《深度神经网络之数据增强、模型保存、模型调用、学习率调整》
文章目录
- 前言
- 一、数据增强
- 1、什么是数据增强?
- 2、数据增强的实现方法
- (1)几何变换
- 翻转:
- 旋转:
- 平移:
- (2)颜色变换
- 亮度调整:
- 对比度调整:
- 色彩抖动:
- (3)其他变换
- 裁剪:
- 添加噪声:
- 3、在模型中的使用
- 二、模型保存
- 1、在Pytorch深度学习框架中模型的保存有两种方法
- (2)即保存了模型的权重参数,同时也将完整的模型保存到文件中
- 2、在Tensflow深度学习框架中模型的保存可以使用model.save()方法。保存的格式有多种,主要的区别也在后缀上
- (1)保存为SaveModel模式
- (2)保存为 HDF5 格式
- 3、保存最优模型
- 三、模型调用
- 1、模型调用
- (1)读取参数的方法
- (2)读取完整模型的方法,无需提前创建model
- 2、模型调用时的注意事项
- 四、学习率调整
- 1、为什么要调整学习率
- 2、学习率
- 3、三种库函数调整学习率的方法
- (1)Pytorch学习率调整策略通过 torch.optim.lr_sheduler 接口实现。并提供3种调整方法:
- 有序调整:等间隔调整(Step),多间隔调整(MultiStep),指数衰减(Exponential),余弦退火(CosineAnnealing);
- 自适应调整:依训练状况伺机而变,通过监测某个指标的变化情况(loss、accuracy),当该指标不怎么变化时,就是调整学习率的时机(ReduceLROnPlateau);
- 自定义调整:通过自定义关于epoch的lambda函数调整学习率(LambdaLR)。
- (2)有序调整StepLR(等间隔调整学习率)
- (3)有序调整MultiStepLR(多间隔调整学习率)
- (4)有序调整ExponentialLR (指数衰减调整学习率)
- (5)有序调整CosineAnnealing (余弦退火函数调整学习率)
- (6)自适应调整ReduceLROnPlateau (根据指标调整学习率)
- (7)自定义调整LambdaLR (自定义调整学习率)
- 4、学习率调整在模型中使用位置
- 五、完整代码展示
- 1、数据增强、学习率调整、模型保存
- 2、调用模型预测
- 总结
前言
在深度学习的探索之旅中,图像识别模型的训练与应用绝非一蹴而就,它需要一系列精细的技术手段保驾护航。数据增强作为扩充数据集的 “魔法”,通过多样化的变换策略,为模型提供更丰富的学习素材,有效缓解过拟合问题;模型保存与调用则像是搭建起知识传承的桥梁,让训练成果得以复用与迁移,极大提高开发效率;而学习率调整堪称训练过程的 “调速器”,精准把控模型参数的更新步长,决定着模型能否快速且稳定地收敛到最优解。本章将深入剖析这些关键技术,揭开它们如何协同发力,推动图像识别模型从训练走向实际应用的神秘面纱。
一、数据增强
1、什么是数据增强?
数据增强是一种通过对原始训练数据进行一系列变换来增加数据多样性的技术。其目的是扩大数据集规模,提高模型的泛化能力,减少过拟合现象的发生。
2、数据增强的实现方法
(1)几何变换
翻转:
包括水平翻转和垂直翻转。例如,在图像识别任务中,许多物体具有左右对称或上下对称的特性,通过翻转可以增加数据的多样性,让模型学习到物体在不同方向上的特征。
旋转:
将图像按照一定角度进行旋转。比如在识别手写数字时,数字的倾斜角度可能各不相同,旋转图像可以使模型对不同角度的数字有更好的识别能力。
平移:
将图像在水平或垂直方向上进行平移。这有助于模型学习到物体在不同位置时的特征,提高对物体位置变化的鲁棒性。
(2)颜色变换
亮度调整:
增加或降低图像的亮度。不同的光照条件下,图像的亮度会有所不同,通过调整亮度可以让模型适应各种光照环境。
对比度调整:
增强或减弱图像的对比度。这可以突出图像中的细节,使模型能够更好地学习到物体的边缘和纹理等特征。
色彩抖动:
对图像的颜色通道进行随机抖动。例如,在识别自然场景图像时,不同季节、不同天气下图像的色彩会有所变化,色彩抖动可以让模型对颜色的变化更具适应性。
(3)其他变换
裁剪:
从原始图像中裁剪出不同大小和位置的子图像。这可以模拟物体在图像中不同的位置和大小,提高模型对物体尺度变化的适应能力。
缩放:将图像按比例放大或缩小。类似于裁剪,缩放操作也能让模型学习到物体在不同尺度下的特征。
添加噪声:
在图像中添加随机噪声,如高斯噪声等。这可以模拟图像在采集或传输过程中受到的干扰,使模型具有更好的抗干扰能力。
3、在模型中的使用
data_transforms = {'train':transforms.Compose([transforms.Resize([300,300]), #对图片进行重设大小transforms.RandomRotation(45), #随机旋转任意角度,每次旋转的角度为45度transforms.CenterCrop(256), #对图片进行中心裁剪,传入的参数为图片的尺寸transforms.RandomHorizontalFlip(p=0.5), #对图片做随机水平翻转transforms.RandomVerticalFlip(p=0.5), #对图片做随机垂直翻转transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),#ColorJitter 可以对图像的亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)进行随机调整。 transforms.RandomGrayscale(p=0.1), #RandomGrayscale 会依据指定的概率随机决定是否把输入的彩色图像转换为灰度图像。transforms.ToTensor(), #将图片转换为张量transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225]) #对数据做归一化处理,归一化数据来源于李飞飞团队]),'valid':transforms.Compose([transforms.Resize([256, 256]),transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])]),}二、模型保存
1、在Pytorch深度学习框架中模型的保存有两种方法
(1)仅保存网络中每一层的权重参数
torch.save(model.state_dict(),'文件名.pth')
(2)即保存了模型的权重参数,同时也将完整的模型保存到文件中
torch.save(model,'文件名.pt')
在Pytorch中,保存模型的后缀有”.pt“和”.pth“,其中”.pt“文件就是指保存的模型不止保存了每个网络层中的权重,同时也将网络的结构保存。”.pth“后缀的文件仅仅将网络层中的权重保存。
2、在Tensflow深度学习框架中模型的保存可以使用model.save()方法。保存的格式有多种,主要的区别也在后缀上
(1)保存为SaveModel模式
save传入的参数是模型保存的名字,如果没有添加路径,那么模型默认会保存到当前项目的目录下。
# 保存模型
model.save('saved_model')
(2)保存为 HDF5 格式
传入的参数实际是模型保存的路径加上模型的名字,可以看到这里模型保存的后缀为”.h5“
# 保存模型
model.save('model.h5')3、保存最优模型
那么模型在代码中的那一块去保存模型,模型的保存应该在测试集中,如果想收获一个效果较好的模型,我们可以设置一个参数,来保存所有训练轮次中效果最好的一个,通过比较模型的评分指标,如果满足某一轮次中的正确率大于当前正确率,则将最后正确率最大的模型保存下来。因为每次满足条件,模型被保存都会覆盖当前的模型,因此最后保存的一定是效果最好的模型。
三、模型调用
1、模型调用
(1)读取参数的方法
model=CNN().to(device) #初始化模型其中的权重参数都是随机给的
model.load_state_dict(torch.load("best.pth")) #加载模型参数之后,这些参数就加载到我们当前的神经网络中
(2)读取完整模型的方法,无需提前创建model
model=torch.load('best.pt')
2、模型调用时的注意事项
首先,我们需要确保自己建立的网络的结构要和调用的训练好的模型要一致,因为,调用的文件中储存的是网络层中的权重参数,如果自己的网络结构与加载的模型不同,那么参数的数量不匹配就会导致错误。在调用模型时我们不需要对模型再训练,只需要调用训练好的模型进行预测。
四、学习率调整
1、为什么要调整学习率
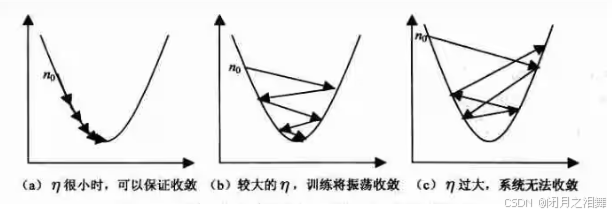
通过观察上图,当学习率非常小时,模型需要花费很长时间才会到达最优点;当模型的学习率较大时模型虽然会收敛,但是是在一个距离最优点较近的位置来回震荡;当模型的学习率非常大时,模型会很大幅度的震荡但是不会收敛。
2、学习率

常用的学习率有0.1、0.01以及0.001等,学习率越大则权重更新越快。一般来说,我们希望在训练初期学习率大一些,使得网络收敛迅速,在训练后期学习率小一些,使得网络更好的收敛到最优解。
调整学习率使用库函数进行调整或手动调整学习率。
3、三种库函数调整学习率的方法
(1)Pytorch学习率调整策略通过 torch.optim.lr_sheduler 接口实现。并提供3种调整方法:
有序调整:等间隔调整(Step),多间隔调整(MultiStep),指数衰减(Exponential),余弦退火(CosineAnnealing);
自适应调整:依训练状况伺机而变,通过监测某个指标的变化情况(loss、accuracy),当该指标不怎么变化时,就是调整学习率的时机(ReduceLROnPlateau);
自定义调整:通过自定义关于epoch的lambda函数调整学习率(LambdaLR)。
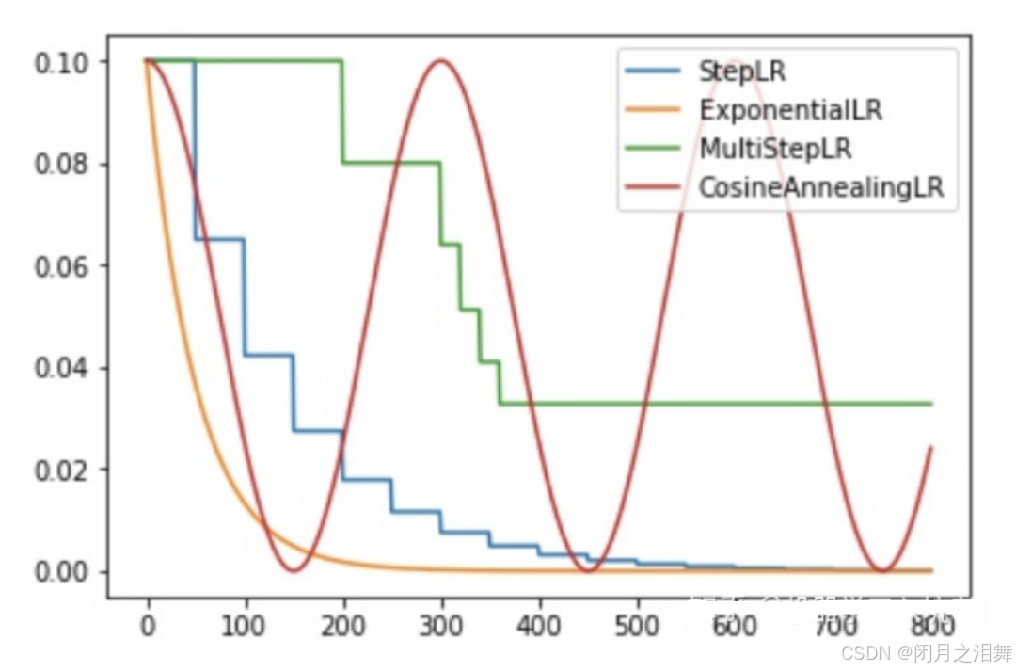
(2)有序调整StepLR(等间隔调整学习率)
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)
参数:
optimizer: 神经网络训练中使用的优化器,如optimizer=torch.optim.Adam(…)
step_size(int): 学习率下降间隔数,单位是epoch,而不是iteration.
gamma(float):学习率调整倍数,默认为0.1
每训练step_size个epoch,学习率调整为lr=lr*gamma.
(3)有序调整MultiStepLR(多间隔调整学习率)
torch.optim.lr_shceduler.MultiStepLR(optimizer, milestones, gamma=0.1)
参数:
milestone(list): 一个列表参数,表示多个学习率需要调整的epoch值,如milestones=[10, 30, 80].
(4)有序调整ExponentialLR (指数衰减调整学习率)
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma)
参数:
gamma(float):学习率调整倍数的底数,指数为epoch,初始值我lr, 倍数为γepoch
(5)有序调整CosineAnnealing (余弦退火函数调整学习率)
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0)
参数:
Tmax(int):学习率下降到最小值时的epoch数,即当epoch=T_max时,学习率下降到余弦函数最小值,当epoch>T_max时,学习率将增大;
etamin: 学习率调整的最小值,即epoch=Tmax时,lrmin=etamin, 默认为0.
(6)自适应调整ReduceLROnPlateau (根据指标调整学习率)
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1,
patience=10,verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
(7)自定义调整LambdaLR (自定义调整学习率)
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
参数:
lr_lambda(function or list): 自定义计算学习率调整倍数的函数,通常时epoch的函数,当有多个参数组时,设为list.
4、学习率调整在模型中使用位置
定义完模型的优化器后,再指定学习率,下面采用的是等间隔调整学习率
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 创建优化器
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5) #指定学习率调整库,以及参数
每轮训练完之后,要使用scheduler.step()更新学习率,这里参数设置的是,每训练五轮,调整一次学习率,学习率的初始值为0.001,当训练五次时学习率为0.001x0.5。
epochs = 30
best_acc = 0
for epoch in range(epochs):print(f"epoch{epoch+1}")train(train_dataloader, model, loss_fn, optimizer)scheduler.step() #在每个epoch的训练中,使用scheduler.step()语句更新学习率test(test_dataloader, model, loss_fn)
print("Done")
五、完整代码展示
1、数据增强、学习率调整、模型保存
import os
import numpy as np
from PIL import Image
import torch
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
from torchvision import datasets
from torch import nndef train_test_file(root,dir):file_txt=open(dir+'.txt','w')path=os.path.join(root+dir)for roots,directories,files in os.walk(path):if len(directories)!=0:dirs=directorieselse:now_dir=roots.split('\\')for file in files:path_1=os.path.join(roots,file)print(path_1)file_txt.write(path_1+' '+str(dirs.index(now_dir[-1]))+'\n')file_txt.close()root=r'..\data\食物分类\food_dataset\\'
train_dir='train'
test_dir='test'
train_test_file(root,train_dir)
train_test_file(root,test_dir)class food_dataset(Dataset):def __init__(self,file_path,transform=None):self.file_path=file_pathself.imgs=[]self.labels=[]self.transform=transformwith open(self.file_path) as f:samples=[x.strip().split(' ') for x in f.readlines()]for img_path,label in samples:self.imgs.append(img_path)self.labels.append(label)# 初始化:把图片目录加载到selfdef __len__(self):return len(self.imgs)def __getitem__(self, idx):image=Image.open(self.imgs[idx])if self.transform:image=self.transform(image)label=self.labels[idx]label=torch.from_numpy(np.array(label,dtype=np.int64))return image,labeldata_transforms = {'train':transforms.Compose([transforms.Resize([300,300]),transforms.RandomRotation(45),transforms.CenterCrop(256),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),transforms.RandomGrayscale(p=0.1),transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])]),'valid':transforms.Compose([transforms.Resize([256, 256]),transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])]),}#training_data包含了本次需要训练的全部数据集
training_data=food_dataset(file_path='./trainda.txt',transform=data_transforms['train'])
test_data=food_dataset(file_path='./testda.txt',transform=data_transforms['valid'])#training_data需要具备索引的功能,还需要确保数据是tensor
train_dataloader=DataLoader(training_data,batch_size=8,shuffle=True)
test_dataloader=DataLoader(test_data,batch_size=8,shuffle=True)device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"class CNN(nn.Module): # 通过调用类的形式来使用神经网络,神经网络的模型nn.moudledef __init__(self):super(CNN,self).__init__() # 继承父类的初始化self.conv1=nn.Sequential(nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1,padding=2,),nn.ReLU(), #(16,28,28)nn.MaxPool2d(kernel_size=2) #(16,14,14))self.conv2=nn.Sequential(nn.Conv2d(16,32,5,1,2), #32,14,14nn.ReLU(),nn.Conv2d(32, 32, 5, 1, 2), # 32,14,14nn.ReLU(),nn.MaxPool2d(2))self.conv3=nn.Sequential(nn.Conv2d(32,64,5,1,2), #128,7,7nn.ReLU())self.out=nn.Linear(64*64*64,20)def forward(self, x): # 前向传播,指明数据的流向,使神经网络连接起来,函数名称不能修改x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)x=x.view(x.size(0),-1)out=self.out(x)return outmodel = CNN().to(device) # 将刚刚定义的模型传入到GPU中def train(dataloader, model, loss_fn, optimizer):model.train() # 告诉模型,即将开始训练,其中的w进行随机化操作,已经更新w,在训练过程中,w会被修改"""pytorch提供两种方式来切换训练和测试的模式,分别是model.train()和model.eval()一般用法是,在训练开始之前写上model.train(),在测试时写上model.eval()"""batch_size_num = 1for X, y in dataloader: # 其中batch为每一个数据的编号X, y = X.to(device), y.to(device) # 将训练数据集和标签传入cpu和gpupred = model.forward(X)loss = loss_fn(pred, y) # 通过交叉熵损失函数计算loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() # 梯度值清零loss.backward() # 反向传播计算得到的每个参数的梯度值woptimizer.step() # 根据梯度更新网络w参数loss_value = loss.item() # 从tensor数据中提取数据出来,tensor获取损失值if batch_size_num % 10 == 0:print(f"loss:{loss_value:>7f}[number:{batch_size_num}]")batch_size_num += 1food_type={0:"八宝粥",1:"巴旦木",2:"白萝卜",3:"板栗",4:"菠萝",5:"草莓",6:"蛋",7:"蛋挞",8:"骨肉相连",9:"瓜子",10:"哈密瓜",11:"汉堡",12:"胡萝卜",13:"火龙果",14:"鸡翅",15:"青菜",16:"生肉",17:"圣女果",18:"薯条",19:"炸鸡"}def test(dataloader, model, loss_fn):global best_accsize = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()a = (pred.argmax(1) == y)b = (pred.argmax(1) == y).type(torch.float)test_loss /= num_batchescorrect /= size# result=zip(pred.argmax(1).tolist(),y.tolist())# for i in result:# print(f"当前测试的结果为:{food_type[i[0]]}\t当前真实的结果为:{food_type[i[1]]}")print(f"Test result:\n Accurracy:{(100 * correct)}%,AVG loss:{test_loss}")if correct > best_acc:best_acc=correct#1.保存模型参数的2种方法(模型的文件扩展名:一般为pt\pth\t7)torch.save(model.state_dict(),'./model/best3.pth')print(best_acc * 100)#2.保存完整模型,将网络框架也保存下来# torch.save(model,'best1.pt')loss_fn = nn.CrossEntropyLoss() # 创建交叉熵损失函数对象,适合做多分类optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 创建优化器,使用SGD随机梯度下降
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)# params:要训练的参数,一般传入的都是model.parameters()
# lr是指学习率,也就是步长# loss表示模型训练后的输出结果与样本标签的差距,如果差距越小,就表示模型训练越好,越逼近于真实的模型
# train(train_dataloader,model,loss_fn,optimizer) #训练一次完整的数据,多轮训练
# test(test_dataloader,model,loss_fn)epochs = 30
best_acc = 0
for epoch in range(epochs):print(f"epoch{epoch+1}")train(train_dataloader, model, loss_fn, optimizer)scheduler.step() #在每个epoch的训练中,使用scheduler.step()语句更新学习率test(test_dataloader, model, loss_fn)
print("Done")2、调用模型预测
import numpy as np
from PIL import Image
import torch
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
from torch import nnclass food_dataset(Dataset):def __init__(self,file_path,transform=None):self.file_path=file_pathself.imgs=[]self.labels=[]self.transform=transformwith open(self.file_path) as f:samples=[x.strip().split(' ') for x in f.readlines()]for img_path,label in samples:self.imgs.append(img_path)self.labels.append(label)# 初始化:把图片目录加载到selfdef __len__(self):return len(self.imgs)def __getitem__(self, idx):image=Image.open(self.imgs[idx])if self.transform:image=self.transform(image)label=self.labels[idx]label=torch.from_numpy(np.array(label,dtype=np.int64))return image,label#数据增强
data_transforms = {'train':transforms.Compose([transforms.Resize([300,300]),transforms.RandomRotation(45),transforms.CenterCrop(256),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),transforms.ColorJitter(brightness=0.2,contrast=0.1,saturation=0.1,hue=0.1),transforms.RandomGrayscale(p=0.1),transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])]),'valid':transforms.Compose([transforms.Resize([256, 256]),transforms.ToTensor(),transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])]),
}#数据集加载#training_data包含了本次需要训练的全部数据集
training_data=food_dataset(file_path='./trainda.txt',transform=data_transforms['train'])
test_data=food_dataset(file_path='./testda.txt',transform=data_transforms['valid'])#数据打包
#training_data需要具备索引的功能,还需要确保数据是tensor
train_dataloader=DataLoader(training_data,batch_size=32,shuffle=True)
test_dataloader=DataLoader(test_data,batch_size=32,shuffle=True)device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"#定义卷积神经网络,这里的网络结构要和保存模型的网络结构一样
class CNN(nn.Module): # 通过调用类的形式来使用神经网络,神经网络的模型nn.moudledef __init__(self):super(CNN,self).__init__() # 继承父类的初始化self.conv1=nn.Sequential(nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1,padding=2,),nn.ReLU(), #(16,28,28)nn.MaxPool2d(kernel_size=2) #(16,14,14))self.conv2=nn.Sequential(nn.Conv2d(16,32,5,1,2), #32,14,14nn.ReLU(),nn.Conv2d(32, 32, 5, 1, 2), # 32,14,14nn.ReLU(),nn.MaxPool2d(2))self.conv3=nn.Sequential(nn.Conv2d(32,64,5,1,2), #128,7,7nn.ReLU())self.out=nn.Linear(64*64*64,20)def forward(self, x): # 前向传播,指明数据的流向,使神经网络连接起来,函数名称不能修改x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)x=x.view(x.size(0),-1)out=self.out(x)return outdef test_ture(dataloader,model,loss_fn):label=[]predicted=[]size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()predicted.append(pred.argmax(1))label.append(y)test_loss /= num_batchescorrect /= sizeprint(f"Test result:\n Accurracy:{(100 * correct)}%,AVG loss:{test_loss}")print(f"真实值:{label}")print(f"预测值:{predicted}")""加载模型""model = CNN().to(device) # 将刚刚定义的模型传入到GPU中
#将模型的权重参数保存下来,torch.save(model.state_dict(),path)
model.load_state_dict(torch.load("./model/best3.pth",map_location='cpu'))##除了保存参数还将网络框架保存了下来(w,b,模型cnn)
# model=torch.load("./model/best.pt")#定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss() # 创建交叉熵损失函数对象,适合做多分类
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#调用测试函数
test_ture(test_dataloader,model,loss_fn)总结
通过数据增强、以及学习率的调整我们可以使模型的效果更好,使准确率等分类指标增加,通过模型的保存和模型的加载,我们既可以自己训练模型它也可以使用他人训练好的模型,由于个人设备资源的限制,由个人训练的模型往往不如,网上训练好的开源模型。
相关文章:

《深度神经网络之数据增强、模型保存、模型调用、学习率调整》
文章目录 前言一、数据增强1、什么是数据增强?2、数据增强的实现方法(1)几何变换翻转:旋转:平移: (2)颜色变换亮度调整:对比度调整:色彩抖动: (3&…...

【Java学习笔记】random的使用
random使用方法 使用说明:返回的是(0<n<1)这个范围中的任意带正号的double值 代码实例 public class helloworld{public static void main(String[] args){System.out.println(Math.random());} }生成0-100中的任意数代码示例 public class Main {public …...

Redis的string类型使用
第一步:添加缓存 以若依岗位代码为例 一:首先从redis中查询岗位信息,如果查询到了则直接返回。 二:如果redis中没有数据,则直接从数据库中查询。查询后放到redis并返回 package com.ruoyi.system.service.impl;imp…...

AIGC架构与原理
AIGC(AI Generated Content,人工智能生成内容)的架构与原理 AIGC通过整合数据采集、模型训练、推理服务等模块,结合深度学习与生成对抗网络(GAN)等技术,实现从数据到内容的自动化生成。 一、AIG…...

安全复健|windows常见取证工具
写在前面: 此博客仅用于记录个人学习内容,学识浅薄,若有错误观点欢迎评论区指出。欢迎各位前来交流。(部分材料来源网络,若有侵权,立即删除) 取证 01系统运行数据 使用工具:Live-F…...

Oracle EBS R12.2 汉化
一、前言 在使用oracle ebs时,使用中文会更好的理解整个ebs流程,以下介绍oracle r12中文补丁的方式 如果你的系统除了支持英语外,还支持其他语言,比如中文,那你在下载补丁的时候除了下载Generic Platform版本外&#…...

【Java面试笔记:基础】12.Java有几种文件拷贝方式?哪一种最高效?
在 Java 中,文件拷贝可以通过多种方式实现,不同方式的性能和适用场景有所差异。 1. Java 文件拷贝方式 传统 IO 方式 使用 FileInputStream 和 FileOutputStream,通过循环读取和写入数据实现文件拷贝。 示例代码: try (InputStream is = new FileInputStream("sou…...

互联网大厂Java面试:RocketMQ、RabbitMQ与Kafka的深度解析
互联网大厂Java面试:RocketMQ、RabbitMQ与Kafka的深度解析 面试场景 面试官:马架构,您好!欢迎参加我们的面试。今天我们将围绕消息中间件展开讨论,尤其是RocketMQ、RabbitMQ和Kafka。您有十年的Java研发和架构设计经…...

kali安装切换jdk1.8.0_451java8详细教程
kali安装切换jdk1.8.0_451java8详细教程 下载链接: jdk-8u451-linux-i586.tar.gz 链接: https://pan.baidu.com/s/1lpgI0JMfHpZ__RxsF8UoBw?pwdx3z2 提取码: x3z2 解压jdk 首先将下载好的压缩包放在kali虚拟机中,一般是直接拖到桌面 然后cd到压缩包…...

众趣科技X世界读书日丨数字孪生技术赋能图书馆空间智慧化运营
4月23日,是第30个“世界读书日”,不仅是庆祝阅读的日子,更是思考知识传播未来的契机。 图书馆作为主要传播图书的场所,在科技的发展中,图书馆正面临前所未有的挑战,联合国数据显示,全球近30%的…...
)
Python内置函数-aiter()
Python内置函数 aiter() 用于获取异步可迭代对象的异步迭代器,是异步编程中的核心工具之一。 1. 基本概念 异步可迭代对象:实现了 __aiter__() 和 __anext__() 方法的对象,支持 async for 循环。 异步迭代器:通过 aiter() 获取的…...
)
Java 实现单链表翻转(附详细注释)
1. 引言 单链表(Singly Linked List)是一种常见的数据结构,在算法和数据结构的学习中占有重要地位。翻转单链表是一道经典的面试题,本文将介绍几种常见的 Java 实现方法,并详细讲解关键步骤的含义。 2. 单链表定义 …...

基于HPC的气候模拟GPU加速实践全流程解析
基于HPC的气候模拟GPU加速实践全流程解析 关键词:气候模型、GPU加速、CUDA编程、性能优化、分布式训练 摘要: 本文针对全球气候模拟中10^12级网格点实时计算需求,提出基于CUDA的并行计算架构。通过改进WRF模式的分块矩阵乘法算法,…...
)
【初级】前端开发工程师面试100题(一)
本题库共计包含100题,考察html,css,js,以及react,vue,webpack等基础知识掌握情况。 HTML基础篇 说说你对HTML语义化的理解? 语义化就是用合适的标签表达合适的内容,比如<header>表示页眉,<nav>表示导航。这样不仅代码更清晰,对SEO也友好,屏幕阅读器也能…...

大模型框架技术演进与全栈实践指南
一、大模型框架概述 大模型框架是支撑大规模语言模型(LLM)训练、推理和应用开发的核心技术体系,涵盖分布式训练、高效推理、应用编排等全流程。从AlphaGo到GPT-4,大模型框架的进化推动AI从实验室走向工业化落地。据IDC预测…...

【Bug】 [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed
当你在进行深度学习相关操作时,若因缺少本地的 CA 证书而无法下载资源,下面为你介绍几种解决办法: 方法一:更新 CA 证书 在大多数 Linux 发行版中,你可以使用包管理器来更新 CA 证书。例如,在基于 Debian…...

第七章:Workspace Security
Chapter 7: Workspace Security 从变形金刚到安全防护罩:如何为代理设置权限边界? 在上一章多后端配置,我们学会了让代理像变形金刚一样切换不同环境。但就像超级英雄需要遵守法律一样,代理也需要一个“安全防护罩”来限制它的操…...

【论文阅读】Hierarchical Group-Level Emotion Recognition
【论文阅读】Hierarchical Group-Level Emotion Recognition 摘要1.介绍2.相关工作3.方法4.实验5.分析 摘要 本篇博客参考IEEE于2021年收录的论文Hierarchical Group-Level Emotion Recognition,对其主要内容进行总结,以便加深理解和记忆 1.介绍 1&am…...
CUDA安装及环境配置)
(2025最新版)CUDA安装及环境配置
CUDA安装 文章目录 CUDA安装检查本地环境下载CUDA安装包CUDA安装检查是否安装成功 学习深度学习的小伙伴在配置环境的时候必不可少的一件事就是安装CUDA,在这个过程中也是容易踩很多坑,所以这里写一篇教程来帮助新入门的小伙伴快速安装CUDA,减…...

ODC 4.3.4 发布:三大核心功能升级,打造更好的数据开发体验
ODC 是OceanBase提供的企业级数据库协同开发平台,提供了团队协作开发的基础框架,和14种工单任务类型。此次升级的 ODC 4.3.4版本,重点优化了30余项功能,主要聚焦快速上手、配置管理和核心功能中的改进,来为用户打造更高…...

JavaFX 第一篇 Hello World
1、简介 JavaFX 是一个用于构建客户端应用程序的 Java 库,作为 Java 标准库的一部分(JDK 8 到 10),从 JDK 11 开始,JavaFX 将以独立模块发布,将不再包含在 JDK标准库中,他是 Java 应用程序开发的…...

es的range失效
es的range失效的解决方法 问题描述 当我们es使用keyword类型存储数字时,当我们使用range时我们发现range失效的问题,例如以下的用例: 我们创建一个test1的索引test1: 使用_bulk进行批量导入数据: 进行查询我们发现我…...
)
gem5-gpu教程03 当前的gem5-gpu软件架构(因为涉及太多专业名词不知道该如何翻译所以没有汉化)
Current gem5-gpu Software Architecture 这是当前gem5-gpu软件架构的示意图。 CudaCore (src/gpu/gpgpu-sim/cuda_core.*, src/gpu/gpgpu-sim/CudaCore.py) Wrapper for GPGPU-Sim shader_core_ctx (gpgpu-sim/gpgpu-sim/shader.h) Sends instruction, global and const m…...

【C++】vector扩容缩容
vector扩容缩容 1 扩容 一般来说,主要是重新分配内存 2 缩容 resize 缩小后,vector 的容量(capacity())可能保持不变,需要显式调用 shrink_to_fit() 来释放内存。 验证代码: #include <vector>…...

【鸿蒙HarmonyOS】深入理解router与Navigation
5. 路由 1.页面路由(router模式) 1.概述 页面路由指的是在应用程序中实现不同页面之间的跳转,以及数据传递。 我们先明确自定义组件和页面的关系: 自定义组件:Component 装饰的UI单元,页面:即应用的UI…...

手机端touch实现DOM拖拉功能
touch实现DOM拖拉功能 1、面板交互流程图 [ 用户触摸拖动手柄 ]↓ [ 记录起始位置、偏移量 ]↓ [ 实时更新面板 translateY ]↓ [ 手指松开 → 判断释放位置 ]↓ [ 达到恢复条件? → 复位 ]2、详细实现步骤 2.1 初始面板位置 const initialPosition () > tr…...

Discuz!与DeepSeek的AI融合:打造智能网址导航新体验——以“虎跃办公”为例
在数字化办公需求日益增长的今天,高效获取优质资源成为职场人士的核心痛点。传统网址导航网站往往面临信息过载、个性化不足、交互体验单一等问题,难以满足用户精准触达目标资源的需求。本文将深入剖析“虎跃办公”这一基于Discuz!系统构建的网址导航网站…...

【AI】Windows环境安装SPAR3D单图三维重建心得
效果一览 左图为原始单个图像,右图为通过SPAR3D重建后的三维建模,可以看出效果还是不错的。 本地环境配置 系统:Windows 11 专业版CPU:i5-13400F内存:32GBGPU:RTX3060 12GBcuda:11.8conda&…...

关于Agent的简单构建和分享
前言:Agent 具备自主性、环境感知能力和决策执行能力,能够根据环境的变化自动调整行为,以实现特定的目标。 一、Agent 的原理 Agent(智能体)被提出时,具有四大能力 感知、分析、决策和执行。是一种能够在特定环境中自主行动、感…...

【C/S通信仿真】
文章目录 一、实验背景与目的二、实验设计与实现思路1. 设计思想2. 核心代码实现 总结 一、实验背景与目的 在网络编程中,TCP 协议是实现可靠通信的核心。本次实验基于 Windows 平台,使用 WinSock2 库实现客户端与服务器的双向数据传递,模拟…...

Tomcat 8 启动闪退解决方案:版本差异与调试技巧详解
在使用 Tomcat 8 时,启动闪退是常见问题,核心原因多与 JAVA_HOME 环境变量配置、版本特性及启动脚本逻辑相关。本文结合官方文档与专家实践,提供分版本解决方案及调试技巧,适用于开发与运维场景。 一、核心问题:JAVA_…...

【Project】基于spark-App端口懂车帝数据采集与可视化
文章目录 hadoop完全分布式部署hdfs-site.xmlcore-site.xmlmarpred-site.xmlyarn-site.xml spark集群部署spark-env.sh mongodb分片模式部署config 服务器初始化config 副本集 shard 服务器初始化shard 副本集 mongos服务器添加shard设置chunk大小 启动分片为集合 user 创建索引…...

基于ARM+FPGA+DSP的储能协调控制器解决方案,支持国产化
储能协调控制器的作用与设计方案 一、核心作用 实时监测与协调控制 实时采集储能系统电压、电流、温度等参数,监测电池电量状态及充放电功率,动态调整储能与电网、负载的功率交互,保障能源供需平衡15。支持一次调频(AGC&a…...

将天气查询API封装为MCP服务
下面我将展示如何将一个天气查询API封装为符合MCP协议的服务。我们将使用Python实现,包括服务端和客户端。 ## 1. 服务端实现 python # weather_mcp_server.py from fastapi import FastAPI, HTTPException from pydantic import BaseModel from typing import Di…...

JSON实现动态按钮管理的Python应用
在开发桌面应用程序时,动态生成用户界面元素并根据配置文件灵活管理是一项常见需求。本文将介绍如何使用Python的wxPython库结合JSON配置文件,开发一个支持动态按钮创建、文件执行和配置管理的桌面应用程序。该应用允许用户通过设置界面配置按钮名称和关…...

基于GA遗传优化TCN-BiGRU注意力机制网络模型的时间序列预测算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 (完整程序运行后无水印) 2.算法运行软件版本 matlab2024b(提供软件版本下载) 3.部分核心程序 (完整版代码包…...
备份还原)
MongoDB(docker版)备份还原
docker启动MongoDB docker run -d -p 27017:27017 --name my-mongo -v /mongodb/db:/data/db mongo备份MongoDB 使用mongodump备份数据库时,默认会将备份数据保存在当前工作目录下的dump文件夹中。 docker容器中默认备份在当前工作目录,所以此处指定当…...

[蓝桥杯 2025 省 Python B] 异或和
暴力(O(n^2)): def xor_sum(n, arr):total 0for i in range(n):for j in range(i 1, n):total (arr[i] ^ arr[j]) * (j - i)return total# 主函数 if __name__ "__main__":n int(input())arr list(map(int, input().split()…...

HTTP代理基础:网络新手的入门指南
目录 一、为什么需要了解HTTP代理? 二、HTTP代理的“中间人”角色 三、代理的三大核心类型 四、HTTP代理的5大实用场景 五、设置代理的三种方式 六、代理的优缺点分析 七、如何选择代理服务? 八、安全使用指南 九、未来趋势 结语 一、为什么需要…...

GRE 多层级网络数据处理系统
一、整体架构 多层级网络数据处理系统,从底层硬件中断到上层协议处理,涵盖了数据包的接收、转发、解封装、路由决策和发送全流程。系统采用分层处理和模块化设计,结合了传统Linux网络协议栈与快速路径(Fast Path࿰…...

展望未来,楼宇自控系统如何全方位推动绿色建筑智能高效发展
在全球积极践行可持续发展理念的时代背景下,绿色建筑已成为建筑行业发展的必然趋势。绿色建筑追求在全生命周期内,最大限度地节约资源、保护环境和减少污染,为人们提供健康、舒适、高效的使用空间。而楼宇自控系统作为建筑智能化的核心技术&a…...

【计算机视觉】CV项目实战- Florence-SAM 多模态视觉目标检测+图像分割
Florence-SAM多模态视觉分析系统:技术解析与实战指南 一、项目架构与技术解析1.1 核心模型架构1.2 支持的任务模式 二、环境配置与部署实战2.1 本地部署指南2.2 运行演示系统 三、核心功能实战解析3.1 图像开放词汇检测3.2 视频目标跟踪 四、高级应用与二次开发4.1 …...

2025-04-23 Python深度学习3——Tensor
文章目录 1 张量1.1 数学定义1.2 PyTorch中的张量 2 创建 Tensor2.1 直接创建**torch.tensor()****torch.from_numpy()** 2.2 依据数值创建**torch.zeros() / torch.zeros_like()****torch.ones() / torch.ones_like()****torch.full() / torch.full_like()****torch.arange() …...
:双核 AMP 通信实验)
ZYNQ笔记(十三):双核 AMP 通信实验
版本:Vivado2020.2(Vitis) ZYNQ 裸机双核 AMP 实验: CPU0 接收串口的数据,并写入 OCM 中,然后利用软件产生中断触发 CPU1;CPU1 接收到中断后,根据从 OCM 中读出的数据控制呼吸灯的频…...

黑马Java基础笔记-3
短路逻辑运算符与逻辑运算符 逻辑运算符 符号作用说明&逻辑与(且)并且,两边都为真,结果才是真|逻辑或或者,两边都为假,结果才是假^逻辑异或相同为 false,不同为 true!逻辑非取反 短路逻辑…...

4.23学习总结
虽然之前写过的相关dfs和bfs的题,但方法忘的差不多了,重写了一遍相关的算法题,今天完成了岛屿数量的算法题,我利用的是bfs的算法,遍历每个结点,如果是1就count,然后再bfs向四周遍历并标记已经走过 初步看了…...

ElasticSearch:高并发场景下如何保证读写一致性?
在Elasticsearch高并发场景下,可以通过以下多种方式来保证读写一致性: 等待主分片和副本分片都确认(类似半同步机制) 设置consistency参数:在写操作时,可以设置consistency参数来控制写操作的一致性级别。…...
)
Qt基础007(Tcp网络编程)
文章目录 QTcp服务器的关键流程QTtcp客户端的关键流程TCP协议Socket QTcp服务器的关键流程 工程建立,需要在.pro加入网络权限 创建一个基于 QTcpServer 的服务端涉及以下关键步骤: 创建并初始化 QTcpServer 实例: 实例化 QTcpServer 。 调…...

visio导出的图片过大导致latex格式转成pdf之后很不清楚
联想电脑解决方法 右键打开方式选择【照片】,然后选择调整图片大小,将像素的宽度和高度调低。...
)
leetcode刷题——判断对称二叉树(C语言版)
题目描述: 示例 1: 输入:root [6,7,7,8,9,9,8] 输出:true 解释:从图中可看出树是轴对称的。 示例 2: 输入:root [1,2,2,null,3,null,3] 输出:false 解释:从图中可看出最…...