MySQL数据库精研之旅第十期:打造高效联合查询的实战宝典



专栏:MySQL数据库成长记
个人主页:手握风云
目录
一、简介
1.1. 为什么要使用联合查询
1.2. 多表联合查询时的计算
1.3. 示例
二、内连接
2.1. 语法
2.2. 示例
三、外连接
4.1. 语法
4.2. 示例
一、简介
1.1. 为什么要使用联合查询
一次查询需要从多张表中获取到数据,成为联合查询,或者叫表联合查询。
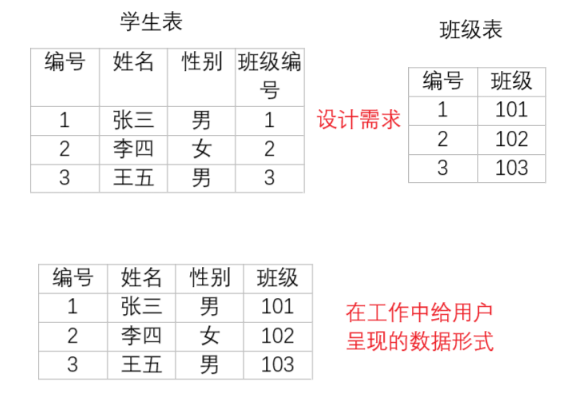
在数据设计时由于范式的要求,数据被拆分到多个表中,那么要查询⼀个条数据的完整信息,就要从多个表中获取数据,如下图所示:要获取学生的基本信息和班级信息就要从学生表和班级表中获取,这时就需要使用联合查询。
1.2. 多表联合查询时的计算
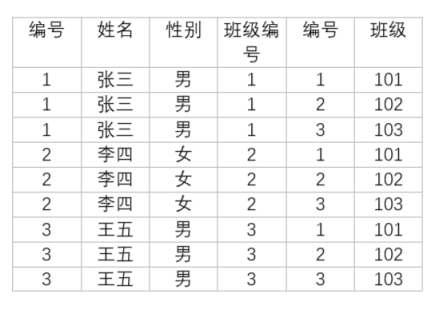
- 参与查询的所有表取笛卡尔积,结果集在临时表中
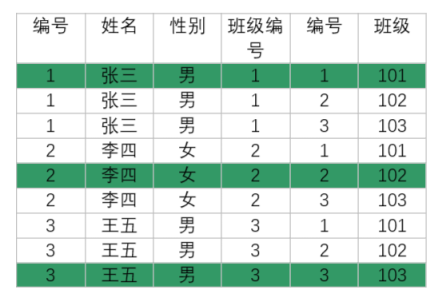
- 观察哪些记录是有效数据,根据两个表的关联关系过滤掉⽆效数据
如果联合查询表的个数越多,表中的数据量越大,临时表就会越大,所以根据实际情况确定联合查询表的个数。
1.3. 示例
-- 课程表
create table if not exists course(id bigint auto_increment primary key,`name` varchar(30) not null
);
insert into course (`name`) values ('Java'),('C++'),('操作系统'),('计算机网络'),('数据结构');
insert into course (`name`) values ('MySQL');
select* from course;-- 班级表
create table if not exists class(id bigint auto_increment primary key,`name` varchar(30) not null
);
insert into class (`name`) values ('101班'),('102班'),('103班');
select * from class;-- 学生表
create table if not exists student(id bigint auto_increment primary key,`name` varchar(30) not null,sno varchar(30) not null,age bigint,gender tinyint,enroll_date date,class_id bigint,foreign key (class_id) references class(id)
);
insert into student (`name`,sno,age,gender,enroll_date,class_id) values
('Paul','10001',18,1,'2025-09-01',1),
('Amy','10002',19,0,'2025-09-01',1),
('Jack','10003',19,1,'2025-09-01',1),
('Mary','10004',18,0,'2025-09-01',1);
insert into student (`name`,sno,age,gender,enroll_date,class_id) values
('Bob','20001',19,1,'2025-09-01',2),
('Alice','20002',19,0,'2025-09-01',2),
('Nick','20003',18,1,'2025-09-01',2),
('Kelen','20004',18,0,'2025-09-01',2);
update student set id = id - 4 where id >= 9;
select * from student;-- 成绩表
create table if not exists score(id bigint auto_increment primary key,score float not null,student_id bigint,course_id bigint,foreign key (student_id) references student(id),foreign key (course_id) references course(id)
);
insert into score (score,student_id,course_id) values
(70.5, 1, 1),
(98.5, 1, 3),
(33, 1, 5),
(98, 1, 6),
(60, 2, 1),
(59.5, 2, 5),
(33, 3, 1),
(68, 3, 3),
(99, 3, 5),
(67, 4, 1),
(23, 4, 3),
(56, 4, 5),
(72, 4, 6),
(81, 5, 1),
(37, 5, 5),
(56, 6, 2),
(43, 6, 4),
(79, 6, 6);我们接下来要查询Paul的详细信息,包括个人信息和班级信息。
- 确定参与查询的表
select * from student,class;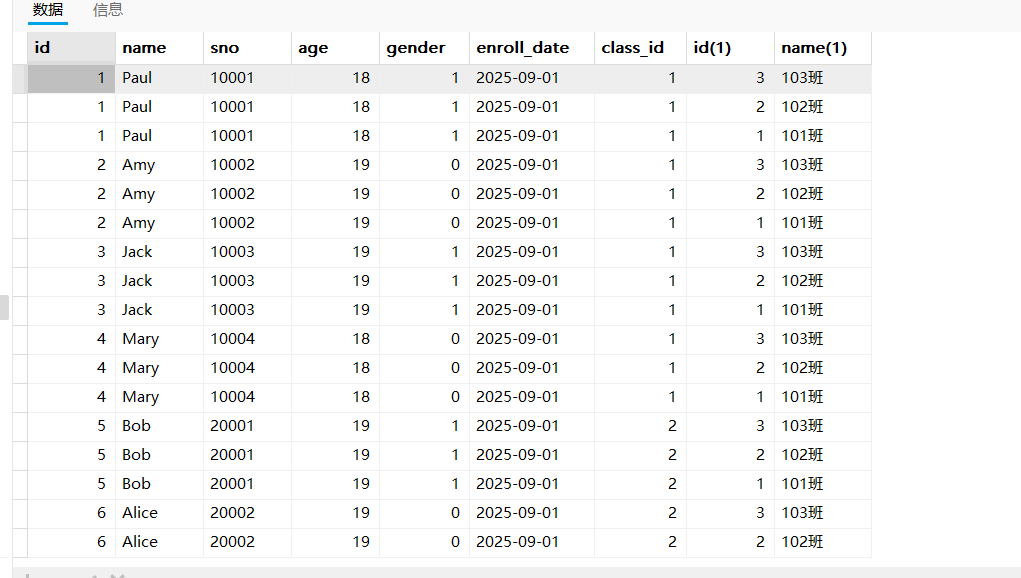
- 确定连接条件
select * from student,class where class_id = id;但此时一执行,就会报错:olumn 'id' in where clause is ambiguous.这是因为student表与class表里面都有id列,我们没有指定,程序也不知道比较哪个。
select * from student,class where student.class_id = class.id;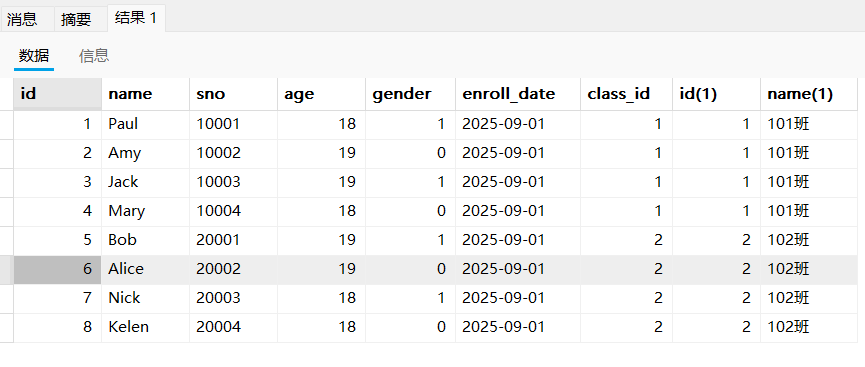
- 加⼊查询条件
select * from student,class where student.class_id = class.id and student.`name` = 'Paul';
- 精减查询结果字段
select student.id,student.`name`,student.age,student.gender,student.enroll_date,class.`name` from student,class where student.class_id = class.id and student.`name` = 'Paul';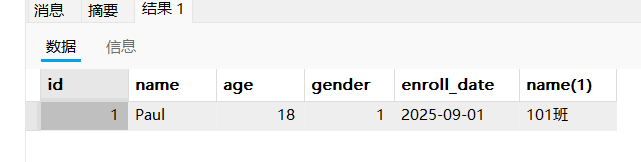
- 指定别名简化查询
select * from student s,class c where s.class_id = c.id and s.`name` = 'Paul'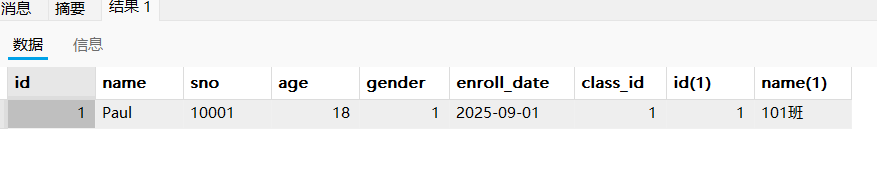
二、内连接
2.1. 语法
select 字段 from 表1 别名1, 表2 别名2 where 连接条件 and 其他条件;
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 where 其他条件;join两侧连接的是表名,on后面是连接条件。示例如下:
select s.id,s.`name`,s.age,s.gender,s.enroll_date,c.`name` from student s inner join class c on s.class_id = c.id;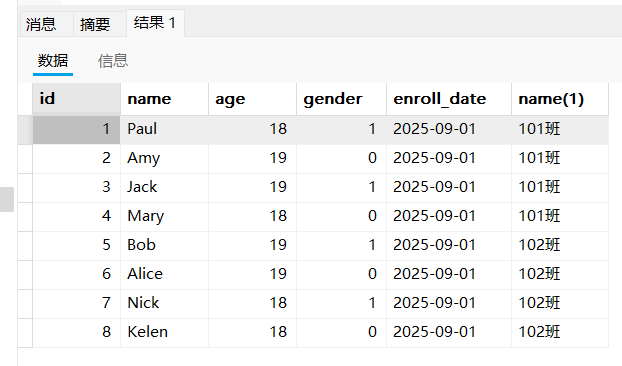
2.2. 示例
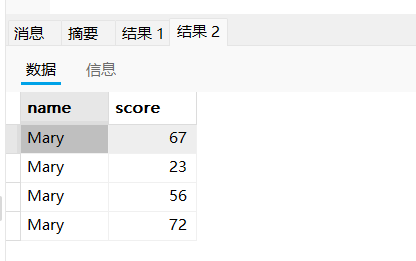
- 查询Mary的所有成绩
select * from student stu,score sco where stu.id = sco.student_id and stu.`name` = 'Mary';
select stu.`name`,sco.score from student stu,score sco where stu.id = sco.student_id and stu.`name` = 'Mary';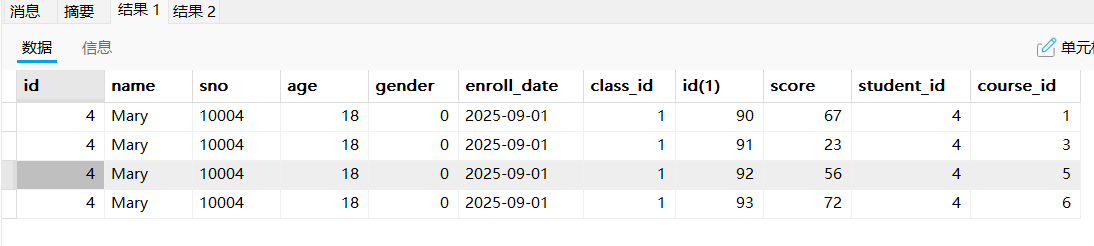
- 查询所有同学的总成绩,及同学的个人信息
select stu.id,stu.`name`,sco.student_id,sum(sco.score) from student stu,score sco where stu.id = sco.student_id group by sco.student_id;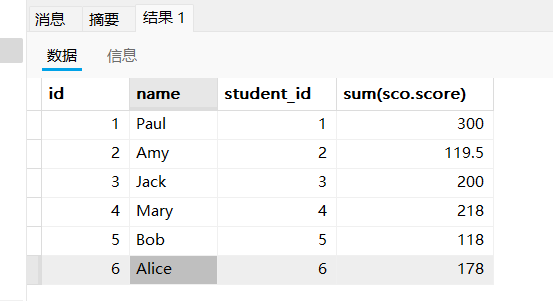
select stu.id,stu.`name` as 姓名,sum(sco.score) 总分 from student stu,score sco where stu.id = sco.student_id group by sco.student_id;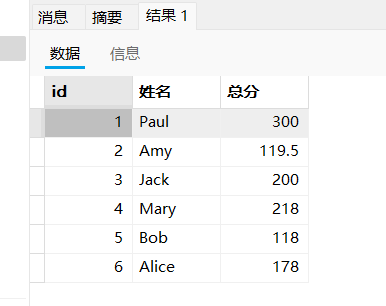
- 查询所有同学每⻔课的成绩,及同学的个⼈信息
我们先看下三个表的字段,找出关联关系。
desc student;
desc score;
desc course;select * from student stu,score sco,course c where stu.id = sco.student_id and c.id = sco.course_id;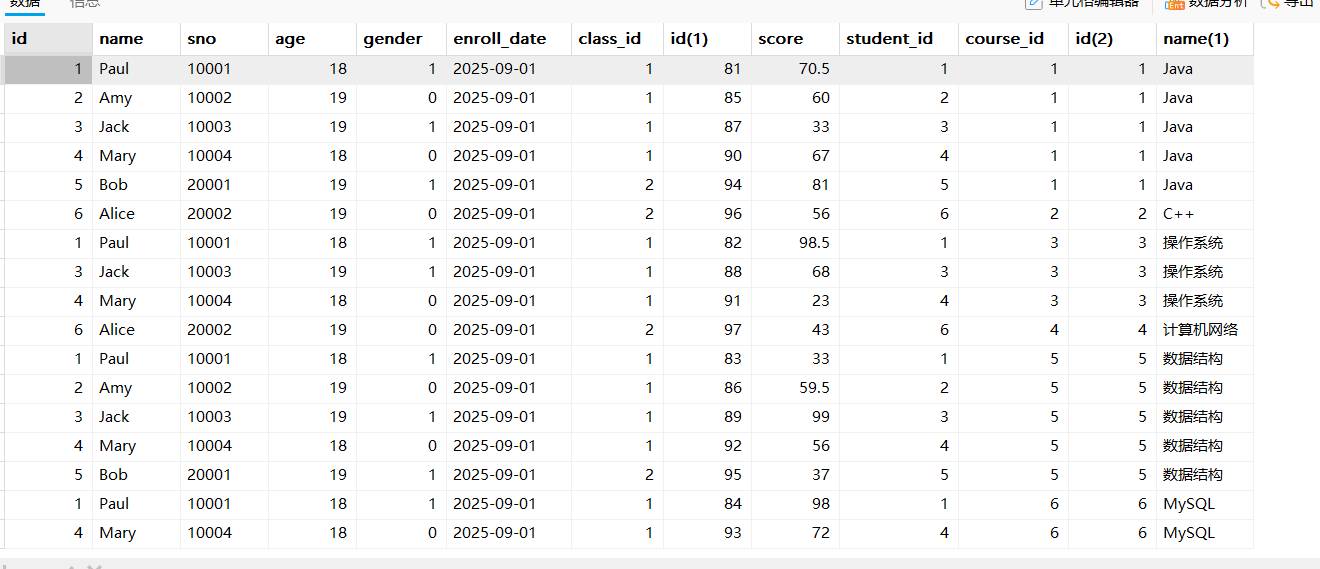
也可以使用join进行多表连接
select * from student stu join score sco on stu.id = sco.student_id join course c on c.id = sco.course_id;在工作中尽量少对大表进行表关联查询,一般表关联的个数不超过3个。
三、外连接
- 外连接分为左外连接、右外连接和全外连接三种类型,MySQL不支持全外连接,并且执行过程中,右外连接又会被优化成左外连接。
- 左外连接:返回左表的所有记录和右表中匹配的记录。如果右表中没有匹配的记录,则结果集中对应字段会显示为NULL。
- 右外连接:与左外连接相反,返回右表的所有记录和左表中匹配的记录。如果左表中没有匹配的记 录,则结果集中对应字段会显示为NULL。
无论是哪种外连接,必须先找到基准表。左外连接是以左表为基准,右外连接是以右表为基准。基准表中的记录都会显示出来。
4.1. 语法
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段名 from 表名1 right join 表名2 on 连接条件;4.2. 示例
- 查询没有参加考试的同学信息(左外连接)
select * from student;
select * from score;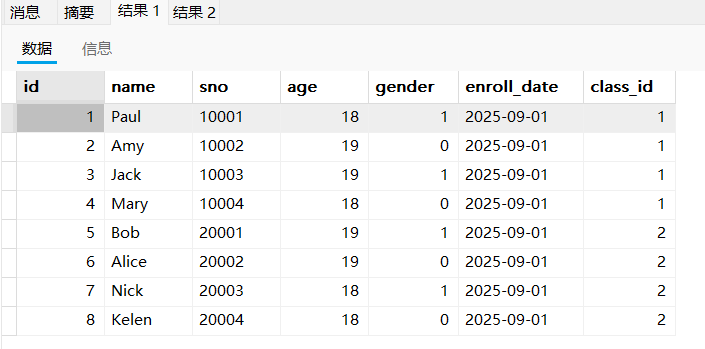
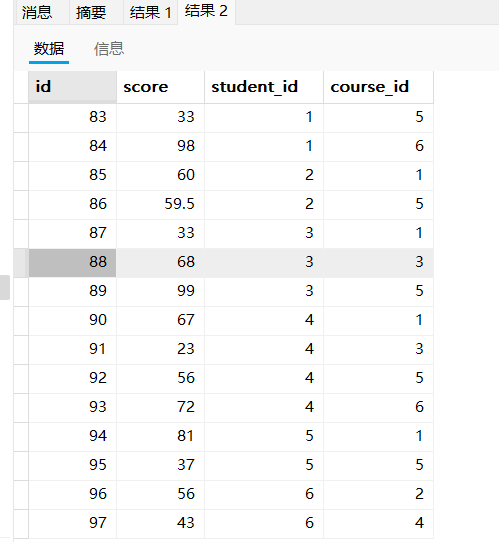
由于成绩表里面没有学号为7和8的同学,所以我们无法通过内连接查询。
select * from student stu left join score sco on stu.id = sco.student_id;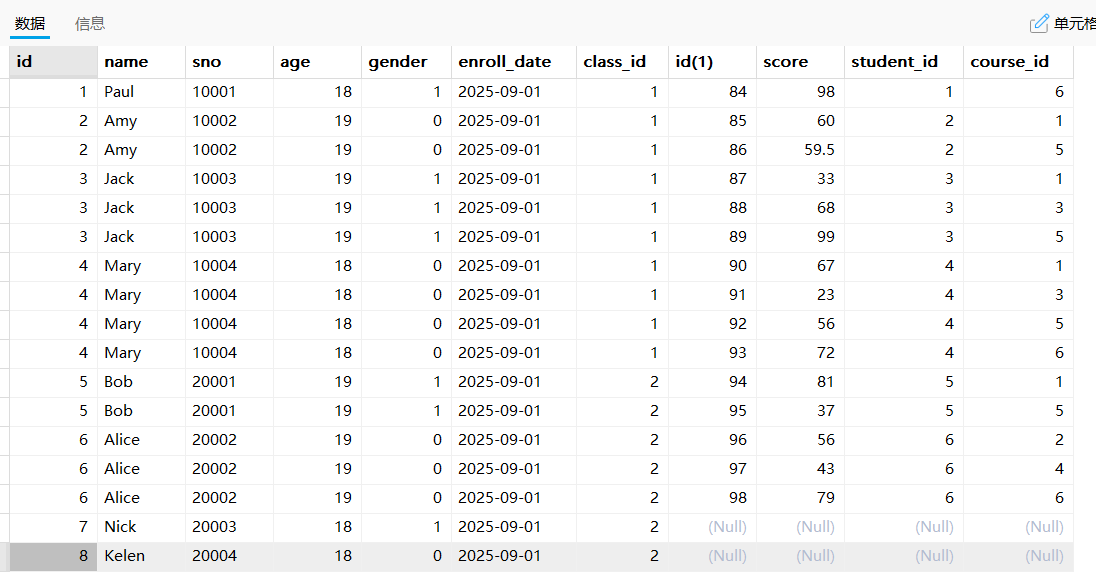
接着就可以继续使用where条件进行过滤,将成绩表为空的找出来。
select * from student stu left join score sco on stu.id = sco.student_id where sco.score is null;
- 查询没有学生的班级(右外连接)
select * from student s right join class c on s.class_id = c.id;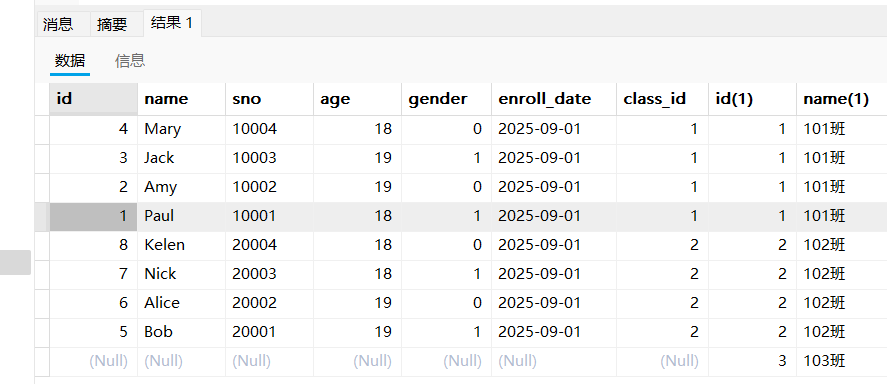
select * from student s right join class c on s.class_id = c.id where s.id is null;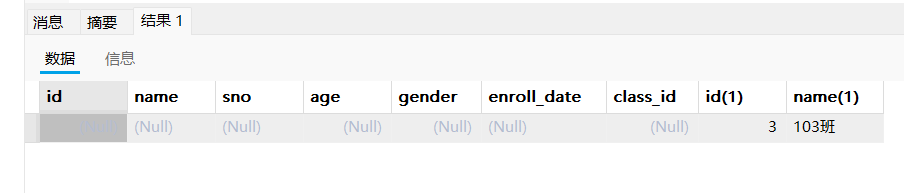
select c.`name` as '没有学生的班级' from student s right join class c on s.class_id = c.id where s.id is null;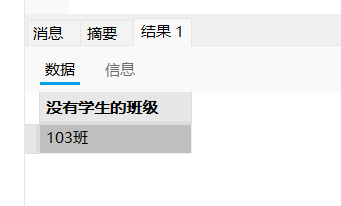
相关文章:

MySQL数据库精研之旅第十期:打造高效联合查询的实战宝典
专栏:MySQL数据库成长记 个人主页:手握风云 目录 一、简介 1.1. 为什么要使用联合查询 1.2. 多表联合查询时的计算 1.3. 示例 二、内连接 2.1. 语法 2.2. 示例 三、外连接 4.1. 语法 4.2. 示例 一、简介 1.1. 为什么要使用联合查询 一次查询需…...

【Redis】集合类型Set 常用命令详解
1. sadd - 添加 语法:sadd key value > sadd testset A 1 > sadd testset B 1 > sadd testset C 1 > sadd testset C # set的值不能重复 0 > smembers set1 # 查询指定set的所有值,乱序 1) "B" 2) "A" 3) "C&qu…...

React 5 种组件提取思路与实践
在开发时,经常遇到一些高度重复但略有差异的 UI 模式,此时我们当然会把组件提取出去,但是组件提取的方式有很多,怎么根据不同场景选取合适的方式呢?尤其时在复杂的业务场景中,组件提取的思路影响着着代码的可维护性、可读性以及扩展性。本文将以一个[详情]组件为例,探讨…...

第十五届蓝桥杯 2024 C/C++组 合法密码
目录 题目: 题目描述: 题目链接: 思路: substr函数: 思路详解: 代码: 代码详解; 题目: 题目描述: 题目链接: P10906 [蓝桥杯 2024 国 B] 合法密码 -…...

云原生时代的双轮驱动
在当今数字化浪潮汹涌澎湃的时代,企业 IT 主管、CIO、CTO 们肩负着引领企业乘风破浪、实现数字化转型的重任。而主数据平台与数据中台,宛如企业数字化征程中的双引擎,为企业发展注入强劲动力。 一、主数据与数据中台:企业数据世界…...
定时器TIMER详解及实战含源码)
GD32F407单片机开发入门(六)定时器TIMER详解及实战含源码
文章目录 一.概要二.通用定时器内部结构1.时基单元2.时钟源3.输入捕获4.输出比较 三.通用定时器内部特色四.TIME定时器1ms中断例程五.工程源代码下载六.小结 一.概要 定时器就是计数器,应用在我们生活的方方面面,比如有闹钟、计时器等。在GD32F407VET6定…...

时序数据库 TDengine 助力石油石化业务, 平滑接替 Oracle 数据库
小T导读:胜软科技在石油石化行业中选择使用 TDengine 处理时序数据,不仅显著降低了运维数据库的成本,也大幅减少了存储空间的占用,实现了从原有的 40 多套 Oracle 数据库向仅 9 套 TDengine集群的精简替换。在迁移过程中ÿ…...

【问题解决】本机navicat连接云服务器mysql
一般情况下,当你使用navicat等工具连接云服务器会因为mysql的安全机制,导致无法连接root用户,但是在测试环境中,不考虑安全性的前提条件下,可以通过修改MySQL的配置文件来连接云服务器mysql的root用户。 选择数据库&am…...

STM32F407 的通用定时器与串口配置深度解析
在 STM32F407 芯片的开发过程中,通用定时器和串口的配置与使用是极为关键的技能点。本文将结合提供的代码示例,深入剖析这两个模块的配置流程、工作原理以及实际应用,助力开发者更好地掌握相关技术。 一、通用定时器 (一&#x…...

深入探究Linux项目自动化构建工具:make与Makefile
目录 引言 一、make与Makefile概述 1.1 背景 1.2 理解 二、make工作原理 2.1 查找Makefile 2.2 确定目标文件 2.3 处理文件依赖 三、Makefile实例分析 3.1 简单C程序示例 3.2 项目清理机制 四、结合行缓冲区概念的有趣现象 五、结语 引言 在Linux软件开发的世界里…...

【Hive入门】Hive基础操作与SQL语法:DDL操作全面指南
目录 1 Hive DDL操作概述 2 数据库操作全流程 2.1 创建数据库 2.2 查看数据库 2.3 使用数据库 2.4 修改数据库 2.5 删除数据库 3 表操作全流程 3.1 创建表 3.2 查看表信息 3.3 修改表 3.4 删除表 4 分区与分桶操作 4.1 分区操作流程 4.2 分桶操作 5 最佳实践与…...

STM32F103 “BluePill” 上的 DMA 原理与实践
摘要:本文深入浅出地介绍什么是 DMA(直接存储器访问),它的核心原理、硬件架构,以及在 STM32F103(BluePill)上常见的几种使用场景(ADC、UART、内存拷贝等)。通过对比 CPU 轮询、中断、DMA 三种方式的数据搬运效率,结合寄存器级和 HAL 库示例代码,并附带性能测试与优化…...

软考软件设计师30天备考指南
文章目录 一、考情分析(一)综合知识(二)案例分析 二、30天学习规划(一)第1 - 5天:基础夯实(二)第6 - 10天:核心知识突破(三)第11 - 15…...
比较:AWS VPC peering与 AWS Transit Gateway
简述: VPC 对等连接和 Transit Gateway 用于连接多个 VPC。VPC 对等连接提供全网状架构,而 Transit Gateway 提供中心辐射型架构。Transit Gateway 提供大规模 VPC 连接,并简化了 VPC 间通信管理,相比 VPC 对等连接,支持大量 VPC 的 VPC 间通信管理。 VPC 对等连接 AWS V…...

【AI大模型】MCP:AI应用的“超级扩展坞”
一、什么是MCP MCP(Model Context Protocol,模型上下文协议)是一种新兴的开放协议,于2024年11月由Anthropic公司(Claude的开发者)开源。它的核心目标是建立一个类似USB-C的标准化协议,统一AI模…...

线程封装
目录 makefile Thread.hpp main.cc 以面向对象的方式造轮子 #ifndef _THREAD_HPP__ // 如果没有定义过 _THREAD_HPP__ #define _THREAD_HPP__ // 则定义 _THREAD_HPP__// 这里是头文件的实际内容(类、函数声明等)#endif // 结束条件…...

【Java后端】MyBatis 与 MyBatis-Plus 如何防止 SQL 注入?从原理到实战
在日常开发中,SQL 注入是一种常见但危害巨大的安全漏洞。如果你正在使用 MyBatis 或 MyBatis-Plus 进行数据库操作,这篇文章将带你系统了解:这两个框架是如何防止 SQL 注入的,我们又该如何写出安全的代码。 什么是 SQL 注入&#…...

智能穿戴的终极形态会是AR眼镜吗?
清晨的地铁里,戴着普通眼镜的小张正通过镜片查看实时导航路线,眼前的虚拟箭头精准指引换乘方向;手术室里,主刀医生透过镜片看到患者血管的3D投影,如同获得透视眼般精准避开危险区域;装修现场,设…...
Hive3.1.2安装指南)
ubantu18.04(Hadoop3.1.3)Hive3.1.2安装指南
说明:本文图片较多,耐心等待加载。(建议用电脑) 注意所有打开的文件都要记得保存。本文的操作均在Master主机下进行 第一步:准备工作 本文是在之前Hadoop搭建完集群环境后继续进行的,因此需要读者完成我之…...

Hive 多表查询案例
文章目录 前提条件Hive 多表查询案例JOIN案例JOIN查询数据准备1. 内连接(INNER JOIN)2. 左外连接(LEFT OUTER JOIN)3. 右外连接(RIGHT OUTER JOIN)4. 全外连接(FULL OUTER JOIN)5. 多…...
)
4.23刷题记录(栈与队列专题)
第一部分:基础知识 栈先进后出,队列先进先出栈用stack实现,主要函数有pop,push,top队列由queue或者deque实现,主要函数有front,back,push,pop,emplace&#…...
)
Python常用的第三方模块之【jieba库】支持三种分词模式:精确模式、全模式和搜索引擎模式(提高召回率)
Jieba 是一个流行的中文分词Python库,它提供了三种分词模式:精确模式、全模式和搜索引擎模式。精确模式尝试将句子最精确地切分,适合文本分析;全模式则扫描文本中所有可能的词语,速度快但存在冗余;搜索引擎…...

Redisson实战:分布式系统中的五大典型应用场景
引言 在分布式系统架构中,数据一致性、高并发控制和资源协调是开发者面临的核心挑战。Redisson作为基于Redis的Java客户端,不仅提供了丰富的分布式对象和服务,还简化了分布式场景下的编程模型。本文将通过实际代码示例,解析Redis…...

webrtc建立连接的过程
WebRTC 连接全过程:从零到视频通话的每一步 WebRTC 是个神奇的技术,让浏览器直接进行点对点(P2P)音视频通话或数据传输,不用每次都靠服务器中转。想知道 Alice 和 Bob 是怎么通过 WebRTC 建立视频通话的吗?…...

system verilog 语句 耗时规则
在 SystemVerilog 中,确实有一类语句是**不消耗仿真时间(zero simulation time)**的,我们一般叫它们: ✅ 零延迟语句(Zero-Time Statements) 🔹1. 什么是“不费时间”的语句? 这些语句在仿真时…...

【Docker】在Ubuntu平台上的安装部署
写在前面 docker作为一种部署项目的辅助工具,真是太好用了需要魔法,不然无法正常运行笔者环境:ubuntu22.04 具体步骤 更新系统包索引 sudo apt update安装必要依赖包 sudo apt install -y apt-transport-https ca-certificates curl softwa…...

2025年阅读论文的常用工具推荐
在快速发展的学术界,阅读和整理论文的能力对于研究者和学生来说至关重要。随着科技的进步,各种工具应运而生,帮助我们更高效地处理文献。本文将为您推荐一些2025年最常用的阅读论文工具,让您的学术之路更加顺畅。 1. SumiNote S…...

pod内部共享命名空间与k8s命名空间是一个东西吗?
文章目录 小知识-命名空间**下面着重介绍一下刚刚提到的内部命名空间**IPC NamespaceNetwork Namespace 本文摘自于我的免费专栏《Kubernetes从0到1(持续更新)》请多关注 小知识-命名空间 注意,首先我要强调一点,Kubernetes命名空…...

Linux笔记---进程间通信:匿名管道
1. 管道通信 1.1 管道的概念与分类 管道(Pipe) 是进程间通信(IPC)的一种基础机制,主要用于在具有亲缘关系的进程(如父子进程、兄弟进程)之间传递数据,其核心特性是通过内核缓冲区实…...
桥接模式)
JAVA设计模式——(三)桥接模式
JAVA设计模式——(三)桥接模式(Bridge Pattern) 介绍理解实现武器抽象类武器实现类涂装颜色的行为接口具体颜色的行为实现让行为影响武器修改武器抽象类修改实现类 测试 适用性 介绍 将抽象和实现解耦,使两者可以独立…...

设计模式--工厂模式详解
工厂模式 作用: 实现了创建者与调用者的分离 详细分类 简单工厂模式 工厂方法模式 抽象工厂模式 OOP七大原则: 开闭原则:一个软件的实体应该对拓展开发,对修改关闭 依赖反转原则:要针对接口编程,不…...

每天五分钟深度学习PyTorch:图像的处理的上采样和下采样
本文重点 在pytorch中封装了上采样和下采样的方法,我们可以使用封装好的方法可以很方便的完成采样任务,采样分为上采样和下采样。 上采样和下采样 下采样(缩小图像)的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。 下采样( 放大图像)的…...

前端面试场景题
目录 1.项目第一次加载太慢优化 / vue 首屏加载过慢如何优化 2.说说了解的es6-es10的东西有哪些 ES6(ES2015)之后,JavaScript 新增了许多实用的数组和对象方法,下面为你详细介绍: 3.常见前端安全性问题 XSS&#…...

国际化不生效
经过我的重重检查 最终发现是 版本问题。 原本下载默认next版本cnpm install vue-i18nnext 下载 国际化插件 cnpm install vue-i18n^9.14.3 删除掉node_models,再重新加载包:cnpm install 这时候就可以正常显示了 国际化操作: en.js zh…...

新一代人工智能驱动医疗数智化:范式变革、实践方向及路径选择
人工智能(AI)正以前所未有的速度重构医疗健康行业的底层逻辑,从数据获取、知识建模到临床决策支持,AI不仅是“辅助工具”,更日益成为医疗生产力体系的核心引擎。随着大模型、计算平台和数智基础设施的迅猛发展,医疗数智化正进入从“点状创新”走向“系统重构”的深水区。…...
颜色空间转换-----将图像从 RGB 色彩空间转换为 I420 格式函数RGB2I420())
OpenCV 图形API(55)颜色空间转换-----将图像从 RGB 色彩空间转换为 I420 格式函数RGB2I420()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将图像从 RGB 色彩空间转换为 I420 色彩空间。 该函数将输入图像从 RGB 色彩空间转换为 I420。R、G 和 B 通道值的常规范围是 0 到 255。 输出图…...

大模型安全吗?数据泄露与AI伦理的黑暗面!
大模型安全吗?数据泄露与AI伦理的黑暗面! 随着人工智能技术的飞速发展,尤其是大型语言模型(如GPT-3、BERT等)的出现,AI的应用场景越来越广泛,从智能客服到内容生成,从医疗诊断到金融…...

穿越链路的旅程:深入理解计算机网络中的数据链路层
一、引言 在计算机网络的七层模型中,数据链路层(Data Link Layer) 是连接物理世界与逻辑网络世界的关键一环。它位于物理层之上,网络层之下,负责将物理层的“比特流”转换成具有结构的数据帧,并确保数据在…...

《AI大模型应知应会100篇》第35篇:Prompt链式调用:解决复杂问题的策略
第35篇:Prompt链式调用:解决复杂问题的策略 摘要 在大模型应用中,单次提示的能力往往受限于上下文长度和任务复杂度。为了解决这些问题,Prompt链式调用应运而生。本文将深入探讨如何通过分解任务、设计逻辑链路、传递中间结果&am…...

管理100个小程序-很难吗
20公里的徒步-真难 群里的伙伴发起了一场天目山20公里徒步的活动,想着14公里都轻松拿捏了,思考了30秒后,就借着春风带着老婆孩子就出发了。一开始溪流清澈见底,小桥流水没有人家;青山郁郁葱葱,枯藤老树没有…...

算法恢复训练-Part01-数组
注:参考的某算法训练营的计划 核心注意点 在 Golang(和大多数主流语言,如 C/C)中,二维数组按行访问的效率更高。因为它符合 Go 的内存连续存储结构,能提高 CPU Cache 命中率,减少内存跳跃带来…...

软件黑盒与白盒测试详解
黑盒测试与白盒测试的核心对比 一、定义与核心目标 黑盒测试 定义:将程序视为“黑盒”,仅通过输入和输出验证功能是否符合需求规格,不关注内部代码逻辑。目标:确保功能完整性、输入输出正确性及用户体验,例如验证购物车…...

本文通俗简介-优雅草星云物联网AI智控系统软件介绍-星云智控是做什么用途的??-优雅草卓伊凡
本文通俗简介-优雅草星云物联网AI智控系统软件介绍-星云智控是做什么用途的??-优雅草卓伊凡 星云智控:物联网设备实时监控的革新力量 一、引言 在科技飞速发展的当下,物联网技术的广泛应用使得各类设备的实时监控与管理变得愈发…...

达梦统计信息收集情况检查
查询达梦某个对象上是否有统计信息 select id,T_TOTAL,N_SMAPLE,N_DISTINCT,N_NULL,BLEVEL,N_LEAF_PAGES,N_LEAF_USED_PAGES,LAST_GATHERED from sysstats where id IN (select id from sysobjects where upper(name)upper(&objname));可能有系统对象,可以增加…...

【MQ篇】RabbitMQ之发布订阅模式!
目录 引言一、 回顾:简单模式与工作队列模式的局限 😔二、 发布/订阅模式详解:消息的“广播站” 📻三、 RabbitMQ 中的交换机类型:不同的“广播方式” 📻四、 Java (Spring Boot) 代码实战Fanout 模式的完整…...
添加自定义水印保护)
如何批量为多张图片(JPG、PNG、BMP、WEBP 等格式)添加自定义水印保护
「鹰迅批量处理工具箱」提供了强大的批量水印添加功能,支持常见的图片格式,如 JPG、JPEG、PNG、BMP、GIF、WEBP 等。用户不仅可以选择添加文字水印或图片水印,还能自定义设置水印的样式、位置和透明度等参数,操作简单而高效&#…...

LeetCode每日一题4.23
题目 问题分析 计算每个数字的数位和:对于从 1 到 n 的每个整数,计算其十进制表示下的数位和。 分组:将数位和相等的数字放到同一个组中。 统计每个组的数字数目:统计每个组中有多少个数字。 找到并列最多的组:返回数…...

Kafka简介
简介 基本概念 Kafka是分布式发布 - 订阅消息系统,最初由LinkedIn开发,后成为Apache项目一部分,可类比为放鸡蛋的篮子,生产者产蛋放入,消费者从中取蛋 。 消息系统 优势:分布式系统,易扩展&am…...

大数据利器:Kafka与Spark的深度探索
在大数据领域,Kafka和Spark都是极为重要的工具。今天就来和大家分享一下我在学习和使用它们过程中的心得。 Kafka作为分布式消息系统,优势显著。它吞吐量高、延迟低,能每秒处理几十万条消息,延迟最低仅几毫秒;可扩展性…...

使用logrotate实现日志轮转
logrotate 是一个强大的 Linux 工具,用于自动化管理日志文件的轮转、压缩、删除和归档。它能有效防止日志文件无限增长,节省磁盘空间,同时保持日志的可追溯性。以下是详细讲解 logrotate 的用法,涵盖安装、配置、测试、自动化、常…...