ubantu18.04(Hadoop3.1.3)Hive3.1.2安装指南

说明:本文图片较多,耐心等待加载。(建议用电脑)
注意所有打开的文件都要记得保存。本文的操作均在Master主机下进行
第一步:准备工作
本文是在之前Hadoop搭建完集群环境后继续进行的,因此需要读者完成我之前教程的所有操作。
准备我们的 Hive安装包文件和mysql jdbc 包
首先需要下载Hive安装包文件, Hive官网下载地址
也可以直接点击这里从百度云盘下载软件(提取码:ziyu)。进入百度网盘后,进入“软件”目录,找到apache-hive-3.1.2-bin.tar.gz文件,下载到本地。
https://dev.mysql.com/downloads/connector/j/mysql jdbc 包https://dev.mysql.com/downloads/connector/j/
我这里呢从网盘直接下载的,因为我从官网没有看到所需要的版本。大家可以找我拿,或者也从网盘下,也很快。
然后我们将下载好的两个文件放到之前的共享文件夹(之前都讲过,可以在第一章看到)
然后拖到下载里
第二步:安装Hive3.1.2
1.将两台虚拟机都启动。
2.下载并解压Hive安装包
进去Master终端,(右键-》打开终端)(注意下面的最后一个命令是你自己的用户名)
注意中文版是下载,英文版是DownLoads)
cd ~/下载
sudo tar -zxvf ./apache-hive-3.1.2-bin.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv apache-hive-3.1.2-bin hive # 将文件夹名改为hive
sudo chown -R hadoop-202202810203:hadoop-220202810203 hive 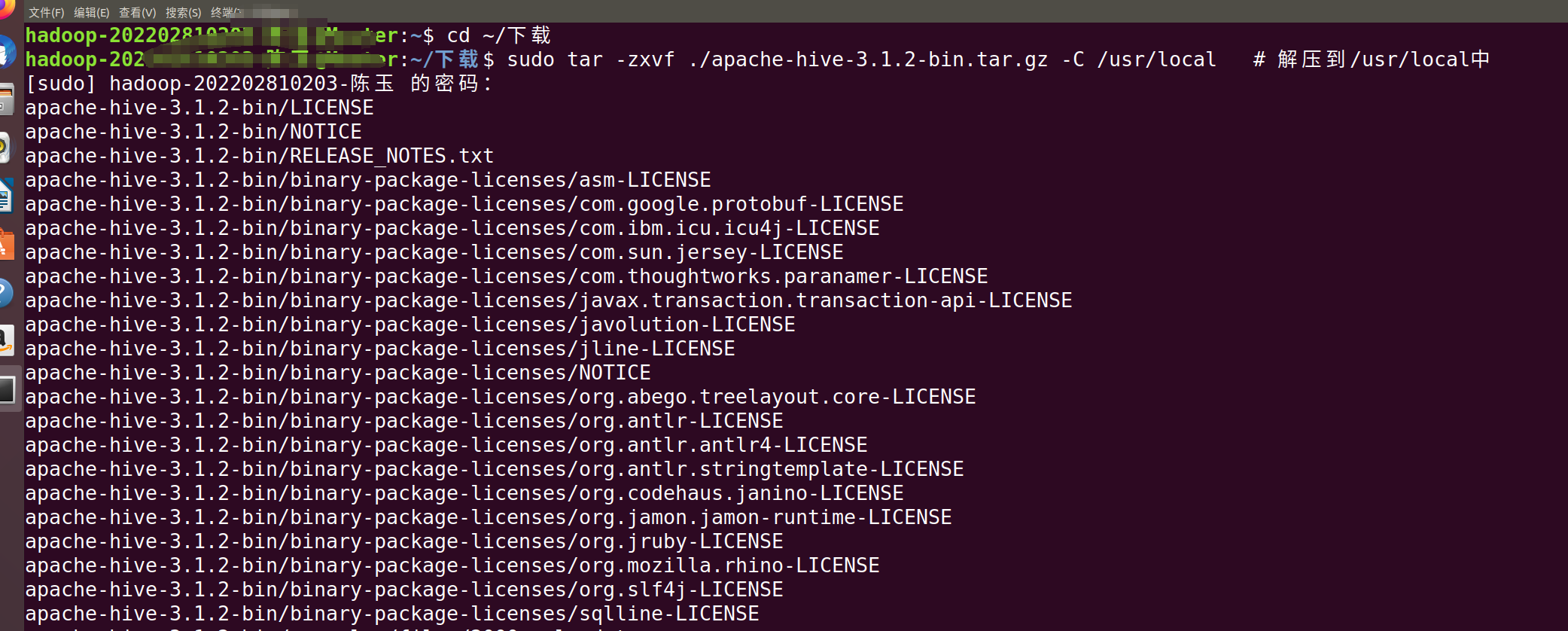
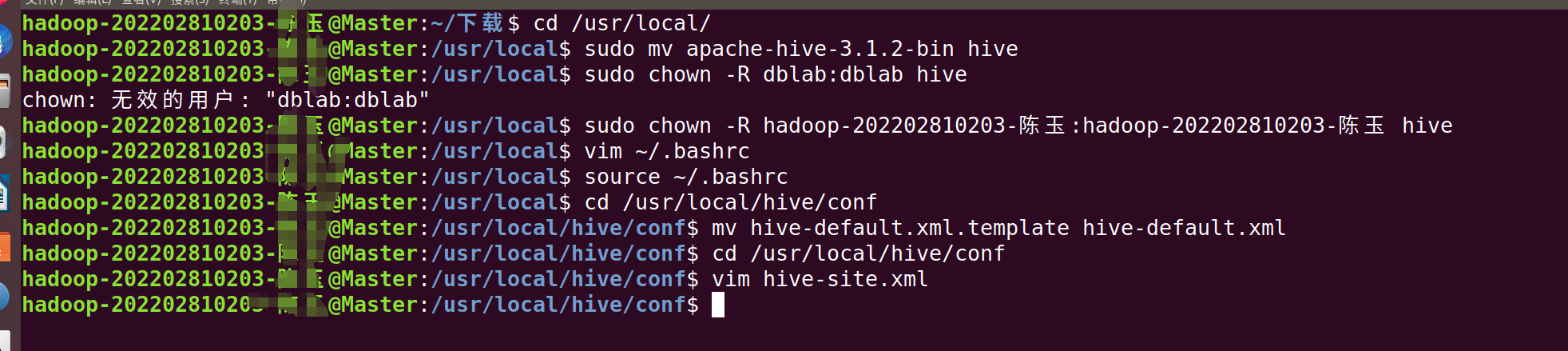
3. 配置环境变量
继续在终端输入以下命令
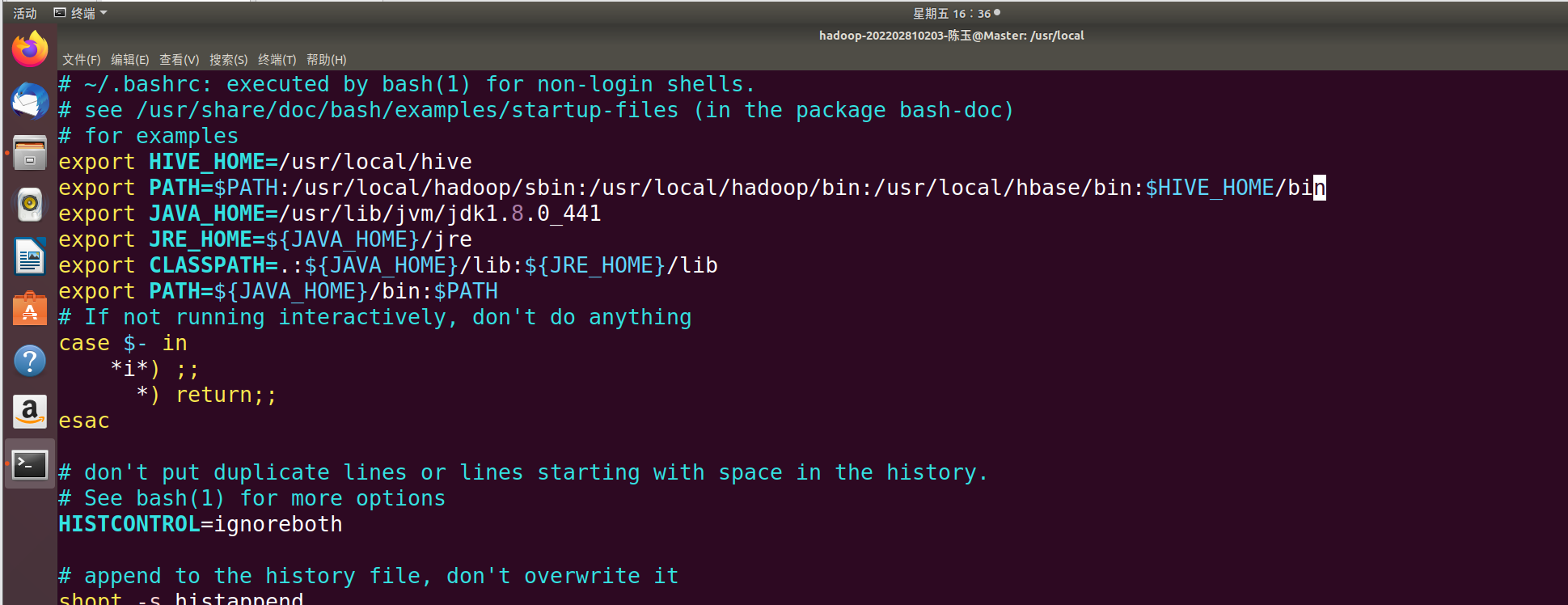
vim ~/.bashrcexport HIVE_HOME=/usr/local/hive
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin:/usr/local/hbase/bin:$HIVE_HOME/bin
将之前的内容替换为以上内容。
保存退出,继续输入:
source ~/.bashrc4.修改/usr/local/hive/conf下的hive-site.xml
继续输入以下内容“
cd /usr/local/hive/conf
mv hive-default.xml.template hive-default.xmlcd /usr/local/hive/conf
vim hive-site.xml
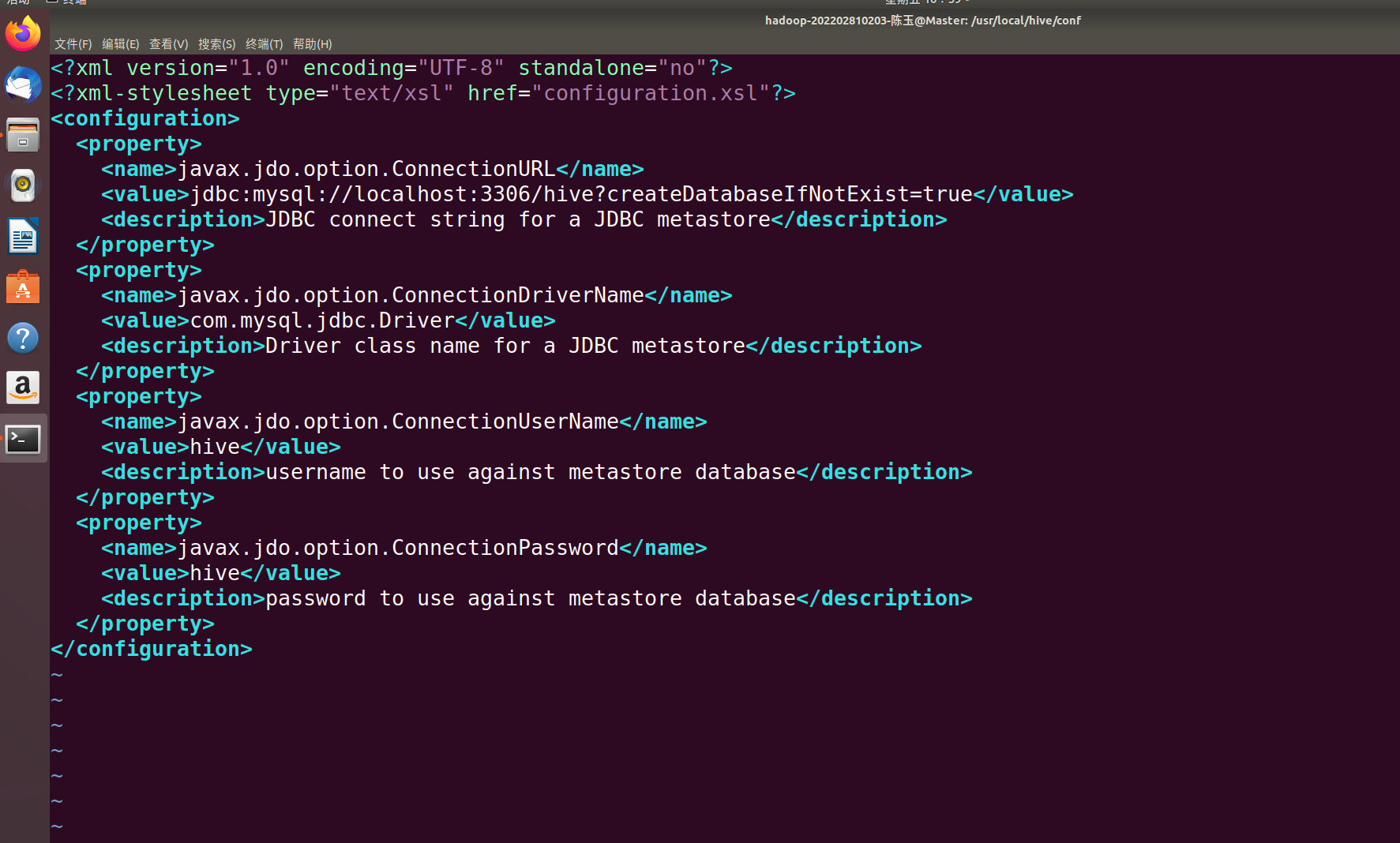
在hive-site.xml中添加如下配置信息:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?useSSL=false&createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
然后,按键盘上的“ESC”键退出vim编辑状态,再输入:wq,保存并退出vim编辑器。
第三步:安装并配置mysql
1.Ubuntu下mysql
在终端继续执行以下命令:
cd ~
sudo apt update
sudo apt install mysql-server
 按下Y回车
按下Y回车
安装完成后,启动mysql
sudo systemctl start mysql
为了方便之后的登录,我们先修改 MySQL 的 root 用户认证方式
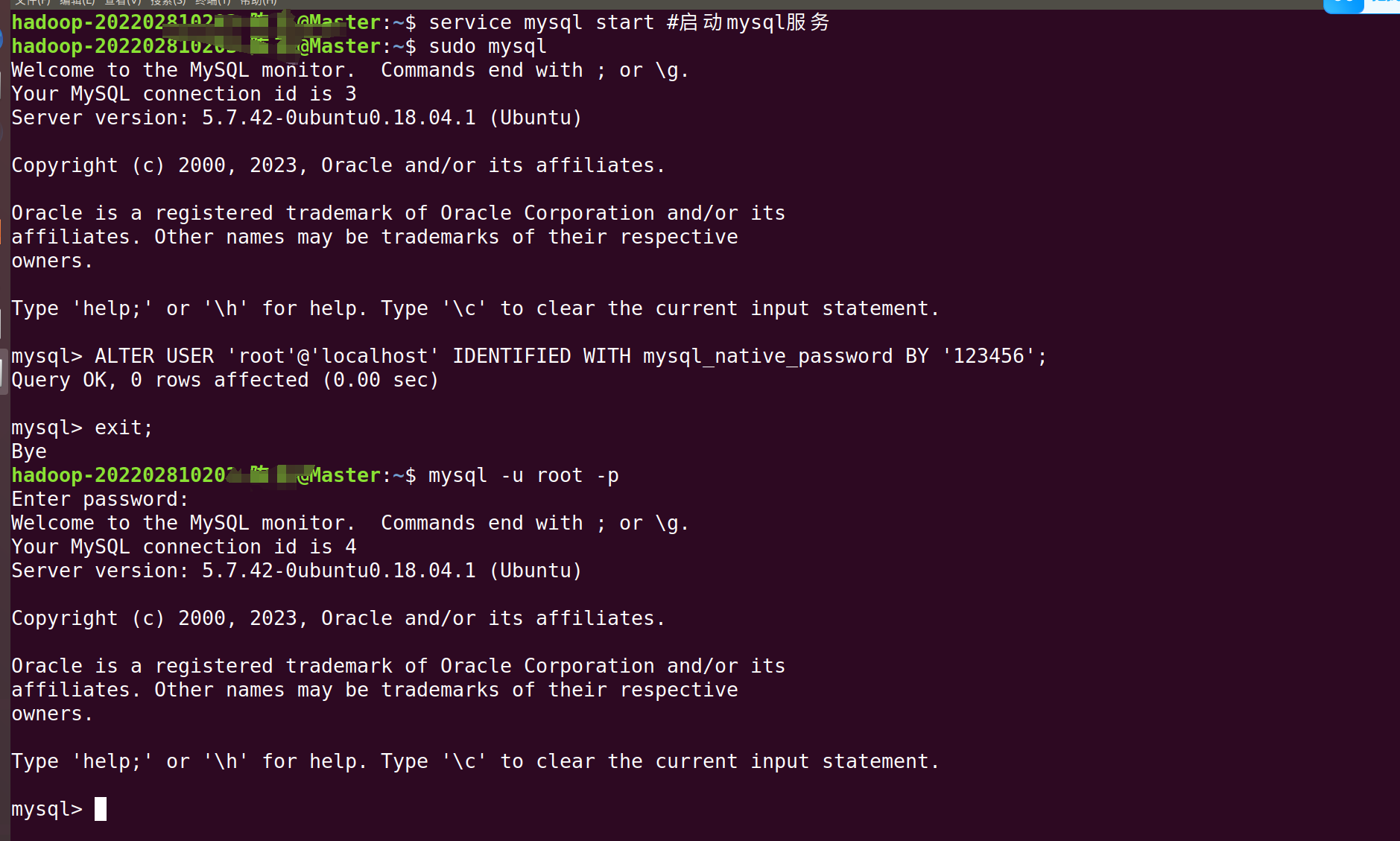
1. 用 sudo 登录 MySQL:
sudo mysql2. 修改 root 用户的验证方式为 mysql_native_password:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';4. 现在再用密码登录试试:(密码是我们刚刚设置的123456)
mysql -u root -p然后输入你的密码123456。
 5.mysql jdbc 包
5.mysql jdbc 包
输入exit退出mysql
exit;我们继续在终端输入以下命令(注意中文版是下载,英文版是DownLoads)
cd ~/下载
tar -zxvf mysql-connector-java-5.1.40.tar.gz #解压
cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib #将mysql-connector-java-5.1.40-bin.jar拷贝到/usr/local/hive/lib目录下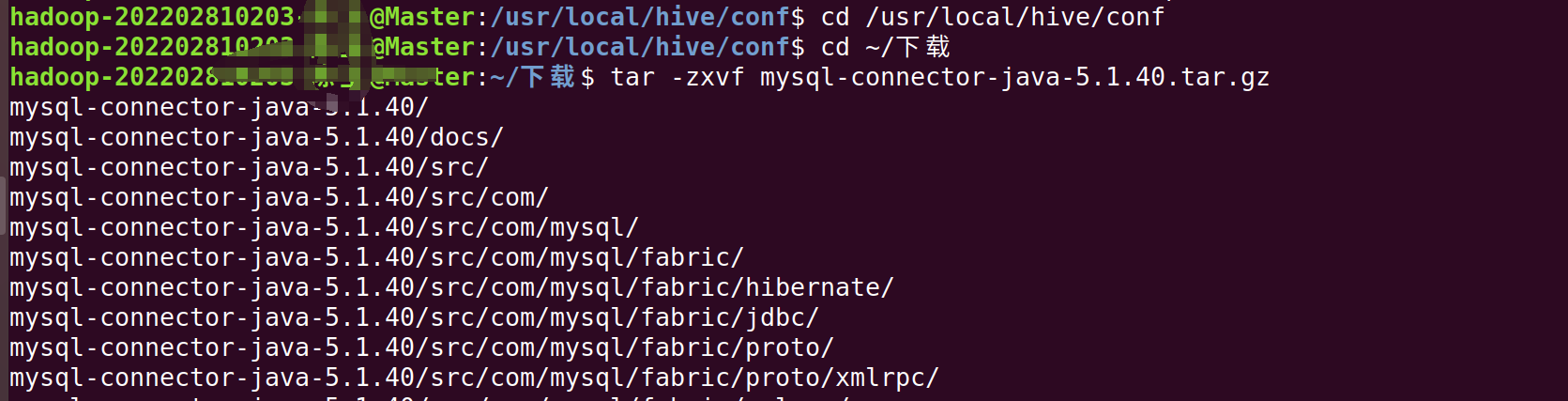
6.新建hive数据库。
mysql -u root -p 输入密码123456登录到mysql输入下面的命令
create database hive; #这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据7.配置mysql允许hive接入:
继续在mysql输入以下内容:
grant all on *.* to hive@localhost identified by 'hive'; #将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
flush privileges; #刷新mysql系统权限关系表这里忘了截屏了,应该不会出错 ,然后记得Exit
8.启动hive
启动hive之前,请先启动hadoop集群。
1.进去Master终端,(右键-》打开终端),启动,并用jps检查是否成功启动
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver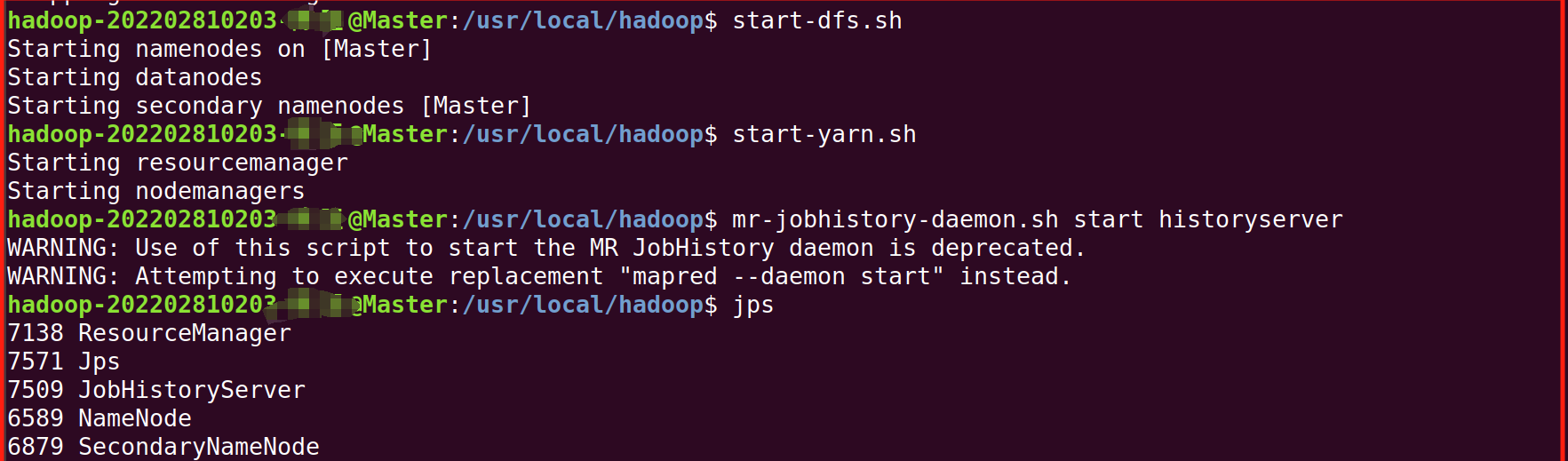
我们再启动是会报错,为了避免报错,我们进行如下操作
2. 在终端继续输入以下命令:
find /usr/local/hive/ -name "guava*.jar"
find /usr/local/hadoop/ -name "guava*.jar"
如果两个一样,你可以跳过这一步。 不一样就执行以下命令:(注意下面的版本号用自己的)
rm /usr/local/hive/lib/guava-19.0.jar
cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib/
3.在终端继续输入以下命令:
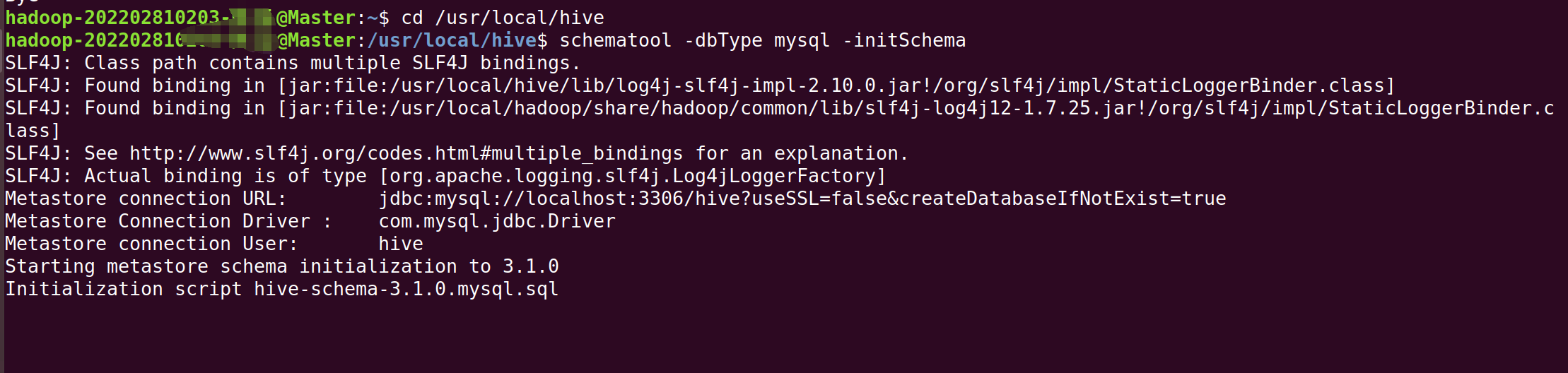
cd /usr/local/hiveschematool -dbType mysql -initSchema
4.启动,在终端输入
hive #启动hive启动进入Hive的交互式执行环境以后,会出现如下命令提示符:
hive>第四步:Hive的常用HiveQL操作
这一个我单独成一章,大家可以在我的专栏里看到。我这里直接进行下一步。
第五步:Hive简单编程实践
退出上面的hive,(输入exit)在终端继续输入下面的命令
1.1)创建input目录,output目录会自动生成。其中input为输入目录,output目录为输出目录。命令如下:
cd /usr/local/hadoop
mkdir input2)然后,在input文件夹中创建两个测试文件file1.txt和file2.txt,命令如下:
cd /usr/local/hadoop/input
echo "hello world" > file1.txt
echo "hello hadoop" > file2.txt为了后续区分,我们之前有好多文件都弄到一个目录里了,这里我们新创建 HDFS 目标目录
创建 HDFS 目标目录(如果未创建)
hdfs dfs -mkdir -p /user/hadoop/input2

将本地文件上传到 HDFS
hadoop fs -put /usr/local/hadoop/input/file1.txt /user/hadoop/input2/
hadoop fs -put /usr/local/hadoop/input/file2.txt /user/hadoop/input2/
3)执行如下hadoop命令:
cd ..
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /user/hadoop/input2 /user/hadoop/output2
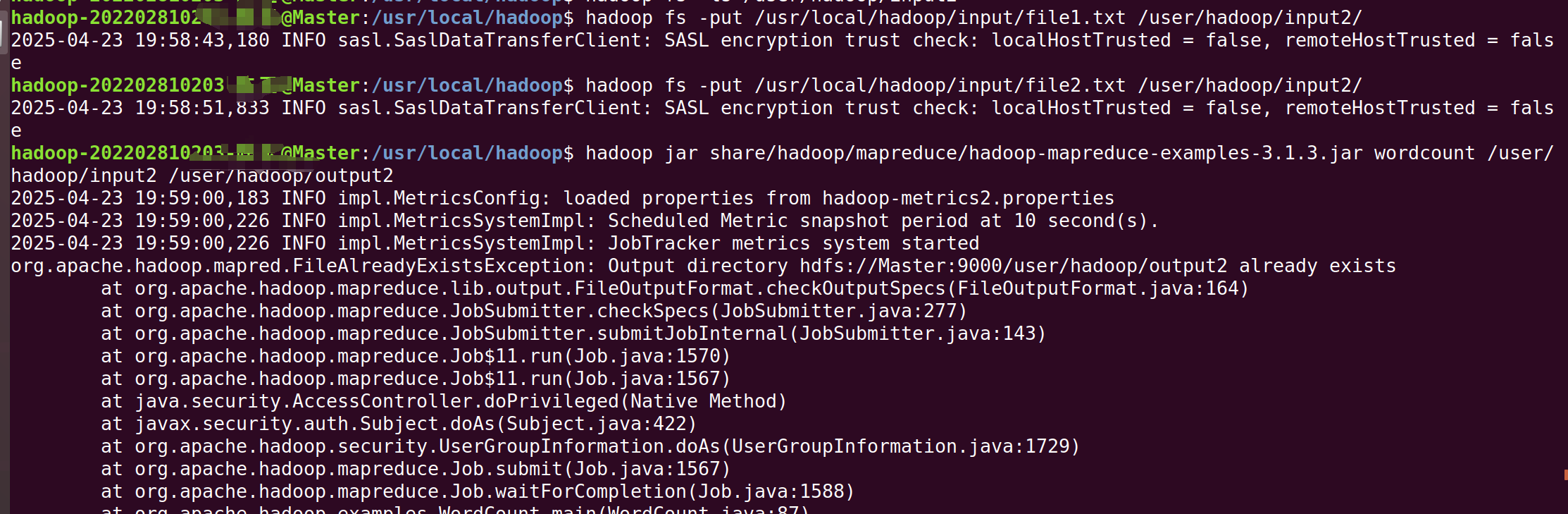
./bin/hdfs dfs -cat /user/hadoop/output2/*

下面我们通过HiveQL实现词频统计功能,此时只要编写下面7行代码,而且不需要进行编译生成jar来执行。HiveQL实现命令如下:
我们先进入hive,直接启动
在终端输入
hive1. 创建表 docs
首先创建一个表 docs,它将存储每一行文本
create table docs(line string);2. 将文件数据加载到表中
然后,使用 LOAD DATA 命令将本地文件系统中的数据加载到 docs 表中。这里的路径 'file:///usr/local/hadoop/input' 是文件存放路径。
load data inpath 'file:///usr/local/hadoop/input' overwrite into table docs;3. 创建表 word_count 并统计词频
在创建表 word_count 时,HiveQL 查询会:
-
使用
explode和split函数将每行文本按空格分割为单词,并将其作为word列。 -
对每个单词进行计数,并按字母顺序排序。
create table word_count as select word, count(1) as count from (select explode(split(line, ' ')) as word from docs) w group by word order by word;详细步骤解释:
-
split(line, ' '):使用split函数将line列的每一行文本按空格切割成单词。 -
explode():explode将每个文本行拆分成多个单词,每个单词成为一行数据。 -
group by word:按word列分组,并使用count(1)来计算每个单词的出现次数。 -
order by word:按字母顺序对单词进行排序.
继续在终端输入:
select * from word_count;
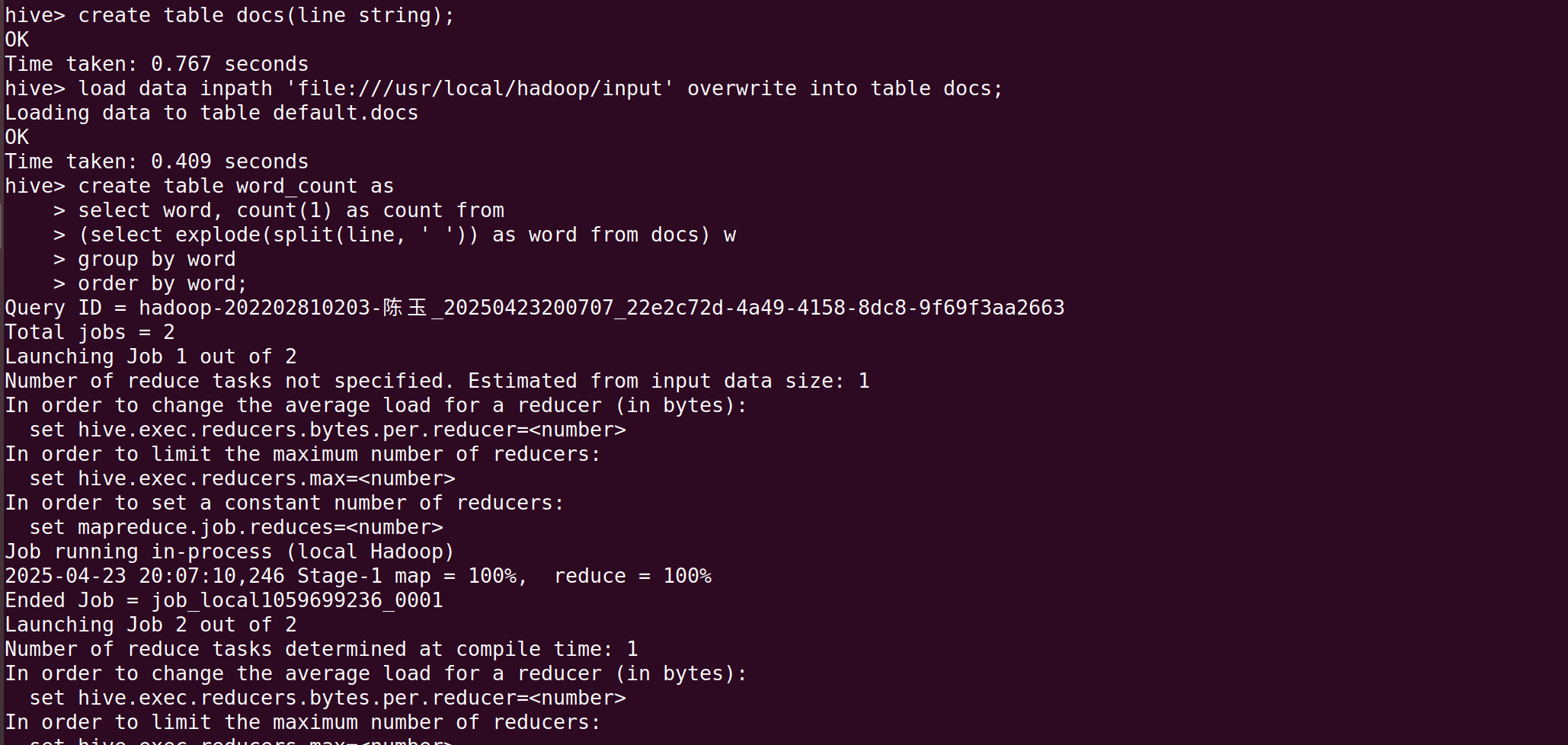
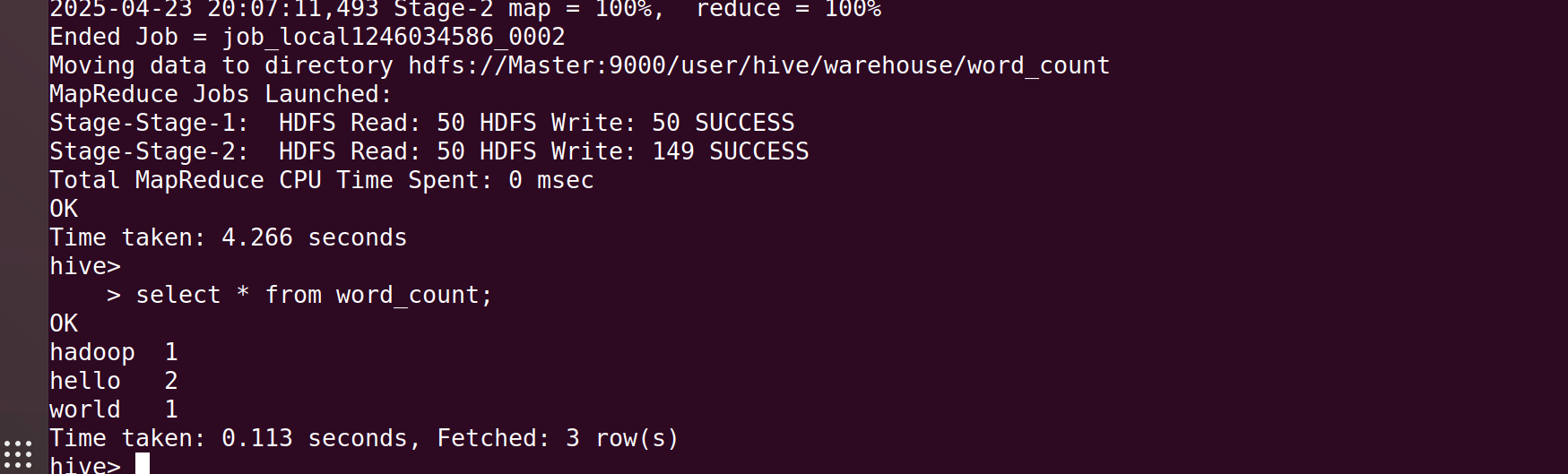
出现如上界面即为成功。
结语:整体的操作步我都给大家写出来,并且截图了,大家只需要无脑粘贴就好了,具体的讲解可以看我的资料里的文档解释更加详细,这个实验就结束了。
上面内容制作不易,喜欢的点个赞和收藏支持一下吧!!
后期会持续更新更多大数据内容,如果想共同学习,就点点关注把(
相关文章:
Hive3.1.2安装指南)
ubantu18.04(Hadoop3.1.3)Hive3.1.2安装指南
说明:本文图片较多,耐心等待加载。(建议用电脑) 注意所有打开的文件都要记得保存。本文的操作均在Master主机下进行 第一步:准备工作 本文是在之前Hadoop搭建完集群环境后继续进行的,因此需要读者完成我之…...

Hive 多表查询案例
文章目录 前提条件Hive 多表查询案例JOIN案例JOIN查询数据准备1. 内连接(INNER JOIN)2. 左外连接(LEFT OUTER JOIN)3. 右外连接(RIGHT OUTER JOIN)4. 全外连接(FULL OUTER JOIN)5. 多…...
)
4.23刷题记录(栈与队列专题)
第一部分:基础知识 栈先进后出,队列先进先出栈用stack实现,主要函数有pop,push,top队列由queue或者deque实现,主要函数有front,back,push,pop,emplace&#…...
)
Python常用的第三方模块之【jieba库】支持三种分词模式:精确模式、全模式和搜索引擎模式(提高召回率)
Jieba 是一个流行的中文分词Python库,它提供了三种分词模式:精确模式、全模式和搜索引擎模式。精确模式尝试将句子最精确地切分,适合文本分析;全模式则扫描文本中所有可能的词语,速度快但存在冗余;搜索引擎…...

Redisson实战:分布式系统中的五大典型应用场景
引言 在分布式系统架构中,数据一致性、高并发控制和资源协调是开发者面临的核心挑战。Redisson作为基于Redis的Java客户端,不仅提供了丰富的分布式对象和服务,还简化了分布式场景下的编程模型。本文将通过实际代码示例,解析Redis…...

webrtc建立连接的过程
WebRTC 连接全过程:从零到视频通话的每一步 WebRTC 是个神奇的技术,让浏览器直接进行点对点(P2P)音视频通话或数据传输,不用每次都靠服务器中转。想知道 Alice 和 Bob 是怎么通过 WebRTC 建立视频通话的吗?…...

system verilog 语句 耗时规则
在 SystemVerilog 中,确实有一类语句是**不消耗仿真时间(zero simulation time)**的,我们一般叫它们: ✅ 零延迟语句(Zero-Time Statements) 🔹1. 什么是“不费时间”的语句? 这些语句在仿真时…...

【Docker】在Ubuntu平台上的安装部署
写在前面 docker作为一种部署项目的辅助工具,真是太好用了需要魔法,不然无法正常运行笔者环境:ubuntu22.04 具体步骤 更新系统包索引 sudo apt update安装必要依赖包 sudo apt install -y apt-transport-https ca-certificates curl softwa…...

2025年阅读论文的常用工具推荐
在快速发展的学术界,阅读和整理论文的能力对于研究者和学生来说至关重要。随着科技的进步,各种工具应运而生,帮助我们更高效地处理文献。本文将为您推荐一些2025年最常用的阅读论文工具,让您的学术之路更加顺畅。 1. SumiNote S…...

pod内部共享命名空间与k8s命名空间是一个东西吗?
文章目录 小知识-命名空间**下面着重介绍一下刚刚提到的内部命名空间**IPC NamespaceNetwork Namespace 本文摘自于我的免费专栏《Kubernetes从0到1(持续更新)》请多关注 小知识-命名空间 注意,首先我要强调一点,Kubernetes命名空…...

Linux笔记---进程间通信:匿名管道
1. 管道通信 1.1 管道的概念与分类 管道(Pipe) 是进程间通信(IPC)的一种基础机制,主要用于在具有亲缘关系的进程(如父子进程、兄弟进程)之间传递数据,其核心特性是通过内核缓冲区实…...
桥接模式)
JAVA设计模式——(三)桥接模式
JAVA设计模式——(三)桥接模式(Bridge Pattern) 介绍理解实现武器抽象类武器实现类涂装颜色的行为接口具体颜色的行为实现让行为影响武器修改武器抽象类修改实现类 测试 适用性 介绍 将抽象和实现解耦,使两者可以独立…...

设计模式--工厂模式详解
工厂模式 作用: 实现了创建者与调用者的分离 详细分类 简单工厂模式 工厂方法模式 抽象工厂模式 OOP七大原则: 开闭原则:一个软件的实体应该对拓展开发,对修改关闭 依赖反转原则:要针对接口编程,不…...

每天五分钟深度学习PyTorch:图像的处理的上采样和下采样
本文重点 在pytorch中封装了上采样和下采样的方法,我们可以使用封装好的方法可以很方便的完成采样任务,采样分为上采样和下采样。 上采样和下采样 下采样(缩小图像)的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。 下采样( 放大图像)的…...

前端面试场景题
目录 1.项目第一次加载太慢优化 / vue 首屏加载过慢如何优化 2.说说了解的es6-es10的东西有哪些 ES6(ES2015)之后,JavaScript 新增了许多实用的数组和对象方法,下面为你详细介绍: 3.常见前端安全性问题 XSS&#…...

国际化不生效
经过我的重重检查 最终发现是 版本问题。 原本下载默认next版本cnpm install vue-i18nnext 下载 国际化插件 cnpm install vue-i18n^9.14.3 删除掉node_models,再重新加载包:cnpm install 这时候就可以正常显示了 国际化操作: en.js zh…...

新一代人工智能驱动医疗数智化:范式变革、实践方向及路径选择
人工智能(AI)正以前所未有的速度重构医疗健康行业的底层逻辑,从数据获取、知识建模到临床决策支持,AI不仅是“辅助工具”,更日益成为医疗生产力体系的核心引擎。随着大模型、计算平台和数智基础设施的迅猛发展,医疗数智化正进入从“点状创新”走向“系统重构”的深水区。…...
颜色空间转换-----将图像从 RGB 色彩空间转换为 I420 格式函数RGB2I420())
OpenCV 图形API(55)颜色空间转换-----将图像从 RGB 色彩空间转换为 I420 格式函数RGB2I420()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将图像从 RGB 色彩空间转换为 I420 色彩空间。 该函数将输入图像从 RGB 色彩空间转换为 I420。R、G 和 B 通道值的常规范围是 0 到 255。 输出图…...

大模型安全吗?数据泄露与AI伦理的黑暗面!
大模型安全吗?数据泄露与AI伦理的黑暗面! 随着人工智能技术的飞速发展,尤其是大型语言模型(如GPT-3、BERT等)的出现,AI的应用场景越来越广泛,从智能客服到内容生成,从医疗诊断到金融…...

穿越链路的旅程:深入理解计算机网络中的数据链路层
一、引言 在计算机网络的七层模型中,数据链路层(Data Link Layer) 是连接物理世界与逻辑网络世界的关键一环。它位于物理层之上,网络层之下,负责将物理层的“比特流”转换成具有结构的数据帧,并确保数据在…...

《AI大模型应知应会100篇》第35篇:Prompt链式调用:解决复杂问题的策略
第35篇:Prompt链式调用:解决复杂问题的策略 摘要 在大模型应用中,单次提示的能力往往受限于上下文长度和任务复杂度。为了解决这些问题,Prompt链式调用应运而生。本文将深入探讨如何通过分解任务、设计逻辑链路、传递中间结果&am…...

管理100个小程序-很难吗
20公里的徒步-真难 群里的伙伴发起了一场天目山20公里徒步的活动,想着14公里都轻松拿捏了,思考了30秒后,就借着春风带着老婆孩子就出发了。一开始溪流清澈见底,小桥流水没有人家;青山郁郁葱葱,枯藤老树没有…...

算法恢复训练-Part01-数组
注:参考的某算法训练营的计划 核心注意点 在 Golang(和大多数主流语言,如 C/C)中,二维数组按行访问的效率更高。因为它符合 Go 的内存连续存储结构,能提高 CPU Cache 命中率,减少内存跳跃带来…...

软件黑盒与白盒测试详解
黑盒测试与白盒测试的核心对比 一、定义与核心目标 黑盒测试 定义:将程序视为“黑盒”,仅通过输入和输出验证功能是否符合需求规格,不关注内部代码逻辑。目标:确保功能完整性、输入输出正确性及用户体验,例如验证购物车…...

本文通俗简介-优雅草星云物联网AI智控系统软件介绍-星云智控是做什么用途的??-优雅草卓伊凡
本文通俗简介-优雅草星云物联网AI智控系统软件介绍-星云智控是做什么用途的??-优雅草卓伊凡 星云智控:物联网设备实时监控的革新力量 一、引言 在科技飞速发展的当下,物联网技术的广泛应用使得各类设备的实时监控与管理变得愈发…...

达梦统计信息收集情况检查
查询达梦某个对象上是否有统计信息 select id,T_TOTAL,N_SMAPLE,N_DISTINCT,N_NULL,BLEVEL,N_LEAF_PAGES,N_LEAF_USED_PAGES,LAST_GATHERED from sysstats where id IN (select id from sysobjects where upper(name)upper(&objname));可能有系统对象,可以增加…...

【MQ篇】RabbitMQ之发布订阅模式!
目录 引言一、 回顾:简单模式与工作队列模式的局限 😔二、 发布/订阅模式详解:消息的“广播站” 📻三、 RabbitMQ 中的交换机类型:不同的“广播方式” 📻四、 Java (Spring Boot) 代码实战Fanout 模式的完整…...
添加自定义水印保护)
如何批量为多张图片(JPG、PNG、BMP、WEBP 等格式)添加自定义水印保护
「鹰迅批量处理工具箱」提供了强大的批量水印添加功能,支持常见的图片格式,如 JPG、JPEG、PNG、BMP、GIF、WEBP 等。用户不仅可以选择添加文字水印或图片水印,还能自定义设置水印的样式、位置和透明度等参数,操作简单而高效&#…...

LeetCode每日一题4.23
题目 问题分析 计算每个数字的数位和:对于从 1 到 n 的每个整数,计算其十进制表示下的数位和。 分组:将数位和相等的数字放到同一个组中。 统计每个组的数字数目:统计每个组中有多少个数字。 找到并列最多的组:返回数…...

Kafka简介
简介 基本概念 Kafka是分布式发布 - 订阅消息系统,最初由LinkedIn开发,后成为Apache项目一部分,可类比为放鸡蛋的篮子,生产者产蛋放入,消费者从中取蛋 。 消息系统 优势:分布式系统,易扩展&am…...

大数据利器:Kafka与Spark的深度探索
在大数据领域,Kafka和Spark都是极为重要的工具。今天就来和大家分享一下我在学习和使用它们过程中的心得。 Kafka作为分布式消息系统,优势显著。它吞吐量高、延迟低,能每秒处理几十万条消息,延迟最低仅几毫秒;可扩展性…...

使用logrotate实现日志轮转
logrotate 是一个强大的 Linux 工具,用于自动化管理日志文件的轮转、压缩、删除和归档。它能有效防止日志文件无限增长,节省磁盘空间,同时保持日志的可追溯性。以下是详细讲解 logrotate 的用法,涵盖安装、配置、测试、自动化、常…...

第52讲:农业AI + 区块链——迈向可信、智能、透明的未来农业
目录 一、为什么农业需要“AI+区块链”? 二、核心应用场景解读 1. 农产品溯源系统 2. 农业信贷与保险精准评估 3. 农业碳足迹追踪与碳汇交易 三、案例实战分享:智能溯源 + 区块链合约 四、面临挑战与展望 五、总结 在数字农业时代,“AI” 和 “区块链” 是两股不容忽…...

视频智能分析平台EasyCVR无线监控:全流程安装指南与功能应用解析
在当今数字化安防时代,无线监控系统的安装与调试对于保障各类场所的安全至关重要。本文将结合EasyCVR视频监控的强大功能,为您详细阐述监控系统安装过程中的关键步骤和注意事项,帮助您打造一个高效、可靠的监控解决方案。 一、调试物资准备与…...

Spring Cloud Eureka 与 Nacos 深度解析:从架构到对比
一、Eureka:经典微服务注册中心 (一)核心定位与特性 Spring Cloud Eureka 是 Netflix 开源的服务注册与发现组件,在微服务架构中扮演 "大脑" 角色,负责服务的注册、发现与状态管理。其核心优势在于通过心跳…...

深入详解Java中的@PostConstruct注解:实现简洁而高效初始化操作
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...
(组件引用查找工具实现笔记))
【Unity笔记】Unity 编辑器扩展:一键查找场景中组件引用关系(含完整源码)(组件引用查找工具实现笔记)
摘要: 本文介绍了如何在 Unity 编辑器中开发一款实用的编辑器扩展工具 —— ComponentReferenceFinder,用于查找场景中对某个自定义组件的引用关系。该工具特别适用于大型项目、多人协作或引入外部插件后,快速定位组件间的耦合关系。 本文从需…...

实体店的小程序转型之路:拥抱新零售的密码-中小企实战运营和营销工作室博客
实体店的小程序转型之路:拥抱新零售的密码-中小企实战运营和营销工作室博客 在当今数字化浪潮的冲击下,实体店面临着前所未有的挑战,但小程序的出现为实体店转型新零售带来了新的曙光。先来看一组惊人的数据,据相关统计ÿ…...

Mysql安装与备份配置分析
若之前存有msqyl的数据缓存,建议用以下命令将数据文件删除干净 mysql-server:主程序 mysql:客户端工具 mysql-devel:开发库 mysql-libs:共享库文件 /var/lib/mysql:数据目录 /etc/my.cnf : 主配置文件 …...

Android APP 爬虫操作
工具 夜神模拟器、charles、mitm 等 mitm的使用参考:Mitmproxy对Android进行抓包(真机)_mitmproxy 安卓-CSDN博客 charles的使用参考:【全网最详细】手把手教学Charles抓包工具详细自学教程,完整版安装教程,详细介绍…...

与Ubuntu相关命令
windows将文件传输到Ubuntu 传输文件夹或文件 scp -r 本地文件夹或文件 ubuntu用户名IP地址:要传输到的文件夹路径 例如: scp -r .\04.py gao192.168.248.129:/home/gao 如果传输文件也可以去掉-r 安装软件 sudo apt-get update 更新软件包列表 sudo apt insta…...

Unity常用内置变换矩阵
Unity引擎提供了一系列内置的变换矩阵,这些矩阵在着色器中用于处理物体、摄像机和光照的坐标变换,是游戏开发中不可或缺的工具。它们帮助开发者在顶点着色器和片段着色器中实现坐标转换、光照计算等功能。 主要变换矩阵类型 模型矩阵 (Model Matrix) /…...

算法题-图论
图的表示 207.课程表 127.单词接龙 图的遍历 DFS 递归。。。 200.岛屿数量 239.矩阵中的最长递增路径 BFS 102.二叉树的层序遍历 看到最短,首先想到的是BFS 542.01矩阵 207.课程表 127.单词接龙 拓扑排序 对于一个有向无环图G进行拓扑排序,是将G中…...
安装笔记)
Java 8(Ubuntu 18.04.6 LTS)安装笔记
一、前言 本文与【MySQL 8(Ubuntu 18.04.6 LTS)安装笔记】同批次:先搭建数据库,再安装JVM,后面肯定就是部署Web应用了——典型的单机部署,真可谓“麻雀虽小五脏俱全”。 二、准备 (1ÿ…...

unity编辑器的json验证及格式化
UNITY编辑器的json格式化和验证工具资源-CSDN文库https://download.csdn.net/download/qq_38655924/90676188?spm1001.2014.3001.5501 反复去别的网站验证json太麻烦了 用这个工具能方便点 # Unity JSON工具 这是一个Unity编辑器扩展,用于验证、格式化和压缩JSO…...

C语言中小写字母转大写字母
一、题目引入 这一题运行结果是什么? 二、代码分析 在这个代码中 首先 -> 定义了一个字符数组空间内存是80 里面存储的是字符串123abcdEFG*& 接着 -> 定义了一个整型变量j 后面的循环会用到 然后 -> 使用了<stdio.h>中的库函数puts(ch)原样打印…...

深度学习--卷积神经网络调整学习率
文章目录 前言一、学习率1、什么学习率2、什么是调整学习率3、目的 二、调整方法1、有序调整1)有序调整StepLR(等间隔调整学习率)2)有序调整MultiStepLR(多间隔调整学习率)3)有序调整ExponentialLR (指数衰减调整学习率)4)有序调整…...

桥接模式:分离抽象与实现的独立进化
桥接模式:分离抽象与实现的独立进化 一、模式核心:解耦抽象与实现的多层变化 在软件设计中,当抽象(如 “手机品牌”)和实现(如 “操作系统”)都可能独立变化时,使用多层继承会导致…...

配置kafka与spark连接
一、配置kafka 首先进到software目录当中,如下图所示: 安装包上传/解压/重命名/解压过后的目录如下图所示: 修改配置: cd config vi server.properties 全部修改语句如下所示(以node01为样例)࿱…...

WebXR教学 05 项目3 太空飞船小游戏
准备工作 自动创建 package.json 文件 npm init -y 安装Three.js 3D 图形库,安装现代前端构建工具Vite(用于开发/打包) npm install three vite 启动 Vite 开发服务器(推荐)(正式项目开发) …...