹理偏差较小,更注重形状信息,在直接在风格化ImageNet上训练时,形状偏差接近人类水平,且本文展示了形状聚焦学习可使图像级监督的ViT模型具备自动分割能力,这与之前关于自监督ViT可自动分割前景物体的研究不同。
- 特征可视化与泛化研究:有方法用于可视化CNN特征并研究现成特征的性能,本文类似地研究了ViT现成特征的泛化能力,并与CNN进行比较。同时,Transformer模型的感受野覆盖整个输入空间,相比CNN更能建模全局上下文和保留结构信息,本文致力于展示ViT灵活感受野和基于内容的上下文建模对学习特征的鲁棒性和泛化性的有效性。
视觉Transformer的有趣特性-Intriguing Properties of Vision Transformers
视觉Transformer对遮挡具有鲁棒性吗?-Are Vision Transformers Robust to Occlusions?
该部分主要研究视觉Transformer(ViT)在遮挡场景下的鲁棒性,通过设计不同的遮挡方式进行实验,并从模型准确率、注意力可视化和特征相关性等方面进行分析,得出ViT对遮挡具有高度鲁棒性的结论,具体内容如下:
- 遮挡建模方法:采用PatchDrop策略定义遮挡,即将输入图像表示为patch序列,选择部分patch并将其像素值设为零来创建遮挡图像。具体有三种变体:
- 随机PatchDrop:随机选择M个patch进行丢弃,如将224×224×3的图像分成196个16×16×3的patch,丢弃100个patch相当于损失51%的图像内容。
- 显著(前景)PatchDrop:利用自监督ViT模型DINO定位显著像素,选择包含前Q%前景信息的补丁进行丢弃,Q%不总是对应像素百分比。
- 非显著(背景)PatchDrop:与显著PatchDrop方法类似,选择包含最低Q%前景信息的补丁进行丢弃。

图2:一张示例图像及其不同的遮挡版本(随机遮挡、显著区域遮挡和非显著区域遮挡)。被遮挡的图像能够被Deit-S模型[3]正确分类,但却被ResNet50模型[28]错误分类。遮挡(黑色)区域的像素值被设为零。
- 模型在遮挡下的鲁棒性能:使用在ImageNet上预训练的模型进行视觉识别任务,在验证集上研究遮挡的影响。定义信息损失(IL)为丢弃patch数与总patch数的比率,通过改变IL获得不同遮挡水平。结果显示,ViT模型在对抗遮挡方面比CNN表现更出色。例如,在随机PatchDrop中,当50%的图像信息被随机丢弃时,ResNet50(2300万参数)准确率仅0.1%,而DeiT-S(2200万参数)可达70%;当90%的图像信息被随机遮挡时,Deit-B仍有37%的准确率,且这种鲁棒性在不同ViT架构中一致。同时,ViT对前景和背景内容的移除也表现出显著的鲁棒性。
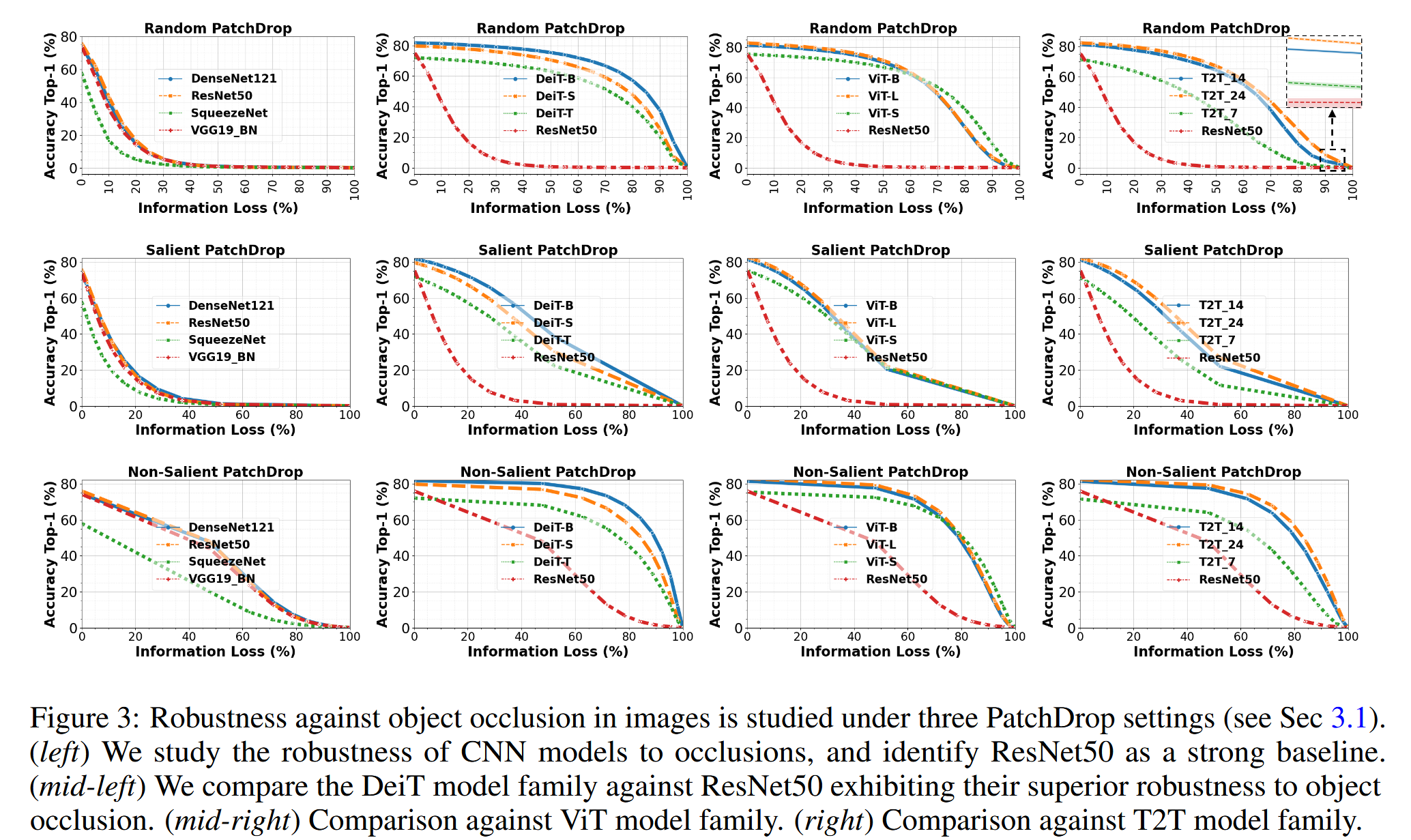
图3:在三种补丁丢弃设置下(见3.1节)研究了图像中对物体遮挡的鲁棒性。(左图)我们研究了卷积神经网络(CNN)模型对遮挡的鲁棒性,并将ResNet50确定为一个强大的基线模型。(左中图)我们将DeiT模型系列与ResNet50进行比较,结果表明DeiT模型系列对物体遮挡具有更强的鲁棒性。(右中图)与视觉Transformer(ViT)模型系列进行比较。(右图)与T2T模型系列进行比较。 - ViT表示对信息损失的鲁棒性:为理解模型在遮挡下的行为,可视化不同层每个头的注意力发现,初始层关注所有区域,深层则更聚焦于图像非遮挡区域的剩余信息。通过计算原始图像和遮挡图像特征/令牌之间的相关系数,发现ViT的类令牌比ResNet50的特征更鲁棒,信息损失更少,且该趋势在不同类别的图像中都成立。

图4:与在ImageNet上预训练的DeiT-B模型的多个层中每个注意力头相关的注意力图(在整个ImageNet验证集上取平均值)。所有图像都用相同的掩码(右下角)进行了遮挡(随机补丁丢弃)。请注意,模型的较后层如何清晰地关注图像的未遮挡区域以做出决策,这证明了该模型具有高度动态的感受野。
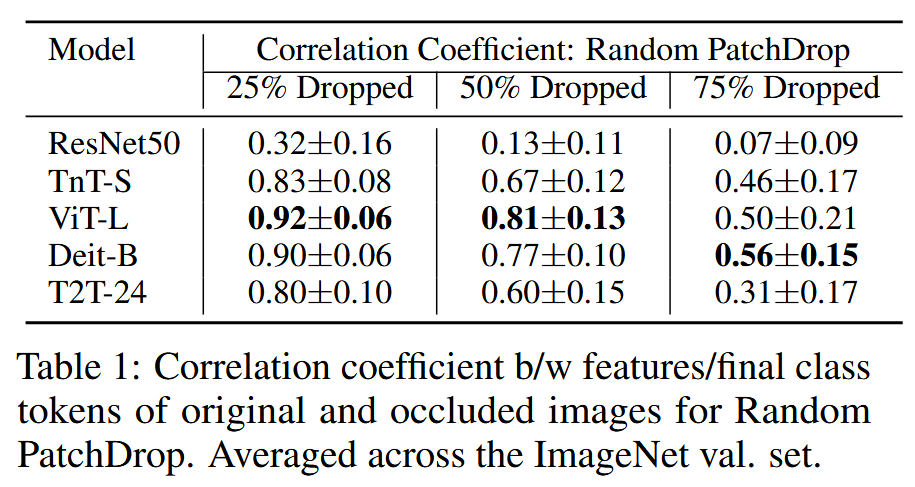
表1:在随机补丁丢弃情况下,原始图像与被遮挡图像的特征/最终类别令牌之间的相关系数。数据为在ImageNet验证集上的平均值。

图5:在50%随机遮挡情况下,原始图像与被遮挡图像的特征/最终令牌之间的相关性。结果是对每个超类中的各类别取平均值得到的。
形状与纹理:Transformer能否对两种特征同时建模?-Shape vs. Texture: Can Transformer Model Both Characteristics?
这部分主要探究Transformer能否同时对形状和纹理特征进行建模,通过实验表明ViT在形状识别上比CNN表现更优,且引入形状token后能在同一架构中平衡两种特征的建模,还能实现无像素级监督的自动语义分割,具体内容如下:
- 训练无局部纹理模型:借鉴前人研究,通过创建名为SIN的风格化ImageNet数据集,去除训练数据中的局部纹理线索,然后在该数据集上训练DeiT模型。研究发现,在ImageNet上训练的ViT比类似容量的CNN具有更高的形状偏差,而在SIN上训练的ViT在形状识别任务上表现更优,DeiT-S在SIN上训练时甚至能达到人类水平的性能。
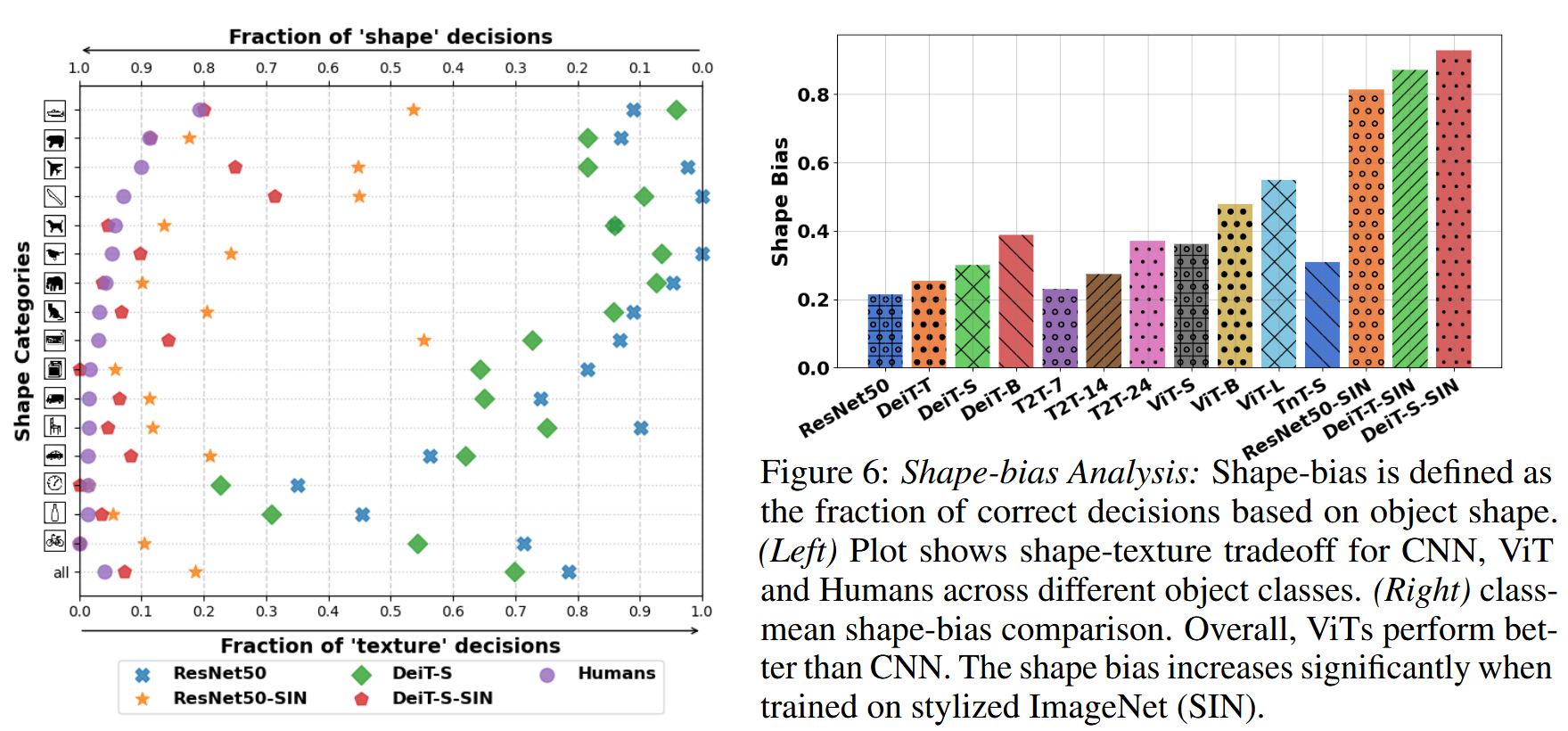
图6:形状偏差分析:形状偏差被定义为基于物体形状做出正确决策的比例。(左图)该图展示了卷积神经网络(CNN)、视觉Transformer(ViT)和人类在不同物体类别上在形状与纹理方面的权衡情况。(右图)为类别平均形状偏差比较。总体而言,视觉Transformer(ViT)的表现优于卷积神经网络(CNN)。当在风格化的ImageNet(SIN)上进行训练时,形状偏差会显著增加。 - 形状蒸馏:采用知识蒸馏方法,引入新的token令牌,从在SIN数据集上训练的CNN(ResNet50-SIN)中蒸馏形状知识到ViT模型。实验表明,ViT的特征具有动态性,可通过辅助token聚焦于所需特征。引入形状token后,ViT模型在分类性能和形状偏差度量上实现了更平衡的表现,且类token和形状token之间的余弦相似度较低,证实了它们能建模独特特征,这是CNN难以实现的。

表3:在风格化ImageNet(SIN)上训练的模型的性能比较。视觉Transformer(ViT)生成的动态特征可以由辅助令牌进行控制。“cls”代表类别令牌。在蒸馏过程中,与[3]相比,使用相同的特征时,类别令牌(cls)和形状令牌收敛到截然不同的结果。
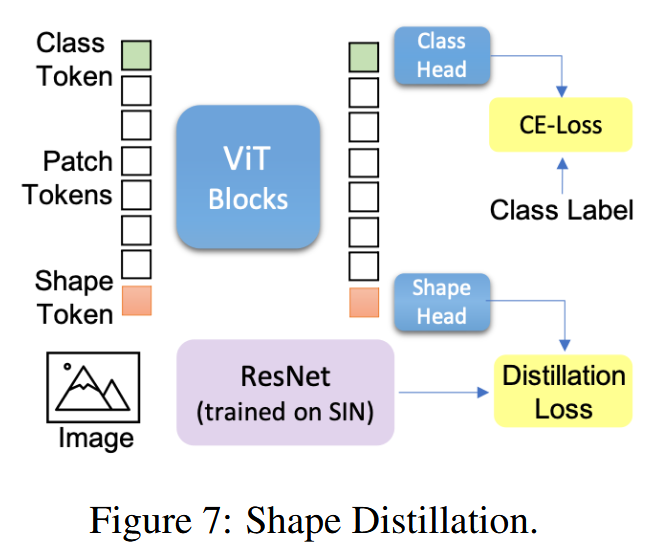
图7:形状蒸馏。 - 形状偏置的ViT实现自动目标分割:训练无局部纹理或经过形状蒸馏的ViT能够专注于场景中的前景物体,忽略背景,从而实现图像的自动语义分割,尽管模型从未见过像素级的物体标签。通过计算Jaccard指数评估,发现这种方法下的ViT模型在PASCAL - VOC12验证集上的表现接近自监督方法DINO。
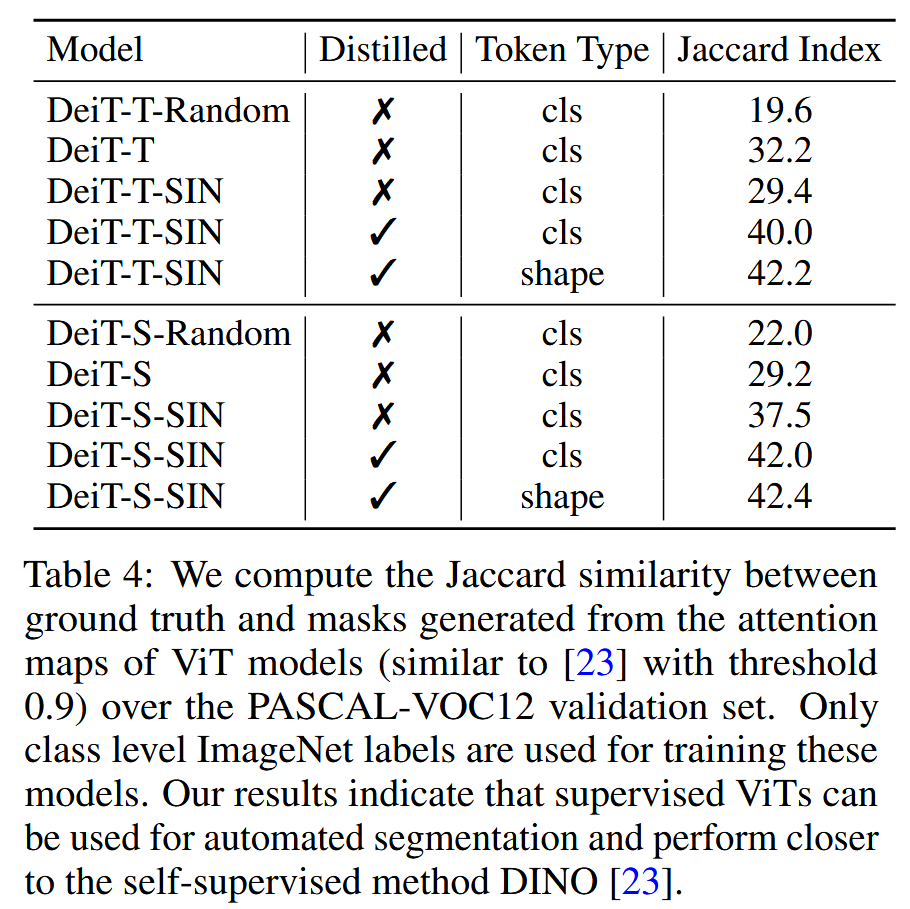
表4:我们在PASCAL-VOC12验证集上,计算了真实标注与由视觉Transformer(ViT)模型的注意力图生成的掩码之间的杰卡德相似度(与[23]中的方法类似,阈值设为0.9)。在训练这些模型时仅使用了ImageNet的类别级别标签。我们的结果表明,有监督的ViT模型可用于自动分割,并且其表现与自监督方法DINO [23]更为接近。

图8:视觉Transformer(ViT)生成的分割图。形状蒸馏模型的表现优于标准监督模型。
位置编码是否保留全局图像上下文?-Does Positional Encoding Preserve the Global Image Context?
这部分内容主要研究位置编码对ViT保持全局图像上下文的作用,通过对图像patch进行打乱操作改变其空间结构,分析模型在结构信息变化下的表现,发现位置编码对ViT性能并非至关重要,具体如下:
- 对空间结构的敏感性:定义一种对输入图像patch的打乱操作,去除图像中的结构信息(空间关系)。以DeiT模型为例,研究其在输入图像空间结构被干扰时的准确率变化。结果显示,当图像空间结构受到干扰时,DeiT模型比CNN更能保持准确率,这表明位置编码并非做出正确分类决策的绝对关键因素,模型并非依靠位置编码中保存的patch序列信息来“恢复”全局图像上下文。

图9:对图像应用洗牌操作以消除其结构信息的示意图。(放大查看效果最佳)
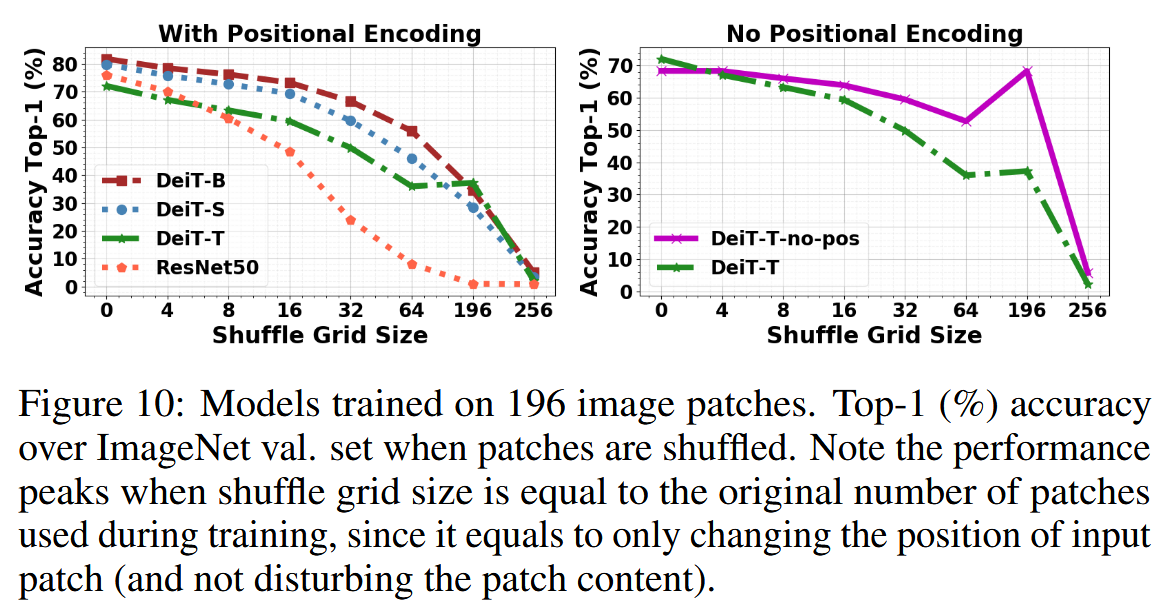
图10:使用196个图像补丁训练的模型。在ImageNet验证集上,当补丁被打乱时的top-1准确率(%)。请注意,当打乱网格大小等于训练时使用的原始补丁数量时,性能达到峰值,因为这仅仅相当于改变了输入补丁的位置(而不会干扰补丁内容)。 - 位置编码的实际作用:实验表明,没有位置编码时,ViT仍能表现出较好的排列不变性,甚至比使用位置编码的ViT表现更好。在改变ViT训练时的patch大小时,发现随着patch尺寸减小,模型在未打乱自然图像上的准确率和排列不变性都会下降。总体而言,ViT的排列不变性性能主要归因于其动态感受野,它能根据输入patch调整注意力,使元素适度打乱不会显著降低性能。
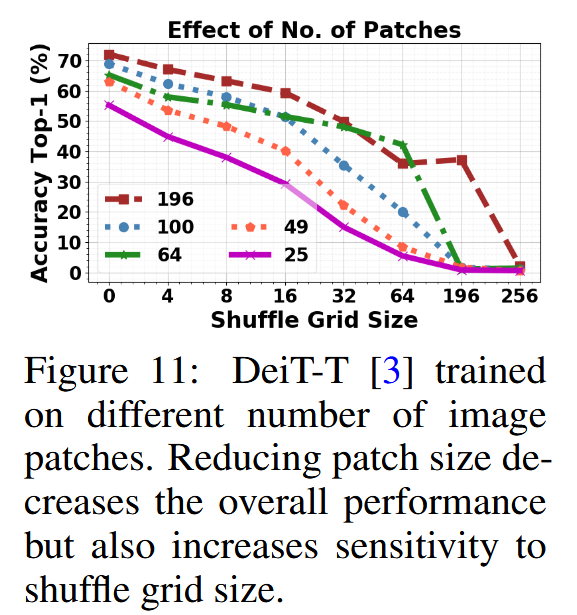
图11:使用不同数量图像补丁训练的DeiT-T模型[3]。减小补丁大小会降低整体性能,但也会增加对打乱网格大小的敏感性。
视觉Transformer对对抗性和自然扰动的鲁棒性-Robustness of Vision Transformers to Adversarial and Natural Perturbations
这部分主要研究视觉Transformer(ViT)对对抗性和自然扰动的鲁棒性,探讨了形状偏置与鲁棒性的关系,以及不同训练条件和攻击方式下ViT的表现,具体内容如下:
- 研究问题:在分析ViT编码形状信息能力后,探究更高的形状偏置是否有助于实现更好的鲁棒性。
- 实验方法:通过计算平均腐败误差(mCE),在多种合成的常见图像腐败情况(如雨水、雾气、雪花和噪声等)下,对具有相似参数数量的ViT(如DeiT-S)和ResNet50进行测试;同时研究它们在无目标的通用对抗补丁攻击以及特定样本攻击(包括单步的快速梯度符号法(FGSM)和多步的投影梯度下降攻击(PGD))下的鲁棒性。
- 实验结果
- 常见图像腐败:ViT(如DeiT-S)比经过增强训练(Augmix)的ResNet50更能抵抗图像腐败;同时,在ImageNet或SIN上未经增强训练的CNNs和ViTs对腐败更敏感,这表明增强训练有助于提高对常见腐败的鲁棒性。

表4:常见图像损坏情况下的平均损坏误差(mCE)[13](数值越低越好)。虽然视觉Transformer(ViT)相比卷积神经网络(CNN)具有更好的鲁棒性,但为实现更高形状偏差而进行的训练会使CNN和ViT在面对自然分布变化时都更加脆弱。与在ImageNet或风格化ImageNet(SIN)上未经增强训练的模型相比,所有经过增强训练(无论是ViT还是CNN)的模型的mCE都更低。 - 对抗攻击:在对抗攻击方面,在SIN上训练的ViTs和CNNs比在ImageNet上训练的模型更容易受到攻击,这体现了形状偏置与鲁棒性之间的权衡关系。不过,即使参数较少,ViT在对抗攻击下的鲁棒性也高于CNN 。
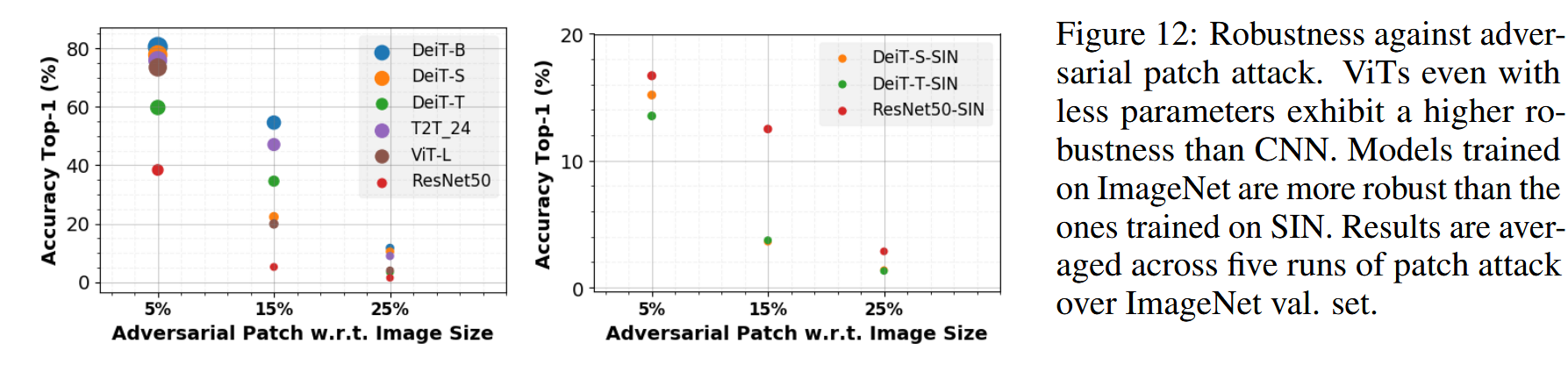
图12:对抗对抗补丁攻击的鲁棒性。即使参数较少,视觉Transformer(ViT)也比卷积神经网络(CNN)表现出更高的鲁棒性。在ImageNet上训练的模型比在风格化ImageNet(SIN)上训练的模型更具鲁棒性。结果是在ImageNet验证集上进行五次补丁攻击的平均值。
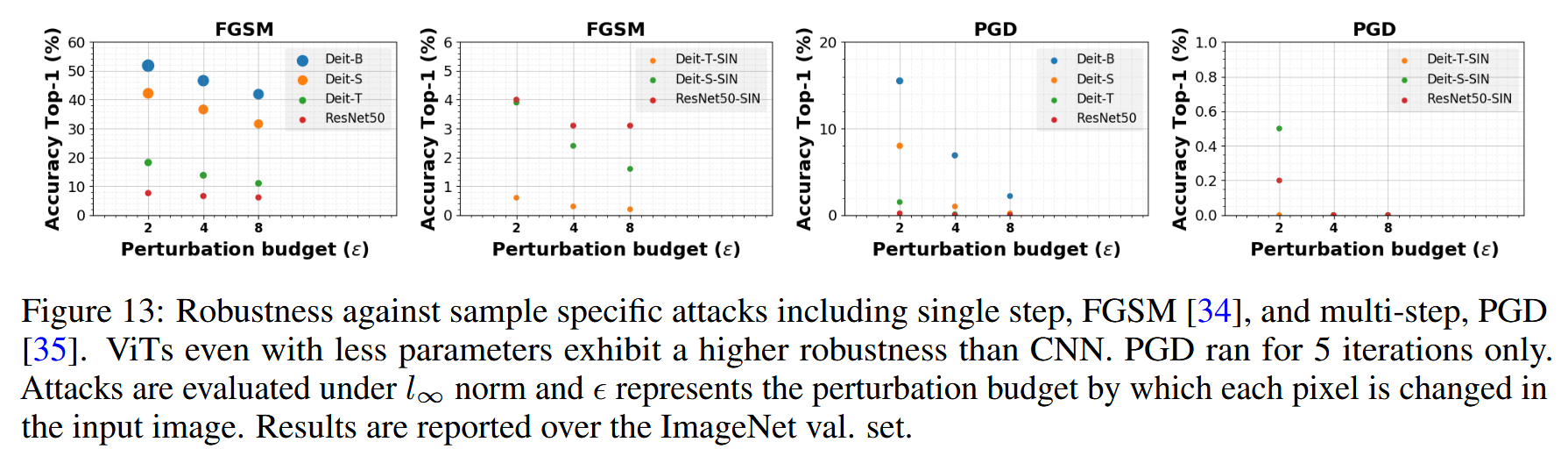
图13:针对特定样本攻击(包括单步的快速梯度符号法(FGSM)[34]和多步的投影梯度下降法(PGD)[35])的鲁棒性。即使参数较少,视觉Transformer(ViT)也比卷积神经网络(CNN)表现出更高的鲁棒性。PGD仅运行5次迭代。攻击在无穷范数((l_{\infty}) norm)下进行评估,ϵ表示输入图像中每个像素的扰动预算。结果是在ImageNet验证集上报告的。
- 常见图像腐败:ViT(如DeiT-S)比经过增强训练(Augmix)的ResNet50更能抵抗图像腐败;同时,在ImageNet或SIN上未经增强训练的CNNs和ViTs对腐败更敏感,这表明增强训练有助于提高对常见腐败的鲁棒性。
视觉Transformer的有效现成标记-Effective Off-the-shelf Tokens for Vision Transformer
这部分主要研究了视觉Transformer(ViT)现成特征的有效性,发现ViT模型各块生成的类令牌可单独处理,通过实验确定了有效令牌组合方式,且其在多种任务中的特征转移性优于CNN,具体内容如下:
- 特征提取与转移方法:ViT模型独特之处在于每个块都能生成可被分类头单独处理的类令牌。通过分析DeiT模型块级分类准确率,发现深层块生成的类令牌更具判别力。基于此,在CUB、Flowers和iNaturalist等数据集上进行迁移学习实验,将不同块的类令牌(可选地结合平均补丁令牌)连接起来,训练线性分类器来转移特征。结果表明,连接最后四个块的类令牌(DeiT-S(ensemble)策略)在迁移学习中表现最佳;连接所有块的类令牌和平均补丁令牌虽能达到类似性能,但训练所需参数更多。
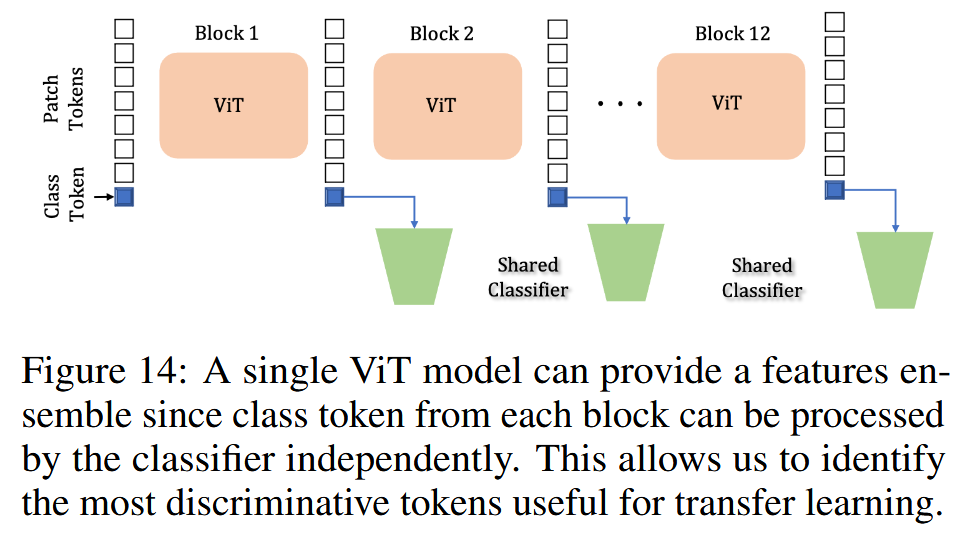
图14:单个视觉Transformer(ViT)模型可以提供特征集合,因为每个模块的类别令牌都可以由分类器独立处理。这使我们能够识别出对迁移学习最有用、最具判别力的令牌。
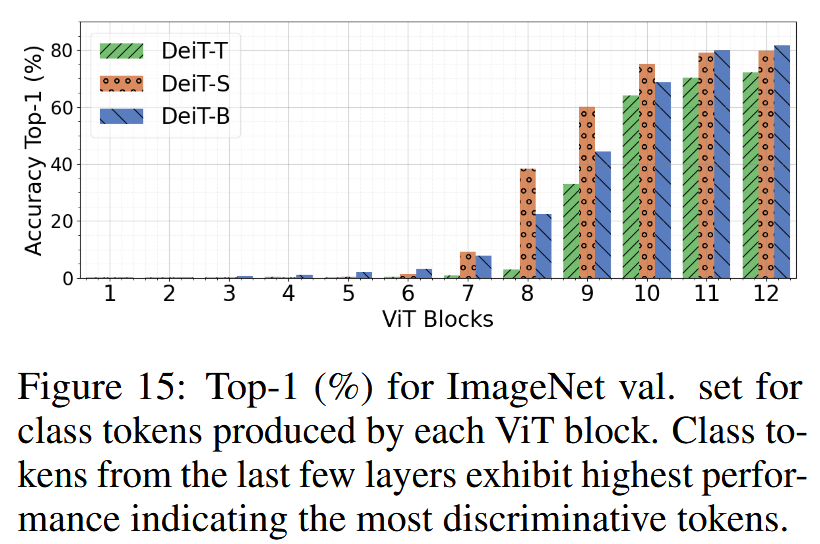
图15:ImageNet验证集上,由每个视觉Transformer(ViT)模块生成的类别令牌的top-1准确率(%)。最后几层的类别令牌表现最佳,这表明它们是最具判别力的令牌。
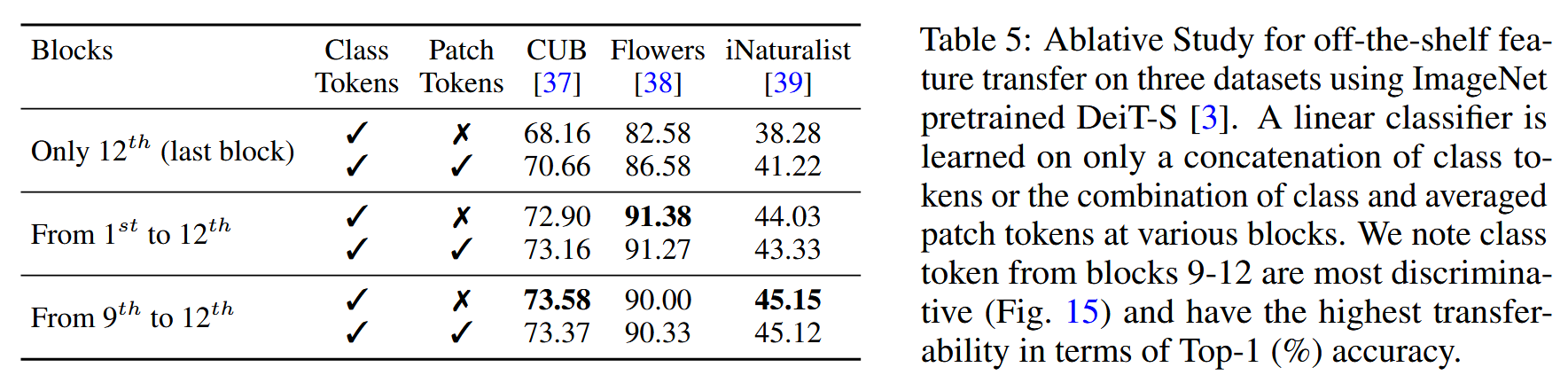
表5:使用在ImageNet上预训练的DeiT-S [3],在三个数据集上进行现成特征转移的消融研究。通过连接不同块的类令牌,或连接类令牌与平均补丁令牌的组合,来训练一个线性分类器。我们注意到,第9 - 12块的类令牌最具判别力(见图15),在top-1准确率方面具有最高的可迁移性。 - 视觉分类任务中的应用:在多个视觉分类数据集(如Aircraft、CUB、DTD、GTSRB、Fungi、Places365和iNaturalist)上,使用从ImageNet预训练的ViT模型提取的特征训练线性分类器,并在测试集上评估性能。结果显示,ViT特征相较于CNN基线有明显提升,其中DeiT-T模型参数约为ResNet50的五分之一,但在所有数据集中表现更优,且采用集成策略的模型在所有数据集上取得了最佳结果。
- 少样本学习任务中的应用:在包含多个领域数据集的大规模少样本学习基准meta-dataset上进行实验。使用在ImageNet上预训练的网络提取特征,在每个下游数据集的少样本学习设置下,利用支持集图像的特征学习线性分类器进行评估。结果表明,ViT特征在这些不同领域的转移性能优于CNN基线,且采用集成策略可进一步提升ViT的转移性能,在包含手绘草图的QuickDraw数据集中,ViT的表现提升也与其在形状偏置方面优于CNN的结论相符。
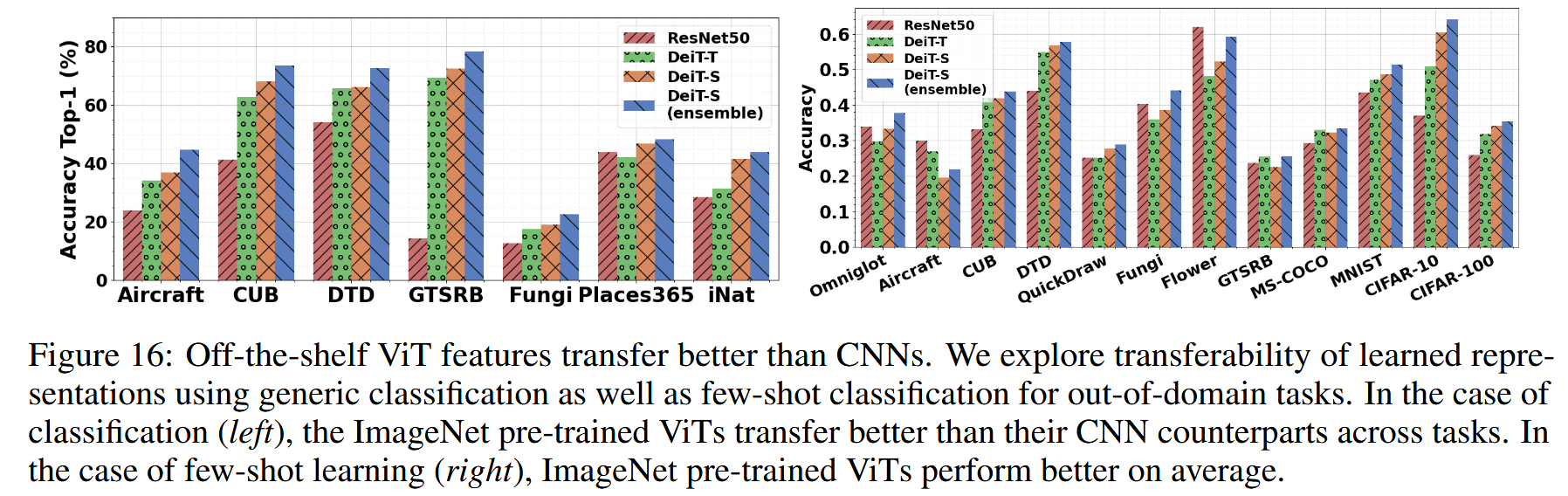
图16:现成的视觉Transformer(ViT)特征的迁移效果优于卷积神经网络(CNNs)。我们通过通用分类以及针对域外任务的少样本分类,探究学习到的表征的可迁移性。在分类任务(左图)中,在ImageNet上预训练的ViT在不同任务中的迁移效果优于对应的CNN。在少样本学习任务(右图)中,在ImageNet上预训练的ViT平均表现更优。
讨论和结论-Discussion and Conclusion
这部分主要对研究进行总结和讨论,阐述了ViT在多方面的优势、研究存在的局限,并提出了未来研究方向,具体如下:
- 研究结论:通过对多种ViT模型在十五个视觉数据集上的测试,验证了ViT在处理遮挡、分布转移、补丁排列、自动分割以及抵抗对抗攻击和常见损坏方面,相较于CNN具有明显优势。同时,单个ViT模型的现成特征经组合形成的特征集合,在多个下游任务中展现出强大的转移性。
- 未来研究方向
- 多线索融合:探索如何有效结合ViT中不同令牌建模的多种线索,使其相互补充,进一步提升模型性能。
- 改进自动分割:研究将本文方法与DINO相结合的可行性,如探究基于风格化ImageNet(SIN)的自监督能否提升DINO的分割能力,以及修改DINO训练方案,融合基于纹理(IN)的局部视图和基于形状(SIN)的全局视图,是否能增强其自动分割能力并使其更具通用性。
- 研究局限:当前实验基于ImageNet(ILSVRC’12)预训练的ViT,该数据集存在潜在偏差,数据多来自西方,包含性别、种族刻板印象且部分群体代表性不足,同时还存在隐私风险,未来将使用改进版本的ImageNet进行研究。
相关文章:
NIPS2021 | 视觉 Transformer 的有趣特性
Intriguing Properties of Vision Transformers 摘要-Abstract引言-Introduction相关工作-Related Work视觉Transformer的有趣特性-Intriguing Properties of Vision Transformers视觉Transformer对遮挡具有鲁棒性吗?-Are Vision Transformers Robust to Occlusions…...
)
贪心算法-2208.将数组和减半的最小操作数-力扣(LeetCode)
一、题目解析 这里要注意恰好这个字眼,说明对任意数减小一半是不需要向上取整的,所以我们需要定义double类型的数据。 二、算法解析 我们需要将数组和减小为一半的次数最少,所以根据贪心算法,我们需要取数组中最大的数进行减半操…...

如何搭建spark yarn 模式的集群集群。
下载 App 如何搭建spark yarn 模式的集群集群。 搭建Spark on YARN集群的详细步骤 Spark on YARN模式允许Spark作业在Hadoop YARN资源管理器上运行,利用YARN进行资源调度。以下是搭建步骤: 一、前提条件 已安装并配置好的Hadoop集群(包括HDF…...

嵌入式开发面试典型编程题解析:排序算法、指针操作、字符处理、递归原理等基础原理的深度解析。
在嵌入式开发面试中,编程题是常见的考察形式,旨在检验求职者对基础编程知识的掌握和应用能力。以下是几道典型的嵌入式面试编程题及详细解析,帮助新手逐步理解和掌握相关知识点。 一、用交换法对学生成绩降序排序 题目描述 在嵌入式系统开…...

DeepSeek+即梦:AI视频创作从0到1全突破
目录 一、开启 AI 视频创作大门:前期准备1.1 注册与登录1.2 熟悉工具界面1.3 硬件与网络要求 二、用 DeepSeek 构思视频脚本2.1 明确创作主题与目标2.2 编写优质提示词2.3 生成并优化脚本 三、即梦 AI 实现画面生成3.1 文生图基础操作3.2 调整参数提升画质3.3 保持人…...

npm init、换源问题踩坑
文章目录 一、 问题复现二、问题解决 一、 问题复现 成功安装nodejs 以及 npm 版本如下: > node -v > v20.18.0 > npm -v > 10.8.2使用 npm init 命令时延时过长,考虑换源,使用指令 npm config set registry https://registr…...

TRex 控制台命令解析
TRex 是一种高性能的网络测试工具,用于生成和分析网络流量。以下是对这些命令的简要解释: 一、help Console Commands(控制台命令) capture:管理 PCAP 捕获。debug:用于开发的内部调试器。events&#x…...

【Shell 脚本入门】轻松上手的实战指南
🌈 个人主页:Zfox_ 🔥 系列专栏:Shell脚本编程 目录 一:🔥 什么是 Shell 🦋 常见的 Shell 类型 二:🔥 什么是 Shell 脚本 🦋 Shell 脚本规则🦋 第…...

数据结构*栈
栈 什么是栈 这里的栈与我们之前常说的栈是不同的。之前我们说的栈是内存栈,它是JVM内存的一部分,用于存储局部变量、方法调用信息等。每个线程都有自己独立的栈空间,当线程启动时,栈就会被创建;线程结束,…...
持续更新中....)
零基础制作Freertos智能小车(教程非常简易)持续更新中....
从现开始,将陆续推出各类简单的DIY电子设计,由简入深,将自己的制作过程全部分享出来,巩固自己知识的同时希望借此机会认识更多喜欢电子设计的小伙伴。 本次小车的主控芯片采用stm32f103c8t6,主要是便宜好用&am…...

Leetcode - 双周赛155
目录 一,3527. 找到最常见的回答二,3528. 单位转换 I三,3529. 统计水平子串和垂直子串重叠格子的数目四,3530. 有向无环图中合法拓扑排序的最大利润 一,3527. 找到最常见的回答 题目列表 本题是一道模拟题࿰…...

详解RabbitMQ工作模式之工作队列模式
目录 工作队列模式 概念 特点 应用场景 工作原理 注意事项 代码案例 引入依赖 常量类 编写生产者代码 编写消费者1代码 编写消费者2代码 先运行生产者,后运行消费者 先运行消费者,后运行生产者 工作队列模式 概念 在工作队列模式中&#x…...

QGIS+mcp的安装和使用
QGISmcp的安装和使用 安装qgis_mcp 下载qgis_mcp: git clone https://github.com/jjsantos01/qgis_mcp.git安装uv uv是一个由Rust语言编写的python包管理工具,旨在提供比传统工具(如 pip)更高效的依赖管理和虚拟环境操作。 p…...

Java基础361问第16问——枚举为什么导致空指针?
我们看一段代码 public enum Color {RED, BLUE, YELLOW;public static Color parse(String color) {return null;} }public static void main() {Color color Color.parse("");// 极具迷惑性,大家日常开发肯定这么写过switch (color) {case RED:break;c…...

在 C# .NET 中驾驭 JSON:使用 Newtonsoft.Json 进行解析与 POST 请求实战
JSON (JavaScript Object Notation) 已经成为现代 Web 应用和服务之间数据交换的通用语言。无论你是开发后端 API、与第三方服务集成,还是处理配置文件,都绕不开 JSON 的解析与生成。在 C# .NET 世界里,处理 JSON 有多种选择,其中…...

CentOS7——Docker部署java服务
1、安装Docker 首先要确保系统已安装 Docker,若未安装,可以参考我的另一篇文章现在CentOS7上安装Docker,文章地址如下: CentOS7系统安装Docker教程-CSDN博客 Docker当中要安装必备的软件,比如Java运行必要的JDK&#…...

Python-Part2-集合、字典与推导式
Python-Part2-集合、字典与推导式 1. set集合 ⽆序,去掉重复数据。 set1 {1,2,3,4,5,5,4,3,2,1}print(type(set1))print(set1)set2.add(66666)set2.remove(55)#不能使用下标访问set,所以修改操作一般为remove操作 add操作2.dict 字典 字典ÿ…...

《AI大模型应知应会100篇》第39篇:多模态大模型应用:文本、图像和音频的协同处理
第39篇:多模态大模型应用:文本、图像和音频的协同处理 摘要 随着人工智能技术的发展,多模态大模型(Multimodal Large Models)已经成为AI领域的热点之一。这些模型能够同时处理文本、图像、音频等多种模态数据…...

kvm学习小结
安装相关包 安装虚拟化相关包 apt install qemu-kvm qemu-system libvirt-clients libvirt-daemon-system vlan bridge-utils 安装界面相关包 apt install xinit gdmd 配置机器允许root登录 检查cpu是否支持虚拟化 egrep -o vmx|svm /proc/cpuinfo 执行命令systemctl s…...

k8s基本概念-YAML
YAML介绍 YAML是“YAML Aint a Markup Language” (YAML不是一种置标语言)的递归缩进写,早先YAML的意思其实是:“Yet Another Markup Language”(另一种置标语言) YAML是一个类似XML、JSON的标记性语言。YAML强调以数据为中心,并不是以标识语言为重点。因而YAML本身的定义…...

wps批注线条怎么取消去掉wps批注后有竖线
wps批注线条怎么取消去掉wps批注后有竖线 问题 图片 解决方案 图片 word批注线条取消的方法: 1.打开Word文档,点击需要删除的批注。 2.然后点击工具栏“审阅”选项。 3.接着点击“接受“ 4.接受对文档所做的所有修订(H)...
)
深度解析算法之分治(归并)
48.排序数组 题目链接 给你一个整数数组 nums,请你将该数组升序排列。 你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。 示例 1: 输入: nums [5,2,3,1] 输出&am…...

僵尸进程是什么?
僵尸进程(Zombie Process)是指在 Unix/Linux 系统中,一个子进程已经终止,但其父进程尚未对它进行善后处理(即没有读取其退出状态),导致子进程的进程表项仍然保留在系统中。由于这个进程已经结束…...

城市群出行需求的时空分形
城市群出行需求的时空分形 原文:He, Zhengbing. “Spatial-temporal fractal of urban agglomeration travel demand.” Physica A: Statistical Mechanics and its Applications 549 (2020): 124503. 1. Introduction(引言) 城市区域的重…...
安装开发环境)
LangChain入门(二)安装开发环境
1.安装conda Conda 是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。 Anaconda是一个开源的Python发行版本,其包含了conda、python等软件包,numpy、pandas、scipy等科学…...

如何开展有组织的AI素养教育?
一、AI素养的定义与核心内涵 AI素养是智能时代个体适应与创新能力的综合体现,其内涵随着技术发展动态扩展,包含以下核心维度: 知识体系:理解AI基本原理(如算法、数据、算力)、技术边界及发展趋势ÿ…...

InnoDB对LRU算法的优化
标准 LRU 算法的核心思想是:当缓存空间不足时,淘汰掉最近最少使用的数据块(Page)。它通常用一个链表来实现,链表头部是最近访问的 Page,链表尾部是最久未访问的 Page。 然而,在数据库系统中直接…...

云原生--核心组件-容器篇-7-Docker私有镜像仓库--Harbor
1、Harbor的定义与核心作用 定义: Harbor是由VMware开源的企业级容器镜像仓库系统,后捐赠给 CNCF (Cloud Native Computing Foundation)。它基于Docker Registry扩展了企业级功能,用于存储、分发和管理容器镜像(如Docker、OCI标准…...

TypeScript 实用类型深度解析:Partial、Pick、Record 的妙用
需求背景:在后台系统的用户管理模块中,我们常遇到这样的场景:修改用户资料时只需要传部分字段,展示用户列表时要隐藏敏感信息,快速查找用户需要ID索引等等,这些业务需求都可以通过 TypeScript 的实用类型优…...

【Pandas】pandas DataFrame rmod
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

如何搭建spark yarn 模式的集群集群
以下是搭建Spark YARN模式集群的一般步骤: 准备工作 - 确保集群中各节点安装了Java环境,并配置好 JAVA_HOME 环境变量。 - 各节点间能通过SSH免密登录。 - 安装并配置好Hadoop集群,YARN作为Hadoop的资源管理器,Spark YARN模式需要…...
)
云原生--核心组件-容器篇-6-Docker核心之-镜像仓库(公共仓库,私有仓库,第三方仓库)
1、Docker仓库的定义与核心作用 定义: Docker仓库(Docker Registry)是用于存储、分发和管理Docker镜像的集中式存储库。它类似于代码仓库,但专门用于容器镜像的版本控制和共享。它允许开发人员和IT团队高效地管理、部署和分享容器…...

mysql8.0版本部署+日志清理+rsync备份策略
mysql安装:https://blog.csdn.net/qq_39399966/article/details/120205461 系统:centos7.9 数据库版本:mysql8.0.28 1.卸载旧的mysql,保证环境纯净 rpm -qa | grep mariadb mariadb-5.... rpm -e --nodeps 软件 rpm -e --nodeps mariadb-5.…...

搭建spark yarn 模式的集群集群
一.引言 在大数据处理领域,Apache Spark 是一个强大的分布式计算框架,而 YARN(Yet Another Resource Negotiator)是 Hadoop 的资源管理系统。将 Spark 运行在 YARN 模式下,可以充分利用 YARN 强大的资源管理和调度能力…...

在uni-app中使用Painter生成小程序海报
在uni-app中使用Painter生成小程序海报 安装Painter 从GitHub下载Painter组件:https://github.com/Kujiale-Mobile/Painter 将painter文件夹复制到uni-app项目的components目录下 配置页面 在需要使用海报的页面的pages.json中配置 {"path": "pag…...

Uni-app网络请求AES加密解密实现
Uni-app 网络请求封装与 AES 加密解密实现 下面我将为你提供一个完整的 Uni-app 网络请求封装方案,包含 POST 请求的统一处理、请求参数和响应数据的 AES 加密解密。 1. 创建加密解密工具类 首先创建一个 crypto.js 文件用于处理 AES 加密解密: // u…...

uniapp实现统一添加后端请求Header方法
uniapp把请求写完了,发现需要给接口请求添加头部,每个接口去添加又很麻烦,uniapp可以统一添加,并且还能给某些接口设置不添加头部。 一般用于添加token登录验证信息。 在 main.js 文件中配置。 代码如下: // 在…...

uniapp打包apk如何实现版本更新
我们做的比较简单,在后端设置版本号,并在uniapp的config.js中定义版本号,每次跟后端的进行对比,不一致的话就更新。 一、下载apk 主要代码(下载安装包,并进行安装,一般得手动同意安装…...

【Java开发日记】OpenFeign 的 9 个坑
目录 坑一:用对Http Client 1.1 feign中http client 1.2 ribbon中的Http Client 坑二:全局超时时间 坑三:单服务设置超时时间 坑四:熔断超时时间 4.1 使用feign超时 4.2 使用ribbon超时 4.3 使用自定义Options 坑五&…...

RocketMQ 存储核心:深入解析 CommitLog 设计原理
一、引言 在分布式消息队列系统中,消息存储的可靠性和高吞吐能力是衡量系统优劣的核心指标。Apache RocketMQ 作为一款高性能、高可用的分布式消息中间件,其独特的 CommitLog 存储机制在消息持久化过程中扮演了关键角色。本文将深入剖析 CommitLog 的设…...
)
【C++ Qt】快速上手 显⽰类控件(Label、LCDNumber、ProcessBar、CalendarWidget)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本文围绕Qt中常用的显示类控件展开,重点讲解了 QLabel(文本/图片显示)、QLCDNumber(数字显示࿰…...

Docker和K8s面试题
1.Docker底层依托于linux怎么实现资源隔离的? 基于Namespace的视图隔离:Docker利用Linux命名空间(Namespace)来实现不同容器之间的隔离。每个容器都运行在自己的一组命名空间中、包括PID(进程)、网络、挂载…...

shell--数组、正则表达式RE
1.数组 1.1定义 什么是数组? 数组也是一种变量,常规变量只能保存一个值,数组可以保存多个值 1.2 分类 普通数组:只能用整数作为数组的索引--0 下标 有序数组(普通数组):(index)索引(为整数,从0开始) 关联数组:可以使用字符串作为数组的索引 1.3 普通数组 引用: ec…...

java 使用 POI 为 word 文档自动生成书签
poi 版本:4.1.0 <properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><…...

redis+lua+固定窗口实现分布式限流
用key的过期时间替代固定窗口的时间戳 -- KEYS[1]: 限流的key -- ARGV[1]: 限流窗口大小(秒) -- ARGV[2]: 限流阈值local key KEYS[1] local window tonumber(ARGV[1]) local limit tonumber(ARGV[2])-- 尝试获取当前计数 local current redis.call…...

什么是SQL92标准,有什么特点和影响?
一、SQL92简介 SQL92标准是1992年由美国国家标准协会(ANSI)和国际标准化组织(ISO)联合制定的数据库语言标准,正式名称为"SQL:1992"或ISO/IEC 9075:1992。他是关系型数据库管理系统(R…...

Flink Checkpoint 与实时任务高可用保障机制实战
在实时数仓体系中,数据一致性和任务稳定性是核心保障。本文围绕 Flink Checkpoint 机制,深入讲解高可用保障的最佳实践和工程实现。 一、业务背景与痛点 在金融风控、营销实时推荐、智能监控等场景中,实时数仓的每一条数据都至关重要。常见的业务痛点包括: 断点恢复困难:…...

WebRtc08:WebRtc信令服务器实现
如何使用socket.io发送消息 发送消息 // 给本次连接发送消息 socket.emit()// 给某个房间内所有人发送消息 io.in(room).emit()// 除了自己以外,给某个房间的所有人发消息 socket.to(room).emit();// 除本连接外,给所有人发消息 socket.broadcast.emit…...

基于 SpringBoot 与 Redis 的缓存预热案例
文章目录 “缓存预热” 是什么?项目环境搭建创建数据访问层预热数据到 Redis 中创建缓存服务类测试缓存预热 “缓存预热” 是什么? 缓存预热是一种优化策略,在系统启动或者流量高峰来临之前,将一些经常访问的数据提前加载到缓存中…...

Python对比两张CAD图并标记差异的解决方案
以下是使用Python对比两张CAD图并标记差异的解决方案,结合图像处理和CAD结构分析: 一、环境准备与库选择 图像处理库:使用OpenCV进行图像差异检测、颜色空间转换和轮廓分析。CAD解析库:若为DXF格式,使用ezdxf解析实体…...