依赖于切片级标签,结合信息瓶颈理论,对弱监督病理切片分类模型进行微调
小罗碎碎念
在医学AI领域,病理全切片图像(WSI)分析意义重大,但面临诸多难题。
高分辨率的WSI使得获取精确注释极为困难,且计算成本高昂。
多实例学习(MIL)虽能利用WSI级弱监督缓解注释压力,却存在实例级表示能力不足的问题。传统基于ImageNet-1K预训练模型因域差距大,会丢失关键信息;自监督学习(SSL)虽有潜力,但任务特定特征未被充分挖掘。
这促使研究人员探索更有效的方法来提升WSI分析的性能和泛化能力。
针对上述困境,本文提出了基于变分信息瓶颈(IB)理论的高效WSI微调框架。

IB模块能将超大型实例袋提炼为稀疏实例袋,大幅减轻计算负担,同时保留关键任务信息。
该框架仅依赖WSI级弱标签,先通过优化IB模块损失函数得到稀疏实例集,接着微调骨干网络以学习任务特定特征,最后利用微调后的实例特征训练分类器。
此外,该框架还能结合SSL进一步提升性能,并融入多样的数据增强策略,有效增强模型在不同数据集上的泛化能力。
在实验环节,研究人员使用五个病理WSI数据集进行全面评估。
结果显示,相较于先前方法,该框架在准确率和泛化能力上均实现显著提升。
在多个数据集的分类任务中,无论是采用经典的MIL架构,还是结合SSL进行微调,该方法都展现出卓越的性能。
这一成果为医学AI在病理诊断中的实际应用提供了更强大的技术支持,有望推动该领域的进一步发展,助力实现更精准、高效的病理诊断。
交流群
欢迎大家加入【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
目前小罗全平台关注量61,000+,交流群总成员1400+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
知识星球
对推文中的内容感兴趣,想深入探讨?在处理项目时遇到了问题,无人商量?加入小罗的知识星球,寻找科研道路上的伙伴吧!
一、文献概述
“Task-specific Fine-tuning via Variational Information Bottleneck for Weakly-supervised Pathology Whole Slide Image Classification”由Honglin Li等人撰写。

文章提出一种基于变分信息瓶颈的弱监督病理全切片图像分类任务特定微调框架,有效解决计算成本高和监督有限的问题,在多个数据集上提升了分类精度和泛化能力。
研究背景
数字病理学中全切片图像(WSI)分析面临高分辨率导致的标注困难和计算成本高的问题。
多实例学习(MIL)虽缓解了标注成本,但现有方法存在实例级表示能力不足等问题。
预训练模型(如ImageNet-1K预训练和自监督学习(SSL))在WSI分析中存在信息丢失和任务特定特征未充分探索的缺陷。
相关工作
MIL用于WSI分析主要有显式建模和隐式学习两类方法;
SSL在计算机视觉和自然语言处理中表现良好,但因计算限制难以直接用于WSI分析;
信息瓶颈(IB)理论可用于深度学习,其具有信息压缩和特征归因等特性,启发研究人员解决WSI分析中的微调与计算限制问题。
方法
基于MIL的WSI分析将WSI划分为实例袋,通过骨干网络提取特征并聚合预测。
引入IB模块,利用其信息压缩特性,通过优化变分下界,将大尺寸实例袋压缩为稀疏实例袋,降低计算成本。
设计损失函数,结合任务损失和信息损失,在训练时通过蒙特卡罗采样和重参数化技巧优化。
方法包含三个阶段:
- 学习瓶颈生成稀疏实例集;
- 微调骨干网络;
- 利用所有微调实例特征训练传统注意力WSI-MIL分类器。
实验
使用五个数据集评估方法,包括组织病理学和细胞病理学图像,对模型进行预训练和微调。
在多个数据集上对比不同方法,结果表明该微调方法能显著提升WSI分类性能,结合SSL可进一步提高性能。
在域迁移实验中,该方法在不同数据集上也展现出良好的泛化能力。通过消融实验研究学习率、Top-K选择和拉格朗日乘数等因素的影响,可视化注意力图展示了微调特征的可解释性提升。
结论
提出的微调方法在弱监督下通过IB模块降低计算成本,结合SSL提升性能,泛化能力强,在实际病理诊断中具有应用潜力。
二、重点关注
2-1:T - SNE可视化
这是一张利用T - SNE(t分布随机邻域嵌入)对不同图像块表示进行可视化的图。

展示了四种不同预训练或训练方式下图像块特征的分布情况:
- ImageNet - 1k(a):v - score为0.285 ,特征点分布较为分散、杂乱,说明其特征缺乏任务特异性的聚类。ImageNet - 1k是大规模图像数据集,用其预训练模型在迁移到病理图像任务时,因域差距大,特征对病理分类任务针对性不强。
- Full Supervision(b):v - score为0.745 ,特征点形成了较为明显、紧凑的聚类。全监督学习因有完整准确标注,能让模型学习到更具区分度、适合分类任务的特征 。
- Self - supervised(c):v - score为0.394 ,特征点分布比ImageNet - 1k稍集中,但仍不够理想。自监督学习虽能利用数据自身结构学习特征,但在特定病理分类任务上,未充分挖掘任务专属特征 。
- IB Fine - tuning(ours)(d):v - score为0.538 ,特征点分布相比ImageNet - 1k和自监督学习,更趋近于任务特异性分布,比前两者更集中。说明本文提出的基于变分信息瓶颈(IB)的微调方法,能将杂乱特征转化为更贴合病理全切片图像分类任务的特征分布,且相比其他弱监督方式,其微调特征更接近全监督特征分布。
v - scores作为聚类评估指标,数值越高,表明特征在聚类上表现越好,更有利于分类任务。 总体体现出本文方法在将通用特征转化为任务特异性特征上的优势。
2-2:基于变分信息瓶颈(IB)的微调原理
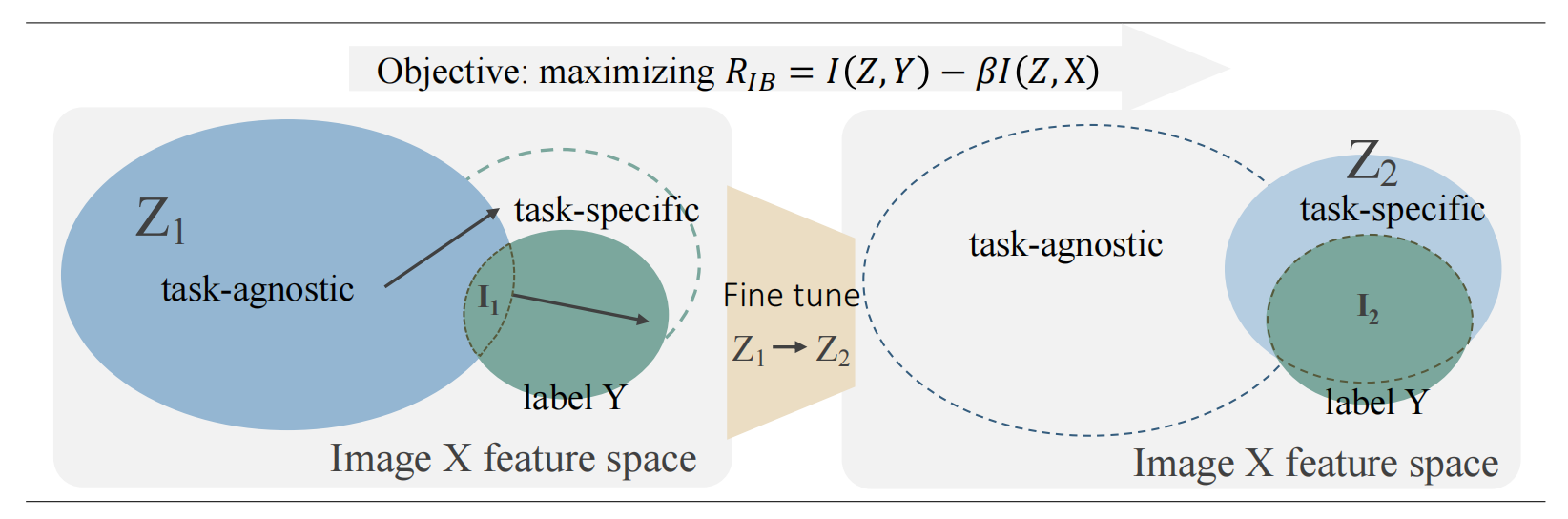
目标函数
目标是最大化 R I B = I ( Z , Y ) − β I ( Z , X ) R_{IB}=I(Z,Y) - \beta I(Z,X) RIB=I(Z,Y)−βI(Z,X) 。
其中:
- I ( Z , Y ) I(Z,Y) I(Z,Y) 是潜在表示向量 Z Z Z 与标签 Y Y Y 之间的互信息,衡量 Z Z Z 对 Y Y Y 的预测能力;
- I ( Z , X ) I(Z,X) I(Z,X) 是 Z Z Z 与图像 X X X 之间的互信息;
- β \beta β 是权衡参数。
特征空间变化
- 左侧: Z 1 Z_1 Z1 代表初始的与任务无关(task - agnostic)的特征表示,它所在的特征空间包含大量与特定任务无关信息。 I 1 I_1 I1 是 Z 1 Z_1 Z1 与标签 Y Y Y 的交集部分,体现了 Z 1 Z_1 Z1 中与任务相关的特征 。
- 右侧:经过微调(Fine tune Z 1 → Z 2 Z_1 \to Z_2 Z1→Z2 ), Z 2 Z_2 Z2 是调整后的特征表示。为最大化 R I B R_{IB} RIB :
- 增大 I ( Z , Y ) I(Z,Y) I(Z,Y) 项,使得 Z 2 Z_2 Z2 与 Y Y Y 的重叠部分(即 I 2 I_2 I2 )相比 Z 1 Z_1 Z1 与 Y Y Y 的重叠部分增大,意味着 Z 2 Z_2 Z2 对标签 Y Y Y 有更强的预测能力,更具任务特异性(task - specific)。
- 减小 I ( Z , X ) I(Z,X) I(Z,X) 项,让 Z 2 Z_2 Z2 与图像 X X X 的重叠部分相比 Z 1 Z_1 Z1 减小,即过滤掉图像 X X X 中与任务无关的特征 。
总体而言,该微调方案通过优化目标函数,使特征表示从初始的任务无关状态转变为更具任务特异性、能更好预测标签且过滤掉无关信息的状态 。
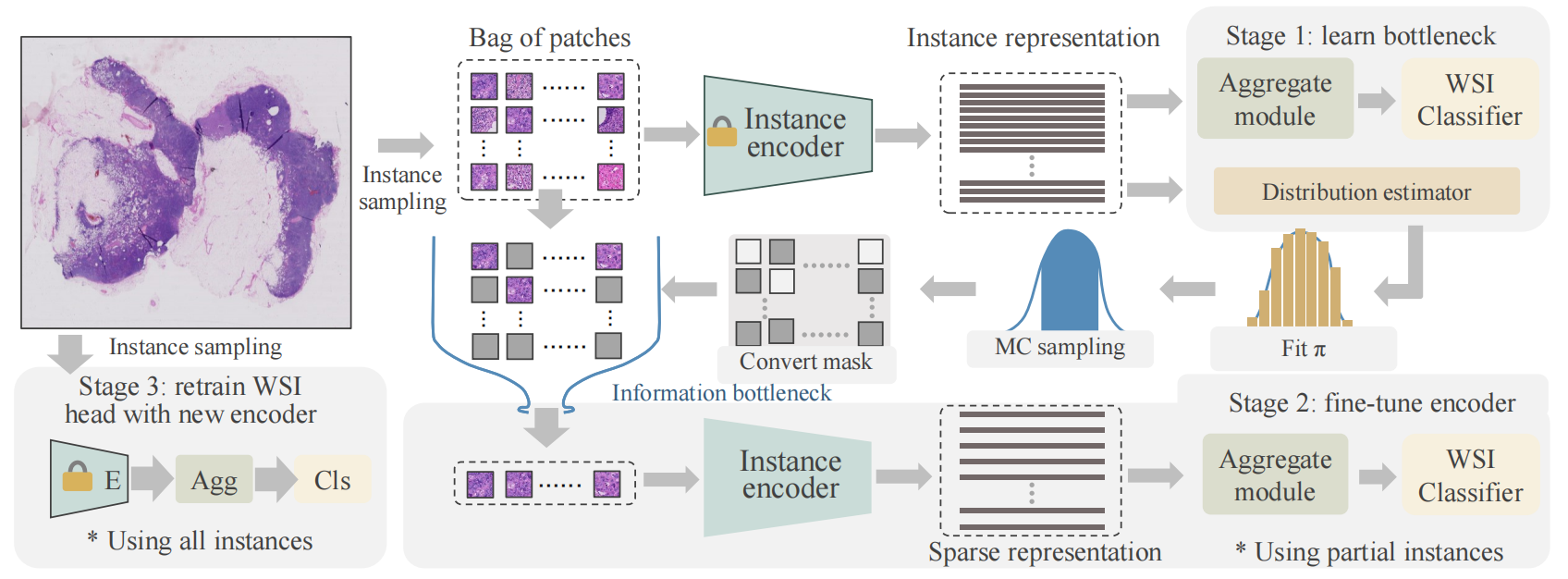
2-3:微调流程
这是病理全切片图像多实例学习(WSI - MIL)任务特定微调的工作流程图,主要分为三个阶段:
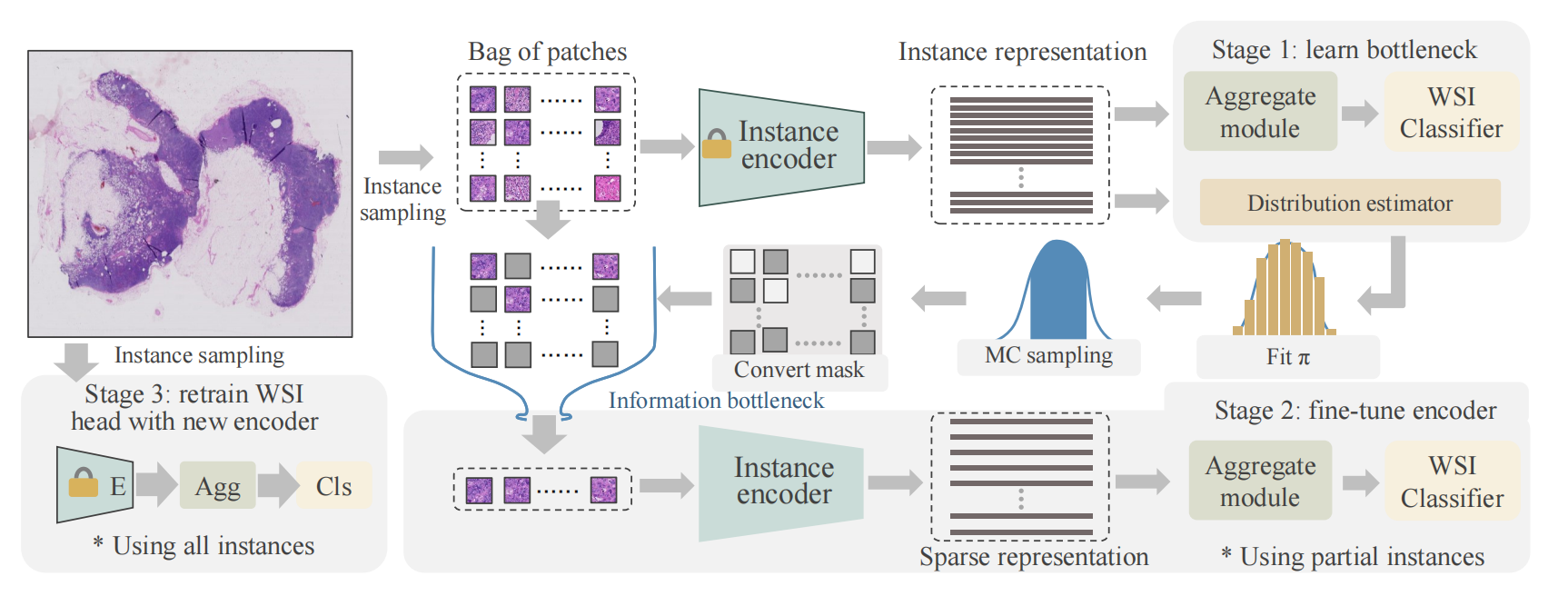
第一阶段:学习瓶颈(Stage 1: learn bottleneck )
- 对病理全切片图像进行实例采样(Instance sampling),得到图像块集合(Bag of patches) 。
- 通过实例编码器(Instance encoder)获取实例表示(Instance representation)。
- 利用聚合模块(Aggregate module)和分布估计器(Distribution estimator),结合蒙特卡罗采样(MC sampling)等操作拟合分布(Fit π ) ,学习信息瓶颈(IB)模块,生成实例掩码(Instance masks) 。此阶段固定预训练的骨干网络参数,目的是通过IB模块筛选出关键实例 。
第二阶段:微调编码器(Stage 2: fine - tune encoder )
- 固定第一阶段生成的掩码,将图像块集合提炼为稀疏集合(Sparse representation),减少计算量 。
- 对WSI头部(即分类相关部分)进行微调,并对骨干网络进行端到端的调整 。该过程仅使用部分实例(Using partial instances),进一步学习任务特定的特征表示 。
第三阶段:用新编码器重新训练WSI头部(Stage 3: retrain WSI head with new encoder )
利用经过微调后的所有实例特征(Using all instances),训练WSI - MIL分类器头部,完成整个模型的训练,使其能更好地完成病理全切片图像的分类任务 。
三、实验
3-1:数据集和任务
作者使用五个数据集评估方法。
在包含组织病理学和细胞病理学图像的三个数据集上评估IN - 1K、SSL和作者方法的切片级分类性能:
- 两个公开的组织病理学WSI数据集,用于肿瘤/正常二分类的Camelyon - 16 [5]
- 用于肿瘤亚型分类的癌症基因组图谱乳腺癌数据集(TCGA - BRCA) [34]
引入一个内部细胞病理学WSI数据集,即用于宫颈癌早期筛查的液基细胞学(LBP - CECA),以验证方法在组织病理学和细胞病理学上的通用性。
除在封闭数据集上的原始评估外,作者还在Camelyon - 16 - C(由Camelyon - 16通过随机合成域迁移生成)和来自五个不同中心的Camelyon - 17 [29]上评估方法的泛化性,这种情况在实际病理诊断中频繁出现,一直阻碍着自动WSI分析在现实世界中的应用。
数据集详情
Camelyon - 16 [2]是用于乳腺癌转移检测(肿瘤/正常分类)的公开数据集,包含270个训练集和130个测试集。经过预处理后,在20倍放大下共获得约150万个图像块。
癌症基因组图谱乳腺癌数据集(TCGA - BRCA)[6]是用于乳腺浸润性癌队列中浸润性导管癌(IDC)与浸润性小叶癌(ILC)亚型分类的公开数据集。将WSI在20倍放大下分割为不重叠的含组织图像块,从1038个WSI中整理出约200万个图像块。
液基细胞学宫颈癌早期病变筛查数据集(LBP - CECA)用于验证作者的方法在细胞病理学上的通用性。该WSI包含4个类别(阴性、意义不明确的非典型鳞状上皮细胞(ASC - US)、低级别鳞状上皮内病变(LSIL)、不典型鳞状细胞 - 不除外高度鳞状上皮内病变/高级别鳞状上皮内病变(ASC - H/HSIL) [4]) ,在20倍放大下分割为重叠度为25、大小为256的图像块,从1393个WSI中整理出约320万个图像块。
Camelyon - 16 - C是通过对Camelyon - 16 [2]测试集进行随机合成域迁移生成的模拟数据集。包含三种干扰:根据[8]中的代码实现的Jpeg压缩、亮度和色调调整,严重程度均为2 。
Camelyon - 17 [3]数据集来自五个不同中心,是Camelyon - 16的官方扩展挑战。在本文中,作者将所有肿瘤阳性WSI和随机选择的阴性WSI组合,构成真实域迁移测试集,最终抽取164个WSI用于测试。
预处理方面,作者遵循CLAM - SB [30]中的操作,主要包括HSV、模糊、阈值处理和轮廓方法,以定位每个WSI中的组织区域。然后从组织区域提取20倍放大下大小为256×256的不重叠图像块。
3-2:预训练和微调
作者的工作主要聚焦于微调方法。
由于良好的预训练初始化能带来更好的微调性能,作者采用主流预训练方法:
- 1)ImageNet - 1k(IN - 1K)数据预训练。
- 2)使用SimCLR [11]、MoCo [17]和DINO [8]的SSL预训练。
- 3)对于Camelyon - 16和LBP - CECA,因存在全面的肿瘤区域注释,作者使用注释对图像块骨干网络进行预训练,这作为作者方法的性能上限。
在骨干网络微调阶段,作者使用AdamW优化器,以25个训练轮次对骨干网络和WSI模型进行端到端微调,WSI的批量大小为1(实例袋大小为512),骨干网络学习率为1e - 5,WSI头部学习率为1e - 3 。
对于ResNet中的批量归一化(BN)层,作者将其转为评估模式,以在微调期间固定统计量,因为作者发现由于实例间的相似性,实例袋中前K个实例的分布在估计统计量方面存在局限。
骨干网络的浅层被冻结,因其仅关注形态特征,而深层关注语义特征。
3-3:切片级分类
评估指标
由于三个数据集均存在类别不平衡问题,所有实验均报告宏平均AUC和宏平均F1分数。
对于Camelyon - 16,将官方训练集按9:1的比例随机划分为训练集和验证集,实验重复进行5次,并报告官方测试集的结果。对于TCGA - BRCA,作者采用与HIPT [9]相同的运行设置进行10折交叉验证。
此外,LBP - CECA数据集按6:1:3的比例随机划分为训练集、验证集和测试集,实验同样进行5次。报告多次运行或交叉验证运行的性能指标的均值和标准差。
与基线方法比较
分类结果总结在表1中。
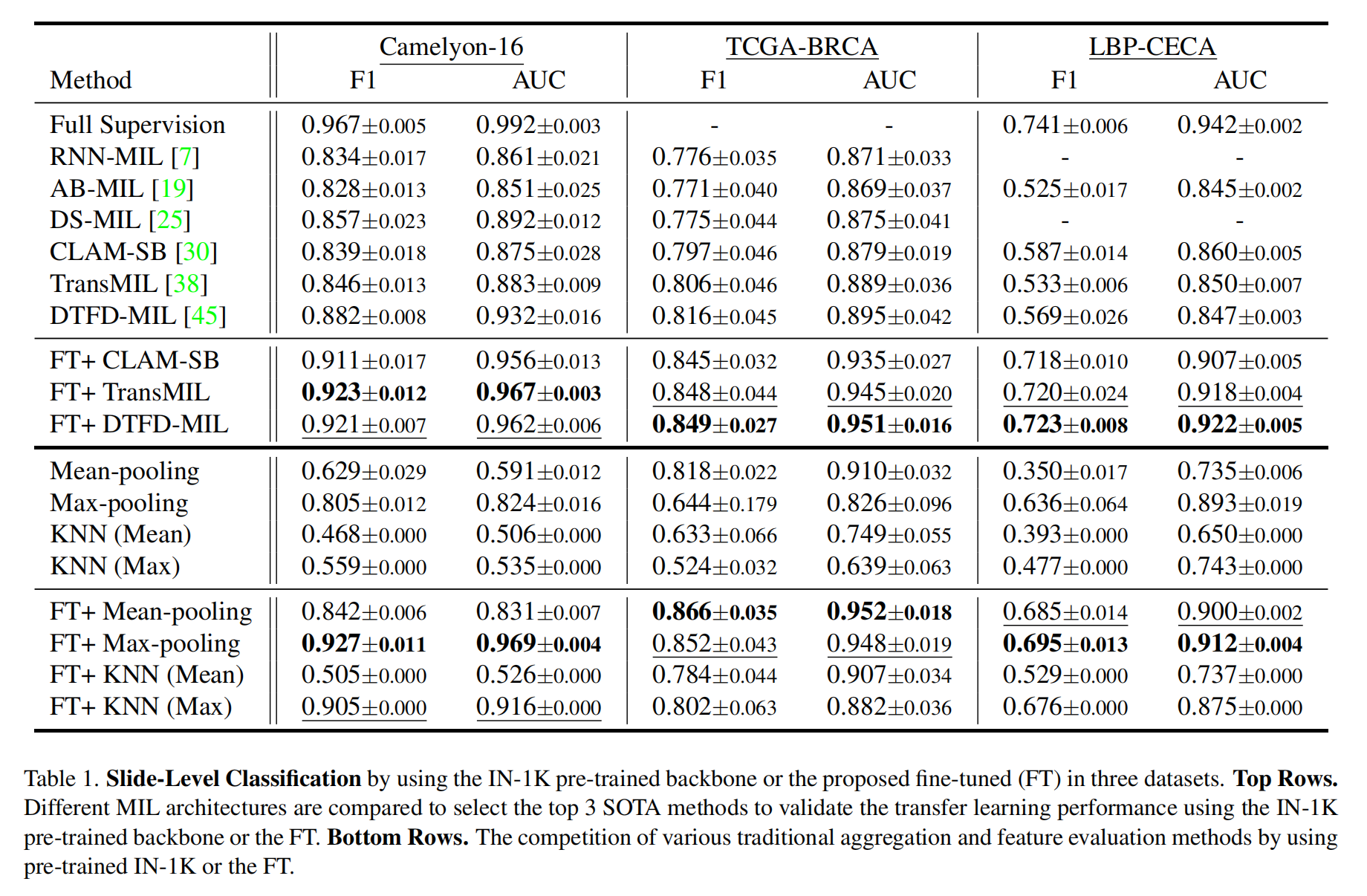
作者首先展示全图像块监督的结果作为性能上限,然后直接评估几种经典的WSI - MIL方法,包括RNN - MIL [7]、AB - MIL [19]、DS - MIL [25]、CLAM - SB [30]、TransMIL [38]、DTFD - MIL [45] 。
由于来自IN - 1K预训练ResNet - 50的骨干网络特征不合适,所有这些WSI - MIL基线方法在三个分类任务中的性能都相对较低。
然后作者对骨干网络应用微调(FT),通过包括CLAM - SB(纯全局注意力,实例间无交叉)、TransMIL(长序列自注意力)和DTFD - MIL(多层注意力路径后聚合,适用于图像块不平衡)三种WSI架构获取用于WSI分类的特征。
结果表明,在AUC指标下,配备FT特征后性能有明显且一致的提升。基于IN - 1K预训练的普通FT,CLAM - SB在Camelyon - 16、TCGA - BRCA和LBP - CECA上的性能分别相对提升9.26%、6.37%、5.47% 。
在相同条件下,TransMIL和DTFD - MIL在三个数据集上都取得了新的最优结果(SOTA),且能获得更好的相对提升,特别是在LBP - CECA上,相比CLAM - SB分别有8.00%和8.85%的增长。在F1指标下也有类似的性能提升。
对于表1的最后两行,作者比较了简单的平均/最大池化训练和KNN评估。具有竞争力的结果表明,作者在MIL框架骨干网络中提出的FT方法可以提升WSI分类性能,即使是对于最简单的特征级平均/最大池化。
此外,任务特定特征有助于作者更好地挖掘不同WSI - MIL架构的特性。显然,在LBP - CECA中,更复杂的架构TransMIL和DTFD - MIL在冻结预训练参数时无法表现出理想性能。相比之下,通过针对特定目标微调骨干网络,它们的能力可以进一步增强。
而且,不同特征聚合方法的效果因任务而异。在肿瘤区域较小的Camelyon - 16中,最大池化聚合表现出更好的性能,而在TCGA - BRCA中平均池化效果更好。
3-4:自监督学习与微调的结合
在本节中,作者通过将SSL与FT相结合,进一步提升切片级分类性能。
与基线方法比较
由于在小的组织病理学图像块中没有明显的单一语义对象,作者主要比较基于对比学习或增强的SSL方法,如MoCo [17]、DINO [8]和SimCLR [11] 。
为进行公平比较,作者展示了先前工作[9, 10]中SSL方法的结果。所有结果均基于相同的CLAM - SB [30] WSI架构。
实验结果总结在表2中。与普通的IN - 1K相比,MoCo和DINO(结合FT)分别实现了7.85%和7.39%的持续增长。
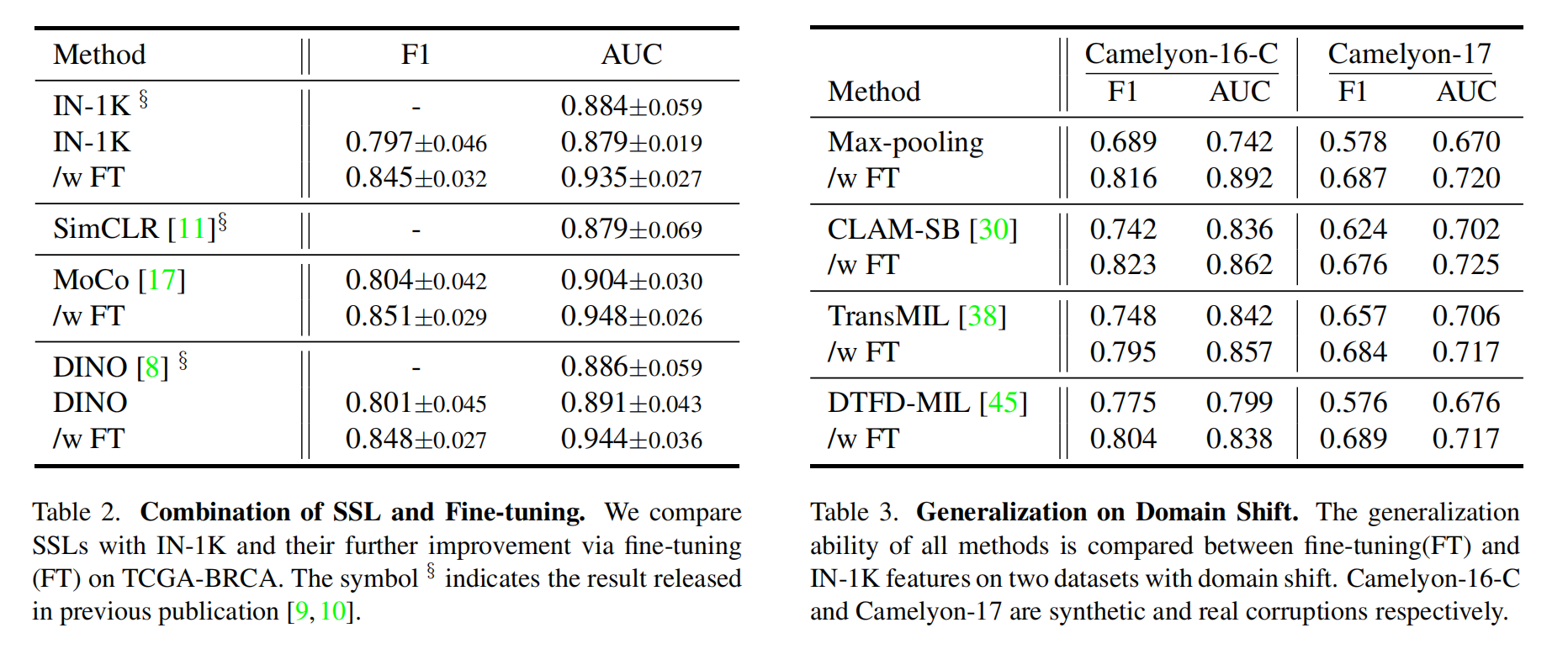
此外,与结合FT的IN - 1K相比,它们分别有1.39%和0.96%的小幅增长。通过SSL,从WSI的所有图像块中学习到内在的与任务无关的特征,在对所有模块应用作者提出的FT后,可以从标签和部分数据中提炼出任务特定特征。
在这种SSL与FT结合的范式中,全面探索了数据和标签,从而实现先进的WSI分析。
3-5:域迁移下的泛化性
在本节中,作者评估切片级分类模型在域迁移[46] [20]情况下的泛化性,这对于实际临床应用至关重要,因为医院间病理图像处理在染色、样本制备和成像设备方面存在差异。
评估指标
Camelyon - 16 - C数据集由Camelyon - 16测试集通过合成域迁移生成,采用[46]中提出的亮度、JPEG和色调的随机组合。
对于Camelyon - 17,因其与Camelyon - 16相似但来自五个不同医疗中心,作者从每个中心随机收集30个样本,以评估自然域迁移下的鲁棒性。
作者直接在Camelyon - 16 - C和来自Camelyon - 17的150个额外数据上评估模型,运行次数为5次,设置与4.1节相同。
由于篇幅限制,结果的标准差未列出,更清晰全面的比较见附录。
与基线方法比较
泛化性结果评估总结在表3中。
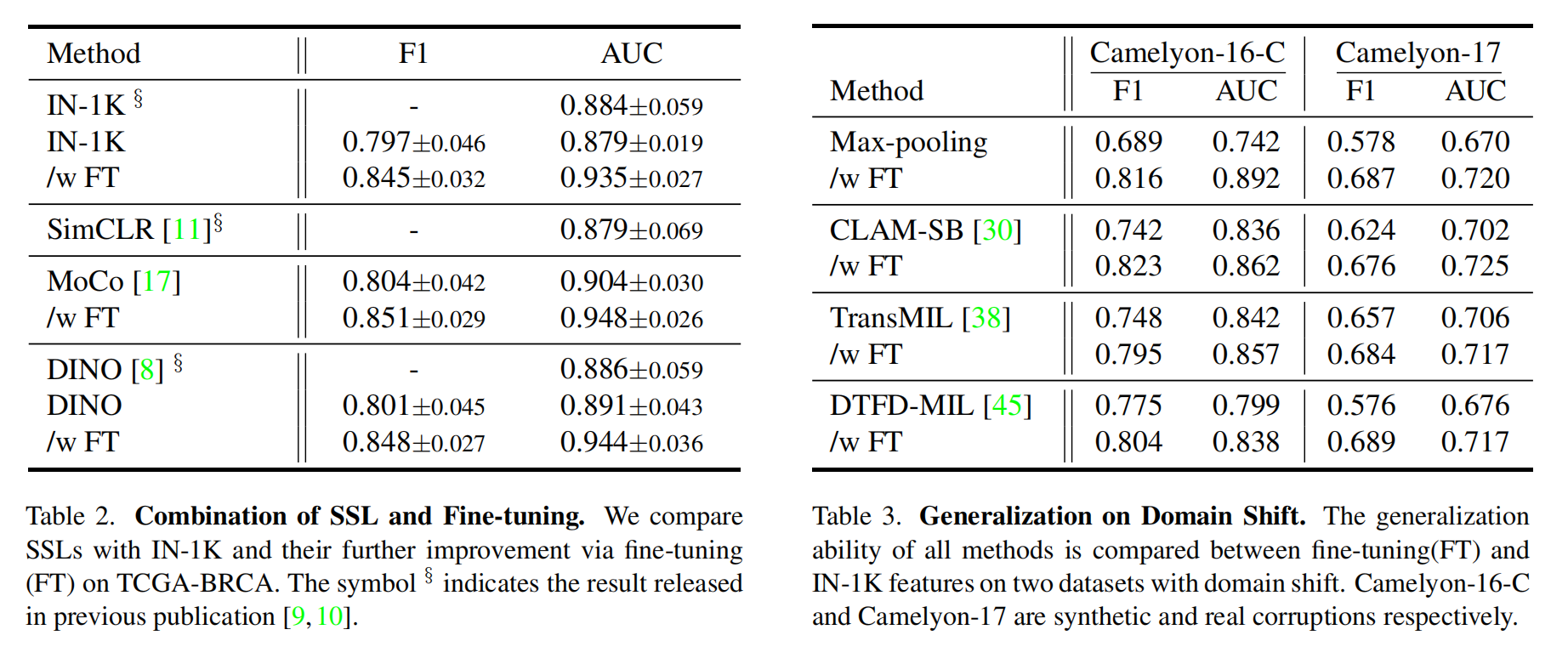
结果表明,在F1指标下,为WSI头部配备微调特征后性能有一致提升:总体而言,通过使用所提出的微调方法,所有模型在一定程度上都能抵抗域迁移。
与冻结IN - 1K参数相比,最大池化在Camelyon - 16 - C和Camelyon - 17上分别获得了18.43%和18.86%的显著性能提升。CLAM - SB分别实现了10.91%、8.33%的提升。TransMIL分别实现了6.28%、4.11%的提升。DTFD - MIL分别实现了2.90%、11.30%的提升。
相比之下,尽管DTFD - MIL对不同域已有一定鲁棒性,但其泛化性仍可通过作者提出的FT优化进一步提升。
有趣的是,在AUC指标下的性能提升远小于F1指标。基于注意力的三种池化方法在F1指标下,在Camelyon - 16 - C和Camelyon - 17上分别实现了6.70%和7.91%的平均提升,而在AUC指标下仅为2.93%和2.98%,这表明WSI - MIL模型的分类能力(以F1衡量)可能比排序能力(以AUC衡量)弱得多。
然而,从敏感性和特异性角度看,医生在临床诊断中可能更关注F1而非AUC。最重要的是,模型在实际应用中部署后分类阈值通常保持固定,这体现了作者方法在实际应用中的更有意义的贡献。
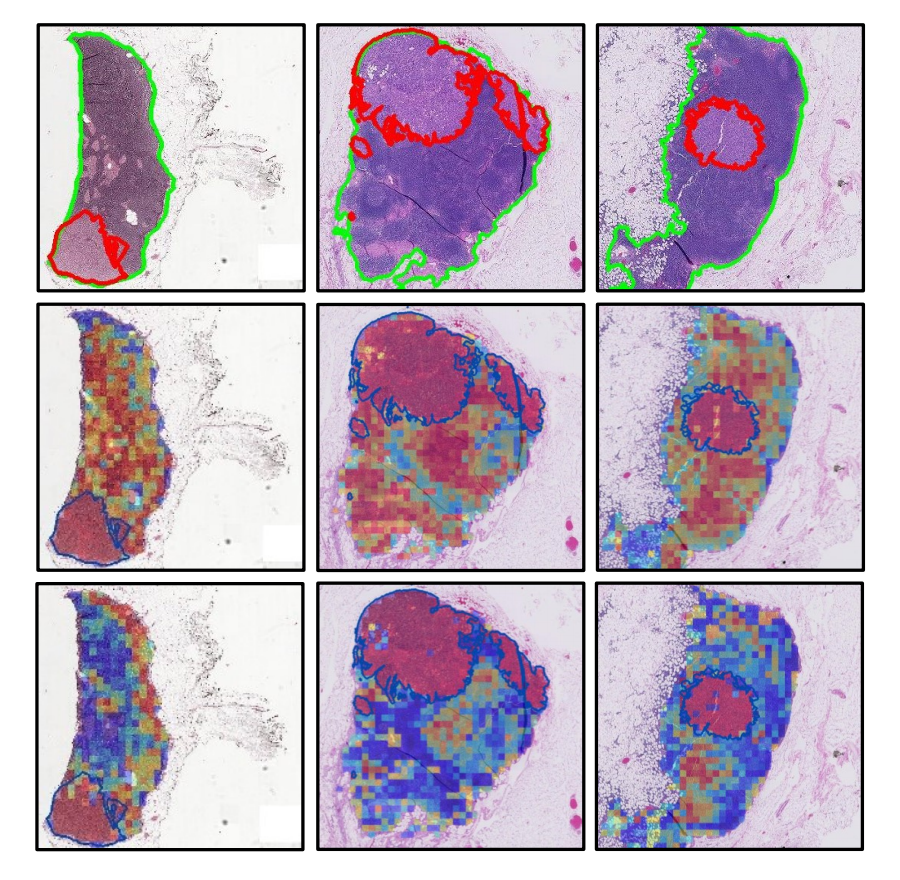
3-6:可解释性和可视化
在此,作者进一步展示微调特征带来的可解释性提升。
如图4所示,将CLAM - SB [30]的注意力分数可视化为热图,以确定感兴趣区域(ROI)并解释用于诊断的重要形态。
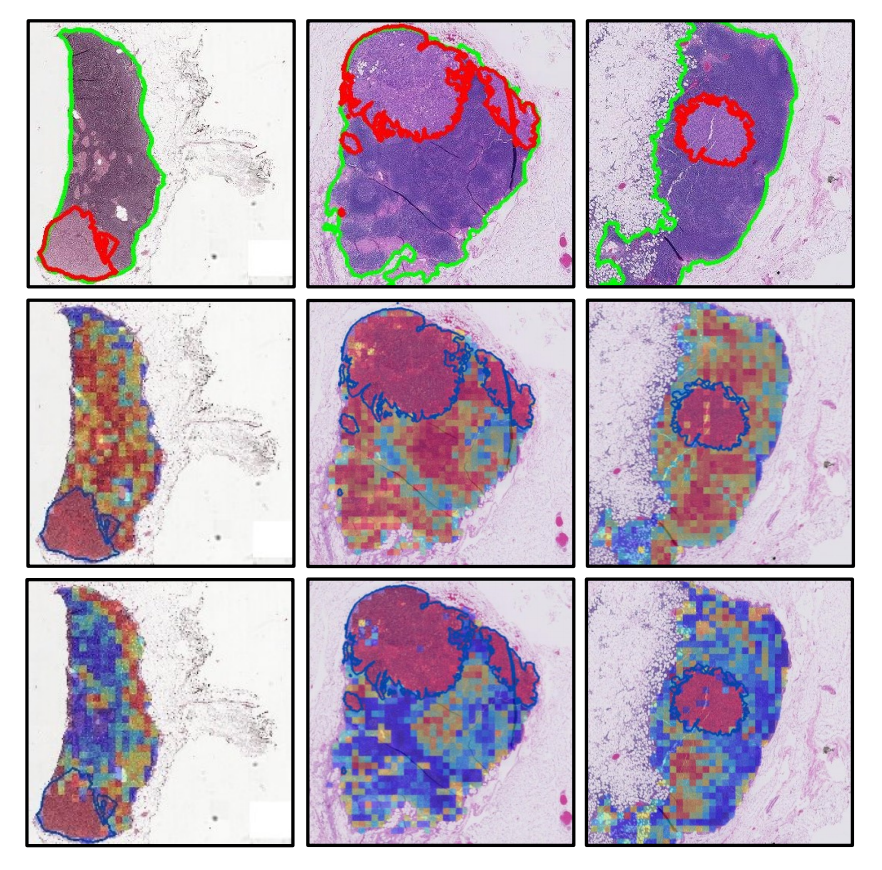
显然,具有微调特征的模型更关注肿瘤区域。
四、项目复现思路
环境配置
基础依赖
安装PyTorch和NumPy(需匹配CUDA版本):
pip install torch numpy
关键库安装
• openslide-python:用于读取WSI文件(需先安装系统依赖):
sudo apt-get install openslide-tools # Ubuntupip install openslide-python
• nvidia-dali-cuda110:加速数据预处理(CUDA 11.0版本):
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist nvidia-dali-cuda110
其他依赖
根据requirements.txt安装剩余包:
pip install -r requirements.txt
Stage-1a: 基线模型训练
生成无重叠图像块(Patches)
脚本: create_patches.sh
• 作用:将WSI分割为固定大小的无重叠图像块。
• 输入:WSI文件(通常为.svs格式)存放于DATA_DIR。
• 输出:图像块保存至PATCHES_DIR。
• 关键参数示例:
# create_patches.sh示例内容
python create_patches.py \--source DATA_DIR/wsi/ \--save_dir PATCHES_DIR/ \--patch_size 256 \--segmentation --mask_level 0 \--stitch --patch_level 0 \--preset csv --patch \--step_size 256 # 无重叠
• 执行命令:
bash create_patches.sh
提取图像块特征
脚本: create_feature.sh
• 作用:使用预训练模型(如ResNet50)提取图像块特征。
• 输入:Stage-1a生成的图像块。
• 输出:特征文件(.h5或.pt格式)保存至FEATURES_DIR。
• 关键参数示例:
python extract_features.py \--data_h5_dir PATCHES_DIR/ \--data_slide_dir DATA_DIR/wsi/ \--csv_path DATASET.csv \--feat_dir FEATURES_DIR/ \--batch_size 64 \--slide_ext .svs
• 执行命令:
bash create_feature.sh
训练基线WSI分类模型
脚本: train.sh
• 作用:基于CLAM框架训练注意力多实例学习模型。
• 输入:Stage-1b生成的特征文件。
• 输出:模型权重保存至RESULTS_DIR。
• 关键参数示例:
python main.py \--drop_out --early_stopping \--weighted_sample --task task_name \--features_dir FEATURES_DIR/ \--split_dir SPLIT_DIR/ \--results_dir RESULTS_DIR/ \--model_type clam_sb \--n_classes 2
• 执行命令:
bash train.sh
Stage-1b: 变分信息瓶颈(VIB)训练
脚本: vib_train.sh
• 作用:在基线模型基础上引入变分信息瓶颈,增强任务相关特征。
• 改动点:模型加入随机层,损失函数包含KL散度项。
• 执行命令:
bash vib_train.sh # 参数与train.sh类似,需指定--model_type vib
Stage-2: 端到端微调(Top-K区域)
提取Top-K重要区域
脚本: extract_topk_rois.sh
• 作用:使用VIB模型推断并选择每个WSI中最关键的K个图像块。
• 输出:包含Top-K图像块路径的.pt文件。
• 关键参数:
python extract_topk.py \--model_path RESULTS_DIR/vib_model.pth \--k 100 # 选择前100个块
• 执行命令:
bash extract_topk_rois.sh
端到端微调
脚本: e2e_train.sh
• 作用:基于Top-K区域,联合微调图像块编码器和WSI分类头。
• 关键改动:
• 使用端到端训练(而非固定特征)。
• 仅对Top-K区域计算损失。
• 执行命令:
bash e2e_train.sh
Stage-3: 使用微调后的骨干网络
重新生成特征
使用Stage-2微调后的编码器提取特征:
bash create_feature.sh # 需修改特征提取脚本中的模型路径
重新训练WSI分类头
重复Stage-1a或Stage-1b,但使用新特征:
bash train.sh # 更新--features_dir参数
常见问题
-
OpenSlide安装失败
• 确保系统已安装libopenslide-dev(Linux)或从官方下载二进制文件(Windows)。 -
CUDA版本不匹配
•nvidia-dali-cuda110需CUDA 11.x。若使用其他版本,替换为nvidia-dali-cudaXX(XX为CUDA主版本)。 -
内存不足
• 减少--batch_size或使用更小的k值(Stage-2)。
注意!请根据实际数据路径和任务调整脚本参数。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!
相关文章:

依赖于切片级标签,结合信息瓶颈理论,对弱监督病理切片分类模型进行微调
小罗碎碎念 在医学AI领域,病理全切片图像(WSI)分析意义重大,但面临诸多难题。 高分辨率的WSI使得获取精确注释极为困难,且计算成本高昂。 多实例学习(MIL)虽能利用WSI级弱监督缓解注释压力&…...

UE5 NDisplay 单主机打包运行
前言 最近在做UE的左右眼双屏输出,找了半天只有近年来比较火的NDispaly可以做这件事了,看了一下官方的教程写的很全面,但是相对笼统了一些,发现B站和一些博客了也写了有,但是我建议还是好好过一遍官方文档吧࿰…...

Kubernetes/KubeSphere 安装踩坑记:从 context deadline exceeded 到成功部署的完整排障笔记
目录 Kubernetes/KubeSphere 安装踩坑记:从 context deadline exceeded 到成功部署的完整排障笔记 一、问题现象 二、第一手日志采集 三、定位思路 四、分步解决 4-1 处理 pause:3.8 4-2 处理 kube-apiserver:v1.31.0 五、再次安装并验证 六、经验总结 七…...

SpringMVC 静态资源处理 mvc:default-servlet-handler
我们先来看看效果,当我把这一行注释掉的时候: 我们来看看页面: 现在我把注释去掉: 、 可以看到的是,这个时候又可以访问了 那么我们就可以想,这个 <mvc:default-servlet-handler />它控制着我们页面的访问…...

2、Linux操作系统下,ubuntu22.04版本安装搜狗输入法
1.添加中文语言支持,打开此窗口的步骤如下: system setting>language and region>language>install/remove language,之后弹出下面的窗口,点击“reminder me later勾选Chinese(simplified)&#…...
)
go语言八股文(四)
1.go语言中defer的变量快照在什么情况下会生效 1. 变量在 defer 被注册时的值被捕获 当 defer 被注册时,它会捕获变量在那一刻的值。如果变量是值类型(如基本类型、结构体等),defer 会捕获该值的副本;如果变量是指针类…...

烽火HG680-MC_晨星MSO9385芯片-2+8G_安卓9.0_不分地区通刷卡刷固件包
烽火HG680-MC_晨星MSO9385芯片-28G_安卓9.0_不分地区通刷卡刷固件包 刷机教程: 1、准备一个优盘卡刷强刷刷机,用一个usb2.0的8G以下U盘,fat32,2048块单分区格式化(强刷对U盘非常非常挑剔,usb2.…...

秒杀压测计划 + Kafka 分区设计参考
文章目录 前言🚀 秒杀压测计划(TPS预估 测试流程)1. 目标设定2. 压测工具推荐3. 压测命令示例(ab版)4. 测试关注指标 📦 Kafka Topic 分区设计参考表1. 单 Topic 设计2. 分区路由规则设计(Part…...

跨境电商货物体积与泡重计算器:高效便捷的物流计算工具
跨境电商货物体积与泡重计算器:高效便捷的物流计算工具 工具简介 货物体积与泡重计算器是一款免费的在线工具,专门为物流从业者、跨境电商卖家和需要计算货物运输体积重量的用户设计。这款工具可以帮助您快速计算货物的体积和对应的空运、快递泡重&…...

隧道代理ip的优势
日益复杂的互联网环境中,爬虫技术已经成为大数据不可或缺的一环。提到代理IP,大部分人首先想到的是普通的静态IP或动态代理IP,然而,隧道代理IP――这一更为高效、灵活的选择,在许多场景中能为开发者们提供绝佳的技术支…...

Selenium自动化测试+OCR-获取图片页面小说
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 随着爬虫技术的发展,反爬虫技术也越来越高。 目前有些网站通过自定义字体库的方式实现反爬,主要表现在页面数据显示正常,但是…...
MySQL 锁等待超时问题解析:Lock wait timeout exceeded;try restarting transaction
目录 一、问题背景二、问题原因三、解决方案1. 重启事务2. 优化事务管理3. 调整锁等待超时设置4. 分析并优化锁竞争5. 查找并终止持有锁的操作6. 优化 SQL 语句四、预防措施五、总结在使用 MySQL 数据库时, Lock wait timeout exceeded;try restarting transaction 这个错误…...
)
学习笔记2(Lombok+算法)
Lombok : 介绍: Lombok 是一个在 Java 开发中广泛使用的开源库,它的主要作用是通过注解的方式,减少 Java 代码中大量的样板代码(如 getter、setter、构造函数等),从而让代码更加简洁、易读和易…...

【音视频】SDL简介
官网:官网 文档:文档 SDL(Simple DirectMedia Layer)是一套开放源代码的跨平台多媒体开发库,使用C语言写成。SDL提供数种控制图像、声音、输出入的函数,让开发者只 要用相同或是相似的代码就可以开发出跨多…...

信创系统资产清单采集脚本:主机名+IP+MAC 一键生成 CSV
原文链接:信创系统资产清单采集脚本:主机名IPMAC 一键生成 CSV Hello,大家好啊!今天给大家带来一篇在信创终端操作系统上自动批量采集主机名、IP 和 MAC 并导出为 CSV 表格的实战文章!本方案使用 sshpass 和 Bash 脚本…...
Python数据存储实战:JSON文件读写与复杂结构化数据处理指南)
Python爬虫(8)Python数据存储实战:JSON文件读写与复杂结构化数据处理指南
目录 一、背景与核心价值二、JSON基础与核心应用场景2.1 JSON数据结构规则2.2 典型应用场景 三、Python json模块核心操作3.1 基础读写:dump()与load()3.2 字符串与对象的转换:dumps()与loads() 四、处理复杂数据类型4.1 日期时间对象…...

OpenStack私有云详细介绍
引言 企业部署云计算服务的模式有公有云、私有云、混合云三大类。 公有云是云计算服务提供商为公众提供服务的云计算平台,理论上任何人都可以通过授权接入该平台。 私有云是云计算服务提供商为企业在其内部建设的专有云计算系统,私有云系统存在于企业防火…...
)
6.图的OJ题(1-10,未完)
310. 最小高度树 - 力扣(LeetCode) 分析:n个顶点的无环无向连通图,有n-1条边。 1)任意两点有且只有一条路径 2)路径最远的两顶点必为叶子节点 且根据证明可以得出以下两个性质: 1.最小高度树的根…...

【愚公系列】《Manus极简入门》005-DeepSeek与Manus的创新之处
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...

犬面部检测数据集VOC+YOLO格式987张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):987 标注数量(xml文件个数):987 标注数量(txt文件个数):987 标注…...

深入解析MyBatis-Plus中的lambdaUpdate与lambdaQuery
一、引言 在现代Java持久层开发中,MyBatis-Plus作为MyBatis的增强工具,提供了许多便捷的功能,其中lambdaUpdate和lambdaQuery是基于Lambda表达式的两种强大操作方式。它们不仅提高了代码的可读性,还减少了SQL编写错误,…...

OneNet云平台
一、基础信息 设备名称:test1 设备密钥:N1drd3BZc0h0WDNWaXRtdjlFbjUxTHFhTGtWcW1VWjQ 产品ID:EcO4iSzv5b url: 端口号:1883 password:version2018-10-31&resproducts%2FEcO4iSzv5b%2Fdevices%2Fte…...

使用Nestjs, Bun 和 NCC 打造高效的 Node.js 应用构建流程
使用Nestjs, Bun 和 NCC 打造高效的 Node.js 应用构建流程 在现代 Node.js 应用开发中,构建和打包流程的效率对项目的迭代速度和部署效果有着重要影响。本文将介绍如何结合 Nestjs ,Bun 和 NCC 工具,构建出高效且优化的 Node.js 应用。 一、项目构建的…...

迷你世界UGC3.0脚本Wiki组件事件管理
迷你世界UGC3.0脚本Wiki Menu On this page Sidebar Navigation 快速入门 首页 组件介绍 MOD、组件介绍 什么是Lua编程 开发者常见问题 组件介绍 组件函数 组件属性 全局函数 对象介绍 触发器脚本交互 脚本方法 二维表介绍 组件说明 事件 触发器事件管理 组件事件管理 函数库 服…...

多层pcb批量工厂哪家好?
在电子产业高速发展的当下,多层PCB作为硬件设备的核心载体,其品质与交付效率直接影响终端产品的市场竞争力。面对从消费电子到航空航天等领域的多元化需求,选择一家技术过硬、服务灵活且具备规模化生产能力的工厂至关重要。经过对当前行业动态…...

【MQ篇】RabbitMQ之死信交换机!
目录 引言:消息不死,只是变成死信?初识死信交换机:死信从哪来?DLX 干啥的?什么是死信?什么是死信交换机 (DLX)?死信的旅程:如何从队列到达 DLX 并被路由?&…...

CI/CD解决方案TeamCity在游戏开发中的应用价值与优势分析
TeamCity是用于游戏开发的最流行的CI/CD工具之一。从独立开发者到3A工作室和游戏发行商,各种规模的公司都在使用。无论您在制作流程中使用何种工具,TeamCity都支持您为任何的工作流程设置全面的构建-测试-发布管道。 TeamCity如何增强您的游戏开发工作流…...

泰迪杯实战案例超深度解析:运输车辆安全驾驶行为分析与安全评价系统设计
(第七届泰迪杯数据挖掘挑战赛C题特等奖案例解析) 一、案例背景与目标 1.1 应用场景与痛点 在道路运输行业,不良驾驶行为(如急加速、急减速、疲劳驾驶)是引发交通事故的主要诱因,占事故总量的70%以上。某运输企业通过车联网系统采集了450辆运输车辆的高频数据(每秒1条)…...

C++初阶-模板初阶
目录 1.泛型编程 2.函数模板 2.1函数模板概念 2.2实现函数模板 2.3模板的原理 2.4函数模板的实例化 2.4.1隐式实例化 2.4.2显式初始化 2.5模板参数的匹配原则 3.类模板 3.1类模板定义格式 3.2类模板的实例化 4.总结 1.泛型编程 对广泛的类型法写代码,我…...

计算机网络自顶向下思维导图
主要就是记录下自己做的1-6章的思维导图,内容包含了每章每节内的重点内容 可能又错别字以及错误,欢迎指出 需要注意使用的是第七版的书 第一章 第二章 第二章二 第三章 第四章 第五章 第六章...
)
机器学习-入门-线性模型(1)
机器学习-入门-线性模型(1) 文章目录 机器学习-入门-线性模型(1)3.1 线性回归3.2 最小二乘解3.3 多元线性回归 3.1 线性回归 f ( x i ) w x i b 使得 f ( x i ) ≃ y i f(x_i) wx_i b \quad \text{使得} \quad f(x_i) \simeq y_i f(xi)wxib使得f(xi)≃yi 离散属性…...

Spark-Streaming3
无状态转换操作与有状态转换操作 无状态转换操作: 无状态转换操作仅处理当前时间跨度内的数据。例如,设置的采集时间为三秒,则只处理这三秒内的数据。 有状态转换操作(UpdateStateByKey): 有状态转换操作可以跨批次处理数据。涉及…...

【Pandas】pandas DataFrame rfloordiv
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

【Spark入门】Spark简介:分布式计算框架的演进与定位
目录 1 大数据计算框架的演进历程 1.1 Hadoop MapReduce:第一代分布式计算框架 1.2 Spark的诞生与革新 2 Spark的核心架构与优势 2.1 Spark架构概览 2.2 Spark的核心优势解析 3 Spark的适用场景与定位 3.1 典型应用场景 3.2 技术定位分析 4 Spark与Hadoop…...

基于ArcGIS的洪水淹没分析技术-洪水灾害普查、风险评估及淹没制图中的实践技术
洪水灾害是全球面临的主要自然灾害之一,对人类社会和自然环境造成巨大影响。准确的洪水淹没分析对于灾害预防、风险评估及应急响应至关重要。ArcGIS作为一款强大的地理信息系统软件,在洪水淹没分析领域具有显著优势。ArcGIS的洪水淹没分析主要依赖于其强…...

【数据可视化-38】基于Plotly得泰坦尼克号数据集的多维度可视化分析
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...
基础))
数据库MySQL学习——day6(多表查询(JOIN)基础)
文章目录 1、关系型数据库中的表关系2、连接(JOIN)的基本概念3、INNER JOIN(内连接)3.1. 概念3.2. 语法结构 4、LEFT JOIN(左连接)4.1. 概念4.2. 语法结构 5、RIGHT JOIN(右连接)&am…...

Mysql如何高效的查询数据是否存在
文章目录 1. 三种方法2. 查询语句执行流程3. 三种方式对比 1. 三种方法 在业务中,我们有时候需要查询某个数据在数据表中是否存在,常见的方式有三种 SELECT COUNT(*) FORM tb_name WHERE conditionSELECT 1 FROM tb_name WHERE conditionSELECT EXISTS (SELECT 1 FROM tb_nam…...
)
MySQL快速入门篇---增删改查(下)
目录 一、修改(Update) 1.语法 2.示例 二、删除(Delete) 1.语法 2.示例 三、聚合函数 1.示例 1.1、COUNT 1.2、SUM 1.3、AVG 1.4、MAX 1.5、MIN 四、分组查询(GROUP BY) 1.语法 2.示例 …...

Mysql中隐式内连接和显式内连接的区别
1. 内连接(INNER JOIN) 内连接是数据库中一种常见的连接方式,用于从两个或多个表中返回满足连接条件的记录,即只返回两张表中匹配的行。 示例场景:有学生表(包含学生 ID 和姓名)和成绩表&…...

检测软件系统如何确保稳定运行并剖析本次检测报告?
检测软件系统,能及时找出问题,确保软件稳定运行,保障用户使用体验。下面会具体剖析本次检测报告。 检测概述 本次检测覆盖了系统性能、功能完整性等关键方面。它对软件整体状况做了严格评估。检测时对系统代码展开深度审查。还借助专业工具…...

【Office-Excel】单元格输入数据后自动填充单位
1.自定义设置单元格格式 例如我想输入数字10,回车确认后自动显示10kg。 右击单元格或者快捷键(Ctrl1),选择设置单元格格式,自定义格式输入: 0"kg"格式仍是数字,但是显示是10kg&…...
)
GAMES202-高质量实时渲染(Real-Time Shadows)
目录 Shadow MappingshadowMapping的问题shadow mapping背后的数学PCF(Percentage Closer Filtering)PCSS(Percentage closer soft shadows)VSSM(Variance Soft Shadow Mapping)优化步骤3优化步骤1SAT&…...

vue+neo4j+flask 音乐知识图谱推荐系统
文章结尾部分有CSDN官方提供的学长 联系方式名片 文章结尾部分有CSDN官方提供的学长 联系方式名片 关注B站,有好处! 编号: F027 架构: vueflaskneo4jmysql 亮点:协同过滤推荐算法知识图谱可视化 支持爬取音乐数据,数据超过3万条&…...

JavaScript 中 undefined 和 not defined 的区别
在 JavaScript 的调试过程中,你是否经常看到 undefined 却不知其来源?是否曾被 ReferenceError: xxx is not defined 的错误提示困扰?这两个看似相似的概念,实际上是 JavaScript 类型系统中最重要的分水岭。本文将带你拨开迷雾&am…...

设计一个新能源汽车控制系统开发框架,并提供一个符合ISO 26262标准的模块化设计方案。
今天,设计一个新能源汽车控制系统开发框架,并提供一个符合ISO 26262标准的模块化设计方案。以下为经过工业验证的技术方案: 一、系统架构设计 采用AUTOSAR Adaptive平台构建分布式系统,核心模块包括: 车辆控制单元(VC…...

基于STM32、HAL库的HX710A模数转换器ADC驱动程序设计
一、简介: HX710A是一款高精度24位模数转换器(ADC)芯片,专为电子秤和其他高精度测量应用设计。它通常与称重传感器(如应变片)配合使用,具有以下特点: 24位无失码精度 可编程增益:128或64 内置低噪声可编程放大器 片上稳压器,可直接为传感器供电 简单的数字接口(时钟+数据…...

python合并一个word段落中的run
在python-docx中,一个段落可以包含多个Run对象,每个Run对象可以具有不同的样式。如果你希望将一个段落中的所有Run对象合并为一个Run对象,同时保留所有文本内容,可以通过以下步骤实现: 合并Run对象的方法 遍历段落的…...

pytorch搭建并训练神经网络
#从小白开始学习人工智能# #学习笔记# 工具:pytorch 一、基础概念 1.神经网络是什么? 神经网络是人类受到生物神经细胞结构启发而研究出的算法体系。又称为人工神经网络(Artificial neural network) 最简版神经网络结构图&a…...

GCC 内建函数汇编展开详解
1. 引言 GNU 编译器集合(GCC)是广泛使用的开源编译器套件,支持多种编程语言,其中 C 语言编译器是其核心组件之一。在 C 语言编译过程中,GCC 不仅处理用户编写的标准 C 代码,还提供了一类特殊的函数——内建…...