【Google Colab】利用unsloth针对医疗数据集进行大语言模型的快速微调(含跑通原代码)
【本文概述】
为了快速跑通,首先忽略算力等问题,使用google colab云端服务器,选择unsloth/DeepSeek-R1-Distill-Llama-8B大语言模型进行微调,微调参数只进行了简单的设置。
在微调的时候,实际说明colab对8B的模型微调算力不足,故只选取了数据集中的一部分进行训练,最终的微调实现效果并不好,但的确可以看到很明显的调试效果,暂可视为本项目运行成功,后期再考虑算力、数据集、微调参数、微调模型的质量等,适合初期尝试利用unsloth进行微调理解的项目。
【准备工作】
- Colab: 只需要一个 Google 账户,免费版提供 T4 GPU(约 15GB 显存),足够跑 7B 参数模型。
- 本地环境: 用于部署的电脑建议至少 8GB 内存(运行 7B 模型),若有 NVIDIA GPU 可加速。
- 网络: 稳定的互联网连接,用于下载模型和数据集
【项目流程】
【0-建立项目】
在云端硬盘中新建笔记本
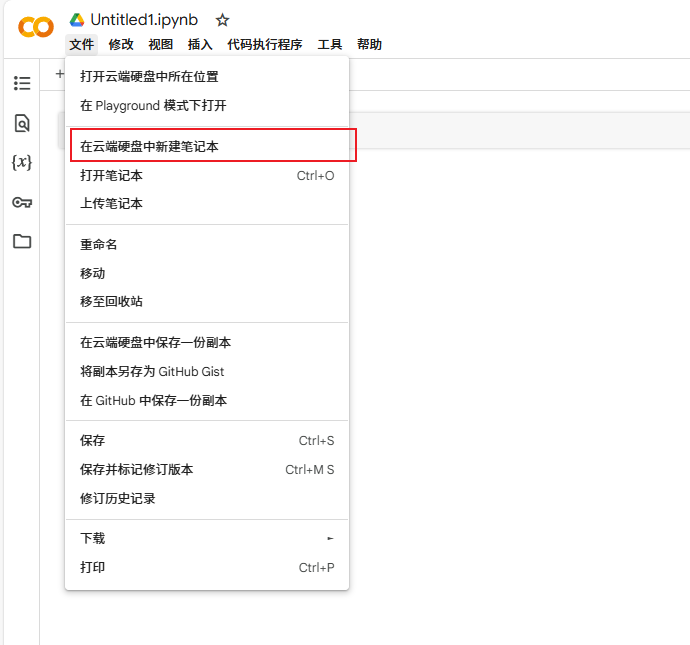
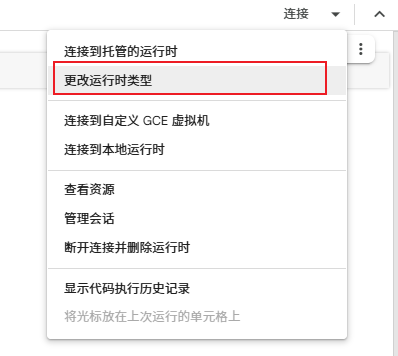
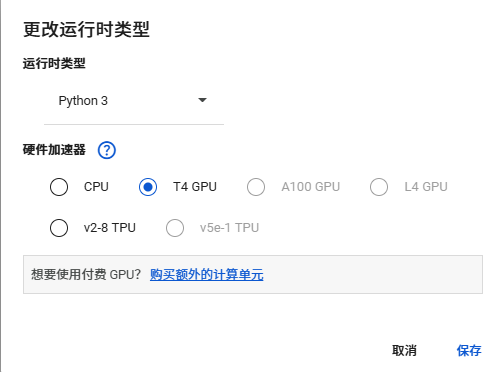
更改运行时类型,选择T4 GPU后进行保存
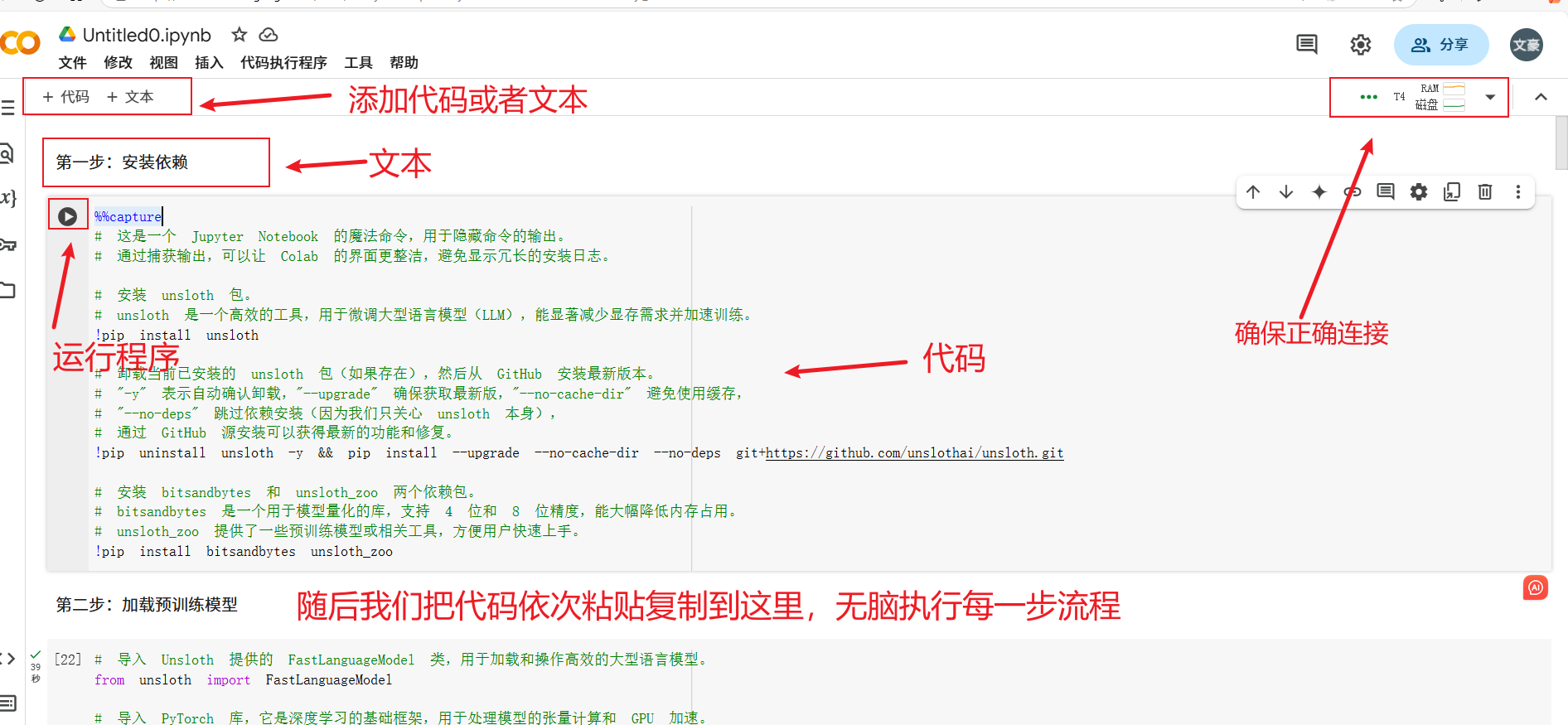
【1-安装依赖】
在 Colab 新建笔记本,运行以下代码安装所需库:
这些库包括 Unsloth 主程序、bitsandbytes(用于量化模型)和 unsloth_zoo(预训练模型支持)。
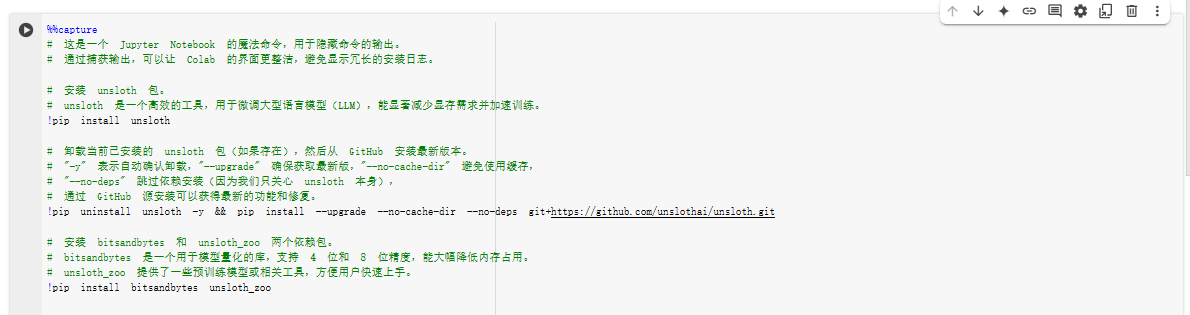
%%capture
# 这是一个 Jupyter Notebook 的魔法命令,用于隐藏命令的输出。
# 通过捕获输出,可以让 Colab 的界面更整洁,避免显示冗长的安装日志。# 安装 unsloth 包。
# unsloth 是一个高效的工具,用于微调大型语言模型(LLM),能显著减少显存需求并加速训练。
!pip install unsloth# 卸载当前已安装的 unsloth 包(如果存在),然后从 GitHub 安装最新版本。
# "-y" 表示自动确认卸载,"--upgrade" 确保获取最新版,"--no-cache-dir" 避免使用缓存,
# "--no-deps" 跳过依赖安装(因为我们只关心 unsloth 本身),
# 通过 GitHub 源安装可以获得最新的功能和修复。
!pip uninstall unsloth -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git# 安装 bitsandbytes 和 unsloth_zoo 两个依赖包。
# bitsandbytes 是一个用于模型量化的库,支持 4 位和 8 位精度,能大幅降低内存占用。
# unsloth_zoo 提供了一些预训练模型或相关工具,方便用户快速上手。
!pip install bitsandbytes unsloth_zoo
随后在colab上配置系统环境变量,以便正确地使用CUDA。通过设置LD_LIBRARY_PATH和CUDA_HOME,它确保系统能够找到CUDA的动态链接库和安装路径,从而让依赖CUDA的程序(如深度学习框架TensorFlow、PyTorch等)能够正常运行。

import os
os.environ['LD_LIBRARY_PATH'] = '/usr/local/cuda/lib64:' + os.environ.get('LD_LIBRARY_PATH', '')
os.environ['CUDA_HOME'] = '/usr/local/cuda' 为了确保项目顺利运行,再通过pip命令安装和管理Python库。
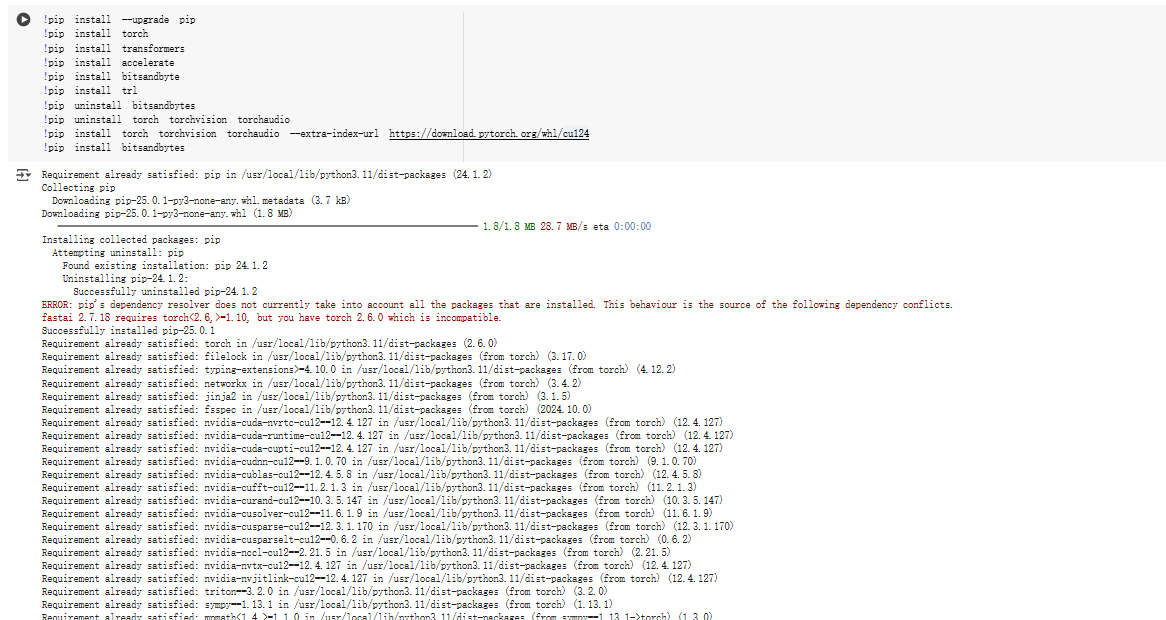
!pip install --upgrade pip
!pip install torch
!pip install transformers
!pip install accelerate
!pip install bitsandbyte
!pip install trl-
torch、torchvision、torchaudio:通过指定--extra-index-url https://download.pytorch.org/whl/cu124,安装的是与colab中CUDA 12.4兼容的版本。 -
transformers、accelerate、bitsandbytes、trl:安装的是这些库的最新版本(通过pip install命令默认行为)。
以下对安装的库进行简单解释
pip(升级):
!pip install --upgrade pip:升级pip到最新版本,确保后续安装操作能够顺利进行。
torch(PyTorch):
!pip install torch:安装PyTorch库。PyTorch是一个流行的深度学习框架,广泛用于研究和生产环境。
!pip install torchvision torchaudio:安装与PyTorch配套的torchvision(用于计算机视觉任务)和torchaudio(用于音频处理任务)库。
!pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124:指定从PyTorch的CUDA 12.4版本的预编译包中安装PyTorch及其配套库。这通常是为了确保与特定版本的CUDA兼容。
transformers:
!pip install transformers:安装Hugging Face的transformers库。这是一个用于自然语言处理(NLP)的库,提供了预训练模型(如BERT、GPT等)的接口和工具。
accelerate:
!pip install accelerate:安装accelerate库。这是一个用于简化分布式训练和混合精度训练的库,由Hugging Face开发。
bitsandbytes:
!pip install bitsandbytes:安装bitsandbytes库。这是一个用于优化深度学习模型的库,特别是在量化和内存优化方面。
!pip uninstall bitsandbytes:卸载bitsandbytes库。可能是为了重新安装特定版本或解决冲突。
!pip install bitsandbytes:重新安装bitsandbytes库。
trl:
!pip install trl:安装trl(Transformer Reinforcement Learning)库。这是一个用于强化学习和Transformer模型结合的库。
【在安装对应库时有可能出现的问题】
在安装上述库时执行后期代码出现了版本冲突的问题,现给出执行中可能能帮助解决的方案:
-
bitsandbytes的卸载与重新安装:卸载了bitsandbytes,然后又重新安装了。为了解决版本冲突或确保安装的是正确的版本。 -
torch的卸载与重新安装:卸载了torch、torchvision和torchaudio,然后通过指定CUDA版本的URL重新安装。为了确保安装的PyTorch版本与CUDA 12.4兼容。
!pip uninstall bitsandbytes
!pip uninstall torch torchvision torchaudio
!pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124
!pip install bitsandbytes
!pip install --upgrade torch torchvision transformers通过再执行这些代码后后期没有出现版本冲突的报错。
【2-加载预训练模型】
首先验证unsloth是否成功安装的代码:
from unsloth import FastLanguageModel
print("Unsloth installed successfully!")可以打印说明已经成功安装,如果无法打印则说明unsloth没有安装成功,重复上述的步骤

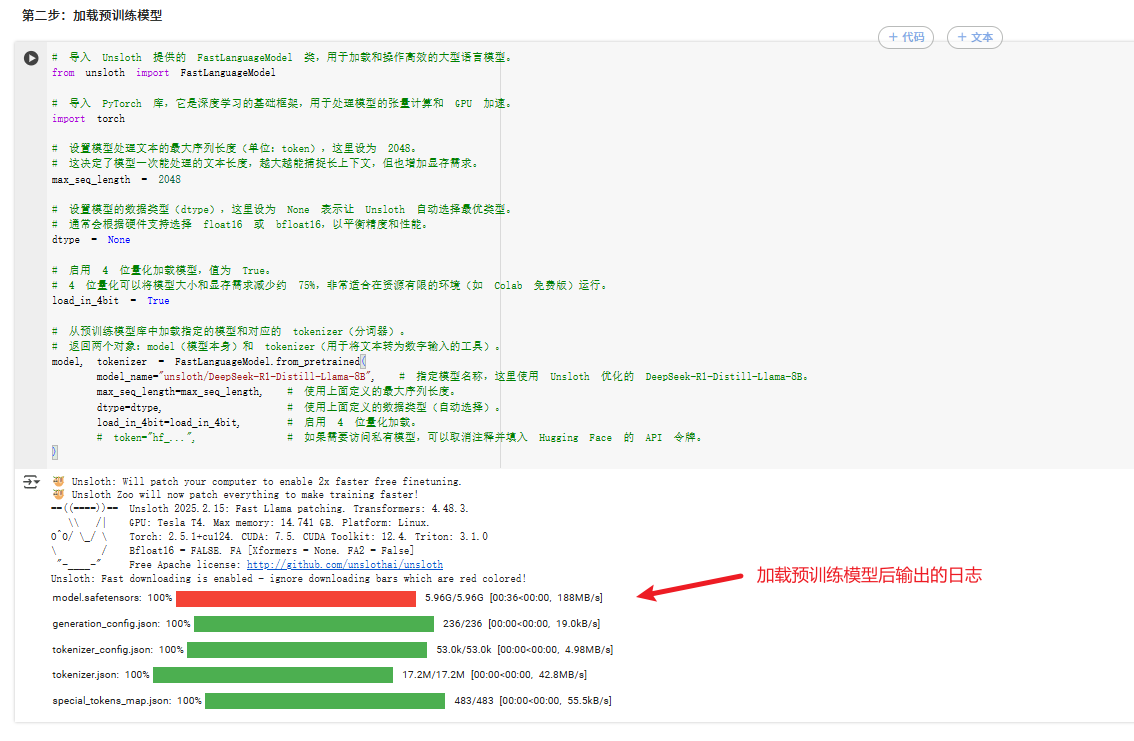
验证成功后,选择一个基础模型,这里用 unsloth/DeepSeek-R1-Distill-Llama-8B:

# 导入 PyTorch 库,它是深度学习的基础框架,用于处理模型的张量计算和 GPU 加速。
import torch
# 导入 Unsloth 提供的 FastLanguageModel 类,用于加载和操作高效的大型语言模型。
from unsloth import FastLanguageModel# 设置模型处理文本的最大序列长度(单位:token),这里设为 2048。
# 这决定了模型一次能处理的文本长度,越大越能捕捉长上下文,但也增加显存需求。
max_seq_length = 2048# 设置模型的数据类型(dtype),这里设为 None 表示让 Unsloth 自动选择最优类型。
# 通常会根据硬件支持选择 float16 或 bfloat16,以平衡精度和性能。
dtype = None# 启用 4 位量化加载模型,值为 True。
# 4 位量化可以将模型大小和显存需求减少约 75%,非常适合在资源有限的环境(如 Colab 免费版)运行。
load_in_4bit = True# 从预训练模型库中加载指定的模型和对应的 tokenizer(分词器)。
# 返回两个对象:model(模型本身)和 tokenizer(用于将文本转为数字输入的工具)。
model, tokenizer = FastLanguageModel.from_pretrained(model_name="unsloth/DeepSeek-R1-Distill-Llama-8B", # 指定模型名称,这里使用 Unsloth 优化的 DeepSeek-R1-Distill-Llama-8B。max_seq_length=max_seq_length, # 使用上面定义的最大序列长度。dtype=dtype, # 使用上面定义的数据类型(自动选择)。load_in_4bit=load_in_4bit, # 启用 4 位量化加载。# token="hf_...", # 如果需要访问私有模型,可以取消注释并填入 Hugging Face 的 API 令牌。
)
【3-微调前测试】
先测试模型未经训练的表现:
这里调用推理模型进行推理,理想状态下,输出可能是泛泛而谈,微调后会更精准。但在本项目执行的时候微调结果不比微调前好,是因为训练集不够,暂时忽略这个问题。
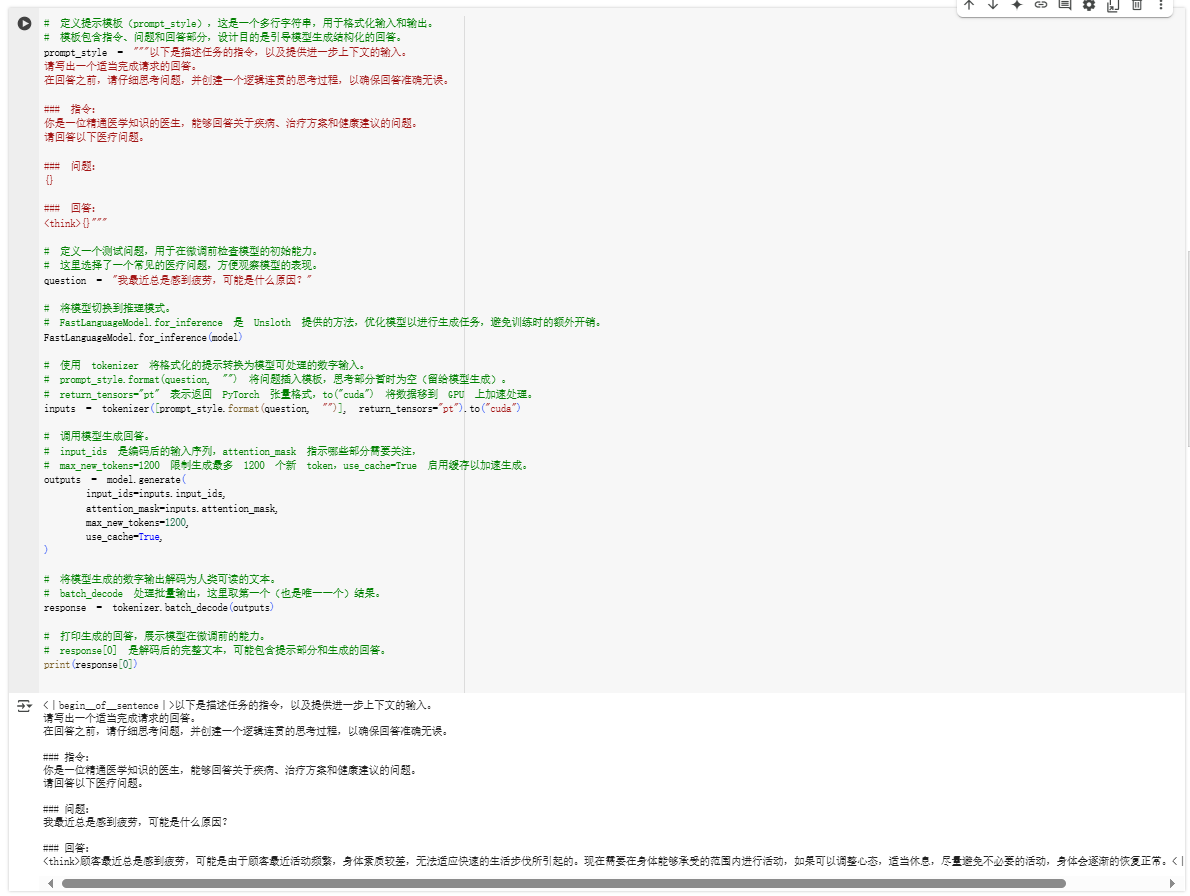
# 定义提示模板(prompt_style),这是一个多行字符串,用于格式化输入和输出。
# 模板包含指令、问题和回答部分,设计目的是引导模型生成结构化的回答。
prompt_style = """以下是描述任务的指令,以及提供进一步上下文的输入。
请写出一个适当完成请求的回答。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。### 指令:
你是一位精通医学知识的医生,能够回答关于疾病、治疗方案和健康建议的问题。
请回答以下医疗问题。### 问题:
{}### 回答:
<think>{}"""# 定义一个测试问题,用于在微调前检查模型的初始能力。
# 这里选择了一个常见的医疗问题,方便观察模型的表现。
question = "我最近总是感到疲劳,可能是什么原因?"# 将模型切换到推理模式。
# FastLanguageModel.for_inference 是 Unsloth 提供的方法,优化模型以进行生成任务,避免训练时的额外开销。
FastLanguageModel.for_inference(model)# 使用 tokenizer 将格式化的提示转换为模型可处理的数字输入。
# prompt_style.format(question, "") 将问题插入模板,思考部分暂时为空(留给模型生成)。
# return_tensors="pt" 表示返回 PyTorch 张量格式,to("cuda") 将数据移到 GPU 上加速处理。
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")# 调用模型生成回答。
# input_ids 是编码后的输入序列,attention_mask 指示哪些部分需要关注,
# max_new_tokens=1200 限制生成最多 1200 个新 token,use_cache=True 启用缓存以加速生成。
outputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,
)# 将模型生成的数字输出解码为人类可读的文本。
# batch_decode 处理批量输出,这里取第一个(也是唯一一个)结果。
response = tokenizer.batch_decode(outputs)# 打印生成的回答,展示模型在微调前的能力。
# response[0] 是解码后的完整文本,可能包含提示部分和生成的回答。
print(response[0])
【4-加载与格式化数据集】
使用 shibing624/medical 中文医疗数据集:
在这里定义了一个叫做 train_prompt_style 的字符串模板,给模型的一份“任务说明书”。
目的是告诉模型,它现在是一位精通医学知识的医生,需要回答医疗相关的问题。这个模板分为几个部分:首先,写一个总体的任务描述,提醒模型要认真思考并给出准确的回答;接着,明确指令,设定模型的角色和任务;然后,用 {} 留了三个占位符,分别用来填入具体的问题、思考过程和最终的回答。这样,就能确保模型在训练时按照这个结构生成内容,比如先分析问题,再给出专业建议。这样设计既清晰又有逻辑,方便模型学习如何像医生一样思考和回应。
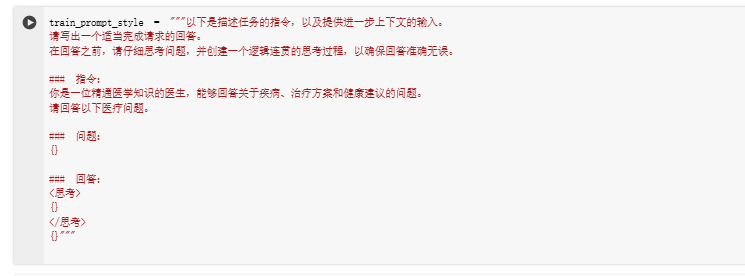
train_prompt_style = """以下是描述任务的指令,以及提供进一步上下文的输入。
请写出一个适当完成请求的回答。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。### 指令:
你是一位精通医学知识的医生,能够回答关于疾病、治疗方案和健康建议的问题。
请回答以下医疗问题。### 问题:
{}### 回答:
<思考>
{}
</思考>
{}"""
在这段代码里主要是为了准备训练数据,让模型能理解和生成医疗相关的回答。
首先,定义一个结束标记EOS_TOKEN,这是从分词器里拿来的,用来告诉模型每段文本到哪里结束。接着,从 datasets 库里导入了 load_dataset 函数,用它加载了一个医疗数据集 shibing624/medical,选了finetune 配置里的前 200 条训练数据。为了搞清楚数据长什么样,打印它的字段名,结果是 instruction、input 和 output。
然后,写一个函数 formatting_prompts_func,用来把这些数据格式化成想要的样子:从数据里抽出instruction 作为问题,input 作为思考过程,output 作为回答,再用之前定义的 train_prompt_style 模板把它们组合起来,加上结束标记,最后存进一个列表里。
通过 dataset.map 方法,批量处理所有数据,最后输出第一条格式化后的文本,看看是不是按预期工作。这一步的目的是让数据变成模型能直接学习的格式,确保训练顺利进行。

# 定义结束标记(EOS_TOKEN),用于指示文本的结束
EOS_TOKEN = tokenizer.eos_token # 必须添加结束标记# 导入数据集加载函数
from datasets import load_dataset
# 加载指定的数据集,选择中文语言和训练集的前500条记录
dataset = load_dataset("shibing624/medical", 'finetune', split = "train[0:200]", trust_remote_code=True)
# 打印数据集的列名,查看数据集中有哪些字段
print(dataset.column_names)
格式化数据集中的记录,并且进行打印查看
# 定义一个函数,用于格式化数据集中的每条记录
def formatting_prompts_func(examples):# 从数据集中提取问题、复杂思考过程和回答inputs = examples["instruction"]cots = examples["input"]outputs = examples["output"]texts = [] # 用于存储格式化后的文本# 遍历每个问题、思考过程和回答,进行格式化for input, cot, output in zip(inputs, cots, outputs):# 使用字符串模板插入数据,并加上结束标记text = train_prompt_style.format(input, cot, output) + EOS_TOKENtexts.append(text) # 将格式化后的文本添加到列表中return {"text": texts, # 返回包含所有格式化文本的字典}dataset = dataset.map(formatting_prompts_func, batched = True)
dataset["text"][0]
【5-执行微调训练】
配置 LoRA 并开始训练:
训练约需实践视数据量而定。

# 将模型切换到训练模式。
# FastLanguageModel.for_training 是 Unsloth 提供的方法,确保模型准备好进行参数更新,而不是仅用于推理。
FastLanguageModel.for_training(model)# 配置并返回一个支持参数高效微调(PEFT)的模型。
# get_peft_model 使用 LoRA 技术,只更新模型的部分参数,从而减少显存需求和计算开销。
model = FastLanguageModel.get_peft_model(model, # 传入之前加载的预训练模型,作为微调的基础。r=16, # 设置 LoRA 的秩(rank),控制新增可训练参数的规模。值越大,模型调整能力越强,但显存需求也增加。target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],# 指定需要应用 LoRA 的模型模块,这些是 Transformer 架构中的关键部分(如注意力机制和前馈网络)。lora_alpha=16,# LoRA 的缩放因子,影响新增参数对模型的贡献程度。通常与 r 成比例设置,这里为 16。lora_dropout=0,# 设置 LoRA 层的 dropout 比率,用于防止过拟合。这里设为 0,表示不丢弃任何参数。bias="none",# 指定是否为 LoRA 参数添加偏置项。"none" 表示不添加,保持轻量化。use_gradient_checkpointing="unsloth",# 启用梯度检查点技术,Unsloth 优化版本能节省显存,支持更大的批量大小或模型。random_state=3407,# 设置随机种子,确保每次运行时模型初始化的随机性一致,便于结果复现。use_rslora=False,# 是否使用 Rank-Stabilized LoRA(一种改进的 LoRA 变体)。这里设为 False,使用标准 LoRA。loftq_config=None,# 设置是否使用 LoftQ(一种量化技术)。这里设为 None,表示不启用。
)
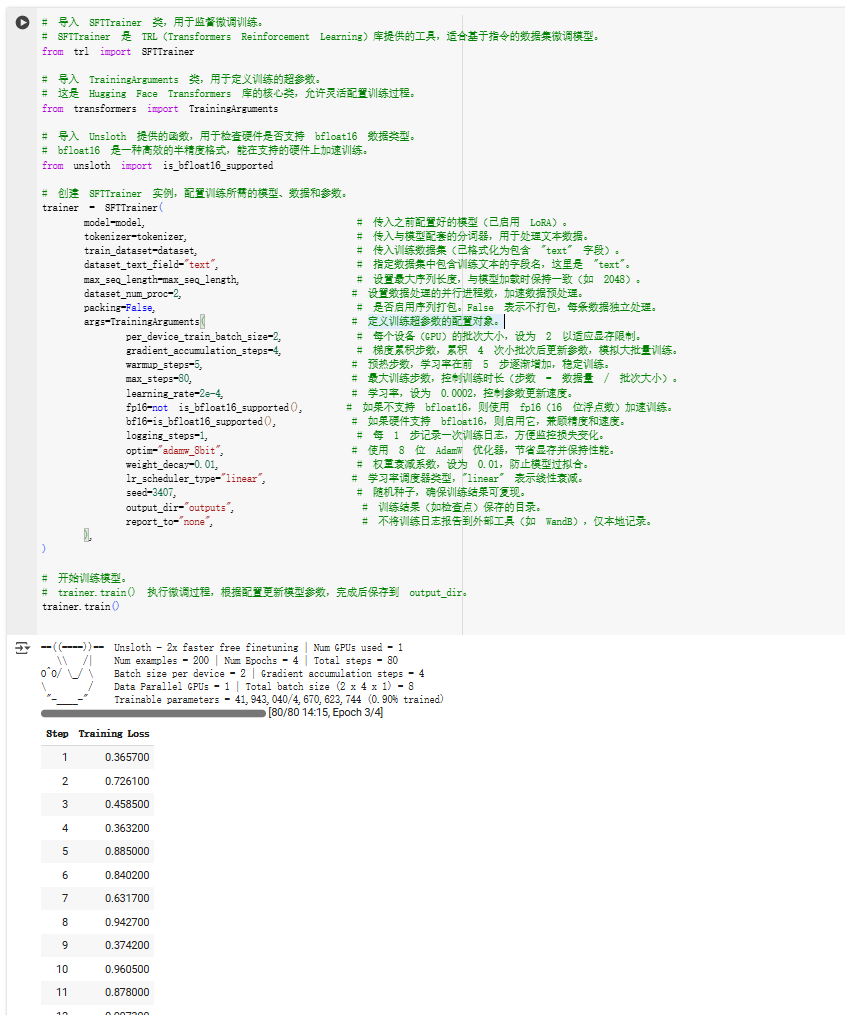
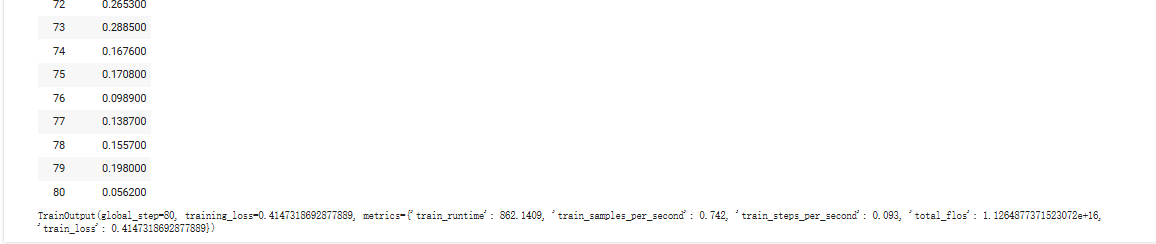
80次的训练步数完成后,unsloth会给出模型训练中的关键信息:
TrainOutput(global_step=80, training_loss=0.4147318692877889, metrics={'train_runtime': 862.1409, 'train_samples_per_second': 0.742, 'train_steps_per_second': 0.093, 'total_flos': 1.1264877371523072e+16, 'train_loss': 0.4147318692877889})
即:
-
训练进度:已经完成了80个训练步骤。
-
训练性能:平均损失值为0.4147,训练过程耗时约862秒。
-
效率指标:每秒处理约0.742个样本,每秒完成约0.093个训练步骤,总共执行了约1.13×10¹⁶次浮点运算。
# 导入 SFTTrainer 类,用于监督微调训练。
# SFTTrainer 是 TRL(Transformers Reinforcement Learning)库提供的工具,适合基于指令的数据集微调模型。
from trl import SFTTrainer# 导入 TrainingArguments 类,用于定义训练的超参数。
# 这是 Hugging Face Transformers 库的核心类,允许灵活配置训练过程。
from transformers import TrainingArguments# 导入 Unsloth 提供的函数,用于检查硬件是否支持 bfloat16 数据类型。
# bfloat16 是一种高效的半精度格式,能在支持的硬件上加速训练。
from unsloth import is_bfloat16_supported# 创建 SFTTrainer 实例,配置训练所需的模型、数据和参数。
trainer = SFTTrainer(model=model, # 传入之前配置好的模型(已启用 LoRA)。tokenizer=tokenizer, # 传入与模型配套的分词器,用于处理文本数据。train_dataset=dataset, # 传入训练数据集(已格式化为包含 "text" 字段)。dataset_text_field="text", # 指定数据集中包含训练文本的字段名,这里是 "text"。max_seq_length=max_seq_length, # 设置最大序列长度,与模型加载时保持一致(如 2048)。dataset_num_proc=2, # 设置数据处理的并行进程数,加速数据预处理。packing=False, # 是否启用序列打包。False 表示不打包,每条数据独立处理。args=TrainingArguments( # 定义训练超参数的配置对象。per_device_train_batch_size=2, # 每个设备(GPU)的批次大小,设为 2 以适应显存限制。gradient_accumulation_steps=4, # 梯度累积步数,累积 4 次小批次后更新参数,模拟大批量训练。warmup_steps=5, # 预热步数,学习率在前 5 步逐渐增加,稳定训练。max_steps=80, # 最大训练步数,控制训练时长(步数 = 数据量 / 批次大小)。learning_rate=2e-4, # 学习率,设为 0.0002,控制参数更新速度。fp16=not is_bfloat16_supported(), # 如果不支持 bfloat16,则使用 fp16(16 位浮点数)加速训练。bf16=is_bfloat16_supported(), # 如果硬件支持 bfloat16,则启用它,兼顾精度和速度。logging_steps=1, # 每 1 步记录一次训练日志,方便监控损失变化。optim="adamw_8bit", # 使用 8 位 AdamW 优化器,节省显存并保持性能。weight_decay=0.01, # 权重衰减系数,设为 0.01,防止模型过拟合。lr_scheduler_type="linear", # 学习率调度器类型,"linear" 表示线性衰减。seed=3407, # 随机种子,确保训练结果可复现。output_dir="outputs", # 训练结果(如检查点)保存的目录。report_to="none", # 不将训练日志报告到外部工具(如 WandB),仅本地记录。),
)# 开始训练模型。
# trainer.train() 执行微调过程,根据配置更新模型参数,完成后保存到 output_dir。
trainer.train()
【6-微调后测试】
用相同问题测试效果:
理想状态下,回答更贴近医疗专业知识。
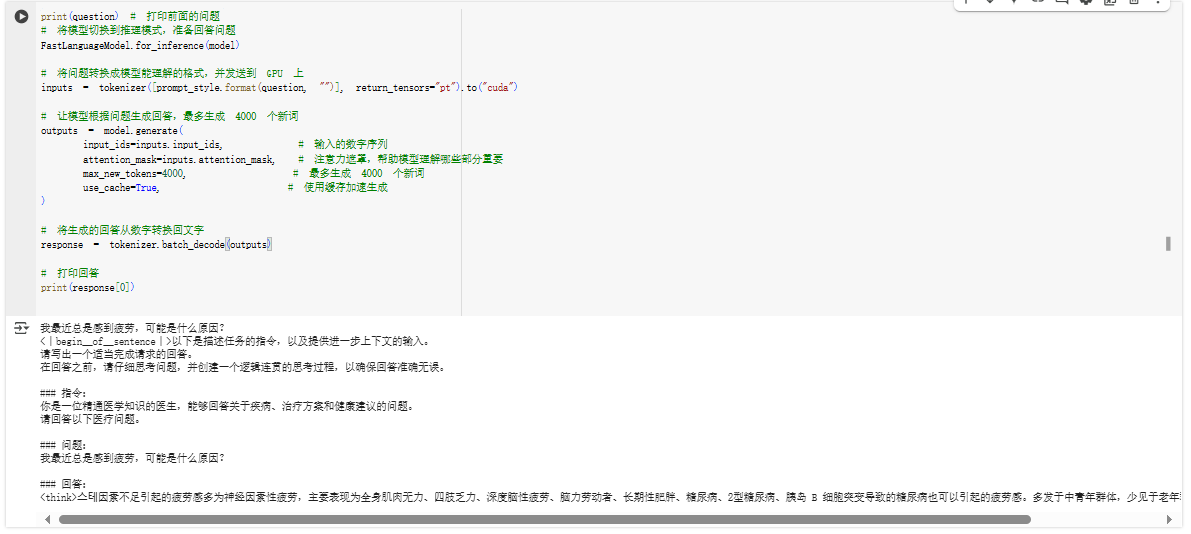
给出的回复是:
我最近总是感到疲劳,可能是什么原因? <|begin▁of▁sentence|>以下是描述任务的指令,以及提供进一步上下文的输入。 请写出一个适当完成请求的回答。 在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。 ### 指令: 你是一位精通医学知识的医生,能够回答关于疾病、治疗方案和健康建议的问题。 请回答以下医疗问题。 ### 问题: 我最近总是感到疲劳,可能是什么原因? ### 回答: <think>스테因素不足引起的疲劳感多为神经因素性疲劳,主要表现为全身肌肉无力、四肢乏力、深度脑性疲劳、脑力劳动者、长期性肥胖、糖尿病、2型糖尿病、胰岛 B 细胞突变导致的糖尿病也可以引起的疲劳感。多发于中青年群体,少见于老年群体。<|end▁of▁sentence|>
print(question) # 打印前面的问题
# 将模型切换到推理模式,准备回答问题
FastLanguageModel.for_inference(model)# 将问题转换成模型能理解的格式,并发送到 GPU 上
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")# 让模型根据问题生成回答,最多生成 4000 个新词
outputs = model.generate(input_ids=inputs.input_ids, # 输入的数字序列attention_mask=inputs.attention_mask, # 注意力遮罩,帮助模型理解哪些部分重要max_new_tokens=4000, # 最多生成 4000 个新词use_cache=True, # 使用缓存加速生成
)# 将生成的回答从数字转换回文字
response = tokenizer.batch_decode(outputs)# 打印回答
print(response[0])
到此, 微调项目执行完成。
当前因为训练的数据集很少,最后输出的回答效果并不好,后期需要加大数据量等。
理想状态下,最终的输出模式应该是如下图所示:

【7-导出微调后的模型-可选】
将微调后的模型保存为 GGUF 格式
GGUF,全称是 GPT-Generated Unified Format(GPT 生成的统一格式),是一种专门为存储和部署大型语言模型(LLM)设计的文件格式。简单来说,它就像一个“打包盒”,把模型的所有必要信息都装在一起,比如模型的权重(参数)、分词器(tokenizer)信息、超参数(hyperparameters)和元数据(metadata),全都压缩成一个二进制文件。这样做的好处是方便高效地加载和运行模型,尤其是在本地设备上。
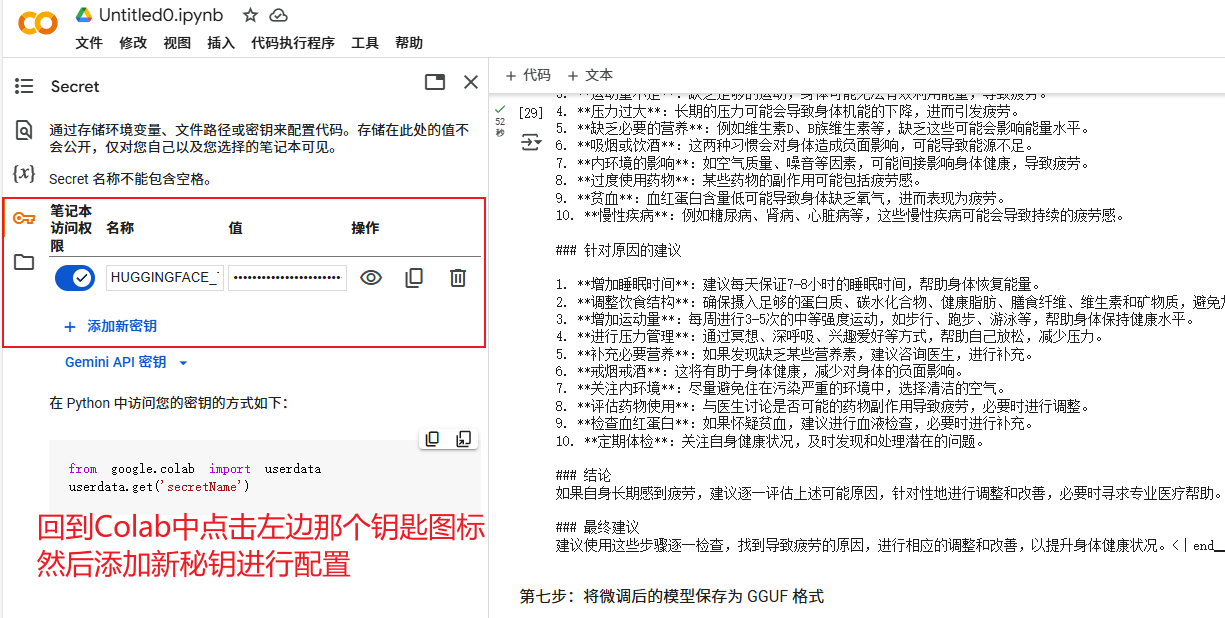
执行前我们需要先在Colab中配置token的环境变量
# 导入 Google Colab 的 userdata 模块,用于访问用户数据
from google.colab import userdata# 从 Google Colab 用户数据中获取 Hugging Face 的 API 令牌
HUGGINGFACE_TOKEN = userdata.get('HUGGINGFACE_TOKEN')# 将模型保存为 8 位量化格式(Q8_0)
# 这种格式文件小且运行快,适合部署到资源受限的设备
if True: model.save_pretrained_gguf("model", tokenizer,)# 将模型保存为 16 位量化格式(f16)
# 16 位量化精度更高,但文件稍大
if False: model.save_pretrained_gguf("model_f16", tokenizer, quantization_method = "f16")# 将模型保存为 4 位量化格式(q4_k_m)
# 4 位量化文件最小,但精度可能稍低
if False: model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
配置HUGGINGFACE_TOKEN的环境变量
首先我们先获取到Huggingface的token

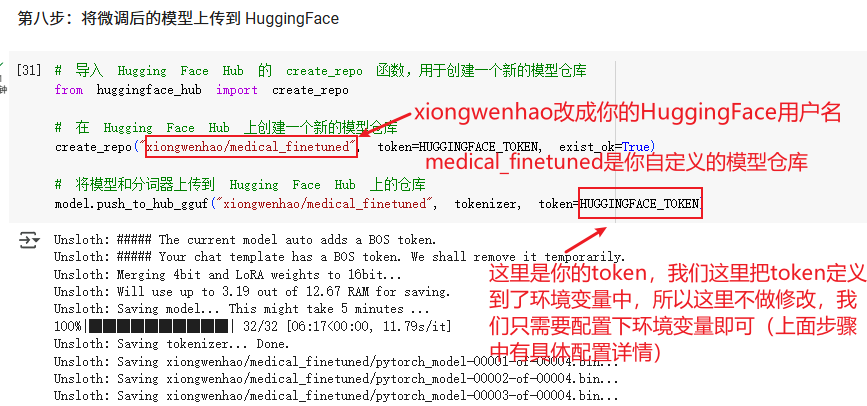
将微调后的模型上传到 HuggingFace
# 导入 Hugging Face Hub 的 create_repo 函数,用于创建一个新的模型仓库
from huggingface_hub import create_repo# 在 Hugging Face Hub 上创建一个新的模型仓库
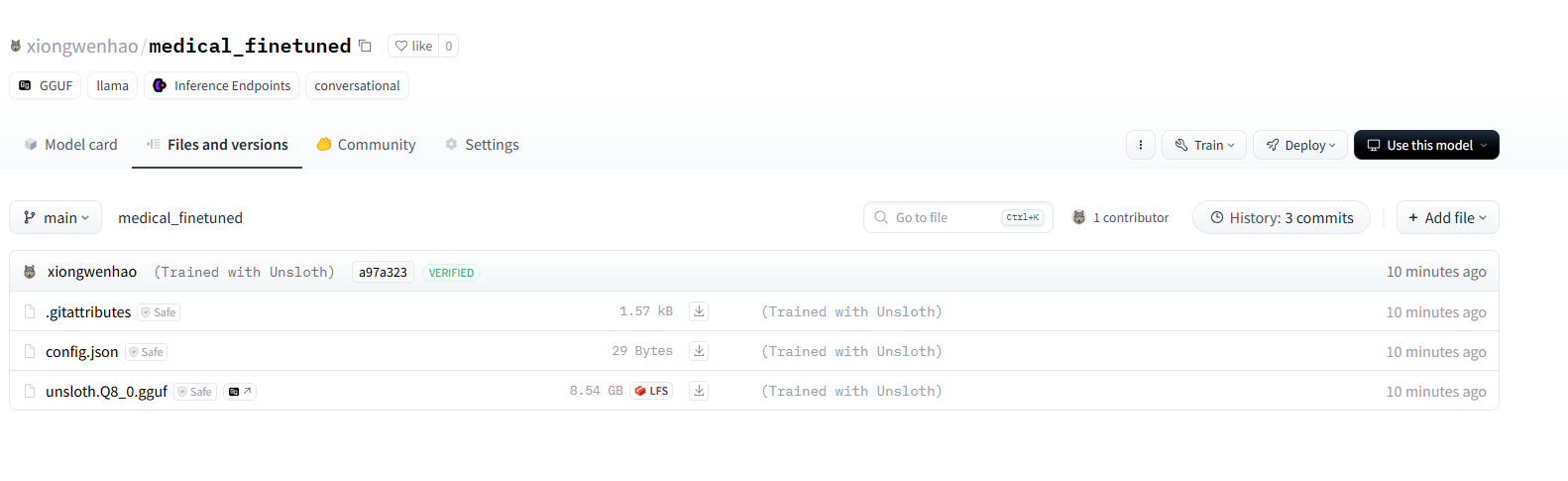
create_repo("xiongwenhao/medical_finetuned", token=HUGGINGFACE_TOKEN, exist_ok=True)# 将模型和分词器上传到 Hugging Face Hub 上的仓库
model.push_to_hub_gguf("xiongwenhao/medical_finetuned", tokenizer, token=HUGGINGFACE_TOKEN)
使用Ollama运行微调后的模型
ollama run hf.co/{用户名}/{上传到HuggingFace的模型名称}
示例:ollama run hf.co/xiongwenhao/medical_finetuned
注:本人在第7步保存和导出模型没有测试成功,参考项目见“参考资料”中的地址,本文在这一步仅作为存档,以免后续需要使用时原帖失效。
【参考资料】
[1] 轻松微调大模型:利用 Colab 和 Unsloth 实现高效训练:https://blog.csdn.net/weixin_66401877/article/details/145892615
相关文章:
)
【Google Colab】利用unsloth针对医疗数据集进行大语言模型的快速微调(含跑通原代码)
【本文概述】 为了快速跑通,首先忽略算力等问题,使用google colab云端服务器,选择unsloth/DeepSeek-R1-Distill-Llama-8B大语言模型进行微调,微调参数只进行了简单的设置。 在微调的时候,实际说明colab对8B的模型微调…...

基于STM32、HAL库的ADS1255IDBR模数转换器ADC驱动程序设计
一、简介: ADS1255IDBR是德州仪器(TI)生产的一款高精度、低噪声、24位ΔΣ模数转换器(ADC),主要特性包括: 24位无丢失码分辨率 高达23位有效分辨率(ENOB) 数据速率可达30kSPS 低噪声: 2.5μV RMS (20SPS时) 可编程增益放大器(PGA): 1-64V/V 单/差分输入配置 内置自校准和系…...

T检验、F检验及样本容量计算学习总结
目录 〇、碎语一、假设检验1.1 两种错误1.2 z检验和t检验1.3 t检验1.3.1 单样本t检验1.3.2 配对样本t检验1.3.3 独立样本t检验1.4 方差齐性检验1.4 卡方检验二、样本容量的计算2.1 AB测试主要的两种应用场景2.2 绝对量的计算公式2.3 率的计算公式参考资料〇、碎语 听到最多的检…...
PDFMathTranslate:让数学公式在PDF翻译中不再痛苦
在日常的论文阅读、教材翻译中,我们经常会遇到一个极其恼人的问题:PDF里的数学公式翻译错乱。即使用上了各种强大的PDF翻译工具,公式依然可能被拆碎、误解,甚至丢失。针对这个痛点,PDFMathTranslate 应运而生。 本文将…...
:docker常用命令)
Docker(二):docker常用命令
一、帮助命令 1、docker 帮助命令 命令说明docker version / docker -v查看docker的版本信息docker info查看docker详细信息docker --help / docker -h查看docker帮助命令,可以查看到相关的其他命令 二、Docker镜像命令 1、docker pull 从远程仓库docker hub 上拉…...

Missashe考研日记-day28
Missashe考研日记-day28 1 专业课408 学习时间:2h学习内容: 今天先是预习了OS关于虚拟内存管理的内容,然后听了一部分视频课,明天接着学。知识点回顾: 1.传统存储管理方式特征:一次性、驻留性。2.局部性原…...

基于esp32实现键值对存储读写c程序例程
在基于 ESP32 的系统中,我们可以使用 NVS(Non-Volatile Storage,非易失性存储)来实现系统配置参数的掉电存储和读写。NVS 是 ESP32 提供的一种存储机制,允许我们将键值对数据存储在闪存中,即使设备掉电&…...

半导体行业如何开展风险管理?有没有半导体风控案例参考?
近年来,供应链中断事件的频发,成了越来越多半导体人的噩梦: ❗ 地缘冲突引爆“氖气危机”,生产成本激增! ❗ 关税政策反复,被迫调整全球供应链布局! ❗ 自然灾害导致工厂停工,原材…...

使用 malloc 函数模拟开辟一个 3x5 的整型二维数组
在 C 语言中,二维数组是非常常见的数据结构,用于表示矩阵或者表格形式的数据。而在动态内存分配的情况下,我们通常使用 malloc 函数来为数组分配内存。这篇博客将介绍如何通过 malloc 动态分配一个 3x5 的整型二维数组,并且使用下…...

Github 热点项目 rowboat 一句话生成多AI智能体!5分钟搭建企业级智能工作流系统
今日高星项目推荐:rowboat凭借1705总星数成为智能协作工具黑马!亮点速递:①自然语言秒变AI流水线——只需告诉它“帮外卖公司处理配送异常”,立刻生成多角色协作方案;②企业工具库即插即用,Python包HTTP接口…...

Redis05-进阶-主从
零、文章目录 Redis05-进阶-主从 1、搭建主从架构 (1)概述 单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。 (2)集群概况 我们搭建的主从…...

rockermq多线程消费者配置
rockermq多线程消费者配置 增加消费者数量实现消费者consumer多线程消费 或是 task分布式部署,原理一样 都是增加 consumer数量,程序在多线程 处理的地方已经添加过 分布式redisson锁 保证数据在多线程下的唯一性。 配置 task.yml 配置文件 (…...

Spring框架的ObjectProvider用法-笔记
在Spring框架中,ObjectProvider 是一个用于灵活获取Bean实例的接口,它允许开发者以编程方式有条件地或可选地获取Bean,而无需强制依赖注入,避免在Bean不存在时启动失败。 1. ObjectProvider 的核心功能 ObjectProvider 是Spring…...

DigitalOcean推出Valkey托管缓存服务
今天我们激动地宣布推出DigitalOcean的Valkey托管缓存服务,这是我们全新的托管数据库服务,能够无缝替换托管缓存(此前称为托管Redis)。Valkey托管缓存服务在你一直依赖的功能基础上,还提供了增强工具来支持你的开发需求…...

如何通过挖掘需求、SEO优化及流量变现成功出海?探索互联网产品的盈利之道
挖掘需求,优化流量,实现变现:互联网出海产品的成功之路 在当今全球化的数字时代,越来越多的企业和个人选择将业务扩展到国际市场。这一趋势不仅为企业带来了新的增长机会,也为个人提供了通过互联网产品实现盈利的途径…...

ASP.NET图片盗链防护指南
图片盗链(Hotlinking)是指其他网站直接链接到你服务器上的图片资源,这会消耗你的带宽和服务器资源。以下是几种在ASP.NET中防止图片盗链的有效方法: 1. 使用URL重写模块(推荐) 在Web.config中配置URL重写规则: xml <system.webServer> <rewrite> …...
)
2025-4-25 情绪周期视角复盘(mini)
直接说结论,没有前戏哈,国芳集团这波消费的行情就相当于当时机器人大周期里的DS的一个补涨周期,那么红宝丽就是接替了中毅达的衣钵的趋势穿越龙,趋势穿越龙没有结束,仅仅是主升暂停,高位震荡,后…...

Java求职者面试:从Spring Boot到微服务的技术深度探索
场景:互联网大厂Java求职者面试 角色介绍: 面试官:技术精湛,负责把控面试质量。谢飞机:搞笑的程序员,偶尔能答对问题。 第一轮:基础知识 面试官:谢飞机,你能简要介绍…...
 -- 图形界面)
wsl(8) -- 图形界面
1. 前言 记录一些关于wsl2图形界面的事情。 2. x11-apps wsl2默认已支持图形界面,只是我们选择安装的wsl2 ubuntu发行版是非桌面的,其中没有集成桌面应用,Linux的桌面和windows不同,windows的桌面系统是内核的一部分࿰…...
)
socket套接字-UDP(中)
socket套接字-UDP(上)https://blog.csdn.net/Small_entreprene/article/details/147465441?fromshareblogdetail&sharetypeblogdetail&sharerId147465441&sharereferPC&sharesourceSmall_entreprene&sharefromfrom_link UDP服务器…...

Android源码编译命令详解
一、引言 先看下面几条指令,相信编译过Android源码的人都再熟悉不过的。 source setenv.sh lunch make -j8记得最初刚接触Android时,同事告诉我用上面的指令就可以编译Android源码,指令虽短但过几天就记不全或者忘记顺序,每次编译时还需要看看自己的云笔记,冰冷的指令总…...

AI 发展历史与关键里程碑_附AI 模型清单及典型应用场景以及物流自动化适合的模型选择
AI 发展历史与关键里程碑_附AI 模型清单及典型应用场景以及物流自动化适合的模型选择 下面分三部分进行介绍: 1. AI 发展历史与关键里程碑 1950 年:图灵测试 1950 年,艾伦图灵提出“图灵测试”(Turing Test),首次以可检验的方式讨论机器能否“思考”。# 图灵测试示意:…...
)
MVCC(多版本并发控制)
MVCC(多版本并发控制)是数据库实现高并发事务的核心技术之一,其核心是通过数据多版本解决读写冲突。以下从技术原理、实现细节、应用场景、优缺点四个方面深入解析。 一、技术原理 1. 核心思想 数据多版本化:每…...

可以隐藏列的表格
今天积累一个可以隐藏列的表格的实现方法 需求: 表格中有一部分列可以隐藏,在列名右侧有一个复选框,点击勾选展示,否则隐藏另有一个小工具栏,其中有每一列对应的复选框,点击可以将隐藏的列再次展示 思路…...

学习MySQL的第十二天
夕阳西下 云霞满天 一、存储过程概述 1.1 理解 含义:存储过程的英文是 Stored Procedure。它的思想很简单,就是一组经过预先编译的SQL语句的封装。 执行过程:存储过程预先存储在MySQL服务器上,需要执行的时候,客户端只需要向服务器端发出调用存储过程的命令,服…...

用Python做有趣的AI项目4:AI 表情识别助手
本项目将使用 计算机视觉 CNN 模型来识别人脸表情,例如: 开心 😊 | 生气 😠 | 悲伤 😢 | 惊讶 😲 | 厌恶 😒 | 害怕 😱 | 中性 😐 🧠 项目目标 实时摄像头…...

2005-2020年 各省-绿色信贷水平原始数据及测算
各省-绿色信贷水平原始数据及测算(2005-2020年).ziphttps://download.csdn.net/download/2401_84585615/90259771 https://download.csdn.net/download/2401_84585615/90259771 绿色信贷是指金融机构向符合环保要求的企业或项目提供的贷款,旨…...

STM32F103_HAL库+寄存器学习笔记21 - CAN接收过滤器:CPU减负神器,提升系统效率的第一道防线
在STM32F103的CAN总线应用中,硬件过滤器(Filter)承担着关键角色。 本章将从寄存器层面深入剖析CAN接收过滤器的工作机制与配置方法,帮助理解如何高效筛选关键信息,减轻CPU负担。 通过合理使用过滤器,不仅能…...

java_基础Java 转义字符学习笔记
Java 转义字符学习笔记 在Java编程中,转义字符用于表示那些无法直接在代码中表示的字符。以下是一些常用的Java转义字符: \t - 制表符:用于实现对齐功能。\n - 换行符:用于在文本中换行。\ - 反斜杠:表示一个反斜杠字…...
之web APIs)
JavaScript基础(七)之web APIs
第二部分:Web APIs 目录 第二部分:Web APIs 五、DOM-节点操作 5.1 日期对象 5.1.1 实例化 5.1.2 时间对象方法 5.1.3 时间戳 5.2 节点操作 5.2.1 DOM节点 5.2.2 查找节点 父节点查找: 子节点查找: 兄弟关系查找: 5.2.3 增加节点 创建节点 5.2.4 删除节点 …...

强化学习机器人路径规划——Sparrow复现
强化学习机器人路径规划——Sparrow-v1.1复现教程 Sparrow是一个开源的移动机器人路径规划模拟器,重视模拟速度和轻量化,使用DDQN强化学习方法进行训练。本文在其基础上,增加了绘制训练曲线教程,并给出了自制地图文件,以实现在自己的地图上进行训练。 模型示意图 源码地…...

怎样给MP3音频重命名?是时候管理下电脑中的音频文件名了
在处理大量音频文件时,给这些文件起一个有意义的名字可以帮助我们更高效地管理和查找所需的内容。通过使用专业的文件重命名工具如简鹿文件批量重命名工具,可以极大地简化这一过程。本文将详细介绍如何利用该工具对 MP3 音频文件进行重命名。 步骤一&am…...
:迈向功能构建的关键一步)
【Nova UI】十二、打造组件库之按钮组件(上):迈向功能构建的关键一步
序言 在上一篇文章中,我们深入探索了 icon 组件从测试到全局注册的全过程🎯,成功为其在项目中稳定运行筑牢了根基。此刻,组件库的建设之旅仍在继续,我们将目光聚焦于另一个关键组件 —— 按钮组件。按钮作为用户与界面…...

C++初阶-STL简介
目录 1.什么是STL 2.STL的版本 3.STL的六大组件 4.STL的重要性 4.1在笔试中 4.2在面试中 4.3.在公司中 5.如何学习STL 6.总结和之后的规划 1.什么是STL STL(standard template library-标准模板库);是C标准库的重要组成部分…...
洛谷 P6880 JOI2020 奥运公交 题解)
(最短路)洛谷 P6880 JOI2020 奥运公交 题解
题意 给定一个 n n n 点 m m m 边的有向图,每条边从 u u u 指向 v v v,经过这条边的代价为 c c c。点编号为 1 1 1 到 n n n,无自环。 我们可以翻转一条边,即让他从 u u u 指向 v v v 变为从 v v v 指向 u u u&#…...

动态规划算法题1
动态规划做题步骤 确定状态表示:dp表中某一个位置中的值所表示的含义就是状态表示根据状态表示推导状态转移方程:dp[i]等于什么状态转移方程就是什么,用之前或者之后的状态,推导出dp[i]的值初始化(防止越界):根据状态…...

π0.5:带开放世界泛化的视觉-语言-动作模型
25年4月来自具身机器人创业公司 PI 公司的论文“π0.5: a Vision-Language-Action Model with Open-World Generalization”。 为了使机器人发挥作用,它们必须在实验室之外的现实世界中执行实际相关的任务。虽然视觉-语言-动作 (VLA) 模型在端到端机器人控制方面已…...
:ESP32-s3多串口开发实践)
ESP32开发入门(四):ESP32-s3多串口开发实践
摘要 本文详细介绍ESP32-S3芯片的UART外设开发方法,涵盖UART0(默认调试串口)、UART1和UART2的配置与使用技巧,并提供完整示例代码,帮助开发者快速实现多设备串口通信。 一、ESP32-S3串口硬件资源 ESP32-S3芯片提供3个UART控制器࿱…...

树莓派学习专题<10>:使用V4L2驱动获取摄像头数据--申请和管理缓冲区
树莓派学习专题<10>:使用V4L2驱动获取摄像头数据--申请和管理缓冲区 1. 申请和管理缓冲区代码2. 代码解析3. 实测结果 1. 申请和管理缓冲区代码 /* 数据缓冲区 */ typedef struct tag_BufDesc {void *pvBufPtr ;size_t szBuf…...

Android10.0 Android.bp文件详解,以及内置app编写Android.bp文件
1.前言 在10.0的系统rom定制化开发中,在内置app的时候都是常用的用法,用Android.mk的常用,但是某些时候,会 使用Android.bp的方式来内置app,接下来就来使用常用的方式来写内置so aar jar等文件 2.Android.bp文件详解,以及内置app编写Android.bp文件的介绍 根据设计,An…...

git回退commit
在Git中回退提交(commit)主要有两种方法:使用 `git reset` 或 `git revert`,具体取决于是否需要保留提交历史或是否已推送到远程仓库。以下是详细步骤: 一、使用 `git reset`(适合本地未推送的提交) `git reset` 会移动分支的 HEAD 指针到指定提交,可选择是否保留修改。…...
)
arcpy列表函数的应用(4)
动态获取字段信息 在处理要素类或表时,可能需要动态获取字段信息,以便根据字段类型或名称进行特定操作。可以使用arcpy.ListFields()函数获取字段列表,并根据需要筛选字段。 示例: python # 获取指定要素类的所有字段 fields …...

02 业务流程架构
业务流程架构提供了自上而下的组织鸟瞰图,是业务流程的全景图。根据所采用的方法不同,有时被称为流程全景图或高层级流程图,提供了业务运营中所有业务流程的整体视图。 这样有助于理解企业内部各个业务流程之间的相互关系以及它们如何共同工…...

「Mac畅玩AIGC与多模态01」架构篇01 - 展示层到硬件层的架构总览
一、概述 AIGC(AI Generated Content)系统由多个结构层级组成,自上而下涵盖交互界面、API 通信、模型推理、计算框架、底层驱动与硬件支持。本篇梳理 AIGC 应用的六层体系结构,明确各组件在系统中的职责与上下游关系,…...

如何有效防止 SQL 注入攻击?
🔒 如何有效防止 SQL 注入攻击? SQL 注入(SQL Injection)是黑客通过构造恶意输入,篡改 SQL 查询语句的攻击方式。以下是 7 大防御策略,涵盖开发、测试和运维全流程。 ✅ 1. 使用参数化查询(Pre…...

路由交换网络专题 | 第九章 | NAT地址转换 | NAT回流
拓扑图 (1)配置实现内网用户可以通过 NAT 转换地址访问外网。 // 配置一条静态路由通往PC2 [AR1]ip route-static 0.0.0.0 0 60.1.1.10 // 配置ACL匹配网段 [AR1]acl 2000 [AR1-acl-basic-2000]rule permit source 192.168.1.10 0.0.0.0 // 设置地址池(不…...

DFPatternFunctor遍历计算图
文件:include/tvm/relay/dataflow_pattern_functor.h 功能:定义 DFPatternFunctor 基类,为 DFPattern 提供访问者模式(Visitor Pattern)的实现框架,支持对不同类型的模式节点进行差异化处理。 继承关系: template &…...

Spring Boot中@RequestParam、@RequestBody、@PathVariable的区别与使用
Spring Boot中RequestParam、RequestBody、PathVariable的区别与使用 前言 在当今的Web开发领域,Spring Boot凭借其简洁、高效和强大的功能,成为了Java开发者构建Web应用的首选框架。在开发过程中,处理来自客户端的请求参数是一项常见且关键…...

大模型 SFT 中的关键技术总结学习
文章目录 微调策略LoRA 微调核心思想具体实现过程超参数与技巧实现步骤 QLoRA 相关技术1. 核心原理2. 技术优势3. 实现流程4. 应用场景 P-tuning核心思想关键技术点训练流程优点应用场景 P-tuning v2Prefix Tuning一、关键概念前缀(Prefix)虚拟标…...

AI如何重塑DDoS防护行业?六大变革与未来展望
一、AI驱动的攻击与防御:攻防博弈的全面升级 AI技术的引入使DDoS攻防进入“智能对抗”时代,攻击者与防御方均借助AI提升效率,形成新的技术平衡。 1. 攻击端:AI赋能攻击的智能进化 动态流量生成:攻击者利用生成对抗网…...