Flink部署与应用——部署方式介绍
引入
我们通过Flink相关论文的介绍,对于Flink已经有了初步理解,这里简单的梳理一下Flink常见的部署方式。
Flink 的部署方式
StandAlone模式
介绍
StandAlone模式是Flink框架自带的分布式部署模式,不依赖其他的资源调度框架,特点:
- 分布式多台物理主机部署
- 依赖于Java8或Java11JDk环境
- 仅支持Session模式提交Job
- 支持高可用配置
但是有以下缺点:
- 资源利用弹性不够(资源总量是定死的;job退出后也不能立刻回收资源)
- 资源隔离度不够(所有job共享集群的资源)
- 所有job共用一个jobmanager,负载过大
- 只能运行Flink程序,不能能运行其他的编程模型
OnYarn模式
介绍
YARN是一个通用的资源调度框架,特点是:
- 可以运行多种编程模型,例如MR、Storm、Spark、Flink等
- 性能稳定,运维经验丰富
- 灵活的资源分配和资源隔离
- 每提交一个application都会有一个专门的ApplicationMater(JobManager)
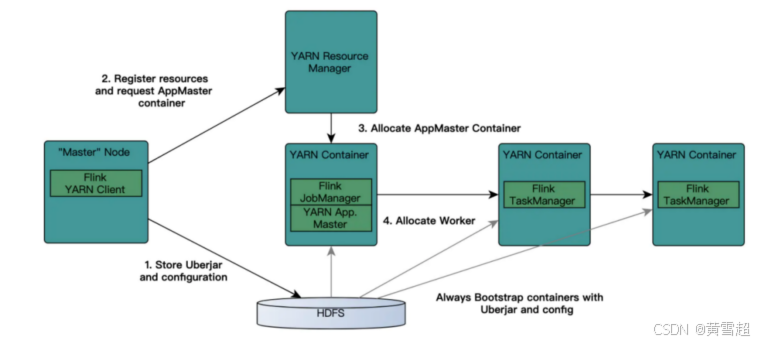
ResouManager(NM):
- 负责处理客户端请求
- 监控NodeManager
- 启动和监控APPlicationMaster
- 资源的分配和调度
NodeManager:
- 管理单个Worker节点上的资源
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
- 汇报资源状态
ApplicationMaster:
- 负责数据的切分
- 为应用申请计算资源,并分配给Task
- 任务的监控与容错
- 运行在Worker节点上
Container:
- 资源抽象,封装了节点上的多维度资源,如CPU,内存,网络资源等
Flink On Yarn 的三种模式
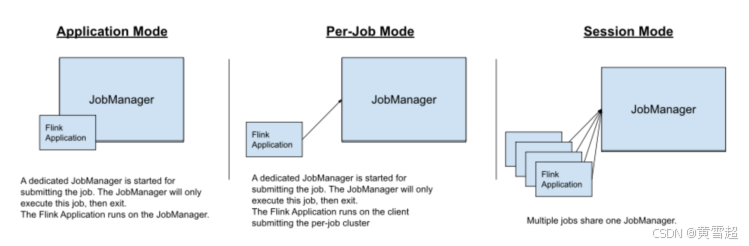
Flink程序可以运行为以下3种模式:
- Application Mode【生产中建议使用的模式】:每个job独享一个集群,job退出集群则退出,用户类的main方法在集群上运行
- Per-Job Mode:每个job独享一个集群,job退出集群则退出,用户类的main方法在client端运行;(大job,运行时长很长,比较合适;因为每起一个job,都要去向yarn申请容器启动jm,tm,比较耗时)
- Yarn Session Mode:多个job共享同一个集群<jobmanager/taskmanager>、job退出集群也不会退出,用户类的main方法在client端运行;(需要频繁提交大量小job的场景比较适用;因为每次提交一个新job的时候,不需要去向yarn注册应用)
上述3种模式的区别点在:
集群的生命周期和资源的隔离保证
用户类的main方法是运行在client端,还是在集群端
yarn application模式提交
bin/flink run-application -t yarn-application \
-yjm 1024 -yqu default -ys 2 \
-ytm 1024 -p 4 \
-c com.chaos.flink.java.KafkaSinkYarn /root/flink_test-1.0.jar
- bin/flink run-application :这是用于运行 Flink 应用程序的命令入口。
- -t yarn-application :指定在 YARN 集群上运行应用程序。
- -yjm 1024 :设置 JobManager 的内存大小为 1024 MB。
- -yqu default :指定 YARN 队列的名称为 default。
- -ys 2 :设置 YARN 服务,这里可能是指 YARN 的一些特定配置,比如在 YARN 上运行的实例数量。
- -ytm 1024 :设置 TaskManager 的内存大小为 1024 MB。
- -p 4 :设置 Flink 作业的并行度为 4。
- -c com.chaos.flink.java.KafkaSinkYarn :指定主类的完整类名为 com.chaos.flink.java.KafkaSinkYarn,这是应用程序的入口类。
- /root/flink_test-1.0.jar :指定要运行的 Flink 应用程序的 JAR 包路径。
yarn perJob模式提交
Yarn-Per-Job 模式:每个作业单独启动集群,隔离性好,JM(JobManager) 负载均衡,main 方法在客户端执行。在 per-job 模式下,每个 Job 都有一个 JobManager,每个TaskManager 只有单个 Job。
特点: 一个任务会对应一个 Job,每提交一个作业会根据自身的情况,都会单独向 yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
提交命令 (申请容器启动flink集群以及提交job,是合二为一的)
bin/flink run -m yarn-cluster -yjm 1024 \
-ytm 1024 -yqu default -ys 2 -p 4 \
-c com.chaos.TaskDemo /root/flink_test-1.0.jar
- -m:master的运行模式
- -yjm:JobManager的所在Yarn容器的内存大小
- -ytm:TaskManager的所在Yarn容器额内存大小
- -yqu:Yarn任务队列的名称
- -ys:每个TaskManager的slot数量
- -p:并行度
- -c:main方法全类名
yarn session模式提交
Yarn-Session 模式:所有作业共享集群资源,隔离性差,JM 负载瓶颈,main 方法在客户端执行。适合执行时间短,频繁执行的短任务,集群中的所有作业 只有一个 JobManager,另外,Job 被随机分配给 TaskManager
特点: Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到 yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。
- 基本操作命令
# 提交命令: bin/yarn-session.sh –help# 停止命令: yarn application -kill application_1550836652097_0002 - 具体操作步骤
- 先开辟资源启动session模式集群
# 老版本: bin/yarn-session.sh -n 3 -jm 1024 -tm 1024 # -n --> 指定需要启动多少个Taskmanager# 新版本: bin/yarn-session.sh -jm 1024 -tm 1024 -s 2 -m yarn-cluster -ynm hello -qu default -jm:jobmanager memory -tm:taskmanager memory -m yarn-cluster:集群模式(yarn集群模式) -s:规定每个taskmanager上的taskSlot数(槽位数) -nm:自定义appliction名称 -qu:指定要提交到的yarn队列 - 启动的服务进程
YarnSessionClusterEntrypoint(AppMaster,即JobManager)
注意:此刻并没有taskmanager,也就是说,taskmanager是在后续提交job时根据资源需求动态申请容器启动的。 - 向已运行的session模式集群提交job
bin/flink run -d -yid application_1550579025929_62420 -p 4 -c com.chaos.flink.java.TaskDemo /root/flink_test-1.0.jar
- 先开辟资源启动session模式集群
Flink On Yarn 的优劣势
优势:
- 与现有大数据平台无缝对接(Hadoop2.4+)
- 部署集群与任务提交都非常简单
- 资源管理统一通过Yarn管理,提升整体资源利用率类
- 基于Native方式,TaskManager资源按需申请和启动,防止资源浪费
- 容错保证:借助于Hadoop Yarn提供的自动failover机制,能保证JobManager,TaskManager节点异常恢复
劣势:
- 资源隔离问题,尤其是网络资源的隔离,Yarn做的还不够完善
- 离线和实时作业同时运行相互干扰等问题需要重视
- Kerberos认证超期问题导致Checkpoint无法持久化
On Kubernetes模式
介绍
Flink on Kubernetes 是将 Apache Flink 部署在 Kubernetes 集群上的一种方式,使用户能够利用 Kubernetes 的强大功能进行资源管理、弹性伸缩和高可用性管理。
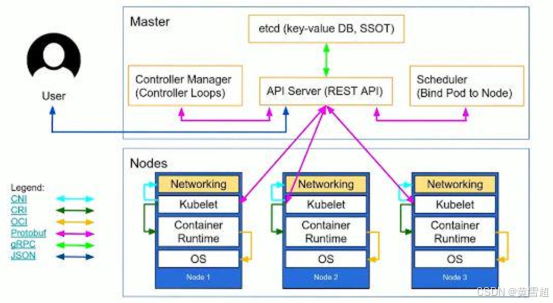
Master节点:
- 负责整个集群的管理,资源管理
- 运行APIServer,ControllerManager,Scheduler服务
- 提供Etcd高可用键值存储服务,用来保存Kubernetes集群所有对象的状态信息和网络信息
Node:
- 集群操作的单元,Pod运行宿主机
- 运行业务负载,业务负载会以Pod的形式运行
Kubelet:
- 运行在Node节点上,维护和管理该Node上的容器
Container Runtime:
- Docker容器运行环境,负责容器的创建和管理
Pod:
- 运行在Node节点上,多个相关Container的组合
- Kubunetes创建和管理的最小单位
核心概念
- ReplicationController(RC):RC是K8s集群中最早的保证Pod高可用的API对象,通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。
- Service:Service是对一组提供相同功能的Pods的抽象,并为它们提供一个统一的入口。
- PersistentVolume(PV):容器的数据都是非持久化的,在容器消亡以后数据也跟着丢失,所以Docker提供了Volume机制以便将数据持久化存储。
- ConfigMap:ConfigMap用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件。
Flink On Kubunetes的三种模式
Session 模式:启动一个长期运行的 Flink 集群,所有作业共享该集群资源。适合多个作业需要共享资源的场景。
Application 模式:为每个作业启动一个独立的 Flink 集群,作业之间资源隔离,互不影响。
Native Kubernetes 模式:Flink 原生支持 Kubernetes,通过 Kubernetes API 进行资源管理和调度,能够动态分配和释放 TaskManager。
Flink On Kubunetes的优缺点
优点:
-
强大的资源管理与弹性伸缩:Kubernetes 可根据作业负载动态分配和释放资源,实现 Flink 集群的弹性伸缩。这提高了资源利用率,降低了成本,尤其在业务波动时可快速调整资源以满足需求。
-
高可用性与容错能力:Kubernetes 能自动重启故障 Pod 并重新调度 TaskManager,确保 Flink 作业持续运行,保障数据处理的可靠性和稳定性。
-
深度云原生集成:Flink on Kubernetes 与云原生生态系统深度融合,可与云服务(如对象存储、消息队列)无缝协作,便于构建完整的云原生数据处理解决方案。
-
简化的部署与运维:通过 Flink Kubernetes Operator 提供的抽象接口,用户可以更高效地部署和管理 Flink 集群,减少手动操作,降低运维负担。
-
多租户支持:Kubernetes 的命名空间功能可实现多租户隔离,为多团队或项目共用集群提供了便利,提高了资源的隔离性和安全性。
缺点:
-
部署复杂度增加:与在专用集群上部署 Flink 相比,Flink on Kubernetes 需要熟悉 Kubernetes 的概念和工具(如 Pod、Deployment、Service 等),增加了学习曲线和部署前的准备工作。
-
资源管理的潜在挑战:Kubernetes 的资源调度策略可能与 Flink 的需求不完全匹配,导致资源分配效率降低。例如,在某些情况下,Kubernetes 的默认调度算法可能无法满足 Flink 对数据本地性的要求,影响作业性能。
-
性能开销:在 Kubernetes 上运行 Flink 会引入额外的性能开销,包括容器的启动时间和 Kubernetes 的调度延迟。此外,如果 Kubernetes 集群的资源紧张,可能导致 Flink 作业的性能下降。
-
网络配置复杂性:在 Kubernetes 集群中,网络配置可能较为复杂,需要确保 Flink 的各个组件之间能够正确通信。
-
长期运行作业的资源管理:对于长期运行的 Flink 作业,需要持续监控和管理资源使用情况。Kubernetes 的资源配额和限制机制可以帮助控制资源使用,但需要合理配置以避免对作业的性能产生负面影响。
相关文章:

Flink部署与应用——部署方式介绍
引入 我们通过Flink相关论文的介绍,对于Flink已经有了初步理解,这里简单的梳理一下Flink常见的部署方式。 Flink 的部署方式 StandAlone模式 介绍 StandAlone模式是Flink框架自带的分布式部署模式,不依赖其他的资源调度框架,…...

数据挖掘技术与应用课程论文——数据挖掘中的聚类分析方法及其应用研究
数据挖掘中的聚类分析方法及其应用研究 摘要 聚类分析是数据挖掘技术中的一个重要组成部分,它通过将数据集中的对象划分为多个组或簇,使得同一簇内的对象具有较高的相似性,而不同簇之间的对象具有较低的相似性。 本文系统地研究了数据挖掘中的多种聚类分析方法及其应用。首先…...

SIEMENS PLC程序解读 ST 语言 车型识别
1、ST程序代码 IF #Type1_MIX < #CFG_Type.Type.CT AND #CFG_Type.Type.CT < #Type1_MAX AND #CFG_Type.Type.CT<>0 THEN#Type[1] : 1;FOR #I : 0 TO 39 DOIF #CFG_Type.Type.CT/10 (#Type1_MIX 10 * #I)/10 THEN#Sub_Type."1"[#I 1] : 1;END_IF; E…...

神经网络基础[损失函数,bp算法,梯度下降算法 ]
关于神经网络的基础的概念可以看我前面的文章 损失函数 在深度学习中, 损失函数是用来衡量模型参数的质量的函数, 衡量的方式是比较网络输出和真实输出的差异 作用:指导模型的训练过程,通过反向传播算法计算梯度,从而更新网络的参数,最终使…...
)
python打印颜色(python颜色、python print颜色、python打印彩色文字、python print彩色、python彩色文字)
文章目录 python怎么打印彩色文字1. 使用ANSI转义码:2. 使用colorama库(更好的跨平台支持):3. 使用termcolor库: python怎么打印彩色文字 在Python中打印彩色文字有几种方法: 1. 使用ANSI转义码ÿ…...

数字域残留频偏的补偿原理
模拟域的频谱搬移一般通过混频器实现。一般情况下模拟域调整完频偏后数字域还会存在一部分残留频偏这部分就需要在数字域补偿。原理比较简单本文进行下粗略总结。首先我们需要了解下采样具体可参考下信号与系统笔记(六):采样 - 知乎。 采样前和采样后,角…...

Linux文件管理2
Linux 文件管理是系统操作的核心内容之一,涉及文件和目录的创建、删除、移动、查看、权限管理等操作。以下是 Linux 文件管理的核心知识点和常用操作总结: 一、文件系统结构 Linux 文件系统采用 树形结构,以 /(根目录࿰…...

C++----模拟实现string
模拟实现string,首先我们要知道成员变量有哪些: class _string{private:char* _str;size_t capacity;//空间有多大size_t size;//有效字符多少const static size_t npos;};const size_t _string::npos-1;//static在外面定义不需要带static,np…...

Python torch.optim.lr_scheduler 常用学习率调度器使用方法
在看学习率调度器之前,我们先看一下学习率的相关知识: 学习率 学习率的定义 学习率(Learning Rate)是深度学习中一个关键的超参数,它决定了在优化算法(如梯度下降法)更新模型参数时࿰…...

从零开始学Python游戏编程39-碰撞处理1
在《从零开始学Python游戏编程38-精灵5》代码的基础上,添加两个敌人的防御塔,玩家的坦克无法移动到防御塔所在的空格中,如图1所示。 图1 游戏中的碰撞处理 1 游戏中空格的坐标 在《从零开始学Python游戏编程36-精灵3》中提到,可…...

同步定时器的用户数要和线程组保持一致,否则jmeter会出现接口不执行’stop‘和‘×’的情况
调试压测时发现了一个问题就是线程计划总是出现‘stop’的按钮无法执行完毕 发现时同步定时器导致的,就是有接口使用了同步定时器,但是这个同步定时器的用户数量设置的<线程组用户数量时,会出现执行无法结束的情况,如下…...

如何在Linux用libevent写一个聊天服务器
废话少说,先看看思路 因为libevent的回调机制,我们可以借助这个机制来创建bufferevent来实现用户和用户进行通信 如果成功连接后我们可以直接在listener回调函数里创建一个bufferevent缓冲区,并为每个缓冲区设置相应的读回调和事件回调&…...

Virtuoso ADE采用Spectre仿真中出现MOS管最小长宽比满足要求依然报错的情况解决方法
在ADE仿真中错误问题如下: ERROR (CMI-2440): "xxx.scs" 46338: I2.M1: The length, width, or area of the instance does not fit the given lmax-lmin, wmax-wmin, or areamax-areamin range for any model in the I2.M3.nch_hvt group. The channel w…...

防火墙原理与应用总结
防火墙介绍: 防火墙(Firewall)是一种网络安全设备,其核心目标是通过分析数据包的源地址、端口、协议等内容,保护一个网络区域免受来自另一个网络区域的网络攻击和网络入侵行为,同时允许合法流量自由通行。…...
)
Graph Database Self-Managed Neo4j 知识图谱存储实践2:通过官方新手例子入门(未完成)
官方入门例子:neo4j-graph-examples/get-started: An introduction to graph databases and Neo4j for new users 官方例子仓库:https://github.com/neo4j-graph-examples 下载数据 git clone https://github.com/neo4j-graph-examples/get-started …...

GIT下载步骤
git官方链接: 添加链接描述...

C++中的vector和list的区别与适用场景
区别 特性vectorlist底层实现动态数组双向链表内存分配连续内存块非连续内存块随机访问支持,通过索引访问,时间复杂度O(1)不支持,需遍历,时间复杂度O(n)插入/删除末尾操作效率高,时间复杂度O(1)任意位置操作效率高&am…...

软件测试入门学习笔记
今天学习新知识,软件测试。 什么是软件测试? 使用人工和自动手段来运行或测试某个系统的过程,目的在于检验它是否满足规定的需求或弄清实际结果与预期结果之间的差别。 软件测试的目的? 1)为了发现程序࿰…...
)
2025年深度学习模型发展全景透视(基于前沿技术突破与开源生态演进的交叉分析)
2025年深度学习模型发展全景透视 (基于前沿技术突破与开源生态演进的交叉分析) 一、技术突破与能力边界拓展 智能水平跃升 2025年开源模型如Meta Llama-4、阿里Qwen2.5-VL参数规模突破1300亿,在常识推理能力测试中首次超越人类基准线7.2%谷歌…...

时间复杂度分析
复杂度分析的必要性: 当给我们一段代码时,我们是以什么准则来判断代码效率的高低呢?每一段代码都会消耗一段时间,或占据一段数据空间,那么自然是在实现相同功能的情况下,代码所耗时间最少,所占…...

BGE-m3 和 BCE-Embedding 模型对比分析
以下是对 BGE-m3 和 BCE-Embedding 模型在 embedding 领域的多维度对比分析,基于公开的技术文档和实验数据: 1. 基础信息对比 维度BGE-m3 (智源研究院)BCE-Embedding (网易)发布时间2024 年 1 月2023 年 9 月模型架构Transformer-basedTransformer-base…...

题目 3320: 蓝桥杯2025年第十六届省赛真题-产值调整
题目 3320: 蓝桥杯2025年第十六届省赛真题-产值调整 时间限制: 2s 内存限制: 192MB 提交: 549 解决: 122 题目描述 偏远的小镇上,三兄弟共同经营着一家小型矿业公司 “兄弟矿业”。公司旗下有三座矿山:金矿、银矿和铜矿,它们的初始产值分别用…...

计算机组成原理第二章 数据的表示和运算——2.1数制与编码
计算机组成原理第二章 数据的表示和运算——数制与编码 一、基本概念与核心知识点 1.1 数制系统基础 1.1.1 进位计数制 定义:以固定基数(如2、8、10、16)表示数值的系统核心要素: 基数(R):允…...

基于归纳共形预测的大型视觉-语言模型中预测集的**数据驱动校准**
摘要 本研究通过分离共形预测(SCP)框架,解决了大型视觉语言模型(LVLMs)在视觉问答(VQA)任务中幻觉缓解的关键挑战。虽然LVLMs在多模态推理方面表现出色,但它们的输出常常表现出具有…...

Golang | 自行实现并发安全的Map
核心思路,读写map之前加锁!哈希思路,大map化分为很多个小map...

【Python数据库编程实战】从SQL到ORM的完整指南
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心代码实现案例1:SQLite基础操作案例2:MySQL连接池案例3:SQLAlchemy ORM …...

深入剖析扣子智能体的工作流与实战案例
前面我们已经初步带大家体验过扣子工作流,工作流程是 Coze 最为强大的功能之一,它如同扣子中蕴含的奇妙魔法工具,赋予我们的机器人处理极其复杂问题逻辑的能力。 这篇文章会带你更加深入地去理解并运用工作流解决实际问题 目录 一、工作流…...

【计算机网络】IP地址
IPv4 五类地址 1.0.0.0 ~ 126.255.255.255A类子网8位,主机24位128.0.0.0 ~ 191.255.255.255B类子网16位,主机16位192.0.0.0 ~ 223.255.255.255C类子网24位,主机8位224.0.0.0 ~ 239.255.255.255D类不分网络地址和主机地址,作为组播…...

基于CATIA参数化管道建模的自动化插件开发实践——NX建模之管道命令的参考与移植
引言 在机械设计领域,CATIA作为行业领先的CAD软件,其强大的参数化建模能力备受青睐。本文介绍如何利用Python的PySide6框架与CATIA二次开发技术,开发一款智能管状体生成工具。该工具借鉴了同类工业软件NX的建模的管道命令,通过Py…...
)
运维之SSD硬盘(SSD hard Drive for Operation and Maintenance)
背景 SSD的产生背景是计算技术发展和市场需求驱动的结果。早期计算机使用磁芯存储器,后来被半导体存储器取代,提高了速度和可靠性。随着电子设备小型化,对轻便、低功耗存储器的需求增长,SSD因无机械部件、速度快、耗电少而受到关…...
)
基于javaweb的SSM+Maven红酒朔源管理系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...
教程)
HTML 地理定位(Geolocation)教程
HTML 地理定位(Geolocation)教程 简介 HTML5 的 Geolocation API 允许网页应用获取用户的地理位置信息。这个功能可用于提供基于位置的服务,如导航、本地搜索、天气预报等。本教程将详细介绍如何在网页中实现地理定位功能。 工作原理 浏览器可以通过多种方式确定…...

RHEL与CentOS:从同源到分流的开源操作系统演进
RHEL与CentOS:从同源到分流的开源操作系统演进 一、核心关系:源代码的重构与社区化 RHEL(Red Hat Enterprise Linux)与CentOS(Community ENTerprise Operating System)的关系可以概括为“同源异构”。RHE…...
:广播消息)
架构师面试(三十六):广播消息
题目 在像 IM、短视频、游戏等实时在线类的业务系统中,一般会有【广播消息】业务,这类业务具有瞬时高流量的特点。 在对【广播消息】业务实现时通常需要同时写 “系统消息库” 和更新用户的 “联系人库” 的操作,用户的联系人表中会有未读数…...

Spine 动画教程:皮肤制作
一、前言 搁了很久的抖音直播小玩法开发,最近又让我想起来了。由于是初次尝试,所以我将开发费用的预算降到为零。不但不买服务器采用 UnitySDK 的指令直推,而且游戏的资产也用 AI 生成,主打省时又省钱。 但是图片有了࿰…...

Rust 学习笔记:函数和控制流
Rust 学习笔记:函数和控制流 Rust 学习笔记:函数和控制流函数(Function)语句和表达式带返回值的函数注释控制流if 表达式使用 else if 处理多个条件在 let 语句中使用 if循环loop从循环中返回值循环标签消除多个循环之间的歧义带 …...

探秘LLM推理模型:hidden states中藏着的self verification的“钥匙”
推理模型在数学和逻辑推理等任务中表现出色,但常出现过度推理的情况。本文研究发现,推理模型的隐藏状态编码了答案正确性信息,利用这一信息可提升推理效率。想知道具体如何实现吗?快来一起来了解吧! 论文标题 Reasoni…...
在vector store中存储embbdings)
《Learning Langchain》阅读笔记8-RAG(4)在vector store中存储embbdings
什么是 vector store? 与专门用于存储结构化数据(如 JSON 文档或符合关系型数据库模式的数据)的传统数据库不同,vector stores处理的是非结构化数据,包括文本和图像。像传统数据库一样,vector stores也能执…...
)
【C/C++】深入理解指针(五)
文章目录 深入理解指针(五)1.回调函数是什么?2.qsort使用举例2.1 使用qsort函数排序整型数据强调 2.2 使用qsort排序结构数据 3.qsort函数的模拟实现 深入理解指针(五) 1.回调函数是什么? 回调函数就是⼀个通过函数指针调⽤的函数。 如果你把函数的指…...

【vue】【element-plus】 el-date-picker使用cell-class-name进行标记,type=year不生效解决方法
typedete,自定义cell-class-name打标记效果如下: 相关代码: <el-date-pickerv-model"date":clearable"false":editable"false":cell-class-name"cellClassName"type"date"format&quo…...
---管理命令、配置安装)
RocketMQ 主题与队列的协同作用解析(既然队列存储在不同的集群中,那要主题有什么用呢?)---管理命令、配置安装
学习之前呢需要会使用linux的基础命令 一.RocketMQ 主题与队列的协同作用解析 在 RocketMQ 中,主题(Topic)与队列(Queue)的协同设计实现了消息系统的逻辑抽象与物理存储分离。虽然队列实际存储在不同集群的 B…...

解决视频处理中的 HEVC 解码错误:Could not find ref with POC xxx【已解决】
问题描述 今天在使用 Python 处理视频时遇到了以下错误: [hevc 0x7f8a1d02b7c0] Could not find ref with POC 33之前没接触过视频处理,查了一下,这个错误通常发生在处理 HEVC(H.265)编码 的视频时,原因…...

NEGATIVE LABEL GUIDED OOD DETECTION WITH PRETRAINED VISION-LANGUAGE MODELS
1. 介绍: 这篇论文也是基于CLIP通过后处理的方法实现的OOD的检测,但是设计点在于,之前的方法是使用的ID的类别,这篇工作是通过添加一些在语义上非常不同于ID的类别的外分布类来做的OOD检测。 CLIP做OOD检测的这个系列里面我看的以及记录的第一篇就是MCM的方法,这也是确实是…...

Appium自动化 -- 环境安装
1.安装Appium-Python-Clientpip install Appium-Python-Client 2.AndroidSdk安装和环境配置 AndroidSdk下载地址:https://www.androiddevtools.cn/# 下载后解压 SDK Manager.exe 安装sdk tools、sdk plaform-tools、sdk build-tools AndroidSDK 环境变量配…...

Zeppelin在spark环境导出dataframe
1.Zeppelin无法直接访问本地路径 如果zeppelin无法直接访问本地路径,可先将dataframe写到s3,在通过读取s3路径下载文件 %pyspark # 示例:用 PySpark 处理数据 df spark.createDataFrame([(1, "Alice"), (2, "Bob")], …...
)
Vue3 上传后的文件智能预览(实战体会)
目录 前言1. Demo12. Demo2 前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 爬虫神器,无代码爬取,就来:bright.cn 此处的基本知识涉及较少,主要以Demo的形式供大…...

面试常问问题:Java基础篇
一、面向对象编程(OOP) 四大特性 封装、继承、多态、抽象的具体实现与区别? 抽象类与接口的区别?何时选择抽象类或接口? 重写(Override)和重载(Overload)的规则与区别&…...

测试流程?
需求分析 组织需求评审会议,邀请开发团队和测试团队参与。产品经理详细讲解需求,确保开发和测试人员对需求理解一致。 测试计划 分配测试人员:根据项目需求和测试人员的技能,分配测试任务和范围。确定测试策略:包括测…...

Python命名参数的使用
Python脚本传递参数的方式有: 使用sys.argv按照先后的顺序传入对应的参数使用argparse包加载和解析传递的命名参数 下面代码是第2中使用的实例: parser argparse.ArgumentParser(description参数使用说明) parser.add_argument(--time, -t, typestr,…...

赛灵思 XCKU115-2FLVB2104I Xilinx Kintex UltraScale FPGA
XCKU115-2FLVB2104I 是 AMD Xilinx Kintex UltraScale FPGA,基于 20 nm 先进工艺,提供高达 1 451 100 个逻辑单元(Logic Cells),77 721 600 bit 的片上 RAM 资源,以及 5 520 个 DSP 切片(DSP48E…...