【redis】主从复制
Redis的单机模式仅部署单个实例,一旦节点宕机或网络故障,所有依赖Redis的服务将不可用,这就是所谓的单点故障问题。单节点需承担全部读写请求,并发量高时可能成为性能瓶颈。单节点受限于物理内存容量,无法突破内存物理上限存储海量数据。所有请求都怼到一个实例,磁盘IO、网络IO、带宽、CPU等资源都会成为瓶颈。
主从复制(Master-Replica)通过部署主节点(Master)和多个从节点(Replica),实现数据副本分发:
- 主节点:处理所有写请求,数据变更后异步/半同步复制到从节点。
- 从节点:以只读形式提供数据查询,承担读请求压力。
注意:读写分离并不是Redis自带,需要客户端手动实现。
主从复制的多种拓扑结构
Redis主从复制支持多种拓扑结构,不同结构适用于不同场景,核心目的是实现数据冗余、读写分离和高可用。
一主一从(Master + Single Replica)
单个主节点(Master)搭配一个从节点(Replica),从节点通过 replicaof 命令与主节点建立复制关系。
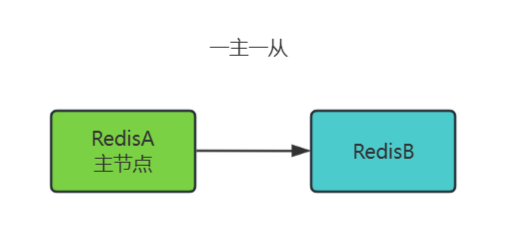
工作原理:
- 主节点处理所有写请求,从节点异步复制主节点数据。
- 从节点可接受只读请求,分担主节点的读压力。
优点:
- 简单易用:配置简单,适合快速搭建备份环境。
- 基础高可用:主节点故障时,可手动将从节点提升为主节点。
- 数据冗余:至少保留一份完整数据副本。
缺点:
- 读扩展有限:仅一个从节点,读性能提升有限。
- 资源利用率低:从节点可能长期处于低负载状态。
适用场景:
- 小型系统的基础数据备份。
- 测试环境验证主从复制功能。
- 对读性能要求不高的容灾场景。
一主多从(Master + Multiple Replicas)
一个主节点(Master)连接多个从节点(Replicas),所有从节点直接复制主节点数据。
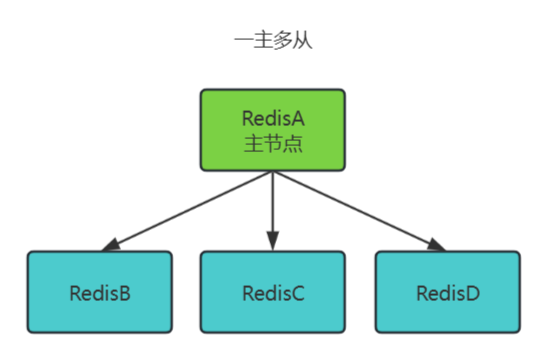
工作原理:
- 主节点处理写请求,所有从节点异步复制主节点数据。
- 读请求可分摊到多个从节点,实现水平扩展。
优点:
- 高读吞吐量:多个从节点并行处理读请求,适合读多写少场景。
- 灵活扩展:按需动态增加从节点,提升读性能。
- 多副本冗余:数据安全性更高,多个从节点可同时故障。
缺点:
- 主节点压力大:所有从节点直接连接主节点,主节点需处理大量复制流量。
- 网络带宽消耗:主节点需向多个从节点发送相同数据,可能成为网络瓶颈。
适用场景:
- 高并发读场景(如热点数据查询、排行榜读取)。
- 多机房部署时,从节点分布在多个机房实现就近读取。
- 需要多副本冗余的高可靠性系统。
级联复制(Chained Replication)
主节点 → 从节点(中间层) → 更多从节点,形成树状层级结构。例如:主节点A复制到从节点B,从节点B再作为“主节点”复制到从节点D、E。
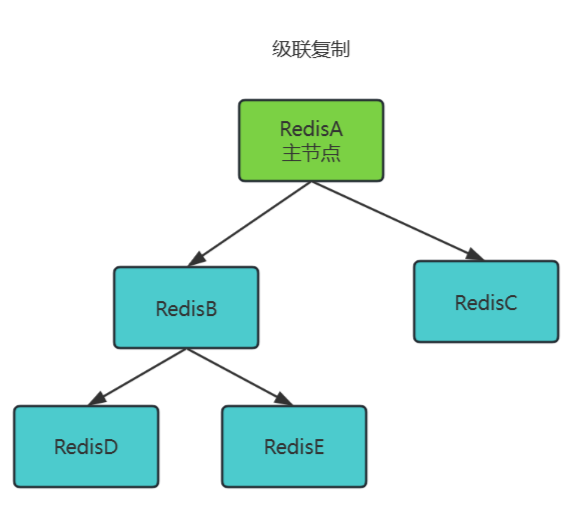
工作原理:
- 中间层从节点既是主节点的副本,又是下级节点的“主节点”。
- 数据从主节点逐级异步复制到下级节点。
优点:
- 降低主节点压力:主节点只需复制到少数中间层节点,减少直接连接的从节点数量。
- 优化网络带宽:分散复制流量,避免主节点成为带宽瓶颈。
- 跨地域复制:中间层节点可部署在不同地域,减少跨区域带宽占用。
缺点:
- 数据延迟累积:层级越深,底层节点数据同步延迟可能越大。
- 故障风险扩散:中间层节点故障会影响其下级所有从节点。
- 运维复杂度高:需监控多层级节点,故障排查难度增加。
适用场景:
- 主节点带宽有限时,需支撑大量从节点。
- 多数据中心部署(如主节点在中心机房,中间层节点分布到边缘节点)。
- 需要层级化管理的企业级架构(如总部-分公司的数据同步)。
对比与选型建议
| 类型 | 读扩展能力 | 主节点压力 | 数据延迟 | 适用规模 | 典型场景 |
|---|---|---|---|---|---|
| 一主一从 | 低 | 低 | 低 | 小型系统 | 数据备份、基础容灾 |
| 一主多从 | 高 | 高 | 低 | 中型系统 | 高并发读、多副本冗余 |
| 树状结构 | 高 | 低 | 高(累积) | 大型分布式系统 | 跨地域复制、带宽优化 |
级联主从复制实战部署
Redis节点规划:
- Master: 127.0.0.1:6380
- Slave1: 127.0.0.1:6381(直连Master)
- Slave2: 127.0.0.1:6382(直连Slave1)
在/test/目录分别新建/test/6380、/test/6381、/test/6382三个目录,用来存放redis的数据文件。
启动Master,这里为了便于演示,查看日志情况,都使用非守护进程的方式启动:
$ redis-server --dir /test/6380 --port 6380
启动两个Slave:
$ redis-server --dir /test/6381 --port 6381
$ redis-server --dir /test/6382 --port 6382
现在三台Redis还没有建立任何关系,现在使用REPLICAOF命令对Slave1进行主从复制(旧版本使用slaveof命令):
$ redis-cli -p 6381 REPLICAOF 127.0.0.1 6380
OK
在Master节点的日志可以看到与slave1建立复制关系:
4568:M 16 Apr 2025 14:13:32.876 * Replica 127.0.0.1:6381 asks for synchronization
4568:M 16 Apr 2025 14:13:32.876 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for '5d5d90144633f080a3d7d3716c9f8e4368a8d934', my replication IDs are 'a532518e375fa630202ed97a4cfb6793994e84f6' and '0000000000000000000000000000000000000000')
4568:M 16 Apr 2025 14:13:32.876 * Replication backlog created, my new replication IDs are '8b9acbd5b3737e524d64c2dfb6ac4c9022439b8e' and '0000000000000000000000000000000000000000'
4568:M 16 Apr 2025 14:13:32.876 * Starting BGSAVE for SYNC with target: disk
4568:M 16 Apr 2025 14:13:32.876 * Background saving started by pid 4584
4584:C 16 Apr 2025 14:13:32.878 * DB saved on disk
4584:C 16 Apr 2025 14:13:32.879 * RDB: 0 MB of memory used by copy-on-write
4568:M 16 Apr 2025 14:13:32.954 * Background saving terminated with success
4568:M 16 Apr 2025 14:13:32.954 * Synchronization with replica 127.0.0.1:6381 succeeded
同样在Slave1节点的日志可以看到:
4573:S 16 Apr 2025 14:13:32.875 * MASTER <-> REPLICA sync started
4573:S 16 Apr 2025 14:13:32.875 * REPLICAOF 127.0.0.1:6380 enabled (user request from 'id=3 addr=127.0.0.1:35164 laddr=127.0.0.1:6381 fd=8 name= age=0 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=44 qbuf-free=40910 argv-mem=22 obl=0 oll=0 omem=0 tot-mem=61486 events=r cmd=replicaof user=default redir=-1')
4573:S 16 Apr 2025 14:13:32.875 * Non blocking connect for SYNC fired the event.
4573:S 16 Apr 2025 14:13:32.875 * Master replied to PING, replication can continue...
4573:S 16 Apr 2025 14:13:32.875 * Trying a partial resynchronization (request 5d5d90144633f080a3d7d3716c9f8e4368a8d934:1).
4573:S 16 Apr 2025 14:13:32.876 * Full resync from master: 8b9acbd5b3737e524d64c2dfb6ac4c9022439b8e:0
4573:S 16 Apr 2025 14:13:32.876 * Discarding previously cached master state.
4573:S 16 Apr 2025 14:13:32.954 * MASTER <-> REPLICA sync: receiving 175 bytes from master to disk
4573:S 16 Apr 2025 14:13:32.954 * MASTER <-> REPLICA sync: Flushing old data
4573:S 16 Apr 2025 14:13:32.954 * MASTER <-> REPLICA sync: Loading DB in memory
4573:S 16 Apr 2025 14:13:32.956 * Loading RDB produced by version 6.2.6
4573:S 16 Apr 2025 14:13:32.956 * RDB age 0 seconds
4573:S 16 Apr 2025 14:13:32.956 * RDB memory usage when created 1.83 Mb
4573:S 16 Apr 2025 14:13:32.956 # Done loading RDB, keys loaded: 0, keys expired: 0.
4573:S 16 Apr 2025 14:13:32.956 * MASTER <-> REPLICA sync: Finished with success
对Slave2执行同样的操作,同样可以在Slave1和Slave2中日志中观察到建立复制关系。
在主节点(Master)上查看复制状态:
$ redis-cli -p 6380 info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=1676,lag=1
master_failover_state:no-failover
master_replid:8b9acbd5b3737e524d64c2dfb6ac4c9022439b8e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1676
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1676
在第一级从节点(Slave1)上查看复制状态:
$ redis-cli -p 6381 info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6380
master_link_status:up
master_last_io_seconds_ago:10
master_sync_in_progress:0
slave_read_repl_offset:1718
slave_repl_offset:1718
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:1
slave0:ip=127.0.0.1,port=6382,state=online,offset=1718,lag=1
master_failover_state:no-failover
master_replid:8b9acbd5b3737e524d64c2dfb6ac4c9022439b8e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1718
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1718
在第二级从节点(Slave2)上查看复制状态:
$ redis-cli -p 6382 info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6381
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_read_repl_offset:1788
slave_repl_offset:1788
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:8b9acbd5b3737e524d64c2dfb6ac4c9022439b8e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1788
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1065
repl_backlog_histlen:724
这时我们对Master写入一个key,两个Slave是可以访问到的,但是Slave是不能写入的,只能读。
$ redis-cli -p 6380 set aa bb
OK$ redis-cli -p 6381 get aa
"bb"$ redis-cli -p 6382 get aa
"bb"$ redis-cli -p 6382 set cc dd
(error) READONLY You can't write against a read only replica.
此时如果把Master关掉,Slave1都会报一个如下的错误,Slave2不会报错:
4573:S 16 Apr 2025 14:36:38.340 * Connecting to MASTER 127.0.0.1:6380
4573:S 16 Apr 2025 14:36:38.340 * MASTER <-> REPLICA sync started
4573:S 16 Apr 2025 14:36:38.340 # Error condition on socket for SYNC: Connection refused
此时Slave1和Slave2的数据还是可以读的(提供读服务):
$ redis-cli -p 6381 get aa
"bb"$ redis-cli -p 6382 get aa
"bb"
使用主从复制模式,如果Master挂了,需要人工手动指定其中一个Slave升为Master,这里我把6381升为Master:
$ redis-cli -p 6381 REPLICAOF no one
然后Slave1的日志就会打印,Master模式开启:
4573:M 16 Apr 2025 14:41:24.908 * Discarding previously cached master state.
4573:M 16 Apr 2025 14:41:24.909 # Setting secondary replication ID to 8b9acbd5b3737e524d64c2dfb6ac4c9022439b8e, valid up to offset: 1971. New replication ID is e21f3798a676bb852f0b9a5ce73344b4eef57963
4573:M 16 Apr 2025 14:41:24.909 * MASTER MODE enabled (user request from 'id=248 addr=127.0.0.1:36272 laddr=127.0.0.1:6381 fd=8 name= age=0 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=36 qbuf-free=40918 argv-mem=14 obl=0 oll=0 omem=0 tot-mem=61478 events=r cmd=replicaof user=default redir=-1')
这样原来的Slave1也就是新的Master又可以对外提供写服务了:
$ redis-cli -p 6381 set xx oo
OK$ redis-cli -p 6381 get xx
"oo"$ redis-cli -p 6382 get xx
"oo"
核心配置参数详解
主节点相关
# 从节点连接主节点的密码
masterauth "password"
# 主节点自身密码
requirepass "password"# 复制积压缓冲区大小(默认1MB,建议根据数据量调整)
# 主节点将最近的写命令存入缓冲区,从节点断线重连后从中恢复同步,避免全量复制。
# 若网络不稳定或数据量大,增大repl-backlog-size(如256MB~1GB)。
repl-backlog-size 256mb# 缓冲区保存时间(秒,超时后释放)
repl-backlog-ttl 3600# 主节点等待从节点ACK确认的超时时间(默认60秒)
# 跨地域部署时,增大repl-timeout避免因高延迟触发超时。
repl-timeout 120# 是否允许从节点写入(默认no,从节点应只读)
# 若从节点需临时写入测试数据,可设为no(不推荐生产环境)。
replica-read-only yes# 是否启用无盘同步(适用于磁盘IO慢的场景)
# 主节点磁盘性能差时,启用repl-diskless-sync直接通过内存传输RDB文件。
# Disk-backed:master先将数据存在RDB文件并保存到磁盘上,再发送给slave
# Diskless:master直接在内存中生成RDB文件并通过socket发送给slave
repl-diskless-sync yes# 无盘同步等待时间(等待更多从节点连接后批量同步)
# 若从节点数量多,设置repl-diskless-sync-delay合并同步请求。
repl-diskless-sync-delay 5# 主从断开时是否返回旧数据
replica-serve-stale-data yes# 复制缓冲区限制
client-output-buffer-limit replica 256mb 64mb 60
从节点相关
# 指定主节点IP和端口
replicaof 192.168.1.100 6379# 主节点密码(需与主节点requirepass一致)
masterauth your_master_password# 断线重试间隔(默认10秒,指数退避)
# 频繁断连时,缩短 repl-ping-replica-period 加快心跳检测。
repl-ping-replica-period 10# 是否开启增量复制(默认yes)
# 若主从数据差异大,从节点会触发全量同步(发送RDB文件)。
repl-diskless-load disabled# 从节点同步后是否清空旧数据(默认yes)
# 允许从节点在同步期间继续响应旧数据查询。
replica-serve-stale-data yes# 主节点压缩数据后发送(节省带宽,消耗CPU)
repl-diskless-sync-enabled yes
repl-diskless-sync-max-bitmap-size 64mb# 从节点复制延迟阈值(单位秒,超时触发告警)
# 最少要有1个slave写数据,否则master停止写请求
min-replicas-to-write 1
# 作用:主节点仅在至少N个从节点延迟小于阈值时才接受写请求(类似半同步)。
# # slave延迟超过10s,master停止写请求
min-replicas-max-lag 10
主从复制的改进与缺点
主从复制对单机模式的改进:
-
故障恢复与高可用性:从节点可作为主节点的冷备或热备(需配合哨兵Sentinel等监控工具),主节点宕机后可晋升新主,降低系统不可用时间。
-
读写分离提升性能:写请求由主节点处理,读请求分发到多个从节点,充分利用多节点资源,显著提升读吞吐量。
-
数据冗余与备份:主从节点存储相同副本,即使主节点数据丢失,仍可通过从节点恢复,降低数据风险。
-
动态扩展能力:根据业务增长灵活添加从节点,突破单机内存容量限制(需配合集群模式完全解决)。
主从复制的限制与注意事项:
-
异步复制的数据一致性:默认异步复制下,主从数据可能存在短暂延迟(秒级),无法实现强一致性。
-
写操作仍受主节点单点限制:写压力仍集中在主节点,需通过分片(Cluster)解耦。
-
故障切换复杂度:主节点故障需依赖额外组件(如 Sentinel)实现自动切换,否则需人工干预。
主从复制的原理
| 类型 | 同步方式 | 数据一致性 | 性能影响 |
|---|---|---|---|
| 全量复制 | 首次连接时 | 强一致 | 高IO压力 |
| 部分复制 | 断线重连后 | 最终一致 | 低资源消耗 |
全量复制的触发条件
- 首次建立主从关系:从节点首次执行REPLICAOF命令连接主节点。
- 数据差异过大:从节点落后主节点太多(超出复制积压缓冲区范围)。
- 复制ID不匹配:主节点重启导致复制ID变更,从节点无法增量同步。
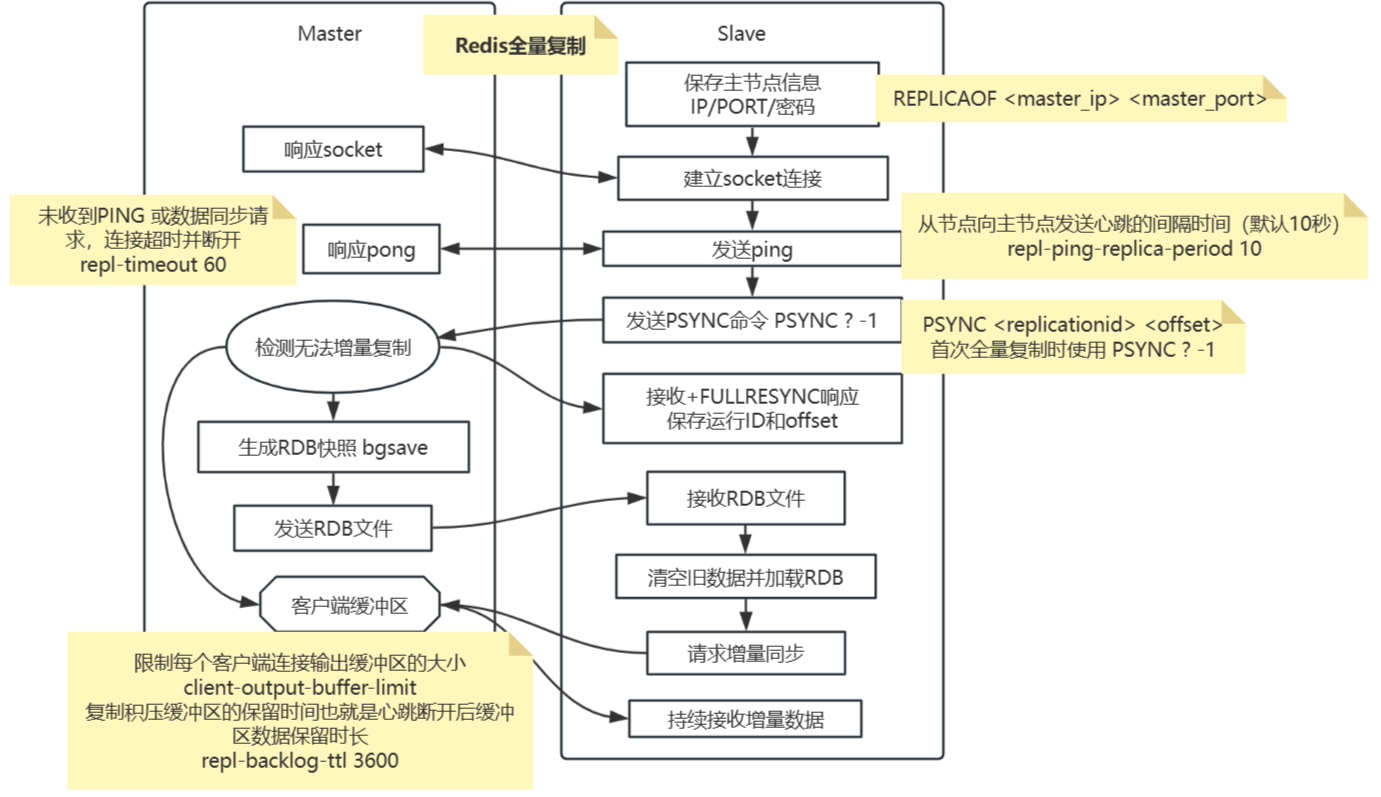
全量复制的完整流程
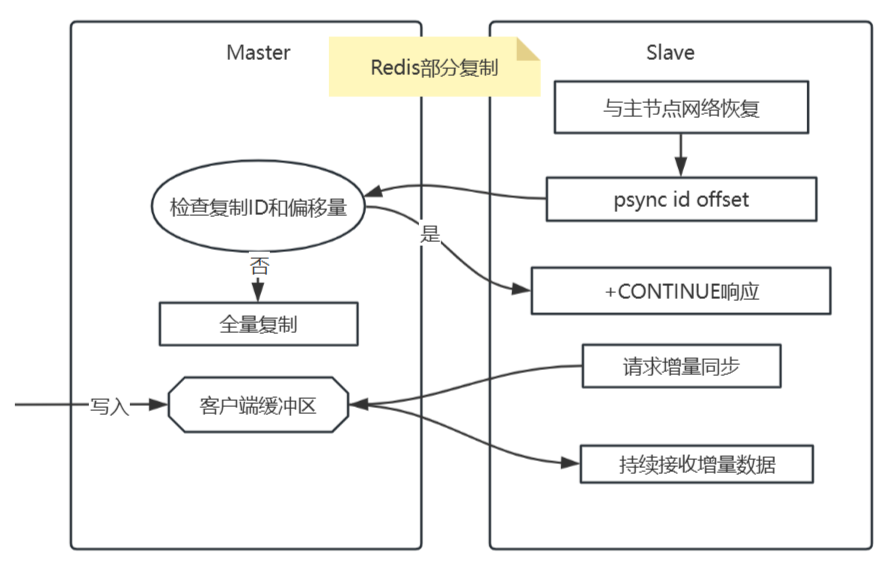
部分复制的触发条件
- 主从节点的复制ID一致
- 从节点的复制偏移量仍在主节点的复制积压缓冲区内。
部分复制的完整流程
相关文章:

【redis】主从复制
Redis的单机模式仅部署单个实例,一旦节点宕机或网络故障,所有依赖Redis的服务将不可用,这就是所谓的单点故障问题。单节点需承担全部读写请求,并发量高时可能成为性能瓶颈。单节点受限于物理内存容量,无法突破内存物理…...

Qt多线程学习初级指南
一、引言部分 1. 多线程编程的重要性 在当今计算环境中,多线程编程已成为开发高性能应用程序的关键技术。现代应用程序面临着三大挑战: GUI响应性:用户界面需要保持流畅响应,即使在进行后台计算时 多核利用率:随着多…...

《解锁vLLM:大语言模型推理的加速密码》
《解锁vLLM:大语言模型推理的加速密码》 引言:AI 时代的推理引擎之光 在当今的人工智能领域,大语言模型无疑是最为耀眼的明星。它们犹如智能世界的基石,为无数的应用和创新提供了强大的支持。从日常的智能聊天机器人,到复杂的文本生成、机器翻译任务,大语言模型都展现出…...

1.1 java开发的准备工作
准备工作 一.JDK 开始写java程序之前需要安装jdk jdk是java开发工具,包含着JRE和里面的JVM(虚拟机,可以使得不同环境下都能运行Java程序),和开发工具。 二.了解写程序的三大步骤步骤 java成功运行主要需要经过代码编写,编译&a…...

矩阵运算 第30次CCF-CSP计算机软件能力认证
n和d差距这么大 就可以想到改变矩阵运算顺序来解决这道题 假设两个矩阵,分别为a行b列与b行c列,那么一次矩阵运算复杂度是a乘以c乘以b,对于这题,如果从左往右运算复杂度将会到 1e4乘以1e4乘以20>1e9 (n1e4,d20),常识…...

【Tools】Git常见操作
Git 1 配置 包括: 用户信息、分支策略、合并策略、钩子脚本路径等。 git config -l # 等价 --local --list git config --global --list # 全局 git config --local --list # 当前仓库git config user.name git config user.emailgit config user.name "Your Name"…...

国产RK3568+FPGA以 “实时控制+高精度采集+灵活扩展” 为核心的解决方案
RK3568FPGA方案在工业领域应用的核心优势 一、实时性与低延迟控制 AMP架构与GPIO中断技术 通过非对称多处理架构(AMP)实现Linux与实时操作系统(RTOS/裸机)协同,主核负责调度,从核通过GPIO中断响应紧…...

UnoCSS原子CSS引擎-前端福音
UnoCSS是一款原子化的即时按需 CSS 引擎,其中没有核心实用程序,所有功能都是通过预设提供的。默认情况下UnoCSS应用通过预设来实现相关功能。 UnoCSS中文文档: https://www.unocss.com.cn 前有很多种原子化的框架,例如 Tailwind…...
数据分类的艺术:从理论到实践的全面指南)
0.(新专栏目录)数据分类的艺术:从理论到实践的全面指南
前言 话说天下大数据事,分久必合,合久必分。在这个数据爆炸的时代,我们见证了数据的分散与聚合,见证了数据从孤岛到互联的转变。 回望数据发展的历程,最初企业的数据系统往往是各自为政的,各部门、各系统…...

leetcode 二分查找应用
34. Find First and Last Position of Element in Sorted Array 代码: class Solution { public:vector<int> searchRange(vector<int>& nums, int target) {int low lowwer_bound(nums,target);int high upper_bound(nums,target);if(low high…...

航电系统之编队运动控制技术篇
航电系统的编队运动控制技术是现代航空航天领域的关键技术之一,涉及多飞行器协同飞行中的导航、通信、控制与决策。 一、技术原理 编队运动控制技术的核心目标是通过航电系统实现多飞行器(如无人机、卫星等)在空间或时间上的协同运动。其基本…...
中的脚本(Script))
Elasticsearch(ES)中的脚本(Script)
文章目录 一. 脚本是什么?1. lang(脚本语言)2. source(脚本代码)3. params(参数)4. id(存储脚本的标识符)5. stored(是否为存储脚本)6. script 的…...

Collection集合,List集合,set集合,Map集合
文章目录 集合框架认识集合集合体系结构Collection的功能常用功能三种遍历方式三种遍历方式的区别 List集合List的特点、特有功能ArrayList底层原理LinkedList底层原理LinkedList的应用场list:电影信息管理模块案例 Set集合set集合使用哈希值红黑树HashSet底层原理HashSet集合元…...

Kafka 核心使用机制总结
Kafka 核心使用机制总结 Kafka 核心使用机制总结1. 分区 (Partitions) - 实现伸缩性与并行处理2. 副本 (Replicas) / 复制因子 (Replication Factor) - 实现高可用与容错3. 消费者组 (Consumer Groups) - 控制消息分发与消费进度4. 数据保留策略 (Retention Policies) - 管理存…...

【MCP】第二篇:IDE革命——用MCP构建下一代智能工具链
【MCP】第二篇:IDE革命——用MCP构建下一代智能工具链 一、引言二、IDE集成MCP2.1 VSCode2.1.1 安装VSCode2.1.2 安装Cline2.1.3 配置Cline2.1.4 环境准备2.1.5 安装MCP服务器2.1.5.1 自动安装2.1.5.2 手动安装 2.2 Trae CN2.2.1 安装Trae CN2.2.2 Cline使用2.2.3 内…...

WebSocket是h5定义的,双向通信,节省资源,更好的及时通信
浏览器和服务器之间的通信更便利,比http的轮询等效率提高很多, WebSocket并不是权限的协议,而是利用http协议来建立连接 websocket必须由浏览器发起请求,协议是一个标准的http请求,格式如下 GET ws://example.com:3…...

【PostgreSQL教程】PostgreSQL 特别篇之 语言接口连接Perl
博主介绍:✌全网粉丝22W+,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物联网、机器学习等设计与开发。 感兴趣的可…...
,源码可白嫖!)
springboot-基于Web企业短信息发送系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 当今社会已经步入了科学技术进步和经济社会快速发展的新时期,国际信息和学术交流也不断加强,计算机技术对经济社会发展和人民生活改善的影响也日益突出,人类的生存和思考方式也产生了变化。本系统采用B/S架构,数据库是MySQL…...

Centos9安装docker
1. 卸载docker 查看是否安装了docker yum list | grep docker卸载老版本docker,拷贝自官网 sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine卸载新版本…...

MySQL表的操作
MySQL表的操作 1. 创建表 在创建表前,需要先进入到某个数据库: use db_name创建表时,最好提前设计好表应该有的所有内容,否则后续添加或删除表的列可能会引发一连串的问题。 create table tb_name (field1 data_type [comment…...

Jmeter中同步定时器使用注意点
1.设置数量不可大于总线程数量,不然会一直等待 2.设置数量必须与总线程数量成整数倍数,不然还是要一直等。 3.当配置的数量小于线程数时,最好把循环打开,避免最后一次未准备好的线程数量达不到并发数。...

从零开始搭建Django博客③--前端界面实现
本文主要在Ubuntu环境上搭建,为便于研究理解,采用SSH连接在虚拟机里的ubuntu-24.04.2-desktop系统搭建,当涉及一些文件操作部分便于通过桌面化进行理解,通过Nginx代理绑定域名,对外发布。 此为从零开始搭建Django博客…...

使用Handsontable实现动态表格和下载表格
1.效果 2.实现代码 首先要加载Handsontable,在示例中我是cdn的方式引入的,vue的话需要下载插件 let hot null;var exportPlugin null;function showHandsontable(param) {const container document.getElementById("hot-container");// 如果…...

结合地理数据处理
CSV 文件不仅可以存储表格数据,还可以与地理空间数据结合,实现更强大的地理处理功能。例如,你可以将 CSV 文件中的坐标数据转换为点要素类,然后进行空间分析。 示例:将 CSV 文件中的坐标数据转换为点要素类 假设我们有…...

使用Geotools实现将Shp矢量文件加载SLD并合并图例生成-以湖南省周边城市为例
目录 前言 一、技术实现简介 1、生成成果说明 2、生成流程图说明 二、具体生成实践 1、渲染地图 2、生成图例 3、合并图像及输出 三、总结 前言 在当今数字化时代,地理信息系统(GIS)技术已成为城市管理、资源规划、环境监测等众多领域…...

openGauss数据库:起源、特性与对比分析
openGauss数据库:起源、特性与对比分析 一、起源与发展历程 1. 技术背景与开源历程 openGauss是由华为公司主导开发的开源关系型数据库管理系统,其技术根源可追溯至PostgreSQL。2019年,华为在内部整合了多个数据库产品线(如GMDB…...

相机中各个坐标系的转换关系如像素坐标系到世界坐标系以及相机标定的目的
一、背景 无论是机器人领域、SLAM还是自动驾驶领域,都会涉及相机标定,但是看了很多博客,都是各种坐标系的变换,没有从上层说明进行坐标变换的目的是什么,以及相机标定完成后,是已知像素坐标求世界坐标&…...

ubuntu24设置拼音输入法,解决chrome不能输入中文
## 推荐方案:使用 Fcitx5 Fcitx5 是当前在 Wayland 环境下兼容性最好的输入法框架。 ### 1. 安装 Fcitx5 bash sudo apt update sudo apt install fcitx5 fcitx5-chinese-addons fcitx5-frontend-gtk3 fcitx5-frontend-gtk4 fcitx5-frontend-qt5 fcitx5-module-c…...
——创建,退出)
linux内核进程管理(1)——创建,退出
linux源码阅读——进程管理(1) 1. 进程的基本介绍1.1 linux中进程和线程的区别1.2 task_struct中的基本内容1.3 命名空间ns(namespace)命名空间结构图Linux 中的命名空间类型 1.4 进程标识符 2. 创建一个进程的流程2.1 CLONE宏2.2 创建进程系统调用1. do…...
)
容器修仙传 我的灵根是Pod 第8章 护山大阵(DaemonSet)
第三卷:上古遗迹元婴篇 第8章 护山大阵(DaemonSet) 九霄之上,雷云如怒海翻腾。 天调度宗的护山大阵「九霄雷光阵」正发出悲鸣,七十二根镇山雷柱已有半数熄灭。每根雷柱底部,本该守护节点的「雷符傀儡」&a…...

使用Python将YOLO的XML标注文件转换为TXT文件格式
使用Python将YOLO的XML标注文件转换为TXT文件格式,并划分数据集 import xml.etree.ElementTree as ET import os from os import listdir, getcwd from os.path import join import random from shutil import copyfile from PIL import Image# 只要改下面的CLASSE…...

在面试中被问到spring是什么?
Spring框架的核心回答 1. 定义与定位 Spring是一个轻量级、开源的企业级应用开发框架,旨在简化Java应用的开发,提供全面的编程和配置模型。它的核心目标是解决企业应用开发的复杂性,通过模块化设计和松耦合架构,帮助开发者更高效…...

MongoDB Ubuntu 安装
MongoDB 安装 https://www.mongodb.com/zh-cn/docs/manual/installation/ https://www.mongodb.com/zh-cn/docs/manual/tutorial/install-mongodb-on-ubuntu/ https://www.mongodb.com/zh-cn/docs/manual/reference/ulimit/ https://www.mongodbmanager.com/download ubun…...
:Elasticsearch 7的安装与配置、Kibana安装)
ElasticSearch深入解析(三):Elasticsearch 7的安装与配置、Kibana安装
文章目录 〇、简介1.Elasticsearch简介2.典型业务场景3.数据采集工具4.名词解释 一、安装1.使用docker(1)创建虚拟网络(2)Elasticsearch安装步骤 2.使用压缩包 二、配置1.目录介绍2.配置文件介绍3.elasticsearch.yml节点配置4.jvm.options堆配置问题:为什么说堆内存…...

初始SpringBoot
此文介绍一些有关我对SpringBoot的学习理解, 声明:此处我的IDEA是企业版的,可能和社区版会有一些差异 1. 第⼀个SpringBoot程序 1. SpringBoot介绍 我们看下Spring官方的介绍 可以看到,Spring让Java程序更加快速,简单和安全.Spring对于速…...
:dp思想、基础线性dp)
【算法笔记】动态规划基础(一):dp思想、基础线性dp
目录 前言动态规划的精髓什么叫“状态”动态规划的概念动态规划的三要素动态规划的框架无后效性dfs -> 记忆化搜索 -> dp暴力写法记忆化搜索写法记忆化搜索优化了什么?怎么转化成dp?dp写法 dp其实也是图论首先先说结论:状态DAG是怎样的…...
)
C++入门基础(2)
Hello~,欢迎大家来到我的博客进行学习! 目录 1.缺省参数2.函数重载3.引用3.1 引用的概念和定义3.2 引用的特性3.3引用的使用3.4 const引用3.5 指针和引用的关系扩展 4. nullptr 1.缺省参数 缺省参数是声明或定义函数时为函数的参数指定⼀个缺省值。在调用该函数时&…...
中文教程(部分一)_Day15)
OpenCV-Python (官方)中文教程(部分一)_Day15
18.图像梯度 梯度简单来说就是求导。 OpenCV 提供了三种不同的梯度滤波器,或者说高通滤波器:Sobel, Scharr和Laplacian。Sobel,Scharr 其实就是求一阶或二阶导数。Scharr 是对 Sobel(使用小的卷积核求解求解梯度角度时)的优化。Laplacian 是…...

大厂面试:MySQL篇
前言 本章内容来自B站黑马程序员java大厂面试题和小林coding 博主学习笔记,如果有不对的地方,海涵。 如果这篇文章对你有帮助,可以点点关注,点点赞,谢谢你! 1.MySQL优化 1.1 定位慢查询 定位 一个SQL…...

软件工程的13条“定律”:从Hyrum定律到康威定律,再到Zawinski定律
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

Linux删除大文件df空间avail空间不增加
背景 根磁盘被同事写满,使用> 删除一些安装包后,df中的avail空间还是0 排除有进程正在占用文件,已使用lsof命令检测过我所删的文件是没有进程在使用 原因 是文件系统预留空间在作祟 解决 # 文件系统预留块 tune2fs -l /dev/vda2 | gr…...

【C语言-选择排序算法】实现对十个数进行排序
目录 前言 一、选择排序算法原理 二、选择排序算法实现对十个数进行排序 三、代码运行示例 四、选择排序算法的时间复杂度和空间复杂度分析 五、选择排序算法的优缺点 六、总结 前言 在计算机科学领域,排序算法是基石般的存在,它们就像是整理杂乱…...
)
驱动开发硬核特训 · Day 18:深入理解字符设备驱动与子系统的协作机制(以 i.MX8MP 为例)
日期:2025年04月23日 回顾:2025年04月22日(Day 17:Linux 中的子系统概念与注册机制) 本日主题:字符设备驱动 子系统协作机制剖析 学习目标:理解字符设备的注册原理,掌握其与子系统间…...

SQL Server 2022 常见问题解答:从安装到优化的全场景指南
SQL Server 2022 作为微软最新的数据库管理系统,在性能、安全性和云集成方面带来了多项革新。然而,用户在实际使用中仍可能遇到各类问题。本文将围绕安装配置、性能优化、备份恢复、安全设置、高可用性方案、兼容性问题及错误代码解析等核心场景…...

软件开发版本库命名规范说明
背景:近期一直再更新自己所开发的一个前端大文件上传npm库(enlarge-file-upload),为了让库的发版更加规范,于是参考了各种文档写下了这篇关于软件开发库的版本命名规范,且不仅局限于前端的版本命名规范,适用于整个软件…...

Kafka 详解
1.基本概念:Kafka 是分布式发布 - 订阅消息系统,具有高吞吐量、可扩展性等优势,支持点对点和发布订阅两种消息模式,涉及 Broker、Topic、Partition 等多种角色。 2.安装步骤:需先安装 JDK 和 Zookeeper,下…...
)
【Qwen2.5-VL 踩坑记录】本地 + 海外账号和国内账号的 API 调用区别(阿里云百炼平台)
API 调用 阿里云百炼平台的海内外 API 的区别: 海外版:需要进行 API 基础 URL 设置国内版:无需设置。 本人的服务器在香港,采用海外版的 API 时,需要进行如下API端点配置 / API基础URL设置 / API客户端配置…...

硬核解析:整车行驶阻力系数插值计算与滑行阻力分解方法论
引言:阻力优化的核心价值 在汽车工程领域,行驶阻力是影响动力性、经济性及排放的核心因素。根据统计,车辆行驶中约60%的燃油消耗用于克服阻力(风阻、滚阻、传动内阻等)。尤其在电动化趋势下,阻力降低1%可提…...
:滑动窗口)
【网络原理】TCP提升效率机制(一):滑动窗口
目录 一. 前言 二. 滑动窗口 三. 丢包现象 1)ACK报文丢失 2)数据丢失 四. 总结 一. 前言 TCP最核心的机制就是可靠传输 ,确认应答,超时重传,连接管理这些都保证了可靠传输,得到了可靠传输,…...

移动端使用keep-alive将页面缓存和滚动缓存具体实现方法 - 详解
1. 配置组件名称 确保列表页组件设置了name选项,(组合式API额外配置): <!-- vue2写法 --> export default {name: UserList // 必须与 <keep-alive> 的 include 匹配 }<!-- vue3写法 --> defineOptions({na…...