django之数据的翻页和搜索功能
数据的翻页和搜素功能
目录
1.实现搜素功能
2.实现翻页功能
一、实现搜素功能
我们到bootstrap官网, 点击组件, 然后找到输入框组, 并点击作为额外元素的按钮。
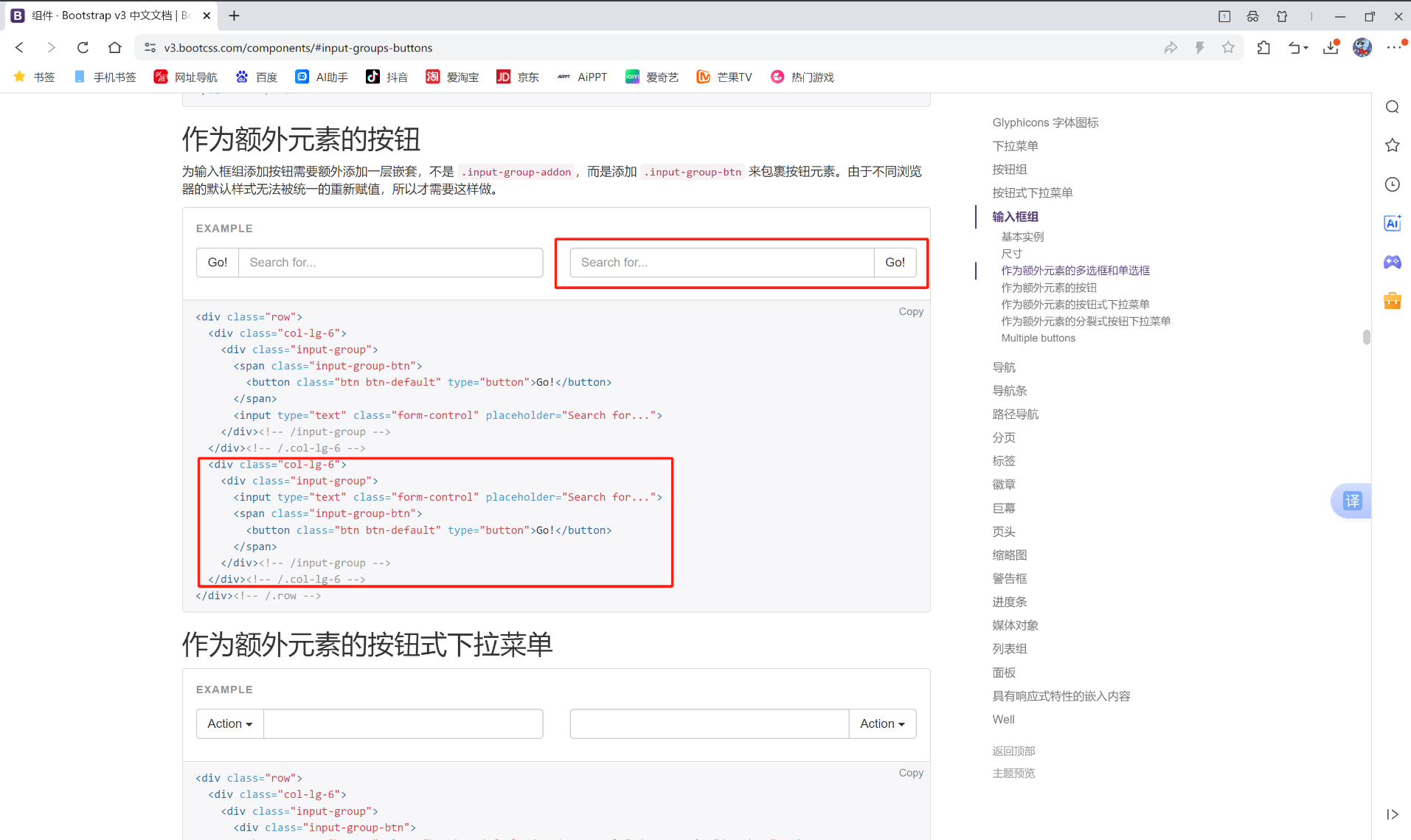
我们需要使用上面红色框里面的组件, 就是搜素组件, 代码部分就是下面红色框框出来的部分。
把这里的代码复制到assets_list.html里面:
{% extends "index/model_tmp.html" %}{% block content %}<div class="container"><a href="/assets/add/" class="btn btn-success">添加信息</a>{# 实现搜素查询, 将查询的框和按钮都放在右边 #}<div style="float: right">{# 这里面搜素信息, 需要用到get请求方法, 所以还是要用到form, method是get, 之后使用搜素功能会在网址里面多一个参数, 叫做search, 网址格式变为http://ip:port/路径?search=搜素的内容 #}<form method="get">{# 这里面就是网上复制粘贴的代码 #}<div class="input-group" style="float: right;width: 300px;"><input type="text" class="form-control" name="search" placeholder="Search for..."><span class="input-group-btn"><button class="btn btn-default" type="submit">搜索</button></span></div></form></div><div class="panel panel-danger"><div class="panel-heading"><h3 class="panel-title">资产表</h3></div><div class="panel-body"><table class="table table-hover"><thead><tr><th>ID</th><th>手机号</th><th>状态</th><th>创建时间</th><th>使用者</th><th>价格</th></tr></thead><tbody>{% for data in assets_list %}<tr><th scope="row">{{ data.id }}</th><td>{{ data.mobile }}</td>{% if data.status == 1 %}<td style="color: green">{{ data.get_status_display }}</td>{% else %}<td style="color: red">{{ data.get_status_display }}</td>{% endif %}<td>{{ data.create_time|date:"Y-m-d" }}</td><td>{{ data.user.name }}</td><td>{{ data.price }}</td><td style="color: green"><a href="/assets/{{ data.id }}/modify"><span style="color: green;"class="glyphicon glyphicon-pencil"aria-hidden="true"></span></a><a href="/assets/{{ data.id }}/del/"><span style="color: red;"class="glyphicon glyphicon-trash"aria-hidden="true"></span></a></td></tr>{% endfor %}</tbody></table></div></div></div>
{% endblock %}
后端代码assets.py:
from django.core.exceptions import ValidationError
from django.core.validators import RegexValidator
from django.shortcuts import render, redirect
from django.utils.safestring import mark_safe
from django import formsfrom project_one import models# Create your views here.
def assets(request):# 搜索信息dict_data = {}# 获取搜素框里的内容, 就是获取网址里面的search参数的值value = request.GET.get('search')if value:# 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__containsdict_data["mobile__contains"] = value# 通过搜素框里面的内容, 在表格里查找手机号, 将查找的结果展示出来assets_list = models.Assets.objects.filter(**dict_data)return render(request, "assets/assets_list.html", {"assets_list": assets_list})
这里的assets函数, 还是上次写好的函数, 路由也是上次配置好的, 我们这篇文章只需要修改这个函数里面的内容即可。
运行结果:
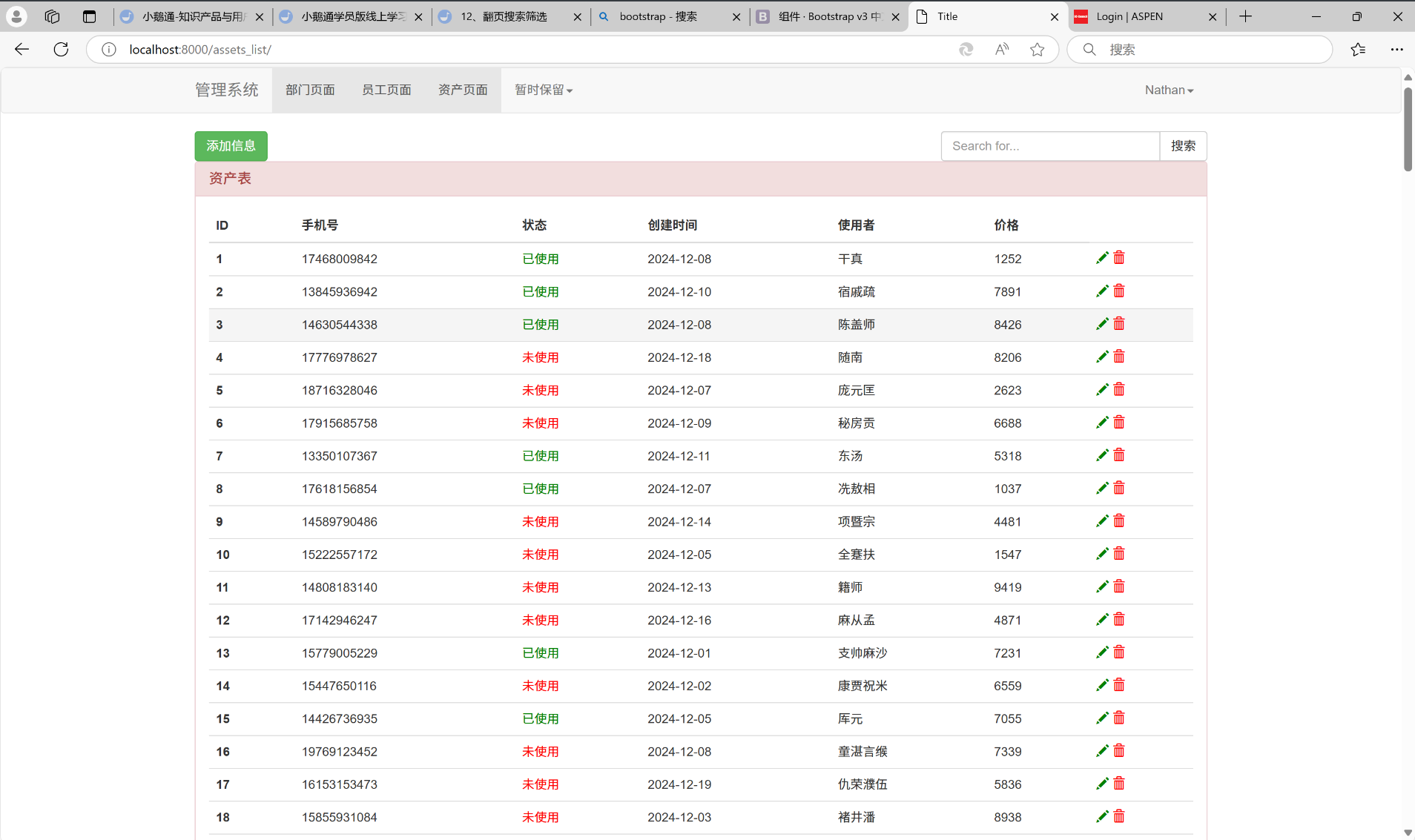
这里面有很多数据, 我们使用搜素功能看看有什么结果。
假如我们搜素158:
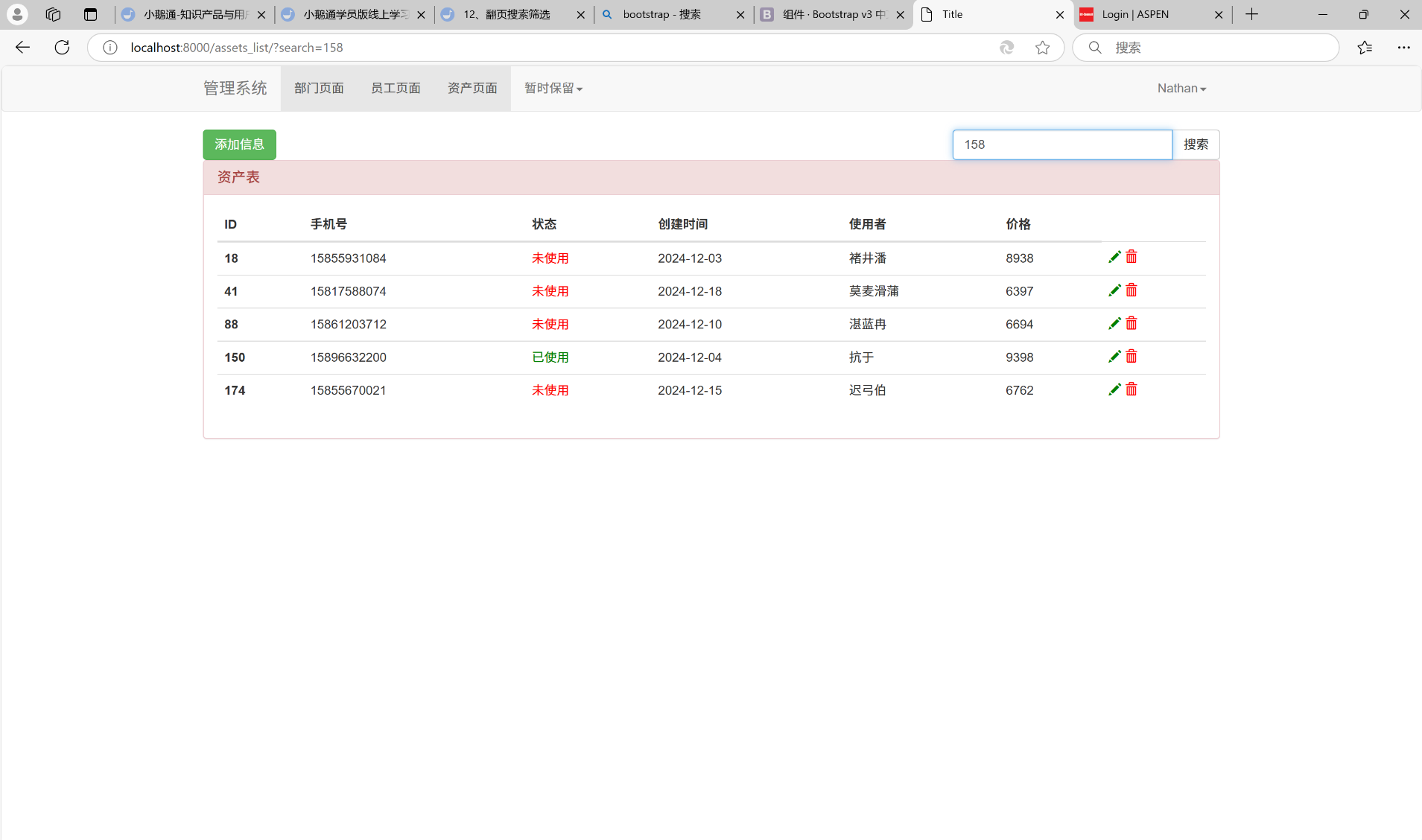
页码会展示带有158的电话号码(这个搜素, 可以搜素匹配手机号的任意位置, 但是搜所的内容, 和匹配的电话里面的数字必须连续匹配的上, 比如搜素框里面是33589, 但是实际有个电话号码有部分包含33580, 这种情况就匹配不出来)。
还有当我们在搜索框没有任何内容的时候, 再点击搜索按钮, 就会把所有数据都展示出来。
这个就是搜素功能。整体代码相对简单, 不过需要注意的是: value = request.GET.get(‘search’)这行代码, 是用户获取在url里面的search参数的值, 比如象上面我搜索的158, 在url里面后面跟着?search=158, 所以这里的value, 获取的就是158。
if value: // 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__contains dict_data["mobile__contains"] = value这里的代码意思是如果获取到了搜索框里面的内容, 那就添加字典里面, 并且
key为
mobile__contains, 这个mobile__contains千万不能写错, 下划线_是两个, 不能漏写也不能多写, 这个是按照手机号来查询数据。然后 再用assets_list = models.Assets.objects.filter(**dict_data)这行代码, 将我想要查询的数据查询出来, 注意在filter里面要用**dict_data, 因为dict_data是个字典。
二、实现翻页功能
我们在bootstrap里面找到分页的代码:
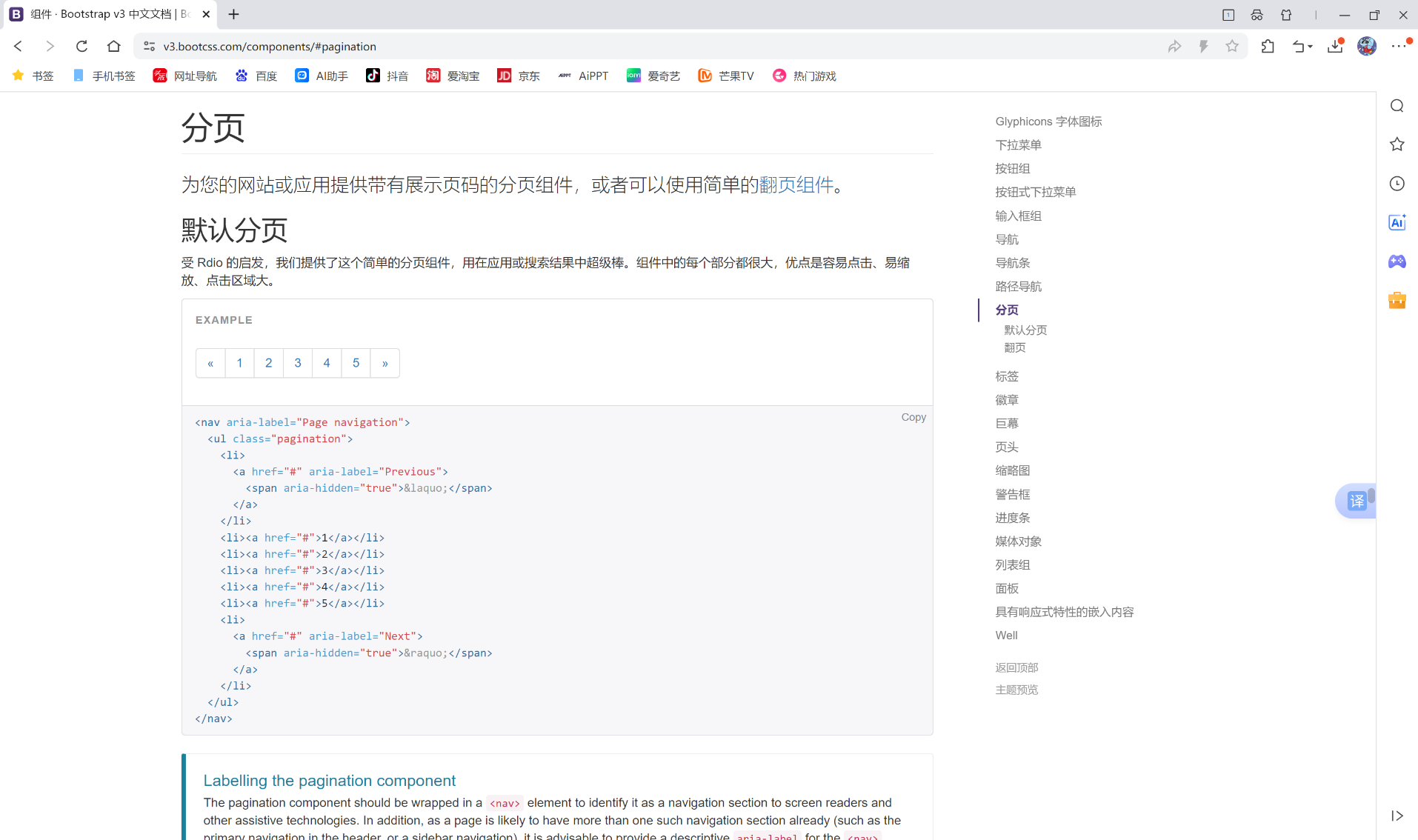
将它复制黏贴到代码里面:
assets.html:
{% extends "index/model_tmp.html" %}{% block content %}<div class="container"><a href="/assets/add/" class="btn btn-success">添加信息</a>{# 实现搜素查询 #}<div style="float: right"><form method="get"><div class="input-group" style="float: right;width: 300px;"><input type="text" class="form-control" name="search" placeholder="Search for..."><span class="input-group-btn"><button class="btn btn-default" type="submit">搜索</button></span></div></form></div><div class="panel panel-danger"><div class="panel-heading"><h3 class="panel-title">资产表</h3></div><div class="panel-body"><table class="table table-hover"><thead><tr><th>ID</th><th>手机号</th><th>状态</th><th>创建时间</th><th>使用者</th><th>价格</th></tr></thead><tbody>{% for data in assets_list %}<tr><th scope="row">{{ data.id }}</th><td>{{ data.mobile }}</td>{% if data.status == 1 %}<td style="color: green">{{ data.get_status_display }}</td>{% else %}<td style="color: red">{{ data.get_status_display }}</td>{% endif %}<td>{{ data.create_time|date:"Y-m-d" }}</td><td>{{ data.user.name }}</td><td>{{ data.price }}</td><td style="color: green"><a href="/assets/{{ data.id }}/modify"><span style="color: green;"class="glyphicon glyphicon-pencil"aria-hidden="true"></span></a><a href="/assets/{{ data.id }}/del/"><span style="color: red;"class="glyphicon glyphicon-trash"aria-hidden="true"></span></a></td></tr>{% endfor %}</tbody></table></div></div>{# 实现分页查询 #}<ul class="pagination"><li><a href="#" aria-label="Previous"><span aria-hidden="true">«</span></a></li><li><a href="?page=1">1</a></li><li><a href="?page=2">2</a></li><li><a href="?page=3">3</a></li><li><a href="?page=4">4</a></li><li><a href="?page=5">5</a></li><li><a href="#" aria-label="Next"><span aria-hidden="true">»</span></a></li></ul></div>
{% endblock %}
后端assets.py:
from django.core.exceptions import ValidationError
from django.core.validators import RegexValidator
from django.shortcuts import render, redirect
from django.utils.safestring import mark_safe
from django import formsfrom project_one import models# Create your views here.
def assets(request):# assets_list = models.Assets.objects.all()# 搜索信息dict_data = {}# 获取搜素框里的内容, 就是获取网址里面的search参数的值value = request.GET.get('search')if value:# 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__containsdict_data["mobile__contains"] = value# assets_list = models.Assets.objects.filter(**dict_data)# 获取分页组件里面选中的页码, 也是获取网址里面的page参数的值page = int(request.GET.get('page', 1))# 每一页查询10条数据page_size = 10# 当前页开始的数据start = (page - 1) * page_size# 当前页结尾的数据end = page_size * page# 利用切片, 实现分页查询, 查询出当页数据assets_list = models.Assets.objects.filter(**dict_data)[start:end]return render(request, "assets/assets_list.html", {"assets_list": assets_list})
运行结果:
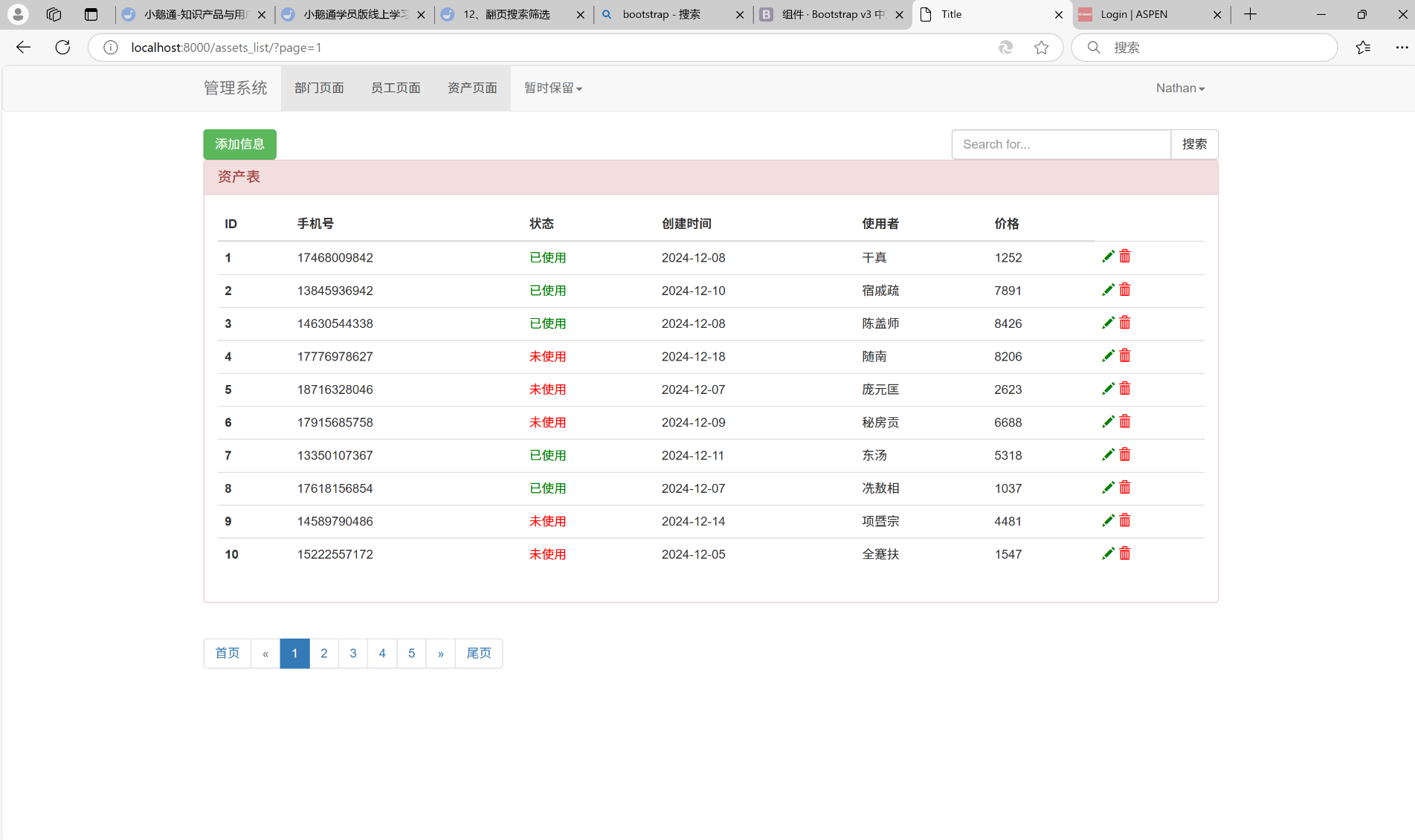
我们会发现, 当我们点击第一页的时候, 就给我们展示第一页的数据
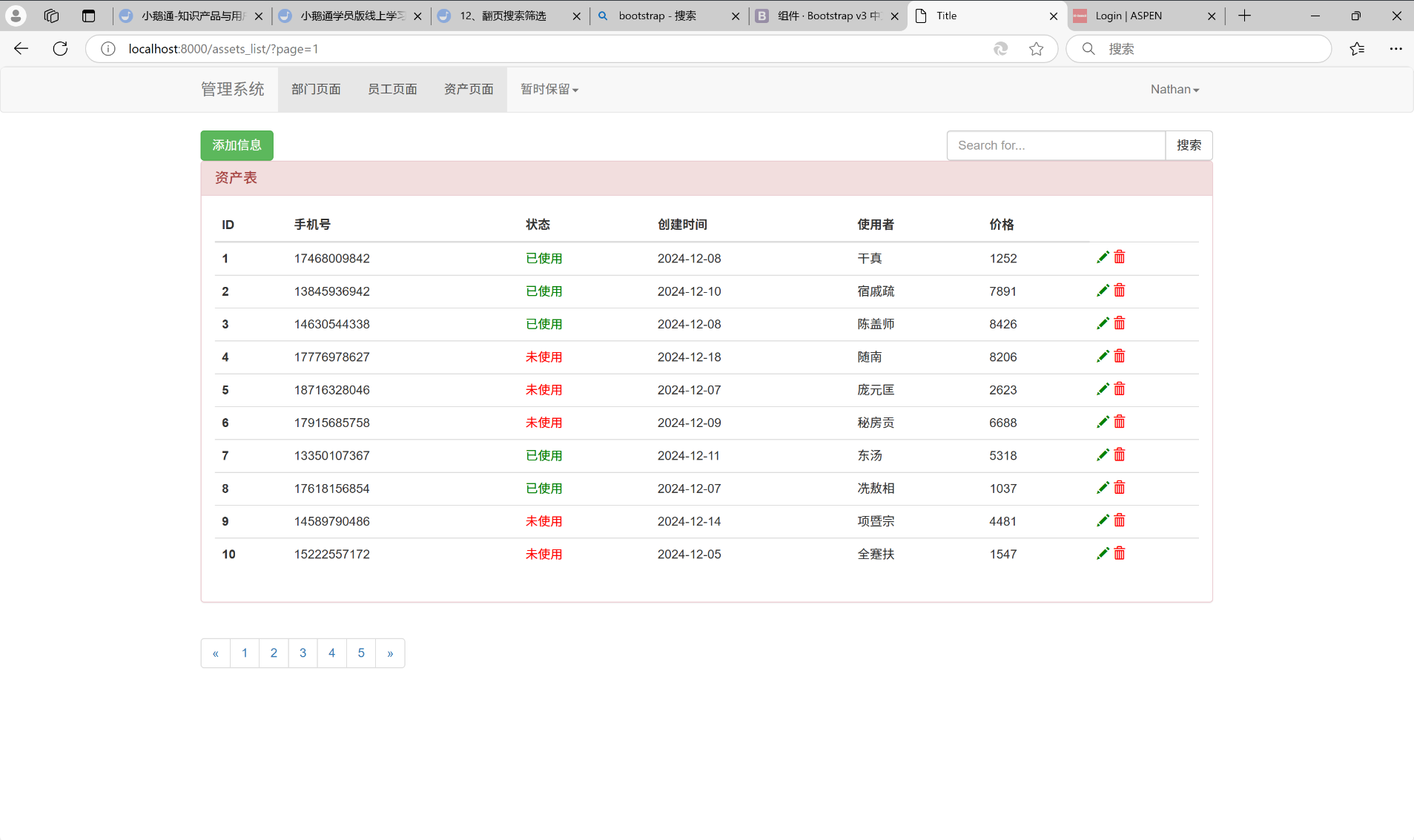
点击第几页, 就给我们展示第几页的数据。
但是光这五页数据, 肯定是不够的。当我们数据量大的时候, 需要几十页甚至于上百页上千页数据。
不过这又出现了一个问题, 如果有上百页上千页数据的话, 难道我们需要在分页组件里写上百条上千条li和a吗?这样显然不可行, 所以我们可以统一写五个带有页码的按钮, 但是这五个按钮, 页码会变化。
假如我们有20页数据要展示:
当我们点击1到3页的时候, 这五个按钮依然显示1, 2, 3, 4, 5, 但是当我们点击4的时候, 这五个按钮就要显示2, 3, 4, 5, 6了, 后面以此类推, 当我们点击18, 19或者20的时候, 这五个按钮显示16, 17, 18, 19, 20。我们可以发现一个规律, 就是我们选中的页数, 除了1, 2, 3, 18, 19, 20以外, 其他所有我们选中的页码, 离最左边和最右边的页码始终相差2。而页码最前面只有点击到4的时候, 五个按钮里面的页码才会开始发生变化, 页码最后面只有到18开始, 页码才不会变化。
我们可以设plus=2, 这个2指的是我们选中的页码, 离最左边和最右边的页码始终相差2。开始页用start_page, 结束页用end_page。
代码:
assets.py部分代码:
# 统计表当中的总个数data_asset_count = models.Assets.objects.filter(**dict_data).count()# 求得表中的总个数都需要多少页来展示, page_num代表总页数, div代表剩余的数据还有多少条page_count, div = divmod(data_asset_count, page_size)if div:page_count += 1# 我们需要在分页组件里面展示五个页码。# 当我们选中的页数, 和最左边最右边显示的页数相差2, 所以我们将plus设置为2, 比如我选择第三页, 那最左边显示的页码是1最右边显示的页码是5。plus = 2# 我们想要分页功能, 展示其中5个页码, 如果想要展示不同个页数的页码, 自己可以调整。# 当总页数不超过5页的时候, 1 + 2 * plus意思是当前选择的页, 加上左边还有两页, 右边也还有两页, 总共是5页。if data_asset_count <= 1 + 2 * plus:# 开始页数为1start_page = 1# 结束位置就是总页数end_page = data_asset_count# 这里面全是总页数大于5页的情况else:# 如果我目前选择的页码, 小于等于3if page <= plus + 1:# 开始页还是1start_page = 1# 结束页是5, 1 + 2 * plus这个意思上面有注释。end_page = 1 + 2 * plus# 如果我目前选择的页码加上2能够大于总页数, 那就说明分页组件里面的页码是最后五页数据了, 比如总页数为20, 我选择的是第19页, 19+2=21>20elif page + plus > page_count: # 这里写>=也可以# 开始页为总页数减去两倍的plus, 比如总共有20页, 当我们分页组件显示的页码是最后五页的时候, 最左边应该显示的是16。所以正好是总页数-两倍的plusstart_page = page_count - 2 * plus# 结尾页展示的就是总页数end_page = page_count# 如果我们目前选择的页码就在正中间, 排除1, 2, 3, 19, 20页的其它所有页数。else:# 开始页数就是当前分页组件选择的页数-plusstart_page = page - plus# 结束页数就是当前分页组件选择的页数+plusend_page = page + plus
然后我们需要实现动态添加html代码:
# 创建一个列表, 用于存储html代码, 以字符串来保存到列表中html_list = []# 分页组件返回到首页功能html_list.append(f"""<li><a href="?page=1">首页</a></li>""")# 如果当前选择的页码>1, 可以往前退一页, 否则不能在往前退了。在li标签上加class="disabled"代表禁用if page > 1:html_list.append(f"""<li><a href="?page={page - 1}"><span aria-hidden="true">«</span></a></li>""")else:html_list.append("""<li class="disabled"><spanaria-hidden="true">«</span></li>""")# 分页组件的中间翻页的内容, 点击第几页就到第几页, 在分页组件当中, 选中的页码会有背景色。li标签里面的class='active'代表选中了那个页码, 会出现背景色for page_num in range(start_page, end_page + 1):if page_num == page:html_list.append(f"<li class='active'><a href='?page={page_num}'>{page_num}</a></li>")else:html_list.append(f"<li><a href='?page={page_num}'>{page_num}</a></li>")# 如果当前选择的页码<总页数, 可以往前进一页, 否则不能在往进退了。在li标签上加class="disabled"代表禁用if page < page_count:html_list.append(f"""<li><a href="?page={page + 1}"><span aria-hidden="true">»</span></a></li>""")else:html_list.append("""<li class="disabled"><spanaria-hidden="true">»</span></li>""")# 分页组件进入到尾页功能html_list.append(f"""<li><a href="?page={page_count}">尾页</a></li>""")# join就是将列表当中所有的内容全部拼接在一起为字符串。mark_safe函数的作用是将字符串里面的内容, 转换为html元素。# mark_safe也是django框架里面的函数, 需要手动导入, 导入语句为from django.utils.safestring import mark_safepage_string = mark_safe("".join(html_list))
最后不要忘记return了。
# 不能忘记将page_string传给前端。
return render(request, "assets/assets_list.html", {"assets_list": assets_list})
完整代码:
from django.core.exceptions import ValidationError
from django.core.validators import RegexValidator
from django.shortcuts import render, redirect
from django.utils.safestring import mark_safe
from django import formsfrom project_one import models# Create your views here.
def assets(request):# assets_list = models.Assets.objects.all()# 搜索信息dict_data = {}# 获取搜素框里的内容, 就是获取网址里面的search参数的值value = request.GET.get('search')if value:# 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__containsdict_data["mobile__contains"] = value# assets_list = models.Assets.objects.filter(**dict_data)# 获取分页组件里面选中的页码, 也是获取网址里面的page参数的值page = int(request.GET.get('page', 1))# 每一页查询10条数据page_size = 10# 当前页开始的数据start = (page - 1) * page_size# 当前页结尾的数据end = page_size * page# 利用切片, 实现分页查询, 查询出当页数据assets_list = models.Assets.objects.filter(**dict_data)[start:end]# 统计表当中的总个数data_asset_count = models.Assets.objects.filter(**dict_data).count()# 求得表中的总个数都需要多少页来展示, page_num代表总页数, div代表剩余的数据还有多少条page_count, div = divmod(data_asset_count, page_size)if div:page_count += 1# 我们需要在分页组件里面展示五个页码。# 当我们选中的页数, 和最左边最右边显示的页数相差2, 所以我们将plus设置为2, 比如我选择第三页, 那最左边显示的页码是1最右边显示的页码是5。plus = 2# 我们想要分页功能, 展示其中5个页码, 如果想要展示不同个页数的页码, 自己可以调整。# 当总页数不超过5页的时候, 1 + 2 * plus意思是当前选择的页, 加上左边还有两页, 右边也还有两页, 总共是5页。if data_asset_count <= 1 + 2 * plus:# 开始页数为1start_page = 1# 结束位置就是总页数end_page = data_asset_count# 这里面全是总页数大于5页的情况else:# 如果我目前选择的页码, 小于等于3if page <= plus + 1:# 开始页还是1start_page = 1# 结束页是5, 1 + 2 * plus这个意思上面有注释。end_page = 1 + 2 * plus# 如果我目前选择的页码加上2能够大于总页数, 那就说明分页组件里面的页码是最后五页数据了, 比如总页数为20, 我选择的是第19页, 19+2=21>20elif page + plus > page_count: # 这里写>=也可以# 开始页为总页数减去两倍的plus, 比如总共有20页, 当我们分页组件显示的页码是最后五页的时候, 最左边应该显示的是16。所以正好是总页数-两倍的plusstart_page = page_count - 2 * plus# 结尾页展示的就是总页数end_page = page_count# 如果我们目前选择的页码就在正中间, 排除1, 2, 3, 19, 20页的其它所有页数。else:# 开始页数就是当前分页组件选择的页数-plusstart_page = page - plus# 结束页数就是当前分页组件选择的页数+plusend_page = page + plus# 创建一个列表, 用于存储html代码, 以字符串来保存到列表中html_list = []# 分页组件返回到首页功能html_list.append(f"""<li><a href="?page=1">首页</a></li>""")# 如果当前选择的页码>1, 可以往前退一页, 否则不能在往前退了。在li标签上加class="disabled"代表禁用if page > 1:html_list.append(f"""<li><a href="?page={page - 1}"><span aria-hidden="true">«</span></a></li>""")else:html_list.append("""<li class="disabled"><spanaria-hidden="true">«</span></li>""")# 分页组件的中间翻页的内容, 点击第几页就到第几页, 在分页组件当中, 选中的页码会有背景色。li标签里面的class='active'代表选中了那个页码, 会出现背景色for page_num in range(start_page, end_page + 1):if page_num == page:html_list.append(f"<li class='active'><a href='?page={page_num}'>{page_num}</a></li>")else:html_list.append(f"<li><a href='?page={page_num}'>{page_num}</a></li>")# 如果当前选择的页码<总页数, 可以往前进一页, 否则不能在往进退了。在li标签上加class="disabled"代表禁用if page < page_count:html_list.append(f"""<li><a href="?page={page + 1}"><span aria-hidden="true">»</span></a></li>""")else:html_list.append("""<li class="disabled"><spanaria-hidden="true">»</span></li>""")# 分页组件进入到尾页功能html_list.append(f"""<li><a href="?page={page_count}">尾页</a></li>""")# join就是将列表当中所有的内容全部拼接在一起为字符串。mark_safe函数的作用是将字符串里面的内容, 转换为html元素。# mark_safe也是django框架里面的函数, 需要手动导入, 导入语句为from django.utils.safestring import mark_safepage_string = mark_safe("".join(html_list))# 不能忘记将page_string传给前端。return render(request, "assets/assets_list.html", {"assets_list": assets_list, "page_string": page_string})
这里代码比较长, 但每一行代码都有注释, 大家慢慢看, 慢慢学, 其实逻辑上不是很困难, 但是代码量比较大, 处理的过程比较复杂。
运行结果:
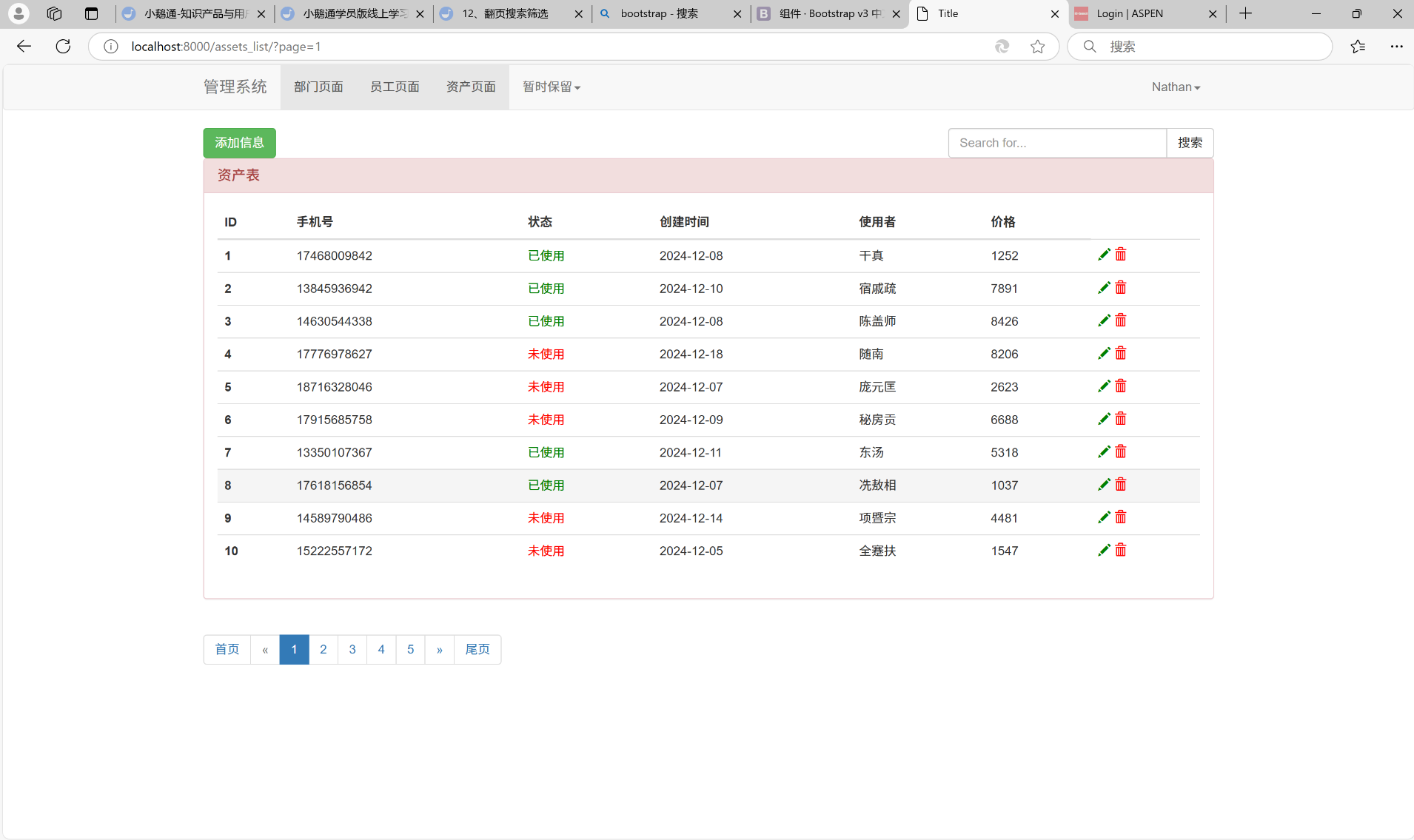
默认是第一页的数据
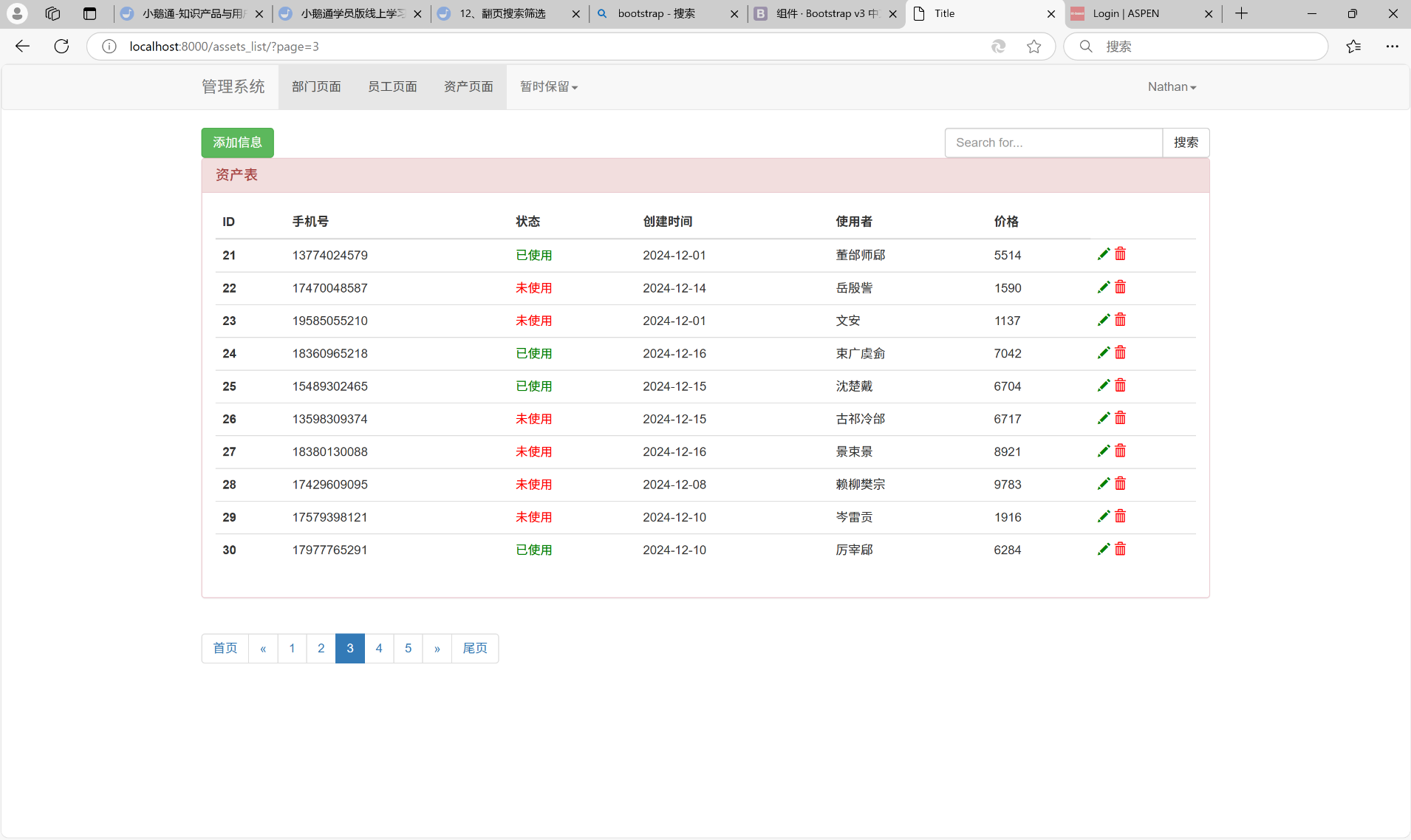
然后我们点击第三页:
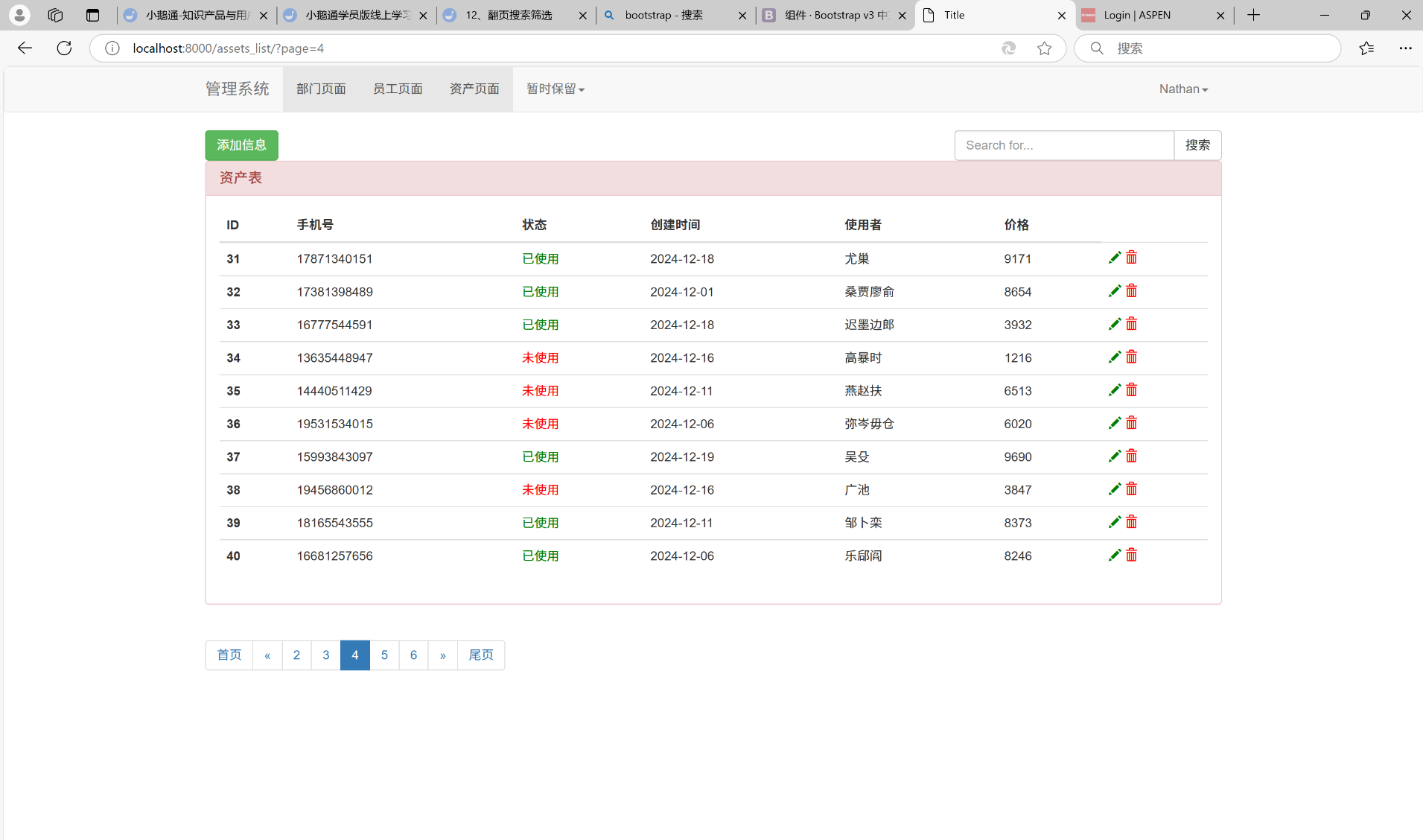
点击第四页:
往后翻页, 直到点击第13页:
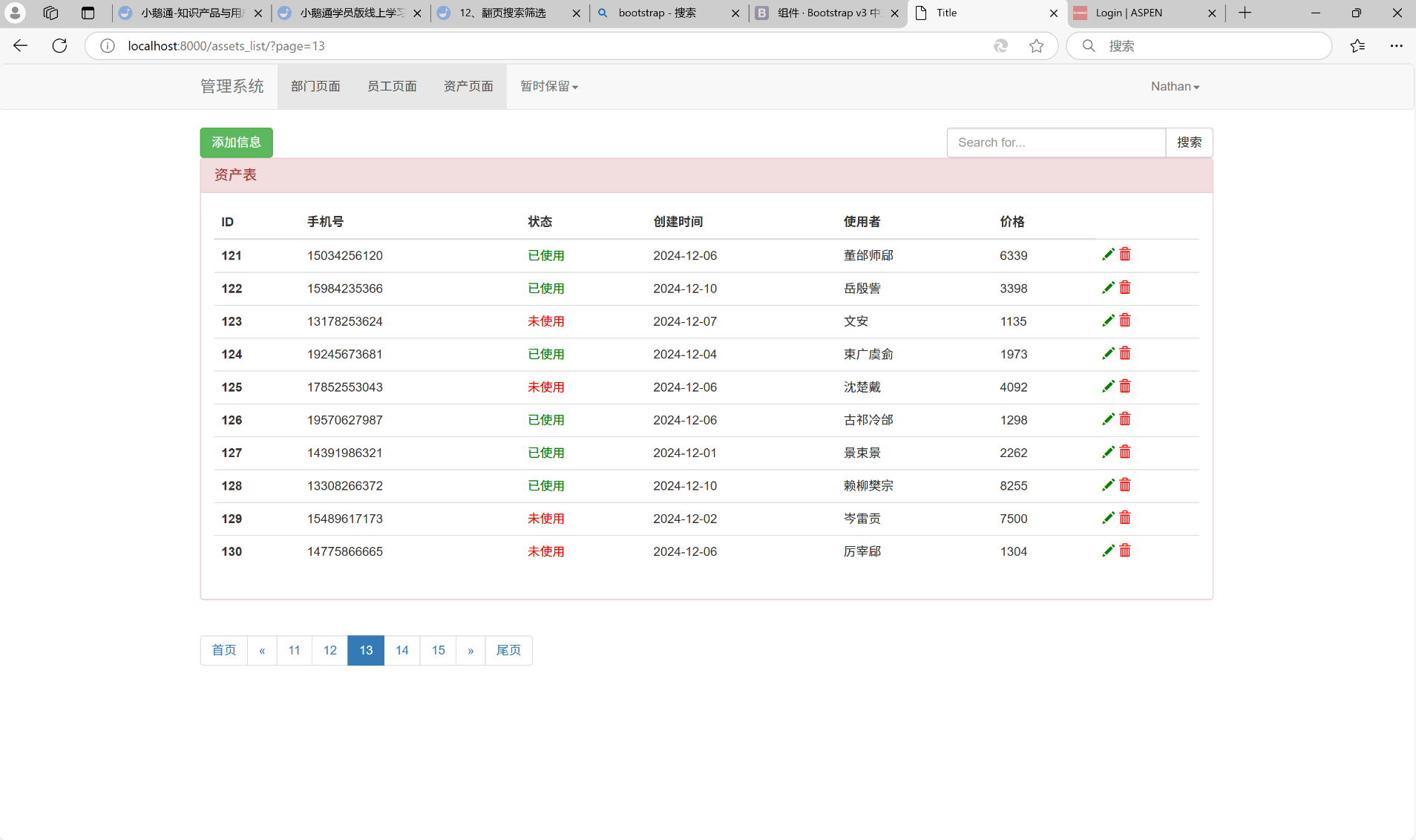
往后翻页, 直到点击第18页:
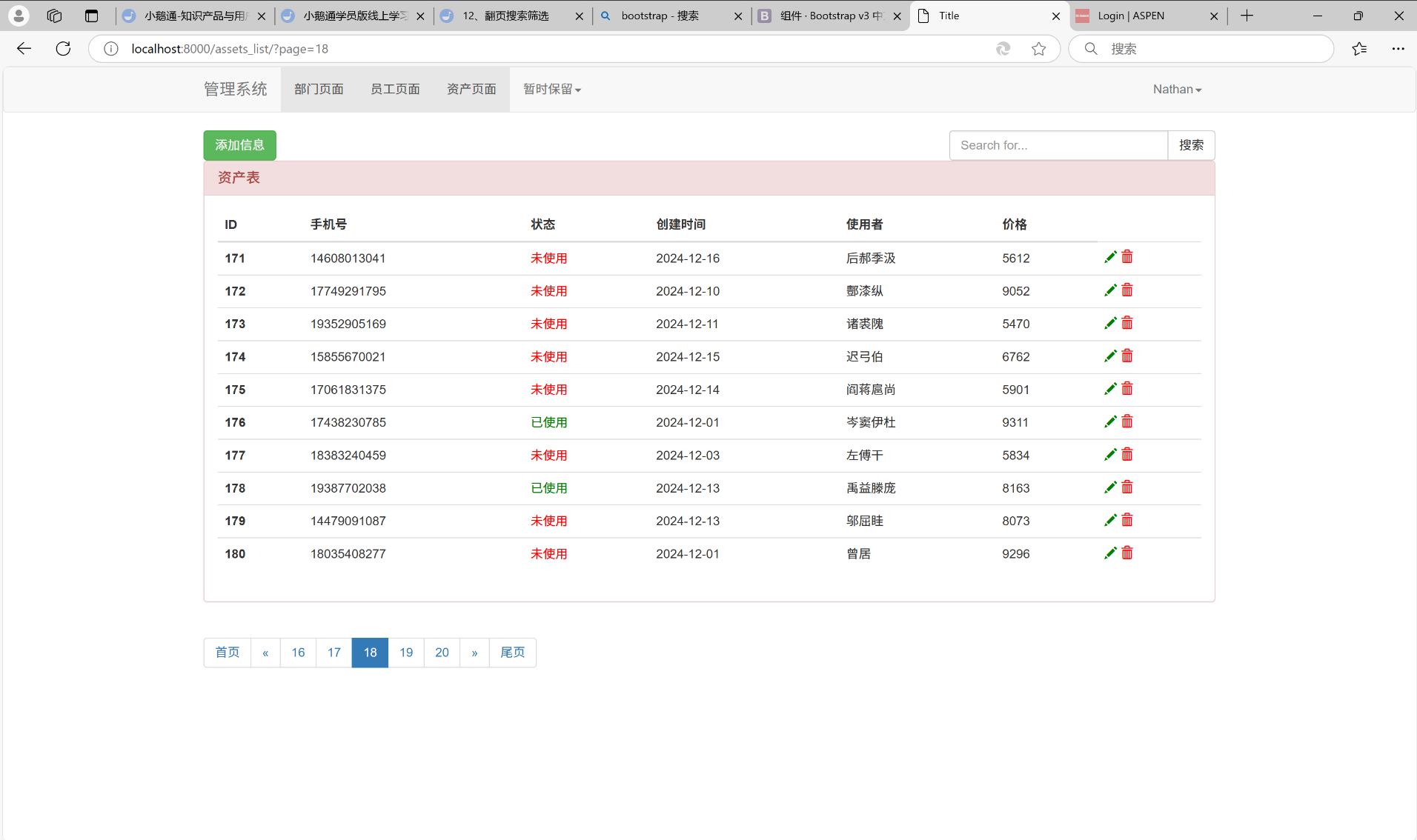
第19页:
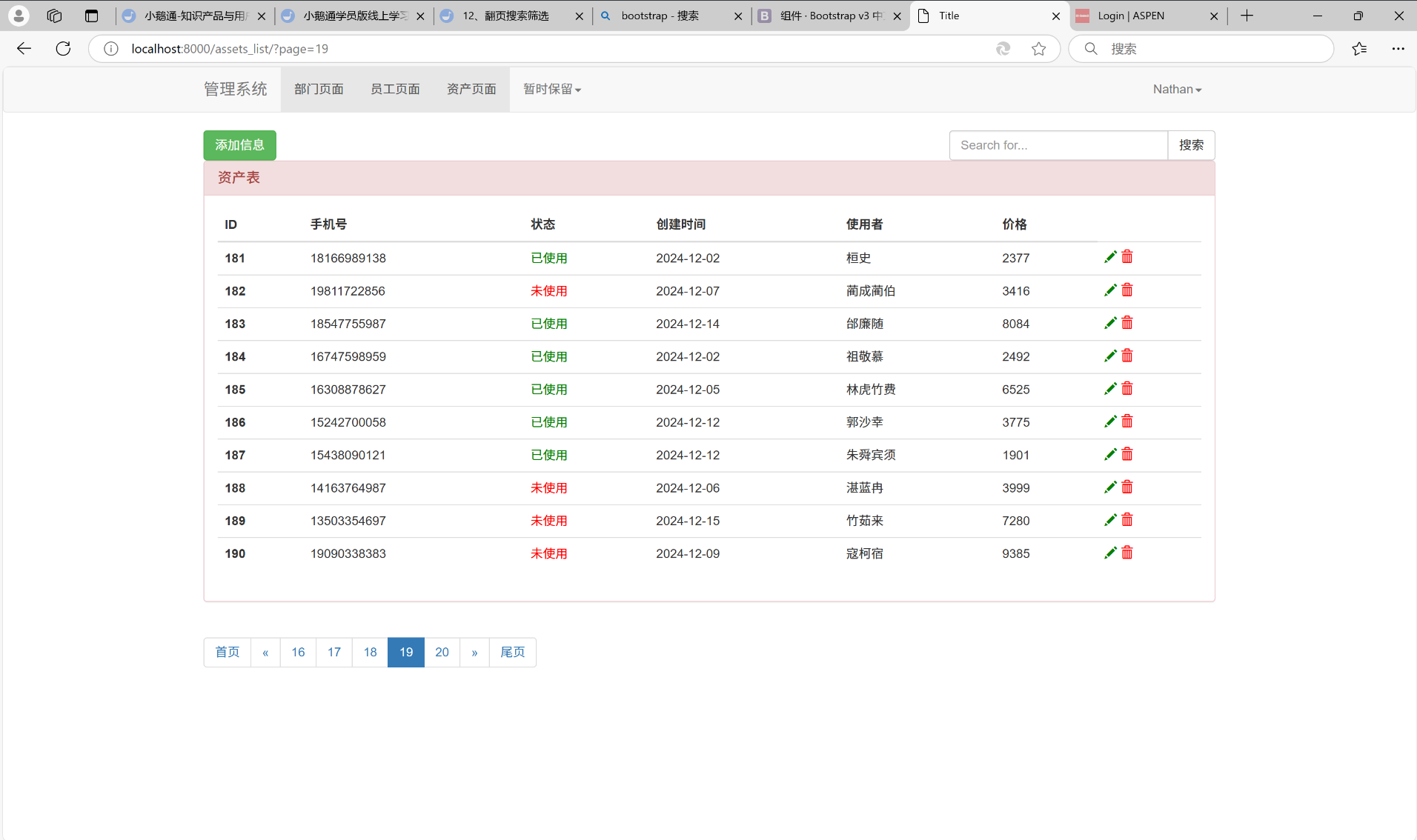
第20页:
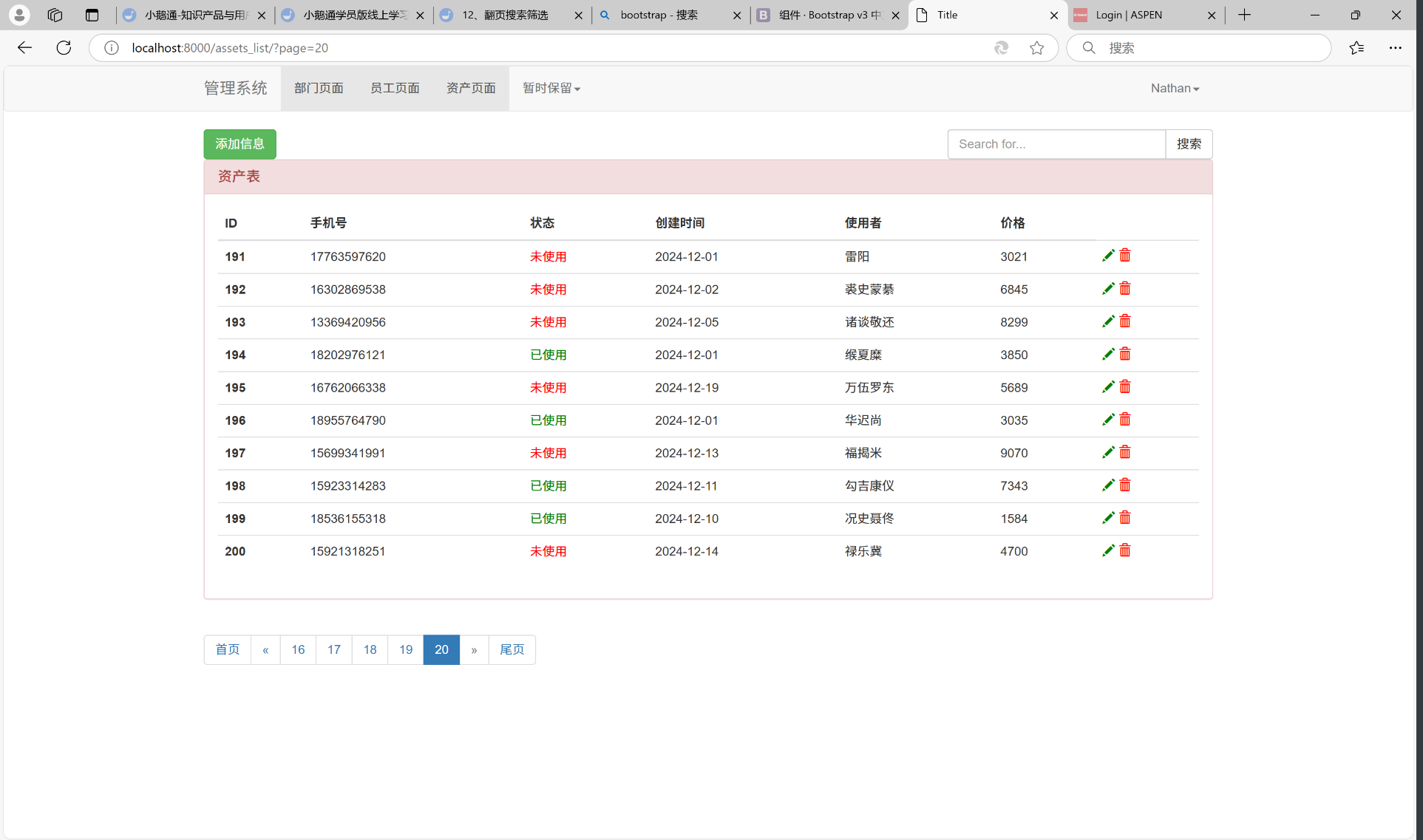
点击首页:
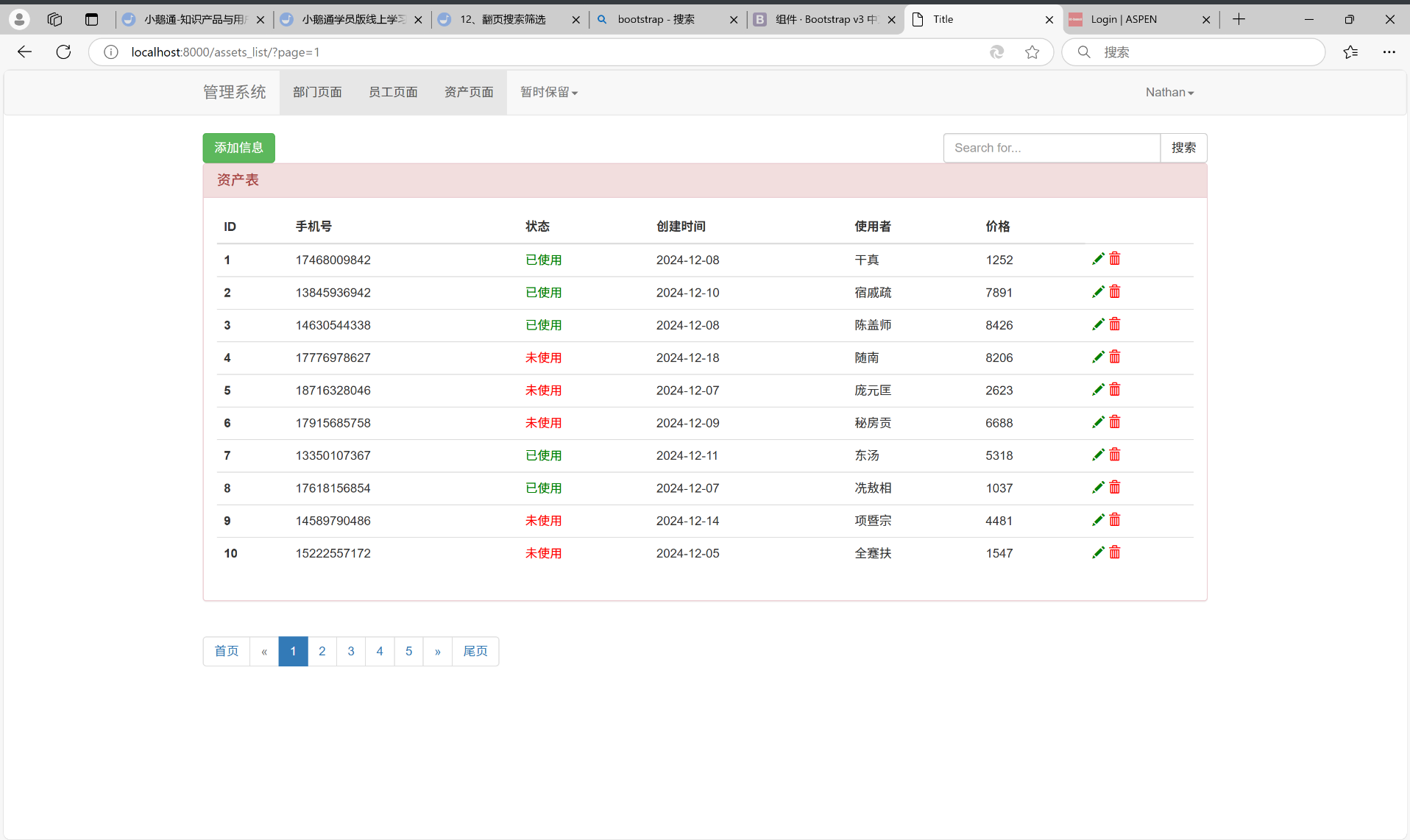
它帮我们跳转到了第一页。
点击尾页:
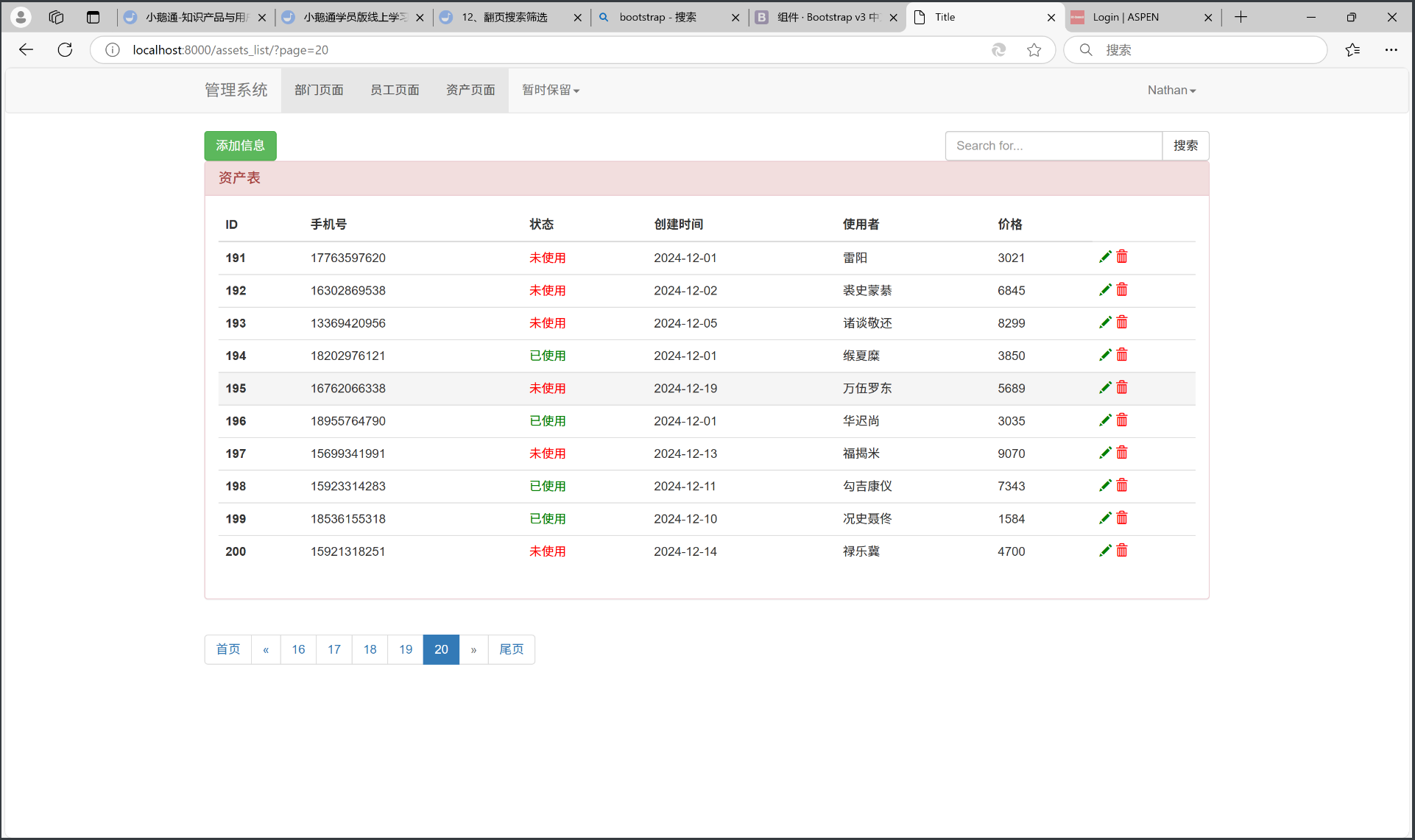
它帮我们跳转到了最后一页。点击左边的<<按钮:
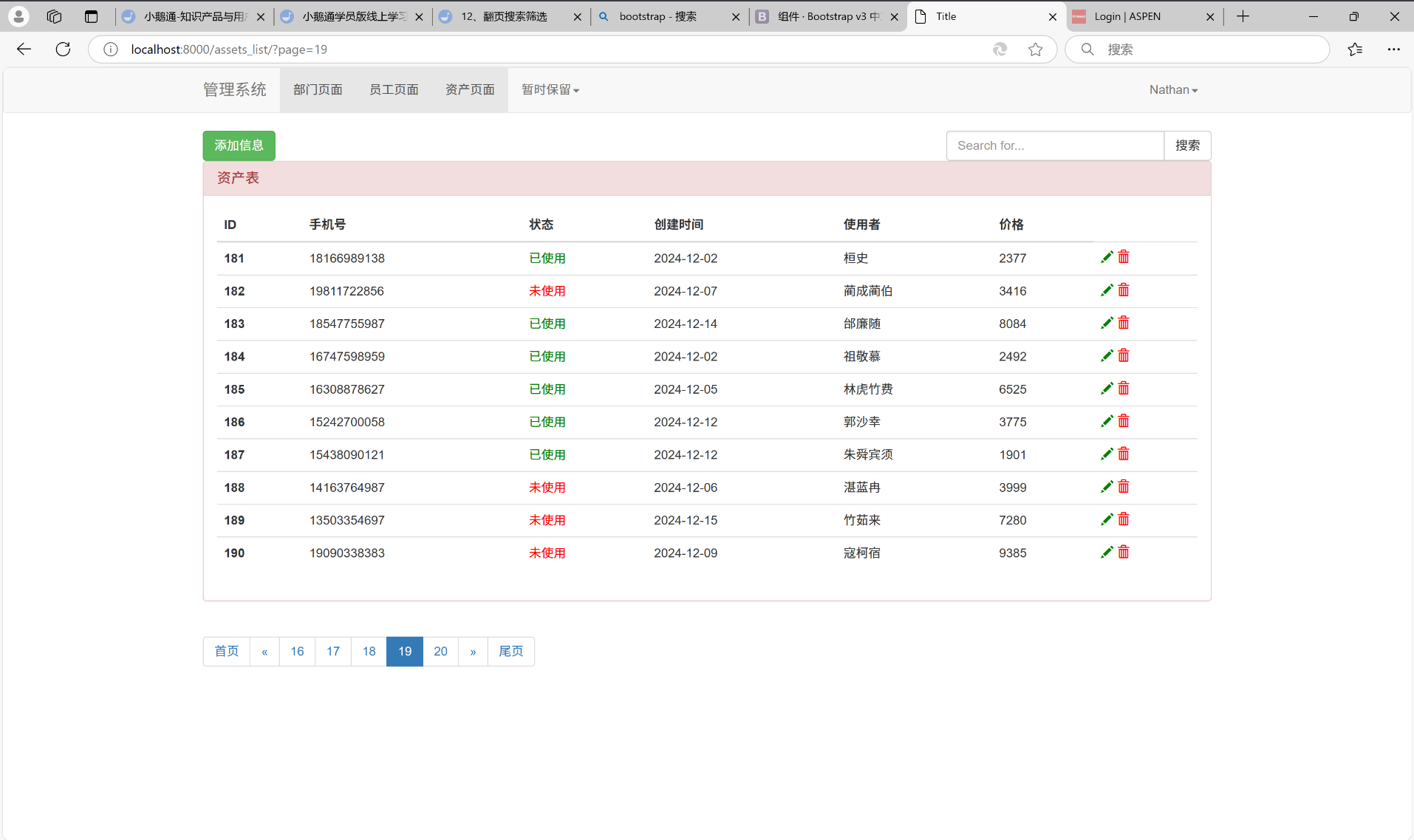
点击一下, 页数往回退一页。
直到退到第一页, 就不能在往回退数据了。
如图:
鼠标放到<<上面的时候, 有个红色圈代表禁止使用那个按钮。
>>也是一个道理, 也是每点击一次网后面翻一页, 直到翻到最后一页, 鼠标放到>>上面的时候, 有个红色圈代表禁止使用那个按钮。同样也不能继续往后翻页了。
好了, 这就是我们这篇文章的搜索和翻页功能了!!!
以上就是Django数据的翻页和搜索功能的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大.
人生路漫漫, 白鹭常相伴!!!
相关文章:

django之数据的翻页和搜索功能
数据的翻页和搜素功能 目录 1.实现搜素功能 2.实现翻页功能 一、实现搜素功能 我们到bootstrap官网, 点击组件, 然后找到输入框组, 并点击作为额外元素的按钮。 我们需要使用上面红色框里面的组件, 就是搜素组件, 代码部分就是下面红色框框出来的部分。 把这里的代码复制…...

linux复习
1.关于进程 1.1 概念 用户角度:进程是程序的一次执行实例,也就是正在运行的程序 内核角度:操作系统分配内存和cpu资源的实体 操作系统使用内核数据结构 程序的代码及数据 描述进程,Linux中对应的内核数据结构就是task_struct…...

Post-Processing PropertySource instance详解 和 BeanFactoryPostProcessor详解
PropertySourcesBeanFactoryPostProcessor详解 1. 核心概念 BeanFactoryPostProcessor 是 Spring 框架中用于在 BeanFactory 初始化阶段 对 Environment 中的 PropertySource 进行后处理的接口。它允许开发者在 Bean 创建之前 对属性源进行动态修改,例如添加、删除…...
以管理员权限启动(UAC))
go 编译的 windows 进程(exe)以管理员权限启动(UAC)
引言 windows 系统,在打开某些 exe 的时候,会弹出“用户账户控制(UAC)”的弹窗 “你要允许来自xx发布者的此应用对你的设备进行更改吗?” UAC(User Account Control,用户账户控制)是 Windows 操作系统中的…...

Elasticsearch性能优化实践
一、背景与挑战 基金研报搜索场景中,我们面临以下核心挑战: 数据规模庞大:单索引超500GB原始数据,包含300万份PDF/Word研报文档查询性能瓶颈:复杂查询平均响应时间超过10秒,高峰期CPU负载达95%存储…...

【Web API系列】Web Shared Storage API 深度解析:WindowSharedStorage 接口实战指南
前言 在当今 Web 应用日益复杂的背景下,跨页面数据共享与隐私保护已成为现代浏览器技术演进的重要命题。传统 Web 存储方案(如 Cookies、LocalStorage)在应对多维度用户特征存储、跨上下文数据共享等场景时,逐渐暴露出技术瓶颈与…...

Eureka、LoadBalance和Nacos
Eureka、LoadBalance和Nacos 一.Eureka引入1.注册中心2.CAP理论3.常见的注册中心 二.Eureka介绍1.搭建Eureka Server 注册中心2.搭建服务注册3.服务发现 三.负载均衡LoadBalance1.问题引入2.服务端负载均衡3.客户端负载均衡4.Spring Cloud LoadBalancer1).快速上手2)负载均衡策…...

智能体MCP 实现数据可视化分析
参考: 在线体验 https://www.doubao.com/chat/ 下载安装离线体验 WPS软件上的表格分析 云上创建 阿里mcp:https://developer.aliyun.com/article/1661198 (搜索加可视化) 案例 用cline 或者cherry studio实现 mcp server:excel-mcp-server、quickchart-mcp-server...
)
3小时速通Python-Python学习总部署、总预览(一)
目录 Python的关键字有哪些: 编辑 代码:1-5: 代码:6-10: 代码:11-15: 代码:16-20: 代码:21-25: 代码:26-27: Pyt…...

机器学习基础 - 分类模型之决策树
决策树 文章目录 决策树简介决策树三要素1. 特征的选择1. ID32. C4.53. CART2. 剪枝处理0. 剪枝的作用1. 预剪枝2. 后剪枝QA1. ID3, C4.5, CART 这三种决策树的区别2. 树形结构为何不需要归一化?3. 分类决策树与回归决策树的区别4. 为何信息增益会偏向多取值特征?4. 为何信息…...

Java面向对象的三大特性
## 1. 封装(Encapsulation) 封装是将数据和操作数据的方法绑定在一起,对外部隐藏对象的具体实现细节。通过访问修饰符来实现封装。 示例代码: java public class Student { // 私有属性 private String name; private int age; …...

【Pandas】pandas DataFrame truediv
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...
----修改编码器计数方向)
GTS-400 系列运动控制器板(六)----修改编码器计数方向
运动控制器函数库的使用 运动控制器驱动程序、 dll 文件、例程、 Demo 等相关文件请通过固高科技官网下载,网 址为: www.googoltech.com.cn/pro_view-3.html 1 Windows 系统下动态链接库的使用 在 Windows 系统下使用运动控制器,首先要安装驱动程序。在安装前需要提…...

卷积神经网络迁移学习:原理与实践指南
引言 在深度学习领域,卷积神经网络(CNN)已经在计算机视觉任务中取得了巨大成功。然而,从头开始训练一个高性能的CNN模型需要大量标注数据和计算资源。迁移学习(Transfer Learning)技术为我们提供了一种高效解决方案,它能够将预训练模型的知识…...

Django 入门实战:从环境搭建到构建你的第一个 Web 应用
Django 入门实战:从环境搭建到构建你的第一个 Web 应用 恭喜你选择 Django 作为你学习 Python Web 开发的起点!Django 是一个强大、成熟且功能齐全的框架,非常适合构建中大型的 Web 应用程序。本篇将通过一个简单的例子,带你走完…...

【后端】构建简洁的音频转写系统:基于火山引擎ASR实现
在当今数字化时代,语音识别技术已经成为许多应用不可或缺的一部分。无论是会议记录、语音助手还是内容字幕,将语音转化为文本的能力对提升用户体验和工作效率至关重要。本文将介绍如何构建一个简洁的音频转写系统,专注于文件上传、云存储以及…...

http通信之axios vs fecth该如何选择?
在HTTP通信中,axios和fetch都是常用的库或原生API用于发起网络请求。两者各有特点,适用于不同的场景。下面详细介绍它们的差异和各自的优势: fetch 特点: 原生支持:fetch是现代浏览器内置的API,不需要额外…...

iostat指令介绍
文章目录 1. 功能介绍2. 语法介绍3. 应用场景4. 示例分析 1. 功能介绍 iostat (input/output statistics),是 Linux/Unix 系统中用于监控 CPU 使用率和 磁盘 I/O 性能的核心工具,可实时展示设备负载、吞吐量、队列状态等关键指标。 可以使用 man iostat查…...
——大模型(LLMs)分词(Tokenizer)详解)
NLP高频面试题(五十)——大模型(LLMs)分词(Tokenizer)详解
在自然语言处理(NLP)任务中,将文本转换为模型可处理的数字序列是必不可少的一步。这一步通常称为分词(tokenization),即把原始文本拆分成一个个词元(token)。对于**大型语言模型(LLM,Large Language Model,大型语言模型)**而言,选择合适的分词方案至关重要:分词的…...

桌面我的电脑图标不见了怎么恢复 恢复方法指南
在Windows操作系统中,“我的电脑”或在较新版本中称为“此电脑”的图标,是访问硬盘驱动器、外部存储设备和系统文件的重要入口。然而,有些用户可能会发现桌面上缺少了这个图标,这可能是由于误操作、系统设置更改或是不小心删除造成…...
)
【Qt】控件的理解 和 基础控件 QWidget 属性详解(通俗易懂+附源码+思维导图框架)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 通过上一章对信号槽的理解相信你对Qt的认识肯定有了很大的进步,下面将通过本篇文章带你深入的认识Widget控件(主窗口࿰…...

oracle将表字段逗号分隔的值进行拆分,并替换值
需求背景:需要源数据变动,需要对历史表已存的字段值根据源数据进行更新。如果是单字段存值,直接根据映射表关联修改即可。但字段里面若存的值是以逗号分割,比如旧值:‘old1,old2,old3’,要根据映射关系调整…...

用c语言实现——一个带头节点的链队列,支持用户输入交互界面、初始化、入队、出队、查找、判空判满、显示队列、遍历计算长度等功能
一、知识介绍 带头节点的链队列是一种基于链表实现的队列结构,它在链表的头部添加了一个特殊的节点,称为头节点。头节点不存储实际的数据元素,主要作用是作为链表的起点,简化队列的操作和边界条件处理。 1.节点结构 链队列的每…...
)
webpack基础使用了解(入口、出口、插件、加载器、优化、别名、打包模式、环境变量、代码分割等)
目录 1、webpack简介2、简单示例3、入口(entry)和输出(output)4、自动生成html文件5、打包css代码6、优化(单独提取css代码)7、优化(压缩过程)8、打包less代码9、打包图片10、搭建开发环境(webpack-dev-server…...

【项目】基于MCP+Tabelstore架构实现知识库答疑系统
基于MCPTabelstore架构实现知识库答疑系统 整体流程设计(一)Agent 架构(二)知识库存储(1)向量数据库Tablestore(2)MCP Server (三)知识库构建(1&a…...

C语言高频面试题——malloc 和 calloc区别
在 C 语言中,malloc 和 calloc 都是用于动态内存分配的函数,但它们在 内存初始化、参数形式 和 使用场景 上有显著区别。以下是详细的对比分析: 1. 函数原型 malloc void* malloc(size_t size);功能:分配 未初始化 的连续内存块…...

深入探讨JavaScript性能瓶颈与优化实战指南
JavaScript作为现代Web开发的核心语言,其性能直接影响用户体验与业务指标。随着2025年前端应用的复杂性持续增加,性能优化已成为开发者必须掌握的核心技能。本文将从性能瓶颈分析、优化策略、工具使用三个维度,结合实战案例,系统梳理JavaScript性能优化的关键路径。 一、Ja…...

[创业之路-376]:企业法务 - 创业,不同的企业形态,个人承担的风险、收益、税费、成本不同
在企业法务领域,创业时选择不同的企业形态,个人在风险承担、收益分配、税费负担及运营成本方面存在显著差异。以下从个人独资企业、合伙企业、有限责任公司、股份有限公司四种常见形态展开分析: 一、个人承担的风险 个人独资企业 风险类型&…...

【Lua】Lua 入门知识点总结
Lua 入门学习笔记 本教程旨在帮助有编程基础的学习者快速入门Lua编程语言。包括Lua中变量的声明与使用,包括全局变量和局部变量的区别,以及nil类型的概念、数值型、字符串和函数的基本操作,包括16进制表示、科学计数法、字符串连接、函数声明…...

低空经济 WebGIS 无人机配送 | 图扑数字孪生
2024 年,”低空经济” 首次写入政府工作报告,在政策驱动下各地纷纷把握政策机遇,从基建网络、场景创新、产业生态、政策激励等方面,构建 “规划-建设-应用-赋能” 的系统性布局,作为新质生产力的重要体现,推…...
)
【程序员 NLP 入门】词嵌入 - 如何基于计数的方法表示文本? (★小白必会版★)
🌟 嗨,你好,我是 青松 ! 🌈 希望用我的经验,让“程序猿”的AI学习之路走的更容易些,若我的经验能为你前行的道路增添一丝轻松,我将倍感荣幸!共勉~ 【程序员 NLP 入门】词…...

基于机器学习的多光谱遥感图像分类方法研究与定量评估
多光谱遥感技术通过获取可见光至红外波段的光谱信息,为地质勘探、农业监测、环境调查等领域提供了重要支持。与普通数码相机相比,多光谱成像能记录更丰富的波段数据(如近红外、短波红外等),从而更精准地识别地物特征。…...

BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection
背景 基于多视角图片的3D感知被LSS证明是可行的,它使用估计的深度将图像特征转化为3D视椎,再将其压缩到BEV平面上。对于这个得到的BEV特征图,它支持端到端训练以及各种下游任务。但是对于深度估计这一块学习的深度质量如何,到目前为止没有相关工作研究。 贡献 本文的贡献…...

【Linux】静态库 动态库
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、👑静态库和动态库 静态库: 动态库: 🌠手动制作静态库 && 手动调用一下我们自己写的静态库 1> 安装到系统里面 ✨生成静…...
:TCP黏包)
Java转Go日记(六):TCP黏包
服务端代码如下: // socket_stick/server/main.gofunc process(conn net.Conn) {defer conn.Close()reader : bufio.NewReader(conn)var buf [1024]bytefor {n, err : reader.Read(buf[:])if err io.EOF {break}if err ! nil {fmt.Println("read from client…...
LCD显示温度(DS18B20教程)(LCD1602教程)(延时函数教程)(单总线教程))
(51单片机)LCD显示温度(DS18B20教程)(LCD1602教程)(延时函数教程)(单总线教程)
演示视频: LCD显示温度 源代码 如上图将9个文放在Keli5 中即可,然后烧录在单片机中就行了 烧录软件用的是STC-ISP,不知道怎么安装的可以去看江科大的视频: 【51单片机入门教程-2020版 程序全程纯手打 从零开始入门】https://www.…...

【通过Docker快速部署Tomcat9.0】
文章目录 前言一、部署docker二、部署Tomcat2.1 创建存储卷2.2 运行tomcat容器2.3 查看tomcat容器2.4 查看端口是否监听2.5 防火墙开放端口 三、访问Tomcat 前言 Tomcat介绍 Tomcat 是由 Apache 软件基金会(Apache Software Foundation)开发的一个开源 …...
)
云原生--基础篇-3--云原生概述(云、原生、云计算、核心组成、核心特点)
1、什么是云和原生 (1)、什么是云? “云”指的是云计算环境,代表应用运行的基础设施和资源。依赖并充分利用云计算的弹性、分布式和资源池化能力。 核心含义: 1、云计算基础设施 云原生应用的设计和运行完全基于云…...

Spark-Streaming
Spark-Streaming概述 DStream实操 案例一:WordCount案例 需求:使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并统计不同单词出现的次数 实验步骤: 添加依赖 <dependency> <gro…...

乐视系列玩机------乐视2 x620红灯 黑砖刷写教程以及新版刷写工具的详细释义
乐视x620在上期解析了普通黑砖情况下的救砖刷机过程。但在一些例外的情况下。使用上面的步骤会一直刷写报错 。此种情况就需要另外一种强制刷写方法来救砖 通过博文了解💝💝💝 1💝💝💝-----详细解析乐视2 x620系列 红灯 黑砖线刷救砖的步骤 2💝💝💝----图…...

若依SpringCloud项目-定制微服务模块
若依SpringCloud项目-定制微服务模块 关于微服务先不过多介绍,刚开始熟悉并不能讲的很彻底,成熟的微服务项目-若依SpringCloud就是一个典型的微服务架构工程(网上有很多教程了,不明白的可以学习一下)。 我正在看的视…...

【扫描件批量改名】批量识别扫描件PDF指定区域内容,用识别的内容修改PDF文件名,基于C++和腾讯OCR的实现方案,超详细
批量识别扫描件PDF指定区域内容并重命名文件方案 应用场景 本方案适用于以下场景: 企业档案数字化管理:批量处理扫描的合同、发票等文件,按内容自动分类命名财务票据处理:自动识别票据上的关键信息(如发票号码、日期)用于归档医疗记录管理:从扫描的检查报告中提取患者I…...

学习Docker遇到的问题
目录 1、拉取hello-world镜像报错 1. 检查网络连接 排查: 2. 配置 Docker 镜像加速器(推荐) 具体解决步骤: 1.在服务器上创建并修改配置文件,添加Docker镜像加速器地址: 2. 重启Docker 3. 拉取hello-world镜像 2、删除镜像出现异常 3、 容器内部不能运行ping命令 …...

Docker 数据卷
目录 一、数据卷(Data Volume) 二、使用 1、单独建立数据卷 2、挂载主机数据卷 3、数据卷容器挂载 基本语法: 工作原理: 主要用途: 使用事例: 一、数据卷(Data Volume) 数据卷的使用,类似于 Linux 下对目录或文件进行 mount 数据卷(Data Volume)是一个可供一个或多…...
双链表)
【数据结构】励志大厂版·初级(二刷复习)双链表
前引:今天学习的双链表属于链表结构中最复杂的一种(带头双向循环链表),按照安排,我们会先进行复习,如何实现双链表,如基本的头插、头删、尾删、尾插,掌握每个细节,随后进…...

通过dogssl申请ssl免费证书
SSL证书作为实现HTTPS加密的核心工具,能够确保用户与网站之间的数据传输安全。尤其是在小程序之类的开发时,要求必须通过https发起请求的情况下。学会如何免费申请一个ssl证书就很有必要了。这里我分享一下,我通过dogssl如何申请ssl的。 一&…...

路由与路由器
路由的概念 路由是指在网络通讯中,从源设备到目标设备路径的选择过程。路由器是实现这一过程的关键设备,它通过转发数据包来实现网络的互联。路由工作在OSI参考模型的第三层,‘网络层’。 路由器的基本原理 路由器通过维护一张路由表来决定…...

Docker底层原理浅析 | namespace+cgroups+文件系统
本文目录 1. Linux NamespaceLinux系统里是否只能有一个pid为1的进程?namespace机制查看namespacenamespace机制测试使用Docker验证namespace机制 2. Dcoerk网络模式3.Control groups4.文件系统(联合文件系统)5. 容器格式 1. Linux Namespace…...
 算法来处理传感器测量,各传感器的参数设置,高度数据融合、不同传感器融合模式)
【无人机】使用扩展卡尔曼滤波 (EKF) 算法来处理传感器测量,各传感器的参数设置,高度数据融合、不同传感器融合模式
目录 #1、IMU #2、磁力计 #3、高度 #典型配置 #4、气压计 #静压位置误差修正 #气压计偏置补偿 #5、全球导航系统/全球定位系统--GNSS/GPS #位置和速度测量 #偏航测量 #GPS 速度的偏航 #双接收器 #GNSS 性能要求 #6、测距 #条件范围辅助-Conditional range aidin…...

常见的raid有哪些,使用场景是什么?
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)是一种将多个物理硬盘组合成一个逻辑硬盘的技术,目的是通过数据冗余和/或并行访问提高性能、容错能力和存储容量。不同的 RAID 级别有不同的实现方式和应用场景。以下…...