【论文阅读】平滑量化:对大型语言模型进行准确高效的训练后量化

论文题目:SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
论文地址:[2211.10438] SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
代码地址:https://github.com/mit-han-lab/smoothquant
目录
【摘要】
【1 引言】
【2 预备知识】
【3 量化难度的综述】
【4 SmoothQuant】
【5 实验】
5.1 设置
5.2 精确量化
5.3 加速和节省内存
5.4 放大:单个节点内的530B模型
5.5 消融研究
【6 相关工作】
【7 结论】
◆大语言模型参数量巨大,计算和存储成本极高。为了降低部署成本,常用的方法是量化(Quantization),即用低精度(如8-bit整数)代替高精度(如16-bit浮点数)存储和计算。但大语言模型的激活值(即每层输出的中间结果)会出现异常大的离群值(outliers),导致直接量化后精度暴跌。
◆核心问题:如何在不重新训练模型的情况下(即“训练后量化”),高效且准确地量化大语言模型?本论文就是要解决这个问题。
【摘要】
大型语言模型( large language models,LLMs )表现出优异的性能,但计算和内存密集型。量化可以减少内存,加速推理。然而,现有方法无法同时保持精度和硬件效率。提出了SmoothQuant,一种免训练,精度保持和通用的训练后量化( PTQ ,post-training quantization)解决方案,以实现LLMs的8位权重,8位激活( W8A8 )量化。基于权重易于量化而激活不易量化的事实,SmoothQuant通过数学等价变换将量化难度从激活离线迁移到权重,平滑了激活异常值。Smooth Quant对LLMs中的所有矩阵乘法,包括OPT、BLOOM、GLM、MT-NLG、Llama-1/2、Falcon、Mistral和Mixtral模型,都能实现权重和激活的INT8量化。对于LLMs,展示了高达1.56倍的加速比和2倍的内存减少,而精度损失可以忽略不计。SmoothQuant能够在单个节点内服务530B LLM。我们的工作提供了一种turn-key解决方案,降低了硬件成本,并使LLMs大众化。
图1:近年来,大型语言模型的模型大小正以比GPU内存更快的速度发展,导致内存的供应和需求之间存在很大的差距。量化和模型压缩技术可以帮助弥合这一鸿沟。
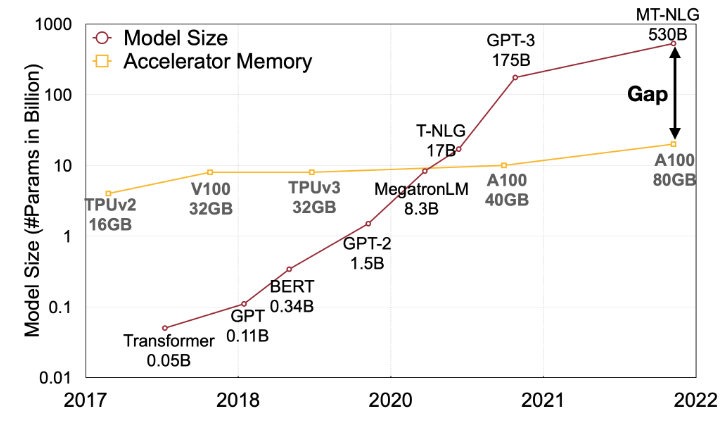
【1 引言】
大规模语言模型( Large-scale language models,LLMs )在各种任务( Brown et al , 2020a ; Zhang et al , 2022)上表现出优异的性能。然而,由于其巨大的模型规模,服务LLMs是耗能的。例如,GPT-3 ( Brown et al , 2020a)模型包含175B个参数,将消耗至少350GB的内存,FP16,需要8 × 48GB的A6000 GPU或者5 × 80GB的A100 GPU就可以进行推理。由于巨大的计算和通信开销,推理延迟也可能是现实应用所不能接受的。量化是降低LLMs成本的一种有前途的方法。通过使用低比特整数量化权重和激活,可以减少GPU的内存需求,在大小和带宽上,并加速计算密集型操作(即,线性层中的GEMM * ,注意中的BMM)。例如,与FP16相比,权重和激活的INT8量化可以将GPU的内存使用量减半,并将矩阵乘法的吞吐量提高近一倍。
然而,与CNN模型或更小的transformer模型(如BERT ( Devlin et al , 2019) )不同,LLMs的激活难以量化。当将LLMs放大到6.7 B参数以上时,在激活中会出现幅度较大的系统异常值,从而导致较大的量化误差和精度下降。ZeroQuant (姚洋等, 2022)采用动态的每令牌激活量化和分组权重量化(定义见图3 Sec . 2 )。它可以高效地实现并且对GPT - 3 - 350M和GPT - J - 6B具有较好的精度。然而,对于拥有1750亿个参数(见5.2节)的大型OPT模型,它无法保持精度。LLM.int8 ( ) (Dettmers et al., 2022)通过进一步引入混合精度分解(也就是说,它在FP16中保留离群点,并使用INT8用于其他激活)来解决该精度问题。然而,在硬件加速器上高效地实现分解是很困难的。因此,为LLMs推导一个高效的、硬件友好的、更好的免训练量化方案,将INT8用于所有计算密集型操作仍然是一个开放的挑战。
我们提出了SmoothQuant,一种准确高效的LLMs训练后量化( PTQ )解决方案。SmoothQuant依赖于一个关键的观察:即使由于异常值的存在,激活比权重更难量化,但不同的令牌在它们的通道中表现出相似的变化。基于这一观察,SmoothQuant离线将量化难度从激活迁移到权重(图2 )。SmoothQuant提出了一种数学上等价的逐通道缩放变换,显著地平滑了跨通道的幅值,使模型易于量化。由于SmoothQuant可以兼容多种量化方案,我们为SmoothQuant (见表2 , O1 ~ O3)实现了三种效率级别的量化设置。实验表明,SmoothQuant是硬件高效的:它可以保持OPT - 175B ( Zhang et al , 2022)、BLOOM - 176B ( Scao et al , 2022)、GLM - 130B ( Zeng et al , 2022)和MT - NLG 530B (史密斯等, 2022)的性能,在PyTorch上可以达到1.51倍的加速和1.96倍的内存节省。Smooth Quant易于实现。我们将SmoothQuant集成到目前最先进的转换器服务框架FasterTransformer中,获得了高达1.56倍的加速比,与FP16相比,内存使用量减少了一半。值得注意的是,与FP16相比,SmoothQuant只需要使用一半的GPU就可以为OPT - 175B等大型模型提供服务,同时速度更快,并且可以在一个8 - GPU节点内为530B模型提供服务。我们的工作通过提供一个统包解决方案来降低服务成本,从而使LLMs的使用更加大众化。我们希望SmoothQuant可以启发未来更多地使用LLMs。
图2:SmoothQuant的直觉:激活值X很难量化,因为离群值扩大了量化范围,对大多数值来说,剩下的有效位数很少。我们在离线阶段将激活的尺度方差迁移到权重W上,以降低激活的量化难度。平滑后的激活( X )和调整后的权重( W )均易于量化。

【2 预备知识】
量化是将一个高精度的数值映射到离散的层次。我们研究整数均匀量化( Jacob等, 2018) (具体为INT8 ),以获得更好的硬件支持和效率。量化过程可以表示如公式(1)所示:
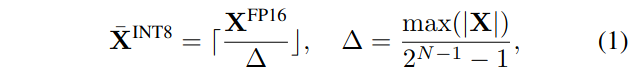
其中,X是浮点张量,![]() 是量化对应物,Δ是量化步长,⌈·⌋是取整函数,N是比特数(在我们的案例中, 8)。这里为了简单起见,假设张量在0处对称;对于非对称情形(例如,在ReLU之后),通过增加一个零点( Jacob et al , 2018)进行类似的讨论。
是量化对应物,Δ是量化步长,⌈·⌋是取整函数,N是比特数(在我们的案例中, 8)。这里为了简单起见,假设张量在0处对称;对于非对称情形(例如,在ReLU之后),通过增加一个零点( Jacob et al , 2018)进行类似的讨论。
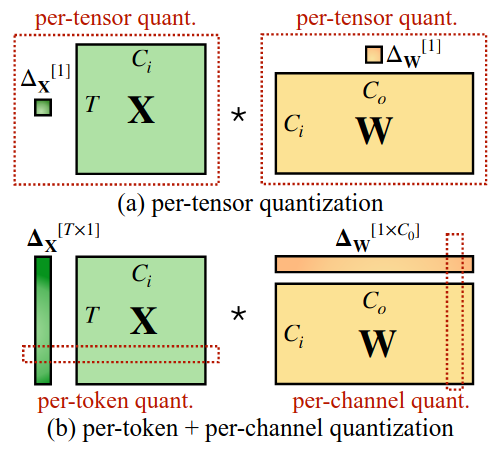
这种量化器使用最大绝对值来计算∆,以保留激活中的异常值,这对于(Dettmers et al., 2022)的准确性非常重要。我们可以通过一些校准样本的激活离线地计算出Δ,我们称之为静态量化。也可以利用激活的运行时统计得到Δ,我们称之为动态量化。如图3所示,量化具有不同的粒度级别。每张量化对整个矩阵使用单一步长。我们可以通过对每个令牌(每令牌量化)或每个权重输出通道(每通道量化)相关的激活使用不同的量化步长来进一步实现更细粒度的量化。粗粒度版本的逐通道量化是针对不同的通道组采用不同的量化步长,称为分组量化(Shen et al., 2020; Yao et al., 2022)。
图3:每个张量,每个标记和每个通道量化的定义。按张量量化是最有效的实现方法。对于矢量量化,为了有效地利用INT8 GEMM核,我们只能使用外部维度(即令牌维度T和输出通道维度Co)的比例因子,而不能使用内部维度(即,在通道维度Ci)的比例因子。
对于Transformers ( Vaswani et al , 2017)中的一个线性层,![]()
其中,T为令牌数,Ci为输入通道,Co为输出通道(见图3 ,为简便起见,略去批次维度),通过将权重量化为INT8,可以比FP16减少一半的存储量。然而,为了加快推断速度,需要将权重和激活都量化到INT8 (即W8A8)中,以利用整数核(例如, INT8 GEMM),即以广泛的硬件(例如, NVIDIA GPU , Intel CPU ,高通DSP等。)为支撑。
扩展:GEMM(General Matrix Multiply)是线性代数中矩阵乘法的一种通用表示,通常指两个矩阵的乘法运算,它是许多高性能计算和机器学习算法的核心组成部分。LLM通常基于Transformer架构,包括大量的自注意力(self-attention)和前馈神经网络(feed-forward networks)层,这些层的计算本质上可以归结为大规模的矩阵乘法,即GEMM操作。例如,自注意力层中的查询(Query)、键(Key)和值(Value)向量的计算,以及前馈网络中的全连接层(fully connected layers),都需要执行GEMM操作。由于GEMM操作的计算密集性,其效率直接影响到模型的训练和推理速度。因此,现代的深度学习框架和硬件加速器(如GPU和TPU)都高度优化了GEMM的实现,以充分利用并行计算能力,减少内存访问延迟,提高数据传输效率,从而加速模型的训练和推理过程。
【3 量化难度的综述】
众所周知,由于激活中的异常值,LLMs很难被量化。我们首先回顾了激活量化的困难,并在异常值中寻找模式。我们在图4 (左)中可视化了具有较大量化误差的线性层的输入激活和权重。
图4为OPT-13B中线性层在Smooth Quant前后的输入激活量和权重。观察:( 1 )原始激活图中有少数几个通道的幅值非常大的(大于70 );( 2 )一个激活通道内的方差较小;( 3 )原始权重分布平坦且均匀。SmoothQuant将离群通道从激活迁移到权重。最后,激活中的异常值被极大地平滑,而权重仍然是相当平滑和平坦的。
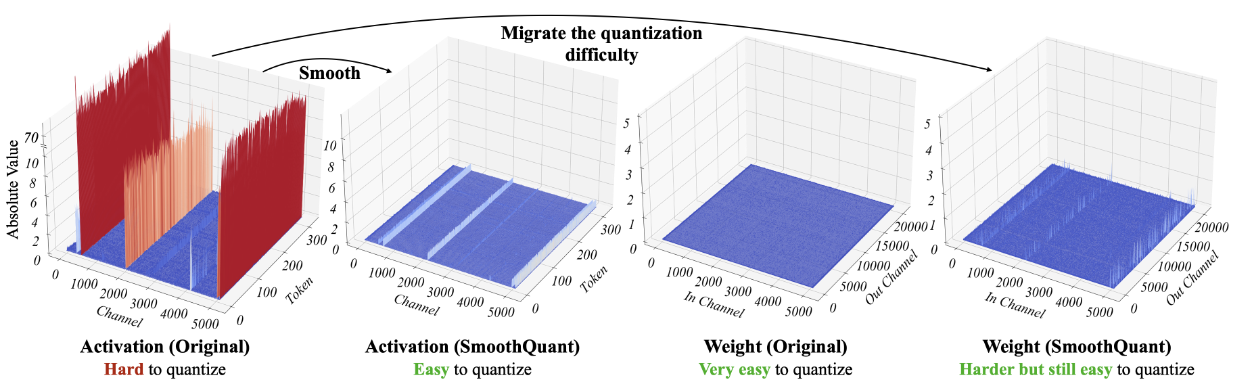
我们可以发现激励我们的方法的几种模式:
1 .激活比权重更难量化。权重分布比较均匀、扁平,易于量化。先前的工作表明,使用INT8甚至INT4量化LLMs的权重不会降低(Dettmers et al., 2022; Yao et al., 2022; Zeng et al., 2022)的精度,这与我们的观察相呼应。
2 .离群点使得激活量化变得困难。激活状态中异常值的规模是100 ×大于大多数激活状态值。在按张量量化的情况下(式1 ),大的异常值主导了最大幅度测量,导致非出格点信道的有效量化比特/电平较低(图2 ):假设信道i的最大幅度为mi,整个矩阵的最大值为m,则信道i的有效量化电平为2^8 · mi / m。对于非出格点信道,有效量化电平很小( 2-3 ),导致较大的量化误差。
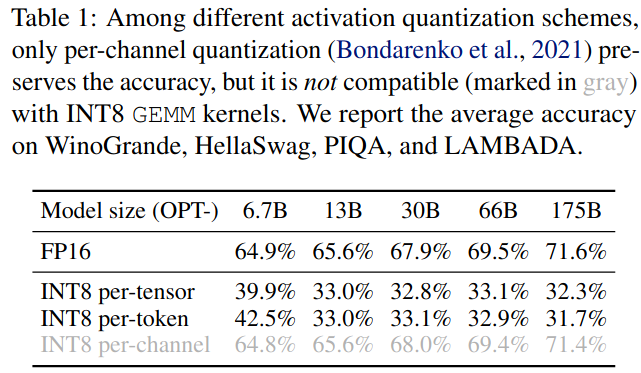
3 .异常值在固定通道中持续存在。在一小部分通道中出现离群值。如果一个通道存在离群点,则它持续出现在所有令牌(图4 ,红色)中。对于给定的令牌,通道间的方差为大(某些通道的激活非常大,但大多数通道的激活很小),但给定通道跨令牌的幅度间的方差为小(离群点通道是一致大的)。由于异常值的持久性和每个通道内的小方差性,如果我们可以对激活(也就是说,对每个通道使用不同的量化步长)进行每通道量化,则量化误差将比每张量化小得多,而每令牌量化几乎没有帮助。在表1中,我们验证了我们的假设,即模拟的逐通道激活量化成功地桥接了FP16基线的准确性,这与Bondarenko et al.的发现相呼应。
表1:在不同的激活量化方案中,只有每通道量化保持了精度,但它与INT8 GEMM内核不兼容(用灰色标示)。我们报告了在WinoGrande,HellaSwag,PIQA和LAMBADA上的平均准确率。
然而,单通道激活量化并不能很好地映射到硬件加速的GEMM内核,它依赖于在高吞吐率(例如, Tensor Core MMAs)下执行的操作序列,并且不能容忍在该序列中插入吞吐率较低的(例如,转换或CUDA Core FMAs)的指令。在这些内核中,缩放只能沿着矩阵乘法(即激活的令牌维度T ,权重的输出通道维度Co ,见图3)的外维进行,可以在矩阵乘法结束后应用,见公式(2)。
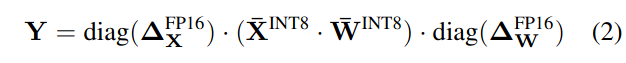
因此,先前的工作都是对线性层(Dettmers et al., 2022; Yao et al., 2022)使用按令牌激活量化,尽管它们不能解决激活量化(仅略优于per - tensor)的困难。
【4 SmoothQuant】
与单通道激活量化(这是不可行的)不同,我们提出通过将输入激活除以单通道平滑因子![]() 进行"平滑"。为了保持线性层的数学等价性,我们按照相反的方向对权重进行相应的调整,见公式(3)。
进行"平滑"。为了保持线性层的数学等价性,我们按照相反的方向对权重进行相应的调整,见公式(3)。
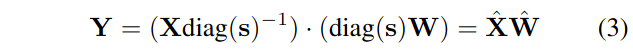
◆对于公式3的解释
对每一层的输入激活值 X 和权重 W,按通道i 缩放:
激活值:Xi′=Xi/si
权重:Wi′=Wi×si
输出不变:Y=X×W=X′×W′
其中 si 是第 i 通道的缩放系数。
考虑到输入X通常是由之前的线性操作产生的,我们可以很容易地将平滑因子融合到之前层的参数中,这不会带来额外的缩放带来的内核调用开销。对于其他一些情况,当输入来自残差加法时,我们可以像Wei et al. (2022)那样,在残差分支上添加一个额外的缩放。
将量化难度从激活迁移到权重。我们的目标是选择每个通道的平滑因子s,使得![]() 易于量化。为了减小量化误差,应该增加所有信道的有效量化比特数。当所有通道的最大幅度相同时,总的有效量化比特数最大。因此,一个直观的选择是
易于量化。为了减小量化误差,应该增加所有信道的有效量化比特数。当所有通道的最大幅度相同时,总的有效量化比特数最大。因此,一个直观的选择是![]() ,其中j对应第j个输入通道。这种选择保证了在划分后,所有的激活通道都会有相同的最大值,易于量化。需要注意的是,激活的范围是动态的;对于不同的输入样本,它是不同的。在这里,我们使用来自预训练数据集(Jacob et al., 2018)的校准样本来估计激活通道的规模。然而,这个公式将所有的量化困难都推到了权重上。我们发现,在这种情况下,权重(离群通道现在被迁移到权重中)的量化误差会很大,从而导致(见图10)的精度下降。另一方面,通过选择
,其中j对应第j个输入通道。这种选择保证了在划分后,所有的激活通道都会有相同的最大值,易于量化。需要注意的是,激活的范围是动态的;对于不同的输入样本,它是不同的。在这里,我们使用来自预训练数据集(Jacob et al., 2018)的校准样本来估计激活通道的规模。然而,这个公式将所有的量化困难都推到了权重上。我们发现,在这种情况下,权重(离群通道现在被迁移到权重中)的量化误差会很大,从而导致(见图10)的精度下降。另一方面,通过选择![]() ,我们也可以将所有的量化难度从权重推进到激活。同样,由于激活量化误差的存在,模型性能较差。因此,我们需要在权重和激活之间拆分量化难度,使它们都易于量化。
,我们也可以将所有的量化难度从权重推进到激活。同样,由于激活量化误差的存在,模型性能较差。因此,我们需要在权重和激活之间拆分量化难度,使它们都易于量化。
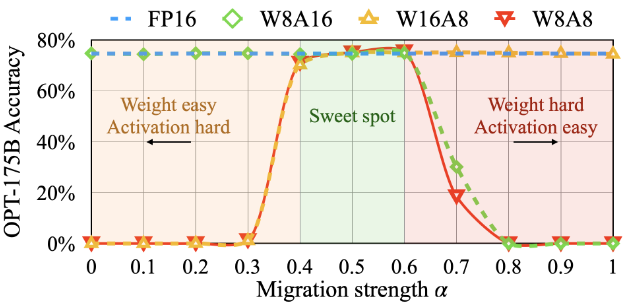
如何选择缩放系数 Sj?这里我们引入一个超参数,迁移强度α,来控制我们想要从激活迁移到权重的难度,使用以下公式,见公式(4)。
![]()
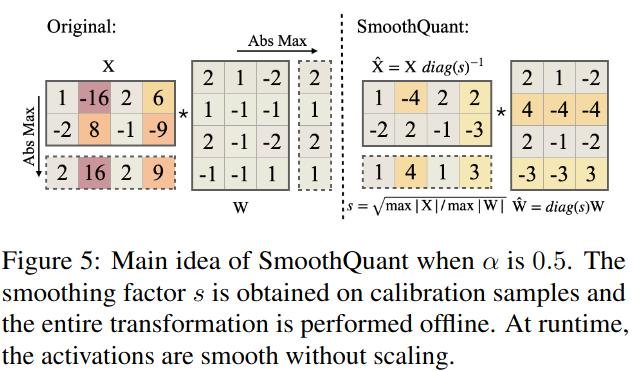
我们发现,对于大多数模型,例如所有的OPT ( Zhang et al , 2022)和BLOOM ( Scao et al , 2022)模型,α = 0.5是一个很好的均衡点,可以均匀地分割量化难度,特别是当我们对权重和激活(例如,预张量,静态量化)使用相同的量化器时。该公式保证了对应通道的权值和激活具有相似的最大值,从而具有相同的量化难度。图5给出了取α = 0.5时的平滑变换。对于其他一些激活异常值更显著的模型( ( e.g . , GLM-130B ( Zeng et al , 2022)有30 %的异常值,这对激活量化更困难),我们可以选择更大的α将更多的量化难度迁移到权重上(如0.75 )。
图5:α = 0.5时SmoothQuant的主要思想。在校准样本上获得平滑因子s,并离线执行整个变换。在运行时,激活是平滑的,没有缩放。
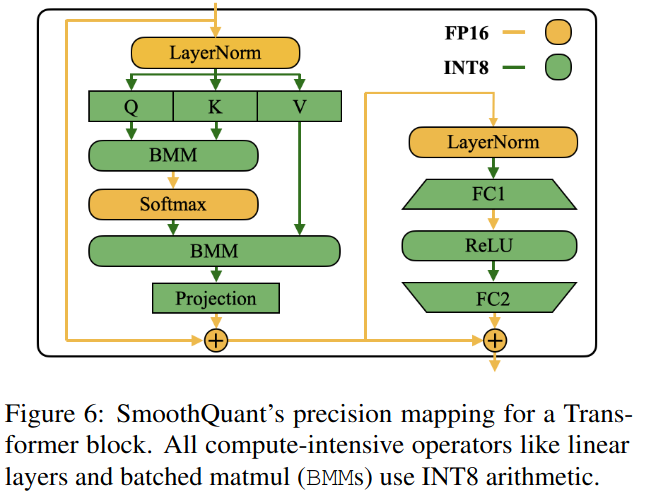
将Smoothquant应用于Transformer模块。线性层占据了LLM模型的大部分参数和计算量。默认情况下,我们对自注意力和前馈层的输入激活进行尺度平滑,用W8A8对所有线性层进行量化。我们还对注意力计算中的BMM算子进行了量化。我们在图6中设计了变压器块的量化流程。我们使用INT8量化注意力层中线性层和BMM等计算密集型操作符的输入和权重,同时保持ReLU、Softmax和LayerNorm等其他轻量级元素操作的激活为FP16。这样的设计有助于我们平衡准确性和推理效率。
图6:Transformer块的SmoothQuant精度映射。所有计算密集型的算子如线性层和批处理矩阵( BMMs )都使用INT8算法。
【5 实验】
5 . 1设置
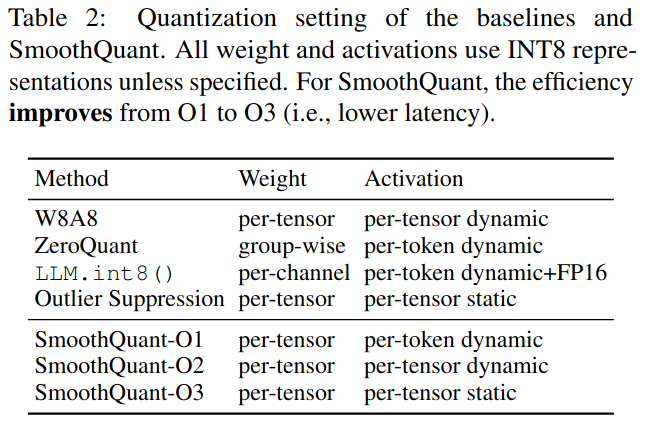
基线。我们与INT8训练后量化设置中的四个基线进行比较,即不重新训练模型参数:W8A8 naive量化、ZeroQuant (姚洋等, 2022)、LLM . int8 ( ) (德特默斯et al , 2022)和Outlier Suppression ( Wei et al . , 2022)。由于SmoothQuant与量化方案是正交的,我们提供了从O1到O3的渐进有效的量化水平。基线和SmoothQuant的详细量化方案如表2所示。
表2:基线和SmoothQuant的量化设置。除非特别说明,所有的权重和激活都使用INT8表示。对于SmoothQuant,效率从O1提高到O3 (也就是说,更低的延迟)。
模型和数据集。我们选择了三个家族的LLMs来评估SmoothQuant:OPT ( Zhang et al , 2022),BLOOM ( Scao et al , 2022)和GLM - 130B ( Zeng et al , 2022)。我们使用七个零样本评估任务:LAMBADA (帕佩尔诺等, 2016),HellaSwag (策勒斯et al , 2019),PIQA ( Bisk et al , 2020),WinoGrande (坂口等, 2019),OpenBookQA (米哈伊洛夫等, 2018),RTE ( Wang et al . , 2018),COPA (罗米尔等, 2011)和一个语言建模数据集WikiText ( Merity et al , 2016)来评估OPT和BLOOM模型。由于GLM130B的训练集中出现了上述的一些基准,我们使用MMLU ( Hendrycks et al , 2020),MNLI (威廉姆斯等, 2018),QNLI ( Wang et al . , 2018)和LAMBADA来评估GLM - 130B模型。对于OPT和BLOOM模型,我们使用了lm - eval - harness来评估,而GLM - 130B的官方报告则是对其本身的评估。最后,我们将我们的方法扩展到MT - NLG 530B (史密斯等, 2022),并首次实现了在单个节点内服务> 500B的模型。值得注意的是,我们关注的是量化前后的相对性能变化,而不是绝对值的变化。
激活平滑。对于所有的OPT和BLOOM模型,迁移强度α = 0.5是一个普遍的点,而对于GLM - 130B,α = 0.75,因为它的激活更难以量化( Zeng et al , 2022)。我们通过在Pile ( Gao et al , 2020)验证集的子集上运行快速网格搜索得到一个合适的α。为了获得激活统计量,我们从预训练数据集Pile中用512个随机句子校准一次平滑因子和静态量化步长,并对所有下游任务使用相同的平滑和量化模型。通过这种方式,我们可以对量化LLMs的通用性和零样本性能进行基准测试。
实施。我们实现了带有两个后端的SmoothQuant:( 1 )用于概念证明的PyTorch Huggedface;( 2 ) FasterTransformer,作为一个在生产环境中使用的高性能框架的例子。在PyTorch Huggingface和FasterTransformer两个框架中,我们使用CUTLASS INT8 GEMM内核实现了INT8线性模块和批处理矩阵乘法( BMM )函数。我们简单地将原来的浮点( FP16 )线性模块和bmm函数替换为我们的INT8核作为INT8模型。
5.2 精确量化
Opt-175B的结果。SmoothQuant可以处理非常大的LLMs的量化,这些LLMs的激活更加难以量化。我们在OPT-175B上进行量化研究。
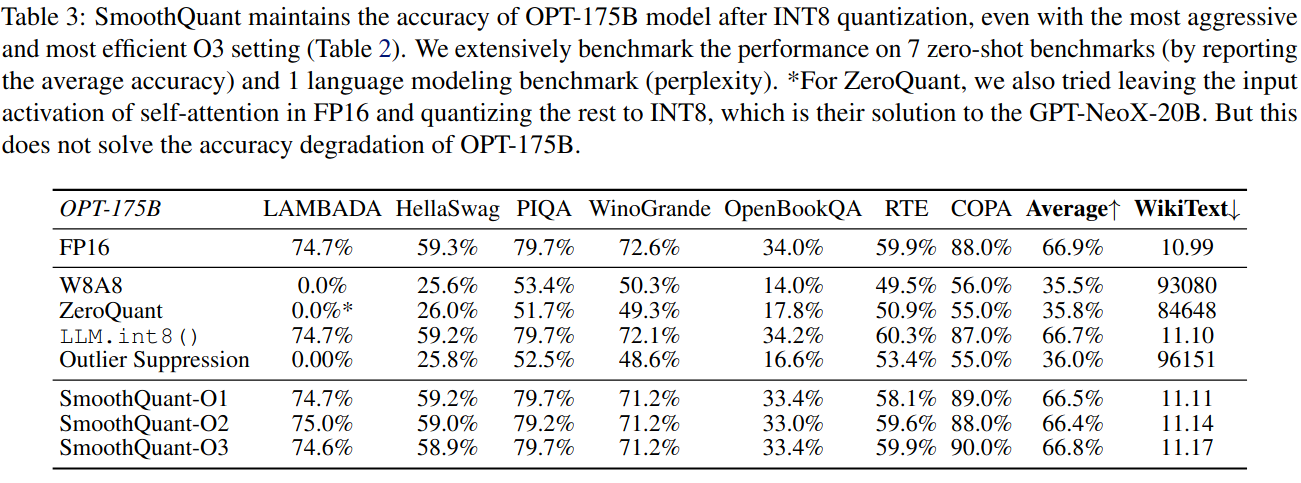
如表3所示,SmoothQuant可以在所有评价数据集上匹配所有量化方案的FP16精度。LLM.int8 ( )可以匹配浮点精度,因为它们使用浮点值来表示异常值,这导致了较大的延迟开销(表11 )。W8A8,ZeroQuant和Outlier Suppression基线产生几乎随机的结果,表明幼稚地量化LLMs的激活会破坏性能。
表3:SmoothQuant在INT8量化之后仍然保持了OPT-175B模型的精度,即使在O3设置最激进、最高效的情况下也是如此(表2 )。我们在7个零样本基准(通过报告平均准确率)和1个语言建模基准(perplexity)上进行了广泛的性能测试。*对于ZeroQuant,我们还尝试将自注意力的输入激活保留在FP16中,其余部分量化到INT8中,这是他们对GPT - NeoX - 20B的解决方案。但这并不能解决OPT - 175B的精度下降问题。
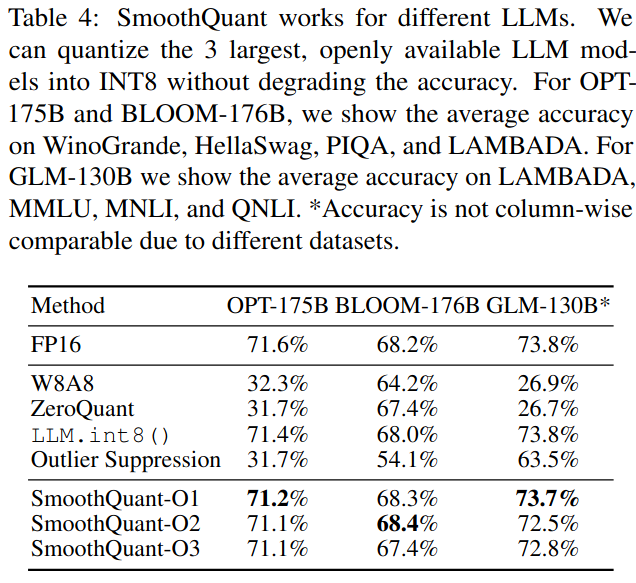
不同LLM的结果。表4:SmoothQuant适用于不同的LLM。我们可以将3个最大的、公开可用的LLM模型量化为INT8,而不会降低精度。对于OPT-175B和BLOOM-176B,我们展示了在WinoGrande,HellaSwag,PIQA和LAMBADA上的平均精度。对于GLM-130B,我们展示了在LAMBADA,MMLU,MNLI和QNLI上的平均精度。由于不同的数据集,*精度不是列可比的。
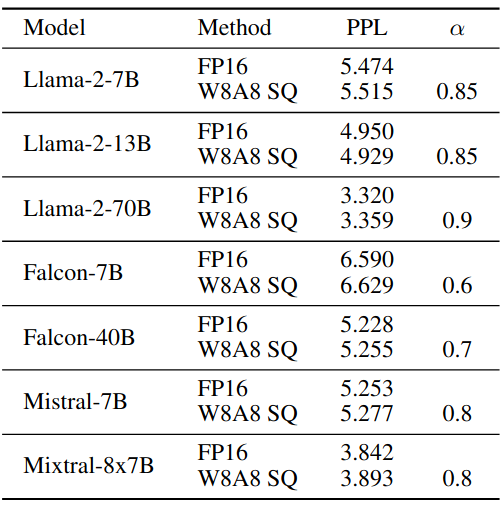
不同大小LLMs上的结果。图7:当量化到INT8时,SmoothQuant-O3 (最有效的设置,定义在表2中)保持了OPT模型在不同尺度下的准确性。LLM.int8 ( )要求混合精度,且速度较慢。
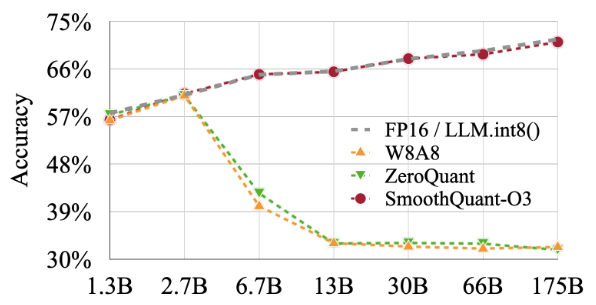
指令微调LLM的结果。表5:SmoothQuant在OPT- IML模型上的性能。
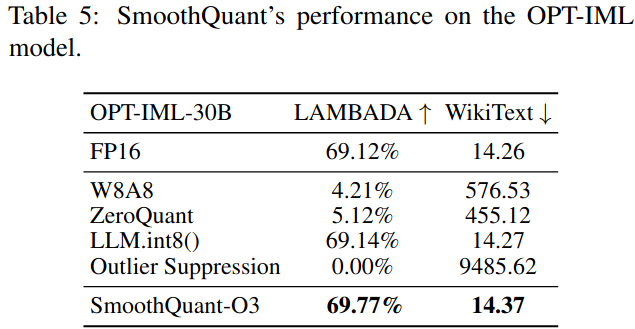
关于Llama模型的结果。表6:SmoothQuant可以实现LLaMA模型的无损W8A8量化。结果在序列长度为512的WikiText - 2数据集上令人困惑。我们使用了每令牌激活量化,对于SmoothQuant,α = 0.8。
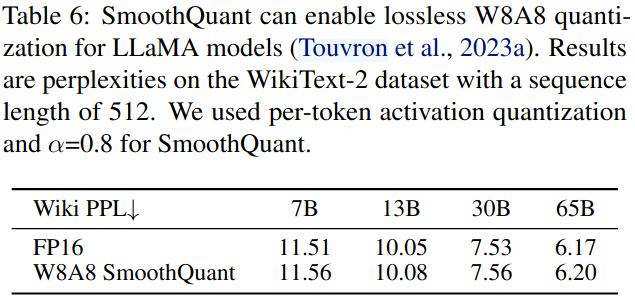
Llama-2, Falcon, Mistral, and Mixtral模型上的结果。表7:SmoothQuant可以实现Llama - 2,Falcon,Mixtral和Mixtral模型的无损W8A8量化。结果在序列长度为2048的WikiText - 2数据集上令人困惑。我们对SmoothQuant使用了每令牌激活量化和每通道权重量化。
5.3 加速和节省内存
在本节中,我们展示了集成到PyTorch和FasterTransformer中的SmoothQuant - O3的实测加速比和内存节省情况。
Context-Stage:Pytorch实现。图8:SmoothQuant - O3的PyTorch实现在单个NVIDIA A100 ~ 80GB GPU上对OPT模型实现了高达1.51倍的加速和1.96倍的内存节省,而LLM . int8 ( )在大多数情况下降低了推断速度。
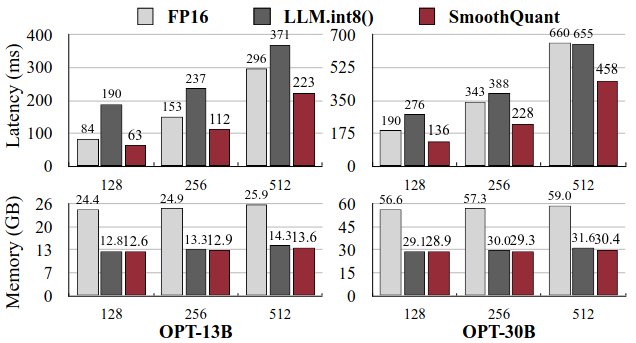
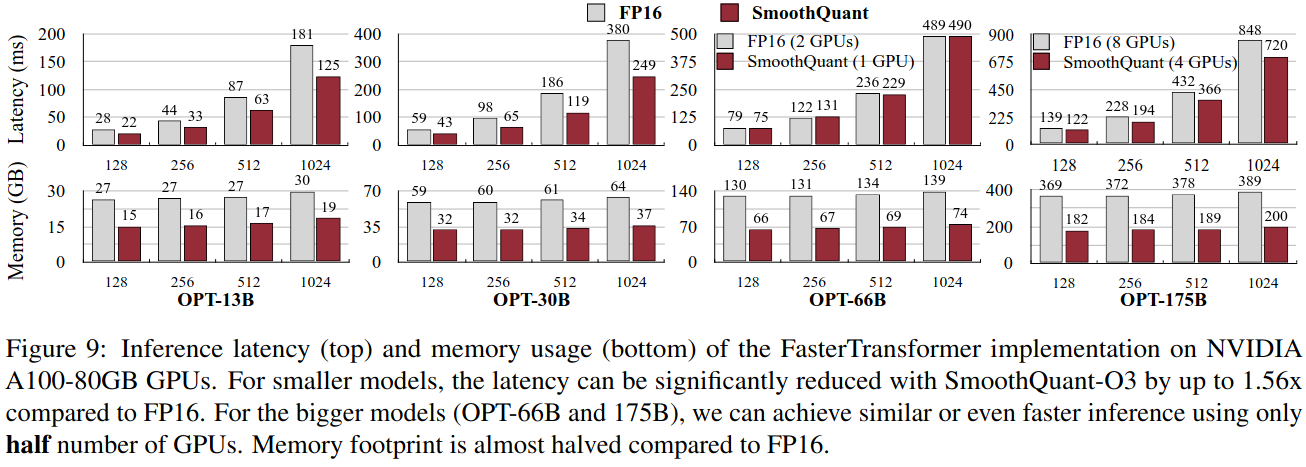
Context-Stage:Faster Transformer实现。图9为FasterTransformer在NVIDIA A100 ~ 80GB GPU上实现的推理延迟(上)和内存使用量(下)。对于较小的模型,与FP16相比,SmoothQuant - O3可以显著降低延迟,最高可降低1.56倍。对于较大的模型( OPT - 66B和175B),我们只需要使用一半的GPU就可以实现相似甚至更快的推断。与FP16相比,内存占用几乎减半。
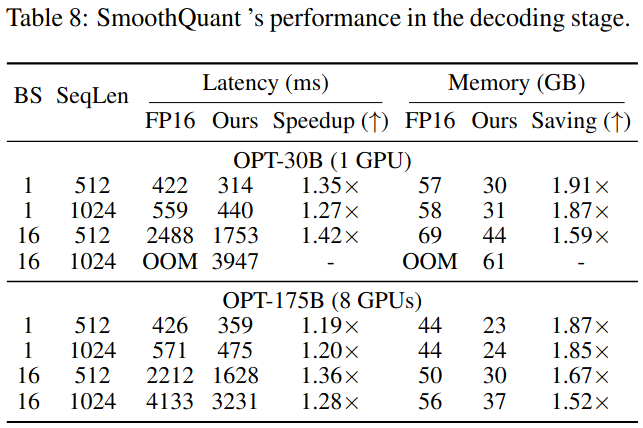
解码阶段。表8:SmoothQuant在解码阶段的性能。
5.4 放大:单个节点内的530B模型
表9:Smooth Quant可以将MT - NLG 530B量化到W8A8,精度损失可以忽略不计。

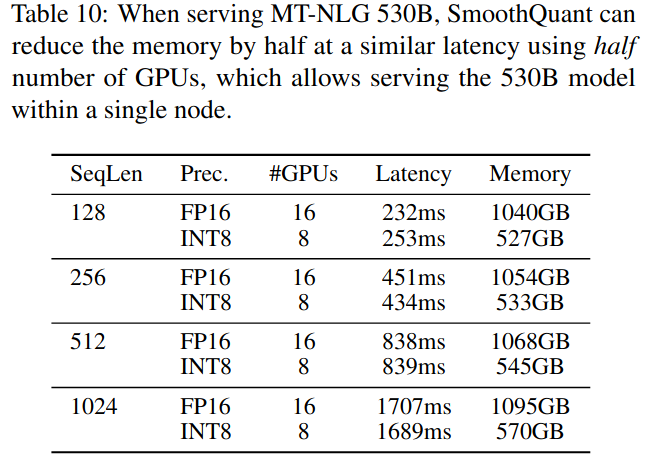
表10:在服务MT - NLG 530B时,SmoothQuant可以使用一半的GPU在相似的延迟下减少一半的内存,这允许在单个节点内服务530B模型。
5.5 消融研究
量化方案。表11:不同量化方案的GPU延迟( ms )。量化方案(从Pertoken到Per - tensor ,从动态到静态,从O1到O3 ,如表2所示)越粗,延迟越低。在所有设置下,与FP16相比,SmoothQuant实现了较低的延迟,而LLM . int8 ( )则较慢。批次大小为4 .
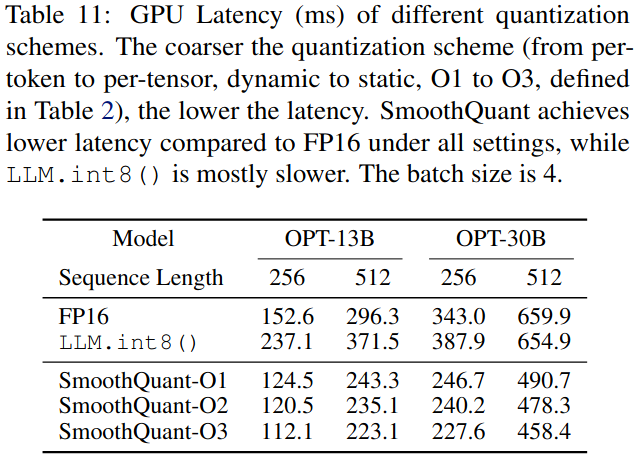
迁移强度。图10:一个合适的迁移强度α 使得激活和权重都易于量化。如果α太大,权重将很难量化;如果太小,激活就很难量化。
◆综上,实现步骤简述如下:
校准:确定每个通道的平滑因子si。
变换:对模型权重和激活值进行平滑缩放。
量化:将权重和激活值转换为8-bit整数。
【6 相关工作】
大型语言模型( LLMs )。经过预训练的语言模型通过扩展在各种基准上取得了显著的性能。
模型量化。量化是减小模型规模和加速推理的有效方法。
LLMs的量化。GPTQ 只对权重进行量化,而不对激活进行量化。Zero Quant 和nuQmm 对LLMs采用逐令牌分组量化方案,需要定制CUDA内核。它们的最大评估模型分别为20B和2.7 B,无法保持OPT175B等LLMs的性能。LLM.int8 ( )使用混合INT8 / FP16分解来处理激活异常值。然而,这样的实现会导致较大的延迟开销,甚至会慢于FP16的推理速度。离群点抑制使用非等比例缩放LayerNorm和token - wise裁剪来处理激活离群点。然而,它仅在BERT和BART等小型语言模型上取得了成功,并且无法保持对LLMs的准确性(表4 )。我们的算法保留了LLMs (截止到176B ,我们可以找到最大的开源LLM)的性能,采用了有效的逐张量静态量化方案,无需重新训练,允许我们使用现成的INT8 GEMM实现较高的硬件效率。
【7 结论】
我们提出了SmoothQuant,一种精确而有效的训练后量化方法,可以对高达530B参数的LLMs实现无损的8比特权重和激活量化。SmoothQuant能够对LLMs中所有GEMM的权重和激活进行量化,与混合精度激活量化基准相比,显著降低了推理延迟和内存使用。我们将SmoothQuant集成到PyTorch和FasterTransformer中,获得了高达1.56倍的推理加速,并将内存占用减少了一半。SmoothQuant通过提供统包解决方案来降低服务成本,实现了LLMs应用的大众化。
◆为什么这种方法有效?
激活值离群值被抑制:通过按通道缩放,大幅降低激活值的动态范围。
权重容忍度高:权重分布均匀,即使动态范围稍增大,量化误差影响小。
数学等价:缩放是线性操作,不改变模型输出结果,无需微调。
◆SmoothQuant就像给大模型做了一次“动态范围平衡手术”操作。
把激活值的“高血压”(离群值)通过缩放降压;
把“血压”转移给权重(因为它身体好,扛得住);
最终实现无需训练、高效部署的8-bit量化,几乎不掉精度。
这种方法简单、实用,成为大模型量化部署的重要工具之一。
至此,本文分享的内容就结束了。
相关文章:

【论文阅读】平滑量化:对大型语言模型进行准确高效的训练后量化
论文题目:SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models 论文地址:[2211.10438] SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models 代码地址:http…...

mysql游标分页详解:让分页又快又稳的终极方案
一、什么是游标分页? 游标分页是一种更高效的分页方式,它通过"记住当前位置"而不是"数页码"来实现分页。就像看书时夹书签一样,游标分页会记住你看到哪里了,下次直接从那里继续。 传统分页 vs 游标分页 传…...
)
图论---染色法(判断是否为二分图)
O(nm) 二分图:可以把所有的点划分到两边,使得边只在集合之间,集合内部没有边。 二分图当且仅当图中不含奇数环(边数为奇数条) #include <iostream> #include <vector> #include <cstring> using …...
的股票价格预测(附完整matlab代码,公式,原理,可用于毕业论文设计))
算法 | 基于SSA-CNN-LSTM(麻雀算法优化卷积长短期记忆神经网络)的股票价格预测(附完整matlab代码,公式,原理,可用于毕业论文设计)
以下是一个基于SSA-CNN-LSTM(麻雀算法优化卷积长短期记忆神经网络)的股票价格预测MATLAB项目实例,包含完整代码和详细注释。代码分为数据预处理、模型构建、优化算法、训练预测四个部分。 🚜🚜🚜🚜🚜🚜🚜🚜🚜🚜🚜🚜🚜 1. 数据预处理 %% 数据加…...
)
在html中如何创建vue自定义组件(以自定义文件上传组件为例,vue2+elementUI)
1、先上代码:vueUpload.js var dom <div class"upload-file"><el-upload :action"uploadFileUrl" :before-upload"handleBeforeUpload" :file-list"fileList" :limit"limit":on-error"handleUpl…...
 创建asp .net core空项目)
Asp.Net Core 基于(asp.net core 2.2) 创建asp .net core空项目
文章目录 ASP.NET Core 应用程序的标准入口点,用于配置和启动一个 Web 主机(WebHost)。`InProcess` 代码分析解决 HTTP Error 500.31 - Failed to load ASP.NET Core runtime 的完整方案**`launchSettings.json` 配置文件分析**ASP.NET Core 中的配置源详解ASP.NET Core 应用…...

AiFlutter 低代码平台介绍
产品概述 AiFlutter 低代码平台是一款基于拖拽组件和配置流程图的可视化开发工具,旨在简化移动应用开发过程。无需编写代码,用户即可通过拖拽组件快速搭建应用界面,并通过配置流程图设计页面逻辑。平台支持硬件通信功能,用户可直…...

Flutter Dart 集合类型List Set Map详解军 以及循环语句 forEaclh map where any every
List基础用法 var list1 ["西瓜", "苹果", "香蕉", true, 0];var list2 <String>["西瓜", "苹果", "香蕉"];List list3 ["西瓜", "苹果", "香蕉"];list3.add("草莓&…...
 iot-msk-pipeline)
aws(学习笔记第三十九课) iot-msk-pipeline
文章目录 aws(学习笔记第三十九课) iot-msk-pipeline学习内容:1. 整体架构1.1 代码链接1.2 代码调整1.2 整体架构(概要)1.3 整体架构(详细) 2. 代码解析2.1 创建IotProducerDestination2.2 创建IotProducer2.3 创建MSK client的EC22.4 创建MSK cluster2.5 创建Main …...

2025上海车展:赛轮思AI携手行业领军企业展示xUI——混合式、智能体化的AI助理平台
用户将可首次全面体验集成多模态SLM (端侧大语言模型)的Cerence xUl,此次演示由长城汽车和TCL合作呈现 马萨诸塞州伯灵顿,2025年4月22日——Cerence Inc.(NASDAQ: CRNC)(“赛轮思AI”),全球对话…...

聚合分销小程序系统开发方案:整合AI对话、网盘、淘客CPS/CPA、电影票团购与会员卡业务
一、系统架构设计 技术架构 分层设计:采用微服务架构,分为平台层(分销管理、数据库、交易系统)、管理体系层(数据管理、权限控制)和功能层(AI对话、网盘、CPS/CPA拉新、电影票团购、会员卡&…...

设计模式-- 原型模式详解
原型模式(prototype) 原型模式:用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型相同或相似的新对象,原型模式属于创造性模式,它同样提供了创建对象的最佳方式之一。(效率很高…...

ARM服务器与X86服务器核心区别分析
ARM服务器与X86服务器核心区别分析 一、架构设计与指令集差异 指令集本质 ARM:基于RISC(精简指令集),指令定长且简单,单周期执行效率高,硬件设计复杂度低,适合低功耗场景。 X86…...

嵌入式:ARM系列分类及主要应用场景
在嵌入式系统和移动计算领域,Arm Cortex 系列处理器凭借其多样化的架构和卓越的性能,成为了众多设备的核心 “大脑”。从高端智能手机到工业控制设备,从物联网终端到安全芯片,Cortex 系列处理器以不同的型号和特性,满足…...

Axure PR 9 中继器 标签
大家好,我是大明同学。 这期内容,我们来了解一下Axure中继器数据表标签交互设计。 预览地址:https://n05kfs.axshare.com 好的,这里就结束了。 我是大明同学。 下期见。...

Django【应用 01】django-plotly-dash安装及使用
django-plotly-dash 的使用文档:https://django-plotly-dash.readthedocs.io/en/stable/introduction.html 以下内容大部分保留原文档的内容,添加实际的步骤和必要的说明。 django-plotly-dash安装及使用 1.安装配置1.1 安装1.2 注册组件1.3 配置框架1.…...

【MFC】 VS2022打开低版本的MFC,双击.rc文件,DIalog加载失败,页面弹窗fatal error RC***:cannot open*****
打开以前的MFC示例报错,打开VS2019的实例以及更早VS版本的实例都一样,打不开,还报错; 错误 MSB8041 此项目需要 MFC 库。从 Visual Studio 安装程序(单个组件选项卡)为正在使用的任何工具集和体系结构安装它们。 GxCameraEvents_VS2015 C:\P…...

ClickHouse 中`MergeTree` 和 `ReplicatedMergeTree`表引擎区别
在 ClickHouse 中,MergeTree 和 ReplicatedMergeTree 都是用于存储和管理数据的表引擎,但它们的主要区别在于是否支持数据复制。下面详细解释两者的不同点及其适用场景。 MergeTree 定义: MergeTree 是 ClickHouse 中最基本的表引擎之一&a…...

PubMed PDF下载 cloudpmc-viewer-pow逆向
目标:https://pmc.ncbi.nlm.nih.gov/articles/ pdf的下载链接是直接存在的 但是第一次单击下载不会触发PDF下载,而是跳转到验证页面然后又跳回概览页面 再次点击下载按钮,PDF就能正常下载了。现在要分析下载PDF要验证什么,如cooki…...

C语言面试高频题——strcat、strncat、strcmp、strcpy 哪些函数会导致内存溢出?
1. 函数功能与内存溢出风险 (1) strcat 功能:将源字符串追加到目标字符串的末尾。 原型: char *strcat(char *dest, const char *src);内存溢出风险: strcat 不会检查目标缓冲区的大小,直接将源字符串追加到目标字符串后。如果目…...

Linux套接字+Sqlite实例:客户端-服务器应用程序教程
本文将详细介绍如何创建一个基于客户端-服务器架构的应用程序,实现用户注册、登录、单词查询以及历史记录查询。该应用通过TCP套接字进行客户端和服务器之间的通信,并通过SQLite数据库进行用户和查询记录的管理。教程会逐步解析客户端和服务器端的实现&a…...

用 Python 打造打篮球字符动画!控制台彩色炫酷输出,抖音搞怪视频灵感还原
一、引言:从抖音搞怪视频到 Python 字符动画的奇妙之旅 刷抖音时刷到一个神级操作 —— 博主用 01 数字矩阵还原了明星打篮球的经典画面,字符在控制台随动作节奏炫彩跳动,瞬间点燃了技术宅的 DNA!作为 Python 图像处理爱好者&…...
与入侵防御系统(IPS):功能对比与部署实践)
入侵检测系统(IDS)与入侵防御系统(IPS):功能对比与部署实践
入侵检测系统(IDS)与入侵防御系统(IPS):功能对比与部署实践 在网络安全防御体系中,入侵检测系统(Intrusion Detection System, IDS)与入侵防御系统(Intrusion Preventio…...
)
力扣-hot100(找到字符串中的所有字母异位词)
438. 找到字符串中所有字母异位词 中等 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。 示例 1: 输入: s "cbaebabacd", p "abc" 输出: [0,6] 解释: 起始索引等于 0…...

零信任架构:重塑网络安全的IT新范式
在信息技术(IT)的风云变幻中,网络安全领域正迎来一场深刻变革——零信任架构(Zero Trust Architecture)。2025年,随着远程办公的常态化、云服务的普及以及网络攻击的日益复杂化,传统的“城堡与护…...
大模型微调 - transformer架构
什么是Transformer Transformer 架构是由 Vaswani 等人在 2017 年提出的一种深度学习模型架构,首次发表于论文《Attention is All You Need》中 Transformer 的结构 Transformer 编码器(Encoder) 解码器(Decoder) …...
)
Python图形界面编程(二)
目录 六、控件属性和事件响应 1、基本的操控 2、示例 七、对话框 六、控件属性和事件响应 1、基本的操控 有的控件有对对应的函数,可以用来设置以及获取属性或者设置属性,或者以字典下标的形式来获取,设置对应的属性: 比如&…...

MongoDB 图片 URL 存储异常问题解决方案
项目场景: 在开发一个在线考试系统时,前端需要提交学生的答题截图到后端,后端使用 MinIO 存储图片并保存图片 URL 到 MongoDB 数据库。系统需要支持多次提交图片,并将所有图片 URL 以数组形式存储在 MongoDB 的 screenShot 字段中…...

run code执行ts配置
1、全局安装typescript npm install –g typescript 执行tsc –v,可输出版本号,代表安装成功 2、创建tsConfig文件 npx tsc –init 创建成功目录下会出现tsconfig.json文件 3、安装ts-node,支持执行运行ts文件 npm install –g ts-node 控制…...

Python 虚拟环境管理:venv 与 conda 的选择与配置
文章目录 前言一、虚拟环境的核心价值1.1 依赖冲突的典型场景1.2 隔离机制实现原理 二、venv 与 conda 的架构对比2.1 工具定位差异2.2 性能基准测试(以创建环境 安装 numpy 为例) 三、venv 的配置与最佳实践3.1 基础工作流3.2 多版本 Python 管理 四、…...

【前缀和计算和+哈希表查找次数】Leetcode 560. 和为 K 的子数组
题目要求 给定一个整数数组 nums 和一个整数 k,统计并返回该数组中和为 k 的子数组的个数。 子数组是数组中元素的连续非空序列。 示例 1 输入:nums [1, 1, 1], k 2 输出:2 示例 2 输入:nums [1, 2, 3], k 3 输出…...
:[macOS 64bit App开发]:如何使用CFStringRef类型字符串?)
[原创](现代Delphi 12指南):[macOS 64bit App开发]:如何使用CFStringRef类型字符串?
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

89.WPF 中实现便捷的数字输入框:DecimalUpDown 控件的使用 WPF例子 C#例子.
在 WPF 开发中,经常会遇到需要用户输入数字的场景。为了提供更好的用户体验,我们可以使用一个功能强大的控件——DecimalUpDown,它来自第三方库 Extended WPF Toolkit。这个控件不仅支持用户通过键盘输入数字,还支持通过鼠标滚轮或…...
循环程序举例)
【时时三省】(C语言基础)循环程序举例
山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 例题: 用公式4/π≈1-3/1+5/1-7/1+...求π的近似值,直到发现某一项的绝对值小于10的-6次方为止(该项不累加)。 解题思路: 这是求值的近似方法中的一种。求π值可以用不同的近似方法。如下面的表达式都可以…...

Linux常用中间件命令大全
1.nginx 执行命令之前需要先进入sbin目录查看nginx版本: ./nginx -v检查配置文件正确性: ./nginx -t启动nginx服务: ./nginx停止nginx服务: ./nginx -s stop启动完成后可以查看nginx进程: ps -ef|grep nginx可以通过绝…...

数图信息科技邀您共赴第二十五届中国零售业博览会
数图信息科技邀您共赴第二十五届中国零售业博览会 2025年5月8日至10日,数图信息科技将精彩亮相第二十五届中国零售业博览会(CHINASHOP 2025),与行业伙伴共探零售数字化转型新机遇! 数图展会新品抢先看 数图商品一…...

路由器的基础配置全解析:静态动态路由 + 华为 ENSP 命令大全
🚀 路由器的基础配置全解析:静态&动态路由 华为 ENSP 命令大全 🌐 路由器的基本概念📍 静态路由配置📡 动态路由协议:RIP、OSPF、BGP🖥 华为 ENSP 路由器命令大全🔹 路由器基本…...
)
「Java EE开发指南」如何使用MyEclipse的可视化JSF编辑器设计JSP?(一)
本教程介绍在MyEclipse中开发EJB 3无状态会话bean,由于JPA实体和EJB 3实体非常相似,因此本教程不涉及EJB 3实体Bean的开发。在本教程中,您将学习如何: Visual JSF Designer(可视化JSF设计器)的目标是使创建…...

【设计】接口幂等性设计
1. 幂等性定义 接口幂等性: 无论调用次数多少,对系统状态的影响与单次调用相同。 比如用户支付接口因网络延迟重复提交了三次。 导致原因: 用户不可靠(手抖多点)网络不可靠(超时重传)系统不可…...

深入理解机器学习:人工智能的核心驱动力
在当今数字化时代,机器学习作为人工智能领域的关键技术,正以前所未有的速度改变着我们的生活和工作方式。从智能语音助手到精准的医疗诊断,从个性化的推荐系统到自动驾驶汽车,机器学习的应用无处不在,其影响力深远而广…...
)
CI/CD自动化部署(持续集成和持续交付/部署)
持续集成:开发人员频繁地将代码集成到共享仓库,然后自动运行测试持续交付:自动准备好发布,但需要手动触发部署持续部署:完全自动化的,不需要人工干预 流程: 比如,当开发人员提交代…...

如何理解计算机网卡完成数据传输的串并转换
计算机网卡的串并转换(串行-并行转换)是网络通信中的一个关键硬件功能,主要涉及数据的传输形式转换。它的核心目的是解决计算机内部处理数据的方式(并行)与网络传输数据的方式(串行)之间的差异。以下是通俗易懂的解释: 1. 串行传输 vs. 并行传输 并行传输: 计算机内部…...

基于Axure的动态甘特图设计:实现任务增删改与时间拖拽交互
甘特图作为项目管理核心工具,其动态交互能力直接关系到团队协作效率。本文以Axure RP 9为载体,通过中继器(Repeater)与动态面板(Dynamic Panel)的深度结合,设计一款支持任务名称动态编辑、时间轴…...

XMOS空间音频——在任何设备上都能提供3D沉浸式空间音频且实现更安全地聆听
2025年3月,全球规模最大的嵌入式行业盛会——德国纽伦堡国际嵌入式展(Embedded World 2025,EW 25)圆满落幕。在这场汇聚全球 950 家展商、3 万余专业观众的科技盛宴中,XMOS 展位人头攒动,多款尖端产品和多…...

使用功能包组织C++节点的具体教程
在 ROS(Robot Operating System)中,使用功能包(package)来组织 C 节点是一种常见且有效的方式,它能让代码结构更清晰、便于管理和复用。 1. 环境准备 确保已经安装了 ROS,这里以 ROS 2 Humble…...

免费的车牌势识别系统
背景 就是想要一个车牌识别系统 直接上教程 需要首先安装python3 然后执行下面的命令 pip install hyperlpr3 lpr3 rest --port 9999 --host 0.0.0.0 --workers 1 访问地址地址 # 9999 与上述端口一致 http://你的ip:9999/api/v1/docs 测试效果 准备一张图片 lpr3 sa…...

微信小程序蓝牙连接打印机打印单据完整Demo【蓝牙小票打印】
文章目录 一、准备工作1. 硬件准备2. 开发环境 二、小程序配置1. 修改app.json 三、完整代码实现1. pages/index/index.wxml2. pages/index/index.wxss3. pages/index/index.js 四、ESC/POS指令说明五、测试流程六、常见问题解决七、进一步优化建议 下面我将提供一个完整的微信…...

阿里云基于本地知识库构建RAG应用 | 架构与场景
RAG(检索增强生成,Retrieval-Augmented Generation)是一种结合了检索和生成技术的框架,旨在通过外部知识库的检索来增强大语言模型(LLM)的生成能力。 其核心架构包括两个主要部分: 检索模块&a…...
)
Python----深度学习(基于深度学习Pytroch簇分类,圆环分类,月牙分类)
一、引言 深度学习的重要性 深度学习是一种通过模拟人脑神经元结构来进行数据学习和模式识别的技术,在分类任务中展现出强大的能力。 分类任务的多样性 分类任务涵盖了各种场景,例如簇分类、圆环分类和月牙分类,每种任务都有不同的…...

Python图像处理——基于Retinex算法的低光照图像增强系统
1.项目内容 (1)算法介绍 ①MSRCR (Multi-Scale Retinex with Color Restoration) MSRCR 是多尺度 Retinex 算法(MSR)的扩展版,引入了色彩恢复机制以进一步提升图像增强质量。MSR 能有效地压缩图像动态范围ÿ…...