第3讲、大模型如何理解和表示单词:词嵌入向量原理详解
1. 引言
大型语言模型(Large Language Models,简称LLM)如GPT-4、Claude和LLaMA等近年来取得了突破性进展,能够生成流畅自然的文本、回答复杂问题、甚至编写代码。但这些模型究竟是如何理解人类语言的?它们如何表示和处理单词?本文将深入探讨大模型的基础机制——词嵌入向量,揭示AI是如何"理解"文字的。
2. 从符号到向量:语言表示的基础
2.1 词向量的概念
在传统自然语言处理中,单词通常被表示为独热编码(One-Hot Encoding)——一个只有一个元素为1,其余都为0的稀疏向量。例如,在一个有10000个单词的词汇表中,"苹果"这个词可能被表示为一个长度为10000的向量,其中只有第345位是1,其余都是0。
然而,这种表示方法存在明显缺陷:向量维度过高且稀疏,更重要的是,无法表达单词之间的语义关系。例如,"苹果"和"梨"在语义上很接近,但它们的独热编码向量可能完全不同,计算相似度时得到的结果是0。
2.2 词嵌入向量的基本原理
词嵌入向量(Word Embedding)解决了上述问题,它是"通过将离散空间向连续空间映射后得到的词向量"。每个单词被映射到一个低维度(通常为几百维)的稠密向量空间中,这些向量捕捉了单词的语义和句法特性。
词嵌入向量的核心优势在于:语义上相似的词在向量空间中的距离也相近。这种特性使得模型能够理解词与词之间的关系,从而更好地处理自然语言。
3. 词嵌入向量的实现方式
3.1 Word2Vec
Word2Vec是由Google在2013年开源的词嵌入技术,它通过两种模型来学习词向量:
- CBOW (Continuous Bag of Words):使用上下文预测目标词。给定一个词的上下文(周围的词),预测这个词是什么。
- Skip-gram:与CBOW相反,使用目标词预测上下文。给定一个词,预测它周围可能出现的词。

Word2Vec能够捕捉到丰富的语义关系,最著名的例子是向量的代数运算能够表示语义关系:
vector('国王') - vector('男人') + vector('女人') ≈ vector('女王')
vector('巴黎') - vector('法国') + vector('意大利') ≈ vector('罗马')
这种现象表明,词嵌入不仅能够捕捉相似性,还能捕捉词汇之间的语义关系和类比关系。
####案例代码
import streamlit as st
import pandas as pd
from sklearn.decomposition import PCA
from openai import OpenAI
from dotenv import load_dotenv
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib# 指定中文字体路径(macOS)
font_path = "/System/Library/Fonts/PingFang.ttc" # macOS 中文字体
my_font = fm.FontProperties(fname=font_path)# 设置 matplotlib 默认字体
matplotlib.rcParams['font.family'] = my_font.get_name()
matplotlib.rcParams['axes.unicode_minus'] = False
# 加载环境变量
load_dotenv()# OpenAI 客户端
client = OpenAI(
)# 嵌入生成函数
def get_word_embeddings(words, model="text-embedding-3-large"):try:response = client.embeddings.create(input=words, model=model)return [item.embedding for item in response.data]except Exception as e:st.error(f"Error occurred: {e}")return []# 主界面
st.title("🧠 词嵌入向量空间可视化")st.write("输入一些单词,看看它们在二维空间里的分布!")# 文本输入
user_input = st.text_area("请输入单词(每行一个单词):","国王\n皇后\n男人\n女人\n猫\n狗\n苹果\n橙子"
)if user_input:words = [w.strip() for w in user_input.split("\n") if w.strip()]if len(words) < 2:st.warning("请输入至少两个单词!")else:with st.spinner("生成词嵌入向量中..."):embeddings = get_word_embeddings(words)if embeddings:st.success("嵌入向量生成成功!")st.write(f"每个单词的向量维度:**{len(embeddings[0])}**")# 用 PCA 降到 2Dpca = PCA(n_components=2)reduced = pca.fit_transform(embeddings)# 转成 DataFramedf = pd.DataFrame(reduced, columns=["x", "y"])df["word"] = words# 画出散点图fig, ax = plt.subplots(figsize=(10, 6))ax.scatter(df["x"], df["y"], color="blue")# 在点旁边标注单词for i, word in enumerate(df["word"]):ax.text(df["x"][i]+0.01, df["y"][i]+0.01, word, fontsize=12)ax.set_title("词嵌入二维空间可视化")ax.set_xlabel("主成分1 (PCA1)")ax.set_ylabel("主成分2 (PCA2)")st.pyplot(fig)# 图的解释st.subheader("图表解释 🧠")st.markdown("""- 每个点代表一个单词在嵌入空间中的位置。- **相近的单词**,在二维平面上会靠得更近,表示语义相似。- 方向和距离代表潜在的语义关系,比如“国王-男人+女人≈皇后”。- 注意:因为是降维展示,实际高维特征被简化了,但依然可以直观感知单词间的语义结构。""")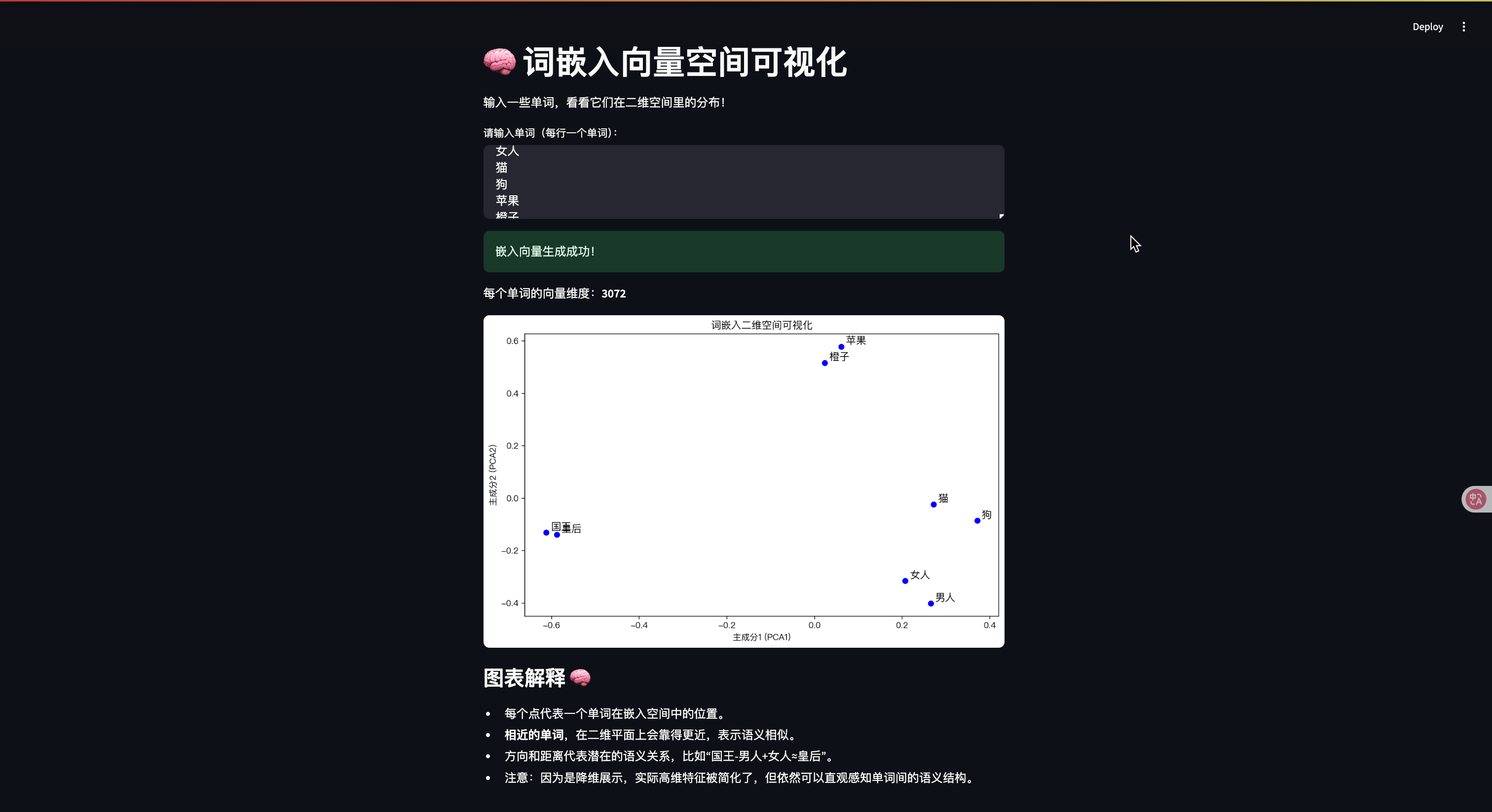
3.2 GloVe
GloVe (Global Vectors for Word Representation) 是由斯坦福大学开发的另一种流行的词嵌入模型。与Word2Vec不同,GloVe结合了全局矩阵分解和局部上下文窗口方法的优点。
GloVe基于共现矩阵——记录每个单词与其上下文词的共现频率,然后通过矩阵分解技术学习词向量。这使得GloVe能够更好地捕捉全局统计信息。
3.3 FastText
FastText是Facebook AI Research开发的一种改进型词嵌入模型。它的主要创新在于将单词分解为子词(subword)单元,通常是字符n-gram。
例如,单词"apple"的3-gram表示为:<ap, app, ppl, ple, le>。这种方法的优势在于:
- 能够处理词汇表外的词(OOV问题)
- 对拼写错误有一定的容忍度
- 特别适合处理形态丰富的语言(如芬兰语、土耳其语等)
4. 大模型中的词嵌入技术
在现代大型语言模型(如BERT、GPT系列、LLaMA等)中,词嵌入技术得到了进一步的发展和应用。
4.1 上下文相关的词嵌入
传统的Word2Vec等模型为每个词生成一个固定的向量,而不考虑上下文。这意味着多义词(如"苹果"可以指水果或公司)只有一个表示。
而现代大模型采用了上下文相关的词嵌入技术。例如,BERT模型会根据词出现的上下文生成不同的表示:
"我喜欢吃苹果" → vector("苹果") 表示水果意义
"苹果公司发布新产品" → vector("苹果") 表示公司意义
这种动态表示极大地提高了模型理解语言的能力。

4.2 Transformer中的词嵌入
在Transformer架构(现代大模型的基础)中,词嵌入通常包含三个部分:
- 词嵌入 (Token Embeddings):单词本身的向量表示
- 位置嵌入 (Positional Embeddings):表示单词在序列中的位置
- 段嵌入 (Segment Embeddings):用于区分不同段落或句子(主要用于BERT等模型)
这三种嵌入向量相加后,形成了输入Transformer各层的初始表示。位置嵌入特别重要,因为它使模型能够了解单词的顺序,这对于理解语言至关重要。
5. 大模型中的Token化过程
大模型处理文本的第一步是将输入分解为"token"。这些token可以是完整单词、子词单元(subword units)或单个字符。
5.1 BPE算法
字节对编码(Byte Pair Encoding, BPE)是GPT等模型常用的分词算法。BPE首先将每个单词分解为字符序列,然后反复合并最常见的字符对,形成新的子词单元。
BPE的优势在于能够平衡词汇表大小和表示能力,有效处理罕见词和复合词。
例如,英文单词"unhappiness"可能被分解为:["un", "happiness"]或["un", "happy", "ness"],而中文"人工智能"可能被分解为:["人工", "智能"]。
5.2 SentencePiece和WordPiece
SentencePiece和WordPiece是其他常用的子词分词算法,它们与BPE类似,但在细节实现上有所不同。这些算法都允许模型处理开放词汇表,提高了模型的灵活性和泛化能力。
6. 词嵌入向量的特性与误区
6.1 重要特性
- 语义相似性:语义相近的词在向量空间中距离较近
- 类比关系:向量间的关系可以表示语义关系
- 降维可视化:通过t-SNE等技术降维后,可以直观地看到词汇聚类
6.2 常见误区
注意点: 词嵌入向量并不直接表示语义,而是词与词之间语义的相似度。因此,不必去纠结每个向量值到底代表什么意思。
许多人误以为词向量的每个维度对应某种具体的语义属性(如第一维表示性别,第二维表示生物/非生物等)。实际上,词嵌入空间通常是高度纠缠的,单个维度很少有明确的语义解释。
词嵌入是在特定任务和数据集上学习得到的分布式表示,它们捕捉的是词与词之间的相对关系,而非绝对语义。
7. 词嵌入向量的实际应用
词嵌入技术被广泛应用于各种自然语言处理任务:
- 文本分类:通过词向量表示文档,进行情感分析、主题分类等
- 命名实体识别:识别文本中的人名、地名、组织名等专有名词
- 机器翻译:作为神经机器翻译系统的基础表示
- 问答系统:帮助理解问题和生成答案
- 文本相似度计算:判断两段文本的语义相似程度
7.1 实战案例:使用Python实现词向量计算
下面我们通过一个实际案例,展示如何使用Python和预训练模型来计算和使用词向量。我们将使用流行的Gensim库和预训练的Word2Vec模型来演示:
import streamlit as st
import gensim.downloader as api
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib# 指定中文字体路径(macOS)
font_path = "/System/Library/Fonts/PingFang.ttc"
my_font = fm.FontProperties(fname=font_path)# 设置 matplotlib 中文字体和负号显示
matplotlib.rcParams['font.family'] = my_font.get_name()
matplotlib.rcParams['axes.unicode_minus'] = False# 设置页面配置
st.set_page_config(page_title="Word2Vec 词向量可视化", layout="wide")@st.cache_resource(show_spinner=True)
def load_model():return api.load('word2vec-google-news-300')# 加载模型
model = load_model()st.title("📌 Word2Vec 词向量可视化工具")# 分页
tab1, tab2, tab3, tab4 = st.tabs(["词向量查询", "词语相似度", "类比推理", "向量可视化"])# --- 1. 词向量查询 ---
with tab1:st.header("🔍 查看词向量")word = st.text_input("输入一个英文单词:", "computer")if st.button("获取词向量"):if word in model:vec = model[word]st.write(f"词向量维度: {vec.shape}")st.write("前10个维度的值:", vec[:10])else:st.error("词不在词汇表中,请尝试其他单词")# --- 2. 词语相似度 ---
with tab2:st.header("🔗 计算词语相似度")col1, col2 = st.columns(2)with col1:word1 = st.text_input("单词1", "computer")with col2:word2 = st.text_input("单词2", "laptop")if st.button("计算相似度"):if word1 in model and word2 in model:sim = model.similarity(word1, word2)st.success(f"'{word1}' 和 '{word2}' 的余弦相似度为:{sim:.4f}")else:st.error("一个或两个词不在词汇表中")# --- 3. 类比推理 ---
with tab3:st.header("🧠 类比推理(word1 - word2 + word3 ≈ ?)")col1, col2, col3 = st.columns(3)with col1:w1 = st.text_input("词1 (如 king)", "king")with col2:w2 = st.text_input("词2 (如 man)", "man")with col3:w3 = st.text_input("词3 (如 woman)", "woman")if st.button("进行类比推理"):try:result = model.most_similar(positive=[w3, w1], negative=[w2], topn=5)st.write(f"'{w1}' 之于 '{w2}',相当于 '{w3}' 之于:")for word, score in result:st.write(f"- {word}: {score:.4f}")except KeyError as e:st.error(f"词汇错误: {e}")# --- 4. 向量可视化 ---
with tab4:st.header("📈 词向量可视化(PCA降维)")words_input = st.text_area("输入一组英文单词,用逗号分隔(如:king,queen,man,woman,computer)","king, queen, man, woman, computer, banana, apple, orange, prince, princess")raw_words = [w.strip() for w in words_input.split(",")]words = [w for w in raw_words if w in model]skipped = [w for w in raw_words if w not in model]if st.button("生成可视化图像"):if len(words) < 2:st.warning("请至少输入两个词,并确保它们在词汇表中")else:vectors = [model[w] for w in words]pca = PCA(n_components=2)reduced = pca.fit_transform(vectors)fig, ax = plt.subplots(figsize=(12, 8))ax.set_facecolor("#f9f9f9") # 浅色背景ax.grid(True, linestyle='--', alpha=0.5) # 显示网格线# 绘制点ax.scatter(reduced[:, 0], reduced[:, 1],color="#1f77b4", s=100, alpha=0.7, edgecolor='k', linewidth=0.5)# 标签字体大小适配数量font_size = max(8, 14 - len(words) // 5)# 添加标签for i, word in enumerate(words):ax.annotate(word, xy=(reduced[i, 0], reduced[i, 1]),fontsize=font_size, fontproperties=my_font,xytext=(5, 2), textcoords='offset points',bbox=dict(boxstyle='round,pad=0.3', edgecolor='gray', facecolor='white', alpha=0.6),arrowprops=dict(arrowstyle='->', color='gray', lw=0.5))ax.set_title("📌 Word2Vec 词向量 2D 可视化 (PCA)", fontsize=18, pad=15)st.pyplot(fig)if skipped:st.info(f"以下词不在模型词汇表中,已跳过:{', '.join(skipped)}")# 自动分析生成说明st.subheader("🧠 分析说明")explanation = []# 简单聚类分析:找最近的词对from scipy.spatial.distance import euclideanpairs = []for i in range(len(words)):for j in range(i + 1, len(words)):dist = euclidean(reduced[i], reduced[j])pairs.append(((words[i], words[j]), dist))pairs.sort(key=lambda x: x[1])top_similar = pairs[:3] # 取最相近的三个词对for (w1, w2), dist in top_similar:explanation.append(f"🔹 **{w1}** 和 **{w2}** 在图中非常接近,表明它们在语义上可能较为相关(距离约为 {dist:.2f})。")# 计算均值中心,找偏离大的词(即“异类”)center = reduced.mean(axis=0)dists_to_center = [(words[i], euclidean(reduced[i], center)) for i in range(len(words))]dists_to_center.sort(key=lambda x: x[1], reverse=True)outlier_word, max_dist = dists_to_center[0]explanation.append(f"🔸 **{outlier_word}** 与其他词的平均距离最大(约为 {max_dist:.2f}),可能表示它语义上偏离较远。")# 输出说明for line in explanation:st.markdown(line)运行结果示例:
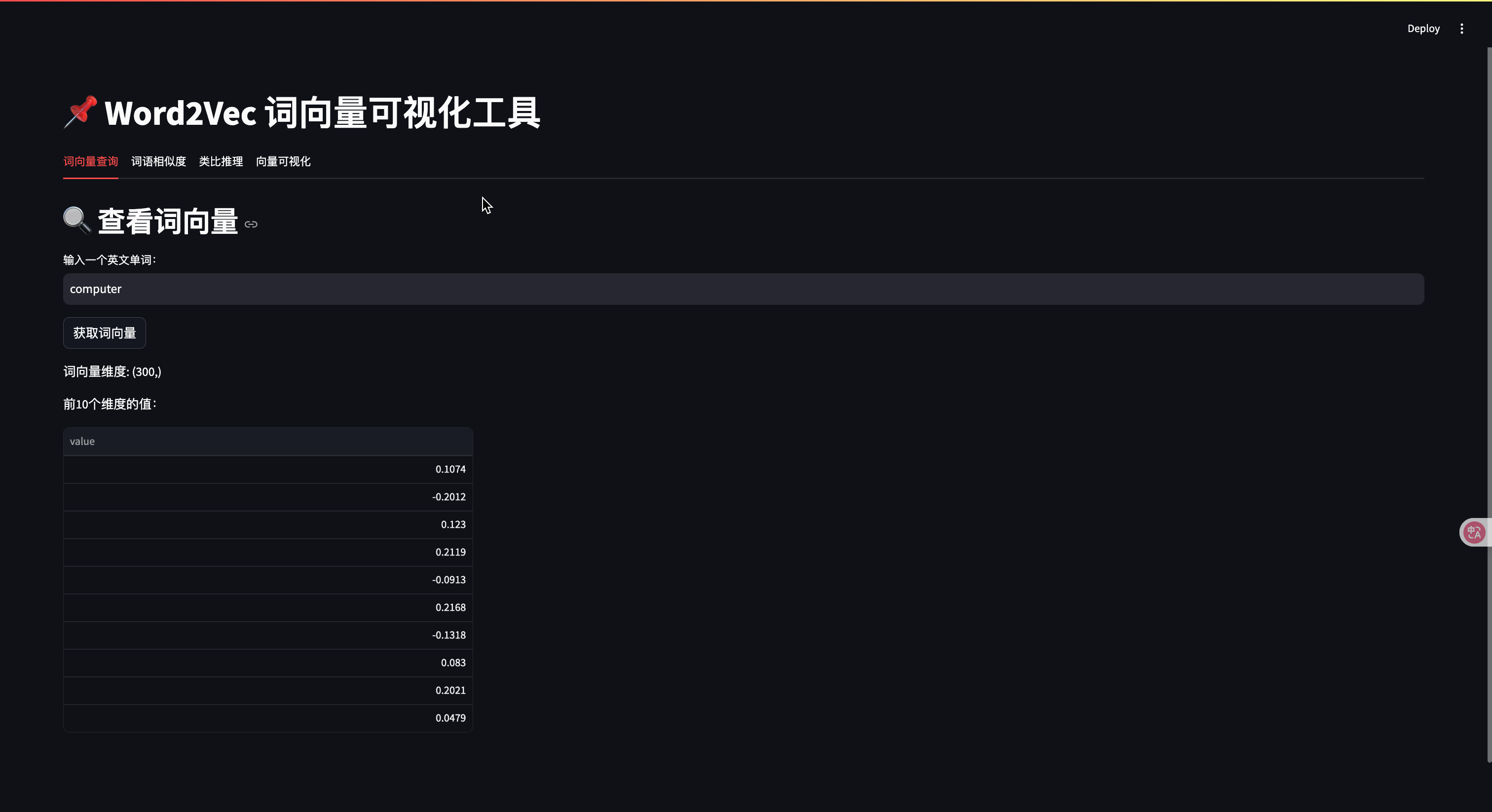
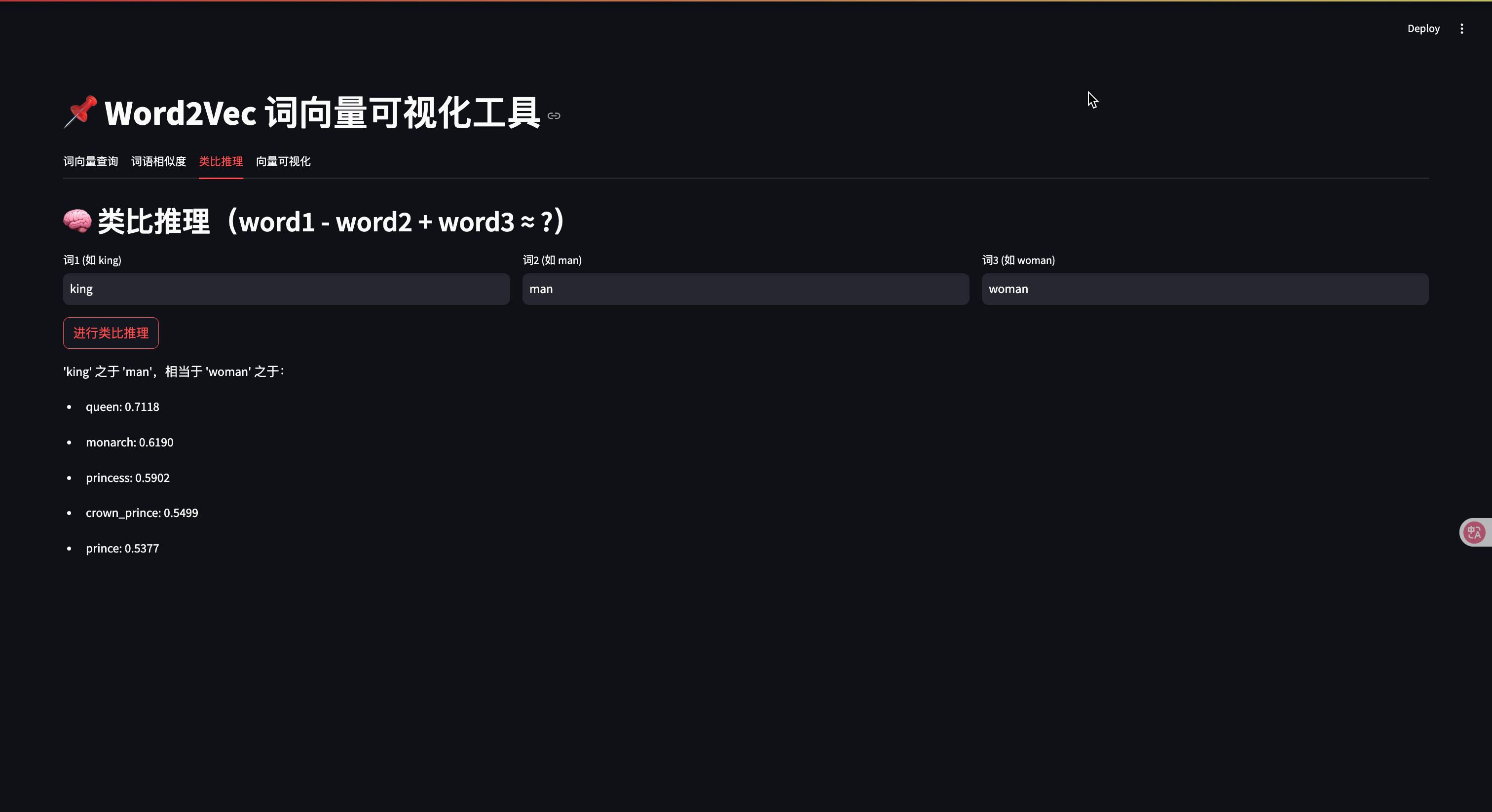
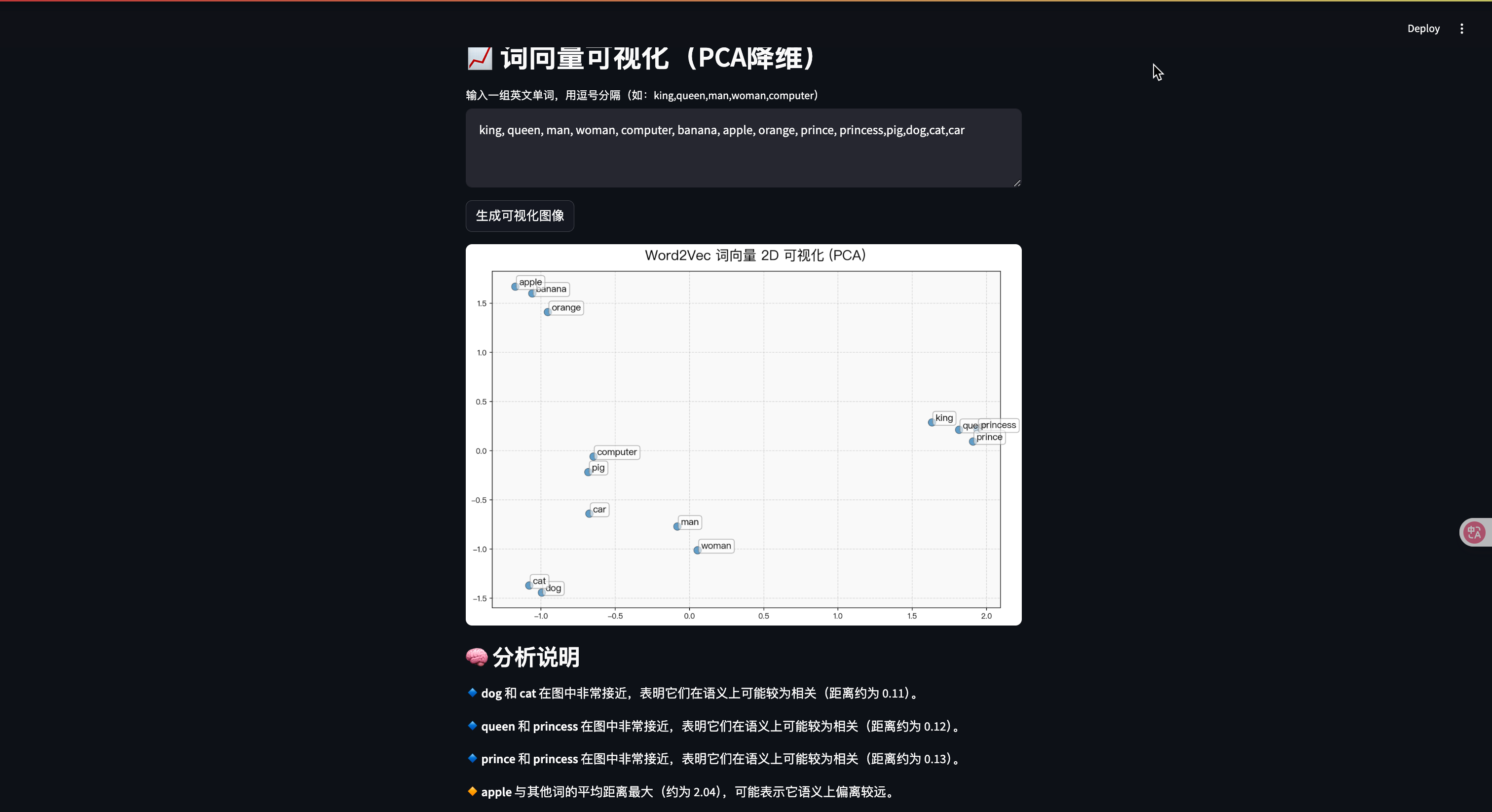
这个案例展示了词向量的四个核心应用:
- 获取词语的向量表示
- 计算词语之间的语义相似度
- 进行词向量的代数运算来发现类比关系
- 可视化词向量空间的语义结构
通过这个例子,我们可以直观地理解词嵌入如何捕捉单词之间的语义关系,以及如何在实际应用中利用这些关系。这种能力是大模型理解自然语言的基础。
8. 总结与展望
词嵌入向量技术是大模型理解人类语言的基础。从最初的Word2Vec到现代Transformer架构中的上下文相关表示,词嵌入技术不断发展,使AI能够更精确地理解和生成自然语言。
未来,词嵌入技术可能会向以下方向发展:
- 多模态嵌入:将文本、图像、音频等不同模态的信息统一表示
- 知识增强型嵌入:融合结构化知识库信息的词嵌入
- 更高效的计算方法:降低大模型中词嵌入计算的资源消耗
- 多语言统一表示:开发能够跨语言捕捉语义的通用嵌入空间
通过深入理解词嵌入向量的原理,我们不仅能更好地应用大模型,也能洞察人工智能是如何"思考"的,为未来的AI发展提供思路。
相关文章:

第3讲、大模型如何理解和表示单词:词嵌入向量原理详解
1. 引言 大型语言模型(Large Language Models,简称LLM)如GPT-4、Claude和LLaMA等近年来取得了突破性进展,能够生成流畅自然的文本、回答复杂问题、甚至编写代码。但这些模型究竟是如何理解人类语言的?它们如何表示和处…...

关于STM32f1新建工程
创建文件夹 首先创建一个存放工程的文件夹,建议建立在D,E盘 新建工程 在kiel5里面 找到刚刚建立的文件夹,然后在此文件夹里面新建一个文件夹用来存放本次工程,文件夹可以根据工程内容所编写,然后给自己工程也就是…...

Linux:进程间通信---匿名管道
文章目录 1. 进程间通信1.1 什么是进程间通信?1.2 为什么进程要进行进程间通信?1.3 怎么实现进程间通信? 2. 匿名管道2.1 匿名管道的原理2.2 匿名管道的系统接口2.3 匿名管道的使用2.4 匿名管道的运用场景 序:在上一篇文章中我们知…...

python代做推荐系统深度学习知识图谱c#代码代编神经网络算法创新
以下是针对推荐系统、深度学习、知识图谱和神经网络算法创新的代码框架及开发建议,适用于C#和Python的跨语言协作项目。以下内容分为几个部分,涵盖技术选型、代码示例和创新方向。 1. 推荐系统(Python C#) Python部分࿰…...

【动手学大模型开发】VSCode 连接远程服务器
Visual Studio Code(VSCode)是一款由微软开发的免费、开源的现代化代码编辑器。它以其轻量级、高性能和广泛的编程语言支持而受到开发者的青睐。VSCode 的核心特点包括: 跨平台:支持 Windows、macOS 和 Linux 操作系统。扩展市场…...

PostgreSQL 漏洞信息详解
PostgreSQL 漏洞信息详解 PostgreSQL 作为一款开源关系型数据库,其安全漏洞会被社区及时发现和修复。以下是 PostgreSQL 漏洞相关的重要信息和资源。 一、主要漏洞信息来源 1. 官方安全公告 PostgreSQL 安全信息页面:https://www.postgresql.org/sup…...

华为L410上制作内网镜像模板:在客户端配置模板内容
华为L410上制作内网镜像模板:在客户端配置模板内容 在本教程中,我们将继续在华为L410上配置内网镜像模板,具体介绍如何在客户端设置以便于在首次开机时自动安装软件。我们将主要使用WeChat作为示例。 1. 制作镜像模板,开启 rc.l…...

分布式队列对消息语义的处理
在分布式系统中,消息的处理语义(Message Processing Semantics)是确保系统可靠性和一致性的关键。有三种语义: 在分布式系统中,消息的处理语义(Message Processing Semantics)是确保系统可靠性和…...

《免费开放”双刃剑:字节跳动Coze如何撬动AI生态霸权与暗涌危机?》
战略动机分析 降低技术门槛为数据采集接口 Coze平台宣称**“30秒无代码生成AI Bot”,大幅降低了企业开发AI应用的技术门槛。任何不懂编程的业务人员都可以通过可视化流程和提示词,在半分钟内搭建聊天机器人或智能代理。这种极低门槛意味着更多企业和个人…...

AI 开发工具提示词集体开源!解锁 Cursor、Cline、Windsurf 等工具的核心逻辑
✨ 前言:提示词,AI 编程工具的灵魂 随着大模型编程能力的迅速提升,AI 编程工具如雨后春笋般涌现,涵盖了从代码编辑器(如 Cursor、Windsurf、Cline)到应用生成服务(如 Lovable、Bolt.new、V0&am…...

MYSQL 常用字符串函数 和 时间函数详解
一、字符串函数 1、CONCAT(str1, str2, …) 拼接多个字符串。 SELECT CONCAT(Hello, , World); -- 输出 Hello World2、SUBSTRING(str, start, length) 或 SUBSTR() 截取字符串。 SELECT SUBSTRING(MySQL, 3, 2); -- 输出 SQ3、LENGTH(str) 与 CHAR_LENGTH…...

Ubuntu 下 Nginx 1.28.0 源码编译安装与 systemd 管理全流程指南
一、环境与依赖准备 为确保编译顺利,我们首先更新系统并安装必要的编译工具和库: sudo apt update sudo apt install -y build-essential \libpcre3 libpcre3-dev \zlib1g zlib1g-dev \libssl-dev \wgetbuild-essential:提供 gcc、make 等基…...

线程怎么创建?Java 四种方式一网打尽
🚀 Java 中线程的 4 种创建方式详解 创建方式实现方式是否推荐场景说明1. 继承 Thread 类class MyThread extends Thread❌ 不推荐简单学习、单线程场景2. 实现 Runnable 接口class MyRunnable implements Runnable✅ 推荐更适合多线程共享资源3. 实现 Callable 接…...

高效使用DeepSeek对“情境+ 对象 +问题“型课题进行开题!
目录 思路"情境 对象 问题"型 课题选题的类型有哪些呢?这要从课题题目的构成说起。通过对历年来国家社会科学基金立项项目进行分析,小编发现,课题选题类型非常丰富,但一般是围绕限定词、研究对象和研究问题进行不同的组…...

【GCC bug】libstdc++.so.6: version `GLIBCXX_3.4.29‘ not found
在 conda 环境安装 gcc/gxx 之后,运行开始遇到了以下的报错 File "/mnt/data/home/xxxx/miniforge3/envs/GAGAvatar/lib/python3.12/site-packages/google/protobuf/internal/wire_format.py", line 13, in <module>from google.protobuf import de…...

python卸载报错:No Python 3.12 installation was detected已解决
问题背景 在卸载Python 3.12.5时,遇到了一个棘手的问题:运行安装包python.exe点击Uninstall后,系统提示No Python 3.12 installation was detected. 尝试了网上各种方法(包括注册表清理、修复repair,卸载unins…...

【Hive入门】Hive分区与分区表完全指南:从原理到企业级实践
引言 在大数据时代,高效管理海量数据成为企业面临的核心挑战。Hive作为Hadoop生态系统中最受欢迎的数据仓库解决方案,其分区技术是优化数据查询和管理的关键手段。本文将全面解析Hive分区技术的原理、实现方式及企业级最佳实践,帮助您构建高性…...

AI之FastAPI+ollama调用嵌入模型OllamaBgeEmbeddings
以下是对该 FastAPI 代码的逐行解析和详细说明: 代码结构概览 from fastapi import Depends # 导入依赖注入模块def get_embedder():return OllamaBgeEmbeddings(base_url="http://ollama-cluster:11434",timeout=30,max_retries=5)@app.post("/embed")…...
)
RK3588芯片NPU的使用:yolov8-pose例子图片检测在安卓系统部署与源码深度解析(rknn api)
一、本文的目标 将yolo8-pose例子适配安卓端,提供选择图片后进行姿态识别功能。通过项目学习源码和rknn api。二、开发环境说明 主机系统:Windows 11目标设备:搭载RK3588芯片的安卓开发板核心工具:Android Studio Koala | 2024.1.1 Patch 2,NDK 27.0三、适配(迁移)安卓 …...

【HTTP/3:互联网通信的量子飞跃】
HTTP/3:互联网通信的量子飞跃 如果说HTTP/1.1是乡村公路,HTTP/2是现代高速公路系统,那么HTTP/3就像是一种革命性的"传送门"技术,它彻底重写了数据传输的底层规则,让信息几乎可以瞬间抵达目的地,…...

2024 年:Kubernetes 包管理的新前沿
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:历代文学,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编程,高并发设计…...

SIEMENS PLC 程序 GRAPH 程序解读 车型入库
1、程序载图1 2、程序截图2 3、程序解释 这是一个基于西门子 GRAPH 编程的车型 1 入库顺序控制流程图,通过状态机结构(状态框 S 与转移条件 T)描述完整工作流程,具体如下: 整体流程概述 初始化:从 S1&am…...

c++11新特性随笔
1.统一初始化特性 c98中不支持花括号进行初始化,编译时会报错,在11当中初始化可以通过{}括号进行统一初始化。 c98编译报错 c11: #include <iostream> #include <set> #include <string> #include <vector>int main() {std:…...

微信小程序文章管理系统开发实现
概述 在内容为王的互联网时代,高效的文章管理系统成为各类平台的刚需。幽络源平台今日分享一款基于SSM框架开发的微信小程序文章管理系统完整解决方案,该系统实现了多角色内容管理、智能分类、互动交流等功能。 主要内容 一、用户端功能模块 多角…...

3种FSC标签你用对了吗?
如果你留意过产品上的FSC小树标识,也许会发现它们很相似但又各不相同。 根据产品使用的FSC认证材料的不同比例,共有三种不同类型的FSC标签: 1、FSC 100% 所有使用的材料均来自负责任管理的FSC认证森林。 标签文本为:“ From well-…...
——深度学习归一化详解)
NLP高频面试题(五十四)——深度学习归一化详解
引言:大模型训练中的归一化需求 随着人工智能技术的快速发展,**大模型(Large Language Models, LLMs)**的规模与能力都呈爆发式增长。诸如GPT-4、BERT、PaLM等模型参数量从最初的百万级到如今的千亿、万亿级别,训练难度和效率问题日益显著。在超大模型的训练过程中,梯度…...

第5.5章:ModelScope-Agent:支持多种API无缝集成的开源框架
5.5.1 ModelScope-Agent概述 ModelScope-Agent,由阿里巴巴旗下ModelScope社区开发,是一个开源的、模块化的框架,旨在帮助开发者基于大型语言模型快速构建功能强大、灵活性高的智能代理。它的核心优势在于支持与多种API和外部系统的无缝集成&…...

筑牢数字防线:商城系统安全的多维守护策略
一、构建网络安全防护屏障 网络安全是商城系统安全的第一道防线。企业应采用先进的防火墙技术,实时监控和过滤进出网络的流量,阻止非法访问和恶意攻击。入侵检测与防御系统(IDS/IPS)也是不可或缺的安全组件,它能够及…...
)
PTC加热片详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 三、程序设计 main文件 jdq.h文件 jdq.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 PTC是正温度系数热敏电阻的英文简称,其电阻值随着PTC热敏电阻本体温度的升高呈现阶跃性的增加。温度越高&…...
图像结构分析和形状描述符------在图像中查找轮廓函数findContours())
OpenCV 图形API(64)图像结构分析和形状描述符------在图像中查找轮廓函数findContours()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在二值图像中查找轮廓。 该函数使用[253]中的算法从二值图像检索轮廓。轮廓是形状分析以及对象检测和识别的有用工具。请参阅 OpenCV 示例目录中…...
基于osg和osgearth实现三维地图上添加路网数据(矢量shp))
GIS开发笔记(15)基于osg和osgearth实现三维地图上添加路网数据(矢量shp)
一、实现效果 二、实现原理 准备路网图层数据(.shp、.prj、.dbf、.cpg),设置样式、贴地,添加图层到地球节点。 三、参考代码 {// 获取当前可执行程序所在的目录QString exeDir = QCoreApplication::applicationDirPath();// 构造 Shapefile 文件的完整路径...

Golang日志模块之xlog
基于douyu的xlog 依赖 github.com/douyu/jupiter/pkg/xlog go.uber.org/zap gopkg.in/natefinch/lumberjack.v2log相关结构体 types/log.go type Log struct {Env string toml:"env"InfoLogFileName string toml:"infoLogFileName"Error…...

guvcview-源码记录
guvcview源码记录 一、概述二、项目结构1. guvcview2. gview_audio3. gview_encoder4. gview_render1. render.c2. render_sdl2.c3. render_osd_crosshair.c4. render_osd_vu_meter.c5. render_fx.c 3. gview_v4l2core 三、四、五、六、 一、概述 项目地址:guvcvie…...

对比2款国产远控软件,贝锐向日葵更优
贝锐向日葵和ToDesk是两款国产的远程控制软件,其中贝锐向日葵比较老牌,2009年就推出了最早的版本,而ToDesk则是在前几年疫情期间出现的。如果要在这两款远控软件中进行一个对比和选择,我们可以从功能配置、性能表现、系统支持、使…...

SOC估算:开路电压修正的安时积分法
SOC估算:开路电压修正的安时积分法 基本概念 开路电压修正的安时积分法是一种结合了两种SOC估算方法的混合技术: 安时积分法(库仑计数法) - 通过电流积分计算SOC变化 开路电压法 - 通过电池电压与SOC的关系曲线进行校准 方法原…...

maxscript根据音频创建动画表情
方案1: Python pydub / Audacity phoneme recognition 来提取语音中的音素(phonemes)并输出为 JSON 供 3ds Max 使用 方案2: Papagayo输出.pgo 文件,通过 Python 脚本解析,然后转换成 JSON。 下面介绍下方案2&#…...

使用ast解ob混淆时关于types的总结
在AST解OB混淆过程中,babel/types模块(简称types)是核心操作工具,以下是典型应用场景及具体代码示例: 一、字符串解密场景 场景:OB混淆常将字符串存储为十六进制或Unicode编码,需还原为明文 ty…...
:sort)
每天学一个 Linux 命令(32):sort
可访问网站查看,视觉品味拉满: http://www.616vip.cn/32/index.html sort 是 Linux 中用于对文本文件的行进行排序的命令,支持按字典序、数字、月份等多种方式排序。以下是详细说明和示例: 命令语法 sort [选项]... [文件]...常用选项 -n 或 --numeric-sort 按数值大小…...

解释两个 Django 命令 makemigrations和migrate
python manage.py makemigrations 想象一下,你正在设计一个房子。在开始建造之前,你需要一个详细的蓝图来指导建筑过程。在 Django 中,当你定义或修改模型(比如 Employee),你实际上是在设计数据库的“房子…...

tkinter的窗口构建、原生组件放置和监测事件
诸神缄默不语-个人技术博文与视频目录 本文关注用Python3的tkinter包构建GUI窗口,并用tkinter原生组件来进行排版(通过pack() / grid() / place(),并监测基础的事件(如按钮被点击后获取文本框输入信息、单/多选框选择结果等&…...

Hot100方法及易错点总结2
本文旨在记录做hot100时遇到的问题及易错点 五、234.回文链表141.环形链表 六、142. 环形链表II21.合并两个有序链表2.两数相加19.删除链表的倒数第n个节点 七、24.两两交换链表中的节点25.K个一组翻转链表(坑点很多,必须多做几遍)138.随机链表的复制148.排序链表 N…...

WebUI可视化:第6章:项目实战:智能问答系统开发
第6章:项目实战:智能问答系统开发 学习目标 ✅ 完整实现前后端分离的问答系统 ✅ 掌握本地AI模型的集成方法 ✅ 实现对话历史管理功能 ✅ 完成系统部署与性能优化 6.1 项目整体设计 6.1.1 系统架构 graph TDA[用户界面] -->|输入问题| B(Web服务器)B -->|调用模型| …...

项目质量管理
项目质量管理核心要点与高频考点解析 一、项目质量管理核心框架 三大核心过程: 规划质量管理:制定质量标准和计划(预防为主)。实施质量保证:审计过程,确保符合标准(过程改进)。控…...

利用TTP协议 ETag + 路由守卫 实现前端发版后通知用户更新得一个方案
利用 ETag 做提示更新的实现方案 ETag(Entity Tag)是万维网协议HTTP的一部分,是HTTP协议提供的若干机制中的一种Web缓存验证机制,是一个可以与Web资源关联的记号(token),并且允许客户端进行缓存…...

uniapp-商城-36-shop 购物车 选好了 进行订单确认2 支付方式颜色变化和颜色滤镜filter
颜色滤镜,在好多网页都这样使用,滤掉彩色,显示黑白,这在一些关键的日子中都这样使用。 1、依然回到订单确认页面 看到支付的颜色了嘛? <view class"payType"><view class"box" :class&q…...

CSRF请求伪造
该漏洞主要是关乎于用户,告诫用户不可乱点击链接,提升自我防范,才能不落入Hacker布置的陷阱! 1. cookie与session 简单理解一下两者作用 1.1. 🍪 Cookie:就像超市的会员卡 存储位置:你钱包里…...

爬虫瑞数6案例:深圳大学总医院,webEnv补环境
爬虫瑞数6案例:深圳大学总医院,webEnv补环境 一、准备工作二、webEnv补环境三、验证cookie四、验证请求结果五、总结声明: 该文章为学习使用,严禁用于商业用途和非法用途,违者后果自负,由此产生的一切后果均与作者无关 前言: 之前出了一篇深圳大学总医院爬虫教程,那时候…...

运维 vm windows虚拟机nat网络配置
参考 VMWare虚拟机网络配置 - 秋夜雨巷 - 博客园 vm设置虚拟网络段 设置网络段 网关地址 设置DHCP 自动化分配网络段 主机:设置ip 控制面板\所有控制面板项\网络连接 出现设置的虚拟机网卡 设置ip 虚拟机:设置ip...

PPO 强化学习机械臂 IK 训练过程可视化利器 Tensorboard
视频讲解: PPO 强化学习机械臂 IK 训练过程可视化利器 Tensorboard PPO 强化学习过程中,设置了verbose会显示数据,但还是不够直观,这里上一个可视化利器,Tensorboard,实际上stable baselines3中已经有了这部…...

巧记英语四级单词 Unit5-中【晓艳老师版】
ignore v.无视,不理睬 发音“一个闹”,对付一个无理取闹的孩子,最好的方式就是无视 不理睬ignorant a.无知的,不礼貌的 对于什么事都无视,中国第一个不平等条约问也不知道就是无知的neglect n.忽视 negative消极的&a…...