【C++】14.容器适配器 | stack | queue | 仿函数 | priority_queue
1. 容器适配器
什么是适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设 计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
在C++中,容器适配器(Container Adapters) 是一种特殊的类模板,它们基于现有的标准容器(如 deque、vector、list)实现,通过限制或调整底层容器的接口,提供特定的数据结构和操作方式。容器适配器并不直接管理数据存储,而是通过组合现有容器来实现功能,仅暴露符合特定需求的接口。
容器适配器的核心特点
-
封装底层容器
容器适配器内部使用已有的容器(如deque或vector)来存储数据,但隐藏了底层容器的复杂性,仅提供特定操作。 -
简化接口
仅暴露与特定数据结构相关的操作。例如,std::stack只允许在栈顶插入或删除元素,而不需要直接访问中间元素。 -
灵活性
允许用户选择底层容器的类型(需满足特定操作要求)。例如,std::stack默认使用deque,但也可以替换为vector或list。
常见的容器适配器
C++标准库中提供了三种主要的容器适配器:
| 容器适配器 | 功能描述 | 默认底层容器 | 核心操作 |
|---|---|---|---|
std::stack | 后进先出(LIFO)的栈 | deque | push(), pop(), top() |
std::queue | 先进先出(FIFO)的队列 | deque | push(), pop(), front(), back() |
std::priority_queue | 优先级队列(最大堆/最小堆) | vector | push(), pop(), top() |
底层容器的选择
容器适配器依赖底层容器实现存储,但不同适配器对底层容器的要求不同:
-
std::stack-
需要底层容器支持
push_back()、pop_back()和back()。 -
可用容器:
deque(默认)、vector、list。
-
-
std::queue-
需要底层容器支持
push_back()(插入队尾)和pop_front()(删除队首)。 -
可用容器:
deque(默认)、list。 -
不可用
vector:因为vector的pop_front()是 O(n) 操作。
-
-
std::priority_queue-
需要底层容器支持随机访问迭代器(用于堆操作)。
-
可用容器:
vector(默认)、deque。 -
不可用
list:因为list不支持随机访问。
-
容器适配器 vs 普通容器
| 特性 | 容器适配器 | 普通容器(如 vector) |
|---|---|---|
| 接口复杂度 | 简单,仅暴露特定操作 | 复杂,提供丰富的操作(如随机访问) |
| 灵活性 | 依赖底层容器的实现 | 直接管理数据存储 |
| 使用场景 | 特定数据结构(如栈、队列) | 通用数据存储和操作 |
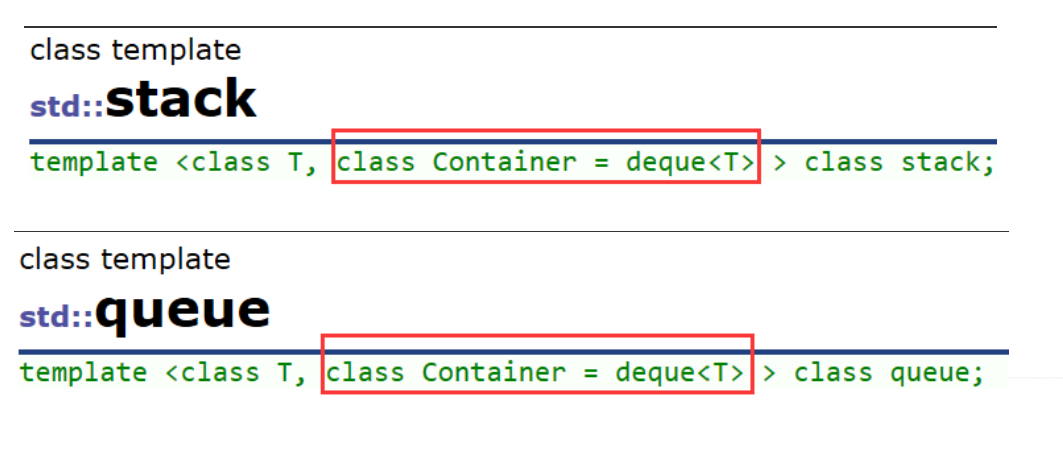
2.STL标准库中stack和queue的底层结构
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为 容器适配器,这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认 使用deque,比如:
2.1 stack(后进先出,LIFO)
功能
-
后进先出的数据结构,支持在顶部插入和删除元素。
成员函数
-
push(val): 在栈顶插入元素。 -
pop(): 移除栈顶元素(不返回)。 -
top(): 返回栈顶元素的引用。 -
empty(): 检查栈是否为空。 -
size(): 返回元素数量。
在c语言数据结构中,我们有讲到过栈和队列,并且用c语言来模拟实现了一次,这里就不再过多介绍栈和队列了
对于stack的使用也是比较简单的具体可查看文档 stack的文档介绍
这里我们直接来模拟实现,记得我们在c语言实现栈的结构是这样定义的

这样定义的话,增删查改这些操作都需要自己去实现,C++中有没有什么更好的方法呢?就是我们上面提到的容器适配器,直接复用适配的容器来进行我自己的操作,这样不就简单多了
namespace Ro
{template <class T, class Container = vector<T>>class stack{private:Container _con;};
}哪些容器可以支持stack呢,其实只需要底层容器支持 push_back()、pop_back() 和 back(),就能够作为stack的底层容器,就比如vector,list,deque,我们可以在文档中看到,默认是使用deque作为默认容器的,但是目前我们还不了解deque,所以先用vector作为底层容器来模拟实现
namespace Ro
{template <class T, class Container = vector<T>>
class stack
{
public:void push(const T& val){_con.push_back(val);}T& top(){return _con.back();}const T& top() const{return _con.back();}void pop(){_con.pop_back();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}
private:Container _con;
};
}让别人来替我打工,简直是美滋滋
我们再来测试一下:
void test_stack()
{stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);while (!st.empty()){cout << st.top() << ' ';st.pop();}cout << endl;
}
2.2 queue(先进先出,FIFO)
功能
-
先进先出的数据结构,支持在队尾插入元素,队首删除元素。
成员函数
-
push(val): 在队尾插入元素。 -
pop(): 移除队首元素(不返回)。 -
front(): 返回队首元素的引用。 -
back(): 返回队尾元素的引用。 -
empty(): 检查队列是否为空。 -
size(): 返回元素数量。
和stack一样,也是容器适配器,但是queue底层容器不支持vector,原因如下:
-
容器需支持
front()、back()、push_back()、pop_front()。 -
不可用
vector:因为pop_front()的时间复杂度为 O(n)。
namespace Ro
{template<class T, class Container = list<T>>class queue{public:void push(const T& val){_con.push_back(val);}void pop(){_con.pop_front();}T& front(){return _con.front();}T& back(){return _con.back();}const T& front() const{return _con.front();}const T& back() const{return _con.back();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}private:Container _con;};
}这就是容器适配器,我们只需要给他一个适配的底层容器,就可以做到一样的操作,至于我是怎么做的,那是底层容器的事情,使用错误时,底层容器也会报错,例如我们这里使用vector作为底层容器,编译器是会给我们报错的

我们再来测试一下:
void test_queue()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);while (!q.empty()){cout << q.front() << ' ';q.pop();}
}
2.3 deque
那在这之前我们就要先来看看vector和list的优缺点,对比一下

deque呢其实就是vector和list的缝合,为什么这么说呢?我们接下来就来介绍一下
C++中的deque(双端队列)是一种序列容器,允许在容器的前端和后端高效地插入和删除元素,同时支持快速的随机访问。以下是关于deque的详细介绍:
定义与特点
- 双端队列:deque是“double-ended queue”的缩写,它允许在序列的两端(前端和后端)进行快速的插入和删除操作。
- 随机访问:支持通过下标(
operator[])或迭代器快速访问任意位置的元素,时间复杂度为O(1)。 - 动态大小:
deque的大小可以动态增长或缩小,以适应元素的插入和删除。 - 非连续内存:与
vector不同,deque的内存不是连续分配的,而是由多个固定大小的内存块(通常称为“缓冲区”或“块”)组成,这些块通过一个中央控制器(如指针数组)管理。
底层实现
- 分段连续存储:
deque采用分段连续存储策略,每个内存块的大小固定,通常为512字节或4096字节(具体取决于编译器和平台)。 - 中央控制器:维护一个指向每个内存块起始地址的数组或链表,以及每个块的大小信息。
- 动态扩展:当需要插入新元素且当前块已满时,
deque会分配一个新的内存块,并更新中央控制器以包含新块的地址。
总结一下其实就是:
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
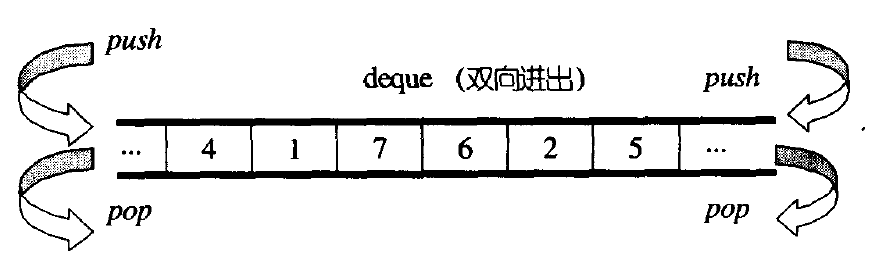
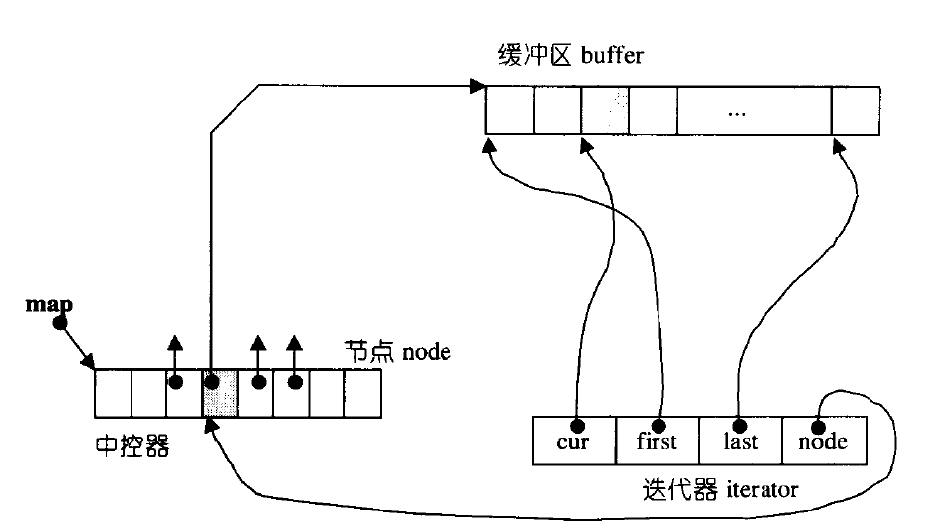
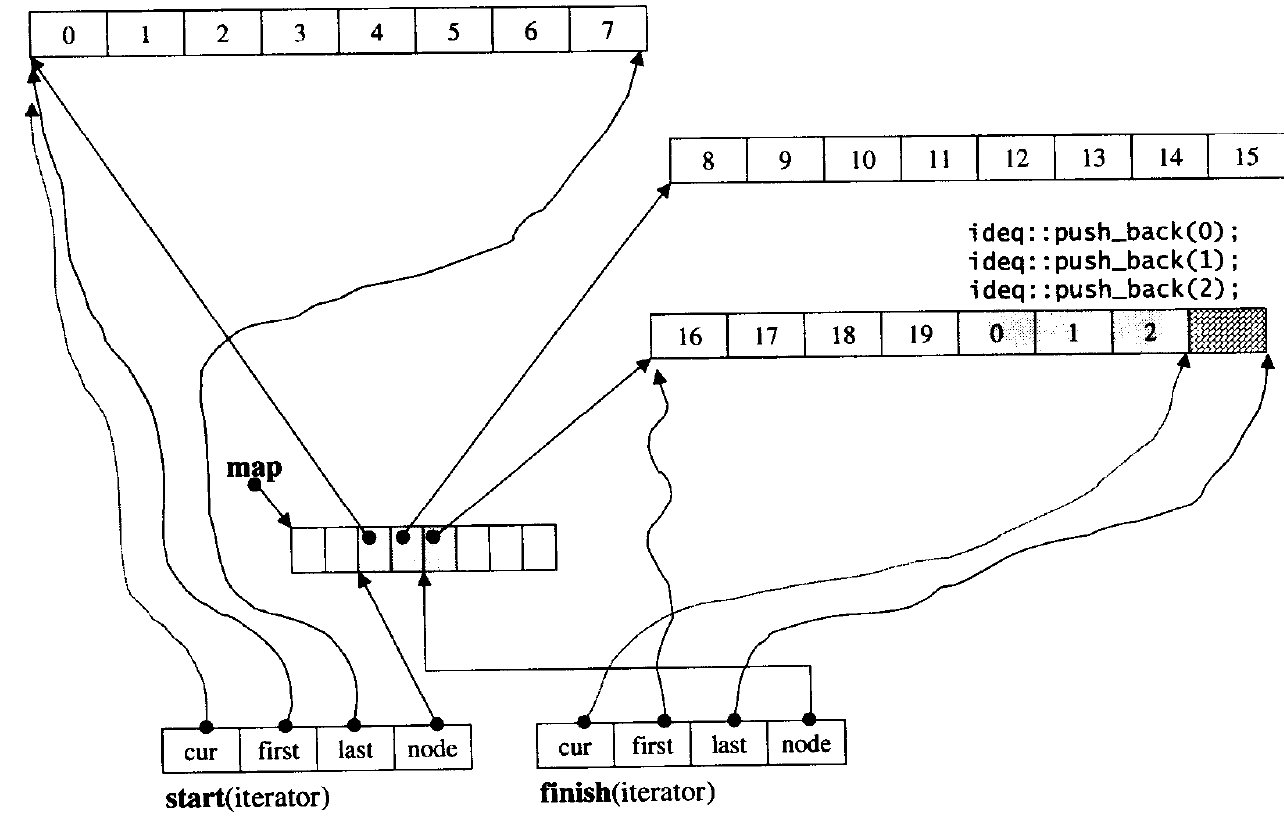
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
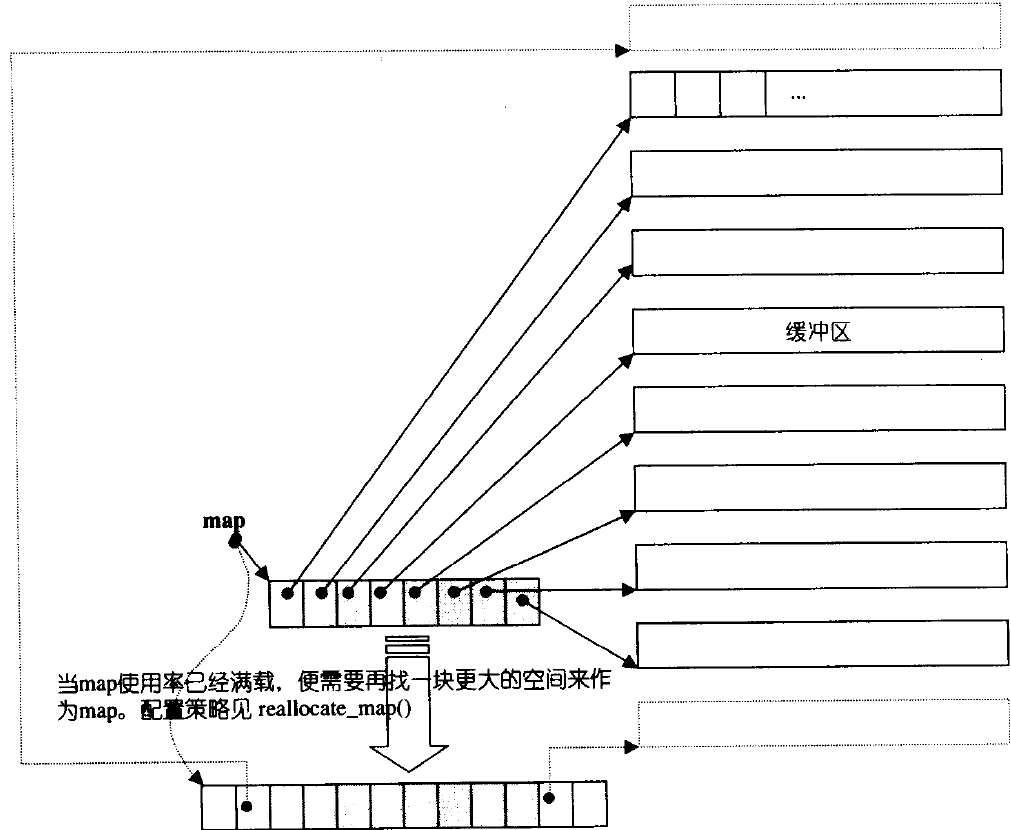
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
那deque是如何借助其迭代器维护其假想连续的结构呢?
// 简化的迭代器结构(仅展示核心成员)
template<typename T>
struct _Deque_iterator
{T* _M_cur; // 指向当前元素T* _M_first; // 指向当前内存块的起始位置T* _M_last; // 指向当前内存块的结束位置(实际是末尾的下一个位置)_Map_pointer _M_node; // 指向中央控制器的某个条目(管理内存块的指针数组)
};_M_cur
-
含义:指向当前迭代器所在位置的元素。
-
作用:直接访问当前元素的值(通过
*it或it->操作)。 -
示例:
deque<int>::iterator it = dq.begin(); int val = *it; // 通过_M_cur获取值
_M_first
-
含义:指向当前内存块(缓冲区)的起始位置。
-
作用:
-
判断迭代器是否在当前块的起始位置(如
it == _M_first)。 -
当迭代器需要向前移动(如
--it)时,若当前处于块的起始位置,则需要跳转到前一个内存块。
-
_M_last
-
含义:指向当前内存块(缓冲区)的结束位置(实际是末尾的下一个位置)。
-
作用:
-
判断迭代器是否在当前块的末尾(如
it == _M_last - 1)。 -
当迭代器需要向后移动(如
++it)时,若当前处于块的末尾,则需要跳转到下一个内存块。
-
_M_node
-
含义:指向中央控制器(
_Map_pointer类型,通常是一个二级指针)。 -
作用:
-
中央控制器是一个指针数组,每个条目指向一个内存块。
-
通过
_M_node可以访问到当前内存块在中央控制器中的位置。 -
当迭代器需要在内存块之间跳转时,通过
_M_node找到相邻内存块的地址。
-
迭代器的关键操作
1. 自增操作(++it)
-
_M_cur向后移动(_M_cur++)。 -
若
_M_cur == _M_last,说明已到当前块的末尾:-
通过
_M_node找到下一个内存块的地址。 -
更新
_M_first、_M_last和_M_cur,使其指向下一个块的起始位置。
-
2. 自减操作(--it)
-
_M_cur向前移动(_M_cur--)。 -
若
_M_cur < _M_first,说明已到当前块的起始位置:-
通过
_M_node找到前一个内存块的地址。 -
更新
_M_first、_M_last和_M_cur,使其指向前一个块的末尾。
-
3. 随机访问(it + n)
-
计算目标位置相对于当前块的位置偏移。
-
若目标位置跨越多个内存块,则调整
_M_node到目标块,并更新_M_first、_M_last和_M_cur。
deque的缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。 与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。 但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。结合了deque的优点,而完美的避开了其缺陷。
3.仿函数
1. 什么是仿函数?
仿函数(Functor) 是一个行为类似函数的对象,它通过重载 operator() 运算符实现函数调用功能。仿函数本质上是类或结构体对象,可以像普通函数一样被调用,但具有对象的状态保存能力。
2. 仿函数与普通函数的区别
| 特性 | 普通函数 | 仿函数 |
|---|---|---|
| 状态保存 | 无法保存状态(无成员变量) | 可以保存状态(通过成员变量) |
| 灵活性 | 固定逻辑 | 可通过构造函数参数动态配置逻辑 |
| 模板参数传递 | 无法直接作为模板参数传递 | 可以作为模板参数传递(类型) |
| 内联优化 | 可能无法内联 | 更易被编译器内联优化 |
3. 如何定义仿函数?
只需在类或结构体中重载 operator() 运算符即可。
示例:实现加法仿函数
class Add
{
public:// 构造函数可接受参数(例如固定加数)Add(int value) : _value(value) {}// 重载 operator()int operator()(int x) const {return x + _value;}private:int _value; // 保存状态
};// 使用仿函数
Add add5(5);
int result = add5(10); // 输出 15
还可以这样写:
class Add
{
public:// 重载 operator()int operator()(int x, int y) const{return x + y;}
};// 使用仿函数
Add add5;
int result = add5(10, 5); // 输出 15还可以作为模板参数来使用,举个例子就可以看出来了
struct Greater
{bool operator()(int a, int b) const {return a > b; // 降序}
};struct Less
{bool operator()(int a, int b) const{return a < b; // 升序}
};vector<int> vec = { 3, 1, 4, 1, 5 };
sort(vec.begin(), vec.end(), Greater());
//sort(vec.begin(), vec.end(), Less());
for (int e : vec)
{cout << e << ' ';
}
cout << endl;这里我们想让它降序就传Greater对象,想升序就传Less对象,这样就可以更方便,底层实现的时候就不用写一个升序版本的排序,又写一个降序版本的排序,省去了麻烦,也让代码没那么冗余
我们来运行一下看看
降序:

升序:

4.仿函数的优势
-
状态保存
可通过成员变量记录中间状态(例如计数器、缓存数据)。class Counter { public:Counter() : _count(0) {}void operator()(int x) {_count += x;}int get() const { return _count; } private:int _count; };std::vector<int> data = {1, 2, 3}; Counter cnt; cnt = std::for_each(data.begin(), data.end(), cnt); std::cout << cnt.get(); // 输出 6 -
模板兼容性
仿函数是类型,可直接作为模板参数传递(例如std::set的比较器)。template<typename T, typename Compare> class PriorityQueue {// 使用 Compare 仿函数类型定义比较逻辑 }; -
性能优化
仿函数比函数指针更易被编译器内联优化。
再次强调需要注意仿函数不是函数
仿函数本质:通过重载 operator() 实现函数行为的对象。
4. priority_queue(优先级队列)
简单来说优先级队列其实就是我们之前数据结构章节讲的堆。
优先级队列(priority_queue) 是一种容器适配器,其元素按优先级顺序出队。与普通队列(先进先出)不同,优先级队列每次取出的是优先级最高的元素。在C++标准模板库(STL)中,priority_queue 默认基于最大堆实现,堆顶元素为最大值。

我们直接来模拟实现一下
namespace Ro
{template<class T>struct Greater{bool operator()(const T& a, const T& b) const{return a > b; // 降序}};template<class T>struct Less{bool operator()(const T& a, const T& b) const{return a < b; // 升序}};template<class T, class Container = vector<T>, class Compare = Less<T>>class priority_queue{public:private:Container _con;};
}仿函数在这里就起到作用了,不然我们模拟实现还要分别实现大堆和小堆两种,这里我们和官方文档一样,也再增加一个类模板,我们想要大堆就传Less对象的仿函数,想要小堆就传Greater对象的仿函数。这里你可能觉得Less是比较升序的,Greater是比较降序的,那么大堆不应该传Greater,小堆不应该传Less吗
在C++的priority_queue中,最大堆使用std::less作为比较函数,而最小堆使用std::greater,这一设计看似与直觉相悖,但实际与堆的优先级判定逻辑和内部维护机制密切相关。以下是详细解释:
核心原因:比较函数定义的是父节点的优先级关系
priority_queue的底层实现通过堆结构维护元素顺序。比较函数的作用是判断父节点是否应保留其位置,而非直接决定元素的绝对顺序。具体规则如下:
1. 最大堆(大顶堆)与 std::less<T>
-
目标:堆顶元素始终为最大值。
-
比较逻辑:
当插入新元素时,堆的调整需要保证父节点 ≥ 子节点。
使用std::less<T>时,若父节点<子节点(比较返回true),则触发交换,将较大的子节点上浮,最终形成最大堆。// 伪代码:堆调整逻辑 if (compare(parent, child)) { // 若父节点 < 子节点(std::less返回true)swap(parent, child); // 交换父子节点,保证父节点更大 }
2. 最小堆(小顶堆)与 std::greater<T>
-
目标:堆顶元素始终为最小值。
-
比较逻辑:
使用std::greater<T>时,若父节点>子节点(比较返回true),则触发交换,将较小的子节点上浮,最终形成最小堆。if (compare(parent, child)) { // 若父节点 > 子节点(std::greater返回true)swap(parent, child); // 交换父子节点,保证父节点更小 }
类比排序:比较函数方向的反转
在排序中,std::less用于升序(从小到大),而std::greater用于降序(从大到小)。但在堆中,比较函数的逻辑被反转,因为它直接决定父节点与子节点的相对关系:
| 场景 | 比较函数 | 排序结果 | 堆类型 | 堆调整目标 |
|---|---|---|---|---|
| 升序排序 | std::less<T> | 元素从小到大排列 | 最大堆 | 父节点 ≥ 子节点(堆顶最大) |
| 降序排序 | std::greater<T> | 元素从大到小排列 | 最小堆 | 父节点 ≤ 子节点(堆顶最小) |
-
关键区别:
排序中的比较函数直接决定相邻元素的顺序,而堆中的比较函数决定父子节点的优先级关系。
push:
// 向上调整
void AdjustUp(size_t child)
{size_t parent = (child - 1) / 2;Compare com;while (child > 0){//if(_con[parent] < _con[child])if (com(_con[parent], _con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
void push(const T& val)
{_con.push_back();AdjustUp(_con.size() - 1);
}我们尾插一个数据就需要向上调整,来满足父子的关系
top:
const T& top() const
{return _con.front();
}empty:
bool empty() const
{return _con.empty();
}size:
size_t size() const
{return _con.size();
}pop:
// 向下调整
void AdjustDown(size_t parent)
{size_t child = parent * 2 + 1;//大堆时默认左孩子比右孩子大,小堆时默认左孩子小Compare com;while (child < _con.size()){//if (child < _con.size() && _con[child] < _con[child + 1])if (child + 1 < _con.size() && com(_con[child], _con[child + 1])){child++;}//if(_con[parent] < _con[child])if (com(_con[parent], _con[child])){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}
}void pop()
{assert(!empty());swap(_con.front(), _con.back());_con.pop_back();AdjustDown(0);
}需要注意的是,优先级队列为空时不能pop,所以我们加个断言
至于实现细节和逻辑我们在之前的数据结构堆中有讲过,这里就不再多介绍。
我们再来测试一下:
Ro::priority_queue<int> pq;
pq.push(1);
pq.push(2);
pq.push(3);
pq.push(4);
pq.push(5);while (!pq.empty())
{cout << pq.top() << " ";pq.pop();
}
cout << endl;
stack.h:
namespace Ro
{template <class T, class Container = vector<T>>class stack{public:void push(const T& val){_con.push_back(val);}T& top(){return _con.back();}const T& top() const{return _con.back();}void pop(){_con.pop_back();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}private:Container _con;};void test_stack(){stack<int> st;st.push(1);st.push(2);st.push(3);st.push(4);while (!st.empty()){cout << st.top() << ' ';st.pop();}cout << endl;}
}queue.h:
namespace Ro
{template<class T, class Container = list<T>>class queue{public:void push(const T& val){_con.push_back(val);}void pop(){_con.pop_front();}T& front(){return _con.front();}T& back(){return _con.back();}const T& front() const{return _con.front();}const T& back() const{return _con.back();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}private:Container _con;};void test_queue(){queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);while (!q.empty()){cout << q.front() << ' ';q.pop();}}
}priority_queue.h:
namespace Ro
{template<class T>struct Greater{bool operator()(const T& a, const T& b) const{return a > b; // 降序}};template<class T>struct Less{bool operator()(const T& a, const T& b) const{return a < b; // 升序}};template<class T, class Container = vector<T>, class Compare = Less<T>>class priority_queue{public:// 向上调整void AdjustUp(size_t child){size_t parent = (child - 1) / 2;Compare com;while (child > 0){//if(_con[parent] < _con[child])if (com(_con[parent], _con[child])){swap(_con[parent], _con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}// 向下调整void AdjustDown(size_t parent){size_t child = parent * 2 + 1;//大堆时默认左孩子比右孩子大,小堆时默认左孩子小Compare com;while (child < _con.size()){//if (child < _con.size() && _con[child] < _con[child + 1])if (child + 1 < _con.size() && com(_con[child], _con[child + 1])){child++;}//if(_con[parent] < _con[child])if (com(_con[parent], _con[child])){swap(_con[parent], _con[child]);parent = child;child = parent * 2 + 1;}else{break;}}}void push(const T& val){_con.push_back(val);AdjustUp(_con.size() - 1);}void pop(){assert(!empty());swap(_con.front(), _con.back());_con.pop_back();AdjustDown(0);}const T& top() const{return _con.front();}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}private:Container _con;};
}相关文章:

【C++】14.容器适配器 | stack | queue | 仿函数 | priority_queue
1. 容器适配器 什么是适配器 适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设 计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。 在C中,容器适配器(Container Adapters&…...

论文阅读:2025 arxiv Aligning to What? Limits to RLHF Based Alignment
Aligning to What? Limits to RLHF Based Alignment https://arxiv.org/pdf/2503.09025 https://www.doubao.com/chat/3871529075012866 速览 这篇论文主要探讨了强化学习从人类反馈(RLHF)在对齐大型语言模型(LLMs)时的局限性…...

利用Arcgis自己绘制shp文件
1.选择自己想要创建的shp文件的位置 我是直接创建在连接文件夹中 2.右键-新建-shp 3.设置名称、要素类型、空间参考 4、点击创建要素 5、右侧选择图层、创建面 6、开始绘制,双击任意位置结束绘制 之后可以改一下shp文件的名字...
)
路由器重分发(OSPF+静态路由)
路由器重分发(OSPF静态路由) 静态路由充当不了翻译官 OSPF路由 OSPF路由需要宣告自己的ip, Router(config)#router ospf 1 Router(config-router)#network 10.10.10.0 0.0.0.255 area 0还要帮静态路由的也宣告一下 Router(config)#ip route…...

KTT入门
Kinetic tournament tree 简称 KTT 下文中全部简写。 KTT 用于解决类以下问题: 已知 N N N 条一次函数,求解一段区间内函数最大值。支持修改操作可以修改 x i x_i xi 或者 b i b_i bi 的值。具体做法: 我们考虑线段树来维护一个类似 Δ \Delta Δ 的东西,我们令当…...

WPF 上位机开发模板
WPF 上位机开发模板 WPF上位机开发模板,集成了基础操作菜单、海康视觉实时图像界面、串口通讯、网口通讯、主流PLC通讯、数据存储、图片存储、参数配置、权限管理、第三方webapi接口接入、数据追溯与查询等功能。 一、项目结构 WpfSupervisor/ ├── Models/ …...

理想星环OS选择NuttX作为MCU侧OS的核心原因分析
文章目录 引言一、POSIX兼容性:降低汽车软件迁移成本二、轻量级与模块化:适配MCU资源约束三、硬实时性能:保障车辆控制确定性四、多芯片适配:加速车企供应链灵活性五、安全与可靠性:构建纵深防御体系六、社区与生态&am…...

IP数据报发送和转发的过程
1. 发送端准备数据 应用程序(比如浏览器)要发送数据,比如访问一个网站。 应用层(HTTP) → 传输层(TCP/UDP) → 网络层(IP)。 IP层负责把数据包打包,加上必要…...

Pinia 详细解析:Vue3 的状态管理利器
一、Pinia 概述 Pinia 是 Vue 3 的官方推荐状态管理库,由 Vue 核心团队维护。它是对 Vuex 的改进和简化,提供了更简洁的 API 和更好的 TypeScript 支持。 Pinia 的核心优势 更简单的 API:相比 Vuex 减少了概念和模板代码完美的 TypeScript…...

pytorch python常用指令
一、常用的conda指令 创建新的python环境 conda create -n env_name python3.x 查看已有的python环境 conda env list 进入已有的python环境 conda activate env_name 退出当前的python环境 conda deactivate 二、常用的pip指令 pip install -r requirements.txt 根据…...
之Spark安装和编程实践)
ubantu18.04(Hadoop3.1.3)之Spark安装和编程实践
说明:本文图片较多,耐心等待加载。(建议用电脑) 注意所有打开的文件都要记得保存。 第一步:准备工作 本文是在之前Hadoop搭建完集群环境后继续进行的,因此需要读者完成我之前教程的所有操作。 以下所有操…...
)
Ubuntu下安装vsode+qt搭建开发框架(二)
Ubuntu下安装vsode+qt搭建开发框架(二) 上一节介绍了vsode下搭建qt环境,采用的项目构建方式是使用qt官方的qmake工具。然而从qt6之后,官方已经开始推荐使用cmake来构建项目;并且许多项目都是cmake直接构建的,用cmake来构建项目具有可以更方便的融合其他开源项目。 一、vs…...

获取房源信息并完成可视化——网络爬虫实战1
房源信息爬虫与可视化分析程序 个人程序全网一手,盗卖必究 项目介绍 本项目是一个基于Python的房源信息爬虫与可视化分析工具,可以爬取链家网的二手房源信息,并对数据进行清洗、分析和可视化展示。通过本工具,用户可以快速了解特…...

css word
介绍 CSS word-spacing 属性,用于指定段字之间的空间,例如: p {word-spacing:30px; }word-spacing属性增加或减少字与字之间的空白。 注意: 负值是允许的。 浏览器支持 表格中的数字表示支持该属性的第一个浏览器版本号。 属…...
)
[mysql]约束(上)
约束 道德约束,法律约束,这个约束在表里面是狭义的. 约束广义的,比如数值型你就不能录入’abc’.字符,定义了varchar(15)范围不能超过数量15. 我们这个章节要说的约束是狭义的,是具体的我们设定的约束, 为什么我们需要约束呢 我们是为了数据的精确性和可靠性,我们了为了防…...

Eclipse 插件开发 2
Eclipse 插件开发 2 1 插件配置 1 插件配置 <?xml version"1.0" encoding"UTF-8"?> <?eclipse version"3.4"?> <plugin><extension point"org.eclipse.ui.commands"><category id"com.xu.learn.…...
--- 版本1)
用go从零构建写一个RPC(仿gRPC,tRPC)--- 版本1
希望借助手写这个go的中间件项目,能够理解go语言的特性以及用go写中间件的优势之处,同时也是为了更好的使用和优化公司用到的trpc,并且作者之前也使用过grpc并有一定的兴趣,所以打算从0构建一个rpc系统,对于生产环境已…...
入门建议)
树莓派(Raspberry Pi)入门建议
树莓派(Raspberry Pi)是一个低成本、信用卡大小的微型电脑,它的核心价值在于高度灵活的可编程性和丰富的硬件扩展能力。根据你的兴趣和需求,它可以用来做各种有趣且实用的项目,以下是常见的应用场景和实例:…...

SpringBoot物资管理系统 | JavaWeb项目设计与实现
概述 基于JavaWeb技术实现了一套完整的物资管理解决方案。该系统适用于企业、学校、医院等机构,提供高效的物资入库、申报、公告管理等功能,帮助用户实现物资管理的数字化与智能化。 主要内容 1. 管理员功能实现 5.1.1 物资管…...

《P1950 长方形》
题目描述 小明今天突发奇想,想从一张用过的纸中剪出一个长方形。 为了简化问题,小明做出如下规定: (1)这张纸的长宽分别为 n,m。小明将这张纸看成是由nm个格子组成,在剪的时候,只能沿着格子的…...

SpringCloud微服务架构
Spring Cloud是一个广泛使用的微服务框架,它基于Spring Boot构建,旨在帮助开发者构建复杂的分布式系统。Spring Cloud提供了多种工具和库,使得开发人员可以轻松地构建和部署微服务架构。以下是一些关键组件和概念,帮助你理解Sprin…...

网络管理知识点
1.传统网络管理:Web网管方式,CLI方式,基于SNMP集中管理 2.SNMP简单网络管理协议 SNMPV1实现方便,安全性弱 SNMPV2支持更多错误 SNMPV3认证加密,访问控制 3.SNMP,UDP传输效率较高,报文容易丢失…...

【Web应用服务器_Tomcat】二、Tomcat 核心配置与集群搭建
在企业级 Java Web 应用的部署场景中,Tomcat 作为主流的 Servlet 容器和 Web 服务器,其核心配置的优化以及集群搭建对于保障应用的高性能、高可用性至关重要。 一、Tomcat 核心配置优化 1.1 server.xml 配置文件解析 Tomcat 的核心配置文件server…...

模板引擎语法-算术运算
模板引擎语法-算术运算 文章目录 模板引擎语法-算术运算[toc]1.加法运算2.减法运算3.乘法与除法运算4.四则运算5.整除运算 在Django框架模板中,没有专门定义关于算术运算的语法。不过,通过一些标签和过滤器的配合使用,可以模拟实现类似“加减…...

MySQL 联合查询教程
MySQL 联合查询教程 在 MySQL 中,联合查询用于从多个表中检索数据,常用于关联表中的信息。联合查询(JOIN)通过将两个或更多表根据一定条件连接起来,从而形成一个虚拟的结果集。MySQL 支持多种类型的联合查询ÿ…...

罗技Flow跨电脑控制
Windows 下载适用于 Windows 10 或更高版本的应用程序 macOS 下载适用于 macOS 12 或更高版本的应用程序 Flow 让您可以在两台电脑之间甚至 Windows 和 macOS 之间畅快办公。 只需将支持 Flow 的鼠标的光标移动到屏幕边缘即可在电脑和操作系统之间切换。支持 Flow 的键盘会…...
)
Unity网络编程入门:掌握Netcode for GameObjects实现多人游戏基础(Day 39)
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

LeetCode100题
LeetCode100 两数之和 遍历数组,以哈希表存数与下标,边存边查,速找和为目标值的两数下标 class Solution {public int[] twoSum(int[] nums, int target) {int[] ansnew int[2];HashMap<Integer,Integer> mapnew HashMap<>();…...

鸿蒙代码@Builder
#代码如下: Entry Component struct CardExample {State title: string "欢迎使用鸿蒙";State content: string "这是一段自定义内容";build() {Column() {this.MyCard({ title: this.title, content: this.content })}.padding(20)}BuilderM…...

Gewechat启动启动报错
Centos7,测试连接时发现这个错误。 [rootxin ~]# curl -i -X POST http://127.0.0.1:2531/v2/api/tools/getTokenId curl: (56) Recv failure: Connection reset by peer 1、删除原容器,重新构建。 docker run -itd \--name gewe \--privileged \-v /ro…...

硅谷甄选41集-71集
第四十三集:完全按照视频敲代码的话会发现左侧顶部tabbar的display:flex失效了,是因为拆分开的子组件里面多了一个div,去掉就好了,vue3不需要再额外包裹元素。因为路径变化了,所以找不到图片的话在前面再加一个…。 第四十五集&am…...

PyQt6实例_消息工具_使用与完整代码分享
目录 使用 每日消息 全局查询 更新数据库 代码 数据库表创建 代码-数据库相关操作 代码-界面与操作逻辑 视频 使用 工具有三个面板:每日消息、全局查询、更新数据库 “每日消息”和“全局查询”,数据源:同花顺7x24小时快讯 “更新…...

docker配置mysql遇到的问题:网络连接超时、启动mysql失败、navicat无法远程连接mysql
目录 1.网络超时 方式1. 网络连接问题 方式2. Docker镜像源问题 方式3.使用国内镜像源 2.启动mysql镜像失败 3.navicat无法远程连接mysql 1.网络超时 安装MySQL时出现超时问题,可能由多种原因导致: 方式1. 网络连接问题 原因:网络不稳定…...

【虚幻C++笔记】碰撞检测
目录 碰撞检测参数详情示例用法 碰撞检测 显示名称中文名称CSphere Trace By Channel按通道进行球体追踪UKismetSystemLibrary::SphereTraceSingleSphere Trace By Profile按描述文件进行球体追踪UKismetSystemLibrary::SphereTraceSingleByProfileSphere Trace For Objects针…...

SpringBoot集成WebSocket,单元测试执行报错
问题描述 SpringBoot集成了WebSocket,单元测试启动后会报如下错误:javax.websocket.server.ServerContainer not available 这是因为SpringBootTest启动时不会启动服务器,所以WebSocket会报错。 解决方案 在注解中添加 webEnvironmen…...

Git基本操作
1. 安装与配置 安装:你可以从 Git 官方网站 下载 Windows 版本的安装程序。运行安装程序,在安装过程中,你可以按照默认设置进行安装,也可以根据自己的需求进行调整。配置:安装完成后,打开 Git Bash&#x…...

C++异步并发支持库future
future: 1.利用共享状态来异步的获取提供者的值 2.future处于共享状态就绪时才是有效的 3.future不能拷贝构造,只能移动构造,并且移动构造后共享状态失效 std::future::get 1.当共享状态就绪时,返回存储在共享状态中的值。 2…...

c++学习小结
内存分配 空间 栈区(stack)。编译器⾃动分配与释放,主要存放函数的参数值,局部变量值等,连续的内存空 间,由⾼地址向低地址扩展。 堆区(heap) 。由程序员分配与释放;不…...

Pygame物理模拟:实现重力、弹跳与简单物理引擎
Pygame物理模拟:实现重力、弹跳与简单物理引擎 大家好,欢迎来到本期的技术分享!今天我们将一起探讨如何使用Python和Pygame库来实现一个简单的物理模拟系统,其中包括重力、弹跳以及一个基础的物理引擎。如果你对游戏开发或者物理仿真感兴趣,那么这篇文章一定会让你受益匪…...

Python dotenv 使用指南:轻松管理项目环境变量
一、为什么要使用环境变量管理? 很多开发者容易把自己开发的项目上传到Github上,但偶尔会忘记把数据库密码、支付接口密钥等敏感信息和谐掉,当代码提交上去时,这些信息就像裸奔一样暴露在所有人面前。更糟糕的是,不同…...

网络攻防第一~四集
来源于一下 【小迪安全】红蓝对抗 | 网络攻防 | V2023全栈培训_哔哩哔哩_bilibili 目录 第一集 第二集 第一集 web架构包括系统、中间件、程序源码、数据库 系统 windows、linux、windows server 中间件 是前端语言和数据库是当做一个桥梁,当做解析作用&…...

TI---sysconfig生成宏
核心内容概览 1. 宏定义的总体作用 SysConfig生成的宏定义是硬件配置的符号化映射,将图形化界面的配置参数转化为可直接引用的编译时常量,核心价值包括: 免硬编码:避免手动写入硬件参数(如引脚号、波特率࿰…...

【C】初阶数据结构13 -- 快速排序
本篇文章主要讲解经典的排序算法 -- 快速排序算法 目录 1 递归版本的快速排序 1) 算法思想 (1) hoare 版本 (2) 双指针版本 (3) 挖坑法 2) 代码 3) 时间复杂度…...

Spring Boot 3.4 实战指南:从性能优化到云原生增强
一、核心新特性概览 Spring Boot 3.4 于 2024 年 11 月正式发布,带来 6 大维度的 28 项改进。以下是实战开发中最具价值的特性: 1. 性能革命:虚拟线程与 HTTP 客户端优化 虚拟线程支持:Java 21 引入的虚拟线程在 Spring Boot 3…...

Git分支重命名与推送参数解析
这两个参数的解释如下: git branch -M master 中的 -M 参数 -M 是 --move --force 的组合简写,表示强制重命名当前分支为 master。如果当前分支已经存在名为 master 的分支,-M 会强制覆盖它(慎用,可能导致数据丢失&…...

深度学习中的预训练与微调:从基础概念到实战应用全解析
摘要 本文系统解析深度学习中预训练与微调技术,涵盖核心概念、技术优势、模型复用策略、与迁移学习的结合方式,以及微调过程中网络参数更新机制、模型状态分类等内容。同时深入分析深层神经网络训练难点如梯度消失/爆炸问题,为模型优化提供理…...

EMC-148.5MHz或85.5辐射超标-HDMI
EMC 148.5MHz或85.5辐射超标-HDMI 遇到了一台设备过不了EMC ,经排查主要是显示器的HDMI问题 解决办法看看能否更换好一点的HDMI线缆...
:团队协作最佳实践)
DeepSeek系列(9):团队协作最佳实践
团队知识库构建 在知识经济时代,团队知识的有效管理和传递是组织核心竞争力的关键。DeepSeek可以成为打造高效团队知识库的得力助手,让知识管理从繁重工作变为自动化流程。 知识库架构设计 多层次知识结构 一个高效的团队知识库应具备清晰的层级结构,DeepSeek可以协助:…...

信息系统项目管理工程师备考计算类真题讲解十
一、立项管理 1)折现率和折现系数:折现也叫贴现,就是把将来某个时间点的金额换算成现在时间点的等值金额。折现时所使用的利率叫折现率,也叫贴现率。 若n年后能收F元,那么这些钱在现在的价值,就是现值&am…...

第1章 基础知识
1.1 机器语言 1.2 汇编语言的产生 用汇编语言编写程序的工作过程如下: 1.编写程序:汇编程序包括汇编指令、伪指令、其他符号,如下图。其中,“伪指令”并不是由计算机直接执行的指令,而是帮助编译器完成“编译”的符号。 2.编译:将汇编程序转换成机器码。 3.计算机执行。 …...