Python----深度学习(基于深度学习Pytroch线性回归和曲线回归)
一、引言
在当今数据驱动的时代,深度学习已成为解决复杂问题的有力工具。它广泛应用于图像识别、自然语言处理和预测分析等领域。回归分析是统计学的一种基础方法,用于描述变量之间的关系。通过回归模型,我们可以预测连续的数值输出,这在经济学、工程学、医疗等领域有着至关重要的应用。
其中,线性回归是最简单且最常用的回归方法之一,它假设预测变量与目标变量之间存在线性关系。虽然线性回归在许多场景中表现良好,但当数据具有非线性特征时,它的预测能力可能会受到限制。在这些情况下,曲线回归(如多项式回归或其他非线性模型)通常可以提供更好的拟合效果。
二、线性回归
2.1、定义
线性回归是一种基本的预测分析方法,它通过拟合一条直线来描述自变量(特征)与因变量(目标)之间的关系。

2.2、设计思路
导入模块
import numpy as np
import torch
import random
import torch.nn as nn
import matplotlib.pyplot as plt输入数据
point = [[1.8, 8.5], [1.6, 8.4], [2.3, 7.2], [0.7, 8.6], [1.8, 7.6], [4.9, 4.1], [2.5, 6.6], [4.4, 4.1],[7.4, 0.6], [1.9, 7.5],[5.8, 2.2], [6.8, 0.6], [2.9, 6.1], [5.6, 2.1], [1.0, 8.4], [5.3, 3.1], [3.2, 6.8], [3.2, 5.1],[6.4, 0.9], [2.9, 5.6],[5.5, 2.9], [4.7, 4.3], [8.0, 0.9], [2.1, 6.2], [7.2, 0.7], [4.1, 4.0], [5.6, 2.4], [1.3, 7.7],[3.2, 6.0], [4.7, 2.8],[5.4, 2.9], [4.0, 4.6], [4.3, 4.1], [1.3, 8.5], [2.5, 7.1], [4.1, 4.2], [5.4, 3.4], [6.4, 2.8],[7.0, 2.9], [2.4, 7.0],[1.2, 7.6], [7.5, 0.4], [7.7, 0.7], [1.8, 8.2], [0.6, 8.9], [4.5, 4.2], [7.3, 0.3], [7.4, 1.2],[4.0, 5.7], [7.0, 0.4],[6.7, 2.3], [1.3, 7.9], [1.7, 7.2], [4.8, 3.7], [1.3, 7.3], [5.4, 3.8], [3.9, 5.6], [3.1, 5.7],[3.2, 6.3], [2.5, 6.6],[0.9, 8.9], [1.4, 7.5], [0.8, 8.1], [1.9, 8.3], [4.2, 3.6], [1.7, 7.2], [7.7, 0.5], [5.5, 2.1],[4.2, 5.2], [3.9, 4.9],[4.2, 4.4], [4.0, 5.9], [4.3, 3.4], [7.0, 1.0], [7.6, 0.8], [7.3, 0.1], [5.6, 3.0], [6.4, 3.0],[-0.0, 9.1], [2.9, 6.7],[4.4, 3.6], [6.4, 2.2], [5.3, 3.2], [5.7, 2.7], [6.5, 1.5], [7.4, 1.1], [6.2, 2.1], [5.6, 1.4],[5.7, 2.0], [3.0, 5.2],[4.5, 5.6], [6.8, 1.7], [6.5, 1.3], [4.2, 4.5], [3.3, 6.5], [2.7, 5.2], [5.8, 3.5], [7.8, 0.9],[5.5, 3.0], [1.2, 8.0],[4.2, 4.2], [0.9, 8.6], [7.0, 1.0], [0.2, 9.6], [5.9, 3.0], [2.3, 6.5], [3.3, 5.1], [5.9, 2.2],[6.8, 1.7], [4.6, 3.8],[6.3, 1.3], [1.2, 8.4], [6.8, 1.6], [5.0, 2.3], [7.4, 0.1], [3.1, 5.9], [4.9, 3.8], [1.8, 7.5],[7.9, 0.3], [2.8, 5.2],[2.4, 7.2], [4.0, 4.0], [6.8, 1.7], [6.6, 1.9], [4.9, 4.4], [6.4, 2.9], [7.3, 0.7], [2.1, 7.6],[1.9, 7.7], [0.7, 9.2],[3.7, 4.8], [0.5, 8.9], [4.8, 4.4], [5.7, 2.7], [4.0, 3.8], [6.1, 1.6], [6.7, 0.3], [0.3, 8.5],[5.3, 1.7], [2.9, 5.6],[0.9, 7.8], [2.9, 6.5], [0.2, 8.8], [8.0, 0.7], [1.8, 6.7], [3.0, 6.0], [5.0, 3.7], [2.8, 5.3],[4.2, 5.2], [4.5, 5.2],[8.1, 0.6], [4.4, 3.9], [7.3, 1.4], [5.7, 2.0], [1.9, 7.2], [3.5, 4.4], [4.4, 4.4], [2.6, 6.3],[6.0, 2.9], [2.5, 7.1],[6.0, 2.3], [6.5, 1.2], [0.3, 9.6], [2.3, 6.6], [7.6, 0.4], [0.2, 9.3], [1.1, 8.7], [3.5, 5.2],[7.0, 2.0], [6.5, 2.1],[7.8, 0.6], [4.1, 4.3], [1.2, 8.9], [1.0, 8.9], [5.6, 3.4], [5.6, 2.0], [4.7, 3.3], [7.7, 0.8],[7.4, 1.4], [3.2, 4.9],[4.8, 3.9], [5.6, 2.8], [1.4, 8.7], [2.4, 7.2], [8.0, 0.3], [4.9, 3.8], [2.3, 6.9], [5.8, 2.7],[1.9, 7.0], [5.0, 2.9],[2.2, 7.4], [6.1, 2.6], [6.7, 1.0], [4.6, 3.6], [7.9, 0.2], [3.1, 5.8], [4.7, 4.1], [1.5, 8.1],[2.3, 7.0], [4.2, 5.0],[5.6, 2.2], [5.9, 2.6], [3.3, 4.8], [2.5, 5.6], [2.1, 7.5], [0.8, 7.4], [6.2, 2.6], [4.2, 3.8],[0.8, 8.3], [4.5, 4.1],[6.2, 2.0], [7.8, 1.0], [2.6, 6.0], [4.2, 4.2], [1.6, 7.8], [4.1, 4.2], [5.8, 2.7], [4.0, 5.8],[0.9, 7.8], [6.7, 1.6],[0.2, 8.2], [1.1, 7.7], [2.1, 7.1], [6.0, 2.8], [4.0, 4.9], [7.5, 1.6], [6.1, 1.7], [3.5, 5.9],[6.3, 1.6], [8.0, 0.3],[5.4, 2.6], [7.6, 0.2], [5.8, 2.9], [1.9, 6.6], [0.4, 8.2], [5.7, 2.1], [3.2, 6.2], [5.2, 3.5],[7.6, 0.2], [1.8, 7.3],[0.5, 8.4], [5.5, 3.6], [5.2, 3.4], [6.0, 2.3], [5.0, 3.8], [3.3, 5.5], [7.4, 1.3], [4.2, 4.3],[2.4, 7.0], [2.1, 6.5],[7.7, 0.7], [5.6, 2.7], [6.3, 1.4], [5.3, 2.0], [0.4, 8.5], [2.0, 7.7], [5.8, 3.8], [4.3, 4.5],[0.9, 8.9], [3.7, 4.7],[7.0, 1.5], [6.2, 2.0], [2.5, 6.2], [3.8, 5.5], [1.8, 8.4], [3.3, 5.5], [7.9, 0.4], [1.9, 7.8],[5.6, 3.1], [7.9, 0.6],[4.8, 3.7], [5.1, 3.9], [6.9, 1.3], [3.3, 5.8], [3.8, 5.1], [5.3, 3.5], [1.3, 7.8], [0.8, 8.2],[1.9, 7.8], [4.9, 3.6],[6.8, 2.4], [7.5, 0.2], [4.8, 3.3], [3.9, 4.4], [4.3, 4.2], [6.2, 1.9], [7.2, 0.8], [2.7, 6.0],[1.1, 7.7], [7.0, 0.1],[0.8, 7.3], [5.6, 3.5], [0.8, 8.1], [4.7, 3.8], [3.9, 4.5], [4.7, 3.2], [1.3, 7.7], [7.2, 0.8],[4.2, 4.0], [1.2, 8.9]]划分训练集和测试集
# 将 point1 分割为训练集和测试集
random.shuffle(point) # 随机打乱数据
split_index = int(0.1 * len(point)) # 取前 10% 的数据作为测试集train_point = point[split_index:]
test_point = point[:split_index]x_train = np.array([point[0] for point in train_point])
y_train = np.array([point[1] for point in train_point])x_test = np.array([point[0] for point in test_point])
y_test = np.array([point[1] for point in test_point])
转换为Tensor张量
x_train = torch.from_numpy(x_train).float()
y_train = torch.from_numpy(y_train).float()构建模型
class ModelClass(nn.Module):def __init__(self):super().__init__()self.layer1 = nn.Linear(1, 8)self.layer2 = nn.Linear(8, 1)def forward(self, x):x = torch.tanh(self.layer1(x))x = self.layer2(x)return xmodel = ModelClass()构建损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=0.01)模型训练
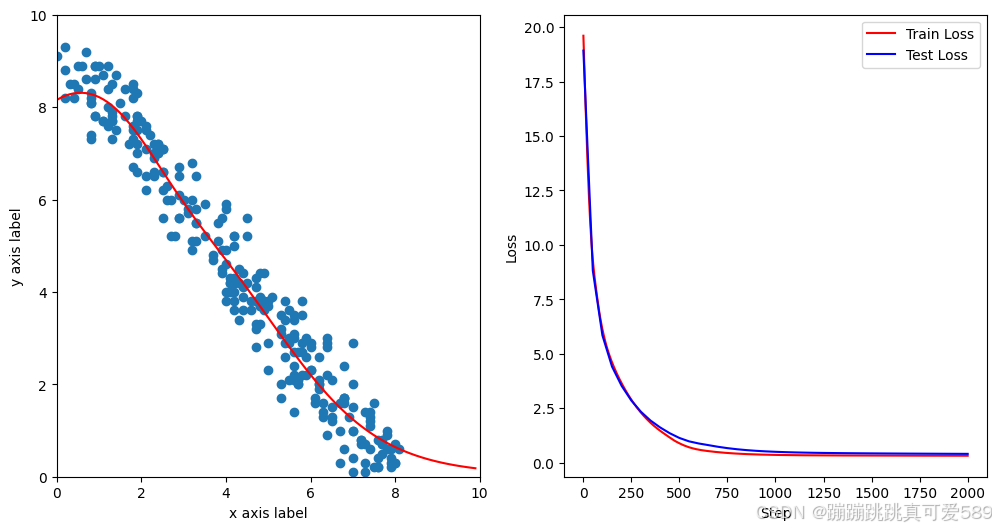
for n in range(1, 2001):# 前向传播y_pred = model(x_train.unsqueeze(1))# 计算损失loss = criterion(y_pred.squeeze(1), y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if n % 100 == 0 or n == 1:print(n,loss.item())可视化
step_list = []
loss_list = []
test_step_list = []
test_loss_list = []for n in range(1, 2001):# 前向传播y_pred = model(x_train.unsqueeze(1))# 计算损失loss = criterion(y_pred.squeeze(1), y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 更新右侧的损失图数据并绘制step_list.append(n)loss_list.append(loss.detach())# 显示频率设置if n % 100 == 0 or n == 1:print(n,loss.item())# 绘制左侧的拟合图ax1.clear()ax1.set_xlim(0, 10)ax1.set_ylim(0, 10)ax1.set_xlabel("x axis label")ax1.set_ylabel("y axis label")ax1.scatter(x_train, y_train)x_range = torch.tensor(np.arange(0, 10, 0.1)).unsqueeze(1).float()y_range = model(x_range).detach().numpy()ax1.plot(x_range, y_range, 'r') # 绘制拟合线# 计算测试集损失y_pred_test = model(torch.tensor(x_test).unsqueeze(1).float())loss_test = criterion(y_pred_test.squeeze(1), torch.from_numpy(y_test).float())test_step_list.append(n)test_loss_list.append(loss_test.detach())ax2.clear()ax2.plot(step_list, loss_list, 'r-', label='Train Loss')ax2.plot(test_step_list, test_loss_list, 'b-', label='Test Loss') # 绘制测试集损失ax2.set_xlabel("Step")ax2.set_ylabel("Loss")ax2.legend()
plt.show()完整代码
import numpy as np
import torch
import random
import torch.nn as nn
import matplotlib.pyplot as plt# 创造数据,数据集
point = [[1.8, 8.5], [1.6, 8.4], [2.3, 7.2], [0.7, 8.6], [1.8, 7.6], [4.9, 4.1], [2.5, 6.6], [4.4, 4.1],[7.4, 0.6], [1.9, 7.5],[5.8, 2.2], [6.8, 0.6], [2.9, 6.1], [5.6, 2.1], [1.0, 8.4], [5.3, 3.1], [3.2, 6.8], [3.2, 5.1],[6.4, 0.9], [2.9, 5.6],[5.5, 2.9], [4.7, 4.3], [8.0, 0.9], [2.1, 6.2], [7.2, 0.7], [4.1, 4.0], [5.6, 2.4], [1.3, 7.7],[3.2, 6.0], [4.7, 2.8],[5.4, 2.9], [4.0, 4.6], [4.3, 4.1], [1.3, 8.5], [2.5, 7.1], [4.1, 4.2], [5.4, 3.4], [6.4, 2.8],[7.0, 2.9], [2.4, 7.0],[1.2, 7.6], [7.5, 0.4], [7.7, 0.7], [1.8, 8.2], [0.6, 8.9], [4.5, 4.2], [7.3, 0.3], [7.4, 1.2],[4.0, 5.7], [7.0, 0.4],[6.7, 2.3], [1.3, 7.9], [1.7, 7.2], [4.8, 3.7], [1.3, 7.3], [5.4, 3.8], [3.9, 5.6], [3.1, 5.7],[3.2, 6.3], [2.5, 6.6],[0.9, 8.9], [1.4, 7.5], [0.8, 8.1], [1.9, 8.3], [4.2, 3.6], [1.7, 7.2], [7.7, 0.5], [5.5, 2.1],[4.2, 5.2], [3.9, 4.9],[4.2, 4.4], [4.0, 5.9], [4.3, 3.4], [7.0, 1.0], [7.6, 0.8], [7.3, 0.1], [5.6, 3.0], [6.4, 3.0],[-0.0, 9.1], [2.9, 6.7],[4.4, 3.6], [6.4, 2.2], [5.3, 3.2], [5.7, 2.7], [6.5, 1.5], [7.4, 1.1], [6.2, 2.1], [5.6, 1.4],[5.7, 2.0], [3.0, 5.2],[4.5, 5.6], [6.8, 1.7], [6.5, 1.3], [4.2, 4.5], [3.3, 6.5], [2.7, 5.2], [5.8, 3.5], [7.8, 0.9],[5.5, 3.0], [1.2, 8.0],[4.2, 4.2], [0.9, 8.6], [7.0, 1.0], [0.2, 9.6], [5.9, 3.0], [2.3, 6.5], [3.3, 5.1], [5.9, 2.2],[6.8, 1.7], [4.6, 3.8],[6.3, 1.3], [1.2, 8.4], [6.8, 1.6], [5.0, 2.3], [7.4, 0.1], [3.1, 5.9], [4.9, 3.8], [1.8, 7.5],[7.9, 0.3], [2.8, 5.2],[2.4, 7.2], [4.0, 4.0], [6.8, 1.7], [6.6, 1.9], [4.9, 4.4], [6.4, 2.9], [7.3, 0.7], [2.1, 7.6],[1.9, 7.7], [0.7, 9.2],[3.7, 4.8], [0.5, 8.9], [4.8, 4.4], [5.7, 2.7], [4.0, 3.8], [6.1, 1.6], [6.7, 0.3], [0.3, 8.5],[5.3, 1.7], [2.9, 5.6],[0.9, 7.8], [2.9, 6.5], [0.2, 8.8], [8.0, 0.7], [1.8, 6.7], [3.0, 6.0], [5.0, 3.7], [2.8, 5.3],[4.2, 5.2], [4.5, 5.2],[8.1, 0.6], [4.4, 3.9], [7.3, 1.4], [5.7, 2.0], [1.9, 7.2], [3.5, 4.4], [4.4, 4.4], [2.6, 6.3],[6.0, 2.9], [2.5, 7.1],[6.0, 2.3], [6.5, 1.2], [0.3, 9.6], [2.3, 6.6], [7.6, 0.4], [0.2, 9.3], [1.1, 8.7], [3.5, 5.2],[7.0, 2.0], [6.5, 2.1],[7.8, 0.6], [4.1, 4.3], [1.2, 8.9], [1.0, 8.9], [5.6, 3.4], [5.6, 2.0], [4.7, 3.3], [7.7, 0.8],[7.4, 1.4], [3.2, 4.9],[4.8, 3.9], [5.6, 2.8], [1.4, 8.7], [2.4, 7.2], [8.0, 0.3], [4.9, 3.8], [2.3, 6.9], [5.8, 2.7],[1.9, 7.0], [5.0, 2.9],[2.2, 7.4], [6.1, 2.6], [6.7, 1.0], [4.6, 3.6], [7.9, 0.2], [3.1, 5.8], [4.7, 4.1], [1.5, 8.1],[2.3, 7.0], [4.2, 5.0],[5.6, 2.2], [5.9, 2.6], [3.3, 4.8], [2.5, 5.6], [2.1, 7.5], [0.8, 7.4], [6.2, 2.6], [4.2, 3.8],[0.8, 8.3], [4.5, 4.1],[6.2, 2.0], [7.8, 1.0], [2.6, 6.0], [4.2, 4.2], [1.6, 7.8], [4.1, 4.2], [5.8, 2.7], [4.0, 5.8],[0.9, 7.8], [6.7, 1.6],[0.2, 8.2], [1.1, 7.7], [2.1, 7.1], [6.0, 2.8], [4.0, 4.9], [7.5, 1.6], [6.1, 1.7], [3.5, 5.9],[6.3, 1.6], [8.0, 0.3],[5.4, 2.6], [7.6, 0.2], [5.8, 2.9], [1.9, 6.6], [0.4, 8.2], [5.7, 2.1], [3.2, 6.2], [5.2, 3.5],[7.6, 0.2], [1.8, 7.3],[0.5, 8.4], [5.5, 3.6], [5.2, 3.4], [6.0, 2.3], [5.0, 3.8], [3.3, 5.5], [7.4, 1.3], [4.2, 4.3],[2.4, 7.0], [2.1, 6.5],[7.7, 0.7], [5.6, 2.7], [6.3, 1.4], [5.3, 2.0], [0.4, 8.5], [2.0, 7.7], [5.8, 3.8], [4.3, 4.5],[0.9, 8.9], [3.7, 4.7],[7.0, 1.5], [6.2, 2.0], [2.5, 6.2], [3.8, 5.5], [1.8, 8.4], [3.3, 5.5], [7.9, 0.4], [1.9, 7.8],[5.6, 3.1], [7.9, 0.6],[4.8, 3.7], [5.1, 3.9], [6.9, 1.3], [3.3, 5.8], [3.8, 5.1], [5.3, 3.5], [1.3, 7.8], [0.8, 8.2],[1.9, 7.8], [4.9, 3.6],[6.8, 2.4], [7.5, 0.2], [4.8, 3.3], [3.9, 4.4], [4.3, 4.2], [6.2, 1.9], [7.2, 0.8], [2.7, 6.0],[1.1, 7.7], [7.0, 0.1],[0.8, 7.3], [5.6, 3.5], [0.8, 8.1], [4.7, 3.8], [3.9, 4.5], [4.7, 3.2], [1.3, 7.7], [7.2, 0.8],[4.2, 4.0], [1.2, 8.9]]# 将 point1 分割为训练集和测试集
random.shuffle(point) # 随机打乱数据
split_index = int(0.1 * len(point)) # 取前 10% 的数据作为测试集 # 划分数据集
train_point = point[split_index:] # 训练集包含 90% 的数据
test_point = point[:split_index] # 测试集为前 10% 的数据 # 将训练集和测试集的数据分别提取为特征和目标
x_train = np.array([point[0] for point in train_point]) # 训练特征
y_train = np.array([point[1] for point in train_point]) # 训练目标 x_test = np.array([point[0] for point in test_point]) # 测试特征
y_test = np.array([point[1] for point in test_point]) # 测试目标 # 转换为PyTorch的张量
x_train = torch.from_numpy(x_train).float() # 将训练特征转换为浮点型张量
y_train = torch.from_numpy(y_train).float() # 将训练目标转换为浮点型张量 # 定义前向模型
class ModelClass(nn.Module): def __init__(self): super().__init__() # 定义网络层 self.layer1 = nn.Linear(1, 8) # 第一个线性层,输入为1维,输出为8维 self.layer2 = nn.Linear(8, 1) # 第二个线性层,输入为8维,输出为1维 def forward(self, x): # 前向传播函数 x = torch.tanh(self.layer1(x)) # 第一个层的输出应用tanh激活函数 x = self.layer2(x) # 经过第二个层 return x # 实例化模型
model = ModelClass() # 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=0.01) # Adam优化器 # 初始化绘图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6)) # 创建绘图窗口,包含两个子图 # 开始迭代
step_list = [] # 用于存储训练的步骤
loss_list = [] # 用于存储训练损失
test_step_list = [] # 用于存储测试的步骤
test_loss_list = [] # 用于存储测试损失 for n in range(1, 2001): # 训练迭代2000轮 # 前向传播 y_pred = model(x_train.unsqueeze(1)) # 将训练输入传入模型,reshape为合适维度 # 计算损失 loss = criterion(y_pred.squeeze(1), y_train) # 计算模型预测值与真实值之间的损失 # 反向传播和优化 optimizer.zero_grad() # 清除之前的梯度 loss.backward() # 计算当前损失的梯度 optimizer.step() # 更新模型参数 # 更新右侧的损失图数据并绘制 step_list.append(n) # 记录当前步数 loss_list.append(loss.detach()) # 记录当前损失值 # 显示频率设置 if n % 100 == 0 or n == 1: # 每100步输出一次损失值 print(n, loss.item()) # 打印当前步数和损失值 # 绘制左侧的拟合图 ax1.clear() # 清除当前图 ax1.set_xlim(0, 10) # 设置x轴范围 ax1.set_ylim(0, 10) # 设置y轴范围 ax1.set_xlabel("x axis label") # x轴标签 ax1.set_ylabel("y axis label") # y轴标签 ax1.scatter(x_train, y_train) # 绘制训练数据点 x_range = torch.tensor(np.arange(0, 10, 0.1)).unsqueeze(1).float() # 生成预测输入范围 y_range = model(x_range).detach().numpy() # 计算拟合线的预测输出 ax1.plot(x_range, y_range, 'r') # 绘制拟合线 # 计算测试集损失 y_pred_test = model(torch.tensor(x_test).unsqueeze(1).float()) # 模型对测试集进行预测 loss_test = criterion(y_pred_test.squeeze(1), torch.from_numpy(y_test).float()) # 计算测试集损失 test_step_list.append(n) # 记录测试步数 test_loss_list.append(loss_test.detach()) # 记录测试损失 ax2.clear() # 清除当前测试损失图 ax2.plot(step_list, loss_list, 'r-', label='Train Loss') # 绘制训练损失 ax2.plot(test_step_list, test_loss_list, 'b-', label='Test Loss') # 绘制测试集损失 ax2.set_xlabel("Step") # x轴标签 ax2.set_ylabel("Loss") # y轴标签 ax2.legend() # 显示图例 plt.show() # 显示绘图窗口 三、曲线回归
3.1定义
曲线回归是一种用于拟合非线性关系的回归分析方法。与线性回归不同,曲线回归允许因变量与自变量之间存在更复杂的关系。常见的曲线回归形式包括多项式回归、指数回归和对数回归等。在多项式回归中,我们可以通过引入高次项来扩展模型的灵活性
常见模型
多项式回归:用于拟合二次或更高次的曲线,例如二次曲线
逻辑回归:虽然名字中有“回归”,逻辑回归实际上是用于分类问题的模型。
指数回归与对数回归:用于处理特定类型的数据关系,比如指数增长数据或对数增长数据。
3.2、设计思路
输入数据
point = [[0.5, 8.6], [0.5, 9.3], [0.6, 8.9], [0.6, 8.3], [0.6, 8.0], [0.7, 7.8], [0.7, 8.9], [0.7, 9.7],[0.7, 9.1], [0.8, 9.2],[0.8, 8.5], [0.8, 8.4], [0.9, 8.8], [0.9, 8.6], [0.9, 8.2], [1.0, 8.2], [1.0, 6.6], [1.0, 6.3],[1.0, 6.9], [1.1, 7.1],[1.1, 7.7], [1.1, 6.5], [1.2, 7.0], [1.2, 7.7], [1.2, 6.1], [1.3, 7.7], [1.3, 6.5], [1.3, 6.9],[1.3, 5.3], [1.4, 5.7],[1.4, 5.8], [1.4, 5.6], [1.5, 6.8], [1.5, 6.7], [1.5, 6.6], [1.6, 3.6], [1.6, 5.3], [1.6, 6.9],[1.6, 5.9], [1.7, 6.0],[1.7, 4.7], [1.7, 5.0], [1.8, 4.5], [1.8, 5.6], [1.8, 4.2], [1.9, 3.8], [1.9, 4.5], [1.9, 5.8],[1.9, 6.7], [2.0, 6.5],[2.0, 6.3], [2.0, 4.9], [2.1, 5.9], [2.1, 3.6], [2.1, 3.8], [2.2, 4.8], [2.2, 4.3], [2.2, 4.6],[2.2, 4.1], [2.3, 3.5],[2.3, 2.9], [2.3, 4.4], [2.4, 4.5], [2.4, 3.6], [2.4, 4.3], [2.5, 5.0], [2.5, 2.3], [2.5, 4.4],[2.5, 6.0], [2.6, 3.4],[2.6, 3.6], [2.6, 3.6], [2.7, 4.9], [2.7, 3.6], [2.7, 5.1], [2.8, 5.1], [2.8, 3.5], [2.8, 2.0],[2.8, 3.7], [2.9, 2.5],[2.9, 3.3], [2.9, 2.8], [3.0, 2.5], [3.0, 1.4], [3.0, 4.1], [3.1, 2.8], [3.1, 4.1], [3.1, 2.2],[3.1, 3.1], [3.2, 3.2],[3.2, 3.0], [3.2, 3.7], [3.3, 3.7], [3.3, 2.9], [3.3, 4.0], [3.4, 2.7], [3.4, 3.0], [3.4, 2.3],[3.4, 1.8], [3.5, 3.4],[3.5, 3.9], [3.5, 3.1], [3.6, 3.1], [3.6, 2.4], [3.6, 2.1], [3.7, 2.3], [3.7, 1.3], [3.7, 2.7],[3.8, 2.0], [3.8, 2.2],[3.8, 3.0], [3.8, 2.0], [3.9, 3.1], [3.9, 1.9], [3.9, 0.0], [4.0, 1.6], [4.0, 1.9], [4.0, 1.8],[4.1, 2.6], [4.1, 2.0],[4.1, 1.2], [4.1, 2.5], [4.2, 2.0], [4.2, 0.1], [4.2, 1.7], [4.3, 1.2], [4.3, 2.4], [4.3, 2.1],[4.4, 1.3], [4.4, 1.0],[4.4, 1.6], [4.4, 2.8], [4.5, 2.8], [4.5, 2.1], [4.5, 1.9], [4.6, 3.0], [4.6, 2.3], [4.6, 2.3],[4.7, 3.0], [4.7, 0.4],[4.7, 1.6], [4.7, 1.1], [4.8, 2.6], [4.8, 2.9], [4.8, 2.9], [4.9, 2.5], [4.9, 2.4], [4.9, 1.9],[5.0, 1.9], [5.0, 2.9],[5.0, 1.4], [5.0, 2.0], [5.1, 3.4], [5.1, 2.5], [5.1, 1.7], [5.2, 2.7], [5.2, 2.2], [5.2, 1.9],[5.3, 1.5], [5.3, 2.6],[5.3, 1.9], [5.3, 1.2], [5.4, 2.2], [5.4, 2.6], [5.4, 1.2], [5.5, 1.8], [5.5, 2.4], [5.5, 3.0],[5.6, 2.7], [5.6, 3.6],[5.6, 2.2], [5.6, 2.4], [5.7, 2.2], [5.7, 3.3], [5.7, 2.2], [5.8, 3.0], [5.8, 0.9], [5.8, 2.6],[5.9, 2.5], [5.9, 1.5],[5.9, 2.4], [5.9, 2.1], [6.0, 2.2], [6.0, 1.7], [6.0, 2.8], [6.1, 1.4], [6.1, 2.5], [6.1, 2.0],[6.2, 2.5], [6.2, 2.5],[6.2, 1.0], [6.2, 2.4], [6.3, 1.1], [6.3, 2.9], [6.3, 3.5], [6.4, 2.3], [6.4, 5.0], [6.4, 2.8],[6.5, 1.5], [6.5, 4.0],[6.5, 3.6], [6.6, 3.8], [6.6, 2.7], [6.6, 2.6], [6.6, 2.1], [6.7, 3.1], [6.7, 3.6], [6.7, 3.5],[6.8, 2.7], [6.8, 3.0],[6.8, 2.5], [6.9, 2.9], [6.9, 3.9], [6.9, 3.6], [6.9, 3.4], [7.0, 3.4], [7.0, 3.4], [7.0, 4.5],[7.1, 3.9], [7.1, 4.6],[7.1, 4.4], [7.2, 4.1], [7.2, 3.2], [7.2, 2.7], [7.2, 4.2], [7.3, 4.1], [7.3, 5.7], [7.3, 3.7],[7.4, 3.0], [7.4, 4.0],[7.4, 3.9], [7.5, 4.3], [7.5, 3.5], [7.5, 4.4], [7.5, 6.2], [7.6, 4.0], [7.6, 5.7], [7.6, 6.6],[7.7, 6.1], [7.7, 5.4],[7.7, 2.5], [7.8, 5.6], [7.8, 4.1], [7.8, 5.9], [7.8, 5.1], [7.9, 4.5], [7.9, 5.1], [7.9, 5.5],[8.0, 5.8], [8.0, 5.0],[8.0, 6.0], [8.1, 5.8], [8.1, 5.9], [8.1, 5.6], [8.1, 5.2], [8.2, 4.0], [8.2, 6.4], [8.2, 4.5],[8.3, 6.2], [8.3, 5.7],[8.3, 5.3], [8.4, 4.9], [8.4, 6.9], [8.4, 5.0], [8.4, 7.4], [8.5, 5.0], [8.5, 7.5], [8.5, 7.1],[8.6, 6.4], [8.6, 6.0],[8.6, 7.5], [8.7, 5.8], [8.7, 7.7], [8.7, 6.2], [8.7, 6.6], [8.8, 6.2], [8.8, 8.1], [8.8, 7.7],[8.9, 7.4], [8.9, 8.2],[8.9, 7.4], [9.0, 7.6], [9.0, 6.7], [9.0, 7.7], [9.0, 8.2], [9.1, 7.7], [9.1, 9.2], [9.1, 9.1],[9.2, 8.5], [9.2, 7.4],[9.2, 8.5], [9.3, 9.2], [9.3, 8.3], [9.3, 9.7], [9.3, 8.5], [9.4, 8.2], [9.4, 9.9], [9.4, 8.5],[9.5, 9.9], [9.5, 8.7]]划分训练集和测试集
# 将 point1 分割为训练集和测试集
random.shuffle(point) # 随机打乱数据
split_index = int(0.1 * len(point)) # 取前 10% 的数据作为测试集train_point = point[split_index:]
test_point = point[:split_index]x_train = np.array([point[0] for point in train_point])
y_train = np.array([point[1] for point in train_point])x_test = np.array([point[0] for point in test_point])
y_test = np.array([point[1] for point in test_point])
转换为Tensor张量
x_train = torch.from_numpy(x_train).float()
y_train = torch.from_numpy(y_train).float()构建模型
class ModelClass(nn.Module):def __init__(self):super().__init__()self.layer1 = nn.Linear(1, 8)self.layer2 = nn.Linear(8, 1)def forward(self, x):x = torch.tanh(self.layer1(x))x = self.layer2(x)return xmodel = ModelClass()构建损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=0.01)模型训练
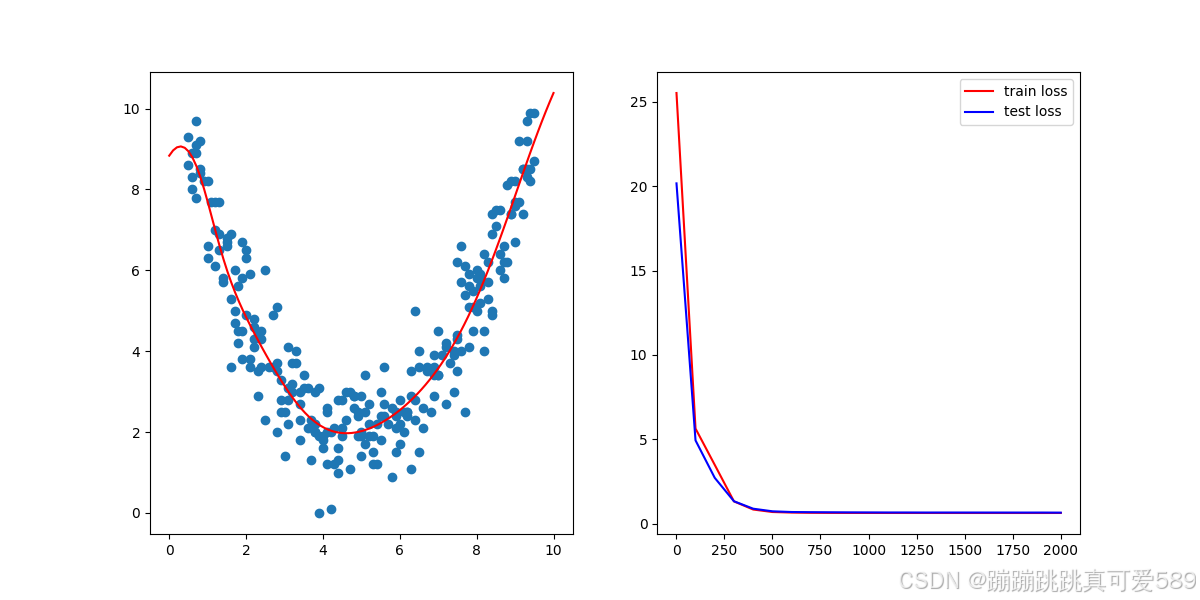
for n in range(1, 2001):# 前向传播y_pred = model(x_train.unsqueeze(1))# 计算损失loss = criterion(y_pred.squeeze(1), y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()if n % 100 == 0 or n == 1:print(n,loss.item())可视化
step_list = []
loss_list = []
test_step_list = []
test_loss_list = []for n in range(1, 2001):# 前向传播y_pred = model(x_train.unsqueeze(1))# 计算损失loss = criterion(y_pred.squeeze(1), y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 更新右侧的损失图数据并绘制step_list.append(n)loss_list.append(loss.detach())# 显示频率设置if n % 100 == 0 or n == 1:print(n,loss.item())# 绘制左侧的拟合图ax1.clear()ax1.set_xlim(0, 10)ax1.set_ylim(0, 10)ax1.set_xlabel("x axis label")ax1.set_ylabel("y axis label")ax1.scatter(x_train, y_train)x_range = torch.tensor(np.arange(0, 10, 0.1)).unsqueeze(1).float()y_range = model(x_range).detach().numpy()ax1.plot(x_range, y_range, 'r') # 绘制拟合线# 计算测试集损失y_pred_test = model(torch.tensor(x_test).unsqueeze(1).float())loss_test = criterion(y_pred_test.squeeze(1), torch.from_numpy(y_test).float())test_step_list.append(n)test_loss_list.append(loss_test.detach())ax2.clear()ax2.plot(step_list, loss_list, 'r-', label='Train Loss')ax2.plot(test_step_list, test_loss_list, 'b-', label='Test Loss') # 绘制测试集损失ax2.set_xlabel("Step")ax2.set_ylabel("Loss")ax2.legend()
plt.show()完整代码
import numpy as np
import torch
import random
import torch.nn as nn
import matplotlib.pyplot as plt# 创造数据,数据集
point = [[0.5, 8.6], [0.5, 9.3], [0.6, 8.9], [0.6, 8.3], [0.6, 8.0], [0.7, 7.8], [0.7, 8.9], [0.7, 9.7],[0.7, 9.1], [0.8, 9.2],[0.8, 8.5], [0.8, 8.4], [0.9, 8.8], [0.9, 8.6], [0.9, 8.2], [1.0, 8.2], [1.0, 6.6], [1.0, 6.3],[1.0, 6.9], [1.1, 7.1],[1.1, 7.7], [1.1, 6.5], [1.2, 7.0], [1.2, 7.7], [1.2, 6.1], [1.3, 7.7], [1.3, 6.5], [1.3, 6.9],[1.3, 5.3], [1.4, 5.7],[1.4, 5.8], [1.4, 5.6], [1.5, 6.8], [1.5, 6.7], [1.5, 6.6], [1.6, 3.6], [1.6, 5.3], [1.6, 6.9],[1.6, 5.9], [1.7, 6.0],[1.7, 4.7], [1.7, 5.0], [1.8, 4.5], [1.8, 5.6], [1.8, 4.2], [1.9, 3.8], [1.9, 4.5], [1.9, 5.8],[1.9, 6.7], [2.0, 6.5],[2.0, 6.3], [2.0, 4.9], [2.1, 5.9], [2.1, 3.6], [2.1, 3.8], [2.2, 4.8], [2.2, 4.3], [2.2, 4.6],[2.2, 4.1], [2.3, 3.5],[2.3, 2.9], [2.3, 4.4], [2.4, 4.5], [2.4, 3.6], [2.4, 4.3], [2.5, 5.0], [2.5, 2.3], [2.5, 4.4],[2.5, 6.0], [2.6, 3.4],[2.6, 3.6], [2.6, 3.6], [2.7, 4.9], [2.7, 3.6], [2.7, 5.1], [2.8, 5.1], [2.8, 3.5], [2.8, 2.0],[2.8, 3.7], [2.9, 2.5],[2.9, 3.3], [2.9, 2.8], [3.0, 2.5], [3.0, 1.4], [3.0, 4.1], [3.1, 2.8], [3.1, 4.1], [3.1, 2.2],[3.1, 3.1], [3.2, 3.2],[3.2, 3.0], [3.2, 3.7], [3.3, 3.7], [3.3, 2.9], [3.3, 4.0], [3.4, 2.7], [3.4, 3.0], [3.4, 2.3],[3.4, 1.8], [3.5, 3.4],[3.5, 3.9], [3.5, 3.1], [3.6, 3.1], [3.6, 2.4], [3.6, 2.1], [3.7, 2.3], [3.7, 1.3], [3.7, 2.7],[3.8, 2.0], [3.8, 2.2],[3.8, 3.0], [3.8, 2.0], [3.9, 3.1], [3.9, 1.9], [3.9, 0.0], [4.0, 1.6], [4.0, 1.9], [4.0, 1.8],[4.1, 2.6], [4.1, 2.0],[4.1, 1.2], [4.1, 2.5], [4.2, 2.0], [4.2, 0.1], [4.2, 1.7], [4.3, 1.2], [4.3, 2.4], [4.3, 2.1],[4.4, 1.3], [4.4, 1.0],[4.4, 1.6], [4.4, 2.8], [4.5, 2.8], [4.5, 2.1], [4.5, 1.9], [4.6, 3.0], [4.6, 2.3], [4.6, 2.3],[4.7, 3.0], [4.7, 0.4],[4.7, 1.6], [4.7, 1.1], [4.8, 2.6], [4.8, 2.9], [4.8, 2.9], [4.9, 2.5], [4.9, 2.4], [4.9, 1.9],[5.0, 1.9], [5.0, 2.9],[5.0, 1.4], [5.0, 2.0], [5.1, 3.4], [5.1, 2.5], [5.1, 1.7], [5.2, 2.7], [5.2, 2.2], [5.2, 1.9],[5.3, 1.5], [5.3, 2.6],[5.3, 1.9], [5.3, 1.2], [5.4, 2.2], [5.4, 2.6], [5.4, 1.2], [5.5, 1.8], [5.5, 2.4], [5.5, 3.0],[5.6, 2.7], [5.6, 3.6],[5.6, 2.2], [5.6, 2.4], [5.7, 2.2], [5.7, 3.3], [5.7, 2.2], [5.8, 3.0], [5.8, 0.9], [5.8, 2.6],[5.9, 2.5], [5.9, 1.5],[5.9, 2.4], [5.9, 2.1], [6.0, 2.2], [6.0, 1.7], [6.0, 2.8], [6.1, 1.4], [6.1, 2.5], [6.1, 2.0],[6.2, 2.5], [6.2, 2.5],[6.2, 1.0], [6.2, 2.4], [6.3, 1.1], [6.3, 2.9], [6.3, 3.5], [6.4, 2.3], [6.4, 5.0], [6.4, 2.8],[6.5, 1.5], [6.5, 4.0],[6.5, 3.6], [6.6, 3.8], [6.6, 2.7], [6.6, 2.6], [6.6, 2.1], [6.7, 3.1], [6.7, 3.6], [6.7, 3.5],[6.8, 2.7], [6.8, 3.0],[6.8, 2.5], [6.9, 2.9], [6.9, 3.9], [6.9, 3.6], [6.9, 3.4], [7.0, 3.4], [7.0, 3.4], [7.0, 4.5],[7.1, 3.9], [7.1, 4.6],[7.1, 4.4], [7.2, 4.1], [7.2, 3.2], [7.2, 2.7], [7.2, 4.2], [7.3, 4.1], [7.3, 5.7], [7.3, 3.7],[7.4, 3.0], [7.4, 4.0],[7.4, 3.9], [7.5, 4.3], [7.5, 3.5], [7.5, 4.4], [7.5, 6.2], [7.6, 4.0], [7.6, 5.7], [7.6, 6.6],[7.7, 6.1], [7.7, 5.4],[7.7, 2.5], [7.8, 5.6], [7.8, 4.1], [7.8, 5.9], [7.8, 5.1], [7.9, 4.5], [7.9, 5.1], [7.9, 5.5],[8.0, 5.8], [8.0, 5.0],[8.0, 6.0], [8.1, 5.8], [8.1, 5.9], [8.1, 5.6], [8.1, 5.2], [8.2, 4.0], [8.2, 6.4], [8.2, 4.5],[8.3, 6.2], [8.3, 5.7],[8.3, 5.3], [8.4, 4.9], [8.4, 6.9], [8.4, 5.0], [8.4, 7.4], [8.5, 5.0], [8.5, 7.5], [8.5, 7.1],[8.6, 6.4], [8.6, 6.0],[8.6, 7.5], [8.7, 5.8], [8.7, 7.7], [8.7, 6.2], [8.7, 6.6], [8.8, 6.2], [8.8, 8.1], [8.8, 7.7],[8.9, 7.4], [8.9, 8.2],[8.9, 7.4], [9.0, 7.6], [9.0, 6.7], [9.0, 7.7], [9.0, 8.2], [9.1, 7.7], [9.1, 9.2], [9.1, 9.1],[9.2, 8.5], [9.2, 7.4],[9.2, 8.5], [9.3, 9.2], [9.3, 8.3], [9.3, 9.7], [9.3, 8.5], [9.4, 8.2], [9.4, 9.9], [9.4, 8.5],[9.5, 9.9], [9.5, 8.7]]# 将 point1 分割为训练集和测试集
random.shuffle(point) # 随机打乱数据
split_index = int(0.1 * len(point)) # 取前 10% 的数据作为测试集 # 划分数据集
train_point = point[split_index:] # 训练集包含 90% 的数据
test_point = point[:split_index] # 测试集为前 10% 的数据 # 将训练集和测试集的数据分别提取为特征和目标
x_train = np.array([point[0] for point in train_point]) # 训练特征
y_train = np.array([point[1] for point in train_point]) # 训练目标 x_test = np.array([point[0] for point in test_point]) # 测试特征
y_test = np.array([point[1] for point in test_point]) # 测试目标 # 转换为PyTorch的张量
x_train = torch.from_numpy(x_train).float() # 将训练特征转换为浮点型张量
y_train = torch.from_numpy(y_train).float() # 将训练目标转换为浮点型张量 # 定义前向模型
class ModelClass(nn.Module): def __init__(self): super().__init__() # 定义网络层 self.layer1 = nn.Linear(1, 8) # 第一个线性层,输入为1维,输出为8维 self.layer2 = nn.Linear(8, 1) # 第二个线性层,输入为8维,输出为1维 def forward(self, x): # 前向传播函数 x = torch.tanh(self.layer1(x)) # 第一个层的输出应用tanh激活函数 x = self.layer2(x) # 经过第二个层 return x # 实例化模型
model = ModelClass() # 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=0.01) # Adam优化器 # 初始化绘图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6)) # 创建绘图窗口,包含两个子图 # 开始迭代
step_list = [] # 用于存储训练的步骤
loss_list = [] # 用于存储训练损失
test_step_list = [] # 用于存储测试的步骤
test_loss_list = [] # 用于存储测试损失 for n in range(1, 2001): # 训练迭代2000轮 # 前向传播 y_pred = model(x_train.unsqueeze(1)) # 将训练输入传入模型,reshape为合适维度 # 计算损失 loss = criterion(y_pred.squeeze(1), y_train) # 计算模型预测值与真实值之间的损失 # 反向传播和优化 optimizer.zero_grad() # 清除之前的梯度 loss.backward() # 计算当前损失的梯度 optimizer.step() # 更新模型参数 # 更新右侧的损失图数据并绘制 step_list.append(n) # 记录当前步数 loss_list.append(loss.detach()) # 记录当前损失值 # 显示频率设置 if n % 100 == 0 or n == 1: # 每100步输出一次损失值 print(n, loss.item()) # 打印当前步数和损失值 # 绘制左侧的拟合图 ax1.clear() # 清除当前图 ax1.set_xlim(0, 10) # 设置x轴范围 ax1.set_ylim(0, 10) # 设置y轴范围 ax1.set_xlabel("x axis label") # x轴标签 ax1.set_ylabel("y axis label") # y轴标签 ax1.scatter(x_train, y_train) # 绘制训练数据点 x_range = torch.tensor(np.arange(0, 10, 0.1)).unsqueeze(1).float() # 生成预测输入范围 y_range = model(x_range).detach().numpy() # 计算拟合线的预测输出 ax1.plot(x_range, y_range, 'r') # 绘制拟合线 # 计算测试集损失 y_pred_test = model(torch.tensor(x_test).unsqueeze(1).float()) # 模型对测试集进行预测 loss_test = criterion(y_pred_test.squeeze(1), torch.from_numpy(y_test).float()) # 计算测试集损失 test_step_list.append(n) # 记录测试步数 test_loss_list.append(loss_test.detach()) # 记录测试损失 ax2.clear() # 清除当前测试损失图 ax2.plot(step_list, loss_list, 'r-', label='Train Loss') # 绘制训练损失 ax2.plot(test_step_list, test_loss_list, 'b-', label='Test Loss') # 绘制测试集损失 ax2.set_xlabel("Step") # x轴标签 ax2.set_ylabel("Loss") # y轴标签 ax2.legend() # 显示图例 plt.show() # 显示绘图窗口 相关文章:
)
Python----深度学习(基于深度学习Pytroch线性回归和曲线回归)
一、引言 在当今数据驱动的时代,深度学习已成为解决复杂问题的有力工具。它广泛应用于图像识别、自然语言处理和预测分析等领域。回归分析是统计学的一种基础方法,用于描述变量之间的关系。通过回归模型,我们可以预测连续的数值输出…...

重构智能场景:艾博连携手智谱,共拓智能座舱AI应用新范式
2025年4月24日,智能座舱领域创新企业艾博连科技与国产大模型独角兽智谱,在上海国际车展艾博连会客厅签署合作协议。双方宣布将深度整合智谱在AI大模型领域的技术积淀与艾博连在汽车智能座舱场景的落地经验,共同推进下一代"有温度、懂需求…...

Streamlit从入门到精通:构建数据应用的利器
在数据科学与机器学习日益普及的今天,如何快速将模型部署为可交互的应用成为了许多数据科学家的重要任务。Streamlit,作为一个开源的Python库,专为数据科学家设计,能够帮助我们轻松构建美观且直观的Web应用。本文将从入门到精通&a…...
)
4.1.1 类的序列化与反序列化(XmlSerializer)
本文介绍XML序列化和反序列化操作 本例子中被序列化的类(Devices)中有一个List,其元素类型为:DigitalInputInfo. 序列化以及反序列化都很简单: 序列化:即把类的对象输出到文件中。 StreamWriter streamWriter new StreamWriter(filePath); …...

新增优惠券
文章目录 概要整体架构流程技术细节小结 概要 接口分析 一个基本的新增接口,按照Restful风格设计即可,关键是请求参数。之前表分析时已经详细介绍过这个页面及其中的字段,这里不再赘述。 需要特别注意的是,如果优惠券限定了使…...

Qt 处理 XML 数据
在 Qt 中,处理 XML 数据通常使用 Qt 提供的 QDomDocument、QXmlStreamReader 和 QXmlStreamWriter 类。这些类可以帮助你读取、修改和写入 XML 数据。 1. 使用 QDomDocument 处理 XML QDomDocument 提供了对 XML 文档的 DOM(Document Object Model&…...
)
STM32F407使用ESP8266实现阿里云OTA(下)
文章目录 前言一、函数分析1.get_bin()函数2.download_bin()函数3.串口1中断函数二、完整工程分析前言 从上一章中,我们已经成功连接阿里云并且成功拿到了升级包的下载地址,在本文我们将升级包下载下来并且存储到SD卡中,最终将程序写入FLASH中完成APP的跳转,至此我们的OTA…...
)
树型结构(知识点梳理及例题精讲)
大家好啊,这一集,我们来学习树型结构,请确保看完预习篇,再来看此篇哦 树型结构(预习课)-CSDN博客 话不多说,直接开讲 -------------------------------------------------------分割线-------…...

使用HYPRE库并行装配IJ稀疏矩阵指南: 矩阵预分配和重复利用
使用HYPRE库并行装配IJ稀疏矩阵指南 HYPRE是一个流行的并行求解器库,特别适合大规模稀疏线性系统的求解。下面介绍如何并行装配IJ格式的稀疏矩阵,包括预先分配矩阵空间和循环使用。 1. 初始化矩阵 首先需要创建并初始化一个IJ矩阵: #incl…...

win11什么都不动之后一段时间黑屏桌面无法显示,但鼠标仍可移动,得要熄屏之后才能进入的四种解决方法
现象: 1. 当时新建运行的资源管理器的任务卡了或者原本资源管理器卡了 比如:当时在文本框中输入explorer 注:explorer.exe是Windows的文件资源管理器,它用于管理Windows的图形外壳,包括桌面和文件管理 按住CtrlAltEs…...

C语言编程--15.四数之和
题目: 给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复)&…...

从单机工具到协同平台:开源交互式模拟环境的技术演进之路
从单机工具到协同平台:开源交互式模拟环境的技术演进之路 一、引言:从“孤岛”到“生态”的模拟技术变革 二十年前,模拟软件如LAMMPS(分子动力学)、ANSYS(工程仿真)以单机版为主,用…...

Python函数与模块笔记
Python函数与模块笔记 目录 函数 无参函数带参函数变量作用域Lambda函数常用内置函数 模块与包 模块的定义与导入包的使用常用模块(keyword、random、sys、time) 一、函数 1. 无参函数 定义语法: def 函数名(): 代码块 return [表达式]…...

Jenkins:开启高效软件开发的魔法之门
一、Jenkins 是什么 Jenkins 是一款基于 Java 开发的开源持续集成工具,在软件开发流程中占据着举足轻重的地位。它的前身是 Hudson ,于 2004 年由 Sun 公司的 Kohsuke Kawaguchi 开发,2011 年因商标纠纷更名为 Jenkins。发展至今,…...

正则表达式学习指南
正则表达式学习指南 在编程的世界里,正则表达式(Regular Expressions,简称regex)是一门不可或缺的艺术,它赋予了开发者强大的文本处理能力,让看似复杂的字符串匹配和替换任务变得简单而高效。本文旨在为初…...

React-组件通信
1、父子组件通信 (1)父传子(props 传值) // 父组件 function App() {const name 张三return (<div className"App"><Son name{name} /></div>); }// 子组件 function Son(props) {return (<div…...
)
MuJoCo 机械臂 PPO 强化学习逆向运动学(IK)
视频讲解: MuJoCo 机械臂 PPO 强化学习逆向运动学(IK) 代码仓库:https://github.com/LitchiCheng/mujoco-learning 结合上期视频,我们安装了stable_baselines3和gym,今天用PPO尝试强化学习得到关节空间到达…...

代码随想录算法训练营第一天:数组part1
今日学习的文章链接和视频链接 ● 自己看到题目的第一想法 ● 看完代码随想录之后的想法 ● 自己实现过程中遇到哪些困难 ● 今日收获,记录一下自己的学习时长 状态 思路理解完成 30% 代码debug完成 60% 代码模板总结并抽象出来 100% 题目 704 二分查找 题目链接…...
排序与变序算法)
C++学习:六个月从基础到就业——STL算法(二)排序与变序算法
C学习:六个月从基础到就业——STL算法(二)排序与变序算法 本文是我C学习之旅系列的第二十六篇技术文章,也是第二阶段"C进阶特性"的第四篇,主要介绍C STL算法库中的排序和变序算法。查看完整系列目录了解更多…...

JVM性能优化之年轻代参数设置
一、引言 在Java应用开发中,性能问题往往是最难预测却又最影响用户体验的关键因素。即便代码逻辑完美,若JVM(Java虚拟机)配置不当,也可能导致频繁GC停顿、内存泄漏,甚至引发系统崩溃。JVM性能优化并非简单…...

A*迷宫寻路
二、实验内容 以寻路问题为例实现A*算法的求解程序,设计两种不同的估价函数: 1.设置两种地图: 根据题意,用矩阵设置两个地图。 地图1:设置5行5列的迷宫,代码如下: 地图2:设置20行…...

秒出PPT推出更强版本,AI PPT工具进入新纪元!
在现代职场中,PPT是我们沟通和展示信息的重要工具。无论是做产品演示,还是准备工作汇报,一份精美的PPT能大大提升演示效果。然而,传统的PPT制作往往需要消耗大量时间,尤其是在排版、设计和内容调整上。如今,…...

electron-updater实现自动更新
electron-updater 是一个专为 Electron 应用设计的自动更新工具,能够帮助开发者轻松实现跨平台的自动更新功能。它支持 Windows、macOS 和 Linux 系统,通过简单的配置即可集成到 Electron 应用中,自动检查应用的最新版本并在后台完成更新。el…...

Ubuntu22学习记录
Ubuntu22学习记录 虚拟机挂载共享文件夹离线安装.net core3.1离线安装mysql离线安装supervisor离线安装nginx开机自启 虚拟机挂载共享文件夹 sudo vmhgfs-fuse .host:/ /mnt/hgfs -o allow_other 挂载路径:/mnt/hgfs/离线安装.net core3.1 离线安装mysql 离线安装…...
)
【MinerU】:一款将PDF转化为机器可读格式的工具——RAG加强(Docker版本)
目录 创建容器 安装miniconda 安装mineru CPU运行 GPU加速 多卡问题 创建容器 构建Dockerfile文件 开启ssh服务,设置密码为1234等操作 # 使用官方 Ubuntu 24.04 镜像 FROM ubuntu:24.04# 安装基础工具和SSH服务 RUN apt-get update && \apt-get ins…...

leetcode 69和367
69. Sqrt(x) 代码: class Solution { public:int mySqrt(int x) {int left 0;int right x;long long mid 0;int res 0;long long temp 0;while(left < right){mid left ((right - left)>>1);temp mid*mid;if(temp x){res mid;break;}else if(te…...

# 代码随想录算法训练营Day37 | Leetcode300.最长递增子序列、674.最长连续递增序列、718.最长重复子数组
代码随想录算法训练营Day37 | Leetcode300.最长递增子序列、674.最长连续递增序列、718.最长重复子数组 一、最长递增子序列 相关题目:Leetcode300 文档讲解:Leetcode300 视频讲解:Leetcode300 1. Leetcode300.最长递增子序列 给你一个整数数…...

中小企业技术跃迁:云原生后端如何实现高效低成本系统建设
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:技术变革的“门槛”能否被跨越? 过去十年,云计算与容器化技术飞速发展,互联网巨头纷纷构建自己的云原生基础设施,实现系统模块化、弹性伸缩、自动化运维。然而,中小企业在这股浪潮中…...

系统架构师2025年论文《系统架构风格2》
论软件系统架构风格 摘要: 某市医院预约挂号系统建设推广应用项目是我市卫生健康委员会 2019 年发起的一项医疗卫生行业信息化项目,目的是实现辖区内患者在辖区各公立医疗机构就诊时,可以通过多种线上渠道进行预约挂号。我作为系统架构师参与此项目。本文围绕软件系统架构…...

Java面试实战:电商场景下的Spring Cloud微服务架构与缓存技术剖析
第一轮提问 面试官: 谢飞机,我们先从基础问题开始。请问你知道Spring Boot和Spring Cloud的区别吗? 谢飞机: 当然知道!Spring Boot主要用于快速构建独立运行的Spring应用,而Spring Cloud则是在Spring Boot的基础上实现分布式系统…...

快速配置linux远程开发-go语言
1.go安装包安装 2.go env 配置 go env -w GO111MODULEon go env -w GOPROXYxx go env -w GOSUMDBoff go env -w GOPRIVATExx 3.复制linux公钥到gitlab中,用于通过ssh免密拉取gitlab项目 ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 4.设置…...

C++23文本编码革新:迈向更现代的字符处理
文章目录 一、字符集与编码(P2314R4)二、统一的字符字面量编码(P2316R2)三、具名通用字符转义(P2071R2)四、带分隔的转义序列(P2290R3)五、支持UTF-8作为可移植源文件编码࿰…...

CentOS系统中MySQL安装步骤分享
在 CentOS 系统上安装 MySQL,需要依次进行环境检查、软件源配置、安装 MySQL、启动服务等操作。我将按照规范流程,为你详细分享完整且具体的安装步骤。 在 CentOS 系统中安装 MySQL 数据库,能够为各类应用提供高效稳定的数据存储和管理服务。…...

【产品经理从0到1】Axure介绍
01. 上期内容回顾 创建元件库的时候,在添加原件时不知道怎么操作。讲解很耐心,希望课上分解步骤多带着练习下;PC 端的原型,相对于移动端,非常自由,没有任何的设计规范;但是,要求 PC…...

30天通过软考高项-第二天
30天通过软考高项-第二天 任务:项目立项管理、项目整合管理 思维导图阅读 知识点记忆 章节习题练习 知识点练习 手写回忆ITTO 立项管理-背 1. 项目可研的5个方面 基金社运法 技术可行性、经济可行性、社会效益可行性、运行环境可行性、其他(法律、政…...

yt-dlp 下载时需要 cookie
下载 b 站 歌曲 yt-dlp -x --proxy http://127.0.0.1:1080 --audio-format mp3 https://www.bilibili.com/video/BV1Zn4y1X75b解决方案,使用 firefox 登录相关网站 yt-dlp -o "downloads/%(title)s.%(ext)s" -f "bestvideo[height<1080]bestaud…...

快速上手GO的net/http包,个人学习笔记
更多个人笔记:(仅供参考,非盈利) gitee: https://gitee.com/harryhack/it_note github: https://github.com/ZHLOVEYY/IT_note 针对GO中net/http包的学习笔记 基础快速了解 创建简单的GOHTTP服务 func …...
--多文件上传)
Flask + ajax上传文件(二)--多文件上传
Flask多文件上传完整教程 本教程将详细介绍如何使用Flask实现多文件上传功能,并使用时间戳为上传文件自动命名,避免文件名冲突。 一、环境准备 确保已安装Python和Flask pip install flask项目结构 flask_upload/ ├── app.py ├── upload/ # 上传文…...

sysstat介绍以及交叉编译
文章目录 1. 工具集介绍2. 指令使用参考3. 交叉编译3.1 源码下载3.2 编译步骤 4. 工具验证4.1 将相关工具导入到设备4.2 功能验证 1. 工具集介绍 Sysstat 是一个功能强大的 Linux 系统性能监控工具包,提供实时监控和历史数据分析功能,帮助管理员优化系统…...

常见正则表达式整理与Java使用正则表达式的例子
一、常见正则表达式整理 1. 基础验证类 邮箱地址 ^[a-zA-Z0-9._%-][a-zA-Z0-9.-]\\.[a-zA-Z]{2,}$ (匹配如 userexample.com)手机号 ^1[3-9]\\\\d{9}$ (匹配国内11位手机号,如 13812345678)中文字符 ^[\u4e00-\u9fa5…...

UE5 Assimp 自用
记录一下配assimp库到ue中的过程。因为想在ue里面实现一些几何处理(虽然ue好像有相关的geo的代码),遂配置了一下assimp。 1. 编译整理生成自己所需要的文件。cmake编译,下载github 的官方的assimp-master,然后cmake都是默认的就行…...

java—12 kafka
目录 一、消息队列的优缺点 二、常用MQ 1. Kafka 2. RocketMQ 3. RabbitMQ 4. ActiveMQ 5. ZeroMQ 6. MQ选型对比 适用场景——从公司基础建设力量角度出发 适用场景——从业务场景角度出发 四、基本概念和操作 1. kafka常用术语 2. kafka常用指令 3. 单播消息&a…...

VS Code 智能代理模式:重塑开发体验
在编程领域,效率与精准度无疑是开发者们永恒的追求。而如今,VS Code 推出的智能代理模式(Agent Mode),正以前所未有的方式,彻底颠覆了传统开发流程,为程序员们带来了一场前所未有的效率革命。本…...

基于深度学习和单目测距的前车防撞及车道偏离预警系统
随着人工智能与计算机视觉技术的飞速发展,高级驾驶辅助系统(ADAS)已成为现代汽车智能化的关键标志。它不仅能有效提升行车安全,还能为自动驾驶时代的全面到来奠定坚实基础。本文深入剖析一套功能完备、基于深度学习模型的 ADAS 系统的架构与核心实现,带您领略智能驾驶背后…...

第二篇:Django配置及ORM操作
第二篇:Django配置及ORM操作 文章目录 第二篇:Django配置及ORM操作一、静态文件配置1、为什么要配置静态文件?2、如何配置静态文件?3、静态文件动态解析4、form表单默认是get请求数据 二、request对象方法初识三、pycharm链接数据…...

亚马逊英国站FBA费用重构:轻小商品迎红利期,跨境卖家如何抢占先机?
一、政策背景:成本优化成平台与卖家共同诉求 2024年4月,亚马逊英国站(Amazon.co.uk)发布近三年来力度最大的FBA费用调整方案,标志着英国电商市场正式进入精细化成本管理时代。这一决策背后,是多重因素的叠…...

算法时代的“摩西十诫”:AI治理平台重构数字戒律
一、引言 数字时代的狂飙突进中,人工智能(AI)正以颠覆性的力量重塑人类社会。从医疗诊断到金融决策,从智能制造到舆论传播,AI的触角已延伸至每个角落。 然而,斯坦福大学《2024年人工智能指数报告》揭示的…...

Kafka的ISR机制是什么?如何保证数据一致性?
一、Kafka ISR机制深度解析 1. ISR机制定义 ISR(In-Sync Replicas)是Kafka保证数据一致性的核心机制,由Leader副本(复杂读写)和Follower副本(负责备份)组成。当Follower副本的延迟超过replica.lag.time.max.ms&#…...

Flink 消费 Kafka 数据流的最佳实践
一、前言:Kafka 只是开始,消费才是关键 Kafka 提供了优雅的 Topic 管理与消息缓冲机制,但只有当 Flink 能稳定、有序、无数据丢失地消费并处理这些数据流,实时数仓系统才真正发挥作用。 本篇将围绕 Flink 如何“吃好” Kafka 数据…...

UEC++第10天|UEC++获取对象、RTTI是C++
最近在写UEC项目,这里写几个案例里的问题,还在学习阶段 1. 如何获取小鸟对象? void AFlappyBirdGameModeBase::BeginGame() { // 让管道动起来PipeActor->SetMoveSpeed();// 让小鸟开始飞行// 如何获取到小鸟对象APawn* Pawn UGameplayS…...