# 利用迁移学习优化食物分类模型:基于ResNet18的实践
利用迁移学习优化食物分类模型:基于ResNet18的实践
在深度学习的众多应用中,图像分类一直是一个热门且具有挑战性的领域。随着研究的深入,我们发现利用预训练模型进行迁移学习是一种非常有效的策略,可以显著提高模型的性能,尤其是在数据量有限的情况下。在这篇文章中,我们将探讨如何将ResNet18模型迁移到食物分类项目中,并通过一系列技术优化模型性能。
一、迁移学习的背景
迁移学习是一种机器学习技术,它允许模型在一个任务上训练获得的知识应用到另一个相关任务上。在图像分类领域,迁移学习尤其有效,因为不同类别的图像往往共享一些通用的特征。

二、项目概述
本项目的目标是构建一个能够准确分类食物图像的模型。我们选择了ResNet18作为基础模型,因为它在多个图像分类任务上都表现出色。通过迁移学习,我们可以利用ResNet18在ImageNet数据集上预训练的权重,加速模型的收敛并提高分类准确率。
三、模型迁移
1. 加载预训练模型
我们首先加载了ResNet18的预训练模型,并将其所有参数设置为不需要梯度更新,这样可以防止在训练过程中改变这些预训练的权重。
resnet_model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
for param in resnet_model.parameters():param.requires_grad = False
2. 修改全连接层
由于我们的食物分类任务有20个类别,因此我们需要修改ResNet18的最后一个全连接层,以输出20个类别的预测。
in_features = resnet_model.fc.in_features
resnet_model.fc = nn.Linear(in_features, 20)
3. 选择性更新参数
在迁移学习中,我们通常只更新模型的最后几层参数。在我们的案例中,我们只更新了全连接层的参数。
params_to_update= []
for param in resnet_model.parameters():if param.requires_grad == True:params_to_update.append(param)
四、数据准备与增强
为了提高模型的泛化能力,我们对训练数据进行了一系列的增强操作,包括随机旋转、裁剪、翻转和灰度化等。
data_transforms = {'train': transforms.Compose([transforms.Resize([300, 300]),transforms.RandomRotation(45),transforms.CenterCrop(244),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),transforms.RandomGrayscale(p=0.1),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'valid': transforms.Compose([transforms.Resize([244, 244]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
}
五、模型训练与评估
我们使用交叉熵损失函数和Adam优化器进行模型训练,并采用学习率调度器来动态调整学习率。
optimizer = torch.optim.Adam(params_to_update, lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
在每个训练周期结束后,我们在测试集上评估模型的性能,并记录最佳准确率。
for t in range(epochs):print(f"Epoch {t+1}\n")train(train_dataloader, model, loss_fn, optimizer)scheduler.step()test(test_dataloader, model, loss_fn)
print('最优训练结果为:', best_acc)
完整代码
import numpy as np
from PIL import Image
import torch
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
import torchvision.models as models
from torch import nn'''将resnet18模型迁移到食物分类项目中'''
resnet_model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)for param in resnet_model.parameters():print(param)param.requires_grad = Falsein_features = resnet_model.fc.in_features
resnet_model.fc = nn.Linear(in_features, 20)params_to_update= []
for param in resnet_model.parameters():if param.requires_grad == True:params_to_update.append(param)# 数据增强
data_transforms = {'train': transforms.Compose([transforms.Resize([300, 300]),transforms.RandomRotation(45), # 随机旋转,-45到45度transforms.CenterCrop(244),#从中心裁剪240*240transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转# transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),transforms.RandomGrayscale(p=0.1), # 转换为灰度图transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'valid': transforms.Compose([transforms.Resize([244, 244]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
}class food_dataset(Dataset): #food_dataset是自己创建的类名称,可以改为你需要的名称def __init__(self, file_path, transform=None): #类的初始化,解析数据文件txtself.file_path = file_pathself.imgs = []self.labels = []self.transform = transformwith open(self.file_path) as f: #是把train.txt文件中图片的路径保存在 self.imgs,train.txt文件中标签保存在 sesamples = [x.strip().split(' ') for x in f.readlines()]for img_path, label in samples:self.imgs.append(img_path) #图像的路径self.labels.append(label) #标签,还不是tensor# 初始化:把图片目录加载到selfdef __len__(self):return len(self.imgs)def __getitem__(self, idx):image=Image.open(self.imgs[idx])if self.transform:image=self.transform(image)label=self.labels[idx]label=torch.from_numpy(np.array(label,dtype=np.int64))return image,label#training_data包含了本次需要训练的全部数据集
training_data = food_dataset(file_path=r'D:\Users\妄生\PycharmProjects\人工智能\深度学习\trainda.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path=r'D:\Users\妄生\PycharmProjects\人工智能\深度学习\testda.txt', transform=data_transforms['valid'])#training_data需要具备索引的功能,还需要确保数据是tensor
train_dataloader=DataLoader(training_data,batch_size=64,shuffle=True)
test_dataloader=DataLoader(test_data,batch_size=64,shuffle=True)device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")model = resnet_model.to(device) # 将刚刚定义的模型传入到GPU中def train(dataloader, model, loss_fn, optimizer): # 传入参数 打包的数据,卷积模型,损失函数,优化器model.train() # 表示模型开始训练batch_size_num = 1for x, y in dataloader: # 遍历打包的图片及其对应的标签,其中batch为每一个数据的编号x, y = x.to(device), y.to(device) # 把训练数据集和标签传入cpu或GPUpred = model.forward(x) # 自动初始化 W权值loss = loss_fn(pred, y) # 传入模型训练结果的预测值和真实值,通过交叉熵损失函数计算损失值L0optimizer.zero_grad() # 梯度值清零loss.backward() # 反向传播计算得到每个参数的梯度optimizer.step() # 根据梯度更新网络参数loss = loss.item() # 获取损失值if batch_size_num % 100 == 0:print(f"loss: {loss:>7f}[number:{batch_size_num}]") # 打印损失值,右对齐,长度为7batch_size_num += 1 # 右下方传入的参数,表示训练轮数best_acc =0
def test(dataloader, model, loss_fn): # 定义一个test函数,用于测试模型性能global best_acc # 定义一个全局变量size = len(dataloader.dataset) # 返回打包的图片总数num_batches = len(dataloader) # 返回打包的包的个数model.eval() # 表示模型进入测试模式test_loss, correct = 0, 0 # 初始化两个值,一个用来存放总体损失值,一个存放预测准确的个数with torch.no_grad(): # 一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()时可以减少for x, y in dataloader: # 遍历数据加载器中测试集图片的图片及其标签x, y = x.to(device), y.to(device) # 传入GPUpred = model.forward(x) # 前向传播,返回预测结果test_loss += loss_fn(pred, y).item() # 计算所有的损失值的和,item表示将tensor类型值转化为python标量correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 判断预测的值是等于真实值,返回布尔值,将其转换为0和1,然后求和# a = (pred.argmax(1)== y) dim=1表示每一行中的最大值对应的索引号,dim=日表示每 b=(pred.argmax(1)==y).type(torch.float)test_loss /= num_batches # 总体损失值除以数据条数得到平均损失值correct /= size # 求准确率print(f"Test result:in Accuracy: {(100 * correct)}%, Avg loss: {test_loss}") # 表示准确率机器对应的损失值acc_s.append(correct)loss_s.append(test_loss)if correct > best_acc: # 如果新训练得到的准确率大于前面已经求出来的准确率best_acc = correct # 将新的准确率传入值best_accloss_fn = nn.CrossEntropyLoss() # 创建交叉熵损失雨数对象,因为食物的类别是20
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 创建一个优化器,SGD为随机梯度下降,Adam为一种自适应优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5)#调整学习率函数"训练模型"
epochs = 50acc_s =[]
loss_s=[]
for t in range(epochs):print(f"Epoch {t+1}\n")train(train_dataloader, model, loss_fn, optimizer)scheduler.step()test(test_dataloader, model, loss_fn)
#在每个epoch的训练中,使用scheduler.step()语句进行学习率更新
print('最优训练结果为:',best_acc)
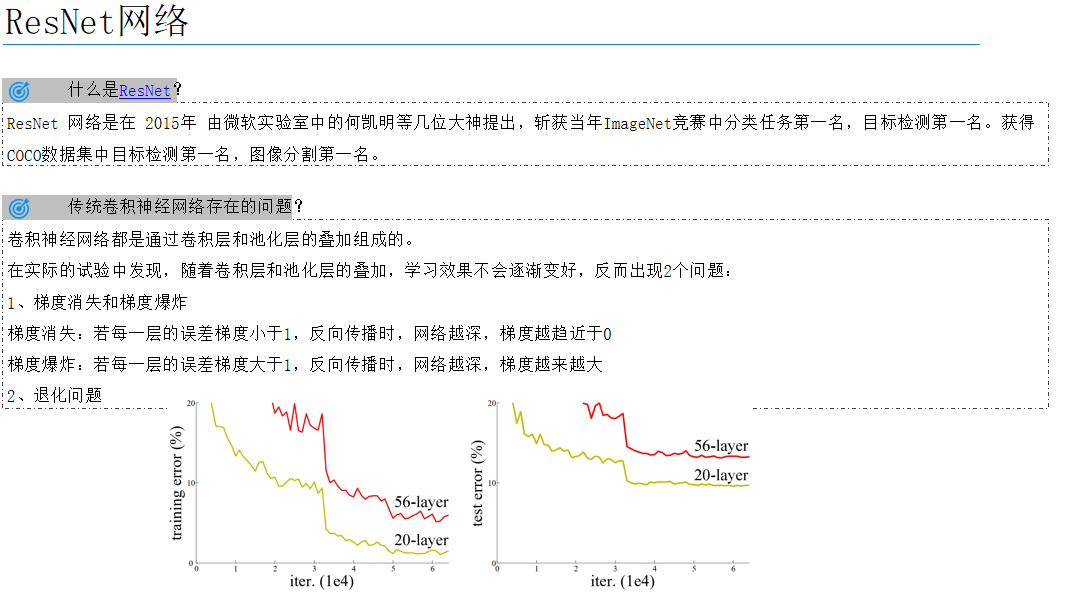
运行结果
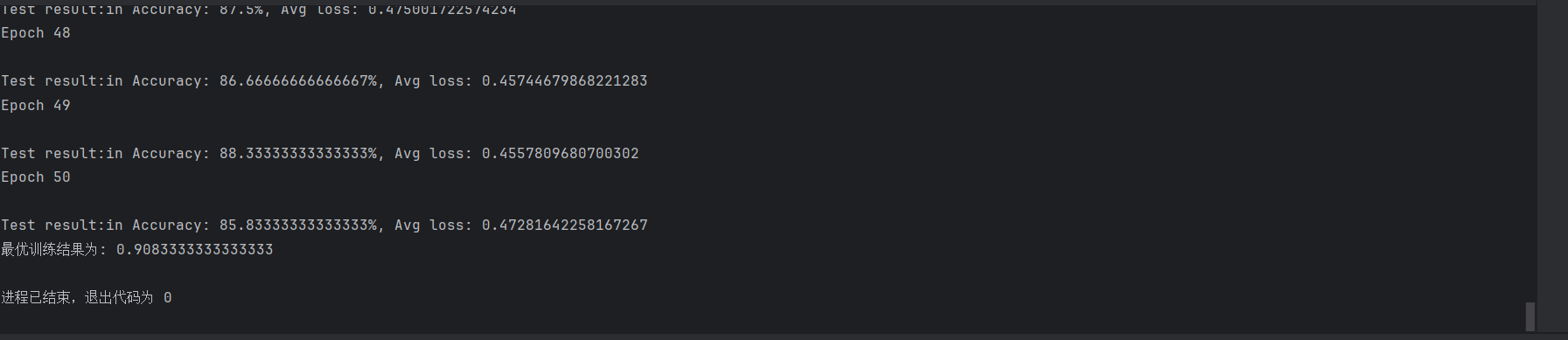
六、总结
通过本项目,我们成功地将ResNet18模型迁移到了食物分类任务中,并通过迁移学习显著提高了模型的性能。这种方法不仅减少了训练时间,还提高了模型的泛化能力。未来,我们可以尝试更多的迁移学习策略,如使用不同的预训练模型或调整迁移学习的比例,以进一步提升模型性能。
相关文章:

# 利用迁移学习优化食物分类模型:基于ResNet18的实践
利用迁移学习优化食物分类模型:基于ResNet18的实践 在深度学习的众多应用中,图像分类一直是一个热门且具有挑战性的领域。随着研究的深入,我们发现利用预训练模型进行迁移学习是一种非常有效的策略,可以显著提高模型的性能&#…...

AT24C02芯片简介:小巧强大的串行EEPROM存储器
一、AT24C02概述 AT24C02是一款2K位(即256字节)的串行EEPROM芯片,采用IC(Inter-Integrated Circuit)总线进行通信,适合低功耗、小容量存储需求。 主要特性: 项目 参数 存储容量 2Kb&#x…...
)
【Vue】状态管理(Vuex、Pinia)
个人主页:Guiat 归属专栏:Vue 文章目录 1. 状态管理概述1.1 什么是状态管理1.2 为什么需要状态管理 2. Vuex基础2.1 Vuex核心概念2.1.1 State2.1.2 Getters2.1.3 Mutations2.1.4 Actions2.1.5 Modules 2.2 Vuex辅助函数2.2.1 mapState2.2.2 mapGetters2.…...
)
施磊老师基于muduo网络库的集群聊天服务器(四)
文章目录 实现登录业务登录业务代码补全数据库接口:查询,更新状态注意学习一下里面用到的数据库api测试与问题**问题1:****问题2:** 用户连接信息与线程安全聊天服务器是长连接服务器如何找到用户B的连接?在业务层存储用户的连接信息多线程安全问题加锁! 处理客户端…...
)
深度学习-全连接神经网络(过拟合,欠拟合。批量标准化)
七、过拟合与欠拟合 在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。 1. 概念认知 …...

访问Maven私服的教程
1.首先准备好maven私服的启动器,到bin目录下启动: 2.等待加载,加载过程比较长: 3.访问端口号: 4.仓库简介: 5.在maven的setting中 servers配置信息(设置私服访问的密码): 6.配置私服仓库地址: 7.配置上传地址(私服地址): 8.在自己的副项…...

Linux系统编程 day9 SIGCHLD and 线程
SIGCHLD信号 只要子进程信号发生改变,就会产生SIGCHLD信号。 借助SIGCHLD信号回收子进程 回收子进程只跟父进程有关。如果不使用循环回收多个子进程,会产生多个僵尸进程,原因是因为这个信号不会循环等待。 #include<stdio.h> #incl…...

Linux 内核中 cgroup 子系统 cpuset 是什么?
cpuset 是 Linux 内核中 cgroup(控制组) 的一个子系统,用于将一组进程(或任务)绑定到特定的 CPU 核心和 内存节点(NUMA 节点)上运行。它通过限制进程的 CPU 和内存资源的使用范围,优…...

乐视系列玩机---乐视2 x520 x528等系列线刷救砖以及刷写第三方twrp 卡刷第三方固件步骤解析
乐视2 x520 x528 x526等,搭载了高通骁龙652处理器,骁龙652的GPU性能甚至优于前一年的骁龙810,配备了3GB RAM和32GB ROM的存储空间, 通过博文了解💝💝💝 1💝💝💝-----详细解析乐视2 x520系列黑砖线刷救砖的步骤 2💝💝💝----官方两种更新卡刷步骤以及刷…...

电容加速电路!
大家好,我是记得诚。 今天分享一个小电路:电容加速电路。 下面是一个普通的三极管开关电路,区别是多了一个C1,C1被称为加速电容。作用是:加速三极管VT1的开通和截止,做到快开快关。 工作原理:…...

MCP Host、MCP Client、MCP Server全流程实战
目录 准备工作 MCP Server 实现 调试工作 MCP Client 实现 MCP Host 配置 第一步:配置支持 function calling的 LLM 第二步:添加MCP Server 一般有两种方式,第一种json配置,第二种直接是Command形式,我这里采用Command形式 第三步:使用MCP Server 准备工作 安装…...
)
Win10一体机(MES电脑设置上电自动开机)
找个键盘,带线的那种,插到电脑上,电脑开机;连续点按F11;通过↑↓键选择Enter Setup 然后回车; 选择 smart settings ; 选择 Restore AC Power Loss By IO 回车; 将prower off 改为…...

强化学习和微调 区别如下
强化学习和微调 区别如下 定义与概念 强化学习**:是一种机器学习范式,强调智能体(agent)如何在环境中采取一系列行动,以最大化累积奖励**。智能体通过与环境进行交互,根据环境反馈的奖励信号来学习最优的行为策略。例如,机器人通过不断尝试不同的动作来学习如何在复杂环…...

【EasyPan】文件上传、文件秒传、文件转码、文件合并、异步转码、视频切割分析
【EasyPan】项目常见问题解答(自用&持续更新中…)汇总版 文件上传方法解析 一、方法总览 Transactional(rollbackFor Exception.class) public UploadResultDto uploadFile(...)核心能力: 秒传验证:通过MD5文件大小实现文…...

React18+ 项目搭建-从初始化、技术选型到开发部署的全流程规划
搭建一个 React 项目需要从项目初始化、技术选型到开发部署的全流程规划。以下是详细步骤和推荐的技术栈: 一、项目初始化 1. 选择脚手架工具 推荐工具: Vite(现代轻量级工具,支持 React 模板,速度快)&am…...

day3 打卡训练营
循环语句和判断语句之前已经会了,把列表的方法练一练 浙大疏锦行 python训练营介绍...

MySQL VS SQL Server:优缺点全解析
数据库选型、企业协作、技术生态、云数据库 1.1 MySQL优缺点分析 优点 开源免费 社区版完全免费,适合预算有限的企业 允许修改源码定制功能(需遵守GPL协议) 跨平台兼容性 支持Windows/Linux/macOS,适配混合环境部署 云服务商…...

【CPP】固定大小内存池
程序运行时,通常会频繁地进行内存的分配和释放操作。传统的内存分配方式(如使用new和delete运算符)可能会导致内存碎片的产生,并且每次分配和释放内存都有一定的时间开销。内存池通过在程序启动时一次性分配一大块内存或一次性分配…...

[数据结构]树和二叉树
概念 树是一种 非线性 的数据结构,它是由 n ( n>0 )个有限结点组成一个具有层次关系的集合。 树形结构中,子树之间不能有交集,否则就不是树形结构 双亲结点或父结点 :若一个结点含有子结点,则…...

监控页面卡顿PerformanceObserver
监控页面卡顿PerformanceObserver 性能观察器掘金 const observer new PerformanceObserver((list) > {}); observer.observe({entryTypes: [longtask], })...

Web开发-JavaEE应用JNDI注入RMI服务LDAP服务DNS服务高版本限制绕过
知识点: 1、安全开发-JavaEE-JNDI注入-LADP&RMI&DNS等 2、安全开发-JavaEE-JNDI注入-项目工具&手工原理等 演示案例-WEB开发-JavaEE-JNDI注入&LDAP&RMI服务&DNS服务&高版本限制绕过 JNDI全称为 Java Naming and DirectoryInterface&am…...

深度学习训练中的显存溢出问题分析与优化:以UNet图像去噪为例
最近在训练一个基于 Tiny-UNet 的图像去噪模型时,我遇到了经典但棘手的错误: RuntimeError: CUDA out of memory。本文记录了我如何从复现、分析,到逐步优化并成功解决该问题的全过程,希望对深度学习开发者有所借鉴。 训练数据&am…...
)
【Spring】单例模式的创建方式(Bean解析)
在Java中,单例模式(Singleton Pattern)确保一个类只有一个实例,并提供全局访问点。以下是实现单例的五种常见方式:懒汉式、饿汉式、双重检查锁、静态内部类和枚举,包括代码示例和优缺点分析。 1. 懒汉式&am…...

小小矩阵设计
在电气设计图中,矩阵设计的接线方法是通过结构化布局实现多灵活链接的技术,常用于信号切换、配电调压或更加复杂的控制场景。 今天聊一种在电气图纸中用到的一种简单矩阵接法,一眼就看明白,很大程度简化了程序控制点和继电器的使用…...

IOT项目——双轴追光系统
双轴太阳能追光系统 - ESP32实现 系统概述 这个系统使用: ESP32开发板2个舵机(水平方向和垂直方向)4个光敏电阻(用于检测光照方向)适当的电阻(用于光敏电阻分压) 接线示意图 --------------…...
)
深度学习基石:神经网络核心知识全解析(一)
神经网络核心知识全解析 一、神经网络概述 神经网络作为机器学习领域的关键算法,在现代生活中发挥着重要作用,广泛应用于图像识别、语音处理、智能推荐等诸多领域,深刻影响着人们的日常生活。它通过模拟人类大脑神经系统的结构和功能&#…...
)
什么是 金字塔缩放(Multi-scale Input)
金字塔缩放 什么是金字塔缩放(Multi-scale Input)什么场景下会用到金字塔缩放?图像识别目标跟踪图像压缩视频处理如何在计算机程序中实现金字塔缩放?准备数据缩小数据(构建金字塔的上层)存储数据使用数据(在程序中应用金字塔缩放)金字塔缩放的记忆卡片什么是金字塔缩放(M…...

从零开始配置 Zabbix 数据库监控:MySQL 实战指南
Zabbix作为一款开源的分布式监控工具,在监控MySQL数据库方面具有显著优势,能够为数据库的稳定运行、性能优化和故障排查提供全面支持。以下是使用Zabbix监控MySQL数据库的配置。 一、安装 Zabbix Agent 和 MySQL 1. 安装 Zabbix Agent services:zabbix…...

机器学习超参数优化全解析
机器学习超参数优化全解析 摘要 本文全面深入地剖析了机器学习模型中的超参数优化策略,涵盖了从参数与超参数的本质区别,到核心超参数(如学习率、批量大小、训练周期)的动态调整方法;从自动化超参数优化技术…...
)
【算法】双指针8道速通(C++)
1. 移动零 思路: 拿示例1的数据来举例,定义两个指针,cur和dest,cur表示当前遍历的元素,dest以及之前表示非零元素 先用cur去找非零元素,每找到一个非零元素,就让dest的下一个元素与之交换 单个…...

synchronized锁
在了解锁之前我们要先了解对象布局 什么是java对象布局 在JVM中,对象在内存中存储的布局可以分为三块区域,即实例化之后的对象 对象头:分配的空间是固定的12Byte,由Mark Word(标记字段)和Class Pointer&…...

实训Day-2 流量分析与安全杂项
目录 实训Day-2-1流量分析实战 实训目的 实训任务1 SYN半链接攻击流量分析 实训任务2 SQL注入攻击流量分析一 实训任务3 SQL注入攻击流量分析二 实训任务4 Web入侵溯源一 实训任务5 Web入侵溯源二 编辑 实训Day-2-1安全杂项实战 实训目的 实训任务1 流量分析 FTP…...

LOH 怎么进行深度标准化?
The panel of normals is applied by replacing the germline read depth of the sample with the median read depth of samples with the same genotype in our panel. 1.解释: panel of normal 正常组织,用于识别技术噪音 germline read depth: 胚系测序深度。根…...

[预备知识]3. 自动求导机制
自动求导机制 本章节介绍 PyTorch 的自动求导机制,包括计算图、反向传播和梯度计算的原理及实现。 1. 计算图原理 计算图是深度学习框架中的一个核心概念,它描述了计算过程中各个操作之间的依赖关系。 计算图由节点(节点)和边…...

蓝桥杯中的知识点
总结: 这次考的并不理想 比赛前好多知识点遗漏 但到此为止已经结束了 mod 是 模运算(Modulo Operation)的缩写,表示求两个数相除后的 余数 10mod31 (a % b) (7%21) 1e9代表1乘以10的9次方,…...

2023蓝帽杯初赛内存取证-6
这里需要用到pslist模块,结合一下查找关键词: vol.py -f memdump.mem --profile Win7SP1x64 pslist | grep -E "VeraCrypt" 将2023-06-20 16:47:41 UTC0000世界标准时间转换成北京时间: 答案:2023-06-21 00:47:41...

《MySQL 核心技能:SQL 查询与数据库概述》
MySQL 核心技能:SQL 查询与数据库概述 一、数据库概述1. 什么是数据库2.为什么要使用数据库3.数据库的相关概念3.1 数据库(DB):数据的“仓库”3.2 数据库管理系统(DBMS):数据库的“管家”3.3 SQ…...

三维几何变换
一、学习目的 了解几何变换的意义 掌握三维基本几何变换的算法 二、学习内容 在本次试验中,我们实现透视投影和三维几何变换。我们首先定义一个立方体作为我们要进行变换的三维物体。 三、具体代码 (1)算法实现 // 获取Canvas元素 con…...

TDengine 查询引擎设计
简介 TDengine 作为一个高性能的时序大数据平台,其查询与计算功能是核心组件之一。该平台提供了丰富的查询处理功能,不仅包括常规的聚合查询,还涵盖了时序数据的窗口查询、统计聚合等高级功能。这些查询计算任务需要 taosc、vnode、qnode 和…...
)
15.第二阶段x64游戏实战-分析怪物血量(遍历周围)
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:14.第二阶段x64游戏实战-分析人物的名字 如果想实现自动打怪,那肯定…...
)
vue浅试(1)
先安装了vue nvm安装详细教程(安装nvm、node、npm、cnpm、yarn及环境变量配置) 稍微了解了一下cursor cursor的使用 请出我们的老师: 提示词: 你是我的好朋友也是一个前端专家,你能向我传授前端知识,…...

VSCode连服务器一直处于Downloading
使用vscode的remote插件连接远程服务器时,部分服务器可能会出现一直处于Downloading VS Code Server的情况 早期的一些教程,如https://blog.csdn.net/chongbin007/article/details/126958840, https://zhuanlan.zhihu.com/p/671718415给出的方法是手动下…...

QGIS实用功能:加载天地图与下载指定区域遥感影像
QGIS 实用功能:加载天地图与下载指定区域遥感影像 目录标题 QGIS 实用功能:加载天地图与下载指定区域遥感影像一、安装天地图插件,开启地图加载之旅二、获取天地图密钥,获取使用权限三、加载天地图服务,查看地图数据四…...

mybatis-plus开发orm
1、mybatis 使用mybatis-generator自动生成代码 这个也是有系统在使用 2、mybatis-plus开发orm--有的系统在使用 MybatisPlus超详细讲解_mybatis-plus-CSDN博客...

ubuntu 交叉编译 macOS 库, 使用 osxcross 搭建 docker 编译 OS X 库
1. ubuntu 交叉编译 macOS 库, 使用 osxcross 搭建 docker 编译 OS X 库 1. ubuntu 交叉编译 macOS 库, 使用 osxcross 搭建 docker 编译 OS X 库 1.1. 安装依赖1.2. 安装 osxcross 及 macOS SDK 1.2.1. 可能错误 1.3. 编译 cmake 类工程1.4. 编译 configure 类工程1.5. 单文件…...

抱佛脚之学SSM四
MyBatis基础 一个接口对应一个映射文件 在映射文件中指定对应接口指定的位置 sql语句中id对应方法名par..参数的类型,resul..返回值的类型 WEB-INF下的文件是受保护的,不能直接访问,只能通过请求转发的方式访问 SqlSessionFactory࿱…...

2.5 函数的拓展
1.匿名函数(简化代码) python中没有这个概念,通过lambda关键字可以简化函数的代码写法 2.lambda表达式 arguments lambda 参数列表 : 函数体 print(aarguments(参数)) #测试lambda #原本代码def sum1(x,y):return xyprint(sum1…...

深度学习--卷积神经网络数据增强
文章目录 一、数据增强1、什么是数据增强?2、为什么需要数据增强? 二、常见的数据增强方法1、图像旋转2、图像翻转3、图像缩放4、图像平移5、图像剪切6、图像亮度、对比度、饱和度调整7、噪声添加8、随机扰动 三、代码实现1、预处理2、使用数据增强增加训…...

Buffer of Thoughts: Thought-Augmented Reasoningwith Large Language Models
CODE: NeurIPS 2024 https://github.com/YangLing0818/buffer-of-thought-llm Abstract 我们介绍了思想缓冲(BoT),一种新颖而通用的思想增强推理方法,用于提高大型语言模型(大型语言模型)的准确性、效率和鲁棒性。具体来说,我们提出了元缓冲…...

mybatisX动态切换数据源直接执行传入sql
代码 mapper接口中方法定义如下,其中#dbName代表传入的数据源变量(取值可参考application.properties中spring.datasource.dynamic.datasource指定的数据源) DS("#dbName")List<LinkedHashMap<String, Object>> execu…...