从零开始构建微博爬虫与数据分析系统
从零开始构建微博爬虫与数据分析系统
引言
社交媒体平台蕴含着海量的信息和数据,通过对这些数据的收集和分析,我们可以挖掘出有价值的见解。本文将详细介绍如何构建一个完整的微博爬虫和数据分析系统,从数据爬取、清洗、到多维度分析与可视化。
系统架构
整个系统分为两个主要模块:
- 微博爬虫模块:负责通过API获取微博数据并保存
- 数据分析模块:对获取的数据进行清洗和多维度分析
一、微博爬虫实现
1.1 爬虫设计思路
微博的数据爬取主要基于其Ajax接口,通过模拟浏览器请求获取JSON格式数据。主要挑战在于:
- 需要登录凭证(Cookie)才能访问完整内容
- 接口限制和反爬措施
- 数据格式的解析与清洗
1.2 核心代码实现
WeiboCrawler类是爬虫的核心,主要包含以下功能:
class WeiboCrawler:def __init__(self, cookie=None):# 初始化请求头和会话self.headers = {...}if cookie:self.headers['Cookie'] = cookieself.session = requests.Session()self.session.headers.update(self.headers)def get_user_info(self, user_id):# 获取用户基本信息url = f'https://weibo.com/ajax/profile/info?uid={user_id}'# 实现...def get_user_weibos(self, user_id, page=1, count=20):# 获取用户微博列表url = f'https://weibo.com/ajax/statuses/mymblog?uid={user_id}&page={page}&feature=0'# 实现...def crawl_user_weibos(self, user_id, max_pages=None):# 爬取所有微博并返回结果# 实现...
1.3 数据清洗与存储
爬取的原始数据需要进行清洗,主要包括:
- 去除HTML标签和特殊字符
- 提取时间、内容、图片链接等信息
- 识别转发内容并单独处理
清洗后的数据以结构化文本形式存储,便于后续分析:
def format_weibo(self, weibo):# 格式化微博内容为易读格式created_at = datetime.strptime(weibo['created_at'], '%a %b %d %H:%M:%S %z %Y')text = self.clean_text(weibo.get('text', ''))formatted = f"[{created_at.strftime('%Y-%m-%d %H:%M:%S')}]\n{text}\n"# 处理转发内容、图片链接等# ...return formatted
二、数据分析模块
2.1 数据加载与预处理
WeiboAnalyzer类负责从文本文件加载微博数据,并转换为结构化形式:
def load_data(self):# 从文件加载微博数据with open(self.file_path, 'r', encoding='utf-8') as f:lines = f.readlines()# 提取用户信息和微博内容# ...print(f"成功加载 {len(self.weibos)} 条微博")
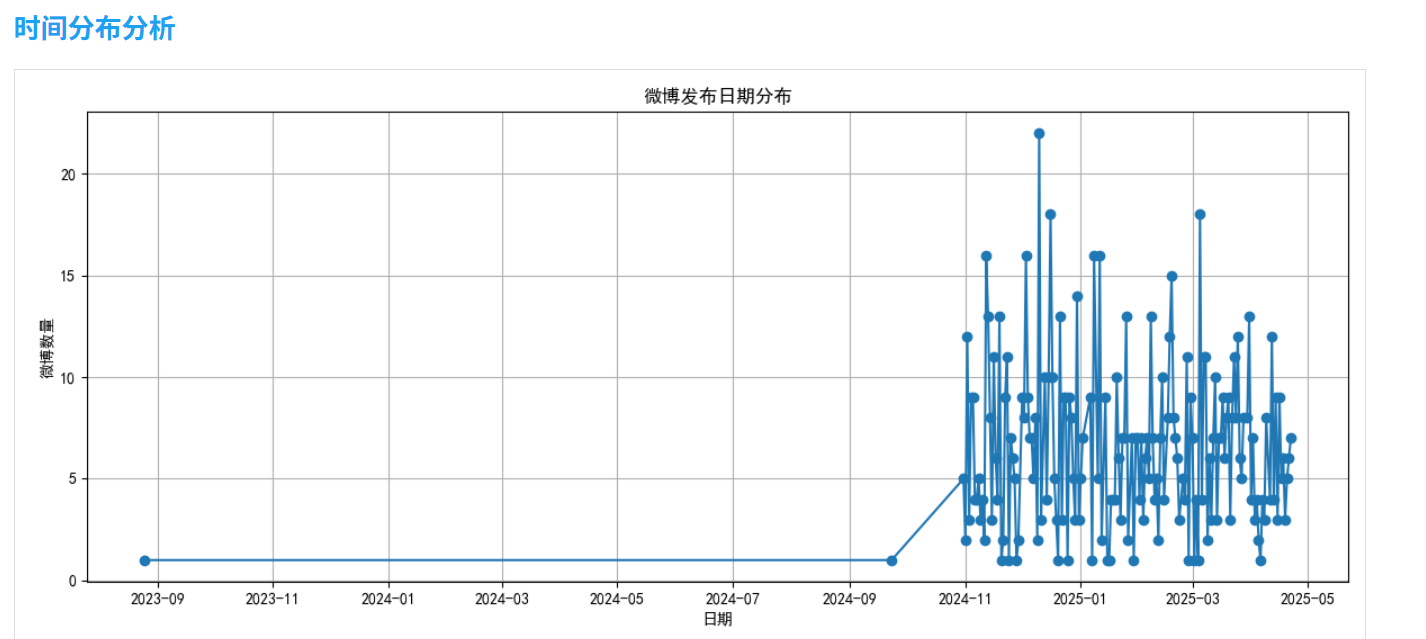
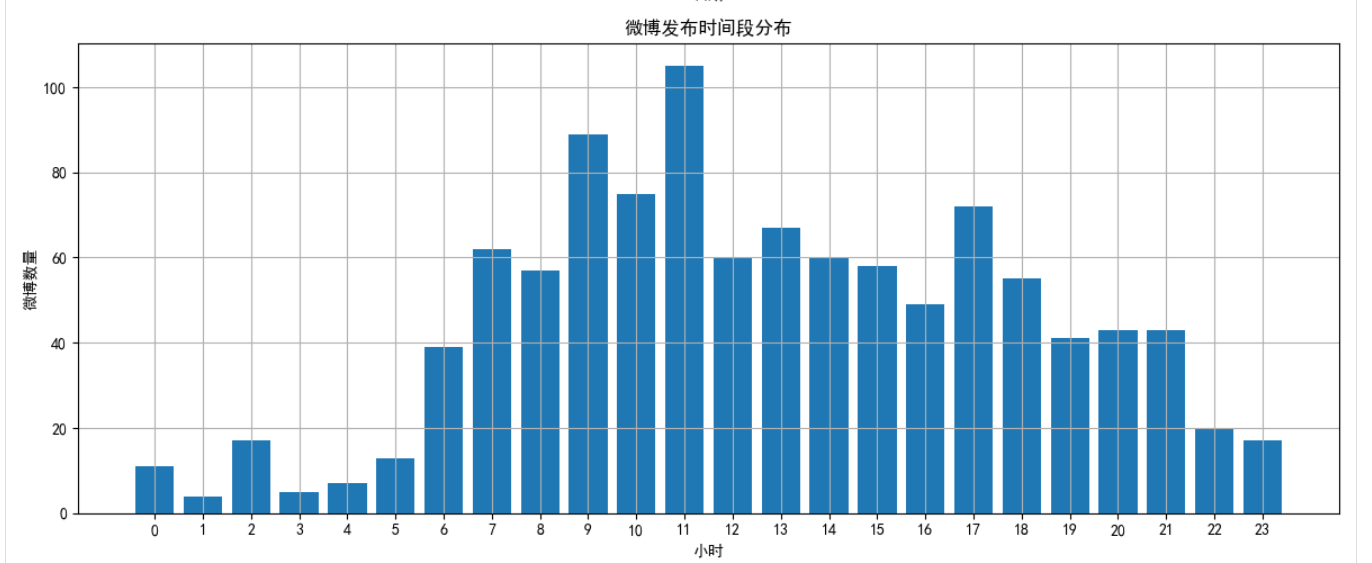
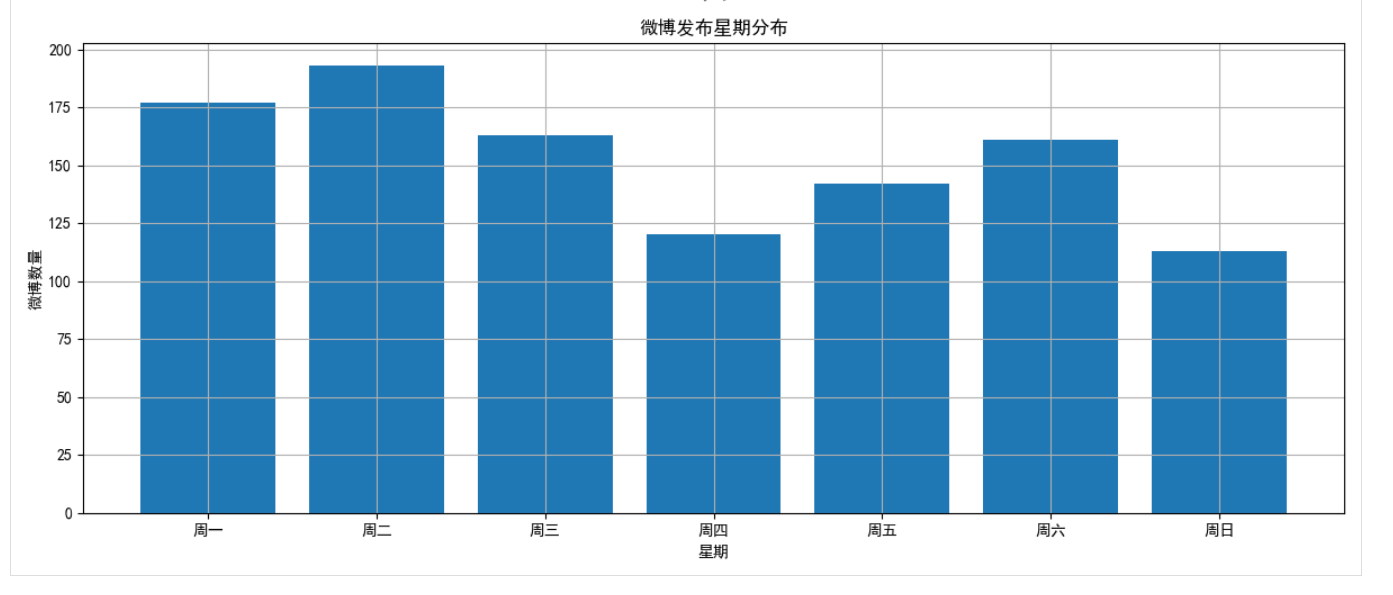
2.2 时间分布分析
分析微博发布的时间规律,包括日期、小时和星期分布:
def time_distribution_analysis(self):# 提取日期和时间dates = [weibo['date'].date() for weibo in self.weibos]hours = [weibo['date'].hour for weibo in self.weibos]weekdays = [weibo['date'].weekday() for weibo in self.weibos]# 使用pandas和matplotlib进行统计和可视化# ...
通过这一分析,我们可以了解用户在什么时间段最活跃,是否有固定的发布模式。
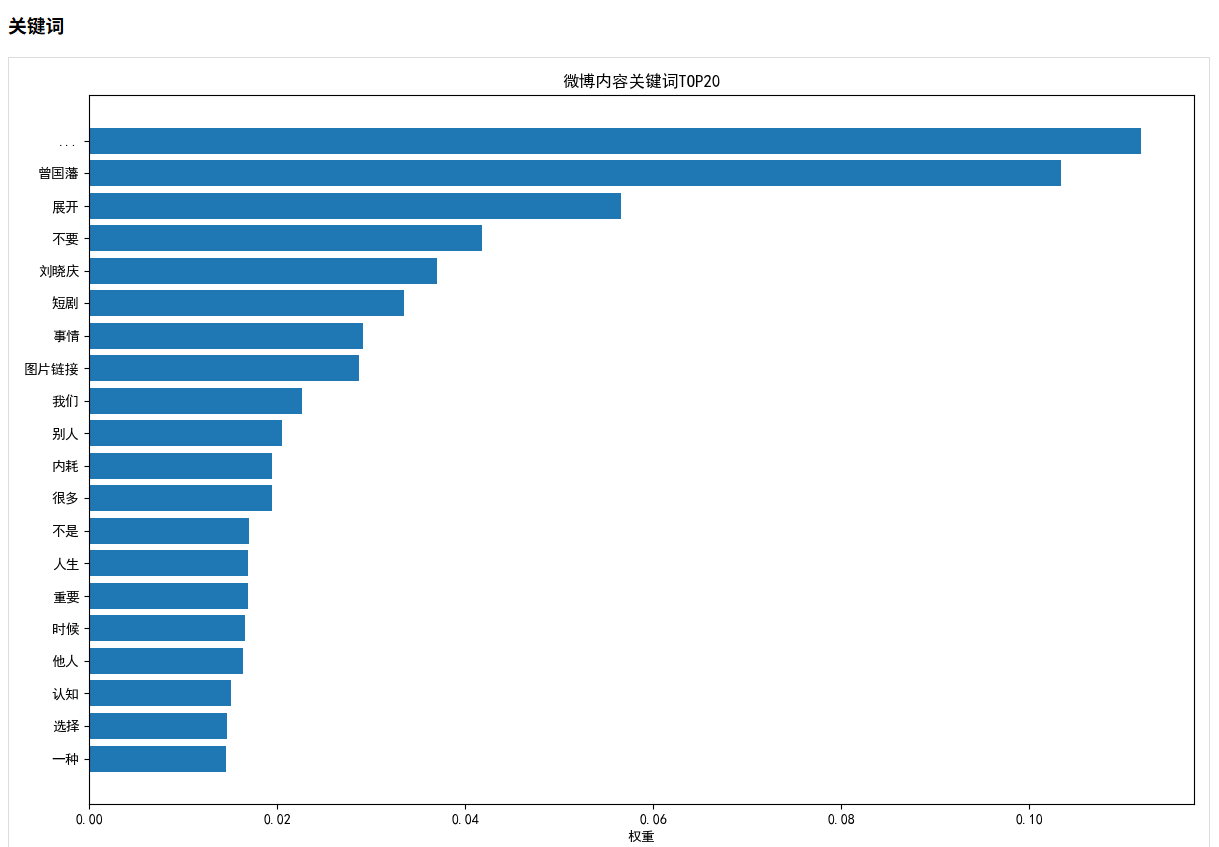
2.3 内容分析与关键词提取
使用jieba分词和TF-IDF算法提取微博内容的关键词:
def content_analysis(self):# 合并所有微博内容all_content = ' '.join([weibo['content'] for weibo in self.weibos])# 使用jieba进行分词jieba.analyse.set_stop_words('stopwords.txt')words = jieba.cut(all_content)# 过滤单个字符和数字filtered_words = [word for word in words if len(word) > 1 and not word.isdigit()]# 统计词频word_counts = Counter(filtered_words)# 提取关键词keywords = jieba.analyse.extract_tags(all_content, topK=50, withWeight=True)# 生成词云和关键词图表# ...
词云能直观地展示内容主题,关键词分析则揭示了用户最关注的话题。
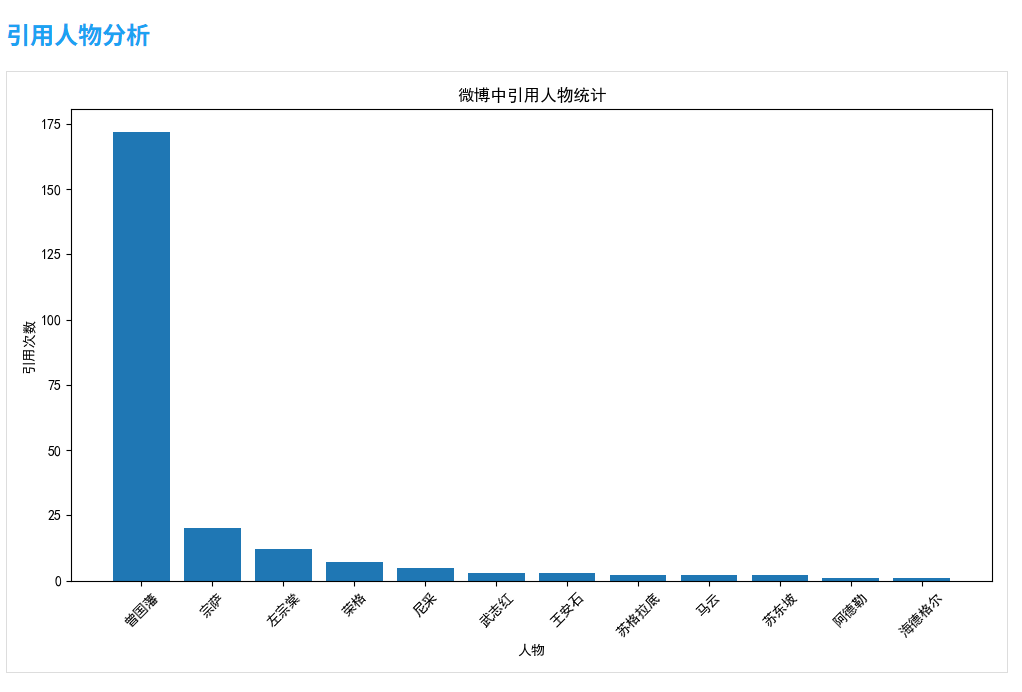
2.4 引用人物分析
分析微博中引用的名人或专家:
def quote_analysis(self):# 定义可能被引用的人物列表famous_people = ['曾国藩', '尼采', '荣格', '苏格拉底', '马云', '武志红', '阿德勒', '王安石', '苏东坡', '海德格尔', '左宗棠', '宗萨']# 统计每个人物被引用的次数quotes = {person: 0 for person in famous_people}for weibo in self.weibos:content = weibo['content']for person in famous_people:if person in content:quotes[person] += 1# 绘制引用人物条形图# ...
这一分析可以揭示用户的思想倾向和崇拜的对象。
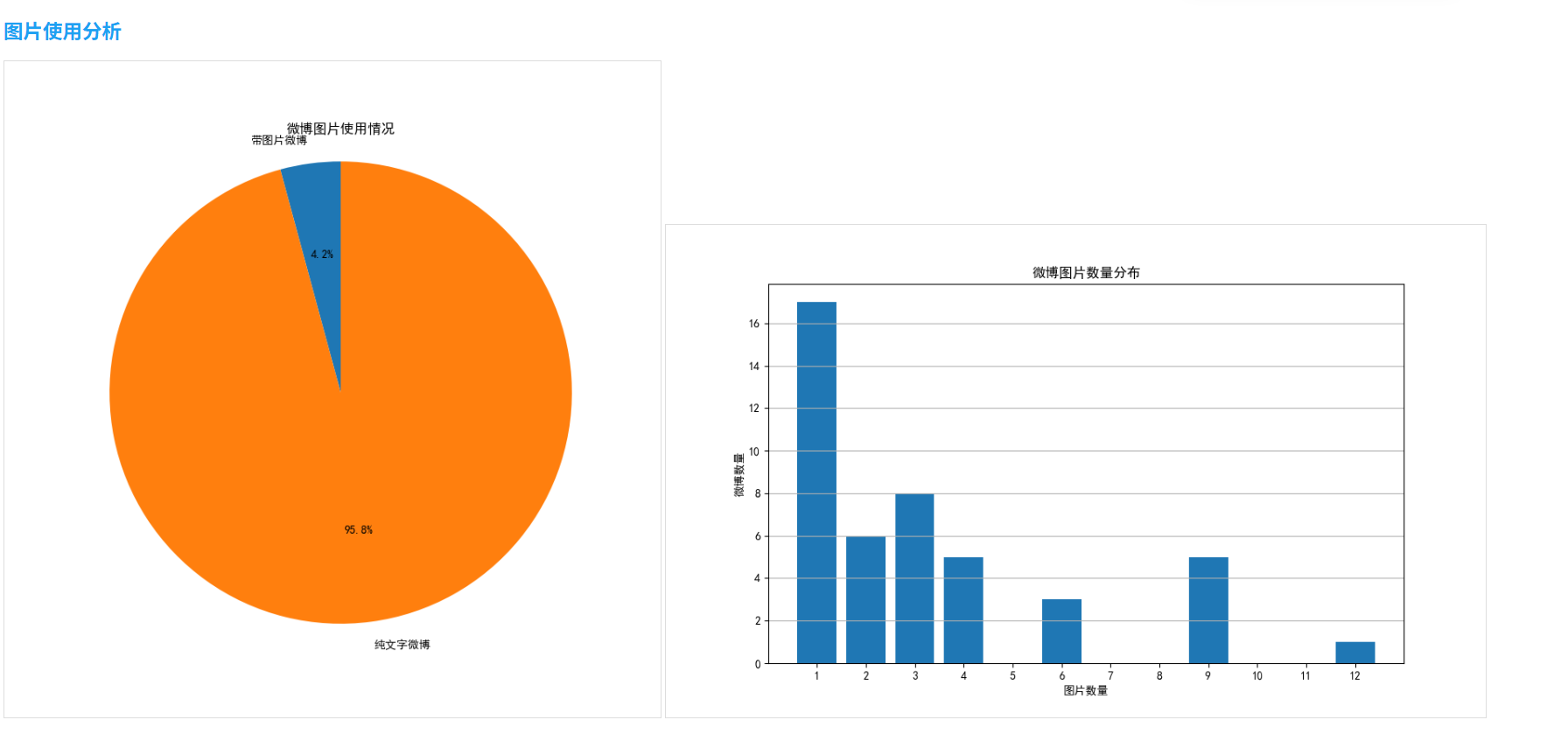
2.5 图片使用分析
分析微博中的图片使用情况:
def image_analysis(self):# 统计带图片的微博数量weibos_with_images = [weibo for weibo in self.weibos if weibo['images']]image_counts = [len(weibo['images']) for weibo in weibos_with_images]# 计算统计数据total_weibos = len(self.weibos)weibos_with_images_count = len(weibos_with_images)percentage = weibos_with_images_count / total_weibos * 100 if total_weibos > 0 else 0# 绘制饼图和分布图# ...
三、可视化报告生成
最终,将所有分析结果整合为一个HTML报告:
def generate_report(self):# 执行所有分析self.time_distribution_analysis()self.content_analysis()self.quote_analysis()self.image_analysis()# 生成HTML报告html_content = f"""<!DOCTYPE html><html><head><meta charset="UTF-8"><title>微博数据分析报告</title><style>body {{ font-family: Arial, sans-serif; margin: 20px; }}h1, h2 {{ color: #1DA1F2; }}.section {{ margin-bottom: 30px; }}img {{ max-width: 100%; border: 1px solid #ddd; }}</style></head><body><h1>微博数据分析报告</h1><!-- 各部分分析结果 --><!-- ... --></body></html>"""with open('weibo_analysis_report.html', 'w', encoding='utf-8') as f:f.write(html_content)
四、实际应用案例
以用户"侯小强"(ID: 1004524612)为例,我爬取了其全部1069条微博并进行分析。以下是一些关键发现:
- 时间分布:该用户主要在晚上8点至10点发布微博,周六和周日活跃度明显高于工作日
- 关键词分析:心理、生活、思考是最常出现的关键词,表明用户关注心理学和个人成长话题
- 引用分析:尼采、荣格、苏格拉底是被最多引用的人物,表明用户对西方哲学有较深兴趣
- 图片使用:约37%的微博包含图片,其中以单图发布为主
网页展示效果如下:


五、技术难点与解决方案
- 反爬虫机制:微博有严格的请求频率限制,我通过设置合理的请求间隔(1秒)和会话保持来解决
- 中文分词挑战:中文分词准确度对内容分析至关重要,使用jieba库并自定义停用词表提高分析质量
- 数据清洗:微博内容中包含大量HTML标签和特殊字符,需要精心设计正则表达式进行清洗
- 可视化定制:调整matplotlib的中文字体和样式设置,确保图表美观且信息丰富
六、总结与展望
本项目实现了一个完整的微博数据爬取和分析系统,可以帮助我们从用户的微博内容中挖掘出有价值的信息。未来的改进方向包括:
- 支持多用户批量爬取和对比分析
- 加入情感分析功能,评估微博的情感倾向
- 增加互动数据(点赞、评论、转发)的分析
- 开发时间序列分析,检测用户兴趣变化趋势
通过这个项目,我们不仅可以了解特定用户的发布规律和内容偏好,还能窥探社交媒体用户的思想动态和关注重点,为社会学和心理学研究提供数据支持。
完整代码:爬取数据代码-weibo_crawler.py
import requests
import json
import time
import os
import re
import argparse
from datetime import datetimeclass WeiboCrawler:def __init__(self, cookie=None):"""初始化微博爬虫:param cookie: 用户登录的cookie字符串"""self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Accept': 'application/json, text/plain, */*','Accept-Language': 'zh-CN,zh;q=0.9','Referer': 'https://weibo.com/','Origin': 'https://weibo.com',}if cookie:self.headers['Cookie'] = cookieself.session = requests.Session()self.session.headers.update(self.headers)def get_user_info(self, user_id):"""获取用户基本信息:param user_id: 用户ID:return: 用户信息字典"""url = f'https://weibo.com/ajax/profile/info?uid={user_id}'try:response = self.session.get(url)if response.status_code == 200:data = response.json()if data.get('ok') == 1 and 'data' in data:return data['data']['user']return Noneexcept Exception as e:print(f"获取用户信息失败: {e}")return Nonedef get_user_weibos(self, user_id, page=1, count=20):"""获取用户的微博列表:param user_id: 用户ID:param page: 页码:param count: 每页微博数量:return: 微博列表"""url = f'https://weibo.com/ajax/statuses/mymblog?uid={user_id}&page={page}&feature=0'try:response = self.session.get(url)if response.status_code == 200:data = response.json()if data.get('ok') == 1 and 'data' in data:return data['data']['list'], data['data']['total']return [], 0except Exception as e:print(f"获取微博列表失败: {e}")return [], 0def clean_text(self, text):"""清理文本内容,去除HTML标签等:param text: 原始文本:return: 清理后的文本"""if not text:return ""# 去除HTML标签text = re.sub(r'<[^>]+>', '', text)# 替换特殊字符text = text.replace(' ', ' ')text = text.replace('<', '<')text = text.replace('>', '>')text = text.replace('&', '&')# 去除多余空格和换行text = re.sub(r'\s+', ' ', text).strip()return textdef format_weibo(self, weibo):"""格式化微博内容:param weibo: 微博数据:return: 格式化后的微博文本"""created_at = datetime.strptime(weibo['created_at'], '%a %b %d %H:%M:%S %z %Y').strftime('%Y-%m-%d %H:%M:%S')text = self.clean_text(weibo.get('text', ''))formatted = f"[{created_at}]\n"formatted += f"{text}\n"# 添加转发内容if 'retweeted_status' in weibo and weibo['retweeted_status']:retweeted = weibo['retweeted_status']retweeted_user = retweeted.get('user', {}).get('screen_name', '未知用户')retweeted_text = self.clean_text(retweeted.get('text', ''))formatted += f"\n转发 @{retweeted_user}: {retweeted_text}\n"# 添加图片链接if 'pic_ids' in weibo and weibo['pic_ids']:formatted += "\n图片链接:\n"for pic_id in weibo['pic_ids']:pic_url = f"https://wx1.sinaimg.cn/large/{pic_id}.jpg"formatted += f"{pic_url}\n"formatted += "-" * 50 + "\n"return formatteddef crawl_user_weibos(self, user_id, max_pages=None):"""爬取用户的所有微博:param user_id: 用户ID:param max_pages: 最大爬取页数,None表示爬取全部:return: 所有微博内容的列表"""user_info = self.get_user_info(user_id)if not user_info:print(f"未找到用户 {user_id} 的信息")return []screen_name = user_info.get('screen_name', user_id)print(f"开始爬取用户 {screen_name} 的微博")all_weibos = []page = 1total_pages = float('inf')while (max_pages is None or page <= max_pages) and page <= total_pages:print(f"正在爬取第 {page} 页...")weibos, total = self.get_user_weibos(user_id, page)if not weibos:breakall_weibos.extend(weibos)# 计算总页数if total > 0:total_pages = (total + 19) // 20 # 每页20条,向上取整page += 1# 防止请求过快time.sleep(1)print(f"共爬取到 {len(all_weibos)} 条微博")return all_weibos, screen_namedef save_weibos_to_file(self, user_id, max_pages=None):"""爬取用户微博并保存到文件:param user_id: 用户ID:param max_pages: 最大爬取页数:return: 保存的文件路径"""weibos, screen_name = self.crawl_user_weibos(user_id, max_pages)if not weibos:return None# 创建文件名filename = f"{user_id}_weibos.txt"# 写入文件with open(filename, 'w', encoding='utf-8') as f:f.write(f"用户: {screen_name} (ID: {user_id})\n")f.write(f"爬取时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")f.write(f"微博数量: {len(weibos)}\n")f.write("=" * 50 + "\n\n")for weibo in weibos:formatted = self.format_weibo(weibo)f.write(formatted)print(f"微博内容已保存到文件: {filename}")return filenamedef main():parser = argparse.ArgumentParser(description='微博爬虫 - 爬取指定用户的微博')parser.add_argument('user_id', help='微博用户ID')parser.add_argument('--cookie', help='登录cookie字符串', default=None)parser.add_argument('--max-pages', type=int, help='最大爬取页数', default=None)parser.add_argument('--cookie-file', help='包含cookie的文件路径', default=None)args = parser.parse_args()cookie = args.cookie# 如果提供了cookie文件,从文件读取cookieif args.cookie_file and not cookie:try:with open(args.cookie_file, 'r', encoding='utf-8') as f:cookie = f.read().strip()except Exception as e:print(f"读取cookie文件失败: {e}")crawler = WeiboCrawler(cookie=cookie)crawler.save_weibos_to_file(args.user_id, args.max_pages)if __name__ == "__main__":main()
数据分析代码:weibo_analsis.py
import re
import os
import matplotlib.pyplot as plt
from datetime import datetime
import jieba
import jieba.analyse
from collections import Counter
import numpy as np
from wordcloud import WordCloud
import matplotlib.font_manager as fm
from matplotlib.font_manager import FontProperties
import pandas as pd
from matplotlib.dates import DateFormatter
import seaborn as sns# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号class WeiboAnalyzer:def __init__(self, file_path):"""初始化微博分析器:param file_path: 微博数据文件路径"""self.file_path = file_pathself.weibos = []self.user_info = {}self.load_data()def load_data(self):"""加载微博数据"""with open(self.file_path, 'r', encoding='utf-8') as f:lines = f.readlines()# 提取用户信息if lines and "用户:" in lines[0]:user_info_match = re.match(r'用户: (.*) \(ID: (.*)\)', lines[0])if user_info_match:self.user_info['name'] = user_info_match.group(1)self.user_info['id'] = user_info_match.group(2)if len(lines) > 2 and "微博数量:" in lines[2]:count_match = re.match(r'微博数量: (\d+)', lines[2])if count_match:self.user_info['count'] = int(count_match.group(1))# 提取微博内容current_weibo = Nonefor line in lines:# 新微博的开始if re.match(r'\[\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\]', line):if current_weibo:self.weibos.append(current_weibo)date_match = re.match(r'\[(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})\]', line)if date_match:date_str = date_match.group(1)content = line[len(date_str) + 3:].strip()current_weibo = {'date': datetime.strptime(date_str, '%Y-%m-%d %H:%M:%S'),'content': content,'images': [],'is_retweet': False,'retweet_content': '','retweet_user': ''}# 图片链接elif line.strip().startswith('https://wx1.sinaimg.cn/'):if current_weibo:current_weibo['images'].append(line.strip())# 转发内容elif current_weibo and line.strip().startswith('转发 @'):current_weibo['is_retweet'] = Trueretweet_match = re.match(r'转发 @(.*): (.*)', line.strip())if retweet_match:current_weibo['retweet_user'] = retweet_match.group(1)current_weibo['retweet_content'] = retweet_match.group(2)# 继续添加内容elif current_weibo and not line.strip() == '-' * 50 and not line.strip() == '=' * 50:current_weibo['content'] += ' ' + line.strip()# 添加最后一条微博if current_weibo:self.weibos.append(current_weibo)print(f"成功加载 {len(self.weibos)} 条微博")def time_distribution_analysis(self):"""分析微博发布时间分布"""if not self.weibos:print("没有微博数据可分析")return# 提取日期和时间dates = [weibo['date'].date() for weibo in self.weibos]hours = [weibo['date'].hour for weibo in self.weibos]weekdays = [weibo['date'].weekday() for weibo in self.weibos]# 创建日期DataFramedf = pd.DataFrame({'date': dates,'hour': hours,'weekday': weekdays})# 按日期统计date_counts = df['date'].value_counts().sort_index()# 按小时统计hour_counts = df['hour'].value_counts().sort_index()# 按星期几统计weekday_counts = df['weekday'].value_counts().sort_index()weekday_names = ['周一', '周二', '周三', '周四', '周五', '周六', '周日']# 创建图表fig, axes = plt.subplots(3, 1, figsize=(12, 15))# 日期分布图axes[0].plot(date_counts.index, date_counts.values, marker='o')axes[0].set_title('微博发布日期分布')axes[0].set_xlabel('日期')axes[0].set_ylabel('微博数量')axes[0].grid(True)# 小时分布图axes[1].bar(hour_counts.index, hour_counts.values)axes[1].set_title('微博发布时间段分布')axes[1].set_xlabel('小时')axes[1].set_ylabel('微博数量')axes[1].set_xticks(range(0, 24))axes[1].grid(True)# 星期几分布图axes[2].bar([weekday_names[i] for i in weekday_counts.index], weekday_counts.values)axes[2].set_title('微博发布星期分布')axes[2].set_xlabel('星期')axes[2].set_ylabel('微博数量')axes[2].grid(True)plt.tight_layout()plt.savefig('time_distribution.png')plt.close()print("时间分布分析完成,结果已保存为 time_distribution.png")def content_analysis(self):"""分析微博内容"""if not self.weibos:print("没有微博数据可分析")return# 合并所有微博内容all_content = ' '.join([weibo['content'] for weibo in self.weibos])# 使用jieba进行分词jieba.analyse.set_stop_words('stopwords.txt') # 如果有停用词表words = jieba.cut(all_content)# 过滤掉单个字符和数字filtered_words = [word for word in words if len(word) > 1 and not word.isdigit()]# 统计词频word_counts = Counter(filtered_words)# 提取关键词keywords = jieba.analyse.extract_tags(all_content, topK=50, withWeight=True)# 创建词云wordcloud = WordCloud(font_path='simhei.ttf', # 设置中文字体width=800,height=400,background_color='white').generate_from_frequencies(dict(word_counts))# 绘制词云图plt.figure(figsize=(10, 6))plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.title('微博内容词云')plt.savefig('wordcloud.png')plt.close()# 绘制关键词条形图plt.figure(figsize=(12, 8))keywords_dict = dict(keywords[:20])plt.barh(list(reversed(list(keywords_dict.keys()))), list(reversed(list(keywords_dict.values()))))plt.title('微博内容关键词TOP20')plt.xlabel('权重')plt.tight_layout()plt.savefig('keywords.png')plt.close()print("内容分析完成,结果已保存为 wordcloud.png 和 keywords.png")def quote_analysis(self):"""分析微博中引用的人物"""if not self.weibos:print("没有微博数据可分析")return# 定义可能被引用的人物列表famous_people = ['曾国藩', '尼采', '荣格', '苏格拉底', '马云', '武志红', '阿德勒', '王安石', '苏东坡', '海德格尔', '左宗棠', '宗萨']# 统计每个人物被引用的次数quotes = {person: 0 for person in famous_people}for weibo in self.weibos:content = weibo['content']for person in famous_people:if person in content:quotes[person] += 1# 过滤掉未被引用的人物quotes = {k: v for k, v in quotes.items() if v > 0}# 按引用次数排序sorted_quotes = dict(sorted(quotes.items(), key=lambda item: item[1], reverse=True))# 绘制引用人物条形图plt.figure(figsize=(10, 6))plt.bar(sorted_quotes.keys(), sorted_quotes.values())plt.title('微博中引用人物统计')plt.xlabel('人物')plt.ylabel('引用次数')plt.xticks(rotation=45)plt.tight_layout()plt.savefig('quotes.png')plt.close()print("引用人物分析完成,结果已保存为 quotes.png")def image_analysis(self):"""分析微博中的图片使用情况"""if not self.weibos:print("没有微博数据可分析")return# 统计带图片的微博数量weibos_with_images = [weibo for weibo in self.weibos if weibo['images']]image_counts = [len(weibo['images']) for weibo in weibos_with_images]# 计算统计数据total_weibos = len(self.weibos)weibos_with_images_count = len(weibos_with_images)percentage = weibos_with_images_count / total_weibos * 100 if total_weibos > 0 else 0# 绘制饼图plt.figure(figsize=(8, 8))plt.pie([weibos_with_images_count, total_weibos - weibos_with_images_count], labels=['带图片微博', '纯文字微博'], autopct='%1.1f%%',startangle=90)plt.title('微博图片使用情况')plt.axis('equal')plt.savefig('image_usage.png')plt.close()# 绘制图片数量分布if image_counts:plt.figure(figsize=(10, 6))counter = Counter(image_counts)plt.bar(counter.keys(), counter.values())plt.title('微博图片数量分布')plt.xlabel('图片数量')plt.ylabel('微博数量')plt.xticks(range(1, max(image_counts) + 1))plt.grid(axis='y')plt.savefig('image_count.png')plt.close()print("图片使用分析完成,结果已保存为 image_usage.png 和 image_count.png")def generate_report(self):"""生成分析报告"""# 执行所有分析self.time_distribution_analysis()self.content_analysis()self.quote_analysis()self.image_analysis()# 生成HTML报告html_content = f"""<!DOCTYPE html><html><head><meta charset="UTF-8"><title>微博数据分析报告</title><style>body {{ font-family: Arial, sans-serif; margin: 20px; }}h1, h2 {{ color: #1DA1F2; }}.section {{ margin-bottom: 30px; }}img {{ max-width: 100%; border: 1px solid #ddd; }}</style></head><body><h1>微博数据分析报告</h1><div class="section"><h2>用户信息</h2><p>用户名: {self.user_info.get('name', '未知')}</p><p>用户ID: {self.user_info.get('id', '未知')}</p><p>微博总数: {self.user_info.get('count', len(self.weibos))}</p><p>分析微博数: {len(self.weibos)}</p></div><div class="section"><h2>时间分布分析</h2><img src="time_distribution.png" alt="时间分布分析"></div><div class="section"><h2>内容分析</h2><h3>词云</h3><img src="wordcloud.png" alt="词云"><h3>关键词</h3><img src="keywords.png" alt="关键词"></div><div class="section"><h2>引用人物分析</h2><img src="quotes.png" alt="引用人物分析"></div><div class="section"><h2>图片使用分析</h2><img src="image_usage.png" alt="图片使用情况"><img src="image_count.png" alt="图片数量分布"></div></body></html>"""with open('weibo_analysis_report.html', 'w', encoding='utf-8') as f:f.write(html_content)print("分析报告已生成: weibo_analysis_report.html")def main():# 创建停用词文件(如果需要)stopwords = ['的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这', '那', '啊', '吧', '把', '给', '但是', '但', '还', '可以', '这个', '这样', '这些', '因为', '所以', '如果', '就是', '么', '什么', '只是', '只有', '这种', '那个', '他们']with open('stopwords.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(stopwords))# 分析微博数据analyzer = WeiboAnalyzer('1004524612_weibos.txt')analyzer.generate_report()if __name__ == "__main__":main()
所有数据以及代码也放在下面的仓库里了:源码链接
参考资料
- Python爬虫实战指南
- 《数据可视化之美》
- 自然语言处理与文本挖掘技术
- jieba中文分词官方文档
相关文章:

从零开始构建微博爬虫与数据分析系统
从零开始构建微博爬虫与数据分析系统 引言 社交媒体平台蕴含着海量的信息和数据,通过对这些数据的收集和分析,我们可以挖掘出有价值的见解。本文将详细介绍如何构建一个完整的微博爬虫和数据分析系统,从数据爬取、清洗、到多维度分析与可视…...

417. 太平洋大西洋水流问题
题目 有一个 m n 的矩形岛屿,与 太平洋 和 大西洋 相邻。 “太平洋” 处于大陆的左边界和上边界,而 “大西洋” 处于大陆的右边界和下边界。 这个岛被分割成一个由若干方形单元格组成的网格。给定一个 m x n 的整数矩阵 heights , heights…...

chili3d调试笔记8 打印零件属性
无效, 返回的是节点不是坐标啥的, 找他的属性 把document和selectednote(空集)传给handleshowproperty方法 怎么获得selectnotes和selectnotes的property值 有selectnotes运行这段就行了 明天再搞...

uniapp Vue2升级到Vue3,并发布到微信小程序的快捷方法
目录 前言:升级项目的两种方式步骤一、新建项目 【选择-默认模版】二、修改-pages.json三、补充-缺少的文件四、修改-Main.js按照 [官方文档-vue2升级vue3迁移指南](https://uniapp.dcloud.net.cn/tutorial/migration-to-vue3.html) 修改 五、升级-uni-ui扩展组件的…...

火山RTC 5 转推CDN 布局合成规则
实时音视频房间,转推CDN,文档: 转推直播--实时音视频-火山引擎 一、转推CDN 0、前提 * 在调用该接口前,你需要在[控制台](https://console.volcengine.com/rtc/workplaceRTC)开启转推直播功能。<br> * 调…...

Mujoco xml < sensor>
< sensor> jointposjointveljointactuatorfrcframequatgyroaccelerometerframeposframelinveltouchobjtype"site" objname"imu" 和site"imu"的区别python中与sensor有关的写法传感器名字索引第几个idid索引传感器名字传感器数量sensor中的…...

示例:spring xml+注解混合配置
以下是一个 Spring XML 注解的混合配置示例,结合了 XML 的基础设施配置(如数据源、事务管理器)和注解的便捷性(如依赖注入、事务声明)。所有业务层代码通过注解简化,但核心配置仍通过 XML 管理。 1. 项目结…...

同样的html标记,不同语言的文本,显示的字体和粗细会不一样吗
同样的 HTML 标记,在不同语言的文本下,显示出来的字体和粗细确实可能会不一样,原因如下: 🌍 不同语言默认字体不同 浏览器字体回退机制 CSS 里写的字体如果当前系统不支持,就会回退到下一个,比如…...

Linux进程6-alarm闹钟定时终止、raise发送信号、abort终止、pause挂起进程验证
目录 1.alarm函数 1.1关键点 1.2单个alarm函数定时 1.3两个alarm函数定时 2.raise函数 2.1核心行为 2.2 raise与 kill 的区别 2.3程序: 3.abort函数 4.pause 函数 4.1 pause简单挂起 4.2父进程挂起,子进程发信号 1.alarm函数 函数原型&…...

SpringCloud组件—Eureka
一.背景 1.问题提出 我们在一个父项目下写了两个子项目,需要两个子项目之间相互调用。我们可以发送HTTP请求来获取我们想要的资源,具体实现的方法有很多,可以用HttpURLConnection、HttpClient、Okhttp、 RestTemplate等。 举个例子&#x…...

类加载器与jvm的内存
1. 类加载器与内存的关系 类加载器的字节码放在方法区(元空间)中,同时类加载器加载类后类的信息(成员变量、成员方法及修饰符等)存放在方法区中。类的信息所占内存的回收要同时满足两个条件:类的实例被回收…...
)
【C++】新手入门指南(下)
文章目录 前言 一、引用 1.引用的概念和定义 2.引用的特性 3.引用的使用 4.const引用 5.指针和引用的关系 二、内联函数 三、nullptr 总结 前言 这篇续上篇的内容新手入门指南(上),继续带大家学习新知识。如果你感兴趣欢迎订购本专栏。 一、…...

el-table中el-input的autofocus无法自动聚焦的解决方案
需求 有一个表格展示了一些进度信息,进度信息可以修改,需要点击进度信息旁边的编辑按钮时,把进度变为输入框且自动聚焦,当鼠标失去焦点时自动请求更新接口。 注:本例以vue2 element UI为例 分析 这个需求看着挺简单…...

vimplus 如何修改语言支持的版本,以及如何跳转路径
vimplus修改语言版本 默认的vimplus支持c的版本是17 如何修改我们需要修改.ycm_extra_conf.py文件,这个文件管理了我们的插件配置 找到 把他修改为你想要的版本 增添路径 把你安装的gcc位置提供给他,默认的目前比较老 这里都是他提前为我们准备的路…...

麒麟V10安装MySQL8.4
1、下载安装包 wget https://cdn.mysql.com//Downloads/MySQL-8.4/mysql-8.4.5-1.el7.x86_64.rpm-bundle.tar2、解压 mkdir -p /opt/mysql tar -xvf mysql-8.4.5-1.el7.x86_64.rpm-bundle.tar -C /opt/mysql3、安装MySQL 3.1、卸载mariadb rpm -qa | grep mariadb rpm -e m…...

Varjo-XR3在UE5中,头显中间有一个方块一直显示
深色方块显示在屏幕中间的焦点区域中 屏幕中间的对焦区域中显示的黑色方块。 黑色方块是一个已知问题。它在 Varjo VRTemplate 中不可见,因为它使用具有推荐 VR 设置的前向渲染方法。 但是,如果你将延迟渲染方法与高级功能(如 Lumen、Nani…...

FastText 模型文本分类实验:从零到一的实战探索
在自然语言处理(NLP)领域,文本分类是一个基础而重要的任务,广泛应用于情感分析、主题识别、垃圾邮件过滤等多个场景。最近,我参与了一次基于 FastText 模型的文本分类实验,从数据预处理到模型构建、训练和评…...

不同经营性道路运输从业资格证申请条件全解析
在道路运输领域,获取相应的从业资格证是合法从事经营性运输工作的关键前提。不同类型的运输业务,如旅客运输、货物运输以及危险货物运输,对从业者有着不同的条件要求。 经营性道路旅客运输驾驶员 驾驶证年限:需取得相应的机动车…...

WHAT - 静态资源缓存穿透
文章目录 1. 动态哈希命名的基本思路2. 具体实现2.1 Vite/Webpack 配置动态哈希2.2 HTML 文件中动态引用手动引用使用 index.html 模板动态插入 2.3 结合 Cache-Control 避免缓存穿透2.4 适用于多环境的动态策略 总结 在多环境部署中,静态资源缓存穿透是一个常见问题…...

11、Refs:直接操控元素——React 19 DOM操作秘籍
一、元素操控的魔法本质 "Refs是巫师与麻瓜世界的连接通道,让开发者能像操控魔杖般精准控制DOM元素!"魔杖工坊的奥利凡德先生轻抚着魔杖,React/Vue的refs能量在杖尖跃动。 ——以神秘事务司的量子纠缠理论为基,揭示DOM…...

crontab 定时备份 mysql 数据库
1、使用 mysqldump 命令备份数据 1.1 备份全部数据库的数据和结构 mysqldump -uroot -p123456 -A > /data/backup/db.sql1.2 备份全部数据库的结构(加 -d 参数) mysqldump -uroot -p123456 -A -d > /data/backup/db.sql1.3 备份全部数据库的数据…...

数据库对象与权限管理-视图与索引管理
一、视图(View)管理 1. 视图的定义与本质 视图(View)是Oracle数据库中的逻辑表,它不直接存储数据,而是通过预定义的SQL查询动态生成结果集。视图的本质可以理解为: 虚拟表:用户可…...

德施曼重磅发布五大突破性技术及多款重磅新品,开启AI智能管家时代
当智能锁拥抱人文关怀,万物有灵便有了具象化的表达。 4月22日,智能锁领军品牌德施曼“万物有灵”2025全球新品发布会在乌镇隆重举行,为智能锁行业带来了AI时代的革新方案。 会上,德施曼创始人/CEO祝志凌重磅发布了五大突破性技术&…...
)
单元测试学习笔记(一)
自动化测试 通过测试工具/编程模拟手动测试步骤,全自动半自动执行测试用例,对比预期输出和实际输出,记录并统计测试结果,减少重复的工作量。 单元测试 针对最小的单元测试,Java中就是一个一个的方法就是一个一个的单…...

Rest Client插件写http文件直接发送请求
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言📌 插件介绍:🚀 安装方式:📚 使用示例:⚙️ 功能亮点: 前言 直接在 VSCode …...
Scaling Laws for Neural Language Models)
LLM 论文精读(一)Scaling Laws for Neural Language Models
这篇文章是2020年发表的一篇LLM领域中非常重要的论文,由OpenAI发布,总结了LLM模型规模与训练数据token之间的比例关系,即我们熟知的 Scaling Laws,允许 通过观察小规模训练实验,提前预测大模型的效果表现,降…...

Spring AOP + Logback + MDC全链路日志追踪
1、背景 由于权限管理和安全规范,服务都部署到云上,只能通过日志系统查看日志。 然而,面对海量的日志数据,如何快速定位关键信息和调用链路是一个巨大的挑战。 2、方案调研 在 Spring Boot 中实现全链路日志追踪,核…...

SVT-AV1编码器初始化函数
一 函数解释 这个函数SVT-AV1编码器初始化的核心函数,负责配置编码器组件,分配资源并启动编码线程,以下时对每一行的详细解释。 函数签名和参数检查 EB_API EbErrorType svt_av1_enc_init(EbComponentType *svt_enc_component) { if (svt_enc…...

Unity 导出Excel表格
1.首先,需要导入EPPlus.dll;(我这里用的是Unity 2017.3.0f3) https://download.csdn.net/download/qq_41603955/90670669 2.代码如下: using UnityEngine; using UnityEditor; using System.IO; using OfficeOpenXm…...

Web前端开发技术——HTML5、CSS3、JavaScript
一、HTML 1.基本结构 <html lang "en"><head><meta charset"UTF-8"><meta name"Keywords" content""><meta name"Description" content""><title>Web网页标题</title&g…...

野外价值观:在真实世界的语言模型互动中发现并分析价值观
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

【华为HCIP | 华为数通工程师】821—多选解析—第十二页
多选727、某台路由器的输出信息如下所示,以下描述正确的有哪些选项? A、路由器Router ID为10.0.1.1 B、路由器Router ID为10.0.2.2。 C、本路由器的接口地址为10.0.12.2。 D、本路由器是DR。 解析:display ospf peer //获取的OSPF邻居信…...

Selenium 在爬取过程中,网络响应被退出的解决方案
我在使用 Selenium 爬取网站的时候,直接get url ,却立马闪退,遇到了获取网络响应直接被退出的问题。 这通常是由于 反爬机制、浏览器检测 或 网络限制 导致的。 以下是 完整排查与解决方案: 1. 检查常见原因 问题类型典型表现可…...

楼宇自控怎样全方位融入建筑领域,为绿色建筑发展添砖加瓦
在全球积极倡导可持续发展的大背景下,绿色建筑已成为建筑领域发展的必然趋势。绿色建筑旨在减少对环境的负面影响,提高能源利用效率,为用户提供健康、舒适的室内环境。而楼宇自控系统作为建筑智能化的核心组成部分,正以其独特的技…...
从零搭建一个完整的TTS系统-第二节-中文转拼音)
语音合成(TTS)从零搭建一个完整的TTS系统-第二节-中文转拼音
一、概述 本节我们进行语音合成前端中的第二步,需要把中文转换为拼音。通过python和c两种语言进行实现,python可以直接调用pypinyin库实现。c实现是本节的重点,首先根据词典进行分词,接着把分词后的词进行词典映射,得到…...
)
基于springboot的停车位管理系统(源码+数据库)
12基于springboot的停车位管理系统:前端 thymeleaf、Jquery、bootstrap,后端 Springboot、Mybatis,系统角色分为:用户、管理员,管理员在管理后台录入车位信息,用户在线查找车位、预约车位,解决停…...

深入理解 Spring @Configuration 注解
在 Spring 框架中,@Configuration 注解是一个非常重要的工具,它用于定义配置类,这些类可以包含 Bean 定义方法。通过使用 @Configuration 和 @Bean 注解,开发者能够以编程方式创建和管理应用程序上下文中的 Bean。本文将详细介绍 @Configuration 注解的作用、如何使用它以及…...
java)
15.三数之和(LeetCode)java
个人理解: 1.使用双指针做法,首先对数组进行排序 第一重for循环控制第一个数,对数组进行遍历。双指针初始化为lefti1, rigthnums.length-1。然后使用while循环移动双指针寻找合适的数。因为返回的是数,不是下标,数不能…...
任务书)
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(10卷)任务书
2022年全国职业院校技能大赛 高职组 “大数据技术与应用” 赛项赛卷(10卷)任务书 模块A:大数据平台搭建(容器环境)(15分)任务一:Hadoop 伪分布式安装配置任务二:Flume安装…...

Redis—内存淘汰策略
记:全体LRU,ttl LRU,全体LFU,ttl LFU,全体随机,ttl随机,最快过期,不淘汰(八种) Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存&…...

新能源汽车可视化大屏系统毕业设计
以下是一个基于Python和Flask框架的新能源汽车可视化大屏系统后台代码示例。这个系统提供API接口用于前端大屏展示新能源汽车相关数据。 主应用文件 (app.py) python from flask import Flask, jsonify, request from flask_cors import CORS import random from datetime imp…...

02-keil5的配置和使用
一、创建工程 1、在菜单栏”Project”,在弹出的下拉菜单,选择“New uVision Project”。 2、在弹出的对话框,填写工程的名字,例如工程名字为project。 3、为保存的工程,选择对应的芯片。 4、为当前工程,添…...

电脑硬盘丢失怎么找回?解决硬盘数据恢复的2种方法
无论是个人用户还是企业用户来讲,存储在磁盘中的文档、图片、视频、音频等数据都具有相当的价值。但在日常使用过程中,误删操作、病毒攻击、硬件故障等情况都可能造成电脑硬盘突然消失不见数据丢失。面对电脑硬盘丢失这类问题时,采取正确的应…...

【Spring】依赖注入的方式:构造方法、setter注入、字段注入
在Spring框架中,除了构造器注入(Constructor Injection)和Setter注入(Setter Injection),还有一种依赖注入方式:字段注入(Field Injection)。字段注入通过在Bean的字段上…...

涨薪技术|0到1学会性能测试第22课-关联函数web_reg_save_param_ex
前面的推文我们掌握了性能测试脚本开发3种常见的关联技术,今天开始给大家分享关联函数web_reg_save_param_ex,后续文章都会系统分享干货! LoadRunner最新版本中,使用的关联函数为web_reg_save_param_ex,以前的版本使用的关联函数为web_reg_save_param,但这两个函数实质差…...

Vue 的数据代理机制
2025/4/22 向 一、什么是数据代理机制 通过访问代理对象的属性,来间接访问目标对象的属性,数据代理机制的实现需要依赖Object.defineProperty()方法。 如下所示: <!DOCTYPE html> <html lang"en"> <head><…...

Android-KeyStore安全的存储系统
在 Android 中,AndroidKeyStore 是一个安全的存储系统,用于存储加密密钥。它提供了一种安全的方式来生成、存储和管理密钥,而无需将密钥暴露给应用程序本身。以下是如何使用 AndroidKeyStore 的基本步骤和示例代码。 检查 AndroidKeyStor…...

部署私有gitlab网站
以下是建立私有 GitLab 代码版本维护平台的完整步骤,涵盖环境准备、安装配置、初始化及日常管理,适用于企业/团队内部代码托管: 一、环境准备 1. 服务器要求(最低配置) 用途CPU内存存储系统要求小型团队(…...
洛谷 P6879 JOI2020 Collecting Stamps 3 题解)
(区间 dp)洛谷 P6879 JOI2020 Collecting Stamps 3 题解
题意 给定一个周长为 L L L 的圆,从一个点出发,有 N N N 个黑白熊雕像,编号为 1 1 1 到 N N N,第 i i i 个雕像在顺时针 X i X_i Xi 米处,如果你没有在 T i T_i Ti 秒内收集到这个黑白熊雕像,那…...

AtCoder 第402场初级竞赛 A~E题解
A CBC 【题目链接】 原题链接:A - CBC 【考点】 枚举 【题目大意】 找出所有的大写字母 【解析】 遍历字符串,判断是否为大写字母,如果是则输出。 【难度】 GESP二级 【代码参考】 #include <bits/stdc++.h> using namespace std;int main() {string s;ci…...