黑马商城-微服务笔记

认识微服务
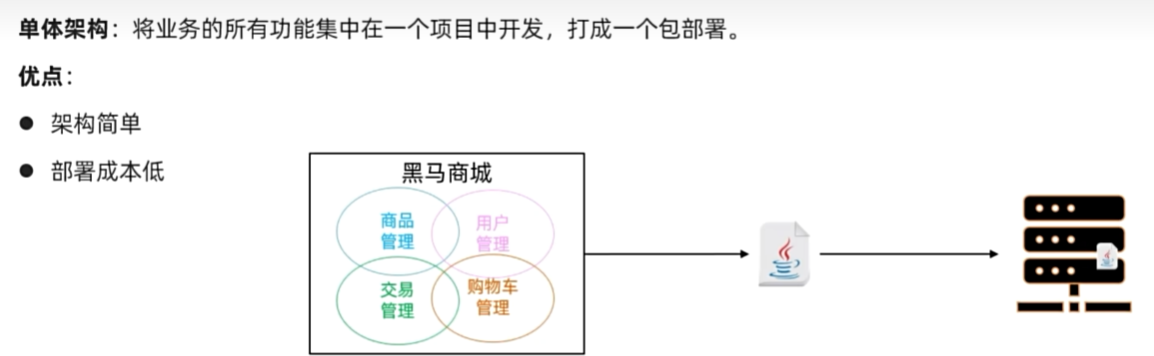
单体架构
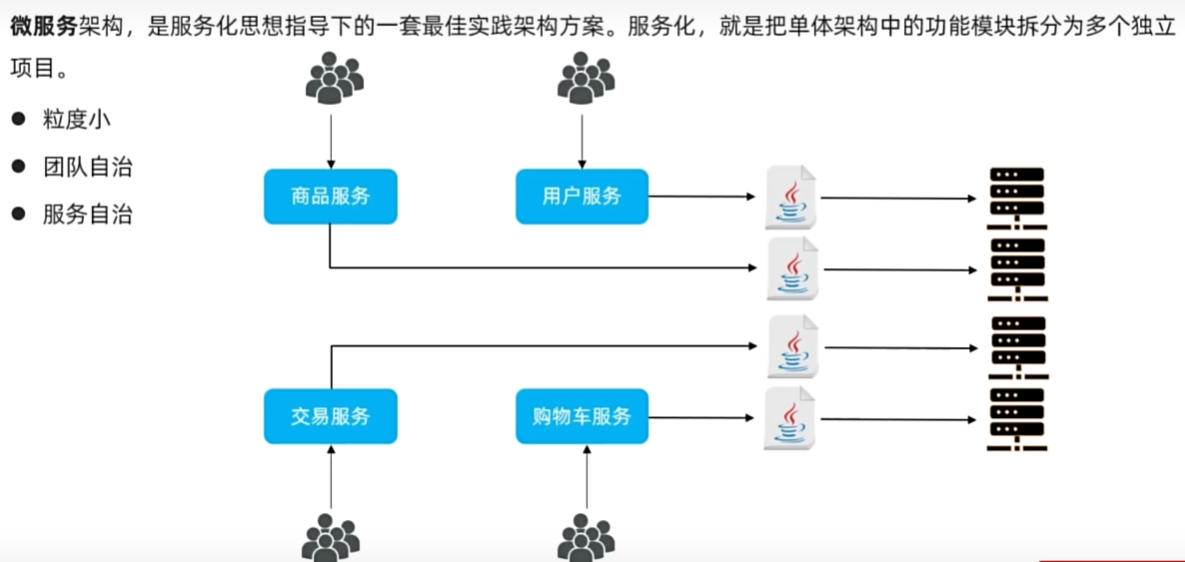
微服务架构
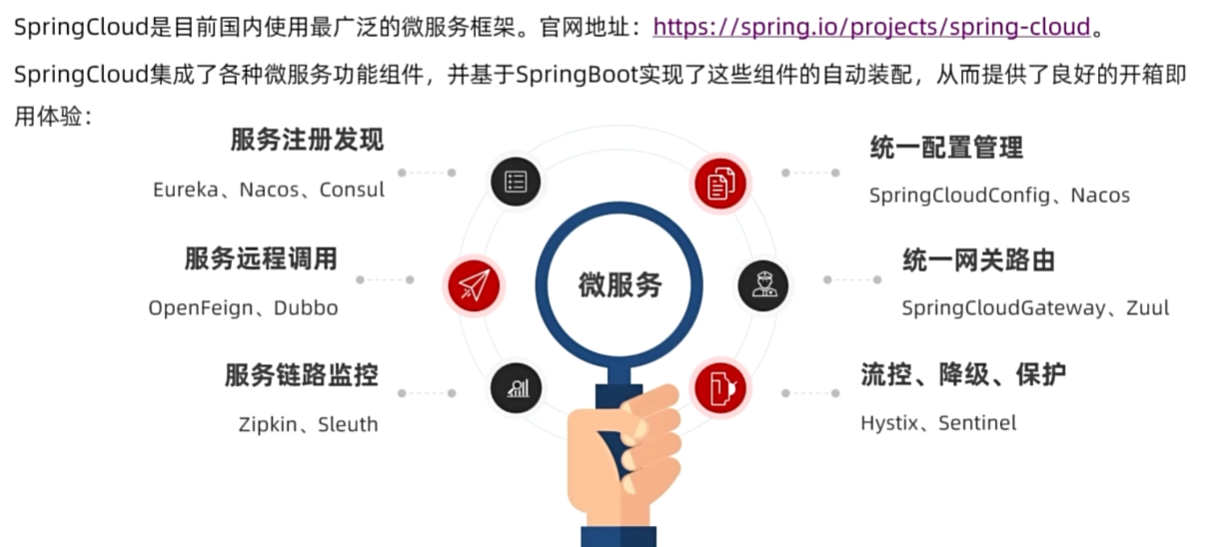
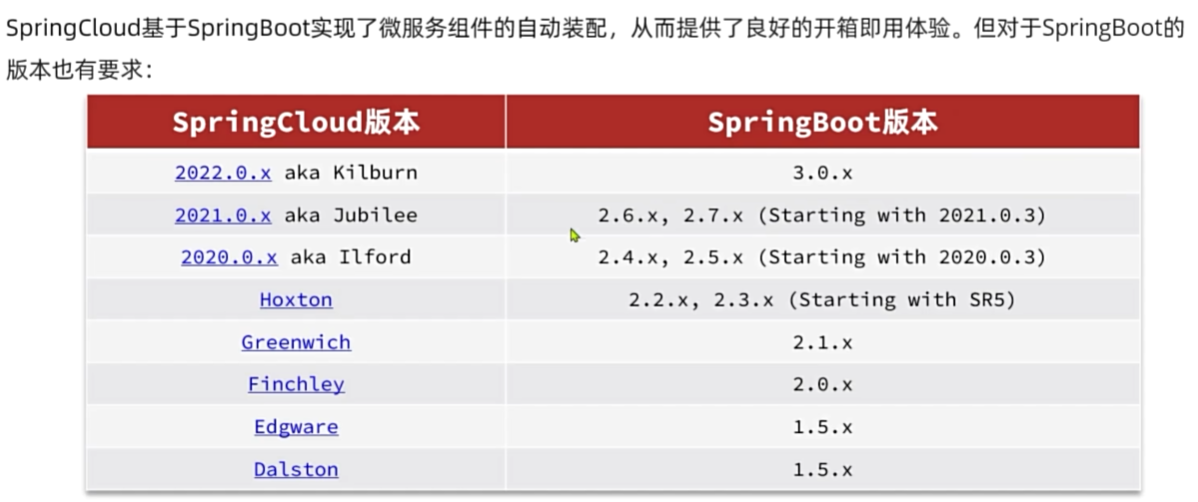
微服务拆分
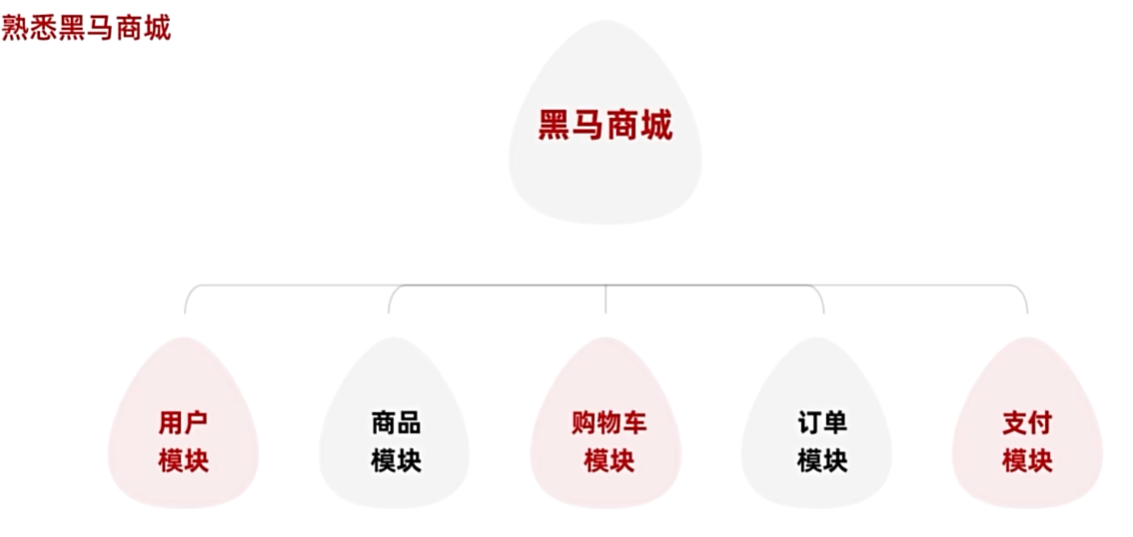
服务拆分原则
什么时候拆分?
●创业型项目:先采用单体架构,快速开发,快速试错。随着规模扩大,逐
渐拆分。
●确定的大型项目:资金充足,目标明确,可以直接选择微服务架构,避免
后续拆分的麻烦。
怎么拆分?
从拆分目标来说,要做到:
高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。
低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖。
从拆分方式来说,一般包含两种方式:
纵向拆分:按照业务模块来拆分
横向拆分:抽取公共服务,提高复用性
拆分服务
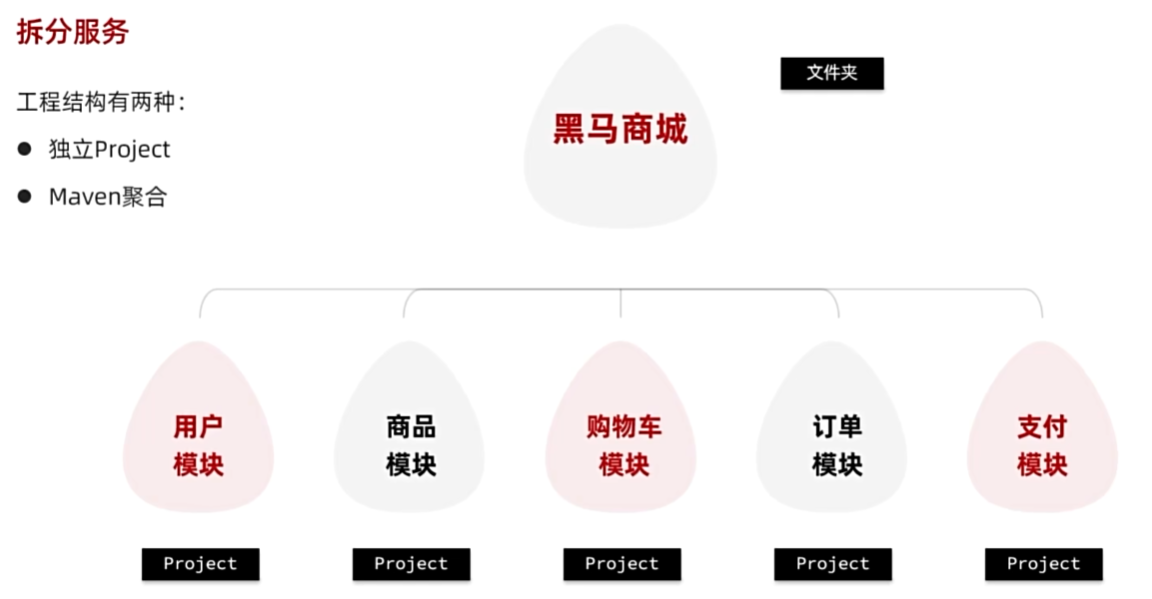
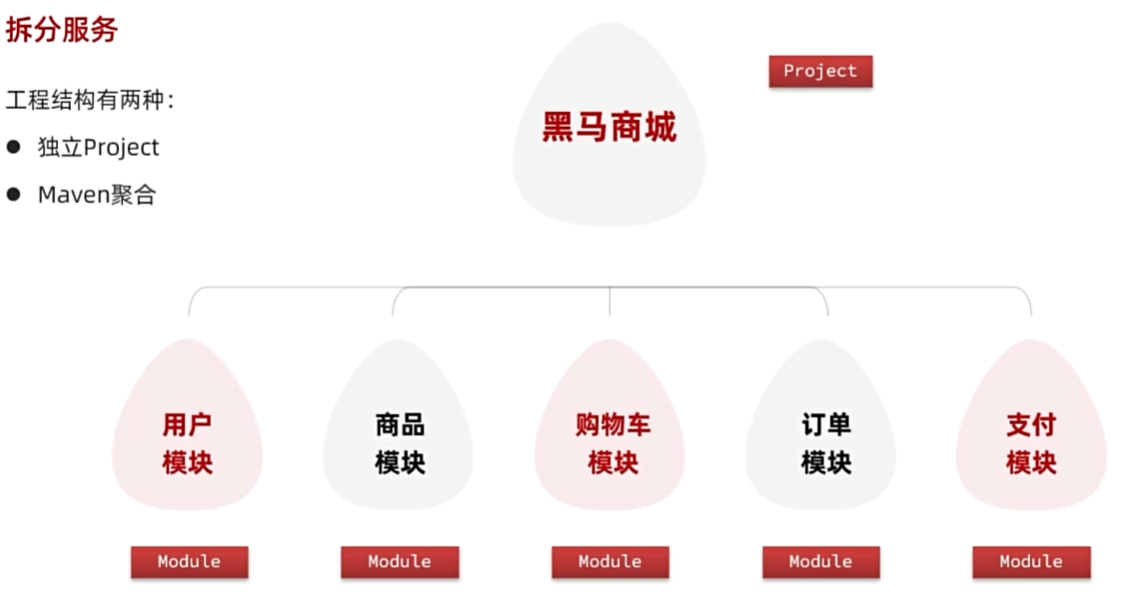
mkdir controller domain service mapper
远程调用
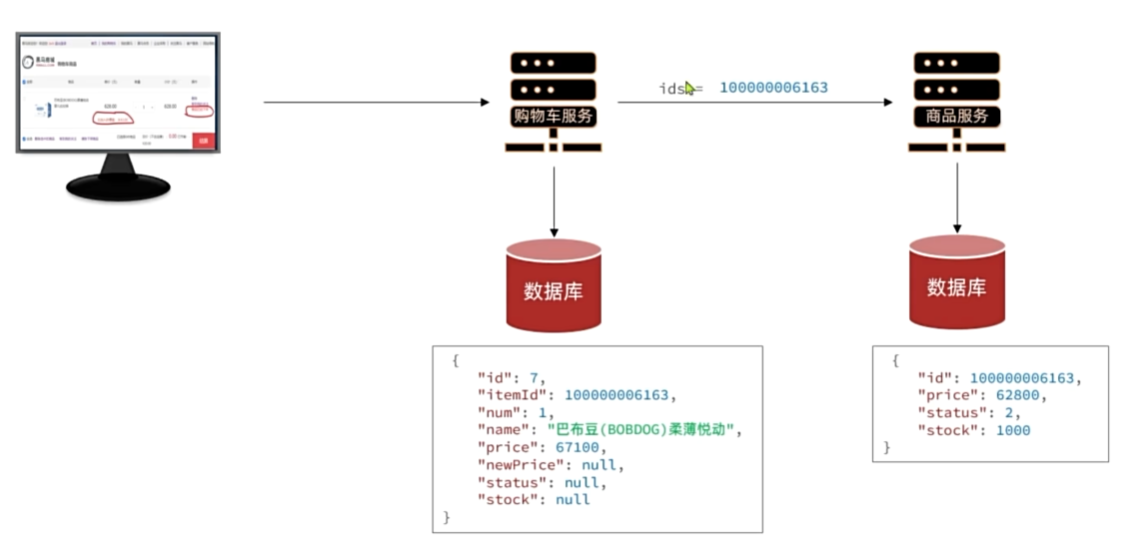
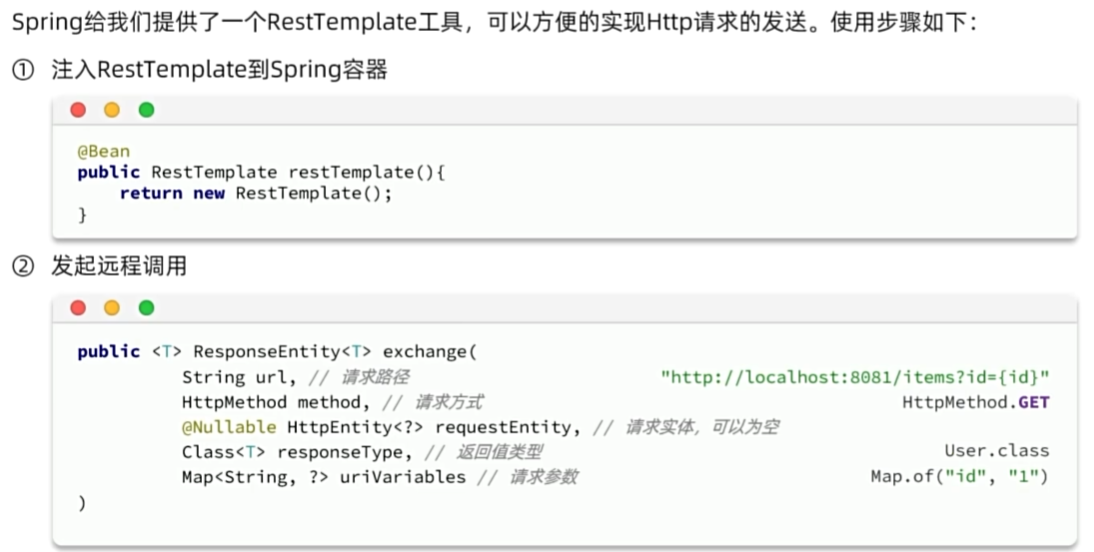
服务治理
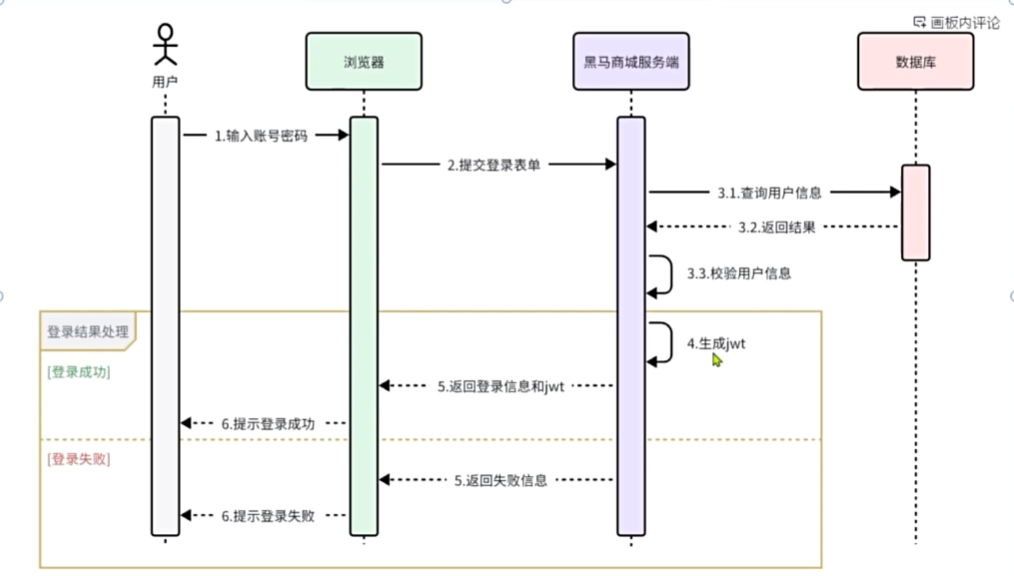
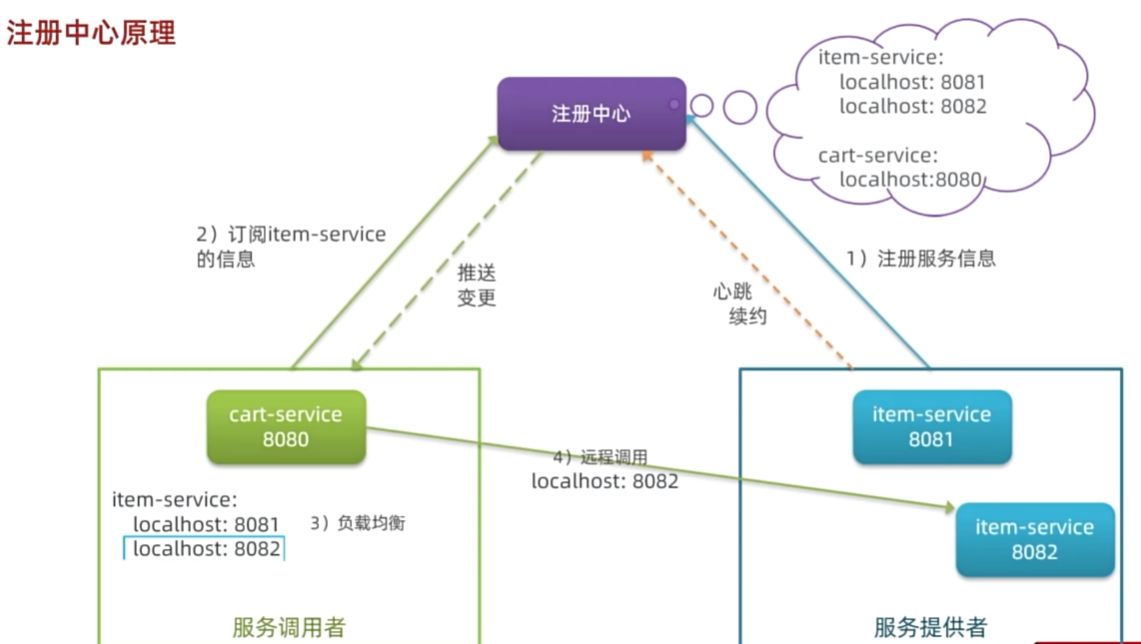
注册中心原理
Nacos:注册中心
docker run -d \
--name nacos \
--env-file ./nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
nacos/nacos-server:v2.1.0-slim
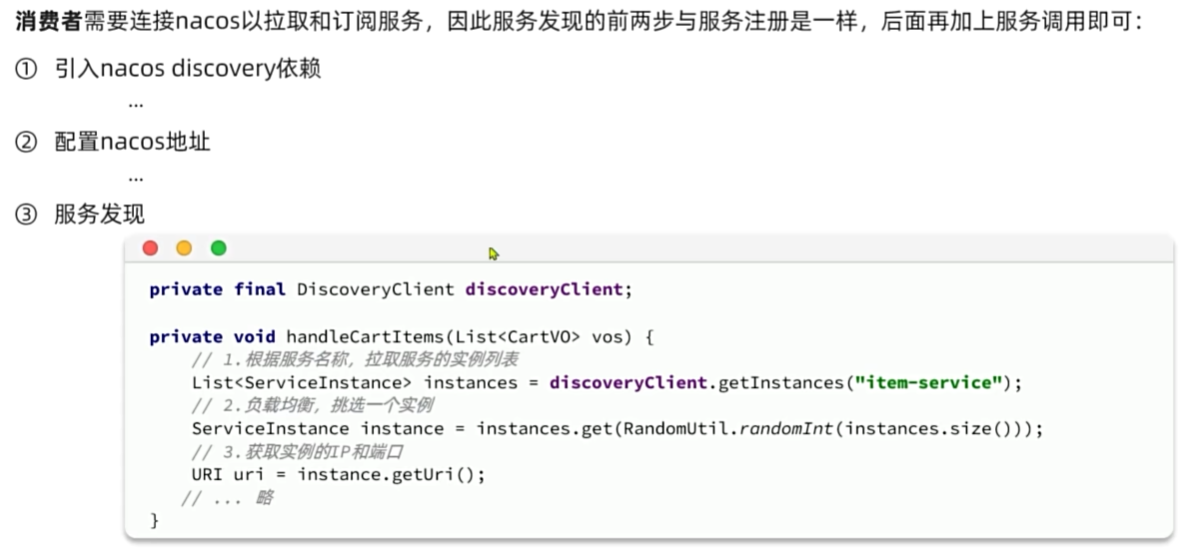
服务发现与负载均衡
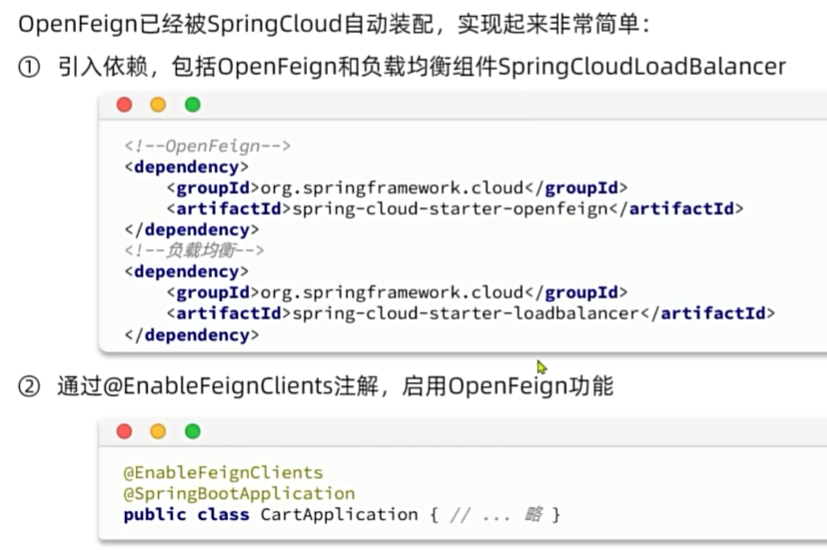
OpenFeign
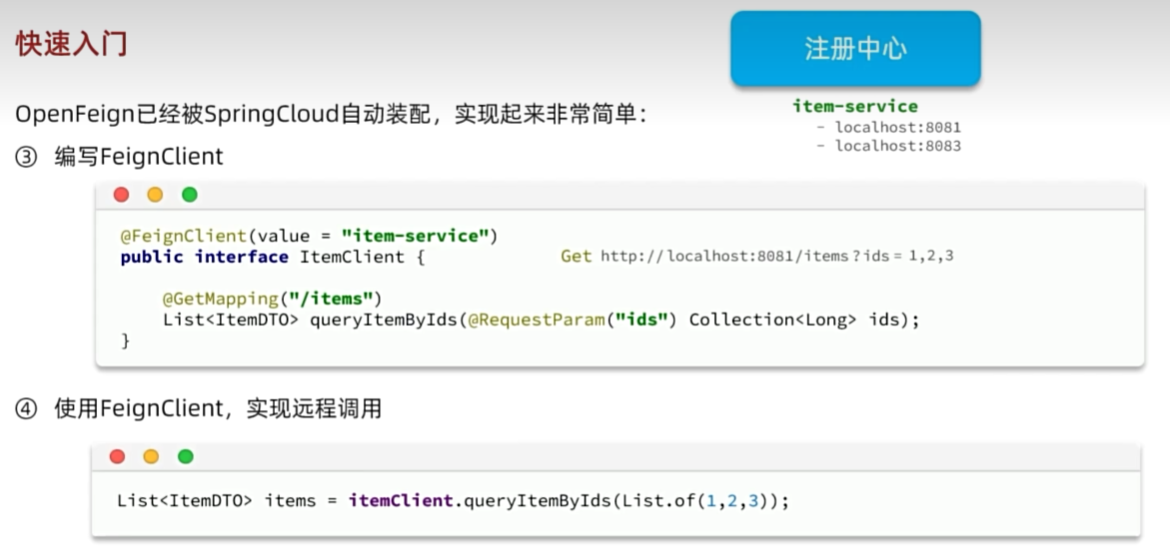
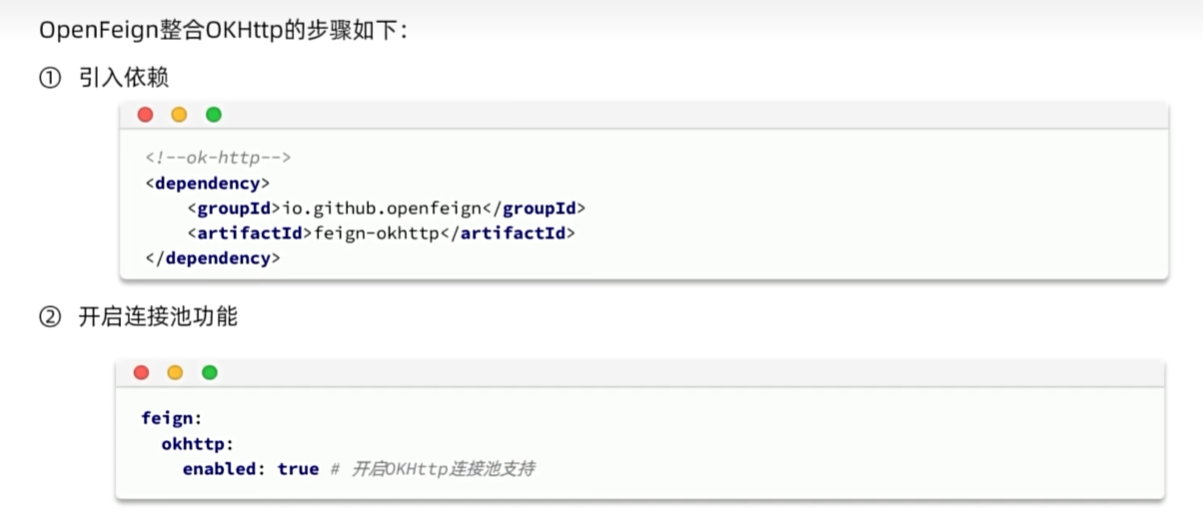
连接池

最佳实践
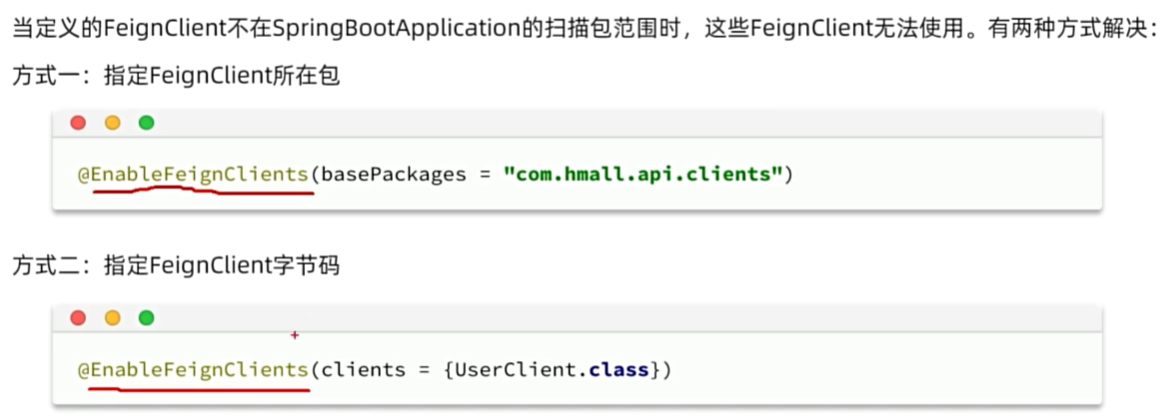
日志输出


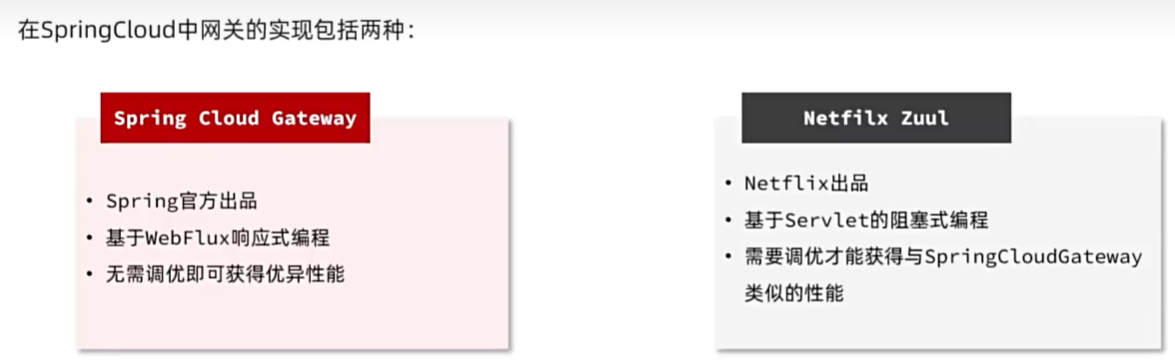
网关路由
快速入门
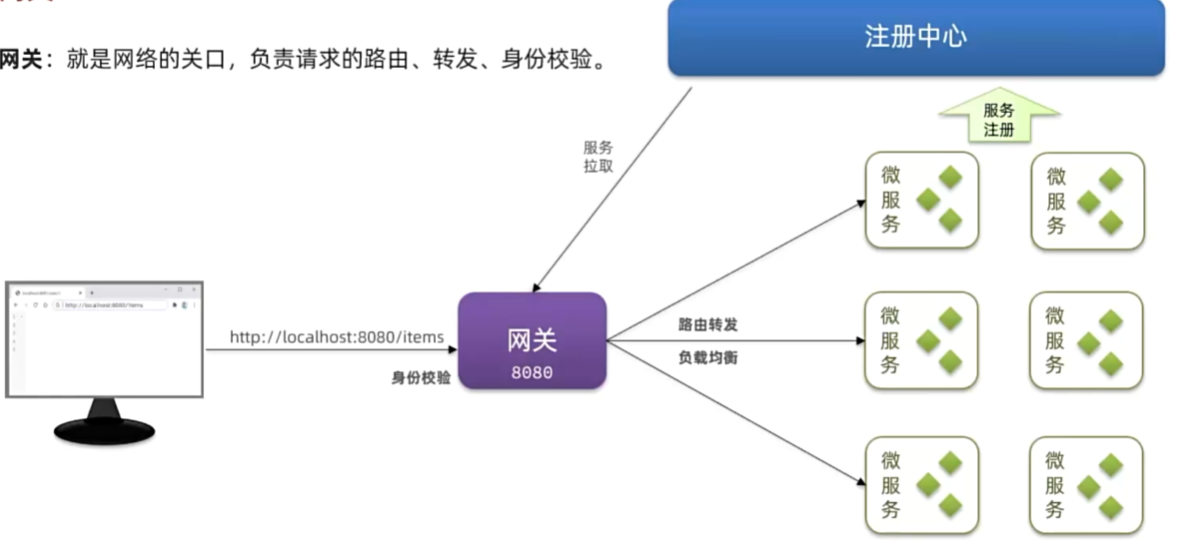
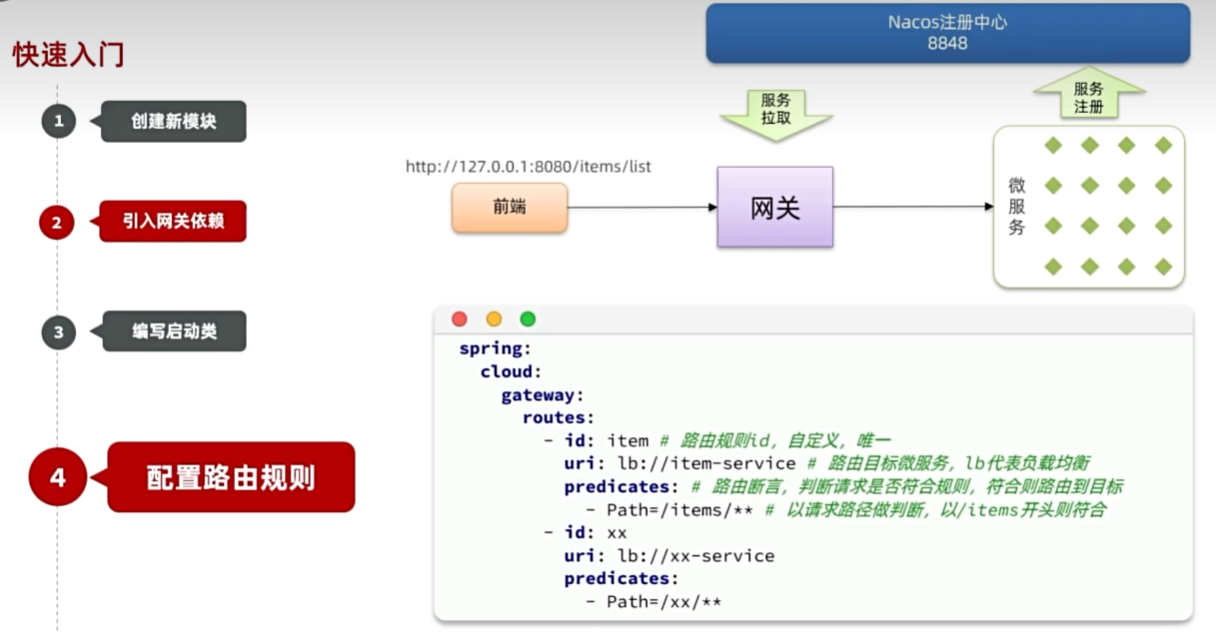
路由属性
网关路由对应的ava类型是RouteDefinition,其中常见的属性有:
id:路由唯一标示
uri:路由目标地址
predicates:路由断言,判断请求是否符合当前路由。
filters:路由过滤器,对请求或响应做特殊处理。
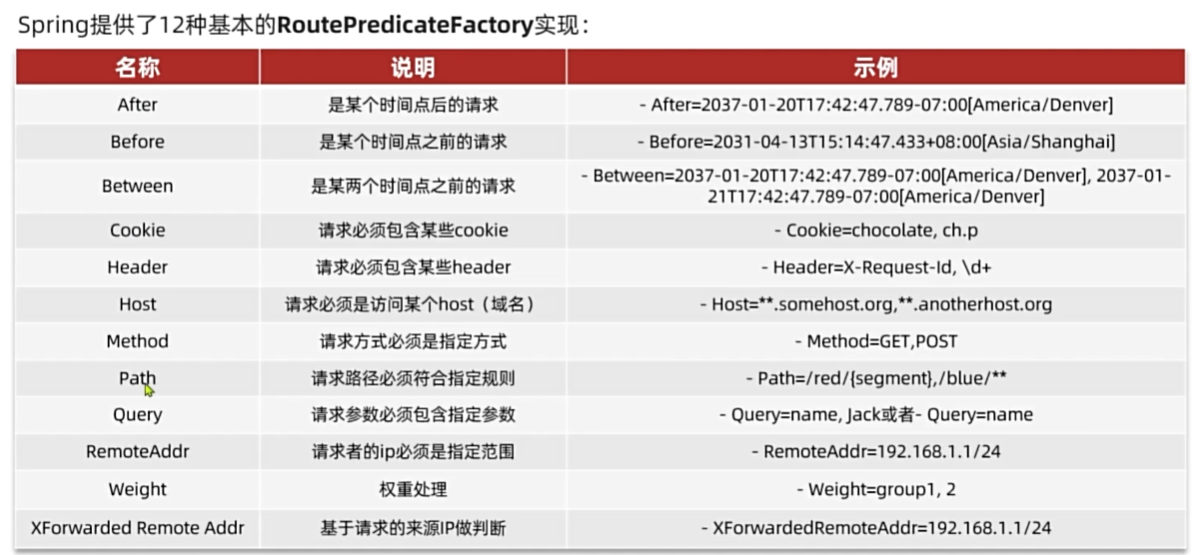
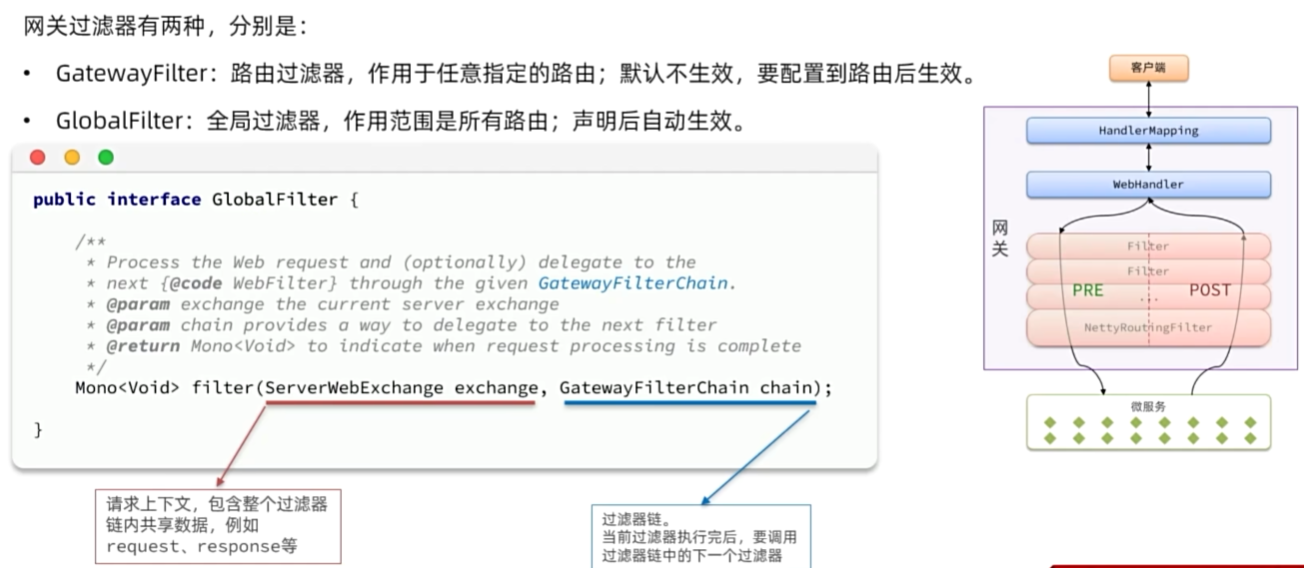
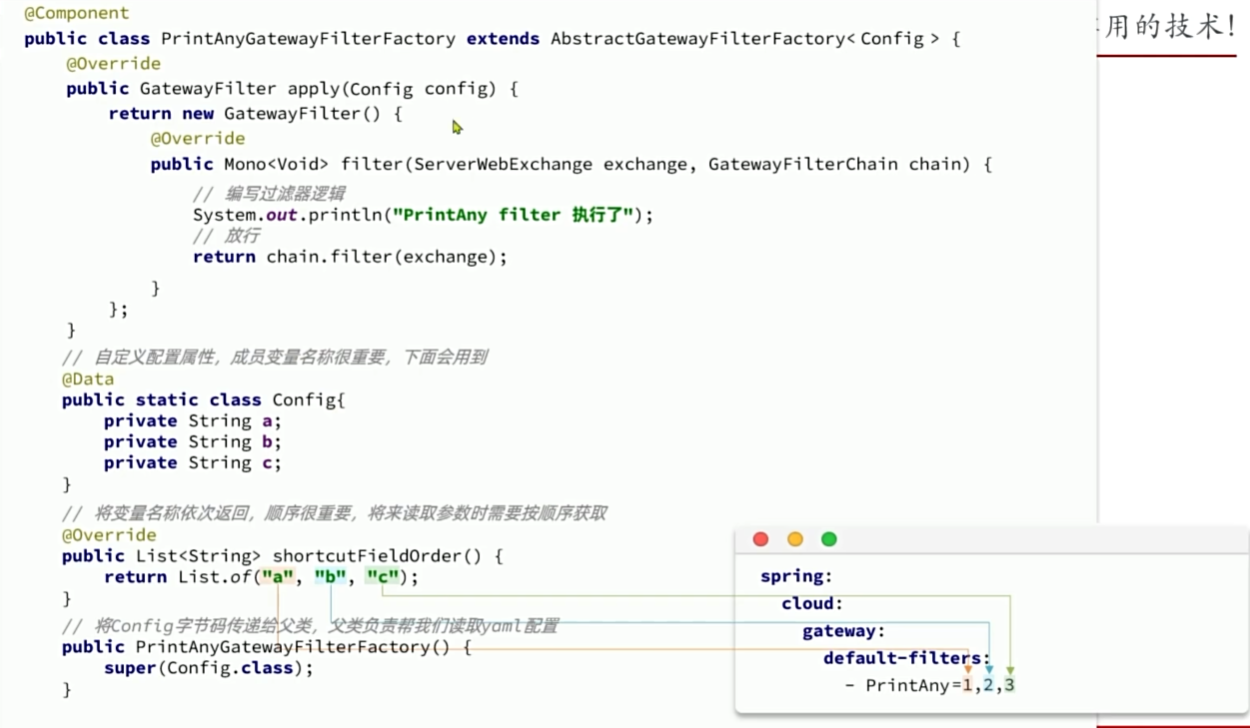
路由断言
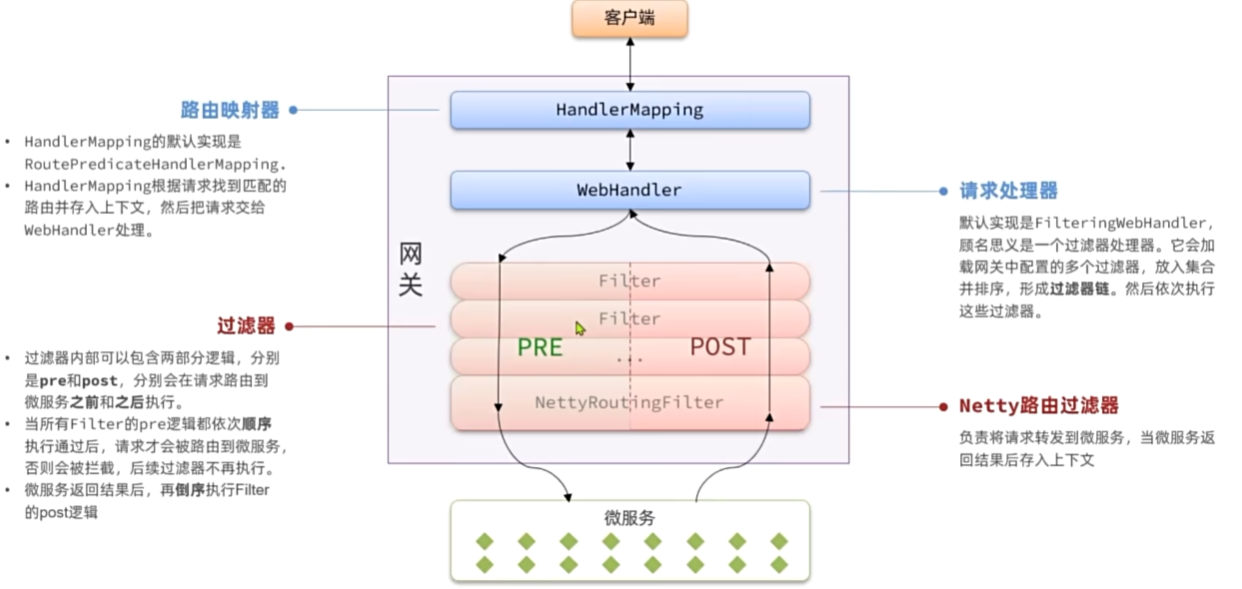
路由过滤器

网关请求处理流程
网关登录校验
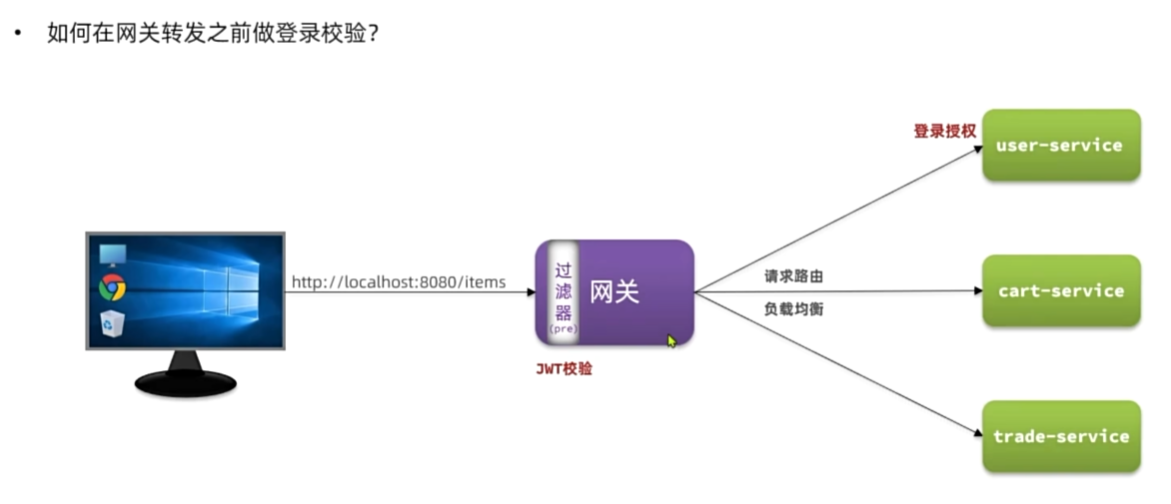
自定义过滤器

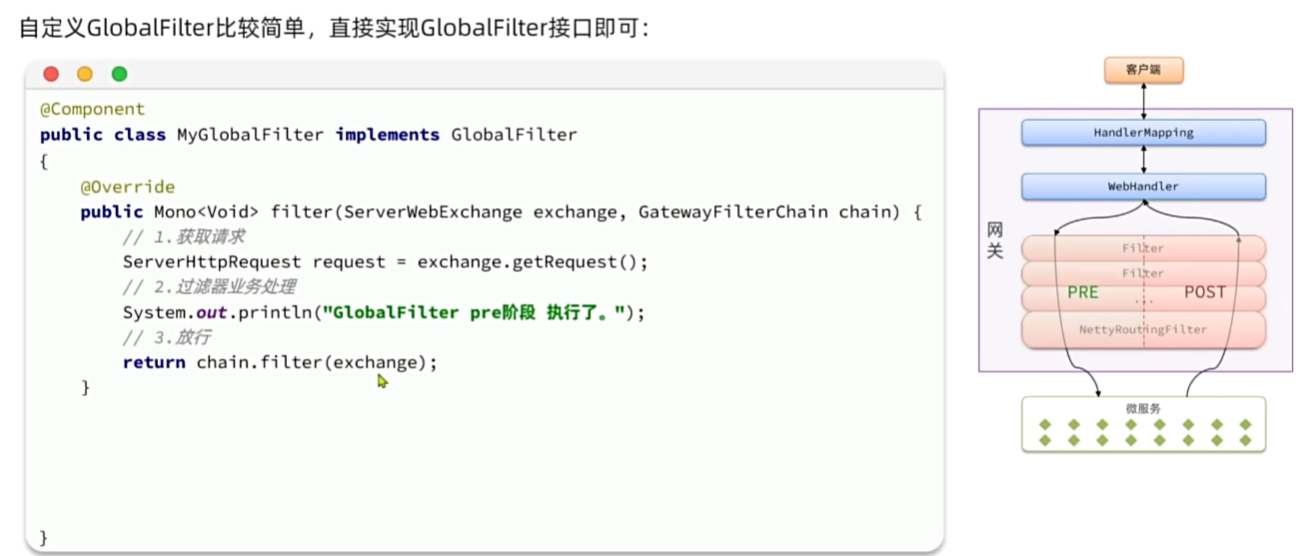

实现登录校验
需求:在网关中基于过滤器实现登录校验功能
提示:黑马商城是基于WT实现的登录校验,目前相关功能在hm-service模块。我们可以将其中的WT
工具拷贝到gateway模块,然后基于GlobalFilter来实现登录校验。
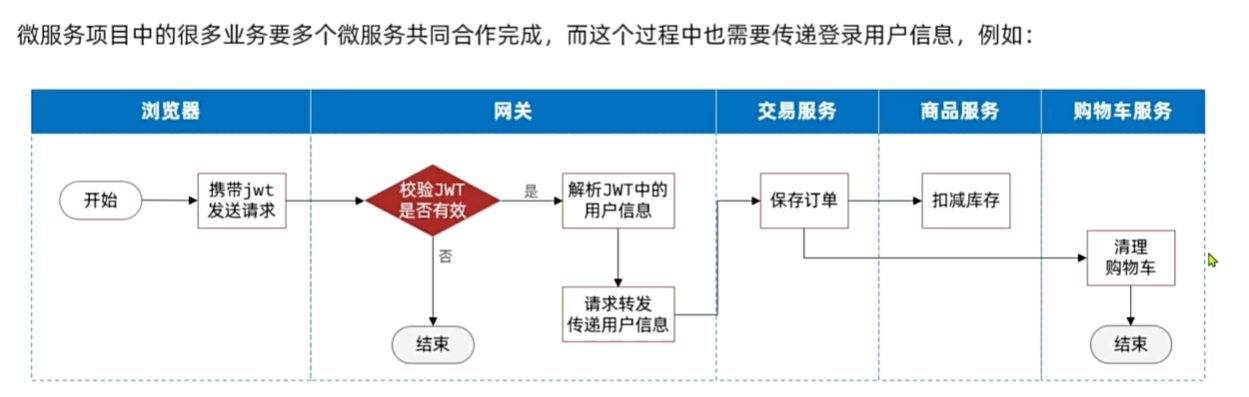
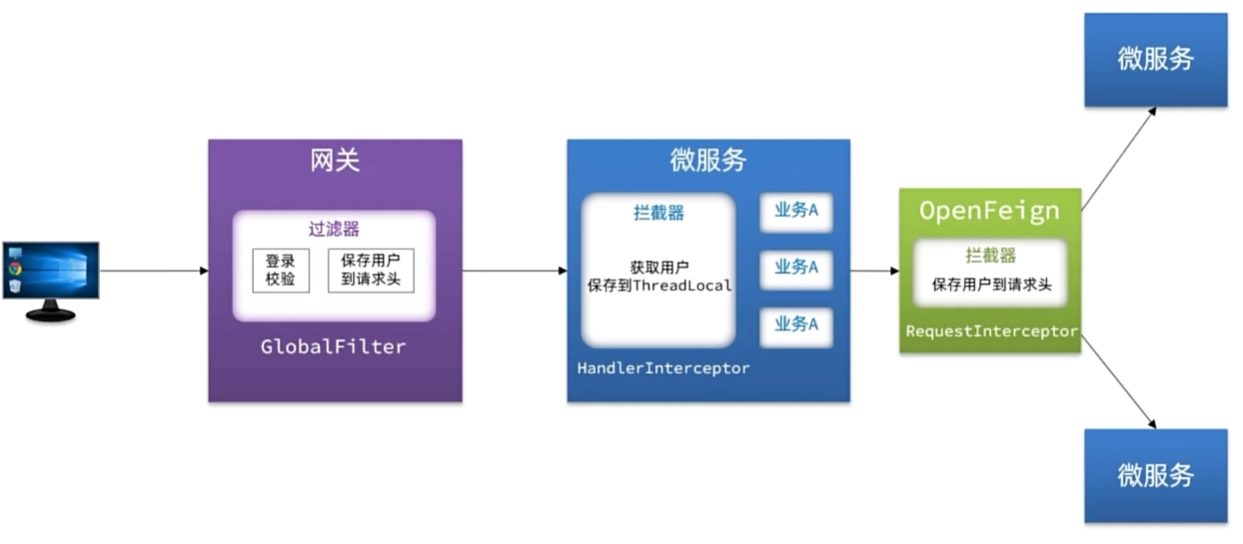
网关传递用户
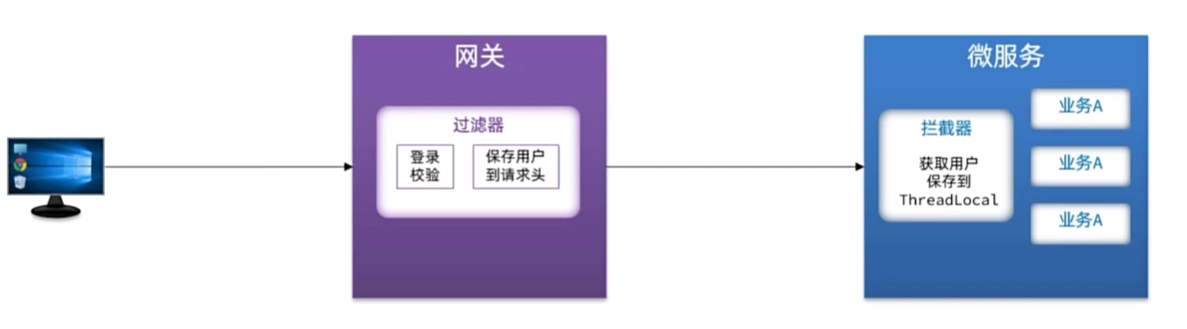
@Configuration
@ConditionalOnClass(DispatcherServlet.class)
public class MvcConfig implements WebMvcConfigurer {@Overridepublic void addInterceptors(InterceptorRegistry registry) {registry.addInterceptor(new UserInfoInterceptor());}
}
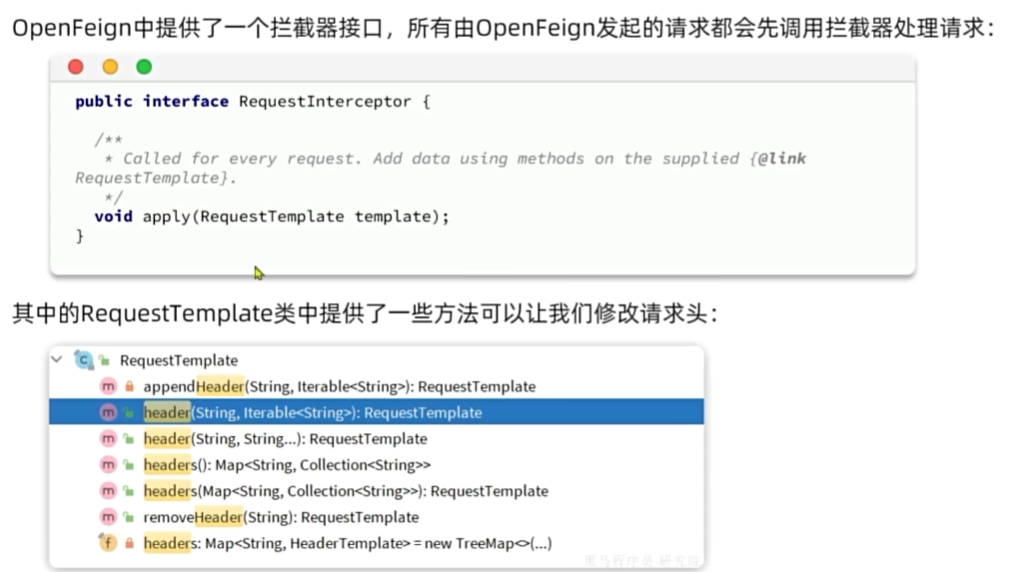
OpenFeign传递用户
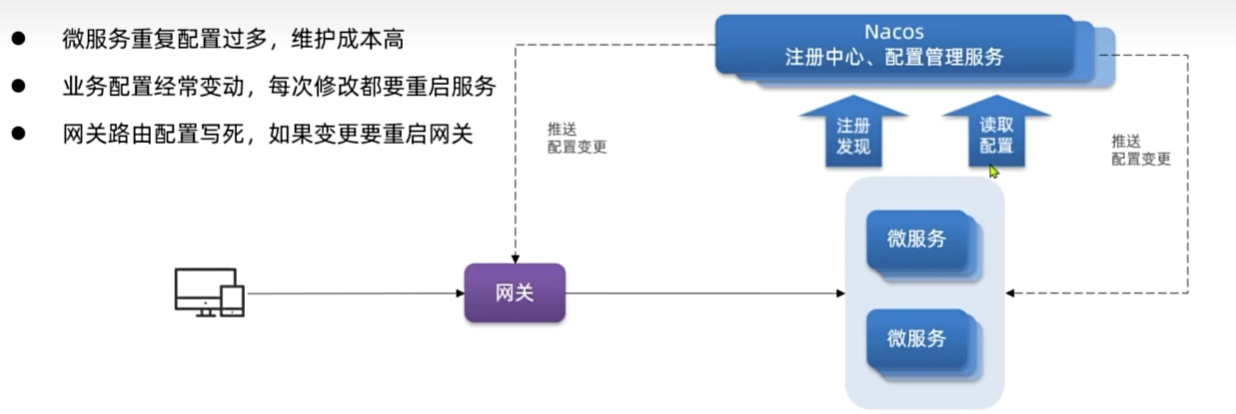
配置管理
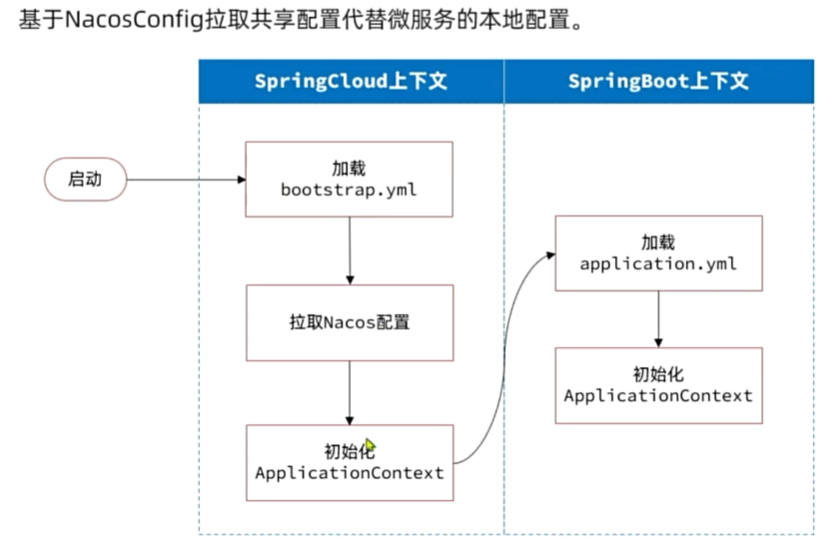
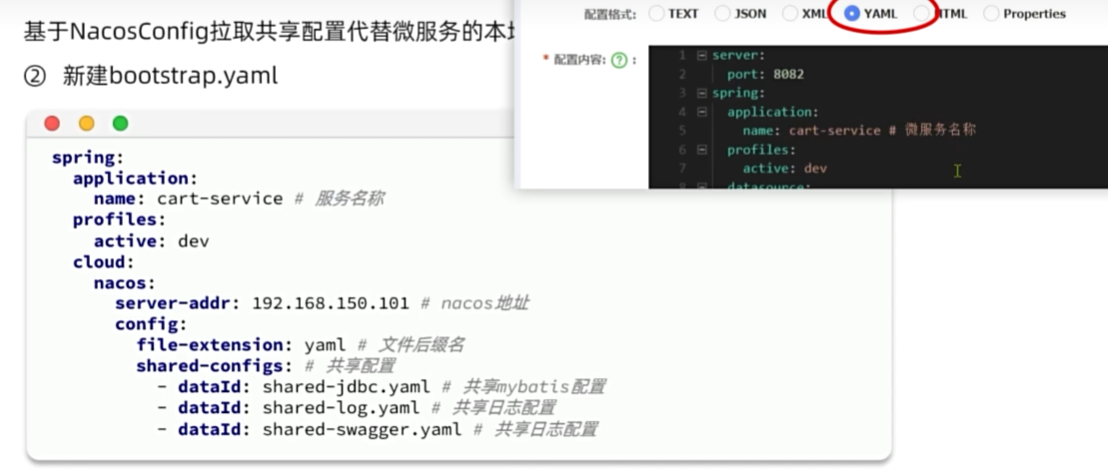
配置热更新
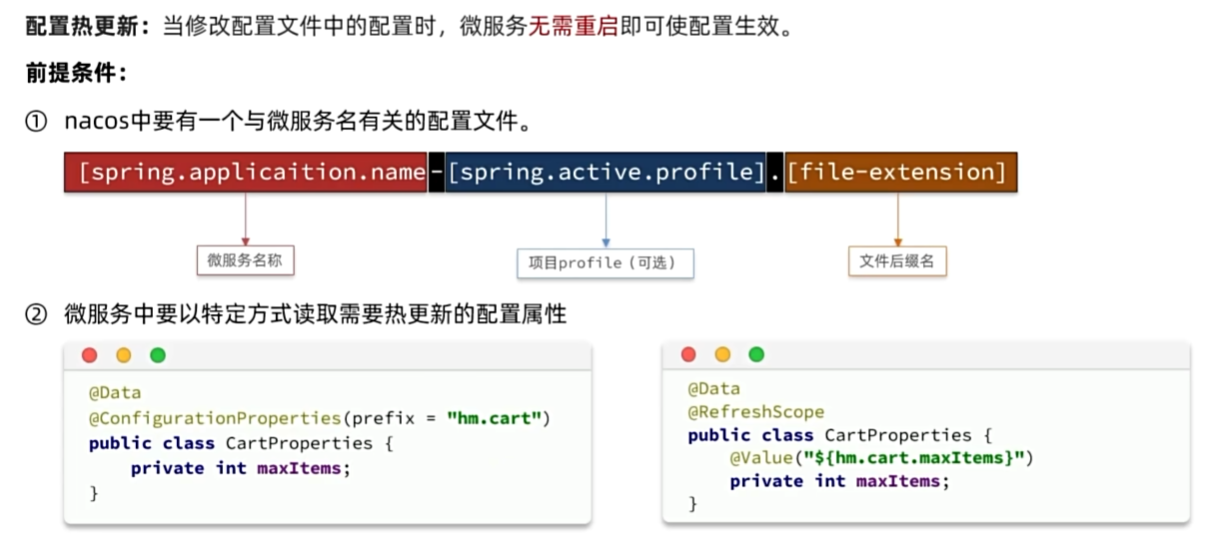
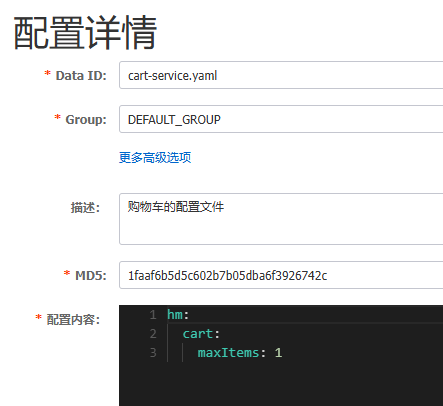
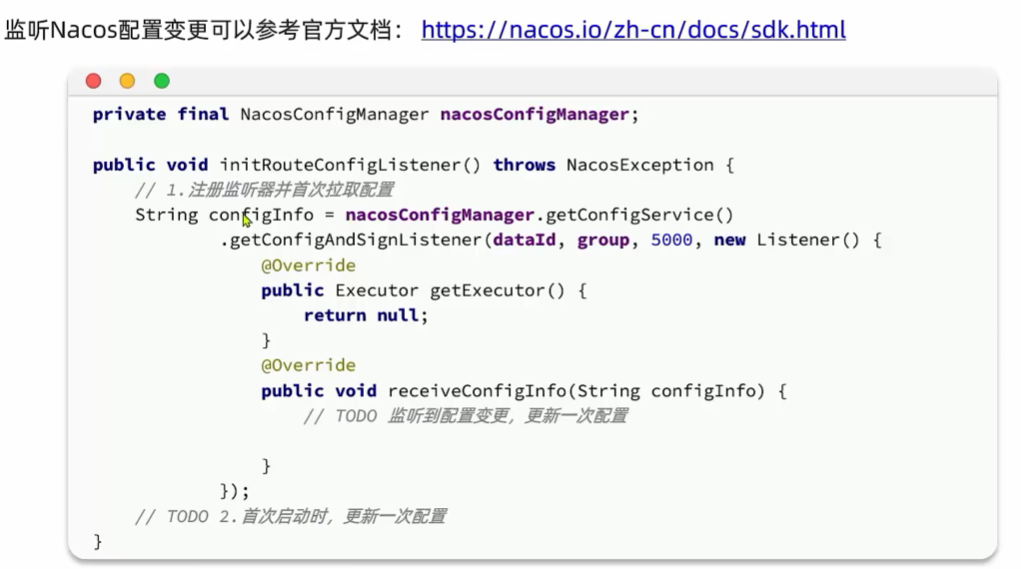
动态路由
要实现动态路由首先要将路由配置保存到Nacos,当Nacos中的路由配置变更时,推送最新配置到网关,实时更新网关
中的路由信息。
我们需要完成两件事情:
①监听Nacos配置变更的消息
②当配置变更时,将最新的路由信息更新到网关路由表

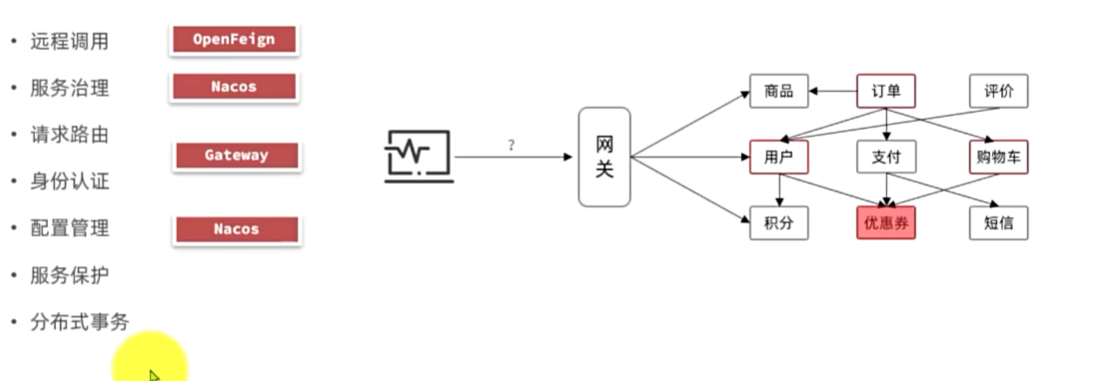
服务保护
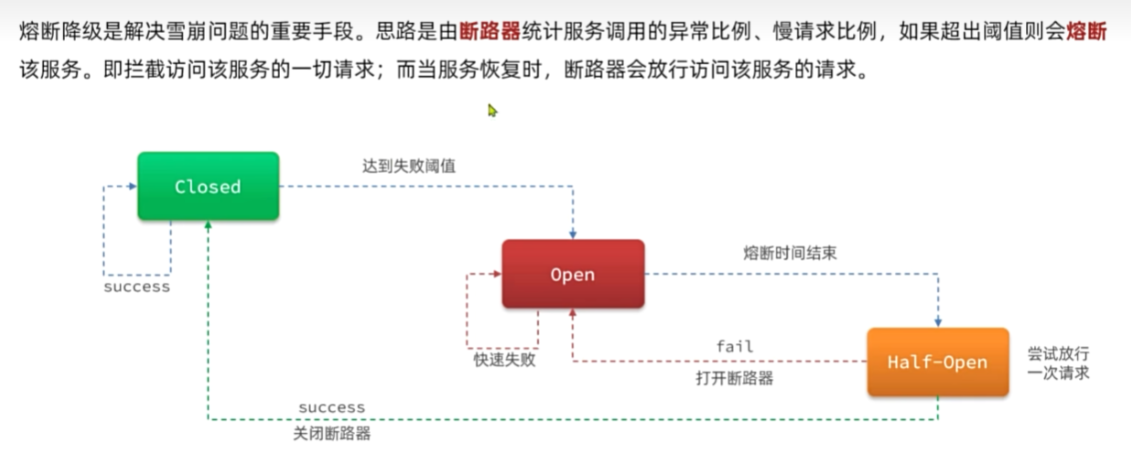
雪崩问题

雪崩问题-解决方案
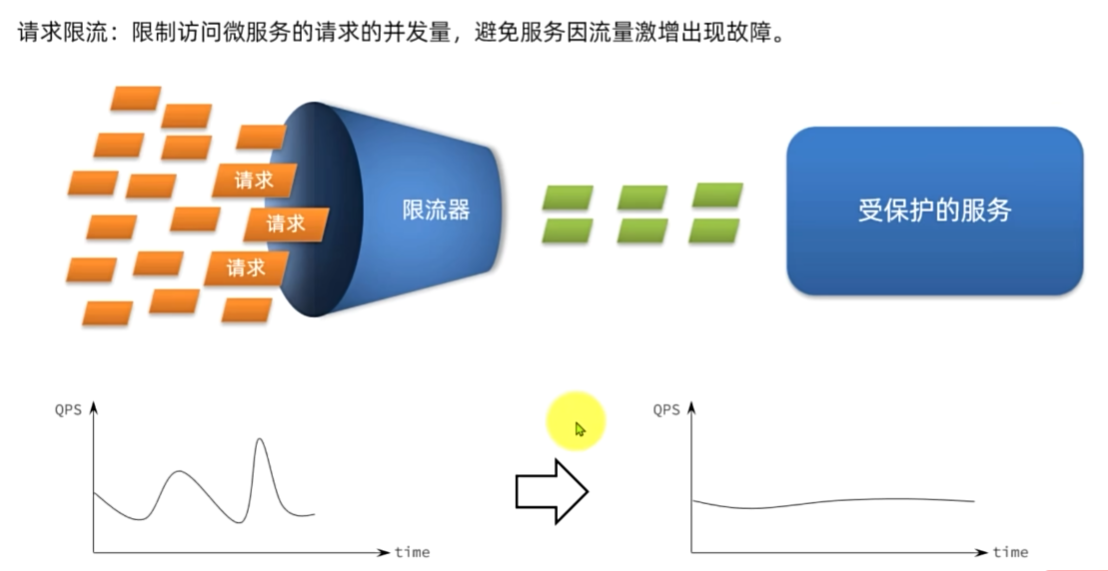
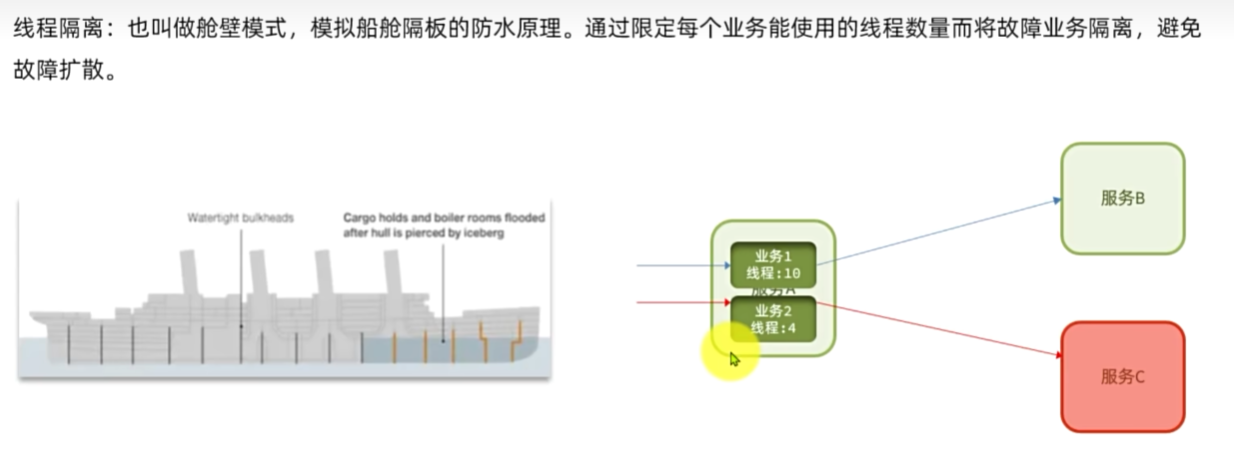
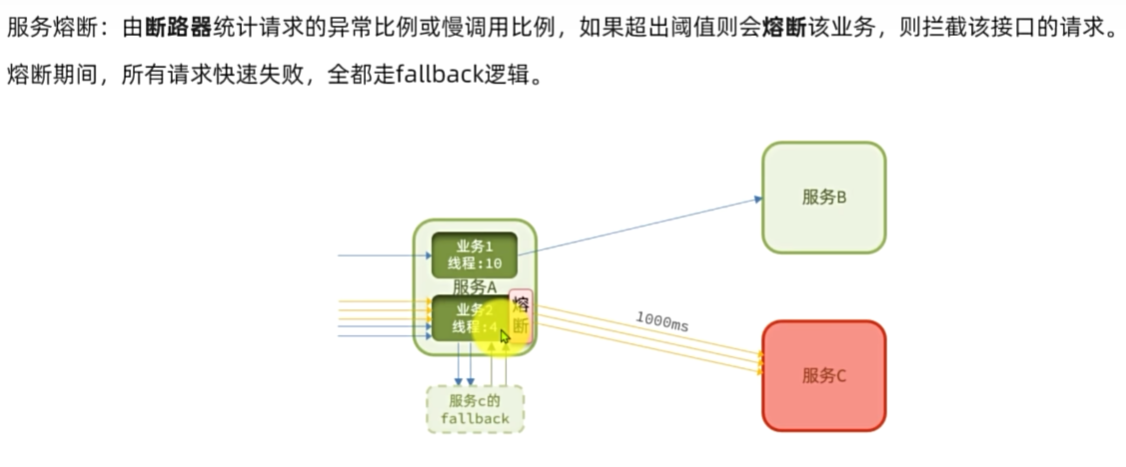
服务保护技术
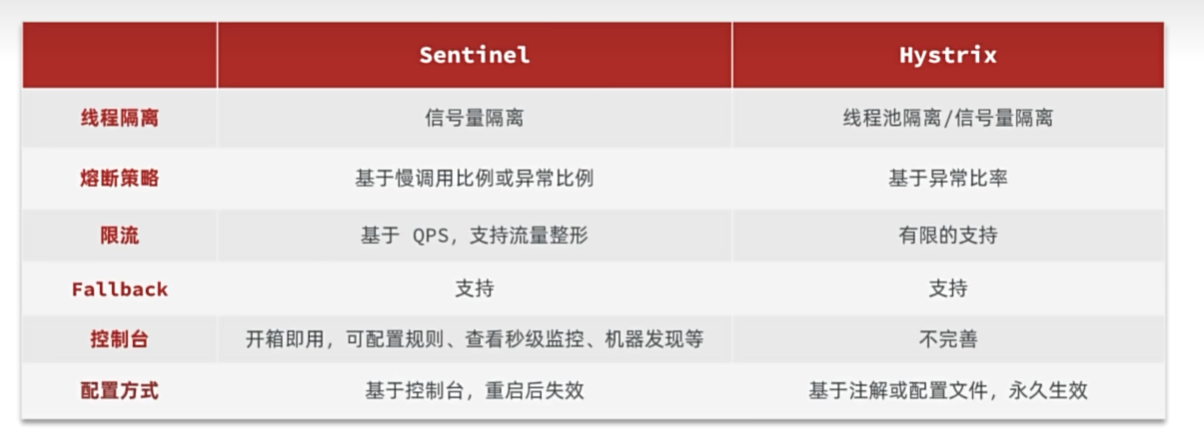
sentinel
Sentinel是阿里巴巴开源的一款微服务流量控制组件。官网地址:https:/sentinelquard.io/zh-cn/index.html
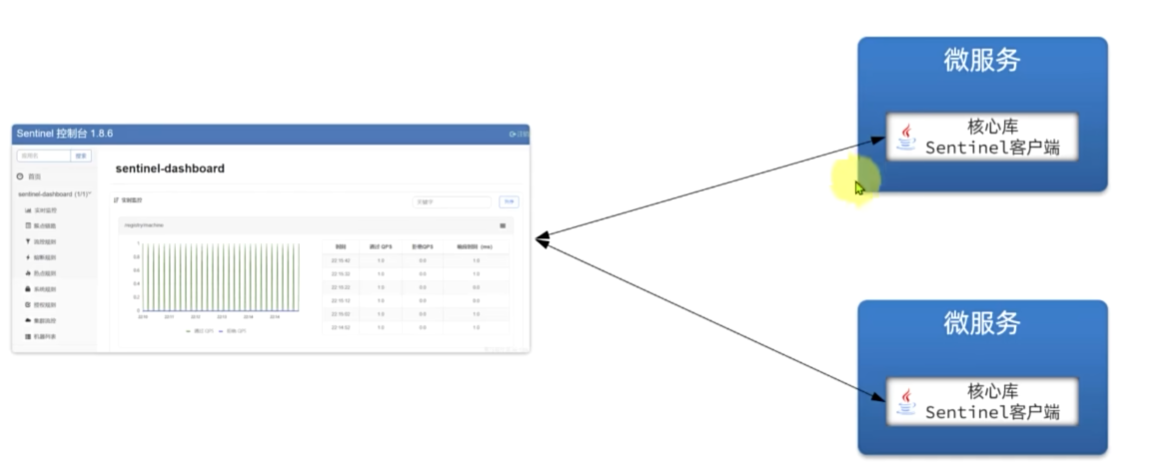
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar
我们在cart-service模块中整合sentinel,连接sentinel-dashboard控制台,步骤如下: 1)引入sentinel依赖
<!--sentinel-->
<dependency><groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2)配置控制台
修改application.yaml文件,添加下面内容:
spring:cloud: sentinel:transport:dashboard: localhost:8090
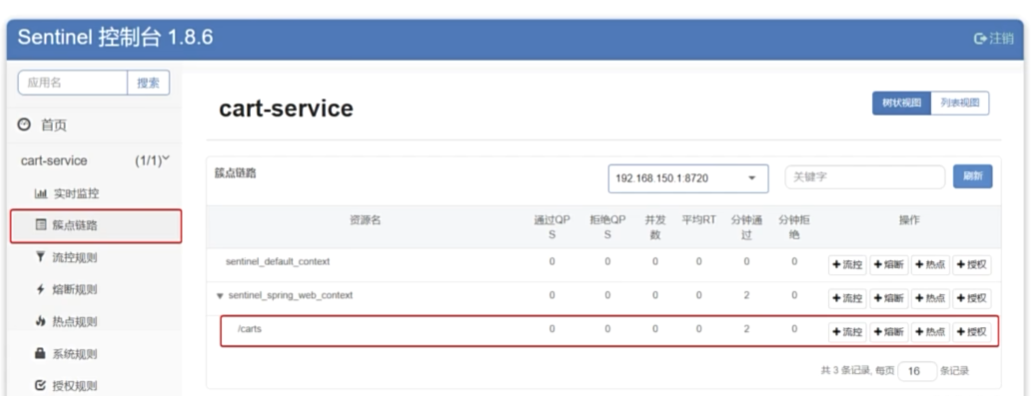
簇点链路
簇点链路,就是单机调用链路。是一次请求进入服务后经过的每一个被Sentinel.监控的资源链。默认Sentinel:会监控
SpringMVC的每一个Endpoint(htp接口)。限流、熔断等都是针对簇点链路中的资源设置的。而资源名默认就是接
口的请求路径:
线程隔离
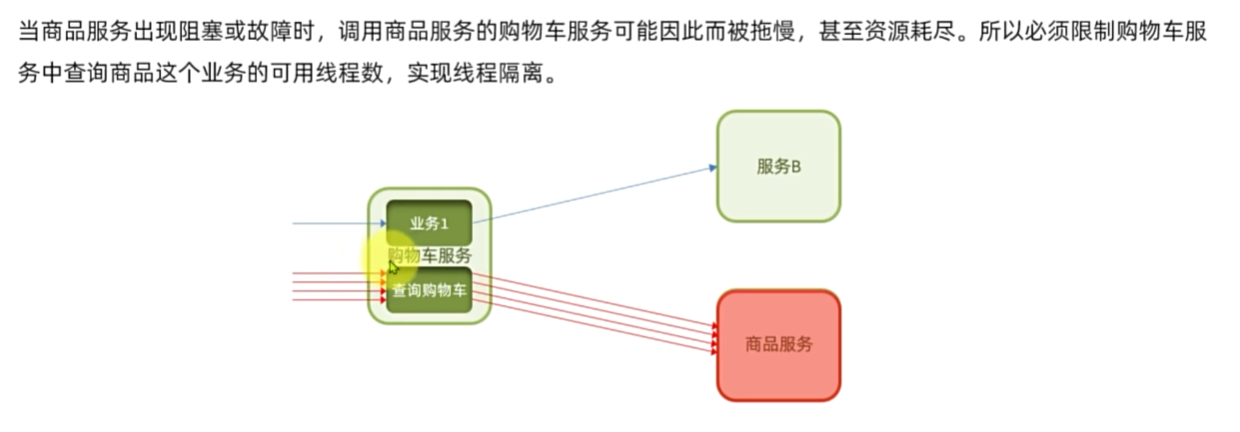
流控是控制接收请求的速度,线程隔离是最多能接收请求的次数,就算流控设置的再慢,如果线程卡住了的话,不设置线程隔离也会导致资源占用
Fallback
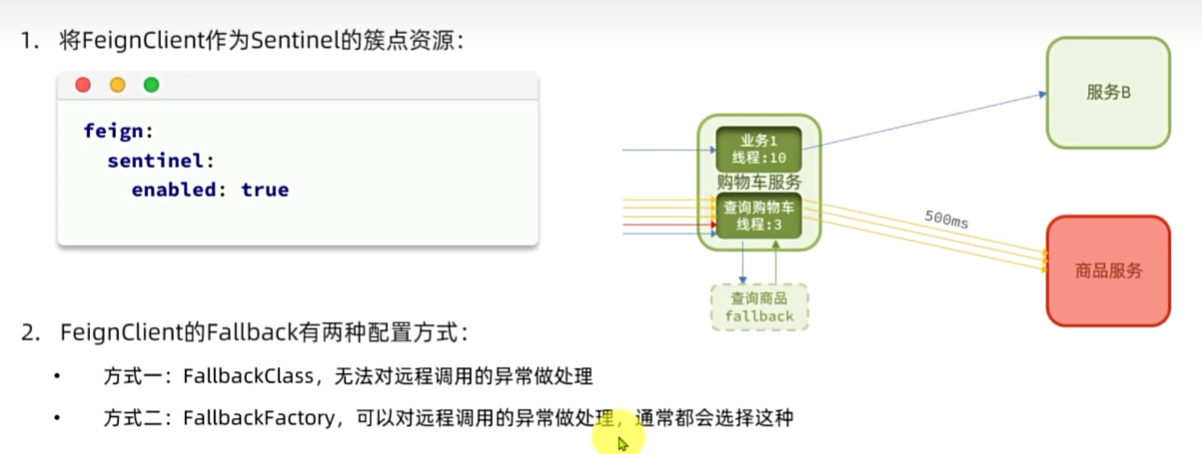
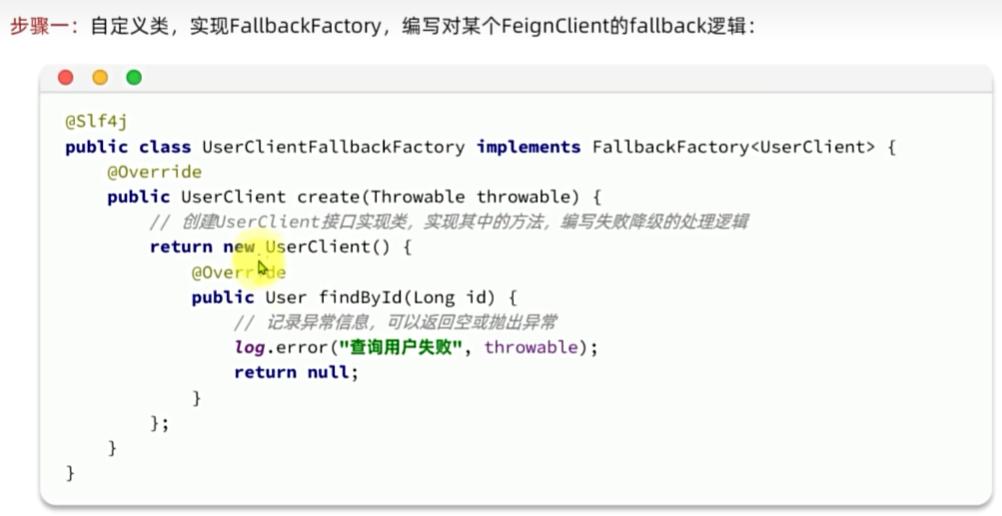

服务熔断
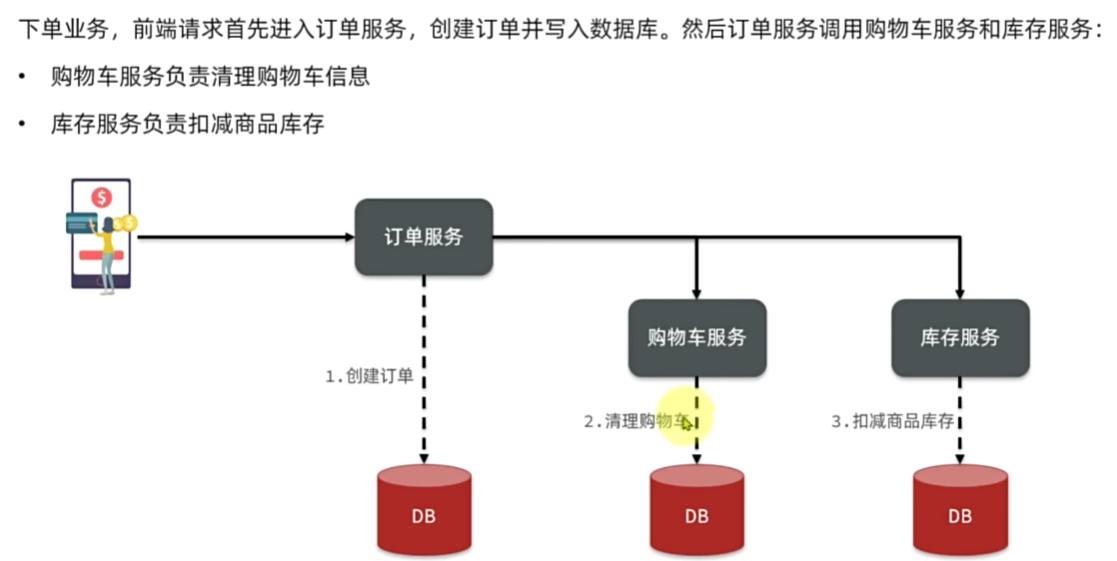
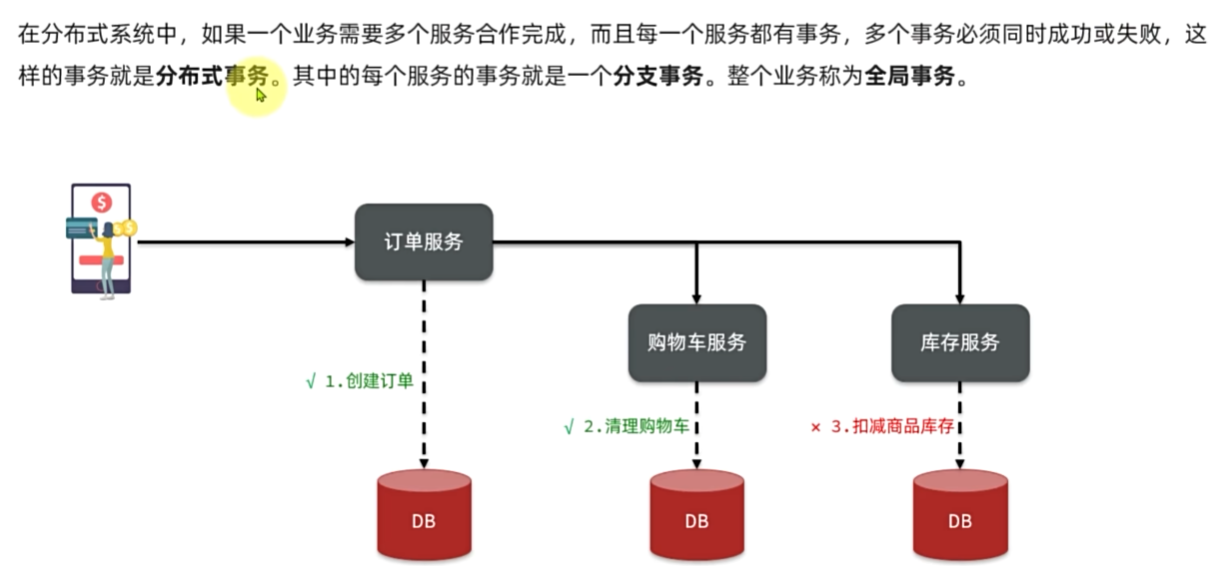
分布式事务
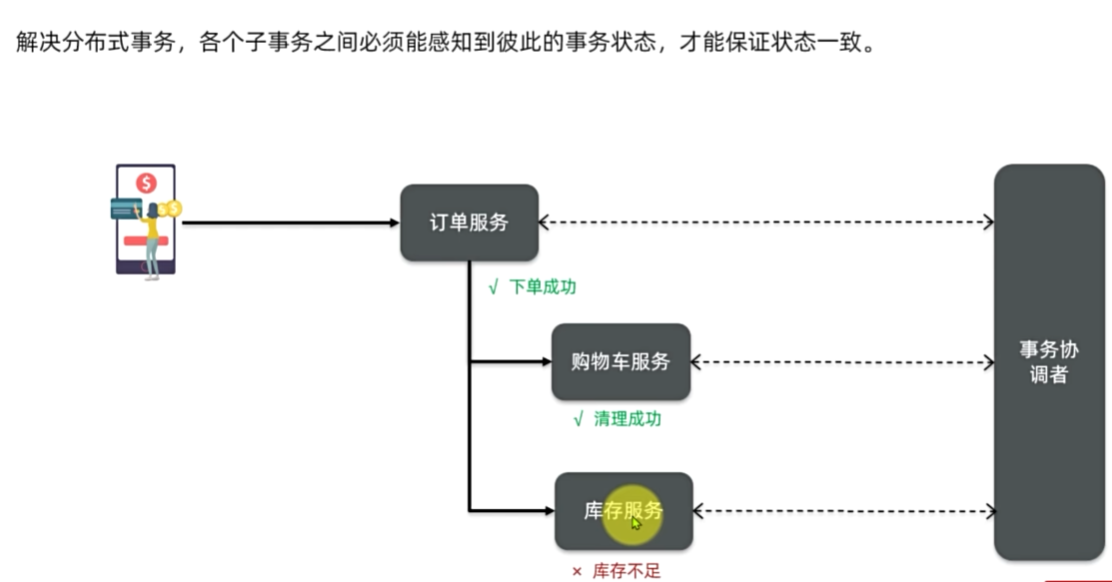
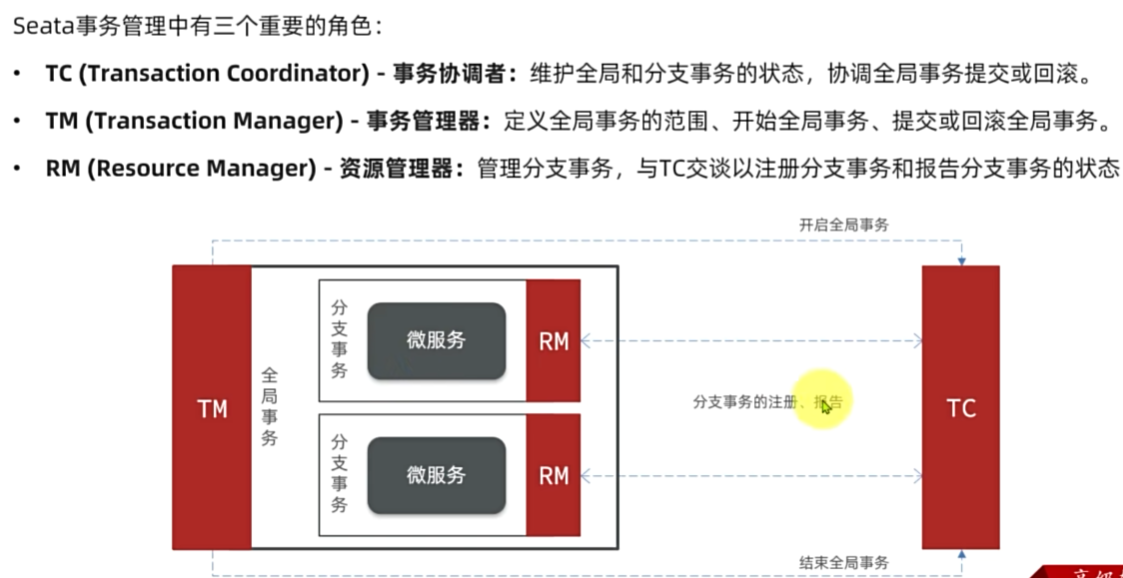
Seata
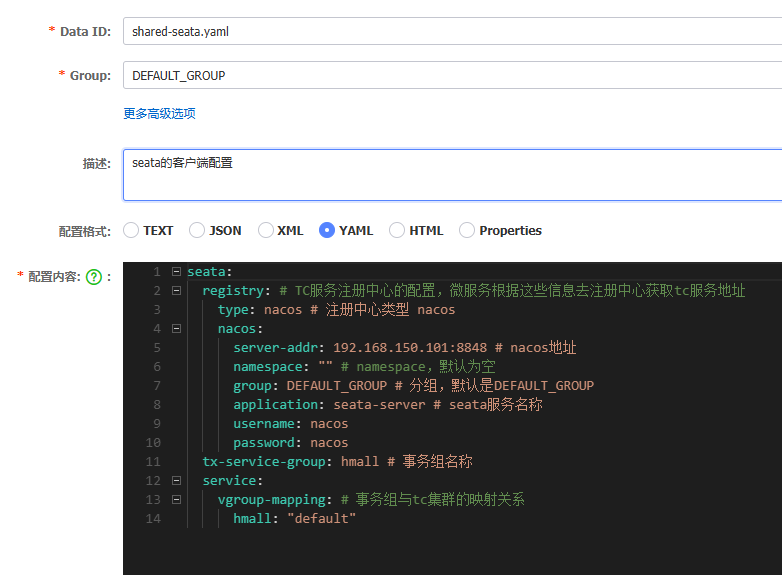
Docker部署
需要注意,要确保nacos、mysql都在hm-net网络中。如果某个容器不再hm-net网络,可以参考下面的命令将某容器加入指定网络:
docker network connect [网络名] [容器名]
在虚拟机的/root目录执行下面的命令:
docker run --name seata \
-p 8099:8099 \
-p 7099:7099 \
-e SEATA_IP=192.168.100.129 \
-v ./seata:/seata-server/resources \
--privileged=true \
--network hm-net \
-d \
seataio/seata-server:1.5.2

XA模式
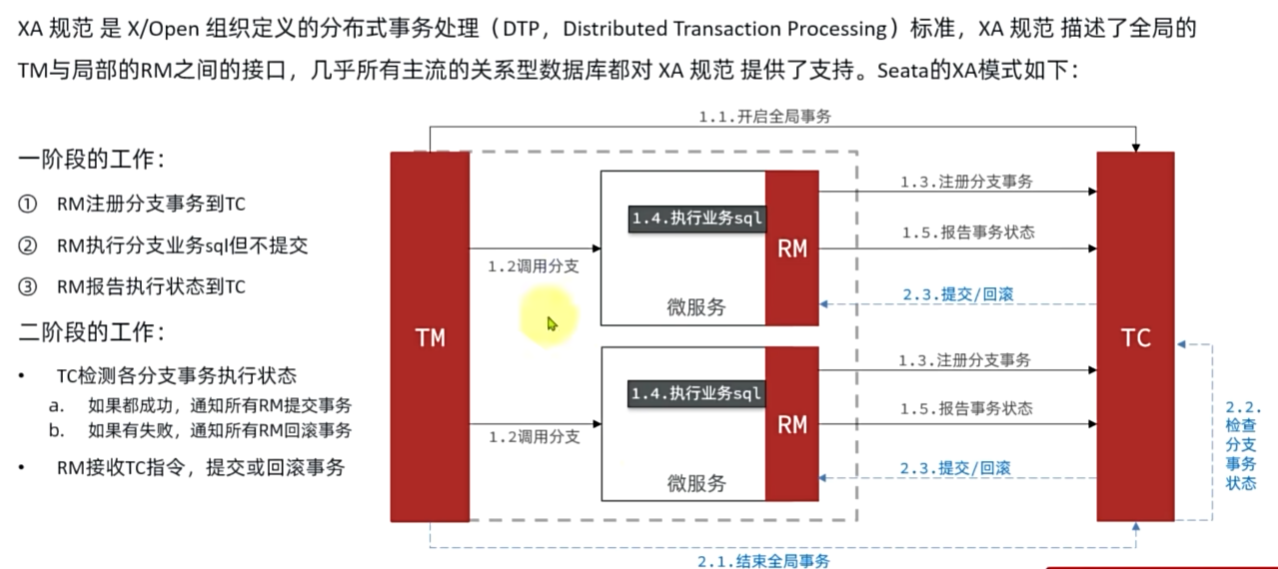
seata:data-source-proxy-mode: XA

AT模式
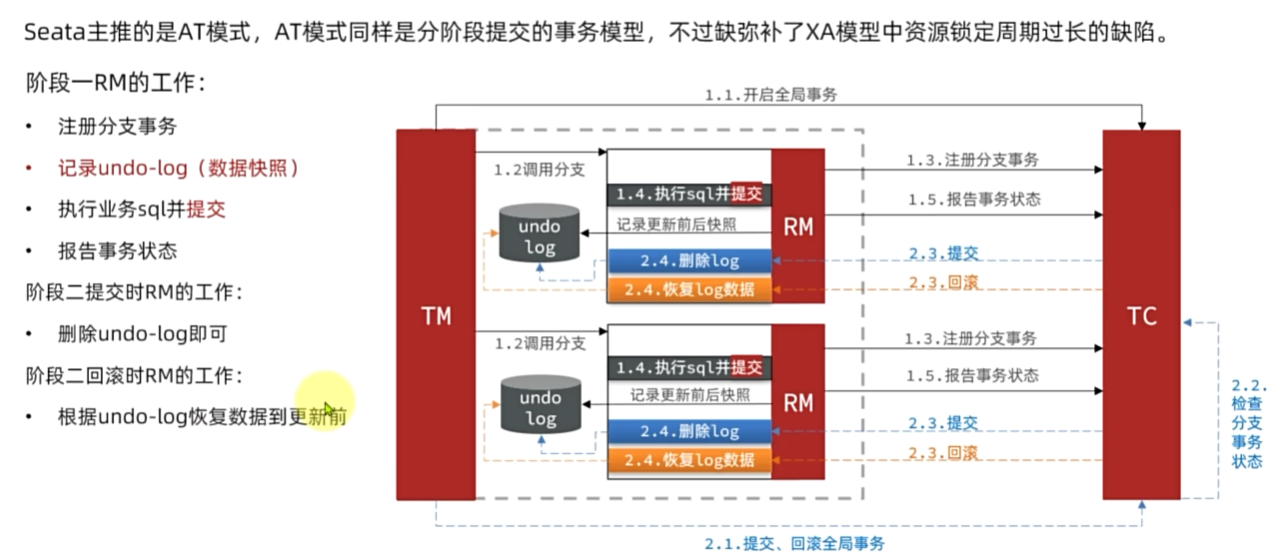
异步通信
RabbitMQ
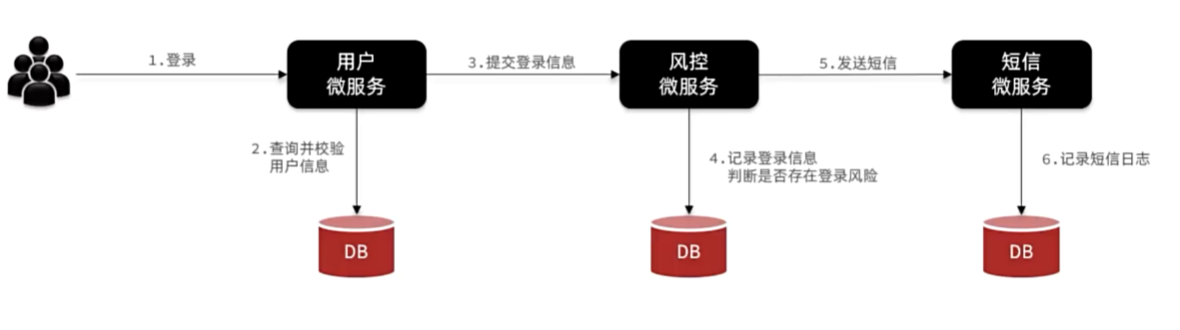
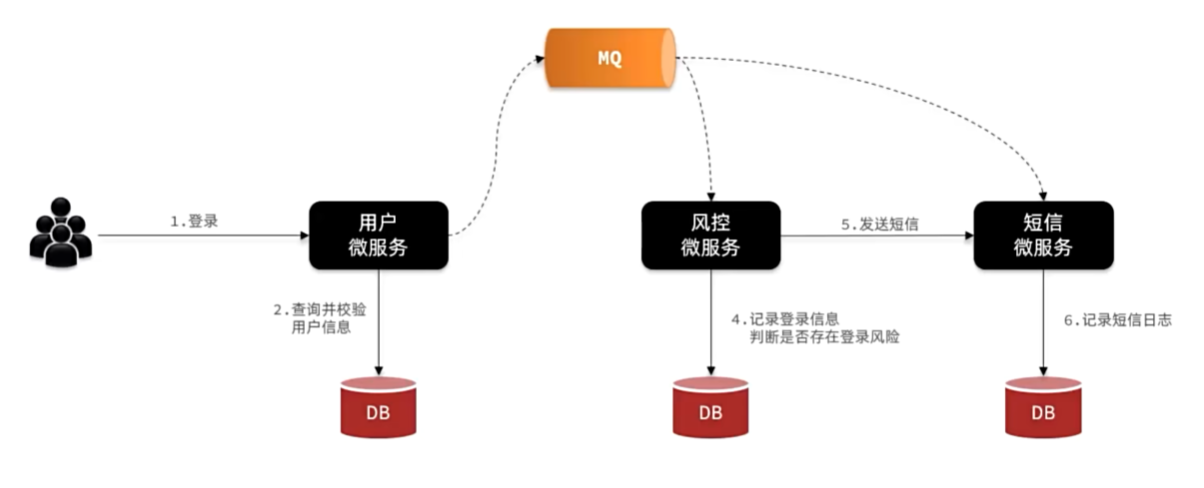
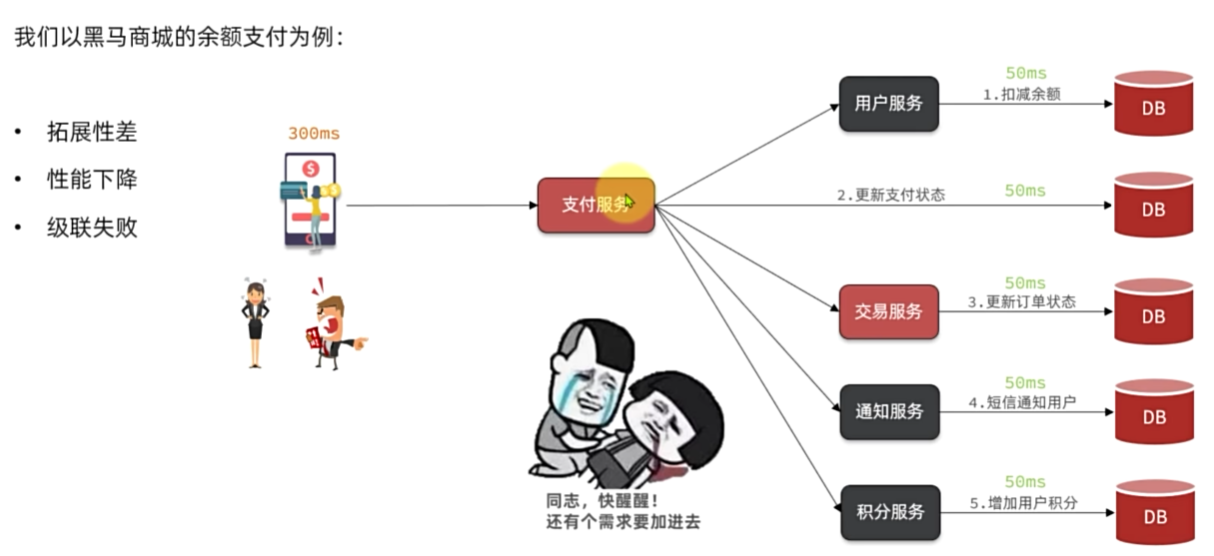
异步调用
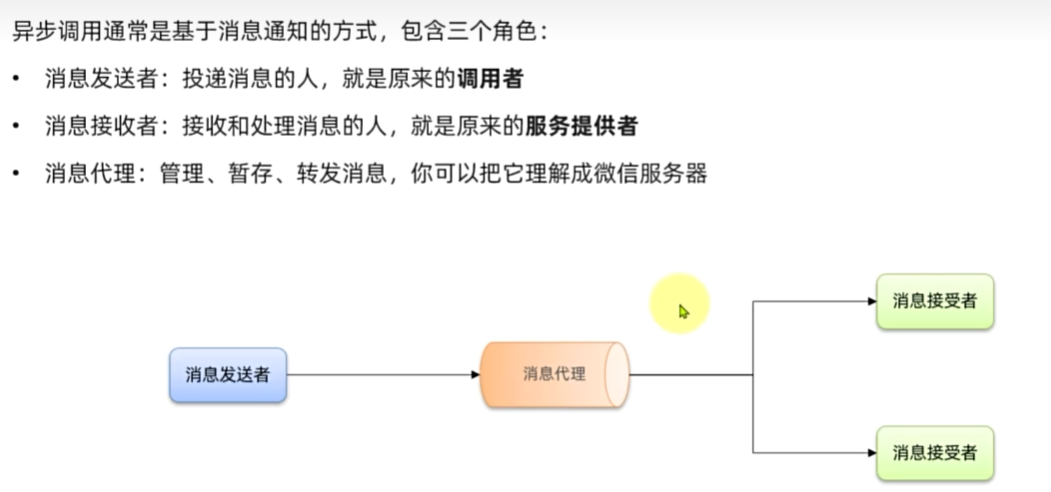
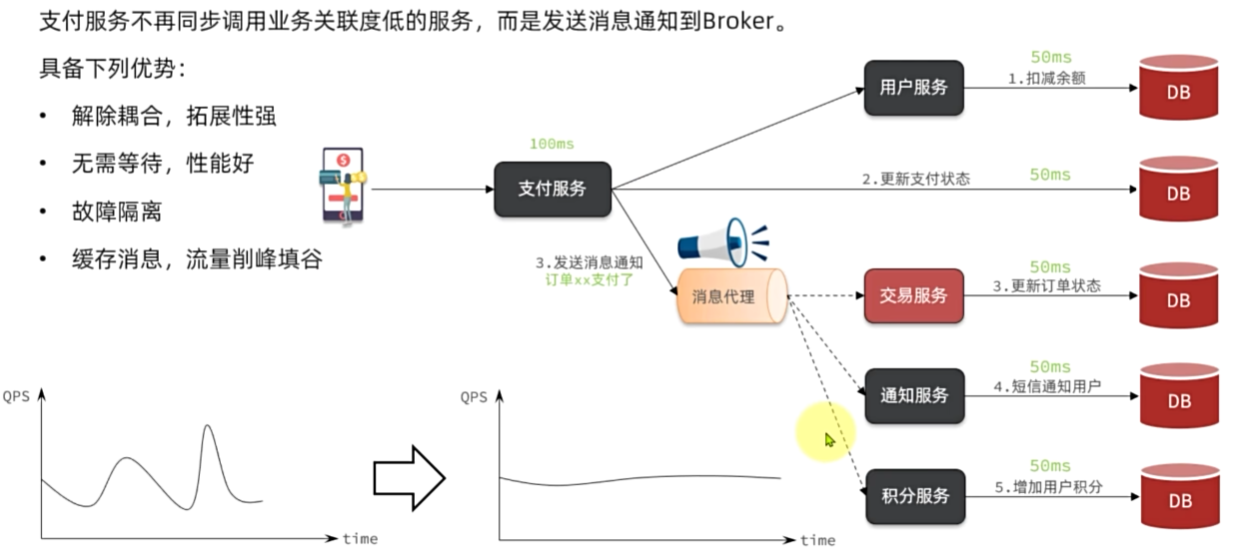
异调用的优势是什么?
耦合度低,拓展性强
异步调用,无需等待,性能好
故障隔离,下游服务故障不影响上游业务
缓存消息,流量削峰填谷
异步调用的问题是什么?
不能立即得到调用结果,时效性差
不确定下游业务执行是否成功
业务安全依赖于Broker的可靠性

追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
安装
docker run \-e RABBITMQ_DEFAULT_USER=itheima \-e RABBITMQ_DEFAULT_PASS=123321 \-v mq-plugins:/plugins \--name mq \--hostname mq \-p 15672:15672 \-p 5672:5672 \--network hm-net\-d \rabbitmq:3.8-management
架构
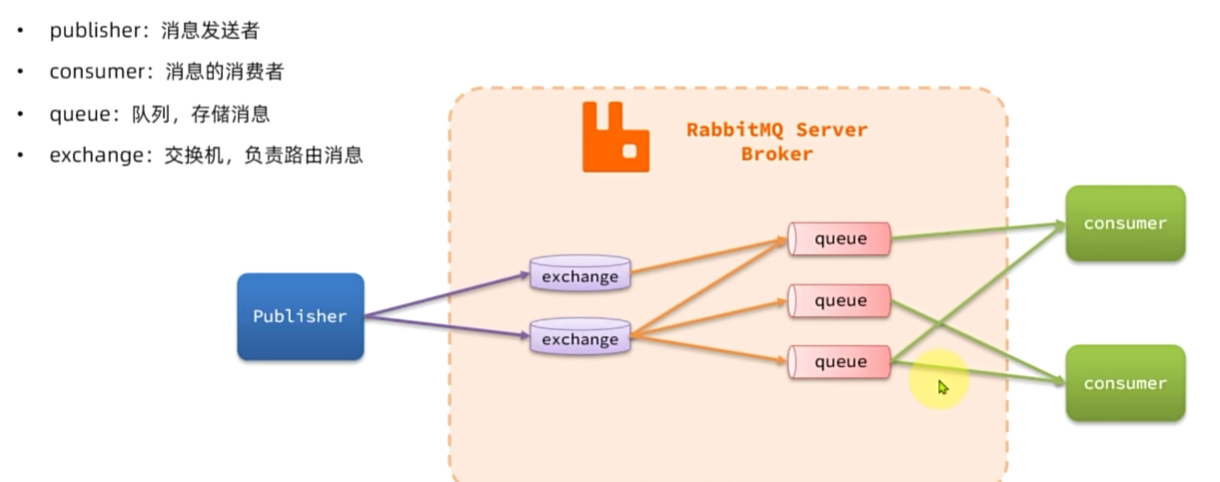
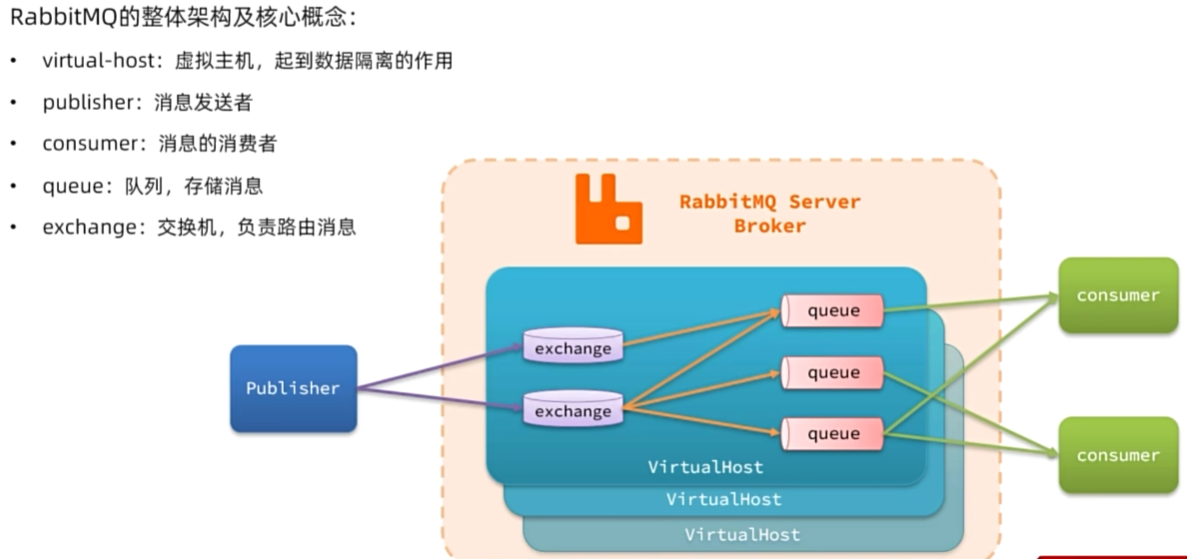
数据隔离
需求:在RabbitMQ的控制台完成下列操作:
新建一个用户hmall
为hmal用户创建一个virtual host
测试不同virtual host之间的数据隔离现象
java客户端

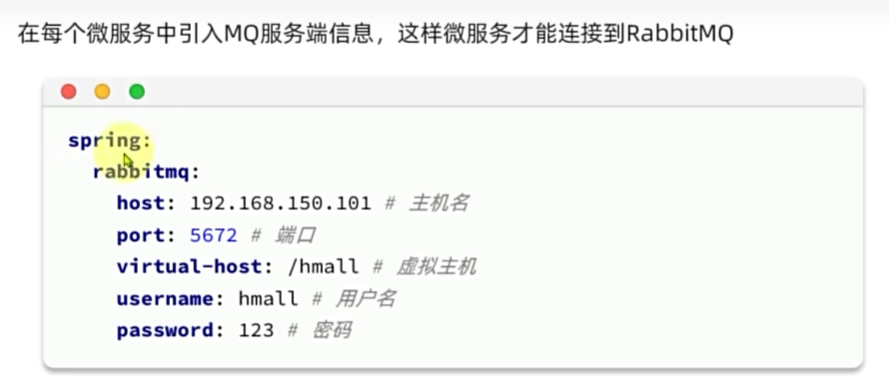
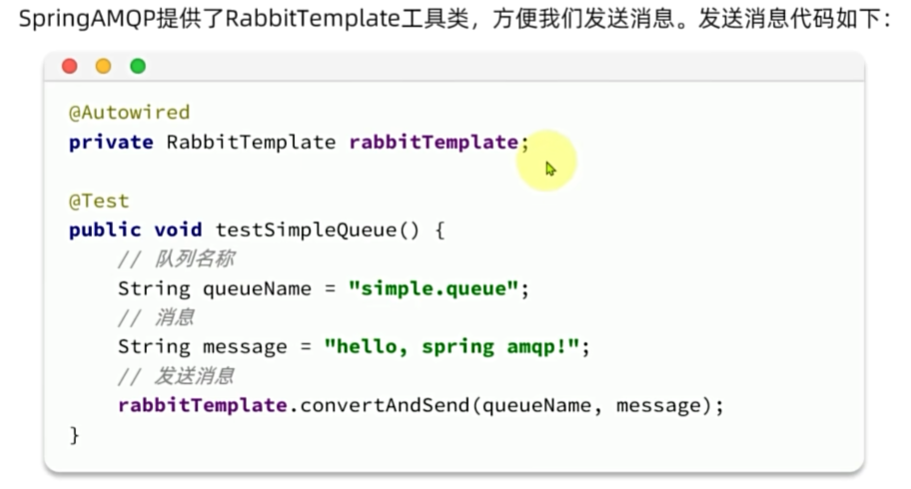

Work Queues
模拟WorkQueue,实现一个队列绑定多个消费者

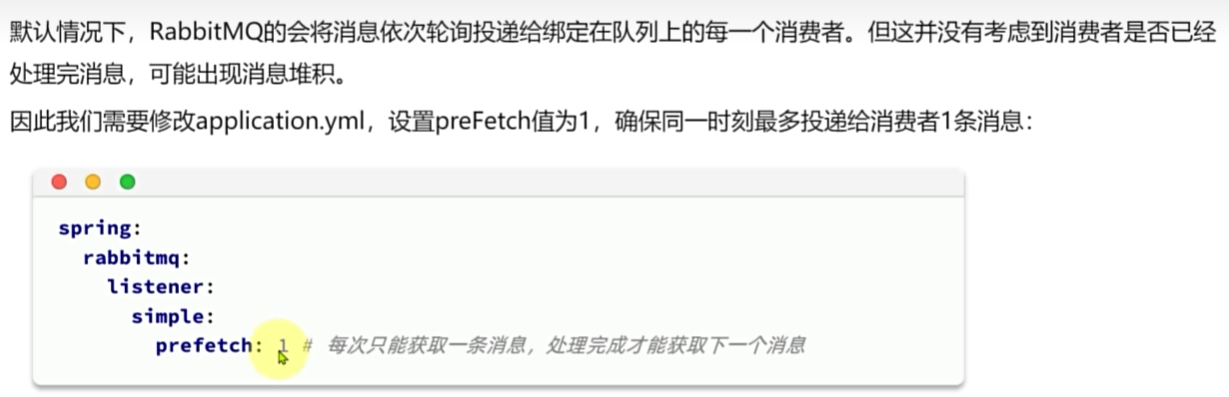
消费者消息推送限制
Work模型的使用:
多个消费者绑定到一个队列,可以加快消息处理速度
同一条消息只会被一个消费者处理
通过设置prefetch来控制消费者预取的消息数量,处理完一条再处理下一条,实现能者多劳
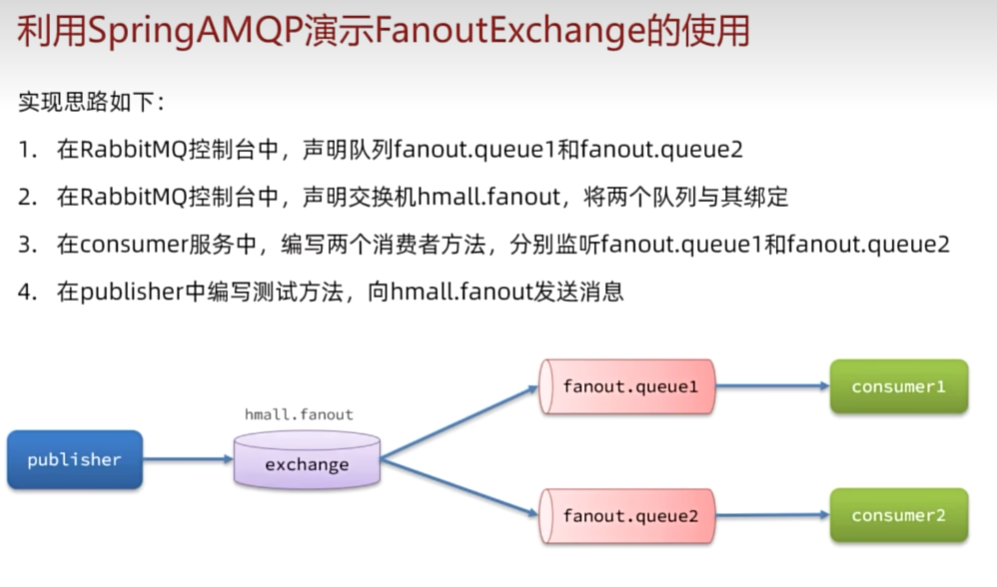
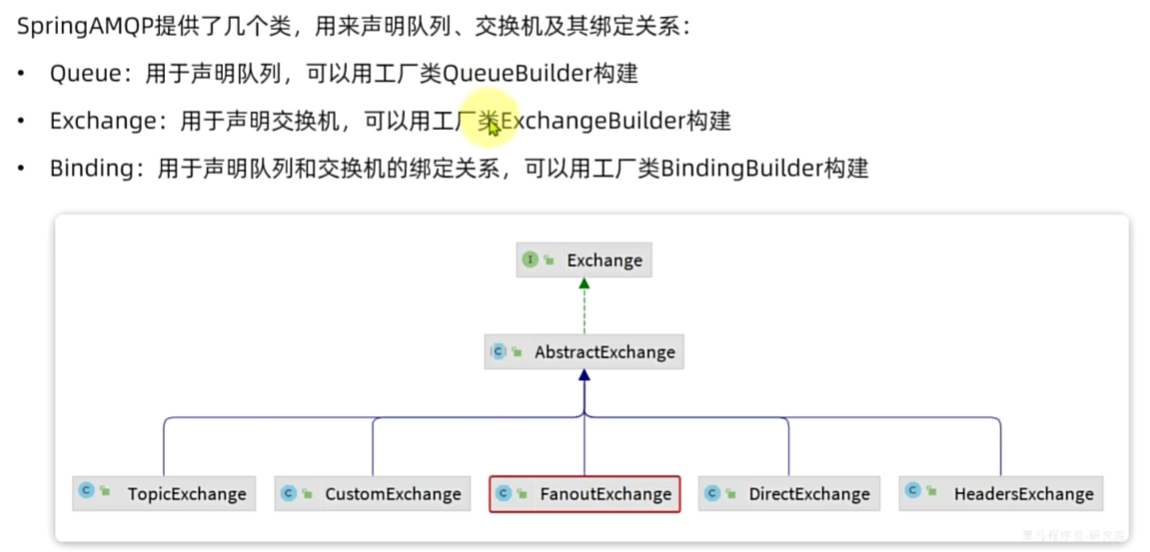
Fanout交换机
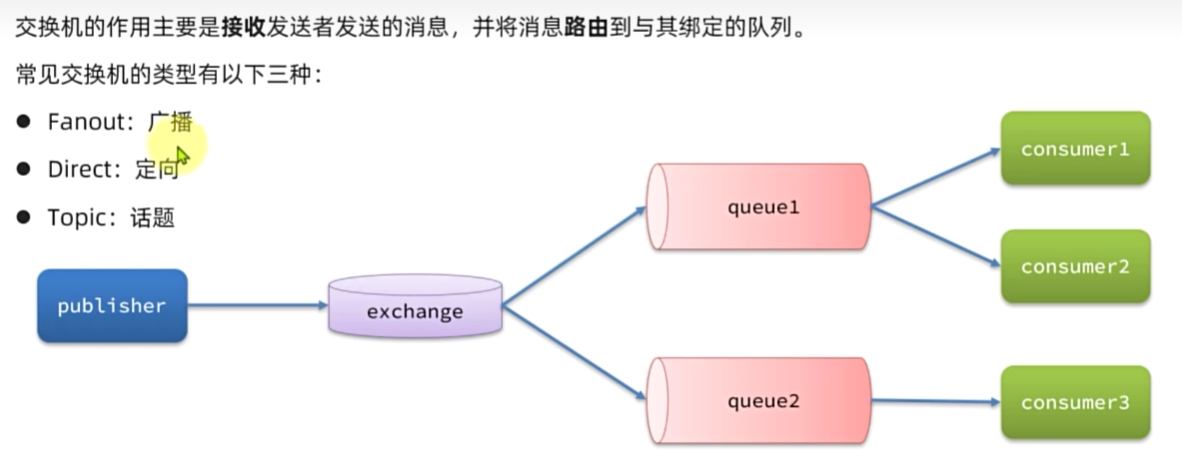
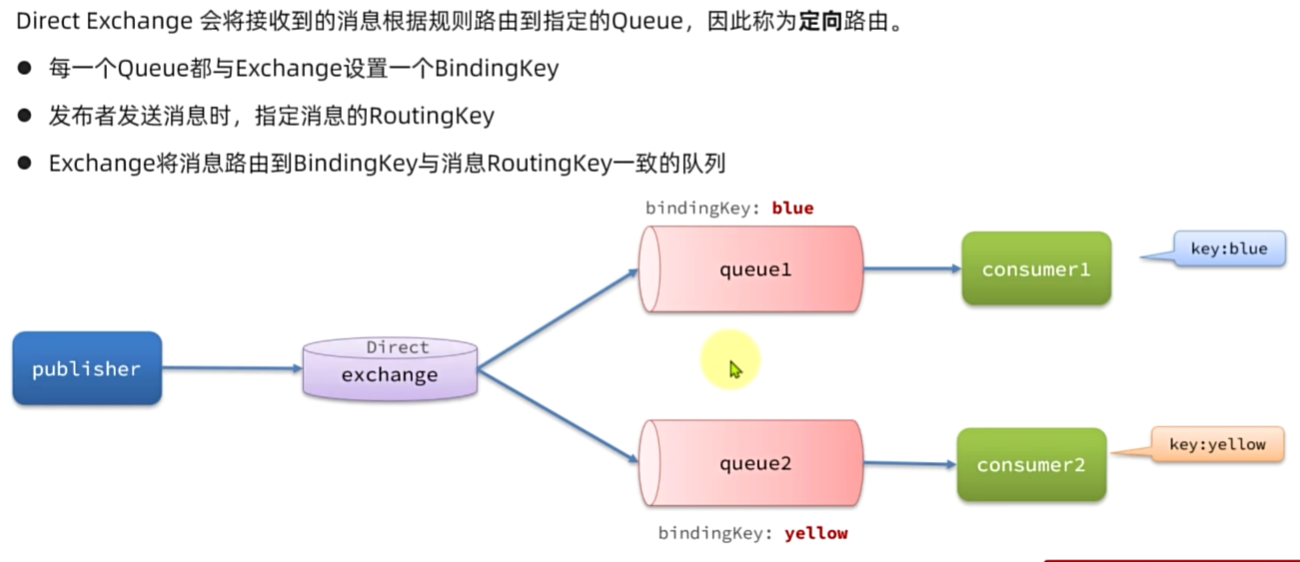
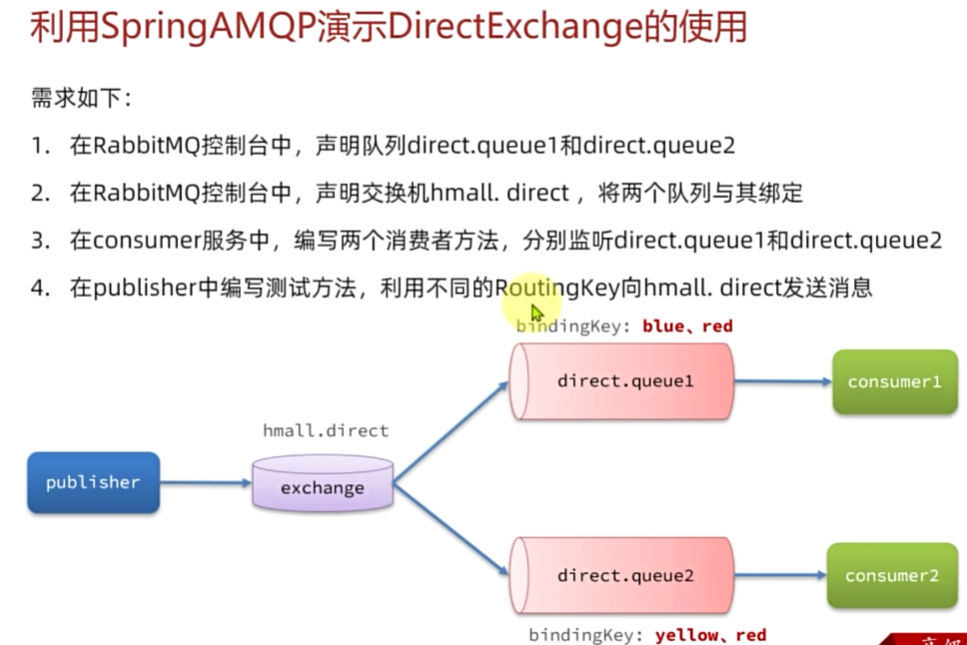
Direct交换机
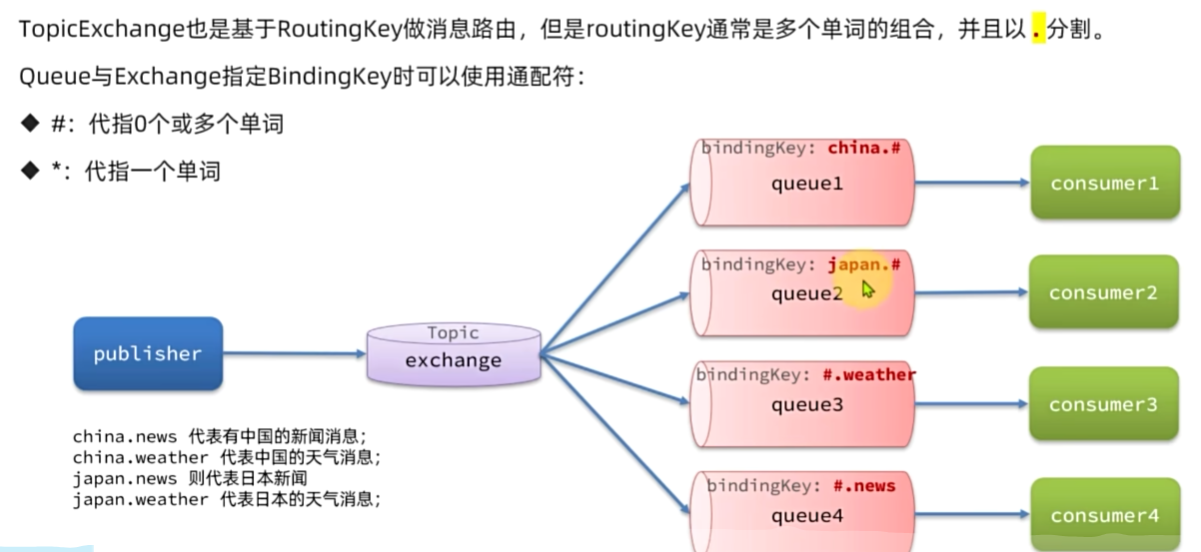
Topic交换机
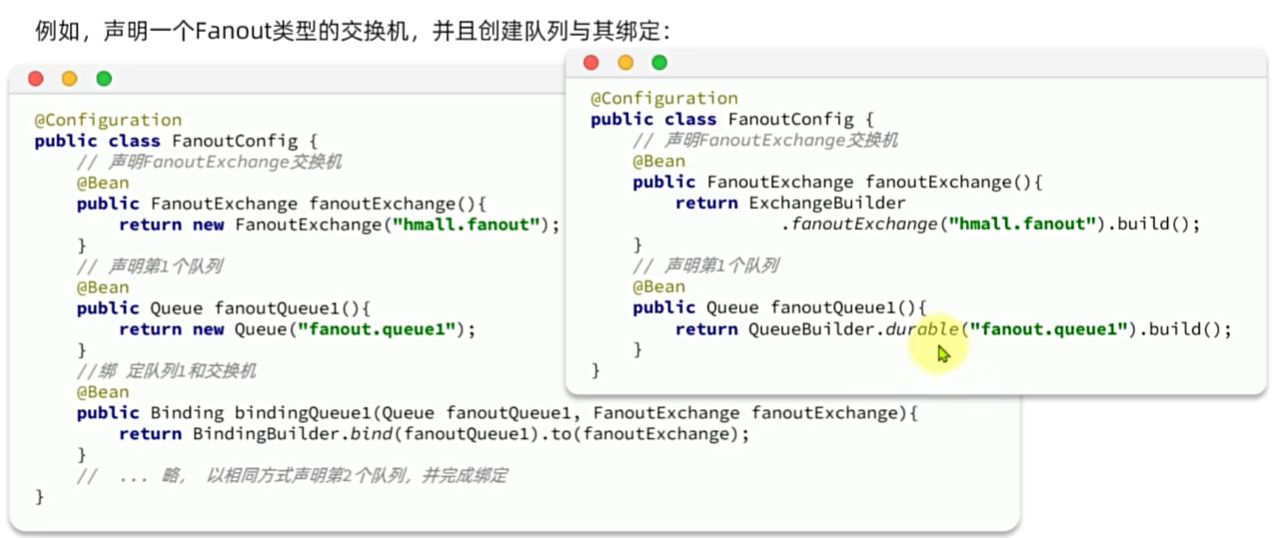
声明队列交换机

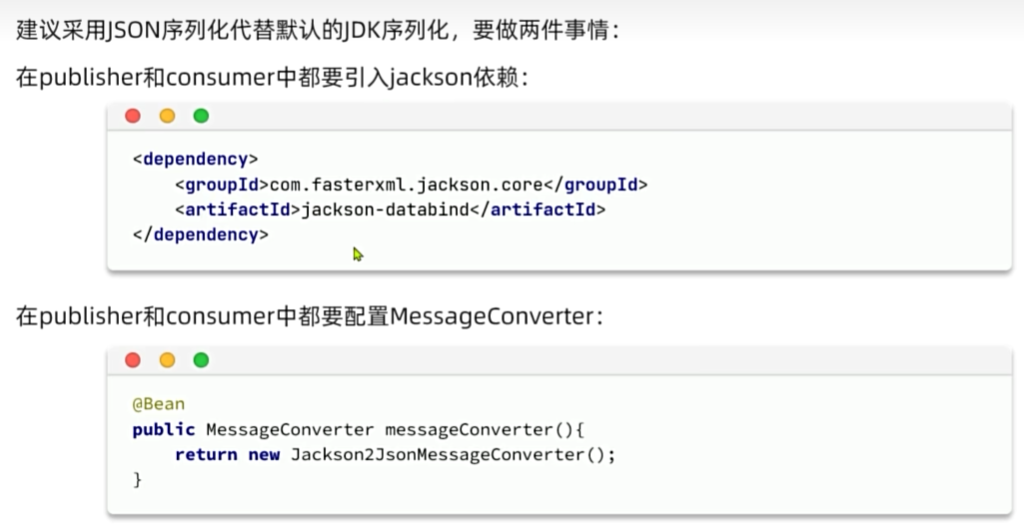
消息转换器

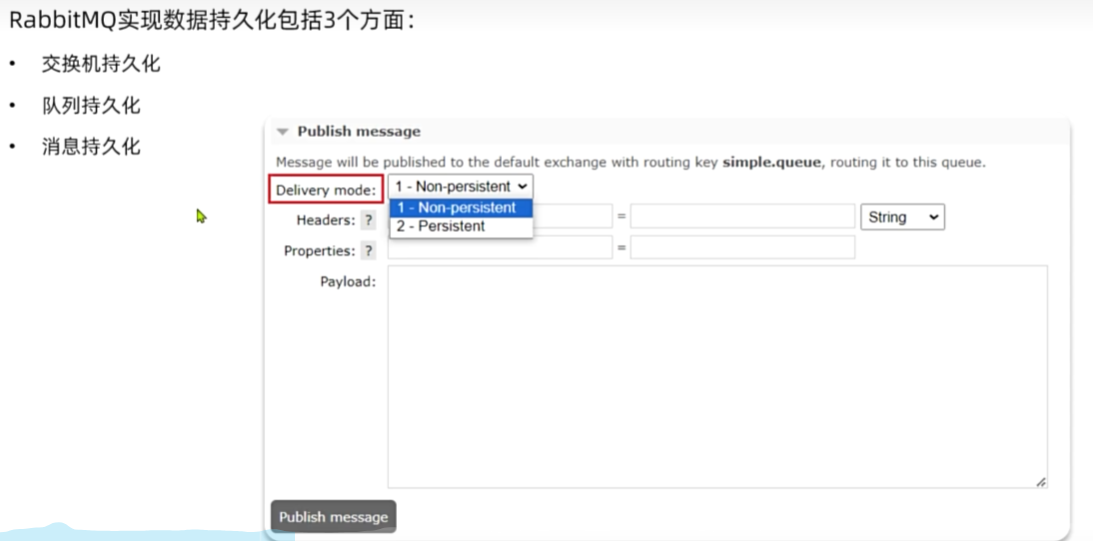
发送者消息可靠性
发送者重连
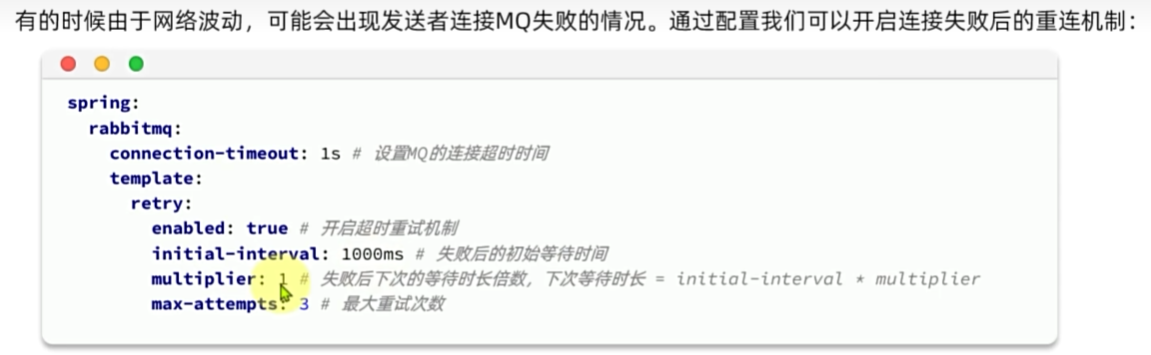

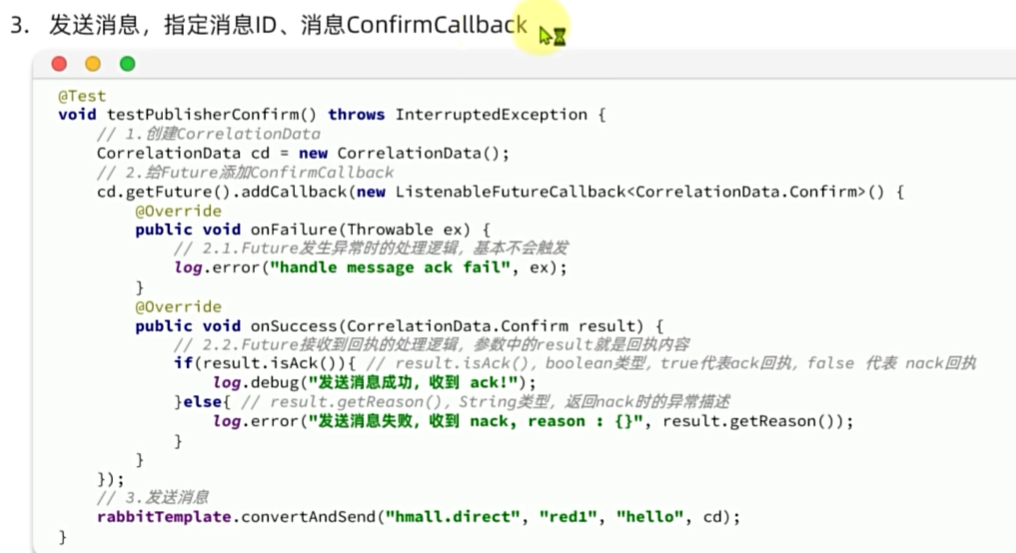
发送者确认
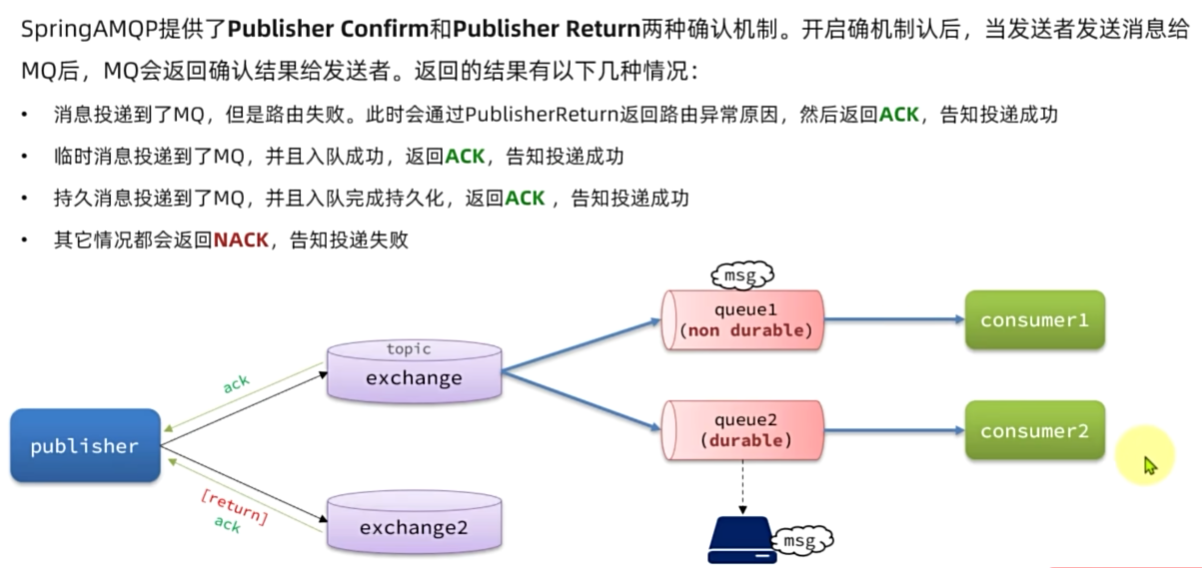
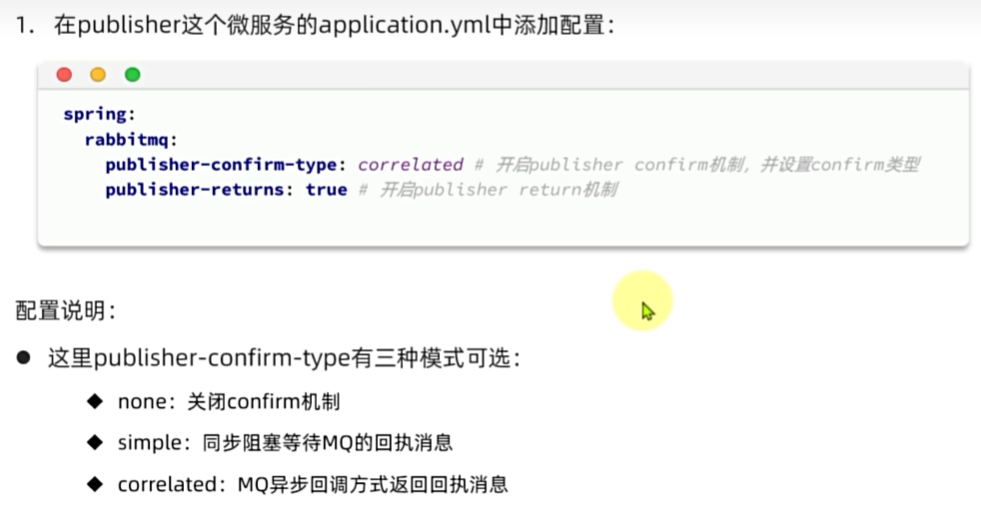
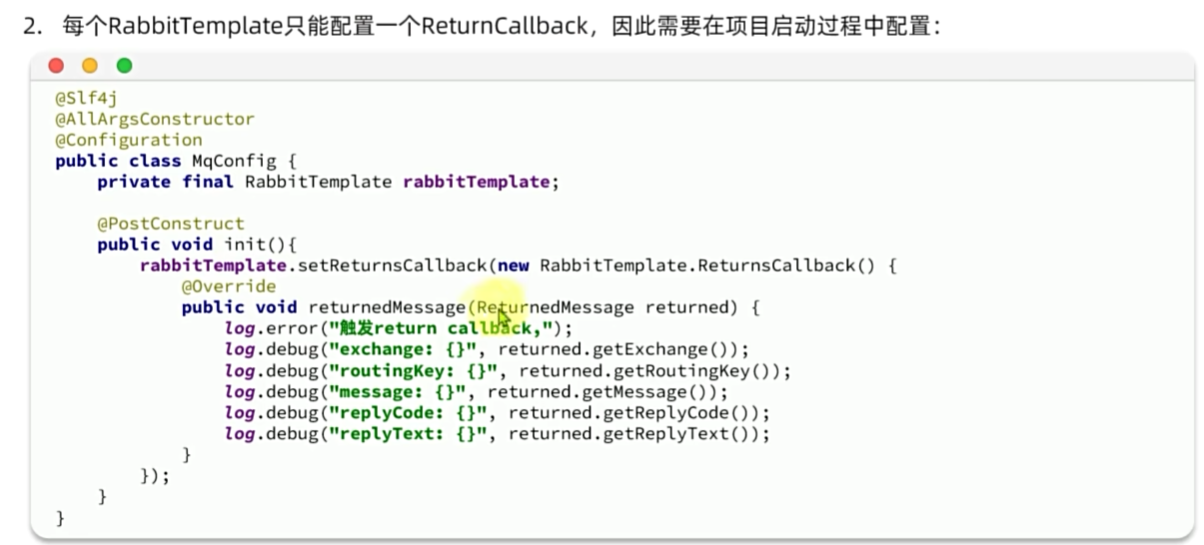
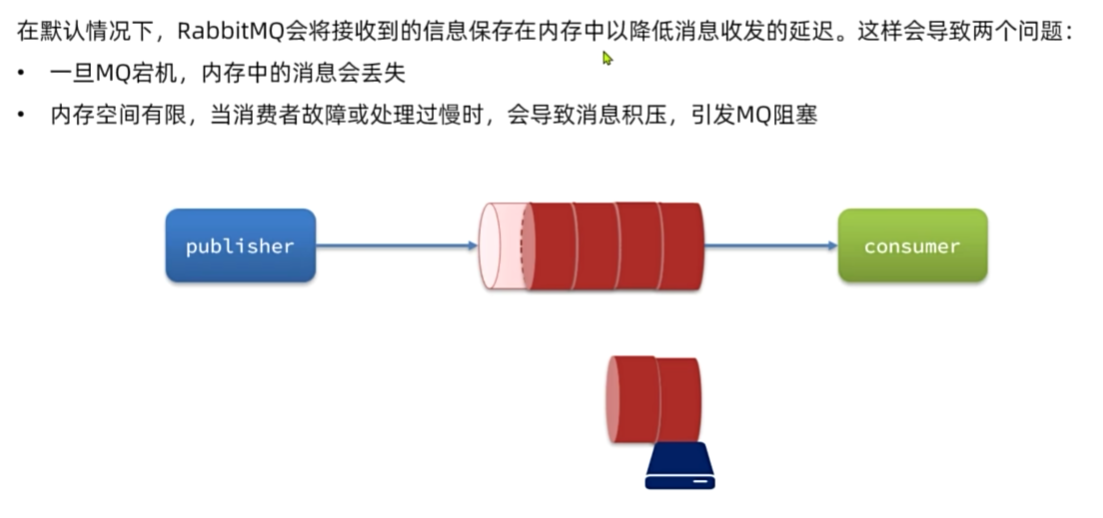
MQ的可靠性
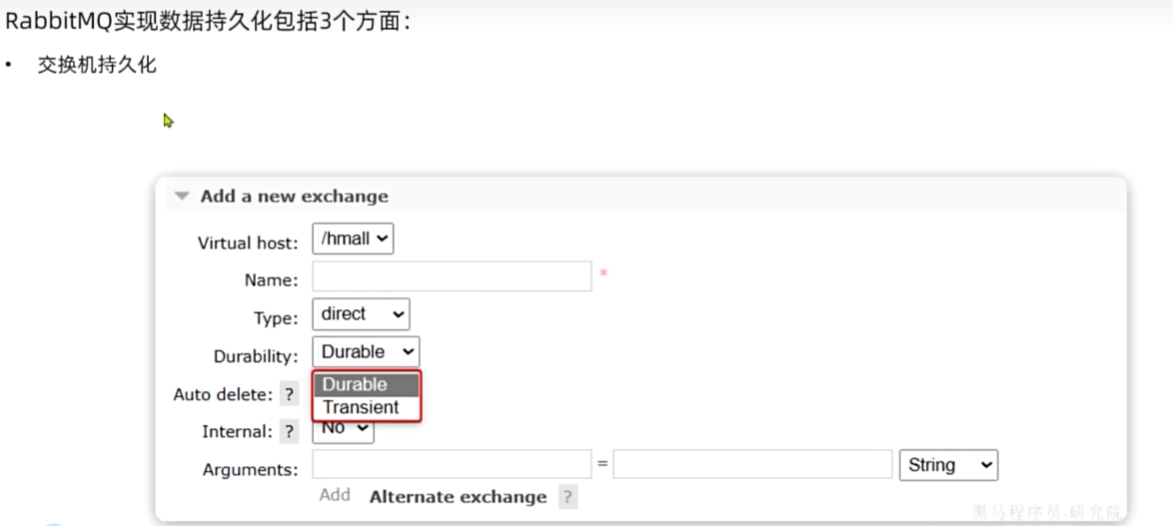
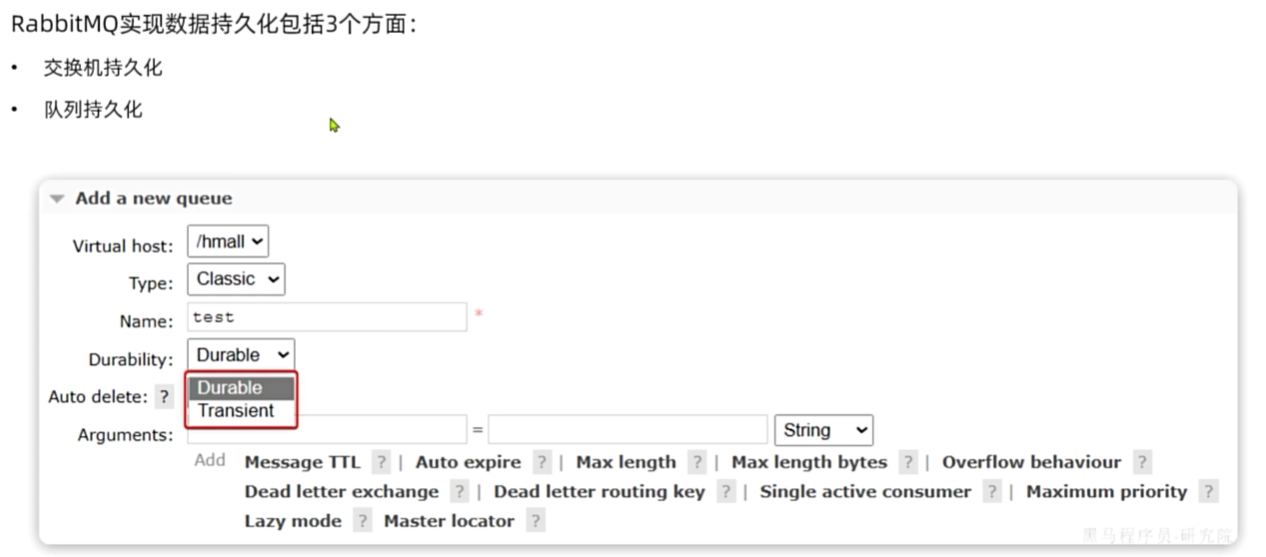
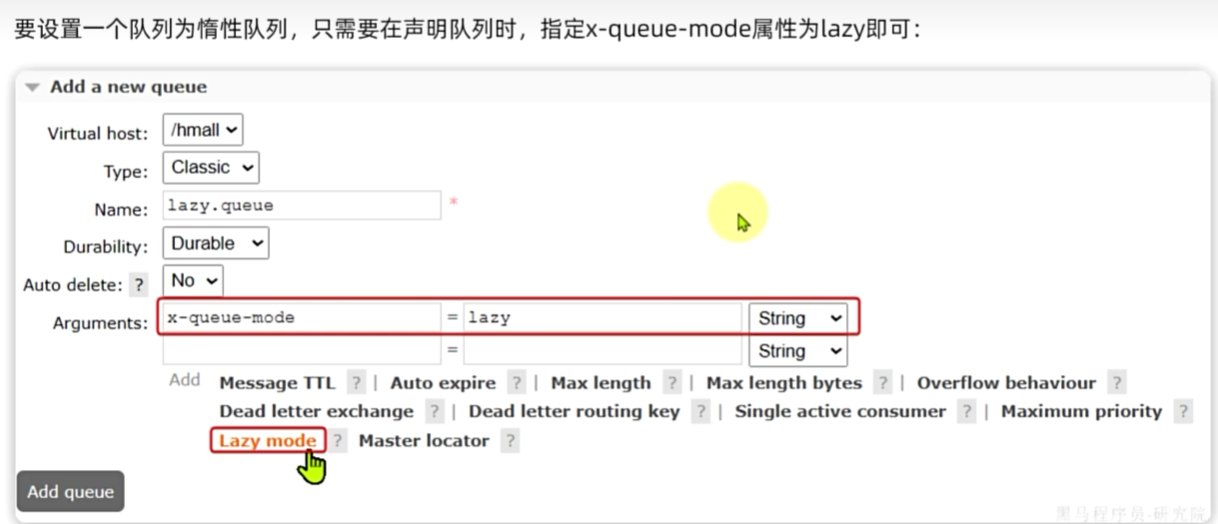
Layz Queue
从RabbitMQ的3.6.0版本开始,就增加了Lazy Queue的概念,也就是惰性队列。
惰性队列的特征如下:
·接收到消息后直接存入磁盘,不再存储到内存
·消费者要消费消息时才会从磁盘中读取并加载到内存(可以提前缓存部分消息到内存,最多2048条)
在3.12版本后,所有队列都是Lazy Queue模式,无法更改。

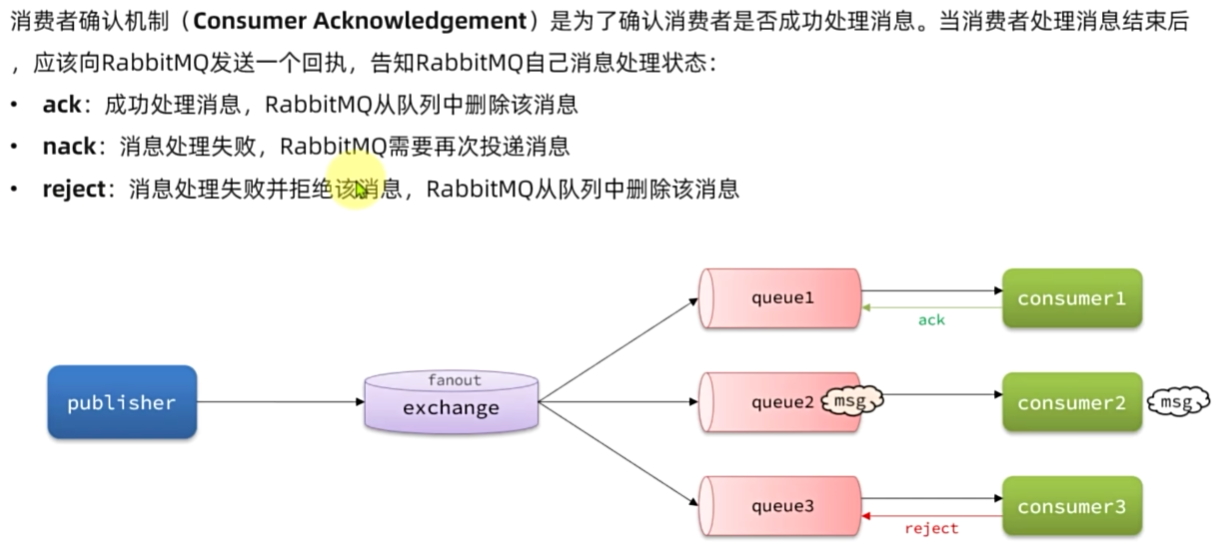
消费者确认机制
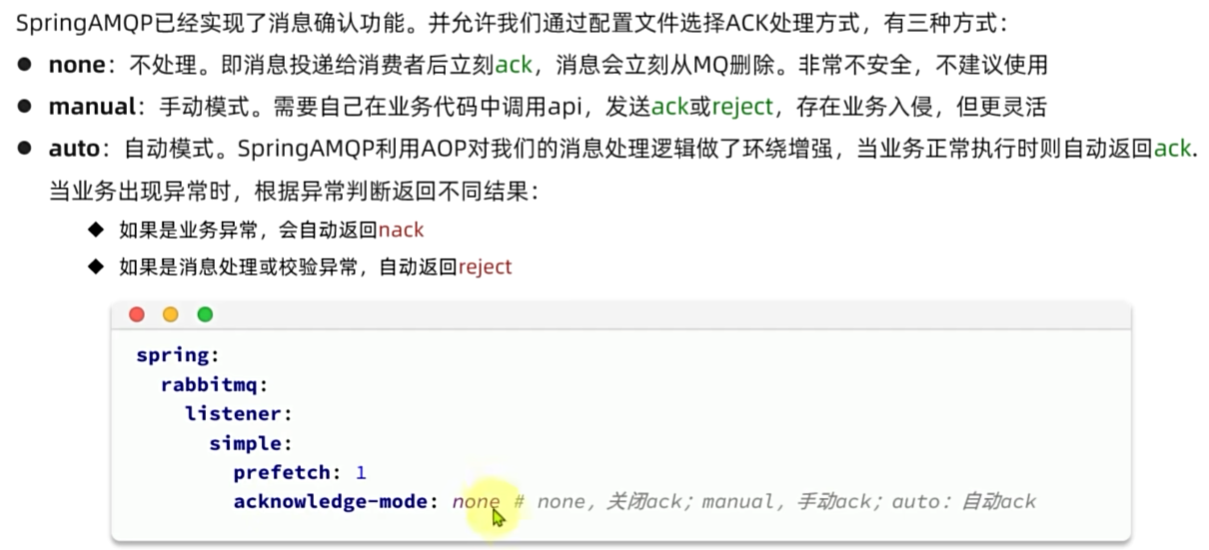
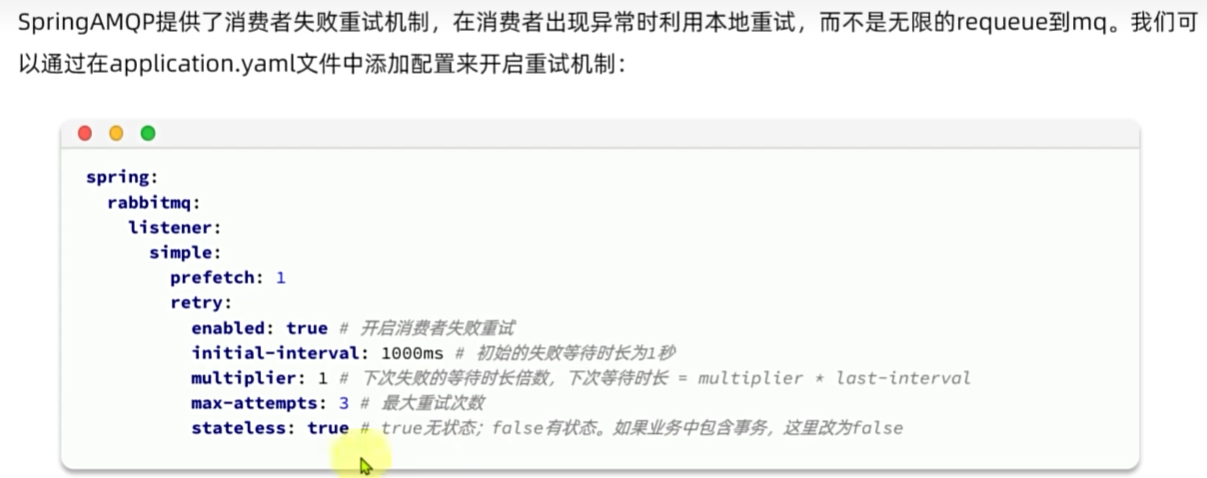
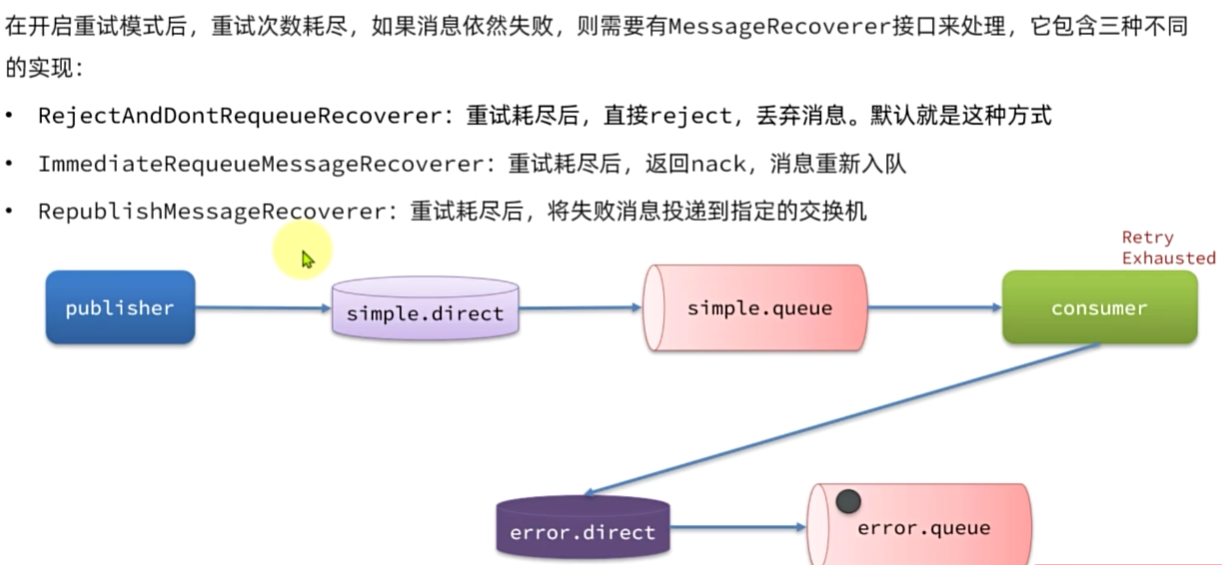
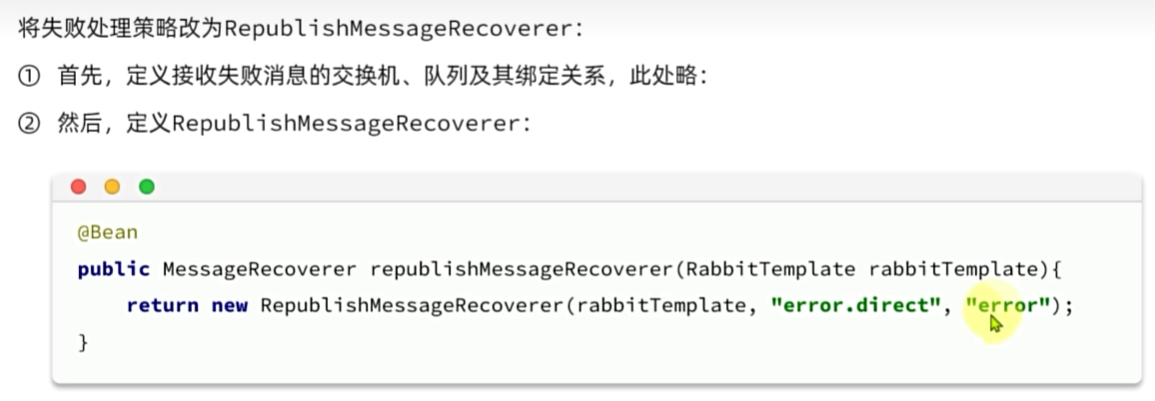
失败消息处理策略
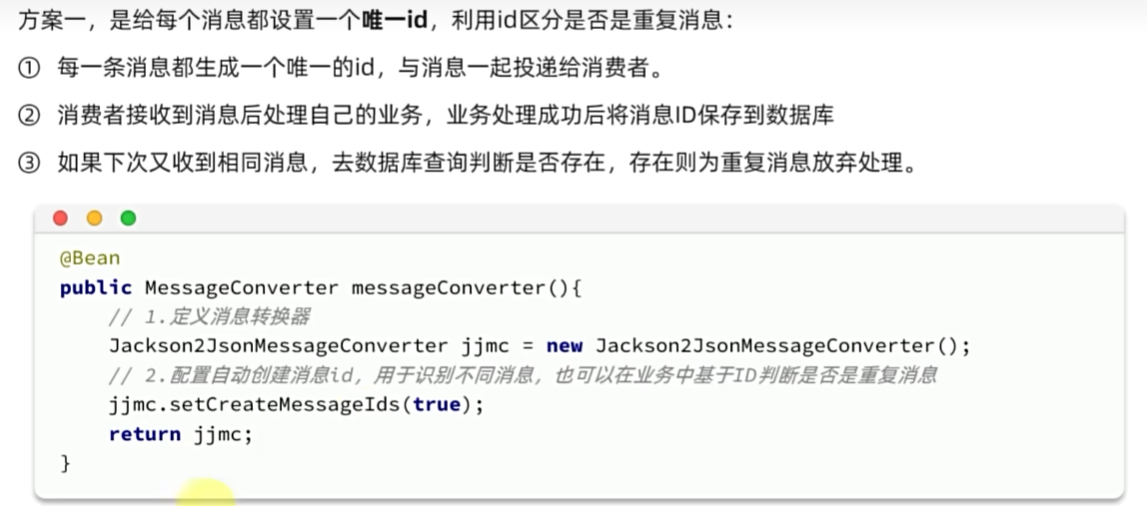
业务幂等性

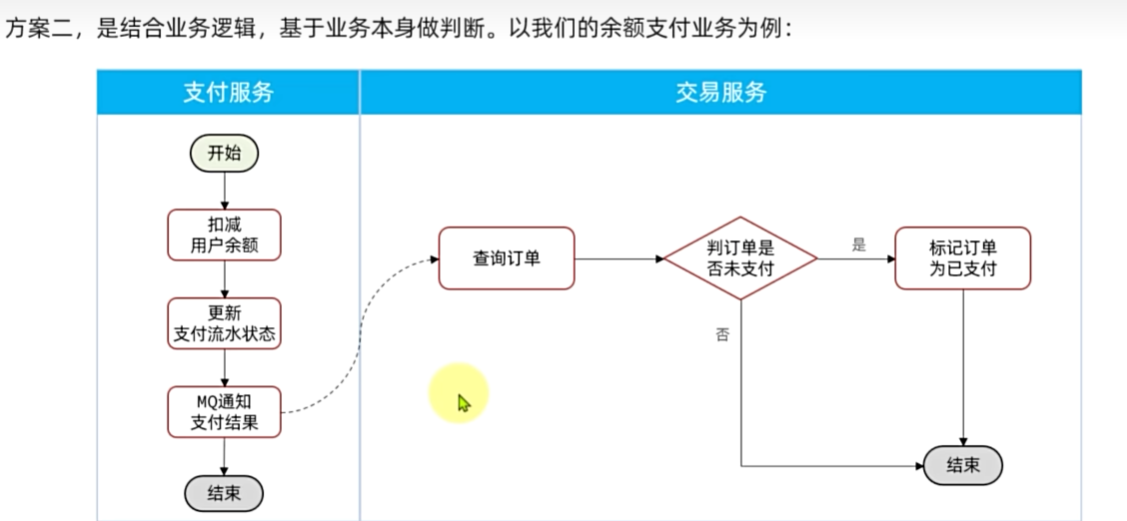
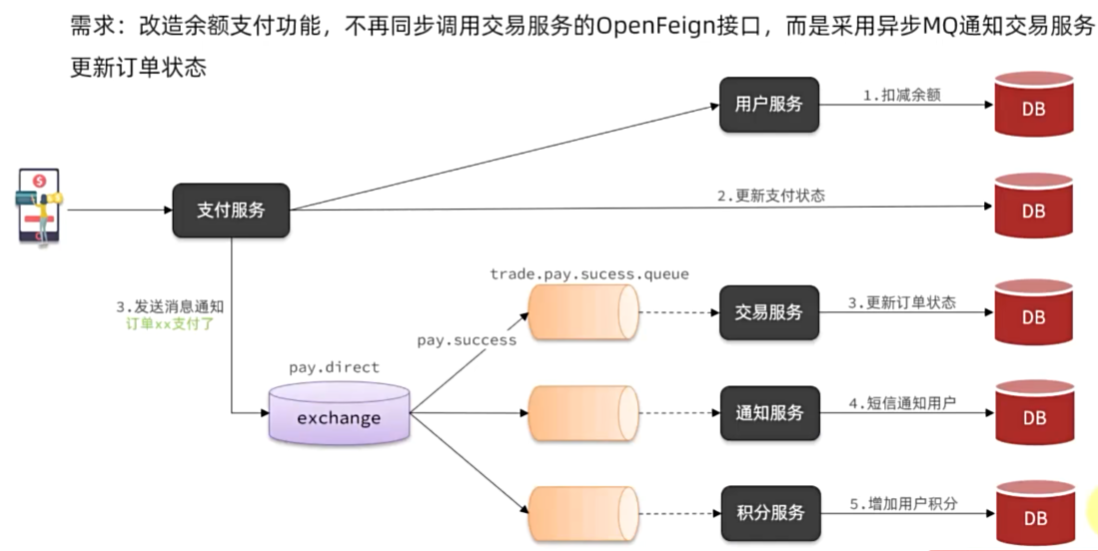
如何保证支付服务与交易服务之间的订单状态一致性?
首先,支付服务会正在用户支付成功以后利用MQ消息通知交易服务
完成订单状态同步。
其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消
费者确认、消费者失败重试等策略,确保消息投递和处理的可靠性。同
时也开启了MQ的持久化,避免因服务宕机导致消息丢失。
最后,我们还在交易服务更新订单状态时做了业务幂等判断,避免
因消息重复消费导致订单状态异常。
如果交易服务消息处理失败,有没有什么兜底方案?
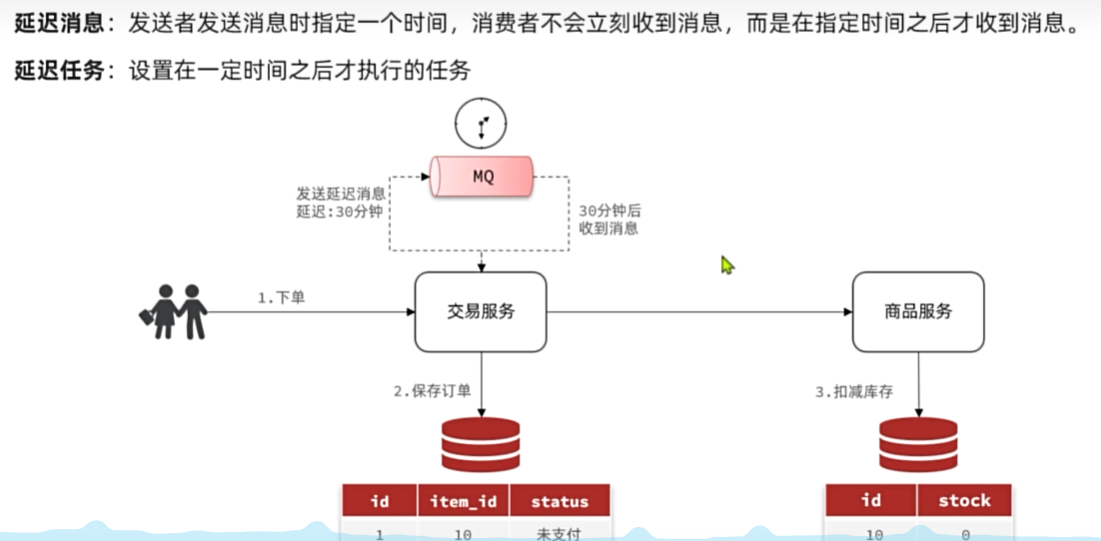
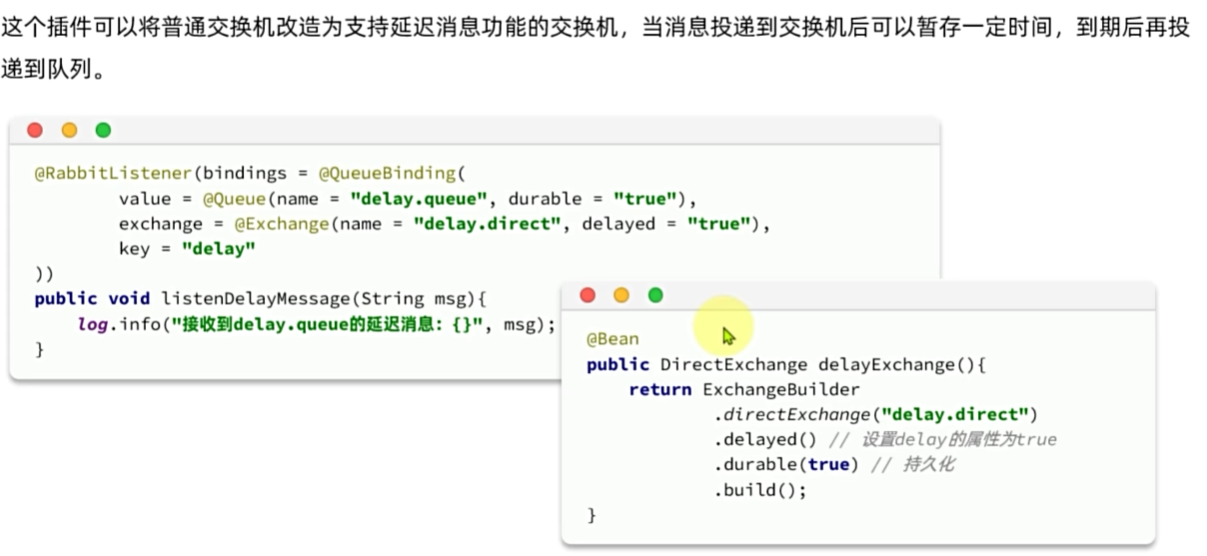
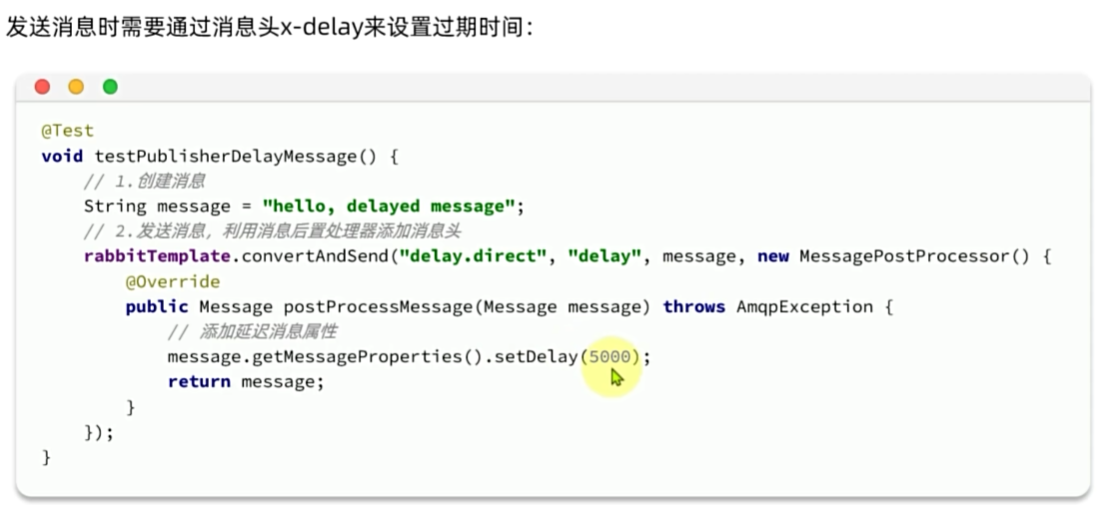
延迟消息
延迟消息:发送者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时间之后才收到消息。
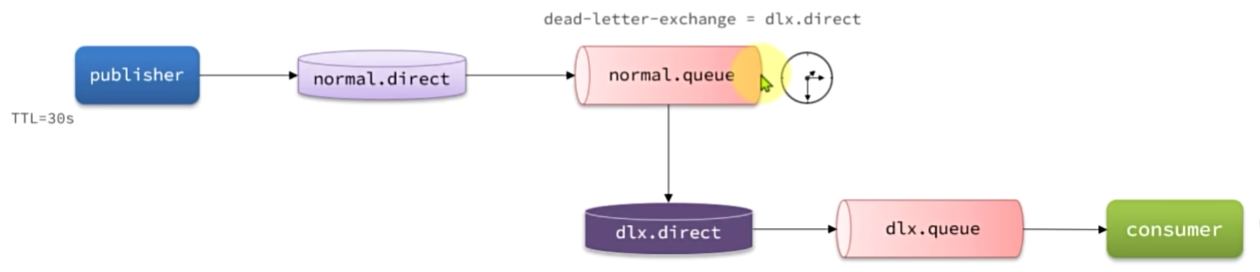
死信交换机
当一个队列中的消息满足下列情况之一时,就会成为死信(dead letter):
·消费者使用basic.rejecti或basic.nack声明消费失败,并且消息的requeue参数设置为false
消息是一个过期消息(达到了队列或消息本身设置的过期时间),超时无人消费
要投递的队列消息堆积满了,最早的消息可能成为死信
如果队列通过dead-letter-exchange属性指定了一个交换机,那么该队列中的死信就会投递到这个交换机中。这个交
换机称为死信交换机(Dead Letter Exchange,简称DLX)。
延迟消息插件
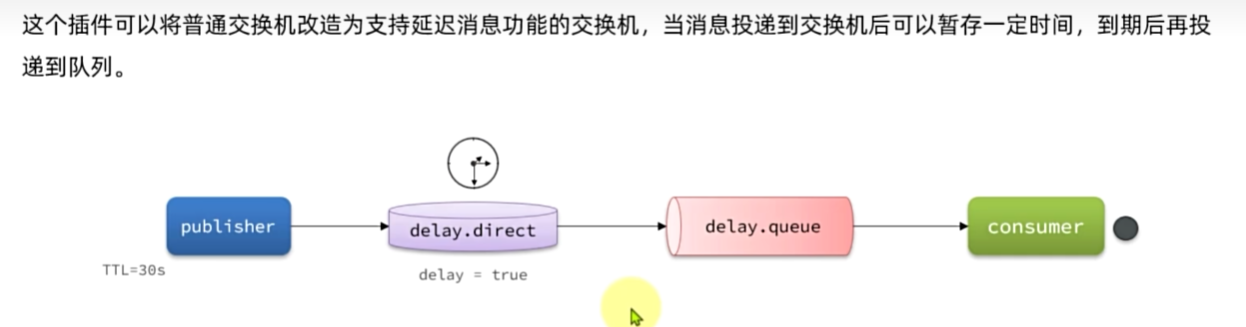
安装
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange
因为我们是基于Docker安装,所以需要先查看RabbitMQ的插件目录对应的数据卷。
docker volume inspect mq-plugins
结果如下:
[{"CreatedAt": "2024-06-19T09:22:59+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/mq-plugins/_data","Name": "mq-plugins","Options": null,"Scope": "local"}
]
插件目录被挂载到了/var/lib/docker/volumes/mq-plugins/_data这个目录,我们上传插件到该目录下。

接下来执行命令,安装插件:
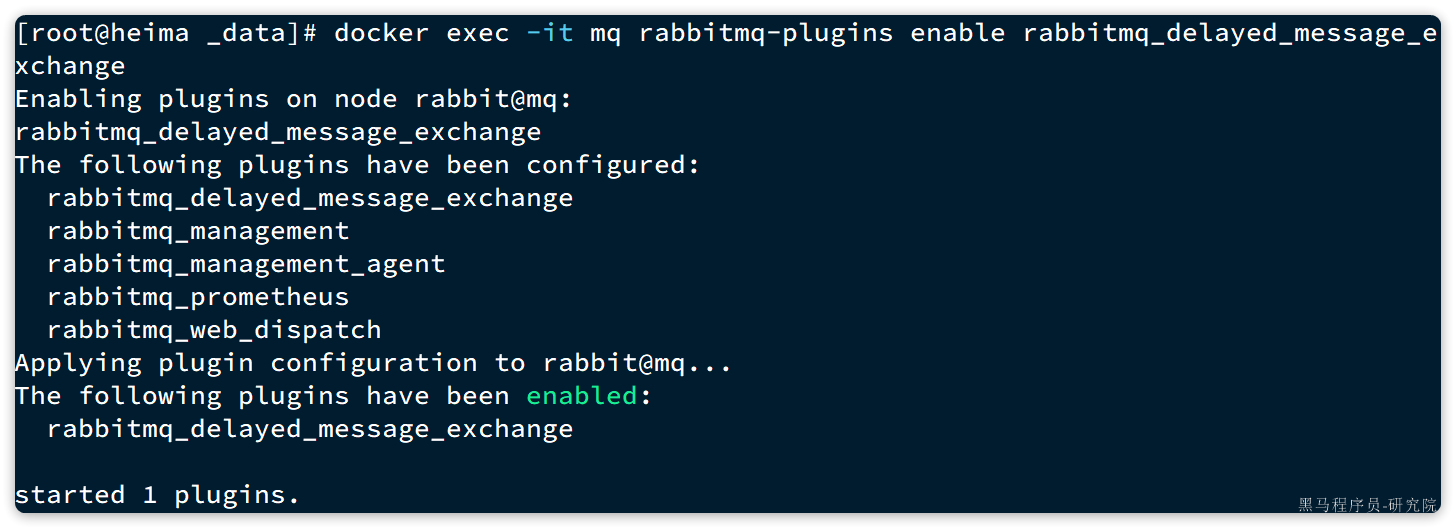
docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange
运行结果如下:
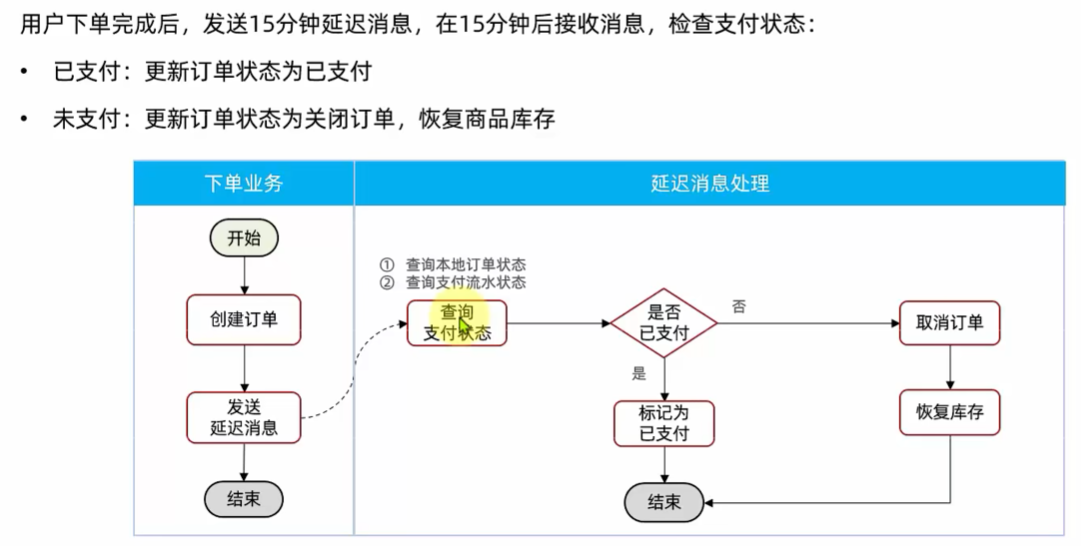
取消超时订单
Elasticsearch分布式搜索
介绍
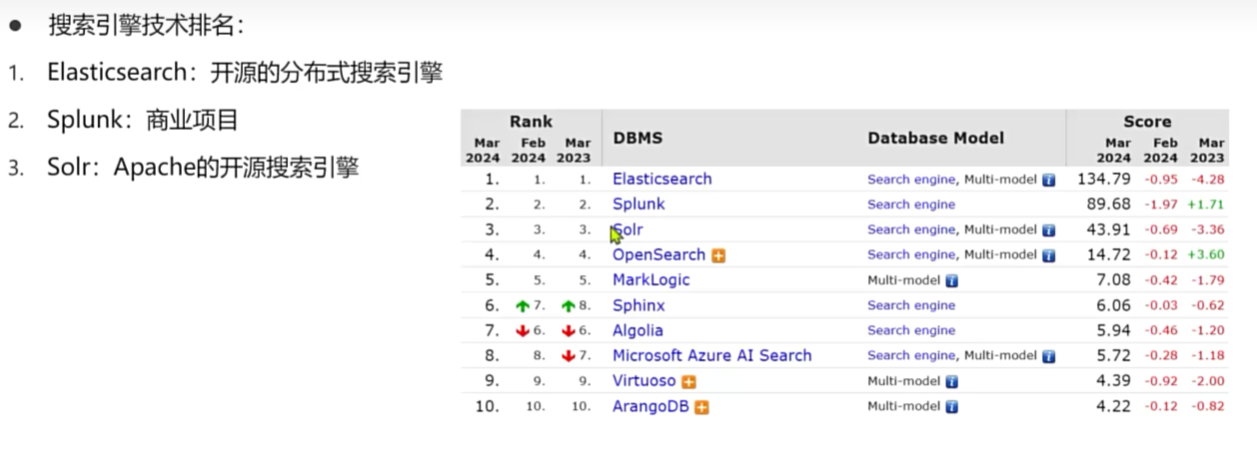



安装elasticsearch
通过下面的Docker命令即可安装单机版本的elasticsearch:
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \-v es-config:/usr/share/elasticsearch/config \--privileged \--network hm-net \-p 9200:9200 \-p 9300:9300 \elasticsearch:7.12.1
安装Kibana
通过下面的Docker命令,即可部署Kibana:
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
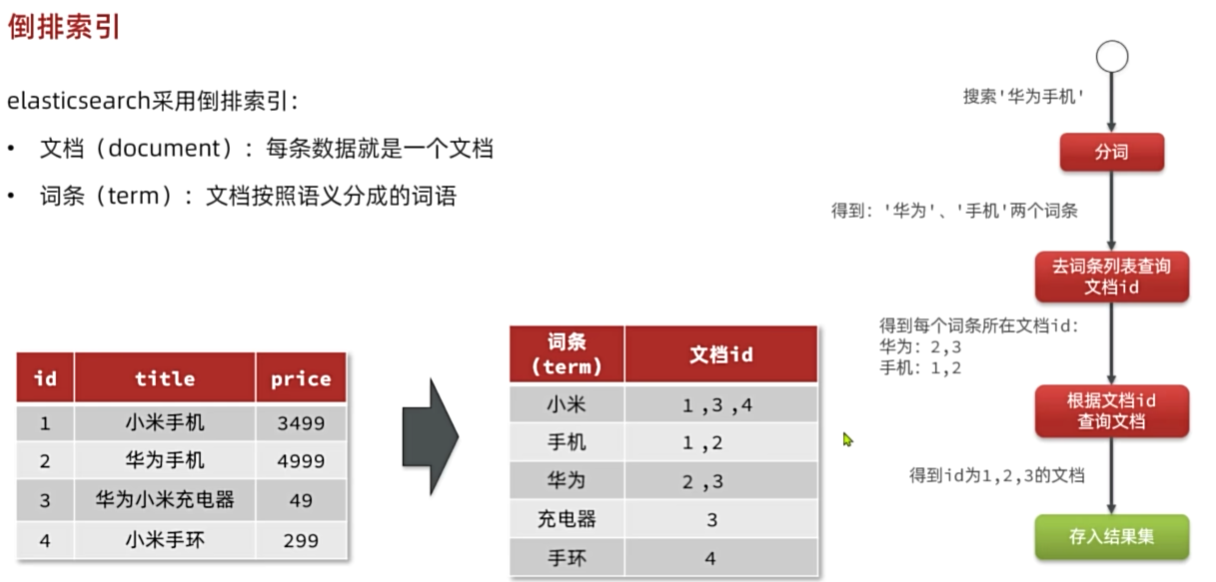
倒排索引
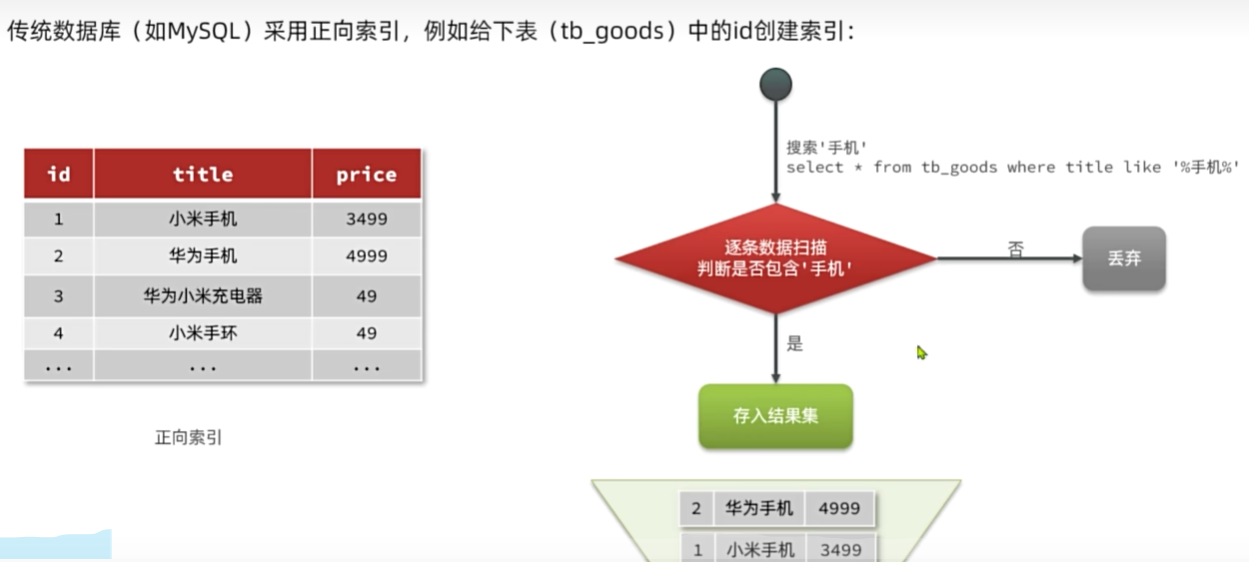
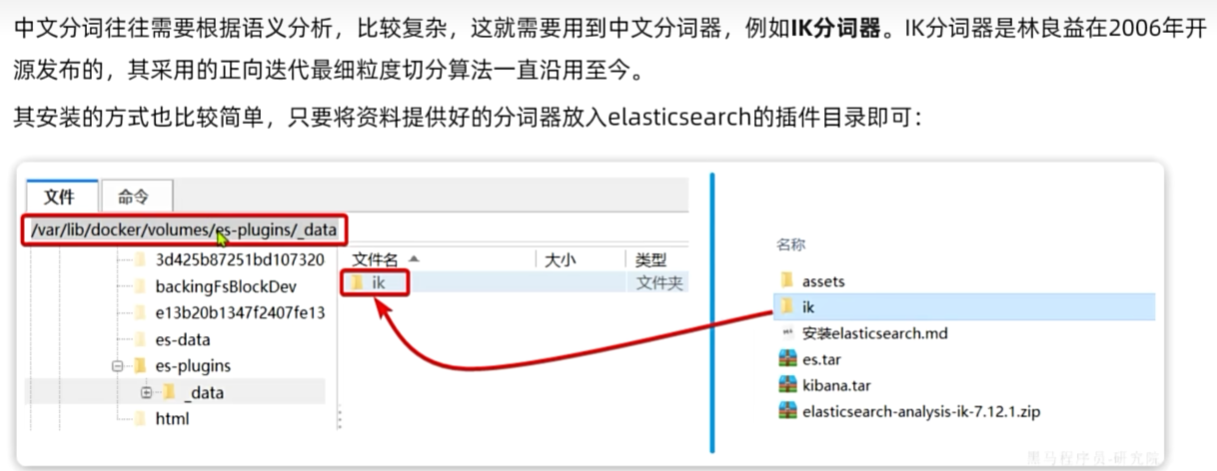
IK分词器
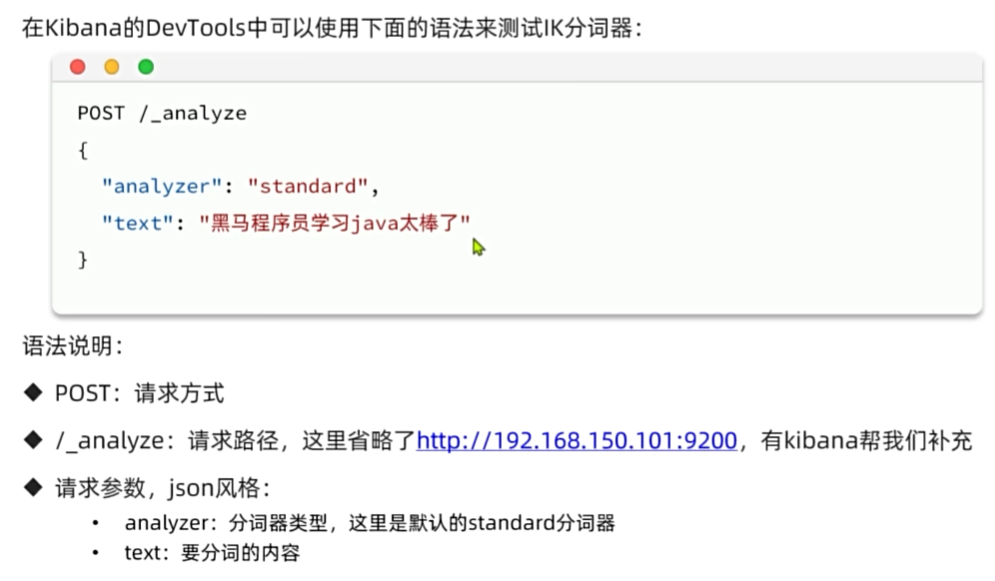
在线安装
docker exec -it es ./bin/elasticsearch-plugin install https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-7.12.1.zip
POST /_analyze
{
“analyzer”: “ik_smart”,
“text”: “传智播客开放全日制大学,刘德华这简直泰裤辣啊”
}
分词器的作用是什么?
创建倒排索引时,对文档分词
用户搜索时,对输入的内容分词
K分词器有几种模式?
ik smart:智能切分,粗粒度
ik max word:最细切分,细粒度IK分词器
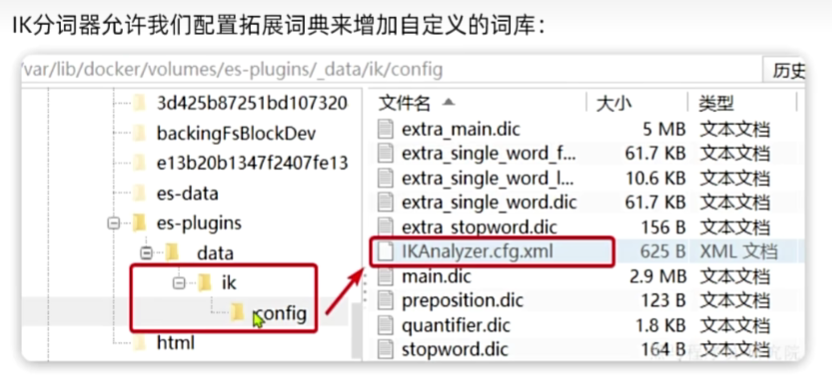
如何拓展分词器词库中的词条?
利用config目录的IkAnalyzer…cfg.xml文件添加拓展词典
在词典中添加拓展词条
基础概念

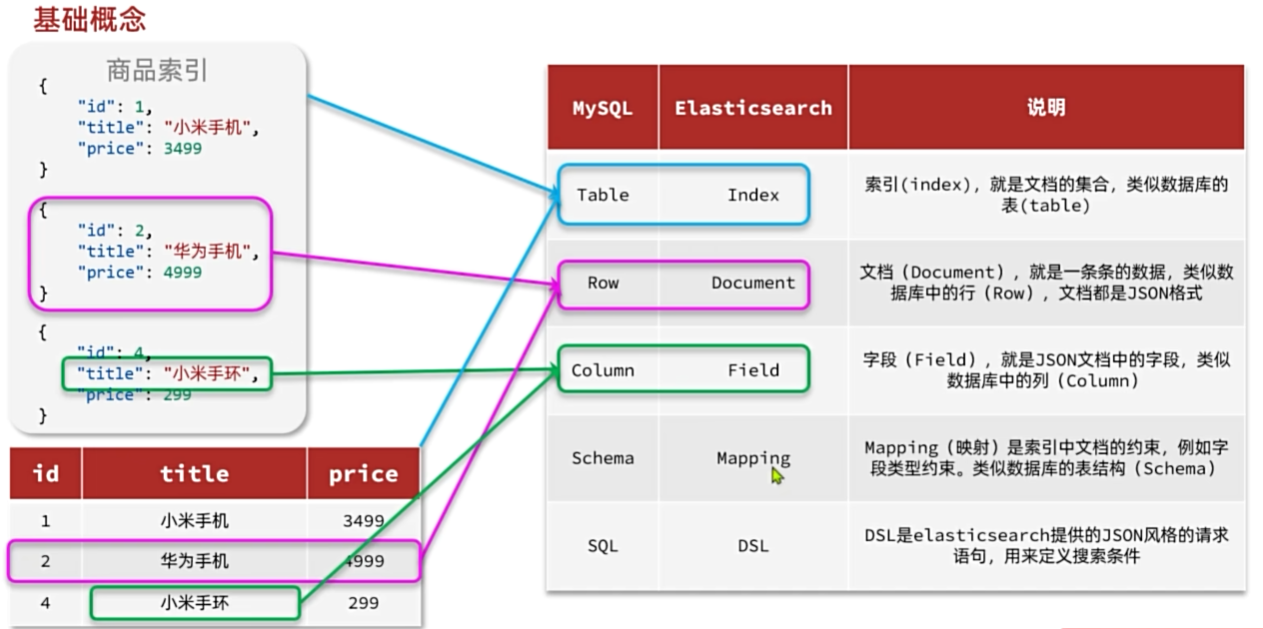
Mapping映射属性
mapping是对索引库中文档的约束,常见的mapping.属性包括:
type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
数值:long、integer、short、byte、double、float,
布尔:boolean
日期:date
对象:object
index:是否创建索引,默认为true
analyzer:使用哪种分词器
properties:该字段的子字段
索引库操作

# 新增索引库
PUT /heima
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_smart"},"age": {"type": "byte"},"email": {"type": "keyword","index": false},"name": {"type": "object", "properties": {"firstNmae": {"type": "keyword"},"lastNmae": {"type": "keyword"}}}}}
}# 查询索引库
GET /heima# 删除索引库
DELETE /heima# 修改索引库
PUT /heima/_mapping
{"properties": {"info": {"type": "byte"}}
}
文档操作CRUD
# 新增文档
POST /heima/_doc/1
{"info": "黑马程序员Java讲师","email": "zy@itcast.cn","name": {"firstName": "云","lastName": "赵"}
}# 查询文档
GET /heima/_doc/1# 删除文档
DELETE /heima/_doc/1# 全量修改
PUT /heima/_doc/2
{"info": "黑马程序员Python讲师","email": "zs@itcast.cn","name": {"firstName": "四","lastName": "赵"}
}# 增量修改
POST /heima/_update/1
{"doc": {"email": "ZhaoYun@itcast.cn"}
}
批量处理

# 批量新增
POST /_bulk
{"index": {"_index":"heima", "_id": "3"}}
{"info": "黑马程序员C++讲师", "email": "ww@itcast.cn", "name":{"firstName": "五", "lastName":"王"}}
{"index": {"_index":"heima", "_id": "4"}}
{"info": "黑马程序员前端讲师", "email": "zhangsan@itcast.cn", "name":{"firstName": "三", "lastName":"张"}}# 批量删除
POST /_bulk
{"delete":{"_index":"heima", "_id": "3"}}
{"delete":{"_index":"heima", "_id": "4"}}
JavaRestClient
客户端初始化
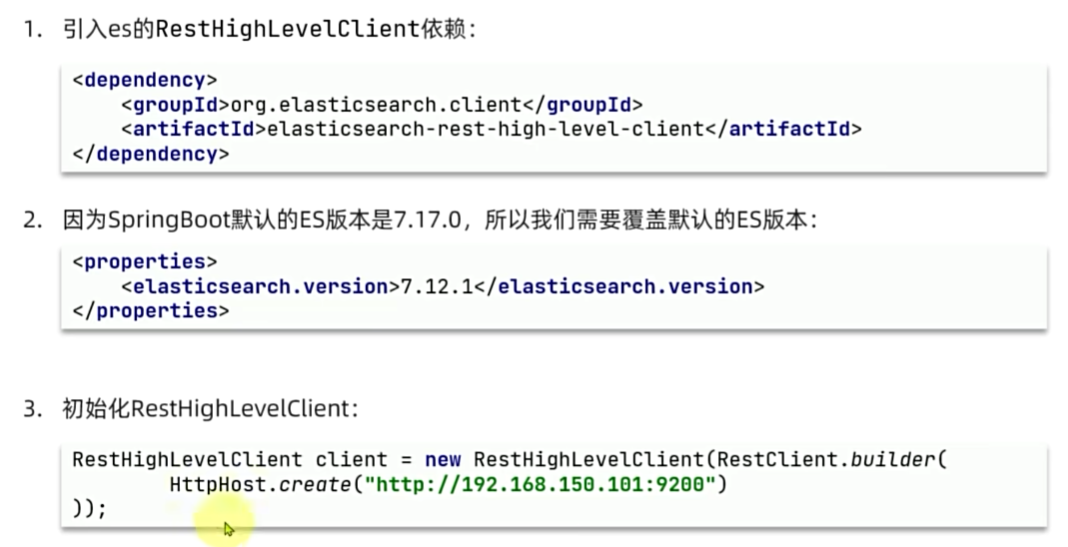
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
商品Mapping映射
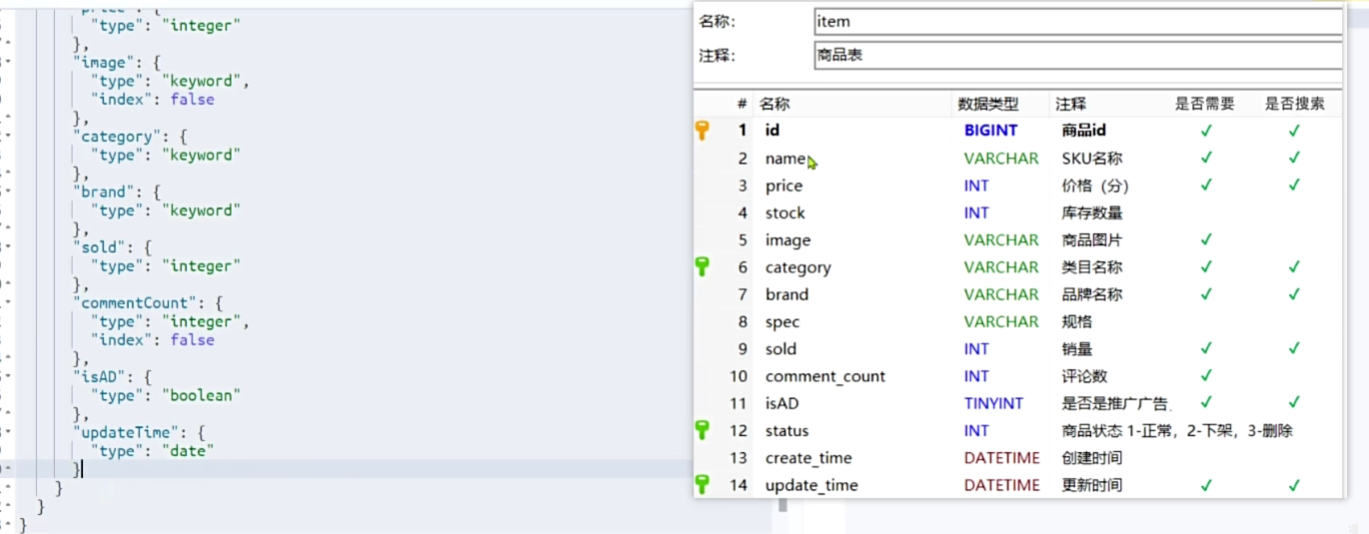
索引库操作
PUT /items
{"mappings": {"properties": {"id": {"type": "keyword"},"name":{"type": "text","analyzer": "ik_max_word"},"price":{"type": "integer"},"stock":{"type": "integer"},"image":{"type": "keyword","index": false},"category":{"type": "keyword"},"brand":{"type": "keyword"},"sold":{"type": "integer"},"commentCount":{"type": "integer","index": false},"isAD":{"type": "boolean"},"updateTime":{"type": "date"}}}
}
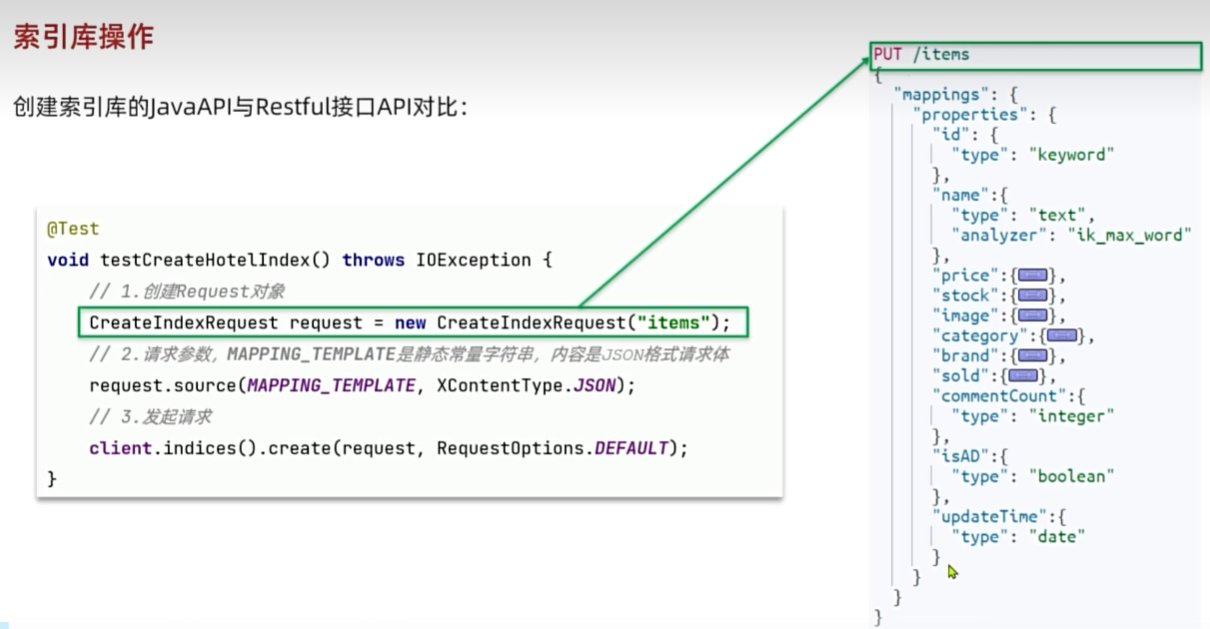

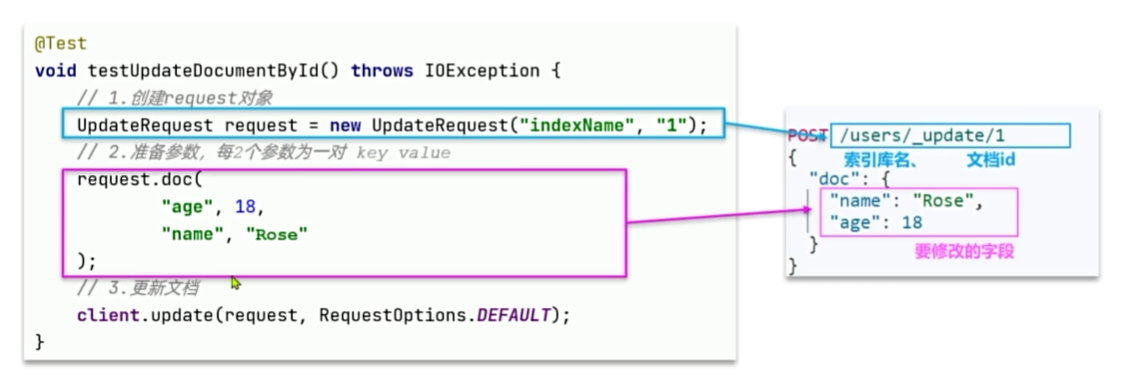
文档的crud

修改文档数据有两种方式:
·方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档。与新增的javaAPI一致。
·方式二:局部更新。只更新指定部分字段。
文档操作的基本步骤:
,初始化RestHighLevelClient
创s建XxxRequest。XXX是Index、Get、Update、Delete
·准备参数(Index和Update时需要)
发送请求。调用RestHighLevelClient#.XXx()方法,XXx是
index、get、update、delete
·解析结果(Get时需要)
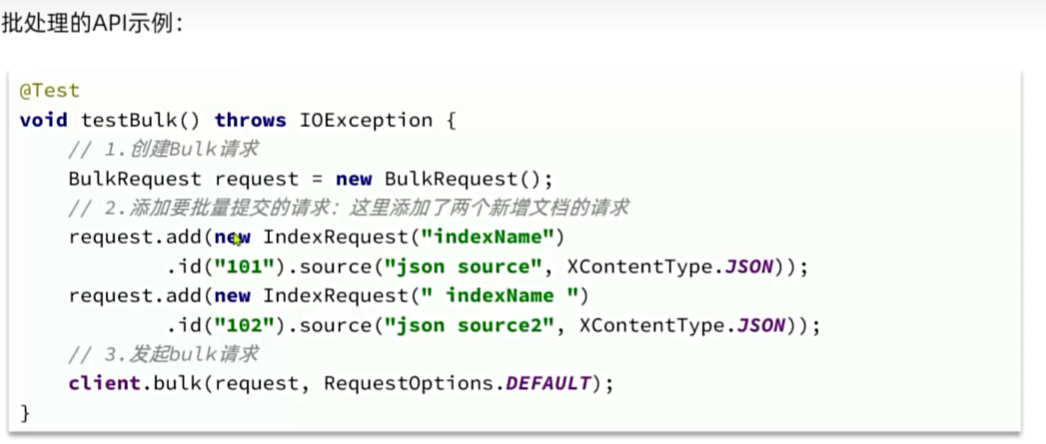
批处理
DSL查询


全文检索

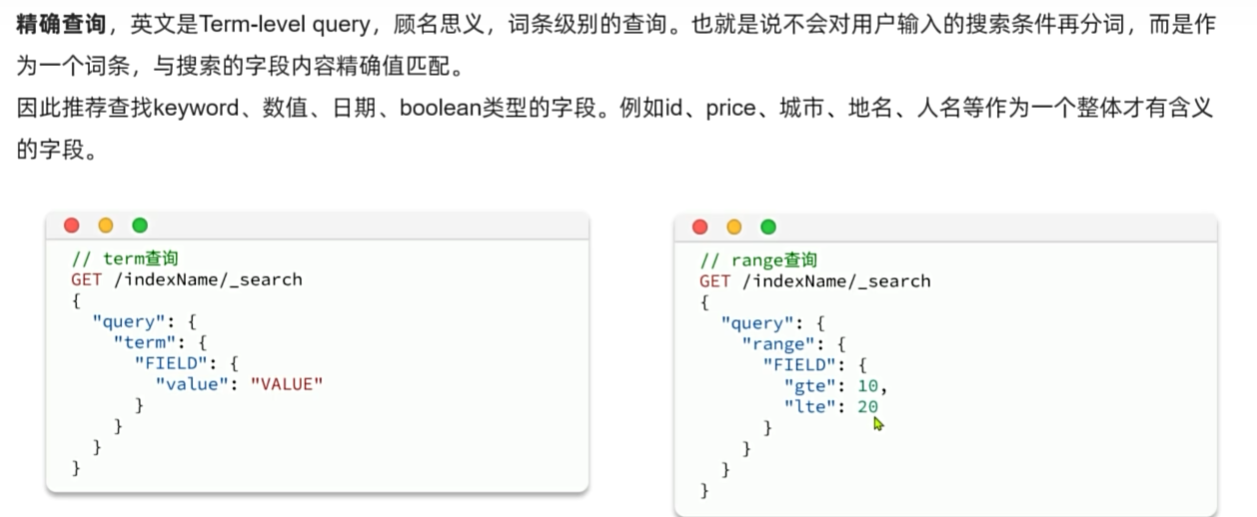
精确查询
复合查询

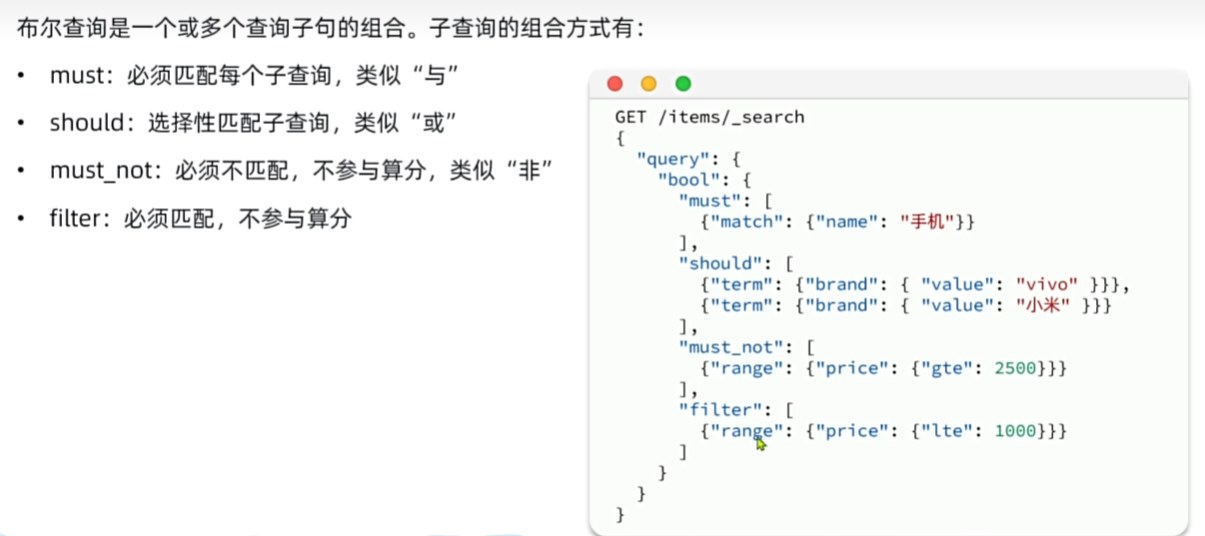
GET /items/_search
{"query": {"match": {"name": "华为"}}
}# 要搜索手机,但品牌必须是华为,价格必须是900~1599,那么可以这样写
GET /items/_search
{"query": {"bool": {"must": [{"match": {"name": "手机"}}],"filter": [{"term": {"brand.keyword": { "value": "华为" }}},{"range": {"price": {"gte": 90000, "lt": 159900}}}]}}
}
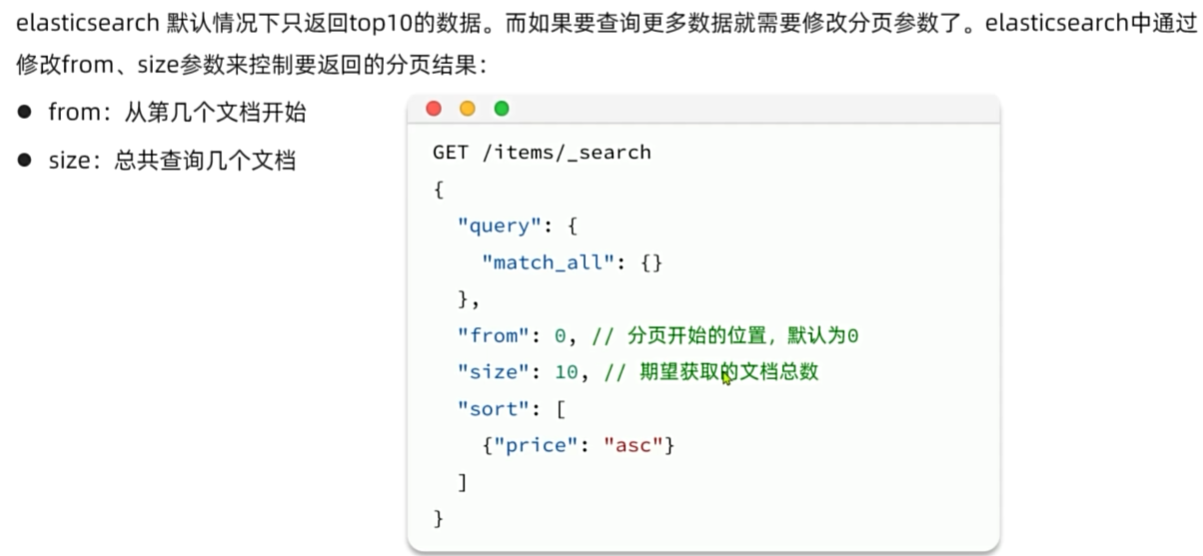
排序和分页

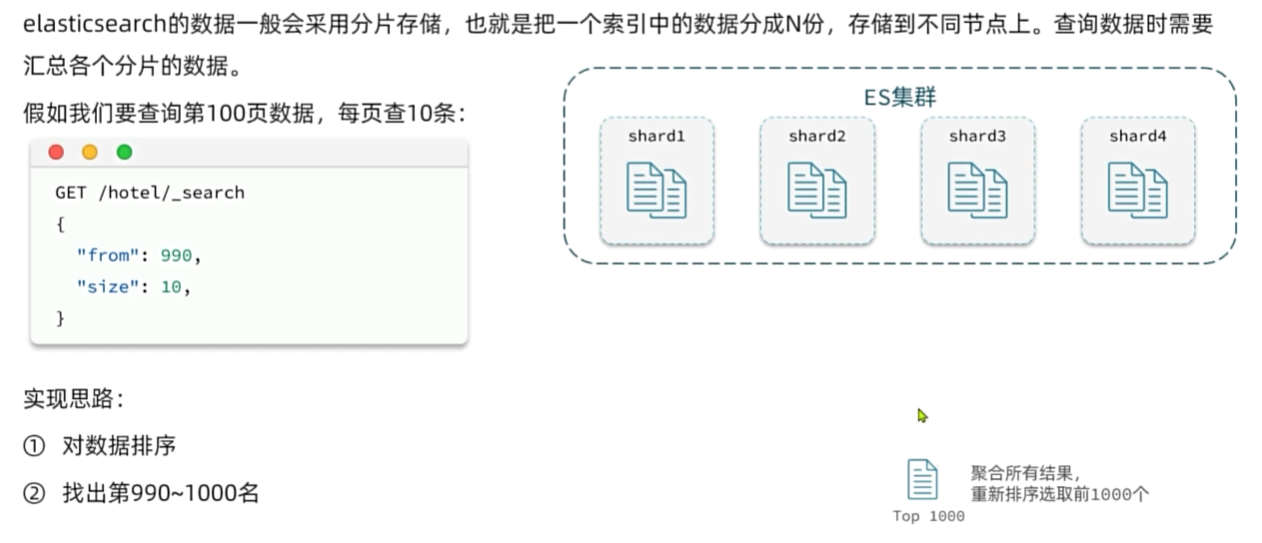
深度分页问题

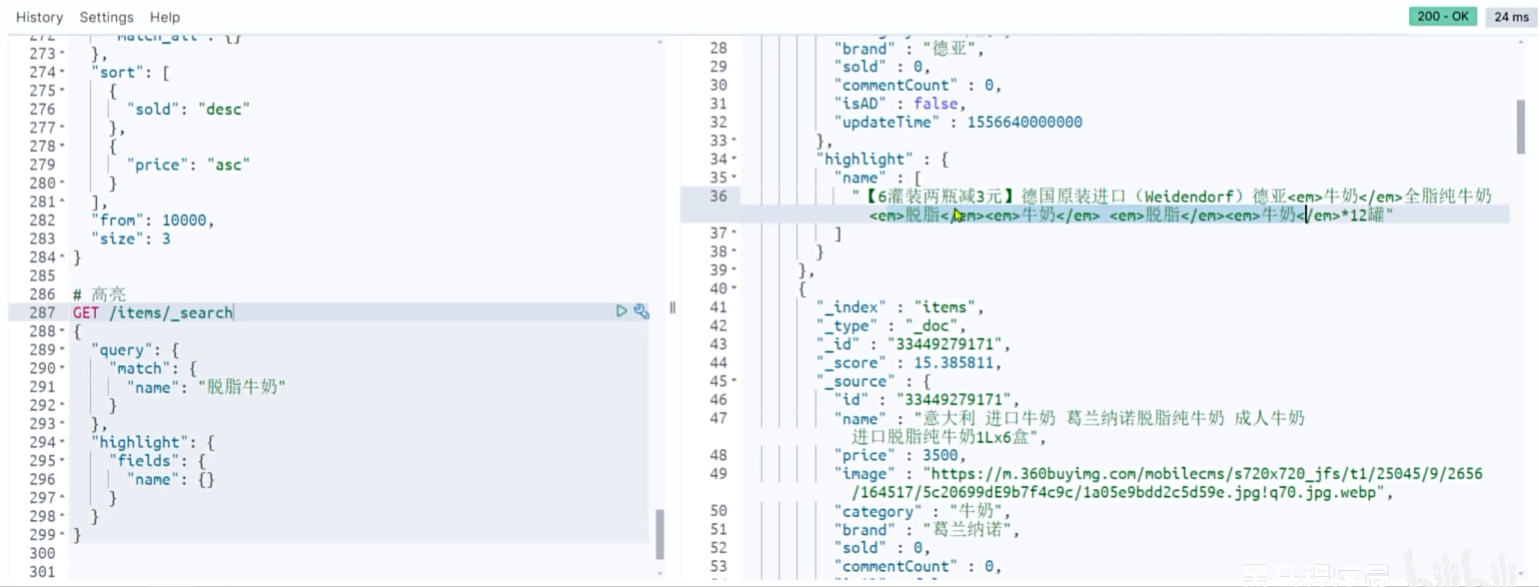
高亮显示
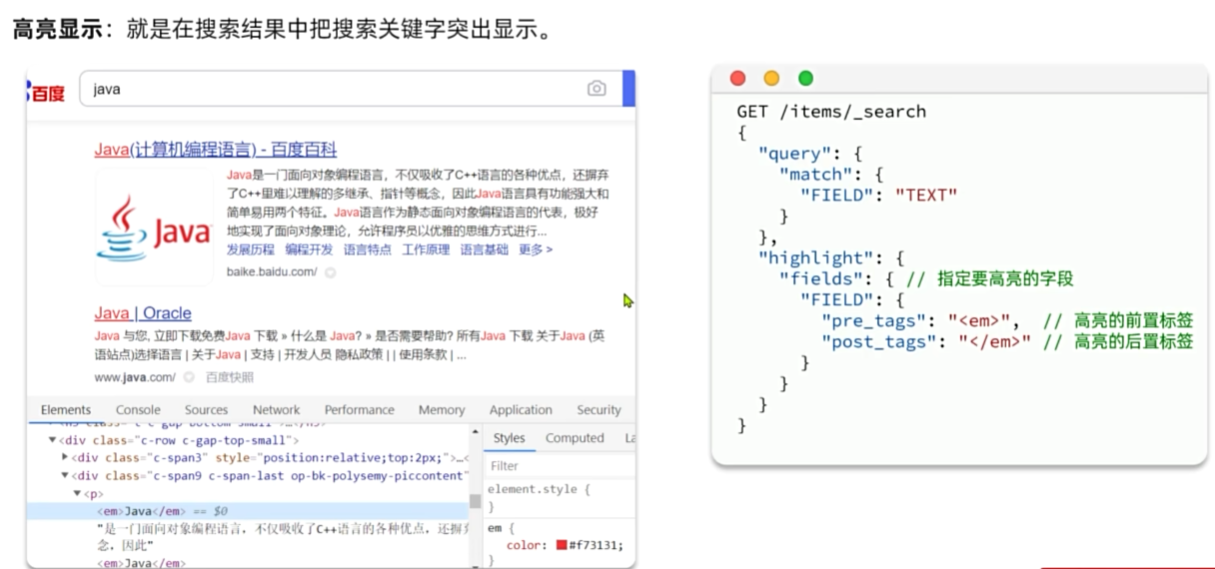

JavaRestClient查询
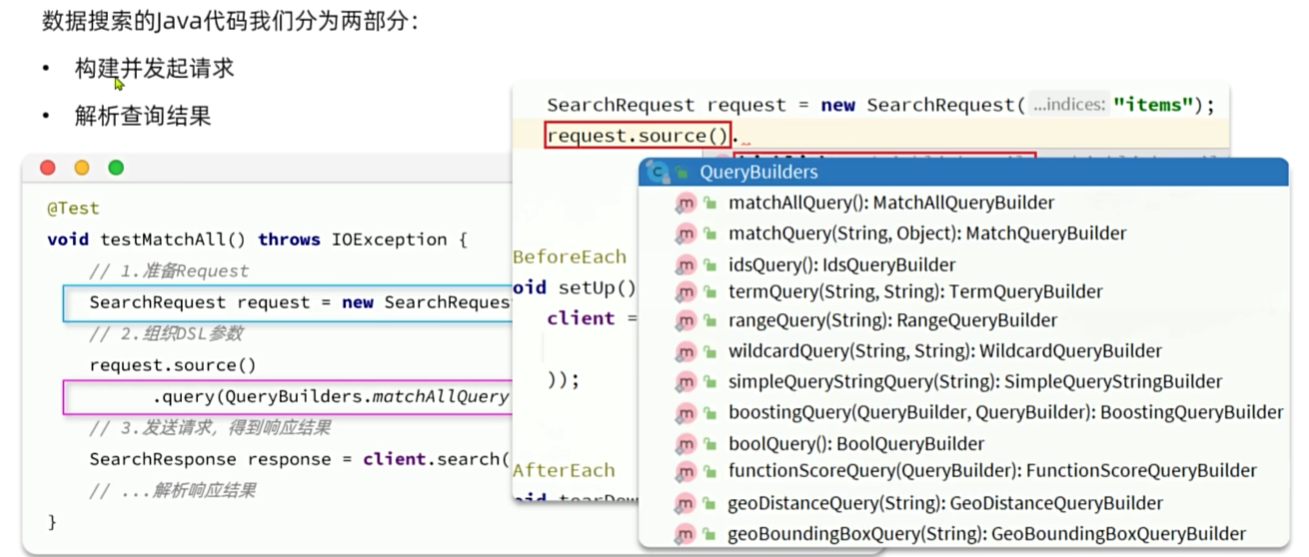
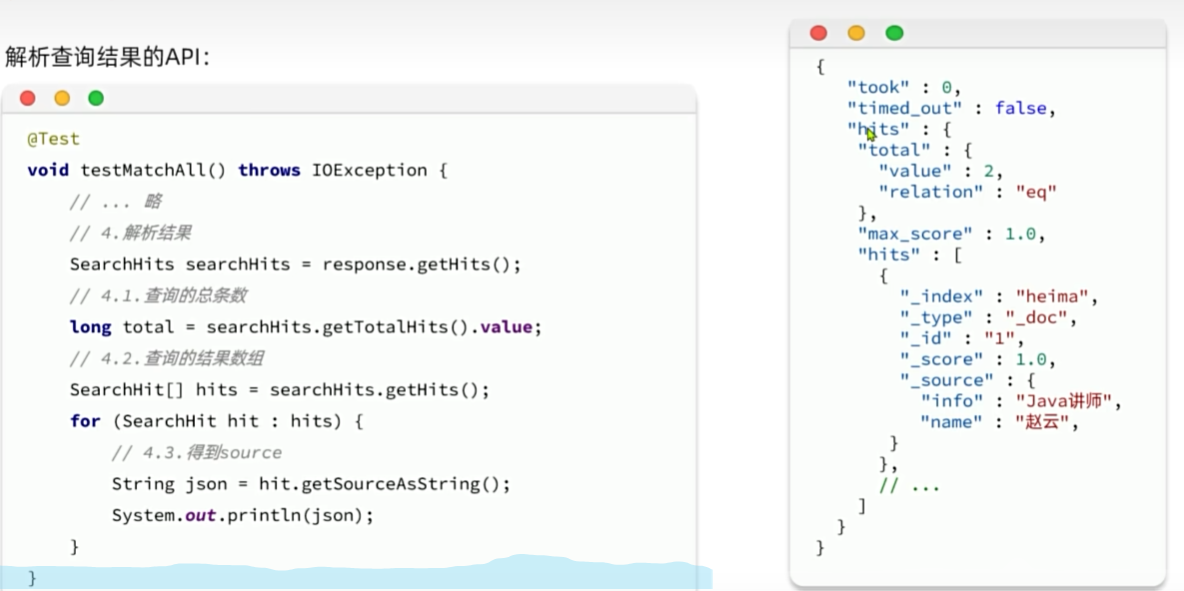
构建查询条件

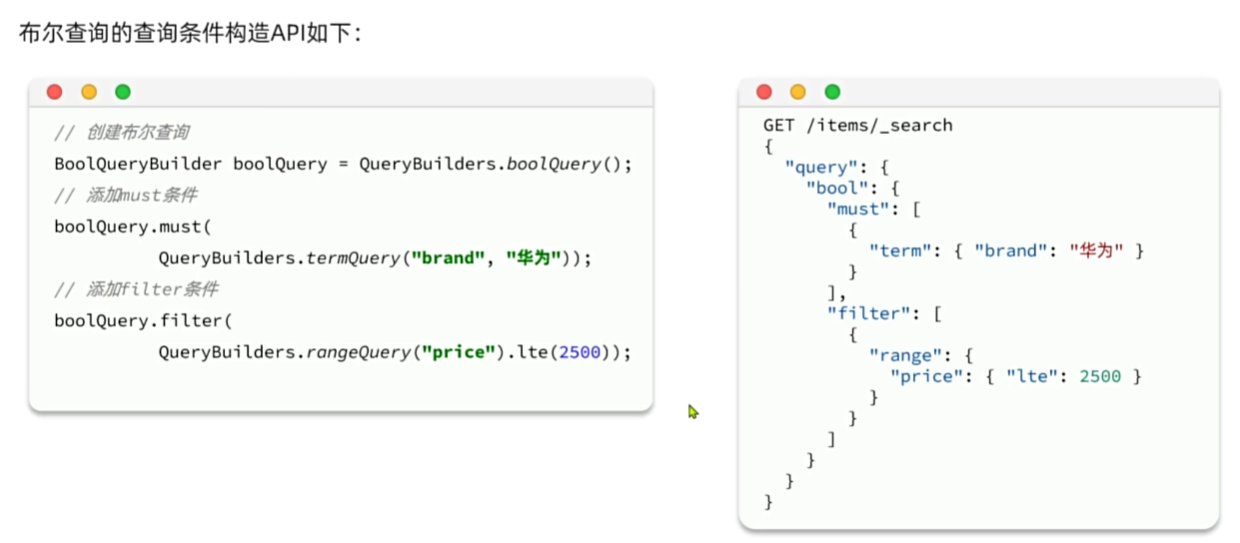
需求:利用javaRestClient:实现搜索功能,条件如下:
搜索关键字为脱脂牛奶
品牌必须为德亚
价格必须低于300
@Test
void testSearch() throws IOException {// 创建request对象SearchRequest request = new SearchRequest("items");// 配置参数request.source().query(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "脱脂牛奶")).filter(QueryBuilders.termQuery("brand.keyword", "德亚")).filter(QueryBuilders.rangeQuery("price").lt(30000)));// 发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//System.out.println("response = " + response);// 解析结果parseResponseResult(response);
}
排序和分页
@Test
void testSortAndPage() throws IOException {// 模拟前端传递的分页参数int pageNo = 1, pageSize = 5;// 创建request对象SearchRequest request = new SearchRequest("items");// 配置参数request.source().query(QueryBuilders.matchAllQuery());request.source().from((pageNo - 1) * pageSize).size(pageSize);request.source().sort("sold", SortOrder.DESC).sort("price", SortOrder.ASC);// 发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//System.out.println("response = " + response);// 解析结果parseResponseResult(response);
}
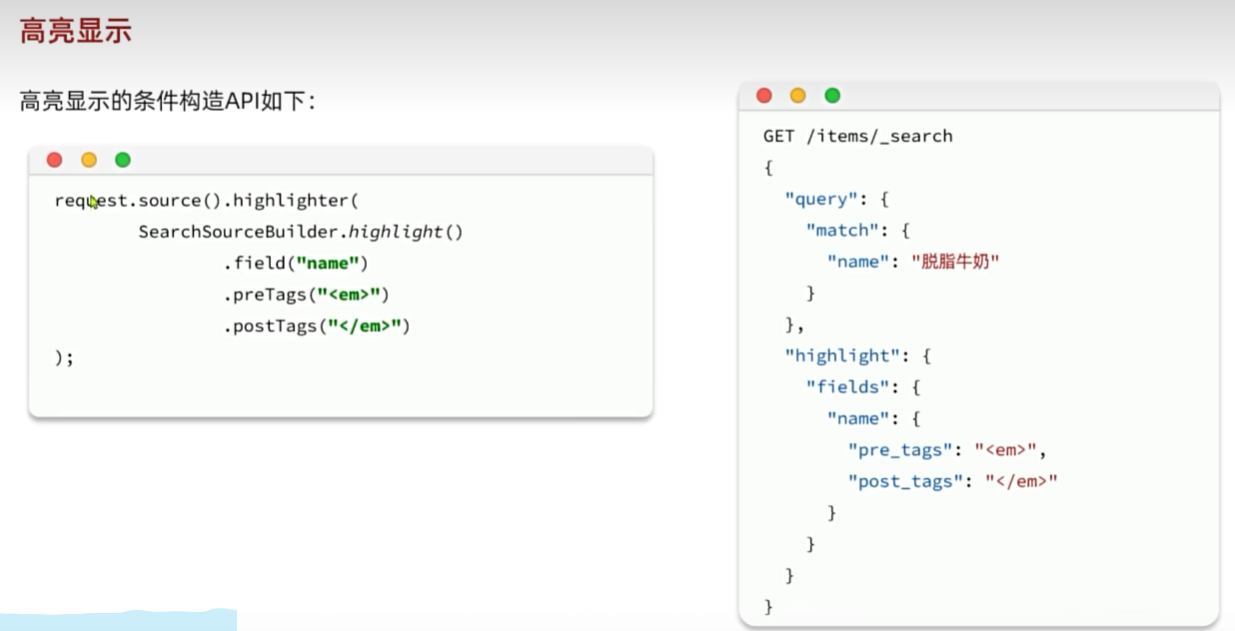
高亮显示
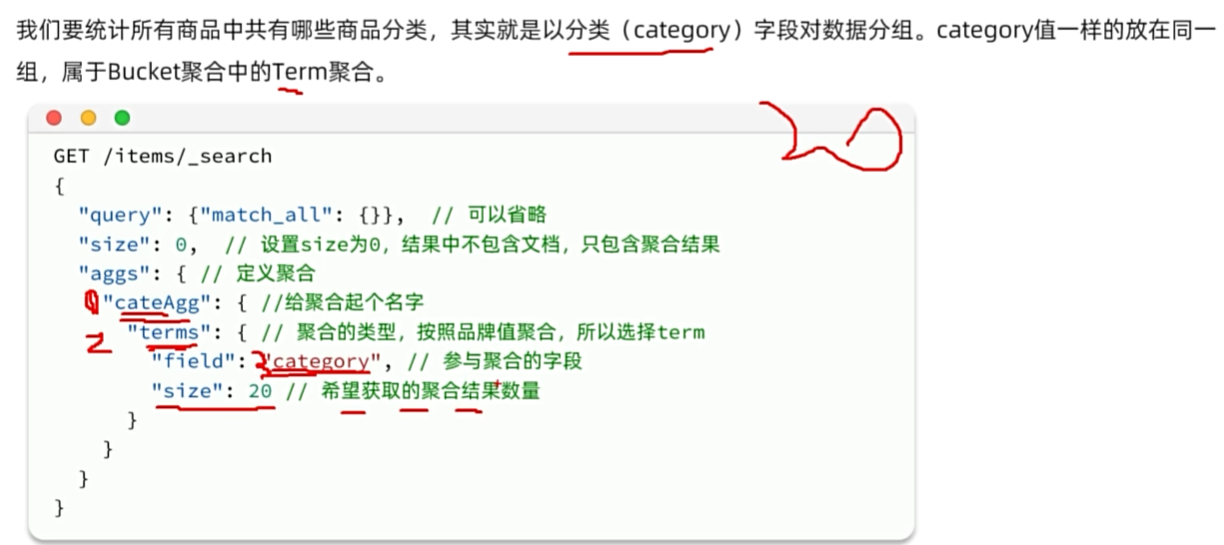
数据聚合

DSL聚合


RestClient聚合
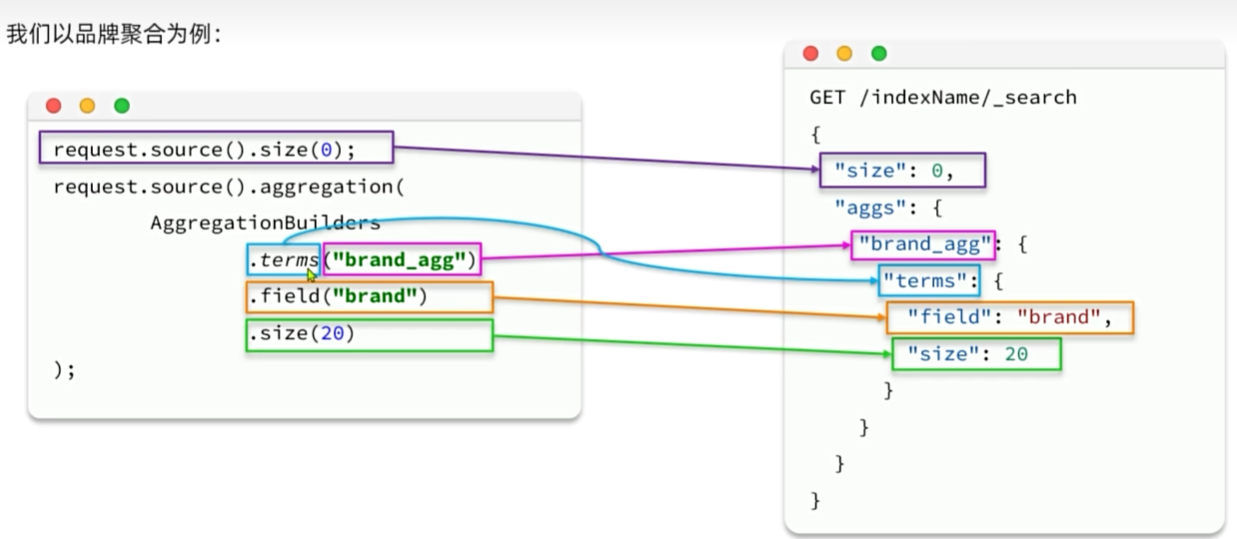
@Test
void testAgg() throws IOException {SearchRequest request = new SearchRequest("items");// 配置参数request.source().size(0);String brandAggName = "brandAgg";request.source().aggregation(AggregationBuilders.terms(brandAggName).field("brand.keyword").size(10));// 发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 解析结果Aggregations aggregations = response.getAggregations();Terms brandTerms = aggregations.get(brandAggName);List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();for (Terms.Bucket bucket : buckets) {System.out.println("brand: " + bucket.getKeyAsString());System.out.println("count: " + bucket.getDocCount());}
}
相关文章:

黑马商城-微服务笔记
认识微服务 单体架构 微服务架构 微服务拆分 服务拆分原则 什么时候拆分? ●创业型项目:先采用单体架构,快速开发,快速试错。随着规模扩大,逐 渐拆分。 ●确定的大型项目:资金充足,目标明确&a…...

XCZU19EG-2FFVC1760I Xilinx赛灵思FPGA Zynq UltraScale+MPSoC
XCZU19EG-2FFVC1760I 属于 Zynq UltraScaleMPSoC EG(Enhanced General)系列,采用 20nm FinFET 工艺制造,该型号的速度等级为 -2(0.85V VCCINT)、工业级温度(-40℃ 至 100℃)…...

第六章 QT基础:3、QT的打包和部署
问题一:什么是打包和部署? 打包和部署是将开发完成的程序分发给用户并使其能够在目标环境中运行的两个重要步骤。 打包:指的是将开发完成的程序及其依赖的所有资源(如图标、配置文件、动态链接库、字体等)打包成一个可…...
)
【测试报告】幸运闪烁抽奖系统(Java+Selenium+Jmeter自动化测试)
一、项目背景 幸运闪烁抽奖系统 是一款基于 Spring Boot 实现的前后端分离式的网络抽奖系统,操作便捷,安全可靠。有管理员和普通用户两个角色,支持管理员创建普通用户、新建活动奖品、创建抽奖活动、进行抽奖、通过短信/邮箱通知中奖用户等功…...

块压缩与图片压缩优缺点对比
块压缩与图片压缩优缺点对比 块压缩(Block Compression) ✅ 优点 硬件加速支持 直接被GPU读取,无需CPU解压显著降低内存带宽消耗(适合移动设备) 随机访问特性 44/88像素块独立压缩支持直接定位读取特定纹理区域 固…...
:K路归并的最优解法)
C++算法(14):K路归并的最优解法
问题描述 给定K个按升序排列的数组,要求将它们合并为一个大的有序数组。例如,输入数组[[1,3,5], [2,4,6], [0,7]],合并后的结果应为[0,1,2,3,4,5,6,7]。 解决方案 思路分析 合并多个有序数组的高效方法是利用最小堆(优先队列&…...

2025.04.23【Treemap】树状图数据可视化指南
Multi-level treemap How to build a treemap with group and subgroups. Customization Customize treemap labels, borders, color palette and more 文章目录 Multi-level treemapCustomization Treemap 数据可视化指南Treemap 的基本概念为什么使用 TreemapTreemap 的应用…...

2025新一代人工智能技术发展及其应用
新一代人工智能技术发展及其应用 一、人工智能概述(一)定义(二)动力(三)发展脉络 二、新一代人工智能技术(一)大语言模型(二)自然语言处理(三&…...
的详细使用)
vue3中slot(插槽)的详细使用
在 Vue 3 中,slot(插槽)是一种强大的组件内容分发机制,它允许父组件向子组件传递内容,从而使组件的使用更加灵活。以下是关于 Vue 3 中 slot 的详细介绍 一、默认插槽 这是最基本的插槽形式。子组件中使用定义一个插…...
)
大模型面经 | 春招、秋招算法面试常考八股文附答案(五)
大家好,我是皮先生!! 今天给大家分享一些关于大模型面试常见的面试题,希望对大家的面试有所帮助。 往期回顾: 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题一) 大模型面经 | 春招、秋招算法面试常考八股文附答案(RAG专题二) 大模型面经 | 春招、秋招算法…...

【PCB工艺】推挽电路及交越失真
推挽电路(Push-Pull Circuit) 推挽电路(Push-Pull Circuit) 是一种常用于功率放大、电机驱动、音频放大等场合的电路结构,具有输出对称、效率高、失真小等优点。 什么是推挽电路? 推挽是指:由两种极性相反的器件(如 NPN 和 PNP、NMOS 和 PMOS)交替导通,一个“推”电…...

接口访问数据库报错问题记录
报错信息: java.sql.SQLException: Access denied for user rootXXX.XX.XX.XX (using password: YES) 解决方法: -- 授予 root 用户从 XXX.XX.XX.XX 访问所有数据库的权限 GRANT ALL PRIVILEGES ON *.* TO 数据库用户XX.XX.XX.XXX IDENTIFIED BY 数…...

神经网络相关内容
划分数据集以及模型定义 def data_split(datax, datay, val_size 0.1, test_size 0.05):输入:datax datay 输出:trainx, valx, testx, trainy, valy, testy, 分别按比例得到训练集、验证集、测试集# 构建数据集pos_test int(len(datax) * (1 - test_…...

python项目实战-后端个人博客系统
本文分享一个基于 Flask 框架开发的个人博客系统后端项目,涵盖用户注册登录、文章发布、分类管理、评论功能等核心模块。适合初学者学习和中小型博客系统开发。 一、项目结构 blog │ app.py │ forms.py │ models.py │ ├───instance │ blog.d…...

谷歌搜索索引编译中的重定向错误解决方案
谷歌搜索索引编译中的重定向错误解决方案 在处理谷歌搜索引擎优化(SEO)过程中遇到的重定向错误问题时,了解其根本原因并采取适当措施至关重要。以下是针对常见重定向错误及其解决方案的具体分析: 1. 滥用301和302重定向 滥用永…...

OpenCV 中的角点检测方法详解
文章目录 引言1. Harris角点检测原理1.1 什么是角点?1.2 Harris算法的核心思想1.3 角点、边缘和平坦区域的区分 2. OpenCV实现Harris角点检测3. 总结 引言 在计算机视觉和图像处理中,特征点检测(Feature Detection)是一个关键任务…...
)
【开源】STM32HAL库驱动ST7789_240×240(硬件SPI+软件SPI)
项目开源链接 github主页https://github.com/snqx-lqh本项目github地址https://github.com/snqx-lqh/STM32F103C8T6HalDemo作者 VXQinghua-Li7 📖 欢迎交流 如果开源的代码对你有帮助,希望可以帮我点个赞👍和收藏 项目说明 最近调试了一款1…...

区块链技术在物联网中的应用:构建可信的智能世界
在当今数字化时代,物联网(IoT)和区块链技术正成为推动科技发展的两大重要力量。物联网通过连接设备实现数据的共享和交互,而区块链则以其去中心化、不可篡改的特性,为物联网的安全性和可信度提供了强大的保障。本文将探…...

uniapp实现app自动更新
uniapp实现app自动更新: 实现步骤: 需要从后端读取最新版本的相关信息前端用户进入首页的时候,需要判断当前版本与后端返回来的版本是否一致,不一致且后端版本大于当前版本的话,就需要提示用户是否需要更新ÿ…...

智能滚动抽奖--测试报告
目录 一、项目背景 二、项目功能 三、测试计划 一)单元集成测试: 二)功能测试: 三)自动化测试: 四)存在问题 五)测试结果评估 四、总结 一、项目背景 1.随着数字营销的兴起&…...

天梯-这是字符串题
隐式转换 隐式转换是指编译器在没有显式提示的情况下,自动将一种数据类型转换为另一种数据类型。这种转换是语言规范允许的,并且通常是为了让代码更简洁、更自然。隐式转换的类型字符类型( char )可以隐式转换为其对应的ASCII码值…...

第六章 QT基础:4、QT的TCP网络编程
一、TCP 通信原理简介 TCP(Transmission Control Protocol)是一种面向连接的可靠通信协议,主要特性如下: [!NOTE] 三次握手建立连接 可靠传输:顺序、无丢包 面向流:数据无结构边界 适用场景:…...

Windows 各版本查找计算机 IP 地址指南
IP 地址是互联网协议地址 (Internet Protocol Address) 的缩写,它是分配给连接到使用互联网协议进行通信的网络的每个设备的数字标签,用于在网络中唯一标识该设备。查找您计算机的 IP 地址对于网络故障排除、配置网络设置、远程访问以及进行其他网络相关…...

程序员思维体操:TDD修炼手册
程序员思维体操:TDD修炼手册 ——从"先写代码"到"测试先行"的认知革命 一、重新认识TDD:不仅仅是写测试 什么是TDD(测试驱动开发) TDD其实很简单,不要看名字很高级复杂,传统开发是直…...

Java 实现SpringContextUtils工具类,手动获取Bean
SpringContextUtils 工具类实现 下面是一个完整的 Spring 上下文工具类实现,用于从 Spring 容器中获取 Bean。这个工具类考虑了线程安全、性能优化和易用性,并提供了多种获取 Bean 的方式。 完整实现代码 import org.springframework.beans.BeansExce…...
【背包】)
动态规划(一)【背包】
目录 01背包问题滚动数组优化(二维-->一维) 完全背包问题优化 多重背包二进制优化 感悟 动态规划 总而言之,就是利用 历史记录, 避免重复计算。 1.确定状态变量(函数) 2.确定状态转移方程 3.确定边界条…...

实验二 多线程编程实验
一、实验目的 1、掌握线程的概念,明确线程和进程的区别。 2、学习Linux下线程创建方法及编程。 3、了解线程的应用特点。 4、掌握用锁机制访问临界区实现互斥的方法。 5、掌握用信号量访问临界区实现互斥的方法。 6、掌握线程下用信号量实现同步操作的方法。 …...
LWE,RLWE,MLWE的区别和联系)
密码学(1)LWE,RLWE,MLWE的区别和联系
一、定义与基本概念 LWE(Learning With Errors): 定义:LWE问题是在给定一个矩阵A和一个向量b^Axe(其中e是一个固定数值范围内随机采集的随机噪音向量)的情况下,求解未知的向量x。本质࿱…...

数据结构-链表
目录 一、链表的基本概念单链表定义双链表定义 二、链表的基本操作1. 创建链表2. 遍历链表3. 插入节点4. 删除节点5. 反转链表 三、链表的实际应用1. 操作系统中的内存管理2. 文件系统中的目录结构3. 浏览器历史记录 四、链表的优缺点优点缺点 五、总结 一、链表的基本概念 链…...

go中redis使用的简单介绍
目录 一、Redis 简介 二、Go中Redis的使用 1. 安装Go Redis包 2. 单机模式 连接示例 3. 哨兵模式 依赖 连接示例 三、Redis集群 1. 集群模式 集群部署 部署结构 使用redis-cli创建集群 连接示例 四、常用数据结构与操作 1. 字符串(String࿰…...

使用 JUnit 4在 Spring 中进行单元测试的完整步骤
以下是使用 JUnit 4 在 Spring 中进行单元测试的完整步骤,包含配置、核心注解、测试场景及代码示例: 1. 添加依赖 在 pom.xml 中引入必要的测试依赖(以 Spring 4/5 JUnit 4 为例): <!-- JUnit 4 --> <depe…...

第七节:进阶特性高频题-Vue3的ref与reactive选择策略
ref:基本类型(自动装箱为{ value: … }对象) reactive:对象/数组(直接解构会丢失响应性,需用toRefs) 一、核心差异对比 维度refreactive适用类型基本类型(string/number/boolean&a…...

Redis 详解:安装、数据类型、事务、配置、持久化、订阅/发布、主从复制、哨兵机制、缓存
目录 Redis 安装与数据类型 安装指南 Windows Linux 性能测试 基本知识 数据类型 String List(双向列表) Set(集合) Hash(哈希) Zset(有序集合) 高级功能 地理位置&am…...

第十篇:系统分析师第三遍——7、8章
目录 一、目标二、计划三、完成情况四、意外之喜(最少2点)1.计划内的明确认知和思想的提升标志2.计划外的具体事情提升内容和标志 五、总结 一、目标 通过参加考试,训练学习能力,而非单纯以拿证为目的。 1.在复习过程中,训练快速阅读能力、掌…...

从 Vue 到 React:React.memo + useCallback 组合技
目录 一、Vue 与 React 的组件更新机制对比二、React.memo 是什么?三、常见坑:为什么我用了 React.memo 还是会重新渲染?四、解决方案:useMemo / useCallback 缓存引用五、Vue 3 中有类似的性能控制需求吗?六、组合优化…...

1656打印路径-Floyd/图论-链表/数据结构
蓝桥账户中心 1.税收: “城市的税收”:所以是中介点的税收,经过该点后加上 2.路径: 用数组存储前驱节点从而串成链表 pre[ i ][ j ]代表的是从 i 到 j 的最短路径上 j 的前驱节点是什么 那么便可以pre[ i ][ j ]k 把k加入pa…...

Linux网络编程 从集线器到交换机的网络通信全流程——基于Packet Tracer的深度实验
这里我们先下载一个软件:Packet Tracer 用来搭建网络拓扑图的,是模拟和查看数据在网络中传输的详细过程的 在软件这里可以添加设备 知识点1【集线器】(Hub) 1、先配置一下主机的IP 这里我们设置IP一定要在同一个网段ÿ…...

深入学习Axios:现代前端HTTP请求利器
文章目录 深入学习Axios:现代前端HTTP请求利器一、Axios简介与安装什么是Axios?安装Axios 二、Axios基础使用发起GET请求发起POST请求并发请求 三、Axios高级特性创建Axios实例配置默认值拦截器取消请求 四、Axios与TypeScript五、最佳实践1. 封装Axios2…...

FANUC机器人GI与GO位置数据传输设置
FANUC机器人GI与GO位置数据传输设置(整数小数分开发) 一、概述 在 Fanuc 机器人应用中,如果 IO 点位足够,可以利用机器人 IO 传输位置数据及偏移位置数据等。 二、操作步骤 1、确认通讯软件安装 首先确认机器人控制柜已经安装…...

微服务 RabbitMQ 组件的介绍、安装与使用详解
微服务 RabbitMQ 组件的介绍、安装与使用 在现代微服务架构中,服务之间的通信通常采用消息队列的方式,来解耦服务之间的依赖、提高系统的可靠性和扩展性。RabbitMQ 作为一种高效、可靠的消息队列系统,已经广泛应用于微服务架构中。本文将介绍…...

Vue3速通笔记
Vue3入门到实战 尚硅谷Vue3入门到实战,最新版vue3TypeScript前端开发教程 1. Vue3简介 2020年9月18日,Vue.js发布版3.0版本,代号:One Piece(n经历了:4800次提交、40个RFC、600次PR、300贡献者官方发版地…...

Spring Boot 项目:如何在 JAR 运行时读取外部配置文件
在 Spring Boot 项目中,我们常常需要在生产环境中灵活地配置应用,尤其是当我们将项目打包为 JAR 文件时,如何在运行时通过外部配置文件(如 application.yml 或 application.properties)替换 JAR 内部的配置就变得尤为重…...

Certimate本地化自动化 SSL/TLS 证书管理解决方案
一、背景与挑战 多域名管理复杂 运维团队往往需要为多个子域、泛域名乃至不同项目的域名分别申请证书,手动操作容易出错且耗时。续期易忘风险 主流免费证书(如 Let’s Encrypt)有效期仅 90 天,需要定期续期,人工监控门…...

vue+flask+lstm高校舆情分析系统 | 可获取最新数据!
文章结尾部分有CSDN官方提供的学长 联系方式名片 文章结尾部分有CSDN官方提供的学长 联系方式名片 关注B站,有好处! 编号:F020 gaoxiao 架构:vueflaskLSTMMySQL 功能: 微博信息爬取、情感分析、基于负面消极内容舆情分…...

Cisco-Torch:思科设备扫描器!全参数详细教程!Kali Linux教程!
简介 cisco-torch 与同类工具的主要区别在于其广泛使用 fork 技术,可以在后台启动多个扫描进程,从而最大限度地提高扫描效率。此外,它还可以根据需要同时使用多种应用层指纹识别方法。我们希望能够快速发现运行 Telnet、SSH、Web、NTP、TFTP…...

Go协程的调用与原理
Goroutine Go不需要像C或者Java那样手动管理线程,Go语言的goroutine机制自动帮你管理线程。 使用goroutine、 Go语言中使用goroutine非常简单,只需要在调用函数的时候在前面加上go关键字,就可以为一个函数创建一个goroutine。 一个gorout…...

论文精读:大规模MIMO波束选择问题的量子计算解决方案
论文精读:大规模MIMO波束选择问题的量子计算解决方案 概要: 随着大规模多输入多输出系统(MIMO)在5G及未来通信技术中的应用,波束选择问题(MBS)成为提升系统性能的关键。传统的波束选择方法面临计…...

将 MySQL 8 主从复制延迟优化到极致
目录 一、网络资源不足引起的复制延迟 1. 执行监控确认延迟原因 2. 估算所需带宽 (1)基本公式 (2)实际测量方法 二、大事务或大查询引起的复制延迟 1. 主库大事务 2. 从库大查询 3. 估算所需 I/O 能力 (1&am…...

路由与OSPF学习
【路由是跨网段通讯的必要条件】 路由指的是在网络中,数据包从源主机传输到目的主机的路径选择过程。 路由通常涉及以下几个关键元素: 1.路由器:是一种网络设备,负责将数据包从一个网络传输到另一个网络。路由器根据路由表来决定…...

Spring Security:企业级安全架构的设计哲学与工程实践
一、核心架构与设计理念 Spring Security作为Spring生态中的安全基石,其架构设计遵循**“分层过滤"与"组件化扩展”**两大原则。整个安全框架本质上是一个由多个过滤器构成的链式处理模型(Filter Chain),每个过滤器负责…...