使用 LangChain + Higress + Elasticsearch 构建 RAG 应用
RAG(Retrieval Augmented Generation,检索增强生成) 是一种结合了信息检索与生成式大语言模型(LLM)的技术。它的核心思想是:在生成模型输出内容之前,先从外部知识库或数据源中检索相关信息,然后将这些信息作为上下文输入给生成模型,从而提升生成内容的准确性、时效性和相关性。
在本文中,我们将使用 LangChain、Higress 和 Elasticsearch 来构建一个 RAG 应用。本文所使用的代码可以在 Github 上找到:https://github.com/cr7258/hands-on-lab/tree/main/gateway/higress/rag-langchain-es
什么是 Higress?
Higress 是一款云原生 API 网关,内核基于 Istio 和 Envoy,可以用 Go/Rust/JS 等编写 Wasm 插件,提供了数十个现成的通用插件。Higress 同时也能够作为 AI 网关,通过统一的协议对接国内外所有 LLM 模型厂商,同时具备丰富的 AI 可观测、多模型负载均衡/fallback、AI token 流控、AI 缓存等能力。
什么是 Elasticsearch?
Elasticsearch 是一个分布式搜索与分析引擎,广泛用于全文检索、日志分析和实时数据处理。Elasticsearch 在 8.x 版本中原生引入了向量检索功能,支持基于稠密向量和稀疏向量的相似度搜索。
什么是 LangChain?
LangChain 是一个开源框架,旨在构建基于大语言模型(LLM)的应用程序。其核心理念是通过将多个功能组件“链”式组合,形成完整的业务流程。例如,可以灵活组合数据加载、检索、提示模板与模型调用等模块,从而实现智能问答、文档分析、对话机器人等复杂应用。
在本文中,我们将仅使用 LangChain 的数据加载功能,RAG 检索能力由 Higress 提供的开箱即用的 ai-search 插件实现。ai-search 插件不仅支持基于 Elasticsearch 的私有知识库搜索,还支持 Google、Bing、Quark 等主流搜索引擎的在线检索,以及 Arxiv 等学术文献的搜索。
RAG 流程分析
数据预处理阶段
在进行 RAG 查询之前,我们首先需要将原始文档进行向量化处理,并将其写入 Elasticsearch。在本文中,我们的文档是一份 Markdown 格式的员工手册,我们使用 LangChain 的 MarkdownHeaderTextSplitter 对文档进行处理。MarkdownHeaderTextSplitter 能够解析 Markdown 文档的结构,并根据标题将文档拆分。Elasticsearch 支持内置的 Embedding模型,本文将使用 Elasticsearch 自带的 ELSER v2 模型(Elastic Learned Sparse EncodeR),该模型会将文本转换为稀疏向量。建议将 ELSER v2 模型用于英语文档的查询,如果想对非英语文档执行语义搜索,请使用 E5 模型。
查询阶段
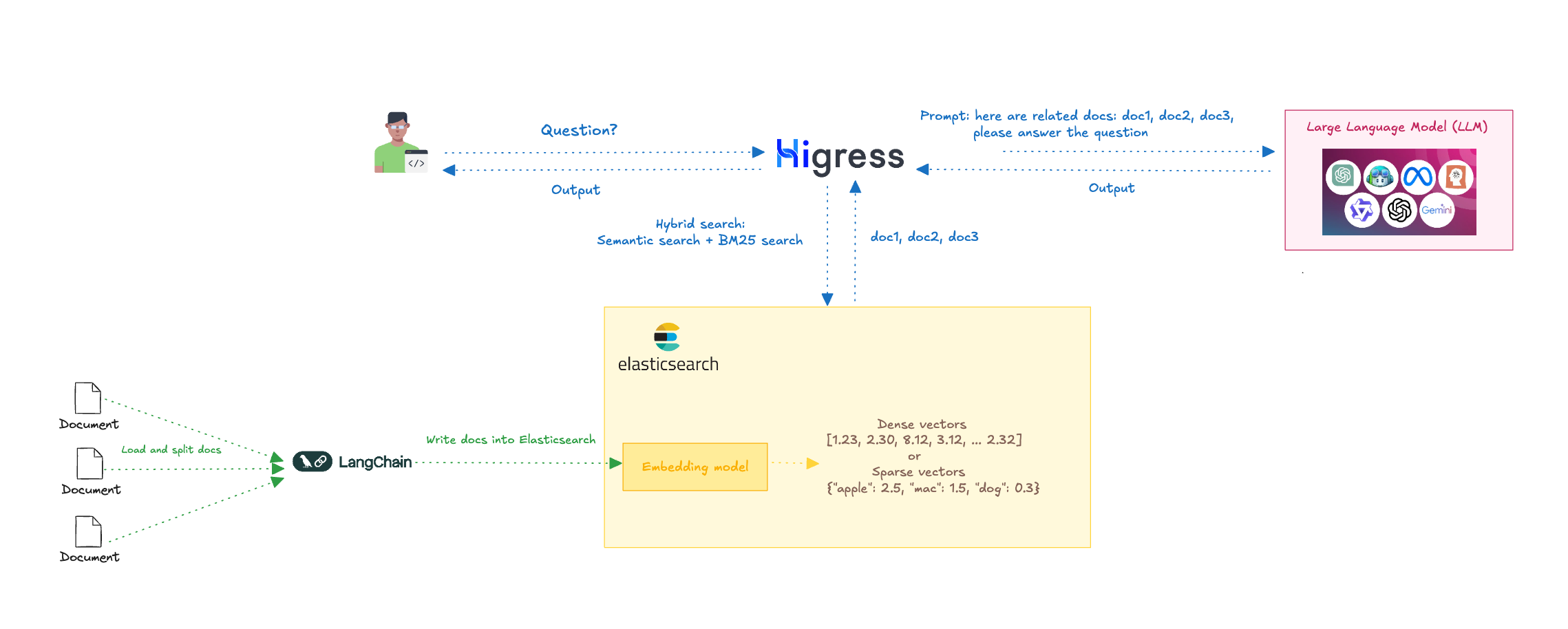
检索增强生成(RAG)是一个多步骤的过程,首先进行信息检索,然后进入生成阶段。其工作流程如下:
-
- 输入查询:首先,从用户的输入查询开始,例如用户提出的问题。
-
- 信息检索:然后,Higress 的 ai-search 插件会从 Elasticsearch 中检索相关信息。ai-search 插件结合语义搜索和全文搜索,使用 RRF(Reciprocal Rank Fusion)进行混合搜索,从而提高搜索的准确性和相关性。
-
- 提示词生成:Higress 将检索到的文档与用户的问题一起,作为提示词输入给 LLM。
-
- 文本生成:LLM 根据检索到的信息生成文本回答,这些回答通常更加准确,因为它们已经通过检索模型提供的补充信息进行了优化。
稀疏向量和稠密向量
这里顺便介绍一下稀疏向量和稠密向量的区别。稀疏向量(Sparse Vectors)和稠密向量(Dense Vectors)是两种常见的向量表示形式,在机器学习、搜索和个性化推荐等场景中都广泛使用。
- 稠密向量(Dense Vectors) 是指在向量空间中,几乎所有的元素都有值(非零)。每个向量元素通常代表了某一特定特征或维度,稠密向量的维度通常较高(如 512 维或更高),并且每个维度的数值都有一定的实际意义,通常是连续的数值,反映了数据的相似度或特征的权重。
- 稀疏向量(Sparse Vectors) 稀疏向量则是指在向量空间中,大多数元素为零,只有少数元素为非零值。这些非零值通常代表了向量中某些重要特征的存在,尤其适用于文本或特定特征的表示。例如,在文本数据中,词袋模型(Bag of Words)就是一个稀疏向量的典型例子,因为在大多数情况下,文本中并不会出现所有可能的词汇,仅有一小部分词汇会出现在每个文档中,因此其他词汇对应的向量值为零。

在 Elasticsearch 中使用稀疏向量进行搜索感觉类似于传统的关键词搜索,但略有不同。稀疏向量查询不是直接匹配词项,而是使用加权词项和点积来根据文档与查询向量的对齐程度对文档进行评分。

部署 Elasticsearch
在代码目录中,我准备了 docker-compose.yaml 文件,用于部署 Elasticsearch。执行以下命令启动 Elasticsearch:
docker-compose up -d
在浏览器输入 http://localhost:5601 访问 Kibana 界面,用户名是 elastic,密码是 test123。
部署 Embedding 模型
Elasticsearch 默认为机器学习(ML)进程分配最多 30% 的机器总内存。如果本地电脑内存较小,可以将 xpack.ml.use_auto_machine_memory_percent 参数设置为 true,允许自动计算 ML 进程可使用的内存占比,从而避免因内存不足而无法部署 Embedding 模型的问题。
在 Kibana 的 Dev Tools 中,执行以下命令进行设置:
PUT _cluster/settings
{"persistent": {"xpack.ml.use_auto_machine_memory_percent": "true"}
}
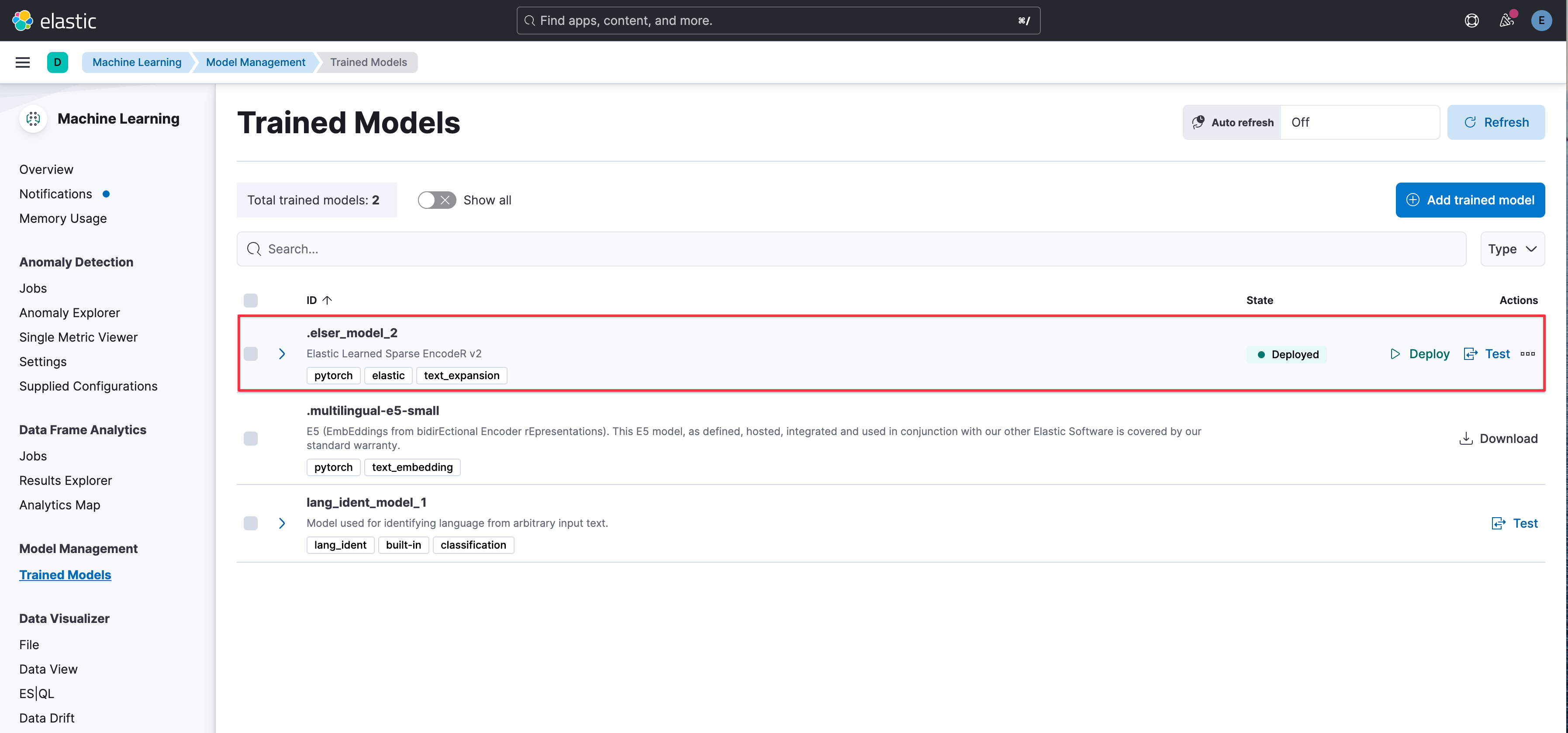
在 Kibana 上访问 Machine Learning -> Model Management -> Trained Models,点击 Download 下载模型,然后点击 Deploy 部署模型。
创建索引映射
在写入数据之前,需要先创建索引映射。其中,semantic_text 字段用于存储稀疏向量,以支持语义搜索;content 字段则用于存储原始文本内容,以支持全文搜索。
在写入数据时,只需写入原始文本。通过 copy_to 配置,content 字段中的文本会自动复制到 semantic_text 字段,并由推理端点进行处理。如果未显式指定推理端点,semantic_text 字段会默认使用 .elser-2-elasticsearch,这是 Elasticsearch 为 ELSER v2 模型预设的默认推理端点。
PUT employee_handbook
{"mappings": {"properties": {"semantic_text": { "type": "semantic_text"},"content": { "type": "text","copy_to": "semantic_text" }}}
}
解析文档并写入 Elasticsearch
安装 LangChain 相关依赖包:
pip3 install elasticsearch langchain langchain_elasticsearch langchain_text_splitters
以下是相关的 Python 代码:
MarkdownHeaderTextSplitter是 LangChain 提供的用于解析 Markdown 文件的工具,它能够根据标题将 Markdown 文档进行拆分。- 在索引内容时,LangChain 会为每个文档计算哈希值,并记录在
RecordManager中,以避免重复写入。在本文中,我们使用了SQLRecordManager,它将记录存储在本地的 SQLite 数据库中。 - 使用
ElasticsearchStore将文档写入 Elasticsearch,只写入content字段(原始文本内容),并将cleanup模式设置为full。该模式可以确保无论是删除还是更新,始终保持文档内容与向量数据库中的数据一致。关于文档去重的几种模式对比,可以参考:How to use the LangChain indexing API。
from langchain_text_splitters import MarkdownHeaderTextSplitter
from elasticsearch import Elasticsearch
from langchain_elasticsearch import ElasticsearchStore
from langchain_elasticsearch import SparseVectorStrategy
from langchain.indexes import SQLRecordManager, index# 1. 加载 Markdown 文件并按标题拆分
with open("./employee_handbook.md") as f:employee_handbook = f.read()headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),("###", "Header 3"),
]markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on, strip_headers=False)
docs = markdown_splitter.split_text(employee_handbook)index_name = "employee_handbook"# 2. 使用 RecordManager 去重
namespace = f"elasticsearch/{index_name}"
record_manager = SQLRecordManager(namespace, db_url="sqlite:///record_manager_cache.sql"
)
record_manager.create_schema()# 3. 写入 Elasticsearch,只写入 content 字段(原始文本)
es_connection = Elasticsearch(hosts="https://localhost:9200",basic_auth=("elastic", "test123"),verify_certs=False
)vectorstore = ElasticsearchStore(es_connection=es_connection,index_name=index_name,query_field="content",strategy=SparseVectorStrategy(),
)index_result = index(docs,record_manager,vectorstore,cleanup="full",
)print(index_result)
执行以下内容解析 Markdown 文件并写入 Elasticsearch:
python3 load-markdown-into-es.py
输入如下,Markdown 文件被拆分成了 22 个文档写入了 Elasticsearch。
{'num_added': 22, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
我们可以先使用 LangChain 的 similarity_search 来测试查询效果。由于其默认的查询语句没有使用我们想要的 RRF 混合搜索,因此需要自定义查询语句。后续在使用 Higress 的 ai-search 插件时,也会采用相同的 RRF 混合搜索方式。
def custom_query(query_body: dict, query: str):new_query_body = {"_source": {"excludes": "semantic_text"},"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"match": {"content": query}}}},{"standard": {"query": {"semantic": {"field": "semantic_text","query": query}}}}]}}}return new_query_bodyresults = vectorstore.similarity_search("What are the working hours in the company?", custom_query=custom_query)
print(results[0])
返回内容如下,可以看到准确匹配到了工作时间的相关文档,公司的上午 9 点到下午 6 点。
page_content='## 4. Attendance Policy
### 4.1 Working Hours
- Core hours: **Monday to Friday, 9:00 AM – 6:00 PM**
- Lunch break: **12:00 PM – 1:30 PM**
- R&D and international teams may operate with flexible schedules upon approval' metadata={'Header 3': '4.1 Working Hours', 'Header 2': '4. Attendance Policy'}
部署 Higress AI 网关
仅需一行命令,即可快速在本地搭建好 Higress AI 网关。
curl -sS https://higress.cn/ai-gateway/install.sh | bash
在浏览器中输入 http://localhost:8001 即可访问 Higress 的控制台界面。配置好 Provider 的 ApiToken 后,就可以开始使用 Higress AI 网关了。这里以通义千问为例进行配置。
Higress AI 网关已经帮用户预先配置了 AI 路由,可以根据模型名称的前缀来路由到不同的 LLM。使用 curl 命令访问通义千问:
curl 'http://localhost:8080/v1/chat/completions' \-H 'Content-Type: application/json' \-d '{"model": "qwen-turbo","messages": [{"role": "user","content": "Who are you?"}]}'
返回内容如下,可以看到成功收到了来自通义千问的响应。
{"id": "335b58a1-8b47-942c-aa9e-302239c6e652","choices": [{"index": 0,"message": {"role": "assistant","content": "I am Qwen, a large language model developed by Alibaba Cloud. I can answer questions, create text such as stories, emails, scripts, and more. I can also perform logical reasoning, express opinions, and play games. My capabilities include understanding natural language and generating responses that are coherent and contextually appropriate. How can I assist you today?"},"finish_reason": "stop"}],"created": 1745154868,"model": "qwen-turbo","object": "chat.completion","usage": {"prompt_tokens": 12,"completion_tokens": 70,"total_tokens": 82}
}
配置 ai-search 插件
接下来在 Higress 控制台上配置 ai-search 插件,首先需要将 Elasticsearch 添加到服务来源中,其中 192.168.2.153 是我本机的 IP 地址,请用户根据实际情况修改。
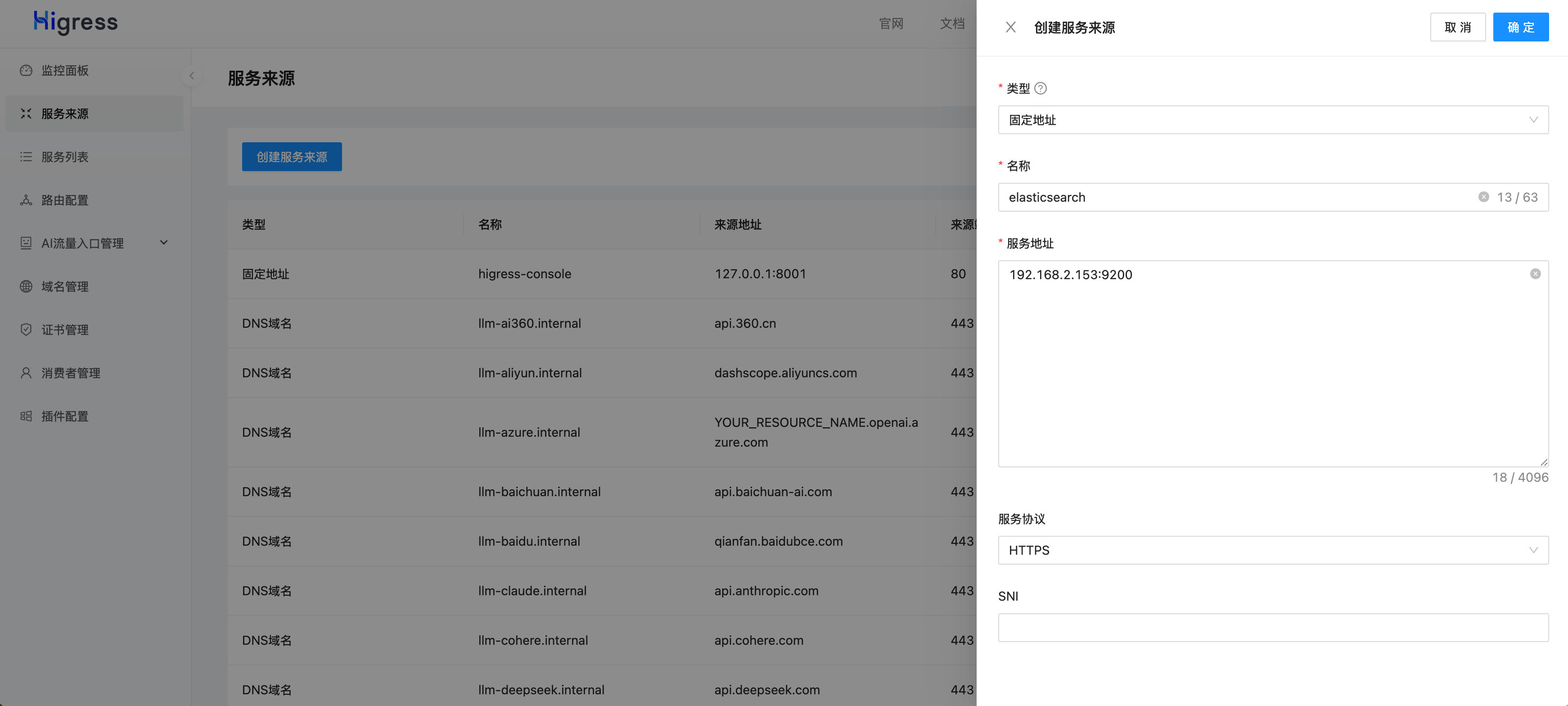
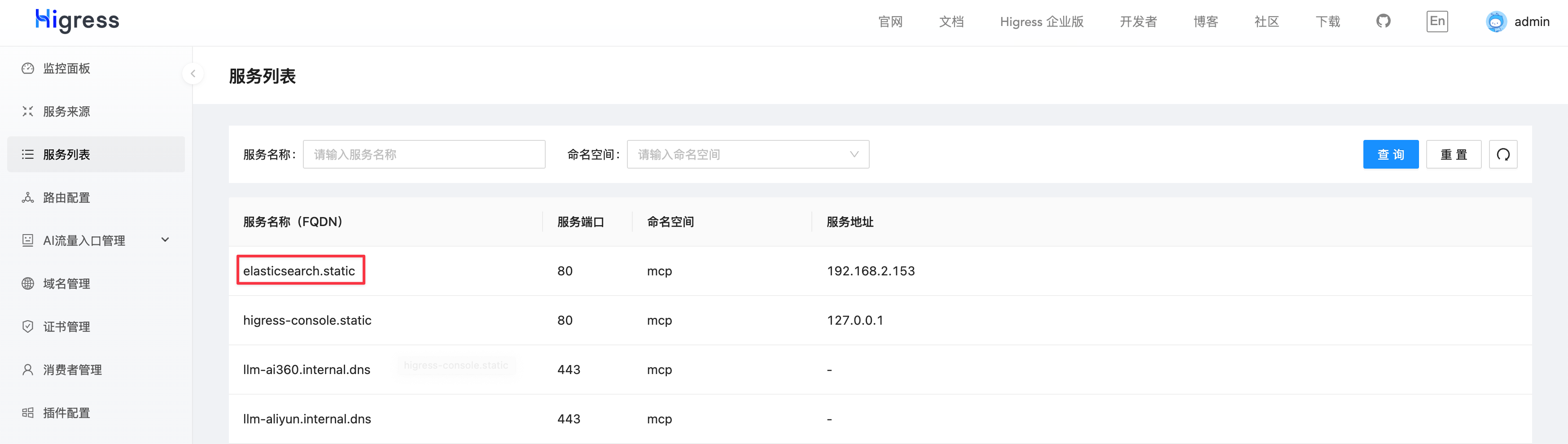
添加完服务来源后,可以在服务列表中找到服务名称(Service Name),在本例中是 elasticsearch.static。
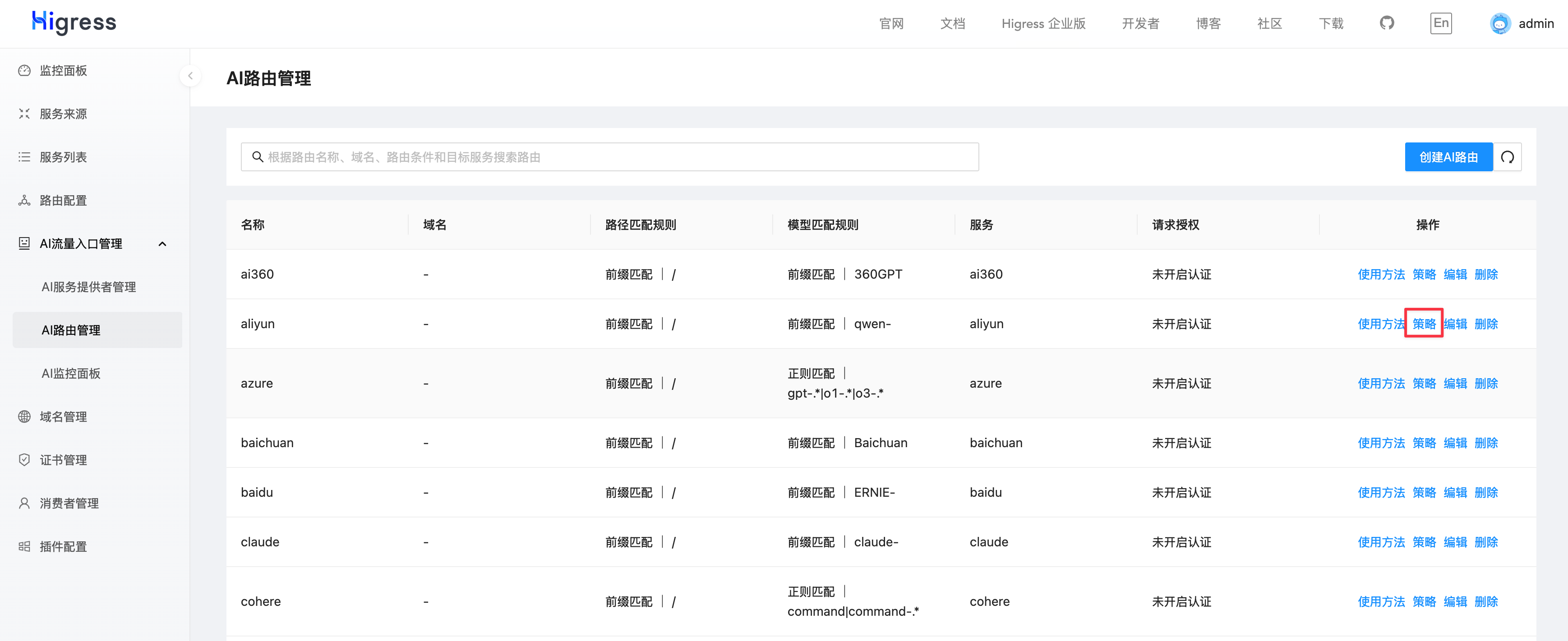
接下来在通义千问的这条 AI 路由中配置 ai-search 插件。
点击 AI 搜索增强 插件:
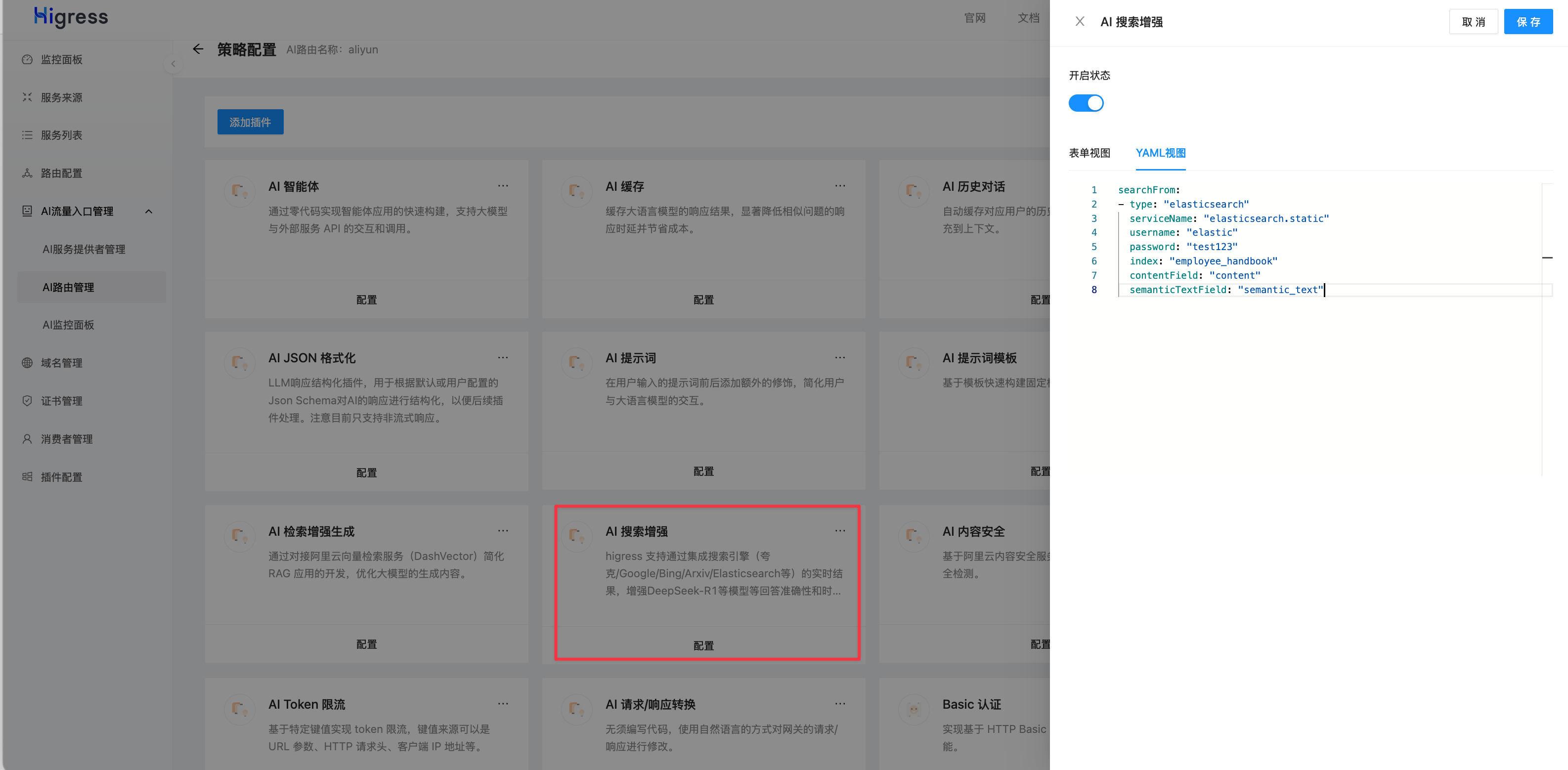
填入以下配置:
searchFrom:
- type: "elasticsearch"serviceName: "elasticsearch.static"username: "elastic"password: "test123"index: "employee_handbook"contentField: "content"semanticTextField: "semantic_text"
RAG 查询
配置好 ai-search 插件后,就可以开始进行 RAG 查询了。让我们先询问一下公司的工作时间是怎么规定的。
curl 'http://localhost:8080/v1/chat/completions' \-H 'Content-Type: application/json' \-d '{"model": "qwen-turbo","messages": [{"role": "user","content": "What are the working hours in the company?"}]}'
返回内容如下,工作时间是上午 9 点到下午 6 点。
{"id": "c10b9d68-2291-955f-b17a-4d072cc89607","choices": [{"index": 0,"message": {"role": "assistant","content": "The working hours in the company are as follows:\n\n- Core hours: Monday to Friday, 9:00 AM – 6:00 PM.\n- Lunch break: 12:00 PM – 1:30 PM.\n\nR\u0026D and international teams may have flexible schedules upon approval."},"finish_reason": "stop"}],"created": 1745228815,"model": "qwen-turbo","object": "chat.completion","usage": {"prompt_tokens": 433,"completion_tokens": 63,"total_tokens": 496}
}
原始文档的内容可能会随着时间的推移而发生变化。接下来,让我们修改 employee_handbook.md 文件中的工作时间,改成上午 8 点到下午 5 点。
然后重新执行 load-markdown-into-es.py 脚本,这次可以看到有一个文档被更新了。
{'num_added': 1, 'num_updated': 0, 'num_skipped': 21, 'num_deleted': 1}
再次询问相同的问题,可以看到返回的答案也相应地更新了。
{"id": "39632a76-7432-92ab-ab86-99a04f211a0d","choices": [{"index": 0,"message": {"role": "assistant","content": "The working hours in the company are as follows:\n\n- **Core hours**: Monday to Friday, 8:00 AM – 5:00 PM.\n- There is a lunch break from **12:00 PM – 1:30 PM**.\n- R\u0026D and international teams may have flexible schedules, but this requires approval.\n\nToday's date is April 21, 2025, so these working hours are still applicable."},"finish_reason": "stop"}],"created": 1745228667,"model": "qwen-turbo","object": "chat.completion","usage": {"prompt_tokens": 433,"completion_tokens": 95,"total_tokens": 528}
}
总结
本文通过实际案例演示了如何利用 LangChain、Higress 和 Elasticsearch 快速搭建 RAG 应用,实现企业知识的智能检索与问答。通过 Higress 的 ai-search 插件,用户可以轻松集成在线搜索和私有知识库,从而打造高效、精准的 RAG 应用。
参考资料
- LangChain Elasticsearch vector store: https://python.langchain.com/docs/integrations/vectorstores/elasticsearch
- How to split Markdown by Headers: https://python.langchain.com/docs/how_to/markdown_header_metadata_splitter/
- How to use the LangChain indexing API: https://python.langchain.com/docs/how_to/indexing/
- Semantic search, leveled up: now with native match, knn and sparse_vector support: https://www.elastic.co/search-labs/blog/semantic-search-match-knn-sparse-vector
- Hybrid search with semantic_text: https://www.elastic.co/docs/solutions/search/hybrid-semantic-text
- Enhancing relevance with sparse vectors: https://www.elastic.co/search-labs/blog/elasticsearch-sparse-vector-boosting-personalization
- What is RAG (retrieval augmented generation)?: https://www.elastic.co/what-is/retrieval-augmented-generation
- No ML nodes with sufficient capacity for trained model deployment: https://discuss.elastic.co/t/no-ml-nodes-with-sufficient-capacity-for-trained-model-deployment/357517
欢迎关注

相关文章:

使用 LangChain + Higress + Elasticsearch 构建 RAG 应用
RAG(Retrieval Augmented Generation,检索增强生成) 是一种结合了信息检索与生成式大语言模型(LLM)的技术。它的核心思想是:在生成模型输出内容之前,先从外部知识库或数据源中检索相关信息&…...
)
【Linux】46.网络基础(3.3)
文章目录 5. 其他重要协议或技术5.1 DNS(Domain Name System)5.1.1 DNS背景5.1.2 域名简介 5.2 ICMP协议5.2.1 ICMP功能5.2.2 ICMP的报文格式5.2.3 ping命令5.2.4 一个值得注意的坑5.2.5 traceroute命令 5.3 NAT技术5.3.1 NAT技术背景5.3.2 NAT IP转换过程5.3.3 NAPT5.3.4 NAT技…...

【Unity笔记】Unity + OpenXR项目无法启动SteamVR的排查与解决全指南
图片为AI生成 一、前言 随着Unity在XR领域全面转向OpenXR标准,越来越多的开发者选择使用OpenXR来构建跨平台的VR应用。但在项目实际部署中发现:打包成的EXE程序无法正常启动SteamVR,或者SteamVR未能识别到该应用。本文将以“Unity OpenXR …...

【sylar-webserver】重构 增加内存池
文章目录 内存池设定结构ThreadCacheCentralCachePageCache allocatedeallocate测试 参考 https://github.com/youngyangyang04/memory-pool 我的代码实现见 https://github.com/star-cs/webserver 内存池 ThreadCache(线程本地缓存) 每个线程独立的内存…...

云账号安全事件分析:黑客利用RAM子账户发起ECS命令执行攻击
事件背景 某企业云监控系统触发高危告警,提示API请求中包含黑客工具特征(cf_framework),攻击者试图通过泄露的RAM子账户凭据调用ECS高危API。以下是攻击关键信息整理: 字段详情告警原因API请求包含黑客工具特征(cf_framework)攻击实体RAM子账户 mq泄露凭证AccessKey ID…...

Node.js 模块导入的基本流程
Node.js 模块导入的基本流程,主要是 CommonJS 模块加载机制(即使用 require())的内部执行步骤。下面我用清晰的结构给你梳理一下这个过程: ✅ Node.js 模块导入的基本流程(使用 require()) const someModu…...

Unitest和pytest使用方法
unittest 是 Python 自带的单元测试框架,用于编写和运行可重复的测试用例。它的核心思想是通过断言(assertions)验证代码的行为是否符合预期。以下是 unittest 的基本使用方法: 1. 基本结构 1.1 创建测试类 继承 unittest.TestC…...

wps批量修改字体
选择这个小箭头 找到需要修改的字体如正文,右击修改选择合适的字体确定即可...

【Linux网络】各版本TCP服务器构建 - 从理解到实现
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

航电系统多模态融合技术要点
一、技术要点 1. 多模态数据特性分析 异构数据对齐:需处理不同传感器(如雷达、摄像头、IMU、ADS-B等)在时间、空间、精度和采样率上的差异,需设计同步机制(如硬件时钟同步、软件插值对齐)。 数据预处…...

【Git】branch合并分支
在 Git 中,将分支合并到 main 分支是一个常见的操作。以下是详细的步骤和说明,帮助你完成这个过程。 1. 确保你在正确的分支上 首先,你需要确保当前所在的分支是 main 分支(或者你要合并到的目标分支)。 检查当前分支…...

uniapp-商城-33-shop 布局搜索页面以及u-search
shop页面上有一个搜索,可以进行商品搜索,这里我们先做一个页面布局,后面再来进行数据i联动。 1、shop页面的搜索 2、搜索的页面代码 <navigator class"searchView" url"/pagesub/pageshop/search/search"> …...

蓝桥杯常考的找规律题
目录 灵感来源: B站视频链接: 找规律题具有什么样的特点: 报数游戏(Java组): 题目描述: 题目链接: 思路详解: 代码详解: 阶乘求和(Java组…...

全球化2.0 | 云轴科技ZStack亮相2025香港国际创科展
4月13-16日,由香港特别行政区政府、香港贸发局主办的2025香港国际创科展(InnoEX)在香港会议展览中心举办,作为亚洲最具影响力的科技盛会之一,本届展会吸引了来自17个国家和地区的500余家顶尖科技企业、科研机构及行业先…...

【Python进阶】数据可视化:Matplotlib从入门到实战
Python数据可视化:Matplotlib完全指南 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心代码实现案例1:折线图(股票趋势&#…...

操作系统——堆与栈详解:内存结构全面科普
文章目录 堆与栈详解:内存结构全面科普一、程序内存结构总览二、各段介绍及特点1. 代码段 .text2. 数据段 .data3. BSS段 .bss4. 堆区 Heap5. 栈区 Stack 三、C语言实例分析四、深入理解:为什么堆空间可能不连续?1. 堆内部结构:链…...

Mysql面试知识点详解
Mysql面试知识点详解 Mysql 是 Java 开发领域中常用的持久层框架,在面试和实际开发中都占据重要地位。本文将深入剖析 Mysql的核心知识点,并结合实战案例,帮助读者全面掌握相关技能。 一、慢查询定位与分析 (一)定位…...

数智读书笔记系列030《曲折的职业道路:在终身工作时代找准定位》与《做自己的教练:战胜工作挑战掌控职业生涯》
书籍简介 《曲折的职业道路:在终身工作时代找准定位》由英国职业发展专家海伦塔珀(Helen Tupper)和莎拉埃利斯(Sarah Ellis)合著,旨在帮助读者应对现代职场中日益普遍的“非直线型”职业路径。两位作者是“神奇的如果”(Amazing If)公司的联合创始人,曾为李维斯、沃达…...

Linux内核之文件驱动随笔
前言 近期需要实现linux系统文件防护功能,故此调研了些许知识,如何实现文件防护功能从而实现针对文件目录防护功能。当被保护的目录,禁止增删改操作。通过内核层面实现相关功能,另外在通过跟应用层面交互从而实现具体的业务功能。…...

【python】如何将文件夹及其子文件夹下的所有word文件汇总导出到一个excel文件里?
根据你的需求,这里提供一套完整的Python解决方案,支持递归遍历子文件夹、提取Word文档内容(段落+表格),并整合到Excel中。以下是代码实现及详细说明: 一个单元格一个word的全部内容 完整代码 # -*- coding: utf-8 -*- import os from docx import Document import pand…...

IDEA中如何统一项目名称/复制的项目如何修改根目录名称
1、问题概述? 在开发中,有时候为了方便,我们会复制一个新的项目,结果出现如下提示: 会在工程的后面提示工程原来的名字。 这种情况就是复制之后名字修改不彻底造成的。 2、彻底的修改工程的名字 2.1、修改pom.xml中…...

Ubuntu-Linux中vi / vim编辑文件,保存并退出
1.打开文件 vi / vim 文件名(例: vim word.txt )。 若权限不够,则在前方添加 sudo (例:sudo vim word.txt )来增加权限; 2.进入文件,按 i 键进入编辑模式。 3.编辑结…...

如何在idea里创建注释模版
✅ 步骤:创建一个类注释的 Live Template(缩写为 cls) ① 打开设置 IDEA 菜单栏点击:File > Settings(或按快捷键 Ctrl Alt S) ② 进入 Live Templates 设置 在左侧菜单找到:Editor > …...

IntelliJ IDEA 新版本中 Maven 子模块不显示的解决方案
一、问题现象与背景 在使用 IntelliJ IDEA 2024 版本开发 Maven 多模块项目时,我发现一个令人困惑的现象:父模块的子模块未在右侧 Maven 工具窗口中显示,仅显示父模块名称(且无 (root) 标识)。而此前在 IntelliJ IDEA…...
)
day48—双指针-通过删除字母匹配到字典最长单词(LeetCode-524)
题目描述 给你一个字符串 s 和一个字符串数组 dictionary ,找出并返回 dictionary 中最长的字符串,该字符串可以通过删除 s 中的某些字符得到。 如果答案不止一个,返回长度最长且字母序最小的字符串。如果答案不存在,则返回空字…...

美乐迪电玩大厅加载机制与 RoomList 配置结构分析
本篇为《美乐迪电玩全套系统搭建》系列的第三篇,聚焦大厅与子游戏的动态加载机制,深入解析 roomlist.json 的数据结构、解析流程、入口配置方式与自定义接入扩展技巧。通过本篇内容,开发者可实现自由控制子游戏接入与分发策略。 一、RoomList…...
的硬盘映射成Windows上,像本地磁盘一样使用)
局域网内,将linux(Ubuntu)的硬盘映射成Windows上,像本地磁盘一样使用
如何把同处一个局域网内的Ubuntu硬盘,映射到Windows上,使得Windows就像使用本地磁盘一样使用Ubuntu的磁盘? 要在同一局域网内的Windows上像本地磁盘一样使用Ubuntu硬盘,可以按照以下步骤操作: 1. 在Ubuntu上设置Samba…...

界面控件DevExpress WPF v25.1预览 - 支持Windows 11系统强调色
DevExpress WPF拥有120个控件和库,将帮助您交付满足甚至超出企业需求的高性能业务应用程序。通过DevExpress WPF能创建有着强大互动功能的XAML基础应用程序,这些应用程序专注于当代客户的需求和构建未来新一代支持触摸的解决方案。 无论是Office办公软件…...

【Hive入门】Hive架构与组件深度解析:从核心组件到生态协同
目录 1 Hive架构全景图 2 核心组件运维职责详解 2.1 Metastore元数据中心 2.2 Driver驱动组件 2.3 Executor执行引擎 3 与HDFS/YARN的协同关系 3.1 HDFS协同架构 3.2 YARN资源调度 4 运维实战案例 4.1 Metastore连接泄露 4.2 小文件合并 5 最佳实践总结 5.1 性能优…...

【图像识别改名】如何批量识别多个图片的区域内容给图片改名,批量图片区域文字识别改名,基于WPF和腾讯OCR的实现方案和步骤
基于WPF和腾讯OCR的批量图像区域文字识别改名方案 本方案适用于以下场景: 大量扫描文档需要根据文档中的特定区域内容(如编号、标题等)进行重命名证件照片需要根据证件号码或姓名进行整理归档企业档案管理需要根据文件上的编号自动分类教育机构需要根据学生试卷上的学号自动…...

从ChatGPT到GPT-4:大模型如何重塑人类认知边界?
从ChatGPT到GPT-4:大模型如何重塑人类认知边界? 在人工智能(AI)领域,近年来最引人注目的进展之一是大型语言模型的发展。从最初的GPT-1到现在的GPT-4,这些模型不仅在技术上取得了显著的进步,而…...
)
QEMU源码全解析 —— 块设备虚拟化(21)
接前一篇文章:QEMU源码全解析 —— 块设备虚拟化(20) 本文内容参考: 《趣谈Linux操作系统》 —— 刘超,极客时间 《QEMU/KVM源码解析与应用》 —— 李强,机械工业出版社 特此致谢! 上一回开始解析blockdev_init函数,讲到了其中调用的blk_new_open函数,该函数的作用…...

vue2练习项目 家乡特色网站—前端静态网站模板
最近一直在学习前端 vue2 开发,基础知识已经学习的差不多了,那肯定需要写几个项目来练习一下自己学习到的知识点。今天就分享一个使用 vue2 开发的一个前端静态网站,【家乡特色网站】 先给大家看一下网站的样式: 这里就只简单的…...

CFIS-YOLO:面向边缘设备的木材缺陷检测轻量级网络解析
论文地址:https://arxiv.org/pdf/2504.11305 目录 一、论文核心贡献 二、创新点详解 2.1 CARAFE动态上采样 工作原理 优势对比 2.2 C2f_FNB轻量模块 计算效率 2.3 Inner-SIoU损失函数 三、实验验证 3.1 消融实验 3.2 对比实验 四、应用部署 4.1 边缘设备部署流程…...

vue3 + element-plus中el-dialog对话框滚动条回到顶部
对话框滚动条回到顶部 1、需要对话框显示后 2、使用 nextTick 等待 Dom 更新完毕 3、通过开发者工具追查到滚动条对应的标签及class“el-overlay-dialog”。追查方法: 4、设置属性 scrollTop 0 或者 执行方法 scrollTo(0, 0) // 对话框显示标识 const dialogVi…...

赛灵思Xilinx FPGa XCKU15P‑2FFVA1156I AMD Kintex UltraScale+
XCKU15P‑2FFVA1156I 是 AMD Kintex UltraScale 系列中的高性能 FPGA,基于 16 nm FinFET UltraScale 架构 制造,兼顾卓越的性能与功耗比,该器件集成 1,143,450 个逻辑单元和 82,329,600 位片上 RAM,配备 1,968 个 DSP 切片&#…...

力扣2492:并查集/dfs
方法一:并查集。如果不仔细读题,可能会想着把每一个一维数组下标为2的位置进行排序即可。但这是不行的。因为有可能有一些节点在其它集合当中。如果这些节点之间存在一个边权值比节点1所在集合的最小边权值还要小,那么求出来的答案就是错的。…...

宝塔面板引发的血案:onlyoffice协作空间无法正常安装的案例分享
今天和客户一起解决:onlyoffice协作空间的安装问题,本来已经发现由于客户用的机械硬盘,某些安装步骤等待的时间不够,已经加了处理。但是安装成功后,登录系统一直提示报错如下 检查docker容器都是正常的,并且health也是正确的,登录就一直报错。后面发现用免费版的安装程序可以正…...

【阿里云大模型高级工程师ACP习题集】2.1 用大模型构建新人答疑机器人
练习题 【单选题】1. 在调用通义千问大模型时,将API Key存储在环境变量中的主要目的是? A. 方便在代码中引用 B. 提高API调用的速度 C. 增强API Key的安全性 D. 符合阿里云的规定 【多选题】2. 以下哪些属于大模型在问答场景中的工作阶段?( ) A. 输入文本分词化 B. Toke…...

C++中的算术转换、其他隐式类型转换和显示转换详解
C中的类型转换(Type Conversion)是指将一个数据类型的值转换为另一个数据类型的过程,主要包括: 一、算术类型转换(Arithmetic Conversions) 算术类型转换通常发生在算术运算或比较中,称为**“标…...

Python自动化selenium-一直卡着不打开浏览器怎么办?
Python自动化selenium 如果出现卡住不打开,就把驱动放当前目录并指定 from selenium import webdriver from selenium.webdriver.chrome.service import Service import time import osdef open_baidu():# 获取当前目录中的chromedriver.exe的绝对路径current_di…...

AI Agent开发第35课-揭秘RAG系统的致命漏洞与防御策略
第一章 智能客服系统的安全悖论 1.1 系统角色暴露的致命弱点 当用户以"你好"开启对话后追问"你之前说了什么",看似无害的互动实则暗藏杀机。2024年数据显示,93%的开源RAG系统在该场景下会完整复述初始化指令,导致系统角色定义(如电商导购)被完全暴露…...

【MySQL】数据库安装
数据库安装 一. Ubantu下安装 MySQL 数据库1. 查看Linux系统版本2. 添加 MySQL APT 源1. Windows 下载发布包2. 上传发布包到 Linux3. 安装发布包 3. 安装 MySQL4. 查看 MySQL 状态5. 开启自启动6. 登录 MySQL 一. Ubantu下安装 MySQL 数据库 1. 查看Linux系统版本 操作系统版…...

OpenGL shader开发实战学习笔记:第十二章 深入光照
1. 深入光照 1.1. 平行光 我们在前面的章节中,已经介绍了平行光的基本原理和实现步骤 平行光的基本原理是,所有的光都从同一个方向照射到物体上,这个方向就是平行光的方向。 1.2. 点光源 点光源的基本原理是,所有的光都从一个…...

1-1 什么是数据结构
1.0 数据结构的基本概念 数据结构是计算机科学中一个非常重要的概念,它是指在计算机中组织、管理和存储数据的方式,以便能够高效地访问和修改数据。简而言之,数据结构是用来处理数据的格式,使得数据可以被更有效地使用。 数据结构…...

【MySQL】:数据库事务管理
一:学习路径 (1)下载安装mysql (2)学习语言:SQL(操作数据库) (3)mysql集群(提升数据库存储效率) (4)SQL使用,M…...

leetcode 647. Palindromic Substrings
题目描述 代码: class Solution { public:int countSubstrings(string s) {int n s.size();//i<j,dp[i][j]表示子字符串s[i,j]是否是回文子串,i>j的dp[i][j]不定义vector<vector<int>> dp(n,vector<int>(n,false));int res 0;for(int i …...

Linux-scp命令
scp(Secure Copy Protocol)是基于 SSH 的安全文件传输命令,用于在本地和远程主机之间加密传输文件或目录。以下是详细用法和示例: 基本语法 scp [选项] 源文件 目标路径常用选项 选项描述-P 端口号指定 SSH 端口(默认…...
)
在CSDN的1095天(创作纪念日)
一早上收到CSDN官方的私信,时间飞逝,转眼间3年了…… 一些碎碎念… 算起来也断更一年多了,上一次更博客是去年的3月份,那时候还在实习,同时也是去年的三月份结束了第一段实习回学校准备考研,考完研12月开始…...

STM32——新建工程并使用寄存器以及库函数进行点灯
本文是根据江协科技提供的教学视频所写,旨在便于日后复习,同时供学习嵌入式的朋友们参考,文中涉及到的所有资料也均来源于江协科技(资料下载)。 新建工程并使用寄存器以及库函数进行点灯操作 新建工程步骤1.建立工程2.…...