《100天精通Python——基础篇 2025 第3天:变量与数据类型全面解析,掌握Python核心语法》
目录
- 一、Python变量的定义和使用
- 二、Python整数类型(int)详解
- 三、Python小数/浮点数(float)类型详解
- 四、Python复数类型(complex)详解---了解
- 五、Python字符串详解(包含长字符串和原始字符串)
- 5.1 处理字符串中的引号
- 5.2 字符串的换行
- 5.3 Python长字符串
- 5.4 Python原始字符串
- 六、Python字符串使用哪种编码格式?
- 七、Python bool布尔类型
- 八、Python input()函数:获取用户输入的字符串
- 九、Python print()函数详解
- 十、Python格式化字符串(格式化输出)
- 10.1 %运算符
- 10.2 str.format()方法
- 10.2.1 索引序号与参数映射
- 10.2.2 格式化模板标签
- 10.3 format() 函数
- 10.4 f-string 方法
- 十一、Python转义字符及用法
- 十二、Python数据类型转换
- 十三、运算符
- 13.1 Python算术运算符
- 13.2 Python赋值运算符
- 13.3 Python位运算符
- 13.4 Python比较运算符
- 13.5 Python逻辑运算符
- 13.6 Python运算符优先级和结合性
- 13.6.1 Python 运算符优先级
- 13.6.2 Python 运算符结合性
- 十四、练习及详解
在今天的学习中,我们将正式走进 Python 的核心语法,系统掌握变量的定义与使用、Python 内置数据类型的特点和用法,并深入理解字符串的处理与编码原理。同时,我们还会学习常用的输入输出函数——input() 和 print(),包括格式化输出的方法。此外,还将介绍 Python 中的各种运算符,帮助你编写更具逻辑性的程序。本节内容是掌握 Python 语言的基石,是进入编程世界不可或缺的一环。
重点内容:
- 变量的定义与使用:学习如何声明变量、变量命名规则以及变量在内存中的基本概念。
- Python数据类型:介绍整数、浮点数、字符串、布尔值等常见数据类型及其转换方法。
- 字符串处理与编码:理解字符串的基本操作、常见编码格式(如UTF-8)、编码与解码。
- 输入输出函数:掌握 input() 和 print() 的用法,支持用户交互与程序调试。
- 格式化输出:讲解 %、format() 和 f-string 三种格式化方式的区别与用法。
- 运算符详解:数学运算符、比较运算符、逻辑运算符、赋值运算符等基础操作符全面讲解。
这一篇文章将为你打通从 "写出一句代码" 到 "写出有逻辑的交互程序" 的关键步骤,是构建编程思维的第一块砖。
一、Python变量的定义和使用
任何编程语言都需要处理数据,比如数字、字符串、字符等,我们可以直接使用数据,也可以将数据保存到变量中,方便以后使用。变量(Variable) 可以看成一个小箱子,专门用来 "盛装" 程序中的数据。每个变量都拥有独一无二的名字,通过变量的名字就能找到变量中的数据。从底层看,程序中的数据最终都要放到内存(内存条)中,变量其实就是这块内存的名字。和变量相对应的是 常量(Constant), 它们都是用来 "盛装" 数据的小箱子,不同的是:变量保存的数据可以被多次修改,而常量一旦保存某个数据之后就不能修改了。
Python 变量的赋值。 在编程语言中,将数据放入变量的过程叫做 赋值(Assignment)。 Python 使用等号 = 作为赋值运算符,具体格式为:
name = value
name 表示变量名;value 表示值,也就是要存储的数据。注意,变量是标识符的一种,它的名字不能随便起,要遵守 Python 标识符命名规范,还要避免和 Python 内置函数以及 Python 关键字重名。例如,下面的语句将整数 10 赋值给变量 n:
n = 10
从此以后,n 就代表整数 10,使用 n 也就是使用 10。更多赋值的例子:
pi = 3.1415926 # 将圆周率赋值给变量 pi
url = 'https://www.runoob.com/' # 将菜鸟教程的地址赋值给变量 url
real = True # 将布尔值赋值给变量 real
变量的值不是一成不变的,它可以随时被修改,只要重新赋值即可;另外你也不用关心数据的类型,可以将不同类型的数据赋值给同一个变量。请看下面的演示:
n = 10 # 将10赋值给变量n
n = 95 # 将95赋值给变量n
n = 200 # 将200赋值给变量n
abc = 12.5 # 将小数赋值给变量abc
abc = 85 # 将整数赋值给变量abc
abc = 'https://www.runoob.com/' # 将字符串赋值给变量abc
注意,变量的值一旦被修改,之前的值就被覆盖了,不复存在了,再也找不回了。换句话说,变量只能容纳一个值。除了赋值单个数据,你也可以将表达式的运行结果赋值给变量,例如:
result = 100 + 20 # 将加法的结果赋值给变量
rem = 25 * 30 % 7 # 将余数赋值给变量
s1 = 'Hello' + 'World' # 将字符串拼接的结果赋值给变量
Python 变量的使用。 使用 Python 变量时,只要知道变量的名字即可。几乎在 Python 代码的任何地方都能使用变量,请看下面的演示:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> n = 10
>>> print(n) # 将变量传递给函数
10
>>> m = n * 10 + 5 # 将变量作为四则运算的一部分
>>> print(m)
105
>>> print(m - 30) # 将由变量构成的表达式作为参数传递给函数
75
>>> m = m * 2 # 将变量本身的值翻倍
>>> print(m)
210
>>> url = 'https://www.runoob.com/'
>>> s1 = '菜鸟教程:' + url # 字符串拼接
>>> print(s1)
菜鸟教程:https://www.runoob.com/
Python 是动态语言、强类型语言。

静态语言: ① 事先声明变量类型,之后变量的值可以改变,但值的类型不能再改变;② 编译时检查。
动态语言: ① 不用事先声明类型,随时可以赋值为其他类型;② 编程时不知道是什么类型,很难推断。静态类型语言有两个特点:
- 变量无须声明就可以直接赋值,对一个不存在的变量赋值就相当于定义了一个新变量。
- 变量的数据类型可以随时改变,比如,同一个变量可以一会儿被赋值为整数,一会儿被赋值为字符串。
注意,不用事先声明类型并不等于没有类型!动态语言是说在书写代码时不用刻意关注类型,但是在编程语言的内部仍然是有类型的。我们可以使用 type() 内置函数类检测某个变量或者表达式的类型,例如:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> num = 20
>>> type(num)
<class 'int'>
>>> num = 13.14
>>> type(num)
<class 'float'>
>>> num = 20 + 15j
>>> type(num)
<class 'complex'>
>>> s1 = 'hello world'
>>> type(s1)
<class 'str'>
强类型语言: 不同类型之间操作,必须先强制类型转换为同一类型。
print('a' + 1)
弱类型语言: 不同类型间可以操作,自动隐式转换,JavaScript 中
console.log(1 + 'a')
但是要注意的是,强与弱只是一个相对概念,即使是强类型语言也支持隐式类型转换。
二、Python整数类型(int)详解
整数就是没有小数部分的数字,Python 中的整数包括正整数、0 和负整数。有些编程语言会提供多种整数类型,每种类型的长度都不同,能容纳的整数的大小也不同,开发者要根据实际数字的大小选用不同的类型。例如C语言提供了 short、int、long、long long 四种类型的整数,它们的长度依次递增,初学者在选择整数类型时往往比较迷惑,有时候还会导致数值溢出。而 Python 则不同,它的整数不分类型,或者说它只有一种类型的整数。Python 整数的取值范围是无限的,不管多大或者多小的数字,Python 都能轻松处理。
当所用数值超过计算机自身的计算能力时,Python 会自动转用高精度计算(大数计算)。
示例代码:
n = 78 # 将 78 赋值给变量 n
print(n)
print(type(n))
# 给x赋值一个很大的整数
x = 8888888888888888888888
print(x)
print(type(x))
# 给y赋值一个很小的整数
y = -7777777777777777777777
print(y)
print(type(y))
运行结果:
78
<class 'int'>
8888888888888888888888
<class 'int'>
-7777777777777777777777
<class 'int'>
x 是一个极大的数字,y 是一个很小的数字,Python 都能正确输出,不会发生溢出,这说明 Python 对整数的处理能力非常强大。不管对于多大或者多小的整数,Python 只用一种类型存储,就是 int。
整数的不同进制。 在 Python 中,可以使用多种进制来表示整数:
- 十进制形式。我们平时常见的整数就是十进制形式,它由 0~9 共十个数字排列组合而成。注意,使用十进制形式的整数不能以 0 作为开头,除非这个数值本身就是 0。
- 二进制形式。由 0 和 1 两个数字组成,书写时以 0b 或 0B 开头。例如,101 对应十进制数是 5。
- 八进制形式。八进制整数由 0~7 共八个数字组成,以 0o 或 0O 开头。注意,第一个符号是数字 0,第二个符号是大写或小写的字母 O。
- 十六进制形式。由
0~9十个数字以及A~F(或a~f)六个字母组成,书写时以0x或0X开头,
如果你对不同进制以及它们之间的转换方法不了解,请点击的链接:https://blog.csdn.net/xw1680/article/details/132417469 学习 计算机组成原理之数据的表示和运算(一) 一文。不同进制整数在 Python 中的使用:
# 十六进制
hex1 = 0x45
hex2 = 0x4Af # 4*16*16+10*16+15 ==>1024+160+15==>1184+15==>1199
print("hex1Value: ", hex1)
print("hex2Value: ", hex2)
# 二进制
bin1 = 0b101
print('bin1Value: ', bin1)
bin2 = 0B110
print('bin2Value: ', bin2)
# 八进制
oct1 = 0o26
print('oct1Value: ', oct1)
oct2 = 0O41
print('oct2Value: ', oct2)
运行结果如下图所示:

数字分隔符。 为了提高数字的的可读性,Python 3.x 允许使用下划线 _ 作为数字(包括整数和小数)的分隔符。通常每隔三个数字添加一个下划线,类似于英文数字中的逗号。下划线不会影响数字本身的值。
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> num = 1_314_520
>>> distance = 384_000_000
>>> print(num)
1314520
>>> print('地球和月球的距离为: ', distance)
地球和月球的距离为: 384000000
三、Python小数/浮点数(float)类型详解
在编程语言中,小数通常以浮点数的形式存储。浮点数和定点数是相对的:小数在存储过程中如果小数点发生移动,就称为浮点数;如果小数点不动,就称为定点数。Python 中的小数有两种书写形式:
- 十进制形式。这种就是我们平时看到的小数形式,例如 13.14、16.80、0.346。书写小数时必须包含一个小数点,否则会被 Python 当作整数处理。
- 指数形式。Python 小数的指数形式的写法为:aEn 或 aen,a 为尾数部分,是一个十进制数;n 为指数部分,是一个十进制整数;E 或 e 是固定的字符,用于分割尾数部分和指数部分。整个表达式等价于 a × 10n。指数形式的小数举例:
- 2.1E5 = 2.1×105,其中 2.1 是尾数,5 是指数。
- 7E-2 = 3.7×10-2,其中 3.7 是尾数,-2 是指数。
- 0.5E7 = 0.5×107,其中 0.5 是尾数,7 是指数。
注意,只要写成指数形式就是小数,即使它的最终值看起来像一个整数。例如 14E3 等价于 14000,但 14E3 是一个小数。Python 只有一种小数类型,就是 float。C语言有两种小数类型,分别是 float 和 double:float 能容纳的小数范围比较小,double 能容纳的小数范围比较大。小数在 Python 中的使用:
f1 = 12.5
print("f1Value: ", f1)
print("f1Type: ", type(f1))
f2 = 0.34557808421257003
print("f2Value: ", f2)
print("f2Type: ", type(f2))
f3 = 0.0000000000000000000000000847
print("f3Value: ", f3)
print("f3Type: ", type(f3))
f4 = 345679745132456787324523453.45006
print("f4Value: ", f4)
print("f4Type: ", type(f4))
f5 = 12e4
print("f5Value: ", f5)
print("f5Type: ", type(f5))
f6 = 12.3 * 0.1
print("f6Value: ", f6)
print("f6Type: ", type(f6))
运行结果如下:
f1Value: 12.5
f1Type: <class 'float'>
f2Value: 0.34557808421257
f2Type: <class 'float'>
f3Value: 8.47e-26
f3Type: <class 'float'>
f4Value: 3.456797451324568e+26
f4Type: <class 'float'>
f5Value: 120000.0
f5Type: <class 'float'>
f6Value: 1.2300000000000002
f6Type: <class 'float'>
从运行结果可以看出,Python 能容纳极小和极大的浮点数。print 在输出浮点数时,会根据浮点数的长度和大小适当的舍去一部分数字,或者采用科学计数法。让人奇怪的是 f6,12.3*0.1 的计算结果很明显是 1.23,但是 print 的输出却不精确。这是因为小数在内存中是以二进制形式存储的,小数点后面的部分在转换成二进制时很有可能是一串无限循环的数字,无论如何都不能精确表示,所以小数的计算结果一般都是不精确的。
在上面提到,Python 中浮点类型之间的运算,其结果并不像我们想象的那样,例如:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> 0.1+0.2
0.30000000000000004
>>> 0.1+0.1-0.2
0.0
>>> 0.1+0.1+0.1-0.3
5.551115123125783e-17
>>> 0.1+0.1+0.1-0.2
0.10000000000000003
为什么在计算这么简单的问题上,计算机会出现这样的低级错误呢?真正的原因在于十进制和数和二进制数的转换。我们知道,计算机其实是不认识十进制数,它只认识二进制数,也就是说,当我们以十进制数进行运算的时候,计算机需要将各个十进制数转换成二进制数,然后进行二进制间的计算。以类似 0.1 这样的浮点数为例,如果手动将其转换成二进制,其结果为:0.1(10)=0.00011001100110011…(2)。可以看到,结果是无限循环的,也就是说,0.1 转换成二进制数后,无法精确到等于十进制数的 0.1。同时,由于计算机存储的位数是有限制的,所以如果要存储的二进制位数超过了计算机存储位数的最大值,其后续位数会被舍弃(舍弃的原则是 "0舍1入")。
这种问题不仅在 Python 中存在,在所有支持浮点数运算的编程语言中都会遇到,它不光是 Python 的 Bug。
明白了问题产生的原因之后,那么该如何解决呢?就 Python 的浮点数运算而言,大多数计算机每次计算误差不会超过 253,这对于大多数任务来说已经足够了。如果需要非常精确的结果,可以使用 decimal 模块(其实就是别人开发好的程序,我们可以直接拿来用),它实现的十进制数运算适合会计方面的应用和有高精度要求的应用。例如:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> # 使用模块前,需要使用import引入
>>> import decimal
>>> a = decimal.Decimal('10.0')
>>> b = decimal.Decimal('3')
>>> print(10.0 / 3)
3.3333333333333335
>>> print(a / b)
3.333333333333333333333333333
>>> # 如果 decimal 模块还是无法满足需求,还可以使用 fractions 模块
>>> # 引入fractions 模块
>>> from fractions import Fraction
>>> print(10 / 3)
3.3333333333333335
>>> print(Fraction(10, 3))
10/3 # 可以看到,通过 fractions 模块能很好地解决浮点类型数之间运算的问题。
四、Python复数类型(complex)详解—了解
复数(Complex)是 Python 的内置类型,直接书写即可。换句话说,Python 语言本身就支持复数,而不依赖于标准库或者第三方库。复数由实部(real)和虚部(imag)构成,在 Python 中,复数的虚部以 j 或者 J 作为后缀,具体格式为:
a + bj # a 表示实部,b 表示虚部
Python 复数的使用:
c1 = 12 + 0.2j
print("c1Value: ", c1)
print("c1Type", type(c1))
c2 = 6 - 1.2j
print("c2Value: ", c2)
# 对复数进行简单计算
print("c1+c2: ", c1 + c2)
print("c1*c2: ", c1 * c2) # (a+bi)(c+di)=(ac-bd)+(ad+bc)i
运行结果:
c1Value: (12+0.2j)
c1Type <class 'complex'>
c2Value: (6-1.2j)
c1+c2: (18-1j)
c1*c2: (72.24-13.2j)
可以发现,复数在 Python 内部的类型是 complex,Python 默认支持对复数的简单计算。
五、Python字符串详解(包含长字符串和原始字符串)
若干个字符的集合就是一个 字符串(String)。 Python 中的字符串必须由双引号 " " 或者单引号 ' ' 包围,具体格式为:
"字符串内容"
'字符串内容'
字符串的内容可以包含字母、标点、特殊符号、中文、日文等全世界的所有文字。下面都是合法的字符串:
"123456789"
"123abc"
"https://blog.csdn.net/xw1680/article/details/136889807"
"学习Python已经6年了"
Python 字符串中的双引号和单引号没有任何区别。而有些编程语言的双引号字符串可以解析变量,单引号字符串一律原样输出,例如 PHP 和 JavaScript。
5.1 处理字符串中的引号
当字符串内容中出现引号时,我们需要进行特殊处理,否则 Python 会解析出错,例如:

由于上面字符串中包含了单引号,此时 Python 会将字符串中的单引号与第一个单引号配对,这样就会把 'I' 当成字符串,而后面的 m a great coder!' 就变成了多余的内容,从而导致语法错误。对于这种情况,我们有两种处理方案:
① 对引号进行转义。 在引号前面添加反斜杠 \ 就可以对引号进行转义,让 Python 把它作为普通文本对待,例如:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> str1 = 'I\'m a great coder!'
>>> str2 = "英文双引号是\",中文双引号是”"
>>> print(str1)
I'm a great coder!
>>> print(str2)
英文双引号是",中文双引号是”
② 使用不同的引号包围字符串。 如果字符串内容中出现了单引号,那么我们可以使用双引号包围字符串,反之亦然。例如:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> str1 = "I'm a great coder!" # 使用双引号包围含有单引号的字符串
>>> str2 = '引文双引号是",中文双引号是"' # 使用单引号包围含有双引号的字符串
>>> print(str1)
I'm a great coder!
>>> print(str2)
引文双引号是",中文双引号是"
运行结果和上面相同。
5.2 字符串的换行
Python 不是格式自由的语言,它对程序的换行、缩进都有严格的语法要求。要想换行书写一个比较长的字符串,必须在行尾添加反斜杠 \,请看下面的例子:
s3 = 'It took me six months to write this Python tutorial. \Please give me more support. \I will keep it updated.'
上面 s3 字符串的比较长,所以使用了转义字符 \ 对字符串内容进行了换行,这样就可以把一个长字符串写成多行。另外,Python 也支持表达式的换行,例如:
num = 20 + 3 / 4 + \2 * 3
print(num)
5.3 Python长字符串
在 2024 Python3.10 系统入门+进阶(二):Python编程环境搭建 一文中的 六、Python注释(多行注释和单行注释)用法详解 小节我们提到,使用三个单引号或者双引号可以对多行内容进行注释,这其实是 Python 长字符串的写法。所谓长字符串,就是可以直接换行(不用加反斜杠 \ )书写的字符串。Python 长字符串由三个双引号 """ 或者三个单引号 ''' 包围,语法格式如下:
"""长字符串内容"""
'''长字符串内容'''
在长字符串中放置单引号或者双引号不会导致解析错误。如果长字符串没有赋值给任何变量,那么这个长字符串就不会起到任何作用,和一段普通的文本无异,相当于被注释掉了。注意,此时 Python 解释器并不会忽略长字符串,也会按照语法解析,只是长字符串起不到实际作用而已。当程序中有大段文本内容需要定义成字符串时,优先推荐使用长字符串形式,因为这种形式非常强大,可以在字符串中放置任何内容,包括单引号和双引号。将长字符串赋值给变量:
long_str = '''It took me 6 months to write this Python tutorial.
Please give me a to 'thumb' to keep it updated.
The Python tutorial is available at https://blog.csdn.net/xw1680/category_12606423.html.'''
print(long_str)
长字符串中的换行、空格、缩进等空白符都会原样输出,所以你不能写成下面的样子:
long_str = '''It took me 6 months to write this Python tutorial.Please give me a to 'thumb' to keep it updated.The Python tutorial is available at https://blog.csdn.net/xw1680/category_12606423.html..
'''
print(long_str)
虽然这样写格式优美,但是输出结果将变成:

字符串内容前后多出了两个空行,并且每一行的前面会多出四个空格。
5.4 Python原始字符串
Python 字符串中的反斜杠 \ 有着特殊的作用,就是转义字符,例如上面提到的 \' 和 \",我们将在 《Python转义字符》 小节中详细讲解,这里大家先简单了解。转义字符有时候会带来一些麻烦,例如我要表示一个包含 Windows 路径 F:\dev_tools\python\python310\python.exe 这样的字符串,在 Python 程序中直接这样写肯定是不行的,不管是普通字符串还是长字符串。因为 \ 的特殊性,我们需要对字符串中的每个 \ 都进行转义,也就是写成 F:\\dev_tools\\python\\python310\\python.exe 这种形式才行。这种写法需要特别谨慎,稍有疏忽就会出错。为了解决转义字符的问题,Python 支持原始字符串。在原始字符串中,\ 不会被当作转义字符,所有的内容都保持 "原汁原味" 的样子。在普通字符串或者长字符串的开头加上 r 前缀,就变成了原始字符串,具体格式为:
str1 = r'原始字符串内容'
str2 = r"""原始字符串内容"""
将上面的 Windows 路径改写成原始字符串的形式:
rstr = r'F:\dev_tools\python\python310\python.exe'
print(rstr)
原始字符串中的引号。 如果普通格式的原始字符串中出现引号,程序同样需要对引号进行转义,否则 Python 照样无法对字符串的引号精确配对;但是和普通字符串不同的是,此时用于转义的反斜杠会变成字符串内容的一部分。请看下面的代码:
str1 = r'I\'m a great coder!'
print(str1) # I\'m a great coder!
需要注意的是,Python 原始字符串中的反斜杠仍然会对引号进行转义,因此原始字符串的结尾处不能是反斜杠,否则字符串结尾处的引号会被转义,导致字符串不能正确结束。在 Python 中有两种方式解决这个问题:一种方式是改用长字符串的写法,不要使用原始字符串;另一种方式是单独书写反斜杠,这是接下来要重点说明的。例如想表示 F:\dev_tools\python\python310\,可以这样写:
str2 = r'F:\dev_tools\python\python310' '\\'
print(str2)
我们先写了一个原始字符串 r'F:\dev_tools\python\python310',紧接着又使用 '\\' 写了一个包含转义字符的普通字符串,Python 会自动将这两个字符串拼接在一起,所以上面代码的输出结果是:F:\dev_tools\python\python310\。由于这种写法涉及到了字符串拼接的相关知识,这里读者只需要了解即可,后续会对字符串拼接做详细介绍。
六、Python字符串使用哪种编码格式?
在实践中,很多初学者都遇到过 "文件显示乱码" 的情况,其多数都是由于在打开文件时,没有选对编码格式导致的。因此,学习 Python 中的字符或字符串,了解其底层的编码格式是非常有必要的。鉴于有些读者并不了解什么是编码格式,本小节先从编码开始讲起。
什么是编码? 虽然很多教程中有关于编码的定义,但对初学者来说并不容易理解,这里先举一个例子。古代打仗,击鼓为号、鸣金收兵,即把要传达给士兵的命令对应为公认的其他形式,这就和编码有相似之处。以发布进攻命令为例,相比用嗓子喊,敲鼓发出的声音传播的更远,并且士兵听到后也不会引起歧义,因此长官下达进攻命令后,传令员就将此命令转化为对应的鼓声,这个转化的过程称为编码;由于士兵都接受过训练,听到鼓声后,他们可以将其转化为对应的进攻命令,这个转化的过程称为解码。
需要说明的是,此例只是形象地描述了编码和解码的原理,真实的编码和解码过程比这要复杂的多。
了解了编码的含义之后,接下来再介绍一下字符编码。我们知道,计算机是以二进制的形式来存储数据的,即它只认识 0 和 1 两个数字。 20 世纪 60 年代,是计算机发展的早期,这时美国是计算机领域的老大,它制定了一套编码标准,解决了 128 个英文字符与二进制之间的对应关系,被称为 ASCII 字符编码(简称 ASCII 码)。
ASCII 码,全称为美国信息交换标准代码,是基于拉丁字母的一套字符编码,主要用于显示现代英语,因为万维网的出现,使得 ASCII 码广为使用,其直到 2007 年 12 月才逐渐被 Unicode 取代。
虽然英语用 128 个字符编码已经够用,但计算机不仅仅用于英语,如果想表示其他语言,128 个符号显然不够用,所以很多其他国家都在 ASCII 的基础上发明了很多别的编码,例如包含了汉语简体中文格式的 GB2312 编码格式(使用 2 个字节表示一个汉字)。也正是由于出现了很多种编码格式,导致了 "文件显示乱码" 的情况。比如说,发送邮件时,如果发信人和收信人使用的编码格式不一样,则收信人很可能看到乱码的邮件。基于这个原因,Unicode 字符集应运而生。Unicode 字符集又称万国码、国际码、统一码等。从名字就可以看出来,它是以统一符号为目标的字符集。Unicode 对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更简单的方式来呈现和处理文字。注意,在实际使用时,人们常常混淆字符集和字符编码这两个概念,我认为它们是不同的:
- 字符集定义了字符和二进制的对应关系,为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程;
- 而字符编码规定了如何将字符的编号存储到计算机中,要知道,有些字符编码(如 GB2312 和 GBK)规定,不同字符在存储时所占用的字节数是不一样的,因此为了区分一个字符到底使用了几个字节,就不能将字符的编号直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码。Unicode 字符集可以使用的编码方案有三种,分别是:
- UTF-8:一种变长的编码方案,使用 1~6 个字节来存储;
- UTF-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
- UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
其中,UTF-8 是目前使用最广的一种 Unicode 字符集的实现方式,可以说它几乎已经一统江湖了。了解了什么是编码,以及什么是字符编码之后,最后解决 "Python使用哪种字符编码?" 这个问题。Python 3.x 中,字符串采用的是 Unicode 字符集,可以用如下代码来查看当前环境的编码格式:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
同时,在 Python 3.x 中也可以用 ord() 和 chr() 函数实现字符和编码数字之间的转换,例如:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> ord('Q')
81
>>> chr(81)
'Q'
>>> ord('网')
32593
>>> chr(32593)
'网'
由此可以知道,在 Unicode 字符集中,字符 'Q' 对应的编码数字为 81,而中文 '网' 对应的编码数字为 32593。值得一提的是,虽然 Python 默认采用 UTF-8 编码,但它也提供了 encode() 方法,可以轻松实现将 Unicode 编码格式的字符串转化为其它编码格式。
七、Python bool布尔类型
Python 提供了 bool 类型来表示真(对)或假(错),比如常见的 5 > 3 比较算式,这个是正确的,在程序世界里称之为真(对),Python 使用 True 来代表;再比如 4 > 20 比较算式,这个是错误的,在程序世界里称之为假(错),Python 使用 False 来代表。True 和 False 是 Python 中的关键字,当作为 Python 代码输入时,一定要注意字母的大小写,否则解释器会报错。值得一提的是,布尔类型可以当做整数来对待,即 True 相当于整数值 1,False 相当于整数值 0。因此,下边这些运算都是可以的:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> False + 1
1
>>> True + 1
2
注意,这里只是为了说明 True 和 False 对应的整型值,在实际应用中是不妥的,不要这么用。总的来说,bool 类型就是用于代表某个事情的真(对)或假(错),如果这个事情是正确的,用 True(或 1)代表;如果这个事情是错误的,用 False(或 0)代表。
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> 5 > 3
True
>>> 4 > 20
False
>>>
False 等价布尔值,相当于 bool(value):
空容器 ⇒ 空集合set 空字典dict 空列表list 空元组tuple
空字符串
None
0
在 Python 中,所有的对象都可以进行真假值的测试,包括字符串、元组、列表、字典、对象等,由于目前尚未学习,因此这里不做过多讲述,后续遇到时会做详细的介绍。
八、Python input()函数:获取用户输入的字符串
input() 是 Python 的内置函数,用于从控制台读取用户输入的内容。input() 函数总是以字符串的形式来处理用户输入的内容,所以用户输入的内容可以包含任何字符。input() 函数的用法为:
str1 = input(prompt='', /)
说明:
- str1 表示一个字符串类型的变量,input 会将读取到的字符串放入 str1 中。
- prompt 表示提示信息,它会显示在控制台上,告诉用户应该输入什么样的内容;如果不写 prompt,就不会有任何提示信息。
input() 函数的简单使用:
a = input("Enter a number: ")
b = input("Enter another number: ")
print("aType: ", type(a))
print("bType: ", type(b))
result = a + b
print("resultValue: ", result)
print("resultType: ", type(result))
运行结果示例:
Enter a number: 10↙
Enter another number: 20↙
aType: <class 'str'>
bType: <class 'str'>
resultValue: 1020
resultType: <class 'str'>
↙ 表示按下回车键,按下回车键后 input() 读取就结束了。
九、Python print()函数详解
参考文章 Python 常用内置函数详解(二):print()函数----打印输出: https://blog.csdn.net/xw1680/article/details/136903561
十、Python格式化字符串(格式化输出)
10.1 %运算符
在 Python 中,可以使用 % 运算符进行灵活多样的格式化处理,通用的语法格式为:
(格式模板) + % + (值组)
格式化处理时,Python 使用一个字符串(格式标记模板)作为格式模板。模板中有格式符,这些格式符为真实值预留位置,并说明真实数值应该呈现的格式。Python 用一个 tuple 将多个值(值组)传递给格式模板,每个值对应一个格式符。值组:既要格式化的字符串或者元组,如果有两个及以上的值则需要用小括号括起来,中间用短号隔开。格式模板:是一组或多组以 % 标记的字符串,通过格式标记模板可以灵活对值组进行格式化。格式模板的语法格式如下:
%[(name)][flags][width].[precision]typecode
格式模板中的格式标记符即可以简单、快速对数据进行格式化处理,也可以进行复杂的自动化处理和计算。其中只有 typecode 参数为必选项,其他选项都是可选项。所以 typecode 参数是最常用的格式化处理操作,每项操作都要用到,所以放到第一个进行介绍:typecode,必选参数,表示获取对应类型的值并格式化到指定位置。格式符为真实值预留位置,并控制显示的格式。格式符可以包含有一个类型码,用以控制显示的类型。主要的格式符有:
s,获取传入对象的str方法的返回值,并将其格式化到指定位置
r,获取传入对象的repr方法的返回值,并将其格式化到指定位置
c,整数:将数字转换成其unicode对应的值,10进制范围为0<=i<=1114111(py27则只支持0-255);字符:将字符添加到指定位置
o,将整数转换成八进制表示,并将其格式化到指定位置
x,将整数转换成十六进制表示,并将其格式化到指定位置
d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
f,将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e)
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E)
%,当字符串中存在格式化标志时,需要用 %%表示一个百分号
这些操作符最常用的是 s、f、d,下面结合实例作以介绍:
print('%+s' % 20.53) # 格式化为字符串
print('%d' % 3.1415926) # 格式化为的整数
print('%f' % 20.53) # 格式化为浮点数,默认保留6位
print('%.2f' % 3.1415926) # 格式化为2位的浮点数
print('%.3f' % 20.53) # 格式化为3位的浮点数
print('%e' % 3.1415926) # 格式化为科学记数法
(name),可选参数,较少使用。通常用在较复杂的字典格式化处理当中。在字典中选择指定的 key,输出字典中指定的 key 对应的值,字典中没有顺序,只有键值对对应即可。如输出字典中手机的品名、销售数量和价格。
phone = '%(品名)s,%(数量)d,%(单价).2f' % {'单价': 3690, '数量': 2, '品名': 'mate20'}
print(phone)
flags,可选参数,默认为右对齐。可供选择的值有:+/-/' '/0。+ 表示右对齐。- 表示左对齐。' ' 为一个空格,表示在正数的左侧填充一个空格,从而与负数对齐。0表示使用0填充。通常与 width 结合使用,演示示例放到 width 中进行介绍。
+ 右对齐;正数前加正号,负数前加负号;
- 左对齐;正数前无符号,负数前加负号;
空格 右对齐;正数前加空格,负数前加负号;
0 右对齐;正数前无符号,负数前加负号;用0填充空白处
width,可选参数,指设置占位的宽度。通常和 flags 参数配合使用,示例如下:
print('%+6s' % '我们') # 字符串右对齐,左侧添加空格占位
print('%+6d' % -3.14) # 格式化为整数,右对齐,左侧添加空格占位
print('%-6s' % '我们') # 字符串左对齐,右侧添加空格占位
print('%-6d' % -3.14) # 格式化为整数,左对齐,右侧添加空格占位
print('% 6s' % '我们') # 字符串右对齐,左侧添加空格占位
print('%06d' % 3.14) # 格式化为整数,右对齐,左侧添加0占位
.precision,可选参数,设置浮点数或字符串的精度。对于浮点数来说,用于设置浮点数的精度,即小数点后保留的位数。对于字符串来说,就是截取字符串的位数。
print('%.2s' % 'Amo') # 取字符串的前两位
print('%.2f' % 3.1415926) # 格式化为小数点保存为2位的浮点数
print('%.6f' % 3) # 格式化为小数点保存为6位的浮点数
print('%.f' % 3.14) # 默认小数点后保留的位数为0
print('%f' % 3.14) # 不写小数点,精度默认为6位小数
对单个字符串进行格式化:
print('%d' % 20.53) # 格式化为整数
print('%6s' % '云从科技') # 格式化为6位居右显示的字符串,不足部分用空格填充
print('%f' % 20.53) # 格式化为浮点数,默认带6位小数
print('%o' % 20) # 格式化为八进制数
如果为多个字符串,需要用括号括起来。并且格式化的字符串和格式模板要一一对应。
print('%d,%f' % (20.53, 20.53)) # 格式化20.53为整数和浮点数
print('%d,%f,%.2f,%.4f' % (20.53, 20.53, 20.53, 20.53)) # 模板和字符串要对应
# 分别格式化3.1415926为宽度为4,空位用0填充和保留两位小数的浮点
print('%04d,%0.2f' % (3.1415926, 3.1415926))
s1 = "横坐标:%s,纵坐标:%s" % (123, 239) # 分别输出横坐标和纵坐标
print(s1)
注意:在模板中,按 % 后面的控制字符格式化字符串,在 % 前面可以添加标示字符串,输出时原文输出标示字符串,标示字符串可以对格式化字符串起到标示或说明作用。模板和值组中的元素要一一对应,否则会报错。多个模板与字符串对应关系如下图所示:

示例:
# 1.整数的格式化输出
print('%o' % 24) # 格式化十进制数为八进制数
print('%x' % 24) # 格式化十进制数为十六进制数
print('%o' % 0x3e) # 格式化十六进制数为八进制数
print('%x' % 0o122) # 格式化八进制数为十六进制数
print('%d' % 0x3e) # 格式化十六进制数为十进制数
print('%d' % 0o122) # 格式化八进制数为十进制数
print('%d' % 3.1415926) # 格式化浮点数为整数
print('%d' % (7 / 3)) # 格式化计算结果为整数
a = 100 / 3 + 5
print('%d' % a) # 格式化变量为整数
# 2.浮点数的格式化输出
print('%f' % 3.14) # 默认保留6位小数
print('%.f' % 3.14) # 默认保留0位小数
print('%.1f' % 3.14) # 保留1位小数
print('%.2f' % 3.1415926) # 保留2位小数
print('%+03.2f' % 3.1415926) # 右对齐宽度为3保留2位小数
print('%+6.1f' % -3.1415926) # 宽度为6,右对齐,保留1位小数,不足用空格填充
print('%-6.1f' % -3.1415926) # 宽度为6,左对齐,保留1位小数,不足用空格填充
print('% 6.1f' % -3.1415926) # 宽度为6,左对齐,保留1位小数,不足用空格填充
print('%06.1f' % -3.1415926) # 宽度为6,右对齐,保留1位小数,不足用0填充
# 3.科学计数法的格式化输出
print('%e' % 31415.92653589) # 科学计数法表示,默认保留6位小数(不包含整数部分)
print('%.3e' % 31415.92653589) # 科学计数法表示,保留3位小数(不包含整数部分)
print('%g' % 31415.92653589) # 默认保留6位有效数字(包含整数部分)
print('%.6e' % 31415.92653589) # 科学计数法表示,默认保留6位小数(不包含整数部分)
print('%.6g' % 31415.92653589) # 保留6位有效数字(包含整数部分)
print('%.2g' % 31415.92653589) # 默认保留2位有效数字(包含整数部分),所以才用科学计数法
# 4.字符串的格式化输出
print('%s' % 'amo') # 字符串输出
print('%5s' % 'amo') # 字符串长度超过5,宽度5不起作用
print('%20s' % 'amo') # 默认右对齐,宽度为20位,不够默认用空格补位
print('%-20s' % 'amo') # 默认左对齐,宽度为20位,不够默认用空格补位
print('%.4s' % 'amo_666') # 截取字符串前4位
print('%8.4s' % 'amo') # 截取字符串前4位,右对齐,设置宽度为8
print('%-8.4s' % 'amo') # 截取字符串前4位,左对齐,设置宽度为8
print('www.%s.com' % 'baidu') # 灵活加入字符串常量,连接格式化字符串
print('%s.%s/%s' % ('amo', 'com', 'book')) # 组合格式化字符
print('1%.1s 2%.1s 3%.2s' % ('吕布', '赵云', '典韦')) # 灵活加入字符串的格式化
# 5.字典的格式化输出
print("%(pid)s,%(type)s,%(resource)s" % {'pid': 1375, 'type': 'cpu', 'resource': 2048})
print("%(002)s" % {'001': '沃尔玛', '002': '中国石油化工集团公司', '003': '荷兰皇家壳牌石油公司'})
world500 = {'沃尔玛': 514405000, '中国石油化工集团公司': 414649900, '荷兰皇家壳牌石油公司': 39655600}
print('%(中国石油化工集团公司).2f' % world500)
stud = {'Jeff': '1001', 'Jack': '1002', 'Joy': '1003', 'May': '1004'}
print('Jeff的学号:%(Jeff)s,May的学号:%(May)s' % stud)
book = {'name': 'Python3入门与进阶', 'price': 69.9, 'author': 'AmoXiang'}
temp = '专栏:%(name)s,价格:%(price).2f,作者:%(author)s'
print(temp % book)
# 6.自动化处理数据
print("Name:%8s Age:%8d Height:%8.2f" % ("Jeff", 37, 1.75))
print("Name:%-8s Age:%-8d Height:%-8.2f" % ("Jeff", 37, 1.75))
print("Name:%8s Age:%08d Height:%08.2f" % ("Jeff", 37, 1.75))
stud = (("Jeff", 37, 1.75), ("Jack", 22, 1.85), ("Joy", 32, 1.69), ("may", 27, 1.68))
print("Name:%8s Age:%08d Height:%08.2f" % (stud[0][0], stud[0][1], stud[0][2]))
print('%s %s %s %s' % ("Jeff", 37, 1.75, ['Facebook', 'CFO']))
print('%(name)s:%(score)02.1f' % {'score': 9.0, 'name': 'Jeff'})
10.2 str.format()方法
在 Python2.6 之后,提供了字符串的 format() 方法对字符串进行格式化操作。format() 功能非常强大,格式也比较复杂,具体语法分解如下:
{参数序号: 格式控制标记}.format(*args,**kwargs)
- 参数序号:参数序号其实是位置参数或关键字参数传递过来的参数变量,对参数序号进行格式控制标记设置其实就是对位置参数或关键字参数进行格式化处理。参数序号可以为空值,为空值时一定对应的是位置参数,并且在顺序上和位置参数一一对应。
- 格式控制标记:用来控制参数显示时的格式,包括:
<填充><对齐><宽度>,<.精度><类型>6 个字段,这些字段都是可选的,可以组合使用。参数序号和格式设置标记用大括号({})表示,可以有多个。{}表示按照顺序匹配位置参数,{n}表示取位置参数索引为n的值 *args:位置参数,是一个元组,可以为多个值。其和参数序号在位置上是一一对应的,数量上是一致的。**kwargs是关键字参数,是一个字典,其通过序号和参数序号进行对应,可以一对一,也可以一对多。使用关键字参数时,参数序号和关键字参数不一定数量一致。下图所示为通过位置参数或关键字参数进行格式化处理的流程:

下面具体介绍如何通过位置参数或关键字参数进行格式化操作。其中,参数序号为传入的参数,格式设置模板是一个由字符串和格式控制说明字符组成的字符串,用来对传入的参数进行格式化设置。格式设置模板用大括号({})表示,可以有多个,其对应 format() 方法中逗号分隔的参数。常量可以是符号、文字,甚至是一段话,根据程序开发需要进行设置。灵活使用常量,可以更大范围发挥 format() 方法的功效。
10.2.1 索引序号与参数映射
'{索引序号: 格式控制标记}'.format(*args,**kwargs)
# args是位置参数,是一个元组
# kwargs是关键字参数,是一个字典
# {}表示按照顺序匹配位置参数,{n}表示取位置参数索引为n的值
① 通过位置参数映射。 就是按照位置顺序用位置参数替换前面的格式字符串的占位符。位置参数按照序号匹配,关键字参数按照名称匹配(注:按照位置填充,大括号只是占位符注,一一对应,按照位置输出结果)
索引序号为空。 如果索引序号为空,索引序号与位置参数按照从左到右的顺序上可以建立映射,实现对传入参数的格式化处理。如索引序号和格式设置标记均为空值时,直接输出位置参数。代码如下:
'{}'.format('中国') # 输出为"中国"
位置参数与索引序号对应关系如下图所示:

位置参数可以为两个或更多,其对应的索引序号也应该和位置索引一一对应。如果索引序号和格式设置标记均为空值时,其实就是直接连接位置参数的字符串。代码如下:
'{}{}'.format('中国', '1949') # 输出为"中国1949"
'{}{}{}'.format('中国', '1949', '70') # 输出为"中国194970"
位置参数对应关系如下图所示:


通过常量可以直接连接或修饰各个序号索引之间的关系,代码如下:
'{}:{}:{}'.format('中国', '1949', '70') # 输出为"中国:1949:70"
'{}«««{}«««{}'.format('中国', '1949', '70') # 输出为"中国«««1949«««70"
通过常量连接或修饰各个序号索引之间的关系如下图所示:

可以通过不同的汉字常量对位置参数进行修饰,如通过 "建国于"、"到2019年已经"、"年" 连接 "中国"、"1949" 及 "70",代码如下:
'{}建国于{}年,到2019年已经{}年!'.format('中国', '1949', '70')
通过不同的汉字常量对位置参数进行修饰的对应关系如下图所示:

索引序号不为空(同一个参数可以填充多次)。 如果索引序号不为空,可以通过设置索引序号内的值和位置参数的索引值进行对应,即通过 {n} 对位置参数索引为n的值进行对应,从而实现对传入的位置参数进行格式化处理。如格式化2019年世界500强企业名单的第一名,代码如下:
'排名:{0} 企业:{1} 收入:{2} 利润:{3}'.format('1', '沃尔玛', '5144.05', '66.7')
索引序号和位置参数不一定要按照这顺序一一对应,可以根据程序需要对索引序号内的位置索引进行设置,本例的索引序号和位置参数是一一对应的,对应关系如下图所示:

改变索引序号的,可以通过设置索引序号和位置参数的索引值对应,即通过{n}对位置参数索引为n的值进行对应,从而实现对传入的位置参数进行格式化处理。如格式化2019年世界500强企业名单的第一名,代码如下:
'企业:{1} 收入:{2} 排名:{0}'.format('1', '沃尔玛', '5144.05', '66.7')
本例索引序号和位置参数是非对应的,位置参数 "沃尔玛" 的索引为1,位置参数 "5144.06" 的索引为2,位置参数 "1" 的索引为0,根据程序需要将相应的索引值通过索引序号进行了对应,如下图所示:

索引序号的值可以重复,即多个索引序号的值可以是同一个位置参数的索引。如输出2018年和2019年世界500强企业名单的第一名企业沃尔玛,代码如下:
'2018:{0} 收入:{2} 2019:{0} 收入:{1}'.format('沃尔玛', '5144.05', '5003.43')
位置参数 "沃尔玛" 的索引为0,位置参数 "5144.06" 为2019年的收入(亿美元),位置参数 "5003.43" 为2018年的收入。在代码中,位置参数 "沃尔玛" 的索引为0在索引序号引用了两次,如下图所示:

同一个位置参数可以填充多次,下面是索引序号和位置参数进行映射的示例:
print('{0}, {1}, {2}'.format('I', 'B', 'M')) # 输出结果为:I, B, M
print('{}, {}, {}'.format('I', 'B', 'M')) # 输出结果为:I, B, M
print('{2}{2}{0}{1}{1}'.format('I', 'B', 'M')) # 输出结果为:MMIBB
print('{0}{1},{0}{2}'.format('I', 'B', 'M')) # 输出结果为:IB,IM
print('{2}{1}{0}-{0}{1}{2}'.format('I', 'B', 'M')) # 输出结果为:MBI-IBM
如果位置参数不确定,也可以使用 *args 形式的位置参数来进行映射,*args 可以将 * 号后面的字符串拆解成一个一个元素,如 *'IBM',将 "IBM" 拆解成 'I','B','M',下面代码实现的效果是一样的:
print('{2}, {1}, {0}'.format(*'IBM')) # 输出 M, B, I
print('{2}, {1}, {0}'.format('I', 'B', 'M')) # 输出 M, B, I
位置参数的值可以来自元组或列表,然后使用 "*args" 形式的位置参数来进行映射,如:
s1 = ['www', 'baidu', 'com']
print('{0}.{1}.{2}'.format(*s1)) # 输出结果为:www.baidu.com
如果索引序号设置字符串过长,可以使用变量代替索引序号设置字符串,如:
order = '排名:{} 企业名称:{} 营业收入:{}万美元 利润:{}万美元'
print(order.format('1', '沃尔玛', '51440500', '667000'))
② 通过关键字参数映射(关键字参数或命名参数)。 索引序号按照关键字参数名称进行映射,kwargs 是关键字参数,是一个字典{xxx}表示在关键字参数中搜素名称一致的。将字典打散成关键字参数给方法(通过 **)format(),进行非常灵活的映射关系。
print('产品:{name}价格:{price}'.format(spec='6G+128G', name='Mate20', price=3669))
print('***{name}***, {price} '.format(spec='6G+128G', name='Mate20', price=3669))
user = {'net': '双4G', 'name': 'Mate 20', 'price': 3669, 'spec': '6GB+128G'}
print('{name},{net},{spec},{price}'.format(**user))
位置参数和关键字参数可以混合使用,如:
print('{server}.{1}.{0}'.format('com', 'baidu', server='www'))
③ 通过元素进行映射。 对于一些需要在字符串或元组中截取部分元素进行格式化处理的情况,可以使用切片技术,但只能单个元素提取,如 0[1],0[2], 不能截取多个元素,如 0[0:3],0[:2] 等。(说明,0[1] 查找位置参数索引为 0 的元组中索引为1的元素)。代码举例如下:
print('{0[1]}--{0[0]}'.format(('猛龙', '01')))
print('{0[0]}.{0[1]}.{0[2]}'.format(['www', 'baidu', 'com']))
print('{0[2]}.{0[1]}.{0[0]}'.format('张三丰'))
print('{0[0]} {0[1]} {0[2]}'.format('www.baidu.com'.split('.')))
在对元素进行格式化时,利用转义符可以对格式化的数据进行灵活的操作,如分别连接元组中的数据,使用 "\n" 转义符实现分行对 NBA 球队进行输出。代码如下:
print('{0[1]}--{0[0]}\n{1[1]}--{1[0]}'.format(('猛龙', '01'), ('勇士', '02')))
print('{0[1][1]}\n{0[0][1]}'.format((('www', 'baidu', 'com'), ('www', 'huawei', 'com'))))
可以对不同元组中的对应元素进行提取,实现相应数据的对应输出。如提取元组中网址中的网址信息,代码如下:
print('{0[1]}、{1[1]}'.format(('www', 'baidu', 'com'), ('www', 'huawei', 'com')))
10.2.2 格式化模板标签
'{索引序号: 格式控制标记}'.format(*args,**kwargs)
本小节重点讲解格式控制标记,格式控制标记用来控制参数显示时的格式,包括:<填充><对齐><宽度>,<.精度><类型> 6个字段,这些字段都是可选的,可以组合使用。其对应关系如下图所示:

格式模板中的格式标记符即可以简单、快速对数据进行格式化处理,也可以进行复杂的自动化处理和计算。
① fill, 可选参数,指 "width" 内除了参数外的字符采用什么方式表示,默认采用空格,可以通过 <填充> 更换,填充字符只能有一个。
s = "PYTHON"
print("{0:30}".format(s))
print("{0:>30}".format(s))
print("{0:*^30}".format(s))
print("{0:-^30}".format(s))
print("{0:3}".format(s))
print("{a:*^8}".format(a="amo")) # 输出***amo***
print("{:0>8}".format("866"))
print("{:$>8}".format("866"))
print("{:0>8}".format("866"))
print("{:-<8}".format("866"))
# 中间对齐方式中如果出现字符两侧无法平均分配填充符,字符后填充符可以多填充
print("{:-^8}".format("866"))
print("{:*<30}>".format("www.amo.com"))
② align, 可选参数,可供选择的值有:</>/^/=。指参数在<宽度>内输出时的对齐方式,分别使用 </>/^/= 表示左对齐、右对齐、居中对齐和在符号后进行补齐。需要注意的是,如果 align 参数为空,对于字符串,默认左对齐。对于数字,默认右对齐。
<(如果是字符串,默认左对齐) 左对齐
^ 中间对齐
>(如果是数字,默认右对齐) 右对齐
=(只用于数字) 在符号后进行补齐
代码:
print("{:10}".format('18'))
print("{:10}".format(18))
print("{:<10}".format('18'))
print("{:<10}".format(18))
print("{:>10}".format('18'))
print("{:0>10}".format('18'))
print('{:A>10}'.format('18'))
print("{:^10}".format('18'))
print('{:0=10}'.format(-18))
print('{:0<10}'.format(-18))
print('{:0>10}'.format(-18))
print('{:0=10}'.format(18))
③ sign,可选参数,sign 可以使用 "+" / "-" / " "。+表示正号, -表示负号宽度指当前槽的设定输出字符宽度,如果该槽参数实际值比宽度设定值大,则使用参数实际长度。如果该值的实际位数小于指定宽度,则按照对齐指定方式在宽度内对齐,默认以空格字符补充。
s = 3.1415926
t = -3.1415926
print("{:+25}".format(s)) # 左对齐,默认
print("{:^25}".format(s)) # 居中对齐
print("{:>-25}".format(s)) # 右对齐
print("{:*^ 25}".format(t)) # 居中对齐且填充*号
print("{:+^25}".format(t)) # 居中对齐且填充+号
print("{:十^25}".format(t)) # 居中对齐且填充汉字"十"
print("{:^+1}".format(t)) # z指定宽度为1,不足变量s的宽度
④ #和0, 可选参数,# 为进制标志,对于进制数,在进制符前加 #,输出时会带上进制前缀,即显示 0b,0o,0x。0为填充0,设置 width 时,没设填充值,加上0,填充0指定位置用0填充。如:
print("{:0>5}".format('18'))
print("{:#x}".format(50)) # 在进制符前加#,输出时会带上进制前缀
print("{:#o}".format(12)) # 在进制符前加#,输出时会带上进制前缀
print("{:#b}".format(22)) # 在进制符前加#,输出时会带上进制前缀
print("{:>#8x}".format(50)) # 在进制符前加#,输出时会带上进制前缀
print("{:=#10o}".format(12)) # 在进制符前加#,输出时会带上进制前缀
⑤ Width, 可选参数, integer 是数字宽度,表示总共输出多少位数字。通常和 align 参数配合使用,示例如下:指当前槽的设定输出字符宽度,如果该槽对应的 format() 参数长度比<宽度>设定值大,则使用参数实际长度。如果该值的实际位数小于指定宽度,则位数将被默认以空格字符补充。如:
print('%+6s' % '我们') # 字符串左对齐
print('%+6d' % -3.14) # 格式化为整数,左对齐
print('%-6s' % '我们') # 字符串左对齐
print('%-6d' % -3.14) # 格式化为整数,左对齐
print('% 6s' % '我们') # 字符串左对齐
print('%06d' % 3.14) # 格式化为整数,左对齐
⑥ 千位符, 千位符用逗号(,),用于显示数字的千位分隔符,例如:
print("{0:^12,}".format(31415926))
print("{0:-^12,}".format(3.1415926))
print("{0:*^12,}".format(31415.926))
⑦ .precision, 可选参数,设置浮点数或字符串的精度。对于浮点数来说,用于设置浮点数的精度,即小数点后保留的位数。对于字符串来说,就是截取字符串的位数。表示两个含义,由 小数点(.) 开头。对于浮点数,精度表示小数部分输出的有效位数。对于字符串,精度表示输出的最大长度。
print("{0:.2f}".format(12345.67890))
print("{0:H^20.3f}".format(12345.67890))
print("{0:.4}".format("PYTHON"))
⑧ type, 可选参数,表示获取对应类型的值并格式化到指定位置。格式符为真实值预留位置,并控制显示的格式。格式符可以包含有一个类型码,用以控制显示的类型,主要的格式符有:
s,字符串 (采用str()的显示)
r,字符串 (采用repr()的显示)
c,整数:将数字转换成其unicode对应的值,10进制范围为 0<=i<=1114111(py27则只支持0-255);字符:将字符添加到指定位置。
o,将整数转换成八进制表示,并将其格式化到指定位置。
x,将整数转换成十六进制表示,并将其格式化到指定位置。
b,将整数转换成二进制整数,并将其格式化到指定位置。
d,将整数、浮点数转换成十进制表示,并将其格式化到指定位置。
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)。
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)。
f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)。
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e)
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E)
%,当字符串中存在格式化标志时,需要用 %%表示一个百分号。
示例:
# 1.如果类型参数未提供,则和调用str(value)效果相同,转换成字符串格式化
print("{}".format(12345.67890))
print("{0:>12}".format(12345.67890))
# 2.对于字符符串类型,可以提供的参数有 's'
print("{:s}".format('3.1415926'))
print("{0:>12s}".format('amo'))
print("{0:>12s}\n{1:>6s}".format('amo', 'amo_xia'))
# 3.整形数值可以提供的参数有 'b' 'c' 'd' 'o' 'x' 'X' 'n' None
print("{:c}".format(1221))
print("{:4d}".format(3145926))
print("{:b}".format(31))
print("{:o}".format(31))
print("{:x}".format(31))
print('{0:o} :{0:x}:{0:o}'.format(31))
# 4.浮点数可以提供的参数有 'e' 'E' 'f' 'F' 'g' 'G' 'n' '%' None
print('{:e}'.format(314159267)) # 科学计数法,默认保留6位小数
print('{:0.2e}'.format(314159267)) # 科学计数法,指定保留2位小数
print('{:f}'.format(314159267)) # 小数点计数法,默认保留6位小数
print('{:0.2f}'.format(314159267)) # 小数点计数法,指定保留2位小数
print('{0:0.2f}\n{0:0.8f}'.format(314159267)) # 小数点计数法,指定保留小数位数
print('{:0.2F}'.format(314159267)) # 小数点计数法,指定保留2位小数
print('{0:0.2F}\n{0:0.8f}'.format(314159267)) # 小数点计数法,指定小数位数
# 5.g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,
# 如果-4<=exp<p,则采用小数计数法,并保留p-1-exp位小数,否则按小数计数法计数,并按p-1保留小数位数。
print('{:1g}'.format(0.000031415926))
print('{:.2g}'.format(0.000031415926))
print('{:.5G}'.format(0.000031415926))
print('{:.3n}'.format(0.000031415926))
print('{:1g}'.format(3.1415926))
print('{:.2g}'.format(3.1415926))
print('{:.5G}'.format(3.1415926))
print('{:.3n}'.format(3.1415926))
综合示例:
import datetime# 1.格式转换
print('{}'.format(3.14)) # 使用str.format()方法将浮点数转换成字符
# 将日期格式化为字符
print('{}'.format(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S")))
print('{:d}'.format(100)) # 转换成字符型、整形和浮点数
print('{:s}'.format('100')) # 转换成字符型、整形和浮点数
print('{:c}'.format(97)) # 转换unicode成字符
print('{:d},{:f}'.format(100, 12.2)) # 转换成整形和浮点数
print('{:8d},{:2d},{:2f}'.format(314, 314, 314)) # 转换成指定格式的十进制
print('{:c},{:c},{:c}'.format(65, 33, 8712)) # 转换成unicode字符
print('{:c}{:c}{:c}{:c}'.format(39321, 26684, 37324, 25289)) # 转换unicode成字符
print('{:o},{:x},{:X}'.format(12, 12, 12)) # 将十进制转换成八进制和十六进制
print('{:d}'.format(0X5A)) # 十六进制数5A转换成10进制数,0X代表十六进制数
print('{:8d}'.format(0B011101)) # 二进制数转换成10进制数,0B代表二进制数
print('{:d}'.format(0O34)) # 八进制数转换成10进制数,0O代表八进制数
print('{:08d}'.format(0O123456)) # 16制数123456转换成10进制数,不足用0填充
print('{:*>8d}'.format(+0X1234)) # 16进制数1234转换成10进制数,右对齐,不足用*
print("{:#x}".format(123)) # 在进制符前加#,输出时会带上进制前缀
print("{:#o}".format(28)) # 在进制符前加#,输出时会带上进制前缀
print("{:#b}".format(15)) # 在进制符前加#,输出时会带上进制前缀# 2.格式化十进制整数
print('{:}'.format(122.22)) # 格式参数为空,默认为10进制
print('{:d}'.format(122)) # 原来是十进制数,转换后为原值
print('{:6d}'.format(122)) # 转换为6位十进制数,空余部分用空格填充
print('{:-6d}'.format(122)) # 转换为6位带符号十进制数,在符号前填充空余部分空格
print('{:08d}'.format(122)) # 转换为8位十进制数,空余部分填充0
print('{:+8d}'.format(122)) # 转换为8位带符号十进制数,在符号前填充空余部分空格
print('{:-8d}'.format(122)) # 转换为8位十进制数,空余部分填充空格
print('{:=8d}'.format(-122)) # 转换为8位十进制数,负号后空余部分填充空格
print('{:=8d}'.format(122)) # 转换为8位十进制数,空余部分填充空格
print('{:*<8d}'.format(122)) # 转换为8位十进制数,左对齐,空余部分填充*
print('{:#>8d}'.format(122)) # 转换为8位十进制数,右对齐,空余部分填充#
print('{:n}'.format(122)) # 原来是十进制数,转换后为原值
print('{:6n}'.format(122)) # 转换为6位十进制数,空余部分用空格填充
print('{:-6n}'.format(122)) # 转换为6位带符号十进制数,在符号前填充空余部分空格
print('{:d}={:2d}={:3d}'.format(122, 122, 122)) # 8位整数显示,不足部分整数前用空格填充
print('{:4d}+{:4d}={:4d}'.format(25, 10, 35)) # 格式化为带符号整数显示数据
add1 = [12, 23, 35, 10, 8] # 加数
add2 = [7, 19, 6, 211, 790] # 被加数
for i in range(5): # 循环输出计算式print('{:<5d}+{:5d}={:5d}'.format(add1[i], add2[i], add1[i] + add2[i])) # 加数设成左对齐# 3.格式化浮点数
print('{:f}'.format(628)) # 格式化为保留1位小数的浮点数
print('{:.1f}'.format(628)) # 格式化为保留1位小数的浮点数
print('{:.2f}'.format(628)) # # 格式化为保留2位小数的浮点数
print('{:.1f}'.format(3.14159)) # 格式化为保留1位小数的浮点数
print('{:.5f}'.format(3.14159)) # 格式化为保留5位小数的浮点数
print('{:>8.3f}'.format(-3.14159)) # 格式化为保留1位小数的浮点数
print('{:<8f}'.format(3.1415926535898, 'f')) # 默认精度保留6位小数
print('{:f}>{:.4f}>{:.2f}'.format(3.1415926, 3.1415926, 3.1415926))
print('{:2f}-{:2f}={:2f}'.format(12.2345, 10, 2.2345)) # 格式化为带符号整数显示数据
one = [3.2345, 6, 5.123, 12.5678, 21] # 计算数
two = [18.54, 43.67564, 3.1315, 21.21, 7.543] # 计算数
thr = [9.1287, 1.876, 6.345, 21.654, 7] # 计算数
s1 = '{:.2f}{:}{:.2f}{:}{:.2f}={:.2f}'
for i in range(5): # 循环输出计算式s1 = '{0:.2f}+{1:.2f}*{2:.2f}={3:.2f}'x = '{:.2f}' # 计算精度_all = float(x.format(one[i])) + float(x.format(two[i])) * float(x.format(thr[i]))print(s1.format(one[i], two[i], thr[i], _all))# 4.格式化百分数
print('{:%}'.format(0.161896)) # 将小数格式化成百分数
print('{:.2%}'.format(0.161896)) # 格式化为保留两位小数的百分数
print('{:.6%}'.format(0.0238912)) # 格式化为保留六位小数的百分数
print('{:.2%}'.format(2 / 16)) # 格式化为保留两位小数的百分数
print('{:.1%}'.format(3.1415926)) # 格式化为保留一位小数的百分数
print('{:.0%}'.format(0.161896)) # 格式化为保留整数的百分数
print('{:8.6%}'.format(0.0238912)) # 格式化为保留六位小数的八位百分数
print('{:8.3%}'.format(0.0238912)) # 格式化为保留三位小数的八位百分数# 5.格式化科学记数法
# ####e和E
print('{:e}'.format(3141592653589)) # 科学计数法,默认保留6位小数
print('{:e}'.format(3.14)) # 科学计数法,默认保留6位小数
print('{:e}'.format(3.14, '0.4e')) # 科学计数法,默认保留6位小数
print('{:0.2e}'.format(3141592653589)) # 科学计数法,保留2位小数
print('{:0.2E}'.format(3141592653589)) # 科学计数法,保留2位小数,大写E表示
# ####g和G
print('{:F}'.format(3.14e+1000000)) # 小数点计数法,无穷大转换成大小字母
print('{:g}'.format(3141592653589)) # 科学计数法,保留2位小数
print('{:g}'.format(314)) # 科学计数法,保留2位小数
print('{:0.2g}'.format(3141592653589)) # 科学计数法,保留2位小数,大写E表示
print('{:G}'.format(3141592653589)) # 小数点计数法,无穷大转换成大小字母
print('{:g}'.format(3.14e+1000000)) # 小数点计数法,无穷大转换成大小字母# 6.格式化金额
print('${:.2f}'.format(1201398.2315)) # 添加美元符号,小数保留两位
print(chr(36) + '{:.2f}'.format(1201398.2315)) # ASCII码添加美元,小数保留两位
print('¥{:,.2f}'.format(1201398.2315)) # 添加人民币符号,用千位分隔符进行区分
print('£{:,.2f}'.format(888800)) # 添加英镑符号,用千位分隔符进行区分
print('{:.2f}'.format(123.6612)) # 添加欧元符号,保留两位小数,千位分隔
print(chr(0x20ac) + '{:,.2f}'.format(1201398.2315)) # 使用16进制编码添加欧元
print(chr(36) + '{:.2f}'.format(1201398.2315)) # ASCII码加美元符号,小数保留两位# 7.格式化字符
print('{:M^20.3}'.format('PYTHON')) # 截取3个字符,宽度20居中,不足用'M'填充
print('{:10}'.format("PYTHON", '10')) # 默认居左,不足部分用' '填充
print('{:.3}'.format('baidu.com')) # 截取3个字符,默认居左显示
print('{:>10}'.format("PYTHON")) # 居右显示,不足部分用' '填充
s = 'baidu.com'
print('{:>20}'.format(s)) # 右对齐,不足指定宽度部分用0号填充
print('{:>4}'.format(s)) # 右对齐,因字符实际宽度大于指定宽度4,不用填充
print('{:*>20}'.format(s)) # 右对齐,不足指定宽度部分用*号填充
print('{:0>20}'.format(s)) # 右对齐,指定0标志位填充
print('{:>20}'.format(s)) # 右对齐,没指定填充值,用默认值空格填充
print('{:0^30}'.format(s)) # 居中对齐,用+号填充不足部分# 8.指定转化
print("repr() shows quotes: {!r}; str() doesn't: {!s}".format('hello', 'world'))
print("joy is a cute {!s}".format("baby")) # !s 相当于对于参数调用str()
print("joy is a cute {!r}".format("baby")) # !s 相当于对于参数调用str()
print('I am {!s}!'.format('Bruce Lee 李小龙'))
print('I am {!r}!'.format('Bruce Lee 李小龙'))
print('I am {!a}!'.format('Bruce Lee 李小龙'))# 9.格式化日期月份
now = datetime.datetime.now()
print('{:%Y-%m-%d %H:%M:%S %A}'.format(now)) # 当前时间格式化为年月日+完整英文星期
print('{:%Y-%m-%d %H:%M:%S %a}'.format(now)) # 当前时间格式化为年月日+简写英文星期
# 中文年月日显示
print('{:%Y}'.format(now), '年', '{:%m}'.format(now), '月', '{:%d}'.format(now), '日')
# 中文时间显示
print('{:%H}'.format(now), '时', '{:%M}'.format(now), '分', '{:%S}'.format(now), '秒')
print('{:%Y-%m-%d %H:%M:%S %a}'.format(now)) # 当前时间格式化为年月日+简写英文星期
print('{:%Y-%m-%d}'.format(now)) # 当前时间格式化为标准年月日
print('{:%y-%m-%d}'.format(now)) # 当前时间格式化为短日期年月日
print('{:%Y<%m>%d}'.format(now)) # 当前时间格式化为长日期年月日, 间隔符为"<"和">"
print('{:%c}'.format(now)) # 本地对应的年月日星期表示
print('{:%B}'.format(now)) # 本地完整的英文月份表示
print('现在是今年第{:%j}天'.format(now)) # 今天是一年中第几天
print('本周是今年第{:%U}周'.format(now)) # 本周是一年中第几周
print('{:%y%m%d}'.format(now)) # 无间隔符短年月日
print('{:%Y-%m}'.format(now)) # 长日期格式年月
print('{:%m-%d}'.format(now)) # 月日显示、
print('{:%m}'.format(now)) # 月份单独显示
print('{:%d}'.format(now)) # 日期单独显示
print('{:%H%M%S}'.format(now)) # 时分秒。无间隔符
print('{:%H:%M:%S}'.format(now)) # 标准时分秒
print('{:%H:%M:%S %I}'.format(now)) # 12小时制 时分秒
print('{:%H:%M}'.format(now)) # 时+分
print('{:%M%S}'.format(now)) # 时钟+分
print('{:%h}'.format(now)) # 只显示时钟点
print('{:%H:%M:%S %p}'.format(now)) # 日期显示按AM,PM显示
print('{:%a}'.format(now)) # 英文星期简写
print('{:%A}'.format(now)) # 英文星期完整显示
week = ['星期日', '星期一', '星期二', '星期三', '星期四', '星期五', '星期六']
print(week[int('{:%w}'.format(now))]) # 中文星期
dt = datetime.datetime(2019, 9, 9)
dm = datetime.datetime(2019, 9, 9, 12, 50, 20)
# 将输入的日期按年月日和时间格式化,因时间没有输入,按0时处理
print('{:%Y-%m-%d %H:%M:%S}'.format(dt))
print('{:%Y-%m-%d}'.format(dt)) # 将输入的日期按年月日格式化
print('{:%Y-%m-%d %H:%M:%S}'.format(dm)) # 将输入的日期按年月日和时间格式化
print('{0:%Y%m%d}{1:03d}'.format(now, 1)) # 年月日 +3位编号
print('{0:%Y%m%d}NO{1:03d}'.format(now, 5)) # 年月日+NO+3位编号
print('{0:%d}NO{1:05d}'.format(now, 8)) # 日期+NO+5位编号
print('{0:%H%M}NO{1:05d}'.format(now, 8)) # 时钟+分 +NO+5位编号
for i in range(5): # 循环输出计算式print('{0:%Y%m%d}NO{1:05d}'.format(now, i + 1))# 10.生成数据编号
print('{:0>3}'.format(1))
print('{:0>5}'.format('03'))
print('a{:0>6}'.format(111))
wx = datetime.datetime.now().date()
now = datetime.datetime.now()
print(str(wx) + '{:0>3}'.format(1)) # 年月日 +3位编号
print('{:%Y%m%d}{:0>3}'.format(now, 1)) # 年月日 +3位编号
print('{:%Y%m%d}NO{:0>5}'.format(now, 5)) # 年月日+NO+3位编号
print('{:%Y}NO{:0>5}'.format(now, 5)) # 日期+NO+3位编号
print('{:%H%M}NO{:0>3}'.format(now, 5)) # # 时钟+分 +NO+3位编号
# 嵌套编号
for i in range(65, 69):for j in range(1, 6):data = chr(i) + '{:0>3}'.format(j) + ' 'print(data, end='')print()# 11.{}内嵌{}
print('{0:>.{1}f} '.format(3.1415926, 2))
long = '1d'
for i in range(1, 10):for j in range(1, 10):print("{0:<{3}}*{1:>{3}}={2:{3}}".format(i, j, i * j, long), end=" ")print("")# 12.数据对齐
10.3 format() 函数
参考文章:全网最细 Python 格式化输出用法讲解
10.4 f-string 方法
由于本文内容太长,不再此处进行赘述,会在后续章节对该知识点进行补充,新手朋友可以先掌握 %运算符 以及 str.format()方法 或者 format() 函数 进行入门。
十一、Python转义字符及用法
在 五、Python字符串详解(包含长字符串和原始字符串) 一小节中我们曾提到过转义字符,就是那些以反斜杠 \ 开头的字符。ASCII 编码为每个字符都分配了唯一的编号,称为编码值。在 Python 中,一个 ASCII 字符除了可以用它的实体(也就是真正的字符)表示,还可以用它的编码值表示。这种使用编码值来间接地表示字符的方式称为转义字符(Escape Character)。
转义字符以 \0 或者 \x 开头,以 \0 开头表示后跟八进制形式的编码值,以 \x 开头表示后跟十六进制形式的编码值,Python 中的转义字符只能使用八进制或者十六进制。具体格式如下:
\0dd #
\xhh # dd 表示八进制数字,hh 表示十六进制数字。
ASCII 编码共收录了 128 个字符,\0 和 \x 后面最多只能跟两位数字,所以八进制形式 \0 并不能表示所有的 ASCII 字符,只有十六进制形式 \x 才能表示所有 ASCII 字符。我们一直在说 ASCII 编码,没有提及 Unicode、GBK、Big5 等其它编码(字符集),是因为 Python 转义字符只对 ASCII 编码(128 个字符)有效,超出范围的行为是不确定的。字符 1、2、3、x、y、z 对应的 ASCII 码的八进制形式分别是 61、62、63、170、171、172,十六进制形式分别是 31、32、33、78、79、7A。下面的例子演示了转义字符的用法:
str1 = 'Oct: \061\062\063'
str2 = 'Hex: \x31\x32\x33\x78\x79\x7A'
print(str1) # Oct: 123
print(str2) # Hex: 123xyz
注意,使用八进制形式的转义字符没法表示 xyz,因为它们的编码值转换成八进制以后有三位。对于 ASCII 编码,0~31(十进制)范围内的字符为控制字符,它们都是看不见的,不能在显示器上显示,甚至无法从键盘输入,只能用转义字符的形式来表示。不过,直接使用 ASCII 码记忆不方便,也不容易理解,所以,针对常用的控制字符,Python 语言又定义了简写方式,完整的列表如下:
| 转义字符 | 说明 |
| -------- | ------------------------------------------------------------ |
| \n | 换行符,将光标位置移到下一行开头。 |
| \r | 回车符,将光标位置移到本行开头。 |
| \t | 水平制表符,也即 Tab 键,一般相当于四个空格。 |
| \a | 蜂鸣器响铃。注意不是喇叭发声,现在的计算机很多都不带蜂鸣器了,所以响铃不一定有效。 |
| \b | 退格(Backspace),将光标位置移到前一列。 |
| \\ | 反斜线 |
| \' | 单引号 |
| \" | 双引号 |
| \ | 在字符串行尾的续行符,即一行未完,转到下一行继续写。 |
转义字符在书写形式上由多个字符组成,但 Python 将它们看作是一个整体,表示一个字符。Python 转义字符综合示例:
# 使用\t排版
str1 = '网站\t\t域名\t\t\t\t\t年龄\t\t价值'
str2 = '猿人学\twww.yuanrenxue.cn\t4\t\t500W'
str3 = '百度\t\twww.baidu.com\t\t20\t\t500000W'
print(str1)
print(str2)
print(str3)print("---------------------------------------------")# \n在输出时换行,\在书写字符串时换行
info = "Python教程: https://www.runoob.com/python3/python3-tutorial.html\n\
C++教程: https://www.runoob.com/cplusplus/cpp-tutorial.html\n\
Linux教程: https://www.runoob.com/linux/linux-tutorial.html"
print(info)
十二、Python数据类型转换
参考文章:Python 常用内置函数详解(三): 类型转换相关函数bin()函数、bool()函数、chr()函数等详解
十三、运算符
13.1 Python算术运算符
算术运算符也即数学运算符,用来对数字进行数学运算,比如加减乘除。下图列出了 Python 支持所有基本算术运算符。

接下来将对上图中各个算术运算符的用法逐一讲解。
① + 加法运算符。 加法运算符很简单,和数学中的规则一样,请看下面的代码:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> m = 10
>>> n = 97
>>> sum1 = m + n
>>> x = 7.2
>>> y = 15.3
>>> sum2 = x + y
>>> print(f'm+n={sum1}, x+y={sum2}')
m+n=107, x+y=22.5
当 + 用于数字时表示加法,但是当 + 用于字符串时,它还有拼接字符串(将两个字符串连接为一个)的作用,请看代码:
>>> name = 'Amo'
>>> age = 18
>>> info = name + '今年' + str(age) + '岁了。'
>>> print(info)
Amo今年18岁了。
② 减法运算符。 减法运算也和数学中的规则相同,请看代码:
a = 1024
b = 2
c = 2048
print('c-a=%d' % (c - a)) # 减法运算 运行结果:c-a=1024
- 除了可以用作减法运算之外,还可以用作求负运算(正数变负数,负数变正数),请看下面的代码:
n = 45
m = -n
x = -83.5
y = -x
r1 = m - n
print(m, ',', y, r1) # 运行结果: -45 , 83.5 -90
注意,单独使用 + 是无效的,不会改变数字的值,例如:
n = 45
m = +n
x = -83.5
y = +x
print(m, '', y) # 运行结果:45 -83.5
③ * 乘法运算符。 乘法运算也和数学中的规则相同,请看代码:
n = 4 * 25
f = 34.5 * 2
print(n, ',', f) # 运行结果:100 , 69.0
* 除了可以用作乘法运算,还可以用来重复字符串,也即将 n 个同样的字符串连接起来,请看代码:
str1 = "hello "
print(str1 * 4) # 输出结果:hello hello hello hello
④ / 和 // 除法运算符。 Python 支持 / 和 // 两个除法运算符,但它们之间是有区别的:/ 表示普通除法,使用它计算出来的结果和数学中的计算结果相同。// 表示整除,只保留结果的整数部分,舍弃小数部分;注意是直接丢掉小数部分,而不是四舍五入。请看下面的例子:
# 整数不能除尽
print("23/5 =", 23 / 5) # 23/5 = 4.6
print("23//5 =", 23 // 5) # 23//5 = 4
print("23.0//5 =", 23.0 // 5) # 23.0//5 = 4.0
print("-23/5 = ", -23 / 5) # -23/5 = -4.6
print("-23//5 = ", -23 // 5) # -23//5 = -5
print("-21//5 = ", -21 // 5) # -21//5 = -5 向下取整
print("-------------------")
# # 整数能除尽
print("25/5 =", 25 / 5) # 25/5 = 5.0
print("25//5 =", 25 // 5) # 25//5 = 5
print("25.0//5 =", 25.0 // 5) # 25.0//5 = 5.0
print("-------------------")
# # 小数除法
print("12.4/3.5 =", 12.4 / 3.5) # 12.4/3.5 = 3.542857142857143
print("12.4//3.5 =", 12.4 // 3.5) # 12.4//3.5 = 3.0
# print(5 / 0) ZeroDivisionError: division by zero
从运行结果可以发现:/ 的计算结果总是小数,不管是否能除尽,也不管参与运算的是整数还是小数。当有小数参与运算时,// 结果才是小数,否则就是整数。需要注意的是,除数始终不能为 0,除以 0 是没有意义的,这将导致 ZeroDivisionError 错误。在某些编程语言中,除以 0 的结果是无穷大(包括正无穷大和负无穷大)。
⑤ % 求余运算符。 Python % 运算符用来求得两个数相除的余数,包括整数和小数。Python 使用第一个数字除以第二个数字,得到一个整数的商,剩下的值就是余数。对于小数,求余的结果一般也是小数。注意,求余运算的本质是除法运算,所以第二个数字也不能是 0,否则会导致 ZeroDivisionError 错误。Python % 使用示例:
print("-----整数求余-----")
print("15%6 =", 15 % 6) # 15%6 = 3
print("-15%6 =", -15 % 6) # -15%6 = 3
print("15%-6 =", 15 % -6) # 15%-6 = -3
print("-15%-6 =", -15 % -6) # -15%-6 = -3
print("-----小数求余-----")
print("7.7%2.2 =", 7.7 % 2.2) # 7.7%2.2 = 1.0999999999999996
print("-7.7%2.2 =", -7.7 % 2.2) # -7.7%2.2 = 1.1000000000000005
print("7.7%-2.2 =", 7.7 % -2.2) # 7.7%-2.2 = -1.1000000000000005
print("-7.7%-2.2 =", -7.7 % -2.2) # -7.7%-2.2 = -1.0999999999999996
print("---整数和小数运算---")
print("23.5%6 =", 23.5 % 6) # 23.5%6 = 5.5
print("23%6.5 =", 23 % 6.5) # 23%6.5 = 3.5
print("23.5%-6 =", 23.5 % -6) # 23.5%-6 = -0.5
print("-23%6.5 =", -23 % 6.5) # -23%6.5 = 3.0
print("-23%-6.5 =", -23 % -6.5) # -23%-6.5 = -3.5
从运行结果可以发现两点:只有当第二个数字是负数时,求余的结果才是负数。换句话说,求余结果的正负和第一个数字没有关系,只由第二个数字决定。%两边的数字都是整数时,求余的结果也是整数;但是只要有一个数字是小数,求余的结果就是小数。
⑥ 次方(乘方)运算符Python。 运算符用来求一个 x 的 y 次方,也即次方(乘方)运算符。由于开方是次方的逆运算,所以也可以使用 ** 运算符间接地实现开方运算。Python ** 运算符示例:
print('----次方运算----')
print('3**4 =', 3 ** 4) # 3**4 = 81
print('2**5 =', 2 ** 5) # 2**5 = 32
print('----开方运算----')
print('81**(1/4) =', 81 ** (1 / 4)) # 81**(1/4) = 3.0
print('32**(1/5) =', 32 ** (1 / 5)) # 32**(1/5) = 2.0
13.2 Python赋值运算符
赋值运算符用来把右侧的值传递给左侧的变量(或者常量);可以直接将右侧的值交给左侧的变量,也可以进行某些运算后再交给左侧的变量,比如加减乘除、函数调用、逻辑运算等。Python 中最基本的赋值运算符是 等号=; 结合其它运算符,= 还能扩展出更强大的赋值运算符。
① 基本赋值运算符。 = 是 Python 中最常见、最基本的赋值运算符,用来将一个表达式的值赋给另一个变量,请看下面的例子:
# 将字面量(直接量)赋值给变量
n1 = 100
f1 = 47.5
s1 = "https://www.baidu.com"
# 将一个变量的值赋给另一个变量
n2 = n1
f2 = f1
# 将某些运算的值赋给变量
sum1 = 25 + 46
sum2 = n1 % 6
s2 = str(1234) # 将数字转换成字符串
s3 = str(100) + "abc"
连续赋值: Python 中的赋值表达式也是有值的,它的值就是被赋的那个值,或者说是左侧变量的值;如果将赋值表达式的值再赋值给另外一个变量,这就构成了连续赋值。请看下面的例子:
a = b = c = 100
= 具有右结合性,我们从右到左分析这个表达式:
- c = 100 表示将 100 赋值给 c,所以 c 的值是 100;同时,c = 100 这个子表达式的值也是 100。
- b = c = 100 表示将 c = 100 的值赋给 b,因此 b 的值也是 100。
- 以此类推,a 的值也是 100。
最终结果就是,a、b、c 三个变量的值都是 100。
= 和
==。= 和==是两个不同的运算符,= 用来赋值,而 == 用来判断两边的值是否相等,千万不要混淆。
② 扩展后的赋值运算符。 = 还可与其他运算符(包括算术运算符、位运算符和逻辑运算符)相结合,扩展成为功能更加强大的赋值运算符,如下表所示,扩展后的赋值运算符将使得赋值表达式的书写更加优雅和方便。
| 运算符 | 说 明 | 用法举例 | 等价形式 |
| ------ | ---------------- | -------- | ------------------------------------- |
| = | 最基本的赋值运算 | x = y | x = y |
| += | 加赋值 | x += y | x = x + y |
| -= | 减赋值 | x -= y | x = x - y |
| *= | 乘赋值 | x *= y | x = x * y |
| /= | 除赋值 | x /= y | x = x / y |
| %= | 取余数赋值 | x %= y | x = x % y |
| **= | 幂赋值 | x **= y | x = x ** y |
| //= | 取整数赋值 | x //= y | x = x // y |
| &= | 按位与赋值 | x &= y | x = x & y |
| |= | 按位或赋值 | x |= y | x = x | y |
| ^= | 按位异或赋值 | x ^= y | x = x ^ y |
| <<= | 左移赋值 | x <<= y | x = x << y,这里的 y 指的是左移的位数 |
| >>= | 右移赋值 | x >>= y | x = x >> y,这里的 y 指的是右移的位数 |
这里举个简单的例子:
n1 = 100
f1 = 25.5
n1 -= 80 # 等价于 n1=n1-80
f1 *= n1 - 10 # 等价于 f1=f1*( n1 - 10 )
print("n1=%d" % n1)
print("f1=%.2f" % f1)
通常情况下,只要能使用扩展后的赋值运算符,都推荐使用这种赋值运算符。但是请注意,这种赋值运算符只能针对已经存在的变量赋值,因为赋值过程中需要变量本身参与运算,如果变量没有提前定义,它的值就是未知的,无法参与运算。例如,下面的写法就是错误的:

13.3 Python位运算符
Python 位运算按照数据在内存中的二进制位(Bit)进行操作,它一般用于底层开发(算法设计、驱动、图像处理、单片机等),在应用层开发(Web 开发、Linux 运维等)中并不常见。Python 位运算符只能用来操作整数类型,它按照整数在内存中的二进制形式进行计算。Python 支持的位运算符如下所示:
| 位运算符 | 说明 | 使用形式 | 举 例 |
| -------- | -------- | -------- | -------------------------------- |
| & | 按位与 | a & b | 4 & 5 |
| | | 按位或 | a | b | 4 | 5 |
| ^ | 按位异或 | a ^ b | 4 ^ 5 |
| ~ | 按位取反 | ~a | ~4 |
| << | 按位左移 | a << b | 4 << 2,表示整数 4 按位左移 2 位 |
| >> | 按位右移 | a >> b | 4 >> 2,表示整数 4 按位右移 2 位 |
① & 按位与运算符。 按位与运算符&的运算规则是:只有参与&运算的两个位都为 1 时,结果才为 1,否则为 0。例如 1&1为 1,0&0为 0,1&0也为 0,这和逻辑运算符 && 非常类似。例如,9&5可以转换成如下的运算:
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
& 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0001 (1 在内存中的存储)
& 运算符会对参与运算的两个整数的所有二进制位进行 & 运算,9&5 的结果为 1。又如,-9&5 可以转换成如下的运算:
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
& 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-9&5 的结果是 5。再强调一遍,& 运算符操作的是数据在内存中存储的原始二进制位,而不是数据本身的二进制形式;其他位运算符也一样。以 -9&5 为例,-9 的在内存中的存储和 -9 的二进制形式截然不同:
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
-0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (-9 的二进制形式,前面多余的0可以抹掉)
按位与运算通常用来对某些位清 0,或者保留某些位。例如要把 n 的高 16 位清 0 ,保留低 16 位,可以进行 n & 0XFFFF 运算(0XFFFF 在内存中的存储形式为 0000 0000 – 0000 0000 – 1111 1111 – 1111 1111)。使用 Python 代码对上面的分析进行验证:
n = 0X8FA6002D
print("%X" % (9 & 5)) # 1
print("%X" % (-9 & 5)) # 5
print("%X" % (n & 0XFFFF)) # 2D
② | 按位或运算符。 按位或运算符|的运算规则是:两个二进制位有一个为 1 时,结果就为 1,两个都为 0 时结果才为 0。例如 1|1 为 1,0|0 为0,1|0 为1,这和逻辑运算中的 || 非常类似。例如,9 | 5 可以转换成如下的运算:
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
| 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1101 (13 在内存中的存储)
9 | 5 的结果为 13。又如,-9 | 5 可以转换成如下的运算:
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
| 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
-9 | 5 的结果是 -9。按位或运算可以用来将某些位置 1,或者保留某些位。例如要把 n 的高 16 位置 1,保留低 16 位,可以进行 n | 0XFFFF0000 运算(0XFFFF0000 在内存中的存储形式为 1111 1111 – 1111 1111 – 0000 0000 – 0000 0000)。使用 Python 代码对上面的分析进行验证:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> n = 0X2D
>>> print("%X" % (9|5) )
D
>>> print("%X" % (-9|5) )
-9
>>> print("%X" % (n|0XFFFF0000) )
FFFF002D
③ ^ 按位异或运算符。 按位异或运算 ^ 的运算规则是:参与运算的两个二进制位不同时,结果为 1,相同时结果为 0。例如 0^1 为 1,0^0 为 0,1^1 为 0。例如,9 ^ 5 可以转换成如下的运算:
0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
^ 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1100 (12 在内存中的存储)
9 ^ 5 的结果为 12。又如,-9 ^ 5 可以转换成如下的运算:
1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
^ 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0101 (5 在内存中的存储)
-----------------------------------------------------------------------------------1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0010 (-14 在内存中的存储)
-9 ^ 5 的结果是 -14。按位异或运算可以用来将某些二进制位反转。例如要把 n 的高 16 位反转,保留低 16 位,可以进行 n ^ 0XFFFF0000 运算(0XFFFF0000 在内存中的存储形式为 1111 1111 – 1111 1111 – 0000 0000 – 0000 0000)。使用 Python 代码对上面的分析进行验证:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> n = 0X0A07002D
>>> print("%X" % (9^5) )
C
>>> print("%X" % (-9^5) )
-E
>>> print("%X" % (n^0XFFFF0000) )
F5F8002D
④ ~按位取反运算符。 按位取反运算符 ~ 为单目运算符(只有一个操作数),右结合性,作用是对参与运算的二进制位取反。例如 ~1 为 0,~0 为1,这和逻辑运算中的 ! 非常类似。例如,~9 可以转换为如下的运算:
~ 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
-----------------------------------------------------------------------------------1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0110 (-10 在内存中的存储)
所以 ~9 的结果为 -10。例如,~-9 可以转换为如下的运算:
~ 1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
-----------------------------------------------------------------------------------0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1000 (8 在内存中的存储)
所以 ~-9 的结果为 8。使用 Python 代码对上面的分析进行验证:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print("%X" % (~9) )
-A
>>> print("%X" % (~-9) )
8
⑤ <<左移运算符。 Python 左移运算符 << 用来把操作数的各个二进制位全部左移若干位,高位丢弃,低位补 0。例如,9<<3 可以转换为如下的运算:
<< 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
-----------------------------------------------------------------------------------0000 0000 -- 0000 0000 -- 0000 0000 -- 0100 1000 (72 在内存中的存储)
所以 9<<3 的结果为 72。又如,(-9)<<3 可以转换为如下的运算:
<< 1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
-----------------------------------------------------------------------------------1111 1111 -- 1111 1111 -- 1111 1111 -- 1011 1000 (-72 在内存中的存储)
所以 (-9)<<3 的结果为 -72。如果数据较小,被丢弃的高位不包含 1,那么左移 n 位相当于乘以 2 的 n 次方。使用 Python 代码对上面的分析进行验证:
>>> print("%X" % (9<<3) )
48
>>> print("%X" % ((-9)<<3) )
-48
⑥ >>右移运算符。 Python 右移运算符 >> 用来把操作数的各个二进制位全部右移若干位,低位丢弃,高位补 0 或 1。如果数据的最高位是 0,那么就补 0;如果最高位是 1,那么就补 1。例如,9>>3 可以转换为如下的运算:
>> 0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 1001 (9 在内存中的存储)
-----------------------------------------------------------------------------------0000 0000 -- 0000 0000 -- 0000 0000 -- 0000 0001 (1 在内存中的存储)
所以 9>>3 的结果为 1。又如,(-9)>>3 可以转换为如下的运算:
>> 1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 0111 (-9 在内存中的存储)
-----------------------------------------------------------------------------------1111 1111 -- 1111 1111 -- 1111 1111 -- 1111 1110 (-2 在内存中的存储)
所以 (-9)>>3 的结果为 -2,如果被丢弃的低位不包含 1,那么右移 n 位相当于除以 2 的 n 次方(但被移除的位中经常会包含 1)。使用 Python 代码对上面的分析进行验证:
>>> print("%X" % (9>>3) )
1
>>> print("%X" % ((-9)>>3) )
-2
13.4 Python比较运算符
比较运算符,也称关系运算符,用于对常量、变量或表达式的结果进行大小比较。如果这种比较是成立的,则返回 True(真),反之则返回 False(假)。Python 支持的比较运算符如下表所示:
| 比较运算符 | 说明 |
| ---------- | ------------------------------------------------------------ |
| > | 大于,如果`>`前面的值大于后面的值,则返回 True,否则返回 False。 |
| < | 小于,如果`<`前面的值小于后面的值,则返回 True,否则返回 False。 |
| == | 等于,如果`==`两边的值相等,则返回 True,否则返回 False。 |
| >= | 大于等于(等价于数学中的 ≥),如果`>=`前面的值大于或者等于后面的值,则返回 True,否则返回 False。 |
| <= | 小于等于(等价于数学中的 ≤),如果`<=`前面的值小于或者等于后面的值,则返回 True,否则返回 False。 |
| != | 不等于(等价于数学中的 ≠),如果`!=`两边的值不相等,则返回 True,否则返回 False。 |
| is | 判断两个变量所引用的对象是否相同,如果相同则返回 True,否则返回 False。 |
| is not | 判断两个变量所引用的对象是否不相同,如果不相同则返回 True,否则返回 False。 |
Python 比较运算符的使用举例:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print("89是否大于100:", 89 > 100)
89是否大于100: False
>>> print("24*5是否大于等于76:", 24 * 5 >= 76)
24*5是否大于等于76: True
>>> print("86.5是否等于86.5:", 86.5 == 86.5)
86.5是否等于86.5: True
>>> print("34是否等于34.0:", 34 == 34.0)
34是否等于34.0: True
>>> print("False是否小于True:", False < True)
False是否小于True: True
>>> print("True是否等于True:", True < True)
True是否等于True: False
补充:== 和 is 的区别。 初学 Python,大家可能对 is 比较陌生,很多人会误将它和 == 的功能混为一谈,但其实 is 与 == 有本质上的区别,完全不是一码事儿。== 用来比较两个变量的值是否相等,而 is 则用来比对两个变量引用的是否是同一个对象,例如:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> s1 = 'hello world'
>>> s2 = 'hello world'
>>> print(s1 == s2)
True
>>> print(s1 is s2)
False
== 用来判断 t1 和 t2 的值是否相等,值都为 hello world,所以返回 True。虽然 t1 和 t2 的值相等,但它们是两个不同的对象,所以 s1 is s2 返回 False。这就好像两个双胞胎姐妹,虽然她们的外貌是一样的,但它们是两个人。编程时,我们关注的通常是值,因此在 Python 代码中 == 出现的频率比 is 高,然而,比较一个变量和一个单例时,应该使用 is。目前,最常使用 is 检查变量绑定的值是不是 None,下面是推荐的写法:
x is None
# 否定的正确写法
x is not None
None 是最常使用 is 测试的单例。哨符对象也是单例,同样使用 is 测试。下面是创建和测试哨符对象的一种方式:
END_OF_DATA = object()
# 省略很多行
def traverse(...):# 又省略很多行if node is END_OF_DATA:return# 等等.....
is 运算符比 == 速度快,因为它不能重载,所以 Python 不用寻找要调用的特殊方法,而是直接比较两个整数 ID。其实,a == b 是语法糖,等同于 a.__eq__(b)。继承自 object 的 __eq__ 方法比较两个对象的 ID,结果与 is 一样。但是,多数内置类型使用更有意义的方式覆盖了 __eq__ 方法,把对象的属性值纳入考虑范围。相等性测试可能涉及大量处理工作,例如,比较大型集合或嵌套层级较深的结构时。通常,我们更关注对象的相等性,而不是同一性。一般来说,is 运算符只用于测试 None,根据我审查代码的经验,is 的用法大多数是错的。如果你不确定,那就使用 ==。这通常正是你想要的行为,而且也适用于 None,尽管速度没那么快。
13.5 Python逻辑运算符
高中数学中我们就学过逻辑运算,例如 p 为真命题,q 为假命题,那么 p且q 为假,p或q 为真,非q 为真。Python 也有类似的逻辑运算,请看下表:
- and,逻辑与运算,等价于数学中的
且,a and b,当 a 和 b 两个表达式都为真时,a and b 的结果才为真,否则为假。 - or,逻辑或运算,等价于数学中的
或,a or b,当 a 和 b 两个表达式都为假时,a or b 的结果才是假,否则为真。 - not,逻辑非运算,等价于数学中的
非,not a,如果 a 为真,那么 not a 的结果为假;如果 a 为假,那么 not a 的结果为真。相当于对 a 取反。
逻辑运算符一般和关系运算符结合使用,例如:
print(14 > 6 and 45.6 > 90) # False
14 > 6 结果为 True,成立,45.6 > 90 结果为 False,不成立,所以整个表达式的结果为 False,也即不成立。有些不负责任的 Python 教程说:Python 逻辑运算符用于操作 bool 类型的表达式,执行结果也是 bool 类型,这两点其实都是错误的!Python 逻辑运算符可以用来操作任何类型的表达式,不管表达式是不是 bool 类型;同时,逻辑运算的结果也不一定是 bool 类型,它也可以是任意类型。请看下面的例子:
print(100 and 200) # 200
print(45 and 0) # 0
print('' or 'hello world') # hello world
print(18.5 or 'hello world') # 18.5
你看,本例中 and 和 or 运算符操作的都不是 bool 类型表达式,操作的结果也不是 bool 值。在 Python 中,and 和 or 不一定会计算右边表达式的值,有时候只计算左边表达式的值就能得到最终结果。另外,and 和 or 运算符会将其中一个表达式的值作为最终结果,而不是将 True 或者 False 作为最终结果。以上两点极其重要,了解这两点不会让你在使用逻辑运算的过程中产生疑惑。对于 and 运算符,两边的值都为真时最终结果才为真,但是只要其中有一个值为假,那么最终结果就是假,所以 Python 按照下面的规则执行 and 运算:
- 如果左边表达式的值为假,那么就不用计算右边表达式的值了,因为不管右边表达式的值是什么,都不会影响最终结果,最终结果都是假,此时 and 会把左边表达式的值作为最终结果。
- 如果左边表达式的值为真,那么最终值是不能确定的,and 会继续计算右边表达式的值,并将右边表达式的值作为最终结果。
对于 or 运算符,情况是类似的,两边的值都为假时最终结果才为假,只要其中有一个值为真,那么最终结果就是真,所以 Python 按照下面的规则执行 or 运算:
- 如果左边表达式的值为真,那么就不用计算右边表达式的值了,因为不管右边表达式的值是什么,都不会影响最终结果,最终结果都是真,此时 or 会把左边表达式的值作为最终结果。
- 如果左边表达式的值为假,那么最终值是不能确定的,or 会继续计算右边表达式的值,并将右边表达式的值作为最终结果。
使用代码验证上面的结论:
C:\Users\amoxiang>python
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> s1 = "hello world"
>>> print(False and print(s1))
False
>>> print(True and print(s1))
hello world
None
>>> print(False or print(s1))
hello world
None
>>> print(True or print(s1))
True
13.6 Python运算符优先级和结合性
优先级和结合性是 Python 表达式中比较重要的两个概念,它们决定了先执行表达式中的哪一部分。
13.6.1 Python 运算符优先级
所谓优先级,就是当多个运算符同时出现在一个表达式中时,先执行哪个运算符。例如对于表达式 a + b * c,Python 会先计算乘法再计算加法;b * c 的结果为 8,a + 8 的结果为 24,所以 d 最终的值也是 24。先计算 * 再计算 +,说明 * 的优先级高于 +。Python 支持几十种运算符,被划分成将近二十个优先级,有的运算符优先级不同,有的运算符优先级相同,请看下表:

结合上图中的运算符优先级,我们尝试分析下面表达式的结果:
print(4 + 4 << 2)
+ 的优先级是 12,<< 的优先级是 11,+ 的优先级高于 <<,所以先执行 4+4,得到结果 8,再执行 8<<2,得到结果 32,这也是整个表达式的最终结果。像这种不好确定优先级的表达式,我们可以给子表达式加上( ),也就是写成下面的样子:
print((4 + 4) << 2)
这样看起来就一目了然了,不容易引起误解。当然,我们也可以使用( )改变程序的执行顺序,比如:
print(4 + (4 << 2))
则先执行 4<<2,得到结果 16,再执行 4+16,得到结果20。虽然 Python 运算符存在优先级的关系,但我不推荐过度依赖运算符的优先级,这会导致程序的可读性降低。因此,我建议读者:
- 不要把一个表达式写得过于复杂,如果一个表达式过于复杂,可以尝试把它拆分来书写。
- 不要过多地依赖运算符的优先级来控制表达式的执行顺序,这样可读性太差,应尽量使用
()来控制表达式的执行顺序。
13.6.2 Python 运算符结合性
所谓结合性,就是当一个表达式中出现多个优先级相同的运算符时,先执行哪个运算符:先执行左边的叫左结合性,先执行右边的叫右结合性。例如对于表达式对于 100 / 25 * 16,/ 和 * 的优先级相同,应该先执行哪一个呢?这个时候就不能只依赖运算符优先级决定了,还要参考运算符的结合性。/ 和 * 都具有左结合性,因此先执行左边的除法,再执行右边的乘法,最终结果是 64.0。Python 中大部分运算符都具有左结合性,也就是从左到右执行;只有 ** 乘方运算符、单目运算符(例如 not 逻辑非运算符)、赋值运算符和三目运算符例外,它们具有右结合性,也就是从右向左执行。13.6.1 Python 运算符优先级 表中列出了所有 Python 运算符的结合性。
小结: 当一个表达式中出现多个运算符时,Python 会先比较各个运算符的优先级,按照优先级从高到低的顺序依次执行;当遇到优先级相同的运算符时,再根据结合性决定先执行哪个运算符:如果是左结合性就先执行左边的运算符,如果是右结合性就先执行右边的运算符。
十四、练习及详解
1.在Python中,所有的对象都都可以进行真值测试。那么print(not 0)的输出结果为()?
A.True
B.False
C.None
D.1
本小题的答案为 A,not 逻辑非运算,not a,如果 a 为真,那么 not a 的结果为假;如果 a 为假,那么 not a 的结果为真。0、''、"" 、None、以及后面学习的空列表、空元组、空集合、空字典在Python中都表示为假,故 not 0 则表示为真,所以print输出即为True,则A选项符合。
2.将一个整数x转换成为一个八进制的字符串,需要用什么方法?
A.int x
B.int(x)
C.oct(x)
D.oct x
本小题的答案为 C,在 Python 中,如果你想将一个整数 x 转换为八进制字符串,可以使用内置函数 oct()。oct(x):返回一个字符串,表示 x 的八进制形式,前缀是 '0o',int x 和 oct x 是无效语法,会报错,int(x) 是将 x 转为整数,不是转为八进制字符串。
3.Python中以下哪项表示空值:
A.Null
B.None
C.0
D.False
本小题的答案为 B,在 Python 中,None 是一个特殊的常量,表示空值或无,通常用于表示“什么都没有”或“空对象”。A. Null:错误,Python 中没有 Null,这是其他语言(如 JavaScript、SQL)中常见的写法。C. 0:表示数字零,不是空值。D. False:布尔类型的假值,也不是空值。
4.Python单行注释的符号是()?
A.//
B.#
C.'''......'''
D."""......"""
本小题的答案为 B,Python 中单行注释使用#,这没啥好说的,固定语法,//其他编程语言的单行注释符,如Java、C等。
5.在Python3.x中,八进制数,必须以()开头:
A.0
B.0/0
C.0o/0O
D.随便
本小题的答案为 C,在 Python 3.x 中,八进制数必须以 0o 或 0O 开头(o 是字母 o,不是数字 0)。A. 0:在 Python 2 中可以这样写八进制,但 Python 3 中会报错。B. 0/0:这是除法操作,不是八进制写法。D. 随便:不正确,Python 有严格的语法规则。

6.在内存中储存的数据可以有多种类型,下面哪个不是Python语言中提供的基本数据类型?
A.字符型
B.字符串型
C.数值型
D.布尔型
本小题的答案为 A,在 Python 中,没有独立的 "字符型" 数据类型。字符是字符串的一部分,因此 Python 中只提供了字符串型(str),而没有单独的字符类型。其他选项:B.字符串型:Python 中有字符串类型,表示文本数据,使用 str 类型。C.数值型:Python 中的数值类型包括整数(int)和浮点数(float)。D.布尔型:Python 中有布尔类型 bool,表示真 (True) 或假 (False)。
7.下列说法错误的是:
A.Python的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断
B.Python利用冒号和代码缩进来决定代码块范围
C.一个代码块语句内必须包含等量的缩进空白
D.Python代码的缩进量只能是4个空格或1个Tab键及其整数倍,不可随意缩进
本小题的答案为 D,在 Python 中,代码的缩进非常重要,缩进用来表示代码块的层级关系。常见的缩进规则是使用 4 个空格来缩进,但 Python 并不强制要求 只使用 4 个空格。你可以使用任意数量的空格(通常为 4 个空格),或者使用 Tab 键(但是不推荐混用空格和 Tab)。最重要的是,缩进要保持一致。所以,D 选项的说法是错误的,因为你可以使用其他数量的空格,只要在一个代码块内保持一致即可。
8.在Python中,采用代码缩进和()区分代码之间的层次:
A.{}
B.:
C.;
D.,
本小题的答案为 B,在 Python 中,代码块的层次是通过 冒号(:) 和 缩进来区分的。冒号用于标识代码块的开始,而缩进则决定代码块的层级。A.{}:这是其他编程语言(如 C、Java)用来表示代码块的符号,而 Python 不使用大括号。C.;:分号用于在一行中分隔多个语句,在 Python 中并不是用于区分代码块层次的。D. ,:逗号用于分隔函数参数、列表元素等,和代码块层次没有关系。
9.11%4的值为:
A.3
B.2.75
C.2
D.0.75
本小题的答案为 A,在 Python 中,% 是取余(模)运算符,它返回除法的余数。11 除以 4 的商是 2,余数是 3,因此 11 % 4 的结果是 3,故答案为A。
10.在Python中,使用内置函数id()可以返回变量所指的()?
A.名称
B.大小
C.内存地址
D.长度
本小题的答案为 C,在 Python 中,内置函数 id() 用于返回对象的内存地址(唯一标识符)。该地址通常是在内存中的位置,但在 Python 中它的具体表示可能会依赖于实现细节。
11.在<爸爸去哪儿>第五季中,嗯哼和Jasper执着于比谁高的场面引得一群阿姨粉捧腹大笑,假设嗯哼身高100cm,Jasper99cm,想要输出下图所示结果,①②③处应填入:

h1 = 100 # 嗯哼的身高
h2 = 99 # Jasper 的身高
print("嗯哼的身高=" + str(h1) + "厘米,Jasper的身高=" + str(h2) + "厘米")
print("嗯哼比Jasper高:" + ① )
print("Jasper比嗯哼高:" + ② )
print("嗯哼和Jasper一样高:" + ③ )A.① str(h1>h2)② str(h2>h1)③ str(h1==h2)
B.① h1>h2② h2>h1③ h1==h2
C.① str(h1<h2)② str(h2<h1)③ str(h1!=h2)
D.① str(h1>h2)② str(h2>h1)③ str(h1=h2)
根据输出结果很好得出,本小题的答案为 A,根据输出结果来看,在位置处很明显要填入比较运算符,故优先排除D选项,然后又要与字符串进行拼接,比较运算符最后的结果为布尔值,要正常拼接则需要将布尔值转为字符串,所以又排除B选项,①处又表示嗯哼比Jasper高:,故排除C选项,最终答案为A。
12.汽车以每小时60公里的速度匀速行驶,判断下列代码的输出结果:
speed = 60
hour = 1
hour += 2
print(str(hour) + "小时后,汽车行驶了" + str(speed * hour) + "公里")A.1小时后,汽车行驶了60公里
B.2小时后,汽车行驶了120公里
C.3小时后,汽车行驶了180公里
D.4小时后,汽车行驶了240公里
本小题的答案为 C,代码的执行流程如下:speed = 60:汽车的速度是每小时 60 公里。hour = 1:初始时,hour 设定为 1 小时。hour += 2:然后 hour 增加了 2 小时,因此 hour 变为 3 小时。print(str(hour) + "小时后,汽车行驶了" + str(speed * hour) + "公里"):最终输出时,hour 是 3 小时,speed * hour 等于 60 * 3 = 180 公里。所以,输出的字符串是 "3小时后,汽车行驶了180公里",即C选项。
13.数学表达式2a/(bc),在Python中可以表示为:
A.2*a/(b*c)
B.2*(a/b)*c
C.2/(b*a/c)
D.2*a/b*c
本小题的答案为 A,给定数学表达式 2a / (bc),按照运算符优先级和括号的规则,应该先计算括号内的部分 b * c,然后再将结果作为除数与 2a 相除。在 Python 中,正确的表示方式是:2 * a / (b * c)。
14.1<2<3 and 4>5 or 6<7 运算结果为:
A.False
B.False True
C.True False
D.True
本小题的答案为 D,Python 中的运算符优先级如下:比较运算符(如 <, >, == 等)优先级高。逻辑运算符(and, or)优先级较低,and 的优先级高于 or。1 < 2 < 3 计算为 True,因为 1 小于 2 且 2 小于 3。4 > 5 计算为 False,因为 4 不大于 5。6 < 7 计算为 True,因为 6 小于 7。1 < 2 < 3 and 4 > 5 or 6 < 7 可以等效为 (True and False) or True,True and False 结果是 False,因为 and 运算要求两个条件都为 True 才为 True。然后,False or True 结果是 True,因为 or 运算只要其中一个条件为 True,整体结果就是 True。因此,整个表达式的值为 True。所以正确答案是:D。
15.X、Y都小于Z用Python表达式如何表示:
A.X<Y<Z
B.X<Z or Y<Z
C.X<Z and Y<Z
D.X<Z & Y<Z
本小题的答案为 C,要表达 "X、Y 都小于 Z" 的条件,意味着我们需要同时检查 X 和 Y 是否都小于 Z。这可以通过使用 and 逻辑运算符来连接两个条件。A.X < Y < Z:这个表达式是检查 X < Y 并且 Y < Z,并不表示 "X 和 Y 都小于 Z"。B. X < Z or Y < Z:这个表达式是检查 "X 小于 Z 或 Y 小于 Z",只要其中一个条件成立,结果就为 True,这与题意不符。D.X < Z & Y < Z:这个表达式会发生位运算(因为 & 是位运算符),而不是逻辑运算,结果也不符合题意。
16.Python不支持的数据类型有?
A.char
B.int
C.float
D.list
本小题的答案为 A,Python 中并没有单独的 char 数据类型。Python 将字符(单个字符)表示为字符串类型 (str),即使它只包含一个字符,也会作为字符串处理。B.int:Python 支持整数类型(int)。C.float:Python 支持浮点数类型(float)。D.list:Python 支持列表类型(list),它是一个常见的集合类型。
17.下列哪个语句在Python中是非法的?
A.x=y=z=1
B.x=(y=z+1)
C.x,y=y,x
D.x+=y
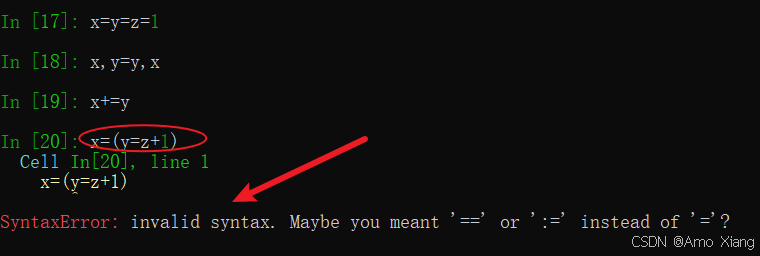
本小题的答案为 B,在 Python 中,B 选项是非法的,因为 Python 不支持在表达式中进行多重赋值(即在括号内的赋值语句)。赋值语句本身是一个语句,不是表达式,因此你不能在一个赋值语句中同时进行另一个赋值。A.x = y = z = 1:这是合法的语法,Python 支持多重赋值,可以将 1 同时赋值给 x、y 和 z。C.x, y = y, x:这是合法的语法,Python 支持元组解包,用于交换 x 和 y 的值。D.x += y:这是合法的语法,+= 是一个增量赋值操作符,等价于 x = x + y。
18.小明每当遇到计算题的时候,都是一问三不知,快来帮他看看下面的正确选项吧:
print(9 % 3 * 2 + 4)
A.10
B.3
C.6
D.4
本小题的答案为 D,Python 中的运算符优先级如下:% 和 * 的优先级比 + 高,所以先进行模运算和乘法运算。运算顺序:9 % 3 先计算,然后再进行乘法运算,再加上 4。让我们逐步分析:9 % 3 计算为 0,因为 9 除以 3 没有余数。0 * 2 计算为 0。0 + 4 计算为 4。所以,最终的结果是 4。
19.以下代码的输出结果为:
# !/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名:test.py
# 第一个注释
print("Hello, Python!") # 第二个注释A.按源代码进行输出
B.Hello, Python!
C.Hello, Python! # 第二个注释
D.!/usr/bin/python-*- coding: UTF-8 -*-文件名:test.py第一个注释print("Hello, Python!") # 第二个注释
本小题的答案为 B,在 Python 中,注释部分(以 # 开头的行)不会被执行,只会被当作代码的说明或注解,完全忽略。所以在运行时,注释部分不会出现在输出结果中。第一行和第二行是文件的编码声明和注释,不会影响代码执行。第三行和第四行也是注释,同样不会影响代码执行。第五行是实际的输出语句 print("Hello, Python!"),这行代码会执行并打印 Hello, Python!。
20.amo写了一段代码,但是却发生了错误,你能帮他看看哪里错了吗?
if True:print("Answer")print("True")
else:print("Answer")print("False")A.第一行True改成true
B.第一行if改成If
C.最后一行缩进错误
D.else改成Else
本小题的答案为 C,在 Python 中,缩进对于代码结构非常重要。在你提供的代码中,问题出在 print("False") 这一行的缩进不正确。它应该与 print("Answer") 处于相同的缩进级别,因为它是在 else 语句块中。A.第一行 True 改成 true:错误,Python 是区分大小写的,True 必须大写,true 是无效的。B.第一行 if 改成 If:错误,if 是一个关键字,在 Python 中应使用小写字母 if,大写字母 If 会导致语法错误。D.else 改成 Else:错误,else 关键字必须是小写,Python 中不允许使用大写 Else。
21.企业每月根据盈利利润来为员工发放奖金,当月利润低于或等于10万元时,奖金可提成10%;利润高于10万,不超过50万元时,不超过10万元的部分按10%提成,高于10万元的部分,可提成7.5%;当利润高于50万时,高出部分按5%提成,奖金精确到1元,小于1元时,不计入奖金.小明据此写了如下代码,你认为有错误吗?
i = float(input("请输入利润:(单位:万元)\n "))
a = i * 0.1
b = 10 * 0.1 + (i - 10) * 0.075
c = 10 * 0.1 + 40 * 0.075 + (i - 50) * 0.05
if i <= 10:print("本月奖金为:" + str(a * 10000) + "元")
if 10 < i <= 50:print("本月奖金为:" + str(b * 10000) + "元")
if i > 50:print("本月奖金为:" + str(c * 10000) + "元")A.没有错误
B.第2、3、4行的a、b、c应该改为a = int(i*0.1)b = int(10*0.1+(i-10)*0.075)c = int(10*0.1+40*0.075+(i-50)*0.05)C.第7行应改为 if i >10 and i <=50:
D.第6、8、10行中str(a*10000)、str(b*10000)、str(c*10000)分别改为str(int(a*10000)) str(int(b*10000)) str(int(c*10000))
本小题的答案为 D,在题目中,奖金需要精确到1元,小于1元的部分不计入奖金。但是当前代码中,直接计算出的奖金可能是小数,而 Python 默认不会进行四舍五入或转换为整数。精确到1元:在代码中,奖金是通过浮动计算的,例如 a * 10000 会得到一个浮动的浮点数,可能包含小数部分。为了符合题目要求,需要 将奖金四舍五入为整数,以确保奖金精确到元。解决方法:可以使用 int() 函数将计算结果转换为整数,这样可以去除小数部分,保证精确到元。比如 str(int(a * 10000))。A.没有错误:错误。当前代码没有对小数部分进行处理,可能会导致输出奖金含有小数部分,而题目要求是精确到1元。B.第2、3、4行的 a、b、c 应该改为 a = int(i * 0.1) 等:不完全正确。虽然你可以将计算过程中的浮动结果转换为整数,但题目并没有要求在计算时立即转换。计算时保持浮动形式,然后最后再转换为整数(如选项 D)更符合题意。C.第7行应改为 if i > 10 and i <= 50:不正确。10 < i <= 50 本身已经是正确的,if i > 10 and i <= 50 的表达式结果与原表达式相同,且并不会解决精度问题。
22.登录微博,用户名为:Python萌新,密码:666999,当用户名和密码都正确时,显示“登录成功”,否则显示“登录失败”,下列代码能否实现此项功能:
# -*- coding: utf-8 -*-
# @Time : 2024-09-20 11:08
# @Author : AmoXiang
username = input("请输入用户名:")
password = input("请输入密码:")
if username == 'Python萌新' or password == '666999':print("登录成功")
else:print("登录失败")A.可以实现
B.不能,应该在1、2行前后加三引号进行多行注释
C.不能,第6行or应改为and
D.不能,第6行的==应改为=
本小题的答案为 C,当前代码使用的是 or 逻辑运算符,这意味着只要用户名或密码之一正确,就会显示 "登录成功"。但是要求是用户名和密码都正确时才登录成功,因此应该使用 and 逻辑运算符来确保两个条件都满足。D.不能,第6行的 == 应改为 =:错误,== 用于比较值,= 用于赋值。此处需要使用 == 来进行条件比较。
23.向往的生活:“空调、wifi、西瓜,电影、漫画、二哈,小桥流水人家,葛优同款沙发。”万事俱备,就差假期,空调和沙发了!假设空调5000元,沙发2000元,我现有存款400元,如果想3个月以后过上理想中的生活,为什么下列代码的输出结果为:每个月至少存6867元?
air_con = 5000 # 空调费用
sofa = 2000 # 沙发费用
account = 400 # 存款
month = 3
money = air_con + sofa - account // month
print("每个月至少存" + str(money) + "元")A.第6行应改为 print("每个月至少存+str(money)+元")
B.第5行应改为 money = (air_con + sofa-account)//month
C.第5行应改为 money = air_con + sofa-account/month
D.第5行应改为 money = (air_con + sofa-account)/month
本小题的答案为 B,在代码中,计算每个月需要存的钱的目的是把空调和沙发的费用减去现有存款,再平均分配到 3 个月,以求得每个月至少需要存多少钱。money = air_con + sofa - account // month,account // month 是对 account 做整数除法。首先会对 account 进行除法操作,然后再计算 air_con + sofa - 的结果。但是这并不是我们想要的,因为我们需要的是先计算总的需要存的钱(air_con + sofa - account),然后再除以月数。D.第5行应改为 money = (air_con + sofa - account) / month:错误,使用了 / 进行浮点数除法。题目要求结果是整数,应该使用 // 进行整数除法。
24.小明小黑小红3个人身高分别是180,185,165,小明想求出他们的平均身高,看看下面的代码有错误吗:
a = 180
b = 185
c = 165
avg = a + b + c / 3
print(avg)A.a=180改成a==180
B.print(avg)改成print avg
C.avg=a+b+c/3改成a+b+c/3
D.avg=a+b+c/3改成avg=(a+b+c)/3
本小题的答案为 D,在当前代码中,问题出在 avg = a + b + c / 3 这一行。根据运算符的优先级,/ 运算符的优先级高于 + 运算符,所以代码实际上是先计算 c / 3,然后再将结果与 a 和 b 相加,导致计算结果不正确。为了正确计算平均值,应该先将 a、b、c 的和加起来,然后再除以 3。正确的写法是:avg = (a + b + c) / 3。A.a = 180 改成 a == 180:错误,== 用于比较值,而不是赋值操作。应保持 a = 180。B.print(avg) 改成 print avg:错误,Python 3.x 中的 print 函数需要带括号,应该写作 print(avg)。C.avg = a + b + c / 3 改成 a + b + c / 3:不正确,因为没有正确的变量赋值。
25.下列哪项输出的不是“北风那个吹,雪花那个飘,雪花那个飘飘,年来到。”:
A. """时间:2018年8月文件名:demo.py'''print("北风那个吹,雪花那个飘,雪花那个飘飘,年来到。")B. """时间:2018年8月文件名:demo.py"""print("""北风那个吹,雪花那个飘,雪花那个飘飘,年来到。""")C.'''时间:2018年8月文件名:demo.py'''print("""北风那个吹,雪花那个飘,雪花那个飘飘,年来到。""")D.# 时间:2018年8月# 文件名:demo.pyprint("北风那个吹,雪花那个飘,雪花那个飘飘,年来到。")
本小题的答案为 A,在这个选项中,代码出现了字符串的开始是三双引号("""),但紧接着用单引号(''')来结束。这样的引号不匹配,导致语法错误,因此不能输出预期的结果。
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习Python语言的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
相关文章:

《100天精通Python——基础篇 2025 第3天:变量与数据类型全面解析,掌握Python核心语法》
目录 一、Python变量的定义和使用二、Python整数类型(int)详解三、Python小数/浮点数(float)类型详解四、Python复数类型(complex)详解---了解五、Python字符串详解(包含长字符串和原始字符串)5.1 处理字符串中的引号5.2 字符串的…...
:聚焦第一关键指标,驱动创业成功)
精益数据分析(24/126):聚焦第一关键指标,驱动创业成功
精益数据分析(24/126):聚焦第一关键指标,驱动创业成功 在创业和数据分析的探索之旅中,我们都在不断寻找能够助力成功的关键因素。今天,我依旧带着与大家共同进步的初心,深入解读《精益数据分析…...
)
【刷题Day26】Linux命令、分段分页和中断(浅)
说下你常用的 Linux 命令? 文件与目录操作: ls:列出当前目录的文件和子目录,常用参数如-l(详细信息)、-a(包括隐藏文件)cd:切换目录,用于在文件系统中导航m…...

互联网实验室的质量管控痛点 质检LIMS系统在互联网企业的应用
在互联网行业流量红利消退与用户体验至上的时代背景下,产品迭代速度与质量稳定性成为企业核心竞争力的分水岭。传统测试实验室依赖人工操作、碎片化工具与线下沟通的管理模式,已难以应对敏捷开发、多端适配、数据安全等复合型挑战。 一、互联网实验室的…...
)
VScode远程连接服务器(免密登录)
一、本机生成密钥对 本地终端输入ssh-keygen,生成公钥(id_rsa.pub)和私钥(id_rsa) 二、在远程服务器根目录的.ssh文件夹的authorized_keys中输入id_rsa的内容 三、修改vscode的config文件.ssh/config,加…...
)
【Go语言】RPC 使用指南(初学者版)
RPC(Remote Procedure Call,远程过程调用)是一种计算机通信协议,允许程序调用另一台计算机上的子程序,就像调用本地程序一样。Go 语言内置了 RPC 支持,下面我会详细介绍如何使用。 一、基本概念 在 Go 中&…...

安卓四大组件之ContentProvider
目录 实现步骤 代码分析 onCreate insert query ContextHolder Cursor 作用与用法 基本步骤: 可能的面试题:为什么使用Cursor? 为什么使用Cursor 使用Cursor的好处 静态内部类实现单例模式 AnndroidManifest.xml配置信息 注释的…...

C#中实现XML解析器
XML(可扩展标记语言)是一种广泛用于存储和传输数据的格式,因其具有良好的可读性和可扩展性,在许多领域都有应用。 实现思路: 词法分析 词法分析的目的是将输入的 XML 字符串分解为一个个的词法单元,例如…...

神经符号混合与跨模态对齐:Manus AI如何重构多语言手写识别的技术边界
在全球化数字浪潮下,手写识别技术长期面临"巴别塔困境"——人类书写系统的多样性(从中文象形文字到阿拉伯语连写体)与个体书写风格的随机性,构成了人工智能难以逾越的双重壁垒。传统OCR技术在处理多语言手写场景时,准确率往往不足70%,特别是在医疗处方、古代文…...
大模型自动生成测试用例、和测试用例评审、RAG知识库管理的web平台系统)
TestBrain开源程序是一款集使用AI(如deepseek)大模型自动生成测试用例、和测试用例评审、RAG知识库管理的web平台系统
一、软件介绍 文末提供程序和源码下载 TestBrain开源程序是一款集使用AI(如deepseek)大模型自动生成测试用例、和测试用例评审、RAG知识库管理的web平台系统一个基于LLM的智能测试用例生成平台(功能慢慢丰富中,未来可能将测试相关的所有活动集成到一起),…...

软件工程效率优化:一个分层解耦与熵减驱动的系统框架
软件工程效率优化:一个分层解耦与熵减驱动的系统框架** 摘要 (Abstract) 本报告构建了一个全面、深入、分层的软件工程效率优化框架,旨在超越简单的技术罗列,从根本的价值驱动和熵减原理出发,系统性地探讨提升效率的策略与实践。…...

【金仓数据库征文】- 深耕国产数据库优化,筑牢用户体验新高度
目录 引言 一、性能优化:突破数据处理极限,提升运行效率 1.1 智能查询优化器:精准优化数据检索路径 1.2 并行处理技术:充分释放多核计算潜力 1.3 智能缓存机制:加速数据访问速度 二、稳定性提升:筑牢…...

前端面试常见部分问题,及高阶部分问题
面试中也极有可能让你徒手写代码,无聊的面试问题o( ̄︶ ̄)o 一、HTML/CSS 基础与进阶 常见问题 什么是语义化标签?有哪些常用语义化标签? 答案:语义化标签是指具有明确含义的 HTML 标签,如 <header>、<footer>、<article>、<section> 等。它们有…...

使用 AutoGen 与 Elasticsearch
作者:来自 Elastic Jeffrey Rengifo 学习如何使用 AutoGen 为你的 agent 创建一个 Elasticsearch 工具。 Elasticsearch 拥有与行业领先的生成式 AI 工具和提供商的原生集成。查看我们的网络研讨会,了解如何超越 RAG 基础,或使用 Elastic 向量…...

kafka与flume的整合、spark-streaming
kafka与flume的整合 前期配置完毕,开启集群 需求1: 利用flume监控某目录中新生成的文件,将监控到的变更数据发送给kafka,kafka将收到的数据打印到控制台(三个node01中运行) 1.在kafka中建立topic kafka…...

高级电影感户外街拍人像摄影后期Lr调色教程,手机滤镜PS+Lightroom预设下载!
调色介绍 高级电影感户外街拍人像摄影后期 Lr 调色,是运用 Adobe Lightroom 软件,对户外街拍的人像照片进行后期处理,以塑造出具有电影质感的独特视觉效果。此调色过程借助 Lr 丰富的工具与功能,从色彩、光影、对比度等多维度着手…...

react 常用钩子 hooks 总结
文章目录 React钩子概念图状态管理钩子 state management副作用钩子 effect hooks引用钩子 Ref hooks上下文钩子其他钩子过渡钩子 处理过渡效果性能优化钩子 performance hooksReact 19 新钩子 React钩子概念图 状态管理钩子 state management useState useReducer useSyncEx…...

2025 年导游证报考条件新政策解读与应对策略
2025 年导游证报考政策有了不少新变化,这些变化会对报考者产生哪些影响?我们又该如何应对?下面就为大家详细解读新政策,并提供实用的应对策略。 最引人注目的变化当属中职旅游类专业学生的报考政策。以往,中专学历报考…...

重置 Git 项目并清除提交历史
在某些情况下,你可能需要完全重置一个 Git 项目,清除所有提交历史,然后将当前代码作为全新的初始提交。本文将详细介绍这个过程的操作步骤和注意事项。 重要警告 ⚠️ 注意:以下操作将永久删除项目的所有提交历史、分支和标签。…...
 很有用,但不是很好)
GitHub Copilot (Gen-AI) 很有用,但不是很好
摘要:以下是我在过去三个月中在实际 、 开发中使用 GitHub Copilot Pro 后的想法。由于技术发展迅速,值得注意的是,这些印象是基于我截至 2025 年 3 月的经验。 1 免费试用促使我订阅 GitHub Copilot Pro 我以前读过有关 AI 代码生成器的文…...

K8S Service 原理、案例
一、理论介绍 1.1、3W 法则 1、是什么? Service 是一种为一组功能相同的 pod 提供单一不变的接入点的资源。当 Service 存在时,它的IP地址和端口不会改变。客户端通过IP地址和端口号与 Service 建立连接,这些连接会被路由到提供该 Service 的…...

Base64编码原理:二进制数据与文本的转换技术
🔄 Base64编码原理:二进制数据与文本的转换技术 开发者的数据编码困境 作为开发者,你是否曾遇到这些与Base64相关的挑战: 📊 需要在JSON中传输二进制数据,但不确定如何正确编码🖼️ 想要在HT…...
—前端—CDN—Nginx—服务集群)
系统设计(1)—前端—CDN—Nginx—服务集群
简介: 本指南旨涵盖前端、CDN、Nginx 负载均衡、服务集群、Redis 缓存、消息队列、数据库设计、熔断限流降级以及系统优化等模块的核心要点。我们将介绍各模块常见的设计方案与优化策略,并结合电商秒杀、SaaS CRM 系统、支付系统等高并发场景讨论实践技巧…...

Easysearch 基础运维扫盲指南:从 HTTP 到 HTTPS、认证与安全访问全解析
Easysearch 基础运维扫盲指南:从 HTTP 到 HTTPS、认证与安全访问全解析 众所周知,原生 Elasticsearch 默认开启的是 HTTP 明文接口,并且不开启任何身份认证或传输加密。若想启用 TLS/SSL 加密及账号密码验证,通常需要配置繁琐的安…...

在Android中如何使用Protobuf上传协议
在 Android 中使用 Protobuf(Protocol Buffers)主要分为以下几个步骤: ✅ 1. 添加 Protobuf 插件和依赖 在项目的 build.gradle(Project 级)文件中添加 Google 的 Maven 仓库(通常默认已有)&am…...

【数据可视化艺术·应用篇】三维管线分析如何重构城市“生命线“管理?
在智慧城市、能源管理、工业4.0等领域的快速发展中,地下管线、工业管道、电力通信网络等“城市血管”的复杂性呈指数级增长。传统二维管理模式已难以应对跨层级、多维度、动态变化的管线管理需求。三维管线分析技术应运而生,成为破解这一难题的核心工具。…...

2025年的营销趋势-矩阵IP
从 2025 年的营销生态来看,创始人 IP 与智能矩阵的结合确实呈现出颠覆性趋势,这一现象背后隐藏着三个值得深度解析的商业逻辑: 一、创始人 IP 的本质是 "信任货币" 的数字化迁徙 当新能源汽车市场陷入参数混战,雷军将个…...

对接金蝶获取接口授权代码
接口服务信息 using RestSharp; using System.Configuration; using System.Threading.Tasks; public class KingdeeAccessTokenService { private readonly RestClient _client; private readonly KingdeeApiConfig _config; public KingdeeAccessTokenService() …...

探秘 3D 展厅之卓越优势,解锁沉浸式体验新境界
(一)打破时空枷锁,全球触达 3D 展厅的首要优势便是打破了时空限制。在传统展厅中,观众需要亲临现场,且必须在展厅开放的特定时间内参观。而 3D 展厅依托互联网,让观众无论身处世界哪个角落,只…...

prometheus通过Endpoints自定义grafana的dashboard模块
1、prometheus自定义的dashboard模块 文件路径/etc/prometheus/config_out/prometheus-env.yaml - job_name: serviceMonitor/monitoring/pfil/0honor_labels: falsekubernetes_sd_configs:- role: endpointsnamespaces:names:- monitoringrelabel_configs:- source_labels:- …...

java排序算法-计数排序
计数排序的思路 计数排序的基本思路: 确定取值范围: 遍历整个待排序的数组,确定数组中元素的取值范围,找到最小值和最大值。创建计数数组: 创建一个计数数组,其长度为取值范围的大小,用于统计…...
)
力扣-hot100(滑动窗口最大值)
239. 滑动窗口最大值 困难 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums […...
)
每日c/c++题 备战蓝桥杯(P1049 [NOIP 2001 普及组] 装箱问题)
洛谷P1049 装箱问题题解:动态规划在背包问题中的经典应用 题目描述 P1049 装箱问题是一道典型的0-1背包问题变种。题目要求在给定箱子容量V和n个物品体积的情况下,选择若干物品装入箱子,使得箱子的剩余空间最小。最终输出这个最小剩余空间的…...

【尚硅谷Redis6】自用学习笔记
Redis介绍 Redis是单线程 多路IO复用技术(类似黄牛买票) 默认有16个库,用select进行切换 默认端口号为6379 Memcached:多线程 锁(数据类型单一,不支持持久化) 五大常用数据类型 Redis key …...

产品更新丨谷云科技ETLCloud V3.9.2版本发布
谷云科技 ETLCloud 集成平台迎来了每月一次的功能迭代,本月发布版本号为 3.9.2 版本,为用户带来了新的功能、优化改进以及问题修复,以下是详细介绍: 新增组件 本次更新新增了众多实用组件,涵盖了京东和 Shopify 相关…...

Promise并发控制与HTTP请求优化
Promise并发方法对比 #mermaid-svg-tnmGzOkgNUCrbvfI {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-tnmGzOkgNUCrbvfI .error-icon{fill:#552222;}#mermaid-svg-tnmGzOkgNUCrbvfI .error-text{fill:#552222;stroke…...

G1垃圾回收器中YoungGC和MixedGC的区别
在 G1 垃圾回收器中,Mixed GC 和 Young GC 的区别主要体现在以下几个方面: 作用范围 Young GC:仅针对年轻代中的Region进行回收,包括 Eden 区和 Survivor 区的 Region。Mixed GC:会回收所有年轻代的 Region 以及部分…...

Web4.0身份革命:去中心化身份系统的全栈实现路径
去中心化身份(DID)技术栈正在重构数字世界的信任根基,本文从密码学协议、存储网络、验证框架三个维度,解析符合W3C标准的身份系统构建方案。通过Hyperledger Aries架构实践,揭示如何实现跨链身份互通、数据主权控制、零…...

iOS/Flutter混合开发之PlatformView配置与使用
环境:Xcode 16.3、Flutter 3.29.2、Dart 3.7.2。 使用背景:需要在flutter界面中嵌入一个iOS原生控件。 步骤: 1. iOS侧实现: 1.1:PlatformView实现 class FLNativeView: NSObject, FlutterPlatformView {private v…...

Libconfig 修改配置文件里的某个节点
THCommandStatus ( { Status "1"; index 5; }, { Status "2"; index 8; }, { Status "3"; index 7; }, { Status "4"; index 0; } ); 比如这是配置文件的内容ÿ…...

【金仓数据库征文】_AI 赋能数据库运维:金仓KES的智能化未来
AI 赋能数据库运维:金仓KES的智能化未来 🌟嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 在当今数字经济飞速发展的时代࿰…...

【MySQL】3分钟解决MySQL深度分页问题
什么是深度分页问题?该如何解决呢?这篇文章展开讲讲 什么是深度分页? 当查询结果集非常大时,需要获取靠后页码的数据,比如第1000页、10000页。 如: SELECT * FROM table LIMIT 10000, 10; -- 获取第10001-10010条…...
)
GitHub 趋势日报 (2025年04月24日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1kortix-ai/sunaSuna - Open Source Generalist AI Agent⭐ 1105⭐ 3639TypeScript2cloudcommunity/Free-CertificationsA curated …...

一种双模式机器人辅助股骨干骨折钢板植入方法
股骨干骨折是一种常见的高能损伤,微创内固定是首选治疗方法。然而,钢板植入过程中存在不可见、不准确和不稳定等问题。山东大学研究团队提出了一种双模式机器人辅助钢板植入方法,通过神经网络模型规划钢板植入轨迹,然后利用机械臂…...
)
全球碳化硅晶片市场深度解析:技术迭代、产业重构与未来赛道争夺战(2025-2031)
一、行业全景:从“材料突破”到“能源革命”的核心引擎 碳化硅(SiC)作为第三代半导体材料的代表,凭借其宽禁带(3.26eV)、高临界击穿场强(3MV/cm)、高热导率(4.9W/cmK&…...

IDEA搭建环境的五种方式
一、普通的java项目 File--New--Project 选择Java,jdk选择1.8版本,然后点next 输入项目名和路径名,点击Finish 创建包结构,编写Class类 编写主方法,输出Hello标志完成 二、普通的javaWeb项目 Java Enterprise-- 勾选…...

隐形革命:环境智能如何重构“人-机-境“共生新秩序
引言 在万物互联的时代,环境智能(Ambient Intelligence, AmI)正以“隐形革命者”的姿态重塑人类生活场景。通过分布式传感器、边缘计算与自适应算法的深度融合,AmI构建出能感知、学习并响应人类行为的智慧环境。 本文基于多领域研…...

Mysql唯一性约束
唯一性约束(Unique Constraint)是数据库设计中用于保证表中某一列或多列组合的值具有唯一性的一种规则。它可以防止在指定列中插入重复的数据,有助于维护数据的完整性和准确性。下面从几个方面为你详细解释 作用 确保数据准确性:…...

QuecPython+GNSS:实现快速定位
概述 QuecPython 结合 GNSS(全球导航卫星系统)模块为物联网设备提供开箱即用的定位能力解决方案。该方案支持 GPS/北斗/GLONASS/Galileo 多系统联合定位,为物联网开发者提供从硬件接入到云端服务的全栈式定位解决方案。 优势特点 多体系定…...
】)
【从零开始:自制一个Java消息队列(MQ)】
🚀 从零开始:自制一个Java消息队列(MQ) 在现代分布式系统中,消息队列(Message Queue,MQ)已经成为一个至关重要的组件。它帮助系统在异步处理、负载均衡、解耦等方面提供了强大的支持…...