算力网络的早期有关论文——自用笔记
2023年底至2024年初阅读有关论文的自用笔记,作为参考。
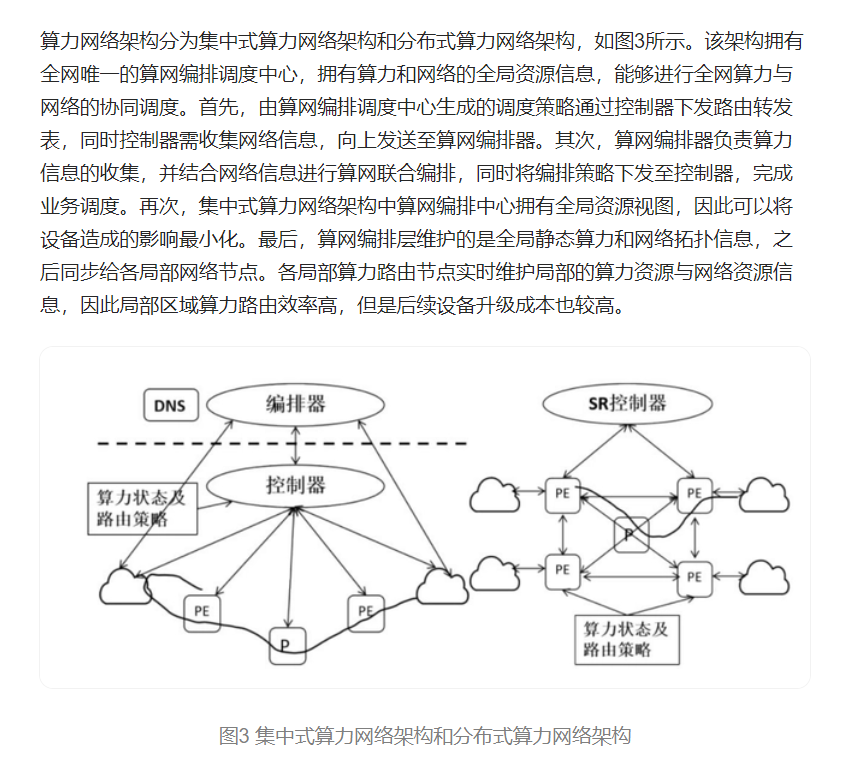
算力网络架构
https://baijiahao.baidu.com/s?id=1727377583404975414&wfr=spider&for=pc
think¬e
是否可以和cpu进程调度联系。
目前:看一些综述深一步了解背景和发展现状,完善认知->学位论文和中文核心查看已有架构和仿真实验,考虑网络如何建模。
感知:仅在拓扑改变时通告,网络划分成子网,最高层只负责调配大致方向,分层调度任务(节点宕机并不会主动通报,可通过网关入口管理子网的形式)
路由:分布式(路由节点进行转发),集中式路由(中国联通研究院的文章,算网编排层,已实现于算网一体调度,不用再关注状态的集中感知)。或者考虑实现混合式路由。
可能需要解决的问题:怎么做到真?算力如何度量?服务优先级如何度量?多级、异构算力的统一标识,路由协议的统一问题
考虑仿真环境的限制,主要关注算力和网络联合调度的部分,服务简单建模为优先级别和服务时间。
下一步:除了继续调研发展现状以外,较少有算力网络路由的外文文献,计算卸载在学术领域的研究更加全面;
| 网络层面 | 算力层面 | 服务层面 | |
|---|---|---|---|
| 资源信息 | 考虑链路质量、拥塞情况和数据实时性要求,选择质量较好且传输时延较低的路径 | 选择算力状态空闲、距离近且网络状态良好的节点 | 优先响应任务敏感性、高优先级服务 |
| 指标 | 时延、带宽、丢包率;吞吐量 | 节点的负载、经济成本、能耗; 节点资源: 计算,通信,内存和存储能力; 节点服务能力:安全性,定位功能 | 算力服务类型,服务数据量,新增请求量 |
| 分类 | 分布式(路由节点),集中式(算网编排层,算网一体调度),混合式 | 组合服务和单体服务 |
当计算时间和调度时间不在同一量级,没有优化意义?计算>>调度,对总体效率提升不大;调度>>计算,效率过低,在附近算
开题
集中式调度可能不适用于时延敏感型业务,面向需要处理大量数据进行分析的业务。
分布式调度虽然有时延优势,但目前东数西算不适用于低时延要求的场景,时延敏感型任务更倾向于在边缘节点处理。因此,集中式调度是东数西算的重要调度方式,它有助于处理大量数据分析的业务,降低计算的经济成本。
以优化目标为驱动;已经实现的东西;
遇到空闲节点附近的网络负载较重的情况,若选择该节点,网络传输时延大;若选择其他节点,任务等待时间大。吞吐量奖励对于俩种情况一致,时延小的奖励高。状态空 间需要提取网络、节点状态特征。
对于网络预测任务预计传输完成时间;对于节点预测任务预计完成时间。作为数据集的死数据就可以。这俩个时间对于实际来说是否可预测?(可以暂时不考虑)
可能是哪些网络指标会严重影响服务完成速度?网络剩余带宽、网络拥塞时队列长度
学位论文
学位论文:docker模拟算力路由节点,分别优化组合服务和单体服务,networkx进行仿真,蚁群算法进行集中式路由优化
算力网络中的服务路由机制研究_关晨晨东南大学
主要工作
基于 Chord协议的分布式算力服务发现方案:算力节点提-=算力 资源并承载服务;算力网关将算力节点中的服务及服务实例状态信息进行发布;算力路由节点作为 Chord 中的实体,负责分布式地维护服务信息,以及完成服务发现
改良 Bkd树的单体服务优化调度算法:将具有多维属性的服务实例状态数据以 Bkd 树的方式进行组织,设计剪枝策略实现对服务实例的高效选择,设计重构策略支持服务实例的动态更新,并融合用户偏好实现对服务实例的优化调度
融合遗传算法、蚁群算法的组合服务调度方案:Bkd 树对服务实例进行过滤,减小搜索空间;然后,经蚁群算法生成可行解,并以遗传算法对生成的可行解进行优化
相关工作:【7】将任播地址作为服务的标识,提供相同功能的服务使用同一任播地址,并根据服务所处的计算站点的负载和网络状态,将客户需求调度至最佳站点
单体服务优化调度问题:根据用户对服务质量的偏好及期望选择服务实例,服务或服务实例的质量以及用户对 QoS 的期望和偏好而进行调度,类似于服务选择问题
基于Chord的服务发现
建模:算力节点中的服务实例的响应性能:响应时间、代价、响应成功率及服务的可用性
假设:1.假设服务部署工作已完成,服务实例位于网络中的不同算力节点中。
2、服务状态感知机制通过监控、遥测等技术手段完成,本文仅考虑如何将感知后的服务及服务实例信息进行发布和发现
问题:服务命名、响应性能状态标识、服务发现(获取可提供服务的节点位置)
分类:
-
集中式:单点瓶颈及控制平面可扩展性差;控制平面及注册中心的可信度及安全性的要求,适用于集群环境
-
DNS服务发现:首先通过本地域名服务器进行解析,若解析成功则可直接完成服务调用,否则向上层 DNS 服务器发送请求进行解析,直至获得服务的位置信息。
-
无结构分布式服务发现:依赖中间转发设备完成,域内采用 OSPF,域间采用 BGP,对现有的BGP 和 IGP 协议进行改进来实现
-
Chord发现:同一服务的所有服务实例信息由同一个算力路由节点维护。通过拼接服务的前缀号prefix,服务功能名serviceName进行哈希计算SID。收到路由请求后,依次将请求转发至其后继节点,来查找维护该服务的节点
bkd树单体服务调度
问题定义:优化目标为在所有维度上(服务响应时间、代价、可用性、响应成功率)全部满足用户期望且综合性能最优
请求到来时,用户期望进行归一化并通过Bkd 树(二叉搜索树)筛选出满足公式(4.3)的服务实例,最终根据用户偏好计算各服务实例的综合得分完成服务实例的调度。
改良bkd树:增加一个buffer,当buffer大小与当前树一样大时将俩树合并;计数布隆过滤器来维护节点的更新,若在过滤器中有该实例说明已更新,则过滤该实例,否则加入备选;若所有实例均无法在四个维度上满足用户需求,则使用KNN算法计算k个与用户期望距离最近的实例。
缺陷:无法解决动态插入数据的问题,更适用于静态数据的存储
实验:服从泊松分布的任务到达, QWS 数据集,生成用户期望
(对完全不了解工作的人清晰的讲解)
基于遗传蚁群算法的组合服务优化调度:为每个服务的服务实例通过 Bkd 树过滤一部分不符合用户期望的服务实例;筛选后的服务实例通过遗传-蚁群算法进行组合,每个服务选择一个服务实例,并按照工作流的方式进行组合,完成业务功能。
实验:基线为qlearning,ACO,比较了优化目标、迭代次数的影响
面向算力感知网络的路由系统仿真设计与实现_顿昊BUAA
think:在实现上考虑是否有提供该服务的节点,该节点算力资源是否足够,然后考虑最小cost的路由。这篇文章优先考虑计算性能的盈余,在算力状态近似的情况下选择网络性能较优的服务节点,可能存在有盈余的计算节点网络负载较重的情况?可能是哪些网络指标会严重影响服务完成速度?最大化网络吞吐量的情况下,确保完成服务,
IETF标准化文稿《Compute First Networking Scenarios and Requirements》
算力网络体系的整体架构应该具备统一纳管底层计算资源、存储资源、网络资源的能力,并能够将底层基础设施资源以统一的标准进行度量,抽象为信息要素加载在网络报文中,通过网络进行共享。
相关技术
设计任播完成服务请求:由于使用任播标识各类计算服务,多个计算服务节点拥有自身ip地址外,还存在具有相同服务标识的ipv4地址的情况 ,且算力路由通告信息基于服务标识地址,所以无法使用普通ipv4完成路由转发。
关于任播:任播是使服务地址可用于两个或多个离散位置的任播节点上的路由系统的做法的名称。无论路由系统选择哪个特定节点来处理特定请求,每个节点提供的服务通常是一致的。对于使用任播分发的服务,没有引用到其他服务器或基于名称的服务分发(“轮询DNS”)的固有要求,(如果应用需要,可以与任播服务分发结合使用)。路由系统根据拓扑和请求节点来决定每个请求使用哪个节点。
节点之间的负载分配在请求和流量负载方面通常是不平衡的,任播节点之间的负载均衡通常很难实现。
p23

应用感知网络,APN6:扩展携带算力状态信息,通过IP报文传递转发实现全网感知
IP隧道:通过对现有网络传输协议报文进行头部的封装/解封装,实现不同网络间的通信功能.宏观来看是虚拟的点对点连接通道,保证将头部封装后的报文能够按照头部路由信息成功传输,同时通道两端具有对数据报封装和解封装的功能。缺点: 无法平衡实际网络的资源损耗,不实际。
主要工作
采用分布式方案:路由节点通过报文传递生成本地算力状态表,入口节点结合出口节点的网络状态生成本地网络状态表,根据算力和网络状态表生成算力路由表指导服务转发。
算力度量->分布式架构->(BGP协议扩展性)算力通告->路由算法->(IP隧道技术)任播服务的路由
算力度量:算力简单定义为cpu及内存使用率
| 计算 | 对CPU/GPU等计算资源运算能力的评估 |
|---|---|
| 通信 | 节点对外通信速率.单节点: 在单位时间内能发送或接收的最大数据量 |
| 内存 | 内存容量,内存带宽 |
| 存储 | 存储容量 、 存储带宽 、 每秒操作数(IO数)及响应时间(IO请求完成时间) |
算力通告: 可将算力状态信息引入BGP UPDATE消息中扩展团体属性,同时増加监听功能函数识别含算力状态信息的BGP报文。算力节点到路由出口节点的算力和网络状态信息感知通过mysql数据库实现。
路由方法:CLRA,首先进行计算性能参数及网络性能参数的初始化,接着对服务注册表遍历,保证为不同计算服务类型计算最优服务节点,对于可提供相应计算服务的节点而言,优先考虑服务节点计算性能盈余,并能在算力状态近似的情况下选择网络性能较优的服务节点,通过迭代借助临时变量完成服务注册表中的计算服务最优节点的获取,保证了算力网络中各计算服务节点具备负载均衡特性。
任播标识的路由:对于不同的服务集群给予相应的服务类型SID,即一个IPv4单播地址。每个服务器有唯一IP地址和SID。使用ipip隧道,即在IPv4报文的上再封装一个外头部IPv4报文, 通过配置两节点之间的隧道自动生成一条路由。**缺点:**不能通过IP-in-IP隧道转发广播或者IPv6数据包,只是连接了两个一般情况下无法直接通讯的IPv4网络而已;在Linux实现,不能与其他操作系统或路由器互相通讯。
实验包括随请求流增加情况下负载变化情况、不同路由算法下用户服务满意度(根据时延判断,不超过1s则满意)、算力网络和传统网络(不考虑算力因子)的平均时延对比,在不同流量强度下取平均、算力通告周期的长短和通告时延的关系
- 算力路由通告时延和入口路由节点与出口路由节点的跳数成正相关。
- 随着算力通告周期的增大,算力路由通告时延也随之增大。
- 入口路由节点与出口路由节点跳数较多的情况下,算力通告周期大于15秒后通告时延会远高于环比增长。
- 考虑到实际需求及资源把控,算力通告周期设置在5秒至10秒之间最佳 。
展望:(1)优化算力度量,考虑多因子;(2)与现网技术和协议的兼容,(3)引入RL、DL规划路由,(4)系统可视化
分布式架构
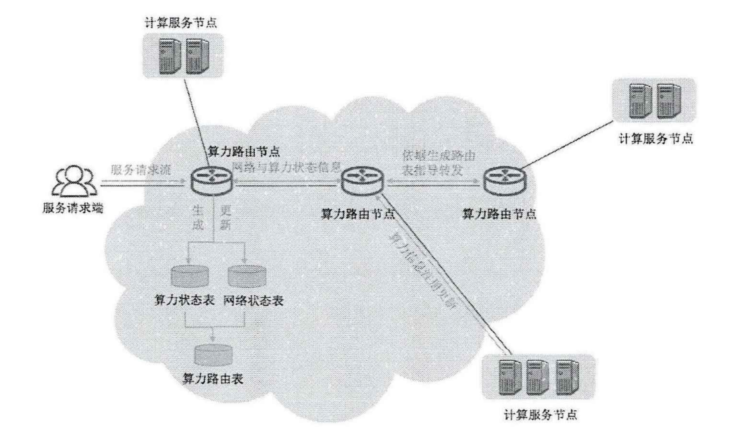
分布式架构:计算服务节点将其所具有的量化算力资源发送给其最近的路由器,由边缘路由器生成转发表
优点:稳定,可扩展性强
集中式架构:基于SDN/NFV,SDN集中控制器维护网络状态表.节点向控制器发送请求报文,控制器生成下发路由项
优点:集中编排,易实现
缺点:控制器计算负担重,出现单点故障
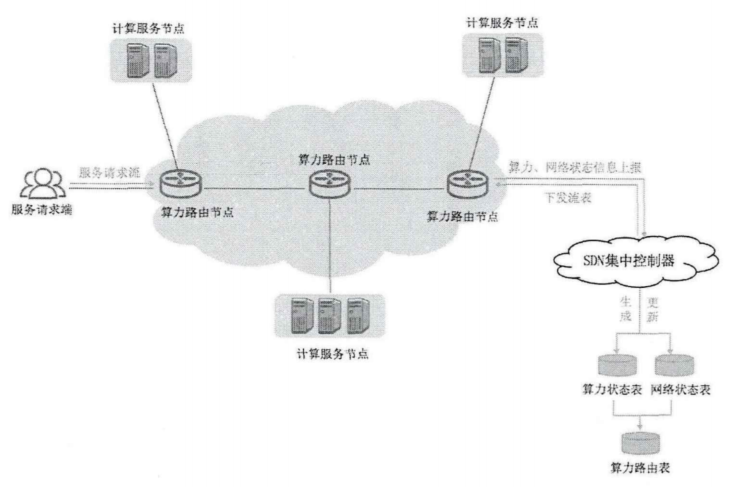
服务请求端:请求通过任播地址(SID)识别服务节点,服务节点已被标记SID,表示某一类型的服务
算力路由入口节点:内部网元,面向客户端,依据路由表指导实现调度
算力路由中心节点:接收转发算力状态信息表
算力路由出口节点:面向服务节点,更新连接节点的算力状态信息,并进行全网通告
计算服务端:为服务请求提供服务
感知过程:计算节点将量化信息上报给最近路由器,周期性通过REST API发送POST请求更新算力负载信息,由此路由器进行算力通告.
决策过程:边缘路由器测量网络状态,调取算力状态表,生成路由信息项和转发表
2023-网内动态通算资源协同利用研究_齐建鹏-北京科技大学-博士
问题与解决
- 通算资源动态变化时的资源匹配度 - 资源稳定匹配评估模型,求出任务与资源的匹配度
- 分布式、动态、精准匹配最优节点
- 约束资源有效覆盖范围,确定资源状态更新间隔
评估动态算力、网络资源和任务的匹配度;匹配稳定、分布式通算资源;划分有效资源约束范围,确定更新间隔,提出分布式通算协同感知与匹配框架;基于信息中心网络仿真器ndnSIM,网络仿真平台NS-3,设计通算资源协同利用的仿真平台
匹配度:网内协同任务在面临可用资源波动时仍然能在一定时间内满足任务的时延需求程度
相关工作
动 态通 算 资 源匹 配 评 估
链 路 内 及 广 域 网 的 通 算 资 源 协 同 计 算
仿真平台:NS-3,omnet(c++);cloudsim(java,不支持网络协议栈);ndnSIM扩展[19];https://github.com/qijianpeng/awesome-edge-computing
算力网络路由调度技术研究-电信科学
T2-网络与信息安全学报
两个核心问题:算力和网络资源如何实时、精准、可量化地感知;算力和网络资源如何一体化路由调度。
一体化路由调度的前提是:异构泛在网络状态和资源状态的实时感知能力,感知过程包括资源状态的量化和信息发布。
无人机、自动驾驶等新型场景涌现出的数据量激增,需要更高的网络化算力支撑。卫星通信摆脱地形环境的限制,和地面通信网络相互补充,将分散的算力节点进行链接,赋能算力网络发展。
资源感知
网络资源
随着算网一体的逐步发展,亟须跨云网的端到端网络性能检测手段。
跨云网性能测量解决方案如图所示,可以实现跨云网的随流检测,实现网络资源状态感知能力升级。该方案不需要云内网络硬件设备升级,从而降低网络演进复杂度。
通过云内虚拟安全网关进行网络测量实现。
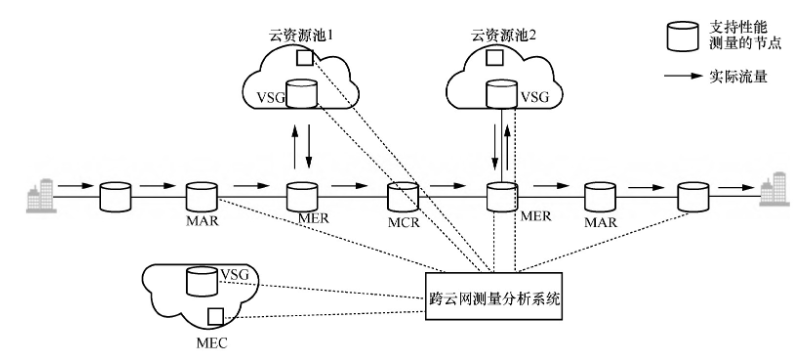
算力感知
面向网络侧,分布式算力路由:面向网络侧的算力资源状态感知,将算力状态信息关联到网络层并进行传播,可用于分布式算力路由调度解决方案。
算力节点首先将算力资源状态信息进行建模度量,定义新的网络协议报文携带算力状态信息,基于网络协议对网络侧通告算力状态信息,
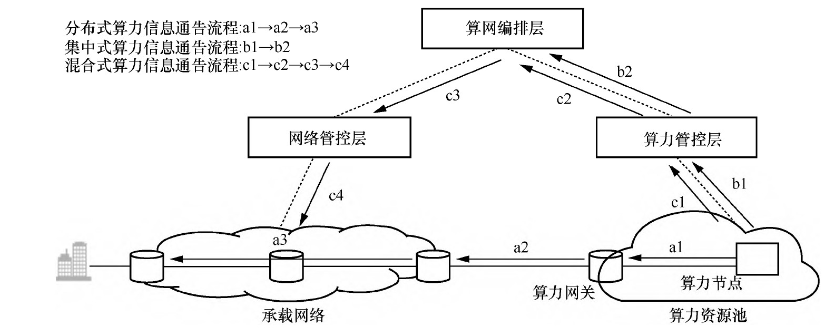
面向算网编排层的算力资源状态感知,可用于集中式算力路由调度解决方案和混合式算力路由调度解决方案。面向算网编排层的算力状态感知是目前算网一体调度实现的现有技术。
面向算网编排层相对于直接面向网络层,可能存在感知速度的差异,但在算力信息的高效利用、现网升级等方面有较大优势。
**集中式算力路由调度:**集中式算力路由调度解决方案中,算力状态信息通告流程如b1→b2所示,算力节点通过南北向接口将算力状态信息逐层向算力管控层、算网编排层通告。
混合式算力路由调度:在混合式算力路由调度解决方案中,也可以通过南北向接口进一步实现算力状态信息由算网编排层向网络侧的传递。
算力状态信息通过算力侧北向接口传递至算网编排层(c1→c2),由算网编排层进行智能化处理(如阈值判定、通告颗粒度调整等)后,由网络侧北向接口下发至网络设备层(c3→c4)。
算力网络路由调度技术
基于网络和算力信息的网络路径选择和算力调度并不是一个全新的课题,在学术界已经有了大量的计算卸载相关技术研究。计算卸载在学术领域的研究更加全面,可以对算力网络的路由调度技术形成有效补充!可以参考计算卸载的相关研究。
考虑:计算节点的负载、经济成本、网络路径;综合考虑网络承载质量(时延、带宽、丢包率等)以及计算节点算力状态(算力类型、负载等)、经济成本、能耗等多重因素。
集中式算力路由调度方案由算网编排系统做出路由决策,分布式算力路由调度方案由算力路由节点(网元设备)做出路由决策。
混合式方案可以面向时延敏感型业务提供分布式路由调度能力,面向普通业务提供集中式路由调度能力。
混合式方案通过南北向接口进行算力资源状态感知与通告。纯分布式方案中算力资源状态通告是基于BGP/IGP 的扩展实现的,算力节点以及承载网中边界网络设备之间通过协议扩展进行信息扩散。
算力网络研究进展综述-网络与信息安全学报
[18]作者对边缘计算的计算任务卸载技术进行了研究,并从卸载决策、资源分配和系统实现 3 个方面进行了全面总结分析。加强边缘计算节点之间的协作,对于优化计算任务的调度、提升计算资源的利用率具有重要意义
[19]作者研究了面向智能物联网的多层算力网络,根据应用的不同算力需求考虑通过云计算、雾计算、边缘计算、海计算之间的交互和算力资源协同,实现算力的智能分发
文献[6]结合信息中心网络技术的命名机制,研究了基于 ICN 的算力网络融合架构和机制,采用计算图实现对算力资源的感知,并通过任务调度器实现对计算任务的分发调度。
算力网络基本架构
两个设计约束:边缘计算节点状态的实时感知和边缘计算资源的分布式协同处理及调度。
边缘计算节点状态的实时感知是合理均衡地使用计算和网络资源、动态高效地处理调度计算任务的基础。
处理及调度:是IETF 发布的关于 CFN 架构的草案,包含CFN 节点(CFN node)、CFN服务(CFN service)、CFN 适配器(CFN adaptor)
CFN 节点:提供节点的计算资源负载情况,向用户终端提供 CFN服务访问的能力。CFN 入口面向客户端,负责服务的实时寻址和流量调度;CFN 出口面向服务端,负责服务状态的查询、汇聚和全网发布。
CFN 服务是 CFN 节点服务注册表中的一个单位,具有SID。用来标识 由多个边缘计算服务节点 提供的特定应用服务,终端设备也采用 SID启动对服务的访问。终端设备无法预知提供服务的边缘计算节点,服务由SID对应节点群的某个节点响应。(在节点群中选择合适的节点?)
一个服务可以部署在多个边缘计算服务节点中
CFN 适配器:通过保持 BIP 信息、识别初始请求包等方式帮助终端设备接入 CFN
控制平面的主要作用是通告扩散服务状态信息;数据平面主要作用是基于 SID 进行寻址和路由转发
关键技术
网络信息:异构泛在计算资源状态,传输时延、抖动、带宽资源利用率等
计算负载:使用的 CPU、正在服务的会话数、每秒查询数、计算时延等;
资源状态感知机制(可考虑资源状态预测):指标变化超过阈值或更新计时器过期时才进行,避免网络波动。
计算资源不仅可以由边缘计算节点来提供,也可能会由终端设备来提供(如家庭网关设备、智能移动终端等)
调度:(可考虑边缘网络域内调度问题和域间调度问题)
原因:计算资源优先,计算能力不同,计算状态动态变化;多节点可完成任务,可分派给多节点协同;
以最短时间将计算任务分发,选择最佳的传输路径
当路由节点收到计算任务的数据包时,基于预先获取的计算任务类型、其他边缘计算节点和计算资源性能的对应关系,确定该计算任务类型对应的至少一个其他边缘计算节点及其计算性能。基于其他节点的计算性能,以及本地节点与其他节点之间的网络链路状态,综合权衡后确定目标计算节点。
传统的任播通常用于单请求−单响应式通信,当网络状态发生变化时,可能会将不同的请求发送到不同的位置;而在 CFN 中,需要在终端设备和服务节点之间进行多请求−多响应式通信。保持流的粘性:确保来自同一流的请求始终由同一边缘计算节点处理。
研究方向
SDN
ICT(信息中心网络):以信息内容为中心的通信模式。设计面向计算服务的命名寻址机制
结合区块链技术:一种将数据区块以时间顺序相连的方式组合,并以密码学方式保证不可篡改和不可伪造的分布式数据库。构建可信算力网络:将算力服务交易和结算的逻辑规则部署在区块链的智能合约层
结合确定性网络技术,构建超低时延算力网络:“准时、准确、快速”
自智算力网络:架构、技术与展望-物联网学报
挑战:
- 算网策略设计过度依赖人工经验
- 智能水平不高,缺少相互协作机制,无法实现系统级独立智能运行
- 无法根据应用场景动态变化,规模扩缩、用户需求变化、业务场景更替
- 忽略实际,局限于业务功能方案设计,缺乏感知、分析、决策、动作各环节综合考虑
将AI与算力网络基础设施、功能流程、服务应用深度融合,实现自主优化、智能自适演进。
本质是通过数据驱动进行自学习、自演进,算力网络中的基础资源感知和建模、资源的编排策略、算网运行的故障处理、算网系统的优化等关键动作,都可以通过智能算法实现自动化。
相关工作
文献[14]一体化编排与路由
文献[15]提出了基于深度强化学习的一体化任务调度策略,将计算任务分配的问题分为节点选择和节点内部任务分配两个阶段,以整合算力资源来提高总体资源利用率,优化节点内部的服务器与计算任务的匹配度来优化调度策略,降低总成本和提高资源使用效率。(该文献非DRL方法。)
文献[16]融智算力网络,从内生智能和业务智能两个维度进行阐述
文献[1]分析了SDN和ICN、区块链、确定性网络等技术的结合思想与技术路线
基于 DRL 的资源按需分配等[23](优化SFC编排)
文献[32]提出基于单域自治与跨域协同的解决方案。首先实现单域全面自治,在此基础上利用不同单域感知的差异性、计算资源的互补性、数据的共享性、域间的交互性,通过跨域协同赋予算网更高层次的智能水平。(局部自智,多域协同完成单域无法解决的问题)
自智算力网络
基于意图的算力网络需要根据用户的业务需求生成最优的算力服务提供策略,并通过对基础设施进行自动配置来进行功能实现。
生成满足用户意图需求的算网融合策略。用户表征、解析、生成策略。
- 流程自动化:算网能够在不依赖人工参与的情况下,利用 AI将单个流程的重复性算网操作转换成由系统自动执行,并将多个环节打通串联,使整个业务工作流的自动化运行
- 服务自优化:算网能够对业务资源的历史数据进行智能分析和预测,实现算网资源和参数配置的自优化,并能够根据用户反馈提升服务质量,形成资源、业务、服务的多重闭环优化
- 能力自主化:算网具备独立管理和控制算网的能力,进行全方位自动化管控,保障系统和业务持续稳定的运行
AI对单点或单域注智赋能,根据业务逻辑将各单域互联。算力网络在接收到上层指令与任务需求时,能够自动解
析业务意图并生成最优策略来对基础设施进行自动化配置,实现全流程的自动化和业务闭环处理。
关键技术
自智网络和算力网络的融合.
感知:对泛在异构、动态时变的计算资源的部署位置、实时状态、负载信息,网络的传输时延、抖动、带宽资源利用率. 多节点感知的算网信息进行聚合来扩展感知的维度和范围,并利用智能算法构建全局统一的算网状态视图; 资源状态预测; 提取感知数据特征;感知业务内容和意图, 考虑网络和计算资源,匹配算力和服务. 用户可能向网络提供所需资源信息, 也有可能需要网络对业务(文字,语音)意图进行解析,生成资源配置策略.
分析:分析用户业务、算网状态、功能流程,针对算力网络中泛在化的异构算力资源以及多样化的业务需求,如何有效地对算力进行标识和度量、对任务内容进行分类解析、对用户的满意度进行测评量化; 风险预判和预测性资源配置 ;分析定位故障节点,提供解决方案; 凝练可用的知识特征
决策:传统的策略生成通常基于人为设定的规则和经验数据,如基于链路基础度量值的路由选择[39]、基于分时的计算节点选择[40]、基于加权代价函数的任务调度[41]. 构建领域知识库, 对任务需求进行分析. 基于 AI 的策略自动生成机制、基于数字孪生等技术的策略验证,以及基于用户反馈的策略自动优化等技术已经成为相关研究的热点。
执行:精准控制算网全元素; 对算网进行全局协同控制; 基于生成的普适性、智能化的控制策略完成端到端的控制流程;自优化和自学习, 自动地选择学习目标、制定学习计划、构建学习方法、评价学习结果
展望
挑战:智能化能力建设缺乏完备的基础设施支撑,核心算法缺少领域知识、数据以及场景验证,融合机制缺少统一标准和评测规范等
- 通信、感知、计算、存储、控制一体化融合
- 基于知识定义的算网自治[43]旨在全域网络感知的基础上,使用 AI 技术处理算网数据生成知识,并利用这些知识帮助算网进行闭环自治。监控网络,采集分析数据,定义知识,知识和用户意图共同干预决策,从而配置网络应用,形成闭环
- 利用不同节点功能的差异性、计算资源的互补性、节点间的交互性,通过多节点协同自适应感知、智能在线适配学习、迁移学习与终身学习、群智能体分布式学习等赋予算网更高层次的智能水平。例如多节点协同的自适应适配学习、多容量权值共享的高效联邦学习策略[44]
- 将 AI 技术应用于故障发现、根因分析、故障自愈等
基于次模优化的边云协同多用户计算任务迁移方法_物联网学报
作者:梁冰,纪雯,中国科学院计算技术研究所
贡献:提出了一种基于边云联合计算的多用户任务卸载方案,设计基于次模理论的贪心算法充分利用云边通信和计算资源。结果:降低计算任务执行的时延和能耗;多用户卸载计算任务时能够保持稳定的系统性能。
- 基于用户 QoE(quality of experience)的效用函数,将问题表示为一个混合整数非线性规划问题。以最大化系统效用为目标,对任务卸载决策、发射功率、边缘节点的计算资源分配以及回程链路的通信资源分配等问题进行了联合优化
- 分解成2 个子问题,分别为固定用户的卸载决策后的资源分配问题,以及优化资源分配问题后对应的最优值函数下的任务卸载决策问题。资源分配问题分解为用户上传发射功率分配问题、边缘端计算资源分配问题和核心网传输带宽分配问题,并利用拟凸和凸优化技术对其求解。
- 证明了系统效用函数是一个次模函数,基于次模理论设计贪心算法求解用户任务的卸载决策问题
相关工作:现有研究集中在用户的卸载决策问题上,未考虑卸载过程中系统有限的通信与计算资源分配的问题;仅考虑用户任务只向边缘端或云端,并未考虑在边云联合计算的环境下用户如何进行卸载的策略以及资源的优化问题
考虑到边缘节点的计算能力以及远端云传输带宽的受限性,仅面向云端或边缘端的任务卸载将带来任务卸载的高时延性问题[1]。本文联合优化了用户计算任务卸载决策、边缘端计算和通信资源及远端传输过程中核心网有限的带宽资源分配,同样适用于仅边端或云端。
CPU cycle:时钟周期数,程序的 CPU 执行时间 =CPU cycle×时钟周期时间。时钟周期时间=1/主频(如2.8GHz),代表cpu识别出来的最小的时间间隔
实验:对比本地计算、边缘计算全卸载、云计算全卸载,后俩种方案同时优化资源分配。实验包括不同用户总数条件下各方案的系统效用;特定任务下的不同用户总数条件下各方案的系统效用;不同用户总数的条件下,边、云、本地计算的分布(思考:服务很少时,倾向于边端提供服务,服务较少时,倾向于向云端迁移,服务较多时,向本地迁移);不同用户对时间偏好权重下的任务卸载平均时耗对比
当卸载用户过多时,边缘计算方案下的边缘节点分配给用户的计算资源会低于本地的计算资源,而云计算方案下用户较低的上行通信资源会导致任务卸载的传输时延过高,进而导致以上 2 种方案的系统效用降低甚至低于本地算的效用。
建模
边缘完成任务的总时间包括:上传时间+执行时间+传回时间;云端完成任务时间包括:上传至边缘测时间+从边缘传至云端时间+执行时间+传回边缘时间,任务完成的输出结果的大小远远小于任务的输入大小,并且考虑到传输的下行速度远大于上行速度,因此忽略边缘传至用户的时间
用户网络为多用户正交频分多址接入,每个信道都是正交的,忽略小区内的干扰。
计算资源上限表示边缘服务器可用的 CPU cycle 总数。所有请求将任务卸载到 MEC 服务器进行计算的用户共同分享 MEC 服务器的计算资源。
云端会为每个用户分配固定且受限的计算资源,因此设置为固定值。核心网的总传输带宽有限。
用户的 QoE 主要由完成任务所产生的时延和能耗体现,用户u的卸载效用函数为:
V u = x u , 1 ( β u t t u l − t u e t u l + β u e E u l − E u e E u l ) + x u , 2 ( β u t t u l − t u c t u l + β u e E u l − E u c E u l ) V_u = x_{u,1}(\beta_u^t \frac{t_u^l-t_u^e}{t_u^l} + \beta_u^e \frac{E_u^l-E_u^e}{E_u^l})+ x_{u,2}(\beta_u^t \frac{t_u^l-t_u^c}{t_u^l} + \beta_u^e \frac{E_u^l-E_u^c}{E_u^l}) Vu=xu,1(βuttultul−tue+βueEulEul−Eue)+xu,2(βuttultul−tuc+βueEulEul−Euc)
l表示本地,e, x u , 1 x_{u,1} xu,1表示边缘,c, x u , 2 x_{u,2} xu,2表示云。涉及通信资源 t u l t_u^l tul、边缘服务器计算资源 E u e E_u^e Eue,云端传输资源 t u c , t u l t_u^c,t_u^l tuc,tul的分配, β \beta β为偏好权重,,所有用户的系统效用函数为: V = ∑ u = 1 U V u V = \sum_{u=1}^UV_u V=∑u=1UVu,目标为最大化V
根据推导,将该式分解为下式。其中,第三项为常数,据此将该优化目标分解成三个优化问题:1) 上传发射功率分配问题(二分法求最优);2)边缘端计算资源分配问题(凸优化求出最优值);3) 核心网传输带宽分配问题((凸优化求出最优值)),然后在最大化V目标下,使用基于次模理论的贪心卸载策略算法求解卸载决策集 X e X^e Xe和 X c X^c Xc
I ( x , p , f , R ) = ∑ u ∈ U e ∪ U c ϕ u + ψ u p u l b ( 1 + p u γ u ) + ∑ u ∈ U e β u t f u l f u e + ∑ u ∈ U c β u t f u l f u c + ∑ u ∈ U c β u t d u f u l c u R u c \begin{aligned}I(x,p,f,R)&=\sum_{u\in\mathcal{U}_e\cup\mathcal{U}_c}\frac{\phi_u+\psi_up_u}{\mathrm{lb}(1+p_u\gamma_u)}+\sum_{u\in\mathcal{U}_e}\frac{\beta_u^tf_u^l}{f_u^e}+\sum_{u\in\mathcal{U}_c}\frac{\beta_u^tf_u^l}{f_u^c}+\sum_{u\in\mathcal{U}_c}\frac{\beta_u^td_uf_u^l}{c_uR_u^c}\end{aligned} I(x,p,f,R)=u∈Ue∪Uc∑lb(1+puγu)ϕu+ψupu+u∈Ue∑fueβutful+u∈Uc∑fucβutful+u∈Uc∑cuRucβutduful
A_Gamebased_Network_Slicing_and_Resource_Scheduling_for_Compute_First_Networkingcxc
基本思想是动态地调度和分配各种类型的资源,以满足不同的服务需求。
两个关键问题是: 1)网络切片代理(NSB)如何为网络资源定价,如何分割网络资源,以从顶级服务提供商(OSP)部署不同的服务?2)OSP如何安排切片资源的通信和计算
方法:利用博弈论建模资源定价和网络切片过程;协调的片内资源调度,平衡计算和通信,合作博弈降低服务延迟
建模
NSB以网络切片将虚拟资源卖给OSP,OPS用于提供服务。NSB设置更高的单位资源价格,出售更多资源量;OSP争取更低资源价格和更少资源数。
不同的服务对相同数量的资源有不同的处理速率。对于相同数量的资源,请求处理速率随通信服务和计算服务而变化。在不失一般性的情况下,我们将容量-能力转换比分别表示为通信和计算的α和β。该比乘容量即为能力
通信能力和计算能力之和不超过租用资源限制。
总延迟包含通信延迟和计算延迟
资源调度实验包含不同规模请求到达率对时延的影响;不同算法在不同转换比例下的影响
Multi-Stage Geo-Distributed Data Aggregation With Coordinated Computation and Communication in Edge Compute First Networking
题目:边缘计算优先网络中具有协调计算与通信的多阶段地理分布式数据聚合 - 2023 - 光学JCR二区
作者:Zhen Liu , Xianming Yuan, Jia Yuan , Jiawei Zhang , Zhiqun Gu , and Long Zhang - BUPT
贡献
提出了CFN中地理分布式数据聚合方案,通过选择集群中心、划分集群和配置光路来最小化作业完成时间(JCT),通过基于JCT重新分配路由和频槽减少带宽消耗。将分布式数据聚合优化问题表述为线性规划模型,结合计算和通信资源提出MGDD-CC算法。解决问题:确定集群成员的平均数量;选择集群中心;通过弹性光网络路由;最小化JCT和FSs。
第一个算法决定了每个阶段的阶段数和聚类中心的集合,其目标是JCT的最小化。在第二种子算法中,提出了一种基于SCT的RSA算法,该算法旨在在不影响JCT的情况下最小化带宽消耗
该算法结合了计算和网络资源,以最小化聚合的时间,同时保证了更低的带宽消耗。该算法将数据聚合过程划分为多个阶段,并在每个阶段使用并行模式对地理分布式数据进行处理。
类似论文:集中式:先局部处理,在dc之间传递中间结果,减少dc流量,缩短jct完成时间;[14]链路分级,解决DC拥塞;[16]dc多任务分配,优化任务完成时间公平性;[19] 地理分布式数据分析中的带宽成本-吞吐量权衡,保证最大延迟。[20]确定本地任务优先级,分配路由和FS(频率时隙数),最小化完成时间和带宽消耗。分布式:优化目标有网络寿命、能量成本、延迟。
建模
模型定义:地理分布的数据聚合时间包括数据处理时间和通信时间。1)数据处理时间(计算):边缘DC上的数据处理时间与数据量成正比,与边缘DC的可用计算资源成反比。2)通信时间(网络):主要包括传输时间、传播时间、节点处理时间和排队时间。 网络节点上的排队和节点处理时间是指路由器/交换机的排队和处理时间远小于传输时间和传播时间,不考虑。
在第一阶段,CCT(集群完成时间)包括局部边缘处理时间、边缘与簇中心的通信时间,以及簇中心之间的处理时间。在阶段(m>1),CCT包括网络中的通信时间和集群中心中的处理时间。SCT取决于瓶颈集群的完成时间。JCT为SCT之和。所有分布数据传输到集群中心后,集群中心开始处理数据。
CCT:(8a)取决于到达集群中心的最慢数据的完成时间。约束(8b)定义通信时间,包括传输时间和传播时间;约束(8c)确保集群只有一个集群中心;约束(8d)保证可存储的数据量不超过集群中心的总可用存储容量;约束(8e)确保从源节点到集群中心的数据只能选择一条路径;约束(8f)保证每个链路上分配的FSs数量不会超过其可用带宽。
RSA(路由和frequency slots分配):最小化网络中利用的最大FSs
毛病:
技术细节:最小化cct路由:对数据量按降序排序,选择k个最短候选路径。如果候选路径上存在可用的FS,则选择可用FSs最大的路径,否则根据数据量调整分配给其他连接的FSs的数量,以提供该服务带宽。最小化带宽路由:对于要聚合的俩个数据,将短时数据的时间扩展至长时数据的时间,即可减少分配给短时数据的带宽
实验细节:
联系本研究题目的应用:本文将算力和网络联系起来的节点是时延,通过考虑处理时延和通信时延最小化聚合时间。
think¬e
-
也许的优化策略:定义RL三要素、策略网络使用GNN+LSTM捕捉时空特征,网络和算力变化具备时空相关性,对于算力来说,节点附近的网络变化预示着节点算力状态的变化,因此具备一定的空间相关性。
-
还需要的部分:状态空间被设计为剩余带宽、流量需求数据量特征和链路介数(有几条k-最短链路经过该路)
-
动作不只是为端到端的需求在k-最短路径中选择路由,而是决定目标节点+路由,启发式或根据某种建模方式计算k条备选链路(其目标节点可能不同),强化学习在备选链路中选择。生成备选链路可否直接生成具体链路?
基于SID的任播是更上层的东西,不关心目标节点,而是路由到节点群。也就是请求通过SID识别节点,路由系统决策后使用任播进行路由。
DeepEdge: A Deep Reinforcement Learning based Task Orchestrator for Edge Computing
任务协调器的主要工作是确定用户的卸载任务是通过WAN在云中处理,还是通过LAN/MAN在边缘处理。然后,如果请求的服务在边缘可用,协调器应该根据延迟、任务长度、带宽和边缘服务器的利用率来选择相应的边缘服务器。
贡献:满足不同需求的应用程序;部署不同数量的移动设备;建模为MDP,应用DDQN;在线训练
相关工作
[18]提出了一个基于DRL的框架,旨在将网络中所有设备的延迟和能耗的总成本最小化
[19]考虑任务完成时间和能耗的DRL代理
[21]减少边缘网络中的延迟、成本和能源消耗。他们通过使用LSTM网络改进了DRL的DQN算法,模拟环境包括多达100个应用程序、60个边缘服务器和一个云服务器
【26】双DQN的在线策略计算卸载算法,根据任务队列状态、能量队列状态以及移动用户与BSs之间的信道质量进行卸载决策
工作
成功条件:满足应用要求,则认为任务成功。(奖励:成功正奖励,不成功负奖励)
动作:在N个边缘服务器和1个云中选择
建模:约束:单个任务可以卸载到云服务器或其中一个边缘服务器;卸载任务的负载不能超过相应的边缘服务器的容量。MAN和WAN延迟时,我们使用了𝑀/𝑀/1队列模型;假设移动设备做出卸载的决定;每个传入的任务都是由一个移动设备通过遵循泊松过程而产生的。
虚拟机带宽是WlanBandwidth 除以主机列表长度和虚拟机列表长度之和,也就是它被均匀的分给每个虚拟机
总网络延迟包括lan和wan延迟。正如预期的那样,在广域网上花费的时间主导了网络延迟。由于单层体系结构不会将任务发送到全局云,因此它没有WAN延迟。假设边缘服务器和边缘协调器都连接到同一个网络上
并且移动设备在移动到相关位置时加入了相关的WLAN。在加入WLAN后,移动设备开始向边缘服务器发送任务。如果决定将任务卸载到全局云,则使用Wi-Fi接入点提供的WAN连接。这些任务有随机的输入/输出文件大小来上传/下载,并且根据指令的数量也有随机的长度。
MDP:协调器可以将卸载的任务a发送到边缘服务器4,但边缘服务器已经分配了一个任务资源,并且在卸载任务a到达之前完成,则边缘服务器的负载在𝑠𝑡+1时不会改变,或st+1与st和at无关,则不能满足马尔可夫属性。解决:状态表示使用活跃MAN任务数量,WLAN、MAN、WAN负载任务数量。
应用程序属性表示应用程序的个人需求,网络属性描述了网络的当前状态,使用了10个功能,其中3个表示应用程序属性,其中7个与网络条件相关。
实验:对于MAN延迟,我们使用了EdgeCloudSim的M/M/1排队模型实现,附加的传播延迟为5 ms。每个实验持续时间为5分钟。比较参数包括奖励、平均vm利用率、服务时间(高于其他方法,任务增多时转移到边缘完成,因为优化目标是任务完成率)、云服务时间、不同任务到达时间(任务到达时间长时,任务失败率教高)
| network attributes | WanBw | 广域网带宽 |
|---|---|---|
| Man-Delay | MAN延迟 | |
| NumberOfTaskToWLAN | 负载任务数量 | |
| NumberOfTaskToMAN | 负载任务数量 | |
| NumberOfTaskToWAN | 卸载到WAN的任务数 | |
| NumberOfActiveMANT | 卸载到MAN但尚未到达目的地的任务数量 | |
| LoadOfEdgeServer | 边缘服务器负载的最新情况,有N个服务器则有N个该属性 | |
| 任务QoS需求和卸载位置 | TaskReqCapacity | 虚拟机处理给定任务所需的能力 |
| DelaySensitivity | 指示任务是否延迟不容忍。它的值在0到1之间。 | |
| WlanID | 生成给定任务的移动设备的Wlan ID |
基于机器学习的车辆边缘计算的工作负载协调器:车辆应用程序的特征、上传/下载大小、任务的计算足迹、LAN、MAN和WAN网络模型,以及移动性
相关文章:

算力网络的早期有关论文——自用笔记
2023年底至2024年初阅读有关论文的自用笔记,作为参考。 算力网络架构 https://baijiahao.baidu.com/s?id1727377583404975414&wfrspider&forpc think¬e 是否可以和cpu进程调度联系。 目前:看一些综述深一步了解背景和发展现状,完善认…...
)
卷积神经网络基础(四)
今天我们继续学习各个激活函数层的实现过程。 目录 5.2 Sigmoid层 六、Affine/Softmax层实现 6.1 Affine层 6.2 批处理版本 5.2 Sigmoid层 sigmoid函数的表达式如下: 用计算图表示的话如下: 计算过程稍微有些复杂,且这里除了乘法和加法…...

【MySQL数据库】表的约束
目录 1,空属性 2,默认值 3,列描述 4,zerofill 5,主键primary key 6,自增长auto_increment 7,唯一键unique 8,外键foreign key 在MySQL中,表的约束是指用于插入的…...

网络威胁情报 | Friday Overtime Trooper
本文将分别从两个环境出发,以实践来体验利用威胁情报分析可疑文件的过程。 Friday Overtime 现在你是一位安全分析人员,正在美美等待周五过去,但就在即将下班之时意外发生了:你的客户发来求助,说他们发现了一些可疑文…...
详细介绍)
GPIO(通用输入输出端口)详细介绍
一、基本概念 GPIO(General - Purpose Input/Output)即通用输入输出端口,是微控制器(如 STM32 系列)中非常重要的一个外设。它是一种软件可编程的引脚,用户能够通过编程来控制这些引脚的输入或输出状态。在…...

学习笔记——《Java面向对象程序设计》-继承
参考教材: Java面向对象程序设计(第3版)微课视频版 清华大学出版社 1、定义子类 class 子类名 extends 父类名{...... }如: class Student extends People{...... } (1)如果一个类的声明中没有extends关…...
)
基于javaweb的SpringBoot校园失物招领系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...
)
什么事Nginx,及使用Nginx部署vue项目(非服务器Nginx压缩包版)
什么是 Nginx? Nginx(发音为 “engine-x”)是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。它以其高性能、高并发处理能力和低资源消耗而闻名。以下是 Nginx 的主要特性和用途: 主要特性 高性能和高并发 Nginx 能够处理大量并发连接,适合高…...

nodejs使用require导入npm包,开发依赖和生产依赖 ,全局安装
nodejs使用require导入npm包,开发依赖和生产依赖 ,全局安装 ✅ 一、Node.js 中使用 require() 导入 npm 包 // 导入第三方包(例如 axios) const axios require(axios);// 使用 axios.get(https://api.example.com).then(res &g…...

CSS在线格式化 - 加菲工具
CSS在线格式化 打开网站 加菲工具 选择“CSS在线格式化” 或者直接访问 https://www.orcc.top/tools/css 输入CSS代码,点击左上角的“格式化”按钮 得到格式化后的结果...

图片转base64 - 加菲工具 - 在线转换
图片转base64 - 加菲工具 先进入“加菲工具” 网 打开 https://www.orcc.top, 选择 “图片转base64”功能 选择需要转换的图片 复制 点击“复制”按钮,即可复制转换好的base64编码数据,可以直接用于img标签。...

性能比拼: Redis vs Dragonfly
本内容是对知名性能评测博主 Anton Putra Redis vs Dragonfly Performance (Latency - Throughput - Saturation) 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 在本视频中,我们将对比 Redis 和 Dragonfly。我们将观察 set 与 get 操作的延迟ÿ…...

如何收集用户白屏/长时间无响应/接口超时问题
想象一下这样的场景:一位用户在午休时间打开某电商应用,准备购买一件心仪已久的商品。然而,页面加载了数秒后依然是一片空白,或者点击“加入购物车”按钮后没有任何反馈,甚至在结算时接口超时导致订单失败。用户的耐心被迅速消耗殆尽,关闭应用,转而选择了竞争对手的产品…...

来啦,烫,查询达梦表占用空间
想象一下oracle,可以查dba_segments,但是这个不可靠(达梦官方连说明书都没有) 先拼接一个sql set lineshow off SELECT SELECT ||||OWNER|||| AS OWNER,||||TABLE_NAME|||| AS TABLE_NAME,TABLE_USED_SPACE(||||OWNER||||,||||T…...

# 利用迁移学习优化食物分类模型:基于ResNet18的实践
利用迁移学习优化食物分类模型:基于ResNet18的实践 在深度学习的众多应用中,图像分类一直是一个热门且具有挑战性的领域。随着研究的深入,我们发现利用预训练模型进行迁移学习是一种非常有效的策略,可以显著提高模型的性能&#…...

AT24C02芯片简介:小巧强大的串行EEPROM存储器
一、AT24C02概述 AT24C02是一款2K位(即256字节)的串行EEPROM芯片,采用IC(Inter-Integrated Circuit)总线进行通信,适合低功耗、小容量存储需求。 主要特性: 项目 参数 存储容量 2Kb&#x…...
)
【Vue】状态管理(Vuex、Pinia)
个人主页:Guiat 归属专栏:Vue 文章目录 1. 状态管理概述1.1 什么是状态管理1.2 为什么需要状态管理 2. Vuex基础2.1 Vuex核心概念2.1.1 State2.1.2 Getters2.1.3 Mutations2.1.4 Actions2.1.5 Modules 2.2 Vuex辅助函数2.2.1 mapState2.2.2 mapGetters2.…...
)
施磊老师基于muduo网络库的集群聊天服务器(四)
文章目录 实现登录业务登录业务代码补全数据库接口:查询,更新状态注意学习一下里面用到的数据库api测试与问题**问题1:****问题2:** 用户连接信息与线程安全聊天服务器是长连接服务器如何找到用户B的连接?在业务层存储用户的连接信息多线程安全问题加锁! 处理客户端…...
)
深度学习-全连接神经网络(过拟合,欠拟合。批量标准化)
七、过拟合与欠拟合 在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。 1. 概念认知 …...

访问Maven私服的教程
1.首先准备好maven私服的启动器,到bin目录下启动: 2.等待加载,加载过程比较长: 3.访问端口号: 4.仓库简介: 5.在maven的setting中 servers配置信息(设置私服访问的密码): 6.配置私服仓库地址: 7.配置上传地址(私服地址): 8.在自己的副项…...

Linux系统编程 day9 SIGCHLD and 线程
SIGCHLD信号 只要子进程信号发生改变,就会产生SIGCHLD信号。 借助SIGCHLD信号回收子进程 回收子进程只跟父进程有关。如果不使用循环回收多个子进程,会产生多个僵尸进程,原因是因为这个信号不会循环等待。 #include<stdio.h> #incl…...

Linux 内核中 cgroup 子系统 cpuset 是什么?
cpuset 是 Linux 内核中 cgroup(控制组) 的一个子系统,用于将一组进程(或任务)绑定到特定的 CPU 核心和 内存节点(NUMA 节点)上运行。它通过限制进程的 CPU 和内存资源的使用范围,优…...

乐视系列玩机---乐视2 x520 x528等系列线刷救砖以及刷写第三方twrp 卡刷第三方固件步骤解析
乐视2 x520 x528 x526等,搭载了高通骁龙652处理器,骁龙652的GPU性能甚至优于前一年的骁龙810,配备了3GB RAM和32GB ROM的存储空间, 通过博文了解💝💝💝 1💝💝💝-----详细解析乐视2 x520系列黑砖线刷救砖的步骤 2💝💝💝----官方两种更新卡刷步骤以及刷…...

电容加速电路!
大家好,我是记得诚。 今天分享一个小电路:电容加速电路。 下面是一个普通的三极管开关电路,区别是多了一个C1,C1被称为加速电容。作用是:加速三极管VT1的开通和截止,做到快开快关。 工作原理:…...

MCP Host、MCP Client、MCP Server全流程实战
目录 准备工作 MCP Server 实现 调试工作 MCP Client 实现 MCP Host 配置 第一步:配置支持 function calling的 LLM 第二步:添加MCP Server 一般有两种方式,第一种json配置,第二种直接是Command形式,我这里采用Command形式 第三步:使用MCP Server 准备工作 安装…...
)
Win10一体机(MES电脑设置上电自动开机)
找个键盘,带线的那种,插到电脑上,电脑开机;连续点按F11;通过↑↓键选择Enter Setup 然后回车; 选择 smart settings ; 选择 Restore AC Power Loss By IO 回车; 将prower off 改为…...

强化学习和微调 区别如下
强化学习和微调 区别如下 定义与概念 强化学习**:是一种机器学习范式,强调智能体(agent)如何在环境中采取一系列行动,以最大化累积奖励**。智能体通过与环境进行交互,根据环境反馈的奖励信号来学习最优的行为策略。例如,机器人通过不断尝试不同的动作来学习如何在复杂环…...

【EasyPan】文件上传、文件秒传、文件转码、文件合并、异步转码、视频切割分析
【EasyPan】项目常见问题解答(自用&持续更新中…)汇总版 文件上传方法解析 一、方法总览 Transactional(rollbackFor Exception.class) public UploadResultDto uploadFile(...)核心能力: 秒传验证:通过MD5文件大小实现文…...

React18+ 项目搭建-从初始化、技术选型到开发部署的全流程规划
搭建一个 React 项目需要从项目初始化、技术选型到开发部署的全流程规划。以下是详细步骤和推荐的技术栈: 一、项目初始化 1. 选择脚手架工具 推荐工具: Vite(现代轻量级工具,支持 React 模板,速度快)&am…...

day3 打卡训练营
循环语句和判断语句之前已经会了,把列表的方法练一练 浙大疏锦行 python训练营介绍...

MySQL VS SQL Server:优缺点全解析
数据库选型、企业协作、技术生态、云数据库 1.1 MySQL优缺点分析 优点 开源免费 社区版完全免费,适合预算有限的企业 允许修改源码定制功能(需遵守GPL协议) 跨平台兼容性 支持Windows/Linux/macOS,适配混合环境部署 云服务商…...

【CPP】固定大小内存池
程序运行时,通常会频繁地进行内存的分配和释放操作。传统的内存分配方式(如使用new和delete运算符)可能会导致内存碎片的产生,并且每次分配和释放内存都有一定的时间开销。内存池通过在程序启动时一次性分配一大块内存或一次性分配…...

[数据结构]树和二叉树
概念 树是一种 非线性 的数据结构,它是由 n ( n>0 )个有限结点组成一个具有层次关系的集合。 树形结构中,子树之间不能有交集,否则就不是树形结构 双亲结点或父结点 :若一个结点含有子结点,则…...

监控页面卡顿PerformanceObserver
监控页面卡顿PerformanceObserver 性能观察器掘金 const observer new PerformanceObserver((list) > {}); observer.observe({entryTypes: [longtask], })...

Web开发-JavaEE应用JNDI注入RMI服务LDAP服务DNS服务高版本限制绕过
知识点: 1、安全开发-JavaEE-JNDI注入-LADP&RMI&DNS等 2、安全开发-JavaEE-JNDI注入-项目工具&手工原理等 演示案例-WEB开发-JavaEE-JNDI注入&LDAP&RMI服务&DNS服务&高版本限制绕过 JNDI全称为 Java Naming and DirectoryInterface&am…...

深度学习训练中的显存溢出问题分析与优化:以UNet图像去噪为例
最近在训练一个基于 Tiny-UNet 的图像去噪模型时,我遇到了经典但棘手的错误: RuntimeError: CUDA out of memory。本文记录了我如何从复现、分析,到逐步优化并成功解决该问题的全过程,希望对深度学习开发者有所借鉴。 训练数据&am…...
)
【Spring】单例模式的创建方式(Bean解析)
在Java中,单例模式(Singleton Pattern)确保一个类只有一个实例,并提供全局访问点。以下是实现单例的五种常见方式:懒汉式、饿汉式、双重检查锁、静态内部类和枚举,包括代码示例和优缺点分析。 1. 懒汉式&am…...

小小矩阵设计
在电气设计图中,矩阵设计的接线方法是通过结构化布局实现多灵活链接的技术,常用于信号切换、配电调压或更加复杂的控制场景。 今天聊一种在电气图纸中用到的一种简单矩阵接法,一眼就看明白,很大程度简化了程序控制点和继电器的使用…...

IOT项目——双轴追光系统
双轴太阳能追光系统 - ESP32实现 系统概述 这个系统使用: ESP32开发板2个舵机(水平方向和垂直方向)4个光敏电阻(用于检测光照方向)适当的电阻(用于光敏电阻分压) 接线示意图 --------------…...
)
深度学习基石:神经网络核心知识全解析(一)
神经网络核心知识全解析 一、神经网络概述 神经网络作为机器学习领域的关键算法,在现代生活中发挥着重要作用,广泛应用于图像识别、语音处理、智能推荐等诸多领域,深刻影响着人们的日常生活。它通过模拟人类大脑神经系统的结构和功能&#…...
)
什么是 金字塔缩放(Multi-scale Input)
金字塔缩放 什么是金字塔缩放(Multi-scale Input)什么场景下会用到金字塔缩放?图像识别目标跟踪图像压缩视频处理如何在计算机程序中实现金字塔缩放?准备数据缩小数据(构建金字塔的上层)存储数据使用数据(在程序中应用金字塔缩放)金字塔缩放的记忆卡片什么是金字塔缩放(M…...

从零开始配置 Zabbix 数据库监控:MySQL 实战指南
Zabbix作为一款开源的分布式监控工具,在监控MySQL数据库方面具有显著优势,能够为数据库的稳定运行、性能优化和故障排查提供全面支持。以下是使用Zabbix监控MySQL数据库的配置。 一、安装 Zabbix Agent 和 MySQL 1. 安装 Zabbix Agent services:zabbix…...

机器学习超参数优化全解析
机器学习超参数优化全解析 摘要 本文全面深入地剖析了机器学习模型中的超参数优化策略,涵盖了从参数与超参数的本质区别,到核心超参数(如学习率、批量大小、训练周期)的动态调整方法;从自动化超参数优化技术…...
)
【算法】双指针8道速通(C++)
1. 移动零 思路: 拿示例1的数据来举例,定义两个指针,cur和dest,cur表示当前遍历的元素,dest以及之前表示非零元素 先用cur去找非零元素,每找到一个非零元素,就让dest的下一个元素与之交换 单个…...

synchronized锁
在了解锁之前我们要先了解对象布局 什么是java对象布局 在JVM中,对象在内存中存储的布局可以分为三块区域,即实例化之后的对象 对象头:分配的空间是固定的12Byte,由Mark Word(标记字段)和Class Pointer&…...

实训Day-2 流量分析与安全杂项
目录 实训Day-2-1流量分析实战 实训目的 实训任务1 SYN半链接攻击流量分析 实训任务2 SQL注入攻击流量分析一 实训任务3 SQL注入攻击流量分析二 实训任务4 Web入侵溯源一 实训任务5 Web入侵溯源二 编辑 实训Day-2-1安全杂项实战 实训目的 实训任务1 流量分析 FTP…...

LOH 怎么进行深度标准化?
The panel of normals is applied by replacing the germline read depth of the sample with the median read depth of samples with the same genotype in our panel. 1.解释: panel of normal 正常组织,用于识别技术噪音 germline read depth: 胚系测序深度。根…...

[预备知识]3. 自动求导机制
自动求导机制 本章节介绍 PyTorch 的自动求导机制,包括计算图、反向传播和梯度计算的原理及实现。 1. 计算图原理 计算图是深度学习框架中的一个核心概念,它描述了计算过程中各个操作之间的依赖关系。 计算图由节点(节点)和边…...

蓝桥杯中的知识点
总结: 这次考的并不理想 比赛前好多知识点遗漏 但到此为止已经结束了 mod 是 模运算(Modulo Operation)的缩写,表示求两个数相除后的 余数 10mod31 (a % b) (7%21) 1e9代表1乘以10的9次方,…...

2023蓝帽杯初赛内存取证-6
这里需要用到pslist模块,结合一下查找关键词: vol.py -f memdump.mem --profile Win7SP1x64 pslist | grep -E "VeraCrypt" 将2023-06-20 16:47:41 UTC0000世界标准时间转换成北京时间: 答案:2023-06-21 00:47:41...