文本预处理(NLTK)
1. 自然语言处理基础概念
1.1 什么是自然语言处理
自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
1.2 自然语言处理的应用领域
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面。
- 文本检索:多用于大规模数据的检索,典型的应用有搜索引擎。
- 机器翻译:跨语种翻译,该领域目前已较为成熟。目前谷歌翻译已用上机翻技术。
- 文本分类/情感分析:本质上就是个分类问题。目前也较为成熟,难点在于多标签分类(即一个文本对应多个标签,把这些标签全部找到)以及细粒度分类(二极情感分类精度很高,即好中差三类,而五级情感分类精度仍然较低,即好、较好、中、较差、差)
- 信息抽取:从不规则文本中抽取想要的信息,包括命名实体识别、关系抽取、事件抽取等。应用极广。
- 序列标注:给文本中的每一个字/词打上相应的标签。是大多数NLP底层技术的核心,如分词、词性标注、关键词抽取、命名实体识别、语义角色标注等等。曾是HMM、CRF的天下,近年来逐步稳定为BiLSTM-CRF体系。
- 文本摘要:从给定的文本中,聚焦到最核心的部分,自动生成摘要。
- 问答系统:接受用户以自然语言表达的问题,并返回以自然语言表达的回答。常见形式为检索式、抽取式和生成式三种。近年来交互式也逐渐受到关注。典型应用有智能客服
- 对话系统:与问答系统有许多相通之处,区别在于问答系统旨在直接给出精准回答,回答是否口语化不在主要考虑范围内;而对话系统旨在以口语化的自然语言对话的方式解决用户问题。对话系统目前分闲聊式和任务导向型。前者主要应用有siri、小冰等;后者主要应用有车载聊天机器人。(对话系统和问答系统应该是最接近NLP终极目标的领域)
- 知识图谱:从规则或不规则的文本中提取结构化的信息,并以可视化的形式将实体间以何种方式联系表现出来。图谱本身不具有应用意义,建立在图谱基础上的知识检索、知识推理、知识发现才是知识图谱的研究方向。
- 文本聚类:一个古老的领域,但现在仍未研究透彻。从大规模文本数据中自动发现规律。核心在于如何表示文本以及如何度量文本之间的距离。
1.3 自然语言处理基本技术
- 分词:基本算是所有NLP任务中最底层的技术。不论解决什么问题,分词永远是第一步。
- 词性标注:判断文本中的词的词性(名词、动词、形容词等等),一般作为额外特征使用。
- 句法分析:分为句法结构分析和依存句法分析两种。
- 词干提取:从单词各种前缀后缀变化、时态变化等变化中还原词干,常见于英文文本处理。
- 命名实体识别:识别并抽取文本中的实体,一般采用BIO形式。
- 指代消歧:文本中的代词,如“他”“这个”等,还原成其所指实体。
- 关键词抽取:提取文本中的关键词,用以表征文本或下游应用。
- 词向量与词嵌入:把单词映射到低维空间中,并保持单词间相互关系不变。是NLP深度学习技术的基础。
- 文本生成:给定特定的文本输入,生成所需要的文本,主要应用于文本摘要、对话系统、机器翻译、问答系统等领域。
2. NLTK
NLTK常见模块及用途:
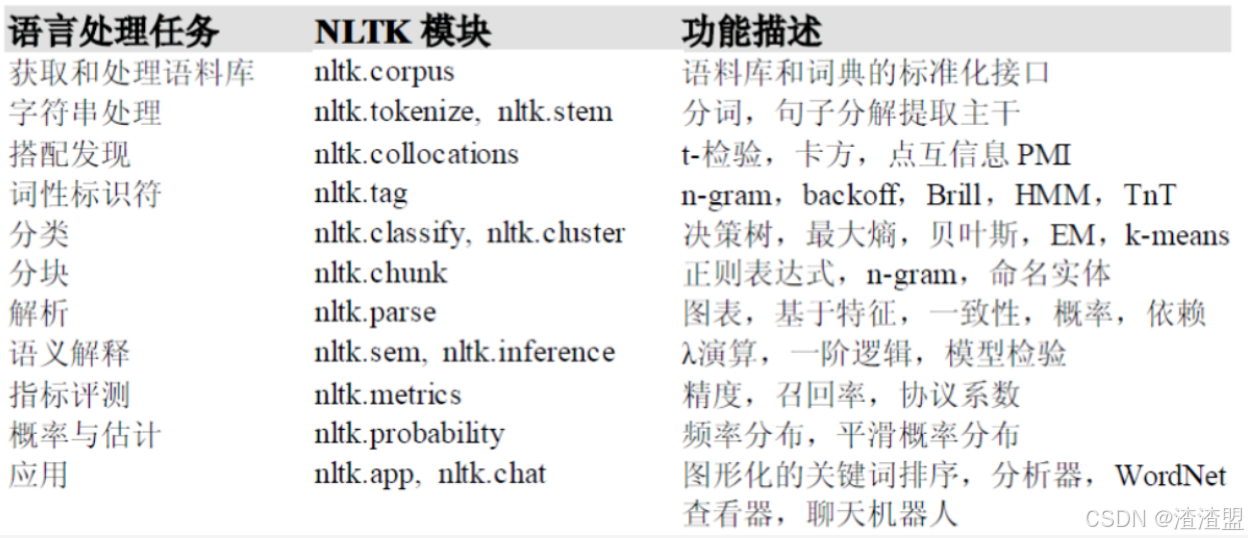
NLTK中的语料库
古腾堡语料库:gutenberg;
网络聊天语料库:webtext、nps_chat;
布朗语料库:brown;
路透社语料库:reuters;
就职演说语料库:inaugural;
其他语料库;
任务实施:
NLTK全称为Natural Language Toolkit,自然语言处理工具包,在NLP领域中,最常使用的一个Python库。
!pip install nltk==3.7
1.字符串处理
1.1 清理与替换
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
lstrip() 方法用于截掉字符串左边的空格或指定字符。
rstrip() 删除 string 字符串末尾的指定字符,默认为空白符,包括空格、换行符、回车符、制表符。
en_str = " .hello world, hello, my name is XiaoLu, "
en_str1 = en_str.strip() # 去头尾空格
print(“去头尾空格后:”+ en_str1)
en_str2 = en_str.lstrip(’ .‘) # 去左边的“ .”
print(“去左边的.后:”+ en_str2)
en_str3 = en_str.rstrip(’, ') # 去右边的“, ”
print(“去右边的,后:”+ en_str3)
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
replace()方法语法:
str.replace(old, new[, max])
参数:
old:将被替换的子字符串。
new:新字符串,用于替换old子字符串。
max:可选字符串, 替换不超过 max 次
en_str.replace(‘hello’,‘hi’) #字符串替换
动手练习1
- 模仿上述代码,在<1>处填写代码,将空格和特殊符号“.”和“&”去除;
- 在<2>处填写代码,将“小陆”替换为“小陆老师”;
- 在<3>处填写代码,将“大家好,”删除。
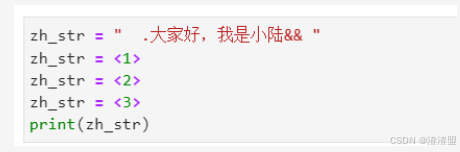
#在这里手敲上面代码并填补缺失代码
zh_str=“.大家好,我是小陆&& "
zh_str=zh_str.strip().lstrip(’ .‘) .rstrip(’&& ')
zh_str=zh_str.replace(“小陆”,“小陆老师”)
zh_str=zh_str.replace(“大家好,”,”")
print(zh_str)
若输出结果为我是小陆老师,则填写正确。
1.2 截取
截取字符串使用变量[头下标:尾下标],就可以截取相应的字符串,其中下标是从0开始算起,可以是正数或负数,下标可以为空表示取到头或尾。
str1 = ‘大家好,我是小陆,我在NEWLAND!’
print(str1[0:3]) # 访问前三个字符
print(str1[3:3+2]) #[3,5)
print(str1[-3:-1]) #和列表一样 可以使用负索引 代表反方向 从右到左 -1代表最后一个(不包含)
print(str1[::2]) #也可以设置步长 [start:stop:step] #隔一个取一个 #start默认为0 stop默认到最后(包含)
print(str1[::-1]) ##字符串逆序最快的办法 -1代表从尾到头 步长为1 进行取值
1.3 连接与分割
字符串连接,就是将2个或以上的字符串合并成一个,看上去连接字符串是一个非常基础的小问题,但是在Python中,我们可以用多种方式实现字符串的连接,稍有不慎就有可能因为选择不当而给程序带来性能损失。
方法1:加号连接
很多语言都支持使用加号连接字符串,Python也不例外,只需要简单的将2个或多个字符串相加就可以完成拼接。
str1 = “大家好,我是小陆,太好了!”
str2 = ‘大家好,我是小陆,吃饭了吗?’
print(str1+str2) # 使用+连接
方法2:使用str.join()方法
join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。join()方法语法:
str.join(sequence)
参数:
sequence:要连接的元素序列。
str3 = [‘我是小陆’,‘我是大陆’,‘太开心了,太棒了!’]
print(‘;’.join(str3)) #使用join进行连接,使用";"对列表中的各个字符串进行连接
分割字符串使用变量.split(“分割标示符号”[分割次数]),分割次数表示分割最大次数,为空则分割所有。
str4 = ‘我是小陆,我是大陆;太开心了,太棒了!’
print(str4.split(‘;’)) # split进行切分,使用“;”对字符串进行切分 得到字符串列表
1.4 比较与排序
sorted() 函数对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
sorted 语法:
sorted(iterable, cmp=None, key=None, reverse=False)
参数说明:
- iterable:可迭代对象。
- cmp:比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
- key:主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse:排序规则,reverse = True 降序 , reverse = False 升序(默认)。
可以看到默认排序,是按照首字母大写到小写,字母顺序从A到Z进行排序。
strs = [‘alice’,‘Uzi’,‘dancy’,‘Mlxg’,‘uzi’]
print(sorted(strs)) #sorted()可以对序列(列表,元组等)进行排序
可以通过定义排序方式函数,带入参数key进行自定义排序,以下代码是按照第二个字母小写的字母顺序进行排序。
#使用显式函数
def sort_func(x):
return x[1].lower() #按照第2个字母小写的字母顺序进行排序
print(sorted(strs,key=sort_func)) #可以通过key关键字 自定义排序方式
可以通过lambda表达式,带入参数key进行自定义排序,以下代码是按照第三个字母大写的字母顺序进行排序。
#使用匿名函数
print(sorted(strs,key=lambda x:x[2].upper())) #按照第3个字母大写的字母顺序进行排序
1.5 查找与包含
index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。index()方法语法:
str.index(str, beg=0, end=len(string))
参数说明:
- str:指定检索的字符串
- beg:开始索引,默认为0。
- end:结束索引,默认为字符串的长度。
str1 = ‘我是小陆;我是大陆;太开心了,太棒了!’
#返回第一次出现的第一个位置的索引
print(str1.index(‘小陆’))
print(str1.index(‘大陆’, 3,len(str1)))
find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。find()方法语法:
str.find(str, beg=0, end=len(string))
参数说明:
- str:指定检索的字符串
- beg:开始索引,默认为0。
- end:结束索引,默认为字符串的长度。
str1 = ‘我是小陆;我是大陆;太开心了,太棒了!’
#index和find的区别是 find更安全 对于找不到的子串会返回-1
print(str1.find(‘怎么回事’))
print(str1.find(‘太开心了’))
1.6 大小写与其他变化
lower()方法转换字符串中所有大写字符为小写。upper()方法将字符串中的小写字母转为大写字母。capitalize()将字符串的第一个字母变成大写,其他字母变小写。title()方法返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写。
str1 = ‘hello,my name is XiaoLU.’
print(str1.lower()) #转换小写
print(str1.upper()) #转换大写
print(str1.capitalize()) #首字母大写
print(str1.title()) #每个单词首字母大写
动手练习2
根据以上学习内容,完成动手练习2。要求输入为“hello xiao lu”,输出为“Lu Xiao Hello”。提示信息如下:
.split():将输入的字符串按空格分离成单独的字符串[::-1]:将字符串倒着打印' '.join():以空格链接.title():每个单词首字母大写

#在这里手敲上面代码并填补缺失代码
str1= “hello xiao lu”
words = str1.split()
reversed_words = words[::-1]
capitalized_words = [word.title() for word in reversed_words]
output_str = ’ '.join(capitalized_words)
print(output_str)
若输出为Lu Xiao Hello,则说明填写正确。
2 模式匹配与正则表达式
学习与验证工具
我们可以使用正则表达式在线验证工具http://regexr.com/ 来实践,左边还有对应的工具和速查表。
可以在这里正则表达式进阶练习https://alf.nu/RegexGolf?world=regex&level=r00 练习正则表达式,挑战更复杂的正则表达式。
re模块
Python通过re模块提供对正则表达式的支持。
使用re模块的一般步骤:
1.将正则表达式的字符串形式编译为Pattern实例
2.使用Pattern实例处理文本并获得匹配结果(一个Macth实例)
3.使用Match实例获得信息,并进行其他的操作
import re #导入re模块
pattern = re.compile(r’hello.*!') # 将正则表达式的字符串形式编译成Pattern对象
match = pattern.match(‘hello, Xiaolu! How are you?’) # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
if match:
print(match.group()) # 使用Match获得分组信息
2.1 匹配字符串
获取包含关键字的句子
import re
text_string=‘’’
文本最重要的来源无疑是网络。我们要把网络中的文本获取形成一个文本数据库。
利用一个爬虫抓取到网络中的信息。爬取的策略有广度爬取和深度爬取。
根据用户的需求,爬虫可以有主题爬虫和通用爬虫之分。
‘’’
regex=‘爬虫’ #关键字
p_string = text_string.split(‘。’)#以句号为分隔符通过split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用来查找匹配当前行是否匹配这个regex,返回的是一个match对象
print(line) #如果匹配到,打印这行信息
可以看到,匹配到了以下两句话:
利用一个爬虫抓取到网络中的信息
根据用户的需求,爬虫可以有主题爬虫和通用爬虫之分
动手练习3
尝试模仿上述代码,在<1>处填写代码,打印包含“文本”这个字符串的行内容。

#在这里手敲上面代码并填补缺失代码
import re
text_string=‘’’
文本最重要的来源无疑是网络。我们要把网络中的文本获取形成一个文本数据库。
利用一个爬虫抓取到网络中的信息。爬取的策略有广度爬取和深度爬取。
根据用户的需求,爬虫可以有主题爬虫和通用爬虫之分。
‘’’
regex=‘文本’ #关键字
p_string = text_string.split(‘。’)#以句号为分隔符通过split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用来查找匹配当前行是否匹配这个regex,返回的是一个match对象
print(line) #如果匹配到,打印这行信息
若输出为以下两句话,说明填写正确。
文本最重要的来源无疑是网络
我们要把网络中的文本获取形成一个文本数据库
匹配任意一个字符
正则表达式中,有一些保留的特殊符号可以帮助我们处理一些常用逻辑。比如下图中的“.”可以匹配任一字符,换行符除外。
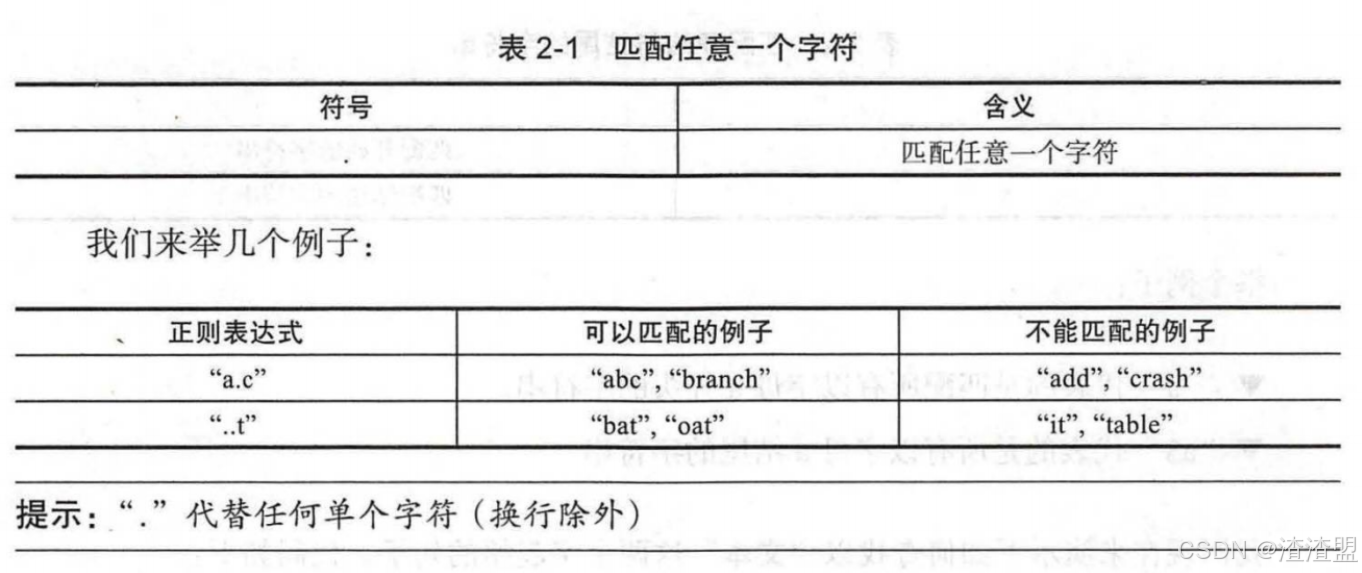
我们现在来演示下如何查找包含“爬”+任意一个字的句子。代码如下:
import re
text_string = ‘文本最重要的来源无疑是网络。我们要把网络中的文本获取形成一个文本数据库。利用一个爬虫抓取到网络中的信息。爬取的策略有广度爬取和深度爬取。根据用户的需求,爬虫可以有主题爬虫和通用爬虫之分。’
regex =‘爬.’
p_string = text_string.split(‘。’) #以句号为分隔符通过split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用来查找匹配当前行是否匹配这个regex,返回的是一个match对象
print(line) # 如果匹配到,打印这行信息
上述代码基本不变,只需要将regex中的“爬”之后加一个“.”即可以满足需求。
我们来看下输出会多一行。因为不仅是匹配到了“爬取”也匹配到了“爬虫”。
利用一个爬虫抓取到网络中的信息
爬取的策略有广度爬取和深度爬取
根据用户的需求,爬虫可以有主题爬虫和通用爬虫之分
匹配起始和结尾字符串

“^a”代表的是匹配所有以字母a开头的字符串。
“a$”代表的是所有以字母a结尾的字符串。
我们现在来演示下如何查找以“文本”这两个字起始的句子。代码如下:
import re
text_string = ‘文本最重要的来源无疑是网络。我们要把网络中的文本获取形成一个文本数据库。利用一个爬虫抓取到网络中的信息。爬取的策略有广度爬取和深度爬取。根据用户的需求,爬虫可以有主题爬虫和通用爬虫之分。’
regex =‘^文本’
p_string = text_string.split(‘。’) #以句号为分隔符通过split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用来查找匹配当前行是否匹配这个regex,返回的是一个match对象
print(line) # 如果匹配到,打印这行信息
输出为
文本最重要的来源无疑是网络
动手练习4
尝试模仿上述代码,在<1>处填写代码,尝试设计一个案例匹配以“信息”这个字符串结尾的行,并打印。

#在这里手敲上面代码并填补缺失代码
import re
text_string = ‘文本最重要的来源无疑是网络。我们要把网络中的文本获取形成一个文本数据库。利用一个爬虫抓取到网络中的信息。爬取的策略有广度爬取和深度爬取。根据用户的需求,爬虫可以有主题爬虫和通用爬虫之分。’
regex =“信息”
p_string = text_string.split(‘。’) #以句号为分隔符通过split切分
for line in p_string:
if re.search(regex,line) is not None: #search 方法是用来查找匹配当前行是否匹配这个regex,返回的是一个match对象
print(line) # 如果匹配到,打印这行信息
若输出为以下这句话,说明填写正确。
利用一个爬虫抓取到网络中的信息
使用中括号匹配多个字符

"[bcr]at"代表的是匹配“bat”,“cat”以及“rat”
我们先看下文字信息。句子和句子之间以句号分隔。
[重要的]今年第七号台风23日登陆广东东部沿海地区。
上海发布车库销售监管通知:违规者暂停网签资格。
[紧要的]中国对印连发强硬信息,印度急切需要结束对峙。
我们希望提取以[重要的]或者[紧要的]为起始的新闻标题。代码如下:
import re
text_string = [‘[重要的]今年第七号台风23日登陆广东东部沿海地区’,’ 上海发布车库销售监管通知:违规者暂停网签资格’,‘[紧要的]中国对印连发强硬信息,印度急切需要结束对峙’]
regex = ‘^[[ 重紧]…]’
for line in text_string:
if re.search(regex,line) is not None:
print(line)
else :
print(‘not match’)
观测下数据集,我们发现一些新闻标题是以“[重要的]”“[紧要的]”为起始,所以我们需要添加“^”特殊符号代表起始,之后因为存在“重”或者“紧”,所以我们使
用“[]”匹配多个字符,然后以“.”“.”代表之后的任意两个字符。运行以上代码,我们看到结果正确提取了所需的新闻标题。
[重要的]今年第七号台风23日登陆广东东部沿海地区
not match
[紧要的]中国对印连发强硬信息,印度急切需要结束对峙
2.2 抽取文本中的数字
通过正则表达式表示年份
[0-9]”代表的是从0到9的所有数字,那相对的”[a-z]” 代表的是从a到z的所有小写字母。
我们通过一个小例子来讲解下如何使用。首先我们定义一个list分配于一个变量strings,匹配年份是在1000 年~ 2999年之间。代码如下:
import re
year_strings=[]
strings = [ ‘1979年,那是一个春天’,‘时速60公里/小时’, ‘你好,2022!’]
for string in strings:
if re.search(‘[1-2][0-9]{3}’, string):# 字符串有中文有数字,匹配其中的数字部分,并且是在1000 ~ 2999之间,{3} 代表的是重复之前的[0-9]三次,是[0-9] [0-9][0-9]的简化写法。
year_strings.append(string)
print(year_strings)
抽取所有的年份
我们使用Python中的re模块的另-个方法 findall() 来返回匹配带正则表达式的那部分字符串。
re.findall(“[a-z]”,“abc1234") 得到的结果是 [“a”,“b”,“c”]。
我们定义一个字符串years_ string, 其中的内容是‘2021是很好的一年,但我相信2022会是更好的一年!’。现在我们来抽取一下所有的年份。代码如下:
import re
years_string = ‘2021是很好的一年,但我相信2022会是更好的一年!’
years = re.findall(‘[2][0-9]{3}’ ,years_string)
years
3.英文文本处理与解析
3.1 分词
文本是不能成段送入模型中进行分析的,我们通常会把文本切成独立含义的字、词或短语,这个过程叫Tokenization。
在NLTK中提供了2种不同的方式的Tokenization,sentence Tokenization(断句)和word Tokenization(分词).
按句子分割使用nltk.sent_tokenize(text) ,分词使用nltk.word_tokenize(sentence)。nltk的分词是句子级别的,所以对于一篇文档首先要将文章按句子进行分割,然后句子进行分词:
!cp -r nltk_data /home/jovyan
import nltk
from nltk import word_tokenize, sent_tokenize
corpus = ‘’‘It is most recommended for those who want to visit China for the first time with short days.
Great contrast of China’s past and present is the best highlight of this tour.
Besides, great accommodation and dinning make your trip more enjoyable.
‘’’
断句
sentences = sent_tokenize(corpus)
print(“断句结果:***”)
print(sentences)
分词
words = word_tokenize(corpus)
print(“分词结果:***”)
print(words)
3.2 停用词
由于一些常用字或者词使用的频率相当的高,英语中比如a,the, he等,每个页面几乎都包含了这些词汇,如果搜索引擎它们当关键字进行索引,那么所有的网站都会被索引,而且没有区分度,所以一般把这些词直接去掉,不可当做关键词。
nltk有内置的停用词列表,首先看看打印停用词的结果。
#导入内置停用词
from nltk.corpus import stopwords
#导入英文停用词
stop_words = set(stopwords.words(‘english’))
print(stop_words)
print(“分词结果:***”)
print(words)
将文本剔除停用词
filtered_corpus = [w for w in words if not w in stop_words]
print(“去除停用词结果:***”)
print(filtered_corpus)
可以看到一些符号如:“,” “.” "'"没有被去掉,这是因为默认的停用词表中没有这部分内容。在很多任务(比如对话任务中)中,停用词还包括下面这些符号和后缀:['!',',','.','?','’','\''],使用下面代码,将他们加上去:
stop_words = set(stopwords.words(‘english’))
#添加符号
new_stopwords = [‘!’,‘,’,‘.’,‘?’,‘’’,‘’',‘good’,‘bad’]
new_stopwords_list = stop_words.union(new_stopwords)
print(new_stopwords_list)
动手练习5
- 在<1>处填写代码,将’good’,'bad’设为需要从停用词表中删除的内容;
- 在<2>处填写代码,从停用词表中删除内容。

#在这里手敲上面代码并填补缺失代码
not_stopwords = {‘good’, ‘bad’}
final_stop_words = set([word for word in stop_words if word not in not_stopwords])
print(final_stop_words)
final_filtered_corpus = [w for w in words if not w in final_stop_words]
print(“去除停用词结果:”)
print(final_filtered_corpus)
如果输出为以下内容,则说明填写正确。

3.3 词性标注
nltk.download(‘averaged_perceptron_tagger’)
词性标注是对分词结果中的每个单词标注一个正确的词性的程序(如名词、动词等)。词性标注是很多NLP任务的预处理步骤,如句法分析。下表为NLTK词性标注对照表:
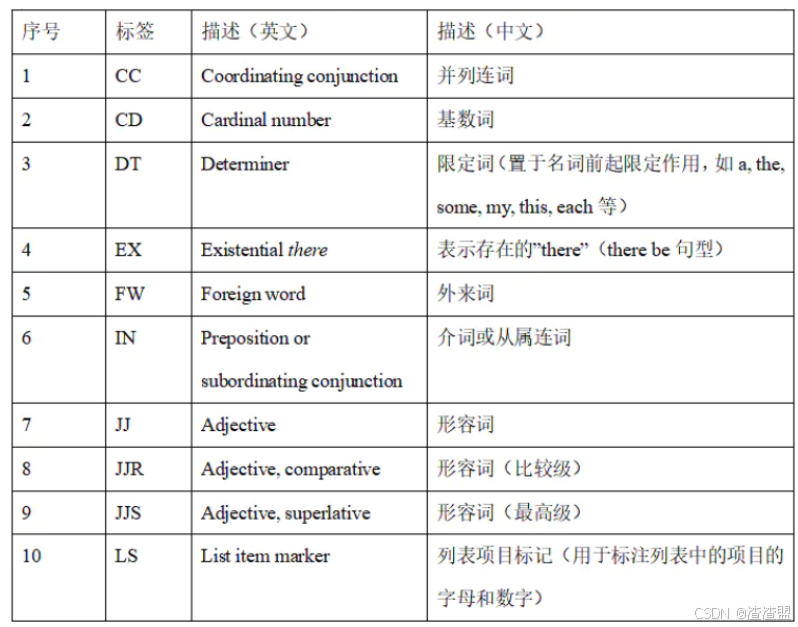
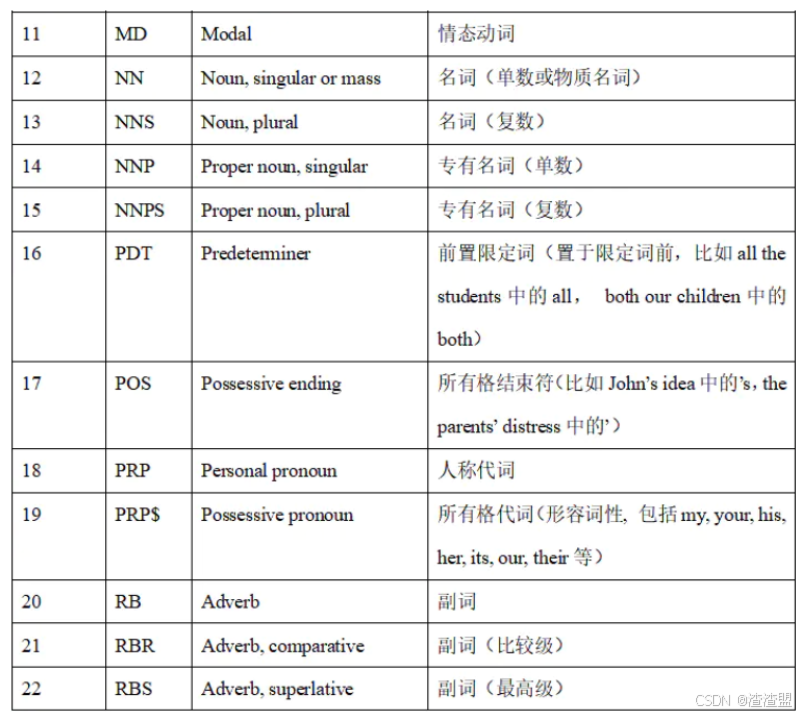
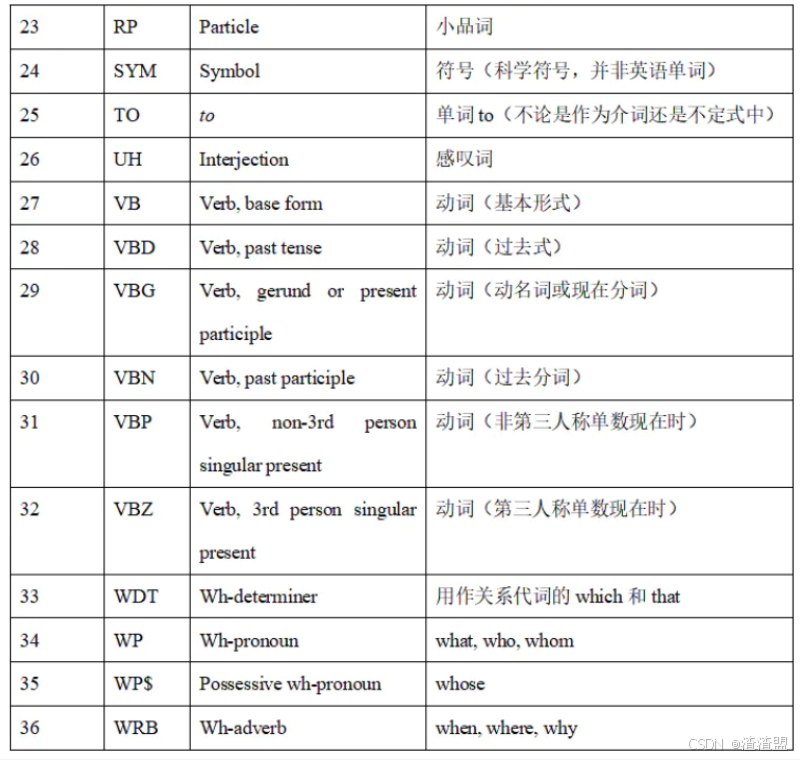
nltk.pos_tag(words):对指定的单词列表进行词性标记,返回标记列表。
import nltk
words = nltk.word_tokenize(‘I love China’)
print(words)
word_tag = nltk.pos_tag(words)
print(word_tag)
从结果我们可以看到China是NNP,NNP代表专有名词。
为什么nltk.pos_tag()方法可以对单词进行词性标记?这是因为NLTK预先使用一些语料库训练出了一个词性标注器,这个词性标注器可以对单词列表进行标记。
词性标注过后,我们可以通过单词的词性来过滤出相应的数据,如我们要过滤出词性为 NNP 的单词,代码如下:
import nltk
document = ‘Today the Netherlands celebrates King’s Day. To honor this tradition, the Dutch embassy in San Francisco invited me to’
sentences = nltk.sent_tokenize(document)
data = []
for sent in sentences:
data = data + nltk.pos_tag(nltk.word_tokenize(sent))
for word in data:
if ‘NNP’ == word[1]:
print(word)
3.4 时态语态归一化
很多时候我们需要对英文中的时态语态等做归一化,这时我们需要 Stemming 词干提取。
Stemming是抽取词的词干或词根形式(不一定能够表达完整语义)。NLTK中提供了三种最常用的词干提取器接口,即Porterstemmer,LancasterStemmer和SnowballStemmer。
PorterStemmer基于Porter词干提取算法,来看例子:
可以用PorterStemmer
import nltk
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem(‘running’))
print(stemmer.stem(‘makes’))
print(stemmer.stem(‘tagged’))
Snowball Stemmer基于Snowball 词干提取算法,来看例子:
也可以用SnowballStemmer
from nltk.stem import SnowballStemmer
stemmer1 = SnowballStemmer(‘english’) #指定为英文
print(stemmer1.stem(‘growing’))
相关文章:
)
文本预处理(NLTK)
1. 自然语言处理基础概念 1.1 什么是自然语言处理 自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于…...

泰迪杯实战案例学习资料:生产线的故障自动识别和人员配置优化
(西南石油大学,第十二届泰迪杯特等奖案例) (深度扩展版) 一、案例背景与目标 1.1 问题背景 在制造业中,生产线设备故障可能导致以下问题: 停机损失:每小时停机成本可达数万元(视行业而定)。 资源浪费:人工排班不合理导致高技能员工闲置或低效分配。 安全隐患:未及…...

dijkstra
open_set是当前正在计算的节点; 每次从当前open_set集合中找出cost最小的节点进行计算更新:从open_set中去除该节点,保存到close_set中; 运动更新可以根据运动模型选择合适的节点运动方式; 【代价的计算方式是&…...

【SSH 端口转发】通过SSH端口转发实现访问远程服务器的 tensorboard
SSH 连接远程服务器时的命令: ssh -L 8001:localhost:8001 usrnameserverip-L: 这是指定进行本地端口转发的选项。也就是说,要将本地机器的一个端口通过 SSH 隧道转发到远程服务器上的某个服务。 8001:localhost:8001: 第一个 80…...

w308汽车销售系统的设计与实现
🙊作者简介:多年一线开发工作经验,原创团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹赠送计算机毕业设计600个选题excel文…...
Spring 学习笔记之 @Transactional 异常不回滚汇总
使用springboot时,只要引入spring-jdbc/jpa相关的依赖后,在想要启用事务的方法上加上Transactional注解就能开启事务,碰到异常就能自动回滚。大大的提高了编码的便捷性性,同时也不侵入代码,保持了代码的简洁性。 默认情…...
| XOR计算)
Java 自定义TCP协议:【特点编码字符串<=>字节<=>特点编码16进制】16进制字符串和编码的转换 (各种编码通过字节向16进制的互转)| XOR计算
文章目录 引言I 各种编码通过字节向16进制的互转。字符串<=>字节<=>16进制 | Java验证微信小程序 JavaScript字符串转gb2312 字符编码,以16进制字符串传输。(接收蓝牙设备的信息,发送北斗终端消息)II xor校验码Java实现验证C# 实现引言 为了避免中文在传输过程…...

大模型的使用
以下是不同类型大模型及其适用场景: 对话模型 - 代表模型:GPT-3.5/4、Claude、LaMDA、ChatGLM等。 - 适用场景:客服机器人为用户解答常见问题,提供实时支持;个人助理帮助用户完成各种任务,如查询信息、设置…...

OSPF的不规则区域和特殊区域
目录 一、OSPF不规则区域类型 1、非骨干区域无法和骨干区域保持连通 2、骨干区域被分割 解决方案 1、使用虚连接 2、使用多进程双向重发布(路由引入) 二、特殊区域 1、STUB区域(末梢区域) 2、totally stub区域(…...

C++学习:六个月从基础到就业——STL:分配器与设计原理
C学习:六个月从基础到就业——STL:分配器与设计原理 本文是我C学习之旅系列的第三十篇技术文章,也是第二阶段"C进阶特性"的第九篇,主要介绍C STL中的分配器设计原理与实现。查看完整系列目录了解更多内容。 引言 在之前…...

QQMusic项目功能总结
QQMusic项目功能总结 一、核心功能分类 (一)界面交互功能 功能模块实现方式使用类(自定义/Qt库)核心类说明窗口布局Head区(图标、搜索框、控制按钮) Body区(左侧功能栏右侧页面区)…...

人形机器人:MCP与人形机器人的联系
MCP(Model Context Protocol)与人形机器人的结合,正在重构智能体与物理世界的交互范式。这种联系不仅体现在技术架构的深度融合,更体现在对机器人认知能力、协作模式和应用场景的全方位赋能。以下从技术整合、场景落地和未来趋势三…...
 画折线统计图python代码)
matplotlib画图工具使用(1) 画折线统计图python代码
Python 画折线统计图(line chart)最常用的是 matplotlib。 最基本的折线图代码如下: import matplotlib.pyplot as plt# 假设这是你的数据 x [1, 2, 3, 4, 5] y [2, 3, 5, 7, 11]# 创建折线图 plt.plot(x, y, markero) # markero 是在点…...

神经网络与深度学习第四章-前馈神经网络
前馈神经网络 在本章中,我们主要关注采用误差反向传播来进行学习的神经网络。 4.1 神经元 神经元是构成神经网络的基本单元。主要是模拟生物神经元的结构和特性,接收一组输入信号并产生输出。 现代神经元中的激活函数通常要求是连续可导的函数。 净输…...
)
TC3xx学习笔记-UCB BMHD使用详解(一)
文章目录 前言UCB BMHDPINDISHWCFGLSENA0-3LBISTENACHSWENABMHDIDSTADCRCBMHDCRCBMHD_NPW0-7 总结 前言 AURIX Tc系列Mcu启动过程,必须要了解BMHD,本文详细介绍BMHD的定义及使用过程 UCB BMHD UCB表示User Configuration Block,UCB是Dflash,存储的地址…...

C语言 函数递归
目录 1.什么是递归 2.递归的限制条件 3.递归的举例 1.递归与迭代 1.递归是什么 递归是学习C语言函数绕不开的一个话题,那什么是递归呢? 递归其实是一种解决问题的方法,在C语言中,递归就是函数自己调用自己。 写一个史上最简单的C语言…...
)
4月25日日记(补)
最近实在是忙的不行了,做不到一天一更,但是实际上只需要每天拿出十分钟就可以写一篇不错的随笔或者说日记,我还是有点倦怠了。 昨天是4月25,我的生日,但是依旧是很忙碌的一天。零点准时拆了朋友们送的礼物,…...

【股票系统】使用docker本地构建ai-hedge-fund项目,模拟大师炒股进行分析。人工智能的对冲基金的开源项目
股票系统: https://github.com/virattt/ai-hedge-fund 镜像地址: https://gitcode.com/gh_mirrors/ai/ai-hedge-fund 项目地址: https://gitee.com/pythonstock/docker-run-ai-hedge-fund 这是一个基于人工智能的对冲基金的原理验证项目。本项目旨在探讨利用人工智能进行…...

Ollama平替!LM Studio本地大模型调用实战
本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续! 🚀 魔都架构师 | 全网30W技术追随者🔧 大厂分布式系统/数据中台实战专家🏆 主导交易系统百万级流量调优 & 车联网平台架构&a…...

2024江西ICPC部分题解
题目列表 A - Maliang Learning PaintingC - LiarG - Multiples of 5H - ConvolutionJ - Magic MahjongK - Magic Tree A - Maliang Learning Painting 题目来源:A - Maliang Learning Painting 思路分析 这是个签到题,直接输出abc即可 #include<b…...
)
RabbitMQ安装流程(Windows环境)
1.下载依赖,Downloads - Erlang/OTP 2.下载RabbitMQ安装包,Installing on Windows | RabbitMQ 3.下载的文件如下 4.安装ErLang依赖 5.安装RabbitMQ 6.RabbitMQ插件管理 6.1 进入Command Prompt命令行界面 6.2 输入rabbitmq-plugins.bat list 查看所有插…...

QT对话框及其属性
Qt中使用QDialog类表示对话框 对话框是一个顶层窗口,出现在程序最上层,用于实现短期任务或者简洁的用户交互 QDialog也是继承自QWidget,可以使用QWidget接口 Qt常用的内置对话框有: 对话框 说明 QFiledialog 文件对话框 QColorDialog 颜色对话框 …...

python怎么查看函数原型及变量是什么类型
python代码中看到一个变量或者对象名,怎么查看这个变量到底是个什么东西,是属性,还是函数,还是模块,还是个包,怎么去查看,要有一个查找流程: 1.可以先用print(变量名)和print(type(变量名)),确认变量是什么类型的参数 2.如果是模块或者类,可以通过dir()函数去查看模…...

住宅代理IP助力大规模数据采集实战
在数字化时代,数据就是燃料,而大规模数据采集则是从信息海洋中提炼价值的关键手段。面对目标网站的严格风控和地域限制,普通代理车轮战往往难以为继——流量一旦被识破,便可能付之东流。这时,住宅代理IP凭借来自真实家…...

【信息融合】卡尔曼滤波EKF毫米波雷达和红外数据信息融合
一、扩展卡尔曼滤波(EKF)的核心原理 EKF是针对非线性系统的改进卡尔曼滤波算法,其核心思想是通过一阶泰勒展开对非线性方程进行局部线性化,并利用雅可比矩阵(Jacobian Matrix)替换线性系统中的状态转移矩阵…...
实操例子)
一篇入门之-评分卡变量分箱(卡方分箱、决策树分箱、KS分箱等)实操例子
一、评分卡分箱-有哪些分箱方法 评分卡的分箱,是指将变量进行离散化。评分卡的分箱方法一般有:等频分箱、等距分箱、卡方分箱、决策树分箱、KS分箱等等。它们都属于自动分箱方法,其中,卡方分箱是实际中最常用的分箱方法。 1.1.等…...

【白雪讲堂】构建与优化企业知识图谱的实战指南
在GEO(生成式引擎优化)时代,知识图谱不仅是企业数据资产的“智慧大脑”,更是连接内容与AI理解之间的核心桥梁。一个高质量的知识图谱,能够显著提高AI平台对企业内容的识别度、相关性与推荐权重,从而在AI搜索…...

作为高速通道光纤传输模式怎么理解以及到底有哪些?
光纤的传输模式主要取决于光纤的结构(如纤芯直径和折射率分布),不同模式对应光波在光纤中传播的不同路径和电磁场分布。以下是光纤传输模式的主要分类及特点: 1. 单模光纤(Single-Mode Fiber, SMF) 核心特点: 纤芯直径极小(通常为 8-10微米),仅允许光以单一模式(…...

setup语法糖
为什么要有setup语法糖: 在选择式API中,一个模块涉及到的数据、方法、声明周期,会比较分撒,位置不集中,不利于解读代码,但是组合式API中的setup函数可以将他们组织在一起,提高了代码的可维护性…...
)
linux socket编程之tcp(实现客户端和服务端消息的发送和接收)
目录 一.创建socket套接字(服务器端) 二.bind将port与端口号进行绑定(服务器端) 2.1填充sockaddr_in结构 2.2bind绑定端口 三.建立连接 四.获取连接 五..进行通信(服务器端) 5.1接收客户端发送的消息 5.2给客户端发送消息 5.3引入多线程 六.客户端通信 6.1创建socke…...

Spring和Spring Boot集成MyBatis的完整对比示例,包含从项目创建到测试的全流程代码
以下是Spring和Spring Boot集成MyBatis的完整对比示例,包含从项目创建到测试的全流程代码: 一、Spring集成MyBatis示例 1. 项目结构 spring-mybatis-demo/ ├── src/ │ ├── main/ │ │ ├── java/ │ │ │ └── com.example/…...

Beta-VAE背景原理及解耦机制分析
Beta-VAE背景原理及解耦机制分析 论文链接:https://openreview.net/forum?idSy2fzU9gl¬eIdSy2fzU9gl 一、Beta-VAE的核心思想 Beta-VAE 是一种改进的变分自编码器(VAE),旨在通过调整潜在变量的独立性来增强模型的解耦能…...

用c语言实现——一个动态顺序存储的串结构
一、思路概要 ①动态顺序存储的串结构: 动态应该使用动态内存分配,也就是用指针来存储字符数组,同时记录长度和当前容量。 这样结构体应该包含三个成员:一个char*指针,一个int表示当前长度,另一个int表示…...

小程序Npm package entry file not found?
修改依赖包的入口文件 看是不是cjs,小程序不支持cjs...

vue3学习之防抖和节流
在前端开发中,我们经常会遇到这样的情况:某些事件(如滚动、输入、点击等)会频繁触发,如果不加以控制,可能会导致性能问题。Vue3 中的防抖(Debounce)和节流(Throttle&a…...

当高级辅助驾驶遇上“安全驾校”:NVIDIA如何用技术给无人驾驶赋能?
高级辅助驾驶技术的商业化落地,核心在于能否通过严苛的安全验证。国内的汽车企业其实也在做高级辅助驾驶,但是吧,基本都在L2级别。换句话说就是在应急时刻内,还是需要人来辅助驾驶,AI驾驶只是决策层,并不能…...

Linux | Mfgtools 修改单独只烧写 Uboot,内核,文件系统
01 1. 打开 mfgtools_for_6ULL 文件夹,找到 cfg.ini 文件,如果您的板子是 EMMC 的修改如下图: 如果您的板子是 NAND 的,修改如下图: 02 2. 打开“Pro...

【Agent python实战】ReAct 与 Plan-and-Execute 的融合之道_基于DeepSeek api
写在前面 大型语言模型(LLM)驱动的 Agent 正在从简单的任务执行者向更复杂的问题解决者演进。在 Agent 的设计模式中,ReAct (Reason + Act) 以其步步为营、动态适应的特性见长,擅长处理需要与环境实时交互、快速响应的任务。而 Plan-and-Execute 则强调前瞻性规划,先制定…...

Native层Trace监控性能
一、基础实现方法 1.1 头文件引用 #include <utils/Trace.h> // 基础版本 #include <cutils/trace.h> // 兼容旧版本1.2 核心宏定义 // 区间追踪(推荐) ATRACE_BEGIN("TraceTag"); ...被监控代码... ATRACE_END();// 函数级自…...

【C++】15. 模板进阶
1. 非类型模板参数 模板参数分类类型形参与非类型形参。 类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。 非类型形参:就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中可将该参数当…...
反射的概念以及关键类Type)
C#进阶学习(十四)反射的概念以及关键类Type
目录 本文末尾有相关类中的总结,如有需要直接跳到最后即可 前置知识: 1、程序集(Assembly) 2、元数据(Metadata) 3、中间语言(IL, Intermediate Language) 中间语言(…...

B. And It‘s Non-Zero
题目链接:https://codeforces.com/problemset/problem/1615/B 位运算之前没怎么写过,所以不会写。留一份题解,作为复习使用。 题解:按位与的结果不为0,则至少有一列全为1.要求删除的数最少,即要求该列原本…...

深入解析NuttX:为何它是嵌入式RTOS领域的标杆?
文章目录 引言一、NuttX简介:轻量级与高兼容性的结合二、架构特点:为何NuttX更灵活?三、横向对比:NuttX vs 主流嵌入式RTOS四、NuttX的核心优势五、何时选择NuttX?结语 引言 在资源受限的嵌入式系统中,实时…...

html初识
html 盖楼第一步:HTML1. HTML是啥玩意儿?2. 动手!搭个你的"网络小窝" (第一个HTML页面)3. 添砖加瓦:常用HTML"建材"详解3.1 标题家族3.2 段落哥俩好3.3 传送门:链接3.4 挂画:图片 盖楼…...

leetcode66.加一
从后向前遍历,直到碰到非9的数(也就是数组中中最后一个非9的数) ,该值+1,然后其后的数字全部0 class Solution {public int[] plusOne(int[] digits) {for (int i digits.length-1; i >0; i--) {if (d…...

【Vue】Vue3项目创建
执行npm run dev,如果报错检查nodejs版本...
)
缓存替换算法之 FIFO(先进先出)
FIFO(First In, First Out,先进先出)是一种常见的缓存替换算法,其基本思想是最早进入缓存的数据项将最先被移除。以下是FIFO的详细讲解: 一、FIFO的数据结构 队列(Queue) 队列是一种典型的线性…...

Linux下的I/O复用技术之epoll
I/O多路复用 指在单个线程或进程中,同时处理多个I/O操作的技术。 旨在提高程序处理多个并发I/O操作的能力,避免程序因等待某个I/O操作而被阻塞。在传统的I/O模型中当程序进行I/O操作时(如读取文件、接受网路数据等),如果数据还未准备好&…...

数据分析管理软件 Minitab 22.2.2 中文版安装包 免费下载
Minitab22.2.2 安装包下载链接: https://pan.baidu.com/s/1cWuDbvcWhYrub01C6QR81Q?pwd6666 提取码: 6666 Minitab软件是现代质量管理统计软件,全球六西格玛实施的共同语言。Minitab 已经在全球120多个国家,5000多所高校被广泛使用。...
)
chrony服务器(1)
简介 NTP NTP(Network Time Protocol,网络时间协议)是一种用于同步计算机系统时间的协议是TCP/IP协议族中的一个应用层协议,主要用于在分布式时间服务器和客户端之间进行时钟同步,提供高精准度的时间校正通过分层的时…...