Representation Flow for Action Recognition论文笔记
原文笔记:
What:
在本文中,我们提出了一种受光流算法启发的CNN层,用于学习动作识别的运动表示,而无需计算光流。我们的表示流层是一个完全可微分的层,旨在捕获模型中任何表示通道的“流”。其迭代流量优化参数与其他模型参数一起学习,最大化动作识别表现。
Why:
借助光流的模型通过额外信息提高了模型效果,但也面临着其他问题:
1、光流本身的计算成本很高
2、使用光流的模型,参数量成倍上升,这会导致训练时间增加
3、使用光流进行训练本身就会造成训练时间增加
4、训练时难以做到端到端
5、即使在推理和过程中也需要计算每一帧的光流,并运行两个并行CNN,限制其实时应用。
Challenge:
最主要的挑战就是在保证使用光流的模型的效果的同时加快训练速度
How:
1、既然光流的计算成本很高,那就补计算光流改成计算特征流,这样仅需增加少量参数,就可以达到使用光流的效果,并且可以实现端到端的训练。
2、计算特征流时可能无法做到GPU的完全占用,会有效率瓶颈,作者采用卷积的方式来实现计算光流的方法从而来计算特征流,解决了该问题。
原文翻译:
Abstract
在本文中,我们提出了一种受光流算法启发的卷积层来学习运动表示。我们的表示流层是一个完全可微的层,旨在捕获卷积神经网络中任何特征通道的“流”以进行动作识别。它用于迭代流优化的参数以端到端的方式与其他 CNN 模型参数一起学习,最大化动作识别性能。此外,我们通过堆叠多个表示流层来新引入的学习“流流(flow of flow)”表示的概念。我们进行了广泛的实验评估,证实了它在计算速度和性能方面优于传统的光流的识别模型的优势。该代码是公开的。1
1. Introduction
活动识别是计算机视觉中的一个重要问题,具有许多社会应用,包括监控,机器人感知,智能环境/城市等。使用视频卷积神经网络(cnn)已经成为这项任务的标准方法,因为它们可以为问题学习更优的表示。双流网络[20],采用RGB帧和光流作为输入,提供了最先进的结果,并且非常受欢迎。使用XYT卷积的三维时空CNN模型,如I3D[3],也发现这种双流设计(RGB +光流)提高了模型的精度。同时提取外观信息和明确的运动流有利于识别。
然而,光流的计算成本很高。它通常需要每帧数百个优化迭代,并导致学习两个独立的 CNN 流(即 RGBstream 和 flow-stream)。这需要大量的计算成本和要学习的模型参数数量大幅增加。此外,这意味着模型即使在推理和过程中也需要计算每一帧的光流,并运行两个并行CNN,限制其实时应用。
以前的工作是在不使用光流作为输入的情况下学习捕获运动信息的表示,例如运动特征网络[15]和ActionFlowNet[16]。然而,尽管它们在模型参数和计算速度方面更有利,但与Kinetics[13]和HMDB[14]等公共数据集上的双流模型相比,它们的性能较差。我们假设光流方法执行的迭代优化产生了其他方法无法捕获的重要特征。
在本文中,我们提出了一种受光流算法启发的CNN层,用于学习动作识别的运动表示,而无需计算光流。我们的表示流层是一个完全可微分的层,旨在捕获模型中任何表示通道的“流”。其迭代流量优化参数与其他模型参数一起学习,最大化动作识别表现。这也可以在没有/训练多个网络流的情况下完成,从而减少模型中的参数数量。此外,我们通过堆叠多个表示流层来新提出学习“流的流”表示的概念。我们对光流计算的位置以及各种超参数、学习参数和融合技术进行了广泛的动作分类实验评估。
我们的贡献是引入了一种新的可区分的CNN层,该层展开了TV-L1光学流方法的迭代。这允许学习光流参数,应用于任何CNN特征图(例如中间表示),并在保持性能的同时降低计算成本。
2. Related Works
捕获运动和时间信息已被研究用于活动识别。早期,手工制作的方法,如密集轨迹[24],通过跟踪时间点来捕获运动信息。许多计算光流的算法已经被开发出来,作为一种捕捉视频中运动的方法。其他的研究还探索了学习帧的顺序,以便在单个“动态图像”中总结视频,用于活动识别[1]。
卷积神经网络(cnn)已被应用于活动识别。最初的方法探索了基于池化或时间卷积的组合时间信息的方法[12,17]。其他作品探索了使用注意力来捕捉活动b[18]的子事件。双流网络已经非常流行:它们接受单个RGB帧(捕获外观信息)和一堆光流帧(捕获运动信息)的输入。通常,模型的两个网络流是分开训练的,最终的预测结果是平均的。还有其他双流CNN作品探索了不同的方式来“融合”或结合运动CNN和外观CNN[7,6]。还有大型3D XYT cnn学习时空模式[26,3],这是由Kinetics[13]等大型视频数据集实现的。然而,这些方法仍然依赖于光流输入来最大化其精度。
虽然已知光流是一个重要的特征,但针对活动识别优化的流往往与真实光流[19]不同,这表明运动表示的端到端学习是有益的。最近,已经有一些工作使用卷积模型学习这种运动表示。Fan等人[5]利用深度学习库实现了TV-L1方法,提高了计算速度,并允许学习一些参数。结果被馈送到双流 CNN 进行识别。一些工作探索了学习CNN来预测光流,也可用于动作识别[4,9,11,16,21]。Lee等人[15]将特征从顺序帧转移到以非迭代的方式捕捉运动。Sun等人[21]通过计算表示和时间差异的梯度,提出了一种光流引导特征(OFF),但缺乏精确流量计算所需的迭代优化。此外,它需要采用 RGB、光流和RGB差异,以实现最先进的性能。
与之前的工作不同,我们提出的具有表示流层的模型仅依赖于 RGB 输入,学习参数要少得多,同时通过迭代优化正确表示运动。它比需要光流输入的视频 CNN 快得多,同时仍然保持与双流模型一样好甚至更好的性能。它在速度和准确性方面明显优于现有的运动表示方法,包括TVNet[5]和OFF[21],我们通过实验证实了这一点。
3. Approach
我们的方法是一个受光流算法启发的完全可微卷积层。与传统的光流方法不同,我们的方法的所有参数都可以端到端学习,最大化动作识别性能。此外,我们的模型旨在计算任何表示通道的“流”,而不是将其输入限制为传统的 RGB 帧。
3.1. Review of Optical Flow Methods
在描述我们的层之前,我们简要回顾了如何计算光流。光流方法是基于亮度一致性假设。也就是说,给定序列图像I1、I2、I1中的点x、y位于I2中的x+∆x、y+∆y,或者I1(x,y)=I2(x+∆x,y+∆y)。这些方法假设帧之间的运动很小,因此可以用泰勒级数近似:I2 = I1 + δI/δx∆x+ δI/δy∆y,其中u = [∆x,∆y]。这些方程求解 u 以获得流,但由于两个未知数,只能近似。
近似光流的标准变分方法(如Brox[2]和TV-L1[27]方法)以序列图像I1、I2为输入。变分光流方法使用迭代优化方法估计光流场u。张量 u ∈ R2×W ×H 是图像中每个位置的 x 和 y 方向的光流。以两个顺序图像作为输入I1, I2,该方法首先计算x和y方向上的梯度:∇I2。初始流量设置为0,u = 0。然后,可以计算基于当前流量估计u捕获两帧之间的运动残差的ρ。为了提高效率,预先计算 ρ的常数部分ρc:
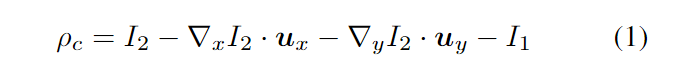
在之后进行迭代优化部分,每次更新u。
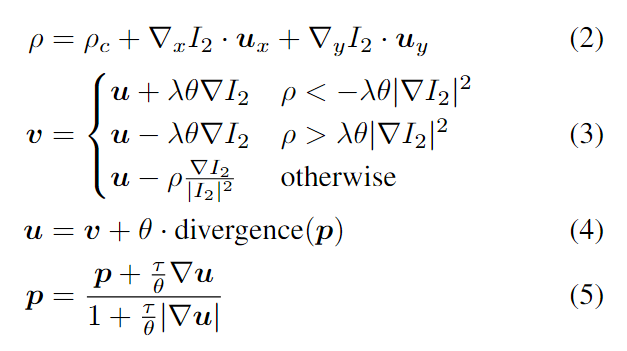
其中θ控制TV-L1正则化项的权值,λ控制输出的平滑度,τ控制时间步长。这些超参数是手动设置的。P是对偶向量场,用来使能量最小化。p的散度或后向差分计算为:
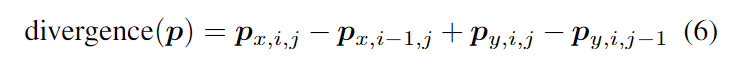
其中px为x方向,py为y方向,p包含图像中所有的空间位置。目标是最小化总变分能量:
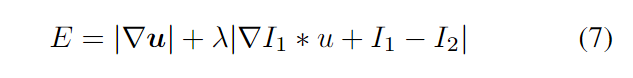
方法对从小到大的多个输入尺度进行迭代优化,并在更大的尺度上使用先前的流量估计u来扭曲I2,从而提供从粗到精的光流估计。这些标准方法需要多次缩放和翘曲才能获得良好的流量估计,需要数千次迭代。
3.2. Representation Flow Layer
受光流算法的启发,我们通过扩展上面概述的一般算法设计了一个完全可微的、可学习的卷积表示流层。主要区别在于 (i) 我们允许层捕获任何 CNN 特征图的流,并且 (ii) 我们学习了其参数,包括 θ、λ 和 τ 以及散度权重。我们还进行了一些关键更改以减少计算时间:(1)我们只使用单尺度,(2)我们不执行任何扭曲,以及(3)我们计算空间大小较小的 CNN 张量上的流。多尺度和翘曲的计算成本很高,每个尺度都需要多次迭代。通过学习流参数,我们可以消除对这些额外步骤的需求。我们的方法应用于低分辨率 CNN 特征图,而不是 RGB 输入,并以端到端的方式进行训练。这不仅有利于其速度,而且还允许模型学习针对活动识别优化的运动表示。
我们注意到亮度一致性假设同样可以应用于 CNN 特征图。我们不是捕获像素亮度,而是捕获特征值一致性。基于 CNN 的相同的假设被设计为空间不变的;即,它们在移动时为同一对象产生大致相同的特征值。
给定输入 F1、F2,来自顺序 CNN 特征图(或输入图像)的单个通道,我们通过将输入特征图与 Sobel 滤波器进行卷积来计算特征图梯度:
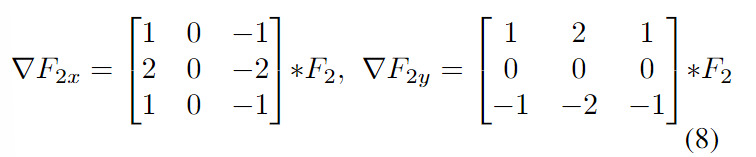
我们先设u = 0, p = 0,每个都有与输入相匹配的宽度和高度,然后我们可以计算出ρc = F2−F1。接下来,根据算法1,我们重复应用公式2-5中的操作进行固定次数的迭代,以实现迭代优化。为了计算散度,我们在第一列(x方向)或第一行(y方向)上用零填充p,然后将其与权重wx, wy进行卷积,以计算公式6:
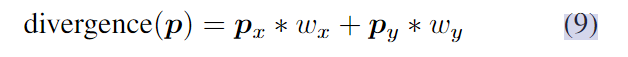
其中初始wx =[−1 1],wy =[−1 1]^T。注意,这些参数也是可微的,可以通过反向传播来学习。我们计算∇u as
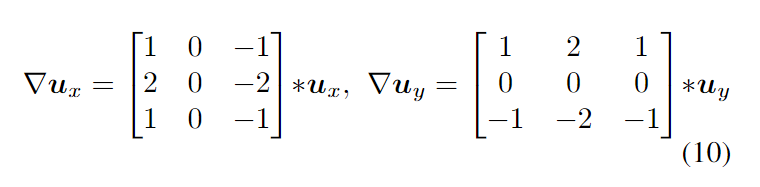
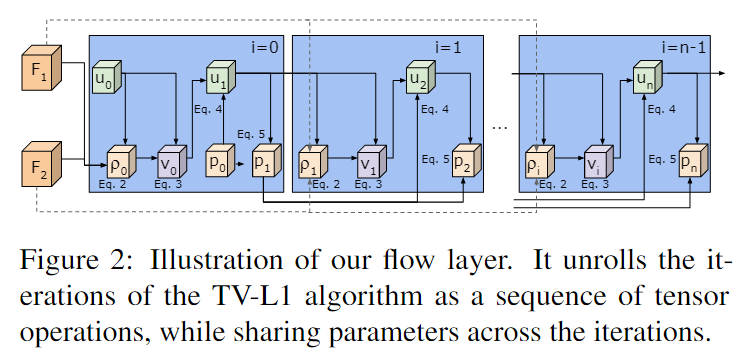
Representation Flow within a CNN 算法 1 和图 2 描述了我们的表示流层的过程。我们的多次迭代流层也可以解释为具有一系列卷积层共享参数(即图 2 中的每个蓝色框),每一层都的行为取决于其前一层的行为。由于这种公式,该层变得完全可微,并允许学习所有参数,包括 (τ, λ, θ) 和散度权重 (wx, wy )。这使得我们学习的表示流层能够针对其任务(即动作识别)进行优化。
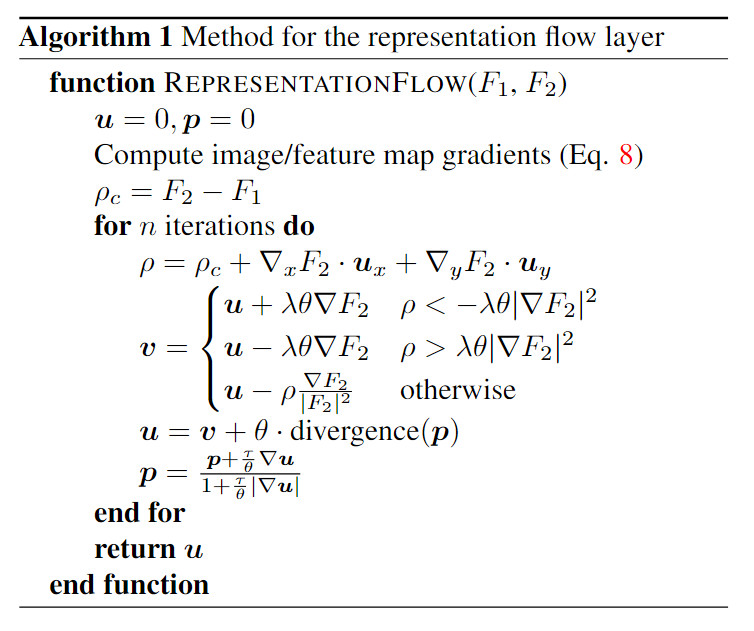
Computing Flow-of-Flow 标准光流算法计算两个序列图像的流。光流图像包含有关运动方向和大小的信息。直接在两个流图像上应用流算法意味着我们正在跟踪像素/位置,显示两个连续帧中的相似运动。在实践中,由于光流结果不一致和非刚性运动,这通常会导致性能下降。另一方面,我们的表示流层是从数据中“学习的”,并且能够通过在流层之间具有多个规则的卷积层来抑制这种不一致和更好的抽象/表示运动。图 6 说明了这种设计,我们在实验部分确认了它的好处。通过堆叠多个表示流层,我们的模型能够捕获更长的时间间隔并考虑具有运动一致性的位置。
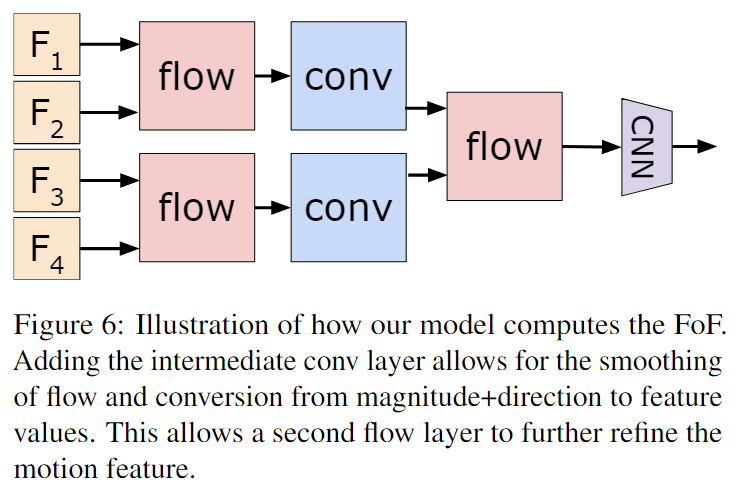
CNN特征图可能有数百或数千个通道,我们的表示流层计算每个通道的流,这可能需要大量的时间和内存。为了解决这个问题,我们应用卷积层在流层之前将通道数从 C 减少到 C'(请注意,C' 仍然比传统的光流算法显着,因为传统的光流算法仅适用于单通道、灰度图像)。对于数值稳定性,我们将此特征图归一化为 [0, 255],匹配标准图像值。我们发现 CNN 特征平均相当小(< 0.5),TVL-1 算法默认超参数是为 [0, 255] 中的标准图像值设计的,因此我们发现这个归一化步骤很重要。使用归一化特征,我们计算流并堆叠 x 和 y 流,从而产生 2C' 通道。最后,我们应用另一个卷积层从 2C' 通道转换为 C 通道。结果被传递到剩余的 CNN 层进行预测。我们从许多帧平均预测来对每个视频进行分类,如图 3 所示。
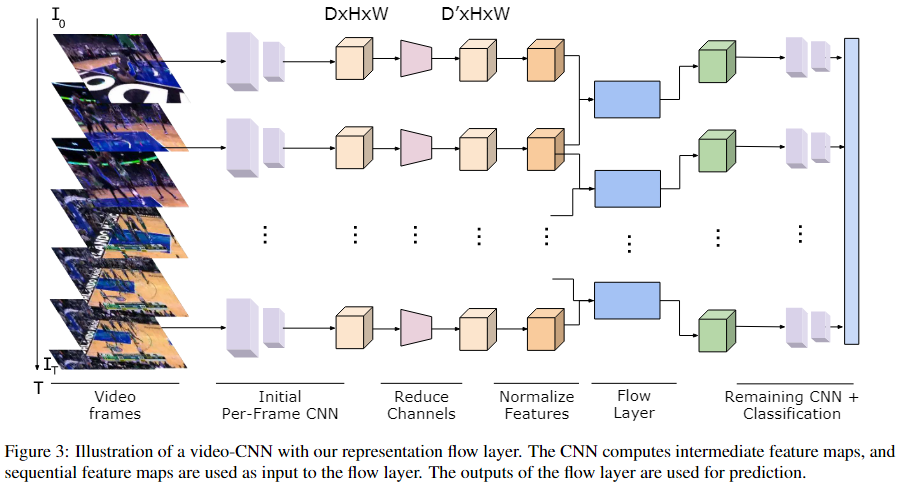
3.3. Activity Recognition Model
我们将表示流层放置在标准活动识别模型中,该模型将 T × C × W × H 张量作为 CNN 的输入。在这里,C 是 3,因为我们的模型使用直接 RGB 帧作为输入。T 是模型过程的帧数,W 和 H 是空间维度。CNN 输出每个时间步的预测,这些被时间平均以产生每个类的概率。该模型经过训练以最小化交叉熵:
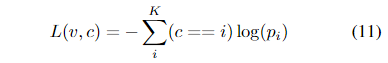
其中 p = M (v), v 是视频,函数 M 是分类 CNN,c 表示 v 属于K class中的哪个。也就是说,我们的流层中的参数与其他层一起训练,使其最大化最终的分类精度。
4. Experiments
Implementation details 我们在 PyTorch 中实现我们的表示流层,我们的代码和模型可用。由于在视频上训练 CNN 的计算成本很高,我们使用了 Kinetics 数据集 [13] 的一个子集,其中包含来自 150 个类别的 100k 视频:Tiny-Kinetics。这允许更快地测试许多模型,同时仍然有足够的数据来训练大型 CNN。对于大多数实验,我们使用大小为 16 × 112 × 112 的 ResNet-34 [10](即 16 帧,空间大小为 112)。为了进一步减少许多研究的计算时间,我们使用了这个较小的输入,这降低了性能,但允许我们使用更大的批量大小并更快地运行许多实验。我们的最终模型在标准的 224 × 224 图像上进行了训练。检查特定训练细节的附录。
Where to compute flow? 为了确定网络中在哪里计算流,我们对比了 在原始RGB输入、在第一个卷积层后、在每五个残差块之后 上应用我们的流层。结果如表1所示。我们发现,计算输入上的流提供了较差的性能,类似于仅流网络的性能,但即使在1层之后也有很大的跳跃(表现变好),这表明计算特征的流动是有益的,同时捕获外观和运动信息。然而,在 4 层之后,随着空间信息过于抽象/压缩(由于池化和大空间感受野大小),性能开始下降,顺序特征变得非常相似,包含较少的运动信息。请注意,与最先进的方法相比,我们该表中的 HMDB 性能非常低,因为使用很少的帧和低空间分辨率(112 × 112)从头开始训练。对于以下实验,除非另有说明,否则我们在第三个残差块之后应用流层。在图 7 中,我们可视化了在块 3 之后计算的学习到的运动表示。
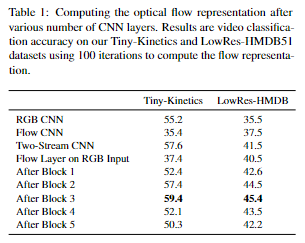

What to learn? 由于我们的方法是完全可微的,我们可以学习任何参数,例如用于计算图像梯度的核,用于散度计算的核,甚至τ, λ, θ。在表2中,我们比较了学习不同参数的效果。我们发现学习Sobel核值由于噪声梯度降低了性能,特别是当批大小有限时,但学习散度和τ, λ, θ是有益的。
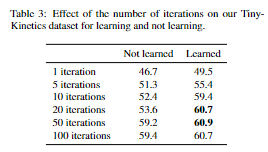
How many iterations for flow? 为了确认迭代是重要的,并确定我们需要多少次迭代,我们试验了不同数量的迭代。我们比较了学习(发散+τ, λ, θ)和不学习参数所需的迭代次数。流在3个剩余块之后进行计算。结果如表3所示。我们发现学习用更少的迭代提供了更好的性能(类似于[5]中的发现),迭代计算特征是很重要的。我们在剩下的实验中使用10或20次迭代,因为它们提供了良好的性能和速度。
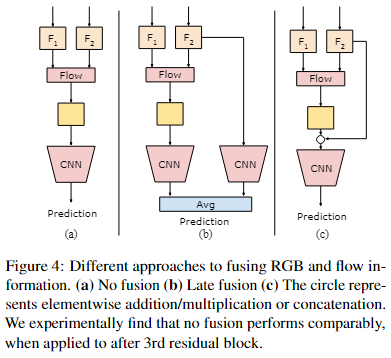
Two-stream fusion? 融合 RGB 和光流特征的双流 CNN 已被广泛研究 [20, 7]。基于这些工作,我们比较了融合RGB和我们的流表示的各种方法,如图4所示。我们比较了无融合、晚期融合(即单独的RGB和流CNN)和加法/乘法/级联融合。在表 4 中,我们比较了网络中不同位置的不同融合方法。我们发现融合 RGB 信息非常重要“当直接从 RGB 输入计算流时”。然而,当 CNN 已经抽象出了很多外观信息时,计算表示流并不那样有益。我们发现 RGB 和流特征的串联与其他特征相比表现不佳。我们不会在任何其他实验中使用双流融合,因为我们发现即使没有任何融合,在第 3 个残差块之后计算表示流也能提供足够的性能。
Flow-of-flow 我们可以多次堆叠我们的层,计算流的流 (FoF)。这的优点是将更多的时间信息组合成一个特征。结果如表5所示。应用TV-L1算法性能相对较差,因为光流特征并没有真正满足亮度一致性假设,因为它们捕获了运动的大小和方向(如图5所示)。应用我们的表示流层两次的性能明显优于 TV-L1 两次,但仍然比我们没有这样做的基线差。然而,我们可以在第一和第二流层之间添加一个卷积层,流卷积流(FcF),(图6),允许模型更好地学习长期流表示。我们发现这表现最好,因为这个中间层能够平滑流并为表示流层产生更好的输入。然而,我们发现添加第三个流层会降低性能,因为运动表示变得不可靠,因为空间感受野大小很大。在图7中,我们可视化了学习到的流流,这是一个更平滑的、类似加速度的特征,具有抽象运动模式。
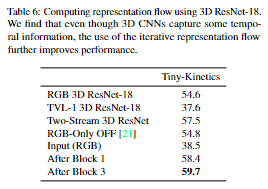
Flow of 3D CNN Feature 由于 3D 卷积捕获了一些时间信息,因此我们测试了从 3D CNN 特征计算的流表示。由于 3D CNN 的训练成本很高,我们遵循 I3D [3] 的方法,将 ImageNet 上预训练的 ResNet-18 膨胀为视频 3D CNN。我们还与[26]中的空间 conv接着时间conv 的 (2+1)D 方法进行了比较。它产生了结合空间和时间信息的类似特征。我们发现即使 3D 和 (2+1)D CNN 已经捕获了一些时间信息,我们的流层也提高了性能:表 6 和表 7。这些实验使用了 10 次迭代并学习流参数。在这些实验中,没有使用 FcF。
我们还与使用 (2+1)D 和 3D CNN 的 OFF [21] 进行了比较。我们观察到,使用捕获时间信息的 CNN,这种方法不会产生有意义的性能提升,而我们的方法确实如此。

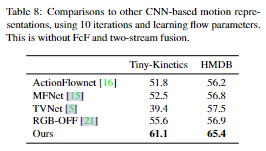
Comparison to other motion representations 与现有的基于 CNN 的运动表示方法进行比较,以确认我们的表示流的有用性。对于这些实验,当可用时,我们使用了作者提供的代码,否则我们自己实现了这些方法。为了更好地与现有工作进行比较,我们使用了 (16×)224 × 224 图像。表 8 显示了结果。MFNet [15] 通过空间移动 CNN 特征图来捕获运动,然后对结果求和,TVNet [5] 将卷积光流方法应用于 RGB 输入,ActionFlowNet [16] 训练 CNN 联合预测光流和活动类。我们还仅使用 RGB 输入与 OFF [21] 进行比较。请注意,[21] 中的 HMDB 性能是使用他们的三流模型(即 RGB + RGB-diff + 光流输入)报告的,这里我们仅使用 RGB 与版本进行比较。我们的方法在 CNN 特征图上应用迭代流计算的方法表现最好。
Computation time 我们在运行时间和参数数量方面将我们的表示流与最先进的双流方法进行了比较。所有的计时都是使用单个Pascal Titan X GPU测量的,对于一批大小为32 × 224 × 224的视频。流/双流cnn包括运行TV-L1算法(OpenCV GPU版本)来计算光流的时间。所有 CNN 都基于 ResNet-34 架构。如表 9 所示,我们的方法明显快于依赖于 TV-L1 或其他光流方法的双流模型,同时表现相似或更好。我们的模型的参数数量是其双流竞争对手的一半(例如,在 2D CNN 的情况下,21M 与 42M)。
Comparison to state-of-the-arts 我们还将我们的动作识别精度与Kinetics和HMDB的最新技术进行了比较。为此,我们使用32 × 224 × 224输入和完整的动力学数据集,使用8个v100来训练我们的模型。我们使用2D ResNet-50作为架构。在实验的基础上,我们将我们的表示流层应用于第3个残差块之后,学习了超参数和散度核,并进行了20次迭代。我们还比较了我们的流-流模型。在[22]之后,使用参数随时间的运行平均值执行评估。我们的结果如表9所示,证实了这种方法明显优于仅使用RGB输入的现有模型,并且与昂贵的双流网络具有竞争力。我们的模型在不使用光流输入的模型中表现最好(即,在每个视频仅采用~ 600ms的模型中)。需要光流的模型要慢10倍以上,包括双流版本的[3,25,26]
5. Conclusion
我们引入了一个受光流算法启发的可学习表示流层。我们通过实验比较了各种形式的层,证实了迭代优化和可学习参数的重要性。在标准数据集上,我们的模型在速度和准确性方面明显优于现有方法。我们还引入了“流的流”的概念来计算长期运动表示,并展示了它对性能的好处。
相关文章:

Representation Flow for Action Recognition论文笔记
原文笔记: What: 在本文中,我们提出了一种受光流算法启发的CNN层,用于学习动作识别的运动表示,而无需计算光流。我们的表示流层是一个完全可微分的层,旨在捕获模型中任何表示通道的“流”。其迭代流量优化…...

云计算领域需掌握的核心技术
云计算作为现代信息技术的核心基础设施,涵盖从基础资源管理到上层应用开发的完整技术栈。它依靠强大的计算能力,使得成千上万的终端用户不担心所使用的计算技术和接入的方式等都能够进行有效的依靠网络连接起来的硬件平台的计算能力来实施多种应用。 一、…...

Android仿今日头条Kotlin版本
软件信息 gradle-8.0Sdk信息 //编译版本 compileSdk33 //最小版本 minSdk24 //目标版本 targetSdk31Android Studio Giraffe | 2022.3.1 Patch 2(建议版本不要太低)MVVMAndroid Jetpack 项目注意 没有服务器,用的是Apifox模拟服务器返回&a…...

Javashop新零售电商系统:构建智能零售生态的终极解决方案
JavaShop Javashop新零售电商系统:构建智能零售生态的终极解决方案引言:数字化转型浪潮中的零售业变革Javashop新零售系统核心优势1. 全渠道融合:打破线上线下壁垒2. 智能化门店管理:赋能传统零售3. 智慧营销与会员运营 系统功能模…...

vscode如何多行同时编辑,vscode快速选中多行快捷键
目录 vscode如何多行同时编辑,vscode快速选中多行快捷键 一、实践情景 二、不同多选情景的操作方案 1、使用 Alt 鼠标点击选择任意行的任意位置 2、使用快捷键 Shift Alt 鼠标拖动 3、使用快捷键添加多行光标 4、结合正则表达式批量编辑 5、使用扩展插件&…...

珈和科技助力“农险提效200%”!“遥感+”技术创新融合省级示范项目荣登《湖北卫视》!
近日,湖北卫视《湖北十分》栏目报道了珈和科技遥感赋能农业保险创新,典型项目入选十大省级卫星应用示范标杆事迹,系统展示了珈和科技在卫星遥感与农业保险融合领域的创新成果。 作为空天农业领域的领军企业,珈和科技依托创新构建…...

UIAutomator 与 Playwright 在 AI 自动化中的界面修改对比
UIAutomator 与 Playwright 在 AI 自动化中的界面修改对比 在 AI 驱动的 UI 自动化中,Playwright(主要用于 Web)和 UIAutomator(用于 Android)的设计定位不同,对界面修改的支持也截然不同。下面从界面修改能力、API 设计、替代方案和实践建议等方面进行分析,对比两者在…...

Redisson Watchdog实现原理与源码解析:分布式锁的自动续期机制
引言 在分布式系统中,Redis分布式锁是解决资源竞争问题的常用方案。然而,当持有锁的客户端因GC、网络延迟或处理时间过长导致锁过期时,可能引发数据一致性问题。Redisson的Watchdog(看门狗)机制通过自动续期解决了这一…...

在C#串口通信中,一发一收的场景,如何处理不同功能码的帧数据比较合理,代码结构好
在 C# 串口通信的一发一收场景里,处理不同功能码的帧数据可采用以下合理的代码结构,它能让代码更具可读性、可维护性和可扩展性。 实现思路 定义帧结构:创建一个类来表示通信帧,其中包含功能码、数据等信息。功能码处理逻辑&…...

easypoi 实现word模板导出
特此非常致谢:easypoi实现word模板 基础的可以参考上文; 但是我的需求有一点点不一样。 这是我的模板:就是我的t.imgs 是个list 但是很难过的是easy poi 我弄了一天,我都没有弄出来嵌套list循环怎么输出显示,更难过…...

集结号海螺捕鱼服务器调度与房间分配机制详解:六
本篇围绕服务器调度核心逻辑进行剖析,重点讲解用户连接过程、房间分配机制、服务端并发策略及常见性能瓶颈优化。适用于具备中高级 C 后端开发经验的读者,覆盖网络会话池、逻辑服调度器与房间生命周期管理等关键模块。 一、服务器结构概览 整体系统采用…...

opencv--图像滤波
图像滤波 含义 方法 噪声是怎么产生的 线性滤波 概念 利用窗口对图像中的像素进行加权求和的滤波方式。 图像来源于小虎教程。 图像的滤波是二维滤波的过程。 滤波器窗口: 滤波器窗口(也称为卷积核或模板)是一个小的矩阵(通常为…...

uniapp返回上一页接口数据更新了,页面未更新
注意:不是组件套组件可以不使用setTimeout延时 返回上一页一般会走onshow,但是接口更新了页面未更新 onShow(() > {// 切换城市后重新调用数据if (areaId.value) {const timer setTimeout(async () > {timer && clearTimeout(timer);…...
)
redis 使用 Docker 部署 简单的Redis 集群(包括哨兵机制)
目录 环境准备 步骤 1:创建 Docker Compose 配置文件 步骤 2:创建配置文件 主节点配置文件 (redis.conf) 从节点配置文件 (slave.conf) 哨兵配置文件 (sentinel.conf) 步骤 3:启动 Redis 集群 步骤 4:验证集群状态 1. 检…...
:摄入 Elasticsearch 官方文档)
私有知识库 Coco AI 实战(三):摄入 Elasticsearch 官方文档
相信经常使用 Elasticsearch 的小伙伴,难免要到 ES 官网查找资料,文档内容多难以查找不说,还有很多个版本,加上各种生态工具如 Filebeat、Logstash 头就更大了。今天我来介绍如何使用 Coco AI 快速搜索 Elasticsearch 官方文档。在…...

12-DevOps-Gitlab托管Jenkinsfile
前面通过执行脚本的方式,完成了pipline流水线的构建。脚本是保存在Jenkins中的,这种方式不利于迁移,也不利于查找脚本的历史变更信息。 通过把脚本放到GitLab中,然后在Jenkins中引用的方式来解决上述的问题。 创建Jenkinsfile文件…...
)
CSS3 基础(边框效果)
一、边框效果 属性功能示例值说明border-radius创建圆角border-radius: 20px;设置元素的圆角半径,支持像素(px)或百分比(%)。值为 50% 时可变为圆形。box-shadow添加阴影box-shadow: 5px 5px 15px rgba(0, 0, 0, 0.5)…...

使用 VSCode 编写 Markdown 文件
目录 一、安装 Markdown 插件二、新建 Markdown 文档三、Markdown 基本语法目录和标题文本样式列表图片链接代码表格注脚与注释符号表情 四、将 Markdown 文档导出为 PDF 一、安装 Markdown 插件 参考文章:【[Markdown] 使用vscode开始Markdown写作之旅】 打开 VSco…...
——项目记录)
搭建 Stable Diffusion 图像生成系统并通过 Ngrok 暴露到公网(实现本地系统网络访问)——项目记录
目录 📚 背景与需求 📝 需求明确 🔑 核心功能 🌍 网络优化 🛠️ 方案确认 ⚙️ 技术栈 📈 实现流程(Flask端口Ngrok注册authtoken) 🎯 优化目标 🔍 实…...

伺服器用什么语言开发呢?做什么用什么?
最近因为要评估帮合作对象做连接我们工具的语言翻译器,所以顺便做了一个小范围的调查,看看那些语言是应该在我们优先制作翻译器的部分,当然,各种语言在伺服器开发中其实各有拥护者,而选择也很常受到应用场景、产业特性…...

实现SpringBoot底层机制【Tomcat启动分析+Spring容器初始化+Tomcat 如何关联 Spring容器】
下载地址: https://download.csdn.net/download/2401_83418369/90675207 一、搭建环境 创建新项目 在pom.xml文件中导入依赖 (一定要刷新Maven)排除内嵌的Tomcat,引入自己指定的Tomcat <?xml version"1.0" enco…...

spark—kafka
消息队列与Kafka介绍 消息队列模式: 点对点模式和发布订阅模式。Kafka主要使用发布订阅模式。 Kafka角色: 包括broker、topic、分区、生产者、消费者、消费者组、副本、leader和follower 术语 解释 Broker 安装了kafka的节点 Topic 每条发…...
)
【AI 加持下的 Python 编程实战 2_09】DIY 拓展:从扫雷小游戏开发再探问题分解与 AI 代码调试能力(上)
DIY 拓展:从扫雷小游戏开发再探问题分解与 AI 代码调试能力(上) 1 起因 最近在看去年刚出了第 2 版《Learn AI-assisted Python Programming》,梳理完 第七章 的知识点后,总感觉这一章的话题很好——问题分解能力的培…...

【JVS更新日志】物联网、智能BI、智能APS 4.23更新说明!
项目介绍 JVS是企业级数字化服务构建的基础脚手架,主要解决企业信息化项目交付难、实施效率低、开发成本高的问题,采用微服务配置化的方式,提供了低代码数据分析物联网的核心能力产品,并构建了协同办公、企业常用的管理工具等&…...

品融电商:领航食品类目全域代运营,打造品牌增长新引擎
品融电商:领航食品类目全域代运营,打造品牌增长新引擎 在竞争激烈的电商市场中,食品类目因其高频消费与强复购属性,成为品牌必争之地。然而,行业同质化严重、用户心智难突破、流量成本攀升等痛点,让许多食…...

非关系型数据库 八股文 Redis相关 缓存雪崩 击穿 穿透
目录 图 缓存雪崩 大量数据同时过期解决方案 也有可能是 Redis 挂了 故障 缓存击穿 用互斥锁解决 热点数据永远不过期 缓存穿透 重点 可能的原因 限制 请求的 访问 缓存空值或者默认值 布隆过滤器(重要) 总结 参考资料 图 缓存雪崩 缓存雪崩是指大量缓存数据同时…...

uniapp自定义拖拽排列
uniapp自定义拖拽排列并改变下标 <!-- 页面模板 --> <template><view class"container"><view v-for"(item, index) in list" :key"item.id" class"drag-item" :style"{transform: translate(${activeInde…...

汽车免拆诊断案例 | 2013款大众辉腾车发动机抖动
故障现象 一辆2013款大众辉腾车,搭载CMV发动机(燃油喷射方式为缸内直喷),累计行驶里程约为21.8万km。该车发动机怠速、加速时均有抖动,且组合仪表上的发动机故障灯异常点亮。 故障诊断 用故障检测仪检测࿰…...

【氮化镓】同质结GaN PiN二极管的重离子单粒子烧毁SEB
2025 年,范德堡大学的 A. S. Senarath 等人通过实验研究的方法,深入探究了在同质结 GaN 垂直 PIN 二极管中,边缘终止设计对重离子诱发的单粒子漏电(SELC)和单粒子烧毁(SEB)的影响。该研究获得了多个美国军方机构的支持,包括空军卓越辐射效应中心、海军研究办公室、能源…...

Java基础 4.23
1.包的命名 命名规则 只能包含数字 字母 下划线 小圆点 但不能用数字开头 不能是关键字或保留字 命名规范 一般是小写字母小圆点 一般是 com.公司名.项目名.业务模块名 比如 com.sina.crm.user 用户模块com.sina.crm.order 订单模块com.sina.crm.utils 工具类 2.常用的包…...

【学习准备】算法和开发知识大纲
1 缘起 今年(2025年)的职业升级结果:不通过。没办法升职加薪了。 需要开始完善学习,以应对不同的发展趋势,为了督促自己学习,梳理出相关学习大纲。 分为算法和开发两部分。 算法,包括基础算法和…...

Godot学习-3D基本环境设置以及3D角色移动
文章目录 一、新建项目和导入资产二、创建玩家场景1.修改模型节点类型为CharacterBody3D2.添加碰撞对象并且设置碰撞区域3.根据动画的运动状态调整碰撞区域 三、使用CSGMesh3D创建地面1.设置网格尺寸2.设置网格材质 四、添加3D相机和光照五、为角色移动编写代码1.基本移动和旋转…...

高效并发编程:无锁编程
无锁编程是一种并发编程的技术,旨在避免使用传统的锁机制来保护共享数据。相比有锁编程,无锁编程可以提供更高的并发性能和可伸缩性。在无锁编程中,线程或进程通过使用原子操作、CAS(Compare-and-Swap)等技术来实现对共…...

Java与C语言核心差异:从指针到内存管理的全面剖析
🎁个人主页:User_芊芊君子 🎉欢迎大家点赞👍评论📝收藏⭐文章 🔍系列专栏:AI 【前言】 在计算机编程领域,Java和C语言都是极具影响力的编程语言。Java以其跨平台性、安全性和面向对象…...

亚远景-基于ASPICE标准的汽车软件过程优化路径
基于ASPICE标准的汽车软件过程优化路径可以从以下几个方面展开: 1. 评估现状与设定目标 评估现状 :企业需要对当前的软件开发过程进行全面评估,识别与ASPICE标准之间的差距,明确薄弱环节。 设定目标 :根据评估结果和…...
:拉霸机模块开发详解与服务器开奖机制)
集结号海螺捕鱼游戏源码解析(第三篇):拉霸机模块开发详解与服务器开奖机制
本篇聚焦“拉霸机”子游戏模块,全面剖析客户端滚轮动画机制、服务端中奖算法、中奖广播同步与配置解析方式,适用于技术团队针对拉霸玩法的二次开发与稳定性优化。 一、模块目录结构说明 拉霸机模块的源码目录一般如下: 子游戏/slot_machine…...

图聚类中的亲和力传播
图中展示的是Affinity Propagation(亲和力传播)算法中的一个关键步骤——更新吸引度矩阵。Affinity Propagation是一种聚类算法,它通过消息传递的方式找到数据集中的代表性样本(称为exemplar或原型),并将其…...

Apache中间件解析漏洞与安全加固
Apache作为全球使用最广泛的Web服务器,其灵活性和模块化设计使其成为开发者的首选。然而,其解析机制和配置不当可能导致严重的安全风险。本文将从漏洞原理、攻击案例和安全配置三个维度,结合真实场景,解析…...

MyBatis-Plus分页插件的使用
从MyBatis-Plus 3.4.0开始,不再使用旧版本的PaginationInterceptor ,而是使用MybatisPlusInterceptor。 下面是MyBatis-Plus 3.4.3.3新版分页的使用方法。 配置 使用分页插件需要配置MybatisPlusInterceptor,将分页拦截器添加进来ÿ…...
:水浒传捕鱼模块逻辑与服务器帧同步详解)
集结号海螺捕鱼游戏源码解析(第二篇):水浒传捕鱼模块逻辑与服务器帧同步详解
本篇将全面解构“水浒传”子游戏的服务端核心逻辑、帧同步机制、鱼群刷新规则、客户端命中表现与服务器计算之间的协同方式,聚焦于 C 与 Unity3D 跨端同步的真实实现过程。 一、水浒传捕鱼模块资源结构 该模块包含三部分核心目录: 子游戏/game_shuihuz…...

开发体育直播系统后台权限设计实践分享|ThinkPHP 技术栈落地案例
今天我们分享的是一套由 东莞梦幻网络科技 自研的体育直播源码,在 ThinkPHP MySQL 技术栈的加持下,后台权限系统如何从0到1落地,并支撑整个平台稳定运行。 一、整体架构设计 用户端(APP / H5 / PC)↓ 前端接口层&am…...

onlyoffice历史版本功能实现,版本恢复功能,编辑器功能实现 springboot+vue2
文章目录 oonlyoffice历史版本功能实现 (编辑器功能实现)springbootvue2前提 需要注意把这个 (改成自己服务器的ip或者域名) 改成 自己服务器的域名或者地址1. onloyoffice 服务器部署 搜索其他文章2. 前段代码 vue 22.1 需要注意把这个 (改成自己服务器…...
)
【漫话机器学习系列】219.支持向量机分类器(Support Vector Classifier)
图解支持向量机分类器(Support Vector Classifier) 在机器学习的分类模型中,支持向量机(Support Vector Machine,SVM)是一种功能强大且广泛应用的监督学习算法。它尤其擅长解决小样本、高维度的数据问题&a…...

深入解析 Spring Boot Test:架构、核心组件与最佳实践
深入解析 Spring Boot Test:架构、核心组件与最佳实践 在现代软件开发中,测试是确保应用程序质量的关键环节。Spring Boot Test作为Spring Boot框架的一部分,提供了一套强大且灵活的测试工具,帮助开发者高效地测试Spring Boot应用…...

Sklearn 与 TensorFlow 机器学习实用指南-第八章 降维-笔记
补充: 本文是关于《Sklearn 与 TensorFlow 机器学习实用指南》的学习笔记,基于八、降维 - 【布客】Sklearn 与 TensorFlow 机器学习实用指南 第二版,感谢译者 本文和原文的区别: 本文会更精简、系统地表述书中概念,…...

动态贴纸+美颜SDK的融合实现:底层架构与性能优化技术全解析
如今,美颜动态贴纸功能已经成为提升用户粘性与平台竞争力的“标配”。但从技术实现角度看,如何高效融合动态贴纸与美颜SDK,并在保证画质与流畅度的前提下实现稳定输出,仍然是一项复杂且极具挑战的工程。 本文将深入解析“动态贴纸…...

Git简介与入门
Git的发明 Git由著名的Linux创始人linus于2005年发明(所以git的界面、使用方式与Linux挺像的,即命令行方式) 经过发展,现在广泛应用于代码管理与团队协作。 Git特性 Git是分布式版本控制系统 分布式 每个开发者拥有完整仓库&…...

车载信息安全架构 --- 汽车网络安全
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

Elasticsearch 堆内存使用情况和 JVM 垃圾回收
作者:来自 Elastic Kofi Bartlett 探索 Elasticsearch 堆内存使用情况和 JVM 垃圾回收,包括最佳实践以及在堆内存使用过高或 JVM 性能不佳时的解决方法。 堆内存大小是分配给 Elasticsearch 节点中 Java 虚拟机的 RAM 数量。 从 7.11 版本开始ÿ…...
)
基于UDP协议的群聊服务器开发(C/C++)
目录 服务器 一、通信 打开网络文件 绑定IP地址与端口号 接收信息 二、数据处理 客户端 三、端口绑定 四、收发信息 五、源码 服务器 在服务器架构设计中,模块解耦是保障系统可维护性的核心准则。本方案采用分层架构将核心功能拆解为通信层与业务处理层两…...