机器学习--线性回归模型
阅读本文之前,可以读一读下面这篇文章:终于有人把线性回归讲明白了
0、引言
线性回归作为统计学与机器学习的入门算法,以其简洁优雅的数学表达和直观的可解释性,在数据分析领域占据重要地位。这个诞生于19世纪的经典算法,至今仍在金融预测、市场营销、医学研究等场景中焕发着蓬勃生机。
我们先看一个例子。
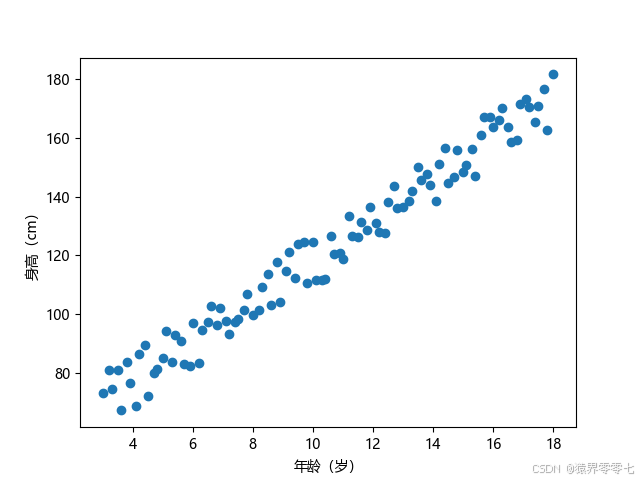
上图中展示了100名青少年男孩年龄与身高之间的关系,其中横坐标是年龄,纵坐标是身高,蓝色原点是青少年身高和年龄的坐标点。从图中可以直观的看出,年龄越大,身高越高,而且增长趋势接近一条直线,我们怎样去表示这种情况呢?中小学时,我们学过,可以用一元一次函数表示一条直线。我们假设有一条直线可以表示身高和年龄的关系。
用x表示年龄,y表示身高。现在x、y都是已知数据(图中点的坐标),那么怎样确定这条直线呢,我们可以尝试在图中画几条直线,看一看哪条更符合实际情况。
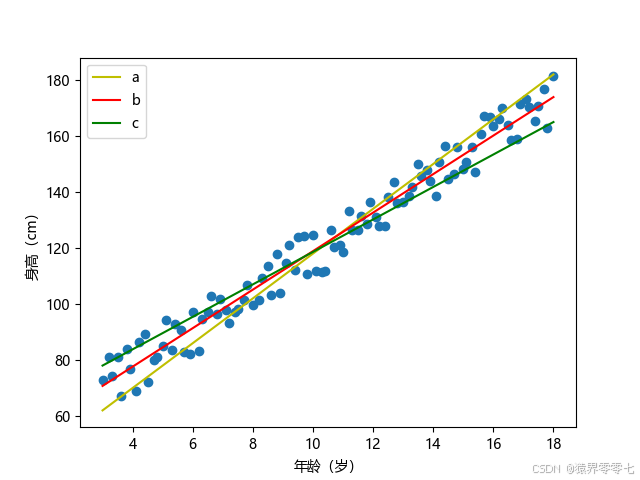
我们在图中画了三条直线a、b、c,这三条直线都经过了一些点,也避开了一些点,貌似这三条直线都可以说明身高与年龄的关系,究竟哪一个更好呢?我们怎样选择最好的呢?
无论我们怎么画都不能将所有的点画到同一条直线上。因为我们画的这些直线,并不能完美表示年龄和身高的关系,所有称之为预测函数。
图中坐标点中x坐标在直线上的值叫做预测值f(x),预测值f(x)与真实值y的差值,称为误差。
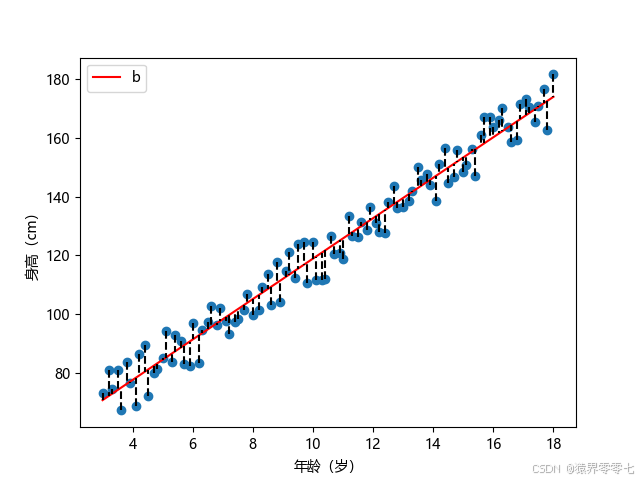
取其中一条直线,画出每个坐标点与预测函数的误差,可以直观的看出,有些点的误差小,有些点的误差大,我们是否可以用误差找到一条合适的直线呢?带着这些问题,让我们一起走进线性回归的世界。
1、定义
上面的例子中,提到影响青少年身高因素只有年龄,像这种寻找只有一个自变量(特征)x,与因变量(标签)y之间的线性关系的模型,叫做一元线性回归。
现实生活中,影响青少年的身高因素,不只是年龄,还有饮食、睡眠、遗传和运动等因素,像这种寻找多个自变量(特征)x,与因变量(标签)y之间的线性关系的模型,叫做多元线性回归。
多元线性回归几何图形很抽象,我们可以简化理解为,二维平面中的一条直线,三维立体空间中的一个平面。总之,它在空间内是直的、平的。
线性回归(Linear Regression)是一种用于建模和分析变量间线性关系的统计学方法,其核心目标是建立自变量(特征)与因变量(目标)之间的最佳线性拟合模型。通过最小化预测值与真实值的误差,量化变量间的关联程度,并用于预测或解释数据规律。
上面一段统计学中线性回归的定义,看着不像人话,看不懂也没关系。
使用数学公式可以表示为:
公式①
其中:
- Y是因变量(真实值);
是自变量(特征或解释变量);
是截距(模型的偏置),有些书籍和文章中使用的是
、
或b;
是自变量的系数(模型的斜率),有些书籍和文章中使用的是
、
;
是误差项,表示模型无法解释的随机误差;
一元线性回归的公式可以简化为:
2、前提条件
- 自变量和因变量在理论上有因果关系;
- 因变量为连续型变量;
- 各自变量与因变量之间存有线性关系;
- 残差
- 多个自变量不存在多重共线性。
其中,线性(Linear)、正态性(Normal)、独立性(Independence)、方差齐性(Equal Variance),俗称LINE,是线性回归分析的四大基本前提条件。
这里稍微解释它们概念:
Q1 线性:解释自变量X和因变量Y必须要有线性关系吗?
---不是!只有当X是连续型数据或者等级数据(不设哑变量)时,才要求X与Y有线性的关系。当X是二分类或无序多分类,没有线性条件的要求。
Q2独立性:要求因变量Y各观察值相互独立吗?
---不是,是要求残差是独立的。
Q3正态性:要求因变量Y各观察值正态分布吗?
---不是,是要求残差正态分布。
Q4方差齐性:要求不同的解释变量X时,因变量Y方差相等吗?
---没错,但是对于多元线性回归分析,更加合理的理解是在不同Y预测值情况下,残差的方差变化不大。
Q5:一定要严格满足LINK吗?
---如果回归分析只是建立自变量与因变量之间关系,无须根据自变量预测因变量的容许区间和可信度等,则方差齐性和正态性可以适当放宽。
3、预测函数
线性回归模型的基本原理是寻找一条直线(或者在多维情况下是一个超平面),以最佳地拟合训练数据,使得模型的预测与真实观测值之间的误差最小化。寻找过程中使用的函数称为预测函数,可以写作、
、
、
等形式,此处我们使用
公式②
初次接触线性回归模型的小伙伴,可能理解上面两个公式比较困难。仔细观察公式② ,其实就和我们小学时就无比熟悉的一元一次方程式: 是同样的性质。只不过,在实际场景中,特征只有一个的情况几乎不存在,通常样例数据中会包含多个特征(
),因此我们常说线性回归模型,也就是多元线性回归模型。
在训练模型过程中,通常使用拥有m个样本,n个特征X的训练集。为了保持样式统一,让截距乘以一个人为构造的特征值都是1的特征
。训练集特征X是一个(m,n+1)的矩阵,特征参数w是一个(n,1)的列向量。
公式②可以写成矩阵的形式
简写为:
公式③
在线性代数中,字母的大小写通常用于区分不同类型的数学对象(如标量、向量、矩阵等),这种区分有助于快速识别变量类型。以下是常见的规则和惯例:
1. 标量(Scalar)
- 表示方法:小写斜体字母(如 a,b,c)。
- 特点:标量是单个数值,无方向性。
示例:a=5, x∈R
2. 向量(Vector)
- 表示方法:
- 小写粗体字母(如 v,w)。
- 手写时可用箭头(如
)。
- 特点:向量是一维数组,有方向和大小。
示例:,
=(3,4)
3. 矩阵(Matrix)
- 表示方法:大写粗体字母(如 A,B)。
- 特点:矩阵是二维数组,表示线性变换或方程组系数。
示例:,
4、模型的目标
线性回归模型的目标是通过优化算法找到一组模型参数(权重),使得模型的预测值尽可能接近真实值,其核心是最小化预测值与真实值之间的误差。常用的最小二乘法和梯度下降法求解
5、最小二乘法
最小二乘法的目标是最小化误差平方和(Sum of Sqaured Error简称:SSE,又叫残差平方和 Residual Sum of Squares简称:RSS),指的是所有训练样本的真实值减与预测值差值的平方的总和,公式如下:
通过转换我们得到了关于自变量w的一元二次的损失函数,一阶导数为0的点是它的极值点。
下面求导过程中涉及线性代数矩阵求导的知识,如果看不懂,可以忽略求导过程,直接看求导结果就可以了,因为python库中已经封装好了对应的方法,不需要自己一步步实现。
矩阵求导简画公式,其中a是常数:
函数为凸函数,一阶导数等于0求最小值点,得到:
公式④
看完参数的整个求导过程,是不是很纳闷,为什么叫“最小二乘法”。一些书籍和文章中是这样解释的,大概意思是:误差平方和中的平方也叫二乘,最小化误差平方和的过程,就叫做最小二乘法。
最小二乘法得到的是解析解,并且是全局最优解。但要求比较严格,多个自变量间不能存在多重共线性,并且随着特征、样本量的增多,会变得越来越耗时。
6、梯度下降法
很多文章中在讲梯度下降时,都会用下山举例说明,我们也从下山的例子开始说起。
假设有一座像下图一样有坡度的山,我们站在山中的某一处,周围可见度有限,我们想要到达山谷,应该怎么做呢?一般我们会观察所在位置的周边,找到最陡峭的方向,并朝着这个方向往下走去,当走了一段距离后,我们会再次观察周边情况,找到最陡峭的方向,然后走下去,就这样我们走一会观察一下,一步步走到了山下。
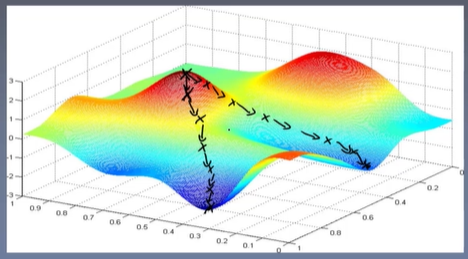
梯度下降法可以类比下山法,也是走一步看一步,每一步都找一个下降最快的方向向下走。下山的过程中会经过很多点,每经过一个点就会得到一组模型参数w,每组模型参数w可以都可以组成一个预测函数,经过的每个点代表所有样本在当前点对应预测函数的预测值与真实值的误差平方和(梯度下降法使用的损失函数也是均方误差)。
什么是梯度?
梯度是微积分中的一个概念,表示一个函数在某个点的变化率或斜率的向量值,因此它是一个向量,梯度的方向是函数增加最快的方向,梯度的大小表示函数在某个点处的变化率的大小。(关于梯度更多的知识,有兴趣的小伙伴可以自学微积分)
可以简单理解为梯度是函数某点上的切线的斜率,其方向是使得函数值上升的方向。
多元线性回归的损失函数画图太复杂,下面我们使用一元线性回归的损失函数画图说明梯度下降的求解过程。
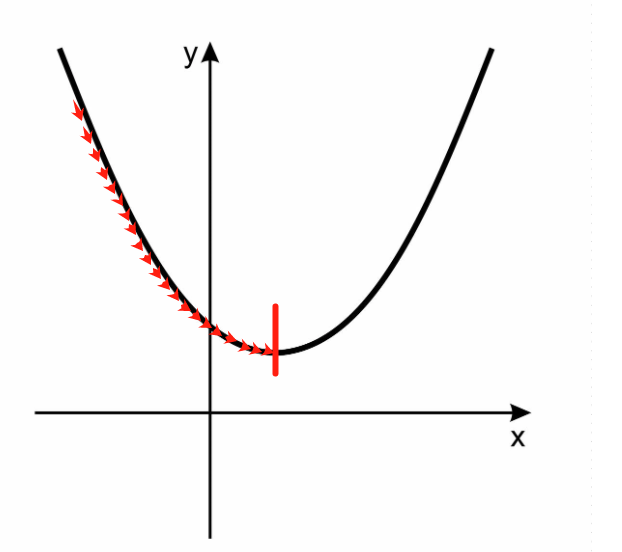
梯度下降法使用的损失函数是均方误差,均方误差是在误差平方和公式的基础上,再除以样本总量m
可以看到损失函数的公式中,多成了一个1/2,其目的只是为了简化后面的求导结果,没有实际意义。并且我们要求解的是极值点,乘以1/2不会改变极值点的位置(不会改变模型参数w),只会影响极值的大小(不需要关系极值大小)。
模型参数个数共n+1个,需要分别求出每一个方向上的梯度,因此需要对每一个求导
公式⑤
此处先埋下一个问题,梯度下降法使用的损失函数为什么是均方误差,而不是误差平方和?
对上面求导结果取负值(梯度是上升方向,取负值后是下降方向),得到梯度下降方向。现在有了方向知道往那走了,接下来就是一次走多远的问题了。
每次走的距离叫做步长,也称为学习率(Learning Rate),是决定每次迭代中参数更新幅度的关键超参数。它直接影响算法的收敛速度、稳定性以及最终能否找到最优解。
有了方向和步长,就可以得到每次迭代(走一步)后的参数,公式如下:
公式⑥
上面是模型参数公式推导的过程,下面说一下梯度下降算法的实现步骤:
- 初始化参数:选择一个初始点(参数值)。
- 计算梯度:计算目标函数在当前参数值处的梯度。
- 更新参数:沿着梯度的反方向更新参数,步长由学习率(learning rate)控制。
- 重复迭代:重复步骤2和3,直到满足停止条件。
第4步中提到了迭代的停止条件,这个条件是人为设定的,比如梯度接近零、达到最大迭代次数等。
梯度下降法有三种常见方式:
- 批量梯度下降(Batch Gradient Descent) :每次迭代使用全部训练数据计算梯度。
- 随机梯度下降(Stochastic Gradient Descent, SGD) :每次迭代随机选择一个样本计算梯度。
- 小批量梯度下降(Mini-batch Gradient Descent) :每次迭代使用一小部分样本计算梯度。
步长大小的影响
适中的步长:可以在收敛速度和稳定性之间平衡,逐步逼近最优解。
步长过小:参数更新缓慢,需要大量迭代才能收敛,计算效率低。
步长过大:可能导致参数更新时 “跳过” 最小值,甚至在梯度方向震荡或发散。
步长的类型与策略
1. 固定步长(Constant Step Size)
-
特点:整个训练过程中步长保持不变(如 α=0.01)。
-
适用场景:简单问题或初始调试,但需手动调优,否则易陷入震荡或收敛过慢。
2. 自适应步长(Adaptive Step Size)
基于梯度历史信息动态调整步长,避免手动调参:
-
AdaGrad:对每个参数使用不同步长,初始步长较大,随迭代递减(适合稀疏数据)。
-
RMSprop:引入滑动平均缓解 AdaGrad 的过度衰减问题。
-
Adam:结合动量(Momentum)和 RMSprop,自适应调整步长并加速收敛,是最常用的策略之一。
3. 学习率衰减(Learning Rate Scheduling)
在训练初期使用较大步长快速收敛,后期逐步减小以精细调整:
-
指数衰减:
(
为衰减因子,如 0.99)。
-
分段常数衰减:在固定迭代次数后手动降低步长(如每 1000 次迭代除以 2)。
-
余弦退火:根据余弦函数周期性调整步长,兼顾全局搜索和局部优化。
如何选择合适的步长?
-
初始调试
-
从较小的初始值开始(如 10−3),逐步增大(如 10−2,10−1),观察损失函数变化:
-
若损失下降后震荡,说明步长偏大;
-
若损失长时间不变,说明步长过小。
-
-
使用学习率预热(Warm-Up):在训练初期用极小步长更新,逐步增加到预设值,避免参数初始化时梯度过大导致发散。
-
-
可视化与监控
-
绘制损失函数随迭代的变化曲线,判断是否收敛或震荡。
-
检查梯度范数(如
),若持续增大,说明步长过大需调小。
-
-
经验与最佳实践
-
深度学习中,常用初始步长范围:
,具体依赖优化器(如 Adam 通常比 SGD 的步长可设更大)。
-
对于非凸问题(如神经网络),动态调整步长(如 Adam)通常比固定步长更鲁棒。
-
7、损失函数
线性回归中常用的损失函数(目标函数)主要用于衡量预测值与真实值之间的差异,以下是几种常见的损失函数:
1、均方误差(Mean Squared Error, MSE)
- 公式:
其中,是真实值,
是预测值,N 是样本数量。
- 特点:
- 对异常值敏感(平方项会放大误差)。
- 数学性质良好,易于求导,适合梯度下降优化。
- 是线性回归中最常用的损失函数。
2、平均绝对误差(Mean Absolute Error, MAE)
- 公式:
- 特点:
- 对异常值不敏感(绝对值项限制误差放大)。
- 但在数学上不可导(在 0 点处导数不连续),可能影响优化稳定性。
- 适合数据存在较多噪声或异常值的场景。
3、均方根误差(Root Mean Squared Error, RMSE)
- 公式:
- 特点:
- 是 MSE 的平方根,结果与真实值单位一致,便于解释。
- 其他特性与 MSE 类似。
4、Huber 损失(Huber Loss)
- 公式:
其中,,δ 是超参数,用于平衡 MSE 和 MAE 的影响。
- 特点:
- 结合 MSE 和 MAE 的优点:误差较小时类似 MSE(可导),误差较大时类似 MAE(鲁棒性强)。
- 适合数据中存在部分异常值的场景。
5、Log-Cosh 损失(Log-Cosh Loss)
- 公式:
- 特点:
- 对误差的平方项和绝对值项都有折中效果,且在所有点都可导。
- 近似于 MSE,但对异常值的惩罚比 MSE 轻,比 MAE 重。
选择建议
- MSE/RMSE:默认选择,适合数据分布稳定、无明显异常值的场景。
- MAE:数据含较多异常值时更鲁棒。
- Huber/Log-Cosh:折中方案,兼顾可导性和鲁棒性。
7、模型评估
线性回归模型的评估方法可分为误差指标评估、统计检验评估和模型诊断三个维度,具体方法如下:
7.1、误差指标评估
-
决定系数(R²)
- 衡量模型对因变量变异的解释比例,取值在[0,1]之间,越接近1拟合效果越好。
- 调整R²:适用于多元回归,通过惩罚变量数量避免过拟合,更客观反映模型解释力。
-
平均绝对误差(MAE)
- 计算预测值与真实值的绝对误差均值,反映平均误差大小,对异常值不敏感。
-
均方误差(MSE)
- 误差平方的平均值,对较大误差更敏感,数学性质优良但单位与原始数据不一致。
-
均方根误差(RMSE)
- MSE的平方根,与原始数据单位一致,直观反映误差水平。
-
平均绝对百分比误差(MAPE)
- 误差百分比化,适用于标准化评估,但对零值敏感。
7.2、统计检验评估
-
模型整体显著性检验(F检验)
- 检验所有自变量联合对因变量的影响是否显著,若p值<0.05则模型有效。
-
回归系数显著性检验(t检验)
- 判断单个自变量对因变量的影响是否显著,p值<0.05表示该变量有统计学意义。
7.3、模型诊断与假设验证
-
残差分析
- 正态性:通过QQ图或Shapiro-Wilk检验残差是否符合正态分布。
- 独立性:Durbin-Watson(DW)检验残差是否存在自相关(理想值接近2)。
- 同方差性:Breusch-Pagan(BP)检验残差方差是否恒定。
-
多重共线性检验
- 计算方差膨胀因子(VIF),若VIF≥10需处理(如删除变量或正则化)。
-
异常值与强影响点检测
- 使用Cook's Distance识别异常值,若值>1需进一步分析。
参考资料:
第二十一讲 | 多元线性回归分析(超级详细)
最强总结!8个线性回归核心点!!
机器学习算法入门之(一) 梯度下降法实现线性回归_使用梯度下降方法实现线性回归算法-CSDN博客
https://zhuanlan.zhihu.com/p/706039687
https://zhuanlan.zhihu.com/p/361449903
线性回归 (Linear Regression) | 菜鸟教程
相关文章:

机器学习--线性回归模型
阅读本文之前,可以读一读下面这篇文章:终于有人把线性回归讲明白了 0、引言 线性回归作为统计学与机器学习的入门算法,以其简洁优雅的数学表达和直观的可解释性,在数据分析领域占据重要地位。这个诞生于19世纪的经典算法…...

HTML应用指南:利用GET请求获取微博签到位置信息
在当今数字化时代,社交媒体平台已成为人们日常生活中不可或缺的一部分。作为中国最受欢迎的社交平台之一,微博不仅为用户提供了一个分享信息、表达观点的空间,还通过其丰富的功能如签到服务,让用户能够记录自己生活中的点点滴滴。…...

如何检测Python项目哪些依赖库没有使用
要检测Python项目中哪些依赖库未被使用,可以采用以下方法: 1. 使用静态分析工具 vulture:静态分析工具,检测未使用的代码和导入 pip install vulture vulture your_project/pyflakes:检查未使用的导入语句 pip ins…...

数据仓库建设全解析!
目录 一、数据仓库建设的重要性 1. 整合企业数据资源 2. 支持企业决策制定 3. 提升企业竞争力 二、数据仓库建设的前期准备 1. 明确业务需求 2. 评估数据源 3. 制定项目计划 三、数据仓库建设的具体流程 1.需求分析 2.架构设计 3.数据建模 4.ETL 开发 5.…...

magic-api连接达梦数据库
引入依赖 然后手写驱动 <dependency><groupId>com.dameng</groupId><artifactId>DmJdbcDriver18</artifactId><version>8.1.1.193</version></dependency> jdbc:dm://127.0.0.1:5236?schemaSALES...

向量检索新选择:FastGPT + OceanBase,快速构建RAG
随着人工智能的快速发展,RAG(Retrieval-Augmented Generation,检索增强生成)技术日益受到关注。向量数据库作为 RAG 系统的核心基础设施,堪称 RAG 的“记忆中枢”,其性能直接关系到大模型生成内容的精准度与…...

WHAT - 区分 Git PR 和 MR
文章目录 PR(Pull Request)MR(Merge Request)相同点总结 git pr 和 git mr 本质上都是「合并请求」的意思,但它们对应的是不同的平台术语。 PR(Pull Request) 平台:GitHub、Bitbuc…...

Axure复选框组件的深度定制:实现自定义大小、颜色与全选功能
在产品设计中,复选框作为用户与界面交互的重要元素,其灵活性直接影响到用户体验。本文将介绍如何利用Axure RP工具,通过高级技巧实现复选框组件的自定义大小、颜色调整,以及全选功能的集成,为产品原型设计增添更多可能…...

Datawhale AI春训营——用AI帮助老人点餐
详细内容见官网链接:用AI帮助老人点餐-活动详情 | Datawhale...

两段文本比对,高亮出差异部分
用法一:computed <div class"card" v-if"showFlag"><div class"info">*红色背景为已删除内容,绿色背景为新增内容</div><el-form-item label"与上季度比对:"><div class"comp…...

uniapp 仿小红书轮播图效果
通过对小红书的轮播图分析,可得出以下总结: 1.单张图片时容器根据图片像素定高 2.多图时轮播图容器高度以首图为锚点 3.比首图长则固高左右留白 4.比首图短则固宽上下留白 代码如下: <template><view> <!--轮播--><s…...

审计效率升级!快速匹配Excel报表项目对应的Word附注序号
财务审计报告一般包括:封面、报告正文、财务报表(Excel工作簿)以及对应的财务报表附注(Word文档)、事务所营业执照以及注册会计师证件。 在审计报告出具阶段,为各报表项目填充对应的Word附注序号ÿ…...

Python 中 `r` 前缀:字符串处理的“防转义利器”
# Python 中 r 前缀:字符串处理的“防转义利器” 在 Python 编程过程中,处理字符串时经常会遇到反斜杠 \ 带来的转义问题,而 r 前缀的出现有效解决了这一困扰。它不仅能处理反斜杠的转义,还在多种场景下发挥着重要作用。接下来&a…...

1️⃣6️⃣three.js_光源
16、光源 3D虚拟工厂在线体验 在 Three.js 中,环境光(AmbientLight)、点光源(PointLight)、平行光(DirectionalLight)、 聚光灯(SpotLight)、半球光(Hemisph…...

AD16如何执行DRC检测
AD16如何执行DRC检测 DRC检测主要用来查看走线是否出现通断,以及是否出现短路。 1)、点击“Tools”---“Design Rule Check…” 2)、全部勾选 3)、勾选“Electrical”中的“Batch”选项,参与DRC检测 4)、勾选“Routing”中的“Batch”选项,…...

PostgreSQL性能优化实用技巧
PostgreSQL的性能优化需从索引设计、查询调优、参数配置、硬件资源等多维度入手。以下为实战中验证有效的优化策略,适用于高并发、大数据量等场 一、索引优化:精准加速查询 1.选择正确的索引类型 BRIN索引:对按时间或数值顺…...

Vue3 ref与props
ref 属性 与 props 一、核心概念对比 特性ref (标签属性)props作用对象DOM 元素/组件实例组件间数据传递数据流向父组件访问子组件/DOM父组件 → 子组件响应性直接操作对象单向数据流(只读)使用场景获取 DOM/调用子组件方法组件参数传递Vue3 变化不再自…...

SpringBoot | 构建客户树及其关联关系的设计思路和实践Demo
关注:CodingTechWork 引言 在企业级应用中,客户关系管理(CRM)是核心功能之一。客户树是一种用于表示客户之间层级关系的结构,例如企业客户与子公司、经销商与下级经销商等。本文将详细介绍如何设计客户树及其关联关系…...

SpringCloud——负载均衡
一.负载均衡 1.问题提出 上一篇文章写了服务注册和服务发现的相关内容。这里再提出一个新问题,如果我给一个服务开了多个端口,这几个端口都可以访问服务。 例如,在上一篇文章的基础上,我又新开了9091和9092端口,现在…...

Springboot3+ JDK21 升级踩坑指南
目录 GetMapping和 RequestBody 一起使用时,会把请求方式由GET变为POST 变更默认的httpClient feign 超时配置失效 GetMapping和 RequestBody 一起使用时,会把请求方式由GET变为POST 变更默认的httpClient 添加依赖 <dependency><groupId&g…...

Qt UDP组播实现与调试指南
在Qt中使用UDP组播(Multicast)可以实现高效的一对多网络通信。以下是关键步骤和示例代码: 一、UDP组播核心机制 组播地址:使用D类地址(224.0.0.0 - 239.255.255.255)TTL设置:控制数据包传播范围(默认1,同一网段)网络接口:指定发送/接收的物理接口二、发送端实现 /…...

idea连接远程服务器kafka
一、idea插件安装 首先idea插件市场搜索“kafka”进行插件安装 二、kafka链接配置 1、检查服务器kafka配置 配置链接前需要保证远程服务器的kafka配置里边有配置好服务器IP,以及开放好kafka端口9092(如果有修改 过端口的开放对应端口就好) …...

第十节:性能优化高频题-虚拟DOM与Diff算法优化
优化策略:同层比较、静态节点标记、最长递增子序列算法 Key的作用:精确识别节点身份 虚拟DOM与Diff算法深度优化策略解析 一、核心优化策略 同层比较机制 Diff算法仅对比同一层级的虚拟节点,避免跨层级遍历带来的性能损耗。 • 实现原理&am…...

vmware workstation的下载地址页面
Fusion and Workstation | VMware...

kubernetes》》k8s》》Dashboard
安装Dashboard 因为我的Kubernetes 版本是 v1.28.2 对应的 Dashboard V2.7.0 wget -O https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml # 因为默认是集群内访问的,需要追加 NodePort访问类型 vim recommended.yaml …...

软考:数值转换知识点详解
文章目录 1. 进制转换1.1 二进制(Binary)、八进制(Octal)、十进制(Decimal)、十六进制(Hexadecimal)之间的转换1.2 手动转换和计算方法1.3 使用编程语言进行进制转换 2. 数据类型转换…...

第15章:MCP服务端项目开发实战:性能优化
第15章:MCP服务端项目开发实战:性能优化 在构建和部署 MCP(Memory, Context, Planning)驱动的 AI Agent 系统时,性能和可扩展性是关键的考量因素。随着用户量、数据量和交互复杂度的增加,系统需要能够高效地处理请求,并能够平滑地扩展以应对更高的负载。本章将探讨 MCP…...

Windows申请苹果开发者测试证书Uniapp使用
注意事项 苹果设备,最好是iPhone XS以上,要不然下载不了Apple DeveloperopenSSL 要是V1版本的来生成证书,要不然HBuilder报错按步骤来,生成证书,生成标识符,添加测试设备,生成描述性文件注册苹果开发者账号 (如果有苹果账号直接登录) 苹果开发者官网 开通付费 点击右上…...

服务器数据恢复—NAS存储中raid5上层lv分区数据恢复案例
NAS数据恢复环境: QNAP TS-532X NAS设备中有两块1T的SSD固态硬盘和3块5T的机械硬盘。三块机械硬盘组建了一组RAID5阵列,两块固态硬盘组建RAID1阵列。划分了一个存储池,并通过精简LVM划分了7个lv。 NAS故障: 硬盘故障导致无法正常…...

uniapp跨平台开发---switchTab:fail page `/undefined` is not found
问题描述 在项目中新增了一个底部tab导航栏,点击底部tabBar,跳转失败,控制台打印错误信息switchTab:fail page /undefined is not found 排查思路 错误信息提示,switchTab跳转的页面路径变成了/undefined,排查新增的pages.json文件,发现pages,以及tabBar中的list均已经加入该导…...

详细讲解 QMutex 线程锁和 QMutexLocker 自动锁的区别
详细讲解 QMutex 线程锁和 QMutexLocker 自动锁的区别 下面我们详细拆解 Qt 中用于线程同步的两个核心类:QMutex 和 QMutexLocker。 🧱 一、什么是 QMutex? QMutex 是 Qt 中的互斥锁(mutex)类,用于防止多个…...

如何获取静态IP地址?完整教程
静态IP地址,因其固定不变的特性,在远程访问、服务器搭建、电商多开、游戏搬砖等场景中显得尤为重要。以下是获取静态IP地址的完整教程,涵盖家庭网络、企业网络和公网静态IP的配置方法: 一、什么是静态IP? 内网IP&…...

JavaScript 里创建对象
咱们来用有趣的方式探索一下 JavaScript 里创建对象的各种“魔法咒语”! 想象一下,你是一位魔法工匠,想要在你的代码世界里创造各种奇妙的“魔法物品”(也就是对象)。你有好几种不同的配方和工具: 1. 随手…...

【华为HCIP | 华为数通工程师】821—多选解析—第十五页
多选794、以下关于高可用性网络特点的描述,正确的是哪些项? A、不会出现故障 B、不能频出现故障 C、一旦出现故障只通过人工干预恢复业务 D出现故障后能很快恢复 解析:高可用性网络拥有良好的可靠性,不间断转发NSF…...

Kaamel视角下的MCP安全最佳实践
在以AI为核心驱动的现代产品体系中,大模型逐渐从实验室走向生产环境,如何确保其在推理阶段的信息安全和隐私保护,成为各方关注的重点。Model Context Protocol(MCP) 作为一个围绕模型调用上下文进行结构化描述的协议&a…...

Kafka 命令行操作与 Spark-Streaming 核心编程总结
一、Kafka 命令行操作详解 1.创建 Topic 命令格式: kafka-topics.sh --create --zookeeper <zk节点列表> --topic <主题名> --partitions <分区数> --replication-factor <副本数> 参数说明: 分区数(partitions…...
(C++))
【华为OD机试真题】428、连续字母长度 | 机试真题+思路参考+代码解析(E卷)(C++)
文章目录 一、题目题目描述输入输出样例1样例2 一、代码与思路🧠C语言思路✅C代码 一、题目 参考:https://sars2025.blog.csdn.net/article/details/139492358 题目描述 ◎ 给定一个字符串,只包含大写字母,求在包含同一字母的子串…...

nodejs获取请求体的中间件 body-parse
虽然 Express 4.16.0 之后已经内置了处理请求体的功能(express.json() 和 express.urlencoded()),但你也可以单独使用老牌中间件 body-parser,它仍然很常用,尤其在某些旧项目中。 📦 一、安装 body-parser …...
)
5.学习笔记-SpringMVC(P61-P70)
SpringMVC-SSM整合-接口测试 (1)业务层接口使用junit接口做测试 (2)表现层用postman做接口测试 (3)事务处理— 1)在SpringConfig.java,开启注解,是事务驱动 2)配置事务管理器(因为事务管理器是要配置数据源对象&…...

腾讯云服务器安全——服务防火墙端口放行
点击服务进入安全策略 添加规则...
)
mfc学习(一)
mfc为微软创建的一个类qt框架的客户端程序,只不过因为微软目前有自己 的亲身儿子C#(.net),所以到2010没有进行维护。然后一些的工业企业还在继续进行维护相关的内容。我目前就接手一个现在这样的项目,其实本质与qt的思路是差不多的…...

【MQ篇】初识RabbitMQ保证消息可靠性
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗! 🌟了解 MQ 请看 : 【MQ篇】初识MQ! 其他优质专栏: 【&…...

神经网络基础[ANN网络的搭建]
神经网络 人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的计算模型。各个神经元传递复杂的电信号,树突接收到输入信号…...

【技术派后端篇】整合WebSocket长连接实现消息实时推送
在技术派平台中,实现了文章被点赞或评论后,在右上角实时弹出消息提醒的功能。相较于之前仅有的消息通知红色标识,这种实时通知在交互体验上有显著提升。本文将详细介绍如何借助WebSocket实现消息的实时通知。 1 基础知识点 1.1 相关概念 W…...

Janus Pro
目录 一、模型概述与开源情况 二、模型能力与性能 三、竞品分析 四、部署成本与个人部署成本比较 五、其他维度比较 1. 模型架构与创新性 2. 社区支持与生态系统 3. 更新频率与维护 4. 适用场景与灵活性 5. 商业化潜力 六、总结 Janus Pro 是中国初创公司 DeepSeek …...

[密码学实战]在Linux中实现SDF密码设备接口
[密码学实战]在Linux中实现SDF密码设备接口 引言 在密码学应用开发中,SDF(Security Device Interface)作为中国国家密码管理局制定的密码设备接口标准,被广泛应用于金融、政务等领域的安全系统中。本文将以GmSSL国产密码库为基础,手把手指导在Linux系统中部署SoftSDF——…...

机器学习基础 - 分类模型之SVM
SVM:支持向量机 文章目录 SVM:支持向量机简介基础准备1. 线性可分2. 最大间隔超平面3. 什么是支持向量?4. SVM 能解决哪些问题?5. 支持向量机的分类硬间隔 SVM0. 几何间隔与函数间隔1. SVM 最优化问题2. 对偶问题1. 拉格朗日乘数法 - 等式约束优化问题2. 拉格朗日乘数法 - …...

PostgreSQL 中的权限视图
PostgreSQL 中的权限视图 PostgreSQL 提供了多个系统视图来查询权限信息,虽然不像 Oracle 的 DBA_SYS_PRIVS 那样集中在一个视图中,但可以通过组合以下视图获取完整的系统权限信息。 一 主要权限相关视图 Oracle 视图PostgreSQL 对应视图描述DBA_SYS_…...

pnpm install报错:此系统上禁止运行脚本
依赖安装 报错信息: pnpm : 无法加载文件 C:\Users\XXX\AppData\Roaming\npm\pnpm.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/go.microsoft.com/fwlink/?LinkID135170 中的 about_Execution_Policies。 所在位置 行:1 …...

解决yarn install 报错 error \node_modules\electron: Command failed.
在电脑重装系统后,重新安装项目依赖,遇到这一报错 完整报错信息如下: error D:\xxxxx\xxxxxx\node_modules\electron: Command failed. Exit code: 1 Command: node install.js Arguments: Directory: D:\xxxxx\xxxxx\node_modules\electron Output: HTTPError: Response cod…...