leetcode hot100尝试1
目录
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 你可以按任意顺序返回答案。 c++ map完成
vector有.length吗
确保 size() 后面有括号,这样就可以正确调用这个成员函数了。希望这能解决你的问题!
你的函数在某些控制路径中没有返回值,
在C++中,对vector进行排序通常使用标准库中的sort函数,该函数定义在 头文件中。sort函数可以对vector中的元素进行排序,其基本用法如下:
vector添加元素
c++循环有python的continue'吗
初始化为全0,可以这么写吗
int hash1[26] = {0};还是int[26]
计算一个数组的哈希值可以吗
c++只有hashmap没有哈系表》?x
逐行解释
解释:
总结:
emplace back 和pushback有何区别,这里能不能换成pushback
str'ing&这里的&可以去掉吗
vector迭代器遍历代码
auto 和 vector::iterator有何区别
迭代器遍历hashmap
这个错误是因为你在尝试对一个std::string对象调用emplace_back方法,但std::string并没有这个方法。emplace_back是std::vector的方法,用于在向量末尾添加新元素。
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 你可以按任意顺序返回答案。 c++ map完成
ChatGLM

要使用C++中的map来解决这个问题,我们可以利用map的键值对特性,其中键是数组中的元素,值是元素的索引。这样,我们可以在遍历数组的过程中,检查map中是否已经存在一个元素,使得当前元素与该元素的和等于目标值target。如果存在,我们就找到了这两个元素;如果不存在,我们将当前元素及其索引添加到map中。
以下是实现这一思路的C++代码:
cpp
复制
#include <iostream>
#include <vector>
#include <map>std::vector<int> twoSum(std::vector<int>& nums, int target) {std::map<int, int> numMap; // 创建一个map来存储数字和它们的索引for (int i = 0; i < nums.size(); i++) {int complement = target - nums[i]; // 计算补数if (numMap.find(complement) != numMap.end()) { // 检查补数是否已经在map中return {numMap[complement], i}; // 如果找到了,返回这两个数的索引}numMap[nums[i]] = i; // 将当前数字和它的索引添加到map中}return {}; // 如果没有找到,返回一个空数组(根据题目假设,这种情况不会发生)
}int main() {std::vector<int> nums = {2, 7, 11, 15};int target = 9;std::vector<int> indices = twoSum(nums, target);std::cout << "Indices: " << indices[0] << ", " << indices[1] << std::endl;return 0;
}
在这段代码中,我们首先创建了一个map,然后在遍历数组的过程中,对于每个元素,我们计算它的补数(即target减去当前元素),并检查这个补数是否已经在map中。如果找到了,我们就返回这两个元素的索引。如果没找到,就将当前元素及其索引添加到map中。根据题目的假设,每个输入只有一个答案,所以函数最终一定会返回两个索引。
![]()
AI编辑
分享

用户_uBiEPA
vector有.length吗
ChatGLM

在C++中,vector没有.length成员函数。要获取vector的长度,应该使用.size()成员函数。.size()会返回vector中元素的数量。
例如,对于一个名为nums的vector,要获取其长度,应该这样写:
cpp
复制
int length = nums.size();
这段代码会将nums中的元素数量赋值给变量length。
需要注意的是,.size()返回的是一个size_t类型的数据,这是一种无符号整数类型。在大多数情况下,可以将其赋值给一个int类型的变量,但为了避免潜在的类型不匹配问题,最好使用size_t类型来接收.size()的返回值。
修改后的代码如下:
cpp
复制
#include <iostream>
#include <vector>
#include <map>std::vector<int> twoSum(std::vector<int>& nums, int target) {std::map<int, int> numMap; // 创建一个map来存储数字和它们的索引for (size_t i = 0; i < nums.size(); i++) { // 使用size_t作为循环变量类型int complement = target - nums[i]; // 计算补数if (numMap.find(complement) != numMap.end()) { // 检查补数是否已经在map中return {numMap[complement], i}; // 如果找到了,返回这两个数的索引}numMap[nums[i]] = i; // 将当前数字和它的索引添加到map中}return {}; // 如果没有找到,返回一个空数组(根据题目假设,这种情况不会发生)
}int main() {std::vector<int> nums = {2, 7, 11, 15};int target = 9;std::vector<int> indices = twoSum(nums, target);std::cout << "Indices: " << indices[0] << ", " << indices[1] << std::endl;return 0;
}
在这个修改后的代码中,我使用了size_t作为循环变量的类型,并且使用了.size()来获取vector的长度。这样更符合C++的标准和最佳实践。

用户_uBiEPA
构造一个vector {1,4,5},怎么写
ChatGLM

在C++中,构造一个包含特定元素的std::vector可以通过多种方式完成。以下是几种常见的方法来构造一个包含元素1, 4, 5的std::vector<int>:
方法一:使用初始化列表
cpp
复制
#include <vector>int main() {std::vector<int> vec = {1, 4, 5};// 现在vec包含了元素1, 4, 5return 0;
}
方法二:使用构造函数和初始化列表
cpp
复制
#include <vector>int main() {std::vector<int> vec({1, 4, 5});// 现在vec包含了元素1, 4, 5return 0;
}
方法三:使用push_back方法
cpp
复制
#include <vector>int main() {std::vector<int> vec;vec.push_back(1);vec.push_back(4);vec.push_back(5);// 现在vec包含了元素1, 4, 5return 0;
}
方法四:使用insert方法
cpp
复制
#include <vector>int main() {std::vector<int> vec;vec.insert(vec.end(), {1, 4, 5});// 现在vec包含了元素1, 4, 5return 0;
}
所有这些方法都可以达到同样的效果,即创建一个包含元素1, 4, 5的std::vector<int>。选择哪种方法取决于个人偏好和具体场景的需求。方法一和方法二是最直接和常用的方式,特别是当初始化列表中的元素已知时。方法三和方法四则提供了更多的灵活性,例如在循环中动态添加元素。

用户_uBiEPA
怎么了
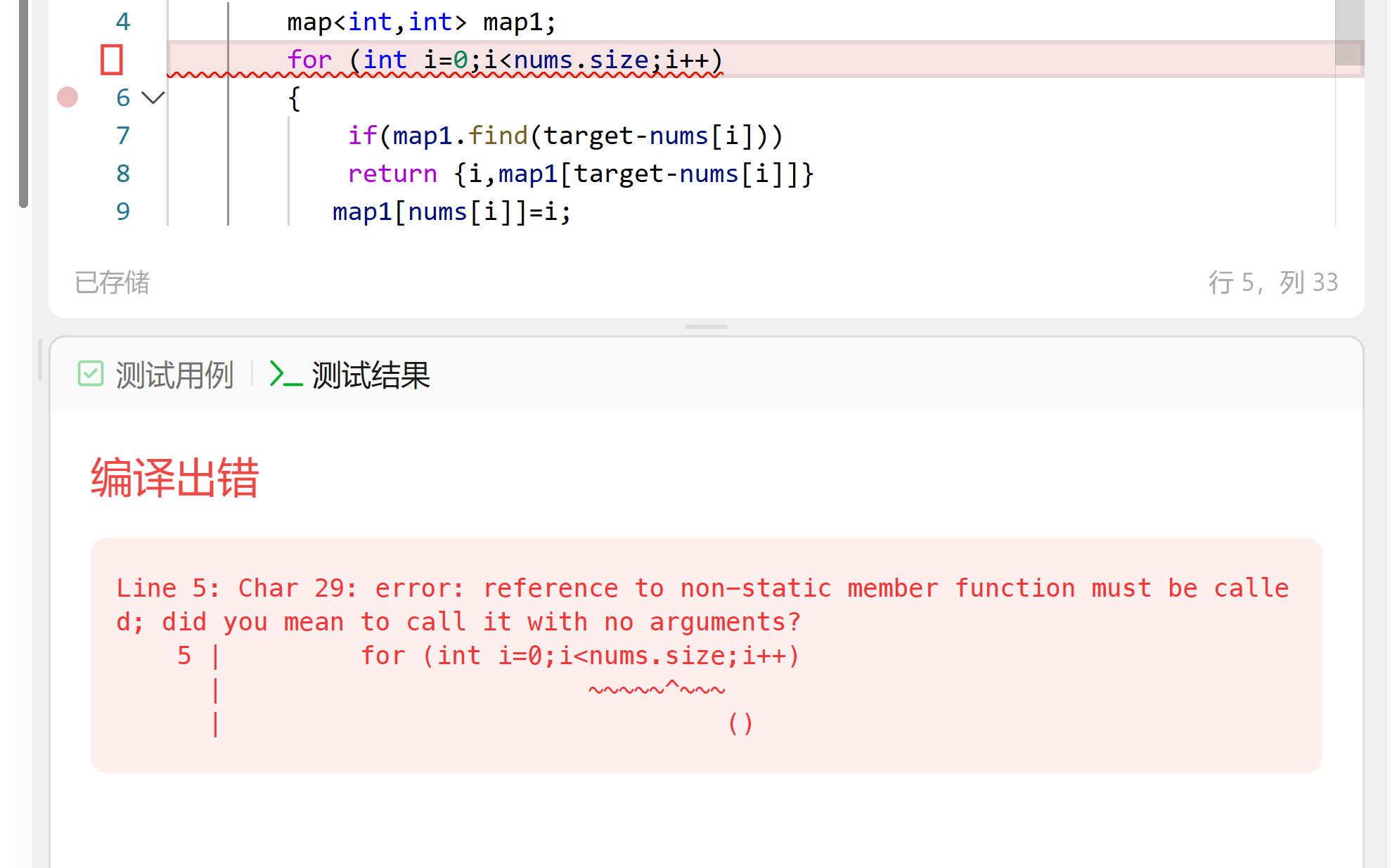
ChatGLM

编译错误指出在第5行第29个字符处有一个错误,提示“引用非静态成员函数必须被调用;你是否打算不带参数地调用它?”这通常意味着你忘记在成员函数后面加上括号。
在你的代码中,nums.size() 应该改为 nums.size() 来正确调用 size() 成员函数。修正后的代码如下:
cpp
复制
for (int i = 0; i < nums.size(); i++) {if (map1.find(target - nums[i]) != map1.end()) {return {i, map1[target - nums[i]]};}map1[nums[i]] = i;
}
确保 size() 后面有括号,这样就可以正确调用这个成员函数了。希望这能解决你的问题!
用户_uBiEPA
这个呢
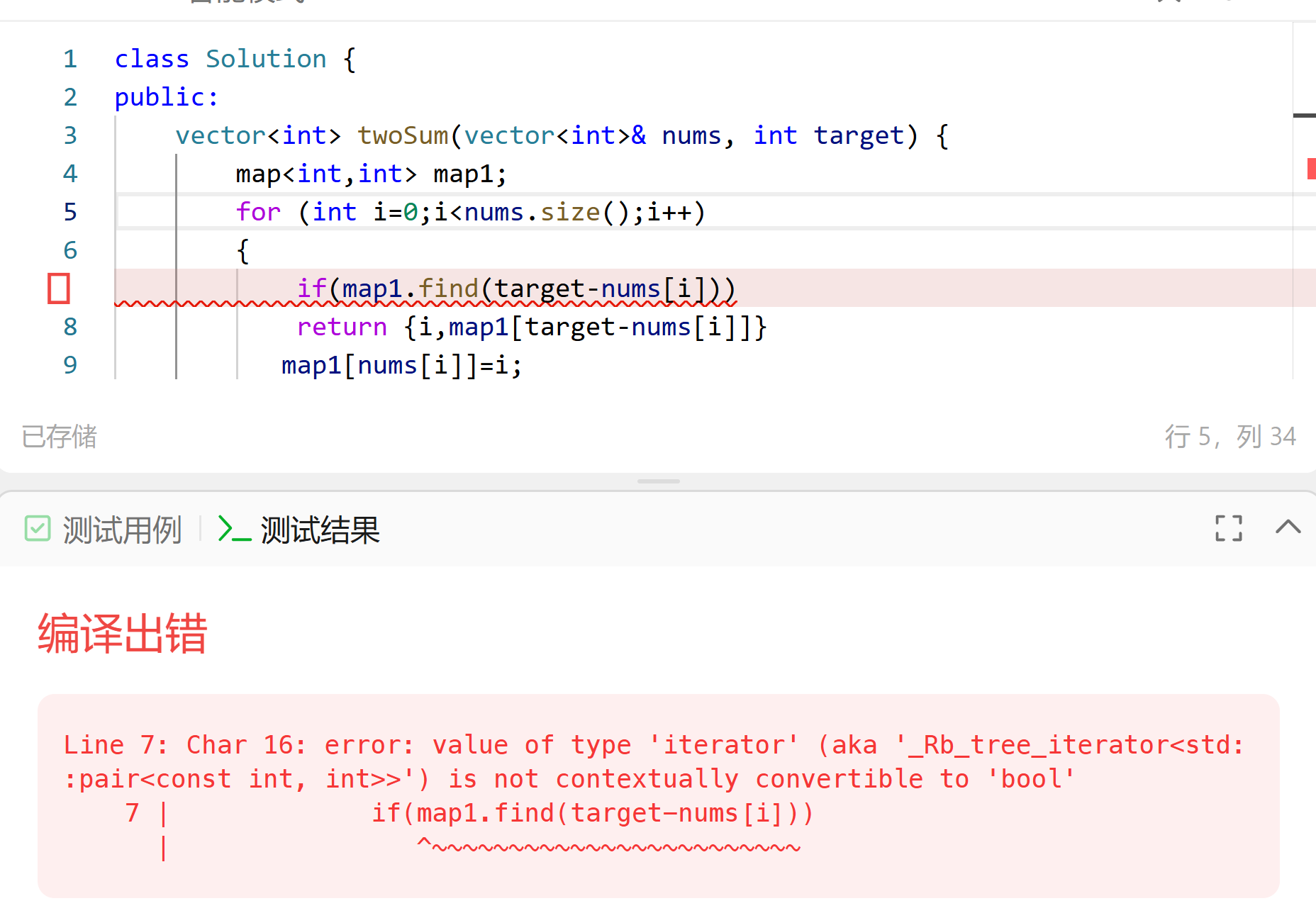
ChatGLM

编译错误指出在第7行第16个字符处有一个错误,提示“value of type ‘iterator’ is not contextually convertible to ‘bool’”。这意味着你试图将一个迭代器的值直接用作布尔表达式,这是不允许的。
在你的代码中,你应该使用 != map1.end() 来判断 find 函数是否找到了对应的键。修正后的代码如下:
cpp
复制
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {map<int, int> map1;for (int i = 0; i < nums.size(); i++) {if (map1.find(target - nums[i]) != map1.end())return {i, map1[target - nums[i]]};map1[nums[i]] = i;}return {}; // 如果没有找到,返回空向量}
};
在这个修正中,我使用了 != map1.end() 来检查 find 函数是否找到了对应的键。如果没有找到,find 会返回 end() 迭代器,所以我们比较的是迭代器而不是布尔值。此外,我还添加了一个返回空向量的语句,以便在没有找到符合条件的元素时能够返回一个空的索引列表。
用户_uBiEPA
class Solution { public: vector<int> twoSum(vector<int>& nums, int target) { map<int,int> map1; for (int i=0;i<nums.size();i++) { if(map1.find(target-nums[i])!=map1.end()) return {i,map1[target-nums[i]]}; map1[nums[i]]=i; } } };这个呢

ChatGLM
这个错误信息表明,
你的函数在某些控制路径中没有返回值,
但函数声明为返回一个 vector<int> 类型的值。为了修复这个问题,你需要在所有可能的执行路径中都确保函数返回一个 vector<int> 值。
在你的代码中,如果在循环中没有找到满足条件的两个数字,函数就会直接结束而没有返回任何东西。为了让编译器满意,你需要在函数的最后添加一个返回语句,即使你认为这种情况永远不会发生(因为题目保证会有解)。这样可以确保函数总是返回一个 vector<int> 值。
下面是修复后的代码:
cpp
复制
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {map<int, int> map1;for (int i = 0; i < nums.size(); i++) {if (map1.find(target - nums[i]) != map1.end()) {return {i, map1[target - nums[i]]};}map1[nums[i]] = i;}// 添加一个不可能到达的返回语句,以使编译器满意return {}; // 返回一个空的 vector}
};
现在,即使在理论上不会达到的代码路径上,函数也有一个返回语句,这将消除编译器关于未返回值的警告或错误。

用户_uBiEPA
vector排序 接口是什么‘
ChatGLM
本次回答已被终止
用户_uBiEPA
sort(vecotor)
ChatGLM
在C++中,对vector进行排序通常使用标准库中的sort函数,该函数定义在<algorithm>头文件中。sort函数可以对vector中的元素进行排序,其基本用法如下:
cpp
复制
#include <vector>
#include <algorithm> // for std::sortint main() {std::vector<int> vec = {4, 1, 3, 2, 5};// 使用默认的升序排序std::sort(vec.begin(), vec.end());// 如果需要降序排序,可以提供自定义的比较函数// 例如,使用标准库中的greater函数对象std::sort(vec.begin(), vec.end(), std::greater<int>());return 0;
}
sort函数的接口如下:
cpp
复制
template <class RandomAccessIterator>
void sort(RandomAccessIterator first, RandomAccessIterator last);template <class RandomAccessIterator, class Compare>
void sort(RandomAccessIterator first, RandomAccessIterator last, Compare comp);
first:指向要排序的序列的第一个元素。last:指向要排序的序列的最后一个元素的下一个位置。comp:可选的比较函数,用于确定元素的排序顺序。如果不提供,则默认使用operator<进行升序排序。
注意,sort函数要求传入的迭代器类型为随机访问迭代器(RandomAccessIterator),而vector的迭代器满足这一要求。
如果你想要对vector进行排序,并且vector中存储的是自定义类型,你可能需要提供一个自定义的比较函数或者重载operator<来告诉sort如何比较这些元素。

用户_uBiEPA
vector添加元素
ChatGLM

在C++中,可以使用push_back()方法将元素添加到std::vector中。以下是如何操作的示例代码:
cpp
复制
#include <iostream>
#include <vector>int main() {// 创建一个空的 vectorstd::vector<int> myVector;// 添加元素到 vector 中myVector.push_back(10);myVector.push_back(20);myVector.push_back(30);// 输出 vector 中的所有元素for (int i = 0; i < myVector.size(); ++i) {std::cout << myVector[i] << " ";}return 0;
}
在这个例子中,我们首先创建了一个空的std::vector<int>对象myVector。然后,我们使用push_back()方法将三个整数(10、20和30)添加到向量中。最后,我们通过循环遍历向量并输出其中的所有元素。
编译并运行这段代码后,你将会看到以下输出结果:
复制
10 20 30
这表明我们已经成功地将元素添加到了std::vector中,并通过循环输出了它们。

用户_uBiEPA
c++循环有python的continue'吗
ChatGLM
是的,C++中有类似于Python的continue语句。在C++中,continue用于跳过当前迭代的剩余部分,直接进入下一次迭代。这在处理循环时非常有用,特别是当你想在满足某个条件时立即开始下一轮循环而不是继续执行当前循环体内的剩余代码。
下面是一个简单的C++示例,展示了如何使用continue:
cpp
复制
#include <iostream>int main() {for (int i = 0; i < 5; ++i) {if (i == 2) {continue; // 跳过当 i 等于 2 时剩余的代码}std::cout << "Iteration: " << i << std::endl;}return 0;
}
在这个例子中,当i等于2时,continue语句会跳过std::cout语句,直接进行下一次迭代。因此,输出将是:
复制
Iteration: 0
Iteration: 1
Iteration: 3
Iteration: 4
注意,continue只影响它所在的循环体,不会跳出外层的循环。如果你需要在嵌套循环中使用continue,它只会跳过内层循环的当前迭代。

用户_uBiEPA
初始化为全0,可以这么写吗

ChatGLM

是的,这段代码是正确的。在C语言中,声明并初始化一个整型数组为全零可以这样写:
c
复制
int hash1[26] = {0};
这里,hash1 是一个包含26个整数的数组,所有的元素都被初始化为0。这是因为在C语言中,如果在数组初始化时不指定具体的初始值,编译器会将未指定的元素自动初始化为零(对于基本数据类型如int)。
用户_uBiEPA
int hash1[26] = {0};还是int[26]
ChatGLM
int hash1[26] = {0}; 是正确的写法。
解释:
int hash1[26]:声明一个名为hash1的整型数组,包含26个元素。= {0}:将数组的所有元素初始化为0。
关于 int[26]:
- 这种写法是错误的,因为它没有指定数组名。
- 正确的写法应该是
int hash1[26],其中hash1是数组名。
其他初始化方法:
- 可以使用循环初始化数组为全0,例如:
c
复制
int hash1[26];
for (int i = 0; i < 26; i++) {hash1[i] = 0;
}
- 如果使用C++,可以使用
std::array或std::vector并使用std::fill或std::fill_n来初始化:
cpp
复制
#include <array>
#include <algorithm>std::array<int, 26> hash1;
std::fill(hash1.begin(), hash1.end(), 0);
或
cpp
复制
#include <vector>
#include <algorithm>std::vector<int> hash1(26);
std::fill(hash1.begin(), hash1.end(), 0);
总结:
int hash1[26] = {0}; 是初始化一个整型数组为全0的常用且正确的写法。

用户_uBiEPA
计算一个数组的哈希值可以吗
ChatGLM

可以计算一个数组的哈希值。哈希值是一个固定长度的数值,用于唯一表示输入数据。对于数组,可以通过多种方式计算其哈希值,例如使用数组元素的值、位置等信息。
以下是一个简单的示例,展示如何计算一个整型数组的哈希值:
c
复制
#include <stdio.h>unsigned int hash_array(int arr[], int size) {unsigned int hash = 0;for (int i = 0; i < size; i++) {hash = hash * 31 + arr[i]; // 31是一个常用的乘数}return hash;
}int main() {int arr[] = {1, 2, 3, 4, 5};int size = sizeof(arr) / sizeof(arr[0]);unsigned int hash_value = hash_array(arr, size);printf("Hash value of the array: %u\n", hash_value);return 0;
}
在这个示例中,我们定义了一个hash_array函数,它遍历数组中的每个元素,并使用一个简单的哈希公式来计算哈希值。这个公式将每个元素的值乘以一个常数(例如31),然后累加到哈希值中。最后,函数返回计算得到的哈希值。
请注意,这个示例中的哈希函数非常简单,可能不适用于所有场景。在实际应用中,可能需要使用更复杂、更安全的哈希函数来减少哈希冲突的可能性。
另外,如果你希望使用C标准库中的哈希函数,可以考虑使用<openssl/sha.h>等库来实现更复杂的哈希算法,如SHA-256等。但请注意,这些库可能需要单独安装和配置。
用户_uBiEPA
有没有现成的?
ChatGLM
在C语言中,可以使用结构体(struct)来模拟哈希表的行为。下面是一个简单的例子,展示了如何创建和使用一个基本的哈希表来存储字符串键和整数值。
c
复制
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#define TABLE_SIZE 10typedef struct {char* key;int value;
} HashEntry;typedef struct {HashEntry entries[TABLE_SIZE];int count;
} HashTable;// 哈希函数
unsigned int hash(const char* key) {unsigned long int value = 0;while (*key) {value = value * 37 + *key++;}value = value % TABLE_SIZE;return value;
}// 初始化哈希表
void initHashTable(HashTable* table) {memset(table->entries, 0, sizeof(HashEntry) * TABLE_SIZE);table->count = 0;
}// 插入键值对
void insert(HashTable* table, const char* key, int value) {unsigned int index = hash(key);if (table->entries[index].key == NULL) {table->entries[index].key = strdup(key); // 复制键table->entries[index].value = value;table->count++;} else {// 处理碰撞的情况,这里简单地覆盖已有的值table->entries[index].value = value;}
}// 查找键对应的值
int find(HashTable* table, const char* key) {unsigned int index = hash(key);if (table->entries[index].key != NULL && strcmp(table->entries[index].key, key) == 0) {return table->entries[index].value;}return -1; // 未找到
}int main() {HashTable table;initHashTable(&table);insert(&table, "apple", 100);insert(&table, "banana", 200);insert(&table, "cherry", 300);printf("Value for 'apple': %d\n", find(&table, "apple"));printf("Value for 'banana': %d\n", find(&table, "banana"));printf("Value for 'cherry': %d\n", find(&table, "cherry"));return 0;
}
这个代码实现了一个简单的哈希表,包括初始化、插入和查找操作。注意,这里的哈希函数只是一个简单的示例,实际应用中可能需要更复杂的哈希函数来减少碰撞的发生。此外,这个哈希表没有处理删除操作,也没有处理多个键映射到同一个位置的碰撞问题(这里简单地覆盖了已有的值)。在生产环境中,你可能需要一个更健壮的实现,比如链地址法或开放寻址法来解决这些问题。

用户_uBiEPA
c++只有hashmap没有哈系表》?x
ChatGLM

在 C++ 中,标准库提供了 std::unordered_map,它是一种哈希表的数据结构,可以用来存储键值对。std::unordered_map 是一种关联容器,它使用哈希表来实现快速的数据检索。
如果你说的是“哈系表”是指哈希表的话,那么 C++ 确实有这种数据结构,就是 std::unordered_map。如果你指的是其他特定的数据结构或者库,可能需要进一步澄清。
以下是一个使用 std::unordered_map 的简单示例:
cpp
复制
#include <iostream>
#include <unordered_map>
#include <string>int main() {std::unordered_map<std::string, int> phone_book;// 添加一些联系人信息phone_book["Alice"] = 123456789;phone_book["Bob"] = 987654321;phone_book["Charlie"] = 555555555;// 访问并打印某个联系人的电话号码std::cout << "Alice's phone number is: " << phone_book["Alice"] << std::endl;// 检查是否存在某个联系人if (phone_book.find("David") != phone_book.end()) {std::cout << "David's phone number is: " << phone_book["David"] << std::endl;} else {std::cout << "David is not in the phone book." << std::endl;}return 0;
}
在这个例子中,我们创建了一个 std::unordered_map 来存储名字和对应的电话号码。然后我们添加了一些联系人信息,访问了某个联系人的电话号码,并检查了另一个联系人是否存在于电话簿中。
如果你需要的是其他的特定功能或者库,请提供更多的上下文信息。

用户_uBiEPA
逐行解释

ChatGLM

当然,让我们逐行解释这段代码:
cpp
复制
class Solution {
public:vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string, vector<string>> mp;for (string& str : strs) {string key = str;sort(key.begin(), key.end());mp[key].emplace_back(str);}vector<vector<string>> ans;for (auto it = mp.begin(); it != mp.end(); ++it) {ans.emplace_back(it->second);}return ans;}
};
解释:
-
类定义:
cpp
复制
class Solution { public:... };定义了一个名为
Solution的类,其中包含一个公共成员函数groupAnagrams。 -
函数定义:
cpp
复制
vector<vector<string>> groupAnagrams(vector<string>& strs) {函数
groupAnagrams接受一个字符串向量strs作为参数,并返回一个二维字符串向量。 -
哈希表声明:
cpp
复制
unordered_map<string, vector<string>> mp;声明了一个无序哈希表
mp,其键是字符串,值是字符串向量。用于存储具有相同字母排列的单词组。 -
遍历字符串向量:
cpp
复制
for (string& str : strs) {遍历输入的字符串向量
strs。 -
生成键:
cpp
复制
string key = str; sort(key.begin(), key.end());对于每个字符串
str,复制一份并将其排序以生成键key。这样可以保证所有字母异位词具有相同的键。 -
插入哈希表:
cpp
复制
mp[key].emplace_back(str);将原始字符串
str插入到哈希表中对应键key的字符串向量中。 -
准备结果:
cpp
复制
vector<vector<string>> ans;初始化一个二维字符串向量
ans,用于存储最终的分组结果。 -
从哈希表提取结果:
cpp
复制
for (auto it = mp.begin(); it != mp.end(); ++it) {ans.emplace_back(it->second); }遍历哈希表
mp,并将每个键对应的字符串向量添加到结果ans中。 -
返回结果:
cpp
复制
return ans;返回分组后的结果
ans。
总结:
这段代码实现了将一组字符串按照字母异位词进行分组的逻辑。通过排序每个字符串生成键,然后将具有相同键的字符串归为一组,最终返回所有这样的分组。
用户_uBiEPA
emplace\_bac
emplace back 和pushback有何区别,这里能不能换成pushback
ChatGLM

emplace_back 和 push_back 都是 C++ 中向容器(如 vector)添加元素的成员函数,但它们在实现细节上有所不同:
-
emplace_back:
- 直接构造:emplace_back 在容器末尾直接构造元素,即直接在容器的内存空间中创建对象。
- 效率:由于避免了临时对象的创建和复制,emplace_back 在某些情况下可能更高效。
- 参数:接受与容器中元素类型构造函数匹配的参数,直接使用这些参数来构造新元素。
-
push_back:
- 复制或移动:push_back 可以接受一个已有的对象,然后将其复制或移动到容器末尾。
- 效率:如果传递的是右值(即临时对象),push_back 会使用移动语义,效率也较高;但如果传递的是左值,则可能涉及复制,相对效率较低。
- 参数:通常接受一个容器元素类型的对象作为参数。
在这里能不能换成 push_back?
可以。在这个特定的代码片段中,mp[key].emplace_back(str); 的目的是将字符串 str 添加到 map 中对应键 key 的向量中。由于 str 是一个左值,使用 push_back 也会得到正确的结果,只是可能稍微不那么高效,因为 push_back 可能会涉及复制操作,而 emplace_back 则直接在目标位置构造对象。
替换后的代码:
cpp
复制
mp[key].push_back(str);
总结:虽然可以替换,但使用 emplace_back 是更现代、更高效的选择,尤其是在处理大型对象或性能敏感的场景时。在这个例子中,替换为 push_back 不会影响程序的正确性,只是可能在性能上略有差异。

用户_uBiEPA
tr
str'ing&这里的&可以去掉吗
ChatGLM

在这段代码中,string& str: strs 中的 & 表示引用。这意味着 str 是对 strs 中元素的引用,而不是副本。这样做的好处是可以避免不必要的复制,提高效率。
如果你去掉 &,那么 str 将成为 strs 中元素的副本。在这种情况下,每次迭代都会创建一个新的字符串副本,这可能会增加额外的开销,尤其是当字符串很大或者集合 strs 很大时。
因此,是否可以去掉 & 取决于具体情况和对性能的要求。如果性能不是主要考虑因素,或者你愿意承担额外的复制开销,那么可以去掉 &。但是,为了保持代码的高效性和最佳实践,建议保留 & 以避免不必要的复制。

用户_uBiEPA
vector迭代器遍历代码
ChatGLM
在C++中,使用vector迭代器遍历vector的代码如下:
cpp
复制
#include <iostream>
#include <vector>int main() {std::vector<int> nums = {1, 2, 3, 4, 5};// 使用迭代器遍历vectorfor (std::vector<int>::iterator it = nums.begin(); it != nums.end(); ++it) {std::cout << *it << " ";}std::cout << std::endl;// 使用范围for循环遍历vector,这是C++11及以后版本的支持的语法for (int num : nums) {std::cout << num << " ";}std::cout << std::endl;// 如果需要修改vector中的元素,可以使用引用for (int& num : nums) {num *= 2; // 将每个元素乘以2}// 再次遍历vector以查看修改后的结果for (int num : nums) {std::cout << num << " ";}std::cout << std::endl;return 0;
}
在这段代码中,我们首先使用迭代器遍历了vector,然后使用C++11引入的范围for循环进行了遍历。在范围for循环中,如果需要修改vector中的元素,可以使用引用(如int& num)。
请注意,使用迭代器遍历是一种更通用的方法,它可以用于所有标准库容器,而范围for循环则提供了一种更简洁的语法。在实际编程中,可以根据需要选择合适的方法。
用户_uBiEPA
auto 和 vector::iterator有何区别
ChatGLM
auto 和 vector::iterator 在C++中都是用来遍历容器的,但它们有一些区别:
-
类型推导:
auto:是一个类型推导关键字,可以让编译器自动推导变量的类型。使用auto可以简化代码,使代码更易读、易维护。vector::iterator:是特定类型的迭代器,明确指出了迭代器属于vector容器。使用vector::iterator时,你需要明确指定迭代器的类型。
-
代码简洁性:
auto:可以使代码更简洁,因为编译器会自动推导出变量的类型,你不需要手动写出完整的类型名。vector::iterator:需要手动指定迭代器的类型,这在类型名较长或复杂时可能会使代码显得冗长。
-
通用性:
auto:不仅可以用于vector,还可以用于任何其他标准库容器,如list、map等。auto提供了更高的通用性。vector::iterator:仅适用于vector容器。如果你需要遍历其他类型的容器,你需要使用相应容器的迭代器类型。
-
性能:
- 在性能上,
auto和vector::iterator没有本质区别。它们都是迭代器,用于遍历容器元素。性能差异主要取决于编译器和具体的使用场景。
- 在性能上,
以下是一个使用auto和vector::iterator遍历vector的示例:
cpp
复制
#include <iostream>
#include <vector>int main() {std::vector<int> nums = {1, 2, 3, 4, 5};// 使用 vector::iterator 遍历for (std::vector<int>::iterator it = nums.begin(); it != nums.end(); ++it) {std::cout << *it << " ";}std::cout << std::endl;// 使用 auto 遍历for (auto it = nums.begin(); it != nums.end(); ++it) {std::cout << *it << " ";}std::cout << std::endl;// 使用范围for循环和 auto 遍历for (auto num : nums) {std::cout << num << " ";}std::cout << std::endl;return 0;
}
在这个示例中,使用auto可以使代码更简洁,而且不需要关心vector中元素的具体类型。而使用vector::iterator则明确指出了迭代器的类型,但在类型名较长时可能会使代码显得冗长。

用户_uBiEPA
迭代器遍历hashmap
ChatGLM

在C++中,遍历std::unordered_map(即hashmap)通常使用迭代器。std::unordered_map的迭代器提供了访问容器中元素的键和值的方法。下面是如何使用迭代器遍历std::unordered_map的示例:
cpp
复制
#include <iostream>
#include <unordered_map>
#include <string>int main() {// 创建一个unordered_map实例std::unordered_map<std::string, int> hashmap = {{"one", 1},{"two", 2},{"three", 3}};// 使用迭代器遍历unordered_mapfor (auto it = hashmap.begin(); it != hashmap.end(); ++it) {// it->first 是键,it->second 是值std::cout << "Key: " << it->first << ", Value: " << it->second << std::endl;}// 使用范围for循环和auto遍历unordered_mapfor (const auto& pair : hashmap) {// pair.first 是键,pair.second 是值std::cout << "Key: " << pair.first << ", Value: " << pair.second << std::endl;}return 0;
}
在这个示例中,我们首先创建了一个std::unordered_map,其中键是std::string类型,值是int类型。然后,我们展示了两种遍历方式:
-
使用迭代器遍历:通过
hashmap.begin()和hashmap.end()获取迭代器的起始和结束位置,然后在循环中通过it->first和it->second访问键和值。 -
使用范围for循环和
auto遍历:这种方法更加简洁,使用auto&可以避免不必要的复制,提高效率。在循环中,pair.first和pair.second分别表示键和值。
这两种方法都可以有效地遍历std::unordered_map中的所有元素。选择哪种方法取决于你的个人偏好和代码风格。
用户_uBiEPA
为什么呀
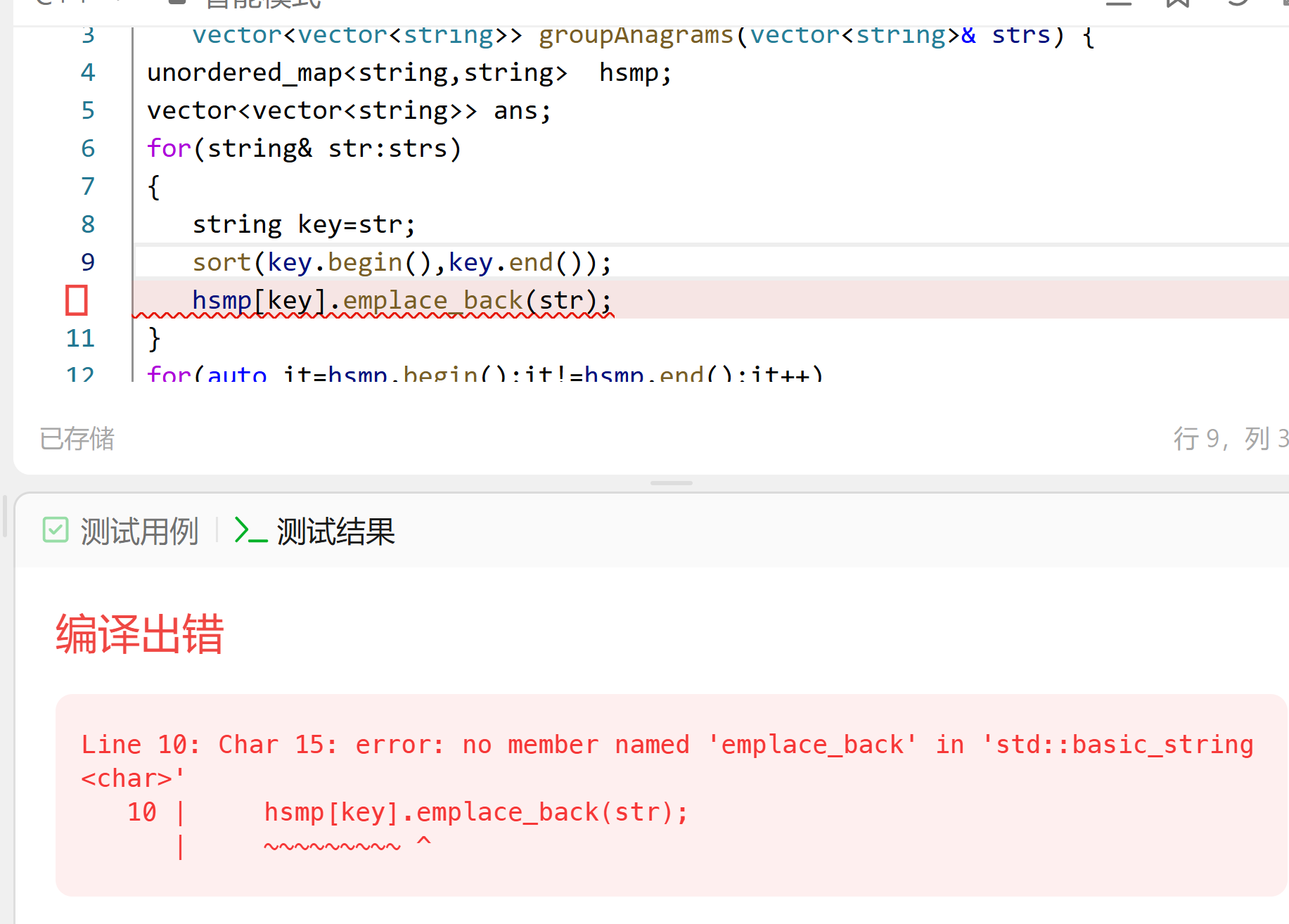
ChatGLM
![]()
引用
这个错误是因为你在尝试对一个std::string对象调用emplace_back方法,但std::string并没有这个方法。emplace_back是std::vector的方法,用于在向量末尾添加新元素。
在你的代码中,hsm[key]返回的是一个std::string类型的对象,因为你定义的unordered_map的值类型是std::string。你应该将unordered_map的值类型改为std::vector<std::string>,这样就可以使用emplace_back方法了。
以下是修正后的代码:
cpp
复制
vector<vector<string>> groupAnagrams(vector<string>& strs) {unordered_map<string, vector<string>> hsmp; // 修改这里vector<vector<string>> ans;for(string& str : strs){string key = str;sort(key.begin(), key.end());hsmp[key].emplace_back(str); // 现在hsmp[key]是一个vector,可以调用emplace_back}for(auto it = hsmp.begin(); it != hsmp.end(); ++it){ans.emplace_back(it->second);}return ans;
}
这样,hsmp[key]就是一个std::vector<std::string>对象,你可以安全地调用emplace_back方法来添加字符串。
相关文章:

leetcode hot100尝试1
目录 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 你可以按任意顺序返回答案。 c m…...

大模型Agent
一 大模型Agent是什么 (一)大模型Agent是指基于大语言模型的,能使用工具与外部世界进行交互的计算机程序 感知(Perception): ● 家庭助理通过摄像头、麦克风、传感器等设备获取家庭成员的活动信息和环境状…...
])
阻塞队列的介绍和简单实现——多线程编程简单案例[多线程编程篇(4)]
目录 前言 阻塞队列 阻塞队列相比普通队列的优势 1.天然线程安全 2.实现生产者-消费者模型更加简单 3.自动等待与唤醒 生产者-消费者模型 JAVA标准库中的阻塞队列 阻塞队列的简单实现 前言 在现代软件开发中,多线程编程能力已经成为程序员必须掌握的一项核心…...

服务器配置环境-condapytorch_20250422
文章目录 前言一、conda环境1.1 创建固定python版本的conda环境1.2 激活 Conda 环境1.3 关闭 Conda 环境 二、版本查看CUDA版本当电脑里有多个CUDN时 对照表下载 资源 前言 一、conda环境 1.1 创建固定python版本的conda环境 conda create --name tang_py_3.12 python3.12.41…...
 和 Gradle 的關係)
Android Gradle Plugin (AGP) 和 Gradle 的關係
Android Gradle Plugin (AGP) 与 Gradle 的核心关系解析 一、功能定位 Gradle 的通用性 Gradle 是跨平台构建工具,支持 Java、Kotlin、C 等多种语言,提供任务自动化、依赖管理等功能。 通过 build.gradle 文件定义构建脚本,管理编译、测试…...
的实现(5)0423)
字典树(前缀树)的实现(5)0423
字典树又称前缀树或Trie树,是处理字符串中常见的数据结构。假设组成所有单词的字符仅是"a"~"z",请实现字典树结构,并包含以下四个功能。 void insert(String word) :添加word,可重复添加。 void delete(Str…...

PHP 反序列化原生类 TIPS字符串逃逸CVE 绕过漏洞属性类型特征
#PHP- 属性类型 - 共有 & 私有 & 保护 1 、对象变量属性: public( 公共的 ): 在本类内部、外部类、子类都可以访问 protect( 受保护的 ): 只有本类或子类或父类中可以访问 private( 私人的 ): 只有本类内部可以使用 2 、序列化数据显示: p…...

专题二十:路由策略与策略路由
一、路由策略 1.1 路由策略的概念 路由策略是通过修改路由表的路由条目来控制数据流量的可达性。即对接受和发布的路由进过滤。这种方式称为路由策略 路由策略功能相关作用控制路由的发布可通过路由策略对所要发布的路由信息进行过滤,只允许发布满足条件的路由信…...

Git 远程操作全攻略:从基础到实战
🌈 个人主页:Zfox_ 🔥 系列专栏:Git 企业级应用 目录 一:🔥 理解分布式版本控制系统 二:🔥 远程仓库 🦋 新建远程仓库🦋 克隆远程仓库🦋 向远程仓…...

VUE自动定义控件SwitchButton
<switch-button style"margin-left: 20rpx;" :buttons["一键打分", "快捷打分"] select"快捷打分" ButtonClick"SwitchButnClick"></switch-button> SwitchButton.vue <template><view class"Di…...

【数据可视化-24】巧克力销售数据的多维度可视化分析
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...

STM32---串口通信USART
目录 一、串口通信协议 二、USART模块介绍 (1)移位寄存器 (2)控制电路 (3)波特率 (4)C语言接口 三、串口的引脚初始化 (1)引脚分布表 &…...
YOLO11改进-Backbone-引入TransXNet替换YOLO backbone 学习全局和局部动态信息,提高检测精度
Vision Transformer 的缺陷:Vision Transformer(ViT)运用多头自注意力机制在计算机视觉领域取得进展,但它缺乏卷积神经网络(CNNs)所具有的归纳偏差,导致泛化能力相对较弱。像 Swin Transformer …...

SQL 多表查询:数据整合与分析的强大工具
SQL 多表查询:数据整合与分析的强大工具 在关系型数据库中,数据通常被组织在多个表中。这种表的分离有助于减少冗余并提高数据的管理效率。然而,在实际应用中,往往需要对多个表中的数据进行整合查询,来获得更完整的信…...
 - 单通道ADC采集、多通道ADC采集、定时器触发连续ADC采集 - STM32CubeMX)
MCU开发学习记录11 - ADC学习与实践(HAL库) - 单通道ADC采集、多通道ADC采集、定时器触发连续ADC采集 - STM32CubeMX
名词解释: ADC: Analog-to-Digital SAR:Successive Approximation Register 本文将介绍ADC的概念、相关函数以及STM32CubeMX生成ADC的配置函数。针对于ADC实践:单通道采集芯片内部温度传感器(ADC1_ch16)&a…...
)
MacOS中安装Python(homebrew,pyenv)
前言 由于MacOS中自带Python,而自带的Python关联到许多系统组件,不推荐 禁止使用自带Python 安装homebrew包管理器 homebrew官网 打开终端(terminal)输入以下命令 /bin/bash -c "$(curl -fsSL https://raw.githubusercon…...

从物理到预测:数据驱动的深度学习的结构化探索及AI推理
在当今科学探索的时代,理解的前沿不再仅仅存在于我们书写的方程式中,也存在于我们收集的数据和构建的模型中。在物理学和机器学习的交汇处,一个快速发展的领域正在兴起,它不仅观察宇宙,更是在学习宇宙。 AI推理 我们…...
)
新书速览|Hadoop与Spark大数据全景解析(视频教学版)
《Hadoop与Spark大数据全景解析:视频教学版》 01 本书内容 《Hadoop与Spark大数据全景解析:视频教学版》结合作者多年在大数据领域的开发实践经验,采用“理论实战”的形式,以大量实例全面介绍Hadoop和Spark的基础知识及其高级应用。作者将丰富的教学经…...

Linux:42线程控制lesson30
代码1:验证join可以去的线程执行完后的退出码/返回值 #include<iostream> #include<unistd.h> #include<pthread.h> #include<string> using namespace std;void* routine(void* arg){string name static_cast<const char*>(arg);i…...

配置 Apache 的 HTTPS
证书文件 文件名 作用 来源 example.com.key 服务器的私钥,用于加密和解密数据。 本地生成 -----BEGIN PRIVATE KEY----- MIIEowIBAAKCAQEAqp5c... -----END PRIVATE KEY----- example.com.csr Certificate Signing Request 证书签名请求文件,包…...

【Flutter高效开发】GetX指南:一文学会状态管理、路由与依赖注入
GetX是Flutter生态中最受欢迎的轻量级全能框架,以其简洁的API设计和卓越的性能著称。本文将带你全面掌握GetX的核心功能和使用技巧,提升你的Flutter开发效率。 一、GetX框架核心优势 1. 三位一体架构设计 模块功能传统方案对比状态管理响应式状态控制…...

第四节:核心概念高频题-Vue生命周期钩子变化
重命名:beforeDestroy→beforeUnmount,destroyed→unmounted 新增:onServerPrefetch(SSR场景) Vue 生命周期钩子变化详解(Vue2 → Vue3) 一、核心钩子重命名与语义优化 销毁阶段语义化升级 • …...

安全邮件系统的Maple实现详解
代码改进版: # # 安全邮件系统实现 - 结合DES和RSA加密 # 功能:实现安全的消息加密、签名和传输 # # -------------------------- # 第一部分:消息准备和加密 # --------------------------# 原始消息内容 message : "This is an atte…...
)
VTK-8.2.0源码编译(Cmake+VS2022+Qt5.12.12)
参考: 安装VTK 详细图文讲解CMake编译VTK,包含详细的编译环境版本 Visual Studio 2022 配置VTK9.3.0 VTK-8.2.0源码编译和初步使用(CmakeVS2015Qt5.14.2) 文章目录 下载编译编译环境介绍配置CMake信息BUILD_SHARED_LIBS控制生成的库是动态链接库…...

【playwright】学习--持续汇总
seleniumplaywrightselenium 需要结合其他自动化框架,比如pytest之后才能支持web自动化测试playwright 不需要其他自动化框架selenium库》webdriver》浏览器驱动playwright库》playwright driver》浏览器驱动 目录 安装playwright通过pip安装通过VScode安装 安装pla…...

深度解析算法之模拟
39.替换所有的问号 题目链接 给你一个仅包含小写英文字母和 ? 字符的字符串 s,请你将所有的 ? 转换为若干小写字母,使最终的字符串不包含任何 连续重复 的字符。 注意:你 不能 修改非 ? 字符。 题目测试用例保证 除 ? 字符 之外&#…...

leetcode刷题日记——插入区间
[ 题目描述 ]: [ 思路 ]: intervals 有序,需要将一个新的范围插入,然后进行整合方法一,将新的范围插入原 intervals 区间,然后使用 56 题的合并区间函数直接解决方法二, 找出能够包容 newInte…...

gbase8s存储学习一 rootdbs存储结构以及寻址分析
主要层次自下而上为 最小物理存储单元page ,多个page 组成逻辑存储单元extent,多个extent 组成物理存储单元chunk ,而多个chunk组成逻辑存储单元dbspace,多个dbspace 组成一个数据库实例 在数据库初始化阶段会生成一个rootdbs表空间,该表空…...

学习设计模式《五》——工厂方法模式
一、基础概念 工厂方法模式的本质是【延迟到子类来选择实现】; 工厂方法模式的定义:定义一个用于创建对象的接口,让子类决定实例化哪一个类,FactoryMethod使一个类的实例化延迟到其子类 。 工厂方法模式的功能 序号说明0工厂方法模…...
 作为 SAML IdP 对接到 Keycloak)
如何将 Azure Active Directory (Azure AD) 作为 SAML IdP 对接到 Keycloak
✅ 一、在 Azure AD 创建 SAML 应用 🔧 1. 登录 Azure 门户 前往 https://portal.azure.com,使用管理员账号登录。 📌 2. 创建企业应用(Enterprise Application) 左侧菜单进入 “企业应用程序”。点击 “新建应用程…...

OCR之身份证识别
前言 OCR身份证识别是光学字符识别技术在身份证领域的应用。通过扫描或拍照获取身份证图像,利用图像处理、深度学习等技术,自动提取姓名、性别、民族、出生日期、地址、身份证号等信息,可大幅提升信息录入效率,广泛应用于政务、金…...

JavaScript 渲染内容爬取:Puppeteer 高级技巧与实践
在现代网络应用中,动态网页内容的爬取一直是开发者面临的挑战之一。Puppeteer 作为一种强大的浏览器自动化工具,为这一问题提供了优雅的解决方案。本文将深入探讨 Puppeteer 的高级技巧,包括动态内容抓取、性能优化、反检测与伪装、复杂自动化…...

组织级项目管理OPM
组织级项目管理(Organizational Project Management, OPM)是一种系统化的管理方法,旨在通过整合项目组合、项目集和项目管理,确保组织的战略目标与项目执行的一致性,提升资源利用效率和项目成功率。以下是其核心内容与框架的详述: 一、组织级项目管理的定义与目标 定义 组…...

HTML与Web 性能优化:构建高速响应的现代网站
HTML 与 Web 性能优化:构建高速响应的现代网站 引言 随着互联网用户对网站加载速度期望的不断提高,前端性能优化已经成为现代 Web 开发的核心竞争力。据 Google 研究表明,页面加载时间每增加 1 秒,用户跳出率就会增加 32%。用户…...

模型 观测者效应
系列文章分享模型,了解更多👉 模型_思维模型目录。观察即影响,存在因注视而变。 1 观测者效应的应用 1.1 工业心理学—霍桑实验中的生产效率谜题 行业背景:20世纪20年代西方电气公司霍桑工厂,研究者试图通过优化照明…...
服务步骤)
Ubuntu启动SMB(Samba)服务步骤
目录 1.基本的Samba服务器搭建流程主要分为四个步骤。 2.Samba工作流程: 3.解读主要配置文件smb.conf 4.开始安装Samba 5.检查Samba服务状态 6.创建Samba共享文件夹 7.配置Samba文件以及设置Samba用户密码 8.重启Samba服务器 9.关闭防火墙 10.Linux客户端…...

使用react的ant-design-pro框架写一个地图组件,可以搜索地图,可以点击地图获取点击的位置及经纬度
首先,先创建一个地图页面,用于显示地图组件,我是在pages文件中创建了一个mapSearch组件。 然后在routes.ts中注册页面。 {path: /mapSearch,name: mapSearch,icon: smile,component: ./mapSearch,}, 第三步就是使用高德地图来创建地图。 关键…...

【每日八股】复习计算机网络 Day4:TCP 协议的其他相关问题
文章目录 昨日内容复习已经建立了 TCP 连接,客户端突然出现故障怎么办?什么时候用长连接?短连接?TCP 的半连接队列与全连接队列?什么是 SYN 攻击?如何避免?TIME_WAIT 的作用?过多如何…...

Git远程操作与标签管理
目录 1.理解分布式版本控制系统 2.远程仓库 3.新建远程仓库 4.克隆远程仓库 5.向远程仓库推送 6.拉取远程仓库 7.配置Git 7.1.忽略特殊文件 7.2.给命令配置别名 8.标签管理 8.1.理解标签 8.2.创建标签 8.3.操作标签 1.理解分布式版本控制系统 Git是目前世界上…...

Element Plus消息通知体系深度解析:从基础到企业级实践
一、核心组件与技术定位 Element Plus的消息通知体系由三个核心组件构成:ElMessage(全局提示)、ElNotification(通知弹窗)和ElMessageBox(交互式对话框)。这套体系的设计目标是为开发者提供轻量…...

SpringCloud组件——Eureka
一.背景 1.问题提出 我们在一个父项目下写了两个子项目,需要两个子项目之间相互调用。我们可以发送HTTP请求来获取我们想要的资源,具体实现的方法有很多,可以用HttpURLConnection、HttpClient、Okhttp、 RestTemplate等。 举个例子&#x…...

[Godot] C#2D平台游戏基础移动和进阶跳跃代码
本文章给大家分享一下如何实现基本的移动和进阶的跳跃(跳跃缓冲、可变跳跃、土狼时间)以及相对应的重力代码,大家可以根据自己的需要自行修改 实现效果 场景搭建 因为Godot不像Unity,一个节点只能绑定一个脚本,所以我…...

C语言对n进制的处理
先看一道题目: 从键盘获取一个正整数,如果把它转为16进制的数字,那么它是一个几位数呢?如果把它转为28进制又是一个几位数呢? 在讲这个题目之前,我们先要了解进制转换 什么是进制转换? 简单来说,进制就是数位的表示方法。 十进制(常用&am…...

rk3568main.cc解析
rk3568main.cc解析 前言解析总结前言 正点原子rk3568学习,rk官方RKNN_MODEL_ZOO文件中 rknn_model_zoo-main/examples/mobilenet/cpp/main.cc 从执行命令:./build-linux.sh -t rk3568 -a aarch64 -d mobilenet 到: cmake ../../examples/mobilenet/cpp \-DTARGET_SOC=rk3…...

【白雪讲堂】[特殊字符]内容战略地图|GEO优化框架下的内容全景布局
📍内容战略地图|GEO优化框架下的内容全景布局 1️⃣ 顶层目标:GEO优化战略 目标关键词: 被AI理解(AEO) 被AI优先推荐(GEO) 在关键场景中被AI复读引用 2️⃣ 三大引擎逻辑&#x…...
-Bootloader)
S32K144学习(16)-Bootloader
1.什么是bootloader Bootloader(引导加载程序) 是存储在设备非易失性存储器(如 ROM、Flash)中的一段特殊程序,负责在设备上电后初始化硬件、加载操作系统(OS)或用户应用程序,并最终…...

反素数c++
先上代码 #include<bits/stdc.h> using namespace std; typedef long long ll; ll n; ll p[]{2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53}; int maxd,maxval; void dfs(int pl,ll tmp,int num,int up){ if((num>maxd)||(nummaxd&&maxval>tmp)){ …...
)
C++ linux打包运行方案(cmake)
文章目录 背景动态库打包方案动态库转静态库动态库打到软件包中 运行 背景 使用C编写的一个小项目,需要打包成ubuntu下的可执行文件,方便分发给其他ubuntu执行,因为docker镜像方案过于臃肿,所以需要把项目的动态库都打在软件包中…...

JavaScript 渲染内容爬取实践:Puppeteer 进阶技巧
进一步探讨如何使用 Puppeteer 进行动态网页爬取,特别是如何等待页面元素加载完成、处理无限滚动加载、单页应用的路由变化以及监听接口等常见场景。 一、等待页面元素加载完成 在爬取动态网页时,确保页面元素完全加载是获取完整数据的关键。Puppeteer…...
)
AI数字人:元宇宙舞台上的闪耀新星(7/10)
摘要:AI数字人作为元宇宙核心角色,提升交互体验,推动内容生产变革,助力产业数字化转型。其应用场景涵盖虚拟社交、智能客服、教育、商业营销等,面临技术瓶颈与行业规范缺失等挑战,未来有望突破技术限制&…...