从检索到生成:RAG 如何重构大模型的知识边界?
目录
一、技术演进图谱说明
二、RAG 技术概述
(一)核心思想说明
(二)RAG 发展路径与研究范式
三、Naive RAG:最基础的检索增强生成范式
(一)Naive RAG 的标准流程
1. 索引(Indexing)
2. 检索(Retrieval)
3. 生成(Generation)
(二)Naive RAG 的问题与挑战
1. 检索阶段的问题
2. 生成阶段的问题
3. 增强整合的难点
(三)思考
四、Advanced RAG:应对基础范式局限的智能增强
(一)概念与特征
(二)Advanced RAG 定位
(三)典型优势与改进方向
五、Modular RAG:从“方法”向“平台”级演进
(一)核心理念与特点
(二)Modular RAG 结构布局
(三)实际优势与应用价值
(四)🔍 三阶段 RAG 模型对比表
六、🥊 RAG vs Fine-tuning:两种提升 LLM 能力的对比分析
(一)📚 方法概述
(二)🔍 举例说明
1. 适合 RAG 的场景
2. 适合微调的场景
(三)⚖️ 组合使用:互为补充的策略
(四)✅ 总结建议
七、总结与趋势展望
干货分享,感谢您的阅读!
随着大语言模型(LLM)在自然语言处理任务中表现出惊人的能力,基于 LLM 构建的智能问答系统、对话机器人、搜索引擎等应用迅速兴起。然而,在实际场景中,用户提出的问题往往涉及最新知识、专业文档或个性化上下文,这些信息可能并未出现在模型的预训练语料中,从而导致模型生成结果出现“幻觉”或过时内容,严重影响可用性与可信度。
面对这一关键痛点,Retrieval-Augmented Generation(RAG) 被提出,试图将信息检索与语言生成相结合:先基于用户查询检索相关文档,再将其与原始问题一同输入语言模型生成答案。RAG 不仅显著降低了幻觉率,还具备知识可更新、输出可追溯等优势,成为行业探索 LLM 实用化路径的重要方向。
随着技术演进,RAG 从最初的 Naive RAG(朴素式检索增强)逐步演变出更复杂的架构,如 Advanced RAG(增强模块协同)与 Modular RAG(平台化组件解耦)。每一阶段的演进,都是对模型幻觉、检索能力、上下文融合质量等问题的深度回应,也体现了从原型验证向工业级落地架构的转变。
本文将系统梳理 RAG 的三大演进阶段,剖析其核心思想、技术架构与实践挑战,并通过图示与对比,帮助读者全面理解 RAG 技术的发展脉络与未来趋势。
一、技术演进图谱说明
如下 RAG 技术树(Technology Tree)图,其概括了 RAG 的发展路径:
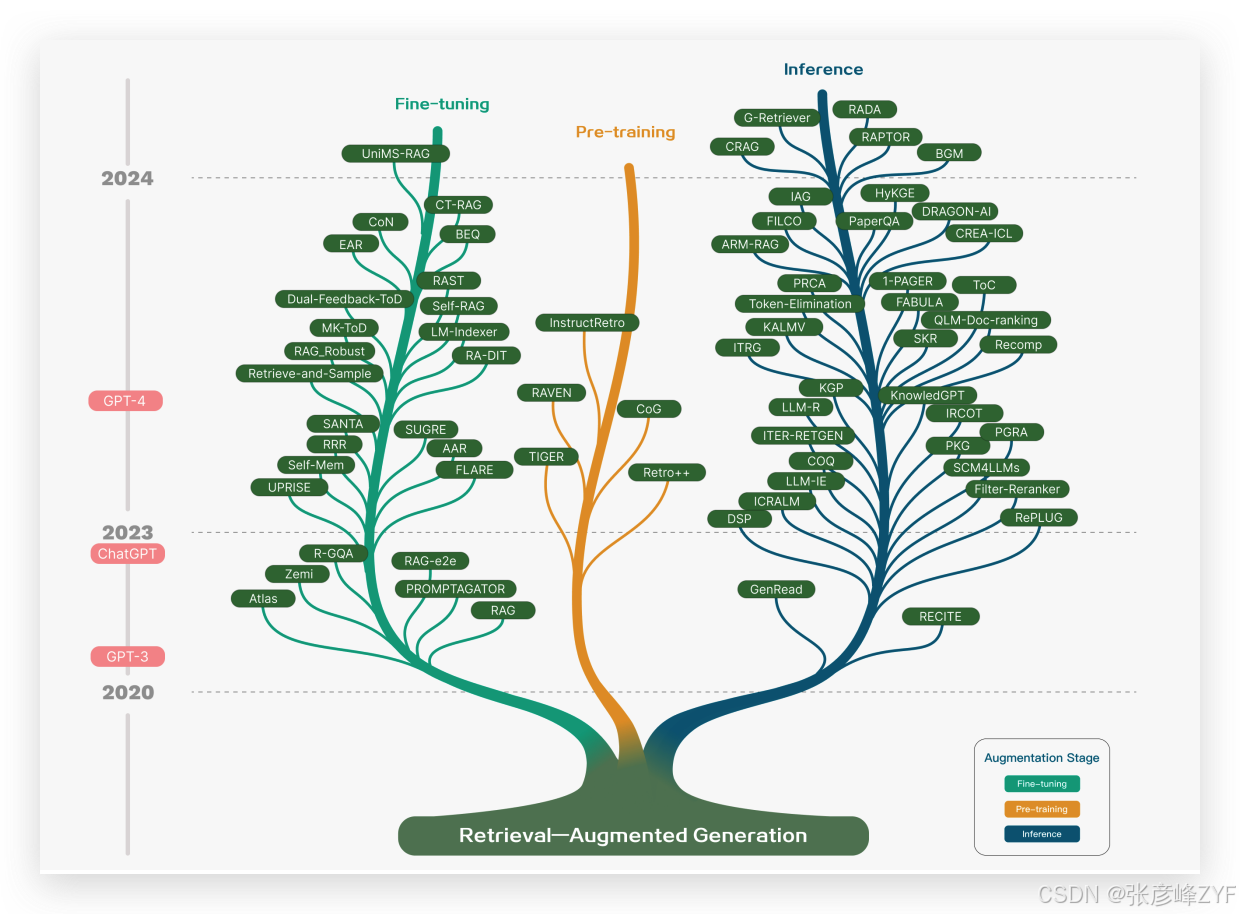
- 初期阶段:以 Transformer 结构为基础,主要是在预训练模型(PTM)中尝试引入外部知识,但手段较为简单。
- 中期阶段:ChatGPT 出现后,RAG 技术开始强调如何在推理过程中为 LLM 提供更有效的外部信息支持,开始大规模应用。
- 近期趋势:研究逐渐扩展至在语言模型的"微调阶段(fine-tuning)和预训练阶段(pre-training)"引入检索机制,追求更高程度的知识融合和生成效果提升。
这张技术树不仅展示了 RAG 的发展历程,还从三个关键阶段(预训练、微调、推理)展现了技术的演进轨迹。
二、RAG 技术概述
(一)核心思想说明
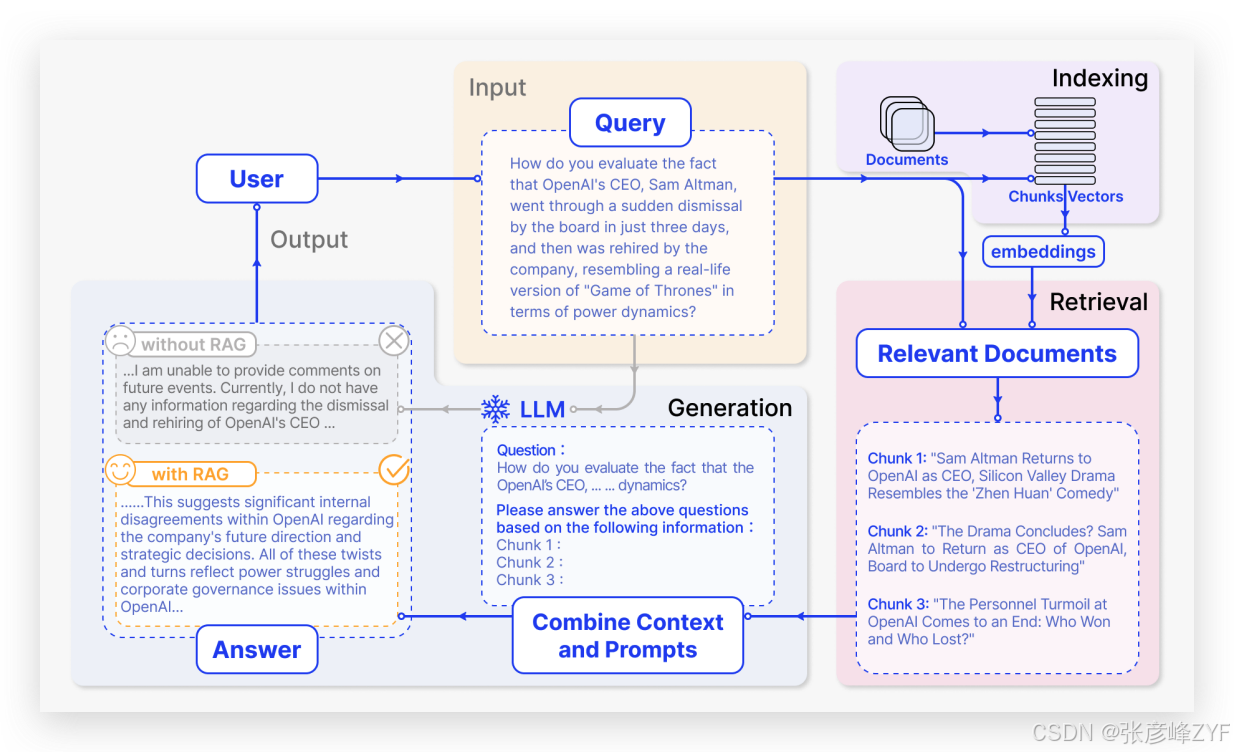
RAG(Retrieval-Augmented Generation)技术的核心思想是:通过引入外部知识库的信息,帮助大语言模型(LLM)回答其训练数据中未涉及的问题,尤其是在处理实时性强或专业性高的查询时,弥补其知识盲区。
我们可以用一个具体例子来说明 RAG 的作用:假设用户向 ChatGPT 询问某条最近的新闻,由于 ChatGPT 本身的知识仅限于其训练数据,它无法获知最新进展。这时,RAG 机制就介入,通过检索当前的相关新闻文章,将相关内容作为上下文和用户的问题一起输入给大模型,从而使其生成出更全面、更准确的回答。
(二)RAG 发展路径与研究范式
RAG 研究的发展经历了三个主要阶段:
-
Naive RAG(初代 RAG):最基础的实现方式,通常只在模型推理阶段加入检索模块,直接将检索到的文档拼接到输入中。这种方式实现简单、成本较低,但在效果和稳定性方面存在明显短板。
-
Advanced RAG(增强型 RAG):为克服初代 RAG 的局限性,研究者开始在多个方面进行改进,比如更智能的检索策略、更高质量的文本选择机制,甚至对生成阶段进行适配优化,提升整体效果。
-
Modular RAG(模块化 RAG):发展到这一阶段,RAG 被设计为更加可组合、可配置的系统,各个模块(如检索器、过滤器、重排序器、生成器)之间协同工作,允许更灵活地适配不同任务需求,并提升系统的可解释性和扩展性。
尽管 RAG 技术相较于单纯的 LLM 能力有显著提升,也更加高效,但每种范式在实际应用中也面临不同的挑战。因此,后续的发展不断在追求更强性能的同时,也在探索更优架构与使用方式。
三、Naive RAG:最基础的检索增强生成范式
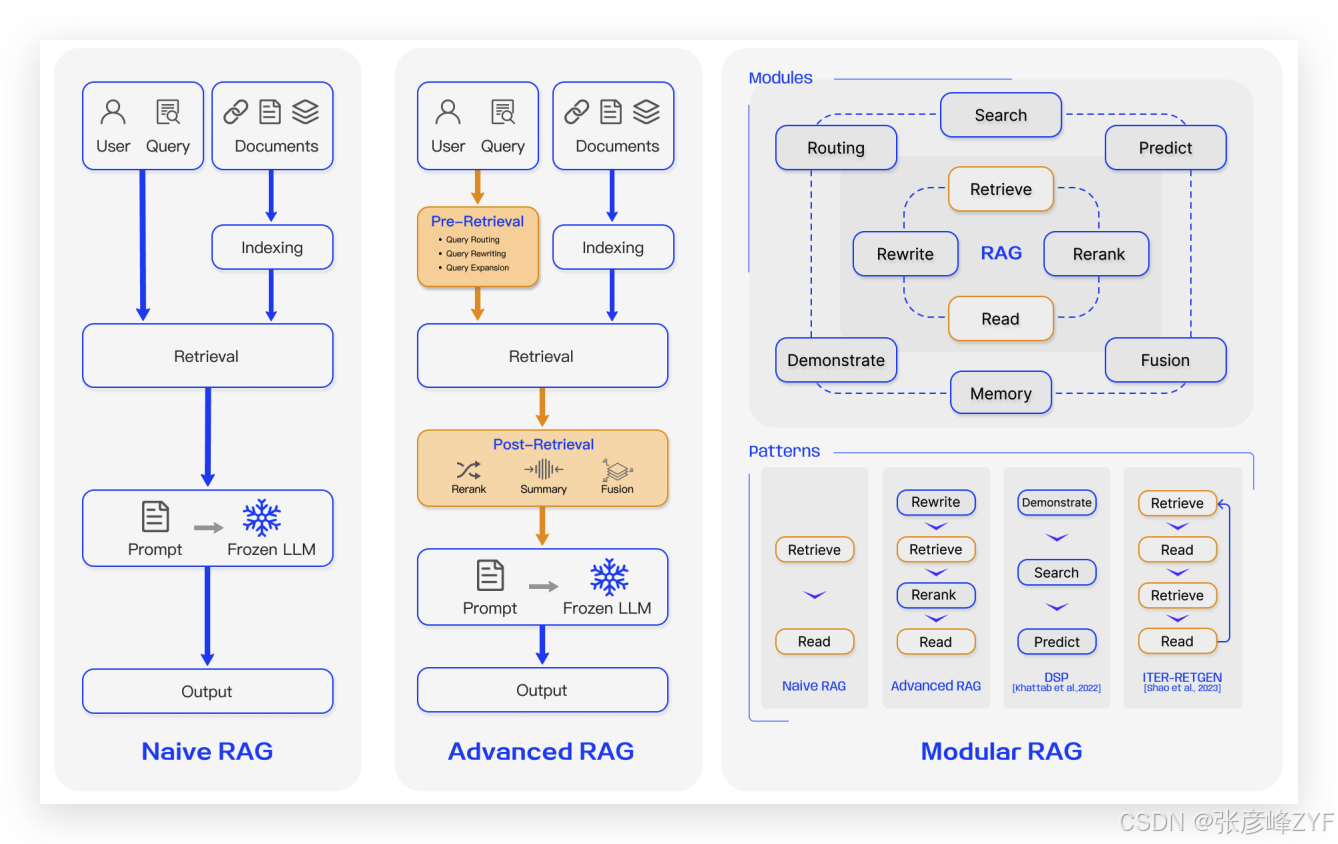
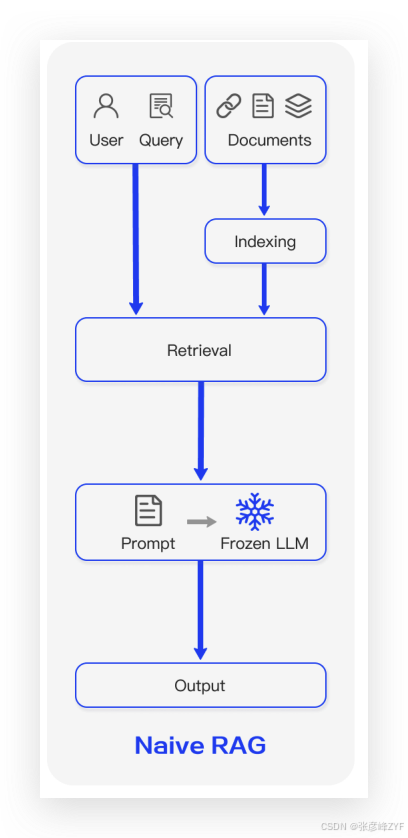
Naive RAG 是最早期、最直接的一种 RAG 实现方式,它随着 ChatGPT 等大语言模型的大规模应用而迅速流行起来。该范式的核心流程可以用“检索—阅读(Retrieve-Read)”框架来概括,整个过程分为三个主要阶段:索引、检索、生成,其代表性流程如图 2所示:
(一)Naive RAG 的标准流程
图中展示了 RAG 在问答场景中的典型应用流程,主要包括以下三个步骤:
1. 索引(Indexing)
- 首先对原始资料(如 PDF、HTML、Word、Markdown 等)进行解析和清洗。
- 将内容统一转为纯文本后,根据语言模型的上下文长度限制进行切分(chunking),形成若干段落块。
- 每个段落块被转化为向量(embedding),并存储到向量数据库中,为后续的语义检索做准备。
2. 检索(Retrieval)
- 用户输入查询问题后,系统使用与索引阶段相同的向量编码器,将问题转换为向量表示。
- 通过计算问题向量与数据库中段落块向量之间的语义相似度,选出前 K 个最相关的文本块。
- 这些检索结果将作为扩展上下文,用于辅助回答问题。
3. 生成(Generation)
- 将用户问题与检索到的段落内容拼接成一个完整提示词(prompt),输入大语言模型进行回答生成。
- 生成阶段的表现会因具体任务设定而异,有些情况下模型会综合使用自身知识与检索信息,有时则会限制只使用提供的文本。
- 若是多轮对话,还可将历史对话上下文一并加入,以保持交互的连贯性。
(二)Naive RAG 的问题与挑战
尽管 Naive RAG 实现简单、成本较低,并能在一定程度上提升大模型的回答准确性,但在实际应用中也暴露出不少问题:
1. 检索阶段的问题
- 召回不足:可能遗漏关键信息,导致生成阶段缺乏有效依据。
- 误召回:检索到不相关或干扰性段落,影响回答质量。
- 向量表示过于粗糙:不能充分捕捉上下文语义,影响精度。
2. 生成阶段的问题
- 幻觉现象(Hallucination):模型可能生成与检索内容不符的信息,产生虚假回答。
- 回答偏离主题:当上下文不够相关时,输出容易跑题或失焦。
- 内容不当或偏见:可能带有不合适的表达,降低可信度。
3. 增强整合的难点
- 冗余:不同来源段落含义重复,生成内容出现重复表达。
- 风格不一致:不同片段之间写作风格、语气差异大,生成结果不够连贯。
- 信息整合困难:模型难以有效判断哪些段落更重要,或如何将多个片段有效融合。
- 简单拼接缺乏加工:生成模型有时过度依赖检索内容,结果变成对原文的“复制粘贴”,缺少进一步加工和总结。
此外,在复杂任务中,一次基于原始问题的检索可能无法覆盖所有关键信息,需要多轮迭代才能获取足够上下文。这也暴露出 Naive RAG 在应对复杂场景时的局限性。
(三)思考
Naive RAG 是构建 RAG 系统的基础形态,其“索引-检索-生成”三步流程为后续的高级和模块化 RAG 提供了原型框架。然而,随着对生成质量、稳定性和适配性的要求提升,它的诸多不足也促使研究者进一步探索更智能的改进方案。
接下来的 Advanced RAG 和 Modular RAG,正是在解决 Naive RAG 局限性的基础上演化而来的。
四、Advanced RAG:应对基础范式局限的智能增强
Advanced RAG 是在 Naive RAG 的基础上发展而来的一种更智能、结构更优化的检索增强生成方式。其提出的初衷,就是为了解决 Naive RAG 在检索精度、生成质量以及信息整合等方面存在的多项不足。
相比于简单的“Retrieve-Read”框架,Advanced RAG 更注重提升系统对查询意图的理解、多轮检索策略的设计,以及上下文融合的能力,目标是构建更稳健、更准确、更具实用性的 RAG 流程。
(一)概念与特征
Advanced RAG 引入了多个关键增强机制,使得模型能够更主动地适配复杂任务场景。相较于传统的“Retrieve-Read”流程,它在以下方面实现了进化:
- 查询重写(Query Reformulation):用户初始问题可能存在歧义或信息不足,Advanced RAG 会利用语言模型对原始查询进行优化重写,提升检索精度。
- 多轮检索(Multi-stage Retrieval):不再满足于单次 Top-K 相似度匹配,系统支持级联检索、重排序、跨步补全等方式,多角度提取相关信息。
- 上下文融合(Context Fusion):在生成阶段引入信息整合模块,对多个检索片段进行聚合、去重、权重评估等处理,保障生成内容结构清晰、内容不冗余。
- 动态控制生成行为(Response Control):根据不同任务目标,模型可设定只依赖检索信息、结合模型内知识,或引入对话上下文进行多轮响应。
(二)Advanced RAG 定位
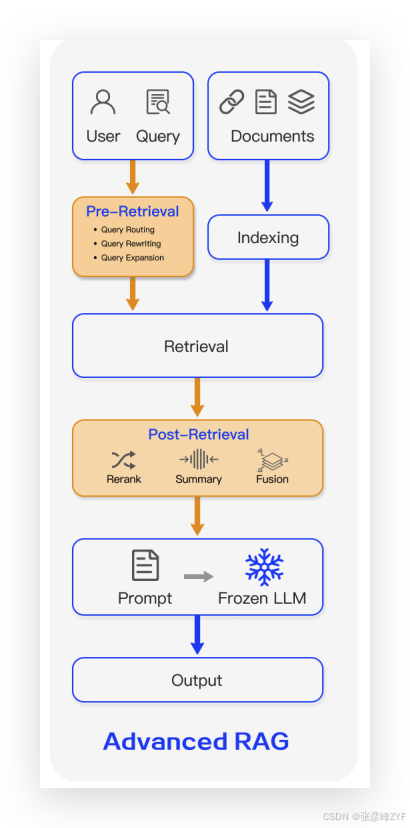
从图中可以看出,Advanced RAG 相较 Naive RAG 拓展出了更多模块交互路径,体现其处理流程的复杂度与灵活性:
- 多个模块(如 Query Reformulator、Retriever、Context Selector)之间建立了非线性连接与反馈路径;
- 图中清晰标示了从单轮检索向多阶段协同增强结构的演化趋势;
- Advanced RAG 模块密度增多,代表功能能力增强,推动整体问答效果从“依赖检索结果”向“融合多源上下文与语言模型知识”过渡。
该阶段的核心目标是:通过结构增强与控制能力,提升信息检索与生成过程的精度、稳定性与适应性。
(三)典型优势与改进方向
| 类别 | Naive RAG | Advanced RAG 的改进 |
|---|---|---|
| 检索精度 | 单轮粗粒度匹配 | 引入查询重写 + 多轮检索机制 |
| 上下文结构 | 简单拼接 | 融合聚合、去重、重要性排序 |
| 响应内容 | 易产生幻觉与冗余 | 强化事实对齐与生成控制能力 |
| 多轮对话支持 | 弱 | 可整合历史上下文,支持多轮 |
通过上述优化,Advanced RAG 在搜索增强问答系统中显著提升了可用性与实用性,逐渐成为企业级落地的首选方案。
五、Modular RAG:从“方法”向“平台”级演进
随着 RAG 技术在真实应用场景中的逐渐落地,系统对可扩展性、可维护性、任务适配能力等提出了更高要求。这一背景下,Modular RAG(模块化 RAG) 作为 RAG 研究范式的最新阶段应运而生。它不仅延续了 Advanced RAG 的多轮增强思路,还进一步将各个组件进行解耦与模块化,实现更高的灵活性、可控性与可组合性。
(一)核心理念与特点
Modular RAG 的主要思想是将传统 RAG 系统中紧耦合的流程,重构为若干独立、可插拔的模块(Module),每个模块专注完成特定任务,如查询生成、检索排序、文档聚合、响应风格控制等。模块之间通过统一的接口协议协同工作,从而形成高度可配置与适配的生成系统。
其显著特点包括:
- 结构解耦:各环节(如 Query Reformulation、Retriever、Ranker、Fusion、Response Generator)均可独立部署、训练、优化,适配不同需求。
- 任务定制化能力强:开发者可以按需组合模块,打造适用于摘要生成、问答、对话等不同任务的专属 RAG 流程。
- 可观测与可调试性好:每个模块输入输出清晰、便于可视化追踪,有利于调优与问题定位。
- 支持多模型协同:不同模块可调用不同类型的语言模型、检索器或评估器,实现多模型融合、增强系统鲁棒性。
这种模块化架构,类似于搭建“乐高式”生成系统,让开发者能够灵活构建和调度最适合当前场景的 RAG 流程。
(二)Modular RAG 结构布局
Modular RAG 作为演化终点,展现了最复杂、最灵活的结构布局:
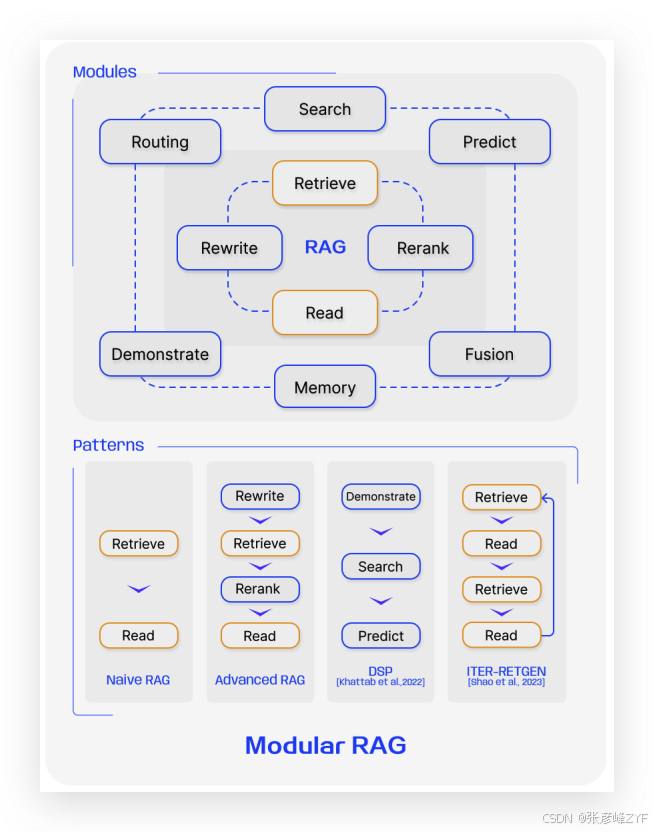
- 图中体现了各模块之间的高度并行、交错连接,打破了原有串行线性流程;
- 除了基础的 Indexer、Retriever、Generator 外,还引入了 Query Optimizer、Selector、Fusion、Evaluator 等多个中间环节;
- 整体呈现出一个可扩展的 DAG(有向无环图)结构,表明模块之间既有主流程连接,也支持分支协同与并行优化;
- 模块之间的边界清晰,可实现动态路由与任务切换,体现了系统的可组合性与智能调度能力。
图示反映出 Modular RAG 不再是单一流程上的“增强”,而是具备全局架构设计与调度能力的“生成框架”。
(三)实际优势与应用价值
| 维度 | Advanced RAG | Modular RAG 的提升 |
|---|---|---|
| 系统结构 | 增强但仍是串行结构 | 完全模块化解耦,支持 DAG 式组合 |
| 任务泛化能力 | 适配部分场景 | 适用于任意复杂问答 / 对话 / 摘要 |
| 训练与调试 | 部分模块可单独训练 | 支持模块级迭代、快速调优 |
| 多模态支持 | 初步探索 | 模块级扩展支持图文多模态任务 |
| 商业部署 | 中等复杂度 | 高灵活性 + 易部署 + 易维护 |
Modular RAG 的提出,标志着 RAG 从“方法”向“平台”级演进。它不仅提升了信息检索增强生成系统的性能,更为构建通用智能助理、企业级问答引擎、多模态 AI 系统打下了坚实的架构基础。
(四)🔍 三阶段 RAG 模型对比表
| 对比维度 | Naive RAG | Advanced RAG | Modular RAG |
|---|---|---|---|
| 架构形式 | 简单线性流程(检索 → 生成) | 增强型流水线(多轮检索 + rerank + 融合) | 模块解耦结构,DAG 式自由组合 |
| 关键模块 | Indexer、Retriever、Generator | 加入 Query Reformulation、Reranker、Fusion 等增强组件 | 每个子任务独立模块化,如 Selector、Evaluator、Prompt Optimizer 等 |
| 查询处理能力 | 原始 Query 单轮检索 | 多轮 Query 优化与重写 | 支持多路径、多策略并行检索与融合 |
| 检索增强方式 | Top-k 相似度排序 | 语义优化、重排序、动态融合 | 自定义检索策略与模块组合,灵活调度多模检索器 |
| 生成效果控制 | 靠 LLM 内部机制 | 提供更多上下文辅助生成 | 可引入控制模块限制风格、格式、可信度 |
| 优势 | 简洁、高效、易部署 | 性能显著提升、适配复杂任务 | 灵活可控、高扩展性、便于调试和演进 |
| 局限性 | 易检索错漏、幻觉严重 | 多组件协同复杂,调优成本上升 | 架构设计复杂、初始投入高 |
| 适用场景 | 简单问答、静态文档检索 | 多轮问答、企业搜索引擎 | 需要强适配性和可维护性的复杂应用(如多语言、多模态问答系统) |
| 图示特征(图3) | 三步直线流程 | 多组件串联增强流程 | 模块化分支结构,模块间连接灵活 |
六、🥊 RAG vs Fine-tuning:两种提升 LLM 能力的对比分析
在增强大型语言模型(LLMs)知识覆盖与任务适应性的实践中,Retrieval-Augmented Generation(RAG) 和 Fine-tuning(微调) 是两种主流手段。它们虽然目标相似,但方法截然不同,各有优势和适配场景。
(一)📚 方法概述
| 对比维度 | RAG(检索增强生成) | Fine-tuning(微调) |
|---|---|---|
| 核心思路 | 在生成前动态检索外部知识,实时构造上下文输入 | 在训练阶段通过监督学习调整模型内部参数 |
| 数据来源 | 外部知识库、数据库、网页、文档等 | 精选标注数据集(需涵盖目标任务知识) |
| 模型调整方式 | 模型结构不变,知识更新靠检索数据更新 | 模型结构内部权重调整 |
| 知识更新 | 快速、灵活:更新数据即可 | 缓慢:需重新训练和部署 |
| 适配任务类型 | 长尾知识、时效性强、变化频繁的任务 | 高精度、重复性强的特定任务 |
| 成本与效率 | 成本低,迭代快 | 成本高,需GPU资源,训练周期长 |
| 可解释性 | 高:可追踪检索内容 | 低:参数黑箱,难以定位生成依据 |
| 偏差风险 | 取决于检索数据质量 | 容易继承训练数据的偏差或标注误差 |
(二)🔍 举例说明
1. 适合 RAG 的场景
- 问答系统需实时访问最新新闻资讯;
- 企业内部知识库接入,如员工手册、合规文档;
- 多模态/多源数据集成,如图文、网页、PDF 混合输入。
2. 适合微调的场景
- 客服机器人固定应答风格;
- 法律合同自动分析器;
- 医疗诊断报告生成器。
(三)⚖️ 组合使用:互为补充的策略
RAG 和微调并非非此即彼。许多系统采用 先微调后 RAG 或 RAG+LoRA 微调融合方案,实现效果和效率的双赢。例如:
- 对 LLM 做轻量微调(如 LoRA)强化任务能力;
- 再通过 RAG 动态接入更新文档或异构数据源;
- 输出结果既有上下文精度,又具备最新知识支持。
(四)✅ 总结建议
| 应用场景 | 优先策略 |
|---|---|
| 快速接入、频繁更新、实时回答 | ✅ 使用 RAG |
| 特定格式要求、精准分类、风格控制 | ✅ 使用 Fine-tuning |
| 有一定模板但内容依赖实时数据 | ✅ 结合两者使用 |
七、总结与趋势展望
回顾 RAG 技术的发展路径,我们可以看到其从早期的 Naive RAG 到 Advanced RAG,再到 Modular RAG,经历了从轻量集成到智能增强、再到模块平台化的逐步演进。
- Naive RAG 适合中小型项目快速试验,优势是实现简单,缺点是检索与生成能力有限;
- Advanced RAG 更适合对生成质量和用户交互要求较高的场景,通过增强结构提高生成效果;
- Modular RAG 则为大规模、长期维护的系统提供了解耦架构,具备更强的适配性与工业可用性。
未来,随着多模态信息融合、Agent 规划与知识图谱集成等方向的发展,RAG 有望成为通用智能系统中不可或缺的组件。
八、📚 参考文献与延伸阅读(References & Further Reading)
-
Lewis, P. et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 9459–9474.
📎 原始论文链接 -
Borgeaud, S. et al. (2022). Improving Language Models by Retrieving from Trillions of Tokens.
International Conference on Machine Learning (ICML), PMLR.
📎 论文地址 -
Arora, D. et al. (2023). GAR-Meets-RAG: A Paradigm for Zero-Shot Information Retrieval.
arXiv preprint arXiv:2310.20158.
📎 arXiv 链接 -
Gao, Y. et al. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey.
Shanghai Research Institute for Intelligent Autonomous Systems & Fudan University.
📎 论文概览 -
Ouyang, L. et al. (2022). Training Language Models to Follow Instructions with Human Feedback (InstructGPT).
NeurIPS, vol. 35, pp. 27730–27744.
📎 arXiv 链接 -
Ma, X. et al. (2023). Query Rewriting for Retrieval-Augmented Large Language Models.
arXiv preprint arXiv:2305.14283.
📎 arXiv 链接 -
Ilin, I. (2023). Advanced RAG Techniques: An Illustrated Overview.
📎 在线文章 -
Izacard, G. & Grave, E. (2021). Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering.
arXiv preprint arXiv:2007.01282.
📎 论文链接 -
Shi, P. et al. (2023). RAGAS: Evaluation of RAG Systems Using Factuality and Groundedness.
📎 GitHub & arXiv -
Ram, O. et al. (2023). Modular RAG: Flexible and Interpretable Retrieval-Augmented Generation Systems.
📎 arXiv
相关文章:

从检索到生成:RAG 如何重构大模型的知识边界?
目录 一、技术演进图谱说明 二、RAG 技术概述 (一)核心思想说明 (二)RAG 发展路径与研究范式 三、Naive RAG:最基础的检索增强生成范式 (一)Naive RAG 的标准流程 1. 索引(In…...

rabbitmq-spring-boot-start版本优化升级
文章目录 1.前言2.优化升级内容3.依赖4.使用4.1发送消息代码示例4.2消费监听代码示例4.3 brock中的消息 5.RabbmitMq的MessageConverter消息转换器5.1默认行为5.2JDK 序列化的缺点5.3使用 JSON 进行序列化 6.总结 1.前言 由于之前手写了一个好用的rabbitmq-spring-boot-start启…...

SVN仓库突然没有权限访问
如果svn仓库突然出现无法访问的情况,提示没有权限,所有账号都是如此,新创建的账号也不行。 并且会突然提示要输入账号密码。 出现这个情况时,大概率库里面的文件有http或者https的字样,因为单独给该文件添加权限导致…...

vue实现静默打印pdf
浏览器中想要打印文件,不依靠浏览器自带的打印窗口,想要实现静默打印(也就是不弹出打印对话框),同时控制打印份数的功能,一种方式是使用vue-plugin-hiprint和本地安装客户端electron-hiprint 本来是浏览器去…...

如何开启远程桌面连接外网访问?异地远程控制内网主机
实现远程桌面连接外网访问,能够突破地域限制,随时随地访问远程计算机,满足远程办公、技术支持等多种需求。下面为你详细介绍开启方法。 一、联网条件 确保本地计算机和远程计算机都有稳定的网络连接,有联网能上网。 二、开启远程…...
----动态规划·数字三角形)
数据结构与算法学习笔记(Acwing提高课)----动态规划·数字三角形
数据结构与算法学习笔记----动态规划数字三角形 author: 明月清了个风 first publish time: 2025.4.23 ps⭐️终于开始提高课的题啦,借的人家的号看,以后给y总补票叭,提高课的题比之前的多很多啊哈哈哈哈,基本上每种题型都对应了…...
debugfs文件系统及常见调试节点介绍)
RK3568平台开发系列讲解(调试篇)debugfs文件系统及常见调试节点介绍
更多内容可以加入Linux系统知识库套餐(教程+视频+答疑) 🚀返回专栏总目录 文章目录 一、什么是debugfs二、/proc/filesystems三、debugfs的挂载3.1、fstab 的文件结构3.2、手动挂载与卸载四、debugfs 常见目录有哪些4.1、/sys/kernel/debug/gpio4.2、/sys/kernel/debug/…...

数字化转型避坑指南:中钧科技如何用“四个锚点”破解转型深水区
数字化转型浪潮下,企业常陷入四大典型陷阱:跟风式投入、数据沼泽化、流程伪在线、安全裸奔化。中钧科技旗下产品以“经营帮”平台为核心,通过针对性方案帮助企业绕开深坑。 陷阱一:盲目跟风,为数字化而数字化 许…...

数字化转型下的批发订货系统:降本增效的关键路径
随着数字化转型的不断深入,越来越多的企业开始拥抱现代化的技术和工具,以提升业务效率、降低运营成本。批发行业,作为一个高度依赖库存和订单管理的行业,数字化转型尤为关键。传统的批发订货系统存在信息不对称、操作复杂、效率低…...

一 、环境的安装 Anaconda + Pycharm + PaddlePaddle
《从零到一实践:系统性学习生成式 AI(NLP)》 一 、环境的安装 Anaconda Pycharm PaddlePaddle 1. Anaconda 软件安装 Anaconda 软件安装有大量的教程,此处不在说明,安装完成之后界面如下: 2. 创建 Anaconda 虚拟环境 Paddl…...

Dhtmlx Gantt教程
想实现的效果 插件安装: npm i dhtmlx-gantt使用该插件的时候,直接导入包和对应的样式即可: import { Gantt} from "dhtmlx-gantt"; import "dhtmlx-gantt/codebase/dhtmlxgantt.css";也可以安装试用版本,…...

大模型框架技术全景与下一代架构演进
一、大模型框架概述 大模型框架是支撑千亿级参数模型训练、推理及产业落地的技术底座,涵盖分布式计算、高效内存管理、多模态融合等核心模块。从GPT-3到Gemini Ultra,大模型框架的迭代推动AI从“作坊式实验”迈向“工业化生产”。据Gartner预测&a…...

官方不存在tomcat10-maven-plugin插件
Maven 中央仓库中没有官方的tomcat10-maven-plugin。Apache Tomcat Maven 插件项目目前仅对以下插件提供官方支持: tomcat6-maven-plugin tomcat7-maven-plugin tomcat8-maven-plugin tomcat9-maven-plugin 如果你想使用 cargo 命令来跑支持 Jakarta EE 的 Tomcat 1…...

vue3 el-table 右击
在 Vue 3 中使用 Element Plus 的 <el-table> 组件时,如果你想实现右击(右键点击)事件的处理,你可以通过监听 contextmenu 事件来实现。contextmenu 事件在用户尝试打开上下文菜单(通常是右键点击)时…...

第一节:核心概念高频题-Vue3响应式原理与Vue2的区别
Vue2:基于Object.defineProperty监听对象属性,需手动处理数组方法重写 Vue3:采用Proxy代理实现全量响应式,支持动态新增属性和深层嵌套对象监听 一、实现机制对比 1. Vue2:基于 Object.defineProperty • 原理&#…...
)
【锂电池剩余寿命预测】CNN卷积神经网络锂电池剩余寿命预测(Pytorch完整源码和数据)
目录 效果一览程序获取程序内容代码分享效果一览 程序获取 获取方式一:文章顶部资源处直接下载:...

web刷题笔记
2024isctf ezrce 禁用了一些关键字符,查询函数,系统执行函数,执行函数都有,空格也和斜杆也禁用了,但是其他一些很大一部分字符都没有禁用,属于关键词禁用的类型,正常的步骤是去查一下列表&#…...

基于FPGA 和DSP 的高性能6U VPX 采集处理板
基于FPGA 和DSP 的高性能6U VPX 采集处理板,是一款处理架构采用FPGADSP 的高性能的6U VPX 采集处理板。板载4 片高速ADC 共8 个采集通道,可支持8 路采样率最高2.6Gsps/14Bit 的模拟信号通道。 板卡FPGA 采用Xilinx 公司KU 系列的XCKU115-2FLVF1924I&…...

uniapp中使用<cover-view>标签
文章背景: uniapp中遇到了原生组件(canvas)优先级过高覆盖vant组件 解决办法: 使用<cover-view>标签 踩坑: 我想实现的是一个vant组件库中动作面板的效果,能够从底部弹出框,让用户进行选择,我直…...

【JavaScript】详讲运算符--算术运算符
1、运算符简介 运算符也叫操作符,通过运算符可以对一个或多个值进行运算,比如:typeof就是运算符,可以来获得一个值的类型,它会将该值的类型以字符串的形式返回,即:typeof 变量名的结果为字符串类型。 <…...

.NET 6 + Dapper + User-Defined Table Type
大家都知道,对于SQL Server IN是有限制条件的,如果IN里面的内容过多,在执行的时候会被自动截断,因而导致查询到的结果不是实际需要的结果。 select * from Payments where Id in (1,2,3,4,...) 为了解决上面的限制,可以…...

使用 Conda 创建新环境
使用 Conda 创建新环境 在使用 Conda 进行包管理和环境隔离时,创建新环境是一个非常常见的操作。通过创建独立的环境,可以避免不同项目之间的依赖冲突,并且能够灵活地管理各个项目的运行环境。 以下是使用 Conda 创建和管理新环境的详细步骤…...

数据为基:机器学习中数值与分类数据的处理艺术及泛化实践
数据为基:机器学习中数值与分类数据的处理艺术及泛化实践 摘要 在机器学习实践中,数据质量对模型效果的影响往往超过算法选择。本文通过详实的案例解析,系统阐述数值型数据与分类数据的特征工程处理方法,揭示数据预处理对模型泛…...

Docker镜像与容器概念解析
Docker镜像与容器概念解析 -更适合大学生宝宝体制的docker学习指南 一、Docker镜像:应用程序的基因库 (1)本质特征:镜像是一个只读的二进制文件包,相当于应用程序的”基因图谱”。就像生物体的DNA决定了生物特征&a…...

基于GMM的语音识别
语音识别是近年来发展非常迅速的一项计算机智能技术,广泛应用在语音控制、身份识别等多个领域。本次项目主要研究语音识别的预处理过程和特征参数的提取环节。通过对原始语音信号进行预加重和分帧、加窗,滤除低频干扰,提升对语音识别有用的部…...

K8S安全认证
一。用户认证的基本框架 在K8S集群中,客户端通常有两类: 1.User Account:一般独立于K8S之外的其他服务管理的用过户账号 2.Service Account:K8S管理的账号,用于为Pod中的服务进程在访问K8S提供身份标识 ApiServer是…...

咖啡机语音芯片方案-WTN6040FP-14S直接驱动4欧/3W喇叭-大功率输出
一、开发背景 随着智能家居市场的快速发展和消费者对家电产品交互体验要求的不断提高,语音提示功能已成为现代咖啡机产品的重要卖点之一。传统咖啡机仅依靠指示灯和简单蜂鸣器提示,无法满足用户对操作引导、状态反馈和个性化体验的需求。 WTN6040FP-14大…...

Vue3集成百度实时语音识别
示例 SpeechRecognitionModal.vue 组件 <template><transition name"modal-fade"><div v-if"isOpen" class"modal-overlay" click.self"handleOverlayClick"><div class"modal-container"><div…...

C# 设计原则总结
跟着视频学习的,记录一下最后的总结。 接口隔离: 单一职责: 里氏替换: 依赖倒置; 迪米特法则; 开闭原则:...

zkPass案例实战之合约篇
目录 一、contracts/contracts/ProofVerifier.sol 1. License 和 Solidity 版本 2. 导入依赖 3. 合约声明和默认分配器地址 4. 验证证明 5. 验证分配器签名 6. 验证验证者签名 7. 签名前缀处理 8. 签名恢复 总结 二、contracts/contracts/SampleAttestation.sol 1. …...

docker学习笔记5-docker中启动Mysql的最佳实践
一、查找目录文件位置 1、mysql的配置文件路径 /etc/mysql/conf.d 2、mysql的数据目录 /var/lib/mysql 3、环境变量 4、端口 mysql的默认端口3306。 二、启动命令 1、启动命令说明 docker run -d -p 3306:3306 -v /app/myconf:/etc/mysql/conf.d # 挂载配置目录 -v…...

彻底禁用windows的语音识别快捷键win+ctrl+s
工作中经常使用ctrls保存,但是经常误触win,结果弹出如下对话框,甚是闹心: 搜索网络,问AI,竟然没有一个好用的不依赖常驻内存软件的办法,最终经过探索与验证,总算是彻底解决了此问题&…...
-Analytic函数集)
大数据学习(112)-Analytic函数集
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

文档构建:Sphinx全面使用指南 — 实战篇
文档构建:Sphinx全面使用指南 — 实战篇 Sphinx 是一款强大的文档生成工具,使用 reStructuredText 作为标记语言,通过扩展兼容 Markdown,支持 HTML、PDF、EPUB 等多种输出格式。它具备自动索引、代码高亮、跨语言支持等功能&#…...
安装移动磐维数据库(PanWeiDB_V2.0-S2.0.2_B01)步骤)
欧拉环境(openEuler 22.03 LTS SP3)安装移动磐维数据库(PanWeiDB_V2.0-S2.0.2_B01)步骤
一、磐维数据库概述 中国移动磐维数据库(ChinaMobileDB),简称“磐维数据库”(PanWeiDB),是中国移动信息技术中心首个基于中国本土开源数据库打造的面向ICT基础设施的自研数据库产品。其产品内核能力基于华…...

【产品经理从0到1】产品规划
产品规划 已经知道要做什么功能,展示什么信息,那这些信息应该 以什么方式展现给用户? 信息架构的概念 一般的商场导览图,都有以下特征: • 每一层都由多个店铺组成; • 商场有出口,有入口&am…...

一篇文章学会开发第一个ASP.NET网页
*开发环境:Visual Studio 2022 ASP.NET Core 6.0* 一、开发环境准备 1.1 安装必备工具 Visual Studio 2022 Community(免费版本) .NET 6.0 SDK 验证安装:命令行执行 dotnet --version 显示6.0.x版本 1.2 创建新项目 打开VS…...
)
[架构之美]Ubuntu源码部署APISIX全流程详解(含避坑指南)
[架构之美]Ubuntu源码部署APISIX全流程详解(含避坑指南) 一、离线安装场景需求分析 1.1 典型应用场景 金融/政务内网环境生产环境安全合规要求边缘计算节点部署1.2 离线安装难点 #mermaid-svg-B25djI0XquaOb1HM {font-family:"trebuchet ms",verdana,arial,sans-s…...
)
【3】CICD持续集成-k8s集群中安装Jenkins-agent(主从架构)
一、背景: Jenkins Master/Slave架构,Master(Jenkins本身)提供Web页面让用户来管理项目和从节点(Slave),项目任务可以运行在Master本机或者分配到从节点运行,一个Master可以关联多个…...

2024从Maven-MySQL-Nginx部署
1、IDEA配置全局Maven设置 第一步:File->Close Project返回到创建工程界面。 第二步:找到bulid---maven设置对应位置。 第三步:选中两栏后的Override---应用---关闭即可。 *************************************************************…...

MySQL运算符
目录 一、mysql运算符 1. 算数运算符 2. 比较运算符 2.1 等号运算符() 2.2 不等于运算符 ! 3.非符号类型的运算符 3.1 空运算 IS NULL、 IS NOT NULL、 ISNULL 3.2 区间查询 BETWEEN 3.3 包含查询 IN、 NOT IN 3.4模糊查询LIKE 4. 逻辑运算符 4.1 AND(逻…...

什么是区块?
“区块”是区块链技术的基本组成部分,是加密货币交易的数字记录簿。一个区块就像是账本中的一页,详细记录了所有的交易细节。每个区块都包含基本信息,如最近的交易列表、标记区块创建时间的时间戳,以及称为“哈希值”的唯一加密代…...

爬虫学习——获取动态网页信息
对于静态网页可以直接研究html网页代码实现内容获取,对于动态网页绝大多数都是页面内容是通过JavaScript脚本动态生成(也就是json数据格式),而不是静态的,故需要使用一些新方法对其进行内容获取。凡是通过静态方法获取不到的内容,…...

LSA六种类型
LAS --- 链路状态通告 链路状态类型、链路状态ID、通告路由器 --- LSA的三元组 --- 可以唯一标识出一条LSA Type --- OSPFv2中,常见的需要掌握LSA有6种 LS ID --- LSA的名字 --- 因为每一种LSA ID的生成方式都不相同,所以导致可能重复,则如…...

第七篇:linux之基本权限、进程管理、系统服务
第七篇:linux之基本权限、进程管理、系统服务 文章目录 第七篇:linux之基本权限、进程管理、系统服务一、基本权限1、什么是权限?2、为什么要有权限?3、权限与用户之间的关系?4、权限对应的数字含义5、使用chmod设定权…...

时序约束 记录
一、基础知识 1、fpga的约束文件为.fdc,synopsys的约束文件为.sdc。想通过fpga验证soc设计是否正确,可以通过syn工具(synplify)吃.fdc把soc code 转换成netlist。然后vivado P&R工具通过吃上述netlist、XDC 出pin脚约束、fdc时序约束三个约束来完成…...

fpga系列 HDL:跨时钟域同步 脉冲展宽同步 Pulse Synchronization
Pulse Synchronization 脉冲同步(Pulse Synchronization)是 FPGA 设计中处理跨时钟域信号传输的常见问题和关键细节。由于不同步的时钟域之间可能存在相位差或频率差异,可能会导致亚稳态问题或数据丢失。脉冲同步的主要目标是确保一个时钟域中…...

链表系列一>两数相加
目录 题目:解析:方法:代码:链表常用技巧: 题目: 链接: link 解析: 方法: 代码: /*** Definition for singly-linked list.* public class ListNode {* int val;* …...

MCP接入方式介绍
上一篇文章,我们介绍了MCP是什么以及MCP的使用。 MCP是什么,MCP的使用 接下来,我们来详细介绍一下MCP的接入 先看官网的架构图 上图的MCP 服务 A、MCP 服务 B、MCP 服务 C是可以运行在你的本地计算机(本地服务器方式ÿ…...

嵌入式WebRTC音视频实时通话EasyRTC助力打造AIOT智能硬件实时通信新生态
一、背景 在当今智能化时代,智能硬件设备正迅速融入人们的生活和工作中,从智能家居、智能穿戴到工业物联网,智能硬件的应用场景不断拓展。实时通信技术作为智能硬件的重要组成部分,能够实现设备之间的无缝连接和交互。基于WevRTC…...