人工智能与机器学习:二元分类决策树构建指南
引言
在人工智能与机器学习的领域里,算法犹如智慧的钥匙,开启着数据洞察的大门。决策树作为其中一颗璀璨的明珠,以其独特的非线性处理能力和可解释性备受瞩目。今天,让我们跟随作者的脚步,深入探究如何构建一个用于二元分类的决策树对象,解锁其中的奥秘。
什么是决策树?
一棵树是由什么组成的呢?从最底部开始,我们有树根。然后是树干,上面连接着几根大树枝。每根大树枝又有越来越小的树枝相互连接,最终形成小枝。小枝上长着树叶。我相信大家都已经知道这些知识了。然而,决策树的构建方式与之类似(这就是为什么叫“决策树”啦)。
决策树是一个相互连接的阈值或决策边界框架,人们可以通过它得出两个或更多的结果。请注意,本文将重点关注两个结果。决策树也可用于回归或预测连续变量,但我们会在另一篇文章中讨论。用文字定义很难完全展现决策树的魅力,可视化它会有趣得多!让我们来看一个经典机器学习问题——电子邮件欺诈检测的假设决策树示例。
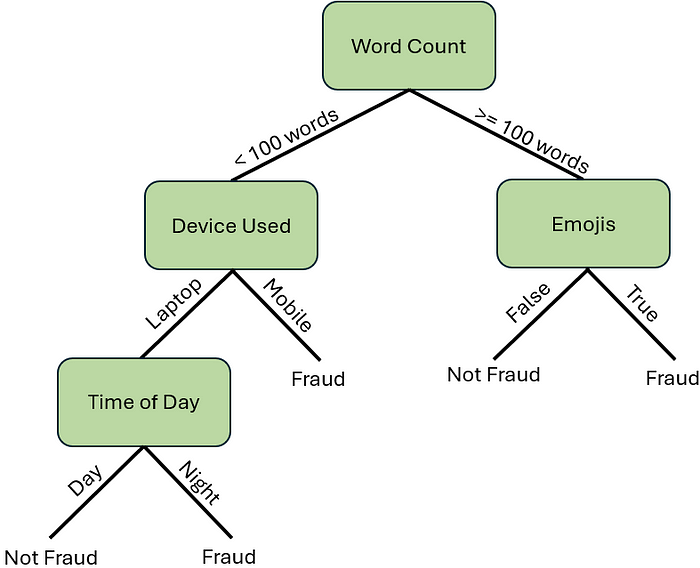
作者提供的图片
决策树有四个关键要素:根节点、决策节点、分支和叶子节点。每个决策树都只有一个根节点。在我们的示例中,根节点代表单词数量。接下来,你会注意到从根节点引出两条线,这些被称为分支。这些特定的分支代表两个阈值:少于 100 个单词 和 100 个单词或更多。这两个分支通向决策节点,分别代表 设备使用情况 和 表情符号。从这里开始就变得有趣了。设备使用情况 决策节点又分支到另一个 时间 决策节点,然而,另一个分支通向一个标记为 欺诈 的叶子节点。另一方面,表情符号 决策节点分支成两个叶子节点,一个标记为 “非欺诈”,另一个标记为 “欺诈”。
这相对来说很简单。决策树从一个根节点开始,使用阈值分支到后续节点,这些节点也使用阈值进行分支,最终通向一个预测结果或标签的叶子节点。
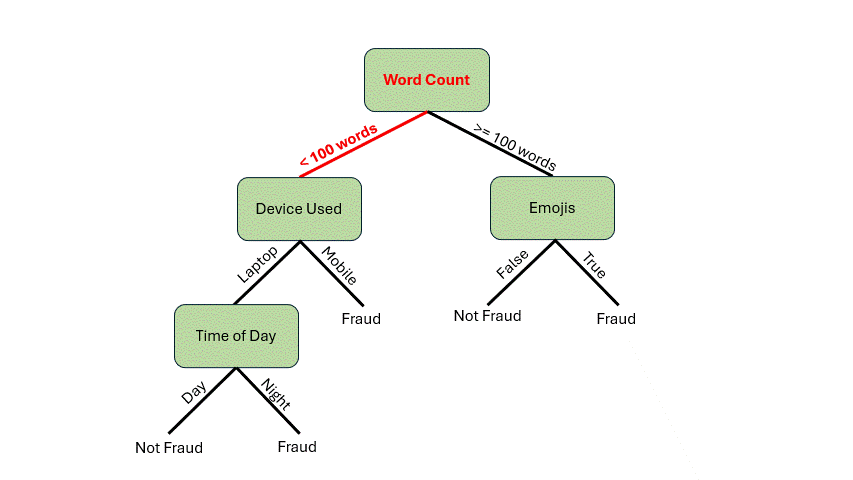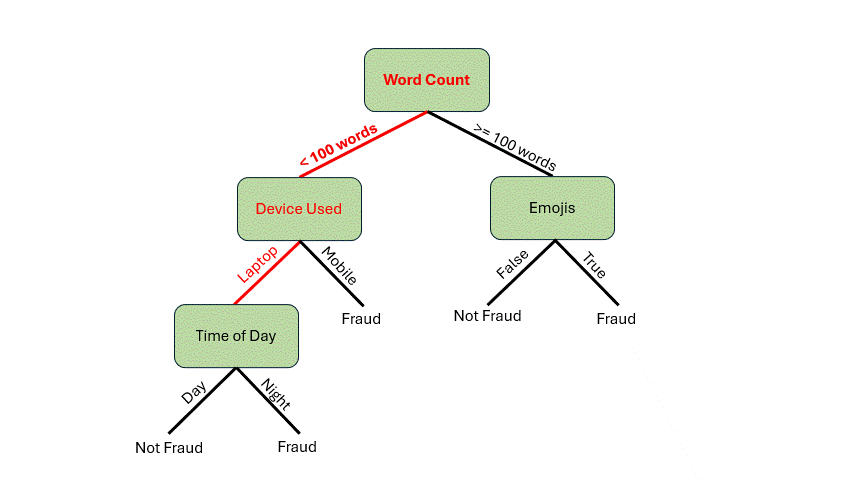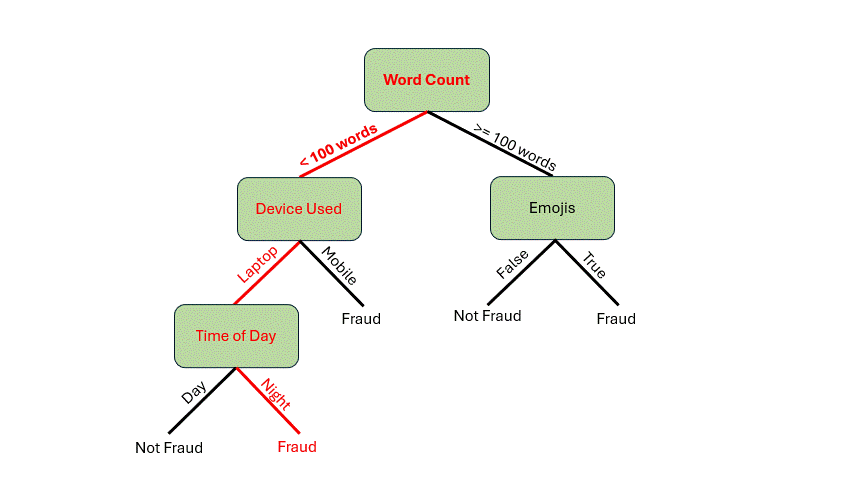
在深入探讨构建决策树的机制之前,让我们先看看它是如何工作的。假设你收到一封电子邮件,想用这个假设模型来判断这封邮件是否是欺诈邮件。以下是这封邮件的特征:
- 85 个单词
- 从笔记本电脑发送的邮件
- 夜间发送的邮件
首先,我们需要检查单词数量。它少于 100 个单词*,所以我们可以从根节点沿着分支到 设备使用情况* 决策节点。由于邮件是从笔记本电脑发送的,我们将遍历到 时间 决策节点。邮件是在夜间发送的,现在我们到达了叶子节点。我们的模型表明这封邮件很可能是欺诈邮件!
作者提供的动图
构建决策树 —— 基尼不纯度
为什么 单词数量 是根节点呢?为什么 设备使用情况 和 表情符号 是接下来的决策节点呢?我们怎么知道什么时候应该提供叶子节点而不是另一个决策节点呢?我们将在这里回答这些问题。
关键在于找到预测目标类别时歧义最小的特征。例如,假设我们有一个包含红色和蓝色两个类别的特征,以及一个目标变量 1 或 0。如果每个 红色 类别都是 1,每个 蓝色 类别都是 0,那么这个特定的特征将是根节点的完美候选,因为我们可以为目标类别获得最大的预测能力。
我提供的例子在现实世界中很少发生,所以我们必须使用一种特定的技术来构建我们的树。我们可以使用几种不同的方法来构建分类决策树,但在本文中,我们将重点关注基尼不纯度指标。看看下面的公式。
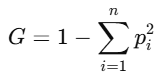
作者提供的图片
使用这个指标,我们可以轻松确定哪些特征在预测目标类别时歧义最小。让我们来看另一个假设的例子,并计算每个特征的基尼不纯度。
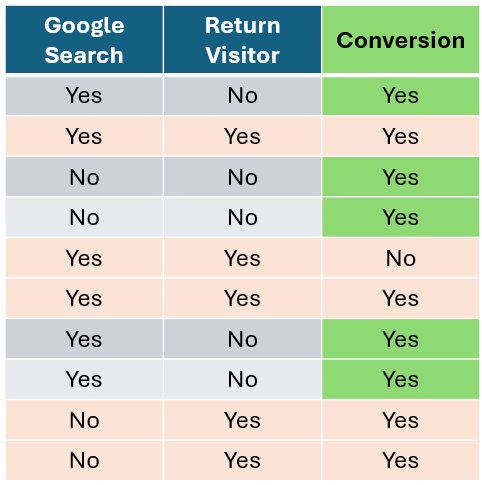
假设你有一个电子商务数据集,想用它来预测某人是否会购买你的产品。
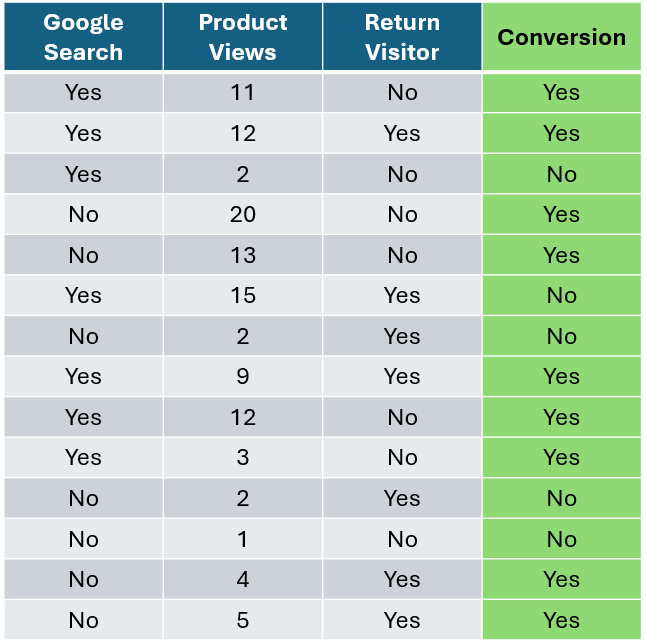
作者提供的图片
让我们从客户是否通过谷歌搜索访问网站这个特征开始,计算每个特征的基尼不纯度。首先,我们隔离通过谷歌搜索访问的客户,统计购买和未购买的客户数量。对于未通过谷歌搜索访问的客户,我们也做同样的操作。
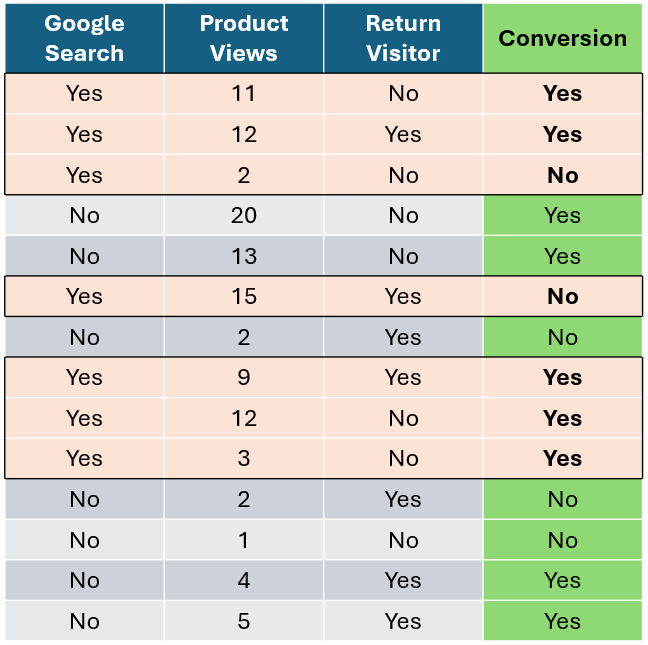
作者提供的图片
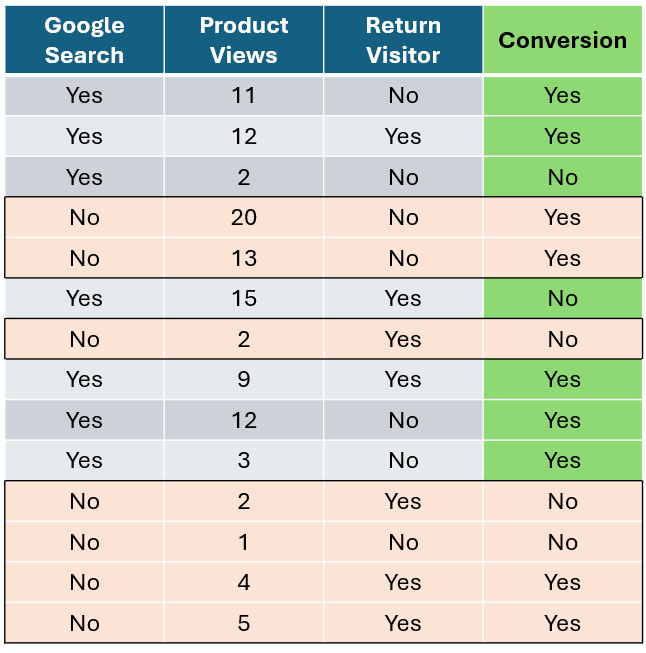
作者提供的图片
现在,来看你见过的最漂亮的数据透视表(开玩笑的啦!)

作者提供的图片
太棒了!现在,我们可以在模型的上下文中计算谷歌搜索的基尼不纯度。让我们代入一些数字,计算通过谷歌搜索和未通过谷歌搜索的基尼不纯度。
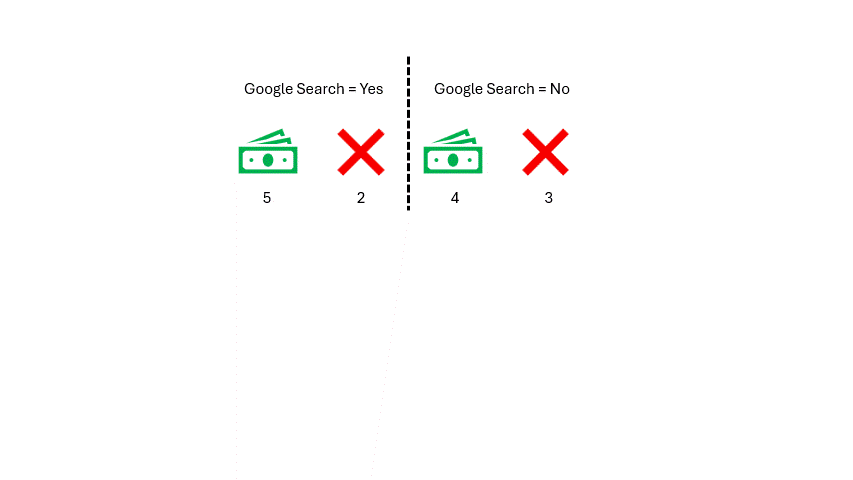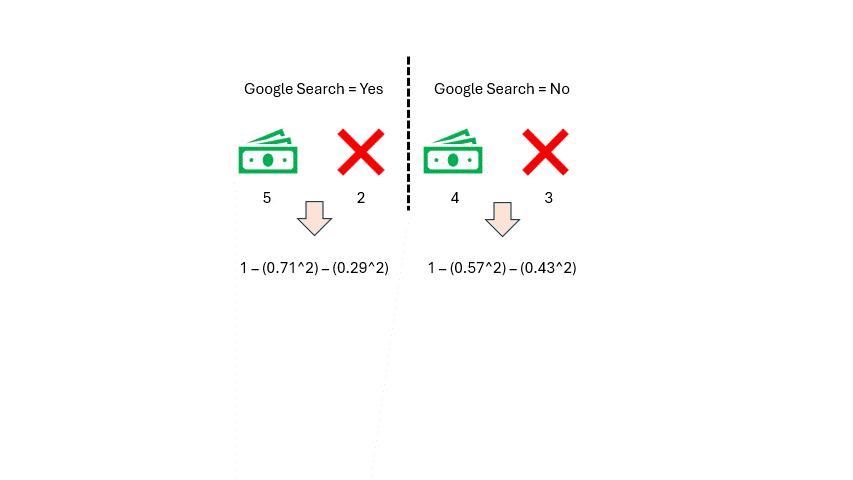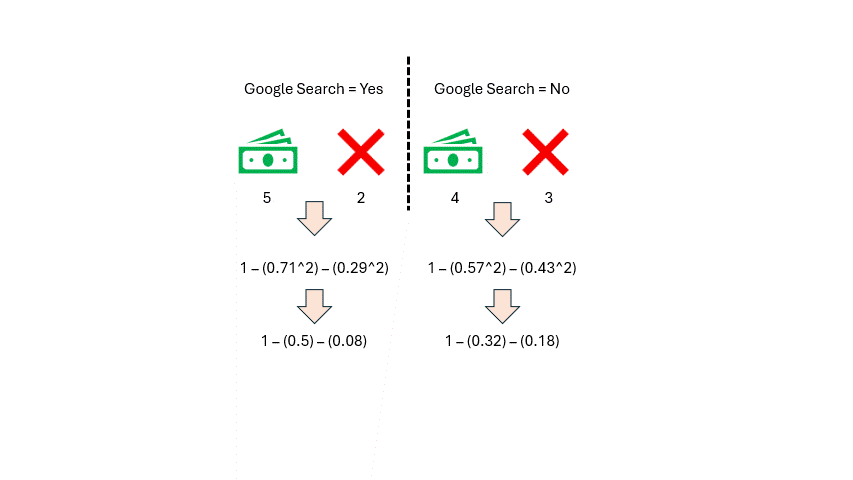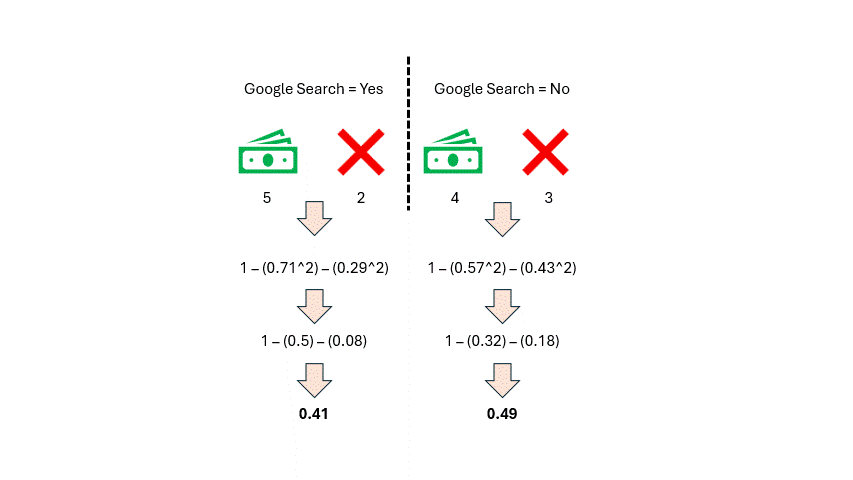
作者提供的图片
如你所见,我们得到了两个基尼不纯度分数,但这个特征我们只需要一个分数。因此,我们将对这两个分数取加权平均值。我们统计特征中每个类别的观测数量(谷歌搜索 = 是 和 谷歌搜索 = 否)。每个类别有七个观测值,所以它们的权重都是 0.5。然后我们按如下方式计算加权平均基尼不纯度:
0.5 * (0.41) + 0.5 * (0.49) = 0.45
现在,计算像我们刚才那样的分类变量的基尼不纯度似乎很简单。但是像 产品浏览量 这样的连续变量呢?这个过程更复杂,但我仍然觉得它很实用。首先,我们将按 产品浏览量 对观测值进行排序,根据每个值设置阈值,然后计算这些阈值的基尼不纯度。让我们直观地分解一下。
首先,让我们按 产品浏览量 对数据进行排序。
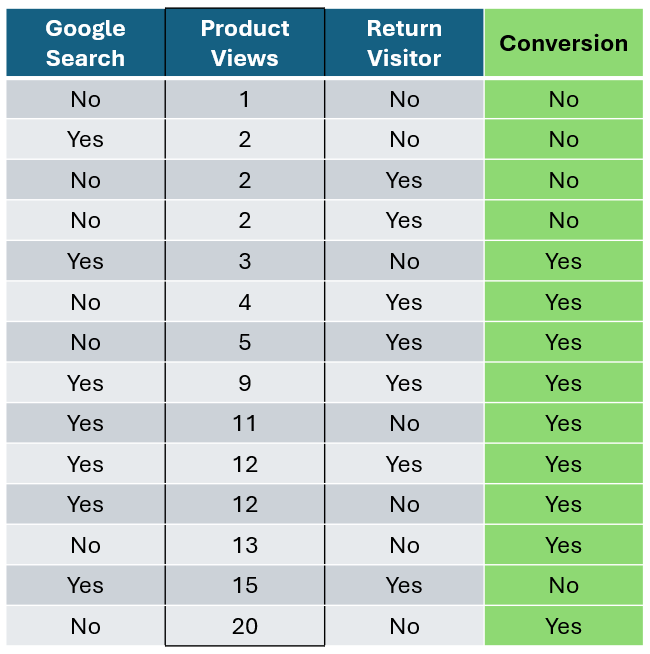
作者提供的图片
接下来,让我们计算后续值之间的阈值。注意,有些值是重复的,所以我们可以跳过,直到遇到一个新的唯一值。
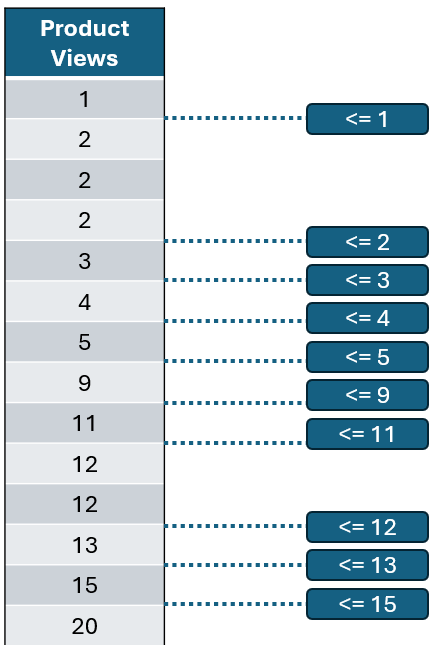
作者提供的图片
接下来是什么呢?基尼不纯度。如你所见,产品浏览量为两个的阈值产生的不纯度分数最低。这就是我们对 产品浏览量 进行分割的地方。
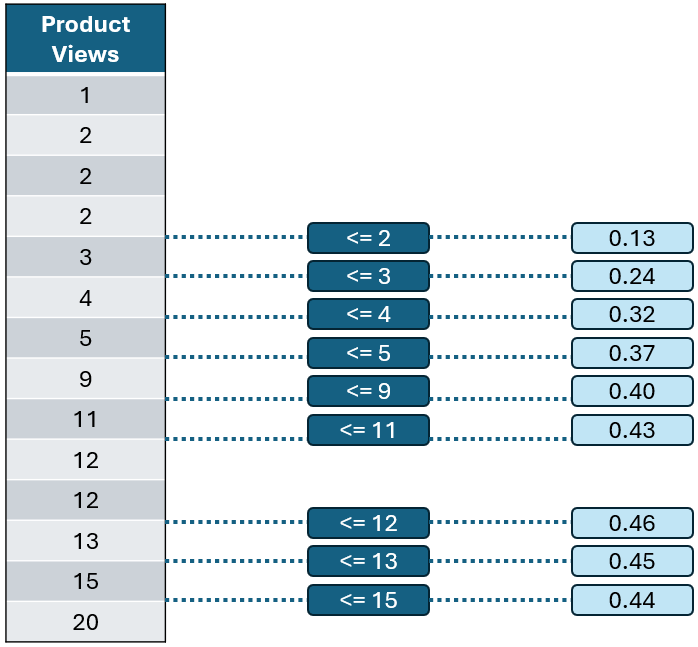
作者提供的图片
最后,让我们计算 回头客 指标的加权基尼不纯度分数,为 0.45。
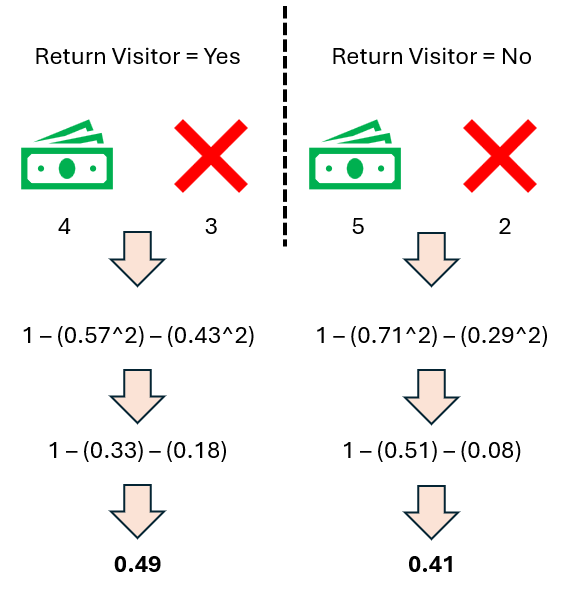
构建树 —— 从根到叶
我们已经拥有了开始构建树所需的一切!让我们从根节点开始。我们怎么知道该指定哪个特征作为根节点呢?这就是基尼不纯度分数发挥作用的地方。这很关键。基尼不纯度分数最低的特征将为我们的目标变量提供最强的预测能力。因此,我们希望决策树从那里开始遍历。在这种情况下,产品浏览量 特征的基尼不纯度分数最低,它将成为我们的根节点。
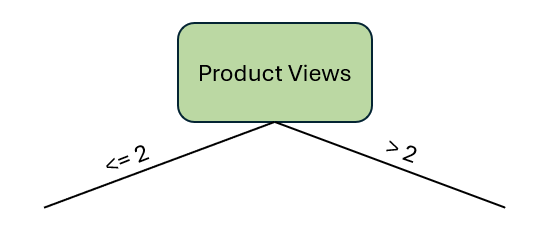
作者提供的图片
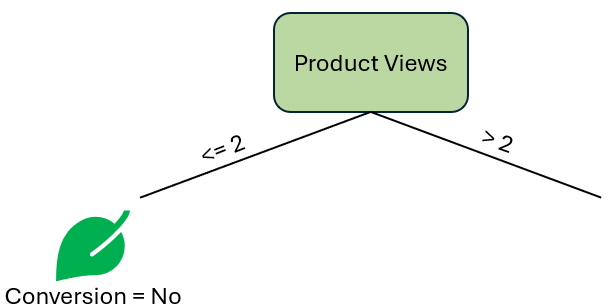
接下来,我们可能需要创建左右决策节点。为什么我说 可能 呢?让我们看看只满足左分支阈值(产品浏览量 ≤ 2)的观测数据。有什么发现吗?我们所有的观测结果都显示转化为 否。因此,继续探索这个节点的进一步分割在逻辑上没有意义。现在,我们有了第一个叶子节点。
作者提供的图片
作者提供的图片
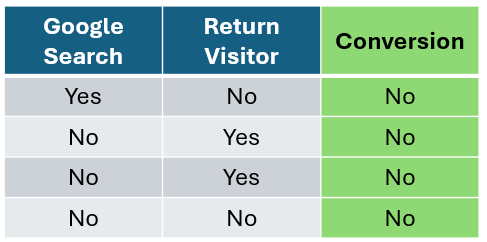
让我们关注右边的决策节点。我们将计算 谷歌搜索 和 回头客 的基尼不纯度分数,分别为 0.17 和 0.16,非常接近。因此,我们的第一个决策节点将是 回头客 特征。
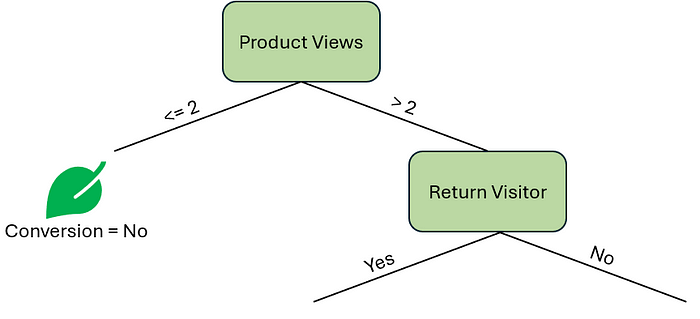
作者提供的图片
让我们在这里暂停一下,考虑一下我们的选择。我们可以通过计算剩余特征 谷歌搜索 的基尼不纯度分数来重复这个过程。另一方面,我们可以通过在分支末端指定叶子节点来结束我们的树。让我们看看剩下的数据。
80% 的回头客最终转化了,而另一方面,100% 的非回头客最终也转化了。再增加一个决策节点会带来更多价值吗?或者,我们应该在这里用一个预测 转化 为 是 的叶子节点来结束我们的树吗?两个叶子节点都会得出 是 的结果,这可能看起来很不寻常,但在构建决策树时这是可能出现的现象。这也让我们思考是否需要 回头客 这个决策节点。
作者提供的图片
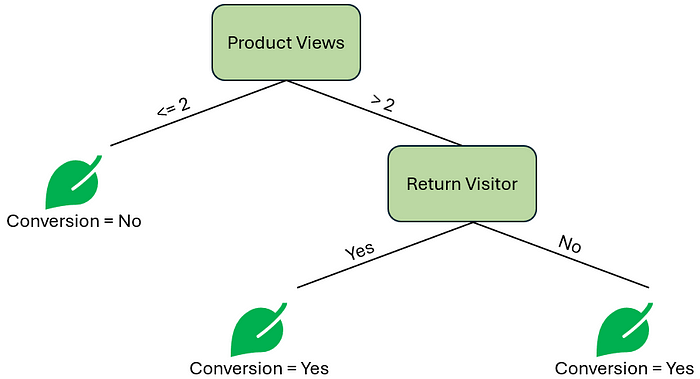
作者提供的图片
在这个阶段,你可能想知道什么时候停止添加决策节点的方法或最佳实践,我们如何确定目标的哪个类别作为叶子节点,以及是否应该有更多的标准来将一个特征作为决策节点。这些和其他超参数可以在模型中进行微调。话说回来,是时候跳进 Python 并构建我们的自定义决策树模块了!请记住,这将涉及几个高级概念。
DIYClassificationDecisionTree 类
让我们从导入库并构建初始化函数开始。这个类有很多属性,让我们深入了解一下。
超参数
我们将在这个对象中使用四个超参数,但也可以包含更多。超参数在任何基于树的模型中都很关键,因为找到这些指标的组合可以帮助我们在避免过拟合数据的同时最大化预测能力。这些是我个人比较喜欢的超参数。我们还将在另一个属性中存储最优超参数集。
max_depth: 我们的树的最大深度,即我们允许在树中创建节点的深度。
min_samples_split: 拆分节点之前所需的最小样本数。这确保了我们为每个可能的预测规则组合保留足够大的样本量。
min_samples_leaf: 类似于 min_samples_split,但这适用于叶子节点。
max_features: 构建树时要考虑的最大特征数量。
其他属性
如果你一直在关注这个系列,你会注意到我喜欢包含一个将数据拆分为训练集和测试集的方法。我也在这里包含了相关的属性。root 属性将存储我们的树。我还为我们的模型包含了各种评估指标,最后,一个空字典用于在微调模型时存储我们的最佳超参数集。
import pandas as pd
import numpy as np
from tqdm import tqdm
import randomclass DIYClassificationDecisionTree:def __init__(self, max_depth=None,min_samples_split=2,min_samples_leaf=0.1,max_features=1.0):## 超参数self.max_depth = max_depthself.min_samples_split = min_samples_splitself.min_samples_leaf = min_samples_leafself.max_features = max_features## 用于存储最终决策树的占位符self.root = None## 训练和测试数据self.X_train = Noneself.y_train = Noneself.X_test = Noneself.y_test = None## 特征名称self.feature_names = None## 评估指标self.confusion_matrix = Noneself.accuracy = Noneself.precision = Noneself.recall = None## 调优后的最佳超参数self.best_hyperparameters = {}
train_test_split 方法
这是我们将数据拆分为训练集和测试集的方法。你会注意到,我也会在这里保存特征名称,以便稍后可视化树时使用。
def train_test_split(self, X, y, test_size=0.2, random_state=None, feature_names=None):if random_state is not None:np.random.seed(random_state)## 打乱索引indices = np.arange(X.shape[0])np.random.shuffle(indices)## 根据测试集大小进行拆分test_count = int(len(X) * test_size)test_indices = indices[:test_count]train_indices = indices[test_count:]## 执行拆分self.X_train = X[train_indices]self.y_train = y[train_indices]self.X_test = X[test_indices]self.y_test = y[test_indices]# 保存特征名称if feature_names is not None:self.feature_names = feature_nameselse:
...
决策树作为机器学习中的强大工具,不仅能处理复杂的非线性数据,还能通过基尼不纯度等方法高效构建模型。本文从理论到实践,详细阐述了决策树的原理、构建方法以及Python实现。希望读者能借此掌握决策树的核心知识,在AI与ML的道路上更进一步,探索更多可能。
相关文章:

人工智能与机器学习:二元分类决策树构建指南
引言 在人工智能与机器学习的领域里,算法犹如智慧的钥匙,开启着数据洞察的大门。决策树作为其中一颗璀璨的明珠,以其独特的非线性处理能力和可解释性备受瞩目。今天,让我们跟随作者的脚步,深入探究如何构建一个用于二…...

Ubuntu下软件运行常见异常退出问题汇总分析
软件在Ubuntu下运行时,可能会遇到各种异常退出情况,常见可分为以下几点: 目录 一、系统资源耗尽导致退出 二、权限导致无法运行 三、找不到依赖的动态库 四、编译可执行文件时,动态库所引用的头文件与动态库不匹配 一、系统资…...

机器学习漏洞大汇总——利用机器学习服务
在本节中,我们将展示机器学习框架中存在的漏洞,这些漏洞会直接处理模型工件,或者通过工件存储或模型注册表的凭证来处理。利用此类漏洞,攻击者可以在企业系统内部进行非常强大的横向移动,从而劫持被利用的模型注册表中的机器学习模型。 WANDB Weave 目录遍历 - CVE-2024-…...

类的六个默认成员函数
如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。 默认成员函数:用户没有显式实现,编译器会生成的成员函数称为默认…...
:剖析创业增长引擎与精益画布指标)
精益数据分析(21/126):剖析创业增长引擎与精益画布指标
精益数据分析(21/126):剖析创业增长引擎与精益画布指标 大家好!在创业和数据分析的探索道路上,我一直希望能和大家携手共进,共同学习。今天,我们继续深入研读《精益数据分析》,剖析…...

SAIL-RK3588协作机器人运动控制器技术方案
一、核心能力与政策适配 政策合规性 满足工信部《智能机器人重点技术攻关指南》要求,支持 EtherCAT主站协议(符合IEC 61158标准),助力企业申报工业机器人研发专项补贴(最高300万元/项目)核心板…...
)
手搓箱图并输出异常值(MATLAB)
看下需求 想要复刻这种箱图,咱们直接开始手搓 %% 可修改 % 生成模拟数据(假设5个用户群体的发帖数) data {randn(100,1)*10 30, ... % 核心用户randn(200,1)*5 10, ... % 边缘用户randn(150,1)*8 20, ... % 积极社交用户randn(8…...

Java:XML被自动转义
在Java中处理XML响应被自动转义的问题时,需结合XML规范及工具特性进行针对性处理。以下是常见原因及解决方案的总结: 一、XML自动转义的原因 字符安全性处理 XML中的保留字符(如 <、>、&)会被自动转义为实体&a…...

Day-3 应急响应实战
应急响应实战一:Web入侵与数据泄露分析 1. Web入侵核心原理 漏洞利用路径 未授权访问:弱口令(如空密码/默认口令)、目录遍历漏洞代码注入攻击:JSP/ASP木马、PHP一句话木马(利用eval($_POST[cmd])&…...

【软件设计师】模拟题一
以下是 10道软考-软件设计师模拟试题,涵盖高频考点和易错点,附带答案和解析: 一、软件工程 1. 在软件开发生命周期中,瀑布模型的主要特点是( ) A. 强调快速原型迭代 B. 阶段间有明…...
:互质的数【省模拟赛】)
每日一练(4~24):互质的数【省模拟赛】
算法:暴力枚举 问题描述 如果两个整数 a, b 除了 1 以外,没有其它的公约数,则称整数 a 与 b 互质。 请问,与 2024 互质的数(包括 1)中,第 2024 小的是多少? 答案提交 这是一道结…...

金融软件测试有哪些注意事项?专业第三方软件测试服务机构分享
在现代金融行业中,软件系统的稳定性和安全性直接关系到资金的安全和业务的正常运转。金融软件因涉及庞大的资金流和敏感的个人及交易信息,对软件测试提出了更高的要求,那么金融软件在进行测试时有哪些注意事项呢?卓码软件测评作为专业的第三…...

关于QT信号、槽、槽函数的讲解
也是好久没有发帖子了,最近博主主要还是在边学QT边完成任务,所以进度很慢,但确实在这几天对于QT自身槽和信号这类特殊的机制有了一定简单的理解,所以还是想记录下来,如果有初学者看到帖子对他有一定的帮助,…...
)
算法训练营第三十天 | 动态规划 (三)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、01背包问题理论基础(一)动态规划五部曲确定dp数组以及下标的含义确定递推公式初始化dp数组确定遍历顺序 二、01背包问题理论基础&#…...

Vue开发网站会有“#”原因是前端路由使用了 Hash 模式
前言 网站链接中出现 #(井号)是因为你的前端路由使用了 Hash 模式(hash mode),这是一种前端框架(如 Vue.js、React 等)中常用的路由策略。 为什么有 # 比如 https://www.zimeinew.com/#/order…...

SpringBootTest报错
Unable to find a SpringBootConfiguration, you need to use ContextConfiguration or … 解决方案:在SpringTest注解中添加属性(classes )填写启动类 如我的启动类是MainApplication.class javax.websocket.server.ServerContainer no…...
理论概述)
【质量管理】现代TRIZ(萃智)理论概述
一、什么是TRIZ理论 TRIZ理论,即发明问题解决理论(Teoriya Resheniya Izobreatatelskikh Zadatch),是由前苏联发明家根里奇阿奇舒勒(Genrich S. Altshuller)于1946年创立的。它是一门基于知识的、面向人的发明问题解决系统化方法学。TRIZ理论通过研究大量的专利,总结出技…...
--回调地狱、promise异步编程、Proxy 与 Reflect 、模块化)
前端面经-JS篇(四)--回调地狱、promise异步编程、Proxy 与 Reflect 、模块化
一、回调地狱 回调地狱(Callback Hell),也称为回调地狱,是指在 JavaScript 中处理多个嵌套的异步回调函数时,代码结构变得非常难以阅读和维护的现象。 为什么会出现回调地狱? 回调地狱通常出现在需要执行…...

【oql】spark thriftserver内存溢出,使用oql查询导致oom的sql
eclipse memory analyzer (mat)软件内的OQL实现查询内促信息。 帮助信息:软件Help/Help Contents/Querying Heap Objects (OQL) 就是查询SparkExecuteStatementOperation 的statement 字段。 select objects s.statement from org.apache.spark.sql.hive.thriftser…...
)
算法设计与分析(基础)
问题列表 一、 算法的定义与特征,算法设计的基本步骤二、 算法分析的目的是什么?如何评价算法,如何度量算法的复杂性?三、 递归算法、分治法、贪婪法、动态规划法、回溯法的基本思想方法。四、 同一个问题,如TSP&#…...

爬虫学习——使用HTTP服务代理、redis使用、通过Scrapy实现分布式爬取
一、使用HTTP服务代理 由于网络环境、网站对用户的访问速度的限制等原因,使得爬取过程会出现IP被封禁,故使用代理可提高爬取速度。在Scrapy中提供了一个HttpProxyMiddleware专门用于进行爬虫代理设置。在使用该代理进行爬取操作时,需要先在ba…...

机器学习中的特征存储是什么?我需要一个吗?
本质上,特征存储是一个专用存储库,用于系统地存储和排列特征,主要用于数据科学家训练模型,并帮助已训练模型的应用程序进行预测。它是一个关键的聚合点,人们可以在此构建或修改从各种数据源提取的特征集合。此外,它还支持从这些特征组中创建和增强新的数据集,以满足处于…...

【C语言】C语言中的联合体与枚举类型
前言 在C语言中,联合体(union)和枚举(enum)是两种非常实用但又常被忽视的自定义数据类型。它们在内存管理、代码可读性以及程序设计的灵活性方面都有着独特的优势。今天,我们就来深入探讨一下联合体和枚举…...

Golang编程拒绝类型不安全
button-chen/containertypesafe-go: 使用泛型包装标准库的容器 list、ring、heap、sync.Pool 和 sync.Map,实现类型安全 简介 在 Go 中,标准库提供了多种容器类型,如 list、ring、heap、sync.Pool 和 sync.Map。然而,这些容器默认…...

炼锌废渣提取钴工艺流程
炼锌废渣中提取钴的工艺流程通常结合湿法冶金技术,针对废渣中钴与锌、铁、铜等金属的复杂共生特性,通过预处理、浸出、除杂、钴富集及提纯等步骤实现钴的高效回收。以下是典型工艺流程的详细说明: 一、预处理 炼锌废渣(如锌浸出…...

Restful接口学习
一、为什么RESTful接口是数据开发的核心枢纽? 在数据驱动的时代,RESTful接口如同数据高速公路上的收费站,承担着数据交换的核心职责。数据工程师每天需要面对: 异构系统间的数据交互(Hadoop集群 ↔ 业务系统…...

仿真每日一练 | ABAQUS应力松弛
应力松弛是弹性材料在应力作用下产生微塑性变形,并且逐渐积累,在保持应变或者位移不变的前提下,表现为应力逐渐下降的现象。今天介绍一个ABAQUS中应力松弛的相关案例,模型如下所示: 图1 模型认识 回顾一下ABAQUS的有限…...

智能电网第4期 | 电力设备全连接组网方案:从有线到无线无缝融合
随着新型电力系统建设的加速推进,电力设备通信网络正面临前所未有的挑战与机遇。在变电站自动化、输电线路监测、配电房智能化等场景中,传统通信方案已难以满足日益增长的连接需求: 环境复杂性:变电站强电磁干扰环境下需保障微秒级…...

Python 面向对象练习
不多bb了,直接上代码吧。 from pprint import pprint class Course:total_course []def __init__(self,name,id):self.name nameself.id idself.is_select FalseCourse.total_course.append(self)def __repr__(self):return (f"{__class__.__name__}("f"学…...
)
无感字符编码原址转换术——系统内存(Mermaid文本图表版/DeepSeek)
安全便捷无依赖,不学就会无感觉。 笔记模板由python脚本于2025-04-24 20:00:05创建,本篇笔记适合正在研究字符串编码制式的coder翻阅。 学习的细节是欢悦的历程 博客的核心价值:在于输出思考与经验,而不仅仅是知识的简单复述。 P…...

机器学习--线性回归模型
阅读本文之前,可以读一读下面这篇文章:终于有人把线性回归讲明白了 0、引言 线性回归作为统计学与机器学习的入门算法,以其简洁优雅的数学表达和直观的可解释性,在数据分析领域占据重要地位。这个诞生于19世纪的经典算法…...

HTML应用指南:利用GET请求获取微博签到位置信息
在当今数字化时代,社交媒体平台已成为人们日常生活中不可或缺的一部分。作为中国最受欢迎的社交平台之一,微博不仅为用户提供了一个分享信息、表达观点的空间,还通过其丰富的功能如签到服务,让用户能够记录自己生活中的点点滴滴。…...

如何检测Python项目哪些依赖库没有使用
要检测Python项目中哪些依赖库未被使用,可以采用以下方法: 1. 使用静态分析工具 vulture:静态分析工具,检测未使用的代码和导入 pip install vulture vulture your_project/pyflakes:检查未使用的导入语句 pip ins…...

数据仓库建设全解析!
目录 一、数据仓库建设的重要性 1. 整合企业数据资源 2. 支持企业决策制定 3. 提升企业竞争力 二、数据仓库建设的前期准备 1. 明确业务需求 2. 评估数据源 3. 制定项目计划 三、数据仓库建设的具体流程 1.需求分析 2.架构设计 3.数据建模 4.ETL 开发 5.…...

magic-api连接达梦数据库
引入依赖 然后手写驱动 <dependency><groupId>com.dameng</groupId><artifactId>DmJdbcDriver18</artifactId><version>8.1.1.193</version></dependency> jdbc:dm://127.0.0.1:5236?schemaSALES...

向量检索新选择:FastGPT + OceanBase,快速构建RAG
随着人工智能的快速发展,RAG(Retrieval-Augmented Generation,检索增强生成)技术日益受到关注。向量数据库作为 RAG 系统的核心基础设施,堪称 RAG 的“记忆中枢”,其性能直接关系到大模型生成内容的精准度与…...

WHAT - 区分 Git PR 和 MR
文章目录 PR(Pull Request)MR(Merge Request)相同点总结 git pr 和 git mr 本质上都是「合并请求」的意思,但它们对应的是不同的平台术语。 PR(Pull Request) 平台:GitHub、Bitbuc…...

Axure复选框组件的深度定制:实现自定义大小、颜色与全选功能
在产品设计中,复选框作为用户与界面交互的重要元素,其灵活性直接影响到用户体验。本文将介绍如何利用Axure RP工具,通过高级技巧实现复选框组件的自定义大小、颜色调整,以及全选功能的集成,为产品原型设计增添更多可能…...

Datawhale AI春训营——用AI帮助老人点餐
详细内容见官网链接:用AI帮助老人点餐-活动详情 | Datawhale...

两段文本比对,高亮出差异部分
用法一:computed <div class"card" v-if"showFlag"><div class"info">*红色背景为已删除内容,绿色背景为新增内容</div><el-form-item label"与上季度比对:"><div class"comp…...

uniapp 仿小红书轮播图效果
通过对小红书的轮播图分析,可得出以下总结: 1.单张图片时容器根据图片像素定高 2.多图时轮播图容器高度以首图为锚点 3.比首图长则固高左右留白 4.比首图短则固宽上下留白 代码如下: <template><view> <!--轮播--><s…...

审计效率升级!快速匹配Excel报表项目对应的Word附注序号
财务审计报告一般包括:封面、报告正文、财务报表(Excel工作簿)以及对应的财务报表附注(Word文档)、事务所营业执照以及注册会计师证件。 在审计报告出具阶段,为各报表项目填充对应的Word附注序号ÿ…...

Python 中 `r` 前缀:字符串处理的“防转义利器”
# Python 中 r 前缀:字符串处理的“防转义利器” 在 Python 编程过程中,处理字符串时经常会遇到反斜杠 \ 带来的转义问题,而 r 前缀的出现有效解决了这一困扰。它不仅能处理反斜杠的转义,还在多种场景下发挥着重要作用。接下来&a…...

1️⃣6️⃣three.js_光源
16、光源 3D虚拟工厂在线体验 在 Three.js 中,环境光(AmbientLight)、点光源(PointLight)、平行光(DirectionalLight)、 聚光灯(SpotLight)、半球光(Hemisph…...

AD16如何执行DRC检测
AD16如何执行DRC检测 DRC检测主要用来查看走线是否出现通断,以及是否出现短路。 1)、点击“Tools”---“Design Rule Check…” 2)、全部勾选 3)、勾选“Electrical”中的“Batch”选项,参与DRC检测 4)、勾选“Routing”中的“Batch”选项,…...

PostgreSQL性能优化实用技巧
PostgreSQL的性能优化需从索引设计、查询调优、参数配置、硬件资源等多维度入手。以下为实战中验证有效的优化策略,适用于高并发、大数据量等场 一、索引优化:精准加速查询 1.选择正确的索引类型 BRIN索引:对按时间或数值顺…...

Vue3 ref与props
ref 属性 与 props 一、核心概念对比 特性ref (标签属性)props作用对象DOM 元素/组件实例组件间数据传递数据流向父组件访问子组件/DOM父组件 → 子组件响应性直接操作对象单向数据流(只读)使用场景获取 DOM/调用子组件方法组件参数传递Vue3 变化不再自…...

SpringBoot | 构建客户树及其关联关系的设计思路和实践Demo
关注:CodingTechWork 引言 在企业级应用中,客户关系管理(CRM)是核心功能之一。客户树是一种用于表示客户之间层级关系的结构,例如企业客户与子公司、经销商与下级经销商等。本文将详细介绍如何设计客户树及其关联关系…...

SpringCloud——负载均衡
一.负载均衡 1.问题提出 上一篇文章写了服务注册和服务发现的相关内容。这里再提出一个新问题,如果我给一个服务开了多个端口,这几个端口都可以访问服务。 例如,在上一篇文章的基础上,我又新开了9091和9092端口,现在…...

Springboot3+ JDK21 升级踩坑指南
目录 GetMapping和 RequestBody 一起使用时,会把请求方式由GET变为POST 变更默认的httpClient feign 超时配置失效 GetMapping和 RequestBody 一起使用时,会把请求方式由GET变为POST 变更默认的httpClient 添加依赖 <dependency><groupId&g…...