wend看源码-APISJON
项目地址
腾讯APIJSON官方网站
定义
APIJSON 可以定义为一个面向HTTP 协议的JSON 规范,一个面向数据访问层的ORM 框架。其主要工作流程包括:前端按照既定格式组装 JSON 请求报文,通过 APIJSON-ORM 将这些报文直接转换为 SQL 语句,进而执行数据库操作,如增删改查等。完成后,系统将数据再按照指定格式封装成 JSON 响应报文,高效地实现前后端的数据交互,并将最终结果反馈给用户。
架构

图2.1 基于APIJSON的交互流程图
通过图2.1 基于APIJSON的交互流程图我们可以发现,APIJSON 的设计思路,主要用于前端可以通过基于APIJSON的语法格式直接处理数据的增删改查。也可以说是后端通过使用APIJSON-ORM 框架,定义了一个万能的Controller接口层,从而使得前端可以通过这个接口实现全部的CRUD 操作。
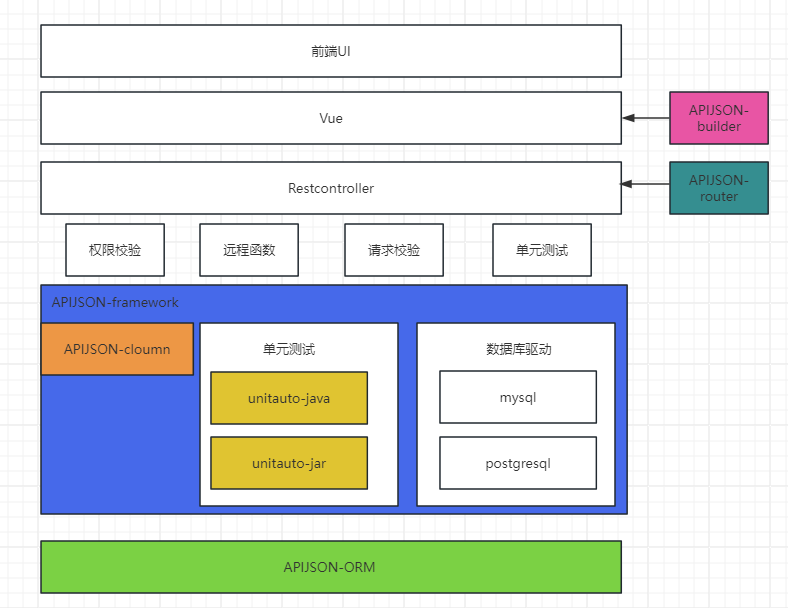
图2.2 基于APIJSON 构件生态的框架图
- APIJSON-ORM:APIJSON-ORM 是 APIJSON 框架的核心组件,它是一个对象关系映射(ORM)框架,专门用于将 JSON 格式的请求自动转换为 SQL 语句,从而快速实现对数据库的增删改查操作。
- APIJSON-framework:APIJSON-framework 是 APIJSON 的基础框架,它提供了一套完整的解决方案,包括请求的解析、处理、权限验证以及响应的封装等,还包含了基于unitAuto 的自动化单元测试的内容。这个框架使得开发者能够快速搭建起一个高效、安全、易用的后端 API 服务。
- APIJSON-cloumn:APIJSON 的字段处理插件,包含了表字段相关工具类
- unitauto-java:unitauto-java 是一个自动化测试框架,它可以自动生成和执行单元测试代码。这个框架旨在减少手动编写测试代码的工作量,提高代码质量和测试覆盖率。
- APIJSON-router:APIJSON 的路由插件,用于将Restful API 转成 APIJSON API格式请求
- APIJSON-builder:采用类似mybaits 中 wrapper 封装的方式组装前端请求报文。用于生成符合 APIJSON 规范的 JSON 请求和响应结构。
主要功能
- APIJSON 定义了前端请求后端操作数据库的JSON报文格式。
- APIJSON-framework 包含一套完整的前后端CRUD操作的解决方案,主要包括权限校验,远程函数/脚本调用,请求合法性校验, 单元测试等功能。
- APIJSON-ROM 简化了后端数据仓储层的操作,大大减少了软件运维过程中的重复造轮子过程,让开发者可以将精力专注于开发创新和商业赋能。
优缺点
- 优点:在此借用APIJSON 官网的图,来表述使用APIJSON的优点:


- 开发提速对比表:

- 缺点(个人观点):
- APIJSON-framework 依赖了mysql和postgresql两个数据库引擎,以及直接集成了作者的另一个自动化单元测试的项目UnitAuto。这使得APIJSON-framework 的技术架构耦合性比较高。
- APIJSON-cloumn 就是一个工具类,在我看来完全可以集成于APIJSON-framework
- APIJSON-ORM 的核心代码有待优化
使用规范
语法
"key[]":{} // 查询数组"key{}":[1,2,3] // 匹配选项范围"key{}":"<=10;length(key)>1..." // 匹配条件范围"key()":"function(arg0,arg1...)" // 远程调用函数"key@":"key0/key1.../targetKey" // 引用赋值"key$":"%abc%" // 模糊搜索"key~":"^[0-9]+$" // 正则匹配"key%":"2018-01-01,2018-10-01" // 连续范围"key+":[1] // 增加/扩展"key-":888.88 // 减少/去除 "name:alias" // 新建别名"@combine":"name~,tag~" // 条件组合"@column":"id,sex,name" // 返回字段"@group":"userId" // 分组方式"@having":"max(id)>=100" // 聚合函数"@order":"date-,name+" // 排序方式"@schema":"sys" // 集合空间"@database":"POSTGRESQL" // 跨数据库"@datasource":"DRUID" // 多数据源"@explain":true // 性能分析"@role":"LOGIN" // 访问角色功能列表
| 功能 | 键值对格式 | 使用示例 |
| 查询数组 | "key[]":{},后面是JSONObject,key可省略。当key和里面的Table名相同时,Table会被提取出来,即 {Table:{Content}} 会被转化为 {Content} | {"User[]":{"User":{}}}(opens new window) ,查询一个User数组。这里key和Table名都是User,User会被提取出来,即 {"User":{"id", ...}} 会被转化为 {"id", ...},如果要进一步提取User中的id,可以把User[]改为User-id[] |
| 匹配选项范围 | "key{}":[],后面是JSONArray,作为key可取的值的选项 | "id{}":[38710,82001,70793](opens new window) ,对应SQL是 ,查询id符合38710,82001,70793中任意一个的一个User数组 |
| 匹配条件范围 | "key{}":"条件0,条件1...",条件为SQL表达式字符串,可进行数字比较运算等 | "id{}":"<=80000,>90000"(opens new window) ,对应SQL是 ,查询id符合id<=80000 | id>90000的一个User数组 |
| 包含选项范围 | "key<>":Object => "key<>":[Object],key对应值的类型必须为JSONArray,Object类型不能为JSON | "contactIdList<>":38710(opens new window) ,对应SQL是 ,查询contactIdList包含38710的一个User数组 |
| 判断是否存在 | "key}{@":{ | "id}{@":{ "from":"Comment", "Comment":{ "momentId":15 }}(opens new window)
|
| 远程调用函数 | "key()":"函数表达式",函数表达式为 function(key0,key1...),会调用后端对应的函数 function(JSONObject request, String key0, String key1...),实现 参数校验、数值计算、数据同步、消息推送、字段拼接、结构变换 等特定的业务逻辑处理, | "isPraised()":"isContain(praiseUserIdList,userId)"(opens new window) ,会调用远程函数 boolean isContain(JSONObject request, String array, String value) ,然后变为 "isPraised":true 这种(假设点赞用户id列表包含了userId,即这个User点了赞) |
| 存储过程 | "@key()":"SQL函数表达式",函数表达式为 | "@limit":10,"@offset":0,"@procedure()":"getCommentByUserId(id,@limit,@offset)"(opens new window)
|
| 引用赋值 | "key@":"key0/key1/.../refKey",引用路径为用/分隔的字符串。以/开头的是缺省引用路径,从声明key所处容器的父容器路径开始;其它是完整引用路径,从最外层开始。 | "Moment":{ "userId":38710},"User":{ "id@":"/Moment/userId"}(opens new window)
|
| 子查询 | "key@":{ | "id@":{ "from":"Comment", "Comment":{ "@column":"min(userId)" }}(opens new window)
|
| 模糊搜索 | "key$":"SQL搜索表达式" => "key$":["SQL搜索表达式"],任意SQL搜索表达式字符串,如 %key%(包含key), key%(以key开始), %k%e%y%(包含字母k,e,y) 等,%表示任意字符 | "name$":"%m%"(opens new window) ,对应SQL是 ,查询name包含"m"的一个User数组 |
| 正则匹配 | "key~":"正则表达式" => "key~":["正则表达式"],任意正则表达式字符串,如 ^[0-9]+$ ,*~ 忽略大小写,可用于高级搜索 | "name~":"^[0-9]+$"(opens new window) ,对应SQL是 ,查询name中字符全为数字的一个User数组 |
| 连续范围 | "key%":"start,end" => "key%":["start,end"],其中 start 和 end 都只能为 Boolean, Number, String 中的一种,如 "2017-01-01,2019-01-01" ,["1,90000", "82001,100000"] ,可用于连续范围内的筛选 | "date%":"2017-10-01,2018-10-01"(opens new window) ,对应SQL是 ,查询在2017-10-01和2018-10-01期间注册的用户的一个User数组 |
| 新建别名 | "name:alias",name映射为alias,用alias替代name。可用于 column,Table,SQL函数 等。只用于GET类型、HEAD类型的请求 | "@column":"toId:parentId"(opens new window) ,对应SQL是 ,将查询的字段toId变为parentId返回 |
| 增加 或 扩展 | "key+":Object,Object的类型由key指定,且类型为Number,String,JSONArray中的一种。如 82001,"apijson",["url0","url1"] 等。只用于PUT请求 | "praiseUserIdList+":[82001],对应SQL是 ,添加一个点赞用户id,即这个用户点了赞 |
| 减少 或 去除 | "key-":Object,与"key+"相反 | "balance-":100.00,对应SQL是 ,余额减少100.00,即花费了100元 |
| 比较运算 | >, <, >=, <= 比较运算符,用于 | ① "id<=":90000(opens new window) ,对应SQL是 ,查询符合id<=90000的一个User数组
|
| 逻辑运算 | &, |, ! 逻辑运算符,对应数据库 SQL 中的 AND, OR, NOT。 | ① "id&{}":">80000,<=90000"(opens new window) ,对应SQL是 ,即id满足id>80000 & id<=90000 ,同"id{}":">90000,<=80000",对应SQL是 ,即id满足id>90000 | id<=80000 ,对应SQL是 ,即id满足 ! (id=82001 | id=38710),可过滤黑名单的消息 |
| 数组关键词,可自定义 | "key":Object,key为 "[]":{} 中{}内的关键词,Object的类型由key指定
| ① 查询User数组,最多5个:
|
| 对象关键词,可自定义 | "@key":Object,@key为 Table:{} 中{}内的关键词,Object的类型由@key指定 | ① 搜索name或tag任何一个字段包含字符a的User列表:
|
| 全局关键词 | 为最外层对象 {} 内的关键词。其中 @database,@schema, @datasource, @role, @explain 基本同对象关键词,见上方说明,区别是全局关键词会每个表对象中没有时自动放入,作为默认值。 | ① 查隐私信息:
|
适用场景
- 全栈开发一个小型web 项目:初识APIJSON,我认为APIJSON 可以大大简化后端,但需要前端同学学习APIJSON 定义的JSON 协议规则语法,以及需要前端同学对数据库操作语法有一定的理解。所以目前看来,我让前端同学直接从原有开发模式转成基于APIJSON 的开发是不现实的。所以我认为APIJSON 更适合个人全栈开发一个小型的web 项目。
- 报表类服务:报表类服务没有复杂的项目逻辑,大多数是基于数据的查询,APIJSON 比较适合。
- 数据维护服务:数据维护服务没有复杂的项目逻辑,大多数是基于数据的增删改查操作,APIJSON 比较适合。
项目重构思路
本人后续准备对APIJSON项目进行重构,编写一个基于APIJSON的开源项目:easy-APIJSON,重构的内容列表包括:
1. 使用配置文件的方式封装APIJSON-ORM 中AbstractSQLConfig 中关于数据库关键字,函数,运算符的配置,我想以文本文档的方式将这些内容封装整理,方便后续的软件维护工作
2. 整体重构 APIJSON-framework
- 去掉强相关的数据库依赖,以及单元测试依赖等;去掉APIJSON-framework 关于权限校验,请求校验等基于数据库操作的内容。
- 将APIJSON-clolumn 的内容集成与APIJSON-framework中;
- 加入通用排序工具,通用分页工具等,丰富APIJSON-framework的内容。

图3.1 easy-APIJSON 架构图
3. 我希望的easy-APIJSON的架构是这样的:easy-APIJSON 整体项目与三方依赖以及数据库无关,APIJSON 提供的是通用的处理方法。用户可以自主选择技术实现方案,如采用数据库配置、代码配置或文件配置等方式去实现某个功能。
4. 基于easy-APIJSON,APIJSON-builder 提供前端明确的语法文档和示例,在easy-APIJSON运行时可提供网页文档。
参考文献
APIJSON 官方网站:腾讯APIJSON官方网站
APIJSON 官方文档:介绍 | apijson-doc
相关文章:

wend看源码-APISJON
项目地址 腾讯APIJSON官方网站 定义 APIJSON 可以定义为一个面向HTTP 协议的JSON 规范,一个面向数据访问层的ORM 框架。其主要工作流程包括:前端按照既定格式组装 JSON 请求报文,通过 APIJSON-ORM 将这些报文直接转换为 SQL 语句,…...
:盒子阴影与文字阴影)
CSS(8):盒子阴影与文字阴影
一:盒子阴影text-shadow属性 1.box-shadow:h-shadow v-shadow blur spread color inset; 默认的是外部阴影outset,不能写在代码上 2.鼠标经过盒子后的阴影 rgba透明度 3.文字阴影 text-shadow:水平偏移 垂直偏移 模糊度 阴影颜色; 注意点…...

Hadoop 系列 MapReduce:Map、Shuffle、Reduce
文章目录 前言MapReduce 基本流程概述MapReduce 三个核心阶段详解Map 阶段工作原理 Shuffle 阶段具体步骤分区(Partition)排序(Sort)分组(Combine 和 Grouping) Reduce 阶段工作原理 MapReduce 应用场景Map…...

web——sqliabs靶场——第十三关——报错注入+布尔盲注
发现是单引号加括号闭合的 尝试联合注入 发现不太行,那尝试报错注入。 测试报错注入 unameadmin) and updatexml(1,0x7e,3) -- &passwdadmin&submitSubmit 爆数据库 unameadmin) and updatexml(1,concat(0x7e,database(),0x7e),3) -- &passwdadmin&a…...

调大Vscode资源管理器字体
对于调整资源管理器字体大小(也就是下图红框),查找了网上很多方法。要么介绍的方法是调整了代码字体,要么是调节了终端字体,要么是通过整体放缩实现的调整,总之都不合适。 唯一的调整方法是在几篇CSDN里看到…...
:控制结构)
【新人系列】Python 入门(十一):控制结构
✍ 个人博客:https://blog.csdn.net/Newin2020?typeblog 📝 专栏地址:https://blog.csdn.net/newin2020/category_12801353.html 📣 专栏定位:为 0 基础刚入门 Python 的小伙伴提供详细的讲解,也欢迎大佬们…...

后端开发详细学习框架与路线
🚀 作者 :“码上有前” 🚀 文章简介 :后端开发 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 为帮助你合理安排时间,以下是结合上述学习内容的阶段划分与时间分配建议。时间安排灵活&a…...

类文件结构详解.上
字节码 在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题&…...

【K8S问题系列 |18 】如何解决 imagePullSecrets配置正确,但docker pull仍然失败问题
如果 imagePullSecrets 配置正确,但在执行 docker pull 命令时仍然失败,可能存在以下几种原因。以下是详细的排查步骤和解决方案。 1. 检查 Docker 登录凭证 确保你使用的是与 imagePullSecrets 中相同的凭证进行 Docker 登录: 1.1 直接登录…...

Vue+Springboot用Websocket实现协同编辑
1. 项目介绍 在本文中,我们将介绍如何使用Vue.js和Spring Boot实现一个支持多人实时协同编辑的Web应用。通过WebSocket技术,我们可以实现文档的实时同步,让多个用户同时编辑同一份文档。 2. 技术栈 前端:Vue.js 3 Vuex后端&am…...

高阶C语言补充:柔性数组
C99中,结构体中最后一个元素允许时未知大小的数组,这就叫做柔性数组成员。 vs编译器也支持柔性数组。 之所以把柔性数组单独列出,是因为: 1、柔性数组是建立在结构体的基础上的。 2、柔性数组的使用用到了动态内存分配。 这使得柔…...

MYSQL——多表查询、事务和索引
概括 出现查询结果个数为笛卡尔积的原因是sql语句: select * from tb_emp,tb_dept; 没有加上where tb_emp.dept_id tb_dept.id;(where条件可以消除笛卡尔积) select * from tb_emp,tb_dept where tb_emp.dept_id tb_dept.id; 查询类型 …...

在 Swift 中实现字符串分割问题:以字典中的单词构造句子
文章目录 前言摘要描述题解答案题解代码题解代码分析示例测试及结果时间复杂度空间复杂度总结 前言 本题由于没有合适答案为以往遗留问题,最近有时间将以往遗留问题一一完善。 LeetCode - #140 单词拆分 II 不积跬步,无以至千里;不积小流&…...
)
Unity类银河战士恶魔城学习总结(P132 Merge skill tree with skill Manager 把技能树和冲刺技能相组合)
【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili 教程源地址:https://www.udemy.com/course/2d-rpg-alexdev/ 本章节实现了解锁技能后才可以使用技能,先完成了冲刺技能的锁定解锁 Dash_Skill.cs using System.Collections; using System…...

JavaScript 中 arguments、类数组与数组的深入解析
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: 前端 文章目录 💯前言💯什么是 arguments 对象2.1 arguments 的定义2.2 arguments 的特性2.3 使用场景 💯深入了解 arguments 的结构3.1 arguments 的内部结构arguments 的关键属性…...

【java-Neo4j 5开发入门篇】-最新Java开发Neo4j
系列文章目录 前言 上一篇文章讲解了Neo4j的基本使用,本篇文章对Java操作Neo4j进行入门级别的阐述,方便读者快速上手对Neo4j的开发。 一、开发环境与代码 1.docker 部署Neo4j #这里使用docker部署Neo4j,需要镜像加速的需要自行配置 docker run --name…...

摄影:相机控色
摄影:相机控色 白平衡(White Balance)白平衡的作用: 白平衡的使用环境色温下相机色温下总结 白平衡偏移与包围白平衡包围 影调 白平衡(White Balance) 人眼看到的白色:会自动适应环境光线。 相…...

UI自动化测试中公认最佳的设计模式-POM
一、概念 什么是POM? POM是PageObjectModule(页面对象模式)的缩写,其目的是为了Web UI测试创建对象库。在这种模式下,应用涉及的每一个页面应该定义为一个单独的类。类中应该包含此页面上的页面元素对象和处理这些元…...
:Verilog基础语法)
数字图像处理(2):Verilog基础语法
(1)Verilog常见数据类型: reg型、wire型、integer型、parameter型 (2)Verilog 常见进制:二进制(b或B)、十进制(d或D)、八进制(o或O)、…...

大公司如何实现打印机共享的?如何对打印机进行管控或者工号登录后进行打印?异地打印机共享的如何实现可以帮助用户在不同地理位置使用同一台打印机完成打印任务?
大公司如何实现打印机共享的?如何对打印机进行管控或者工号登录后进行打印?异地打印机共享的如何实现可以帮助用户在不同地理位置使用同一台打印机完成打印任务? 如果在局域网内,可以不需要进行二次开发,通过对打印机进…...

解决前端页面报错:Not allowed to load local resource
在前后端分离项目中,在前端页面里使用file://的绝对路径访问本地图片,在加载图片的 时候会报出Not allowed to load local resource 的错误。 这是因为浏览器出于安全因素,禁止通过绝对路径访问图片,需要通过虚拟路径进行访问。 …...

Qt 实现网络数据报文大小端数据的收发
1.大小端数据简介 大小端(Endianness)是计算机体系结构的一个术语,它描述了多字节数据在内存中的存储顺序。以下是大小端的定义和它们的特点: 大端(Big-Endian) 在大端模式中,一个字的最高有效…...

2024年11月21日Github流行趋势
项目名称:twenty 项目维护者:charlesBochet, lucasbordeau, Weiko, FelixMalfait, bosiraphael项目介绍:正在构建一个由社区支持的现代化Salesforce替代品。项目star数:21,798项目fork数:2,347 项目名称:p…...

Java的方法、基本和引用数据类型
个人的黑马程序员java笔记 目录 方法 例:方法定义和调用 方法的重载 对于byte, short, int, long类型 方法的内存 基本数据类型 引用数据类型 方法的值的传递的内存原理 方法 方法(method)是程序中最小的执行单元格式 方法定义&a…...

Spark分布式计算中Shuffle Read 和 Shuffle Write的职责和区别
在 Spark 的分布式计算中,Shuffle Read 和 Shuffle Write 是两个与数据重新分区和分发相关的重要阶段。它们的主要职责和区别如下: 1. Shuffle Write Shuffle Write 发生在上游的任务执行阶段,其作用是: 分区数据准备࿱…...

【成品文章+四小问代码更新】2024亚太杯国际赛B题基于有限差分格式的空调形状优化模型
这里仅展示部分内容,完整内容获取在文末! 基于有限差分格式的空调形状优化模型 摘 要 随着科技进步,多功能环境调节设备成为市场趋势,集成了空调、加湿器和空气 净化器功能的三合一设备能提供更舒适健康的室内环境。我们需要分析…...
)
实验三:构建园区网(静态路由)
目录 一、实验简介 二、实验目的 三、实验需求 四、实验拓扑 五、实验任务及要求 1、任务 1:完成网络部署 2、任务 2:设计全网 IP 地址 3、任务 3:实现全网各主机之间的互访 六、实验步骤 1、在 eNSP 中部署网络 2、配置各主机 IP …...

MySQL 三大日志详解
在 MySQL 数据库中,binlog(二进制日志)、redo log(重做日志)和 undo log(回滚日志)起着至关重要的作用。它们共同保障了数据库的高可用性、数据一致性和事务的可靠性。下面将对这三大日志进行详…...

vscode使用ssh配置docker容器环境
1 创建容器,并映射主机和容器的指定ssh服务端口 2 进入容器 docker exec -it <容器ID> /bin/bash 3在容器中安装ssh服务 apt-get update apt-get install openssh-server 接着修改ssh文件信息,将容器的10008端口暴露出来允许root用户使用ssh登录 vim /…...

Python设计模式详解之10 —— 外观模式
引言 Facade设计模式(外观模式)是一种软件设计模式,它提供了一个统一的接口来访问子系统中的一组接口。Facade模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。当一个系统的内部实现非常复杂,或者需要与…...

[服务器] 腾讯云服务器免费体验,成功部署网站
文章目录 概要整体架构流程概要 腾讯云服务器免费体验一个月。 整体架构流程 腾讯云服务器体验一个月, 选择预装 CentOS 7.5 首要最重要的是: 添加阿里云镜像。 不然国外源速度慢, 且容易失败。 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/li…...
——UART串口实现FPGA内部AXILITE寄存器的读写控制)
低速接口项目之串口Uart开发(四)——UART串口实现FPGA内部AXILITE寄存器的读写控制
本节目录 一、设计背景 二、设计思路 三、逻辑设计框架 四、仿真验证 五、上板验证 六、往期文章链接本节内容 一、设计背景 通常,芯片手册或者IP都会提供一系列的用户寄存器以及相关的定义,用于软件开发人员进行控制底层硬件来调试,或封装…...

【Datawhale组队学习】模型减肥秘籍:模型压缩技术4——神经网络架构搜索
神经网络架构搜索是通过自动化方法来设计神经网络架构的一种技术,与传统手工设计网络结构相比,NAS能够在大量可能的架构中进行搜索,找到最优的神经网络架构,从而减少人工调参和设计的时间。学习这章时,重点在于理解NAS…...

用el-scrollbar实现滚动条,拖动滚动条可以滚动,但是通过鼠标滑轮却无效
问题: 用elementplus实现的滚动条的页面中,滑动滚动条可以滚动,但是通过鼠标滑轮却无效,鼠标没有问题。 解决: 在开发者工具中, 元素->时间监听器中发现当我移除网页中祖先元素的滚动事件,该…...

windows下,用CMake编译qt项目,出现错误By not providing “FindQt5.cmake“...
开发环境:windows10 qt5.14, 编译器msvc2017x64,CMake3.30; 现象: CMakeList文件里,如有find_package(Qt5 COMPONENTS Widgets REQUIRED) target_link_libraries(dis_lib PRIVATE Qt5::Widgets) 用CMak…...

windows实现VNC连接ubuntu22.04服务器
最近弄了一个700块钱的mini主机,刷了ubuntu22.04系统,然后想要在笔记本上通过VNC连接,这样就有了一个linux的开发环境。最后实现的过程为: 安装vnc服务器 安装 VNC 服务器软件: sudo apt update sudo apt install t…...

SQL注入--联合注入--理论
什么是SQL注入? SQL注入(SQL Injection)是一种常见的Web安全漏洞。 形成的主要原因是web应用程序在接收相关数据参数时未做好过滤,将其直接带入到数据库中查询,导致攻击者可以拼接执行构造的SQL语句,从而获…...

LaTeX 利用注销 ccmap 宏包实现降重功能
在中文LaTeX中,ccmap 宏包的主要作用是支持复制和粘贴时正确处理中文字符的编码。它的功能对于生成的PDF文档尤其有用,使得PDF中的中文字符在被复制到其他地方时能够以正确的编码显示,而不是乱码或其他不正确的字符。 以下是ccmap的详细功能…...

NVR接入录像回放平台EasyCVR视频融合平台加油站监控应用场景与实际功能
在现代社会中,加油站作为重要的能源供应点,面临着安全监管与风险管理的双重挑战。为应对这些问题,安防监控平台EasyCVR推出了一套全面的加油站监控方案。该方案结合了智能分析网关V4的先进识别技术和EasyCVR视频监控平台的强大监控功能&#…...
)
经验笔记:远端仓库和本地仓库之间的连接(以Gitee为例)
经验笔记:远端仓库和本地仓库之间的连接 方法一:先创建远端仓库,再克隆到本地 创建远端仓库 登录到你的Git托管平台(如Gitee、GitHub、GitLab、Bitbucket等)。点击“New Repository”或类似按钮,创建一个新…...

趋势洞察|AI 能否带动裸金属 K8s 强势崛起?
随着容器技术的不断成熟,不少企业在开展私有化容器平台建设时,首要考虑的问题就是容器的部署环境——是采用虚拟机还是物理机运行容器?在往期“虚拟化 vs. 裸金属*”系列文章中,我们分别对比了容器部署在虚拟化平台和物理机上的架…...

数据科学与SQL:组距分组分析 | 区间分布问题
目录 0 问题描述 1 数据准备 2 问题分析 3 小结 0 问题描述 绝对值分布分析也可以理解为组距分组分析。对于某个指标而言,一个记录对应的指标值的绝对值,肯定落在所有指标值的绝对值的最小值和最大值构成的区间内,根据一定的算法&#x…...
Cesium的ClearCommand的流程
ClearCommand是在每帧渲染前可以将显存的一些状态置为初始值,就如同把擦黑板。当然也包括在绘制过程中擦掉部分的数据,就如同画家在开始绘制的时候会画导览线(如透视线),轮廓出来后这些导览线就会被擦除。 我画了一个…...

DBeaver错误:Public Key Retrieval is not allowed
问题原因 MySQL 8.0 默认使用 caching_sha2_password 认证插件,并要求客户端能够使用 RSA 公钥进行加密操作。如果客户端无法正确处理 RSA 公钥检索,就会触发这个错误。 解决方案 右键编辑连接-连接设置-属性驱动-修改allowPublicKeyRetrieval属性的值…...

slice介绍slice查看器
Android Jetpack架构组件(十)之Slices - 阅读清单 - 腾讯云开发者社区-腾讯云 slice 查看器apk 用adb intall 安装 Releases android/user-interface-samples GitHubMultiple samples showing the best practices in the user interface on Android. - Releases android/u…...
预览pdf文件(pdfh5和vue-pdf)(很详细))
Vue移动端网页(H5)预览pdf文件(pdfh5和vue-pdf)(很详细)
我试了似乎不支持vue3 原文链接:Vue移动端网页(H5)预览pdf文件(pdfh5和vue-pdf)-阿里云开发者社区...

缓存工具类编写
缓存工具类编写 一般操作 在外面日常开发中,经常会有为了减少数据库压力,而将数据保存到缓存中并设置一个过期时间的操作。日常代码如下: Autowired private RedisTemplate<String, String> redisTemplate;public Object queryDataW…...

基于Java Springboot高校会议室预订管理系统
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 数据…...

redis-击穿、穿透、雪崩
击穿、穿透、雪崩经常听人说吧? 那他到底是啥呢?无非就是在有缓存层的情况下,对各种绕过缓存层从而直接落到了DB上的情况进行的分类。 概念性的东西大概如下,我是记不住,后期具体使用与规避这些问题才是大事ÿ…...

javascrip页面交互
元素的三大系列 offset系列 offset初相识 offset系列属性 作用 element.offsetParent 返回作为该元素带有定位的父级元素,如果父级没有定位,则返回body element.offsetTop 返回元素相对于有定位父元素上方的偏移量 element.offsetLeft 返回元素…...