【Project】基于spark-App端口懂车帝数据采集与可视化
文章目录
- hadoop完全分布式部署
- hdfs-site.xml
- core-site.xml
- marpred-site.xml
- yarn-site.xml
- spark集群部署
- spark-env.sh
- mongodb分片模式部署
- config 服务器
- 初始化config 副本集
- shard 服务器
- 初始化shard 副本集
- mongos服务器
- 添加shard
- 设置chunk大小
- 启动分片
- 为集合 user 创建索引并进行分片
- fillder抓包+数据采集
- spark清洗数据
- Flask+echarts进行可视化
- 效果图
hadoop完全分布式部署
hdfs-site.xml
<configuration><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/src/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/src/hadoop/dfs/data</value></property><property><name>dfs.replication</name><value>3</value></property></property><!-- Secondary NameNode 所在主机的ip和端口 --><property><name>dfs.namenode.secondary.http-address</name><value>master02:9890</value></property>
</configuration>core-site.xml
<configuration><!-- --><!-- 设置hadoop的文件系统,由URI指定 --><property><!-- 指定namenode地址节点所在机器 --><name>fs.defaultFS</name><value>hdfs://master01:9000</value></property><!-- 配置hadoop临时目录,默认/tmp/hadoop-${user.name} --><property><name>hadoop.tmp.dir</name><value>/usr/local/src/hadoop/tmp/</value></property></configuration>marpred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master01:10020</value></property>
</configuration>yarn-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master01:10020</value></property>
</configuration>spark集群部署
spark-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export HADOOP_CONF_DIR=/usr/local/src/hadoop-3.2.2/etc/hadoop/
export SPARK_MASTER_IP=master01
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_EXECUTOR_MEMORY=512m
export SPARK_EXECUTOR_CORES=1
export SPARK_WORKER_INSTANCES=1
mongodb分片模式部署
| 服务器名称 | IP地址 | Shard1 (端口/角色) | Shard2 (端口/角色) | Shard3 (端口/角色) | mongos (端口) | Config Server (端口/角色) |
|---|---|---|---|---|---|---|
| master01 | 192.168.121.134 | 27018 (主节点) | 27020 (仲裁节点) | 27019 (副节点) | 27021 | 27022 (主节点) |
| node01 | 192.168.121.135 | 27019 (副节点) | 27018 (主节点) | 27020 (仲裁节点) | 27021 | 27022 (副节点) |
| node02 | 192.168.121.136 | 27020 (仲裁节点) | 27019 (副节点) | 27018 (主节点) | - | 27022 (副节点) |
config 服务器
dbpath=/usr/local/src/mongodb_demo/shardcluster/configServer/data
logpath=/usr/local/src/mongodb_demo/shardcluster/configServer/logs/config_server.log
port=27022
bind_ip=master01
logappend=true
fork=trues
maxConns=5000
replSet=configs
configsvr=true
初始化config 副本集
$ ./mongod -f /usr/local/src/mongodb_demo/shardcluster/configServer/configFile/mongodb_config.conf$ ./mongo --host master01 --port 27022
> rs.initiate()
configs:SECONDARY> rs.add('node01:27022')
configs:PRIMARY> rs.add('node02:27022')shard 服务器
dbpath=/usr/local/src/mongodb_demo/shardcluster/shard/shard1_data
logpath=/usr/local/src/mongodb_demo/shardcluster/shard/logs/shard1.log
port=27018
bind_ip=master01
logappend=true
fork=true
maxConns=5000
replSet=shard1
shardsvr=true
类似地,编辑 shard2.conf 和 shard3.conf,分别修改 dbpath, logpath, port, bind_ip, 和 replSet 参数。
初始化shard 副本集
# 所有节点都启动
$ ./mongod -f /usr/local/src/mongodb_demo/shardcluster/shard/configFile/mongodb_shard1.conf
$ ./mongod -f /usr/local/src/mongodb_demo/shardcluster/shard/configFile/mongodb_shard2.conf
$ ./mongod -f /usr/local/src/mongodb_demo/shardcluster/shard/configFile/mongodb_shard3.conf# master01节点
$ ./mongo --host master01 --port 27018
> rs.initiate()
configs:SECONDARY> rs.add('node01:27019')
configs:PRIMARY> rs.add('node02:27020')# node01节点
$ ./mongo --host node01--port 27018
> rs.initiate()
configs:SECONDARY> rs.add('node02:27019')
configs:PRIMARY> rs.add('master01 :27020')# node02节点
$ ./mongo --host node02 --port 27018
> rs.initiate()
configs:SECONDARY> rs.add('master01 :27019')
configs:PRIMARY> rs.add('node01:27020')
mongos服务器
logpath=/usr/local/src/mongodb_demo/shardcluster/mongos/logs/mongos.log
logappend=true
port=27021
bind_ip=master01
fork=true
configdb=configs/master01:27022,node01:27022,node02:27022
maxConns=20000
类似地,在node01节点配置
添加shard
$ ./mongo --host master01--port 27021mongos> use gateway
mongos> sh.addShard("shard1/master01:27018,node01:27019,node02:27020")
mongos> sh.addShard("shard2/master01:27020,node01:27018,node02:27019")
mongos> sh.addShard("shard3/master01:27019,node01:27020,node02:27018")
设置chunk大小
use config;
db.settings.insertOne({ _id: "chunksize", value: 64 });
启动分片
mongos> use gateway
mongos> sh.enableSharding("xxxdatabase")
为集合 user 创建索引并进行分片
mongos> use xxxdatabase
mongos> db.user.createIndex({"id":1})
mongos> sh.shardCollection("xxxdatabase.xxxcollection",{"id":1})
fillder抓包+数据采集
def data_SalesVolume(self,allcity):'''获取全国和各城市车辆销售量排名数据结果存储到本地和hdfs:param allcity: 城市名称-->list:return:'''data_list = []for city in allcity:city_quote = quote(city)newurl = self.url+f'method=jsb.app.fetch&rank_data_type=116&month=202412&energy_type&price=0%2C-1&manufacturer&rank_city_name={city_quote}&market_time=0&offset=0&count=500&scm_version=1.0.0.2209&iid=3991681621300419&device_id=3991681621296323&ac=wifi&channel=home&aid=36&app_name=automobile&version_code=748&version_name=7.4.8&device_platform=android&os=android&ab_client=a1%2Cc2%2Ce1%2Cf2%2Cg2%2Cf7&ab_group=3167590%2C3577236&ssmix=a&device_type=PCLM10&device_brand=OPPO&language=zh&os_api=28&os_version=9&manifest_version_code=748&resolution=720*1280&dpi=320&update_version_code=7483&_rticket=1738335686380&cdid=637e94d4-1e98-49a9-9b9e-7f567951c149&rom_version=coloros__pq3b.190801.10161630+release-keys&longi_lati_type=0&longi_lati_time=0&content_sort_mode=0&total_memory=3.85&cpu_name=Qualcomm+Technologies%2C+Inc+MSM8998&overall_score=8.6995&cpu_score=7.9848&host_abi=armeabi-v7a'print(f'准备获取=={city}==的数据---{newurl}---')citynames = self.session.get(url=newurl, headers=self.headers).json()city_sales = {city:citynames}data_list.append(city_sales)# print(citynames)print('----------获取销量数据完成-----------')data_json = {'SalesValue':data_list}with open(f'data/data_salesvolume.json','w',encoding='utf-8') as f:json.dump(data_json,f,ensure_ascii=False,indent=4)hdfs_path = "/data_doncar/data_carkm.json" # HDFS 目标路径self.hdfs_client.create(hdfs_path, data_json, overwrite=True) # 上传到 HDFS
spark清洗数据
创建对象
package org.exampleimport org.apache.log4j.{Level, Logger}
import org.apache.spark._
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._object DonCar_spark {def main(args: Array[String]): Unit = {Logger.getLogger("org").setLevel(Level.ERROR)Logger.getLogger("akka").setLevel(Level.ERROR)val spark = SparkSession.builder().appName("car_analysis").master("local[*]").config("spark.mongodb.read.connection.uri", "mongodb://root:123456@192.168.121.134:27017").getOrCreate()
连接mongodb数据库
def readmongocollection(db:String,collection:String) = {spark.read.format("mongodb").option("database",db).option("collection",collection).load()}
创建临时表
val car_info = readmongocollection("doncar_top","car_info")val citys_sv = readmongocollection("doncar_top","citys_sv")val nationwide_sv = readmongocollection("doncar_top","nationwide_sv")citys_sv.createOrReplaceTempView("citys_table")car_info.createOrReplaceTempView("car_table")nationwide_sv.createOrReplaceTempView("nationwide_table")
数据分析 并且把数据存到HDFS
// 各城市汽车销量val citys_sales = spark.sql("select city,sales from citys_table").groupBy("city").sum("sales")// 电车续航排名val brand_max_km = spark.sql("select brand,range_km from car_table").groupBy("brand").max()brand_max_km.limit(7).show()// 油电销量val car_type_sales =spark.sql("select sales,car_type from nationwide_table ").withColumn("category",when(col("car_type") === 0,0).otherwise(1)).groupBy("category").sum("sales")car_type_sales.show()// 能源占比
// 0 纯油
// 1 纯电
// 2 混动
// 3-4 增程val car_type = spark.sql("select car_type,sales from nationwide_table").groupBy("car_type").sum("sales")// car_type.printSchema()val car_type2 = car_type.withColumn("sum(sales)",when(col("car_type") === 3,col("sum(sales)")+car_type.filter(col("car_type") === 4).select("sum(sales)").first().getLong(0)).otherwise(col("sum(sales)")))car_type2.show()//销量——价格关系val price_sales = spark.sql("SELECT min_price,max_price,sales from nationwide_table").withColumn("average_price",(col("min_price") + col("max_price")) / 2).drop("min_price","max_price")price_sales.show()// 品牌销量val brand_sales = spark.sql("SELECT brand_name,model,sales FROM nationwide_table").groupBy("brand_name").sum("sales").sort(col("sum(sales)").desc)brand_sales.show()// 城市销量排名val city_top = citys_sales.sort(col("sum(sales)").desc)city_top.show()// 车辆销售排名val car_top = spark.sql("SELECT model,sales FROM nationwide_table").sort(col("sales").desc)car_top.show()}
}
Flask+echarts进行可视化
from flask import Flask, render_template, redirect, url_for, request, flash, session,jsonify
from SparkAnalysis import analysis
from SparkAnalysis import Get_HdfsData
import pymysqlapp = Flask(__name__)#重定向路由
@app.route('/')
def default():return redirect(url_for('login'))@app.route('/login', methods=['GET', 'POST'])
def login():if request.method == 'POST':username = request.form['username']password = request.form['password']conn = pymysql.connect(host='localhost', # 数据库主机地址user='root', # 数据库用户名password='123456', # 数据库密码database='users' # 数据库名称)with conn.cursor() as cursor:cursor.execute("SELECT * FROM account WHERE username = %s AND password = %s", (username, password))account = cursor.fetchone() # 获取第一行记录conn.close()if account:return redirect(url_for('index'))else:return redirect(url_for('login'))return render_template('login.html')@app.route('/register', methods=['GET', 'POST'])
def register():if request.method == 'POST':username = request.form['username']password = request.form['password']conn = pymysql.connect(host='localhost',user='root',password='123456',database='users')with conn.cursor() as cursor:cursor.execute("SELECT * FROM account WHERE username = %s", (username,))if cursor.fetchone():return redirect(url_for('register'))# 如果用户名不存在,插入新用户cursor.execute("INSERT INTO account (username, password) VALUES (%s, %s)", (username, password))conn.commit()conn.close()return redirect(url_for('login'))return render_template('register.html')@app.route('/index')
def index():return render_template('index.html',map_data=Get_HdfsData.get_map_data(),bar1_x = analysis.get_bar1_data()['brand'].values.tolist(),# bar1_y=Get_HdfsData.get_bar1_data()['range_km'].values.tolist(),bar1_y=[float(num) for num in analysis.get_bar1_data()['range_km'].values.tolist()],type_0 = Get_HdfsData.get_num_data()[0][2:],type_n0 = Get_HdfsData.get_num_data()[1][2:],pie_data = Get_HdfsData.get_pie_data(),scatter_data = Get_HdfsData.get_scatter_data(),bar2_x=analysis.get_bar2_data()['brand_name'].values.tolist()[:5],bar2_y=analysis.get_bar2_data()['sales'].values.tolist()[:5],line1_x_top=Get_HdfsData.get_line1_data()['city'].values.tolist()[:12],line1_y_top=Get_HdfsData.get_line1_data()['value'].values.tolist()[:12],line1_x_last=analysis.get_line1_data()['city'].values.tolist()[-12:],line1_y_last=analysis.get_line1_data()['value'].values.tolist()[-12:],line2_x_top=Get_HdfsData.get_line2_data()['model'].values.tolist()[:10],line2_y_top=Get_HdfsData.get_line2_data()['sales'].values.tolist()[:10],)if __name__ == '__main__':app.run(host='127.0.0.1', port=5001)
echarts部分代码
(function() {var myChart = echarts.init(document.querySelector(".map .chart"));echarts.registerMap('china', chinaData);option = {tooltip: {trigger: 'item',formatter: '{b}<br/>{c} (辆)'},visualMap: {min: 1,max: 40000,text: ['High', 'Low'],realtime: false,calculable: true,inRange: {color: ['lightskyblue', 'yellow', 'orangered']},textStyle: {color: 'red' // 设置字体颜色为红色}},series: [{name: 'city_map',type: 'map',map: 'china',data: map_data,roam: true // 在这里添加 roam 属性}]};myChart.setOption(option);// 监听浏览器缩放,图表对象调用缩放resize函数window.addEventListener("resize", function() {myChart.resize();});}
)();
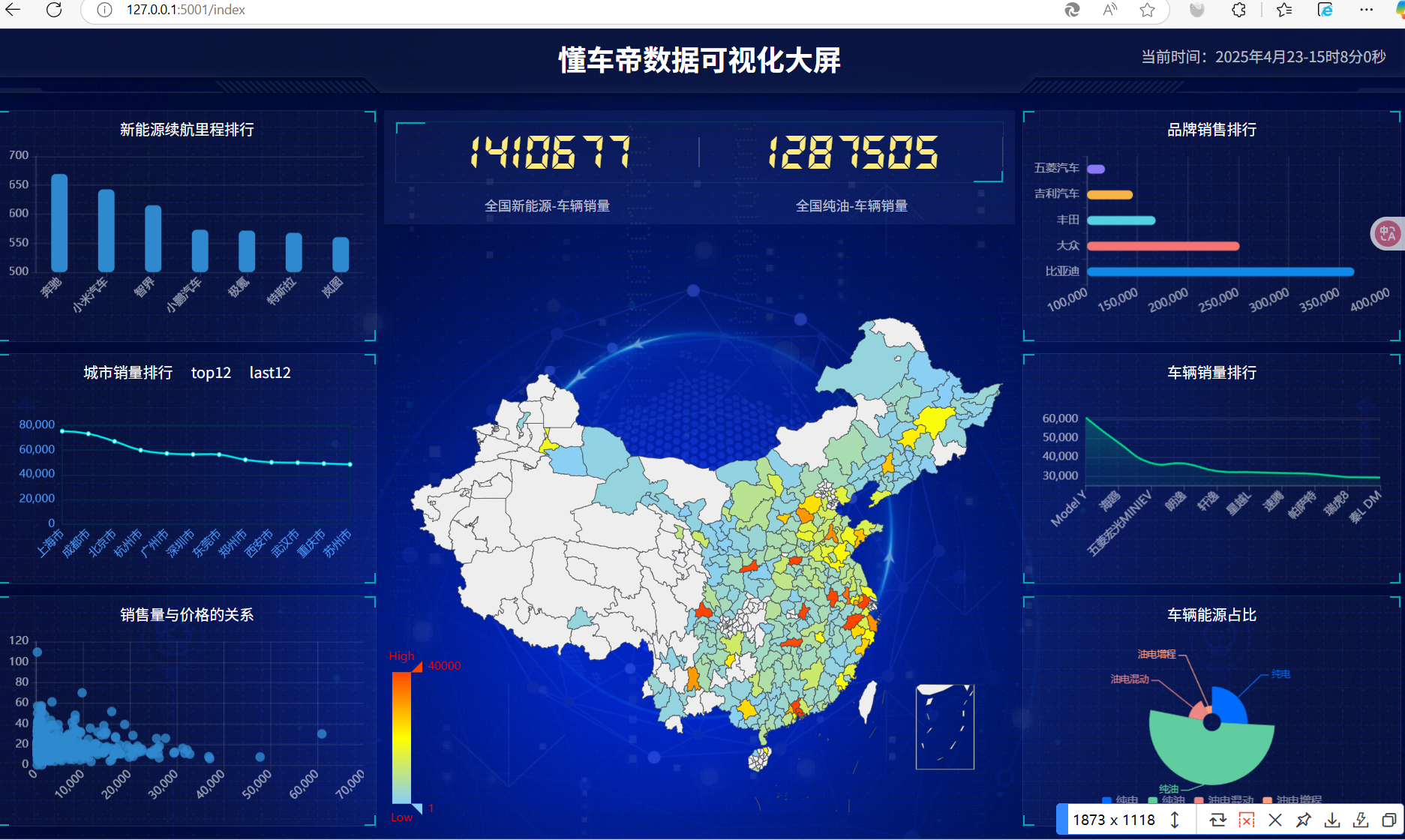
效果图
相关文章:

【Project】基于spark-App端口懂车帝数据采集与可视化
文章目录 hadoop完全分布式部署hdfs-site.xmlcore-site.xmlmarpred-site.xmlyarn-site.xml spark集群部署spark-env.sh mongodb分片模式部署config 服务器初始化config 副本集 shard 服务器初始化shard 副本集 mongos服务器添加shard设置chunk大小 启动分片为集合 user 创建索引…...

基于ARM+FPGA+DSP的储能协调控制器解决方案,支持国产化
储能协调控制器的作用与设计方案 一、核心作用 实时监测与协调控制 实时采集储能系统电压、电流、温度等参数,监测电池电量状态及充放电功率,动态调整储能与电网、负载的功率交互,保障能源供需平衡15。支持一次调频(AGC&a…...

将天气查询API封装为MCP服务
下面我将展示如何将一个天气查询API封装为符合MCP协议的服务。我们将使用Python实现,包括服务端和客户端。 ## 1. 服务端实现 python # weather_mcp_server.py from fastapi import FastAPI, HTTPException from pydantic import BaseModel from typing import Di…...

JSON实现动态按钮管理的Python应用
在开发桌面应用程序时,动态生成用户界面元素并根据配置文件灵活管理是一项常见需求。本文将介绍如何使用Python的wxPython库结合JSON配置文件,开发一个支持动态按钮创建、文件执行和配置管理的桌面应用程序。该应用允许用户通过设置界面配置按钮名称和关…...

基于GA遗传优化TCN-BiGRU注意力机制网络模型的时间序列预测算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 (完整程序运行后无水印) 2.算法运行软件版本 matlab2024b(提供软件版本下载) 3.部分核心程序 (完整版代码包…...
备份还原)
MongoDB(docker版)备份还原
docker启动MongoDB docker run -d -p 27017:27017 --name my-mongo -v /mongodb/db:/data/db mongo备份MongoDB 使用mongodump备份数据库时,默认会将备份数据保存在当前工作目录下的dump文件夹中。 docker容器中默认备份在当前工作目录,所以此处指定当…...

[蓝桥杯 2025 省 Python B] 异或和
暴力(O(n^2)): def xor_sum(n, arr):total 0for i in range(n):for j in range(i 1, n):total (arr[i] ^ arr[j]) * (j - i)return total# 主函数 if __name__ "__main__":n int(input())arr list(map(int, input().split()…...

HTTP代理基础:网络新手的入门指南
目录 一、为什么需要了解HTTP代理? 二、HTTP代理的“中间人”角色 三、代理的三大核心类型 四、HTTP代理的5大实用场景 五、设置代理的三种方式 六、代理的优缺点分析 七、如何选择代理服务? 八、安全使用指南 九、未来趋势 结语 一、为什么需要…...

GRE 多层级网络数据处理系统
一、整体架构 多层级网络数据处理系统,从底层硬件中断到上层协议处理,涵盖了数据包的接收、转发、解封装、路由决策和发送全流程。系统采用分层处理和模块化设计,结合了传统Linux网络协议栈与快速路径(Fast Path࿰…...

展望未来,楼宇自控系统如何全方位推动绿色建筑智能高效发展
在全球积极践行可持续发展理念的时代背景下,绿色建筑已成为建筑行业发展的必然趋势。绿色建筑追求在全生命周期内,最大限度地节约资源、保护环境和减少污染,为人们提供健康、舒适、高效的使用空间。而楼宇自控系统作为建筑智能化的核心技术&a…...

【计算机视觉】CV项目实战- Florence-SAM 多模态视觉目标检测+图像分割
Florence-SAM多模态视觉分析系统:技术解析与实战指南 一、项目架构与技术解析1.1 核心模型架构1.2 支持的任务模式 二、环境配置与部署实战2.1 本地部署指南2.2 运行演示系统 三、核心功能实战解析3.1 图像开放词汇检测3.2 视频目标跟踪 四、高级应用与二次开发4.1 …...

2025-04-23 Python深度学习3——Tensor
文章目录 1 张量1.1 数学定义1.2 PyTorch中的张量 2 创建 Tensor2.1 直接创建**torch.tensor()****torch.from_numpy()** 2.2 依据数值创建**torch.zeros() / torch.zeros_like()****torch.ones() / torch.ones_like()****torch.full() / torch.full_like()****torch.arange() …...
:双核 AMP 通信实验)
ZYNQ笔记(十三):双核 AMP 通信实验
版本:Vivado2020.2(Vitis) ZYNQ 裸机双核 AMP 实验: CPU0 接收串口的数据,并写入 OCM 中,然后利用软件产生中断触发 CPU1;CPU1 接收到中断后,根据从 OCM 中读出的数据控制呼吸灯的频…...

黑马Java基础笔记-3
短路逻辑运算符与逻辑运算符 逻辑运算符 符号作用说明&逻辑与(且)并且,两边都为真,结果才是真|逻辑或或者,两边都为假,结果才是假^逻辑异或相同为 false,不同为 true!逻辑非取反 短路逻辑…...

4.23学习总结
虽然之前写过的相关dfs和bfs的题,但方法忘的差不多了,重写了一遍相关的算法题,今天完成了岛屿数量的算法题,我利用的是bfs的算法,遍历每个结点,如果是1就count,然后再bfs向四周遍历并标记已经走过 初步看了…...

ElasticSearch:高并发场景下如何保证读写一致性?
在Elasticsearch高并发场景下,可以通过以下多种方式来保证读写一致性: 等待主分片和副本分片都确认(类似半同步机制) 设置consistency参数:在写操作时,可以设置consistency参数来控制写操作的一致性级别。…...
)
Qt基础007(Tcp网络编程)
文章目录 QTcp服务器的关键流程QTtcp客户端的关键流程TCP协议Socket QTcp服务器的关键流程 工程建立,需要在.pro加入网络权限 创建一个基于 QTcpServer 的服务端涉及以下关键步骤: 创建并初始化 QTcpServer 实例: 实例化 QTcpServer 。 调…...

visio导出的图片过大导致latex格式转成pdf之后很不清楚
联想电脑解决方法 右键打开方式选择【照片】,然后选择调整图片大小,将像素的宽度和高度调低。...
)
leetcode刷题——判断对称二叉树(C语言版)
题目描述: 示例 1: 输入:root [6,7,7,8,9,9,8] 输出:true 解释:从图中可看出树是轴对称的。 示例 2: 输入:root [1,2,2,null,3,null,3] 输出:false 解释:从图中可看出最…...

STM32与i.MX6ULL内存与存储机制全解析:从微控制器到应用处理器的设计差异
最近做FreeRTos,以及前面设计的RVOS,这种RTOS级别的系统内存上的分布与CortexA系列里面的分布有相当大的区别,给我搞糊涂了。 目录 STM32(Cortex-M系列)的内存与存储机制 Flash存储内容RAM存储内容启动与运行时流程示例…...

经验分享-上传ios的ipa文件
.ipa格式的二进制文件,是打包后生成的文件,无论我们是放上去testflight测试还是正式上传到app store,都需要先上传到苹果开发者中心的app store connect上的构建版本上。 在app store connect上,上传构建版本的功能,它…...

Linux423 删除用户
查找 上面已查过:无法使用sudo 新开个终端试试 之前开了一个终端,按照deepseek排查 计划再开一个进程 开一个终端 后强制删除时显示:此事将被报告...

AI与Web3.0:技术融合
AI与Web3.0:技术融合 分享一下给大家一个从0开始学习ai 的网站。点击跳转到网站。 https://www.captainbed.cn/ccc 前言 随着互联网技术的飞速发展,Web3.0作为下一代互联网形态,正以前所未有的速度改变着我们的生活方式和工作模式。Web3.0强…...

Python爬虫第18节-动态渲染页面抓取之Splash使用上篇
目录 引言 一、Splash 的简介与安装 1.1 简介 1.2 安装 二、Splash 的使用 三、Splash Lua 脚本开发 3.1 脚本入口与返回值 3.2 异步处理 四、Splash 对象属性 4.1 args 4.2 js_enabled 4.3 resource_timeout 4.4 images_enabled 4.5 scroll…...

Linux进程状态及转换关系
目录 1、就绪态(Ready) 2、运行态(Running) 3、僵尸态(Zombie) 4、可中断睡眠态(Interruptible Sleep) 5、不可中断睡眠态(Uninterruptible Sleep) 6、…...

Java基础:认识注解,模拟junit框架
认识注解 自定义注解 注解的原理 元注解 解析注解 应该场景-配合反射做juint框架 public static void main(String[] args) {AnnotationDemo4 a new AnnotationDemo4();Class clazz AnnotationDemo4.class;Method[] methods clazz.getDeclaredMethods();for (Method method …...

chrony服务器
时间有什么作用?约定干什么事情,会出问题,双方约定会达成 一旦有一方的时间不准确,约定都会达不成 不联网,计算机运行一个月,你的计算机就会和标准的时间差一两分钟 通常情况下,硬件时间的运…...

Springboot——Redis的使用
在当今的软件开发领域,缓存技术是提升应用性能的关键手段之一。Redis 作为一款高性能的键值对存储数据库,凭借其出色的读写速度和丰富的数据结构,在缓存场景中得到了广泛应用。Spring Boot 作为一款简化 Spring 应用开发的框架,与…...

【EasyPan】removeFile2RecycleBatch方法及递归操作解析
【EasyPan】项目常见问题解答(自用&持续更新中…)汇总版 文件批量转移到回收站方法解析 一、方法总述 removeFile2RecycleBatch方法实现将用户选中的文件/目录及其子内容批量移入回收站的业务逻辑,主要特点: 递归处理&…...

AIGC的伦理困境:机器生成内容是否该被监管?
AIGC的伦理困境:机器生成内容是否该被监管? 在当今数字时代,人工智能(AI)技术的发展日新月异,其中生成式人工智能(AIGC, AI-Generated Content)作为一项前沿技术,正以前…...

缓存一致性
什么是缓存一致性? 当数据库和缓存之间的额数据内容保持同步或最终一致,称为缓存一致性 为什么缓存不一致会发生? 因为缓存和数据库是两个独立系统,它们的更新过程不是原子操作,就可能发生以下情况: //…...

【Java学习方法】终止循环的关键字
终止循环的关键字 一、break 作用:跳出最近的循环(直接结束离break最近的那层循环) 使用场景:一般搭配if条件判断,如果满足某个条件,就结束循环,(场景:常见于暴力枚举中…...

bert学习
BERT Google在2018年提出的预训练语言模型,通过双向Transformer结构和大规模预训练。 核心特点 双向上下文 与传统模型(如LSTM或单向Transformer)不同,BERT通过同时考虑单词的左右上下文来捕捉更丰富的语义信息。…...

读书笔记:淘宝十年产品与技术演进史
作者:大淘宝技术 原文地址:读书笔记:淘宝十年产品与技术演进史 本文是对《淘宝十年产品事》与《淘宝技术这十年》两本书的阅读笔记总结。通过回顾淘宝过去十年在产品、技术、架构、中间件及开放平台等方面的发展历程,展现了其从初…...

ROS 快速入门教程02
5. Node 节点 以智能手机为例,当我们使用智能手机的某个功能时,大多时候在使用手机的某个APP。同样当我们使用ROS的某个功能时,使用的是ROS的某一个或者某一些节点。 虽然每次我们只使用ROS的某一个或者某一些节点,但我们无法下…...

卷积神经网络常用结构
空间注意力机制(Spatial Attention)详解 空间注意力机制(Spatial Attention)详解 空间注意力机制是计算机视觉中的重要组件,它使网络能够选择性地关注特征图中的重要空间区域,同时抑制不相关区域的影响。 空间注意力机制结构图 空间注意力机制详细解析…...
)
neo4j中节点内的名称显示不全解决办法(如何让label在节点上自动换行)
因为节点过多而且想让节点中所有文字都显示出来而放大节点尺寸 从neo4j中导出png,再转成PDF来查看时,要看清节点里面的文字就得放大5倍才行 在网上看了很多让里面文字换行的办法都不行 然后找到一个比较靠谱的办法是在要显示的标签内加换行符 但是我的节点上显示的是…...

容器化-Docker-进阶
一、自定义镜像:从基础部署到镜像定制 (一)Linux 与 Docker 原生部署 Nginx 对比 Linux 原生部署 Nginx # 安装依赖 sudo apt-get update && sudo apt-get install -y build-essential openssl libpcre3-dev zlib1g-dev # 下载Nginx源码 wget http://nginx.org…...

Sqlserver 自增长id 置零或者设置固定值
在 SQL Server 中,如果需要重置一个表的自增长(Identity)列的当前值,通常有几种方法可以实现。但是,值得注意的是,直接将自增长列的值设置为0并不是一个推荐的做法,因为这会破坏自增长列的连续性…...
详解)
状态模式(State Pattern)详解
文章目录 一、状态模式简介1.1 什么是状态模式?1.2 为什么需要状态模式?1.3 状态模式的核心思想二、状态模式的结构2.1 UML类图2.2 各个组件的详细说明2.3 交互过程三、状态模式的实现步骤(以Java为例)步骤1:创建状态接口步骤2:实现具体状态类步骤3:创建上下文类步骤4:…...

Shopee五道质检系统重构东南亚跨境格局,2025年电商游戏规则悄然改写
在2024年的东南亚跨境电商市场,一场以“质量”为核心的深度变革正在上演。作为头部平台的Shopee率先出招,以一套“五道质检流程”打破行业旧格局,不仅有效遏制高企的退货率,更引发从卖家结构到政策制度的连锁反应。 这场质量革命…...

Unity-无限滚动列表实现Timer时间管理实现
今天我们来做一个UI里经常做的东西:无限滚动列表。 首先我们得写清楚实现的基本思路: 所谓的无限滚动当然不是真的无限滚动,我们只要把离开列表的框再丢到列表的后面就行,核心理念和对象池是类似的。 我们来一点一点实现&#x…...

Python高级爬虫之JS逆向+安卓逆向1.6节: 函数基础
目录 引言: 1.6.1 理解函数 1.6.2 定义函数 1.6.3 调用函数 1.6.4 位置实参 1.6.5 关键字实参 1.6.6 爬虫不要进接单群 引言: 大神薯条老师的高级爬虫+安卓逆向教程: 这套爬虫教程会系统讲解爬虫的初级,中级,高级知识,涵盖的内容包括基础爬虫,高并发爬虫的设计与…...
)
集结号海螺捕鱼组件搭建教程与源码结构详解(第四篇)
本篇将聚焦“冰封领域”场景构建与性能优化策略。本节适合有Unity经验的技术团队,对大型特效场景优化、C与Unity协同通信及资源动态加载有深入需求的开发者。 一、冰封领域场景设计理念 冰封领域是高难度玩法场景,常用于高段位玩家房间,场景…...
)
02.Python代码Pandas - Series全系列分享(使用.特点.说明.取值.函数)
02.Python代码Pandas - Series全系列分享(使用.特点.说明.取值.函数) 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是pandas的使用语法。前后每一小节的内容是存在的有:学习and理解的关联性,希望…...

星火燎原:Spark技术如何重塑大数据处理格局
在数字化浪潮席卷全球的今天,数据已成为企业发展与社会进步的核心驱动力。面对海量且复杂的数据,传统的数据处理技术逐渐显得力不从心。而Apache Spark作为大数据领域的明星框架,凭借其卓越的性能与强大的功能,如同一束璀璨的星火…...

AI大模型和人脑的区别
为什么人脑没有幻觉,但是 AI 大语言模型有幻觉? 人脑和大型语言模型(LLM)在处理信息的方式上存在根本差异,这导致了幻觉现象主要出现在LLM中。LLM的幻觉是指模型生成了貌似合理但实际上错误或虚构的内容。 LLM的工作…...
)
第一章:基于Docker环境快速搭建LangChain框架的智能对话系统:从langchain环境搭建到多轮对话代码实现(大语言模型加载)
文章目录 前言一、langchain环境搭建1、docker容器搭建2、docker容器连接修改密码容器内容修改物理机修改 3、langchain安装 二、langchain构建简单智能对话示例1、基于deepseek的简单问答Demo2、langchain的invoke、stream与astream生成方法1、langchain的invoke、stream与ast…...
二分查找,利用二分查找找局部最小值,选择排序,冒泡排序,插入排序,位运算的基础知识)
数据结构的学习(1)二分查找,利用二分查找找局部最小值,选择排序,冒泡排序,插入排序,位运算的基础知识
一、二分查找某个元素 (1)查找是否存在某个元素在数组中 思想: 1)先看中间位置的值 2)如果中间位置的值大于目标值说明目标值在整个数组中偏左的位置,改变右边界,即Right Mid - 1; 3…...

vue2+Vant 定制主题
参考文档:Vant主题定制-CSDV博客 vant提供了一套默认主题,若想完全替换主题是或者其他样式,则需要定制主题。 定制方法 1、main.js文件引入主题样式源文件 // 导入并安装 Vant 组件库 import Vant from vant // 切记:为了能够覆…...