深度解析算法之分治(归并)
48.排序数组
题目链接
给你一个整数数组 nums,请你将该数组升序排列。
你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。
示例 1:
输入: nums = [5,2,3,1]
输出:[1,2,3,5]
示例 2:
输入: nums = [5,1,1,2,0,0]
输出:[0,0,1,1,2,5]
我们上次解决这个问题是使用快排进行解决的,那么这里是使用归并排序进行解决的
归并是什么呢?说白了就是递归
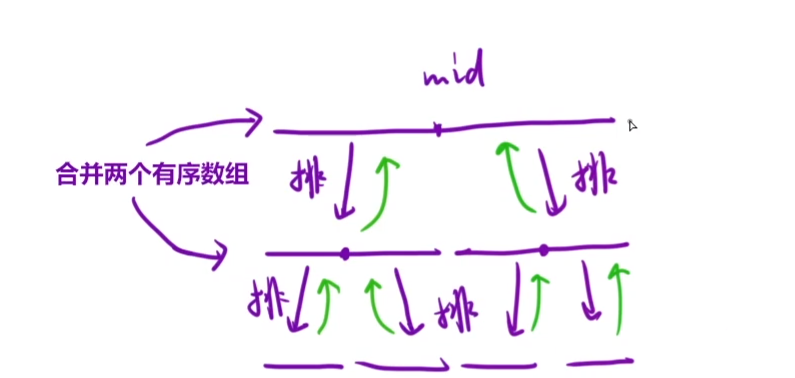
将一个数组根据中间点分成两部分,我们再从左边区间找中间点,依次这样,直到我们最后只剩下一个元素,我们依次进行返回的操作,然后进行上一层的右区间进行递归递归
当我们这一层的判断都搞定了,那么我们就进行合并两个有序数组
当我们左边和右边都排完序之后,那么我们就将这两个有序数组进行合并操作
这种非常像二叉树的后续遍历,先把左边搞好,再把右边搞好,再回到根节点
快排的过程有点类似二叉树的前序遍历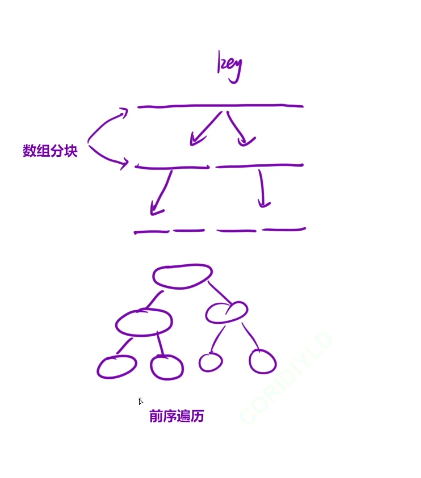
class Solution{public:vector<int> sortArray(vector<int>& nums){mergesort(nums,0,nums.size()-1);//将这段区间进行排序,排完序直接返回就行了return nums;}void mergesort(vector<int>&nums,int left,int right){if(left>=right) return;//特殊情况,如果区间不存在或者是只有一个元素的话//1.先选择中间点划分区间int mid=(left+right)>>1;// >> 1 是位运算中的右移操作,它将结果右移一位,相当于将结果除以2并向下取整。//[left,mid][mid+1,right]//2.将左右区间进行排序的操作mergesort(nums,left,mid);mergesort(nums,mid+1,right);//3.合并两个有序数组vector<int>tmp(right-left+1);//辅助数组,大小和我们的nums大小一样int cur1=left;//指向第一个数组int cur2=mid+1;//指向第二个数组int i=0;//辅助数组while(cur1<=mid&&cur2<=right){tmp[i++]=nums[cur1]<=nums[cur2]?nums[cur1++]:nums[cur2++];//进行判断,如果cur1的大小小于等于cur2的话,那么就让我们的tmp[i]=nums[cur1]的值//就是说白了持续进行对比,谁小谁先放到tmp这个数组中去//i、cur1、cur2这三个指针都得往后进行移动,我们直接放在上面的那个代码中去}//到这里的话可能存在一个数组中还有数据没有移动到tmp中去,下面两句代码就是处理没有遍历完的情况while(cur1<=mid)tmp[i++]=nums[cur1++];//因为此时的指针还没到mid的位置,就是大小比mid小,那么我们直接将cur1这个数字中剩下的元素都放到tmp中while(cur2<=right)tmp[i++]=nums[cur2++];//和上面一样//还原for(int i=left;i<=right;i++){nums[i]=tmp[i-left];//我们的tmp数组需要从0开始进行计数操作吗,所以我们这里使用i-left可以达到从下标0开始进行赋值操作}}};
我们先找出中间点对这段数组进行划分操作,然后依次对左右区间进行排序的操作,这里就是递归调用,然后我们再合并两个数组就行了
最后我们将我们辅助数组中的值直接赋值到我们的nums中就行了
这种代码我们的时间复杂度是这样的
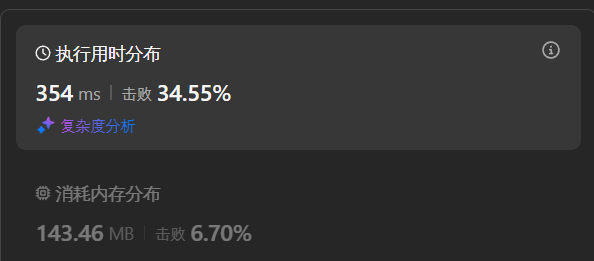
因为我们每次合并的时候都会创建一个辅助数组,这里的开销其实也很大的

我们可以将创建数组的这个操作放在全局的位置
class Solution{vector<int>tmp;//创建辅助数组public:vector<int> sortArray(vector<int>& nums){tmp.resize(nums.size());mergesort(nums,0,nums.size()-1);//将这段区间进行排序,排完序直接返回就行了return nums;}void mergesort(vector<int>&nums,int left,int right){if(left>=right) return;//特殊情况,如果区间不存在或者是只有一个元素的话//1.先选择中间点划分区间int mid=(left+right)>>1;// >> 1 是位运算中的右移操作,它将结果右移一位,相当于将结果除以2并向下取整。//[left,mid][mid+1,right]//2.将左右区间进行排序的操作mergesort(nums,left,mid);mergesort(nums,mid+1,right);//3.合并两个有序数组int cur1=left;//指向第一个数组int cur2=mid+1;//指向第二个数组int i=0;//辅助数组while(cur1<=mid&&cur2<=right){tmp[i++]=nums[cur1]<=nums[cur2]?nums[cur1++]:nums[cur2++];//进行判断,如果cur1的大小小于等于cur2的话,那么就让我们的tmp[i]=nums[cur1]的值//就是说白了持续进行对比,谁小谁先放到tmp这个数组中去//i、cur1、cur2这三个指针都得往后进行移动,我们直接放在上面的那个代码中去}//到这里的话可能存在一个数组中还有数据没有移动到tmp中去,下面两句代码就是处理没有遍历完的情况while(cur1<=mid)tmp[i++]=nums[cur1++];//因为此时的指针还没到mid的位置,就是大小比mid小,那么我们直接将cur1这个数字中剩下的元素都放到tmp中while(cur2<=right)tmp[i++]=nums[cur2++];//和上面一样//还原for(int i=left;i<=right;i++){nums[i]=tmp[i-left];//我们的tmp数组需要从0开始进行计数操作吗,所以我们这里使用i-left可以达到从下标0开始进行赋值操作}}};
这里我们可以看看时间开销
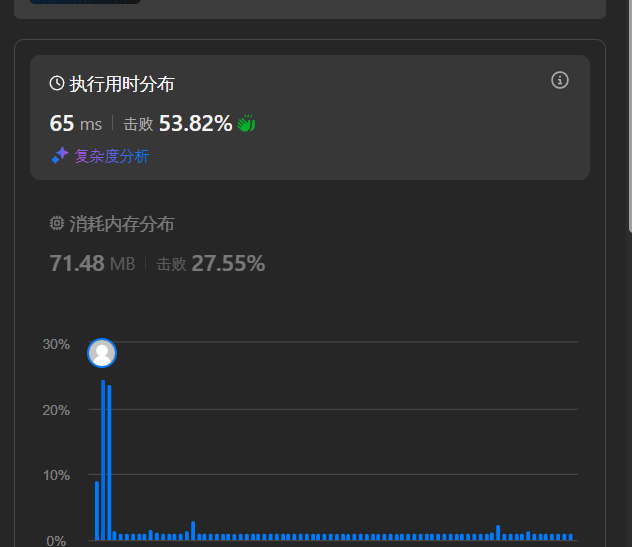
如果在递归中需要创建空间的话,那么我们就将这个操作放在全局上
49.数组中的逆序对
题目链接
在数组中的两个数字如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。
输入一个数组,求出这个数组中的逆序对的总数。
数据范围
给定数组的长度 [0,100][0,100]。
样例
输入:[1,2,3,4,5,6,0]输出:6
暴力解法:暴力枚举
两层for循环就能暴力出所有的情况,但是会超时的
我们求出一个中心点,将整个数组分成两段,分别进行判断 ,递归进行求

利用归并排序解决该问题
逆序对就是一个数之前有多少个数比自身大,那么就有多少组逆序对
那么我们盯着cur2这个区域看就行了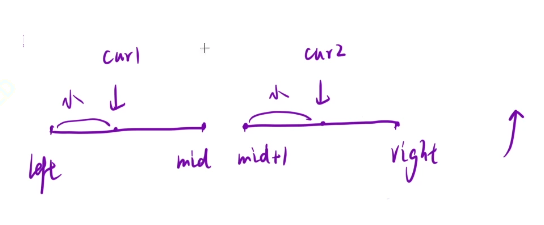
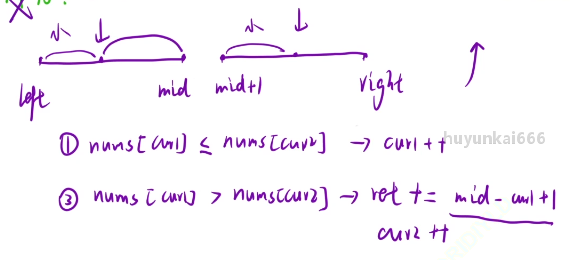 因为我们这里经过了排序了,所以两个区域都是升序的,
因为我们这里经过了排序了,所以两个区域都是升序的,
如果nums[cur1]<=nums[cur2]的话,那么就让cur1++
如果nums[cur1]>nums[cur2]的话,因为区域是升序的吗,所以当前cur1后面的都是比cur2大的数字,所以我们就找到了一堆的逆序数,所以我们的逆序数总和就加上了mid-cur1+1
所以这个题利用归并排序的话时间复杂度就是nlogn
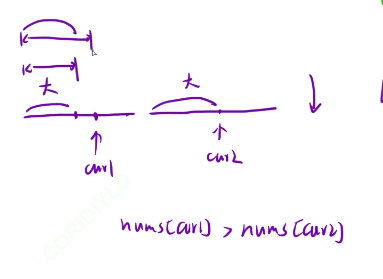
我们这个题是升序的,如果是降序的话这个题怎么做呢?
如果nums[cur1]>nums[cur2]的话,那么我们就统计cur1前面的区域,然后我们将cur1++,但是如果此时的nums[cur1]>nums[cur2],那么我们就会出现重复计算的问题了
如果我们将原先的策略改成:找出某个数之后,有多少个数比较小,然后我们此时就可以利用到了这个降序操作了
如果我们当前cur1大于cur2的话,因为这个是降序的,所以cur2后面的都比cur2小,所以我们找到比cur1小的数就行了,那么cur2后面一大堆比cur1小的,统计完当前数中有多少个数比cur1小的,然后我们的cur1进行右移操作
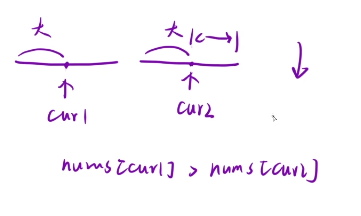
下面是数组为升序的版本
class Solution
{int tmp[999999];//创建一个辅助数组进行数组合并的
public:int inversePairs(vector<int>& nums){return mergeSort(nums,0,nums.size()-1);//将0~n-1这段区间的逆序对都找到}int mergeSort(vector<int>&nums,int left,int right){if(left>=right) return 0;//处理特殊情况,这个区间没有逆序对或者是 只存在一个元素的话int ret=0;//记录最终的结果//1.找一个中间点int mid=(right+left)>>1;//划分为下面的两个区间了//[left,mid][mid+1,right]//2.左边的逆序对的个数+排序+右边的逆序对的个数+排序ret+=mergeSort(nums,left,mid);ret+=mergeSort(nums,mid+1,right);//3.一左一右的情况int cur1=left,cur2=mid+1,i=0;while(cur1<=mid&&cur2<=right){if(nums[cur1]<=nums[cur2]) tmp[i++]=nums[cur1++];else //这个就是cur1的数大于cur2的数{ret+=mid-cur1+1;tmp[i++]=nums[cur2++];//将小的放进去}}//4.处理下排序,将剩下的元素放进去while(cur1<=mid)tmp[i++]=nums[cur1++];while(cur2<=right)tmp[i++]=nums[cur2++];for(int j=left;j<=right;j++){nums[j]=tmp[j-left];}return ret;}
};
归并排序的第一步是递归地将数组拆分成越来越小的子数组,直到每个子数组只有一个元素为止。这个过程是通过 mergeSort(nums, left, mid) 和 mergeSort(nums, mid + 1, right) 完成的。每次递归都会找到数组的中间点 mid,然后对左右两部分递归调用 mergeSort。
在归并的过程中,我们将左右两个子数组合并成一个已排序的数组。在这个过程中,如果左侧的某个元素大于右侧的某个元素,那么这些元素就构成了逆序对。
剩余元素处理:
如果在合并的过程中,某一侧的数组已经处理完了,而另一侧仍然有元素剩余,这时剩下的元素已经是有序的,因此可以直接将它们放入到 tmp 数组中,不需要做任何比较。
将排序后的元素放回原数组:
合并完成后,我们将 tmp 数组中的元素复制回 nums 数组,这样在上层递归中会使用到最新排序好的数组。
下面是降序的代码
class Solution
{int tmp[999999];//创建一个辅助数组进行数组合并的
public:int inversePairs(vector<int>& nums){return mergeSort(nums,0,nums.size()-1);//将0~n-1这段区间的逆序对都找到}int mergeSort(vector<int>&nums,int left,int right){if(left>=right) return 0;//处理特殊情况,这个区间没有逆序对或者是 只存在一个元素的话int ret=0;//记录最终的结果//1.找一个中间点int mid=(right+left)>>1;//划分为下面的两个区间了//[left,mid][mid+1,right]//2.左边的逆序对的个数+排序+右边的逆序对的个数+排序ret+=mergeSort(nums,left,mid);ret+=mergeSort(nums,mid+1,right);//3.一左一右的情况int cur1=left,cur2=mid+1,i=0;while(cur1<=mid&&cur2<=right){if(nums[cur1]<=nums[cur2]) tmp[i++]=nums[cur2++];else {ret+=right-cur2+1;tmp[i++]=nums[cur1++];}}//4.处理下排序,将剩下的元素放进去while(cur1<=mid)tmp[i++]=nums[cur1++];while(cur2<=right)tmp[i++]=nums[cur2++];for(int j=left;j<=right;j++){nums[j]=tmp[j-left];}return ret;}
};
改动的代码在这里
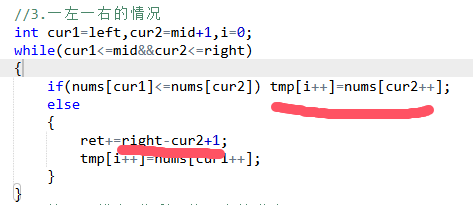
50.计算右侧⼩于当前元素的个数
题目链接
给你一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。
示例 1:
输入: nums = [5,2,6,1]
输出: [2,1,1,0] 解释
5 的右侧有 2 个更小的元素 (2 和 1)
2 的右侧仅有 1 个更小的元素 (1)
6 的右侧有 1 个更小的元素 (1)
1 的右侧有 0 个更小的元素
示例 2:
输入: nums = [-1]
输出:[0]
示例 3:
输入: nums = [-1,-1]
输出:[0,0]
有点像我们的逆序对
使用归并排序
我们需要快速求出当前元素右边有多少个元素比当前元素小
我们这里使用策略二:当前元素右边元素有多少个比我小
如果nums[cur1]<=nums[cur2]的话,那么我们的cur2得往右边进行挪动了
但是如果nums[cur1]>nums[cur2]的话,那么我们就得将nums[cur1]在统计数的那个数组中的对应的位置加上我们有多少个小于cur2的位置的数了,所以我们得找到cur1的原始下标了,我的思路是使用hash,但是如果出现了重复元素的话就不好搞了
我们再创建一个数组,存的是我们原始的下标,一起进行绑定移动就行了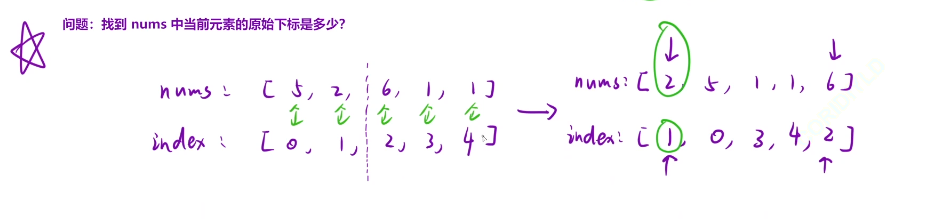
我们这里是需要创建两个辅助数组的,一个是nums合并的辅助数组
一个是原始下标的辅助数组
class Solution{vector<int>ret;vector<int>index;//记录当前元素的原始下标int tmpNums[500010];//nums的辅助数组int tmpIndex[500010];//index的辅助数组public:vector<int> countSmaller(vector<int>& nums){int n=nums.size();ret.resize(n);index.resize(n);//初始化index数组for(int i=0;i<n;i++){index[i]=i;}mergerSort(nums,0,n-1);return ret;}void mergerSort(vector<int>&nums,int left,int right){//先处理边界情况if(left>=right) return ;//要么这个数组只有一个元素,要么就是没有元素//1.根据中间元素划分区间int mid=(right+left)>>1;//[left,mid][mid+1,right]//2.先处理左右两部分mergerSort(nums,left,mid);mergerSort(nums,mid+1,right);//3.处理一左一右的情况int cur1=left,cur2=mid+1,i=0;while(cur1<=mid&&cur2<=right)//降序数组{if(nums[cur1]<=nums[cur2]){//降序数组,谁大就移动谁tmpNums[i]=nums[cur2];tmpIndex[i++]=index[cur2++];}else//nums[cur1]>nums[cur2]{//index[cur2]就是cur2当前的下标ret[index[cur1]]+=right-cur2+1;//重点,先找到原始位置的下标,我们这里统计的是cur1位置后面的数有多少个比cur1小tmpNums[i]=nums[cur1];tmpIndex[i++]=index[cur1++];}}//3.处理排序剩下的排序过程while(cur1<=mid) //说明我们的cur1还有预留的数据,那么我们将剩下的数据全部放到我们的辅助数组中去{tmpNums[i]=nums[cur1];tmpIndex[i++]=index[cur1++];}while(cur2<=right) //说明我们的cur1还有预留的数据,那么我们将剩下的数据全部放到我们的辅助数组中去{tmpNums[i]=nums[cur2];tmpIndex[i++]=index[cur2++];}//还原for(int j=left;j<=right;j++ ){nums[j]=tmpNums[j-left];index[j]=tmpIndex[j-left];}}};
求当前位置的右边有多少个数比cur1小的。所以我们这里是降序的,将大的元素先进行移动到辅助数组中去
51.翻转对
题目链接
给定一个数组 nums ,如果 i < j 且 nums[i] > 2*nums[j] 我们就将 (i, j) 称作一个 重要翻转对。
你需要返回给定数组中的重要翻转对的数量。
示例 1:
输入: [1,3,2,3,1]
输出: 2
示例 2:
输入: [2,4,3,5,1]
输出: 3
找两个数,前面的数是大于后面的那个数的两倍的
策略一:计算当前元素后面,有多少元素的两倍比我小 降序
我们发现cur2位置的两倍的大小比cur1小,那么cur2后面的数字的两别都比cur1小
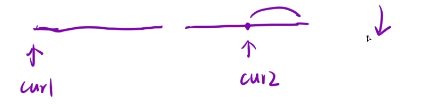
计算翻转对->同向双指针
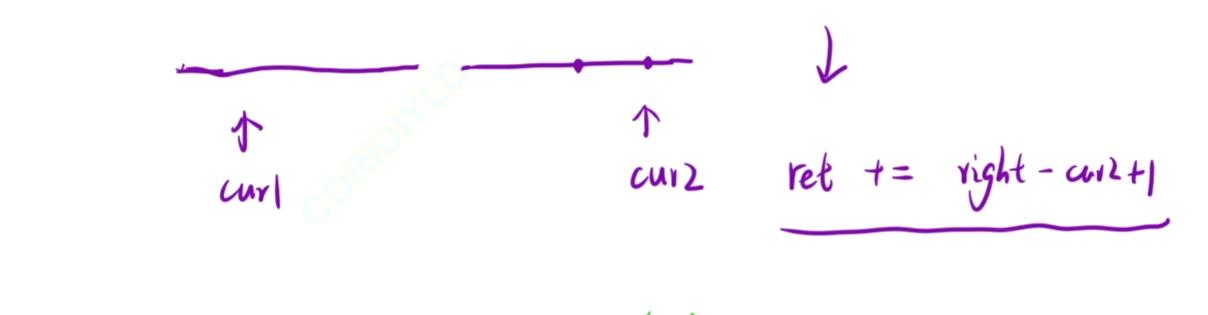
策略二:计算当前元素之前,有多少元素的一半比我大 升序
我们这里移动cur1,如果cur1的一半比cur2小的话,那么cur1右移
当我们发现cur1的一半比cur2大的话,那么cur1后面的一半都比cur2大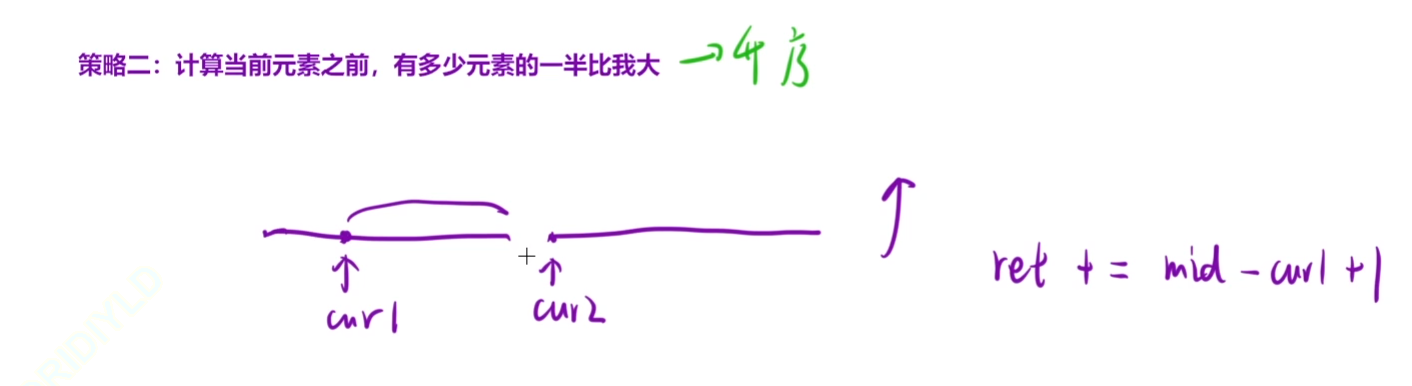
下面是降序的代码
class Solution{int tmp[50010];//辅助数组,帮助我们合并排序public:int reversePairs(vector<int>& nums){return mergeSort(nums,0,nums.size()-1);}int mergeSort(vector<int>&nums,int left,int right){if(left>=right) return 0;//处理异常情况int ret=0; //1.先根据中间元素划分区间int mid=(right+left)>>1;//[left,mid][mid+1,right]//2.先计算左右两侧的翻转对ret+=mergeSort(nums,left,mid);ret+=mergeSort(nums,mid+1,right);//3.先计算翻转对的数量int cur1=left,cur2=mid+1,i=left;while(cur1<=mid)//降序{while(cur2<=right &&nums[cur2]>=nums[cur1]/2.0) cur2++;//向后进行移动,直到找到合适的位置if(cur2>right) break;//如果满足了越界的情况了,那么我们直接break就行了//出了循环就说明我们找到对应的位置了ret+=right-cur2+1;cur1++;//cur1向后移动}//4.合并两个有序数组cur1=left,cur2=mid+1;while(cur1<=mid&&cur2<=right){tmp[i++]=nums[cur1]<=nums[cur2]?nums[cur2++]:nums[cur1++];//因为这里是一个降序的数组,谁大谁就移动到辅助数组中去}while(cur1<=mid)tmp[i++]=nums[cur1++];while(cur2<=right)tmp[i++]=nums[cur2++];//5.还原for(int j=left;j<=right;j++){nums[j]=tmp[j];}return ret;}};
我们先根据中间元素划分区间,然后计算左右两侧的翻转对,这个就是递归调用函数
然后计算翻转对的数量,然后合并两个有序数组,最后就是还原了
。
这里计算翻转对的数量,我们让我们的cur1不动,cur一直往后移动,直到遇到了满足条件的,就是nums[cur2]>=nums[cur1]/2.0的话,那么我们就将cur2后面这段区间进行累加到ret中去,然后再去移动cur1进行下一组的判断,循环结束之后,我们的翻转对的数量就计算出来了
这个时候我们得将当前的这段和别的段进行合并,就是合并两个有序数组的操作,直接合并在tmp这个辅助数组中,合并完成之后可能会有一组数组还有剩余的数据,我们将这些数据放到我们的tmp中去
最后我们需要将原先的数组进行还原操作
为什么需要进行还原操作?
在递归过程中,原始数组 nums 的数据会被拆分成许多子数组,且每个子数组都在递归过程中经过合并操作。在合并过程中,我们将排好序的子数组的元素合并到辅助数组 tmp 中。如果不还原回来,nums 数组就无法保持正确的排序顺序,也无法准确地反映最终的排序结果
我们使用升序的代码进行解决问题
升序就是找当前元素之前有多少个数比我大, 所以此时固定的就是cur2了
class Solution{int tmp[50010];//辅助数组,帮助我们合并排序public:int reversePairs(vector<int>& nums){return mergeSort(nums,0,nums.size()-1);}int mergeSort(vector<int>&nums,int left,int right){if(left>=right) return 0;//处理异常情况int ret=0; //1.先根据中间元素划分区间int mid=(right+left)>>1;//[left,mid][mid+1,right]//2.先计算左右两侧的翻转对(递归调用操作)ret+=mergeSort(nums,left,mid);ret+=mergeSort(nums,mid+1,right);//3.先计算翻转对的数量int cur1=left,cur2=mid+1,i=left;while(cur2<=right)//升序{while(cur1<=mid &&nums[cur2]>=nums[cur1]/2.0) cur1++;//向后进行移动,直到找到合适的位置if(cur1>mid) break;//如果满足了越界的情况了,那么我们直接break就行了//出了循环就说明我们找到对应的位置了ret+=mid-cur1+1;cur2++;//cur1向后移动}//4.合并两个有序数组cur1=left,cur2=mid+1;while(cur1<=mid&&cur2<=right){tmp[i++]=nums[cur1]<=nums[cur2]?nums[cur1++]:nums[cur2++];//因为这里是一个降序的数组,谁大谁就移动到辅助数组中去}while(cur1<=mid)tmp[i++]=nums[cur1++];while(cur2<=right)tmp[i++]=nums[cur2++];//5.还原for(int j=left;j<=right;j++){nums[j]=tmp[j];}return ret;}};
相关文章:
)
深度解析算法之分治(归并)
48.排序数组 题目链接 给你一个整数数组 nums,请你将该数组升序排列。 你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。 示例 1: 输入: nums [5,2,3,1] 输出&am…...

僵尸进程是什么?
僵尸进程(Zombie Process)是指在 Unix/Linux 系统中,一个子进程已经终止,但其父进程尚未对它进行善后处理(即没有读取其退出状态),导致子进程的进程表项仍然保留在系统中。由于这个进程已经结束…...

城市群出行需求的时空分形
城市群出行需求的时空分形 原文:He, Zhengbing. “Spatial-temporal fractal of urban agglomeration travel demand.” Physica A: Statistical Mechanics and its Applications 549 (2020): 124503. 1. Introduction(引言) 城市区域的重…...
安装开发环境)
LangChain入门(二)安装开发环境
1.安装conda Conda 是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。 Anaconda是一个开源的Python发行版本,其包含了conda、python等软件包,numpy、pandas、scipy等科学…...

如何开展有组织的AI素养教育?
一、AI素养的定义与核心内涵 AI素养是智能时代个体适应与创新能力的综合体现,其内涵随着技术发展动态扩展,包含以下核心维度: 知识体系:理解AI基本原理(如算法、数据、算力)、技术边界及发展趋势ÿ…...

InnoDB对LRU算法的优化
标准 LRU 算法的核心思想是:当缓存空间不足时,淘汰掉最近最少使用的数据块(Page)。它通常用一个链表来实现,链表头部是最近访问的 Page,链表尾部是最久未访问的 Page。 然而,在数据库系统中直接…...

云原生--核心组件-容器篇-7-Docker私有镜像仓库--Harbor
1、Harbor的定义与核心作用 定义: Harbor是由VMware开源的企业级容器镜像仓库系统,后捐赠给 CNCF (Cloud Native Computing Foundation)。它基于Docker Registry扩展了企业级功能,用于存储、分发和管理容器镜像(如Docker、OCI标准…...

TypeScript 实用类型深度解析:Partial、Pick、Record 的妙用
需求背景:在后台系统的用户管理模块中,我们常遇到这样的场景:修改用户资料时只需要传部分字段,展示用户列表时要隐藏敏感信息,快速查找用户需要ID索引等等,这些业务需求都可以通过 TypeScript 的实用类型优…...

【Pandas】pandas DataFrame rmod
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

如何搭建spark yarn 模式的集群集群
以下是搭建Spark YARN模式集群的一般步骤: 准备工作 - 确保集群中各节点安装了Java环境,并配置好 JAVA_HOME 环境变量。 - 各节点间能通过SSH免密登录。 - 安装并配置好Hadoop集群,YARN作为Hadoop的资源管理器,Spark YARN模式需要…...
)
云原生--核心组件-容器篇-6-Docker核心之-镜像仓库(公共仓库,私有仓库,第三方仓库)
1、Docker仓库的定义与核心作用 定义: Docker仓库(Docker Registry)是用于存储、分发和管理Docker镜像的集中式存储库。它类似于代码仓库,但专门用于容器镜像的版本控制和共享。它允许开发人员和IT团队高效地管理、部署和分享容器…...

mysql8.0版本部署+日志清理+rsync备份策略
mysql安装:https://blog.csdn.net/qq_39399966/article/details/120205461 系统:centos7.9 数据库版本:mysql8.0.28 1.卸载旧的mysql,保证环境纯净 rpm -qa | grep mariadb mariadb-5.... rpm -e --nodeps 软件 rpm -e --nodeps mariadb-5.…...

搭建spark yarn 模式的集群集群
一.引言 在大数据处理领域,Apache Spark 是一个强大的分布式计算框架,而 YARN(Yet Another Resource Negotiator)是 Hadoop 的资源管理系统。将 Spark 运行在 YARN 模式下,可以充分利用 YARN 强大的资源管理和调度能力…...

在uni-app中使用Painter生成小程序海报
在uni-app中使用Painter生成小程序海报 安装Painter 从GitHub下载Painter组件:https://github.com/Kujiale-Mobile/Painter 将painter文件夹复制到uni-app项目的components目录下 配置页面 在需要使用海报的页面的pages.json中配置 {"path": "pag…...

Uni-app网络请求AES加密解密实现
Uni-app 网络请求封装与 AES 加密解密实现 下面我将为你提供一个完整的 Uni-app 网络请求封装方案,包含 POST 请求的统一处理、请求参数和响应数据的 AES 加密解密。 1. 创建加密解密工具类 首先创建一个 crypto.js 文件用于处理 AES 加密解密: // u…...

uniapp实现统一添加后端请求Header方法
uniapp把请求写完了,发现需要给接口请求添加头部,每个接口去添加又很麻烦,uniapp可以统一添加,并且还能给某些接口设置不添加头部。 一般用于添加token登录验证信息。 在 main.js 文件中配置。 代码如下: // 在…...

uniapp打包apk如何实现版本更新
我们做的比较简单,在后端设置版本号,并在uniapp的config.js中定义版本号,每次跟后端的进行对比,不一致的话就更新。 一、下载apk 主要代码(下载安装包,并进行安装,一般得手动同意安装…...

【Java开发日记】OpenFeign 的 9 个坑
目录 坑一:用对Http Client 1.1 feign中http client 1.2 ribbon中的Http Client 坑二:全局超时时间 坑三:单服务设置超时时间 坑四:熔断超时时间 4.1 使用feign超时 4.2 使用ribbon超时 4.3 使用自定义Options 坑五&…...

RocketMQ 存储核心:深入解析 CommitLog 设计原理
一、引言 在分布式消息队列系统中,消息存储的可靠性和高吞吐能力是衡量系统优劣的核心指标。Apache RocketMQ 作为一款高性能、高可用的分布式消息中间件,其独特的 CommitLog 存储机制在消息持久化过程中扮演了关键角色。本文将深入剖析 CommitLog 的设…...
)
【C++ Qt】快速上手 显⽰类控件(Label、LCDNumber、ProcessBar、CalendarWidget)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本文围绕Qt中常用的显示类控件展开,重点讲解了 QLabel(文本/图片显示)、QLCDNumber(数字显示࿰…...

Docker和K8s面试题
1.Docker底层依托于linux怎么实现资源隔离的? 基于Namespace的视图隔离:Docker利用Linux命名空间(Namespace)来实现不同容器之间的隔离。每个容器都运行在自己的一组命名空间中、包括PID(进程)、网络、挂载…...

shell--数组、正则表达式RE
1.数组 1.1定义 什么是数组? 数组也是一种变量,常规变量只能保存一个值,数组可以保存多个值 1.2 分类 普通数组:只能用整数作为数组的索引--0 下标 有序数组(普通数组):(index)索引(为整数,从0开始) 关联数组:可以使用字符串作为数组的索引 1.3 普通数组 引用: ec…...

java 使用 POI 为 word 文档自动生成书签
poi 版本:4.1.0 <properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><…...

redis+lua+固定窗口实现分布式限流
用key的过期时间替代固定窗口的时间戳 -- KEYS[1]: 限流的key -- ARGV[1]: 限流窗口大小(秒) -- ARGV[2]: 限流阈值local key KEYS[1] local window tonumber(ARGV[1]) local limit tonumber(ARGV[2])-- 尝试获取当前计数 local current redis.call…...

什么是SQL92标准,有什么特点和影响?
一、SQL92简介 SQL92标准是1992年由美国国家标准协会(ANSI)和国际标准化组织(ISO)联合制定的数据库语言标准,正式名称为"SQL:1992"或ISO/IEC 9075:1992。他是关系型数据库管理系统(R…...

Flink Checkpoint 与实时任务高可用保障机制实战
在实时数仓体系中,数据一致性和任务稳定性是核心保障。本文围绕 Flink Checkpoint 机制,深入讲解高可用保障的最佳实践和工程实现。 一、业务背景与痛点 在金融风控、营销实时推荐、智能监控等场景中,实时数仓的每一条数据都至关重要。常见的业务痛点包括: 断点恢复困难:…...

WebRtc08:WebRtc信令服务器实现
如何使用socket.io发送消息 发送消息 // 给本次连接发送消息 socket.emit()// 给某个房间内所有人发送消息 io.in(room).emit()// 除了自己以外,给某个房间的所有人发消息 socket.to(room).emit();// 除本连接外,给所有人发消息 socket.broadcast.emit…...

基于 SpringBoot 与 Redis 的缓存预热案例
文章目录 “缓存预热” 是什么?项目环境搭建创建数据访问层预热数据到 Redis 中创建缓存服务类测试缓存预热 “缓存预热” 是什么? 缓存预热是一种优化策略,在系统启动或者流量高峰来临之前,将一些经常访问的数据提前加载到缓存中…...

Python对比两张CAD图并标记差异的解决方案
以下是使用Python对比两张CAD图并标记差异的解决方案,结合图像处理和CAD结构分析: 一、环境准备与库选择 图像处理库:使用OpenCV进行图像差异检测、颜色空间转换和轮廓分析。CAD解析库:若为DXF格式,使用ezdxf解析实体…...

LINUX427 冒险位 粘滞位 chmod 权限
为什么不同用户能查看的文件夹不同 思索 是因为不同文件夹的权限不同吗?感觉不是 权限不就是只有rwx权限吗? o 对对对 和0GU有关 O 组内的其他用户应该 O是其他用户 不是组内用户 文件创建应该设置了r权限 但是root为什么看到的好像不一样 root 这些…...

10 DPSK原始对话记录
10 DPSK原始对话记录 前言 编程之余,在 Vscode 的 Cline 插件界面中和 ai (dpsk v3-0324) 聊起了天,得到了一个有意思的回答。就像ai有自我意识一样。在此记录。 实际对话内容 时间范围:2025-04-27 23:37:22 - 23:44:17 对话模式:PLAN MODE [23:37:22] 用户提问 “你…...

实现一个瀑布流布局
1、纯CSS实现 实现方式:借助column-count属性来创建 4 列的布局,并使用 column-gap 设置列间距。每个 .img-container 使用 break-inside: avoid 来防止图片被分割。 来看一下完整的代码: <!DOCTYPE html> <html lang"en&qu…...

Linux:进程间通信->共享内存
1. 共享内存的概念 System V共享内存,是一个高效的进程间通信IPC机制,允许多个进程共享同一块物理内存区实现快速的数据交换。如下图所示 这两个进程分别通过页表映射到这一块共享内存中 2. 共享内存的函数 shmget 功能: 创建新的共享内存…...

《Crawl4AI 爬虫工具部署配置全攻略》
《Crawl4AI 爬虫工具部署配置全攻略》 摘要 :在数据驱动的智能时代,高效爬虫工具是获取信息的关键。本文将为你详细解析 Crawl4AI 的安装配置全流程,从基础设置到进阶优化,再到生产环境部署,结合实用技巧与常见问题解…...
)
spring框架学习(下)
这章节讲的主要是spring在生产Bean对象时的过程 Spring实例化对象的基本流程 1、解析bean.xml 2、封装成BeanDifinition类 3、存放到BeanDIfinitionMap里 4、从BeanDIfinitionMap遍历得到bean 5、将bean存放到SingletonObjects 6、调用getBean方法得到bean 以下是简易的…...
)
进程与线程-----C语言经典题目(8)
一.什么是进程 定义: 进程指的是程序在操作系统内的一次执行过程。它不只是程序代码,还涵盖了程序运行时的各类资源与状态信息。包括创建、调度、消亡。 进程的状态(ps -aux): 就绪状态:进程已经…...

lstm用电量预测+网页可视化大屏
视频教学: 训练结果: 详细代码: import pandas as pd import numpy as np from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split from tensorflow.keras.models import Sequential from tensorflow.keras.layers impo…...

linux blueZ 第六篇:嵌入式与工业级应用案例——在 Raspberry Pi、Yocto 与 Buildroot 上裁剪 BlueZ 并落地实战
本篇面向嵌入式与工业级应用场景,深入讲解如何在各类 Linux 构建系统(Raspberry Pi OS、Yocto、Buildroot)中裁剪、交叉编译与集成 BlueZ,以及在工业网关、资产追踪与蓝牙 Mesh 等典型方案中的落地实例与注意要点,帮助你打造稳定、可维护、低功耗的嵌入式蓝牙产品。 目录 …...

Dev控件RadioGroup 如何设置一排有N个显示或分为几行
1.5个选项 全部横排显示,则Columns 5 2.5个选项 每行分两个,则有三行,则Columns 2...

AOSP Android14 Launcher3——Launcher的状态介绍LauncherState类
Launcher3中有一个跟Launcher状态相关的类,叫LauncherState LauncherState 是 Launcher3 中定义各种用户界面状态的抽象基类。你可以把它想象成一个状态机,定义了 Launcher 可能处于的不同视觉和交互模式,例如主屏幕、所有应用列表、最近任务…...
-Redis 基本知识及五大数据类型)
Redis 笔记(三)-Redis 基本知识及五大数据类型
一、redis 基本知识 redis 默认有 16个 数据库,config get databases 查看数据库数量 127.0.0.1:6379> config get databases # 查看数据库数量 1) "databases" 2) "16"默认使用的是第 0个 16 个数据库为:DB 0 ~ DB 15&am…...
线程互斥(锁))
Linux——线程(2)线程互斥(锁)
知识回顾 在学习本篇内容前,我们需要先回顾一下几个概念。 临界资源:多线程执行流共享的资源就叫做临界资源 临界区:每个线程内部,访问临界资源的代码,就叫做临界区 互斥:任何时刻,互斥保证有…...
)
深度解析:具身AI机器人领域最全资源指南(含人形机器人,多足机器人,灵巧手等精选资源)
💡 你是否在寻找具身人工智能(Embodied AI)领域的研究资源?是否希望有一个系统性的资源集合来加速你的研究?今天给大家推荐一个重磅项目! 🌟 为什么需要这个项目? 具身人工智能是一…...

组件之间的信息传递的四种方法!!【vue3 前端】
迎万难 赢万难! 目录 1. 使用 defineProps 传递数据:2. 使用。defineEmits 发送事件:3. 使用 Provide / Inject:4. 使用状态管理(如 Pinia): 1. 使用 defineProps 传递数据: 父组件…...

单片机学习笔记9.数码管
0到99计数 ,段选共阴极 ;0到99计数 ORG 0000H LJMP MAIN ORG 000BH LJMP TIMER0_ISR ORG 0100H; 定义位选控制位 DISPLAY_SELECT BIT 20H.0MAIN:; 定时器 0 初始化MOV TMOD, #01H ; 设置定时器 0 为模式 1MOV TH0, #3CH ; 定时器 0 高 8 位初值,定时 …...

Go 语言 核心知识点
Go 语言(Golang)是由 Google 开发的一种静态类型、编译型语言,设计目标是高效、简洁、并发友好。它借鉴了 C 语言的性能优势,同时引入了现代语言的特性(如垃圾回收、并发原语),并摒弃了传统面向…...
)
【C++ 类和数据抽象】消息处理示例(2)
目录 一、消息处理系统的核心价值 1.1 现代软件架构中的消息驱动 1.2 消息处理系统的关键组件 二、消息处理系统概述 三、Message类设计 3.1 成员变量 3.2. 成员函数 3.3. 私有辅助函数 四、Folder类设计 五、代码实现 六、数据抽象在消息处理系统中的应用 七、总结…...

kafka 中消费者 groupId 是什么
📚 什么是 groupId? groupId 是 Kafka 里消费者组(Consumer Group)的唯一标识。 同一个 groupId 的消费者,一起共享消费,一条消息只给组内一个消费者处理。不同 groupId 的消费者组,各自独立消…...

单相交直交变频电路设计——matlab仿真+4500字word报告
微♥“电击小子程高兴的MATLAB小屋”获取巨额优惠 1.模型简介 硬件电路采用Altium designer设计,仿真采用Matlab软件 本仿真模型基于MATLAB/Simulink(版本MATLAB 2018Rb)软件。建议采用matlab2018Rb及以上版本打开。(若需要其他…...
)
Python中的协程(Coroutine)
Python中的协程(Coroutine) 是一种轻量级的异步执行单元,主要用于解决IO密集型任务的性能问题。Python 3.5引入了 async/await 语法,使得协程变得简洁且易于使用。协程的核心是通过事件循环(Event Loop) 来…...