使用 AutoGen 与 Elasticsearch
作者:来自 Elastic Jeffrey Rengifo

学习如何使用 AutoGen 为你的 agent 创建一个 Elasticsearch 工具。
Elasticsearch 拥有与行业领先的生成式 AI 工具和提供商的原生集成。查看我们的网络研讨会,了解如何超越 RAG 基础,或使用 Elastic 向量数据库构建可投入生产的应用。
为了为你的使用场景构建最佳搜索解决方案,现在就开始免费云试用,或者在本地机器上试用 Elastic。
AutoGen 是微软的一个框架,用于构建可以与人类互动或自主行动的应用程序。它提供了一个完整的生态系统,具备不同层级的抽象,取决于你需要自定义的程度。
如果你想了解更多关于 agent 及其工作原理的内容,建议你阅读这篇文章。

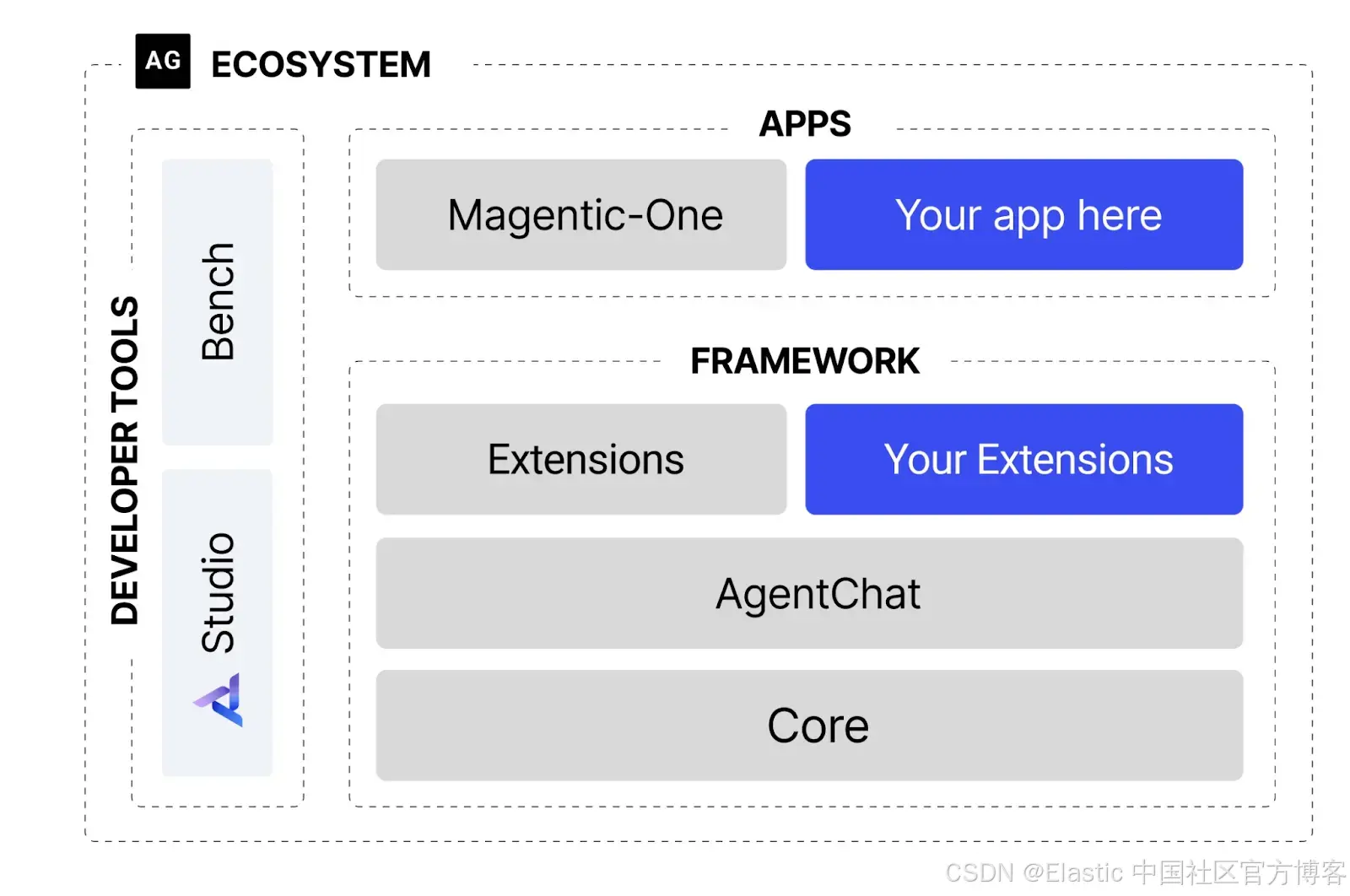
AgentChat 让你可以轻松地在 AutoGen 核心之上实例化预设的 agent,从而配置模型提示词、工具等内容。
在 AgentChat 之上,你可以使用扩展来增强其功能。这些扩展既包括官方库中的,也包括社区开发的。
最高层级的抽象是 Magnetic-One,这是一个为复杂任务设计的通用多 agent 系统,在介绍该方法的论文中已经预先配置好。
AutoGen 以促进 agent 之间的沟通而闻名,提出了具有突破性的交互模式,例如:
-
群聊 - group chat
-
多 agent 辩论
-
agent 混合
-
并发 agent
-
任务交接
在本文中,我们将创建一个使用 Elasticsearch 作为语义搜索工具的 agent,使其能够与其他 agent 协作,在 Elasticsearch 中存储的候选人简历与在线职位之间寻找最佳匹配。
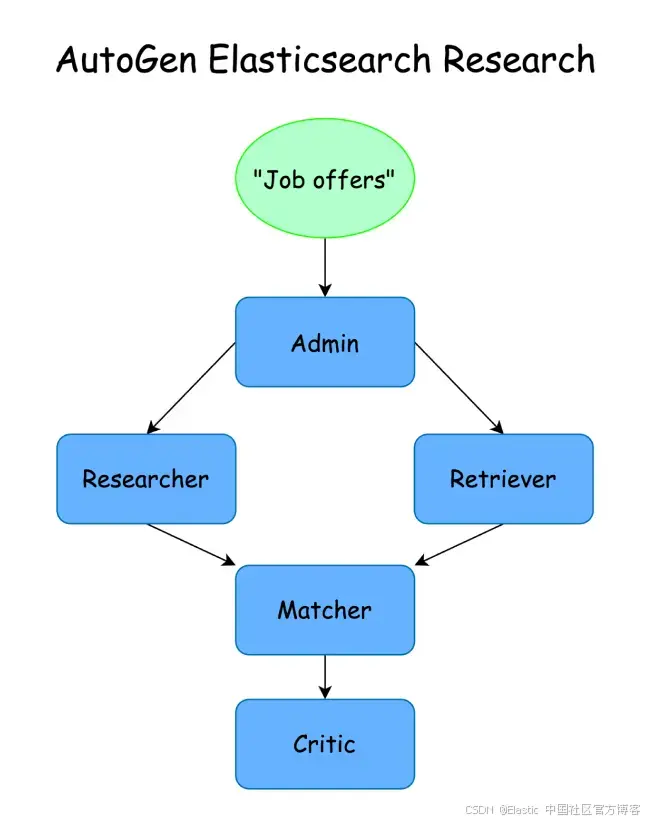
我们将创建一组共享 Elasticsearch 和在线信息的 agents,尝试将候选人与职位进行匹配。我们将使用 “Group Chat” 模式,其中一个管理员负责协调对话和执行任务,而每个 agent 专注于特定任务。
完整示例可在此 Notebook 中查看。
步骤:
-
安装依赖并导入包
-
准备数据
-
配置 agent
-
配置工具
-
执行任务
安装依赖并导入包
pip install autogen elasticsearch==8.17 nest-asyncioimport json
import os
import nest_asyncio
import requestsfrom getpass import getpass
from autogen import (AssistantAgent,GroupChat,GroupChatManager,UserProxyAgent,register_function,
)
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulknest_asyncio.apply()准备数据
设置密钥
对于 agent 的 AI 接口,我们需要提供一个 OpenAI API 密钥。我们还需要一个 Serper API 密钥,以赋予 agent 搜索能力。Serper 在注册时提供 2,500 次免费的搜索调用。我们使用 Serper 让 agent 具备访问互联网的能力,更具体来说,是获取 Google 搜索结果。agent 可以通过 API 发送搜索查询,Serper 会返回 Google 的前几条结果。
os.environ["SERPER_API_KEY"] = "serper-api-key"
os.environ["OPENAI_API_KEY"] = "openai-api-key"
os.environ["ELASTIC_ENDPOINT"] = "elastic-endpoint"
os.environ["ELASTIC_API_KEY"] = "elastic-api-key"Elasticsearch client
_client = Elasticsearch(os.environ["ELASTIC_ENDPOINT"],api_key=os.environ["ELASTIC_API_KEY"],
)推理端点与映射
为了启用语义搜索功能,我们需要使用 ELSER 创建一个推理端点。ELSER 允许我们运行语义或混合查询,因此我们可以向 agent 分配宽泛的任务,而无需输入文档中出现的关键字,Elasticsearch 就能返回语义相关的文档。
try:_client.options(request_timeout=60, max_retries=3, retry_on_timeout=True).inference.put(task_type="sparse_embedding",inference_id="jobs-candidates-inference",body={"service": "elasticsearch","service_settings": {"adaptive_allocations": {"enabled": True},"num_threads": 1,"model_id": ".elser_model_2",},},)print("Inference endpoint created successfully.")except Exception as e:print(f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }")映射
对于映射,我们将把所有相关的文本字段复制到 semantic_text 字段中,以便我们可以对数据执行语义或混合查询。
try:_client.indices.create(index="available-candidates",body={"mappings": {"properties": {"candidate_name": {"type": "text","copy_to": "semantic_field"},"position_title": {"type": "text","copy_to": "semantic_field"},"profile_description": {"type": "text","copy_to": "semantic_field"},"expected_salary": {"type": "text","copy_to": "semantic_field"},"skills": {"type": "keyword","copy_to": "semantic_field"},"semantic_field": {"type": "semantic_text","inference_id": "positions-inference"}}}})print("index created successfully")
except Exception as e:print(f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }")将文档导入 Elasticsearch
我们将加载关于求职者的数据,并要求我们的 agent 根据他们的经验和期望薪资找到最适合的职位。
documents = [{"candidate_name": "John","position_title": "Software Engineer","expected_salary": "$85,000 - $120,000","profile_description": "Experienced software engineer with expertise in backend development, cloud computing, and scalable system architecture.","skills": ["Python", "Java", "AWS", "Microservices", "Docker", "Kubernetes"]},{"candidate_name": "Emily","position_title": "Data Scientist","expected_salary": "$90,000 - $140,000","profile_description": "Data scientist with strong analytical skills and experience in machine learning and big data processing.","skills": ["Python", "SQL", "TensorFlow", "Pandas", "Hadoop", "Spark"]},{"candidate_name": "Michael","position_title": "DevOps Engineer","expected_salary": "$95,000 - $130,000","profile_description": "DevOps specialist focused on automation, CI/CD pipelines, and infrastructure as code.","skills": ["Terraform", "Ansible", "Jenkins", "Docker", "Kubernetes", "AWS"]},{"candidate_name": "Sarah","position_title": "Product Manager","expected_salary": "$110,000 - $150,000","profile_description": "Product manager with a technical background, skilled in agile methodologies and user-centered design.","skills": ["JIRA", "Agile", "Scrum", "A/B Testing", "SQL", "UX Research"]},{"candidate_name": "David","position_title": "UX/UI Designer","expected_salary": "$70,000 - $110,000","profile_description": "Creative UX/UI designer with experience in user research, wireframing, and interactive prototyping.","skills": ["Figma", "Adobe XD", "Sketch", "HTML", "CSS", "JavaScript"]},{"candidate_name": "Jessica","position_title": "Cybersecurity Analyst","expected_salary": "$100,000 - $140,000","profile_description": "Cybersecurity expert with experience in threat detection, penetration testing, and compliance.","skills": ["Python", "SIEM", "Penetration Testing", "Ethical Hacking", "Nmap", "Metasploit"]},{"candidate_name": "Robert","position_title": "Cloud Architect","expected_salary": "$120,000 - $180,000","profile_description": "Cloud architect specializing in designing secure and scalable cloud infrastructures.","skills": ["AWS", "Azure", "GCP", "Kubernetes", "Terraform", "CI/CD"]},{"candidate_name": "Sophia","position_title": "AI/ML Engineer","expected_salary": "$100,000 - $160,000","profile_description": "Machine learning engineer with experience in deep learning, NLP, and computer vision.","skills": ["Python", "PyTorch", "TensorFlow", "Scikit-Learn", "OpenCV", "NLP"]},{"candidate_name": "Daniel","position_title": "QA Engineer","expected_salary": "$60,000 - $100,000","profile_description": "Quality assurance engineer focused on automated testing, test-driven development, and software reliability.","skills": ["Selenium", "JUnit", "Cypress", "Postman", "Git", "CI/CD"]},{"candidate_name": "Emma","position_title": "Technical Support Specialist","expected_salary": "$50,000 - $85,000","profile_description": "Technical support specialist with expertise in troubleshooting, customer support, and IT infrastructure.","skills": ["Linux", "Windows Server", "Networking", "SQL", "Help Desk", "Scripting"]}
]def build_data():for doc in documents:yield {"_index": "available-candidates", "_source": doc}try:success, errors = bulk(_client, build_data())if errors:print("Errors during indexing:", errors)else:print(f"{success} documents indexed successfully")except Exception as e:print(f"Error: {str(e)}")配置 agent
AI 端点配置
让我们根据在第一步中定义的环境变量配置 AI 端点。
config_list = [{"model": "gpt-4o-mini", "api_key": os.environ["OPENAI_API_KEY"]}]
ai_endpoint_config = {"config_list": config_list}创建 agents
我们将首先创建管理员,负责主持对话并执行其他 agent 提出的任务。
然后,我们将创建执行每个任务的 agents:
-
管理员:领导对话并执行其他 agent 的行动。
-
研究员:在网上搜索职位信息。
-
检索员:在 Elastic 中查找候选人。
-
匹配员:尝试将职位和候选人进行匹配。
-
评审员:在提供最终答案之前,评估匹配的质量。
user_proxy = UserProxyAgent(name="Admin",system_message="""You are a human administrator.Your role is to interact with agents and tools to execute tasks efficiently.Execute tasks and agents in a logical order, ensuring that all agents performtheir duties correctly. All tasks must be approved by you before proceeding.""",human_input_mode="NEVER",code_execution_config=False,is_termination_msg=lambda msg: msg.get("content") is not Noneand "TERMINATE" in msg["content"],llm_config=ai_endpoint_config,
)researcher = AssistantAgent(name="Researcher",system_message="""You are a Researcher.Your role is to use the 'search_in_internet' tool to find individualjob offers realted to the candidates profiles. Each job offer must include a direct link to a specific position,not just a category or group of offers. Ensure that all job offers are relevant and accurate.""",llm_config=ai_endpoint_config,
)retriever = AssistantAgent(name="Retriever",llm_config=ai_endpoint_config,system_message="""You are a Retriever.Your task is to use the 'elasticsearch_hybrid_search' tool to retrievecandidate profiles from Elasticsearch.""",
)matcher = AssistantAgent(name="Matcher",system_message="""Your role is to match job offers with suitable candidates.The matches must be accurate and beneficial for both parties.Only match candidates with job offers that fit their qualifications.""",llm_config=ai_endpoint_config,
)critic = AssistantAgent(name="Critic",system_message="""You are the Critic.Your task is to verify the accuracy of job-candidate matches.If the matches are correct, inform the Admin and include the word 'TERMINATE' to end the process.""", # End conditionllm_config=ai_endpoint_config,
)配置工具
对于这个项目,我们需要创建两个工具:一个用于在 Elasticsearch 中搜索,另一个用于在线搜索。工具是一个 Python 函数,我们将在接下来注册并分配给 agent。
工具方法
async def elasticsearch_hybrid_search(question: str):"""Search in Elasticsearch using semantic search capabilities."""response = _client.search(index="available-candidates",body={"_source": {"includes": ["candidate_name","position_title","profile_description","expected_salary","skills",],},"size": 10,"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"match": {"position_title": question}}}},{"standard": {"query": {"semantic": {"field": "semantic_field","query": question,}}}},]}},},)hits = response["hits"]["hits"]if not hits:return ""result = json.dumps([hit["_source"] for hit in hits], indent=2)return resultasync def search_in_internet(query: str):"""Search in internet using Serper and retrieve results in json format"""url = "https://google.serper.dev/search"headers = {"X-API-KEY": os.environ["SERPER_API_KEY"],"Content-Type": "application/json",}payload = json.dumps({"q": query})response = requests.request("POST", url, headers=headers, data=payload)original_results = response.json()related_searches = original_results.get("relatedSearches", [])original_organics = original_results.get("organic", [])for search in related_searches:payload = json.dumps({"q": search.get("query")})response = requests.request("POST", url, headers=headers, data=payload)original_organics.extend(response.json().get("organic", []))return original_organics将工具分配给 agent
为了让工具正常工作,我们需要定义一个调用者,它将确定函数的参数,以及一个执行者,它将运行该函数。我们将定义管理员为执行者,并将相应的 agent 作为调用者。
register_function(elasticsearch_hybrid_search,caller=retriever,executor=user_proxy,name="elasticsearch_hybrid_search",description="A method retrieve information from Elasticsearch using semantic search capabilities",
)register_function(search_in_internet,caller=researcher,executor=user_proxy,name="search_in_internet",description="A method for search in internet",
)执行任务
我们现在将定义一个包含所有 agent 的群聊,其中管理员为每个 agent 分配轮次,指定它要调用的任务,并在根据先前的指令满足定义的条件后结束任务。
groupchat = GroupChat(agents=[user_proxy, researcher, retriever, matcher, critic],messages=[],max_round=50,
)manager = GroupChatManager(groupchat=groupchat, llm_config=ai_endpoint_config)user_proxy.initiate_chat(manager,message="""Compare the candidate profiles retrieved by the Retriever with the job offersfound by the Researcher on the internet.Both candidate profiles and job offers are related to the software industry.Ensure that each match is accurate and beneficial for both parties.Each candidate should be matched with a single job offer.Include the job offer link provided by the Researcher.""",
)推理
(格式化以提高可读性)
输出将如下所示:
Admin (to chat_manager):Compare the candidate profiles retrieved by the Retriever with the job offers found by the Researcher on the internet. Both candidate profiles and job offers are related to the software industry. Ensure that each match is accurate and beneficial for both parties. Each candidate should be matched with a single job offer. Include the job offer link provided by the Researcher.Admin (to chat_manager):Compare the candidate profiles retrieved by the Retriever with the job offers found by the Researcher on the internet. Both candidate profiles and job offers are related to the software industry. Ensure that each match is accurate and beneficial for both parties. Each candidate should be matched with a single job offer. Include the job offer link provided by the Researcher.Next speaker: Matcher
Matcher (to chat_manager):I currently do not have access to external databases or the ability to retrieve specific candidate profiles or job offers. However, I can help guide you on how to effectively match candidates with job offers based on their qualifications and the requirements of the jobs.1. **Identify Key Qualities**: For each job offer, list the key qualifications, skills, and experience required. Look for programming languages, technologies, years of experience, and any other competencies that are mentioned.2. **Analyze Candidate Profiles**: For each candidate, evaluate their skills, education, and experience. Pay special attention to their technical skills and past roles to ensure they align with the job requirements.3. **Create Matching Criteria**: Develop criteria for grading matches, such as:- Exact match (essential skills/experience)- General match (related skills/experience)- Desirable match (preferred qualifications)4. **Match Candidates to Job Offers**: Based on the above analysis, start matching candidates to job offers. Aim to find roles that play to the candidate's strengths and career aspirations.5. **Link Job Offers**: Ensure that for every candidate matched, the corresponding job offer link is provided.Once you have the specific candidate profiles and job offers, you can follow these steps to create accurate and beneficial matches. If you have specific examples or data, I can help you formulate the matches!Next speaker: Retriever
Retriever (to chat_manager):***** Suggested tool call (call_0yjI5x0gvcLAJeDbiDKYPtFD): elasticsearch_hybrid_search *****
Arguments:
{"question":"Retrieve candidate profiles related to software development and engineering."}
********************************************************************************************Next speaker: Admin
>>>>>>>> EXECUTING FUNCTION elasticsearch_hybrid_search...
Call ID: call_0yjI5x0gvcLAJeDbiDKYPtFD
Input arguments: {'question': 'Retrieve candidate profiles related to software development and engineering.'}Admin (to chat_manager):
***** Response from calling tool (call_0yjI5x0gvcLAJeDbiDKYPtFD) *****
[{
…. Researcher (to chat_manager):
***** Suggested tool call (call_X0bSSvAKuilPJ9hY90AJvMud): search_in_internet *****
Arguments:
{"query": "Software Engineer job offers Python Java AWS Microservices Docker Kubernetes"}
….Next speaker: Critic
Critic (to chat_manager):The matches are accurate and beneficial for both candidates and job offers. **Matches Summary:**
1. **John** - Lead Software Engineer, Full Stack (Java, Python, AWS) at Capital One.
2. **Daniel** - Quality Assurance Engineer for Homey - Taro.
3. **Michael** - DevOps Engineer - Kubernetes, Terraform, Jenkins, Ansible, AWS at Cisco.
4. **Sophia** - AI/ML Engineer at Chesterfield, Missouri, United States.
5. **David** - UX/UI Designer at HR Force International in New York.Admin has been informed of the successful candidate-job offer matches.
**TERMINATE**结果
(格式化以提高可读性)
### Candidate: John
- **Profile**: Experienced software engineer with expertise in backend development, cloud computing, and scalable system architecture.
- **Skills**: Python, Java, AWS, Microservices, Docker, Kubernetes.
- **Expected Salary**: $85,000 - $120,000.
- **Match**: [Lead Software Engineer, Full Stack (Java, Python, AWS) at Capital One](https://www.capitalonecareers.com/en/job/new-york/lead-software-engineer-full-stack-java-python-aws/1732/77978761520)### Candidate: Daniel
- **Profile**: Quality assurance engineer focused on automated testing, test-driven development, and software reliability.
- **Skills**: Selenium, JUnit, Cypress, Postman, Git, CI/CD.
- **Expected Salary**: $60,000 - $100,000.
- **Match**: [Quality Assurance Engineer for Homey - Taro](https://www.jointaro.com/jobs/homey/quality-assurance-engineer/)### Candidate: Michael
- **Profile**: DevOps specialist focused on automation, CI/CD pipelines, and infrastructure as code.
- **Skills**: Terraform, Ansible, Jenkins, Docker, Kubernetes, AWS.
- **Expected Salary**: $95,000 - $130,000.
- **Match**: [DevOps Engineer - Kubernetes, Terraform, Jenkins, Ansible, AWS at Cisco](https://jobs.cisco.com/jobs/ProjectDetail/Software-Engineer-DevOps-Engineer-Kubernetes-Terraform-Jenkins-Ansible-AWS-8-11-Years/1436347)### Candidate: Sophia
- **Profile**: Machine learning engineer with experience in deep learning, NLP, and computer vision.
- **Skills**: Python, PyTorch, TensorFlow, Scikit-Learn, OpenCV, NLP.
- **Expected Salary**: $100,000 - $160,000.
- **Match**: [AI/ML Engineer - Chesterfield, Missouri, United States](https://careers.mii.com/jobs/ai-ml-engineer-chesterfield-missouri-united-states)### Candidate: David
- **Profile**: Creative UX/UI designer with experience in user research, wireframing, and interactive prototyping.
- **Skills**: Figma, Adobe XD, Sketch, HTML, CSS, JavaScript.
- **Expected Salary**: $70,000 - $110,000.
- **Match**: [HR Force International is hiring: UX/UI Designer in New York](https://www.mediabistro.com/jobs/604658829-hr-force-international-is-hiring-ux-ui-designer-in-new-york)注意,在每个 Elasticsearch 存储的候选人末尾,你可以看到一个匹配字段,显示最适合他们的职位!
结论
AutoGen 允许你创建多个 agents 群组,它们协作解决问题,复杂度可根据需求调整。可用的模式之一是 “群聊 - group chat”,管理员在 agent 之间主持对话,最终达成成功的解决方案。
你可以通过创建更多 agent 为项目增加更多功能。例如,将匹配结果存储回 Elasticsearch,然后使用 WebSurfer agent 自动申请职位。WebSurfer agent 可以使用视觉模型和无头浏览器浏览网站。
要在 Elasticsearch 中索引文档,你可以使用类似于 elasticsearch_hybrid_search 的工具,但需要添加额外的导入逻辑。然后,创建一个特殊的 agent “ingestor” 来实现索引。完成后,你可以按照官方文档实现 WebSurfer agent。
原文:Using AutoGen with Elasticsearch - Elasticsearch Labs
相关文章:

使用 AutoGen 与 Elasticsearch
作者:来自 Elastic Jeffrey Rengifo 学习如何使用 AutoGen 为你的 agent 创建一个 Elasticsearch 工具。 Elasticsearch 拥有与行业领先的生成式 AI 工具和提供商的原生集成。查看我们的网络研讨会,了解如何超越 RAG 基础,或使用 Elastic 向量…...

kafka与flume的整合、spark-streaming
kafka与flume的整合 前期配置完毕,开启集群 需求1: 利用flume监控某目录中新生成的文件,将监控到的变更数据发送给kafka,kafka将收到的数据打印到控制台(三个node01中运行) 1.在kafka中建立topic kafka…...

高级电影感户外街拍人像摄影后期Lr调色教程,手机滤镜PS+Lightroom预设下载!
调色介绍 高级电影感户外街拍人像摄影后期 Lr 调色,是运用 Adobe Lightroom 软件,对户外街拍的人像照片进行后期处理,以塑造出具有电影质感的独特视觉效果。此调色过程借助 Lr 丰富的工具与功能,从色彩、光影、对比度等多维度着手…...

react 常用钩子 hooks 总结
文章目录 React钩子概念图状态管理钩子 state management副作用钩子 effect hooks引用钩子 Ref hooks上下文钩子其他钩子过渡钩子 处理过渡效果性能优化钩子 performance hooksReact 19 新钩子 React钩子概念图 状态管理钩子 state management useState useReducer useSyncEx…...

2025 年导游证报考条件新政策解读与应对策略
2025 年导游证报考政策有了不少新变化,这些变化会对报考者产生哪些影响?我们又该如何应对?下面就为大家详细解读新政策,并提供实用的应对策略。 最引人注目的变化当属中职旅游类专业学生的报考政策。以往,中专学历报考…...

重置 Git 项目并清除提交历史
在某些情况下,你可能需要完全重置一个 Git 项目,清除所有提交历史,然后将当前代码作为全新的初始提交。本文将详细介绍这个过程的操作步骤和注意事项。 重要警告 ⚠️ 注意:以下操作将永久删除项目的所有提交历史、分支和标签。…...
 很有用,但不是很好)
GitHub Copilot (Gen-AI) 很有用,但不是很好
摘要:以下是我在过去三个月中在实际 、 开发中使用 GitHub Copilot Pro 后的想法。由于技术发展迅速,值得注意的是,这些印象是基于我截至 2025 年 3 月的经验。 1 免费试用促使我订阅 GitHub Copilot Pro 我以前读过有关 AI 代码生成器的文…...

K8S Service 原理、案例
一、理论介绍 1.1、3W 法则 1、是什么? Service 是一种为一组功能相同的 pod 提供单一不变的接入点的资源。当 Service 存在时,它的IP地址和端口不会改变。客户端通过IP地址和端口号与 Service 建立连接,这些连接会被路由到提供该 Service 的…...

Base64编码原理:二进制数据与文本的转换技术
🔄 Base64编码原理:二进制数据与文本的转换技术 开发者的数据编码困境 作为开发者,你是否曾遇到这些与Base64相关的挑战: 📊 需要在JSON中传输二进制数据,但不确定如何正确编码🖼️ 想要在HT…...
—前端—CDN—Nginx—服务集群)
系统设计(1)—前端—CDN—Nginx—服务集群
简介: 本指南旨涵盖前端、CDN、Nginx 负载均衡、服务集群、Redis 缓存、消息队列、数据库设计、熔断限流降级以及系统优化等模块的核心要点。我们将介绍各模块常见的设计方案与优化策略,并结合电商秒杀、SaaS CRM 系统、支付系统等高并发场景讨论实践技巧…...

Easysearch 基础运维扫盲指南:从 HTTP 到 HTTPS、认证与安全访问全解析
Easysearch 基础运维扫盲指南:从 HTTP 到 HTTPS、认证与安全访问全解析 众所周知,原生 Elasticsearch 默认开启的是 HTTP 明文接口,并且不开启任何身份认证或传输加密。若想启用 TLS/SSL 加密及账号密码验证,通常需要配置繁琐的安…...

在Android中如何使用Protobuf上传协议
在 Android 中使用 Protobuf(Protocol Buffers)主要分为以下几个步骤: ✅ 1. 添加 Protobuf 插件和依赖 在项目的 build.gradle(Project 级)文件中添加 Google 的 Maven 仓库(通常默认已有)&am…...

【数据可视化艺术·应用篇】三维管线分析如何重构城市“生命线“管理?
在智慧城市、能源管理、工业4.0等领域的快速发展中,地下管线、工业管道、电力通信网络等“城市血管”的复杂性呈指数级增长。传统二维管理模式已难以应对跨层级、多维度、动态变化的管线管理需求。三维管线分析技术应运而生,成为破解这一难题的核心工具。…...

2025年的营销趋势-矩阵IP
从 2025 年的营销生态来看,创始人 IP 与智能矩阵的结合确实呈现出颠覆性趋势,这一现象背后隐藏着三个值得深度解析的商业逻辑: 一、创始人 IP 的本质是 "信任货币" 的数字化迁徙 当新能源汽车市场陷入参数混战,雷军将个…...

对接金蝶获取接口授权代码
接口服务信息 using RestSharp; using System.Configuration; using System.Threading.Tasks; public class KingdeeAccessTokenService { private readonly RestClient _client; private readonly KingdeeApiConfig _config; public KingdeeAccessTokenService() …...

探秘 3D 展厅之卓越优势,解锁沉浸式体验新境界
(一)打破时空枷锁,全球触达 3D 展厅的首要优势便是打破了时空限制。在传统展厅中,观众需要亲临现场,且必须在展厅开放的特定时间内参观。而 3D 展厅依托互联网,让观众无论身处世界哪个角落,只…...

prometheus通过Endpoints自定义grafana的dashboard模块
1、prometheus自定义的dashboard模块 文件路径/etc/prometheus/config_out/prometheus-env.yaml - job_name: serviceMonitor/monitoring/pfil/0honor_labels: falsekubernetes_sd_configs:- role: endpointsnamespaces:names:- monitoringrelabel_configs:- source_labels:- …...

java排序算法-计数排序
计数排序的思路 计数排序的基本思路: 确定取值范围: 遍历整个待排序的数组,确定数组中元素的取值范围,找到最小值和最大值。创建计数数组: 创建一个计数数组,其长度为取值范围的大小,用于统计…...
)
力扣-hot100(滑动窗口最大值)
239. 滑动窗口最大值 困难 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums […...
)
每日c/c++题 备战蓝桥杯(P1049 [NOIP 2001 普及组] 装箱问题)
洛谷P1049 装箱问题题解:动态规划在背包问题中的经典应用 题目描述 P1049 装箱问题是一道典型的0-1背包问题变种。题目要求在给定箱子容量V和n个物品体积的情况下,选择若干物品装入箱子,使得箱子的剩余空间最小。最终输出这个最小剩余空间的…...

【尚硅谷Redis6】自用学习笔记
Redis介绍 Redis是单线程 多路IO复用技术(类似黄牛买票) 默认有16个库,用select进行切换 默认端口号为6379 Memcached:多线程 锁(数据类型单一,不支持持久化) 五大常用数据类型 Redis key …...

产品更新丨谷云科技ETLCloud V3.9.2版本发布
谷云科技 ETLCloud 集成平台迎来了每月一次的功能迭代,本月发布版本号为 3.9.2 版本,为用户带来了新的功能、优化改进以及问题修复,以下是详细介绍: 新增组件 本次更新新增了众多实用组件,涵盖了京东和 Shopify 相关…...

Promise并发控制与HTTP请求优化
Promise并发方法对比 #mermaid-svg-tnmGzOkgNUCrbvfI {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-tnmGzOkgNUCrbvfI .error-icon{fill:#552222;}#mermaid-svg-tnmGzOkgNUCrbvfI .error-text{fill:#552222;stroke…...

G1垃圾回收器中YoungGC和MixedGC的区别
在 G1 垃圾回收器中,Mixed GC 和 Young GC 的区别主要体现在以下几个方面: 作用范围 Young GC:仅针对年轻代中的Region进行回收,包括 Eden 区和 Survivor 区的 Region。Mixed GC:会回收所有年轻代的 Region 以及部分…...

Web4.0身份革命:去中心化身份系统的全栈实现路径
去中心化身份(DID)技术栈正在重构数字世界的信任根基,本文从密码学协议、存储网络、验证框架三个维度,解析符合W3C标准的身份系统构建方案。通过Hyperledger Aries架构实践,揭示如何实现跨链身份互通、数据主权控制、零…...

iOS/Flutter混合开发之PlatformView配置与使用
环境:Xcode 16.3、Flutter 3.29.2、Dart 3.7.2。 使用背景:需要在flutter界面中嵌入一个iOS原生控件。 步骤: 1. iOS侧实现: 1.1:PlatformView实现 class FLNativeView: NSObject, FlutterPlatformView {private v…...

Libconfig 修改配置文件里的某个节点
THCommandStatus ( { Status "1"; index 5; }, { Status "2"; index 8; }, { Status "3"; index 7; }, { Status "4"; index 0; } ); 比如这是配置文件的内容ÿ…...

【金仓数据库征文】_AI 赋能数据库运维:金仓KES的智能化未来
AI 赋能数据库运维:金仓KES的智能化未来 🌟嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 在当今数字经济飞速发展的时代࿰…...

【MySQL】3分钟解决MySQL深度分页问题
什么是深度分页问题?该如何解决呢?这篇文章展开讲讲 什么是深度分页? 当查询结果集非常大时,需要获取靠后页码的数据,比如第1000页、10000页。 如: SELECT * FROM table LIMIT 10000, 10; -- 获取第10001-10010条…...
)
GitHub 趋势日报 (2025年04月24日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1kortix-ai/sunaSuna - Open Source Generalist AI Agent⭐ 1105⭐ 3639TypeScript2cloudcommunity/Free-CertificationsA curated …...

一种双模式机器人辅助股骨干骨折钢板植入方法
股骨干骨折是一种常见的高能损伤,微创内固定是首选治疗方法。然而,钢板植入过程中存在不可见、不准确和不稳定等问题。山东大学研究团队提出了一种双模式机器人辅助钢板植入方法,通过神经网络模型规划钢板植入轨迹,然后利用机械臂…...
)
全球碳化硅晶片市场深度解析:技术迭代、产业重构与未来赛道争夺战(2025-2031)
一、行业全景:从“材料突破”到“能源革命”的核心引擎 碳化硅(SiC)作为第三代半导体材料的代表,凭借其宽禁带(3.26eV)、高临界击穿场强(3MV/cm)、高热导率(4.9W/cmK&…...

IDEA搭建环境的五种方式
一、普通的java项目 File--New--Project 选择Java,jdk选择1.8版本,然后点next 输入项目名和路径名,点击Finish 创建包结构,编写Class类 编写主方法,输出Hello标志完成 二、普通的javaWeb项目 Java Enterprise-- 勾选…...

隐形革命:环境智能如何重构“人-机-境“共生新秩序
引言 在万物互联的时代,环境智能(Ambient Intelligence, AmI)正以“隐形革命者”的姿态重塑人类生活场景。通过分布式传感器、边缘计算与自适应算法的深度融合,AmI构建出能感知、学习并响应人类行为的智慧环境。 本文基于多领域研…...

Mysql唯一性约束
唯一性约束(Unique Constraint)是数据库设计中用于保证表中某一列或多列组合的值具有唯一性的一种规则。它可以防止在指定列中插入重复的数据,有助于维护数据的完整性和准确性。下面从几个方面为你详细解释 作用 确保数据准确性:…...

QuecPython+GNSS:实现快速定位
概述 QuecPython 结合 GNSS(全球导航卫星系统)模块为物联网设备提供开箱即用的定位能力解决方案。该方案支持 GPS/北斗/GLONASS/Galileo 多系统联合定位,为物联网开发者提供从硬件接入到云端服务的全栈式定位解决方案。 优势特点 多体系定…...
】)
【从零开始:自制一个Java消息队列(MQ)】
🚀 从零开始:自制一个Java消息队列(MQ) 在现代分布式系统中,消息队列(Message Queue,MQ)已经成为一个至关重要的组件。它帮助系统在异步处理、负载均衡、解耦等方面提供了强大的支持…...

WHAT - 已阅读书单
指数基金投资指南✅ 我们终将变富 纳瓦尔宝典 围城✅ 许三观卖血记✅ 骆驼祥子✅ 活着 白鹿原✅ 百年孤独 君主论 阿Q正传✅ 蛤蟆先生去看心理医生✅ 思考,快与慢 三体✅ 人类简史:从动物到上帝✅ 明朝那些事✅ 三国演义✅ 中国历代政治得失✅ 资治…...

代码随想录算法训练营第60期第十七天打卡
今天我们继续进入二叉树的下一个章节,今天的内容我在写今天的博客前大致看了一下部分题目难度不算大,那我们就进入今天的题目。 第一题对应力扣编号为654的题目最大二叉树 这道题目的坑相当多,我第一次题目没有看明白就是我不知道到底是如何…...

C 语言数组详解
一、数组的基本概念 在 C 语言中,数组是一种相同数据类型元素的集合,这些元素在内存中连续存储。通过数组,我们可以用一个统一的名字来管理一组相关的数据,并且通过下标(索引)快速访问其中的每一个元素。例…...

ADVB协议同步
关于视频传输,有多种控制时序。协议标准允许设计者选择有限的几个速率的接口来满足 系统设计目标。例如,一些系统使用总线时序发送信息通过line-by-line;在这个案例中, 容器的sof作为vsync同步的点。horizontal line blanding将插入idles,ADV…...

基于LAB颜色空间的增强型颜色迁移算法
本文算法使用Grok完成所有内容,包含算法改进和代码编写,可大大提升代码编写速度,算法改进速度,提供相关idea,提升效率; 概述 本文档描述了一种基于LAB颜色空间的颜色迁移算法,用于将缩略图D的…...

复合材料高置信度 DIC 测量与高级实验技术研讨会邀请函
邀请函 2025年5月8日 上海 中国复合材料学会官网会议通知 您可以点击上方蓝字跳转官网查看官网信息 主办单位: 中国复合材料学会 协办单位: 研索仪器科技(上海)有限公司 数字图像相关技术(Digital Image Correla…...

解决docker部署MySQL的max_allowed_packet 限制问题
报错 Error querying database. Cause: com.mysql.cj.jdbc.exceptions.PacketTooBigException: Packet for query is too large (2,471 > 2,048). You can change this value on the server by setting the max_allowed_packet variable. ### The error may exist in file …...
))
【XR手柄交互】Unity 中使用 InputActions 实现手柄控制详解(基于 OpenXR + Unity新输入系统(Input Actions))
摘要: 本文主要介绍如何使用 Input Actions(Unity 新输入系统) OpenXR 来实现 VR手柄控制(监听ABXY按钮、摇杆、抓握等操作)。 🎮 Unity 中使用 InputActions 实现手柄控制详解(基于 OpenXR 新…...

C++:继承机制详解
目录 一.继承的概念及定义 一).继承的概念 二).继承定义 1.定义格式 2.继承类型 3.继承类模板 二.基类和派生类间的转换 三.继承中的作用域 四.派生类的默认成员函数 一).4个常见默认成员函数 二).不可被继承的类 五…...

自然语言处理+知识图谱:智能导诊的“大脑”是如何工作的?
智能导诊系统定义与作用 智能导诊系统是一种基于人工智能技术的医疗辅助工具,旨在提高医疗服务效率、改善患者就医体验、降低医院运营成本,通过自然语言处理技术,智能导诊系统能够自动回答患者的常见问题,帮助患者快速了解自己的…...

论文阅读笔记——ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping
ZeroGrasp 论文 多视角重建计算大、配置复杂,本文将稀疏体素重建(快且效果好)引入机器人抓取且只考虑单目重建,通过利用基于物理的接触约束与碰撞检测(这对精确抓取至关重要),提升三维重建质量将…...

Qt 调试信息重定向到本地文件
1、在Qt软件开发过程中,我们经常使用qDebug()输出一些调试信息在QtCreator终端上。 但若将软件编译、生成、打包为一个完整的可运行的程序并安装在系统中后,系统中没有QtCreator和编译环境,那应用程序出现问题,如何输出信息排查…...

Android Studio开发中Application和Activity生命周期详解
文章目录 Application生命周期Application生命周期概述Application关键回调方法onCreate()onConfigurationChanged()onLowMemory()onTrimMemory()onTerminate() Application生命周期管理最佳实践 Activity生命周期Activity生命周期概述Activity生命周期回调方法onCreate()onSta…...