PaddlePaddle线性回归详解:从模型定义到加载,掌握深度学习基础
目录
- 前言
- 一、paddlepaddle框架的线性回归
- 1.1 paddlepaddle模型的定义方式
- 1.1.1 使用序列的方式 nn.Sequential 组网
- 1.1.2 使用类的方式 class nn.Layer组网
- 1.2 数据加载
- 1.3 paddlepaddle模型的保存
- 1.3.1 基础API保存
- 1.3.2 高级API模型的保存
- 1.3.2.1 训练fit进行保存
- 1.3.2.2 利用paddle.Model类进行保存
- 1.4 paddlepaddle模型的加载
- 1.4.1 基础API模型的加载
- 1.4.2 高级API加载
- 1.5 paddlepaddle模型网络结构的查看
- 1.5.1 summary
- 1.5.2 netron
- 1.5.3 visualdl
- 二、曲线拟合
- 1.1案例引入
- 1.2 散点输入
- 1.3 前向计算
- 1.4 Sigmoid函数引入
- 1.5 激活函数的引入
- 1.6 参数初始化
- 1.7 损失函数
- 1.8 开始迭代
- 1.9反向传播
- 1.10 梯度下降显示
- 1.11 曲线拟合代码
- 三、激活函数
- 3.1 激活函数及其导数算法理论讲解
- 3.2 激活函数的作用?
- 3.3 激活函数的概念
- 3.4 Sigmoid
- 总结
前言
书接上文
PyTorch与TensorFlow模型全方位解析:保存、加载与结构可视化-CSDN博客文章浏览阅读479次,点赞6次,收藏17次。本文深入探讨了PyTorch和TensorFlow中模型管理的关键方面,包括模型的保存与加载以及网络结构的可视化。涵盖了PyTorch中模型和参数的保存与加载,以及使用多种工具进行模型结构分析。同时,详细介绍了TensorFlow中模型的定义方式、保存方法、加载流程以及模型结构的可视化技术,旨在帮助读者全面掌握两大深度学习框架的模型管理技巧。https://blog.csdn.net/qq_58364361/article/details/147382076?spm=1011.2415.3001.10575&sharefrom=mp_manage_link
一、paddlepaddle框架的线性回归
从以下5个方面对深度学习框架paddlepaddle框架的线性回归进行介绍
1.paddlepaddle模型的定义
2.paddlepaddle模型的保存
3.paddlepaddle模型的加载
4.paddlepaddle模型网络结构的查看
5.paddlepaddle框架线性回归的代码实现
上面这5方面的内容,让大家,掌握并理解paddlepaddle框架实现线性回归的过程。
1.paddlepaddle 官网 :https://www.paddlepaddle.org.cn/
安装
pip install paddlepaddle==2.6.2 -i https://mirror.baidu.com/pypi/simple
1.1 paddlepaddle模型的定义方式
主要针对基础API
1.1.1 使用序列的方式 nn.Sequential 组网
model=nn.Sequential(nn.Linear(1,1))
#导入库
import numpy as np
import paddle
import paddle.nn as nn
#设置随机数种子 ,保证结果可复现
seed=1
paddle.seed(seed)# 1.散点输入 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
#转化为数组
data=np.array(data)
# 提取x 和y
x_data=data[:,0]
y_data=data[:,1]
#转成张量 转成paddlepaddle张量
x_train=paddle.to_tensor(x_data,dtype=paddle.float32)
y_train=paddle.to_tensor(y_data,dtype=paddle.float32)
# 2. 定义前向模型
# model=paddle.nn.Linear(1,1)#主要针对基础API
#方式1 使用序列的方式 nn.Sequential 组网
model=nn.Sequential(nn.Linear(1,1))# 3.定义损失函数和优化器
#3.1损失函数
criterion=paddle.nn.MSELoss()
#3.2 优化器
optimizer=paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# 4.开始迭代
epochs=500
for epoch in range(1,epochs+1):#前向传播#unsqueeze()扩展一维y_prd=model(x_train.unsqueeze(1))loss=criterion(y_prd.squeeze(1),y_train)#清除之前计算的梯度optimizer.clear_grad()#自动计算梯度loss.backward()#更新参数optimizer.step()# 5.显示频率的设置if epoch % 10==0 or epoch==1:#可以使用float(loss)或者 loss.numpy()会报警告print(f"epoch:{epoch},loss:{float(loss)}")1.1.2 使用类的方式 class nn.Layer组网
#导入库
import numpy as np
import paddle
import paddle.nn as nn
#设置随机数种子 ,保证结果可复现
seed=1
paddle.seed(seed)# 1.散点输入 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
#转化为数组
data=np.array(data)
# 提取x 和y
x_data=data[:,0]
y_data=data[:,1]
#转成张量 转成paddlepaddle张量
x_train=paddle.to_tensor(x_data,dtype=paddle.float32)
y_train=paddle.to_tensor(y_data,dtype=paddle.float32)
#主要针对基础API
#方式 2 单独定义 使用类的方式 class nn.Layer组网
class LinearModel(nn.Layer):def __init__(self):super(LinearModel,self).__init__()self.linear=nn.Linear(1,1)def forward(self,x):x=self.linear(x)return x
# #定义模型的对象
model=LinearModel()# 3.定义损失函数和优化器
#3.1损失函数
criterion=paddle.nn.MSELoss()
#3.2 优化器
optimizer=paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# 4.开始迭代
epochs=500
for epoch in range(1,epochs+1):#前向传播#unsqueeze()扩展一维y_prd=model(x_train.unsqueeze(1))loss=criterion(y_prd.squeeze(1),y_train)#清除之前计算的梯度optimizer.clear_grad()#自动计算梯度loss.backward()#更新参数optimizer.step()# 5.显示频率的设置if epoch % 10==0 or epoch==1:#可以使用float(loss)或者 loss.numpy()会报警告print(f"epoch:{epoch},loss:{float(loss)}")1.2 数据加载
#1.先来看数据加载
#2.模型构建高层API#导入库
import numpy as np
import paddle
import paddle.nn as nn
from paddle.io import DataLoader,TensorDataset
#设置随机数种子 ,保证结果可复现
seed=1
paddle.seed(seed)# 1.散点输入 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
#转化为数组
data=np.array(data)
# 提取x 和y
x_data=data[:,0]
y_data=data[:,1]
#转成张量 转成paddlepaddle张量
x_train=paddle.to_tensor(x_data,dtype=paddle.float32)
y_train=paddle.to_tensor(y_data,dtype=paddle.float32)
#TensorDataset是接收一个值,不是接收两个值,使用列表
dataset=TensorDataset([x_train.unsqueeze(1),y_train.unsqueeze(1)])
#创建Dataloader对象
dataloader=DataLoader(dataset,batch_size=10,shuffle=True)
# 2. 定义前向模型
#方式2 单独定义 使用类的方式 class nn.Layer组网
class LinearModel(nn.Layer):def __init__(self):super(LinearModel,self).__init__()self.linear=nn.Linear(1,1)def forward(self,x):x=self.linear(x)return x
#定义模型的对象
model=LinearModel()# 3.使用高层api进行封装
# step1 使用paddle.Model(xxx)进行封装
model=paddle.Model(model)
#step2 使用prepare
model.prepare(optimizer=paddle.optimizer.SGD(learning_rate=0.01,parameters=model.parameters()),loss=nn.MSELoss(),metrics=paddle.metric.Accuracy())
#step3启动训练
#需要用到数据,训练轮次 是否显示日志过程
model.fit(dataloader,epochs=500,verbose=1)
1.3 paddlepaddle模型的保存
1.3.1 基础API保存
按照字典的形式保存
paddle.save(model.state_dict(),'./基础API/model.pdparams')
#导入库
import numpy as np
import paddle
import paddle.nn as nn
#设置随机数种子 ,保证结果可复现
seed=1
paddle.seed(seed)# 1.散点输入 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
#转化为数组
data=np.array(data)
# 提取x 和y
x_data=data[:,0]
y_data=data[:,1]
#转成张量 转成paddlepaddle张量
x_train=paddle.to_tensor(x_data,dtype=paddle.float32)
y_train=paddle.to_tensor(y_data,dtype=paddle.float32)
# 2. 定义前向模型
# model=paddle.nn.Linear(1,1)#主要针对基础API
#方式1 使用序列的方式 nn.Sequential 组网
# model=nn.Sequential(nn.Linear(1,1))#方式2 单独定义 使用类的方式 class nn.Layer组网
class LinearModel(nn.Layer):def __init__(self):super(LinearModel,self).__init__()self.linear=nn.Linear(1,1)def forward(self,x):x=self.linear(x)return x
#定义模型的对象
model=LinearModel()# 3.定义损失函数和优化器
#3.1损失函数
criterion=paddle.nn.MSELoss()
#3.2 优化器
optimizer=paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# 4.开始迭代
epochs=500
final_checkpoint={}
for epoch in range(1,epochs+1):#前向传播#unsqueeze()扩展一维y_prd=model(x_train.unsqueeze(1))loss=criterion(y_prd.squeeze(1),y_train)#清除之前计算的梯度optimizer.clear_grad()#自动计算梯度loss.backward()#更新参数optimizer.step()# 5.显示频率的设置if epoch % 10==0 or epoch==1:#可以使用float(loss)或者 loss.numpy()会报警告print(f"epoch:{epoch},loss:{float(loss)}")#添加检查点程序if epoch==epochs:#把迭代次数写入final_checkpoint['epoch']=epoch#把训练损失写入final_checkpoint['loss']=loss#基础API模型的保存
paddle.save(model.state_dict(),'./基础API/model.pdparams')
#保存检查点checkpoint信息 是序列化的文件
paddle.save(final_checkpoint, "./基础API/final_checkpoint.pkl")
1.3.2 高级API模型的保存
1.3.2.1 训练fit进行保存
model.fit(dataloader,epochs=500,verbose=1,save_dir='./高层API1',save_freq=10)
#1.先来看数据加载
#2.模型构建高层API#导入库
import numpy as np
import paddle
import paddle.nn as nn
from paddle.io import DataLoader,TensorDataset
#设置随机数种子 ,保证结果可复现
seed=1
paddle.seed(seed)# 1.散点输入 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
#转化为数组
data=np.array(data)
# 提取x 和y
x_data=data[:,0]
y_data=data[:,1]
#转成张量 转成paddlepaddle张量
x_train=paddle.to_tensor(x_data,dtype=paddle.float32)
y_train=paddle.to_tensor(y_data,dtype=paddle.float32)
#TensorDataset是接收一个值,不是接收两个值,使用列表
dataset=TensorDataset([x_train.unsqueeze(1),y_train.unsqueeze(1)])
#创建Dataloader对象
dataloader=DataLoader(dataset,batch_size=10,shuffle=True)
# 2. 定义前向模型
#方式2 单独定义 使用类的方式 class nn.Layer组网
class LinearModel(nn.Layer):def __init__(self):super(LinearModel,self).__init__()self.linear=nn.Linear(1,1)def forward(self,x):x=self.linear(x)return x
#定义模型的对象
model=LinearModel()# 3.使用高层api进行封装
# step1 使用paddle.Model(xxx)进行封装
model=paddle.Model(model)
#step2 使用prepare
model.prepare(optimizer=paddle.optimizer.SGD(learning_rate=0.01,parameters=model.parameters()),loss=nn.MSELoss(),metrics=paddle.metric.Accuracy())
#step3启动训练
#需要用到数据,训练轮次 是否显示日志过程
# model.fit(dataloader,epochs=500,verbose=1)#高级API模型的保存
#保存第一种方式,训练fit进行保存
model.fit(dataloader,epochs=500,verbose=1,save_dir='./高层API1',save_freq=10)
1.3.2.2 利用paddle.Model类进行保存
注意 这边的model.save和基础API中的model.save不一样,基础API是自己申请出来的对象
# 这里是paddle.Model 大类
model.save('./高层API2/model') #save for train 动态图
# 静态图(可以c++调用)
model.save('./高层API2/infer_model',False) #save for inference 静态图(可以c++调用)
#1.先来看数据加载
#2.模型构建高层API#导入库
import numpy as np
import paddle
import paddle.nn as nn
from paddle.io import DataLoader,TensorDataset
#设置随机数种子 ,保证结果可复现
seed=1
paddle.seed(seed)# 1.散点输入 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
#转化为数组
data=np.array(data)
# 提取x 和y
x_data=data[:,0]
y_data=data[:,1]
#转成张量 转成paddlepaddle张量
x_train=paddle.to_tensor(x_data,dtype=paddle.float32)
y_train=paddle.to_tensor(y_data,dtype=paddle.float32)
#TensorDataset是接收一个值,不是接收两个值,使用列表
dataset=TensorDataset([x_train.unsqueeze(1),y_train.unsqueeze(1)])
#创建Dataloader对象
dataloader=DataLoader(dataset,batch_size=10,shuffle=True)
# 2. 定义前向模型
#方式2 单独定义 使用类的方式 class nn.Layer组网
class LinearModel(nn.Layer):def __init__(self):super(LinearModel,self).__init__()self.linear=nn.Linear(1,1)def forward(self,x):x=self.linear(x)return x
#定义模型的对象
model=LinearModel()# 3.使用高层api进行封装
# step1 使用paddle.Model(xxx)进行封装
model=paddle.Model(model)
#step2 使用prepare
model.prepare(optimizer=paddle.optimizer.SGD(learning_rate=0.01,parameters=model.parameters()),loss=nn.MSELoss(),metrics=paddle.metric.Accuracy())
#step3启动训练
#需要用到数据,训练轮次 是否显示日志过程
# model.fit(dataloader,epochs=500,verbose=1)#高级API模型的保存
#保存第一种方式,训练fit进行保存
model.fit(dataloader,epochs=500,verbose=1)#保存方式2 利用paddle.Model类进行保存
#注意 这边的model.save和基础API中的model.save不一样,基础API是自己申请出来的对象
# 这里是paddle.Model 大类
model.save('./hig_API2/model') #save for train 动态图
# 静态图(可以c++调用)
model.save('./hig_API2/infer_model',False) #save for inference 静态图(可以c++调用)
1.4 paddlepaddle模型的加载
1.4.1 基础API模型的加载
model_state_dict=paddle.load('./基础API/model.pdparams')
模型和参数联系起来
model.set_state_dict(model_state_dict)
#导入库
import numpy as np
import paddle
import paddle.nn as nn
#设置随机数种子 ,保证结果可复现
from paddle.io import DataLoader,TensorDataset
seed=1
paddle.seed(seed)# 1.散点输入 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
#转化为数组
data=np.array(data)
# 提取x 和y
x_data=data[:,0]
y_data=data[:,1]
#转成张量 转成paddlepaddle张量
x_train=paddle.to_tensor(x_data,dtype=paddle.float32)
y_train=paddle.to_tensor(y_data,dtype=paddle.float32)
# 2. 定义前向模型
# model=paddle.nn.Linear(1,1)#主要针对基础API
#方式1 使用序列的方式 nn.Sequential 组网
# model=nn.Sequential(nn.Linear(1,1))#方式2 单独定义 使用类的方式 class nn.Layer组网
class LinearModel(nn.Layer):def __init__(self):super(LinearModel,self).__init__()self.linear=nn.Linear(1,1)def forward(self,x):x=self.linear(x)return x
#定义模型的对象
model=LinearModel()# 3.定义损失函数和优化器
#3.1损失函数
criterion=paddle.nn.MSELoss()
#3.2 优化器
optimizer=paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
#基础API模型的加载
model_state_dict=paddle.load('./基础API/model.pdparams')
# optimizer_state_dict=paddle.load('./基础API/optimizer.pdopt')
# final_checkpoint_state_dict=paddle.load('./基础API/final_checkpoint.pkl')
# print(final_checkpoint_state_dict)#模型和参数联系起来
model.set_state_dict(model_state_dict)#训练 评估 和推理
# 模型验证模式
model.eval()
#使用TensorDateset 和DateLoader封装
dataloader_test=DataLoader(TensorDataset([paddle.to_tensor([1.5],dtype=paddle.float32)]),batch_size=1)#迭代
for x_test in dataloader_test:predict=model(x_test[0])print(predict)1.4.2 高级API加载
import paddle
# 3.使用高层api进行封装
# step1 使用paddle.Model(xxx)进行封装
model=paddle.Model(model)
#高级API模型的加载
model.load("./高层API1/final")
#1.先来看数据加载
#2.模型构建高层API#导入库
import numpy as np
import paddle
import paddle.nn as nn
from paddle.io import DataLoader,TensorDataset
#设置随机数种子 ,保证结果可复现
seed=1
paddle.seed(seed)# 1.散点输入 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2], [-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6], [0.4, 34.0], [0.8, 62.3]]
#转化为数组
data=np.array(data)
# 提取x 和y
x_data=data[:,0]
y_data=data[:,1]
#转成张量 转成paddlepaddle张量
x_train=paddle.to_tensor(x_data,dtype=paddle.float32)
y_train=paddle.to_tensor(y_data,dtype=paddle.float32)
#TensorDataset是接收一个值,不是接收两个值,使用列表
dataset=TensorDataset([x_train.unsqueeze(1),y_train.unsqueeze(1)])
#创建Dataloader对象
dataloader=DataLoader(dataset,batch_size=10,shuffle=True)
# 2. 定义前向模型
#方式2 单独定义 使用类的方式 class nn.Layer组网
class LinearModel(nn.Layer):def __init__(self):super(LinearModel,self).__init__()self.linear=nn.Linear(1,1)def forward(self,x):x=self.linear(x)return x
#定义模型的对象
model=LinearModel()# 3.使用高层api进行封装
# step1 使用paddle.Model(xxx)进行封装
model=paddle.Model(model)
#step2 使用prepare
model.prepare(optimizer=paddle.optimizer.SGD(learning_rate=0.01,parameters=model.parameters()),loss=nn.MSELoss(),metrics=paddle.metric.Accuracy())#高级API模型的加载
model.load("./高层API1/final")
#验证
dataset=TensorDataset([paddle.to_tensor([1.5],dtype=paddle.float32),paddle.to_tensor([82],dtype=paddle.float32)])
datalaoder_eval=DataLoader(dataset)
eval_pre=model.evaluate(datalaoder_eval,verbose=1)
print(eval_pre)#预测
dataset=TensorDataset([paddle.to_tensor([1.5],dtype=paddle.float32)])
datalaoder_eval=DataLoader(dataset)
pre_result=model.predict(datalaoder_eval,verbose=1)
print(pre_result)1.5 paddlepaddle模型网络结构的查看
1.5.1 summary
paddle.summary(model,(1,))
1.5.2 netron
netron pycharm 终端下输入 pip install netron
下载好后,在终端下输入 netron,在浏览器上输入 http://localhost:8080 即可
1.5.3 visualdl
安装网络查看库pip install visualdl==2.5.3
看文档查看结构网络(切记运行的程序不能有中文路径)
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/advanced/visualdl_usage_cn.html
这是使用visualdl写入
from visualdl import LogWriter
logwriter=LogWriter(logdir='logs')
这是使用visualdl查看
查看方式 需要写上host 和port 不然不成功
visualdl --logdir ./logs --model ./logs/model.pdmodel --host 0.0.0.0 --port 8040
二、曲线拟合
从以下2个方面对曲线拟合进行介绍
1.曲线拟合算法理论讲解
2.编程实例与步骤
上面这2方面的内容,让大家,掌握并理解曲线拟合算法。
1.1案例引入
蝌蚪变青蛙
在某池塘中,有某类蝌蚪,它们随着天数的增加,开始慢慢需要觅食,在需要觅食之前,都是从卵黄带来的营养维持生命。
于是采集了7只蝌蚪是否需要觅食的数据:
横坐标的单位是天数;
纵坐标是否需要觅食,0是不需要觅食,1是需要觅食。
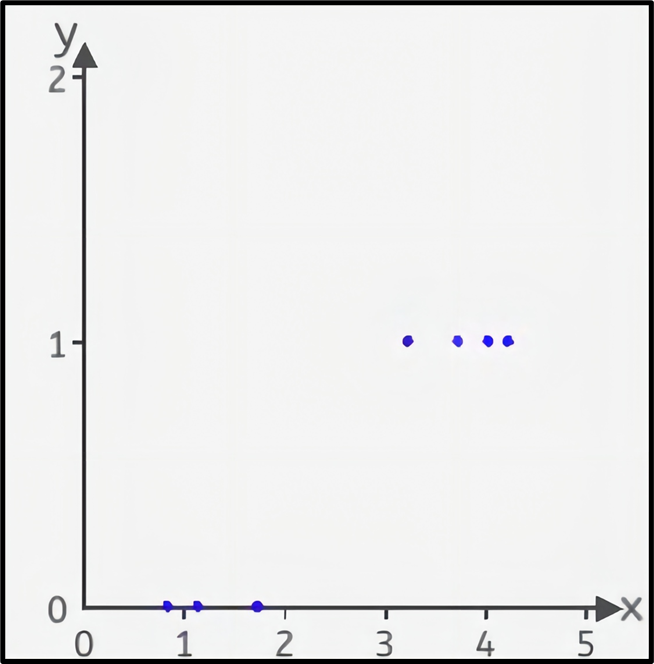
如右图所示 x轴表示天数,y轴表示是否需要觅食。
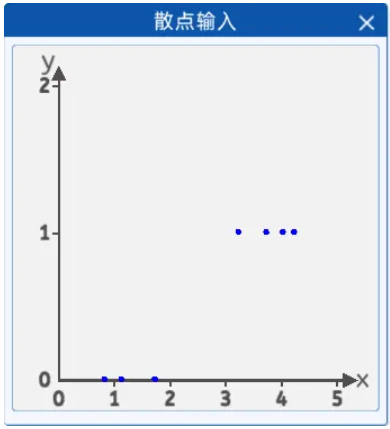
1.2 散点输入
本实验中,采集了天数与是否觅食的的关系数据,x轴表示天数,y轴表示是否觅食,0表示不需要觅食,1表示需要觅食,从图上看有3只蝌蚪是不需要觅食的,3天以下的不需要觅食。有4只需要觅食,大于3天的需要觅食。
并且将它们绘制在一个二维坐标中,其分布如下图所示:
坐标分别为[0.8, 0],[1.1, 0] ,[1.7, 0] ,[3.2, 1] ,[3.7, 1] ,[4.0, 1] ,[4.2, 1]。
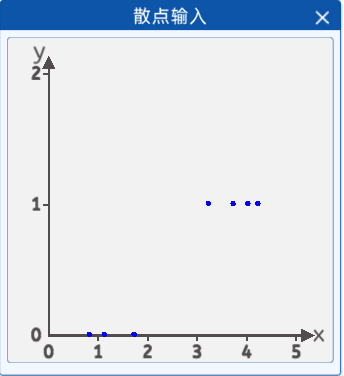
1.3 前向计算
我们的目的是拟合这些散点,通过前向计算,我们通过修改w和b只能部分点落在线上,从实验看直线无法拟合这些点。
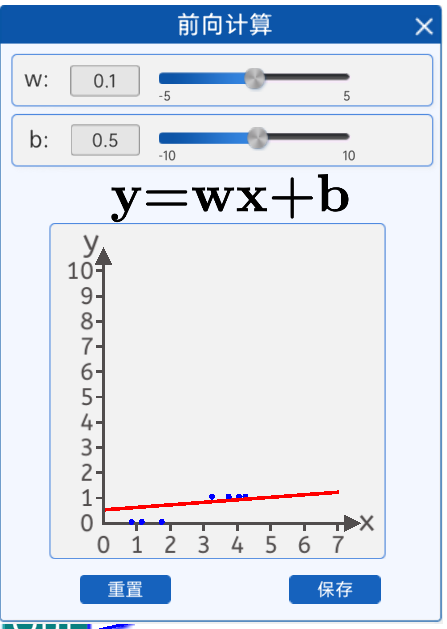
直线无法拟合那应该怎么办呢?
对于直线无法拟合这些点,是不是需要将直线变成曲线来拟合这些散点,在没有引入直线变曲线之前,使用直线是无法拟合这些点的。
这个σ是一个激活函数。
如果σ是阶跃函数,
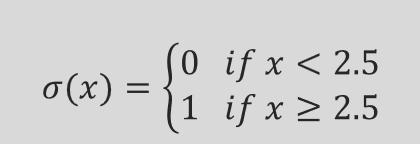
那么这个阶跃函数的缺点是什么?
不连续性:在x=2.5处不连续;
不可导性:在x=2.5处不存在导数;
怎么解决阶跃函数导数不存在的问题呢?
是不是得找一个函数它要处处可微,是连续的,在各个地方都可导的,是不是就能很好的拟合当前曲线了。
1.4 Sigmoid函数引入
sigmoid拟合数据点效果图
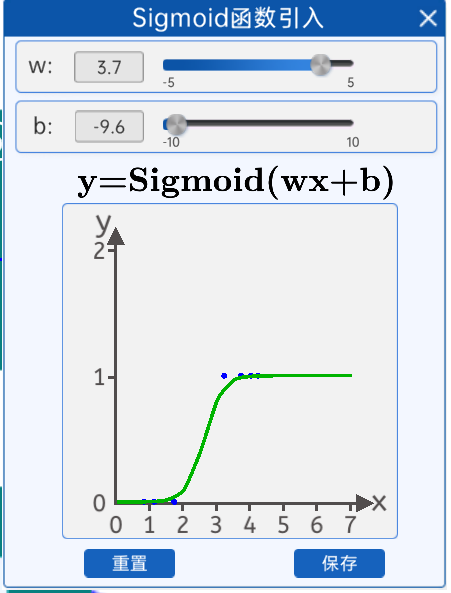
下面引入Sigmoid函数,当然是是前人慢慢发现的这个函数
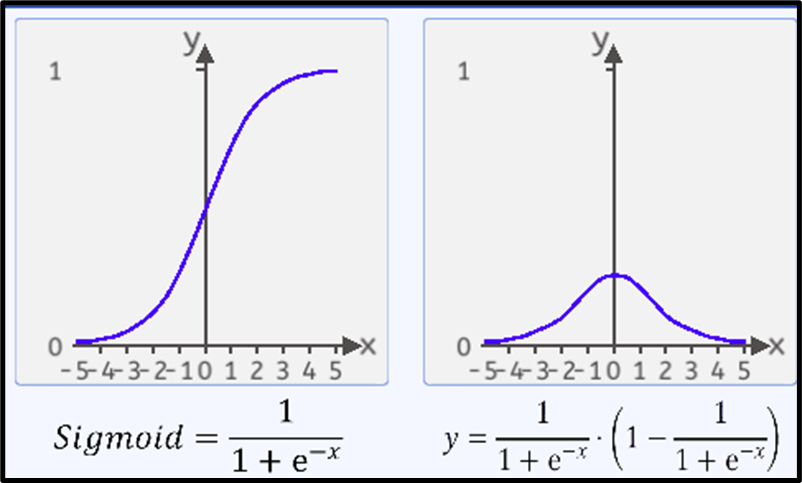
Sigmoid的函数,其函数公式为:
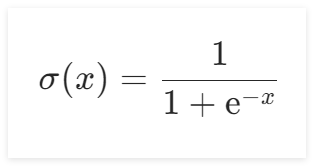
其函数图像如下所示:
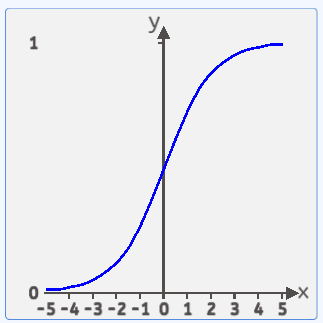
![]() 的值域处于(0,1)之间,两边无限接近于0和1。但永远不等于0和1。定义域是负无穷到正无穷。
的值域处于(0,1)之间,两边无限接近于0和1。但永远不等于0和1。定义域是负无穷到正无穷。
在线性回归中,直线的方程是
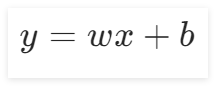
,带入Sigmoid激活函数中,得到:
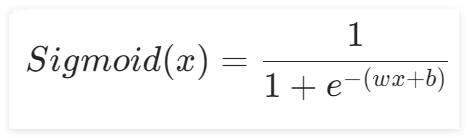
1.5 激活函数的引入
在该实验中,将直线转换成曲线,可以在直线
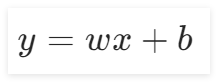
加入一个新的函数
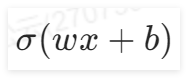
,这个 是一个激活函数,在上面实验中使用的激活函数是Sigmoid函数,当然还有其他激活函数,后面的课程会讲。
是一个激活函数,在上面实验中使用的激活函数是Sigmoid函数,当然还有其他激活函数,后面的课程会讲。
激活函数是神经网络中一种重要的非线性函数,其作用在于引入非线性特性,使得神经网络能够学习和表示更加复杂的数据模式和关系。激活函数通常在每个神经元的输出上应用,将输入信号转换为输出信号。
以下是激活函数的主要作用:
- 引入非线性特性:如果在神经网络中只使用线性变换,例如线性加权和求和,那么整个网络的组合效果将仍然是线性的。激活函数的非线性特性能够在每个神经元上引入非线性转换,从而让神经网络能够学习和表示更加复杂的函数和数据模式。
- 提高模型的表达能力:激活函数的引入增加了神经网络的表达能力,使得网络可以逼近任何复杂的函数,这种特性称为“普遍逼近定理”(Universal Approximation Theorem)。
- 稀疏性和稳定性:一些激活函数(如Relu)具有稀疏性和稳定性的特点,可以缓解梯度消失和梯度爆炸的问题,从而有助于训练更深的神经网络。
梯度消失简单解释:w新=w旧-学习率*梯度 (梯度为0 w新一直等于w旧,引起w不更新就是梯度消失)
梯度爆炸简单解释:w新=w旧-学习率*梯度 (梯度非常大 ,只要大于1,因为模型会有很多层,链式求导法则需要连乘,就会导致梯度爆炸。)
综上所述,激活函数在神经网络中扮演着非常重要的角色,它们的引入使得神经网络具备非线性表达能力,从而能够处理和解决更加复杂的任务。
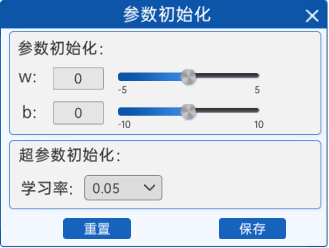
1.6 参数初始化
在之前的前向计算中,可以通过改变自己修改w和b来拟合这条曲线,但是在很多实际场景中,并没办法做到直接求出最优的w,b值,所以需要先随机定一个w和b,然后让梯度下降去拟合这些点。
在“参数初始化”组件中,可以初始化w和b的值以及学习率的值。
1.7 损失函数
根据公式:
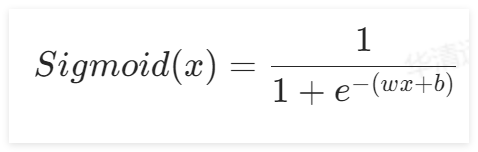
入均方差损失函数中,于是损失函数就成了:
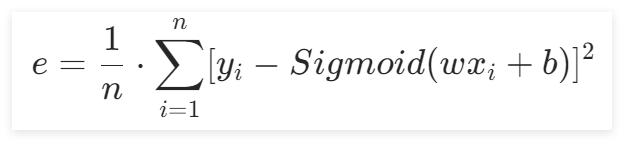

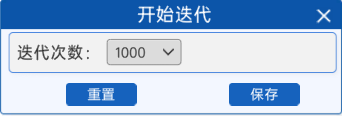
1.8 开始迭代
定义好损失函数后,选择好迭代次数,然后就可以进行反向传播了。
1.9反向传播
在上面得到了损失函数的表达式,本实验中使用梯度下降的方式去降低损失函数值,于是需要对损失函数进行求导:
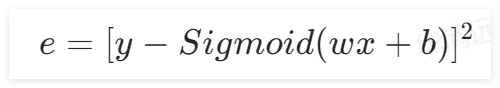
将其拆分成复合函数,得到:
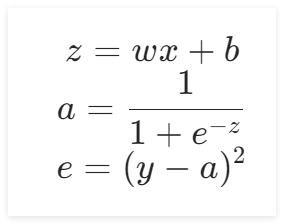
对复合函数求导,可得:
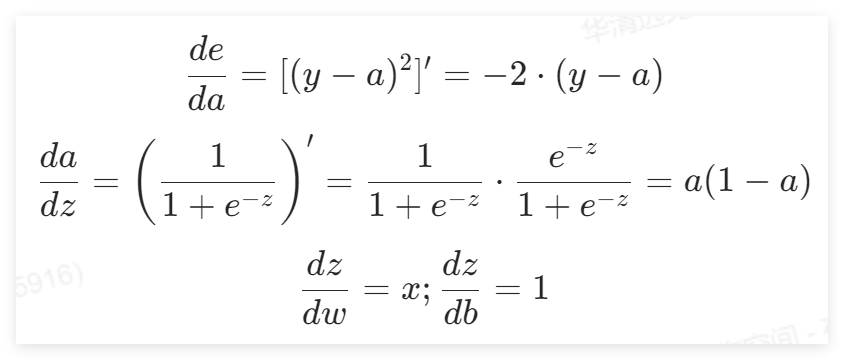
该过程对应了本实验中的“反向传播”组件,其内容如下所示:

1.10 梯度下降显示
为了更好的观察到迭代过程中的参数变化和损失函数的变化,提供了“显示频率组件”,其内容如下图所示:
通过设置显示频率,可以实时反馈当前的参数值和损失值,在“梯度下降显示”组件中可以查看,其组件内容如下图所示:
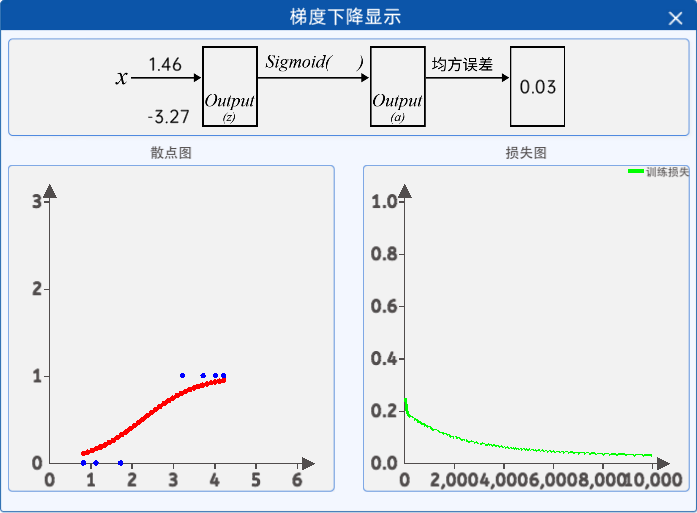
在该图像中,1.46对应的是w的值,-3.27对应的是b的值,0.03是损失值,这三个值都是根据显示频率实时反馈回来的。
左边的图像是根据当前的w和b的值所绘制的曲线,右边的图像是绘制的损失值的变化。
1.11 曲线拟合代码
import numpy as np # 导入 numpy 库,用于数值计算
import matplotlib.pyplot as plt # 导入 matplotlib.pyplot 库,用于绘图# 原始数据,第一列是 x,第二列是 y(标签)
data = np.array([[0.8, 0], [1.1, 0], [1.7, 0], [3.2, 1], [3.7, 1], [4.0, 1], [4.2, 1]])data = np.array(data) # 转换为 numpy 数组 (虽然这里重复了,但保留了原始代码)x_data = data[:, 0] # 获取所有行的第一列 (x 值)
y_data = data[:, 1] # 获取所有行的第二列 (y 值,也就是标签)# 定义 sigmoid 函数
def sigmoid(x):return 1 / (1 + np.exp(-x)) # sigmoid 函数的公式w = 0 # 初始化权重 w
b = 0 # 初始化偏置 b
l = 0.05 # 学习率 learning rate
epochs = 1000 # 迭代次数
fig, (ax1, ax2) = plt.subplots(2, 1) # 创建一个包含两个子图的 figure,垂直排列
epoch_list = [] # 用于存储 epoch 的列表,用于绘制损失曲线
loss_list = [] # 用于存储 loss 的列表,用于绘制损失曲线# 迭代训练
for i in range(1, epochs + 1):z = w * x_data + b # 计算线性模型的输出a = sigmoid(z) # 将线性输出通过 sigmoid 函数,得到预测值loss = np.mean((y_data - a) ** 2) # 计算均方误差损失epoch_list.append(i) # 将当前 epoch 添加到 epoch_listloss_list.append(loss) # 将当前 loss 添加到 loss_list# 反向传播,计算梯度deda = -2 * (y_data - a) # loss 对 a 的导数dadz = a * (1 - a) # sigmoid 函数的导数dzdw = x_data # z 对 w 的导数dzdb = 1 # z 对 b 的导数dw = np.mean(deda * dadz * dzdw) # 计算 w 的梯度db = np.mean(deda * dadz * dzdb) # 计算 b 的梯度# 更新权重和偏置w = w - l * dw # 更新 wb = b - l * db # 更新 b# 每 50 个 epoch 或第一个 epoch,打印 loss 并更新图表if i % 50 == 0 or i == 1:print(f"epoch:{i},loss:{loss}") # 打印 epoch 和 loss# 画图显示x_min = x_data.min() # x 最小值x_max = x_data.max() # x 最大值# 按照等间隔从x_min到x_max之间的数据x_values = np.linspace(x_min, x_max, int(x_max - x_min) * 10) # 在 x_min 和 x_max 之间创建一系列均匀间隔的值y_values = sigmoid(w * x_values + b) # 计算 sigmoid 函数的值# 画第一个图ax1.clear() # 清除 ax1ax1.scatter(x_data, y_data, color='b') # 画散点图# 画曲线ax1.plot(x_values, y_values, c='r') # 画 sigmoid 曲线ax1.set_title(f"Curve Regression: w={round(w, 3)}, b={round(b, 3)}") # 设置 ax1 的标题# 画 ax2ax2.clear() # 清除 ax2ax2.plot(epoch_list, loss_list, color='g') # 画损失曲线ax2.set_xlabel("Epoch") # 设置 x 轴标签ax2.set_ylabel("Loss") # 设置 y 轴标签ax2.set_title(f"Loss Curve") # 设置 ax2 的标题plt.pause(1) # 暂停 1 秒,以便显示图表
三、激活函数
从以下3个方面对激活函数及其导数进行介绍
1.激活函数及其导数算法理论讲解
2.编程实例与步骤
3.实验现象
上面这3方面的内容,让大家,掌握并理解激活函数及其导数算法。
3.1 激活函数及其导数算法理论讲解
24年刚出版的<<激活函数的三十年:神经网络 400 个激活函数的综合调查>>
《Three Decades of Activations: A Comprehensive Survey of 400 Activation Functions for Neural Networks》
包括常用的激活函数和不常用的,400种,大家如果感兴趣可以看看。
文件分享![]() https://share.weiyun.com/3t76DytU
https://share.weiyun.com/3t76DytU
3.2 激活函数的作用?
激活函数的作用就是在神经网络中经过线性计算后,进行的非线性化。
下面讲解Sigmoid,tanh、Relu,Leaky Relu、Prelu、Softmax、ELU七种激活函数。
3.3 激活函数的概念
激活函数给神经元引入了非线性因素,让神经网络可以任意逼近任何非线性函数,
通俗理解为把线性函数转换为非线性函数
3.4 Sigmoid
Sigmoid的函数公式为:
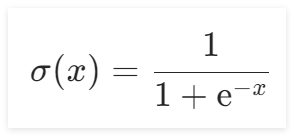
函数图像如下图所示:
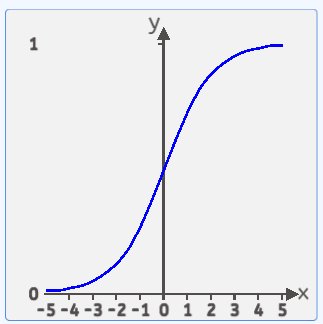
该函数处于(0,1)之间,两边无限接近于0和1,但永远不等于0和1。
sigmoid函数的导数公式为:
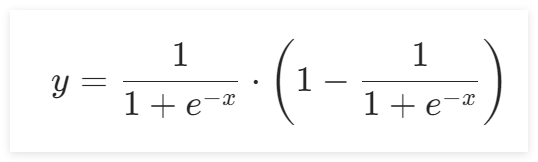
导数图像为:
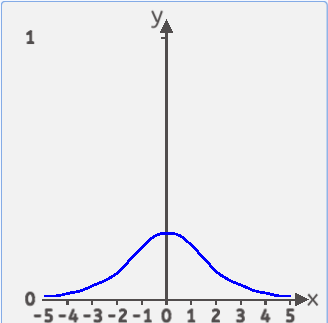
Sigmoid特点总结:
Sigmoid 函数的输出范围被限制在 0 到 1 之间,这使得它适用于需要将输出解释为概率或者介于 0 和 1 之间的任何其他值的场景。
Sigmoid 函数的两端,导数的值非常接近于零,这会导致在反向传播过程中梯度消失的问题,特别是在深层神经网络中。
Sigmoid激活函数有着如下几种缺点:
梯度消失:Sigmoid函数趋近0和1的时候变化率会变得平坦,从导数图像可以看出,当x值趋向两侧时,其导数趋近于0,在反向传播时,使得神经网络在更新参数时几乎无法学习到低层的(不明显的)特征,从而导致训练变得困难。 w新=w旧-lr*梯度
不以零为中心:Sigmoid函数的输出范围是0到1之间,它的输出不是以零为中心的,会导致其参数只能同时向同一个方向更新,当有两个参数需要朝相反的方向更新时,该激活函数会使模型的收敛速度大大的降低
计算成本高:Sigmoid激活函数引入了exp()函数,导致其计算成本相对较高,尤其在大规模的深度神经网络中,可能会导致训练速度变慢。
不是稀疏激活:Sigmoid函数的输出范围是连续的,并且不会将输入变为稀疏的激活状态。在某些情况下,稀疏激活可以提高模型的泛化能力和学习效率。
不以零中心有什么问题?举例讲解:

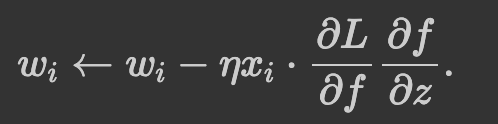
此时,模型为了收敛,w0、w1…改变的方向是统一的,或正或负。所以如果你的最优值是需要w0增加,w1减少,那么不得不向逆风前行的风助力帆船一样,走 Z 字形逼近最优解。如下图所示
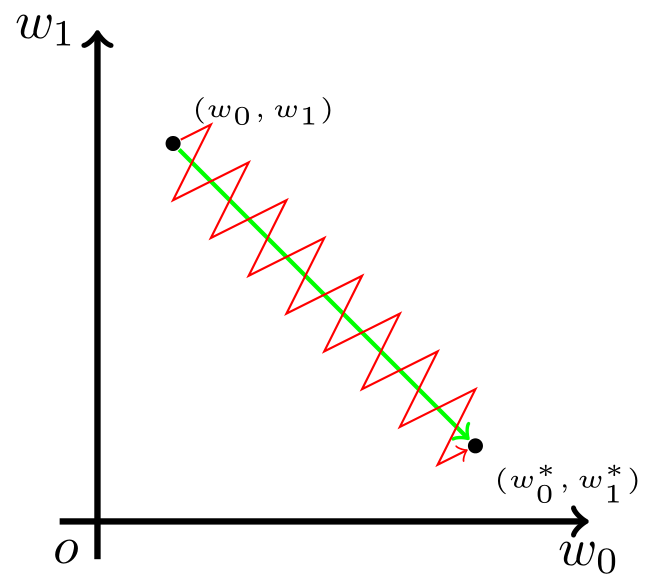
模型参数走绿色箭头能够最快收敛,但由于输入值的符号总是为正,所以模型参数可能走类似红色折线的箭头。如此一来,使用 Sigmoid 函数作为激活函数的神经网络,收敛速度就会慢上不少了。
总结
本文详细介绍了PaddlePaddle框架下线性回归的实现,从模型定义到加载,再到网络结构查看,提供了全面的指导。同时,文章还讲解了曲线拟合的原理,并重点介绍了Sigmoid等激活函数及其导数,强调了激活函数在神经网络中的重要作用。通过本文的学习,读者可以不仅掌握PaddlePaddle的基本使用,还能深入理解线性回归、曲线拟合以及激活函数等核心概念,为后续的深度学习研究打下坚实的基础。
相关文章:

PaddlePaddle线性回归详解:从模型定义到加载,掌握深度学习基础
目录 前言一、paddlepaddle框架的线性回归1.1 paddlepaddle模型的定义方式1.1.1 使用序列的方式 nn.Sequential 组网1.1.2 使用类的方式 class nn.Layer组网1.2 数据加载 1.3 paddlepaddle模型的保存1.3.1 基础API保存1.3.2 高级API模型的保存1.3.2.1 训练fit进行保存1.3.2.2 …...

几种Word转换PDF的常用方法
使用 Word 内置功能 步骤:打开需要转换的 Word 文档,点击左上角的 “文件” 菜单,选择 “另存为”,选择保存位置,在 “保存类型” 下拉菜单中选择 “PDF”,点击 “保存” 按钮即可。适用场景:适…...

【美化vim】
美化vim 涉及文件一个例子 涉及文件 ~/.vimrc修改这个文件即可 一个例子 let mapleader ,set number " 显示行号"set relativenumber " 显示相对行号set incsearch " 实时开启搜索高亮set hlsearch " 搜索结果高亮set autoinden…...

【git】subtree拆分大的git库到多个独立git库
【git】subtree拆分大的git库到多个独立git库 一、拆分一个子目录为独立仓库 # 这就是那个大仓库 big-project git clone gitgithub.com:tom/big-project.git cd big-project# 把所有 eiyo 目录下的相关提交整理为一个新的分支 eiyo_code git subtree split -P eiyo -b eiyo_…...

Elasticsearch 使用reindex进行数据同步或索引重构
1、批量复制优化 POST _reindex {"source": {"index": "source","size": 5000},"dest": {"index": "dest"} }2、提高scroll的并行度优化 POST _reindex?slices5&refresh {"source": {…...

JDBC对数据的增删改查操作:从Statement到PrepareStatement
目录 一 . Statement简介 二. 通过Statement添加数据 1. 创建表 2. 通过Statement添加数据 a. 获取连接 b. 获取Statement对象 c. 定义SQL语句 d. 执行SQL语句 e. 关闭资源 3. 通过Statement修改数据 4. 通过Statement删除数据 三. PreparedStatement的使用(重点) …...

智体OS上线智体管家:对话式智体应用商店访问
DTNS.OS 更新公告 - 智体管家功能发布 🌟 2024年4月22日重要更新:智体管家正式上线 智体管家是智体OS推出的全新功能,旨在让用户通过自然对话轻松发现和使用智体节点上的所有智体应用,相当于为智体网络打造了一个智能化的应用商…...

vscode flutter 插件, vscode运行安卓项目,.gradle 路径配置
Flutter Flutter Widget Snippets Awesome Flutter Snippets i dart-import Dart Data Class Generator Json to Dart Model Dart Getters And Setter GetX Snippets GetX Generator GetX Generator for Flutter flutter-img-syncvscode运行安卓项目,.gradle 路径配…...
数据ETL)
dolphinscheduler实现(oracle-hdfs-doris)数据ETL
dolphinscheduler执行 完整脚本(自行替换相关变量)配置文件conf配置文件解析脚本转base64脚本 完整脚本(自行替换相关变量) user_olsh conf/getInfo.sh Oracle user conf/databases.conf password_olsh conf/getInfo.sh Oracle password conf/databases.conf dblink_olsh conf…...

ViewBS 的工作流程
ViewBS ViewBS 的工作流程 ViewBS 提供多个顶级命令,用于确定所需和最优参数。这些命令可分为两部分:甲基化报告和功能区域的数据可视化。 在甲基化报告部分中,提供多个顶级命令,可以生成关于读取覆盖度、甲基化水平分布、全局甲基化水平等报告。 在功能区域可视化部分…...
)
qt调用deepseek的API开发(附带源码)
今天讲的是使用qt做一个界面(负责接受deepseek返回的数据和客户发送数据的端口)会用流的方式接受数据提高用户体验 测试效果源码流程配置deepseek调用思路deepseek与qt联合开发界面思路 上一篇文章用的不是流开发,会让客户等待很久࿰…...

java中值传递的含义
Java 中的值传递(Pass by Value)详解 在 Java 中,所有参数的传递都是值传递(Pass by Value),但根据传递的数据类型不同(基本类型 vs 引用类型),表现行为会有所不同。 1.…...

【自然语言处理与大模型】如何知道自己部署的模型的最大并行访问数呢?
当你自己在服务器上部署好一个模型后,使用场景会有两种。第一种就是你自己去玩,结合自有的数据做RAG等等,这种情况下一般是不会考虑并发的问题。第二种是将部署好的服务给到别人来使用,这时候就必须知道我的服务到底支持多大的访问…...
单词助手网站)
基于PHP+MySQL实现(Web)单词助手网站
WordHelper 这是一个学习 PHP 的时候依照课程设计的要求,做的一个简单的单词助手。 系统通过 CDN 引入 Vue.js 和 ElementUI,并用 PHP 搭建了一个十分十分简易的后台。 一、设计要求 1、词汇录入与编辑。提供接口让用户录入英文单词、词义、发音、词…...

Java面试实战:谢飞机的求职记 - Spring Boot、Redis与微服务技术问答解析
场景描述 谢飞机,一位自称为“Java全栈大师”的程序员,参加了某互联网大厂的Java开发岗位面试。面试官严肃而专业,针对Spring Boot、Redis缓存以及微服务架构等核心技术展开提问。以下是谢飞机在面试中的表现。 第一轮提问(基础篇…...

【数字图像处理】立体视觉信息提取
双目立体视觉原理 设一个为参考平面,一个为目标平面。增加了一个摄像头后,P与Q在目标面T上有分别的成像点 双目立体视觉:从两个不同的位置观察同一物体,用三角测量原理计算摄像机到该物体的距离的 方法 原理:三角测量…...

解析芯片低功耗设计的底层逻辑与实现方法
芯片低功耗设计的必要性可以从实际需求和技术优化两方面来探讨: 从需求角度看,工艺进步和应用场景共同驱动低功耗设计。 随着CMOS制程持续微缩,晶体管密度和时钟频率提升导致静态功耗显著增加,漏电流问题在先进工艺中尤为明显。…...

uniapp开发2--uniapp中的条件编译总结
以下是对 uni-app 中条件编译的总结: 概念: 条件编译是一种技术,允许你根据不同的平台或环境,编译不同的代码。 在 uni-app 中,这意味着你可以编写一套代码,然后根据要编译到的平台(例如微信小…...

Netty 异步机制深度解析:Future 与 Promise 的前世今生
引言:异步编程的「糖」与「痛」 在高性能网络编程中,「异步」几乎是必备的设计模式,异步的好处就是可以提升系统吞吐量,提升效率。但很多开发者初入 Netty 时,对它的异步机制总有点模糊: 为什么 ChannelF…...

如何查看MySql主从同步的偏移量
1.Mysql的主从同步方案 mysql为了在实现读写分离,主库写,从库读 mysql的同步方案主要是通过从库读取主库的binlog日志的方式。 binlog就是一个记录mysql的操作的日志记录,从库通过拿到主库的binlog知道主库进行了哪些操作,然后在从…...

短信验证码安全实战:三网API+多语言适配开发指南
在短信服务中,创建自定义签名是发送通知、验证信息和其他类型消息的重要步骤。万维易源提供的“三网短信验证码”API为开发者和企业提供了高效、便捷的自定义签名创建服务,可以通过简单的接口调用提交签名给运营商审核。本文将详细介绍如何使用该API&…...

护眼-科学使用显示器
一 显示色温对眼睛的影响 显示器的色温设置对护眼效果至关重要,合适的色温可减少蓝光伤害并缓解视疲劳。最护眼的色温并非固定值,需根据环境光、使用时间和场景动态调整。白天推荐6500K左右,夜晚降至3000K-4000K,并借助自动调节工…...

HarmonyOS:1.7
判断题 1.订阅网络状态变化事件时,通过NetConnection类型的对象调用on方法,传入具体事件类型即可: 错误(False) 2.若使用HTTP发起一个GET请求,直接调用get方法,传入请求资源的URL,即可发起请求ÿ…...

物联网赋能玻璃制造业:实现设备智能管理与生产协同
在当今数字化时代,物联网技术正深刻改变着传统制造业的发展模式,玻璃制造业也不例外。物联网的赋能,为玻璃制造业带来了设备智能管理与生产协同的新机遇,推动其向智能化、高效化迈进。 在设备智能管理方面,物联网通过…...

【我的创作纪念日】 --- 与CSDN走过的第365天
个人主页:夜晚中的人海 不积跬步,无以至千里;不积小流,无以成江海。-《荀子》 文章目录 🎉一、机缘🚀二、收获🎡三、 日常⭐四、成就🏠五、憧憬 🎉一、机缘 光阴似箭&am…...

路由器转发规则设置方法步骤,内网服务器端口怎么让异地连接访问的实现
在路由器上设置端口转发(Port Forwarding)可以将外部网络流量引导到特定的局域网设备,这对于需要远程访问服务器、摄像头、游戏主机等设备非常有用。 登录路由器管理界面,添加端口转发规则让外网访问内网的实现教程分享。以下是设…...

Kotlin 的 suspend 关键字
更多相关知识 Kotlin 的 suspend 关键字是 Kotlin 协程的核心组成部分,它用于标记一个函数可以被挂起(暂停执行)并在稍后恢复执行,而不会阻塞线程。 理解 suspend 的作用需要从以下几个方面入手: 1. 允许非阻塞的异步…...

Java面试实战:从Spring Boot到微服务的深入探讨
Java面试实战:从Spring Boot到微服务的深入探讨 场景:电商场景的面试之旅 在某互联网大厂的面试间,面试官李老师正襟危坐,而对面坐着的是传说中的“水货程序员”赵大宝。 第一轮:核心Java与构建工具 面试官&#x…...
)
文件操作和IO(上)
绝对路径和相对路径 文件按照层级结构进行组织(类似于数据结构中的树型结构),将专门用来存放管理信息的特殊文件称为文件夹或目录。对于文件系统中文件的定位有两种方式,一种是绝对路径,另一种是相对路径。 绝对路径…...
 核心源码深入解析】Apps 模块)
【Dify(v1.2) 核心源码深入解析】Apps 模块
重磅推荐专栏: 《大模型AIGC》 《课程大纲》 《知识星球》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容ÿ…...

小测验——根据调整好的参数进行批量输出
文章目录 一、前言与目的二、思考坐标系怎么生成2.1 补2.2 对于自己投影代码中对数据集参数的情况(取负)总结三、代码2.1 用这套代码可视化 pytorch3d能跑通的例子2.2 gshell的例子2.3 直接手写投影的例子四、思路4.1 确定牛和衣服方向4.2 推测牛的视角4.3 教程学习4.3.1 fov…...

蓝耘平台介绍:算力赋能AI创新的智算云平台
一、蓝耘平台是什么 蓝耘智算云(LY Cloud)是蓝耘科技打造的现代化GPU算力云服务平台,深度整合自研DS满血版大模型技术与分布式算力调度能力,形成"模型算力"双轮驱动的技术生态。平台核心优势如下: 平台定位…...
)
23种设计模式-结构型模式之桥接模式(Java版本)
Java 桥接模式(Bridge Pattern)详解 🌉 什么是桥接模式? 桥接模式用于将抽象部分与实现部分分离,使它们可以独立变化。 通过在两个独立变化的维度之间建立“桥”,避免因多维度扩展导致的类爆炸。 &#x…...

Python常用的第三方模块之数据分析【pdfplumber库、Numpy库、Pandas库、Matplotlib库】
【pdfplumber库】从PDF文件中读取内容 import pdfplumber #打开PDF文件 with pdfplumber.open(DeepSeek从入门到精通(20250204).pdf) as pdf:for i in pdf.pages: #遍历页print(i.extract_text()) #extract_text()方法提取内容print(f----------------第{i.page_number}页结束…...

PerfettoSQL
# Device State: Top App # select id, ts, dur, name from (__query_slice_track__long_battery_tracing_Device_State_Top_app) --> 简便方法 """ INCLUDE PERFETTO MODULE android.battery_stats; select * from android_battery_stats_event_s…...

【Python笔记 03 】运算符
一、算数运算符 1、加减乘除 #加法 print (11) #减法 print (1-1) #乘法 print (1*1) #除法,注:商一定是float浮点数,不管是否能整数,且除数不能为0,如下图: print (1/1) 如果除数为0即报错提示。 …...

组网技术-BGP技术,IS-IS协议,VRRP技术
1.BGP在不同自治系统AS进行路由转发 EBGP外部边界网关协议 IBGP内部边界网关协议 2.AS指的是同一个组织管理下,使用统一选路策略的设备集合 3.AS直接需要直连链路,或者通过VPN协议构造逻辑直连进行邻居建立 4.使用IGP可能存在暴露AS内部的网络信息的…...

Word处理控件Spire.Doc系列教程:C# 为 Word 文档设置背景颜色或背景图片
在 Word 文档中,白色是默认的背景设置。一般情况下,简洁的白色背景足以满足绝大多数场景的使用需求。但是,如果您需要创建简历、宣传册或其他创意文档,设置独特的背景颜色或图片能够极大地增强文档的视觉冲击力。本文将演示如何使…...

极狐GitLab 中如何自定义角色?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 自定义角色 (ULTIMATE ALL) 引入于极狐GitLab 15.7,功能标志为 customizable_roles。默认启用于极狐GitLab 15.9…...

JAVA:Web安全防御
目录 一、Web安全基础与常见威胁 OWASP Top 10核心漏洞解析 • SQL注入(SQLi)、跨站脚本(XSS)、跨站请求伪造(CSRF) • 不安全的反序列化、敏感数据泄露 Java后端常见攻击场景 • 通过HttpServletRequest…...

Nginx:支持 HTTPS
文章目录 Nginx 开启 ssl 以支持 HTTPS1 生成本地证书2 开启 ssl 以支持 HTTPS3 将 https 的请求转发给 http 最终的 nginx.conf 如下 Nginx 开启 ssl 以支持 HTTPS [!IMPORTANT] 在下文中,将采用如下定义。 HTTP端口: 80 HTTPS端口: 443 服务…...
_分布式优化思路02_yxy)
数据库性能优化(sql优化)_分布式优化思路02_yxy
数据库性能优化_分布式优化思路02 1 核心优化策略(二)_分区智能连接优化2 核心优化策略(三)_数据本地化3 核心优化策略(四)_选择正确的数据分发方式1 核心优化策略(二)_分区智能连接优化 分区智能连接出现在多个表进行连接时的优化策略,优化效率非常明显 分区智能连接是指:…...

【网络】代理服务器收尾及高级IO
全是通俗易懂的讲解,如果你本节之前的知识都掌握清楚,那就速速来看我的笔记吧~ 自己写自己的八股!让未来的自己看懂! (全文手敲,受益良多) 本文主要带你了解什么是高级IO,以及常…...

基于大疆行业无人机的特色解决方案-无线通信篇:基于蜂窝以及自组网MESH的无线通信C2链路
基于大疆行业无人机的特色解决方案-无线通信篇:基于蜂窝以及自组网MESH的无线通信C2链路 大疆无人机目前是业内性价比最有优势的无人机产品,尤其是机场3的推出,持续产品升级迭代,包括司空2、大疆智图以及大疆智运等专业软件、各种…...

js实现2D图片堆叠在一起呈现为3D效果,类似大楼楼层的效果,点击每个楼层不会被其他楼层遮挡
js实现2D图片堆叠在一起呈现为3D效果,类似大楼楼层的效果,点击每个楼层不会被其他楼层遮挡。实现过程使用元素的绝对定位,通过伪元素设置背景图片和文字,效果如下: index.jsx: import React, { useEffect,…...

【安装部署】Linux下最简单的 pytorch3d 安装
最近接触一个项目需要用到 pytorch3d 库,找了好多眼花缭乱的资料,最后发现大道至简~ 1、查看 python,cuda,pytorch 的版本 source activate myMRI # 激活环境 python --version # python 版本查看 nvcc --version # cuda…...

【在阿里云或其他 CentOS/RHEL 系统上安装和配置 Dante SOCKS5 代理服务】
在阿里云或其他 CentOS/RHEL 系统上安装和配置 Dante SOCKS5 代理服务 什么是SOCKS5?前提条件步骤 1:安装 Dante SOCKS5 服务步骤 2:创建专用代理用户(推荐)步骤 3:配置 Dante 服务步骤 4:设置日…...

第十五讲、Isaaclab中在机器人上添加传感器
0 前言 官方教程:https://isaac-sim.github.io/IsaacLab/main/source/tutorials/04_sensors/add_sensors_on_robot.html IsaacsimIsaaclab安装:https://blog.csdn.net/m0_47719040/article/details/146389391?spm1001.2014.3001.5502 传感器有助于智能…...

网络设备智能巡检系统-MCP案例总结
一、案例背景与目标 背景: 企业网络中存在多厂商(华为、H3C、思科等)设备,传统巡检需人工逐台登录,效率低且易出错。 目标: 开发基于自然语言的智能巡检系统,实现: 自然语言指令解析多厂商设备自动化巡检结构化报告生成技术栈: Python + Ollama + Netmiko + FastAPI…...
)
力扣2685(dfs)
我们对每个连通块进行dfs,在深搜的过程中,定义两个变量v,e.其中v表示该连通图的节点数量,e表示该连通图中边的数量的两倍。为什么是两倍呢?因为我们针对某个节点进行dfs的过程中,我们让e加上这个节点所连边的数量&…...