【高并发内存池】从零到一的项目之高并发内存池整体框架设计及thread cache设计
个人主页 : zxctscl
专栏 【C++】、 【C语言】、 【Linux】、 【数据结构】、 【算法】
如有转载请先通知
文章目录
- 前言
- 1. 高并发内存池整体框架设计
- 2. 高并发内存池--thread cache
- 2.1 定长内存池的问题
- 2.2 整体框架
- 2.3 自由链表
- 2.4 thread cache哈希桶的对齐规则
- 2.5 ThreadCache类的设计
- 2.5.1 Allocate
- 2.5.2 Deallocate
- 2.6 无锁访问
- 2.7 测试TLS
- 3. 附代码
- 3.1 Common.h
- 3.2 ObjectPool.h
- 3.3 ThreadCache.h
- 3.4 ConcurrentAlloc.h
- 3.5 ThreadCache.cpp
- 3.6 test.cpp
前言
接上回的项目 【高并发内存池】从零到一的项目:项目介绍、内存池及定长内存池的设计继续分享项目创做过程及代码。
1. 高并发内存池整体框架设计
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。malloc本身其实已经很优秀,那么我们项目的原型tcmalloc就是在多线程高并发的场景下更胜一筹,所以这次我们实现的内存池需要考虑以下几方面的问题。
- 性能问题。
- 多线程环境下,锁竞争问题。
- 内存碎片问题。
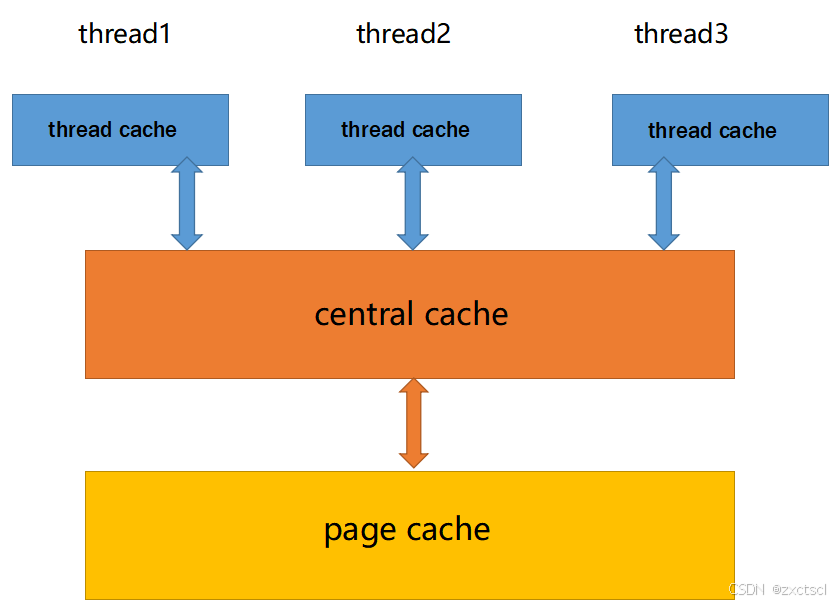
concurrent memory pool主要由以下3个部分构成:
-
thread cache:线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这也就是这个并发线程池高效的地方。
解决了大部分情况下线程锁竞争的情况。 -
central cache:中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对象。central cache合适的时机回收thread cache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存在竞争的,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有thread cache的没有内存对象时才会找central cache,所以这里竞争不会很激烈。
居中调度 -
page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给central cache。当一个span的几个跨度页的对象都回收以后,page cache会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
2. 高并发内存池–thread cache
2.1 定长内存池的问题
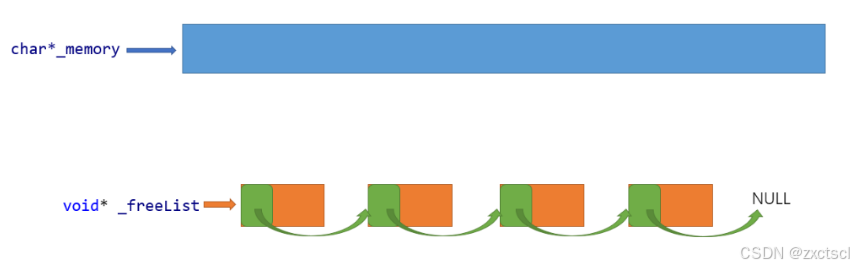
在上一次的分享中,做了一个定长内存池,有一个自由链表,它用来管理好切好的小块内存。需要内存的时候首先在自由链表中找,然后头删,释放的内存就头插到自由链表里。
但这里解决的是定长内存池,指定解决某一个大小。
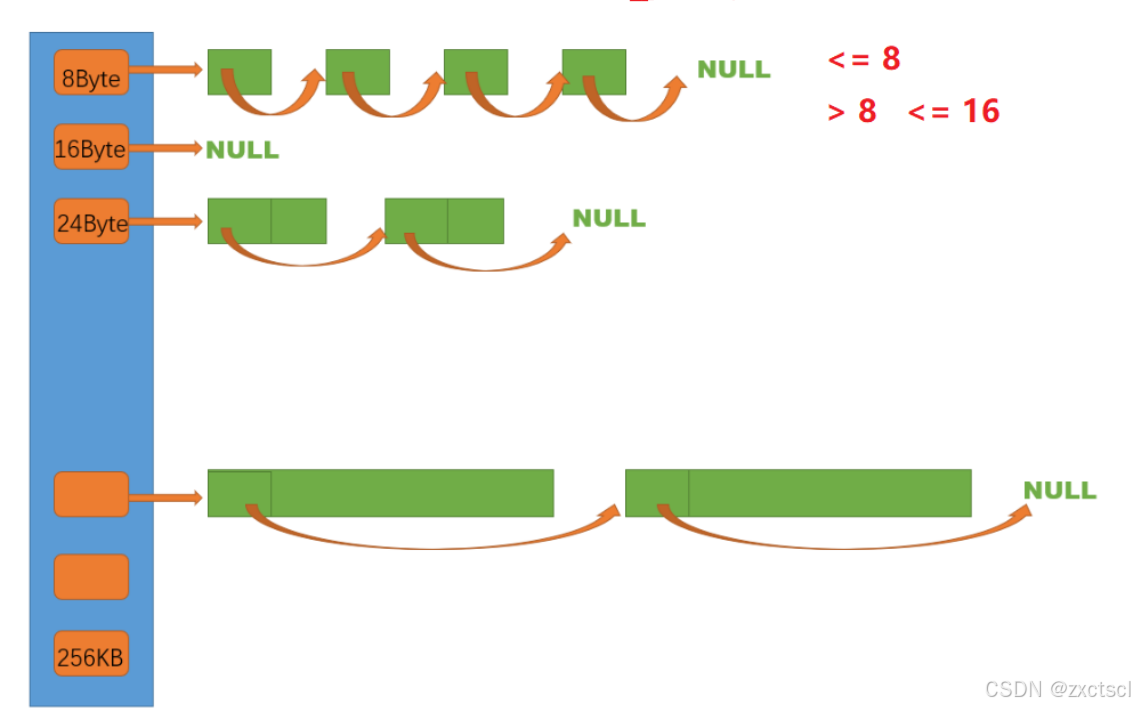
要想解决各种需求下的内存分配,可能是8byte、10byte、16byte等等,这是就考虑利用多个自由链表来实现。
但是如果每一个字节数都挂一个自由链表,就像1字节、2字节这样就麻烦了。此时就用一些平衡的牺牲。
如果需求小于等于8字节的就在8字节这里切,要8-16字节的就在16字节那里切。
如果此时需要5字节,却分配了8字节;需要6字节,却分配了2字节,那么就会导致碎片化的内存用不上,这里的碎片被称为内碎片。会选择一些值去对齐,后面会提到。
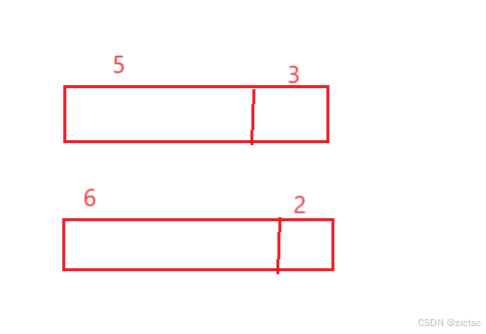
对齐就会产生一些碎片化的内存用不上,利用不上的这些内存就是内碎片。
而外碎片,是一块连续的空间被切成了很多块分出去,只有部分还回来了,它们不连续,导致有足够的空间,却申请不了大块的空间。
2.2 整体框架
thread cache是哈希桶结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表。每个线程都会有一个thread cache对象,这样每个线程在这里获取对象和释放对象时是无锁的。
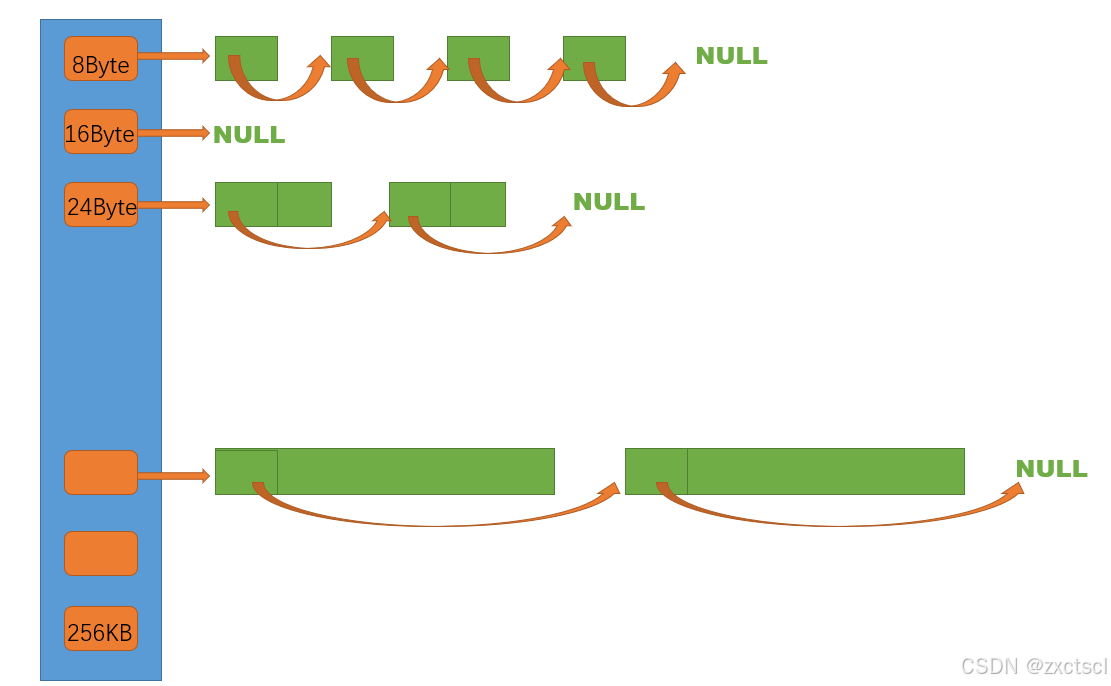
申请内存:
- 当内存申请size<=256KB,先获取到线程本地存储的thread cache对象,计算size映射的哈希桶自由链表下标i。
- 如果自由链表_freeLists[i]中有对象,则直接Pop一个内存对象返回。
- 如果_freeLists[i]中没有对象时,则批量从central cache中获取一定数量的对象,插入到自由链表并返回一个对象。
释放内存:
- 当释放内存小于256k时将内存释放回thread cache,计算size映射自由链表桶位置i,将对象Push到_freeLists[i]。
- 当链表的长度过长,则回收一部分内存对象到central cache。
2.3 自由链表
用void* Allocate(size_t size);来存不同定长哈希桶自由链表大小。
每个桶下面都挂自由链表,为了方便控制,用一个类去封装一下, 这个类FreeList管理切分好的小对象的自由链表。
这个类里面成员变量只有一个指针用来指向链表,提供简单的头删、头插接口。
头插:
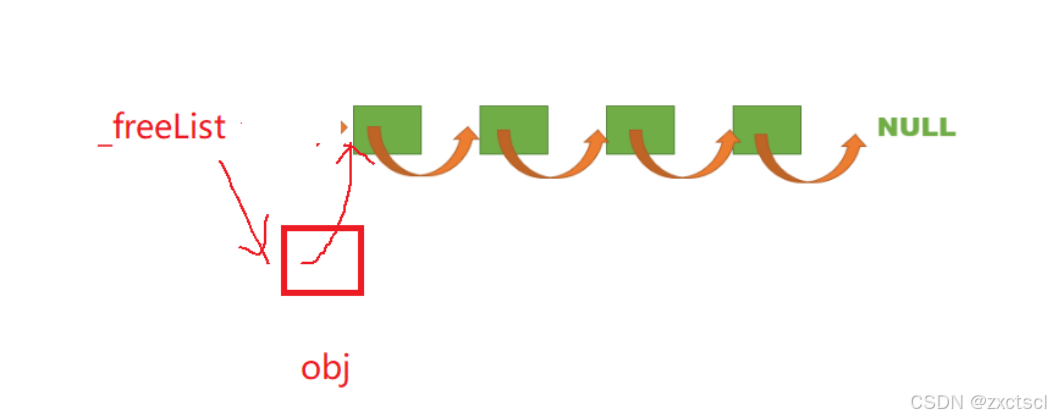
void Push(void* obj){assert(obj);*(void**)obj = _freeList;_freeList = obj;}
再提供一个公共函数NextObj(),给一个对象去取这个对象头上的4个字节或者8个字节。
static void*& NextObj(void* obj)
{return *(void**)obj;
}
头删:
取它头上的4个或者8个字节指向下一个
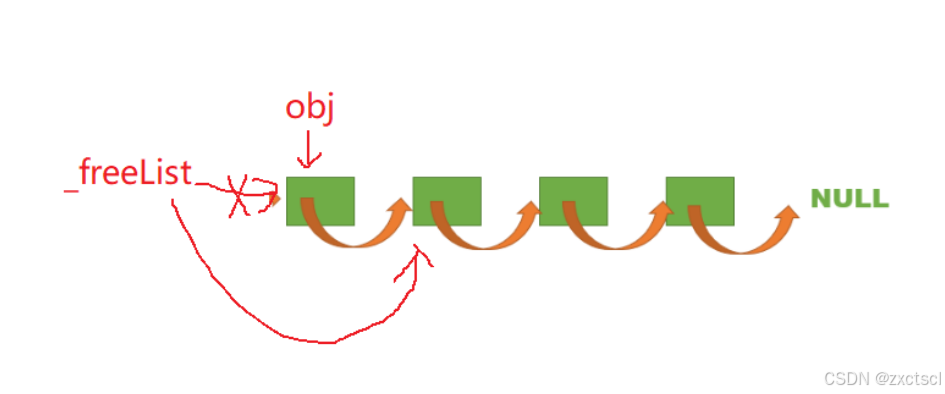
void* Pop(){assert(_freeList);// 头删void* obj = _freeList;_freeList = NextObj(obj);return obj;}
static void*& NextObj(void* obj)
{return *(void**)obj;
}class FreeList
{
public:void Push(void* obj){assert(obj);// 头插//*(void**)obj = _freeList;NextObj(obj) = _freeList;_freeList = obj;}void* Pop(){assert(_freeList);// 头删void* obj = _freeList;_freeList = NextObj(obj);return obj;}bool Empty(){return _freeList == nullptr;}
private:void* _freeList = nullptr;
};
2.4 thread cache哈希桶的对齐规则
给一个定长内存池,该切多大一个内存块分配呢?
就得制定一定的规则。
用静态成员变量来记录最大的内存大小。
static const size_t MAX_BYTES = 256 * 1024;
此时在thread cache设计中,它哈希桶的size不能大于MAX_BYTES。
assert(size <= MAX_BYTES);
那么映射对应对象的桶怎么选择?这里就有一个对齐规则,计算一个申请这个空间大小的内存,该对应哪一个哈希桶。
此时用一个类SizeClass专门来管理这个映射规则:如果所有的都以8字节来对齐,1-8映射8,9-16对应第二个桶,17-24对应第三个桶一直这样分配,此时256*1024=262144都以8字节平分,就除8,就得建32768个自由链表个桶,就很多。

此时就给了一个简化的规则:
整体控制在最多10%左右的内碎片浪费:
[1,128] 8byte对齐 freelist[0,16)[128+1,1024] 16byte对齐 freelist[16,72)[1024+1,8*1024] 128byte对齐 freelist[72,128)[8*1024+1,64*1024] 1024byte对齐 freelist[128,184)[64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)
框架就是:
size_t RoundUp(size_t size){if (size <= 128){}else if (size <= 1024){}else if (size <= 8 * 1024){}else if (size <= 64 * 1024){}else if (size <= 256 * 1024){}else{assert(false);return -1;}}
怎么去算对齐呢?
此时给一个子函数size_t _RoundUp(),用来算对齐数。
如果size模8等于0就不需要处理,对齐的就是8的倍数;如果不等于0就得用(size/8+1)*8,这时候得出来的就是8的倍数。
通用就是这样:
size_t _RoundUp(size_t size, size_t alignNum){size_t alignSize;if (size % alignNum != 0){alignSize = (size / alignNum + 1)*alignNum;}else{alignSize = size;}return alignSize;专业给出的是,用8字节来计算一下,8+8-1=15,再7去翻,7二进制就是000111,~7就是111000,再用15&~7,此时低三位无论是什么都与000,15就是001111,001111&111000就是001000,就是8
static inline size_t _RoundUp(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}
此时对齐规则完整就是:
static inline size_t _RoundUp(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}static inline size_t RoundUp(size_t size){if (size <= 128){return _RoundUp(size, 8);}else if (size <= 1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8 * 1024);}else{assert(false);return -1;}}
计算映射的哪一个自由链表桶,求他对应的下标:
size_t _Index(size_t bytes, size_t alignNum){if (bytes % alignNum == 0){return bytes / alignNum - 1;}else{return bytes / alignNum;}}专业的计算映射的哪一个自由链表桶,如果是1-8之间,那么就整体加上一个8-1=7,此时就变到8-15,然后再右移3位,相当于除8,最后再减1就算出它下标。
static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}// 计算映射的哪一个自由链表桶static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);// 每个区间有多少个链static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128) {return _Index(bytes, 3);}else if (bytes <= 1024) {return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024) {return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024) {return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= 256 * 1024) {return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else {assert(false);}return -1;}2.5 ThreadCache类的设计
ThreadCache类的成员变量是一个存储208个自由链表的数组,成员函数包括申请内存对象,释放内存对象和从中心缓存获取对象。
总的哈希桶就有208个,用一个静态const成员来记录:
static const size_t NFREELIST = 208;
class ThreadCache
{
public:// 申请和释放内存对象void* Allocate(size_t size);void Deallocate(void* ptr, size_t size);// 从中心缓存获取对象void* FetchFromCentralCache(size_t index, size_t size);
private:FreeList _freeLists[NFREELIST];
};
2.5.1 Allocate
有了对齐规则之后,申请内存大小就比较容易。
此时空间,每一个ThreadCache都有一个哈希映射的自由链表,如果这个链表不为空,就弄一个出去。
如果这个自由链表下面对应的没有空的,就找下一层中心缓存去获取对象,获取alignSize大小对象。
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}
2.5.2 Deallocate
释放内存对象,释放后的内存对象,找对映射的自由链表桶,将对象插入进入。
void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);// 找对映射的自由链表桶,对象插入进入size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);
}
2.6 无锁访问
TLS–thread local storage:
linux gcc下 tls
// TLS thread local storage
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;通过静态的TLS 每个线程无锁的获取自己的专属的ThreadCache对象
如果pTLSThreadCache 为空,申请一个ThreadCache,获取这个对象内存
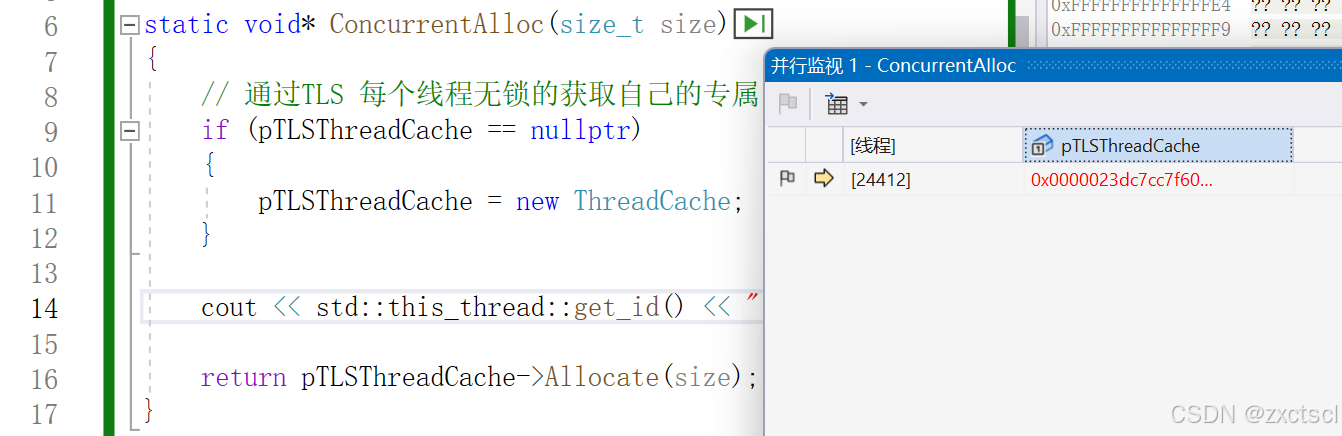
std::this_thread::get_id()可以获取pTLSThreadCache线程号
static void* ConcurrentAlloc(size_t size)
{// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);
}释放ThreadCache,断言一下是否为空,不为空就调用Deallocate(),而Deallocate()要有释放内存大小
static void ConcurrentFree(void* ptr, size_t size)
{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);
}
2.7 测试TLS
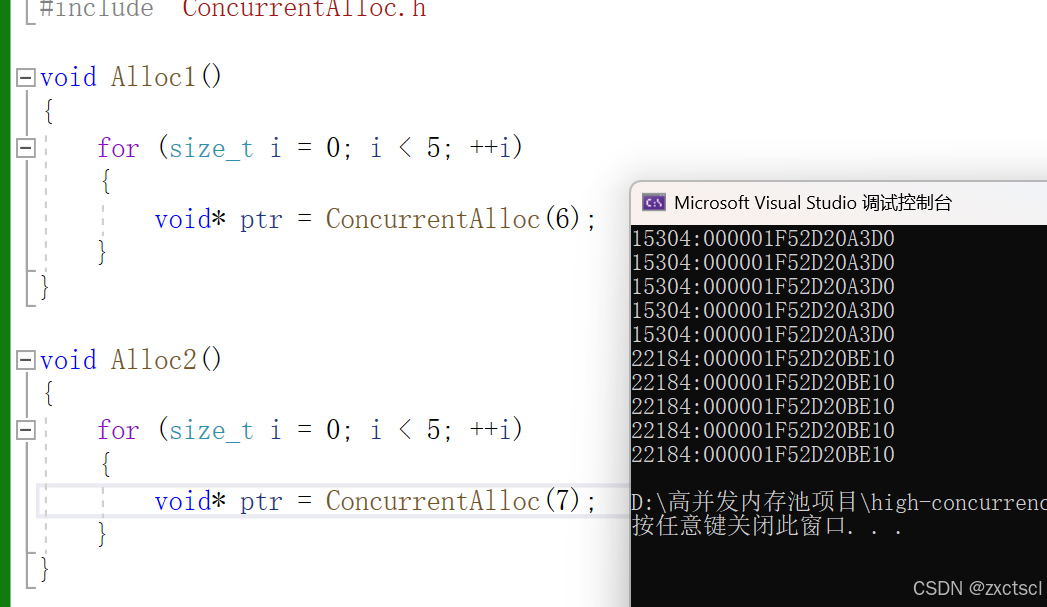
用C++11里面提供的线程相关的,在构造的时候给运行对象和可变参数。
创建多线程场景,申请字节
void Alloc1()
{for (size_t i = 0; i < 5; ++i){void* ptr = ConcurrentAlloc(6);}
}void Alloc2()
{for (size_t i = 0; i < 5; ++i){void* ptr = ConcurrentAlloc(7);}
}void TLSTest()
{std::thread t1(Alloc1);//创建一个线程t1.join();std::thread t2(Alloc2);t2.join();
}int main()
{TLSTest();return 0;
}
并行监视:

3. 附代码
3.1 Common.h
#pragma once#include <iostream>
#include <vector>
#include <thread>
#include <time.h>
#include <assert.h>
using std::cout;
using std::endl;static const size_t MAX_BYTES = 256 * 1024;
static const size_t NFREELIST = 208;static void*& NextObj(void* obj)
{return *(void**)obj;
}// 管理切分好的小对象的自由链表
class FreeList
{
public:void Push(void* obj){assert(obj);// 头插//*(void**)obj = _freeList;NextObj(obj) = _freeList;_freeList = obj;}void* Pop(){assert(_freeList);// 头删void* obj = _freeList;_freeList = NextObj(obj);return obj;}bool Empty(){return _freeList == nullptr;}
private:void* _freeList = nullptr;
};// 计算对象大小的对齐映射规则
class SizeClass
{
public:// 整体控制在最多10%左右的内碎片浪费// [1,128] 8byte对齐 freelist[0,16)// [128+1,1024] 16byte对齐 freelist[16,72)// [1024+1,8*1024] 128byte对齐 freelist[72,128)// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)/*size_t _RoundUp(size_t size, size_t alignNum){size_t alignSize;if (size % alignNum != 0){alignSize = (size / alignNum + 1)*alignNum;}else{alignSize = size;}return alignSize;}*/// 1-8 static inline size_t _RoundUp(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}static inline size_t RoundUp(size_t size){if (size <= 128){return _RoundUp(size, 8);}else if (size <= 1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8 * 1024);}else{assert(false);return -1;}}/*size_t _Index(size_t bytes, size_t alignNum){if (bytes % alignNum == 0){return bytes / alignNum - 1;}else{return bytes / alignNum;}}*/// 1 + 7 8// 2 9// ...// 8 15// 9 + 7 16// 10// ...// 16 23static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}// 计算映射的哪一个自由链表桶static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);// 每个区间有多少个链static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128) {return _Index(bytes, 3);}else if (bytes <= 1024) {return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024) {return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024) {return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= 256 * 1024) {return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else {assert(false);}return -1;}};
3.2 ObjectPool.h
#include "Common.h"#ifdef _WIN32
#include<windows.h>
#else
//
#endif// 定长内存池
//template<size_t N>
//class ObjectPool
//{};// 直接去堆上按页申请空间
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else// linux下brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}template<class T>
class ObjectPool
{
public:T* New(){T* obj = nullptr;// 优先把还回来内存块对象,再次重复利用if (_freeList){void* next = *((void**)_freeList);obj = (T*)_freeList;_freeList = next;}else{// 剩余内存不够一个对象大小时,则重新开大块空间if (_remainBytes < sizeof(T)){_remainBytes = 128 * 1024;//_memory = (char*)malloc(_remainBytes);_memory = (char*)SystemAlloc(_remainBytes >> 13);if (_memory == nullptr){throw std::bad_alloc();}}obj = (T*)_memory;size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_memory += objSize;_remainBytes -= objSize;}// 定位new,显示调用T的构造函数初始化new(obj)T;return obj;}void Delete(T* obj){// 显示调用析构函数清理对象obj->~T();// 头插*(void**)obj = _freeList;_freeList = obj;}private:char* _memory = nullptr; // 指向大块内存的指针size_t _remainBytes = 0; // 大块内存在切分过程中剩余字节数void* _freeList = nullptr; // 还回来过程中链接的自由链表的头指针
};struct TreeNode
{int _val;TreeNode* _left;TreeNode* _right;TreeNode():_val(0), _left(nullptr), _right(nullptr){}
};void TestObjectPool()
{// 申请释放的轮次const size_t Rounds = 5;// 每轮申请释放多少次const size_t N = 100000;std::vector<TreeNode*> v1;v1.reserve(N);size_t begin1 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v1.push_back(new TreeNode);}for (int i = 0; i < N; ++i){delete v1[i];}v1.clear();}size_t end1 = clock();std::vector<TreeNode*> v2;v2.reserve(N);ObjectPool<TreeNode> TNPool;size_t begin2 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v2.push_back(TNPool.New());}for (int i = 0; i < N; ++i){TNPool.Delete(v2[i]);}v2.clear();}size_t end2 = clock();cout << "new cost time:" << end1 - begin1 << endl;cout << "object pool cost time:" << end2 - begin2 << endl;
}
3.3 ThreadCache.h
#pragma once#include "Common.h"class ThreadCache
{
public:// 申请和释放内存对象void* Allocate(size_t size);void Deallocate(void* ptr, size_t size);// 从中心缓存获取对象void* FetchFromCentralCache(size_t index, size_t size);
private:FreeList _freeLists[NFREELIST];
};// TLS thread local storage
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;3.4 ConcurrentAlloc.h
#pragma once#include "Common.h"
#include "ThreadCache.h"static void* ConcurrentAlloc(size_t size)
{// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);
}static void ConcurrentFree(void* ptr, size_t size)
{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);
}3.5 ThreadCache.cpp
#include "ThreadCache.h"void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{// ...return nullptr;
}void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);// 找对映射的自由链表桶,对象插入进入size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);
}
3.6 test.cpp
#include "ObjectPool.h"
#include "ConcurrentAlloc.h"void Alloc1()
{for (size_t i = 0; i < 5; ++i){void* ptr = ConcurrentAlloc(6);}
}void Alloc2()
{for (size_t i = 0; i < 5; ++i){void* ptr = ConcurrentAlloc(7);}
}void TLSTest()
{std::thread t1(Alloc1);t1.join();std::thread t2(Alloc2);t2.join();
}int main()
{//TestObjectPool();TLSTest();return 0;
}
有问题请指出,大家一起进步!!!
相关文章:

【高并发内存池】从零到一的项目之高并发内存池整体框架设计及thread cache设计
个人主页 : zxctscl 专栏 【C】、 【C语言】、 【Linux】、 【数据结构】、 【算法】 如有转载请先通知 文章目录 前言1. 高并发内存池整体框架设计2. 高并发内存池--thread cache2.1 定长内存池的问题2.2 整体框架2.3 自由链表2.4 thread cache哈希桶的对齐规则2.5…...

电气动调节单座V型球阀带阀杆节流套沟槽孔板的作用-耀圣
电气动调节单座V球阀杆节流套是阀门中的一个重要组件,主要用于调节和控制流体介质的流量、压力或流速,同时兼具导向、密封和稳定阀杆运动降低流速减少冲刷的作用。以下是其具体功能和应用场景的详细说明: 1. 节流与流量控制** 作用原理**&am…...

vscode使用笔记
文章目录 安装快捷键 vscode是前端开发的一款利器。 安装 快捷键 ctrlp # 查找文件(和idea的双击shift不一样) ctrlshiftf # 搜索内容...

基于 SpringAI 整合 DeepSeek 模型实现 AI 聊天对话
目录 1、Ollama 的下载配置 与 DeepSeek 的本地部署流程 1.1 下载安装 Ollama 1.2 搜索模型并进行本地部署 2、基于 SpringAI 调用 Ollama 模型 2.1 基于OpenAI 的接口规范(其他模型基本遵循) 2.2 在 IDEA 中进行创建 SpringAI 项目并调用 DS 模型 3、基…...

Idea创建项目的搭建方式
目录 一、普通Java项目 二、普通JavaWeb项目 三、maven的JavaWeb项目 四、maven的Java项目 一、普通Java项目 1. 点击 Create New Project 2. 选择Java项目,选择JDK,点击Next 3. 输入项目名称(驼峰式命名法),可选…...

【MATLAB第115期】基于MATLAB的多元时间序列的ARIMAX的预测模型
【MATLAB第115期】基于MATLAB的多元时间序列的ARIMAX的预测模型 一、简介 ARIMAX(Autoregressive Integrated Moving Average with eXogenous inputs)模型是一种结合自回归(AR)、差分(I)、移动平均&a…...

【以太网安全】——防护高级特性配置总结
目前网络中以太网技术的应用非常广泛、然后、各种网络攻击的纯在(例如针对ARP DHCP 等攻击)不仅造成了网络合法用户无法正常访问网络资源、而且对网络信息安全构成严重威胁、以下配置是对局域网安全配置命令做详解 主要的安全威胁 MAC攻击:泛洪、欺骗 …...

微信小程序 van-dropdown-menu
点击其他按钮,关闭van-dropdown-menu下拉框 DropdownMenu 引入页面使用index.wxmlindex.scssindex.ts(重点)index.ts(全部) DropdownMenu 引入 在app.json或index.json中引入组件 "usingComponents": {"van-dropdown-menu": "vant/weapp…...

再见 Smartdaili,你好 Decodo!
我们将翻开新的篇章,推出新的名称以及更好的代理和刮擦解决方案。了解我们如何帮助全球用户构建、测试和扩展他们的公共网络数据项目。 Smartproxy,即后来的Smartdaili,由一个行业专业人士和企业家团队于2018年创立,其使命是创建一…...
 时间内找到最近的词对)
海量文本中的词语距离:在 O(n) 时间内找到最近的词对
想象一个巨大的日志文件、一部鸿篇巨著或者网络爬虫抓取的数据——它们可能达到 TB 级别。现在,假设你需要找出两个特定的词(比如 词语1 和 词语2)在这段庞大文本中出现时,彼此“靠得最近”的距离是多少。 挑战: …...

TextCNN 模型文本分类实战:深度学习在自然语言处理中的应用
在自然语言处理(NLP)领域,文本分类是研究最多且应用最广泛的任务之一。从情感分析到主题识别,文本分类技术在众多场景中都发挥着重要作用。最近,我参与了一次基于 TextCNN 模型的文本分类实验,从数据准备到…...

前台调用接口的方式及速率对比
一、引言 在现代 Web 开发中,前台与后台的数据交互至关重要,而调用接口是实现这一交互的关键手段。不同的接口调用方式在速率上可能存在差异,这会影响用户体验和应用性能。本文将详细介绍几种常见的前台调用接口方式,并对它们的速…...

高级java每日一道面试题-2025年4月21日-基础篇[反射篇]-如何使用反射获取一个类的所有方法?
如果有遗漏,评论区告诉我进行补充 面试官: 如何使用反射获取一个类的所有方法? 我回答: 在Java中,反射是一种强大的机制,允许程序在运行时检查或“反射”自身,从而动态地操作类、字段、方法和构造函数等。这在需要动态调用方法…...

tomcat集成redis实现共享session
中间件:Tomcat、Redis、Nginx jar包要和tomcat相匹配 jar包:commons-pool2-2.2.jar、jedis-2.5.2.jar、tomcat-redis-session-manage-tomcat7.jar 配置Tomcat /conf/context.xml <?xml version1.0 encodingutf-8?> <!--Licensed to the A…...

2.6 递归
递归 特性: >.一递一归 >.终止条件 一般为:0 1 -1 #测试函数的返回值为函数 def test_recursion():return test_recursion() print(test_recursion()) RecursionError: maximum recursion depth exceeded #案例:计算 …...

鸿蒙应用开发:如何修改APP名称与APP的图标
如何修改APP的名称? 修改APP的名称需要修改entry/src/main/resources/base/element/string.json文件 将EntryAbility_label的value修改为“需要修改成的名字”。 文件目录: 代码修改: {"string": [{"name": "modu…...

AI 模型在前端应用中的典型使用场景和限制
典型使用场景 1. 智能表单处理 // 使用TensorFlow.js实现表单自动填充 import * as tf from tensorflow/tfjs; import { loadGraphModel } from tensorflow/tfjs-converter;async function initFormPredictor() {// 加载预训练的表单理解模型const model await loadGraphMod…...

前端性能优化全攻略:JavaScript 优化、DOM 操作、内存管理、资源压缩与合并、构建工具及性能监控
1 为什么需要性能优化? 1.1 性能优化的核心价值:用户体验与业务指标 性能优化不仅是技术层面的追求,更是直接影响用户体验和业务成败的关键因素。 用户体验(UX): 响应速度:用户期望页面加载时…...

使用 acme.sh 自动更新 SSL 证书的指南
上篇文章讲了一下 如何利用acme.sh来申请ssl,但没有讲3个月到期后 如何续期,续期的时候会碰到什么问题? 1.查看当前的当前签发域名的到期时间 acme.sh list 2.重新申请ssl acme.sh --issue --dns dns_namesilo -d xxx.ai -d *.xxx.ai --dns…...

查看Spring Boot项目所有配置信息的几种方法,包括 Actuator端点、日志输出、代码级获取 等方式,附带详细步骤和示例
以下是查看Spring Boot项目所有配置信息的几种方法,包括 Actuator端点、日志输出、代码级获取 等方式,附带详细步骤和示例: 1. 使用Spring Boot Actuator Actuator是Spring Boot提供的监控和管理工具,包含/configprops端点可查看…...

C++与C
文章目录 C与C命令空间const关键字new/delete表达式引用(重点)概念引用的本质引用的使用场景引用作为函数的参数引用作为函数的返回值 总结 强制转换函数重载extern "C"默认参数 bool类型inline(内联)函数异常处理&…...

Nginx中间件的解析
目录 一、Nginx的核心架构解析 二、Nginx的典型应用场景 三、Nginx的配置优化实践 四、Nginx的常见缺陷与漏洞 一、Nginx的核心架构解析 事件驱动与非阻塞IO模型 Nginx采用基于epoll/kq等系统调用的事件驱动机制,通过异步非阻塞方式处理请求,…...

Ansys Zemax | 在 MATLAB 中使用 ZOS-API 的技巧
附件下载 联系工作人员获取附件 本文将介绍一些在MATLAB中使用 ZOS-API 的技巧,以提高您的工作效率并充分利用 ZOS-API 的功能。 简介 OpticStudio开发了应用程序接口 (API) ,用户可以使用API与不同的脚本环境进行连接和交互。使用API,用…...

js 生成pdf 并上传文件
js 生成pdf 并上传文件 使用 JsPDF html2Canvas 代码直接使用 注意注释 import JsPDF from jspdf import html2Canvas from html2canvas // 上传文件的方法 import { handleUploadImage } from /utils/uploadQuillEditdownPDF() {// 要打印元素的idconst cloneDom document.…...

刷刷刷刷刷sql题
NSSCTF 【SWPUCTF 2021 新生赛】easy_sql 这题虽然之前做过,但为了学习sql,整理一下就再写一次 打开以后是杰哥的界面 注意到html网页标题的名称是 “参数是wllm” 那就传参数值试一试 首先判断注入类型(数字型或字符型) 传1 …...

JavaScript 中的 this 及 this 指向的改变方法
在 JavaScript 的世界里,this是一个既强大又容易让人困惑的概念。它的指向在不同的函数调用场景下会动态变化,而call()、apply()和bind()这三个方法则为我们提供了精确控制this指向的能力。本文将从基础概念出发,结合具体案例,带大…...

安卓模拟器绕过检测全解析:雷电、MuMu、蓝叠、逍遥、夜神与WSA完整指南
安卓模拟器绕过检测全解析:雷电、MuMu、蓝叠、逍遥、夜神与WSA完整指南 模拟器过检测合集雷电mumu蓝叠逍遥夜神WSA 转自风车2025 前言 随着手机游戏和应用的普及,越来越多的用户选择在PC上通过模拟器来运行安卓应用。然而,许多应用和游戏为…...

VSCode中安装GitGraph
前提是先安装git,官方下载地址:Git - Downloads 1. 在VSCode中安装GitGraph插件 2. 文件->首选项->设置,打开设置界面,在设置界面搜索git path 3. 打开配置文件配置git安装路径: 4. 打开源代码管理,…...

StartAI「万物迁移」功能设计师实操教程:模特换衣场景应用
一、功能核心优势解析 智能识别与场景融合 基于迁移学习算法,精准定位服装轮廓(支持复杂材质如蕾丝、镂空设计),自动匹配目标场景的光影方向与色温。 效率革命 传统PS手动换衣需2-3小时,使用万物迁移可压缩至2-5分…...

【RK3588 嵌入式图形编程】-SDL2-扫雷游戏-放置标记
放置标记 文章目录 放置标记1、概述2、更新Globals.h3、放置标记4、渲染标记5、标记计数6、完整代码7、改进建议8、总结在本文中,我们实现标记放置和跟踪以完成的扫雷游戏项目。 1、概述 在我们扫雷游戏文章系列的最后部分中,我们将添加玩家在可疑的地雷位置放置标记的功能。…...
)
【Python】Selenium切换网页的标签页的写法(全!!!)
在使用selenium做网站爬取测试的时候,我们经常会遇到一些需要点击的元素,才能点击到我们想要进入的页面, 于是我们就要模拟 不断地 点点点击 鼠标的样子。 这个时候网页上就会有很多的标签页,你的浏览器网页标签栏 be like: 那…...

Spring Boot多环境配置详解
一、为什么需要多环境配置 在实际项目开发中,我们通常需要将应用部署到不同的环境中,比如: 开发环境(dev) - 开发人员本地开发调试使用测试环境(test) - 测试人员功能测试使用生产环境&#x…...

进阶篇 第 6 篇:时间序列遇见机器学习与深度学习
进阶篇 第 6 篇:时间序列遇见机器学习与深度学习 (图片来源: Tara Winstead on Pexels) 在上一篇中,我们探讨了如何通过精心的特征工程,将时间序列预测问题转化为机器学习可以处理的监督学习任务。我们学习了如何创建滞后特征、滚动统计特征…...
)
RHCE 作业二(密钥登录实验)
1.进入ssh主配置文件恢复配置: 2.vim进入ssh子文件夹查看配置 3.重启服务 /etc/ssh/ key结尾或者.pub结尾的文件全部都是密钥 sshd_confg.d目录是服务的子配置文件 ssh_confg.d目录是客户端你的子配置文件 ~/.ssh/ 是当前用户的配置文件 4.服务器和客户端分别…...

android contentProvider 踩坑日记
写此笔记原因 学习《第一行代码》到第8章节实现provider时踩了一些坑,因此记录下来给后来人和自己一个提示,仅此而已。 包含内容 Sqlite数据库CURD内容provider界面provider项目中书籍管理provider实现逻辑用adb shell确认providercontentResolver接收…...

K8s:概念、特点、核心组件与简单应用
一、引言 在当今云计算和容器技术蓬勃发展的时代,Kubernetes(简称 K8s)已成为容器编排领域的事实标准。它为管理容器化应用提供了高效、可靠的解决方案,极大地简化了应用的部署、扩展和运维过程。无论是小型初创公司还是大型企业…...

基于表面肌电信号sEMG的手势识别——以Ninapro DB1数据集使用CNN网络识别为例
完整代码获取 评论区或者私信留邮箱 接论文辅导!中文核心辅导!SCI三四区辅导! 可接模型改进 任务描述 表面肌电信号( sEMG ) 是一种生物电信号,存在于肌肉神经。 当大脑下达肌肉动作指令,肌肉会产生控制信号ÿ…...

黑盒测试——等价类划分法实验
任务: 设某程序有两个输入:整数x1和整数x2,计算Yf(x1,x2)。x1和x2的取值范围为1< x1<500,1< x2<500。当x1在[1,200) 取值且x2在[1,300] 取值时,Yf(x1,x2) x1x2;当x1在[200,500] 取值且x2在[1,300] 取值时&…...

深度学习4月22笔记
1、过拟合与欠拟合 在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。 1. 概念认知 …...

【MySQL数据库入门到精通-03 数据类型及案列】
文章目录 一、三类数据类型二、数值类型三、字符串类型四、日期时间类型五、日期时间类型 一、三类数据类型 MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。 二、数值类型 比如: 1). 年龄字段 – 不会出现负数…...

【机器学习】决策树算法中的 “黄金指标”:基尼系数深度剖析
一、基尼系数的基本概念 基尼系数(Gini Impurity)在决策树分类算法中,是用于衡量数据纯度的重要指标,与信息熵有着相似的功能。在样本集合里,基尼系数代表随机选取一个样本时,该样本被分错的概率 。假设一…...

植被参数遥感反演技术革命!AI+Python支持向量机/随机森林/神经网络/CNN/LSTM/迁移学习在植被参数反演中的实战应用与优化
在全球气候变化与生态环境监测的重要需求下,植被参数遥感反演作为定量评估植被生理状态、结构特征及生态功能的核心技术,正面临诸多挑战。随着遥感技术的发展,数据复杂度不断提升,模型精度的要求也越来越高。同时,多源…...

【AI】SpringAI 第四弹:接入本地大模型 Ollama
Ollama 是一个开源的大型语言模型服务工具。它的主要作用是帮助用户快速在本地运行大模型, 简化了在 Docker 容器内部署和管理大语言模型(LLM)的过程。 1. 确保Ollama 已经启动 # 查看帮助文档 ollama -h# 自动下载并启动 ollama run deeps…...

C# MP3 伴奏
使用建议: 参数调节指南: 低频人声残留:降低CenterFrequency(800-1500Hz) 高频人声残留:提高CenterFrequency(2500-3500Hz) 消除力度不足:提高EliminationStrength(0.9-1.0) 伴奏失真:降低EliminationSt…...

【springsecurity oauth2授权中心】将硬编码的参数提出来放到 application.yml 里 P3
在application.yml里添加配置 application.yml oauth2:client:id: clientsecret: secretauthentication-method: client_secret_basicgrant-types: authorization_code,refresh_tokenredirect-uris:- http://localhost:8081/login/oauth2/code/client- http://localhost:8081…...

【Ansible】批量管理 Windows自动化运维
一,前期准备 1,控制端(Linux)的要求 Ansible可以在安装了Python 2(2.7版)或Python 3(3.5及更高版本)的任何机器上运行。控制端计算机不支持Windows。 2,客户端&#x…...

AES-128、AES-192、AES-256 简介
AES(Advanced Encryption Standard) 是一种广泛使用的对称加密算法,由美国国家标准与技术研究院(NIST)于2001年正式采纳,用于替代旧的 DES 和 3DES。AES 基于 Rijndael 算法,支持 128 位、192 位…...

osxcross 搭建 macOS 交叉编译环境
1. osxcross 搭建 macOS 交叉编译环境 1. osxcross 搭建 macOS 交叉编译环境 1.1. 安装依赖1.2. 安装 osxcross 及 macOS SDK 1.2.1. 可能错误 1.3. 编译 cmake 类工程1.4. 编译 configure 类工程1.5. 单文件编译及其他环境编译1.6. 打包成 docker 镜像1.7. 使用 docker 编译 …...

联通余额查询接口
接口名称 1) 请求地址 https://ucbss.10010.cn/npfweb/NpfWeb/Mustpayment/getMustpayment?number13112345586&province051&commonBean.phoneNo13112345586&channelType101https://ucbss.10010.cn/npfweb/NpfWeb/Mustpayment/getMustpayment?number13112345586&…...

Python 设计模式:桥接模式
1. 什么是桥接模式? 桥接模式是一种结构型设计模式,它通过将抽象部分与其实现部分分离,使得两者可以独立变化。桥接模式的核心思想是将抽象和实现解耦,从而提高系统的灵活性和可扩展性。 桥接模式的核心思想是将一个类的接口与其…...