深入浅出理解并应用自然语言处理(NLP)中的 Transformer 模型
1 引言
随着信息技术的飞速发展,自然语言处理(Natural Language Processing, NLP)作为人工智能领域的一个重要分支,已经取得了长足的进步。从早期基于规则的方法到如今的深度学习技术,NLP 正在以前所未有的速度改变着我们与计算机交互的方式。
1.1 NLP 技术的发展概述
自然语言处理的历史可以追溯到 20 世纪 50 年代,当时的研究主要集中在机器翻译和简单的语法分析上。随着时间的推移,研究者们逐渐开发出了基于统计模型的方法,这些方法在一定程度上提高了系统的性能。然而,真正意义上的突破发生在 2010 年后,得益于计算能力的增强以及大数据时代的到来,深度学习技术开始被广泛应用于 NLP 领域。特别是循环神经网络(RNN)、长短时记忆网络(LSTM)和门控循环单元(GRU)等模型的出现,极大地提升了处理序列数据的能力。
但是,这些模型也面临着一些挑战,比如难以处理长距离依赖问题、训练时间较长以及并行化困难等。为了解决这些问题,研究者们不断探索新的方法,直到 Transformer 模型的出现,才从根本上改变了这一局面。
1.2 Transformer 模型的重要性
Transformer 模型由 Vaswani 等人于 2017 年提出,其核心思想是完全摒弃了传统的循环机制,转而采用自注意力机制(Self-Attention Mechanism)。这种机制允许模型直接关注输入序列中任意位置的信息,从而有效地解决了长期依赖的问题。此外,由于 Transformer 架构具有高度的并行性,因此相比之前的模型,在训练速度上有显著提升。
Transformer 模型不仅自身表现出色,它还成为了许多后续模型的基础,如 BERT、GPT 系列等。这些模型通过不同的预训练策略,在各种 NLP 任务中取得了前所未有的成绩,包括但不限于文本分类、问答系统、语义相似度计算和机器翻译等。因此,理解 Transformer 的工作原理及其应用对于任何希望深入 NLP 领域的研究者或工程师来说都是至关重要的。
2 Transformer 模型基础
Transformer 模型的出现标志着自然语言处理领域的一个重要转折点。通过引入自注意力机制,它不仅解决了传统序列模型中的一些固有问题,还为后续一系列高性能 NLP 模型奠定了基础。
2.1 自注意力机制简介
在深入探讨 Transformer 之前,理解其核心组件——自注意力机制(Self-Attention Mechanism)是至关重要的。传统的序列模型如 RNN 或 LSTM 依赖于顺序处理输入数据,这限制了它们处理长距离依赖的能力,并且难以并行化。相比之下,自注意力机制允许模型在处理每个位置时都能直接访问整个序列的信息,从而极大地提升了效率和效果。
具体来说,自注意力机制计算的是输入序列中不同位置之间的相似度得分,这些得分被用来加权求和各个位置的表示,生成当前位置的新表示。这个过程可以通过以下公式来概括:
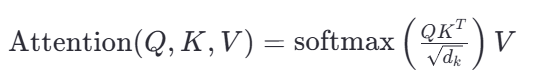
这里,Q、K 和 V 分别代表查询(Query)、键(Key)和值(Value)矩阵,dk 是键向量的维度。通过这种方式,模型可以动态地调整对不同信息的关注程度,使得关键信息能够得到更多的权重。
2.2 多头注意力的工作原理
尽管自注意力机制已经非常强大,但单个注意力层可能无法捕捉到输入数据的所有特征。为了克服这一局限性,Transformer 引入了多头注意力(Multi-head Attention)的概念。简单来说,多头注意力就是同时运行多个自注意力层,每个层关注输入的不同部分或不同的表示子空间。
每个“头”独立进行自注意力计算,然后将结果拼接在一起并通过一个线性变换整合输出。这种方法不仅增加了模型的表达能力,还能让模型从不同的角度理解和处理输入信息。例如,在处理复杂的句子结构时,某些头部可能会专注于语法关系,而其他头部则可能更关注语义信息。
2.3 Transformer 架构详解
了解了自注意力机制和多头注意力之后,我们可以来看看完整的 Transformer 架构。Transformer 主要由编码器(Encoder)和解码器(Decoder)两大部分组成,每个部分又包含了若干相同结构的层堆叠而成。
-
编码器:每层包括一个多头自注意力模块和一个前馈神经网络(Feed-forward Neural Network)。在每一层之间,通常还会加入残差连接(Residual Connection)和层归一化(Layer Normalization),以帮助梯度流动和加速训练。
-
解码器:除了与编码器类似的结构外,解码器还包括一个额外的多头注意力层,用于关注编码器的输出。这种设计允许解码器利用整个输入序列的信息来生成目标序列,非常适合诸如翻译等任务。
此外,Transformer 还在解码器的最后一层加入了掩码(Masking)机制,确保在预测下一个词时只能使用前面的词,避免了信息泄露问题。
3 Transformer vs 传统模型
随着 Transformer 架构的引入,自然语言处理(NLP)领域迎来了新的变革。与传统的循环神经网络(RNN)和卷积神经网络(CNN)相比,Transformer 在多个方面展示了显著的优势。下面我们将详细探讨这些优势以及 Transformer 解决的问题和应用场景。
3.1 与 RNN/CNN 对比的优势
-
并行化处理:RNN 及其变体 LSTM 和 GRU 是基于序列的数据处理模型,这意味着它们需要按顺序处理输入数据。这不仅限制了处理速度,还难以充分利用现代硬件(如 GPU 和 TPU)的并行计算能力。相比之下,Transformer 完全摒弃了递归结构,采用自注意力机制来直接获取输入序列中任意位置的信息,从而实现了更高的并行度,极大地提高了训练和推理效率。
-
长距离依赖问题:尽管 LSTM 和 GRU 通过门控机制在一定程度上缓解了长期依赖问题,但它们仍然难以捕捉非常长距离的依赖关系。Transformer 通过多头注意力机制,让模型能够同时关注输入序列中的不同部分,有效解决了这个问题,使得模型可以更好地理解和生成复杂的文本结构。
-
灵活性和表达能力:CNN 主要适用于局部特征提取,对于文本这种具有丰富语义信息的数据类型,其表现不如预期。而 Transformer 不仅可以捕捉全局信息,还能通过对不同子空间的关注提升模型的表达能力。此外,由于 Transformer 不依赖于特定的任务结构设计,因此它更加灵活,可以适应多种类型的 NLP 任务。
3.2 解决的问题及应用场景
Transformer 模型因其独特的优势,在解决一系列 NLP 挑战的同时也开辟了许多新的应用场景:
-
机器翻译:作为 Transformer 最初的应用场景之一,它已经证明了在机器翻译任务上的卓越性能。通过学习源语言到目标语言的映射,Transformer 可以生成更为流畅和准确的翻译结果。
-
文本生成:无论是文章摘要、故事创作还是自动回复系统,Transformer 都能提供强有力的支持。特别是像 GPT 这样的模型,利用 Transformer 架构进行预训练后,能够在给定上下文的情况下生成连贯且相关的文本。
-
问答系统:Transformer 有助于构建更智能的问答系统,例如 BERT 模型可以通过理解问题和文档内容之间的细微差别,提供更加精确的答案。这对于搜索引擎优化、客户服务自动化等领域具有重要价值。
-
情感分析:通过对文本情绪倾向性的判断,企业可以更好地了解用户反馈,调整产品策略。Transformer 模型在这方面同样表现出色,能够精准地识别出文本背后的情感态度。
4 实战项目:基于 Transformer 的情感分析
在本节中,我们将通过一个具体案例——情感分析,来展示如何使用 Transformer 模型进行 NLP 任务。情感分析是自然语言处理中的一个重要应用,旨在确定文本中表达的情感倾向(例如正面、负面或中立)。我们将详细介绍从环境搭建到模型训练再到结果评估的全过程。
4.1 环境搭建与数据准备
首先,我们需要设置开发环境,并准备好用于训练的数据集。这里,我们将使用 Python 编程语言以及一些流行的库,如 transformers、datasets 和 torch。
- 安装必要的库:
pip install transformers datasets torch- 加载数据集:我们将使用 IMD 电影评论数据集,这是一个广泛应用于情感分析的经典数据集,包含 50,000 条来自 IMDB 网站的电影评论,每条评论被标记为正面或负面。
from datasets import load_dataset# 加载IMDB数据集
dataset = load_dataset('imdb')- 加载预训练模型和分词器:选择一个适合文本分类任务的预训练模型,比如 distilbert-base-uncased,它是一个轻量级版本的 BERT 模型,性能优异且训练速度快。
from transformers import AutoTokenizer, AutoModelForSequenceClassificationmodel_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)- 数据预处理:将原始文本转换成模型可以理解的形式,这通常涉及到分词、截断或填充等步骤。
def preprocess_function(examples):return tokenizer(examples['text'], truncation=True, padding=True)encoded_dataset = dataset.map(preprocess_function, batched=True)4.2 模型训练步骤解析
接下来,我们利用 Hugging Face 提供的 Trainer API 简化训练流程。该 API 提供了高度可定制化的训练选项,非常适合快速原型设计和实验。
- 定义训练参数:
from transformers import TrainingArgumentstraining_args = TrainingArguments(output_dir='./results', # 输出目录num_train_epochs=3, # 训练轮数per_device_train_batch_size=8, # 每个设备上的批次大小per_device_eval_batch_size=8, # 评估时的批次大小warmup_steps=500, # 学习率预热步数weight_decay=0.01, # 权重衰减系数logging_dir='./logs', # 日志目录
)- 训练模型:
from transformers import Trainertrainer = Trainer(model=model,args=training_args,train_dataset=encoded_dataset['train'],eval_dataset=encoded_dataset['test']
)trainer.train()4.3 结果评估与优化策略
训练完成后,下一步是对模型进行评估,并根据结果调整模型以提高性能。
- 评估模型:
eval_results = trainer.evaluate()
print(f"Evaluation results: {eval_results}")这将输出包括准确率在内的多项评价指标。根据这些结果,我们可以判断模型的表现是否达到预期。
- 优化策略:
- 超参数调优:尝试不同的学习率、批次大小等超参数组合。
- 数据增强:增加训练数据的多样性,例如通过同义词替换、随机插入等方式生成新的样本。
- 集成学习:结合多个不同配置或架构的模型预测结果,往往可以获得更好的性能。
5 Transformer 的应用扩展
Transformer 模型自问世以来,已经在自然语言处理(NLP)领域内引发了革命性的变化。它的成功不仅限于文本分类和情感分析等基础任务,还扩展到了更广泛的 NLP 任务中,并在多个前沿研究方向上展现了巨大的潜力。
5.1 在其他 NLP 任务中的应用实例
-
机器翻译:Transformer 架构是当前最先进的机器翻译系统的核心。通过使用大规模的并行语料库进行训练,如 Google 的 Transformer-based 模型可以实现高质量的语言转换,显著提升了翻译的流畅度和准确性。
-
问答系统:基于 Transformer 的模型如 BERT 和 T5 被广泛应用于构建强大的问答系统。这些模型能够理解问题的意图,并从大量文档中提取出最相关的答案,极大地提高了信息检索的效率和精确度。
-
文本生成:GPT 系列模型展示了 Transformer 在生成连贯、富有创意的文本方面的强大能力。无论是故事创作、新闻撰写还是自动摘要,这类模型都能够提供令人印象深刻的表现。
-
命名实体识别(NER)与关系抽取:多语言 Transformer 模型如 XLM-RoBERTa 为跨语言的任务提供了支持,使得单个模型能够在多种语言环境中识别实体并抽取它们之间的关系,这对于全球化的应用尤为重要。
-
对话系统:Transformer 也被用来开发更加智能的对话系统,它能够理解和生成复杂的对话流,支持更加自然的人机交互体验。
5.2 当前研究趋势与未来展望
随着 Transformer 模型的成功,研究人员正在探索更多可能性,以进一步提升其性能并拓展应用场景:
-
更大规模的数据集与更强的计算资源:利用更多的数据和更强的计算能力来训练更大的模型已成为一种趋势。例如,GPT-3 拥有超过 1750 亿个参数,这表明了在增加模型大小方面仍有很大的探索空间。
-
优化模型效率:尽管 Transformer 模型表现优异,但它们的计算成本较高。因此,如何提高模型效率成为了研究的重点之一。诸如 Linformer、Reformer 等改进版本旨在降低计算复杂度,使 Transformer 适用于更广泛的设备和场景。
-
多模态学习:除了纯文本外,Transformer 也开始被应用于图像、视频等多种形式的数据处理中。Vision Transformer (ViT) 和 Swin Transformer 等模型展示了 Transformer 在计算机视觉领域的巨大潜力。
-
自动化机器学习(AutoML)与元学习:结合 AutoML 技术,研究人员正在寻找方法来自动选择最佳的超参数配置或模型结构,从而减少人工干预的需求。同时,元学习的发展也使得模型能够更快地适应新任务,减少了对大规模标注数据的依赖。
6 结论
在深入探讨了 Transformer 模型的基础、其与传统模型的对比、实战项目应用以及扩展应用场景之后,我们可以看到 Transformer 模型是如何从根本上改变了自然语言处理(NLP)领域的。下面将总结本文的关键点,并为初学者和实践者提供一些实用的建议。
6.1 总结关键点
-
自注意力机制的重要性:Transformer 模型的核心在于其自注意力机制,这使得它能够有效地捕捉序列中任意位置的信息,解决了长期依赖问题,同时也提高了处理效率。
-
多头注意力的优势:通过同时运行多个自注意力层,Transformer 可以关注输入的不同方面或子空间,增强了模型的理解能力和表达力。
-
相较于 RNN/CNN 的优势:相比于传统的循环神经网络和卷积神经网络,Transformer 不仅在处理长距离依赖上表现出色,还具有高度的并行化潜力,大大提升了训练速度和性能。
-
广泛应用领域:从机器翻译到问答系统,从文本生成到对话系统,Transformer 及其变体已经在各种 NLP 任务中证明了自己的价值。此外,它还在向多模态学习等领域扩展,展示了强大的适应性和灵活性。
-
持续的研究趋势:当前的研究正致力于优化 Transformer 的效率、探索更大规模的数据集和更强计算资源的应用,以及开发适用于更多场景的改进版本,如 Linformer 和 Reformer 等。
6.2 对于初学者和实践者的建议
对于那些希望进入 NLP 领域或者想要更深入地理解和应用 Transformer 模型的人来说,以下几点建议可能会有所帮助:
-
理论基础的学习:首先确保你对基本概念有扎实的理解,包括但不限于深度学习基础、NLP 基础知识以及 Transformer 架构本身的工作原理。可以通过阅读相关论文、参与在线课程等方式来加强自己的理论知识。
-
动手实践:理论固然重要,但实际操作同样不可或缺。尝试使用开源框架如 Hugging Face 的 Transformers 库进行实验,从简单的文本分类任务开始,逐步挑战更复杂的项目,如问答系统或对话系统。
-
保持更新:NLP 是一个快速发展的领域,新的研究和技术不断涌现。订阅相关的博客、加入社区讨论、参加学术会议都是不错的方式,可以帮助你紧跟最新的研究动态和技术趋势。
-
合作与交流:无论是线上还是线下,寻找志同道合的人一起学习和探讨是非常有益的。你可以通过 GitHub 项目、论坛或是本地/国际会议找到同行,分享经验和见解。
相关文章:
深入浅出理解并应用自然语言处理(NLP)中的 Transformer 模型
1 引言 随着信息技术的飞速发展,自然语言处理(Natural Language Processing, NLP)作为人工智能领域的一个重要分支,已经取得了长足的进步。从早期基于规则的方法到如今的深度学习技术,NLP 正在以前所未有的速度改变着我…...

AEB法规升级后的市场预测与分析:技术迭代、政策驱动与产业变革
文章目录 一、政策驱动:全球法规升级倒逼市场扩容二、技术迭代:从“基础防护”到“场景全覆盖”三、市场格局:竞争加剧与生态重构四、挑战与未来展望五、投资建议结语 近年来,全球汽车安全法规的加速升级正深刻重塑AEB(…...

《代码之美:静态分析工具与 CI 集成详解》
《代码之美:静态分析工具与 CI 集成详解》 引言 在现代软件开发的快节奏环境中,代码质量和效率始终是开发者关注的核心。无论您是初学者,还是经验丰富的资深开发者,一个强大的工具链都能让您如虎添翼。而 Python 的静态代码分析工具,如 pylint、flake8 和 mypy,正是提升…...
2022 版安装与下载教程)
Adobe Photoshop(PS)2022 版安装与下载教程
Adobe Photoshop下载安装和使用教程 Adobe Photoshop,简称“PS”,是由Adobe Systems开发和发行的图像处理软件。Photoshop主要处理以像素所构成的数字图像。使用其众多的编修与绘图工具,可以有效地进行图片编辑和创造工作,…...
)
Universal Value Function Approximators 论文阅读(强化学习,迁移?)
前言 Universal Value Function Approximators 个人实现(请大佬指正) *关于UVFA如何迁移的问题,这也是我为什么反复看这篇文章的原因,我觉值函数逼近的最大用法就是如何迁移,如果仅仅是更改值函数的结构,…...

论文阅读:2024 arxiv HybridFlow: A Flexible and Efficient RLHF Framework
https://www.doubao.com/chat/3875396379023618 HybridFlow: A Flexible and Efficient RLHF Framework https://arxiv.org/pdf/2409.19256 https://github.com/volcengine/verl 速览 这篇论文主要介绍了一个名为HybridFlow的新型框架,旨在提升大语言模型&…...

WPF实现多语言切换
WPF实现多语言切换完整指南 一、基础实现方案 1. 资源文件准备 首先创建不同语言的资源文件: Resources/ ├── Strings.resx // 默认语言(英语) ├── Strings.zh-CN.resx // 简体中文 └── Strings.ja-JP.resx // 日语 Strings.resx (默认英…...

wpf操作主流数据
WPF 操作主流数据库详解 WPF(Windows Presentation Foundation)应用程序经常需要与数据库交互以实现数据的持久化和展示。主流的关系型数据库包括 SQL Server、MySQL、PostgreSQL 和 SQLite。本文将详细介绍如何在 WPF 应用程序中使用这些主…...

Docker Compose--在Ubuntu中安装Docker compose
原文网址:Docker Compose--在Ubuntu中安装Docker compose_IT利刃出鞘的博客-CSDN博客 简介 说明 本文介绍如何在Ubuntu中安装docker compose。 docker-compose是用于管理Docker的,相对于单纯使用Docker更方便、更强大。 如果还没安装docker…...
)
推荐几个免费提取音视频文案的工具(SRT格式、通义千问、飞书妙记、VideoCaptioner、AsrTools)
文章目录 1. 前言2. SRT格式2.1 SRT 格式的特点2.2 SRT 文件的组成2.3 SRT 文件示例 3. 通义千问3.1 官网3.2 上传音视频文件3.3 导出文案 4. 飞书妙记4.1 官网4.2 上传音视频文件4.3 导出文案4.4 缺点 5. VideoCaptioner5.1 GitHub地址5.2 下载5.2.1 通过GitHub下载5.2.2 通过…...

驱动汽车供应链数字化转型的标杆解决方案:全星研发项目管理APQP软件系统:
全星研发项目管理APQP软件系统:驱动汽车供应链数字化转型的标杆解决方案 一、行业痛点与转型迫切性 在汽车行业电动化、智能化浪潮下,主机厂对供应链企业的APQP(先期产品质量策划)合规性、开发效率及体系化管理能力提出严苛要求。…...

PyTorch数据加载与预处理
数据加载与预处理详解 1. 数据集类(Dataset和DataLoader) 1.1 Dataset基类 PyTorch中的Dataset是一个抽象类,所有自定义的数据集都应该继承这个类,并实现以下两个方法: __len__(): 返回数据集的大小__getitem__(): 根据索引返回一个样本 …...

MyBatis 官方子项目详细说明及表格总结
MyBatis 官方子项目详细说明及表格总结 1. 核心子项目说明 1.1 mybatis-3 GitHub 链接:https://github.com/mybatis/mybatis-3功能: MyBatis 核心框架的源码,提供 SQL 映射、动态 SQL、缓存、事务管理等核心功能。主要功能: 支持…...

Java学习手册:常用的内置工具类包
以下是常用 Java 内置工具包。 • 日期时间处理工具包 • java.time包(JSR 310):这是 Java 8 引入的一套全新的日期时间 API,旨在替代陈旧的java.util.Date和java.util.Calendar类。其中的LocalDate用于表示不带时区的日期&…...
-Broker详细——主从复制)
启动你的RocketMQ之旅(六)-Broker详细——主从复制
前言: 👏作者简介:我是笑霸final。 📝个人主页: 笑霸final的主页2 📕系列专栏:java专栏 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一…...

QT跨平台软件开发要点
一、Qt跨平台开发核心优势 1.统一代码基 通过Qt的抽象层(Qt Platform Abstraction, QPA),同一套代码可编译部署到Windows、macOS、Linux、嵌入式系统(如ARM设备)甚至移动端(通过Qt for Android/iOS&#…...

【C语言】柔性数组
目录 一柔性数组的定义与特点 定义: 特点: 注意事项 二柔性数组的使用方法 三示例代码详解 四与其他知识的结合 五总结 前言: 柔性数组是C99标准引入的一种特殊结构体成员类型,允许在结构体的末尾定义一个长度未知的数组…...

AWS中国区ICP备案全攻略:流程、注意事项与最佳实践
导语 在中国大陆地区开展互联网业务时,所有通过域名提供服务的网站和应用必须完成ICP备案(互联网内容提供商备案)。对于选择使用AWS中国区(北京/宁夏区域)资源的用户,备案流程因云服务商的特殊运营模式而有所不同。本文将详细解析AWS中国区备案的核心规则、操作步骤及避坑…...

基于Matlab的MDF文件导入与处理研究
摘要 本文围绕MDF文件格式展开全面研究,系统阐述了MDF文件的基本结构与数据块概念,深入探讨了在Matlab环境下导入和处理这些文件的理论与实践方法。首先,介绍了MDF文件在现代工业和汽车电子领域的应用背景及重要意义。接着,详细剖析了MDF文件的结构,包括头部信息、数据块、…...

架构师备考-设计模式23种及其记忆特点
引言 以下是一篇关于架构师备考中设计模式23种的博文架构及记忆技巧总结,内容清晰、结构系统,适合快速掌握核心知识点。 考试类型是给语句描述或者类图,判断是哪一种设计模式(会出现英文的名词),2024年的两…...

学习记录:DAY18
前端实战与项目部署学习笔记 前言 时间固执沉默无情的流逝, 小心握紧漠然通达的当下。 今天要把前端实战部分学完,有时间写写学科作业 ----4.26---- 放纵注定是场与自我无休止的拉扯,过度的妥协只会跌入自我空虚的深渊 真该死啊,…...
)
【OSG学习笔记】Day 10: 字体与文字渲染(osgText)
osgText库简介 osgText 是OpenSceneGraph(OSG)中用于文本渲染的重要模块,支持在3D场景中添加静态/动态文字、自定义字体、文字样式(颜色、大小、对齐方式等)以及动态更新文本内容。通过结合OSG的场景图机制࿰…...
)
[特殊字符] 深入理解Spring Cloud与微服务架构:全流程详解(含中间件分类与实战经验)
📚 目录 Spring Cloud 简介与发展 Spring Cloud 与 Spring Cloud Alibaba 的关系 为什么需要微服务?单体架构 vs 微服务对比 微服务常用中间件汇总 微服务如何科学拆分? 一个微服务对应一个数据库(服务自治原则) …...

深入理解算力:从普通电脑到宏观计算世界
在科技飞速发展的当下,“算力” 一词频繁出现在我们的视野中,无论是前沿的人工智能领域,还是新兴的区块链世界,算力都扮演着至关重要的角色。但对于大多数普通人来说,算力仿佛是一个既熟悉又陌生的概念。今天ÿ…...

IntelliJ IDEA 2025.2 和 JetBrains Rider 2025.1 恢复git commit为模态窗口
模态提交在 2025.1 中作为插件存在。 如下图所示安装插件 安装完之后,在设置里把下图的配置项打勾...

Linux——动静态库
目录 1. 动静态库基本原理 2. 认识动静态库 3. 动静态库的特点 3.1 静态库的优缺点 3.2 动态库的优缺点 4. 静态库的打包和使用 4.1 打包 4.2 使用 5. 动态库的打包和使用 5.1 打包 5.2 使用 6. 库的理解与加载 6.1 目标文件 6.2 ELF文件 6.3 ELF形成到加载…...

从频域的角度理解S参数:
从频域的角度理解S参数: S参数是一种频域模型,在频域的每一个频点都可以通过该频点的S参数来得到入射信号和反射信号之间的一组关系。这种方法不关注网络内部的具体结构,无论网络内部结构是什么,只要网络是线性不变的,就可以当作“…...

Java 安全:如何保护敏感数据?
Java 安全:如何保护敏感数据? 在当今数字化时代,数据安全成为了软件开发中至关重要的课题。对于 Java 开发者而言,掌握如何在 Java 应用中保护敏感数据是必备的技能。本文将深入探讨 Java 安全领域,聚焦于敏感数据保护…...

PySpark实现ABC_manage_channel逻辑
问题描述 我们需要确定"ABC_manage_channel"列的逻辑,该列的值在客户连续在同一渠道下单时更新为当前渠道,否则保留之前的值。具体规则如下: 初始值为第一个订单的渠道如果客户连续两次在同一渠道下单,则更新为当前渠…...

栈与堆的演示
1、栈与堆的演示 (1)网页视图 (2)代码 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, in…...
)
【Kafka】Windows环境下生产与消费流程详解(附流程图)
1. 背景说明 在搭建基于Kafka的数据流通系统(例如流式推荐、实时日志采集)时,常见的操作是: 生产者 Producer 向 Kafka Topic 写入消息消费者 Consumer 从 Kafka Topic 读取消息本文以Windows本地环境 + Kafka 2.8.1版本为例,手把手演示生产消费流程。 2. 准备条件 Kafka…...

基于FFmpeg命令行的实时图像处理与RTSP推流解决方案
前言 在一些项目开发过程中需要将实时处理的图像再实时的将结果展示出来,此时如果再使用一张一张图片显示的方式展示给开发者,那么图像窗口的反复开关将会出现窗口闪烁的问题,实际上无法体现出动态画面的效果。因此,需要使用码流…...

神经网络笔记 - 感知机
一 感知机是什么 感知机(Perceptron)是一种接收输入信号并输出结果的算法。 它根据输入与权重的加权和是否超过某个阈值(threshold),来判断输出0还是1。 二.计算方式 感知机的基本公式如下: X1, X2 : …...

【双指针】专题:LeetCode 15题解——三数之和
三数之和 一、题目链接二、题目三、题目解析四、算法原理解法一:排序 暴力枚举 利用set去重解法二:排序 双指针处理细节问题1、去重越界问题 2、不漏 五、编写代码六、时间复杂度和空间复杂度 一、题目链接 三数之和 二、题目 三、题目解析 i ! j …...

如何创建一个导入模板?全流程图文解析
先去找到系统内可以上传东西的按钮 把你的模板上传上去,找到对应的fileName 图里的文字写错了,是复制粘贴"filePath"到URL才能下载...

JS自动化获取网站信息开发说明
一、自动获取信息的必要性 1. 提高效率与节省时间 批量处理:自动化可以快速抓取大量数据,比人工手动操作快得多。 24/7 运行:自动化工具可以全天候工作,不受时间限制。 减少重复劳动:避免人工反复执行相同的任务&am…...

Python爬虫-爬取汽车之家各品牌月销量榜数据
前言 本文是该专栏的第54篇,后面会持续分享python爬虫干货知识,记得关注。 在本文中,笔者已整理19篇汽车平台相关的爬虫项目案例。对此感兴趣的同学,可以直接翻阅查看。 而本文,笔者将以汽车之家平台为例子。基于Python爬虫,实现批量爬取“各品牌月销量榜”的数据。废话…...

WPF 调用 OpenCV 库
WPF 调用 OpenCV 库指南 OpenCV 是一个强大的计算机视觉库,WPF 是 Windows 平台的 UI 框架。将两者结合可以实现强大的图像处理和计算机视觉应用。本文将详细介绍如何在 WPF 应用程序中集成和使用 OpenCV 库。 一、准备工作 1. 安装 OpenCV 方法一:通过 NuGet 安装 在 Vi…...
技术的最新进展可总结)
LLM(大语言模型)技术的最新进展可总结
截至2025年4月26日,LLM(大语言模型)技术的最新进展可总结为以下关键方向: 1. 架构创新与性能突破 多模态能力深化:GPT-4o等模型通过统一架构支持文本、图像、音频和视频的跨模态推理,显著提升复杂场景下的…...

Fedora 43 计划移除所有 GNOME X11 相关软件包
Fedora 43 计划移除所有 GNOME X11 相关软件包,这是 Fedora 项目团队为全面拥抱 Wayland 所做的重要决策。以下是关于此计划的详细介绍: 提案内容:4 月 23 日,Neal Gompa 提交提案,建议从 Fedora 软件仓库中移除所有 G…...

解构与重构:“整体部分”视角下的软件开发思维范式
在软件开发的复杂图景中,整体与部分的关系始终是决定项目成败的关键命题。《人月神话》“整体部分”一章以深邃的洞察力,揭示了软件开发过程中系统设计与实现的内在逻辑,不仅探讨了规格说明、设计方法等技术层面的核心要素,更深入…...

NdrpConformantVaryingArrayUnmarshall函数分析--重要
第一部分: void NdrpConformantVaryingArrayUnmarshall( PMIDL_STUB_MESSAGE pStubMsg, uchar ** ppMemory, PFORMAT_STRING pFormat, uchar fMustCopy, uchar fMustAlloc ) { uchar * …...
:基于 BRAM 的 PS、PL 数据交互)
ZYNQ笔记(十四):基于 BRAM 的 PS、PL 数据交互
版本:Vivado2020.2(Vitis) 实验任务: PS 将字符串数据写入BRAM,再将数据读取出来;PL 从 BRAM 中读取数据,bing。通过 ILA 来观察读出的数据,与前面串口打印的数据进行对照࿰…...

月之暗面开源 Kimi-Audio-7B-Instruct,同时支持语音识别和语音生成
我们向您介绍在音频理解、生成和对话方面表现出色的开源音频基础模型–Kimi-Audio。该资源库托管了 Kimi-Audio-7B-Instruct 的模型检查点。 Kimi-Audio 被设计为通用的音频基础模型,能够在单一的统一框架内处理各种音频处理任务。主要功能包括: 通用功…...

文件操作及读写-爪哇版
文章目录 前言 初识文件文件路径里的符号文件分类文件操作方法文件读写字节流输入输出输入输出 字符流输入输出输入输出 前言 Windows用户需知:“/”和“\”, 文件路径分隔符一般都用“/”,但Windows系统一直保留着“\”,这两种符…...

【matlab】绘制maxENT模型的ROC曲线和omission curve
文章目录 一、maxENT模型二、ROC曲线三、实操3.1 数据提取3.2 绘制ROC曲线3.3 绘制遗漏曲线3.4 多次训练的ROC和测试的ROC 一、maxENT模型 前面的文章已经详细讲过了。 maxENT软件运行后,会生成一个html报告,里面有ROC曲线,但我们往往需要自…...
、 撤销、取消撤销 等等功能,))
个人电子白板(svg标签电子画板功能包含正方形、文本、橡皮 (颜色、尺寸、不透明度)、 撤销、取消撤销 等等功能,)
在Http开发中,svg标签电子画板功能包含正方形、文本、橡皮 (颜色、尺寸、不透明度)、 撤销、取消撤销 等等功能, 效果图 代码如下: <!DOCTYPE html> <html lang"en"> <!--<link href&qu…...

Pygame终极项目:从零开发一个完整2D游戏
Pygame终极项目:从零开发一个完整2D游戏 大家好!欢迎来到本期的Pygame教程。今天,我们将从零开始开发一个完整的2D游戏。通过这个项目,你将学习到如何使用Pygame库来创建游戏窗口、处理用户输入、绘制图形、管理游戏状态、实现碰撞检测和音效等。无论你是初学者还是有一定…...

在应用运维过程中,业务数据修改的证据留存和数据留存
在应用运维过程中,业务数据修改的证据留存和数据留存至关重要,以下是相关介绍: 一、证据留存 操作日志记录 : 详细记录每一次业务数据修改的操作日志,包括操作人员、操作时间、修改内容、修改前后数据的对比等。例如,某公司业务系统中,操作日志会精确记录员工小张在 2…...

JAVA JVM面试题
你的项目中遇到什么问题需要jvm调优,怎么调优的,堆的最小值和最大值设置为什么不设置成一样大? 在项目中,JVM调优通常源于以下典型问题及对应的调优思路,同时关于堆内存参数(-Xms/-Xmx)的设置逻…...