django之优化分页功能(利用参数共存及封装来实现)
优化分页功能
目录
1.封装分页代码
2.解决分页时覆盖搜索参数的bug
3.优化分页功能
上一篇文章我们讲到了搜索功能和分页展示数据功能。那这篇文章, 在上篇文章的基础上, 会去优化这些功能并解决搜索功能和分页功能不能一起使用的bug。
一、封装分页代码
原本我们的assets.py里面的assets函数是这么写的:
def assets(request):# assets_list = models.Assets.objects.all()# 搜索信息dict_data = {}# 获取搜素框里的内容, 就是获取网址里面的search参数的值value = request.GET.get('search')if value:# 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__containsdict_data["mobile__contains"] = value# assets_list = models.Assets.objects.filter(**dict_data)# 获取分页组件里面选中的页码, 也是获取网址里面的page参数的值page = int(request.GET.get('page', 1))# 每一页查询10条数据page_size = 10# 当前页开始的数据start = (page - 1) * page_size# 当前页结尾的数据end = page_size * page# 利用切片, 实现分页查询, 查询出当页数据assets_list = models.Assets.objects.filter(**dict_data)[start:end]# 统计表当中的总个数data_asset_count = models.Assets.objects.filter(**dict_data).count()# 求得表中的总个数都需要多少页来展示, page_num代表总页数, div代表剩余的数据还有多少条page_count, div = divmod(data_asset_count, page_size)if div:page_count += 1# 我们需要在分页组件里面展示五个页码。# 当我们选中的页数, 和最左边最右边显示的页数相差2, 所以我们将plus设置为2, 比如我选择第三页, 那最左边显示的页码是1最右边显示的页码是5。plus = 2# 我们想要分页功能, 展示其中5个页码, 如果想要展示不同个页数的页码, 自己可以调整。# 当总页数不超过5页的时候, 1 + 2 * plus意思是当前选择的页, 加上左边还有两页, 右边也还有两页, 总共是5页。if data_asset_count <= 1 + 2 * plus:# 开始页数为1start_page = 1# 结束位置就是总页数end_page = data_asset_count# 这里面全是总页数大于5页的情况else:# 如果我目前选择的页码, 小于等于3if page <= plus + 1:# 开始页还是1start_page = 1# 结束页是5, 1 + 2 * plus这个意思上面有注释。end_page = 1 + 2 * plus# 如果我目前选择的页码加上2能够大于总页数, 那就说明分页组件里面的页码是最后五页数据了, 比如总页数为20, 我选择的是第19页, 19+2=21>20elif page + plus > page_count: # 这里写>=也可以# 开始页为总页数减去两倍的plus, 比如总共有20页, 当我们分页组件显示的页码是最后五页的时候, 最左边应该显示的是16。所以正好是总页数-两倍的plusstart_page = page_count - 2 * plus# 结尾页展示的就是总页数end_page = page_count# 如果我们目前选择的页码就在正中间, 排除1, 2, 3, 19, 20页的其它所有页数。else:# 开始页数就是当前分页组件选择的页数-plusstart_page = page - plus# 结束页数就是当前分页组件选择的页数+plusend_page = page + plus# 创建一个列表, 用于存储html代码, 以字符串来保存到列表中html_list = []# 分页组件返回到首页功能html_list.append(f"""<li><a href="?page=1">首页</a></li>""")# 如果当前选择的页码>1, 可以往前退一页, 否则不能在往前退了。在li标签上加class="disabled"代表禁用if page > 1:html_list.append(f"""<li><a href="?page={page - 1}"><span aria-hidden="true">«</span></a></li>""")else:html_list.append(f"""<li class="disabled"><span aria-hidden="true">«</span></li>""")# 分页组件的中间翻页的内容, 点击第几页就到第几页, 在分页组件当中, 选中的页码会有背景色。li标签里面的class='active'代表选中了那个页码, 会出现背景色for page_num in range(start_page, end_page + 1):if page_num == page:html_list.append(f"<li class='active'><a href='?page={page_num}'>{page_num}</a></li>")else:html_list.append(f"<li><a href='?page={page_num}'>{page_num}</a></li>")# 如果当前选择的页码<总页数, 可以往前进一页, 否则不能在往进退了。在li标签上加class="disabled"代表禁用if page < page_count:html_list.append(f"""<li><a href="?page={page + 1}"><span aria-hidden="true">»</span></a></li>""")else:html_list.append("""<li class="disabled"><span aria-hidden="true">»</span></li>""")# 分页组件进入到尾页功能html_list.append(f"""<li><a href="?page={page_count}">尾页</a></li>""")# join就是将列表当中所有的内容全部拼接在一起为字符串。mark_safe函数的作用是将字符串里面的内容, 转换为html元素。# mark_safe也是django框架里面的函数, 需要手动导入, 导入语句为from django.utils.safestring import mark_safepage_string = mark_safe("".join(html_list))# 不能忘记将page_string传给前端。return render(request, "assets/assets_list.html", {"assets_list": assets_list, "page_string": page_string})
接下来, 我们对以上代码进行封装:
我们在project_one文件夹下面新建一个utils文件夹, 创建PageData.py:
PageData.py代码:
from copy import deepcopy
from django.utils.safestring import mark_safeclass PageData(object):def __init__(self, request, queryset, page_size=10, plus=2, page_param="page"):get_query_dict = deepcopy(request.GET)self.query_dict = get_query_dictself.page_param = page_parampage = request.GET.get(self.page_param, "1")# 判段当前page首部是纯数字# 为了严谨性, 多加个判断, 如果url里面的page参数里面的值是文字的话, 那程序就会报错, 所以这里需要判断, 如果判断出page的值不是纯数字的话, 那就给page默认赋值为1。if page.isdecimal():page = int(page)else:page = 1self.page = pageself.start = (self.page - 1) * page_sizeself.end = self.page * page_sizeself.page_queryset = queryset[self.start: self.end]page_count = queryset.count()page_count, div = divmod(page_count, page_size)if div:page_count += 1self.page_count = page_countself.plus = plus
其实这些就是把上面分页的代码, 变为面向对象的代码来进行封装。
不过要注意的是, get_query_dict = deepcopy(request.GET)这行代码用的是深拷贝, 深拷贝需要导入相应的包:from copy import deepcopy, page.isdecimal()用于判断当前page首部是否是纯数字, 其它的内容大差不差, 就是不要忘记在变量前面加上self, 因为有些变量到后面还要在用, self.page_queryset = queryset[self.start: self.end]是为之后再asserts.py里面需要调用page_queryset做准备的。
二、解决分页是覆盖搜索参数的bug
产生这种现状的原因很简单, 因为我们在分页的时候, 把搜索参数给覆盖掉了, 导致点击分页的时候无法与搜索功能一起实现。为了解决这种问题, 其实不难, 在接下来的代码里面也会体现出来。
我们继续写PageData.py里面的代码, 把功能都封装到page_html函数里面。
代码:
def page_html(self):if self.page_count <= 2 * self.plus + 1:start_page = 1end_page = self.page_countelse:# 如果当前点击的页面是小于3的if self.page <= self.plus:start_page = 1end_page = 2 * self.plus + 1else:# 后五页if (self.page + self.plus) > self.page_count:start_page = self.page_count - self.plus * 2end_page = self.page_countelse:# 大于前五页,小于后五也的其他页面start_page = self.page - self.plusend_page = self.page + self.pluspage_str_list = []# 首页self.query_dict.setlist(self.page_param, [1])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">首页</a></li>')# 上一页if self.page > 1:self.query_dict.setlist(self.page_param, [self.page - 1])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}"><span aria-hidden="true">«</span></a></li>')else:page_str_list.append(f'<li class="disabled"><span aria-hidden="true">«</span></li>')for page_num in range(start_page, end_page + 1):if page_num == self.page:self.query_dict.setlist(self.page_param, [page_num])page_str_list.append(f'<li class="active"><a href="?{self.query_dict.urlencode()}">{page_num}</a</li>')else:self.query_dict.setlist(self.page_param, [page_num])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">{page_num}</a></li>')# 下一页if self.page < self.page_count:self.query_dict.setlist(self.page_param, [self.page + 1])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}"><span aria-hidden="true">»</span></a></li>')else:page_str_list.append(f'<li class="disabled"><span aria-hidden="true">»</span></li>')# 尾页self.query_dict.setlist(self.page_param, [self.page_count])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">尾页</a></li>')
这里面的self.query_dict.setlist(self.page_param, [page_num])这种写法, 就是拼接url参数的, 我们在前面self.page_queryset = queryset[self.start: self.end]这段代码中, 它已经是包含着搜索功能再把参数传进来, 所以我们只需要拼接page参数即可, 这个self.page_param指的就是page这个参数, 方括号里面的内容, 就是页码。
三、优化分页功能
page_html函数里面的代码:
def page_html(self):…………search_page = """<li><div style="float: right"><form method="get"><div class="input-group" style="width: 100px;float: right"><input type="text" class="form-control" name="page"><span class="input-group-btn"><button class="btn btn-success" type="submit">跳转</button></span></div></form></div></li>"""page_str_list.append(search_page)page_string = mark_safe("".join(page_str_list))return page_string
search_page里面的代码, 我们可以去bootstrap里面找, 打开bootstrap网页:
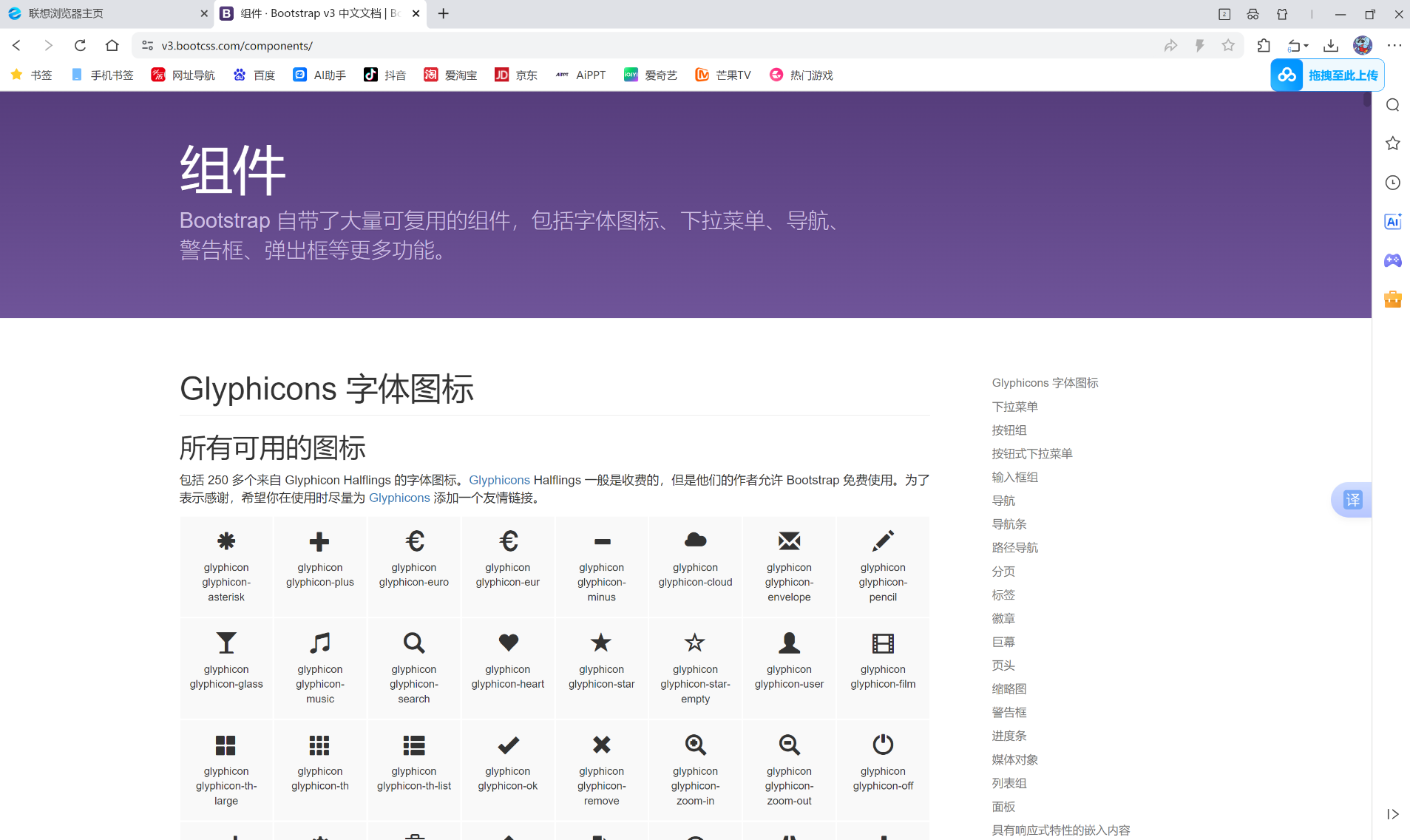
点击右侧的输入框组, 然后再找到作为额外元素的多选框和单选框然后找到相应的代码复制到pycharm即可。
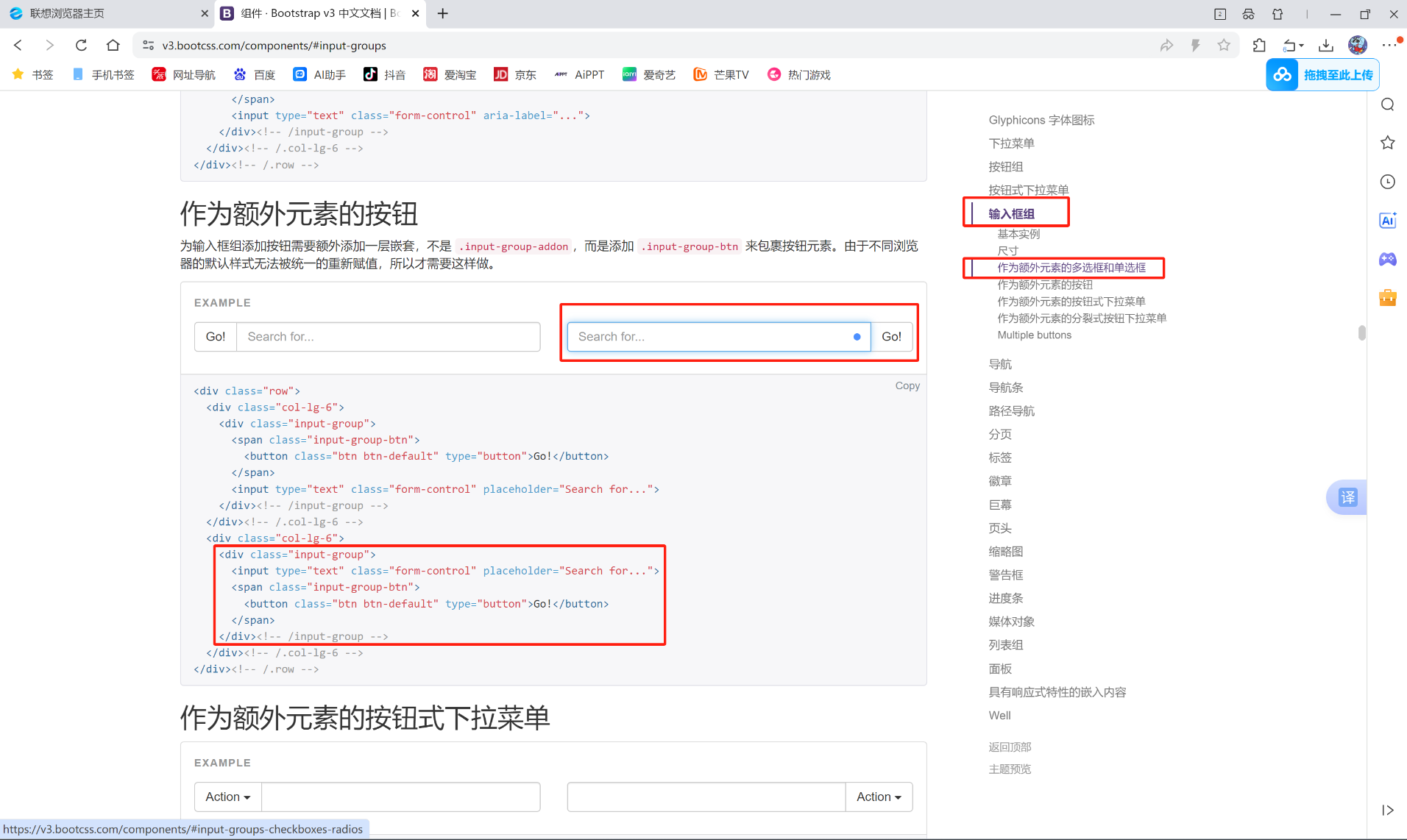
但是再search_page里面, 不要忘记加form表单, 是get请求, 将这个跳转页面功能放到分页的右边, 所以最外面再写一个float: right。
完整的PageData代码.py:
from copy import deepcopy
from django.utils.safestring import mark_safe"""
对以下的分页代码进行封装:
def assets(request):# assets_list = models.Assets.objects.all()# 搜索信息dict_data = {}# 获取搜素框里的内容, 就是获取网址里面的search参数的值value = request.GET.get('search')if value:# 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__containsdict_data["mobile__contains"] = value# assets_list = models.Assets.objects.filter(**dict_data)# 获取分页组件里面选中的页码, 也是获取网址里面的page参数的值page = int(request.GET.get('page', 1))# 每一页查询10条数据page_size = 10# 当前页开始的数据start = (page - 1) * page_size# 当前页结尾的数据end = page_size * page# 利用切片, 实现分页查询, 查询出当页数据assets_list = models.Assets.objects.filter(**dict_data)[start:end]# 统计表当中的总个数data_asset_count = models.Assets.objects.filter(**dict_data).count()# 求得表中的总个数都需要多少页来展示, page_num代表总页数, div代表剩余的数据还有多少条page_count, div = divmod(data_asset_count, page_size)if div:page_count += 1# 我们需要在分页组件里面展示五个页码。# 当我们选中的页数, 和最左边最右边显示的页数相差2, 所以我们将plus设置为2, 比如我选择第三页, 那最左边显示的页码是1最右边显示的页码是5。plus = 2# 我们想要分页功能, 展示其中5个页码, 如果想要展示不同个页数的页码, 自己可以调整。# 当总页数不超过5页的时候, 1 + 2 * plus意思是当前选择的页, 加上左边还有两页, 右边也还有两页, 总共是5页。if data_asset_count <= 1 + 2 * plus:# 开始页数为1start_page = 1# 结束位置就是总页数end_page = data_asset_count# 这里面全是总页数大于5页的情况else:# 如果我目前选择的页码, 小于等于3if page <= plus + 1:# 开始页还是1start_page = 1# 结束页是5, 1 + 2 * plus这个意思上面有注释。end_page = 1 + 2 * plus# 如果我目前选择的页码加上2能够大于总页数, 那就说明分页组件里面的页码是最后五页数据了, 比如总页数为20, 我选择的是第19页, 19+2=21>20elif page + plus > page_count: # 这里写>=也可以# 开始页为总页数减去两倍的plus, 比如总共有20页, 当我们分页组件显示的页码是最后五页的时候, 最左边应该显示的是16。所以正好是总页数-两倍的plusstart_page = page_count - 2 * plus# 结尾页展示的就是总页数end_page = page_count# 如果我们目前选择的页码就在正中间, 排除1, 2, 3, 19, 20页的其它所有页数。else:# 开始页数就是当前分页组件选择的页数-plusstart_page = page - plus# 结束页数就是当前分页组件选择的页数+plusend_page = page + plus# 创建一个列表, 用于存储html代码, 以字符串来保存到列表中html_list = []# 分页组件返回到首页功能html_list.append(f"<li><a href="?page=1">首页</a></li>")# 如果当前选择的页码>1, 可以往前退一页, 否则不能在往前退了。在li标签上加class="disabled"代表禁用if page > 1:html_list.append(f"<li><a href="?page={page - 1}"><span aria-hidden="true">«</span></a></li>")else:html_list.append("<li class="disabled"><spanaria-hidden="true">«</span></li>")# 分页组件的中间翻页的内容, 点击第几页就到第几页, 在分页组件当中, 选中的页码会有背景色。li标签里面的class='active'代表选中了那个页码, 会出现背景色for page_num in range(start_page, end_page + 1):if page_num == page:html_list.append(f"<li class='active'><a href='?page={page_num}'>{page_num}</a></li>")else:html_list.append(f"<li><a href='page={page_num}'>{page_num}</a></li>")# 如果当前选择的页码<总页数, 可以往前进一页, 否则不能在往进退了。在li标签上加class="disabled"代表禁用if page < page_count:html_list.append(f"<li><a href="?page={page + 1}"><span aria-hidden="true">»</span></a></li>")else:html_list.append("<li class="disabled"><spanaria-hidden="true">»</span></li>")# 分页组件进入到尾页功能html_list.append(f"<li><a href="?page={page_count}">尾页</a></li>")# join就是将列表当中所有的内容全部拼接在一起为字符串。mark_safe函数的作用是将字符串里面的内容, 转换为html元素。# mark_safe也是django框架里面的函数, 需要手动导入, 导入语句为from django.utils.safestring import mark_safepage_string = mark_safe("".join(html_list))# 不能忘记将page_string传给前端。return render(request, "assets/assets_list.html", {"assets_list": assets_list, "page_string": page_string})
"""class PageData(object):def __init__(self, request, queryset, page_size=10, plus=2, page_param="page"):get_query_dict = deepcopy(request.GET)self.query_dict = get_query_dictself.page_param = page_parampage = request.GET.get(self.page_param, "1")# 判段当前page首部是纯数字if page.isdecimal():page = int(page)else:page = 1self.page = pageself.start = (self.page - 1) * page_sizeself.end = self.page * page_sizeself.page_queryset = queryset[self.start: self.end]page_count = queryset.count()page_count, div = divmod(page_count, page_size)if div:page_count += 1self.page_count = page_countself.plus = plusdef page_html(self):if self.page_count <= 2 * self.plus + 1:start_page = 1end_page = self.page_countelse:# 如果当前点击的页面是小于3的if self.page <= self.plus:start_page = 1end_page = 2 * self.plus + 1else:# 后五页if (self.page + self.plus) > self.page_count:start_page = self.page_count - self.plus * 2end_page = self.page_countelse:# 大于前五页,小于后五也的其他页面start_page = self.page - self.plusend_page = self.page + self.pluspage_str_list = []# 首页self.query_dict.setlist(self.page_param, [1])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">首页</a></li>')# 上一页if self.page > 1:self.query_dict.setlist(self.page_param, [self.page - 1])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}"><span aria-hidden="true">«</span></a></li>')else:page_str_list.append(f'<li class="disabled"><span aria-hidden="true">«</span></li>')for page_num in range(start_page, end_page + 1):if page_num == self.page:self.query_dict.setlist(self.page_param, [page_num])page_str_list.append(f'<li class="active"><a href="?{self.query_dict.urlencode()}">{page_num}</a></li>')else:self.query_dict.setlist(self.page_param, [page_num])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">{page_num}</a></li>')# 下一页if self.page < self.page_count:self.query_dict.setlist(self.page_param, [self.page + 1])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}"><span aria-hidden="true">»</span></a></li>')else:page_str_list.append(f'<li class="disabled"><span aria-hidden="true">»</span></li>')# 尾页self.query_dict.setlist(self.page_param, [self.page_count])page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">尾页</a></li>')search_page = """<li><div style="float: right"><form method="get"><div class="input-group" style="width: 100px;float: right"><input type="text" class="form-control" name="page"><span class="input-group-btn"><button class="btn btn-success" type="submit">跳转</button></span></div></form></div></li>"""page_str_list.append(search_page)page_string = mark_safe("".join(page_str_list))return page_string注意, 不要忘记返回page_string。
最后再回到assets.py里面:
assets.py文件里面的asserts函数的内容做个修改, 我们需要去除之前写的那一大堆逻辑, 然后再调用我们已经封装好的函数。
def assets(request):# assets_list = models.Assets.objects.all()# 搜索信息dict_data = {}# 获取搜素框里的内容, 就是获取网址里面的search参数的值value = request.GET.get('search')if value:# 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__containsdict_data["mobile__contains"] = valueassets_list = models.Assets.objects.filter(**dict_data)page_object = PageData(request, assets_list)# 调用我们自己写的page_html函数, 在PageData类当中。page_string = page_object.page_html()# 不能忘记将page_string传给前端。return render(request, "assets/assets_list.html",{"assets_list": page_object.page_queryset, "page_string": page_string})
运行结果:
跳转页面功能:
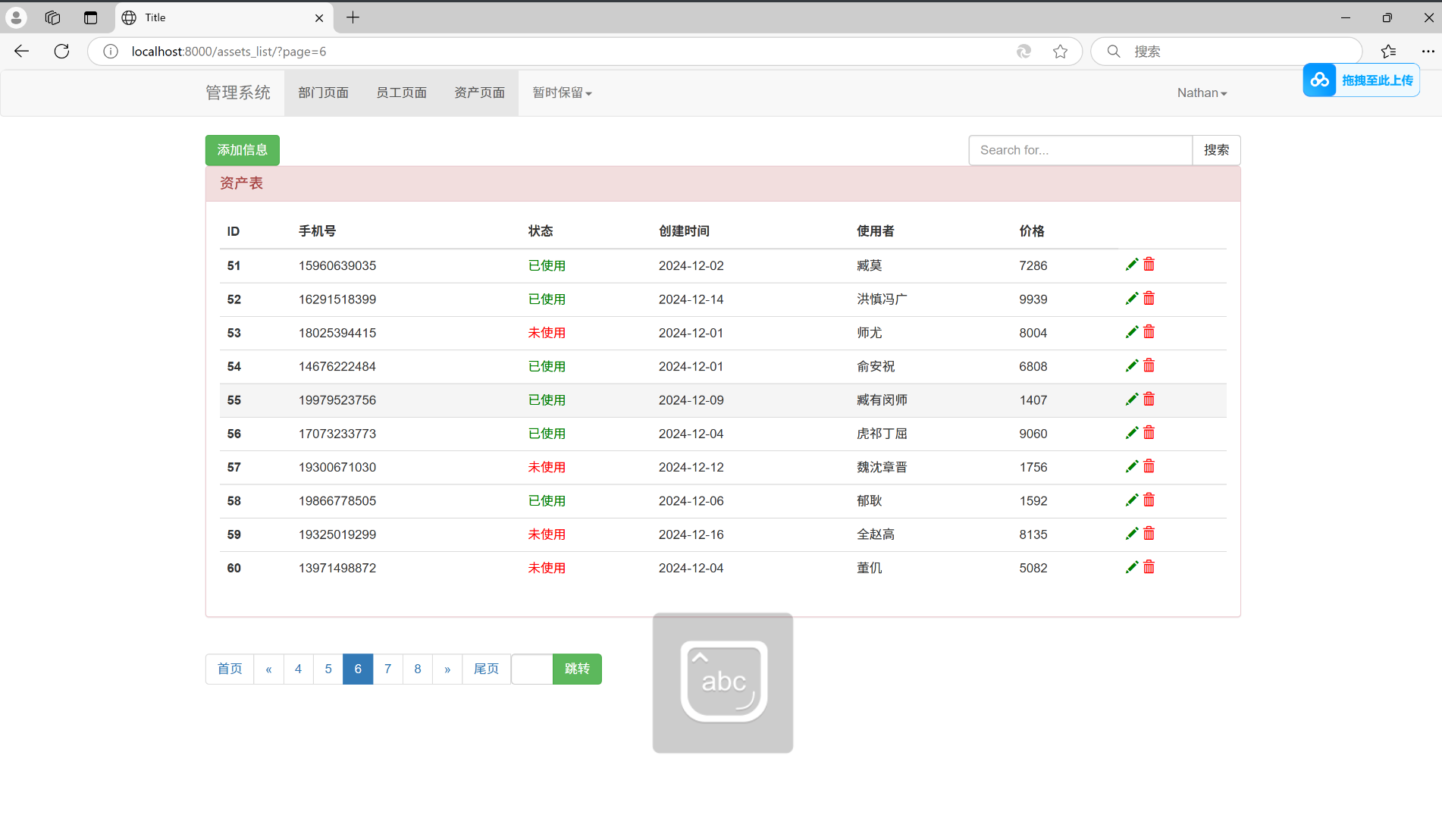
搜索加跳转页面功能:
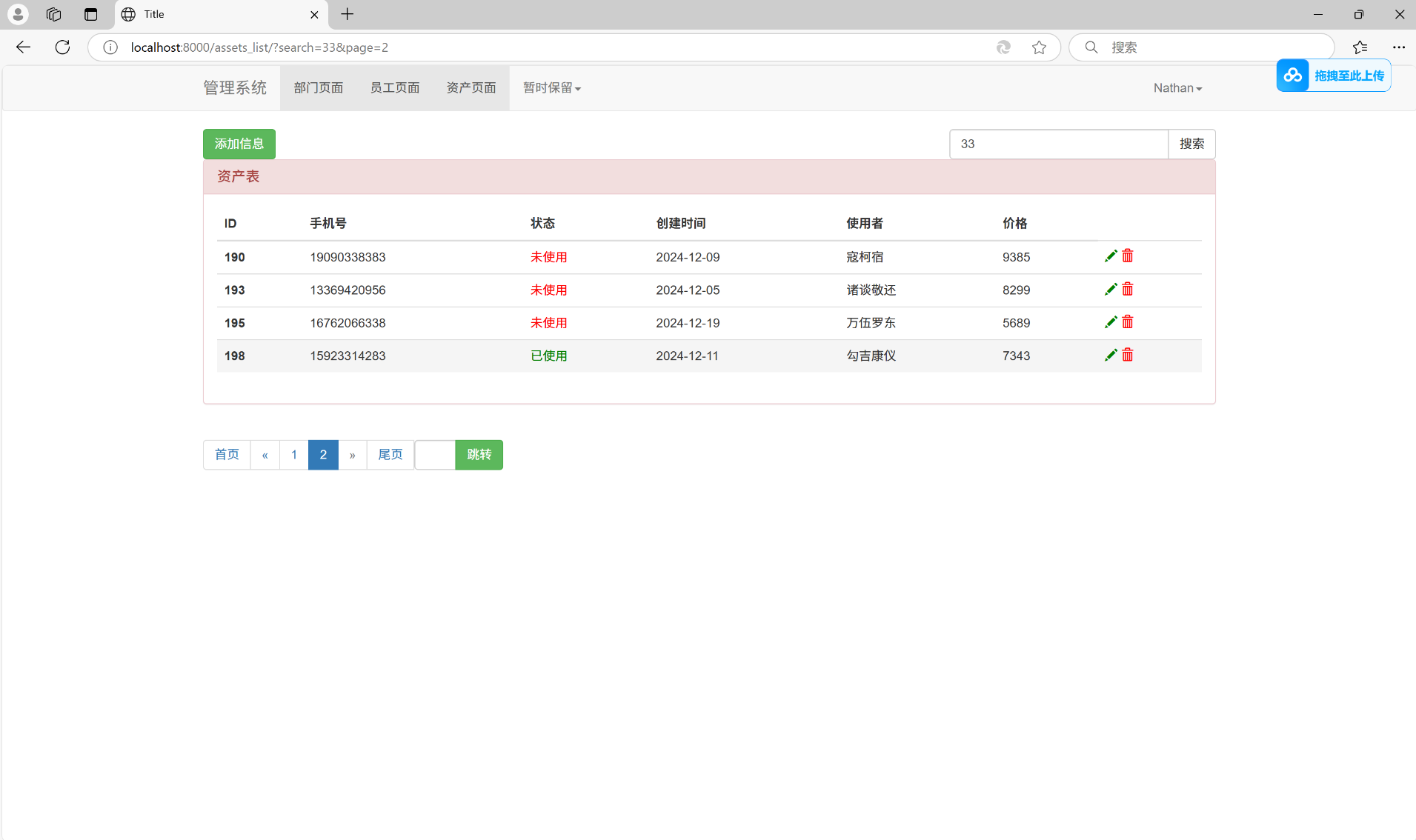
跳转页面功能:
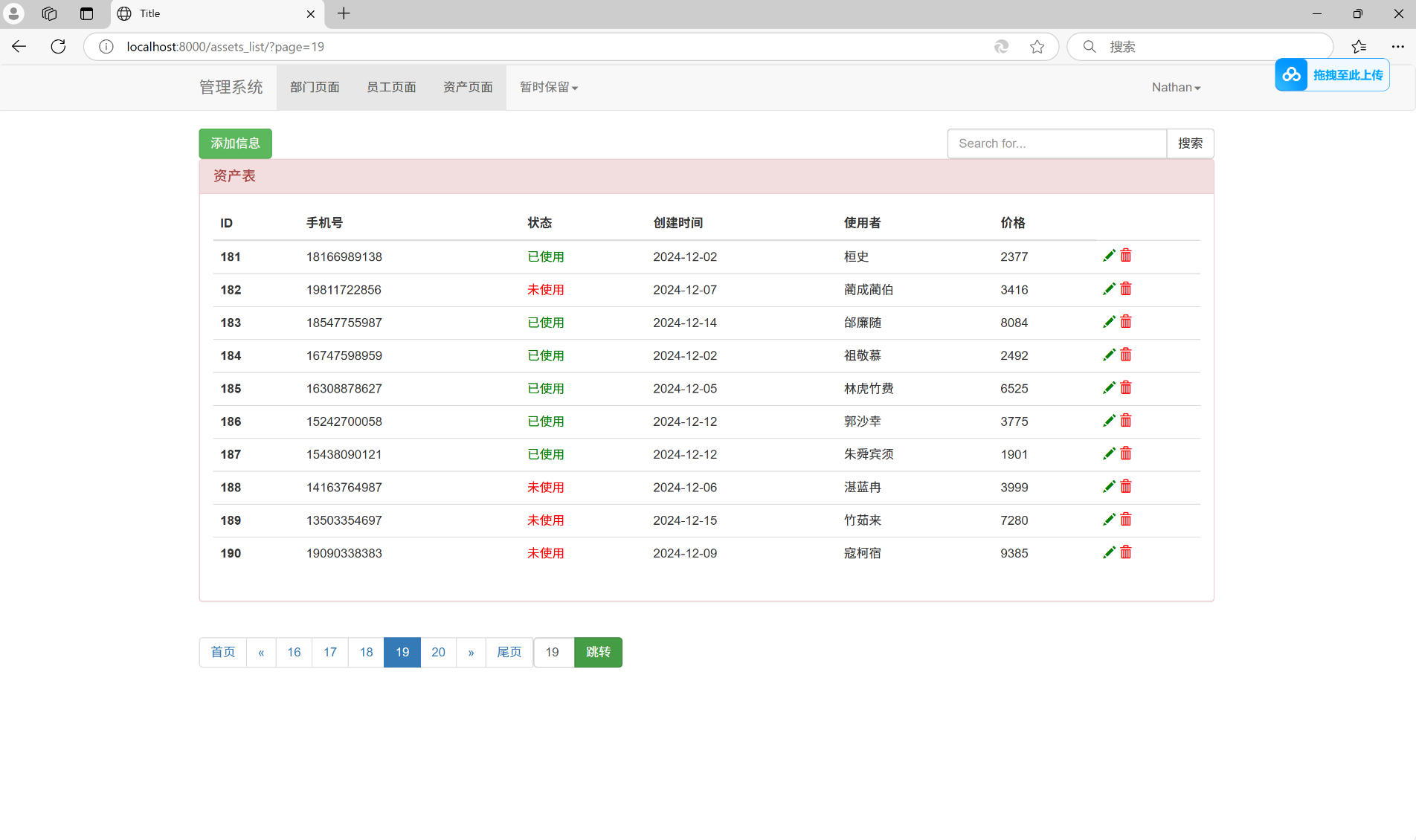
OK, 大功告成!!!
以上就是Django优化分页功能的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大.
人生路漫漫, 白鹭常相伴!!!
相关文章:
)
django之优化分页功能(利用参数共存及封装来实现)
优化分页功能 目录 1.封装分页代码 2.解决分页时覆盖搜索参数的bug 3.优化分页功能 上一篇文章我们讲到了搜索功能和分页展示数据功能。那这篇文章, 在上篇文章的基础上, 会去优化这些功能并解决搜索功能和分页功能不能一起使用的bug。 一、封装分页代码 原本我们的asse…...

linux blueZ 第四篇:BLE GATT 编程与自动化——Python 与 C/C++ 实战
本篇聚焦 BLE(Bluetooth Low Energy)GATT 协议层的编程与自动化实践,涵盖 GATT 基础、DBus API 原理、Python(dbus-next/bleak)示例、C/C++ (BlueZ GATT API)示例,以及自动发现、读写特征、订阅通知、安全配对与脚本化测试。 目录 BLE GATT 基础概念 BlueZ DBus GATT 模…...

前端面试每日三题 - Day 16
这是我为准备前端/全栈开发工程师面试整理的第16天每日三题练习,涵盖事件循环深入解析 、Vue3 响应式系统原理 ,以及 多租户系统设计实践。每道题附带 详细解析、示例代码与脑图建议,助你全面掌握底层原理与架构设计思维。 ✅ 题目 1…...
的完整代码示例,包含数据加载、模型定义、训练和预测全流程)
使用PyTorch实现简单图像识别(基于MNIST手写数字数据集)的完整代码示例,包含数据加载、模型定义、训练和预测全流程
以下是一个使用PyTorch实现简单图像识别(基于MNIST手写数字数据集)的完整代码示例,包含数据加载、模型定义、训练和预测全流程: import torch import torch.nn as nn import torch.optim as optim import torchvision import torc…...

【Android】四大组件之Activity
目录 一、什么是Activity 二、如何创建和配置Activity 三、Activity 跳转与数据传递 四、数据保存与恢复 五、Activity 启动模式 六、自定义返回行为 七、复杂界面布局 你可以把Activity想象成手机屏幕上的一个“页面”。比如,当你打开一个App时,…...
)
数据库原理(1)
第一章 概论 一、基本概念 数据(Data)是数据库中存储的基本对象,描述事物的符号记录。例如学生的学号、姓名等信息都是数据。 数据库(Database,DB)长期存储在计算机内、有组织的、可共享的大量数据的集合。…...

SQL盲注问题深度解析与防范策略
引言 在当今互联网时代,Web应用程序的安全性是重中之重。SQL注入作为一种常见且极具威胁性的攻击手段,而其中的SQL盲注更是因其隐蔽性强、难以察觉而备受关注。攻击者借助SQL盲注,在无法直接获取数据库返回结果的情况下,通过精心构造特殊的SQL语句,利用页面的不同响应来逐…...
,Just In Time Compiler,即时编译技术)
Android JIT( ART即时编译器),Just In Time Compiler,即时编译技术
Android JIT( ART即时编译器),Just In Time Compiler,即时编译技术 Android Runtime (ART) 包含一个具备代码分析功能的即时 (JIT) 编译器,该编译器可以在 Android 应用运行时持续提高其性能。JIT是Just In Time Compiler…...

当自动驾驶遇上“安全驾校”:NVIDIA如何用技术给无人驾驶赋能?
自动驾驶技术的商业化落地,核心在于能否通过严苛的安全验证。国内的汽车企业其实也在做自动驾驶,但是吧,基本都在L2级别。换句话说就是在应急时刻内,还是需要人来辅助驾驶,AI驾驶只是决策层,并不能完全掌握…...

Unity中数据储存
在Unity项目开发中,会有很多数据,有需要保存到本地的数据,也有直接保存在缓存中的临时数据,一般为了方便整个项目框架中各个地方能调用需要的数据,因此都会实现一个数据工具或者叫数据管理类,用来管理项目中所有的数据。 首先保存在缓存中的数据,比如用户信息,我们只需…...

【C++11】可变参数模板
前言: 上文我们学到右值引用及其移动语义,学习到了C11中对性能提升对重要的更新之一。C11进阶之路:右值引用和移动语义,让代码跑得更快!-CSDN博客 本文我们来讲讲,C11的下一个新语法:可变参数模…...

c语言知识整理
一 数据的存储 对于整形的存储 无论是正负在存储中都是使用补码进行存储的 那个一个数字的补码在转换正负时不同的 对于存储中 首位一定是符号位 如果是0 那么是正数 如果是1 那么是负数 (32位 除符号位 缺少的位数使用0补齐) 如果是正数 …...

算法习题-力扣446周赛题解
算法可以调度思维,让程序员的思维发散,找到更好的解决方案。 第一题:执行指令后的得分 题目: 给你两个数组:instructions 和 values,数组的长度均为 n。你需要根据以下规则模拟一个过程: 从下标…...

基于共享上下文和自主协作的 RD Agent 生态系统
在llmangentmcp这个框架中: LLM: 依然是智能体的“大脑”,赋予它们理解、推理、生成和规划的能力,并且也用于处理和利用共享上下文。Agent: 具备特定 R&D 职能的自主单元,它们感知共享上下文࿰…...

Operating System 实验五 进程管理编程实验
实验目标: 写个多线程的程序,重现竞争条件,并通过信号量或者互斥量,解决临界区问题某工厂有两个生产车间和一个装配车间,两个生产车间分别生产A、B两种零件,装配车间的任务是把A、B两种零件组装成产品。两个生产车间每生产一个零件后,都要分别把它们送到装配车间的货架F…...

Deep Reinforcement learning for real autonomous mobile robot navigation
https://www.youtube.com/watch?vKyA2uTIQfxw AI Learns to Park - Deep Reinforcement Learning https://www.youtube.com/watch?vVMp6pq6_QjI Q Learning simply explained | SARSA and Q-Learning Explanation https://www.youtube.com/watch?vMI8ByADM…...
--DNS:因特网的目录服务)
计算机网络 | 应用层(4)--DNS:因特网的目录服务
💓个人主页:mooridy-CSDN博客 💓文章专栏:《计算机网络:自定向下方法》 大纲式阅读笔记_mooridy的博客-CSDN博客 🌹关注我,和我一起学习更多计算机网络的知识 🔝🔝 目录 …...

WPF核心技术解析与使用示例
WPF核心技术解析与使用示例 一、依赖属性(Dependency Property)详解 1. 依赖属性基础 核心概念: 依赖属性是WPF实现数据绑定、样式、动画等特性的基础通过属性系统实现高效的内存管理和值继承标准定义模式: public class MyControl : Control {// 1. 定义…...

JVM运行机制全景图:从源码到执行的全过程
JVM运行机制全景图:从源码到执行的全过程 引言:你真的了解 Java 是怎么跑起来的吗? 许多开发者写完 Java 代码之后,就交给编译器和运行时去“神奇”地执行了。但你有没有想过,一段 .java 文件是如何一步步变成可运行的程序?今天,我们就从 源码 ➝ 字节码 ➝ 类加载 ➝…...

使用 AFL++ 对 IoT 二进制文件进行模糊测试 - 第二部分
在上一部分中,我们研究了如何使用 AFL++ 对简单的物联网二进制文件进行模糊测试。这些程序接受来自文件的输入,并且易于模糊测试。 在本文中,我们将研究套接字二进制文件。使用套接字进行网络通信的模糊测试二进制文件与使用基于文件 I/O 的模糊测试二进制文件不同。Vanill…...

在华为云平台上使用 MQTT 协议:构建高效可靠的物联网通信
🌐 在华为云平台上使用 MQTT 协议:构建高效可靠的物联网通信 随着物联网(IoT)技术的发展,设备间的高效通信变得尤为重要。MQTT(Message Queuing Telemetry Transport)作为一种轻量级的消息传输…...

基于STM32的物流搬运机器人
功能:智能循迹、定距夹取、颜色切换、自动跟随、自动避障、声音夹取、蓝牙遥控、手柄遥控、颜色识别夹取、循迹避障、循迹定距…… 包含内容:完整源码、使用手册、原理图、视频演示、PPT、论文参考、其余资料 资料只私聊...

H.264/AVC标准主流开源编解码器编译说明
An artisan must first sharpen his tools if he is to do his work well. 工欲善其事,必先利其器. 前言 想研究和学习H.264/AVC视频编解码标准的入门的伙伴们,不论是学术研究还是工程应用都离不开对源码的分析,因此首要工作是对各类编解码器进行编译,本文针对主流的一些符…...

Xilinx FPGA支持的FLASH型号汇总
以博主这些年的FPGA开发使用经验来看,FPGA开发的主流还是以Xilinx FPGA为主,贸易战关税战打了这么多年,我们做研发的也不可避免的要涉及一些国产替代的工作;这里把Xilinx FPGA官方支持的各类(国产和非国产)…...
:从设计模式到实战应用)
【C++ 类和数据抽象】消息处理示例(1):从设计模式到实战应用
目录 一、数据抽象概述 二、消息处理的核心概念 2.1 什么是消息处理? 2.2 消息处理的核心目标 三、基于设计模式的消息处理实现 3.1 观察者模式(Observer Pattern) 3.2 命令模式(Command Pattern) 四、实战场景…...

LiveCharts.WPF图表模块封装
WPF LiveCharts.WPF 封装实现 下面是一个完整的 WPF LiveCharts.WPF 封装实现,提供了常用图表的简单使用方式,并支持数据绑定和更新。 一、LiveCharts.WPF 封装类 1. 图表基类 (ChartBase.cs) using LiveCharts; using LiveCharts.Wpf; using System.Collections.Generic;…...

微信小程序,基于uni-app的轮播图制作,轮播图本地文件图片预览
完整代码 <template><swiper class"banner" indicator-dots circular :autoplay"false"><swiper-item v-for "item in picture" :key"item.id"><view><image tap"onPreviewImage(item.img)" :…...

【QQmusic】复习笔记第四章分点讲解
4.1 音乐加载 功能概述 该部分实现了从本地磁盘加载音乐文件到程序中,并在界面上显示的功能。通过QFileDialog类创建文件选择对话框,用户可选择多个音乐文件,程序筛选出有效音频文件后,交由MusicList类管理,并更新到…...

设置右键打开VSCode
在日常的开发工作中,VSCode 是一款非常受欢迎的代码编辑器。为了更加便捷地使用它,我们可以将 VSCode 添加到右键菜单中,这样只需右键点击文件或文件夹,就能快速用 VSCode 打开,极大地提高工作效率。下面我就来介绍一下…...
--2-3查找树)
数据结构和算法(八)--2-3查找树
目录 一、平衡树 1、2-3查找树 1.1、定义 1.2、查找 1.3、插入 1.3.1、向2-结点中插入新键 1.3.2、向一棵只含有一个3-结点的树中插入新键 1.3.3、向一个父结点为2-结点的3-结点中插入新键 1.3.4、向一个父结点为3-结点的3-结点中插入新键 1.3.5、分解根结点 1.4、2…...

JSAPI2.4——正则表达式
一、语法 const str 一二三四五六七八九十 //判断内容 const reg /二/ //判断条件 console.log(reg.test(str)); //检查 二、test与exec方法的区别 test方法:用于判断是否符合规则的字符串,返回值是布尔值 exec方法&…...

FPGA 100G UDP纯逻辑协议栈
随着器件等级的升高,高速serdes的线速率也随之提高,RFSOC 4x最大可支持100G,主流方案为RDMA方案,该方案相对比较复杂,除了需要负责逻辑端的开发,还需操作系统中开发RDMA的驱动,对于对丢包不那么…...

分享一个可以批量巡检GET和POST接口的Shell脚本
一、场景痛点与需求分析 在分布式系统架构中,服务接口的可用性和稳定性直接影响业务连续性。当面临以下场景时,需批量巡检GET和POST接口: 上线验证:新版本发布后批量验证核心接口 故障恢复:异常数据修复后的批量重试…...

机器学习之一:机械式学习
正如人们有各种各样的学习方法一样,机器学习也有多种学习方法。若按学习时所用的方法进行分类,则机器学习可分为机械式学习、指导式学习、示例学习、类比学习、解释学习等。这是温斯顿在1977年提出的一种分类方法。 有关机器学习的基本概念,…...

区分PROJECT_SOURCE_DIR, CMAKE_SOURCE_DIR,CMAKE_CURRENT_SOURCE_DIR
目录 示例工程 PROJECT_SOURCE_DIR的行为 CMAKE_SOURCE_DIR的行为 CMAKE_CURRENT_SOURCE_DIR 示例工程 根目录 |-----CMakeLists.txt |-----sub1 |--------CMakeLists.txt |-----sub2 |--------CMakeLists.txt 根目录下的CMakeList.txt: project(main)message("main …...

Python循环结构深度解析与高效应用实践
引言:循环结构在编程中的核心地位 循环结构作为程序设计的三大基本结构之一,在Python中通过while和for-in两种循环机制实现迭代操作。本文将从底层原理到高级应用,全面剖析Python循环机制的使用技巧与优化策略,助您掌握高效迭代的…...
)
25【干货】在Arcgis中根据字段属性重新排序并自动编号的方法(二)
上一篇关于属性表自动编号的文章因为涉及到代码(【干货】在Arcgis中根据字段属性重新排序并自动编号的方法(一)),担心大家有些东西确实不熟悉,今天就更新一篇不需要代码也能达到这个目的的方法。主要的思路…...

SinSR模型剪枝实验报告
SinSR模型剪枝实验报告 实验概述 我成功地对SinSR模型进行了L1范式剪枝,剪枝比例为50%。通过分析剪枝前后的模型参数和性能,我们得出了以下结论。 剪枝实现方法 创建专用的main_prune.py脚本,用于剪枝训练。创建quick_prune.py脚本&#…...
)
IT社团分析预测项目(pandas、numpy、sklearn)
IT社团人数的增长陷入迟滞,同时不同目标任务和不同经营模式的社团更是层出不穷。在面临内忧外患的情况下,本社团希望结合社团行业现状,分析同学和出勤的数据,挖据数据中的信息,通过对人数流失进行预测寻找到相应的对策…...

C语言中位段的应用
一,位段的主要应用场景 硬件寄存器操作 嵌入式开发中,硬件寄存器通常以位为单位控制设备状态。位段可直接映射到寄存器,简化位操作: typedef struct {unsigned int enable : 1; // 使能位unsigned int mode : 3; // 模式选择&…...

【Linux网络#1】:网络基础知识
1、网络发展 在计算机发展历程中,经历过下面四个阶段: 1.独立模式 独立模式:计算机之间相互独立,每台计算机做自己的事情,彼此之间没有直接信息传递。如果两台计算机需要通信就需要将当前计算机的数据通过某种方式拷贝…...

基于物联网的园林防火监测系统
标题:基于物联网的园林防火监测系统 内容:1.摘要 随着全球气候变化和人类活动影响,园林火灾发生频率呈上升趋势,给生态环境和人类生命财产造成巨大损失。为有效预防和应对园林火灾,本文提出基于物联网的园林防火监测系统。该系统综合运用传感…...

华为云loT物联网介绍与使用
🌐 华为云 IoT 物联网平台详解:构建万物互联的智能底座 随着万物互联时代的到来,物联网(IoT)已成为推动数字化转型的关键技术之一。华为云 IoT 平台(IoT Device Access)作为华为云的核心服务之…...

Redis 数据类型全览:特性、场景与操作实例
Redis 是一款开源的内存数据库,支持多种数据类型,以下是对常见 Redis 数据类型的介绍: 1. String(字符串) 描述 字符串是 Redis 里最基础的数据类型,其值可以是简单的字符串、数字,甚至是二进…...

Qt动态库信号崩溃问题解决方案
在Qt中,当动态库向主程序发送信号导致崩溃时,通常涉及线程安全或对象生命周期问题。以下是逐步解决方案: 1. 检查线程上下文 问题:动态库所在的线程与主程序线程不同,跨线程信号未正确处理。解决方案: 显式…...

Go设计模式-观察者模式
简介 在软件开发中,我们常常会遇到这样的场景:一个对象的状态变化需要通知到多个其他对象,让它们做出相应的反应。观察者模式(Observer Pattern)就是解决这类问题的一种设计模式。在 Go 语言中,由于其简洁…...

《TCP/IP详解 卷1:协议》之第七、八章:Ping Traceroute
目录 一、ICMP回显请求和回显应答 1、ICMP回显请求 2、ICMP回显应答 二、ARP高速缓存 三、IP记录路由选项(Record Route,RR) 1、记录路由选项的工作过程 2、RR 选项的 IP 头部格式 2.1、RR 请求 2.2、RR响应 四、ping 的去返路径 五…...

Unity任务系统笔记
数据结构设计 任务基类包括的字段: string 任务内容; Transform 任务目的地; MyCharacter 任务开启后要更新对话的NPC; MyTalkData 任务开启后相关NPC要说的对话数据; 共同方法:开启任务、完成任务。…...
✨)
Three.js + React 实战系列-3D 个人主页:构建 Hero 场景组件(项目核心)✨
在本节中,我们将完成整个 3D 主业项目中最核心的组件 —— Hero.jsx。 这个组件作为首页的主视觉部分,整合了 3D 模型、动画相机、交互按钮与自适应布局,构建出一个立体、酷炫、可交互的主场景。 前置准备: ✅安装依赖ÿ…...
:深入剖析synchronized关键字的底层原理)
线程池(二):深入剖析synchronized关键字的底层原理
线程池(二):深入剖析synchronized关键字的底层原理 线程池(二):深入剖析synchronized关键字的底层原理一、基本使用1.1 修饰实例方法1.2 修饰静态方法1.3 修饰代码块 二、Monitor2.1 Monitor的概念2.2 Moni…...