IT社团分析预测项目(pandas、numpy、sklearn)
IT社团人数的增长陷入迟滞,同时不同目标任务和不同经营模式的社团更是层出不穷。在面临内忧外患的情况下,本社团希望结合社团行业现状,分析同学和出勤的数据,挖据数据中的信息,通过对人数流失进行预测寻找到相应的对策,从而更好经营本社团。
任务分析
1、分析社团每日出勤班级与人数,明确预测分析目标。
2、了解所要用到的预测的方法。
3、熟悉社团预测的步骤和流程。
模块解析
(一)数据预处理
我们IT社在收集到的数据存在着数据不完整,数据不一致,数据异常的情况,如果用这种异常数据进行分析,那么会影响建模的执行效率,甚至能会造成分析结果出现偏差,所以我们对数据原始数据进行了预处理,通过合并数据进而实现数据清洗,检测与处理了重复值、缺失值、异常值从而提高了数据质量,为下步数据分析与可视化创造环境。
(二)数据分析与可视化
基于上一步清洗过的数据,我们对其进行二次处理,提取出有用字段分别对班级人员分布、每日出勤人数统计与人员出勤Top10进行了数据分析与可视化,一方面便于我们分析提取有用信息,另一方面也为我们下一步的构建模型打下坚实基础。
(三)基于scikit-learn构建模型
scikit-learn(以下简称sklearn)库整合了多种机器学习算法,可以帮助使用者在数据分析过程中快速建立模型,且模型接口统一,使用起来非常方便。同时, skleam拥有优秀的官方文档,该文档知识点详尽、内容丰富,是入门学习sklearn的较佳内容。 我们则使用其中的支持向量机对社团人员等级进行了评估预测
四、项目代码
(一)数据预处理
本模块主要使用Pandas于os对原始数据进行数据清洗通过合并数据进而实现,堆叠合并主键合并和重叠合并进行数据清洗,检测与处理重复值、缺失值、异常值。清洗完毕后,在下个模块中进行数据分析与可视化。
对原始数据进行预处理
if os.path.exists('../File/output/汇总表.csv'):os.remove('../File/output/汇总表.csv')
df=pd.DataFrame(data=None)
for root,dirs,files in os.walk(r"../File/import/"):print(files)for i in files:data=pd.read_excel('../File/import/'+i,header=1,usecols=[1,2,5,6])data.columns=['班级','姓名','班级2','姓名2']data=data[['班级','姓名']].append(data[['班级2','姓名2']],ignore_index=True)data=data[['班级','姓名']]data['时间']=idata['时间']=data['时间'].map(lambda x:str(x)[:-8])df_all=df.append(data,ignore_index=True)df_all.to_csv('../File/output/汇总表.csv',mode='a', header=False)df1=pd.DataFrame(data=None)
for root,dirs,files in os.walk(r"../File/import/"):for i in files:data2=pd.read_excel('../File/import/'+i,header=1,usecols=[5,6])data2.columns=['班级','姓名']data2['时间']=idata2['时间']=data2['时间'].map(lambda x:str(x)[:-8])df_all2=df1.append(data2,ignore_index=True)df_all2.to_csv('../File/output/汇总表.csv',mode='a', header=False)
#data2=pd.read_csv('../File/output/汇总表.csv',header=None,names=['序号','班级','姓名'])
#data=pd.concat([data,data2])
data=pd.read_csv('../File/output/汇总表.csv',header=None,names=['班级','姓名','时间'])提取时间关键词进行转换
date=data['时间'].astype(str).str.split('.')
list=[]
for i in date:s=pd.Series(i)dates='2023-'+s.str.cat(sep='-')list.append(dates)
data['时间']=list
time=pd.to_datetime(data['时间'])
data['日期']=time
data对数据进行去重并重新分配顺序
data=data[['日期','班级','姓名']]
data.dropna(inplace=True)
data=data.reset_index(drop=True)
data.to_excel('../File/output/清洗完毕.xlsx')
data (二)数据分析与可视化
(二)数据分析与可视化
1、人员出勤Top10
本模块主要使用清洗完的数据,进去去重,对同学来的次数进行count统计,并对Top10进行可视化展示:
Pandas版wordcount
word=pd.DataFrame(data[['班级','姓名']])
count=word.groupby(['班级','姓名']).apply(len)
count.sort_values(ascending=False, inplace=True)
wordcount=count.reset_index(name="count")
wordcount.to_excel('../File/output/社团人员.xlsx')条形图:
from pyecharts import Bar
x = Top10['姓名']
y =Top10['count']
bar=Bar("出勤人员Top10","社團總體出勤人员Top10",title_color ="#2F4F4F")
title= '出勤次数'
bar.add(title,x,y,is_convert=True)
bar.render("../File/圖表/Top10条形图.html")
bar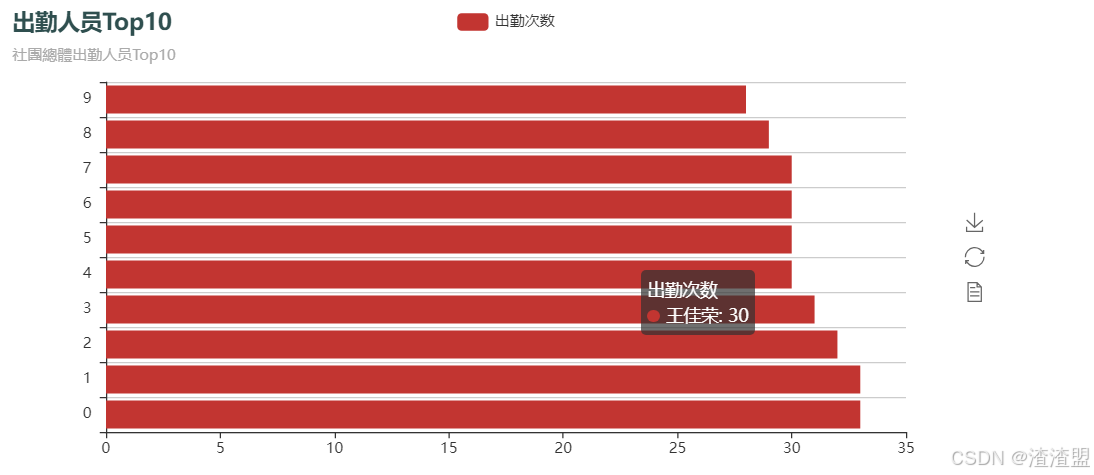 饼图:
饼图:
from pyecharts import Pie
attr = Top10['班级']+Top10['姓名']
v1 = Top10['count']
pie = Pie("出勤人员Top10", title_pos='center')
pie.add("",attr,v1,radius=[40, 75],label_text_color=None,is_label_show=True,is_more_utils=True,legend_orient="vertical",legend_pos="left",center=["65%", "55%"]
)
pie.render(path="../File/圖表/Top10饼状图.html")
pie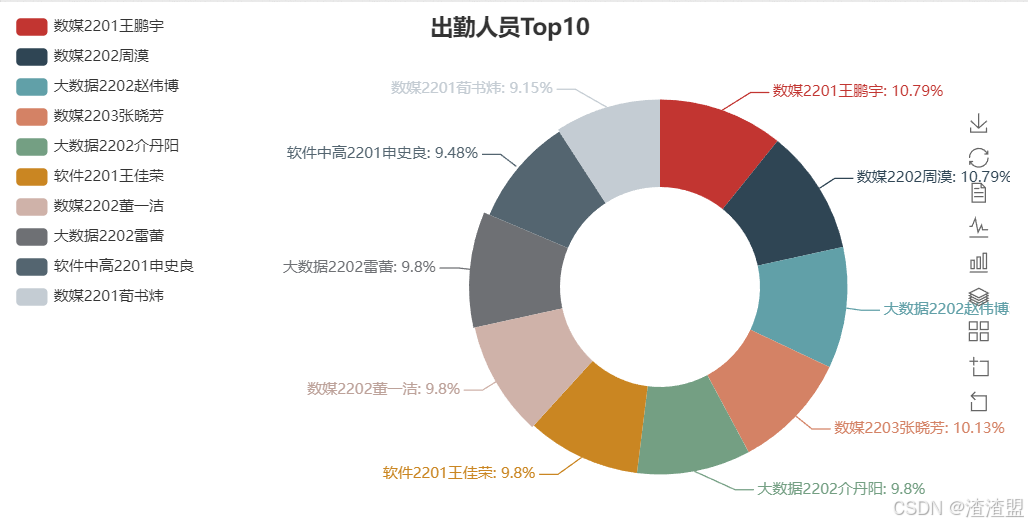
词云图:
from pyecharts import WordCloud
name_list = Top10['姓名']
value_list = Top10['count']
wordcloud = WordCloud(width=800, height=500)
wordcloud.add("",name_list,value_list,word_size_range=[20,100])
wordcloud.render(path="../File/圖表/Top10词云图.html")
wordcloud
2、班级人员分布
本模块主要使用清洗完毕的数据,对其进去再次处理,提取出班级与姓名特征,并进行去重,排序去重。完毕后使用pyecharts进行折线图与饼图的绘制,最后基于班级人员分布对下步工作进行分析。
将提取的有用数据进行去重,清洗
data=pd.read_excel('../File/output/清洗完毕.xlsx')
data=data[['班级','姓名']]
word=pd.DataFrame(data[['班级','姓名']])
count=word.groupby(['班级','姓名']).apply(len)
count.sort_values(ascending=False, inplace=True)
wordcount=count.reset_index(name="count")
calss=wordcount[['班级','姓名']]
calss
根据count属性进行班级的排列
count=calss.groupby(['班级']).apply(len)
count.sort_values(ascending=False, inplace=True)
wordcount=count.reset_index(name="count")
wordcount人员分布可视化图表:
bar=Bar("班级人员分布","社團各班人员分布情況",title_color ="#c1392b")
bar.add("人數",wordcount['班级'],wordcount['count'],xaxis_label_textsize=8)
bar.render("../File/圖表/班级人员分布柱图.html")
bar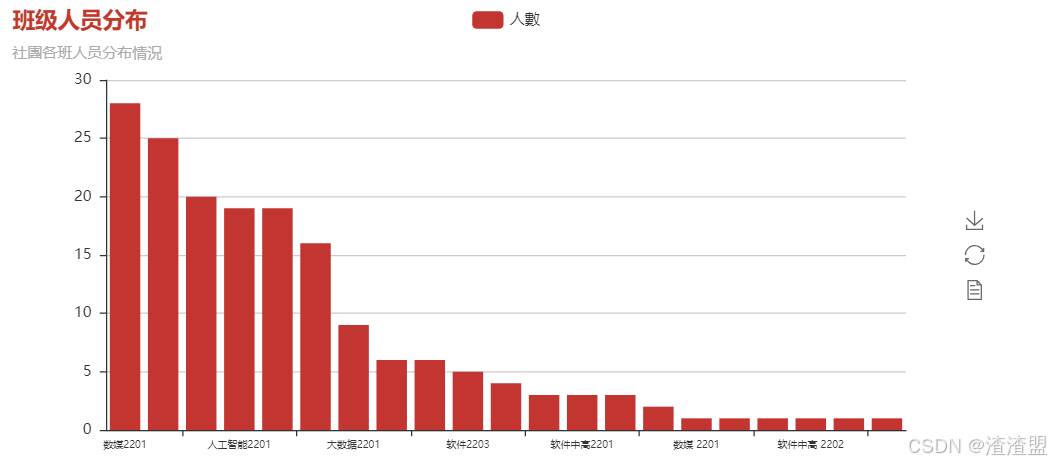
attr = wordcount['班级']
v1 = wordcount['count']
pie = Pie("班级人员分布", title_pos='center')
pie.add("",attr,v1,radius=[40, 75],label_text_color=None,is_label_show=True,is_more_utils=True,legend_orient="vertical",legend_pos="left",center=["65%", "55%"]
)
pie.render(path="../File/圖表/班级人员分布饼图2.html")
pie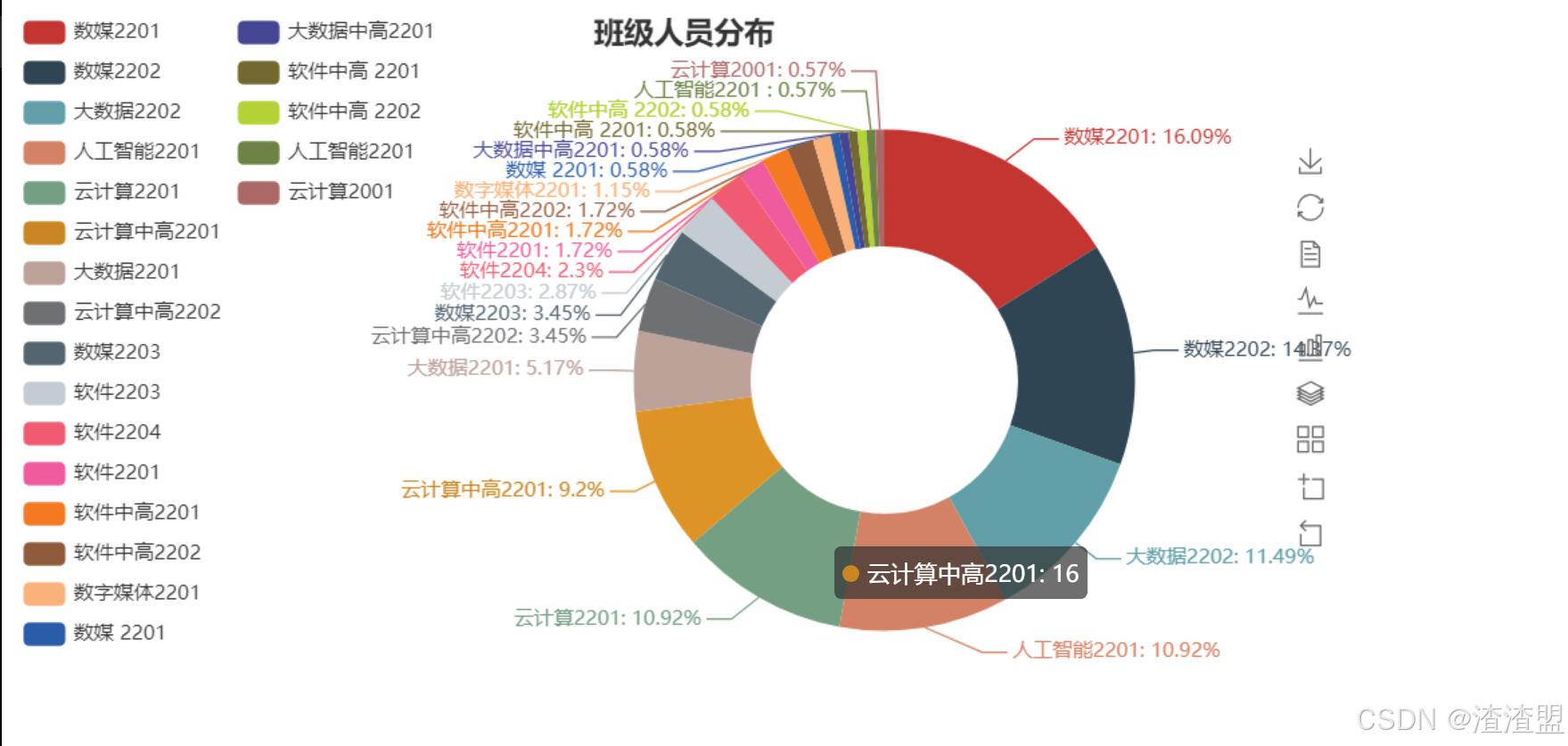
基于班级人员分布分析
从代码分析得出:
数媒2201、2202以及大数据2202、人工智能2201的同学对IT社有更大的兴趣占饼状图的百分之五十一
其次就是云计算2201和中高班的同学对IT社的兴趣仅次于上面各班占百分之二十
最后其余班级的同学对IT社的兴趣可能想简单的了解一下里面的内容占百分之三十
从这些数据上看得出来对于这些对IT社的感兴趣的同学,我们要把握住他们对网络的喜欢,让他们继续坚持下去他们对网络技术的爱好,同时带动那些想要简单了解网络技术的同学们一起努力学习。
3、每日出勤人数统计
本模块主要使用清洗完毕的数据先提取出姓名和日期,在从日期中排序每个时间所到的人员数目,再使用pyecharts进行柱状和折线的绘制,最后基于每日出勤人数统计进行分析。
将数据进行去重,清洗
data=pd.read_excel('../File/output/清洗完毕.xlsx')
data=data[['日期','姓名']]
data['日期']=data['日期'].dt.date根据count数据重新排序
count=data.groupby(['日期']).apply(len)
count.sort_values(ascending=False, inplace=True)
date=count.reset_index(name="count")
date=date.sort_values(by='日期')
date统计出勤人数列出柱状图
from pyecharts import Bar
bar=Bar("出勤人數統計","社團每日出勤人员統計",title_color ="#FFA07A")
bar.add("人數",date['日期'],date['count'],xaxis_label_textsize=8)
bar.render("../File/圖表/出勤人数柱状图.html")
bar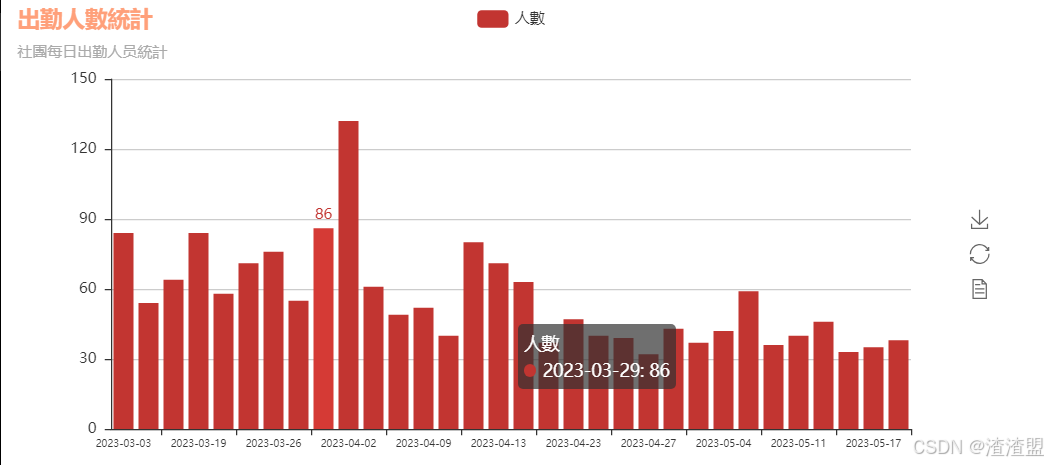 统计出勤人数列出折线图
统计出勤人数列出折线图
attr = date['日期']
v1 = date['count']
line = Line("社團每日出勤人數統計")
line.add("出勤人数", attr, v1, mark_point=["average"])
line.render('../File/圖表/出勤人数折线图.html')
line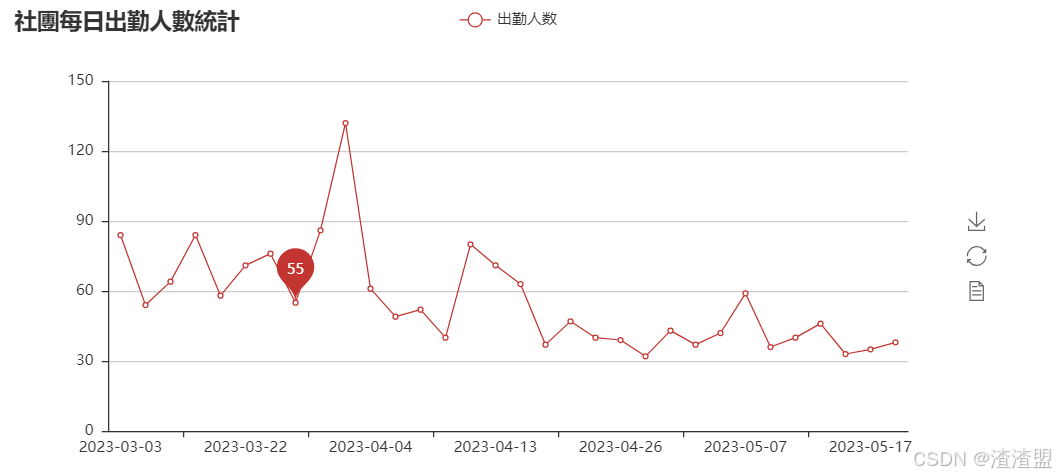
基于每日出勤人数统计的分析
从折线图中我们可以看出:
刚开始稳步提升,4月4号到达顶峰
5月17号人最少、从4月13后出勤人数一直在下滑、明显的下降趋势
5月以后,社团每日出勤趋于稳定
(三)基于scikit-learn构建模型
1、社员等级评估
使用支持向量机算法对社员等级进行评估
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
import warnings
warnings.filterwarnings('ignore')提取可用的数据
data=pd.read_excel('../File/output/社团人员.xlsx')
data=data[['姓名','count']]
data对数据进行标准化并根据count属性添加类别标签
data = pd.get_dummies(data)
data['类别']=pd.cut(data['count'],[0,5,10,20,50],labels=['D','C','B','A'])
data 将添加的类别使用支持向量机进行评估
将添加的类别使用支持向量机进行评估
ry_data=data.iloc[:,:-1]
ry_target=data.iloc[:,-1]ry_data_train,ry_data_test,ry_target_train,ry_target_test= \train_test_split(ry_data,ry_target,test_size=0.2,random_state=15)stdScale=StandardScaler().fit(ry_data_train)
ry_trainScaler=stdScale.transform(ry_data_train)
ry_testScaler=stdScale.transform(ry_data_test)svm=SVC().fit(ry_trainScaler,ry_target_train)ry_pred=svm.predict(ry_testScaler)
print('评估的前20个结果为:\n',ry_pred[:20])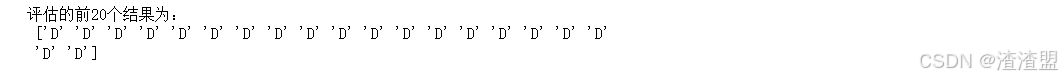 求出评估的准确率
求出评估的准确率
true=np.sum(ry_pred==ry_target_test)
print('评估结果的准确率为:',true/ry_target_test.shape[0])
from sklearn.metrics import accuracy_score
soure=accuracy_score(ry_pred,ry_target_test)
print('评估结果的准确率为:',soure) 用向量机评估出分类的报告
用向量机评估出分类的报告
from sklearn.metrics import classification_report
print('使用向量机评估社团人员类别的分类报告为:','\n',classification_report(ry_target_test,ry_pred))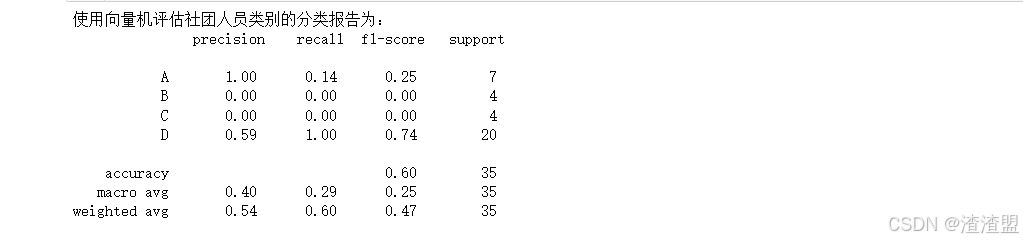 2、人员流失预测
2、人员流失预测
使用决策树预测人员流失状态,发现客户流失规律
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.model_selection import train_test_split定义评价函数
def test_pre(pred):# 混淆矩阵hx = confusion_matrix(y_te, pred, labels=['非流失', '准流失'])print('混淆矩阵:\n', hx)# 精确率P = hx[1, 1] / (hx[0, 1] + hx[1, 1])print('精确率:', round(P, 3))# 召回率R = hx[1, 1] / (hx[1, 0] + hx[1, 1])print('召回率:', round(R, 3))# F1值F1 = 2 * P * R / (P + R)print('F1值:', round(F1, 3))构建社员流失特征
info_user=pd.read_excel('../File/output/流失分析.xlsx')
data=info_user.iloc[:,2:]
data.drop(data[data['满意程度'].isnull()].index,inplace=True)
data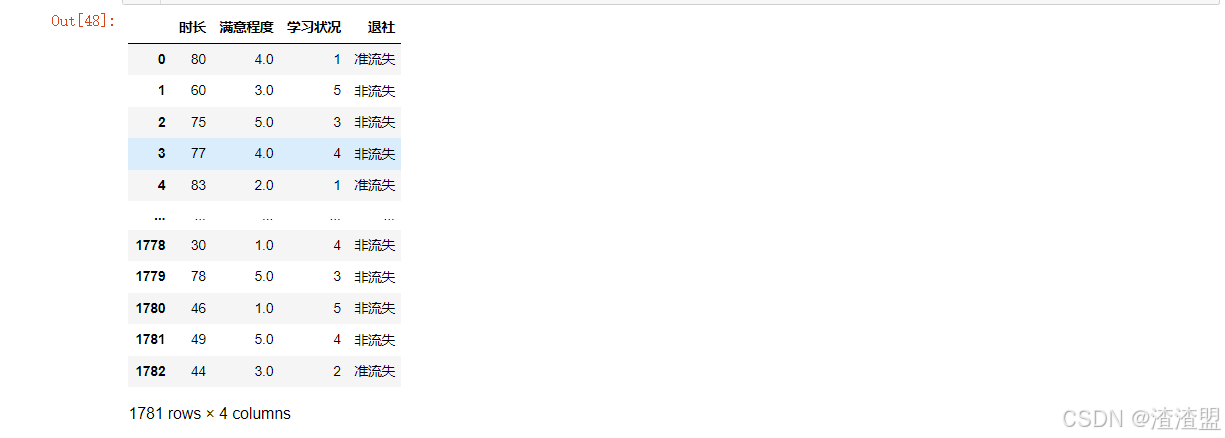 构建决策树模型
构建决策树模型
x_tr,x_te,y_tr,y_te=train_test_split(data.iloc[:,:-1],data['退社'],test_size=0.2,random_state=1314)
dtc=DTC(random_state=1314)
dtc.fit(x_tr,y_tr)
per=dtc.predict(x_te)
test_pre(per)相关文章:
)
IT社团分析预测项目(pandas、numpy、sklearn)
IT社团人数的增长陷入迟滞,同时不同目标任务和不同经营模式的社团更是层出不穷。在面临内忧外患的情况下,本社团希望结合社团行业现状,分析同学和出勤的数据,挖据数据中的信息,通过对人数流失进行预测寻找到相应的对策…...

C语言中位段的应用
一,位段的主要应用场景 硬件寄存器操作 嵌入式开发中,硬件寄存器通常以位为单位控制设备状态。位段可直接映射到寄存器,简化位操作: typedef struct {unsigned int enable : 1; // 使能位unsigned int mode : 3; // 模式选择&…...

【Linux网络#1】:网络基础知识
1、网络发展 在计算机发展历程中,经历过下面四个阶段: 1.独立模式 独立模式:计算机之间相互独立,每台计算机做自己的事情,彼此之间没有直接信息传递。如果两台计算机需要通信就需要将当前计算机的数据通过某种方式拷贝…...

基于物联网的园林防火监测系统
标题:基于物联网的园林防火监测系统 内容:1.摘要 随着全球气候变化和人类活动影响,园林火灾发生频率呈上升趋势,给生态环境和人类生命财产造成巨大损失。为有效预防和应对园林火灾,本文提出基于物联网的园林防火监测系统。该系统综合运用传感…...

华为云loT物联网介绍与使用
🌐 华为云 IoT 物联网平台详解:构建万物互联的智能底座 随着万物互联时代的到来,物联网(IoT)已成为推动数字化转型的关键技术之一。华为云 IoT 平台(IoT Device Access)作为华为云的核心服务之…...

Redis 数据类型全览:特性、场景与操作实例
Redis 是一款开源的内存数据库,支持多种数据类型,以下是对常见 Redis 数据类型的介绍: 1. String(字符串) 描述 字符串是 Redis 里最基础的数据类型,其值可以是简单的字符串、数字,甚至是二进…...

Qt动态库信号崩溃问题解决方案
在Qt中,当动态库向主程序发送信号导致崩溃时,通常涉及线程安全或对象生命周期问题。以下是逐步解决方案: 1. 检查线程上下文 问题:动态库所在的线程与主程序线程不同,跨线程信号未正确处理。解决方案: 显式…...

Go设计模式-观察者模式
简介 在软件开发中,我们常常会遇到这样的场景:一个对象的状态变化需要通知到多个其他对象,让它们做出相应的反应。观察者模式(Observer Pattern)就是解决这类问题的一种设计模式。在 Go 语言中,由于其简洁…...

《TCP/IP详解 卷1:协议》之第七、八章:Ping Traceroute
目录 一、ICMP回显请求和回显应答 1、ICMP回显请求 2、ICMP回显应答 二、ARP高速缓存 三、IP记录路由选项(Record Route,RR) 1、记录路由选项的工作过程 2、RR 选项的 IP 头部格式 2.1、RR 请求 2.2、RR响应 四、ping 的去返路径 五…...

Unity任务系统笔记
数据结构设计 任务基类包括的字段: string 任务内容; Transform 任务目的地; MyCharacter 任务开启后要更新对话的NPC; MyTalkData 任务开启后相关NPC要说的对话数据; 共同方法:开启任务、完成任务。…...
✨)
Three.js + React 实战系列-3D 个人主页:构建 Hero 场景组件(项目核心)✨
在本节中,我们将完成整个 3D 主业项目中最核心的组件 —— Hero.jsx。 这个组件作为首页的主视觉部分,整合了 3D 模型、动画相机、交互按钮与自适应布局,构建出一个立体、酷炫、可交互的主场景。 前置准备: ✅安装依赖ÿ…...
:深入剖析synchronized关键字的底层原理)
线程池(二):深入剖析synchronized关键字的底层原理
线程池(二):深入剖析synchronized关键字的底层原理 线程池(二):深入剖析synchronized关键字的底层原理一、基本使用1.1 修饰实例方法1.2 修饰静态方法1.3 修饰代码块 二、Monitor2.1 Monitor的概念2.2 Moni…...

网络原理 - 9
目录 数据链路层 以太网 以太网帧格式 MAC 地址 DNS(Domain Name System) 完! 数据链路层 这里的内容也是简单了解,除非是做交换机开发,一般程序员不需要涉及~~ 以太网 ”以太网“不是一种具体的网络…...

springboot入门-业务逻辑核心service层
在 Spring Boot 中,Service 层是业务逻辑的核心,负责协调数据访问层(Repository 或 Mapper)和控制器层(Controller),处理业务规则、事务管理以及数据转换。以下是 Service 层的详细说明、常用注…...
)
在RHEL 10上安装和配置TFTP服务器(不使用xinetd)
RHEL10已经废弃xinetd,使用下面的方式安装配置TFTP服务器。 1. 安装TFTP服务器和客户端 sudo dnf install tftp-server tftp -y 2. 配置TFTP服务器 创建TFTP根目录并设置权限 sudo mkdir -p /var/lib/tftpboot sudo chmod -R 777 /var/lib/tftpboot sudo chown -R…...

AIGC在游戏开发中的革命:自动化生成3A级游戏内容
一、智能游戏开发架构 1.1 传统开发痛点与AIGC创新 开发环节 传统痛点 AIGC解决方案 角色原画设计 美术资源产能瓶颈 文生图3D模型自动生成 场景搭建 重复劳动占比高 程序化生成风格迁移 NPC行为设计 模式化严重 强化学习驱动智能行为 任务系统 剧情线性缺乏变化 动态剧情生成系…...

ChatGPT、deepseek、豆包、Kimi、通义千问、腾讯元宝、文心一言、智谱清言代码能力对比
均使用测试时的最强模型 均是一次对话,对话内容一样 均开启深度思考 能联网的都联网了,但是作用不大,因为蓝桥杯刚考完,洛谷题目刚上传没多久 问题一测试了两遍 从问题三开始不再测试智谱清言(它思考时间太长了,前两个…...

Linux扩展
目录 扩展 查找如何进行后台运行程序的指令 使用 & 符号 使用 nohup 命令 使用 screen 或 tmux find命令 基本语法 常用选项 grep 命令 基本语法 常用选项 如何使用 vim 直接定位到错误行 1. 使用 :make 和 :copen 2. 使用 :lineno 定位 3. 通过 :grep 或 :…...

Java Hotspot VM researcher
** therefore, careful design and understanding of modules are essential to fully reap the performance benefits. **...

java—基础
目标 ├── 第一阶段:内容清单 │ └── 目标:建立编程思想 ├── 第二阶段:内容清单 │ └── 目标:提升编程能力 └── 第三阶段:内容清单└── 目标:分析需求,代码实现能力以下是根…...

【OpenCV】第二章——图像处理基础
图像处理基础学习笔记 本章节详细介绍了图像处理的基础内容,包括图像的读取、显示、保存,基本属性的查看,图像的变换与操作,以及常用的图像处理方法。 目录 图像的读取与显示图像基本属性图像的灰度化与二值化图像的色彩空间转换…...

在WSL2+Ubuntu22.04中通过conda pack导出一个conda环境包,然后尝试导入该环境包
如何导出一个离线conda环境?有两种方式,一种是导出env.yml即环境配置,一种是通过conda pack导出为一个环境包,前者只是导出配置(包括包名、版本等),而后者是直接将环境中所有的内容打包…...
---镜中万象:C++类的抽象之境与对象的具体之象)
C++:类和对象(上)---镜中万象:C++类的抽象之境与对象的具体之象
类(Class)是一种用户自定义的数据类型。 文章目录: 前言一、面向过程和面向对象初步认识 二、类的引入 三、类的定义 3.1类是什么? 3.2类的定义 四、类的访问限定符和封装 4.1类的访问限定符 4.2封装 五、类和对象的关系 六、类对…...

碰一碰发视频源码搭建全解析,支持OEM
在数字化交互体验不断升级的背景下,“碰一碰发视频” 功能凭借其便捷性和趣味性,逐渐成为营销推广、社交分享等场景中的热门需求。该功能基于近场通信技术,实现设备间快速的数据传输。本文将详细介绍其源码搭建过程,助力开发者实现…...

搭建spark-local模式
要搭建Spark的local模式,你可以按照以下步骤进行操作(以在Linux系统上安装为例,假设你已经安装了Java环境): 1. 下载Spark安装包:访问Spark官方网站(https://spark.apache.org/downloads.html&a…...

Goland终端PowerShell命令失效
Goland终端Terminal的PowerShell不能使用,明明windows上升级了PowerShell 7设置了配置文件,但是只能在windows终端下使用,goland终端下直接失效报错,安装升级PowerShell请看[博客](Windows11终端升级PowerShell7 - HashFlag - 博客…...

前端节流、防抖函数
节流 什么是节流? 节流就是同一个事件 一秒钟他执行了很多次。但是我不想他执行这么多次,我只想让他执行一次 或者两次。 那该怎么办? why baby why 那我想就是他执行的时候 我就设置一个定时器,如果定时器是空的,等会…...

如何使用WebRTC
WebRTC比较容易使用,只需要很少的步骤,有些消息在浏览器和服务器之间流动,有些则直接在两个浏览器之间流动, 1、建立WebRTC会话 a:建立WebRTC连接需要加入以下几个步骤: 获取本地媒体:getUse…...
 函数中使用 TypeScript 处理 null 和 undefined 的最佳实践)
在 Vue 3 setup() 函数中使用 TypeScript 处理 null 和 undefined 的最佳实践
在 Vue 3 中使用 setup() 函数和 TypeScript 时,null 和 undefined 是两个需要特别关注的类型。虽然它们看起来都表示“没有值”,但它们在 JavaScript 和 TypeScript 中有着不同的含义和使用场景。如果不小心处理它们,可能会导致潜在的 bug 或…...

【C++11】Lambda表达式
前言 上文我们学习了C11新语法,可变参数模板以及用可变参数模板作为形参的emplace接口。【C11】可变参数模板-CSDN博客 本文我们来学习C11下一个新语法,Lambda表达式。 1.Lambda表达式语法 Lambda表达式本质是一个匿名函数对象,与普通函数不同…...

【落羽的落羽 C++】vector
文章目录 一、vector类介绍二、vector中的常用接口三、迭代器失效问题四、vector的使用实例五、vector模拟实现 一、vector类介绍 vector是STL中的一种容器,本质上是顺序表。它和string类的结构很相似,其也有size、capacity、数组等,不同的是…...

DIFY 浅尝 - Dify + Ollama 抓取BBC新闻
假设你已经按照上篇文章 DIFY 浅尝 - DIFY Ollama 添加模型搭建好了本地环境. 创建一个新的工作流 进入你的本地Dify工作台,选择工作室->创建空白应用 选择工作流,输入应用名称BBC旅游新闻,点击创建 创建一个网页爬虫 配置网页爬虫…...
,适合研究学习,附模型研究报告)
基于MTF的1D-2D-CNN-BiLSTM-Attention时序图像多模态融合的故障分类识别(Matlab完整源码和数据),适合研究学习,附模型研究报告
基于MTF的1D-2D-CNN-BiLSTM-Attention时序图像多模态融合的故障分类识别(Matlab完整源码和数据),适合研究学习,附模型研究报告 目录 基于MTF的1D-2D-CNN-BiLSTM-Attention时序图像多模态融合的故障分类识别(Matlab完整…...

nuxt3项目搭建:一、初始化项目流程指南
一、初始化项目 初始化命令 1、创建nuxt3项目 npm create nuxtlatest2、填写项目名称 这里我直接填了nuxt-app 3、选择包管理器 这里的包管理器我们选择pnpm 4、选择是否创建git仓库 选择完包管理器后,脚手架会自动下载依赖,git仓库我已经创建好了…...

案例速成GO+redis 个人笔记
更多个人笔记:(仅供参考,非盈利) gitee: https://gitee.com/harryhack/it_note github: https://github.com/ZHLOVEYY/IT_note (更多GOredis等见内部,会及时更新~&#x…...

C/C++ 头文件包含机制:从语法到最佳实践
在C/C++编程中,头文件(.h 或 .hpp)扮演着至关重要的角色。它们不仅是代码模块化的基石,更是编译器理解程序结构的关键。然而,头文件的使用看似简单,实则暗含许多细节,稍有不慎便可能导致编译错误、代码冗余,甚至隐藏难以调试的问题。本文将从语法、编译器行为到工程实践…...

职业教育新形态数字教材的建设与应用:重构教育生态的数字化革命
教育部新时代职业学校名师(名匠)名校长培养计划、四川省第四批职业学校名师(名匠)培养计划专题 在某职业院校的智能制造课堂上,学生佩戴VR设备,通过数字教材中的虚拟工厂完成设备装配训练,系统实时生成操作评分与改进建议。这一场景折射出职业…...

跟着deepseek学golang--Go vs Java vs JavaScript三语言的差异
文章目录 一、类型系统与编译方式1. 类型检查时机2. 空值安全设计 二、并发模型对比1. 并发单元实现4. 锁机制差异 三、内存管理机制1. 垃圾回收对比2. 对象模型差异 四、工程实践差异1. 依赖管理工具4. 异常处理范式 五、跨平台能力对比1. 编译输出目标 综合对比表五角星说…...

梯度下降法
梯度下降法是一种常见的求最小值(或最值)的方法。它是通过沿着函数梯度的负方向进行迭代更新,直到找到局部最小值或最大值。梯度下降法应用于多元函数时,通过更新参数的方式找到最优解。 梯度下降法步骤: 初始化参数&…...

【Java 数据结构】List,ArrayList与顺序表
目录 一. List 1.1 什么是List 1.2 List 的常见方法 1.3 List 的使用 二. 顺序表 2.1 什么是顺序表 2.2 实现自己的顺序表 2.2.1 接口实现 2.2.2 实现顺序表 三. ArrayList 3.1 ArrayList简介 3.2 ArrayList的三个构造方法 3.2.1 无参构造方法 3.2.2 带一个参数的…...
)
用Python做有趣的AI项目1:用 TensorFlow 实现图像分类(识别猫、狗、汽车等)
项目目标 通过构建卷积神经网络(CNN),让模型学会识别图片中是什么物体。我们将使用 CIFAR-10 数据集,它包含 10 类:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。 🛠️ 开发环境与依赖 安装依赖&…...

正确应对监管部门的数据安全审查
首席数据官高鹏律师团队编著 在当今数字化时代,数据安全已成为企业及各类组织面临的重要议题,而监管部门的数据安全审查更是关乎其生存与发展的关键挑战。随着法律法规的不断完善与监管力度的加强,如何妥善应对这一审查,避免潜在…...

Springboot用IDEA打jar包 运行时 错误: 找不到或无法加载主类
Springboot用IDEA打jar包 运行时 错误: 找不到或无法加载主类 今天遇到个很神奇的问题。 就是我在打包我项目后。用java -jar命令的话 是无法启动这个项目的。 但是我在idea里面进行运行 就可以运行 先说结论 因为我这个是jdk17的项目 而我本机的jdk是1.8 所以说就会出现…...

【Linux网络】构建与优化HTTP请求处理 - HttpRequest从理解到实现
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

【高频考点精讲】实现垂直居中的多种CSS方法比较与最佳实践
前端工程师必看:7种CSS垂直居中方案大比拼(附真实代码) 今天咱们聊聊前端开发中最让人头疼的问题之一——垂直居中。不知道你们有没有遇到过这种情况:明明设置了margin: 0 auto水平居中了,垂直方向怎么折腾都不对劲。全栈老李当年刚入行时,为了一个div居中能折腾一晚上,…...

Java 字符串基础介绍
在 Java 编程中,字符串是不可或缺的一部分。无论是用户界面的消息显示、文件路径的处理,还是用户信息的存储,字符串都扮演着至关重要的角色。本文将带您深入了解 Java 字符串的特性、用法以及一些高级技巧,帮助您在编程实践中更加…...

SpringBoot中暗藏的设计模式
一、工厂模式 想象一下你去奶茶店点单——你只需要告诉店员要"珍珠奶茶",后厨就会自动完成煮茶、加料、封口整套流程。这就是工厂模式在SpringBoot中的体现。 典型应用场景: Bean的创建过程(ApplicationContext就是超级工厂&…...

使用 AFL++ 对 IoT 二进制文件进行模糊测试 - 第一部分
American fuzzy lop 是一款面向安全的模糊测试器,它采用一种新型的编译时插桩和遗传算法,可以自动发现干净、有趣的测试用例,从而触发目标二进制文件中新的内部状态。这显著提高了模糊测试代码的功能覆盖率。 AFL 的地址是https://lcamt uf.coredump.cx/afl/ 。它已经有一段…...

Java 线程的六种状态与完整生命周期详解
🚀 Java 线程的几种状态详解 在 Java 中,线程状态(Thread State)是由 Thread.State 枚举定义的,总共有六种: 状态含义典型场景示例NEW新建状态,线程对象刚创建,还未调用 start() 方…...

常见的机器视觉通用软件
国际常用软件 OpenCV : 特点 :开源免费,社区支持强大,拥有丰富的图像处理和计算机视觉算法库,支持多种编程语言,如 C、Python、Java 等,可实现对象检测、图像分割、特征提取等功能,具…...