卷积神经网络迁移学习:原理与实践指南
引言
在深度学习领域,卷积神经网络(CNN)已经在计算机视觉任务中取得了巨大成功。然而,从头开始训练一个高性能的CNN模型需要大量标注数据和计算资源。迁移学习(Transfer Learning)技术为我们提供了一种高效解决方案,它能够将预训练模型的知识迁移到新任务中,显著减少训练时间和数据需求。本文将全面介绍CNN迁移学习的原理、优势及实践方法。
1、内容
迁移学习是指利用已经训练好的模型,在新的任务上进行微调。迁移学习可以加快模型训练速度,提高模型性能,并且在数据稀缺的情况下也能很好地工作
2、步骤
1、选择预训练的模型和适当的层:通常,我们会选择在大规模图像数据集(如ImageNet)上预训练的模型,如VGG、ResNet等。然后,根据新数据集的特点,选择需要微调的模型层。对于低级特征的任务(如边缘检测),最好使用浅层模型的层,而对于高级特征的任务(如分类),则应选择更深层次的模型。
2、冻结预训练模型的参数:保持预训练模型的权重不变,只训练新增加的层或者微调一些层,避免因为在数据集中过拟合导致预训练模型过度拟合。
3、在新数据集上训练新增加的层:在冻结预训练模型的参数情况下,训练新增加的层。这样,可以使新模型适应新的任务,从而获得更高的性能。
4、微调预训练模型的层:在新层上进行训练后,可以解冻一些已经训练过的层,并且将它们作为微调的目标。这样做可以提高模型在新数据集上的性能。
5、评估和测试:在训练完成之后,使用测试集对模型进行评估。如果模型的性能仍然不够好,可以尝试调整超参数或者更改微调层。
Resnet网络:
原理:
卷积神经网络都是通过卷积层和池化层的叠加组成的。 在实际的试验中发现,随着卷积层和池化层的叠加,学习效果不会逐渐变好,反而出现2个问题:
1、梯度消失和梯度爆炸
梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
2、退化问题
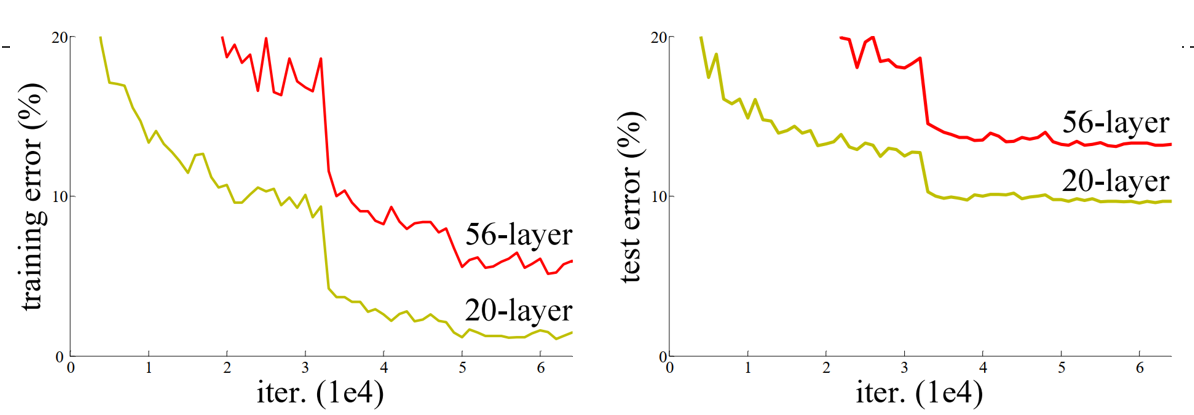
为了解决梯度消失或梯度爆炸问题,论文提出通过数据的预处理以及在网络中使用 BN(Batch Normalization)层来解决。
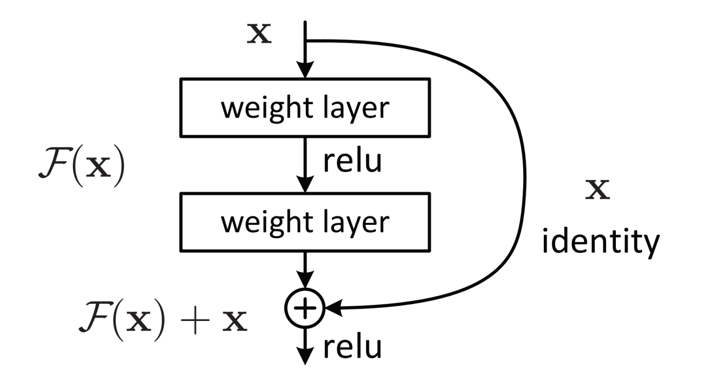
为了解决深层网络中的退化问题,可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为 残差网络 (ResNets)。
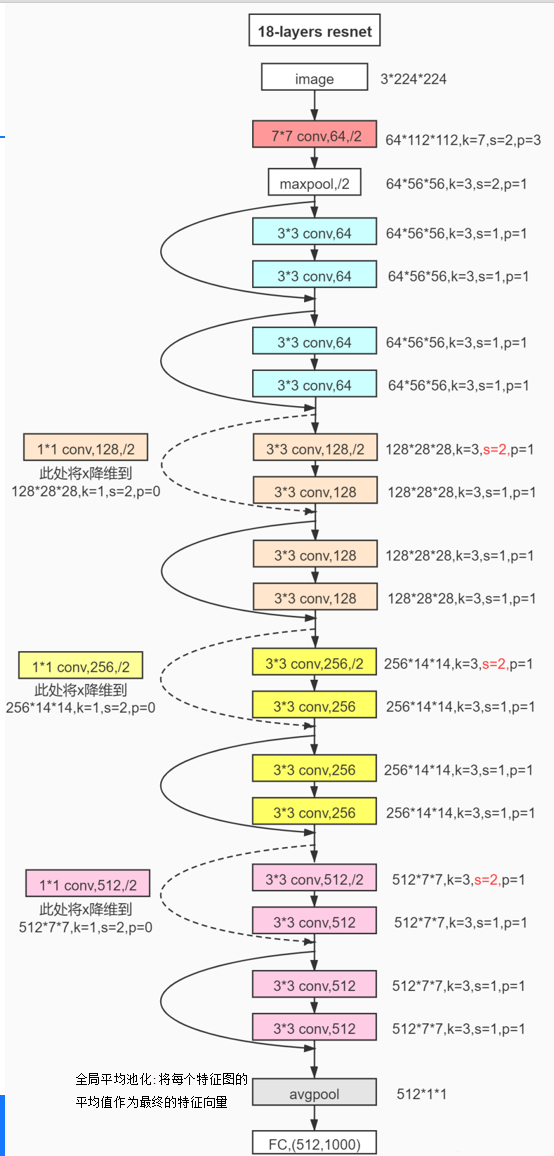
1、18层resnet结构:
2、BN(Batch Normalization)
实例
1、导入相关的库
import torch
from torch.utils.data import DataLoader,Dataset #数据包管理工具,打包数据,
from torchvision import transforms
from torch import nn
import torchvision.models as models
from PIL import Image
import numpy as np2、调取模型并冻结参数
#不再需要自己来搭建模型了。预训练的文件也加载进去了。
# 将resnet18模型迁移到食物分类项目中.#残差网络是固定的网络结构,不需要你自己来类定义了。
resnet_model=models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
#weights=models.ResNet18_Weights.DEFAULT表示使用在 ImageNet 数据集上预先训练好的权重
for param in resnet_model.parameters():print(param)param.requires_grad=False #冻结
#模型所有参数(即权重和偏差)的requires_grad属性设置为False,从而冻结所有模型参数,详细说明:
-
models.resnet18()加载ResNet18架构 -
weights=models.ResNet18_Weights.DEFAULT指定使用官方预训练权重 -
遍历所有参数并冻结
3、对网络模型进行微调
in_features=resnet_model.fc.in_features #获取模型原输入的特征个数
resnet_model.fc=nn.Linear(in_features,20) #创建一个全连接层4、保存需要训练的参数
params_to_update=[] #保存需要训练的参数,仅仅包含全连接层的参数
for param in resnet_model.parameters():if param.requires_grad==True:params_to_update.append(param)5、数据预处理
data_transforms={
'train':
transforms.Compose([transforms.Resize([300, 300]),transforms.RandomRotation(45), # 随机旋转,-45到45度之间随机选transforms.CenterCrop(224), # 从中心开始裁剪[256,256]transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转# transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),transforms.RandomGrayscale(p=0.1), # 概率转换成灰度率,3通道就是R=G=Btransforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'valid':
transforms.Compose([transforms.Resize([224,224]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
数据预处理包括:
-
训练集使用多种数据增强(随机旋转、水平翻转等)
-
验证集只进行简单的resize和归一化
-
归一化参数使用ImageNet的均值和标准差
6、自定义数据集的类
class food_dataset(Dataset):def __init__(self,file_path,transform=None):self.file_path=file_pathself.imgs=[]self.labels=[]self.transform=transformwith open(self.file_path) as f:samples=[x.strip().split(' ') for x in f.readlines()]for img_path,label in samples:self.imgs.append(img_path)self.labels.append(label)def __len__(self):return len(self.imgs)def __getitem__(self, idx):image=Image.open(self.imgs[idx])if self.transform:image=self.transform(image)label = self.labels[idx]label = torch.from_numpy(np.array(label,dtype=np.int64))return image,label这个自定义Dataset类:
-
从文本文件读取图像路径和标签
-
实现
__len__和__getitem__方法,供DataLoader使用 -
应用指定的transform处理图像
7、数据加载器准备
# 创建训练集和测试集实例
training_data = food_dataset(file_path='trainda.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path='testda.txt', transform=data_transforms['valid'])# 创建数据加载器
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
数据加载器提供:
-
批量加载功能(batch_size=64)
-
训练数据随机打乱(shuffle=True)
-
多线程数据预读取
8、训练和测试流程
def train(dataloader,model,loss_fn,optimizer):model.train() #告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w。在训练过程中,w会被修改的
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train()和 model.eval()。
#一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval()for X,y in dataloader: #其中batch为每一个数据的编号X,y=X.to(device),y.to(device) #把训练数据集和标签传入cpu或GPUpred=model.forward(X) #.forward可以被省略,父类中已经对次功能进行了设置。自动初始化loss=loss_fn(pred,y) #通过交叉熵损失函数计算损失值loss# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() #梯度值清零loss.backward() #反向传播计算得到每个参数的梯度值woptimizer.step() #根据梯度更新网络w参数best_acc=0
def test(dataloader, model, loss_fn):global best_accsize = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= size9、循环训练
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(params_to_update, lr=0.001) # Adam优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # 学习率调度# 训练10个epoch
epoch = 10
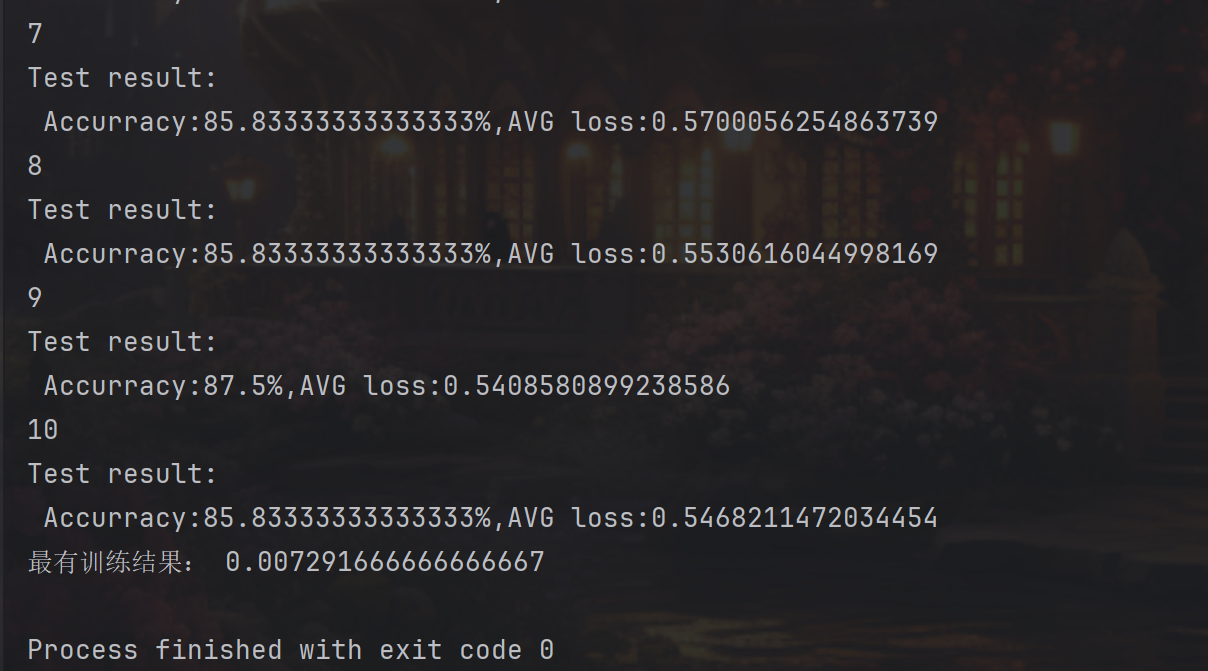
for i in range(epoch):print(f"Epoch {i + 1}")train(train_dataloader, model, loss_fn, optimizer) # 训练scheduler.step() # 更新学习率test(test_dataloader, model, loss_fn) # 测试print('Best accuracy:', best_acc) # 打印最佳准确率主循环流程:
-
定义损失函数和优化器
-
设置学习率调度器(每5个epoch学习率减半)
-
进行10轮训练和测试
-
打印最终最佳准确率
结果展示:
相关文章:

卷积神经网络迁移学习:原理与实践指南
引言 在深度学习领域,卷积神经网络(CNN)已经在计算机视觉任务中取得了巨大成功。然而,从头开始训练一个高性能的CNN模型需要大量标注数据和计算资源。迁移学习(Transfer Learning)技术为我们提供了一种高效解决方案,它能够将预训练模型的知识…...

Django 入门实战:从环境搭建到构建你的第一个 Web 应用
Django 入门实战:从环境搭建到构建你的第一个 Web 应用 恭喜你选择 Django 作为你学习 Python Web 开发的起点!Django 是一个强大、成熟且功能齐全的框架,非常适合构建中大型的 Web 应用程序。本篇将通过一个简单的例子,带你走完…...

【后端】构建简洁的音频转写系统:基于火山引擎ASR实现
在当今数字化时代,语音识别技术已经成为许多应用不可或缺的一部分。无论是会议记录、语音助手还是内容字幕,将语音转化为文本的能力对提升用户体验和工作效率至关重要。本文将介绍如何构建一个简洁的音频转写系统,专注于文件上传、云存储以及…...

http通信之axios vs fecth该如何选择?
在HTTP通信中,axios和fetch都是常用的库或原生API用于发起网络请求。两者各有特点,适用于不同的场景。下面详细介绍它们的差异和各自的优势: fetch 特点: 原生支持:fetch是现代浏览器内置的API,不需要额外…...

iostat指令介绍
文章目录 1. 功能介绍2. 语法介绍3. 应用场景4. 示例分析 1. 功能介绍 iostat (input/output statistics),是 Linux/Unix 系统中用于监控 CPU 使用率和 磁盘 I/O 性能的核心工具,可实时展示设备负载、吞吐量、队列状态等关键指标。 可以使用 man iostat查…...
——大模型(LLMs)分词(Tokenizer)详解)
NLP高频面试题(五十)——大模型(LLMs)分词(Tokenizer)详解
在自然语言处理(NLP)任务中,将文本转换为模型可处理的数字序列是必不可少的一步。这一步通常称为分词(tokenization),即把原始文本拆分成一个个词元(token)。对于**大型语言模型(LLM,Large Language Model,大型语言模型)**而言,选择合适的分词方案至关重要:分词的…...

桌面我的电脑图标不见了怎么恢复 恢复方法指南
在Windows操作系统中,“我的电脑”或在较新版本中称为“此电脑”的图标,是访问硬盘驱动器、外部存储设备和系统文件的重要入口。然而,有些用户可能会发现桌面上缺少了这个图标,这可能是由于误操作、系统设置更改或是不小心删除造成…...
)
【Qt】控件的理解 和 基础控件 QWidget 属性详解(通俗易懂+附源码+思维导图框架)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 通过上一章对信号槽的理解相信你对Qt的认识肯定有了很大的进步,下面将通过本篇文章带你深入的认识Widget控件(主窗口࿰…...

oracle将表字段逗号分隔的值进行拆分,并替换值
需求背景:需要源数据变动,需要对历史表已存的字段值根据源数据进行更新。如果是单字段存值,直接根据映射表关联修改即可。但字段里面若存的值是以逗号分割,比如旧值:‘old1,old2,old3’,要根据映射关系调整…...

用c语言实现——一个带头节点的链队列,支持用户输入交互界面、初始化、入队、出队、查找、判空判满、显示队列、遍历计算长度等功能
一、知识介绍 带头节点的链队列是一种基于链表实现的队列结构,它在链表的头部添加了一个特殊的节点,称为头节点。头节点不存储实际的数据元素,主要作用是作为链表的起点,简化队列的操作和边界条件处理。 1.节点结构 链队列的每…...
)
webpack基础使用了解(入口、出口、插件、加载器、优化、别名、打包模式、环境变量、代码分割等)
目录 1、webpack简介2、简单示例3、入口(entry)和输出(output)4、自动生成html文件5、打包css代码6、优化(单独提取css代码)7、优化(压缩过程)8、打包less代码9、打包图片10、搭建开发环境(webpack-dev-server…...

【项目】基于MCP+Tabelstore架构实现知识库答疑系统
基于MCPTabelstore架构实现知识库答疑系统 整体流程设计(一)Agent 架构(二)知识库存储(1)向量数据库Tablestore(2)MCP Server (三)知识库构建(1&a…...

C语言高频面试题——malloc 和 calloc区别
在 C 语言中,malloc 和 calloc 都是用于动态内存分配的函数,但它们在 内存初始化、参数形式 和 使用场景 上有显著区别。以下是详细的对比分析: 1. 函数原型 malloc void* malloc(size_t size);功能:分配 未初始化 的连续内存块…...

深入探讨JavaScript性能瓶颈与优化实战指南
JavaScript作为现代Web开发的核心语言,其性能直接影响用户体验与业务指标。随着2025年前端应用的复杂性持续增加,性能优化已成为开发者必须掌握的核心技能。本文将从性能瓶颈分析、优化策略、工具使用三个维度,结合实战案例,系统梳理JavaScript性能优化的关键路径。 一、Ja…...

[创业之路-376]:企业法务 - 创业,不同的企业形态,个人承担的风险、收益、税费、成本不同
在企业法务领域,创业时选择不同的企业形态,个人在风险承担、收益分配、税费负担及运营成本方面存在显著差异。以下从个人独资企业、合伙企业、有限责任公司、股份有限公司四种常见形态展开分析: 一、个人承担的风险 个人独资企业 风险类型&…...

【Lua】Lua 入门知识点总结
Lua 入门学习笔记 本教程旨在帮助有编程基础的学习者快速入门Lua编程语言。包括Lua中变量的声明与使用,包括全局变量和局部变量的区别,以及nil类型的概念、数值型、字符串和函数的基本操作,包括16进制表示、科学计数法、字符串连接、函数声明…...

低空经济 WebGIS 无人机配送 | 图扑数字孪生
2024 年,”低空经济” 首次写入政府工作报告,在政策驱动下各地纷纷把握政策机遇,从基建网络、场景创新、产业生态、政策激励等方面,构建 “规划-建设-应用-赋能” 的系统性布局,作为新质生产力的重要体现,推…...
)
【程序员 NLP 入门】词嵌入 - 如何基于计数的方法表示文本? (★小白必会版★)
🌟 嗨,你好,我是 青松 ! 🌈 希望用我的经验,让“程序猿”的AI学习之路走的更容易些,若我的经验能为你前行的道路增添一丝轻松,我将倍感荣幸!共勉~ 【程序员 NLP 入门】词…...

基于机器学习的多光谱遥感图像分类方法研究与定量评估
多光谱遥感技术通过获取可见光至红外波段的光谱信息,为地质勘探、农业监测、环境调查等领域提供了重要支持。与普通数码相机相比,多光谱成像能记录更丰富的波段数据(如近红外、短波红外等),从而更精准地识别地物特征。…...

BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection
背景 基于多视角图片的3D感知被LSS证明是可行的,它使用估计的深度将图像特征转化为3D视椎,再将其压缩到BEV平面上。对于这个得到的BEV特征图,它支持端到端训练以及各种下游任务。但是对于深度估计这一块学习的深度质量如何,到目前为止没有相关工作研究。 贡献 本文的贡献…...

【Linux】静态库 动态库
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、👑静态库和动态库 静态库: 动态库: 🌠手动制作静态库 && 手动调用一下我们自己写的静态库 1> 安装到系统里面 ✨生成静…...
:TCP黏包)
Java转Go日记(六):TCP黏包
服务端代码如下: // socket_stick/server/main.gofunc process(conn net.Conn) {defer conn.Close()reader : bufio.NewReader(conn)var buf [1024]bytefor {n, err : reader.Read(buf[:])if err io.EOF {break}if err ! nil {fmt.Println("read from client…...
LCD显示温度(DS18B20教程)(LCD1602教程)(延时函数教程)(单总线教程))
(51单片机)LCD显示温度(DS18B20教程)(LCD1602教程)(延时函数教程)(单总线教程)
演示视频: LCD显示温度 源代码 如上图将9个文放在Keli5 中即可,然后烧录在单片机中就行了 烧录软件用的是STC-ISP,不知道怎么安装的可以去看江科大的视频: 【51单片机入门教程-2020版 程序全程纯手打 从零开始入门】https://www.…...

【通过Docker快速部署Tomcat9.0】
文章目录 前言一、部署docker二、部署Tomcat2.1 创建存储卷2.2 运行tomcat容器2.3 查看tomcat容器2.4 查看端口是否监听2.5 防火墙开放端口 三、访问Tomcat 前言 Tomcat介绍 Tomcat 是由 Apache 软件基金会(Apache Software Foundation)开发的一个开源 …...
)
云原生--基础篇-3--云原生概述(云、原生、云计算、核心组成、核心特点)
1、什么是云和原生 (1)、什么是云? “云”指的是云计算环境,代表应用运行的基础设施和资源。依赖并充分利用云计算的弹性、分布式和资源池化能力。 核心含义: 1、云计算基础设施 云原生应用的设计和运行完全基于云…...

Spark-Streaming
Spark-Streaming概述 DStream实操 案例一:WordCount案例 需求:使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并统计不同单词出现的次数 实验步骤: 添加依赖 <dependency> <gro…...

乐视系列玩机------乐视2 x620红灯 黑砖刷写教程以及新版刷写工具的详细释义
乐视x620在上期解析了普通黑砖情况下的救砖刷机过程。但在一些例外的情况下。使用上面的步骤会一直刷写报错 。此种情况就需要另外一种强制刷写方法来救砖 通过博文了解💝💝💝 1💝💝💝-----详细解析乐视2 x620系列 红灯 黑砖线刷救砖的步骤 2💝💝💝----图…...

若依SpringCloud项目-定制微服务模块
若依SpringCloud项目-定制微服务模块 关于微服务先不过多介绍,刚开始熟悉并不能讲的很彻底,成熟的微服务项目-若依SpringCloud就是一个典型的微服务架构工程(网上有很多教程了,不明白的可以学习一下)。 我正在看的视…...

【扫描件批量改名】批量识别扫描件PDF指定区域内容,用识别的内容修改PDF文件名,基于C++和腾讯OCR的实现方案,超详细
批量识别扫描件PDF指定区域内容并重命名文件方案 应用场景 本方案适用于以下场景: 企业档案数字化管理:批量处理扫描的合同、发票等文件,按内容自动分类命名财务票据处理:自动识别票据上的关键信息(如发票号码、日期)用于归档医疗记录管理:从扫描的检查报告中提取患者I…...

学习Docker遇到的问题
目录 1、拉取hello-world镜像报错 1. 检查网络连接 排查: 2. 配置 Docker 镜像加速器(推荐) 具体解决步骤: 1.在服务器上创建并修改配置文件,添加Docker镜像加速器地址: 2. 重启Docker 3. 拉取hello-world镜像 2、删除镜像出现异常 3、 容器内部不能运行ping命令 …...

Docker 数据卷
目录 一、数据卷(Data Volume) 二、使用 1、单独建立数据卷 2、挂载主机数据卷 3、数据卷容器挂载 基本语法: 工作原理: 主要用途: 使用事例: 一、数据卷(Data Volume) 数据卷的使用,类似于 Linux 下对目录或文件进行 mount 数据卷(Data Volume)是一个可供一个或多…...
双链表)
【数据结构】励志大厂版·初级(二刷复习)双链表
前引:今天学习的双链表属于链表结构中最复杂的一种(带头双向循环链表),按照安排,我们会先进行复习,如何实现双链表,如基本的头插、头删、尾删、尾插,掌握每个细节,随后进…...

通过dogssl申请ssl免费证书
SSL证书作为实现HTTPS加密的核心工具,能够确保用户与网站之间的数据传输安全。尤其是在小程序之类的开发时,要求必须通过https发起请求的情况下。学会如何免费申请一个ssl证书就很有必要了。这里我分享一下,我通过dogssl如何申请ssl的。 一&…...

路由与路由器
路由的概念 路由是指在网络通讯中,从源设备到目标设备路径的选择过程。路由器是实现这一过程的关键设备,它通过转发数据包来实现网络的互联。路由工作在OSI参考模型的第三层,‘网络层’。 路由器的基本原理 路由器通过维护一张路由表来决定…...

Docker底层原理浅析 | namespace+cgroups+文件系统
本文目录 1. Linux NamespaceLinux系统里是否只能有一个pid为1的进程?namespace机制查看namespacenamespace机制测试使用Docker验证namespace机制 2. Dcoerk网络模式3.Control groups4.文件系统(联合文件系统)5. 容器格式 1. Linux Namespace…...
 算法来处理传感器测量,各传感器的参数设置,高度数据融合、不同传感器融合模式)
【无人机】使用扩展卡尔曼滤波 (EKF) 算法来处理传感器测量,各传感器的参数设置,高度数据融合、不同传感器融合模式
目录 #1、IMU #2、磁力计 #3、高度 #典型配置 #4、气压计 #静压位置误差修正 #气压计偏置补偿 #5、全球导航系统/全球定位系统--GNSS/GPS #位置和速度测量 #偏航测量 #GPS 速度的偏航 #双接收器 #GNSS 性能要求 #6、测距 #条件范围辅助-Conditional range aidin…...

常见的raid有哪些,使用场景是什么?
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)是一种将多个物理硬盘组合成一个逻辑硬盘的技术,目的是通过数据冗余和/或并行访问提高性能、容错能力和存储容量。不同的 RAID 级别有不同的实现方式和应用场景。以下…...

《 C++ 点滴漫谈: 三十四 》从重复到泛型,C++ 函数模板的诞生之路
一、引言 在 C 编程的世界里,类型是一切的基础。我们为 int 写一个求最大值的函数,为 double 写一个相似的函数,为 std::string 又写一个……看似合理的行为,逐渐堆积成了难以维护的 “函数墙”。这些函数逻辑几乎一致࿰…...

EasyRTC打造无人机低延迟高清实时通信监控全场景解决方案
一、方案背景 随着无人机技术的飞速发展,其在航拍、物流配送、农业监测、应急救援等多个领域的应用日益广泛。然而,无人机在实际作业过程中面临着诸多挑战,如通信延迟、数据传输不稳定、监控范围有限等。EasyRTC作为一种高效、低延迟的实时通…...
)
【MATLAB第117期】#源码分享 | 基于MATLAB的SSM状态空间模型多元时间序列预测方法(多输入单输出)
【MATLAB第117期】#源码分享 | 基于MATLAB的SSM状态空间模型多元时间序列预测方法(多输入单输出) 引言 本文使用状态空间模型实现失业率递归预测,状态空间模型(State Space Model, SSM)是一种用于描述动态系统行为的…...
——数据安全与合规)
关于大数据的基础知识(三)——数据安全与合规
成长路上不孤单😊😊😊😊😊😊 【14后😊///计算机爱好者😊///持续分享所学😊///如有需要欢迎收藏转发///😊】 今日分享关于大数据的基础知识(三&a…...

从信息泄露到内网控制
0x01 背景 之前常见用rce、文件上传等漏洞获取webshell,偶然遇到一次敏感信息泄露获取权限的渗透,简单记录一下过程。 0x02 信息泄露 发现系统某端口部署了minio服务,经过探测发现存在minio存储桶遍历 使用利用工具把泄露的文件全部整理一…...

【Qt】QDialog类
🌈 个人主页:Zfox_ 🔥 系列专栏:Qt 目录 一:🔥 对话框 - QDialog 🦋 基本介绍🦋 对话框分类🦋 Qt 内置对话框🎀 QMessageBox -消息对话框🎀 QColo…...

【Spring Boot基础】MyBatis的基础操作:增删查改、列名和属性名匹配 -- XML实现
MyBatis的基础操作 1. MyBatis XML配置文件1.1 简单介绍1.2 配置连接字符串和MyBatis1.3 XMl文件实现--分层1.4 XMl文件实现--举例 2.增删改查操作2.1 增(insert)2.1.1 不使用Param2.1.2 用Param2.1.3 返回自增键 2.2 删(delete)2…...

谷歌推出探索型推荐新范式:双LLM架构重塑用户兴趣挖掘
文章目录 1. 背景1.1 闭环困境1.2 谷歌的两次失败尝试1.2.1 尝试一:轻量微调1.2.2 尝试二:RLHF 强化学习微调 1.3 双LLM范式的提出1.3.1 模型1:Novelty LLM — 负责生成“探索方向”1.3.2 模型2:Alignment LLM — 负责评估“相关性…...
- aarch64架构sigreturn流程)
Linux kernel signal原理(下)- aarch64架构sigreturn流程
一、前言 在上篇中写到了linux中signal的处理流程,在do_signal信号处理的流程最后,会通过sigreturn再次回到线程现场,上篇文章中介绍了在X86_64架构下的实现,本篇中介绍下在aarch64架构下的实现原理。 二、sigaction系统调用 #i…...

使用 LangChain + Higress + Elasticsearch 构建 RAG 应用
RAG(Retrieval Augmented Generation,检索增强生成) 是一种结合了信息检索与生成式大语言模型(LLM)的技术。它的核心思想是:在生成模型输出内容之前,先从外部知识库或数据源中检索相关信息&…...
)
【Linux】46.网络基础(3.3)
文章目录 5. 其他重要协议或技术5.1 DNS(Domain Name System)5.1.1 DNS背景5.1.2 域名简介 5.2 ICMP协议5.2.1 ICMP功能5.2.2 ICMP的报文格式5.2.3 ping命令5.2.4 一个值得注意的坑5.2.5 traceroute命令 5.3 NAT技术5.3.1 NAT技术背景5.3.2 NAT IP转换过程5.3.3 NAPT5.3.4 NAT技…...

【Unity笔记】Unity + OpenXR项目无法启动SteamVR的排查与解决全指南
图片为AI生成 一、前言 随着Unity在XR领域全面转向OpenXR标准,越来越多的开发者选择使用OpenXR来构建跨平台的VR应用。但在项目实际部署中发现:打包成的EXE程序无法正常启动SteamVR,或者SteamVR未能识别到该应用。本文将以“Unity OpenXR …...

【sylar-webserver】重构 增加内存池
文章目录 内存池设定结构ThreadCacheCentralCachePageCache allocatedeallocate测试 参考 https://github.com/youngyangyang04/memory-pool 我的代码实现见 https://github.com/star-cs/webserver 内存池 ThreadCache(线程本地缓存) 每个线程独立的内存…...