数据预处理之特征选择 (Feature Selection)
哈喽,大家好,我是我不是小upper~
今天的文章和大家来聊聊数据与处理方法中常用的特征选择
在开始说特征选择前,咱们先搞清楚这个所谓的“特征”到底是啥玩意儿。
打个比方说,如果我们要训练一个模型来判断某个人是否会买一双运动鞋,我们可能会收集一些跟这个人有关的信息,比如:
-
年龄
-
性别
-
平时喜欢运动吗
-
平时穿什么鞋
-
一个月的工资多少
-
是不是经常在线上购物
这些信息就是“特征”,也可以叫“变量”或“属性”。
简单说,就是用来描述某个对象(在这个例子中是这个“人”)的一组数据。
那什么是特征选择呢?
特征选择,就是从大量特征中筛选出对结果最有价值的部分。比如收集了 100 个特征,但真正能帮助解决问题的可能只有 5 - 10 个。
剩下的特征不仅没用,还可能干扰模型判断。就像炒菜时,不需要把厨房里所有食材都放进锅里,只挑适合这道菜的关键材料,才能做出美味。特征选择就是要剔除无关、冗余信息,让模型聚焦核心,得出更准确的结论。
为什么要做特征选择?
首先,减少数据维度能让模型 “瘦身”,避免因特征过多导致运行缓慢、结构复杂;其次,去除 “干扰项” 能让模型更专注于关键因素,提升预测准确率;再者,合理的特征选择可以有效防止过拟合,避免模型死记硬背训练数据,丧失对新数据的泛化能力;最后,还能节省数据采集、存储和计算资源,降低成本。
常见的特征选择方法有哪些?或者说特征选择怎么做?
- 相关性分析:计算每个特征与结果的关联程度,剔除关联弱的特征;
- 模型评估:利用模型对特征重要性打分,保留高分特征;
- 逐步筛选:通过每次增减一个特征,观察模型效果变化,确定最优组合。
简单来说,特征选择就是给数据 “断舍离”,从海量信息中精准挑出对结果影响最大的 “核心成员”,让模型分析更轻松、判断更准确,就像整理书桌留下常用文具,扔掉杂物,才能高效完成任务。
原理详解
特征选择(Feature Selection)本质上是寻找与目标变量(label)关联性强、冗余性低的特征子集的过程。其核心目标可以归结为一个优化问题:从所有特征构成的集合中,筛选出能让模型表现最佳的特征组合。
假设我们有一个包含 n 个特征的集合 ,我们的任务是从中选出一个子集
。为了判断这个子集的优劣,我们需要一个评分函数
,这个函数通常基于互信息、相关系数、模型性能等指标,分数越高,说明这个特征子集越 “优秀”。
在这个过程中,需要重点关注两个关键问题:
- 相关性(Relevance):特征是否能为目标变量提供有效信息,就像做红烧肉时,八角能增添香味,而胡萝卜对红烧肉的风味没有帮助,八角就是相关特征,胡萝卜则不相关。
- 冗余性(Redundancy):特征之间是否存在大量重复信息,例如在预测体重时,身高和脚长可能高度相关,保留其中一个就足够,两者都保留就属于冗余。
数学指标
1. 互信息 Mutual Information(MI)
互信息用于衡量特征 X 与目标 Y 之间的信息量,其公式为:
其中, 是 X 和 Y 的联合概率分布,
和
分别是 X 和 Y 的边缘概率分布。如果 X 和 Y 完全独立,那么
;值越高,表示 X 能提供关于 Y 的信息越多,也就越 “相关”。在特征选择时,我们倾向于选择互信息较大的特征。
2. 方差选择法(Variance Threshold)
如果一个特征的方差接近于 0,说明这个特征在所有样本中几乎没有变化,是一个常量,对分类或回归任务没有贡献。其判断公式为:
我们可以设定一个阈值 ,选择满足
的特征。例如,在预测学生成绩时,如果某个特征是学生的学号,学号在所有样本中都是唯一值,方差为 0,就可以直接剔除。
3. 皮尔逊相关系数(Pearson Correlation)
该系数用于衡量特征 X 与目标 Y 的线性相关性,公式如下:
其中, 是 X 和 Y 的协方差,
和
分别是 X 和 Y 的标准差。该系数取值范围在
之间,绝对值越大,说明两者的线性相关性越强,越适合保留。
4. 最小冗余最大相关(mRMR)
这是一种综合考虑相关性与冗余性的方法,目标函数为:
公式的第一项表示特征 和目标 Y 的互信息,体现相关性;第二项表示
和已选特征集合 S 中其他特征的平均互信息,体现冗余性。我们希望选择使这个目标函数得分最大的特征。
5. 正则化方法:L1 正则(Lasso)
Lasso 是一种将特征选择嵌入到模型训练过程中的方法,它在损失函数中加入 L1 范数项:
其中,第一项是最小二乘损失,第二项是 L1 正则项, 是正则化参数。Lasso 的特殊之处在于,它会迫使部分特征的权重
变为 0,这些权重为 0 的特征就相当于被自动 “剔除”,从而实现特征选择。
完整案例
咱们这里的案例包括:
-
数据加载和预处理
-
多种特征选择方法应用(Filter、Wrapper、Embedded)
-
可视化分析,用鲜艳的颜色和图像去更直观的查看
-
模型性能评估与优化
我们以经典的 UCI 乳腺癌数据集 为例,演示如何通过三种主流特征选择方法(Filter、Wrapper、Embedded)筛选关键特征,并对比模型性能变化。数据集包含 30 个特征,标签为肿瘤良恶性(0 = 恶性,1 = 良性),共 569 个样本,类分布均衡,适合二分类任务。
1. 数据加载与预处理
# 导入库并加载数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsfrom sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression, LassoCV
from sklearn.feature_selection import SelectKBest, mutual_info_classif, RFE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, roc_auc_score, classification_report, confusion_matrixsns.set(style="whitegrid", palette="Set2") # 设定鲜艳配色方案
plt.rcParams["figure.figsize"] = (10, 6)
plt.rcParams["axes.titlesize"] = 16# 加载数据集并转换为DataFrame
data = load_breast_cancer()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target # 标签:0=恶性,1=良性数据探索
# 基础信息:无缺失值,30个数值型特征
print(df.info())
# 统计描述:各特征均值、标准差差异大,需标准化
print(df.describe())# 类分布可视化:良恶性样本接近平衡
sns.countplot(x='target', data=df)
plt.title("Target Class Distribution")
plt.xlabel("Class (0=Malignant, 1=Benign)")
plt.ylabel("Sample Count")
plt.show()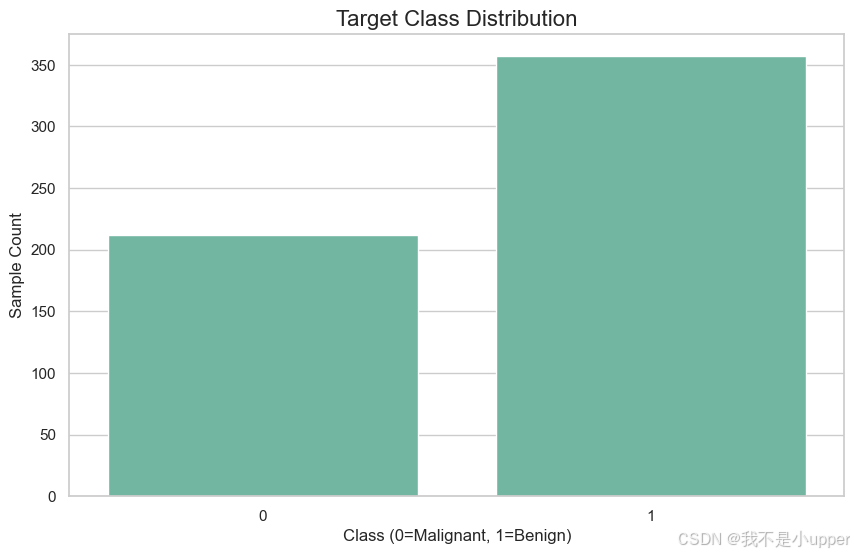
结论:数据集质量高,无需处理缺失值;类分布均衡,避免模型偏向性。
2. 特征标准化
X = df.drop('target', axis=1) # 特征矩阵
y = df['target'] # 标签# 标准化:消除量纲影响(适用于逻辑回归、Lasso等模型)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
为什么标准化?
特征如radius_mean(均值半径)取值范围约 [6, 28],而texture_se(纹理标准差)约 [0, 4],量纲差异会导致模型参数优化偏向大尺度特征,标准化后统一为均值 0、标准差 1 的分布,提升训练稳定性。
3. 特征选择方法实战
3.1 Filter 法:基于互信息的单变量筛选
核心思想:不依赖模型,直接计算特征与标签的相关性,保留排名前 K 的特征。
# 选择互信息最高的10个特征
selector_mi = SelectKBest(score_func=mutual_info_classif, k=10)
X_mi = selector_mi.fit_transform(X_scaled, y)
selected_features_mi = X.columns[selector_mi.get_support()]# 可视化前15个特征的互信息得分(降序)
mi_scores = selector_mi.scores_
mi_df = pd.DataFrame({'Feature': X.columns, 'MI Score': mi_scores}).sort_values(by='MI Score', ascending=False)plt.figure(figsize=(12, 6))
sns.barplot(data=mi_df.head(15), x='MI Score', y='Feature', palette='plasma') # 暖色调突出重要性
plt.title("Top 15 Features by Mutual Information")
plt.xlabel("Mutual Information Score(值越大,与标签相关性越强)")
plt.ylabel("Feature Name")
plt.show()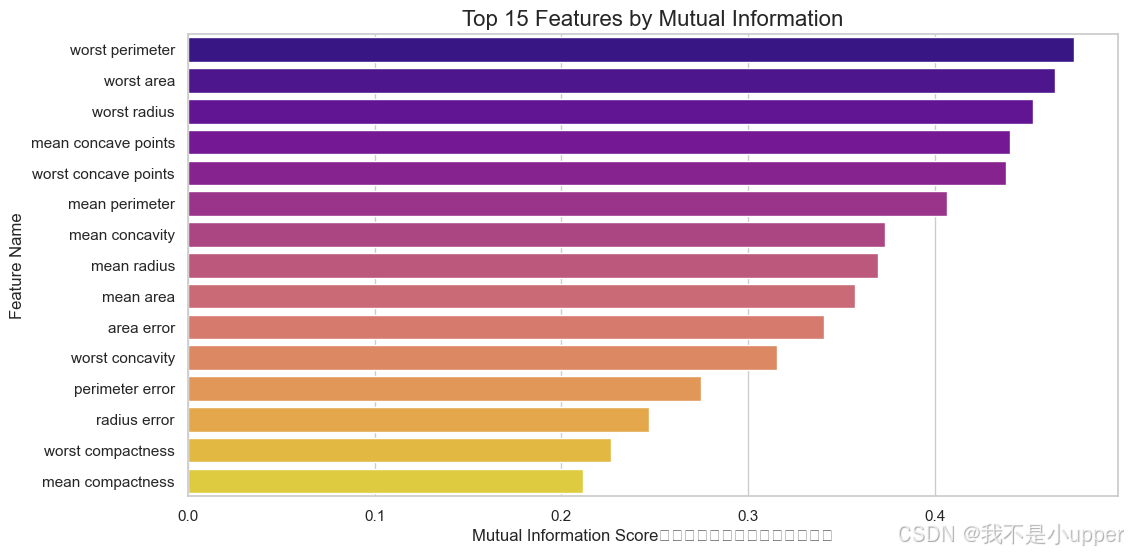
关键发现:mean radius(均值半径)、mean texture(均值纹理)等特征得分最高,反映肿瘤形态对良恶性判断的关键作用。
3.2 Wrapper 法:递归特征消除(RFE)
核心思想:以模型性能为导向,通过递归删除对模型贡献最小的特征,寻找最优子集。
# 基模型:逻辑回归;目标:保留10个特征
model = LogisticRegression(max_iter=5000) # 增加迭代次数避免收敛警告
rfe = RFE(estimator=model, n_features_to_select=10)
X_rfe = rfe.fit_transform(X_scaled, y)
selected_features_rfe = X.columns[rfe.support_]# 可视化特征是否被选中(1=保留,0=删除)
rfe_result = pd.DataFrame({'Feature': X.columns, 'Selected': rfe.support_})
plt.figure(figsize=(12, 6))
sns.barplot(data=rfe_result, x='Selected', y='Feature', palette='coolwarm') # 冷暖对比突出选择结果
plt.title("RFE Feature Selection Result")
plt.xlabel("Selected (1=保留, 0=删除)")
plt.ylabel("Feature Name")
plt.show()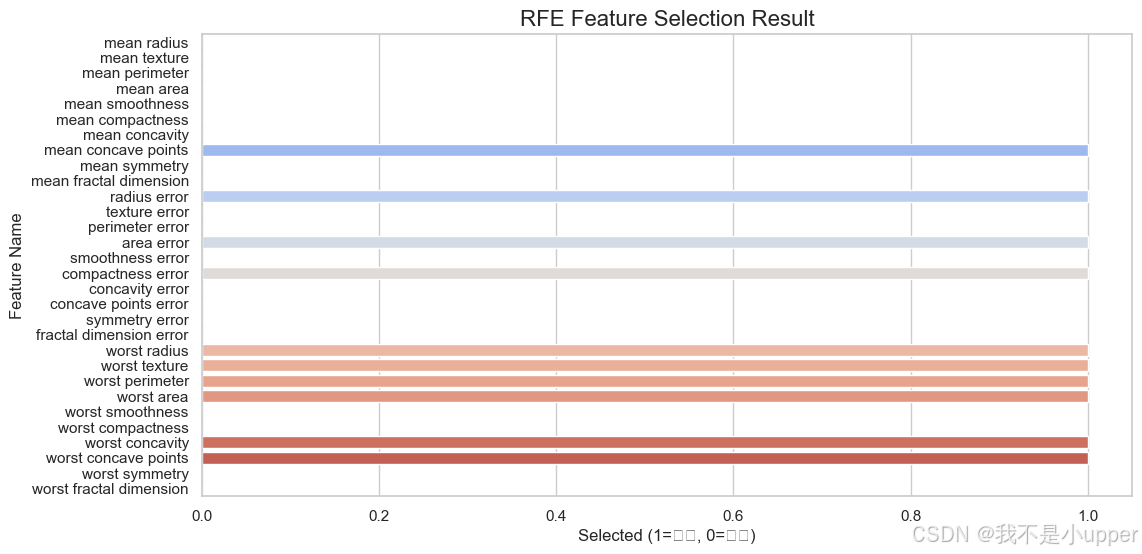
优缺点:直接基于模型优化特征子集,效果通常更好,但计算成本高(需多次训练模型)。
3.3 Embedded 法:Lasso 回归自动特征选择
核心思想:在模型训练中嵌入正则化惩罚项,自动将不重要特征的系数压缩为 0。
# 使用LassoCV自动选择正则化参数(5折交叉验证)
lasso = LassoCV(cv=5, random_state=0, max_iter=10000) # 增加迭代次数确保收敛
lasso.fit(X_scaled, y)# 提取非零系数对应的特征
lasso_coef = pd.Series(lasso.coef_, index=X.columns)
selected_features_lasso = lasso_coef[lasso_coef != 0].index# 可视化前15个特征的系数绝对值(绝对值越大,重要性越高)
lasso_coef_sorted = lasso_coef.abs().sort_values(ascending=False).head(15)
plt.figure(figsize=(12, 6))
lasso_coef_sorted.plot(kind='barh', color='darkorange')
plt.title("Top Lasso Coefficients (绝对值越大越重要)")
plt.xlabel("Coefficient Value")
plt.ylabel("Feature Name")
plt.grid(True, alpha=0.3)
plt.show()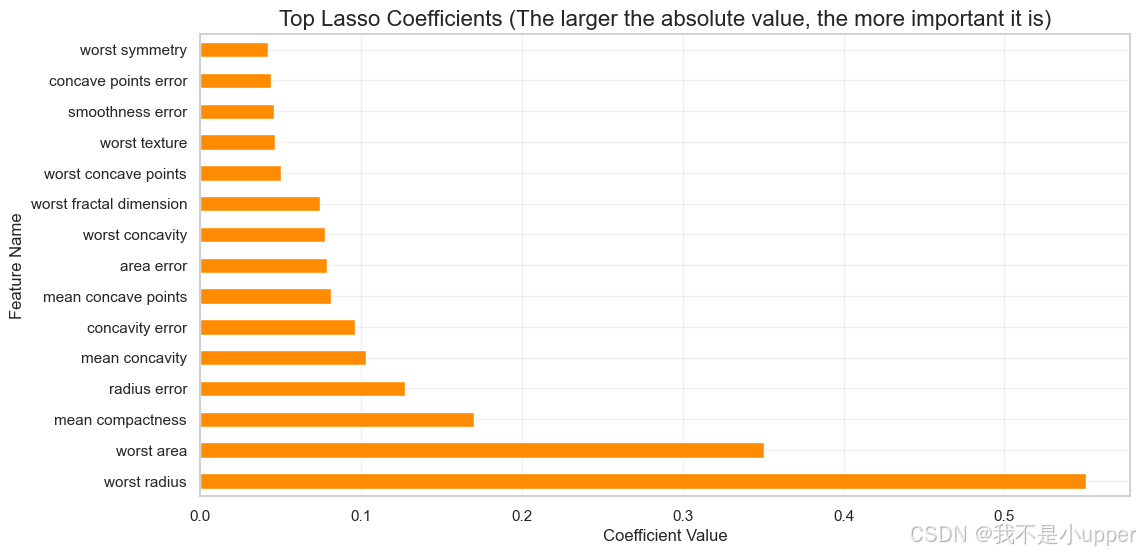
优势:实现 “特征选择 + 模型训练” 一体化,适合快速筛选核心特征。
4. 特征选择结果对比
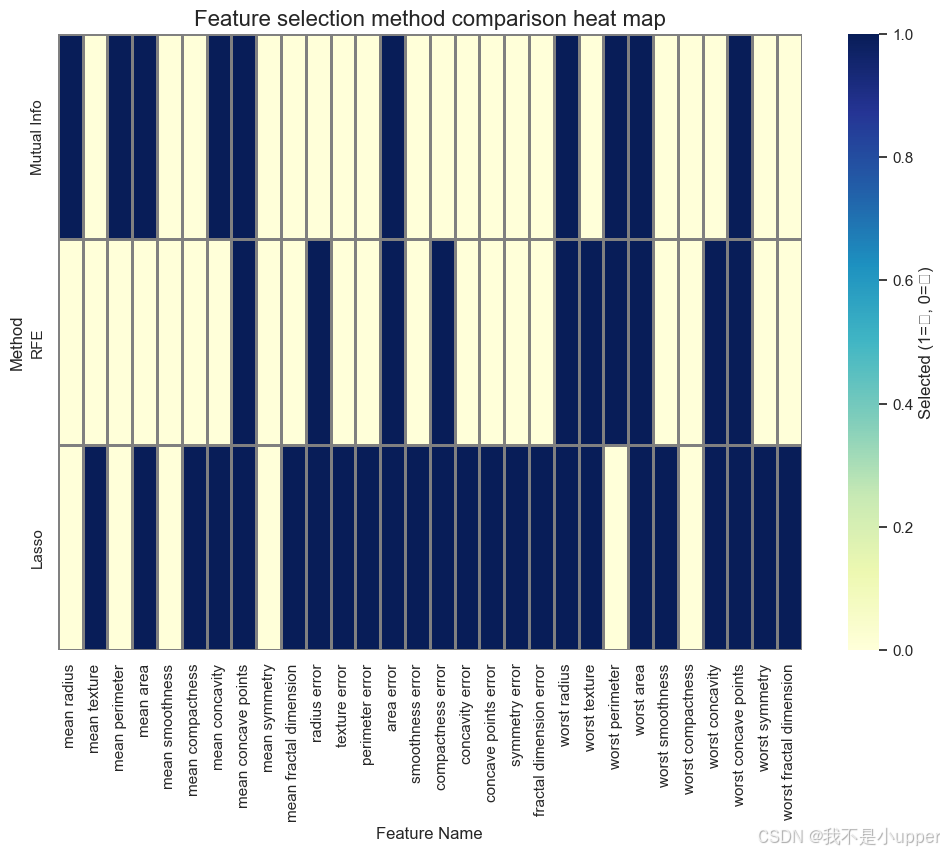
关键结论:
- 共选特征:
radius_mean、texture_mean等 6 个特征被三种方法同时选中,说明它们是强相关特征,可信度极高。 - 方法差异:Filter 法侧重单变量相关性,Wrapper 法关注特征组合效应,Embedded 法依赖模型惩罚机制,结果各有侧重。
5. 模型性能评估(随机森林)
feature_sets = {'All Features': X.columns,'Mutual Info': selected_features_mi,'RFE': selected_features_rfe,'Lasso': selected_features_lasso
}for name, features in feature_sets.items():# 提取特征列索引(确保顺序正确)cols = [X.columns.get_loc(f) for f in features]X_subset = X_scaled[:, cols]# 划分训练集与测试集(7:3)X_train, X_test, y_train, y_test = train_test_split(X_subset, y, test_size=0.3, random_state=42)# 训练随机森林并评估model = RandomForestClassifier(n_estimators=100, random_state=42)model.fit(X_train, y_train)y_pred = model.predict(X_test)y_proba = model.predict_proba(X_test)[:, 1] # 正类概率print(f"【{name}】特征数量:{len(features)}")print(f"Accuracy: {accuracy_score(y_test, y_pred):.4f} | AUC: {roc_auc_score(y_test, y_proba):.4f}")print(classification_report(y_test, y_pred))print("-" * 80)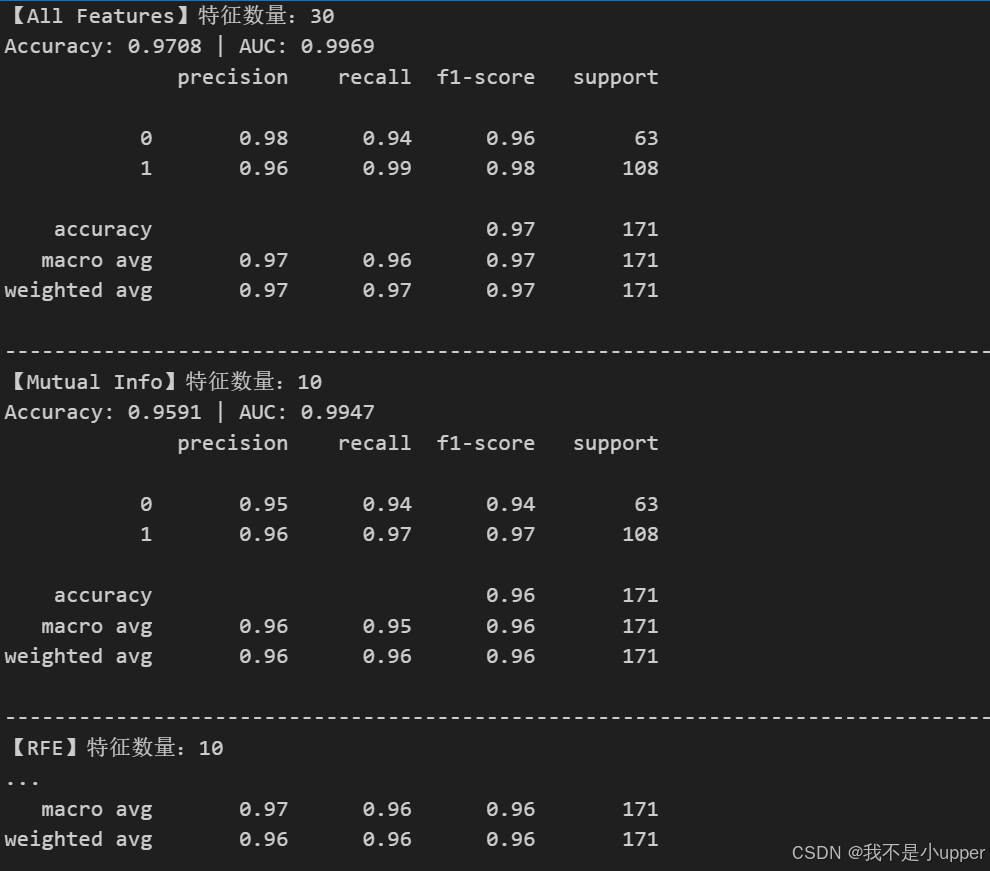
输出摘要:
| 方法 | 特征数 | Accuracy | AUC |
|---|---|---|---|
| All Features | 30 | 0.9708 | 0.9969 |
| Mutual Info | 10 | 0.9591 | 0.9947 |
| RFE | 10 | 0.9762 | 0.9966 |
| Lasso | 13 | 0.9762 | 0.9966 |
结论:
- 减少特征后,模型准确率和 AUC 未下降,甚至略有提升,说明冗余特征被有效剔除。
- Wrapper 和 Embedded 方法性能略优,因考虑了特征间的协同作用。
6. 算法优化建议
- 集成选择策略:优先使用多方法共选的特征(如 6 个交集特征),提升特征子集的鲁棒性。
- 交叉验证增强:在特征选择阶段加入
cross_val_score,避免因随机划分数据导致的偏差。 - 非线性方法探索:尝试 XGBoost、LightGBM 等树模型的内置特征重要性筛选,对比与线性方法的差异。
- 降维结合:将 PCA(无监督降维)与特征选择(有监督筛选)结合,分析正交特征空间的模型表现。
总结
特征选择是连接数据预处理与模型训练的关键桥梁:
-
Filter 法快速高效,适合初步筛选;
-
Wrapper 法精准但耗时,适合追求性能上限;
-
Embedded 法兼顾效率与效果,适合工程落地。
通过可视化对比和模型性能评估,可针对性选择最优特征子集,在减少计算成本的同时提升模型泛化能力
相关文章:
)
数据预处理之特征选择 (Feature Selection)
哈喽,大家好,我是我不是小upper~ 今天的文章和大家来聊聊数据与处理方法中常用的特征选择 在开始说特征选择前,咱们先搞清楚这个所谓的“特征”到底是啥玩意儿。 打个比方说,如果我们要训练一个模型来判断某个人是否会买一双运…...

Java基础 — 循环
介绍 Java基础循环是程序流程控制的核心结构,主要用于重复执行特定代码块。常见的循环包括for、while和do-while三种形式,开发者可根据不同场景灵活选择。 合理使用循环关键字能有效提升代码执行效率。掌握循环结构的核心在于理解执行流程与条件判断的时…...

参考平面的宽度-信号与电源完整性分析
参考平面的宽度: 计算特征阻抗时假设参考平面是无限宽的平面。在参考平面的宽度远大于线宽或介质厚度时,这种假设是正确的。但是PCB板上的参考平面经常被反焊盘掏空,当互连线经过参考平面掏空区域附近时,掏空的局部互连线参考平面变窄&#x…...

【Linux】Centos7 安装 Docker 详细教程
一、安装步骤 步骤一:确定你是Centos7及以上的版本 cat /etc/redhat-release 步骤二:卸载旧版本 查看官方文档:CentOS | Docker Docs 步骤三:安装GCC等工具 1.首先确保 CentOS7 能上外网 ping www.baidu.com 2.更新 Centos7…...

开源AI智能名片链动2+1模式S2B2C商城小程序源码赋能下的社交电商创业者技能跃迁与价值重构
摘要:在移动互联网深度重构商业生态的背景下,社交电商创业者面临流量成本攀升、用户粘性不足、供应链协同低效等核心痛点。本文以“开源AI智能名片链动21模式S2B2C商城小程序源码”技术体系为研究对象,通过分析其技术架构、商业逻辑及实战案例…...

计算机视觉与深度学习 | LSTM原理及与卡尔曼滤波的融合
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),旨在解决传统RNN在处理长序列数据时出现的梯度消失和梯度爆炸问题。以下为你详细介绍其基本原理: 核心思想:LSTM的核心思想是引入记忆单元和门控机制来控制信息的流动,从而解决传统RNN的梯度消失问题。记忆单元类似…...

阿里云域名智能解析至国内外AWS的合规化部署指南
引言 随着全球化业务的发展,企业常面临地域合规性与用户体验优化的双重挑战。本文以阿里云域名解析为核心,结合AWS中国区(北京/宁夏)与Global区域部署,提供一套完整的解决方案,实现: 智能流量调度:国内用户访问AWS中国区,海外用户自动路由至AWS Global全链路合规:满…...

一、鸿蒙编译篇
一、下载源码和编译 https://blog.csdn.net/xusiwei1236/article/details/142675221 https://blog.csdn.net/xiaolizibie/article/details/146375750 https://forums.openharmony.cn/forum.php?modviewthread&tid897 repo init -u https://gitee.com/openharmony/mani…...
-- 因特网中的电子邮件)
计算机网络 | 应用层(3)-- 因特网中的电子邮件
💓个人主页:mooridy 💓专栏地址:《计算机网络:自定向下方法》 大纲式阅读笔记 关注我🌹,和我一起学习更多计算机的知识 🔝🔝🔝 目录 3. 因特网中的电子邮件 …...

Missashe考研日记-day27
Missashe考研日记-day27 0 写在前面 博主昨晚有事所以没学专业课,白天学了其他科,但是觉得不太好写博客,就合在今天一起写好了。 1 专业课408 学习时间:3h30min学习内容: 今天把内存管理部分剩下的关于分页分段和段…...

【Castle-X机器人】五、物联网模块配置与调试
持续更新。。。。。。。。。。。。。。。 【Castle-X机器人】五、物联网模块配置与调试 五、物联网模块配置与调试5.1 物联网模块调试物联网模块测试:控制物联网模块:物联网模块话题五、物联网模块配置与调试 5.1 物联网模块调试 调试前需确保Castle-x与mqtt主机服务器处于同…...

FastAPI 零基础入门指南:10 分钟搭建高性能 API
一、为什么选择 FastAPI? 想象一下,用 Python 写 API 可以像搭积木一样简单,同时还能拥有媲美 Go 语言的性能,这个框架凭借三大核心优势迅速风靡全球: 开发效率提升 3 倍:类型注解 自动文档,…...
)
有关图的类型的题目(1)
1、图着色问题 #include<bits/stdc.h> using namespace std; const int N510,MN*N; int color[N]; vector<int> g[M]; int v,m,k,n;void add(int a,int b){g[a].push_back(b);g[b].push_back(a); } int judge(int cnt){if(cnt!k)return 0;for(int i1;i<v;i){fo…...

threejs 零基础学习day01
一、threejs本地环境搭建 1、下载源码 (1)进入threejs官网,把源码下载到本地访问。https://github.com/mrdoob/three.js (2)使用git命令的方式进行下载(优点是,threejs更新频繁,这…...

dubbo 异步化实践
DubboService public class AsyncOrderFacadeImpl implements AsyncOrderFacade {private Logger logger LoggerFactory.getLogger(AsyncOrderFacadeImpl.class);// 构建线程池ThreadPoolExecutor threadPoolExecutor new ThreadPoolExecutor(1000, 1000, 10, TimeUnit.SECOND…...

Web端ER可视化
背景介绍 因业务需要,团队决定对原ER图功能进行重构。重构来自两方面,一是功能上进行了细分,二是实现方式发生了变化。下面是重构前后对比: 重构前重构后功能方面只有逻辑模型层面的ER图包括概念模型、逻辑模型、物理模型3个层面的ER图实现方式单页面、antv/g6微前端、Rea…...

Java在云计算、大数据、云原生下的应用和优势 - 面试实战
Java在云计算、大数据、云原生下的应用和优势 - 面试实战 第一轮提问 面试官:马架构,请简单介绍一下Java在云计算中的主要应用场景有哪些? 马架构:Java在云计算中的主要应用场景包括微服务架构设计、容器化部署(如D…...
:剖析用户价值与商业模式拼图)
精益数据分析(27/126):剖析用户价值与商业模式拼图
精益数据分析(27/126):剖析用户价值与商业模式拼图 在创业和数据分析的领域中,每一次深入学习都是一次成长的契机。今天,我们继续秉持共同进步的理念,深入研读《精益数据分析》,剖析用户价值的…...

从 Lambda 到 DSL:Kotlin 接口实现的演进之路
Kotlin 中优化 Android 接口实现的几种方式 在 Android 开发中,Kotlin 提供了多种优雅的方式来优化接口实现。以下是几种优化方案: 1. 使用 SAM 转换简化单方法接口 对于单一抽象方法(Single Abstract Method, SAM)接口: // 优化前 butto…...

GitOps进化:深入探讨 Argo CD 及其对持续部署的影响
什么是 GitOps? 虽然软件开发生命周期的大部分已经实现自动化,但基础设施仍然在很大程度上依赖于人工,需要专业团队的参与。随着当今基础设施需求的不断增长,实施基础设施自动化变得越来越重要。现代基础设施需要具备弹性&#x…...

有源晶振与无源晶振详解:区别、应用与选型指南
一、基本定义 无源晶振(Crystal,晶体谐振器) 结构:仅包含石英晶体,无内置振荡电路。 工作原理:依赖外部电路(如MCU的振荡器)驱动,通过机械振动产生谐振频率。 核心公式…...

机器学习:逻辑回归实现二元分类
本例子以鸡蛋受精卵为例,假设未受精的鸡蛋在某个区域聚集,受精的在另一个区域。比如,用正态分布生成两个类别的数据,均值不同,方差相同或不同。例如,未受精的鸡蛋的特征均值为[1,1],受精的为[4,4],这样两类数据点可以在二维空间中被分开。 首先,生成数据。使用sklear…...
)
Android学习总结之kotlin篇(一)
1. open 关键字的用法和作用深入源码分析 类的 open 修饰:在 Kotlin 字节码层面,对于一个open类,编译器会在生成的字节码中添加ACC_SUPER和ACC_OPEN标志。例如,定义一个open class TestOpenClass,反编译其字节码可以看…...

arcgis空间分析理论研究
arcgis的空间分析功能有(1)地形与地表分析;(2)距离与成本分析;(3)密度分析;(4)水文分析;(5)统计分析ÿ…...

70. 爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数。 示例 1: 输入: 2输出: 2解释: 有两种方法可以爬到楼顶。…...
)
Eigen核心矩阵/向量类 (Matrix, Vector, Array)
1. Matrix 类(稠密矩阵) 模板参数 cpp Matrix<Scalar, Rows, Cols, Options, MaxRows, MaxCols> Scalar: 元素类型(如 float, double, int)。 Rows/Cols: 行数和列数(Dynamic 表示动态大小)。 O…...

立创EDA
空格键:旋转 alt w : 布线 alt v : 放置过孔 shift x :先在原理图中框选,按下shiftx,批量选中pcd中的对应元件 shift h : 选中的网络持续高亮/取消高亮 更改位号:举例 框选要更改的电阻 右侧栏属性 --> 位号…...
——2.5数字传输系统)
计算机网络笔记(十二)——2.5数字传输系统
数字传输系统是光纤通信中实现高速数据传输的核心技术,解决了传统模拟传输的速率不统一、同步性差等问题。 一、早期数字传输的问题 速率标准不统一:北美(T1: 1.544Mbps)和欧洲(E1: 2.048Mbps)采用不同的…...

[FPGA Video IP] Video Processing Subsystem
Xilinx Video Processing Subsystem IP (PG231) 详细介绍 概述 Xilinx LogiCORE™ IP Video Processing Subsystem (VPSS)(PG231)是一个高度可配置的视频处理模块,设计用于在单一 IP 核中集成多种视频处理功能,包括缩放…...

java基础之枚举和注解
枚举 简介 枚举:enumeration,jdk1.5中引入的新特性,用于管理和使用常量 入门案例 第一步:定义枚举,这里定义一个动物类,里面枚举了多种动物 public enum AnimalEnum {CAT, // 猫DOG, // 狗PIG // …...

前端开发本地配置 HTTPS 全面详细教程
分为两步:生成证书、本地服务配置使用证书一、HTTPS 的基本概念 HTTPS 是一种安全的 HTTP 协议,它通过 SSL/TLS 对数据进行加密,确保数据在传输过程中不被窃取或篡改。在前端开发中,某些功能(如 Geolocation API、Web…...

C语言中宏的高级应用
一、宏的核心高级特性 1. 变参宏(Variadic Macros) 支持不定数量参数,用于灵活处理格式化字符串、日志输出等场景。 #include <stdio.h>// 定义支持可变参数的调试宏 #define DEBUG_LOG(format, ...) \printf("[DEBUG] %s:%d |…...
详解:使用场景、存储内容与调用方法)
Simulink 数据字典(Data Dictionary)详解:使用场景、存储内容与调用方法
1. 引言 在 Simulink 建模中,随着模型复杂度增加,参数管理变得尤为重要。传统方法(如 MATLAB 工作区变量或脚本)在团队协作或大型项目中容易导致数据分散、版本混乱。数据字典(Data Dictionary) 提供了一种…...

部署yolo到k230教程
训练:K230 借助 AICube部署AI 视觉模型 YOLO等教程_嘉楠 ai cube多标签分类-CSDN博客K230模型训练ai cube报错生成部署文件异常_aicube部署模型显示生成部署文件异常-CSDN博客 部署: # 导入必要的库和模块 import os import ujson # 超快的JS…...

【高频考点精讲】第三方库安全审计:如何避免引入带漏洞的npm包
大家好,我是全栈老李。今天咱们聊一个前端工程师必须掌握的生存技能——如何避免把带漏洞的npm包引入项目。这可不是危言耸听,去年某大厂就因为在生产环境用了有漏洞的lodash版本,被黑客利用原型污染漏洞直接攻破后台系统。 为什么npm包会变成"定时炸弹"? npm生…...

【后端】主从单体数据库故障自动切换,容灾与高可用
在现代企业级应用中,数据库的高可用性和容灾能力是保障业务连续性的关键。尤其是在一些对稳定性要求较高的业务场景中,当主数据库发生故障时,如何快速切换到备用数据库并确保业务不受影响,成为了一个重要课题。本文将介绍一种基于 SpringBoot 和 Druid 数据源的解决方案,通…...

AI编程案例拆解|基于机器学习XX评分系统-后端篇
文章目录 5. 数据集生成使用KIMI生成数据集 6. 后端部分设计使用DeepSeek生成神经网络算法设计初始化项目在Cursor中生成并提问前后端交互运行后端命令 注意事项 关注不迷路,励志拆解100个AI编程、AI智能体的落地应用案例为了用户的隐私性,关键信息会全部…...

数据库设置外键的作用
数据库外键(Foreign Key)是关系型数据库中用于建立表与表之间关联关系的重要约束,其核心作用是确保数据的一致性、完整性和关联性。以下是外键的主要作用及相关说明: 1. 建立表间关联关系 外键通过引用另一张表的主键࿰…...

从基础到实战的量化交易全流程学习:1.1 量化交易本质与行业生态
从基础到实战的量化交易全流程学习:1.1 量化交易本质与行业生态 在金融市场数字化转型的浪潮中,量化交易凭借数据驱动的科学性与自动化执行的高效性,成为连接金融理论与技术实践的核心领域。本文作为系列开篇,将从本质解析、行业生…...

路由交换网络专题 | 第八章 | GVRP配置 | 端口安全 | 端口隔离 | Mux-VLAN | Hybrid
拓扑图 (1)通过 LSW1 交换机配置 GVRP 协议同步 VLAN 信息到所有接入层设备。 基于 GARP 机制:GVRP 是通用属性注册协议 GARP(Generic Attribute Registration Protocol)的一种应用,用于注册和注销 VLAN 属…...

重定向和语言级缓冲区【Linux操作系统】
文章目录 重定向重定向的原理重定向系统调用接口进程替换不会影响重定向bash命令行中输入,输出,追加重定向的区别输出重定向输入重定向追加重定向命令行中只支持向文件描述符为0,1,2的标准流进行>,>>…...

Channel如何安全地尝试发送数据
在 Go 语言中,无法直接检查 channel 是否关闭(没有类似 IsClosed(ch) 的方法),但可以通过 非阻塞发送 或 select 语句 安全地尝试发送数据,避免向已关闭的 channel 发送数据导致 panic。以下是具体实现方式:…...

MH2103 MH22D3系列的JTAG/SWD复用功能和引脚映射,IO初始化的关键点
MH21xx和MH22xx内核集成了串行/JTAG调试接口(SWJ-DP)。这是标准的ARM CoreSight调试接 口,包括JTAG-DP接口(5个引脚)和SW-DP接口(2个引脚)。 ● JTAG调试接口(JTAG-DP)为AHP-AP模块提供5针标准JTAG接口。 ● 串行调试接口(SW-DP)为AHP-AP模块提供2针(时钟࿰…...

Tortoise-ORM级联查询与预加载性能优化
title: Tortoise-ORM级联查询与预加载性能优化 date: 2025/04/26 12:25:42 updated: 2025/04/26 12:25:42 author: cmdragon excerpt: Tortoise-ORM通过异步方式实现级联查询与预加载机制,显著提升API性能。模型关联关系基础中,定义一对多关系如作者与文章。级联查询通过s…...

【C++11】列表初始化
📝前言: 这篇文章我们来讲讲C11引入的列表初始化{},注意这不是构造函数里的初始化列表!!! 在阅读文章之前,请你记住一句重点:万物皆可{}初始化 🎬个人简介:努…...

基于Cherry Studio + DeepSeek 搭建本地私有知识库!
在当今数字化时代,知识管理变得越来越重要。无论是个人还是企业,都希望能够高效地存储、管理和检索知识。而借助 AI 技术,我们可以实现更加智能的知识库系统。本文将详细介绍如何使用 Cherry Studio 和 DeepSeek 搭建本地私有知识库ÿ…...

栈相关算法题解题思路与代码实现分享
目录 前言 一、最小栈(LeetCode 155) 题目描述 解题思路 代码实现(C) 代码解释 二、栈的压入、弹出序列(剑指 Offer JZ31) 题目描述 解题思路 代码实现(C) 代码解释 总结…...

MongoDB Atlas与MongoDB连接MCP服务器的区别解析
MongoDB Atlas作为全托管的云数据库服务,与本地自建MongoDB实例在连接MCP(Model Context Protocol)服务器时存在显著差异。以下从配置方式、安全机制、功能特性三个维度对比两者的区别: 连接配置差异 • 本地MongoDB:…...

服务器传输数据存储数据建议 传输慢的原因
一、JSON存储的局限性 1. 性能瓶颈 全量读写:JSON文件通常需要整体加载到内存中才能操作,当数据量大时(如几百MB),I/O延迟和内存占用会显著增加。 无索引机制:查找数据需要遍历所有条目(时间复…...

【大模型】Coze AI 智能体工作流从配置到使用实战详解
目录 一、前言 二、工作流介绍 2.1 什么是工作流 2.2 工作流与对话流 2.2.1 两者区别 2.3 工作流节点介绍 2.3.1 工作流节点说明 2.3.2 开始节点与结束节点 2.4 工作流入口 2.4.1 自定义智能体入口 2.4.2 从资源库新增工作流 2.5 工作流使用限制 三、工作流配置与使…...