黑马点评redis改 part 4
Redis消息队列实现异步秒杀
一些额外话语:过来人提醒下,不要用stream,可以跳过不看,用专业的消息队列中间件,同时准备好消息队列的八股,否则简陋的stream很容易被问死。 异步持久化还存在消息丢失、消息重复消费的幂等性问题尤其要注意。 另外生成分布式唯一id的方案也不太行,高度依赖Redis的可用性,最好用雪花算法 个人觉得异步持久化这块看着还行,其实问题不小
【黑马点评】 使用RabbitMQ消息队列实现秒杀下单(完美契合点评Redis要求)_黑马点评项目的最大并发量-CSDN博客
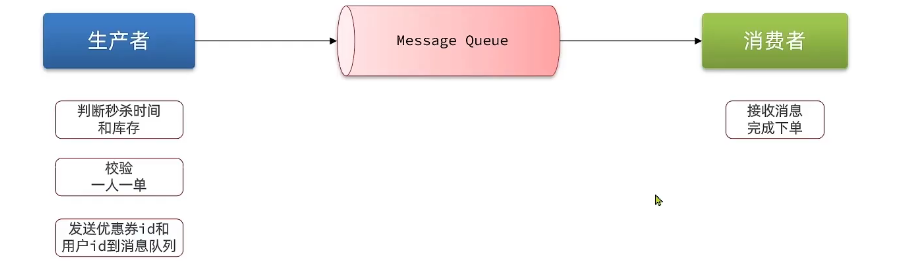
消息队列(MessageQueue),字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
- 消息队列:存储和管理消息,也被称为消息代理(MessageBroker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
mq是独立于jvm以外的项目,不受jvm内存的限制
消息队列不仅仅是做数据存储,还确保我们的数据安全,所有数据均实现持久化,这样呢不管是服务岩机还是重启,数据不会丢失。而且啊他要在消息投递给消费者以后要求消费者做消息的确认,如果消息没有确认,那么那么这个消息就会在队列当中依然存在,下一次呢会再投递给消费者直到成功为止。
Redis提供了三种不同的方式来实现消息队列:
- list结构:基于List结构模拟消息队列
- PubSub:基本的点对点消息模型
- Stream:比较完善的消息队列模型
基于List结构模拟消息队列
消息队列(MessageQueue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。队列是入口和出口不在一边,因此我们可以利用:LPUSH结合RPOP、或者RPUSH结合LPOP来实现。
但是这是非阻塞式的,当没有消息的时候,不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回nu以,并不像JVM的阻塞队列那样会阻塞并等待消息,因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。

我们尝试在redis中实现一些,消费者一侧名字是l1的监听的阻塞队列,阻塞时间是20
BRPOP l1 20另一个
LPUSH l1 e1 e2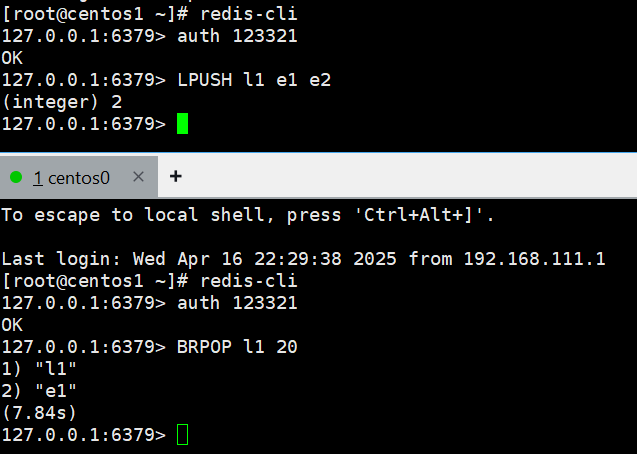
缺点:无法避免消息丢失;只支持单消费者
基于PubSub的消息队列
Pubsub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
- SUBSCRIBE channel [channel]:订阅一个或多个频道
- PUBLISH channel msg:向一个频道发送消息
- PSUBSCRIBE pattern [pattern]:订阅与pattern格式匹配的所有频道
下面是2个消费者,上面的是生成者
为两个消费者分别
SUBSCRIBE order.q1PSUBSCRIBE order.*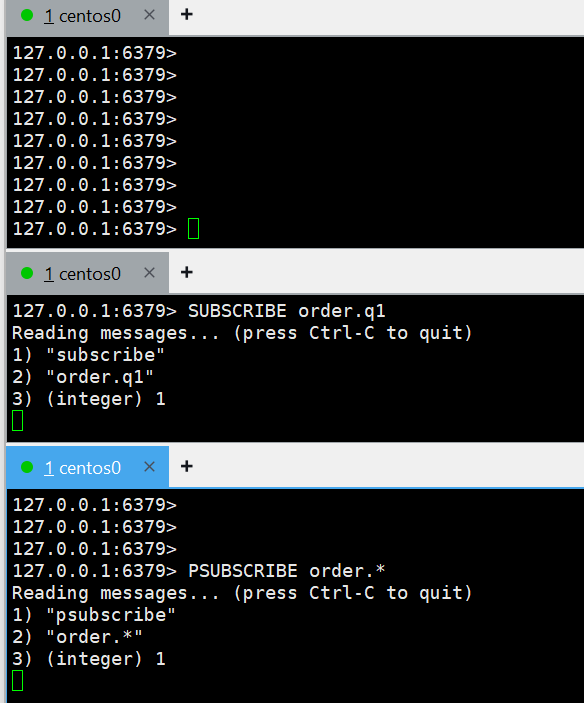
生产者里面这个,双方都受到消息;
PUBLISH order.q1 hellohello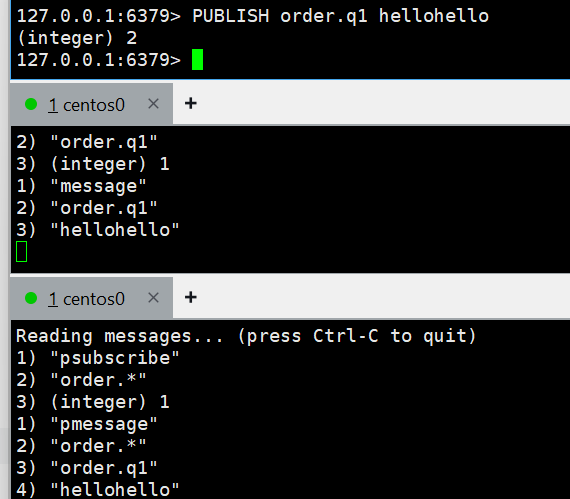 而发送q2只会第二个收到
而发送q2只会第二个收到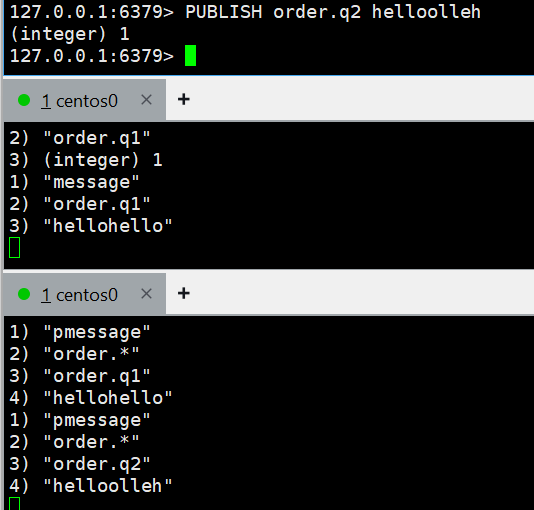
基于PubSub的消息队列有哪些优缺点?
优点:采用发布订阅模型,支持多生产、多消费
缺点:不支持数据持久化;无法避免消息丢失;消息堆积有上限,超出时数据丢失;
基于Stream的消息队列
Stream是Redis5.0引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
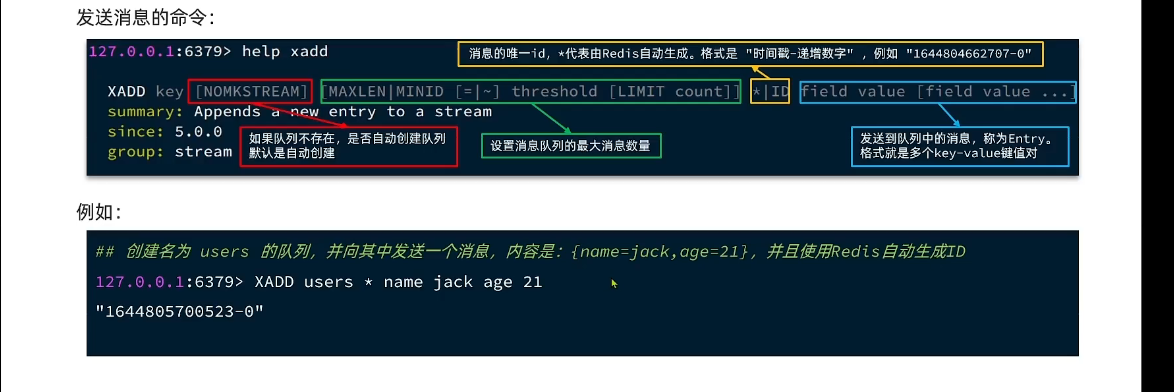
XADD s1 * k1 v1XREAD COUNT 1 STREAMS s1 0
消息已经永久存在,
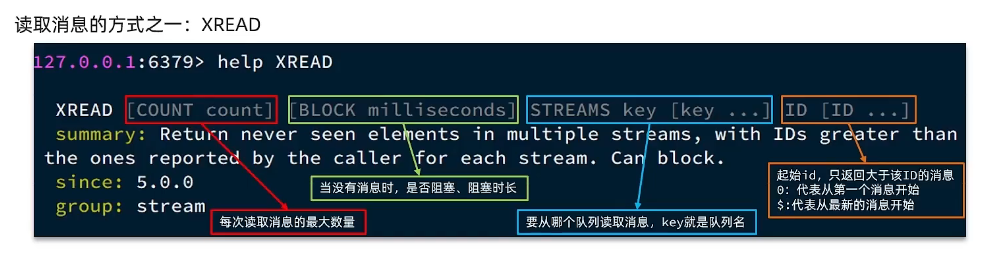
XREAD阻塞方式,读取最新的消息:
127.0.0.1:6379> XREAD COUNT 1 BLOCK 1000 STREAMS uSerS $
(nil)
(1.07s)在业务开发中,我们可以循环的调用XREAD阻塞方式来查询最新消息,从而实现持续监听
队列的效果,伪代码如下:当我们指定起始ID为$时,代表读取最新的消息,如果我们处理1条消息的过程中,又有超过1条以上的消息到达队列,则下次获取时也只能获取到最新的一条,会出现漏读消息的问题。
这里老师是想提醒我们,xread...$是读取这条命令之后接收到的最新消息。执行命令之前发布的消息将不会被包含在结果中,STREAM类型消息队列的XREAD命令特点:
消息可回溯;一个消息可以被多个消费者读取;可以阻塞读取;有消息漏读的风险
基于Stream的消息队列-消费者组
消费者组(ConsumerGroup):将多个消费者划分到一个组中,监听同一个队列。具备下列特点:
- 消息分流:队列中的消息会分流给组内的不同消费者,而不是重复消费,从而加快消息处理的速度
- 消息标示:消费者组会维护一个标示,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标示之后读取消息。确保每一个消息都会被消费
- 消息确认:消费者获取消息后,消息处于pending状态,并存入一个pending-List。当处理完成后需要通过XACK来确认消息,标记消息为已处理,才会从pending-list移除。(在以前的消息队列模式当中如果我们拿到这条消息,没来的及处理挂了,消息丢失,但是现在消息会处于一个待处理状态,不会消失)
创建消费者组:
XGROUP CREATE key groupName ID [MKSTREAM]key:队列名称
groupName:消费者组名称
ID:起始ID标示,$代表队列中最后一个消息,0则代表队列中第一个消息
MKSTREAM:队列不存在时自动创建队列其它常见命令:# 删除指定的消费者组
XGROUP DESTROY key groupName# 给指定的消费者组添加消费者
XGROUP CREATECONSUMER key groupname consumername# 删除消费者组中的指定消费者
XGROUP DELCONSUMER key groupname consumername从消费者组读取消息:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS
key [key ...] ID [ID ...]- group:消费组名称
- consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
- count:本次查询的最大数量
- BLOCK milliseconds:当没有消息时最长等待时间
- NOACK:无需手动ACK,获取到消息后自动确认
- STREAMS key:指定队列名称
- ID:获取消息的起始ID:- "$":从下一个未消费的消息开始- 其它:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从
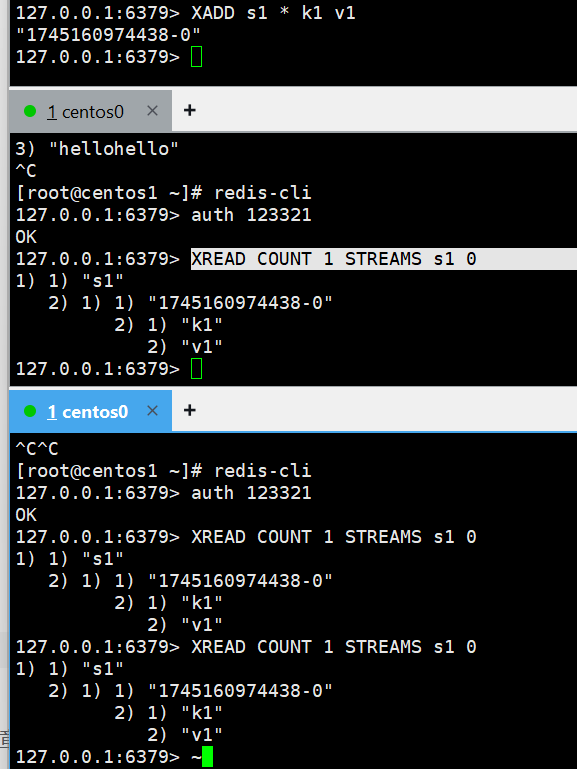
pending-list中的第一个消息开始XGROUP CREATE s1 g1 0
127.0.0.1:6379> XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 >
1) 1) "s1"2) 1) 1) "1745160974438-0"2) 1) "k1"2) "v1"
消费者C1,从队列S1监听的消费者组G1中,读取下一个未消费的消息,等待时间为2S
这次我把消费者的名字改成c2,那么读取的就是k3v3了,因为一个组内只有一个标记,不管谁消费的,只要消费到那里了就标记。
XACK s1 g1 1745160974438-0
#后面还能加你要确认的对应的id号127.0.0.1:6379> XACK s1 g1 1745160974438-0
(integer) 1
127.0.0.1:6379> XPENDING s1 g1 - + 10
(empty array)这样你就获得所有没有确认的消息了那怎么样去读取到penlist里面消息?就是当我们去read这条消息的时候,把大于号改成零或者改成任意都行;代表的含义就是读取penlist的第一条消息。这样就可以再次处理这条消息了。(继续XACK了)
当消费者进入组里后,所有消息存入此消费者的pending-list中,处于pending状态,只有当我们手动xack来确定消息,才会从pending-list中移除,此时可以避免消息读取后,结果程序宕机(不是redis),我们程序还没来得及处理,那么就可以从pending-list中重新获取
while(true){// 尝试监听队列,使用阻塞模式,最长等待 2000 毫秒Object msg = redis.call("XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 >");if(msg == null){ // null说明没有消息,继续下一次continue;}try {// 处理消息,完成后一定要ACKhandleMessage(msg);} catch(Exception e){while(true){Object msg = redis.call("XREADGROUP GROUP g1 c1 COUNT 1 STREAMS s1 0");if(msg == null){ // null说明没有异常消息,所有消息都已确认,结束循环break;}try {// 说明有异常消息,再次处理handleMessage(msg);} catch(Exception e){// 再次出现异常,记录日志,继续循环continue;}}}
}这里一上来就是一个while(true)的死循环,也就是说我们的消费者会循环往复地一直去获取消费者组中的消息啊。所以上来以后,这里就是xreadgroup,读取我们这个组的消息,然后指定消费者名称,然后读取一条block呢就是阻塞啊,如果说有消息,我就直接返回这个消息了,如果没有消息呢,我就最多等待两秒钟,两秒钟还没有啊,我就会返回空了。往下呢是我们的队列名称,最后是大于号,也就是说我们读取的是这个组当中的尚未处理、尚未消费的消息啊。
好,那我们拿到这个结果以后,如果为空,那就说明现在没有消息,我们继续下一次循环,那再来等待就行了啊。那假设说现在我们拿到消息了,拿到消息我肯定去处理,对不对?但是要注意的是,这个消息处理的过程中,如果没有问题,最后完成了一定要去做ack,这样消息就会从pending list里移除了,对不对?但是如果我们处理过程中抛出了异常,那么这个消息因为没有做ack,所以呢他就会依然在我们的pending list当中。这时候我们捕获了异常,我们就可以去处理pending list了。所以呢这里又是一个while(true)啊,我要住里边呢,尝试去读取,你需要注意的是,这一次读取的时候,我们就把大于号替换成零了。我们知道当起始id从大于号改成零以后,代表的含义就是读取的是我们pending list里边的出现了问题的消息,对不对?所以说呢我们现在来这儿读,肯定能拿到对吧,因为你出了异常了嘛,所以肯定能拿到。那我拿到这个消息了以后啊往下走,我是不是就去处理了。那有人说了,什么时候拿不到呢?哎,你别着急啊,听我说。
现在假设我们拿到了,我们往下走,走完以后呢,现在我们处理如果成功了,那你肯定还要再去做确认吧?那你一旦确认这个pending list里边的消息,是不是就会被移除了?那这个时候我们结束以后,继续下一次循环,我再来取,那还能取得到吗?那肯定就取不到了吧。那我就跳出循环了。好,那么就又回到外层循环,继续循环去了,是不是又回归正常的流程?但是呢假设说啊我在pending list里,我取到了这个消息,然后往下走,我去处理这次处理又跑一场了会怎么样?是不是又被我看齐,然后我continue哎又循环啊,再次去plist取,因为你这次处理又出异常了,所以他依然为未确认,是不是依然在pending里?那这个循环就会一直循环一直循环,直到这个消息处理成功为止,对不对?所以一定要成功。那有人说了,我就是不成功,试了几千次都不成功,再怎么办?这个时候你其实可以人工介入了对吧,你可以去接生日,如果这个日志出现嗯长久的问题,你就可以警告了嘛,还警告了对吧,也是没问题的。
好,这是我们整个用Java代码来处理消息的一个流程,大家可以想象的是基于这样一种模式啊,那正常情况下我一定确认,异常情况下,我再判定一次的处理,再确认可以确保我们消息啊至少被消费一次。
STREAM类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
| List | PubSub | Stream | |
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
基于Redis的Stream结构作为消息队列,实现异步秒杀下单
需求:
①创建一个Stream类型的消息队列,名为stream.orders
②修改之前的秒杀下单Lua脚本,在认定有抢购资格后,直接向stream.orders中添加消息,内容包
含voucherld、userld、orderld
③项目启动时,开启一个线程任务,尝试获取stream.orders中的消息,完成下单
XGROUP CREATE stream.orders g1 0 MKSTREAM接下来修改seckill.lua脚本,需要三个参数,因此修改
然后再看键名对不对
最后再看看缓存中有没有秒杀券的库存, 没有的话需要通过之前的接口添加秒杀券--首先要判断的就是库存是否重组,得去读取redis当中的这个key(比如seckill:stock:9)的值
--1.参数列表
--1.1.优惠券id
local voucherId =ARGV[1]
--1.2.用户id
local userId =ARGV[2]
--1.3 订单id
local orderId =ARGV[3]--2.数据key
--2.1.库存key
local stockKey= 'seckill:stock:'..voucherId
--2.2.订单key
local orderKey= 'seckill:order:'..voucherId--3.脚本业务
--3.1.判断库存是否充足getstockKey
if (tonumber(redis.call('get',stockKey))<=0) then
--3.2,库存不足,返回1
return 1
end
--3.2.判断用户是否下单SISMEMBERorderKeyuserId
if(redis.call('sismember',orderKey,userId) == 1) then
--3.3.存在,说明是重复下单,返回2
return 2
end
--3.4.扣库存 incrby stockKey -1
redis.call('incrby',stockKey,-1)
--3.5.下单(保存用户)sadd orderKey userId
redis.call('sadd',orderKey,userId)
--3.6.发送消息到队列中,XADDstr
redis.call('xadd','stream.orders','*','userId',userId,'voucherId',voucherId,'id',orderId)return 0我们有一个实体类叫virtual order,是不是代表我们的订单,将来我们传这些信息的目的,不就是为了创建订单吗,在订单里边他的id啊其实就叫id,然后user id和vtui d,如果说我们现在就叫id的话,将来是不是往这个对象里存的时候,是不是很方便了,因为跟成员变量名称是完全一致的嘛,所以说呢在这个脚本里边啊,我的建议是大家呢把这个地方参数改成id,那这样我们就把三组参数都传进去了
那在这里呢就这段代码voucherorderServiceimpl啊,我们要去做一个改造,因为目前来讲他还是把这个嗯订单信息啊,写入阻塞队列的,所以这段要改造
private IVoucherOrderService proxy;@Overridepublic Result seckillVoucher(Long voucherId) {//获取用户Long userId =UserHolder.getUser().getId();//获取订单idlong orderId = redisIdWorker.nextId("order");//1.执行lua脚本Long result =stringRedisTemplate.execute(SECKILL_SCRIPT,Collections.emptyList(),voucherId.toString(),userId.toString(),String.valueOf(orderId));//第一呢是判断你的购买资格,第二呢还要发送订单的信息到消息队列//2. 判断结果是0int r=result.intValue();if(r!=0) {//2.1 不是0就没有购买资格return Result.fail(r == 1 ? "库存不足" : "不能重复下单");}//3.获取代理对象proxy= (IVoucherOrderService)AopContext.currentProxy();// proxy作为实例变量在多线程环境下可能被覆盖,导致数据不一致。//修复: 在需要时直接获取代理,避免使用实例变量://IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();//proxy.createVoucherOrder(voucherOrder);//返回订单idreturn Result.ok(orderId);}所以说呢我们可以认为这段脚本执行完,那代表用户,前提是这个结果是ok的啊,那么如果结果为零,那就代表着第一用户有购买资格,第二啊,那么消息已经发出,你不用管了,那咱们的业务逻辑其实只要判断嗯,结果是ok的,因此不再需要以下代码
//2.2 为0 有购买资格 ,把下单信息保存到阻塞队列 VoucherOrder voucherOrder = new VoucherOrder(); //订单id voucherOrder.setId(orderId); //2.4.用户id voucherOrder.setUserId(userId); //2.5.代金券id voucherOrder.setVoucherId(voucherId); //2.6.放入阻塞队列 orderTasks.add(voucherOrder);
private class VoucherOrderHandler implements Runnable {String queueName ="stream.orders";@Overridepublic void run() {while (true) {try {// 1. 获取消息队列中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS streams.order >List<MapRecord<String, Object,Object>> list = stringRedisTemplate.opsForStream().read(Consumer.from("g1", "c1"),StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),StreamOffset.create(queueName, ReadOffset.lastConsumed()));
// 这里要注意,老师在前面已经手动创建了消费者组,我们自己不手动创建消费组会出现
// redis更新了,但mysql没更新// 2. 判断消息获取是否成功if(list == null || list.isEmpty()) {// 如果获取失败,说明没有消息,继续下一次循环continue;}// 3. 解析消息中的订单信息MapRecord<String, Object,Object> record = list.get(0);Map<Object, Object> values = record.getValue();VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(values, new VoucherOrder(), true);// 4. 处理获取成功,可以下单handlerVoucherOrder(voucherOrder);// 5. ACK 确认 SACK stream.orders g1 idstringRedisTemplate.opsForStream().acknowledge(queueName, "g1", record.getId());}catch (Exception e) {log.error("处理订单异常",e);handlePendingList();}}}private void handlePendingList() {while (true) {try {// 1. 获取pending-list中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 STREAMS streams.order 0List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(Consumer.from("g1", "c1"),StreamReadOptions.empty().count(1),StreamOffset.create(queueName, ReadOffset.from("0")));// 2. 判断消息获取是否成功if (list == null || list.isEmpty()) {// 如果获取失败,说明pending-list没有异常消息,结束循环break;}// 3. 解析消息中的订单信息MapRecord<String, Object, Object> record = list.get(0);Map<Object, Object> values = record.getValue();VoucherOrder voucherOrder = BeanUtil.fillBeanWithMap(values, new VoucherOrder(), true);// 4. 如果获取成功,可以下单handlerVoucherOrder(voucherOrder);// 5. ACK确认 SACK stream.orders g1 idstringRedisTemplate.opsForStream().acknowledge(queueName, "g1", record.getId());}catch (Exception e){log("处理订单异常",e);}}}}这里一上来就是一个 `while(true)` 的死循环,也就是说我们的消费者会循环往复地一直去获取消费者组中的消息啊。获取我们的消息队列中的订单信息去拿这些信息啊,拿完拿的时候呢不一定会有啊,所以说我们还要做判断对吧。我们去判断判断判断什么啊,判断这个消息获取是否成功对吧。对过去是否成功,那如果说成功了呢,如果获取成功,如果不存在对吧,获取失败,那说明什么,说明没有消息,没有消息,那我们是不是就结束就行了,或者想继续下一次循环啊,因为你没有消息吗,你还在这等着干什么呢,你继续下一次再次尝试过去,看有没有是不是好。
那如果有怎么办对吧,如果有消息会成功,那是不是就要去干什么了,就要去下单了,哎可以下单,对不对,那也就是说接下来要去做这个创建订单的动作了啊,可以到这个位置去了。好,那我们就往下写吧,就可以去创建订单了。那订单创建完了以后呢,是不是就结束了没有,这里要多一个步骤,你要去做这个 `ack` 确认,对不对,你得告诉我们那些队列说你处理了,你不然的话呢你下次还得来处理是吧。所以说呢我们大概的流程是这个样子的啊。
好,那这一段流程的话,可能有同学有点陌生啊,我们可以参考一下以前咱们写的那个伪代码,你看进来以后是不是就循环循环,来了以后上来是不是长时间监听这个队列获取消息对吧,就是这个进行一个队列获取信息,获取完了后,是不是要判断是否有消息啊,判断一下,那如果说这个没有呢,咱们是不是就继续下一次好,那如果说有,咱们不就开始处理,对不对,处理就下单了啊,那处理完了以后呢,那如果说处理成功,你是不是还有 `ack` 确认没问题,那就代表这条消息就彻底处理完了以后就不会再来了。
当然也有可能会破一场,那将来一旦抛了一场怎么办,一旦抛了异常,那这个消息就未确认,是不是那未确认的消息就会进入这个 `pending list` 里了,所以在异常当中,咱是不是去那个 `pending list` 里去取去了。所以说这是我们现在整体的一个流程。所以这个业务其实就是处理这个下单那个业务了。
好,ok,那现在呢我们就差这么 1 3 1 2 4,这几个步骤了,我们去做一下啊。首先第一步获取啊队列中的订单消息啊,会有这个消息,那么其实就是那个命令嘛,哪个命令呢,`xreadgroup` 啊,就这个命令。那你首先要告诉他,你是读取的哪个组是吧,就是你属于哪一组啊,比如说我是 `g1`,然后呢你的消费者叫什么名字啊,那消费者名字的话,这个我们肯定是应该嗯,将来应该是配到这个配置文件里,然后呢不同的节点,将来我们启动多节点的话,那么这个消费者名字应该有多个对吧,这样来就不冲突了。
好,那这个地方我们就先写死啊,比如说 `c1`,然后啊,那么这个明确了你的身份,你是谁,你要来读对吧啊,你是谁啊,我是第一组的 `c1` 这个消费者,紧接着你就开始去配置你要读多少消息了,就是一些读取的参数了,比如 `count` 一代表我读一个,然后你读的时候要不要阻塞啊,`block` 啊,那阻塞阻多久啊,比如说两秒钟,那也就是说我读的时候如果没有消息,我就等啊,最多等两秒钟超过了,我就直接返回结束了是吧,返回一个空好,那再然后呢是什么了,你要读取的这个消息队列的信息了啊,那么就是 `stream gm`,你读取的是哪个小学队列呀,那你得告诉我呀。
好,我们是叫 `stream.order` 吗,是这个名字吧这是我们这个 `stream` 的名字啊,那最后呢是都去标识标识的话,我们这里用的是这个大于号,代表是最近一条未消费的消息是吧,那这是我们如果用命令啊,是这么做的,但是我们现在不是用命令,我们是要啊用java代码了,那其实我们知道在java代码中,和我们的redis提供的这个 ` lettuce`,他把所有的这个操作都封装到了对应的这个 `operation` 对象里对吧,那以前我们玩字符串就是 `ops for value` 玩哈希就是不符哈希,那还有 `set` 这个 `set`,那这里我们玩这个 `stream` 流,那采用的其实就是 `ops for stream` 就这种操作,那它里边怎么样去做这个 `read group` 呢,其实他没有加 `read group`,就是 `read` 就 `read`,但是这个 `read` 参数非常的多,我们可以看到这个参数非常多,那我们属于是要指定消费者这种对吧,那所以你第一个传递参数,其实就是消费者 `consumer` 那有点说的不对呀,你不是先指定组吗,对吧,那组其实是属于这个消费者的一部分信息,所以说呢他在这里统一叫 `consumer` 了,而且呢这个 `consumer` 大概有很多 `consumer`,我们一定要找 `spring` 相关的那个 `spring` 相关的这个呢就是这个 `swim` 里面的这个,它还有一个静态方法叫 `from` 看到没有,那这里就要传什么传 `group`,就这第一个,然后第二个传 `name` 其实就是这个谁 `c` 哎,所以组的名称就位的名称传给他就行了,那不刚好嘛,我们 `g1` 是吧,还有一个是谁呢,`c1` 那这样这俩参数是不是就对住了,好,所以这一部分其实就搞定了,就对应这消费者搞定。
消费者搞定了,你要指定的不是就是读取时的一些信息了,那好,再来往下看它叫什么,它叫 `stream read option`,`read option` 就是什么意思,就是读取的一些选项啊,你读多少个呀,你要不要阻塞呀,这就是读取选项,`stream read option` 啊,`stream read option`,那么 `read option` 呢,这里边我们首先用 `empty` 创建一个空的,紧接着再去指定就行了,指定第一 `count` 读几个啊,我读一个,然后要不要阻塞,阻塞堵了多长时间啊,两秒钟,那这个地方的话,那不是除了直接传两天啊,你看他接触的是 `duration`,`duration` 呢是一个叫做周期,那里面可以传很多很多不同类型的,就是带有时间单位的,看到没有,比天小时,毫秒纳秒等等都可以,在这里我们肯定是秒对吧,那我就说最多等两秒就这么写就行了,那到这好,我们就是读取选项这部分就搞定了,就这一块等于我们这里好。
那再往后最后一部分其实就是什么了,休息队列的名字,还有结束标识是吧,读取标识,那这一部分它叫什么,它叫做 `stream offset`,`offset` 啊,那么 `offset` 的话它其实就是就是偏移量嘛,你读取的位置的意思,它有一个 `create` 函数帮我们去创建,那在这个地方第一要指定的 `stream`,就是你的这个队列名称,就是这个名字啊,这个名字我们可以提前在外面给它定义出来啊,`string` 一个叫嗯叫做 `q name`,就等于这个 `stream.order` 我们把它写死对吧,那这样的话就可以直接在这使用了,直接在这使用它,然后呢是这个 `read offset` 啊,就是说你读到哪里呀,你都去标记是什么呀,对吧啊,那么我们这里同样是有枚举啊,`read offset set`,大家可以看到这里有很多 `last consume` 呢,其实就是指你最近一次呃未消费的消息,而 `latest` 代表最新的消息,那我们肯定选的是这个是不是,那它是枚举的,它是静态常量是吧,那它指的是不是这个大括号大于号呢,我们进去看一下看是吧,而那个 `latest` 最新代表的就是 `dollar` 符嘛啊,所以这里面其实是它的定义好的啊,啊那么当然如果你不想用他这种,你也可以自己定义啊,去 `new` 它也是没问题的,所以我们这里可以直接使用它代表大于号。
那到这儿呢我们就通过这么几个参数,是不是就把这个 `read` 所需要的信息全部指定出来了,那么这个时候你其实就可以拿到这个结果啊,那我们可以看到这个结果返回的是一个什么,是一个 `list` 对吧,是一个类似的啊,那这个地方嗯为什么反应是个 `list`,因为你的 `count` 值不一定是一,你可能是一,可能是二,可能是多个,对不对,所以说它返回的是一个类似的代表,就是我可能读到多个,可能读到多个,那因此我们在这个地方就需要去判断它,判断他是否获取成功,也就是判断这个集合啊,有没有数据,对不对啊,那就 `if` 这个 `list` 是否等等于 `now` 啊,啊如果不等于到的话,那你这个是否是空啊,对不对,那如果为空好,那就证明你这个回血也失败了,那我们干什么,继续下一次循环,`continue`,继续下一次嘛,那我再来读一次,看有没有,是不是啊,那采用这样一种方式去做一下啊,ok,那这样的话我们其实就做完了这个判断了,那代码如果说走到这,那就证明消息是有呃,有说明有订单要处理,我们是不是就可以去处理这个订单了,但是呢我们要处理订单,我是不是得先把它从这个 `list` 里取出来啊,所以这个地方其实要多一步就是去解析啊,消息中的这个订单信息,你去解析一下啊,从它里面去取。
那它是个 `list`,那我们就取肯定取,按照角标取嘛,那虽然说他这里是个例子,但我们明确的知道我看他是一哦,只有一个,所以我直接干零位好了吗,这就拿到了,但是呢大家会注意到,我们这个地方拿到的却是一个什么叫 `map record`,对吧,为什么是一个 `map`,其实底层就是一个 `map`,那这个其实就是消息的id啊,我们知道消息队列里面发的消息,是不是都会有id,那么在这个地方,他为什么后面还有这个键值形式呢,哎这是跟我们发的消息格式有关,我们看一下我们利用这个呃 `stream` 发消息的时候,其实我们发消息不就是建筑格式吗,key value key value,对不对,那这里的key呢,恰好就是我们那个 `virtual order` 类的三个成员变量对吧,那value就是对应的值,所以说呢他在这里是建设的形式,因此呢它返回的我回去啊,就是这样一种 `map` 形式,它封装了一下,那我们可以把它取出来,我们可以通过这个 `record.get value`,这里的 `gd` 啊,就是消息id了,`get value` 拿到的其实就是那个键值对了啊,电路的集合,所以是个 `map`,是不是,那我们现在要做的是什么,其实就是把这个 `map` 转成我们的 `order` 对象,是不是就解决成功了,怎么转呢,我们以前有一个嗯 `bean` 的 `util` 工具类嘛,`hoto` 里面的嘛,它里面有个叫 `popular fiba with map`,`fiba` 的 `map`,这个说过了吧,那你首先把 `map` 给他,然后呢给他一个对象啊,什么对象呢,就是我们的这个要转的对象呢,我们是 `watch order` 是吧,然后告诉他如果出错了怎么办,出错了要不要忽略,那我们就忽略吧,这个地方就直接忽略,那这样就得到 `order` 对象了啊,那拿到 `order` 完成下单不就o了吗,是不是唉,那么最后呢还要去做这个订单那个确认啊,那确认的话同样是用一个什么,用一个我们之前讲的一个命令啊,就是 `sack`,那这里边要传的第一就是你这个队列的名字,我们这个队列是叫 `stream.order` 4是吧,然后呢就是你这个什么你是哪个组,是不是啊,我们是这个基因组啊,这个消息的id啊,啊,那么也就是说你是哪一个消息已经被处理完了,你要告诉他,那么它就会从这个队列中移除了啊。
好,那我们如果用java代码来表示的话,同样是用 `retemplate`,利用 `o stream` 对吧,那这里边就有一个叫做 `acknowledge` 的函数了,你看这里面传三个参数吗,第一个就是key,也就是你这个队列的名字啊,然后呢是 `group` 啊,也就是你是哪个组的,然后呢就是你的这个消息的id了,好,那首先 `group` 的话,我们这里就记一嘛,然后呢这里的什么呢,嗯 `key` 是 `string` `mode`,我们已经定义常量叫 `q name` 了,然后是组叫 `g1`,然后是我们的那个什么呢,就写小写 `d` 我们可以从前面的这个 `record` 里去取,这里面是有的啊,那这个地方的 `get id` 得到的就是消息id好,那这样呢我们的确认动作也就完成了。
好到这里呢,基本的休息处理的流程就处理完了啊,获取消息啊,然后判断一下有没有拿到,没拿到就继续获取,拿到了的话,我们就处理处理完下单,下单完全人是吧,哎搞定了好,那这是正常情况,那还有什么出异常的情况,那一旦在处理消息的过程中抛了异常,那么我们要干什么,我们知道消息一旦破裂,长是不是就没有被 `ack` 确认,那没有被 `ack` 确认,其实就会进入 `pending list`,紧接着我们是不是就应该按照这个逻辑,去 `pending list` 里尝试取出来了,然后再次去做处理,对不对,所以在这儿我们可以封装一个方法,叫 `handle pending list`,加了分数再次来去处理这种异常的消息对吧,去处理这个异常消息啊。
好,那么我们去创建这个函数啊,嗯就在当前内部类的创建吧,就在这创建在这来做好,那怎么做怎么做,其实呢嗯流程很简单啊,那么他这边的做法大家可以看到还是一样,循环进来以后尝试去处理对吧,处理的过程中判断一下这个消息有没有,没有的话就结束是吧,有的话就继续就这样,所以说跟我们上边的这个什么,这段 `while` 循环的流程是不是非常的像,所以我们完全可以把这个代码扣一分放下来啊,看下来以后当然要改啊,首先你这个地方读的时候,你的什么你首先你是读 `pending list`,不再需要这个 `block` 阻塞了,你的结束标识也是零,因为零的时候代表读的不是消息队列了,而是 `pending list`,对不对?所以这一点要注意啊,`pending list` 中的订单信息啊,也就是出现异常的啊,这么去读,那也就是说这个地方要改的话,首先第一 `block` 不需要了,其次的话其实就是这个诶,这里多个括号是吧,其次就是这个地方啊,结束标识不再是 `last consumer` 是零,那他这里边有没有一个结束标识是代表零的,没有对吧,这是 `dollar` 符,这是那个大于号,那所以呢你在干什么,自己传,看到没有,从自己传的时候就直接传零就行,那这个读的就是 `pending list` 好,那么 `pending list` 的读取,然后呢他看一下有没有读到,那没读到说明什么,说明 `pending list` 里边没有什么异常的消息,没有异常消息,那没有异常消息,我还需要继续吗,继续吗,还需要下一次循环,完全不需要了,你都没了,我还继续什么,应该是结束循环才对,结束循环啊,跳出循环好,那就结束了,就会干什么,就会是不是执行这边的逻辑了,继续去处理,对不对啊。
好,那如果说这里边有多多的有,我是不是按照正常逻辑去解析,然后呢得到订单,然后去处理订单就行了,然后确认这个不变跟以前一样对吧,那如果这里又抛出了异常呢,也就是说我在处理 `pending list` 的过程中,又抛了异常呢,是不是又被我看齐,然后我 `continue` 哎又循环啊,再次去 `plist` 取,因为你这次处理又出异常了,所以他依然为未确认,是不是依然在 `pending` 里?那这个循环就会一直循环一直循环,直到这个消息处理成功为止,对不对?所以一定要成功,那有人说了,我就是不成功,试了几千次都不成功,再怎么办?这个时候你其实可以人工介入了对吧,你可以去接生日,如果这个日志出现嗯长久的问题,你就可以警告了嘛,还警告了对吧,也是没问题的。好,这是我们整个用java代码来处理消息的一个流程,大家可以想象的是基于这样一种模式啊,那正常情况下我一定确认,异常情况下,我再判定一次的处理,再确认可以确保我们消息啊至少被消费一次没问题吧。那到这里呢,我们基于消费者组的这种消费模型啊,也就给大家分析完毕了。
这里一上来就是一个 `while(true)` 的死循环,也就是说我们的消费者会循环往复地一直去获取消费者组中的消息。获取消息队列中的订单信息时,由于消息可能不存在,所以需要进行判断。使用 `XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS stream.order >` 命令获取消息,其中:
- `g1` 是消费者组名称
- `c1` 是消费者名称
- `COUNT 1` 表示每次读取1条消息
- `BLOCK 2000` 表示阻塞等待2秒
- `stream.order` 是Stream名称
- `>` 表示读取最新未消费的消息判断消息获取是否成功:
- 如果返回null或空列表,说明当前无消息,直接进入下一次循环
- 如果获取成功,需要解析消息中的订单信息解析过程通过 `BeanUtil.fillBeanWithMap` 将Map格式的Stream消息转换为VoucherOrder对象。处理完订单后需要执行 **XACK** 确认:`XACK stream.order g1 id`,这里通过 `stringRedisTemplate.opsForStream().acknowledge()` 方法实现。
异常处理时会进入 `handlePendingList` 方法,使用 `XREADGROUP GROUP g1 c1 COUNT 1 STREAMS stream.order 0` 读取pending列表(0表示从pending列表开始读取)。处理逻辑与正常消息类似,但不需要阻塞等待,循环直到pending列表处理完毕。
关键点说明:
1. **消费者组必须预先创建**,否则会出现Redis状态更新但MySQL未同步的问题
2. **消息确认机制**:未确认的消息会进入pending列表,需要专门处理
3. **阻塞与非阻塞**:正常消费使用阻塞读,pending处理使用非阻塞读
4. **Stream偏移量**:`>` 读新消息,`0` 读pending列表
5. **消息转换**:通过工具类将Redis的Map消息转为领域对象代码中使用Spring Data Redis的 `opsForStream()` 操作类,其中:
- `Consumer.from("g1", "c1")` 指定消费者组和消费者身份
- `StreamReadOptions` 配置读取参数
- `StreamOffset.create()` 指定Stream名称和读取位置
- `acknowledge()` 方法对应 **XACK** 命令异常处理流程会不断重试pending消息,直到处理成功。这种设计保证了消息的**至少一次消费**语义,但需要业务逻辑做好幂等处理。
如果是proxy为空异常的注意不要集群启动,因为proxy只会在一个服务中被赋值,另一个就是没有被赋值null
这里把主线程的proxy赋值提早到执行Lua脚本之前也许更好,不然proxy在异步线程里可能出现空指针异常;千万不要启动两个服务,不然同一个消费者名字,两个消费者抢一个消息,出现并发报错。
相关文章:

黑马点评redis改 part 4
Redis消息队列实现异步秒杀 一些额外话语:过来人提醒下,不要用stream,可以跳过不看,用专业的消息队列中间件,同时准备好消息队列的八股,否则简陋的stream很容易被问死。 异步持久化还存在消息丢失、消息重复…...

【Python Web开发】01-Socket网络编程01
文章目录 1.套接字(Socket)1.1 概念1.2 类型1.3 使用步骤 Python 的网络编程主要用于让不同的计算机或者程序之间进行数据交换和通信,就好像人与人之间打电话、发消息一样。 下面从几个关键方面通俗易懂地介绍一下: 1.套接字(Socket) 在 Python 网络编…...

『不废话』之Python管理工具uv快速入门
在『不废话』之大模型推理超参数解释『不废话』之动手学MCP 中提到了uv,很多朋友都说没用过,咨询有什么优势? 通常Python新手都会使用conda、miniconda来管理Python环境,稍微高阶水平的会使用pyenv、poetry、virtualenv等工具来管…...

2025年中国高端家电品牌市场分析:海尔Haier、美的Midea、格力GREE三大本土品牌合计占据70%市场份额
一、市场现状:需求升级与结构性增长并存 2024年,中国高端家电市场在复杂的经济环境中展现出“逆势增长”的韧性。尽管全球经济增速放缓,国内家电零售额同比微降0.4%至6957亿元,但高端家电却成为拉动市场的重要引擎。这一现象的背…...
)
【漫话机器学习系列】217.监督式深度学习的核心法则(Supervised Deep Learning Rule Of Thumb)
监督式深度学习的核心法则:你需要多少数据? 原图作者:Chris Albon 在进行深度学习项目时,我们常常面临一个核心问题:我到底需要多少训练数据?这是许多初学者甚至资深工程师都会困惑的问题。图中给出了一个非…...
)
OpenCV --- 图像预处理(六)
OpenCV — 图像预处理(六) 文章目录 OpenCV --- 图像预处理(六)十四,图像边缘检测14.1 高斯滤波14.2 计算图像的梯度与方向14.3 非极大值抑制14.4 双阈值筛选14.5 API和使用 十五,绘制图像轮廓15.1 什么是轮…...

WebRTC服务器Coturn服务器的管理平台功能
1、概述 开源的webrtc服务器提供管理平台功能,用户可以通过web页面进行访问配置coturn服务器,主要包括管理平台功能和telnet的管理功能,coturn相当于telnet服务器,可能通过配置来开启这两个功能,方便查看coturn服务器…...

华为网路设备学习-19 路由策略
一、 二、 注意: 当该节点匹配模式为permit下时,参考if else 当该节点匹配模式为deny下时: 1、该节点中的apply子语句不会执行。 2、如果满足所有判断(if-match)条件时,拒绝该节点并跳出(即不…...

理解RAG第六部分:有效的检索优化
在RAG系统中,识别相关上下文的检索器组件的性能与语言模型在生成有效响应方面的性能同样重要,甚至更为重要。因此,一些改进RAG系统的努力将重点放在优化检索过程上。 从检索方面提高RAG系统性能的一些常见方法。通过实施高级检索技术&#x…...

DOCA介绍
本文分为两个部分: DOCA及BlueField介绍如何运行DOCA应用,这里以DNS_Filter为例子做大致介绍。 DOCA及BlueField介绍: 现代企业数据中心是软件定义的、完全可编程的基础设施,旨在服务于跨云、核心和边缘环境的高度分布式应用工作…...

Hadoop----高可用搭建
目录标题 **什么是高可用?****⭐搭建的步骤**一.jdk**安装配置**- **要点**: 二.zookeeper**集群配置**- **要点** 三.Hadoop高可用的搭建- **要点**①环境变量的配置②配置文件的修改 ③内容分发④集群任务的初次启动 什么是高可用? 通过冗余设计 自动…...

2023蓝帽杯初赛内存取证-1
获取关于内存镜像文件的基本信息: vol.py -f memdump.mem imageinfo 得知Image local date and time : 2023-06-21 01:02:27 0800 Image local date and time是本地时区(中国——东八区) 答案:2023-06-21 01:02:27...

算法之回溯法
回溯法 回溯法定义与概念核心思想回溯法的一般框架伪代码表示C语言实现框架 回溯法的优化技巧剪枝策略实现剪枝的C语言示例记忆化搜索 案例分析N皇后问题子集和问题全排列问题寻路问题 回溯法的可视化理解决策树状态空间树回溯过程 回溯法与其他算法的比较回溯法与动态规划的区…...
 作用是什么?)
Linux 内核中 cgroup(控制组) 作用是什么?
cgroup(Control Groups) 是 Linux 内核提供的一种机制,用于对 进程(或线程)组 进行资源限制、优先级分配、统计监控和任务控制。通过将进程分组管理,可以实现对 CPU、内存、磁盘 I/O、网络等系统资源的精细…...

Relay IR的核心数据结构
在 Apache TVM 的 Relay IR 中,基础节点(Var、Const、Call、Function 和 Expr)是构建计算图的核心数据结构。以下是对它们的详细解析,包括定义、作用、内部组成及相互关系: 1. Expr(表达式基类)…...
:MCP工具开发基础)
【MCP Node.js SDK 全栈进阶指南】初级篇(4):MCP工具开发基础
在MCP(模型上下文协议)的生态系统中,工具(Tools)是一种强大的扩展机制,允许AI模型执行各种操作并获取结果。本文将深入探讨MCP TypeScript-SDK中的工具开发基础,包括工具定义与参数验证、Zod模式详解与高级用法、异步工具处理与错误管理以及工具调用与结果格式化。通过学…...

3Blue1Brown/videos - 数学视频生成代码库
本文翻译整理自:https://github.com/3b1b/videos 文章目录 一、关于本项目相关链接资源关键功能特性 二、注意事项三、工作流1、核心原理2、Sublime 专用配置 四、快捷键功能说明 一、关于本项目 本项目包含用于生成 3Blue1Brown 数学解说视频的代码。 相关链接资源…...

vue3 + element-plus中el-drawer抽屉滚动条回到顶部
el-drawer抽屉滚动条回到顶部 <script setup lang"ts" name"PerformanceLogQuery"> import { ref, nextTick } from "vue"; ...... // 详情 import { performanceLogQueryByIdService } from "/api/performanceLog"; const onD…...

【inlining failed in call to always_inline ‘_mm_aesenclast_si128’】
gcc编译错误:inlining failed in call to always_inline ‘_mm_aesenclast_si128’: target specific option mismatch 消除方法: 假如是GCC,则CFLAGS添加如下编译选项:-maes 假如是cmake,参加如下脚本: …...

DB-GPT支持mcp协议配置说明
简介 在 DB-GPT 中使用 MCP(Model Context Protocol)协议,主要通过配置 MCP 服务器和智能体协作实现外部工具集成与数据交互。 开启mcp服务,这里以网页抓取为例 npx -y supergateway --stdio "uvx mcp-server-fetch" …...

前端之勇闯DOM关
一、DOM简介 1.1什么是DOM 文档对象类型(Document Object Model,简称DOM),是W3C组织推荐的处理课扩展标记语言(HTML或者XML)的标准编程接口 W3C已经定义了一系列的DOM接口,通过这些DOM接口可…...

实现鼠标拖拽图片效果
我们需要一个图片 可以是你的女朋友 可以是男朋友 ,我就拿窝的偶像 一个大佬——>甘为例吧! 哈哈哈哈哈 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport&q…...
方式)
nodejs模块暴露数据的方式,和引入(导入方式)方式
在 Node.js 中,模块之间通过 模块导出(exports) 和 模块导入(require 或 ESModule 的 import) 来进行数据和功能的共享。下面我详细总结一下两种主要的模块系统: 一、CommonJS 模块(Node.js 默认…...

AXOP33552: 400MHz 高速双通道运算放大器
AXOP33552是一款通用型高速双通道运算放大器,产品的工作电压为2V至5.5V,具有400MHz的带宽,f0.1dB的带宽为 120MHz,单通道静态电流为10mA。产品特别对噪声和THD做了优化,其噪声为5nV/√Hz 1MHz,2次谐波为-85…...

Spring Boot日志配置
目录 logback 使用logback 获取日志对象 日志级别 控制日志输出级别 日志输出格式控制 配置方式 日志转存 示例 日志是应用程序不可或缺的一部分,记录着程序运行的信息。主要作用有: 记录日常运营的重要信息记录应用报错信息记录过程数据等…...

不可变数据:基于持久化数据结构的状态管理
不可变数据:基于持久化数据结构的状态管理 一、 什么是不可变数据? 不可变数据是指一旦创建就无法更改的数据。在计算机科学中,不可变数据结构是指其内容或状态不能被修改的数据结构。在不可变数据中,所有修改操作都会生成新的数据副本&#…...
与步幅(Stride)详解及代码示例)
PyTorch卷积层填充(Padding)与步幅(Stride)详解及代码示例
本文通过具体代码示例讲解PyTorch中卷积操作的填充(Padding)和步幅(Stride)对输出形状的影响,帮助读者掌握卷积层的参数配置技巧。 一、填充与步幅基础 填充(Padding):在输入数据边缘…...

C++手撕STL-其叁
Deque 今天我们进入新的容器:deque,一般叫做双端队列。 比起传统的先入先出的队列queue,deque的出场率显然要低得多,事实上deque比起queue来说最大的特点就是多了一个push_front()和pop_front(),其他并没有太多不同。…...

AI大模型-window系统CPU版安装anaconda以及paddle详细步骤-亲测有效
window系统CPU版安装anaconda以及paddle详细步骤-亲测有效 一 安装anaconda 下载地址:anaconda下载 下载成功后,选择非C盘安装,按提示安装即可修改镜像文件 安装成功后,运行anaconda软件,若提示更新则点击更新,更新完后,修改镜像文件 找到用户目录下的.condarc文件,覆…...

UML概览
🥰名片: 🐳作者简介:乐于分享知识的大二在校生 🌳本系列专栏: (点击直达)统一建模语言UML 🫣致读者:欢迎评论与私信,对于博客内容的疑问都会尽量回复哒!!! 本文序: ⛰️本文介绍&…...
 时出错: Can not convert Array to String)
影刀填写输入框(web) 时出错: Can not convert Array to String
环境: 影刀5.26.24 Win10专业版 问题描述: [错误来源]行12: 填写输入框(web) 执行 填写输入框(web) 时出错: Can not convert Array to String. 解决方案: 1. 检查变量内容 在填写输入框之前,打印BT和NR变量的值ÿ…...

LLMs可在2位精度下保持高准确率
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

C语言高频面试题——结构体和联合体区别
在 C 语言中,结构体(struct) 和 联合体(union) 是两种重要的复合数据类型,用于组织和管理多个相关的变量。尽管它们在语法上有些相似,但在内存布局、用途和行为上有显著的区别。以下是详细的对比…...

App爬虫工具篇-mitmproxy
mitmproxy 是一个支持 HTTP 和 HTTPS 的抓包程序,类似 Fiddler、Charles 的功能,它通过控制台的形式和ui界面的方式 此外,mitmproxy 还有两个关联组件,一个是 mitmdump,它是 mitmproxy 的命令行接口,利用它可以对接 Python 脚本,实现监听后的处理;另一个是 mitmweb,它…...

配置openjdk调试环境
先决条件 首先在Ubuntu 18.04上编译SlowDebug版本的openjdk。注意,这里我选择的是x86处理器的电脑。苹果M系列属于ARM芯片,指令集不一样。由于我在苹果上进行垃圾回收调试的时候会报SIGILL错误。为了了解JVM的内部工作原理,不要在这种问题上…...

加油站小程序实战教程13充值规则配置
目录 1 创建数据源2 搭建管理功能最终效果 我们目前已经实现了会员的注册以及登录功能,有了基础的认证之后就进入到了业务部分的开发。会员的话首先是可以进行充值,在充值的时候通常会有一定的赠送,本篇我们来开发一下充值规则的配置功能。 1…...

jQuery — 总结
介绍 jQuery是一款高效、轻量级的JavaScript库,旨在简化网页开发中的常见任务。自2006年发布以来,它凭借直观的语法和强大的功能迅速成为前端开发的标配工具。其核心设计理念是“写更少,做更多”,通过封装复杂的原生JavaScript操作…...

【信息安全工程师备考笔记】第二章 网络信息安全概述
第二章 网络攻击原理与常用方法 2.1 网络攻击概述 概念:损害网络 系统安全属性 的危害行为 危害行为基本类型 信息泄露攻击(机密性)完整性破坏攻击(完整性)拒绝服务攻击(可用性)非法使用攻击…...

国家自然科学基金答辩ppt制作案例模板下载
国家自然科学基金 National Natural Science Foundation of China 支持基础研究,坚持自由探索,发挥导向作用,发现和培养科学技术人才,促进科学技术进步和经济社会协调发展,逐渐形成和发展了由研究项目、人才项目和环境…...

代码随想录第三十七天|华为秋季笔试真题230823
刷题小记: 主要偏向扎实编码基础的考察,但貌似近些年题目难度有所提高,仅供参考。 卡码网136.获取连通的相邻节点列表(卡码网136.获取连通的相邻节点列表) 题目分析: 题目描述: 存在N个转发…...

KUKA机器人KR 3 D1200 HM介绍
KUKA KR 3 D1200 HM是一款小型机器人,型号中HM代表“Hygienic Machine(卫生机械)用于主副食品行业”,也是一款并联机器人。用于执行高速、高精度的抓取任务。这款机器人采用食品级不锈钢设计,额定负载为3公斤ÿ…...

从零开始创建MCP Server实战指南
一、MCP协议核心概念 1.1 什么是MCP? MCP(Model Context Protocol) 是一个标准化的“沟通规则”,由公司Anthropic提出,专门用于让大语言模型(LLM,比如通义千问、ChatGPT等)与外部工…...
:C 语言数组详解)
C语言教程(十二):C 语言数组详解
一、引言数组的基本概念 数组是一组具有相同数据类型的元素的集合,这些元素在内存中连续存储。通过一个统一的数组名和下标来访问数组中的每个元素。使用数组可以方便地处理大量相同类型的数据,避免为每个数据单独定义变量。 二、一维数组 2.1 数组的…...

Linux[基础指令][2]
Linux[基础指令][2] cp(复制) 格式:cp [-rf] 源文件 {普通文件,目录} 拷贝 cp -r 递归拷贝目录 蓝色为目录,白色为具体文件 拷贝后面加一个不存在的文件会新建文件再拷贝 cp -ir -i是覆盖的时候询问 如果目标文件存在就会覆盖原有文件 mv(重命名/剪切) 格式:mv 源文件…...

MySQL_MCP_Server_pro接入cherry_studio实现大模型操作数据库
大模型直接与数据库交互,实现基本增删改查操作。首先贴下代码地址: https://github.com/wenb1n-dev/mysql_mcp_server_pro 安装环境:win10 1、下载代码 git clone https://github.com/wenb1n-dev/mysql_mcp_server_pro 2、使用conda创建…...

linux命令集
命令 grep -r --includeAndroid.bp libcfs ./ 参数说明 选项/参数作用-r递归搜索子目录。--includeAndroid.bp仅搜索名为 Android.bp 的文件(精确匹配文件名)。libcfs要搜索的关键字(单引号包裹特殊字符如 以避免被 Shell 解析ÿ…...

数据结构:链表
链表的概念及结构: 链表的概念: 链表是一种物理储存结构上非连续的储存结构,数据元素的逻辑顺序是通过引用链接次序实现的 那物理存储结构连续是什么意思? 之前我们讲过顺序表,顺序表的底层是数组,如下…...

【高并发内存池】从零到一的项目之高并发内存池整体框架设计及thread cache设计
个人主页 : zxctscl 专栏 【C】、 【C语言】、 【Linux】、 【数据结构】、 【算法】 如有转载请先通知 文章目录 前言1. 高并发内存池整体框架设计2. 高并发内存池--thread cache2.1 定长内存池的问题2.2 整体框架2.3 自由链表2.4 thread cache哈希桶的对齐规则2.5…...

电气动调节单座V型球阀带阀杆节流套沟槽孔板的作用-耀圣
电气动调节单座V球阀杆节流套是阀门中的一个重要组件,主要用于调节和控制流体介质的流量、压力或流速,同时兼具导向、密封和稳定阀杆运动降低流速减少冲刷的作用。以下是其具体功能和应用场景的详细说明: 1. 节流与流量控制** 作用原理**&am…...

vscode使用笔记
文章目录 安装快捷键 vscode是前端开发的一款利器。 安装 快捷键 ctrlp # 查找文件(和idea的双击shift不一样) ctrlshiftf # 搜索内容...