【动手学强化学习】番外8-IPPO应用框架学习与复现
文章目录
- 一、待解决问题
- 1.1 问题描述
- 1.2 解决方法
- 二、方法详述
- 2.1 必要说明
- (1)MAPPO 与 IPPO 算法的区别在于什么地方?
- (2)IPPO 算法应用框架主要参考来源
- 2.2 应用步骤
- 2.2.1 搭建基础环境
- 2.2.2 IPPO 算法实例复现
- (1)源码
- (2)Combat环境补充
- (3)代码结果
- 2.2.3 代码框架理解
- 三、疑问
- 四、总结
一、待解决问题
1.1 问题描述
在Combat环境中应用了MAPPO算法,在同样环境中学习并复现IPPO算法。
1.2 解决方法
(1)搭建基础环境。
(2)IPPO 算法实例复现。
(3)代码框架理解
二、方法详述
2.1 必要说明
(1)MAPPO 与 IPPO 算法的区别在于什么地方?
源文献链接:The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games
源文献原文如下:
为清楚起见,我们将具有 集中价值函数 输入的 PPO 称为 MAPPO (Multi-Agent PPO)。
将 策略和价值函数均具有本地输入 的 PPO 称为 IPPO (Independent PPO)。
总结而言,就是critic网络不再是集中式的了。
因此,IPPO 相对于 MAPPO 可能会更加占用计算、存储资源,毕竟每个agent都会拥有各自的critic网络。
(2)IPPO 算法应用框架主要参考来源
其一,《动手学强化学习》-chapter 20
其二,深度强化学习(7)多智能体强化学习IPPO、MADDPG
✅非常感谢大佬的分享!!!
2.2 应用步骤
2.2.1 搭建基础环境
这一步骤直接参考上一篇博客,【动手学强化学习】番外7-MAPPO应用框架2学习与复现
2.2.2 IPPO 算法实例复现
(1)源码
智能体对于policy的使用分为separated policy与shared policy,即每个agent拥有单独的policy net,所有agent共用一个policy net,二者在源码中都能够使用,对应位置取消注释即可。
与MAPPO的不同就在于,每个agent拥有单独的value net。
import torch
import torch.nn.functional as F
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import sys
from ma_gym.envs.combat.combat import Combat# PPO算法class PolicyNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)self.fc3 = torch.nn.Linear(hidden_dim, action_dim)def forward(self, x):x = F.relu(self.fc2(F.relu(self.fc1(x))))return F.softmax(self.fc3(x), dim=1)class ValueNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim):super(ValueNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)self.fc3 = torch.nn.Linear(hidden_dim, 1)def forward(self, x):x = F.relu(self.fc2(F.relu(self.fc1(x))))return self.fc3(x)def compute_advantage(gamma, lmbda, td_delta):td_delta = td_delta.detach().numpy()advantage_list = []advantage = 0.0for delta in td_delta[::-1]:advantage = gamma * lmbda * advantage + deltaadvantage_list.append(advantage)advantage_list.reverse()return torch.tensor(advantage_list, dtype=torch.float)# PPO,采用截断方式
class PPO:def __init__(self, state_dim, hidden_dim, action_dim,actor_lr, critic_lr, lmbda, eps, gamma, device):self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)self.critic = ValueNet(state_dim, hidden_dim).to(device)self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), critic_lr)self.gamma = gammaself.lmbda = lmbdaself.eps = eps # PPO中截断范围的参数self.device = devicedef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(self.device)probs = self.actor(state)action_dict = torch.distributions.Categorical(probs)action = action_dict.sample()return action.item()def update(self, transition_dict):states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)td_target = rewards + self.gamma * \self.critic(next_states) * (1 - dones)td_delta = td_target - self.critic(states)advantage = compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)old_log_probs = torch.log(self.actor(states).gather(1, actions)).detach()log_probs = torch.log(self.actor(states).gather(1, actions))ratio = torch.exp(log_probs - old_log_probs)surr1 = ratio * advantagesurr2 = torch.clamp(ratio, 1 - self.eps, 1 +self.eps) * advantage # 截断action_loss = torch.mean(-torch.min(surr1, surr2)) # PPO损失函数critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()action_loss.backward()critic_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()def show_lineplot(data, name):# 生成 x 轴的索引x = list(range(100))# 创建图形和坐标轴plt.figure(figsize=(20, 6))# 绘制折线图plt.plot(x, data, label=name,marker='o', linestyle='-', linewidth=2)# 添加标题和标签plt.title(name)plt.xlabel('Index')plt.ylabel('Value')plt.legend()# 显示图形plt.grid(True)plt.show()actor_lr = 3e-4
critic_lr = 1e-3
epochs = 10
episode_per_epoch = 1000
hidden_dim = 64
gamma = 0.99
lmbda = 0.97
eps = 0.2
team_size = 2 # 每个team里agent的数量
grid_size = (15, 15) # 二维空间的大小
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")# 创建环境
env = Combat(grid_shape=grid_size, n_agents=team_size, n_opponents=team_size)
state_dim = env.observation_space[0].shape[0]
action_dim = env.action_space[0].n# =============================================================================
# # 创建智能体(不参数共享:separated policy)
# agent1 = PPO(
# state_dim, hidden_dim, action_dim,
# actor_lr, critic_lr, lmbda, eps, gamma, device
# )
# agent2 = PPO(
# state_dim, hidden_dim, action_dim,
# actor_lr, critic_lr, lmbda, eps, gamma, device
# )
# =============================================================================# 创建智能体(参数共享:shared policy)
agent = PPO(state_dim, hidden_dim, action_dim,actor_lr, critic_lr, lmbda, eps, gamma, device
)win_list = []for e in range(epochs):with tqdm(total=episode_per_epoch, desc='Epoch %d' % e) as pbar:for episode in range(episode_per_epoch):# Replay buffer for agent1buffer_agent1 = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': []}# Replay buffer for agent2buffer_agent2 = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': []}# 重置环境s = env.reset()terminal = Falsewhile not terminal:# 采取动作(不进行参数共享)# a1 = agent1.take_action(s[0])# a2 = agent2.take_action(s[1])# 采取动作(进行参数共享)a1 = agent.take_action(s[0])a2 = agent.take_action(s[1])next_s, r, done, info = env.step([a1, a2])buffer_agent1['states'].append(s[0])buffer_agent1['actions'].append(a1)buffer_agent1['next_states'].append(next_s[0])# 如果获胜,获得100的奖励,否则获得0.1惩罚buffer_agent1['rewards'].append(r[0] + 100 if info['win'] else r[0] - 0.1)buffer_agent1['dones'].append(False)buffer_agent2['states'].append(s[1])buffer_agent2['actions'].append(a2)buffer_agent2['next_states'].append(next_s[1])buffer_agent2['rewards'].append(r[1] + 100 if info['win'] else r[1] - 0.1)buffer_agent2['dones'].append(False)s = next_s # 转移到下一个状态terminal = all(done)# 更新策略(不进行参数共享)# agent1.update(buffer_agent1)# agent2.update(buffer_agent2)# 更新策略(进行参数共享)agent.update(buffer_agent1)agent.update(buffer_agent2)win_list.append(1 if info['win'] else 0)if (episode + 1) % 100 == 0:pbar.set_postfix({'episode': '%d' % (episode_per_epoch * e + episode + 1),'winner prob': '%.3f' % np.mean(win_list[-100:]),'win count': '%d' % win_list[-100:].count(1)})pbar.update(1)win_array = np.array(win_list)
# 每100条轨迹取一次平均
win_array = np.mean(win_array.reshape(-1, 100), axis=1)# 创建 episode_list,每组 100 个回合的累计回合数
episode_list = np.arange(1, len(win_array) + 1) * 100
plt.plot(episode_list, win_array)
plt.xlabel('Episodes')
plt.ylabel('win rate')
plt.title('IPPO on Combat(shared policy)')
plt.show()
(2)Combat环境补充
这里还需要说明的是,由于在奖励设置过程中采用了win(获胜),但是Combat环境中step函数并没有返还该值
buffer_agent1['rewards'].append(r[0] + 100 if info['win'] else r[0] - 0.1)...
win_array = np.array(win_list)
...
因此需要在step()函数中加入对win(获胜)的判断,与return返回值
# 判断是否获胜win = Falseif all(self._agent_dones):if sum([v for k, v in self.opp_health.items()]) == 0:win = Trueelif sum([v for k, v in self.agent_health.items()]) == 0:win = Falseelse:win = None # 平局# 将获胜信息添加到 info 中info = {'health': self.agent_health, 'win': win, 'opp_health': self.opp_health, 'step_count': self._step_count}return self.get_agent_obs(), rewards, self._agent_dones, info
(3)代码结果
左图为separated policy下运行结果,右图为shared policy下运行结果。
明显可以看出,separated policy有着更好的效果,但是代价就是在训练过程中会占用更多的资源。
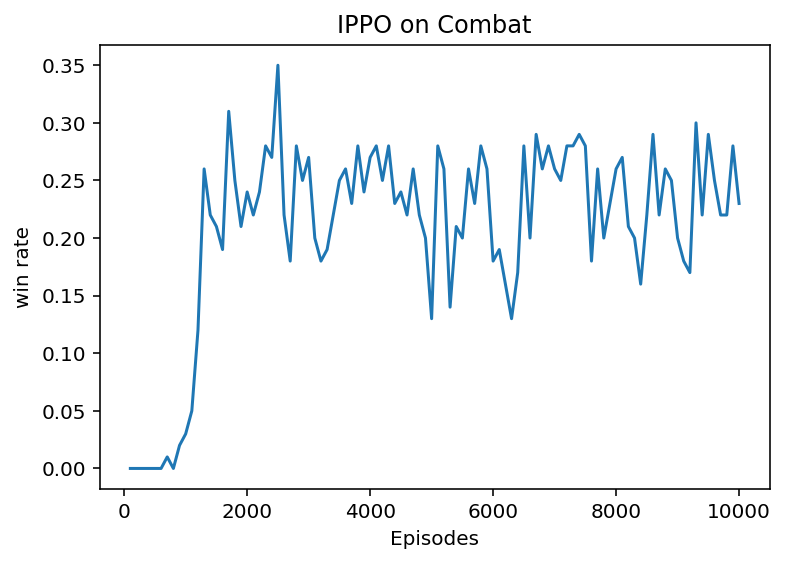
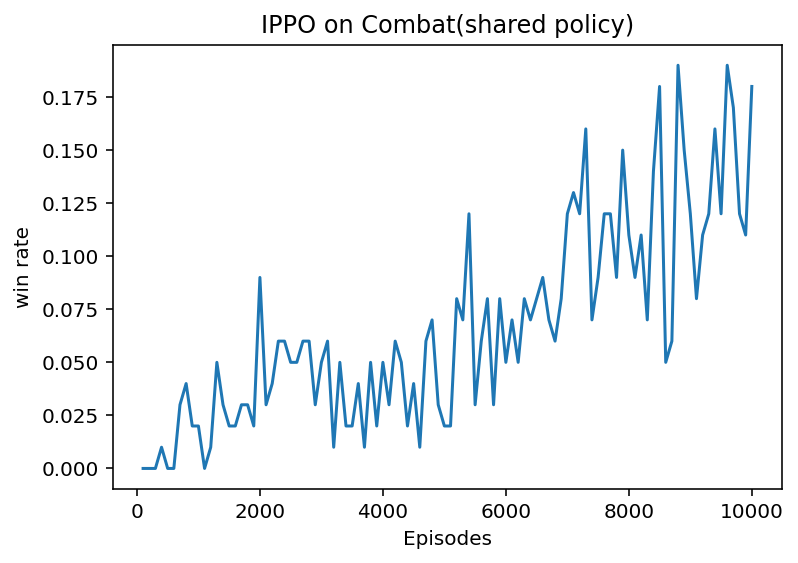
2.2.3 代码框架理解
从2.2.2节源码不难看出,IPPO算法其实就是在PPO算法上改为了多agent的环境,其中policy net,value net的更新原理并没有改变,因此代码框架的理解查看PPO算法原理即可。
参考链接:【动手学强化学习】part8-PPO(Proximal Policy Optimization)近端策略优化算法
三、疑问
- 暂无
四、总结
IPPO算法相对于MAPPO算法会占用更多的资源,如果环境较为简单,可以采用该算法。如果环境比较复杂,建议先采用MAPPO算法进行训练。
相关文章:

【动手学强化学习】番外8-IPPO应用框架学习与复现
文章目录 一、待解决问题1.1 问题描述1.2 解决方法 二、方法详述2.1 必要说明(1)MAPPO 与 IPPO 算法的区别在于什么地方?(2)IPPO 算法应用框架主要参考来源 2.2 应用步骤2.2.1 搭建基础环境2.2.2 IPPO 算法实例复现&am…...
)
C++ 的 输入输出流(I/O Streams)
什么是输入输出流 C 的输入输出操作是通过 流(stream) 机制实现的。 流——就是数据的流动通道,比如: 输入流:从设备(如键盘、文件)读取数据 → 程序 输出流:程序将数据写入设备&…...

Java 安全:如何防止 SQL 注入与 XSS 攻击?
Java 安全:如何防止 SQL 注入与 XSS 攻击? 在 Java 开发领域,安全问题至关重要,而 SQL 注入和 XSS 攻击是两种常见的安全威胁。本文将深入探讨如何有效防止这两种攻击,通过详细代码实例为您呈现解决方案。 一、SQL 注…...

leetcode day36 01背包问题 494
494 目标和 给你一个非负整数数组 nums 和一个整数 target 。 向数组中的每个整数前添加 或 - ,然后串联起所有整数,可以构造一个 表达式 : 例如,nums [2, 1] ,可以在 2 之前添加 ,在 1 之前添加 - &…...

31Calico网络插件的简单使用
环境准备: 1、删除Flannel 2、集群所有node节点拉取所需镜像(具体版本可以依据calico.yaml文件中): docker pull calico/cni:v3.25.0 docker pull calico/node:v3.25.0 docker pull calico/kube-controllers:v3.25.0一、安装Cali…...

进阶篇 第 5 篇:现代预测方法 - Prophet 与机器学习特征工程
进阶篇 第 5 篇:现代预测方法 - Prophet 与机器学习特征工程 (图片来源: ThisIsEngineering RAEng on Pexels) 在前几篇中,我们深入研究了经典的时间序列统计模型,如 ETS 和强大的 SARIMA 家族。它们在理论上成熟且应用广泛,但有…...

实用生活c语言脚本
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <time.h> // 清理临时文件目录 void clean_temp_directory() { const char* temp_dir "/tmp"; // 可自定义需要清理的目录 char command[1024]; …...

从零开始构建微博爬虫与数据分析系统
从零开始构建微博爬虫与数据分析系统 引言 社交媒体平台蕴含着海量的信息和数据,通过对这些数据的收集和分析,我们可以挖掘出有价值的见解。本文将详细介绍如何构建一个完整的微博爬虫和数据分析系统,从数据爬取、清洗、到多维度分析与可视…...

417. 太平洋大西洋水流问题
题目 有一个 m n 的矩形岛屿,与 太平洋 和 大西洋 相邻。 “太平洋” 处于大陆的左边界和上边界,而 “大西洋” 处于大陆的右边界和下边界。 这个岛被分割成一个由若干方形单元格组成的网格。给定一个 m x n 的整数矩阵 heights , heights…...

chili3d调试笔记8 打印零件属性
无效, 返回的是节点不是坐标啥的, 找他的属性 把document和selectednote(空集)传给handleshowproperty方法 怎么获得selectnotes和selectnotes的property值 有selectnotes运行这段就行了 明天再搞...

uniapp Vue2升级到Vue3,并发布到微信小程序的快捷方法
目录 前言:升级项目的两种方式步骤一、新建项目 【选择-默认模版】二、修改-pages.json三、补充-缺少的文件四、修改-Main.js按照 [官方文档-vue2升级vue3迁移指南](https://uniapp.dcloud.net.cn/tutorial/migration-to-vue3.html) 修改 五、升级-uni-ui扩展组件的…...

火山RTC 5 转推CDN 布局合成规则
实时音视频房间,转推CDN,文档: 转推直播--实时音视频-火山引擎 一、转推CDN 0、前提 * 在调用该接口前,你需要在[控制台](https://console.volcengine.com/rtc/workplaceRTC)开启转推直播功能。<br> * 调…...

Mujoco xml < sensor>
< sensor> jointposjointveljointactuatorfrcframequatgyroaccelerometerframeposframelinveltouchobjtype"site" objname"imu" 和site"imu"的区别python中与sensor有关的写法传感器名字索引第几个idid索引传感器名字传感器数量sensor中的…...

示例:spring xml+注解混合配置
以下是一个 Spring XML 注解的混合配置示例,结合了 XML 的基础设施配置(如数据源、事务管理器)和注解的便捷性(如依赖注入、事务声明)。所有业务层代码通过注解简化,但核心配置仍通过 XML 管理。 1. 项目结…...

同样的html标记,不同语言的文本,显示的字体和粗细会不一样吗
同样的 HTML 标记,在不同语言的文本下,显示出来的字体和粗细确实可能会不一样,原因如下: 🌍 不同语言默认字体不同 浏览器字体回退机制 CSS 里写的字体如果当前系统不支持,就会回退到下一个,比如…...

Linux进程6-alarm闹钟定时终止、raise发送信号、abort终止、pause挂起进程验证
目录 1.alarm函数 1.1关键点 1.2单个alarm函数定时 1.3两个alarm函数定时 2.raise函数 2.1核心行为 2.2 raise与 kill 的区别 2.3程序: 3.abort函数 4.pause 函数 4.1 pause简单挂起 4.2父进程挂起,子进程发信号 1.alarm函数 函数原型&…...

SpringCloud组件—Eureka
一.背景 1.问题提出 我们在一个父项目下写了两个子项目,需要两个子项目之间相互调用。我们可以发送HTTP请求来获取我们想要的资源,具体实现的方法有很多,可以用HttpURLConnection、HttpClient、Okhttp、 RestTemplate等。 举个例子&#x…...

类加载器与jvm的内存
1. 类加载器与内存的关系 类加载器的字节码放在方法区(元空间)中,同时类加载器加载类后类的信息(成员变量、成员方法及修饰符等)存放在方法区中。类的信息所占内存的回收要同时满足两个条件:类的实例被回收…...
)
【C++】新手入门指南(下)
文章目录 前言 一、引用 1.引用的概念和定义 2.引用的特性 3.引用的使用 4.const引用 5.指针和引用的关系 二、内联函数 三、nullptr 总结 前言 这篇续上篇的内容新手入门指南(上),继续带大家学习新知识。如果你感兴趣欢迎订购本专栏。 一、…...

el-table中el-input的autofocus无法自动聚焦的解决方案
需求 有一个表格展示了一些进度信息,进度信息可以修改,需要点击进度信息旁边的编辑按钮时,把进度变为输入框且自动聚焦,当鼠标失去焦点时自动请求更新接口。 注:本例以vue2 element UI为例 分析 这个需求看着挺简单…...

vimplus 如何修改语言支持的版本,以及如何跳转路径
vimplus修改语言版本 默认的vimplus支持c的版本是17 如何修改我们需要修改.ycm_extra_conf.py文件,这个文件管理了我们的插件配置 找到 把他修改为你想要的版本 增添路径 把你安装的gcc位置提供给他,默认的目前比较老 这里都是他提前为我们准备的路…...

麒麟V10安装MySQL8.4
1、下载安装包 wget https://cdn.mysql.com//Downloads/MySQL-8.4/mysql-8.4.5-1.el7.x86_64.rpm-bundle.tar2、解压 mkdir -p /opt/mysql tar -xvf mysql-8.4.5-1.el7.x86_64.rpm-bundle.tar -C /opt/mysql3、安装MySQL 3.1、卸载mariadb rpm -qa | grep mariadb rpm -e m…...

Varjo-XR3在UE5中,头显中间有一个方块一直显示
深色方块显示在屏幕中间的焦点区域中 屏幕中间的对焦区域中显示的黑色方块。 黑色方块是一个已知问题。它在 Varjo VRTemplate 中不可见,因为它使用具有推荐 VR 设置的前向渲染方法。 但是,如果你将延迟渲染方法与高级功能(如 Lumen、Nani…...

FastText 模型文本分类实验:从零到一的实战探索
在自然语言处理(NLP)领域,文本分类是一个基础而重要的任务,广泛应用于情感分析、主题识别、垃圾邮件过滤等多个场景。最近,我参与了一次基于 FastText 模型的文本分类实验,从数据预处理到模型构建、训练和评…...

不同经营性道路运输从业资格证申请条件全解析
在道路运输领域,获取相应的从业资格证是合法从事经营性运输工作的关键前提。不同类型的运输业务,如旅客运输、货物运输以及危险货物运输,对从业者有着不同的条件要求。 经营性道路旅客运输驾驶员 驾驶证年限:需取得相应的机动车…...

WHAT - 静态资源缓存穿透
文章目录 1. 动态哈希命名的基本思路2. 具体实现2.1 Vite/Webpack 配置动态哈希2.2 HTML 文件中动态引用手动引用使用 index.html 模板动态插入 2.3 结合 Cache-Control 避免缓存穿透2.4 适用于多环境的动态策略 总结 在多环境部署中,静态资源缓存穿透是一个常见问题…...

11、Refs:直接操控元素——React 19 DOM操作秘籍
一、元素操控的魔法本质 "Refs是巫师与麻瓜世界的连接通道,让开发者能像操控魔杖般精准控制DOM元素!"魔杖工坊的奥利凡德先生轻抚着魔杖,React/Vue的refs能量在杖尖跃动。 ——以神秘事务司的量子纠缠理论为基,揭示DOM…...

crontab 定时备份 mysql 数据库
1、使用 mysqldump 命令备份数据 1.1 备份全部数据库的数据和结构 mysqldump -uroot -p123456 -A > /data/backup/db.sql1.2 备份全部数据库的结构(加 -d 参数) mysqldump -uroot -p123456 -A -d > /data/backup/db.sql1.3 备份全部数据库的数据…...

数据库对象与权限管理-视图与索引管理
一、视图(View)管理 1. 视图的定义与本质 视图(View)是Oracle数据库中的逻辑表,它不直接存储数据,而是通过预定义的SQL查询动态生成结果集。视图的本质可以理解为: 虚拟表:用户可…...

德施曼重磅发布五大突破性技术及多款重磅新品,开启AI智能管家时代
当智能锁拥抱人文关怀,万物有灵便有了具象化的表达。 4月22日,智能锁领军品牌德施曼“万物有灵”2025全球新品发布会在乌镇隆重举行,为智能锁行业带来了AI时代的革新方案。 会上,德施曼创始人/CEO祝志凌重磅发布了五大突破性技术&…...
)
单元测试学习笔记(一)
自动化测试 通过测试工具/编程模拟手动测试步骤,全自动半自动执行测试用例,对比预期输出和实际输出,记录并统计测试结果,减少重复的工作量。 单元测试 针对最小的单元测试,Java中就是一个一个的方法就是一个一个的单…...

Rest Client插件写http文件直接发送请求
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言📌 插件介绍:🚀 安装方式:📚 使用示例:⚙️ 功能亮点: 前言 直接在 VSCode …...
Scaling Laws for Neural Language Models)
LLM 论文精读(一)Scaling Laws for Neural Language Models
这篇文章是2020年发表的一篇LLM领域中非常重要的论文,由OpenAI发布,总结了LLM模型规模与训练数据token之间的比例关系,即我们熟知的 Scaling Laws,允许 通过观察小规模训练实验,提前预测大模型的效果表现,降…...

Spring AOP + Logback + MDC全链路日志追踪
1、背景 由于权限管理和安全规范,服务都部署到云上,只能通过日志系统查看日志。 然而,面对海量的日志数据,如何快速定位关键信息和调用链路是一个巨大的挑战。 2、方案调研 在 Spring Boot 中实现全链路日志追踪,核…...

SVT-AV1编码器初始化函数
一 函数解释 这个函数SVT-AV1编码器初始化的核心函数,负责配置编码器组件,分配资源并启动编码线程,以下时对每一行的详细解释。 函数签名和参数检查 EB_API EbErrorType svt_av1_enc_init(EbComponentType *svt_enc_component) { if (svt_enc…...

Unity 导出Excel表格
1.首先,需要导入EPPlus.dll;(我这里用的是Unity 2017.3.0f3) https://download.csdn.net/download/qq_41603955/90670669 2.代码如下: using UnityEngine; using UnityEditor; using System.IO; using OfficeOpenXm…...

Web前端开发技术——HTML5、CSS3、JavaScript
一、HTML 1.基本结构 <html lang "en"><head><meta charset"UTF-8"><meta name"Keywords" content""><meta name"Description" content""><title>Web网页标题</title&g…...

野外价值观:在真实世界的语言模型互动中发现并分析价值观
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

【华为HCIP | 华为数通工程师】821—多选解析—第十二页
多选727、某台路由器的输出信息如下所示,以下描述正确的有哪些选项? A、路由器Router ID为10.0.1.1 B、路由器Router ID为10.0.2.2。 C、本路由器的接口地址为10.0.12.2。 D、本路由器是DR。 解析:display ospf peer //获取的OSPF邻居信…...

Selenium 在爬取过程中,网络响应被退出的解决方案
我在使用 Selenium 爬取网站的时候,直接get url ,却立马闪退,遇到了获取网络响应直接被退出的问题。 这通常是由于 反爬机制、浏览器检测 或 网络限制 导致的。 以下是 完整排查与解决方案: 1. 检查常见原因 问题类型典型表现可…...

楼宇自控怎样全方位融入建筑领域,为绿色建筑发展添砖加瓦
在全球积极倡导可持续发展的大背景下,绿色建筑已成为建筑领域发展的必然趋势。绿色建筑旨在减少对环境的负面影响,提高能源利用效率,为用户提供健康、舒适的室内环境。而楼宇自控系统作为建筑智能化的核心组成部分,正以其独特的技…...
从零搭建一个完整的TTS系统-第二节-中文转拼音)
语音合成(TTS)从零搭建一个完整的TTS系统-第二节-中文转拼音
一、概述 本节我们进行语音合成前端中的第二步,需要把中文转换为拼音。通过python和c两种语言进行实现,python可以直接调用pypinyin库实现。c实现是本节的重点,首先根据词典进行分词,接着把分词后的词进行词典映射,得到…...
)
基于springboot的停车位管理系统(源码+数据库)
12基于springboot的停车位管理系统:前端 thymeleaf、Jquery、bootstrap,后端 Springboot、Mybatis,系统角色分为:用户、管理员,管理员在管理后台录入车位信息,用户在线查找车位、预约车位,解决停…...

深入理解 Spring @Configuration 注解
在 Spring 框架中,@Configuration 注解是一个非常重要的工具,它用于定义配置类,这些类可以包含 Bean 定义方法。通过使用 @Configuration 和 @Bean 注解,开发者能够以编程方式创建和管理应用程序上下文中的 Bean。本文将详细介绍 @Configuration 注解的作用、如何使用它以及…...
java)
15.三数之和(LeetCode)java
个人理解: 1.使用双指针做法,首先对数组进行排序 第一重for循环控制第一个数,对数组进行遍历。双指针初始化为lefti1, rigthnums.length-1。然后使用while循环移动双指针寻找合适的数。因为返回的是数,不是下标,数不能…...
任务书)
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(10卷)任务书
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(10卷)任务书 模块A:大数据平台搭建(容器环境)(15分)任务一:Hadoop 伪分布式安装配置任务二:Flume安装…...

Redis—内存淘汰策略
记:全体LRU,ttl LRU,全体LFU,ttl LFU,全体随机,ttl随机,最快过期,不淘汰(八种) Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存&…...

新能源汽车可视化大屏系统毕业设计
以下是一个基于Python和Flask框架的新能源汽车可视化大屏系统后台代码示例。这个系统提供API接口用于前端大屏展示新能源汽车相关数据。 主应用文件 (app.py) python from flask import Flask, jsonify, request from flask_cors import CORS import random from datetime imp…...

02-keil5的配置和使用
一、创建工程 1、在菜单栏”Project”,在弹出的下拉菜单,选择“New uVision Project”。 2、在弹出的对话框,填写工程的名字,例如工程名字为project。 3、为保存的工程,选择对应的芯片。 4、为当前工程,添…...

电脑硬盘丢失怎么找回?解决硬盘数据恢复的2种方法
无论是个人用户还是企业用户来讲,存储在磁盘中的文档、图片、视频、音频等数据都具有相当的价值。但在日常使用过程中,误删操作、病毒攻击、硬件故障等情况都可能造成电脑硬盘突然消失不见数据丢失。面对电脑硬盘丢失这类问题时,采取正确的应…...