深度学习框架PyTorch——从入门到精通(3.3)YouTube系列——自动求导基础
这部分是 PyTorch介绍——YouTube系列的内容,每一节都对应一个youtube视频。(可能跟之前的有一定的重复)
- 我们需要Autograd做什么?
- 一个简单示例
- 训练中的自动求导
- 开启和关闭自动求导
- 自动求导与原地操作
- 自动求导分析器
- 高级主题:自动求导的更多细节与高级API
- 高级 API
本节YouTube视频地址:点击这里
PyTorch的自动求导(Autograd)特性是使PyTorch在构建机器学习项目时具备灵活性和高效性的部分原因。它能够在复杂的计算过程中快速且轻松地计算多个偏导数(也称为梯度)。这一操作对于基于反向传播的神经网络学习来说至关重要。
自动求导(Autograd)的强大之处在于,它能在运行时动态地跟踪你的计算过程。这意味着,如果你的模型中存在决策分支,或者存在直到运行时才能确定长度的循环,计算过程仍会被正确跟踪,并且你将获得正确的梯度来推动学习。再加上你的模型是用Python构建的这一事实,这使得它相比那些依赖对结构更固定的模型进行静态分析来计算梯度的框架,具有大得多的灵活性。
我们需要Autograd做什么?
机器学习模型是一个具有输入和输出的函数。在本次讨论中,我们将输入视为一个i维向量 x ⃗ \vec{x} x,其元素为 x i x_{i} xi。然后,我们可以将模型 M M M表示为输入的向量值函数: y ⃗ = M ⃗ ( x ⃗ ) \vec{y}=\vec{M}(\vec{x}) y=M(x)。(我们将 M M M的输出值视为向量,因为一般来说,一个模型可能有任意数量的输出。)
由于我们主要在训练的背景下讨论自动求导,我们关注的输出将是模型的损失。损失函数 L ( y ⃗ ) = L ( M ⃗ ( x ⃗ ) ) L(\vec{y}) = L(\vec{M}(\vec{x})) L(y)=L(M(x))是模型输出的单值标量函数。这个函数表示模型对于特定输入的预测与理想输出之间的差距。注意:在这之后,在上下文明确的情况下,我们通常会省略向量符号,例如用 y y y代替 y ⃗ \vec{y} y 。
在训练模型时,我们希望最小化损失。在理想的完美模型情况下,这意味着调整其学习权重,即该函数的可调整参数,使得对于所有输入损失都为零。在现实世界中,这意味着一个反复调整学习权重的迭代过程,直到我们看到对于各种输入都能得到一个可接受的损失值。
我们如何决定调整权重的幅度和方向呢?我们希望最小化损失,这意味着使其关于输入的一阶导数等于0: ∂ L ∂ x = 0 \frac{\partial L}{\partial x}=0 ∂x∂L=0。
然而,要记住损失并非直接由输入推导而来,而是模型输出的函数(而模型输出又是输入的直接函数), ∂ L ∂ x = ∂ L ( y ⃗ ) ∂ x \frac{\partial L}{\partial x}=\frac{\partial L(\vec{y})}{\partial x} ∂x∂L=∂x∂L(y)。根据微积分的链式法则,我们有 ∂ L ( y ⃗ ) ∂ x = ∂ L ∂ y ∂ y ∂ x = ∂ L ∂ y ∂ M ( x ) ∂ x \frac{\partial L(\vec{y})}{\partial x}=\frac{\partial L}{\partial y}\frac{\partial y}{\partial x}=\frac{\partial L}{\partial y}\frac{\partial M(x)}{\partial x} ∂x∂L(y)=∂y∂L∂x∂y=∂y∂L∂x∂M(x)。
∂ M ( x ) ∂ x \frac{\partial M(x)}{\partial x} ∂x∂M(x) 让情况变得复杂。如果我们再次使用链式法则展开表达式,模型输出关于其输入的偏导数将涉及模型中每个相乘的学习权重、每个激活函数以及每个其他数学变换的许多局部偏导数。每个这样的偏导数的完整表达式是通过计算图中以我们试图测量其梯度的变量为终点的每条可能路径的局部梯度乘积之和。
特别地,我们关注学习权重的梯度,因为它们能告诉我们,为了让损失函数更接近零,每个权重应该朝什么方向调整。
由于这类局部导数的数量(每个局部导数对应模型计算图中的一条不同路径)会随着神经网络深度呈指数级增长,计算这些导数的复杂度也会随之增加。这就是自动求导(Autograd)发挥作用的地方:它会跟踪每一次计算的历史。在PyTorch模型中,每个计算得到的张量都记录着其输入张量的历史以及用于创建它的函数。再加上作用于张量的PyTorch函数都有内置的导数计算实现,这极大地加快了学习所需的局部导数的计算速度。
一个简单示例
前面讲了很多理论知识,不过在实际中使用自动求导(Autograd)是什么样的呢?
让我们从一个简单的例子开始。首先,我们要进行一些导入操作,以便绘制结果图形:
# %matplotlib inlineimport torchimport matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import math
接下来,我们将创建一个输入张量,其元素是在区间 [ 0 , 2 π ] [0, 2\pi] [0,2π]上均匀分布的值,并指定requires_grad=True 。(与大多数创建张量的函数一样,torch.linspace() 接受可选的requires_grad 选项。)设置这个标记意味着在后续的每一次计算中,自动求导(autograd)会在该计算的输出张量中累积计算过程的历史记录。
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
print(a)
输出:
tensor([0.0000, 0.2618, 0.5236, 0.7854, 1.0472, 1.3090, 1.5708, 1.8326, 2.0944,2.3562, 2.6180, 2.8798, 3.1416, 3.4034, 3.6652, 3.9270, 4.1888, 4.4506,4.7124, 4.9742, 5.2360, 5.4978, 5.7596, 6.0214, 6.2832],requires_grad=True)
接下来,我们将进行一次计算,并根据输入绘制其输出:
b = torch.sin(a)
plt.plot(a.detach(), b.detach())
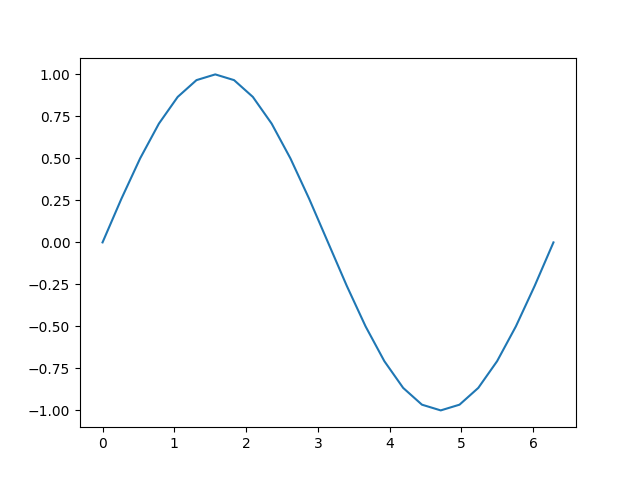
让我们更仔细地看看张量b。当我们打印它时,会看到一个表明它正在跟踪其计算历史的标识:
print(b)
# 输出
tensor([ 0.0000e+00, 2.5882e-01, 5.0000e-01, 7.0711e-01, 8.6603e-01,9.6593e-01, 1.0000e+00, 9.6593e-01, 8.6603e-01, 7.0711e-01,5.0000e-01, 2.5882e-01, -8.7423e-08, -2.5882e-01, -5.0000e-01,-7.0711e-01, -8.6603e-01, -9.6593e-01, -1.0000e+00, -9.6593e-01,-8.6603e-01, -7.0711e-01, -5.0000e-01, -2.5882e-01, 1.7485e-07],grad_fn=<SinBackward0>)
这个grad_fn 给我们一个提示,当我们执行反向传播步骤并计算梯度时,我们需要针对这个张量的所有输入计算 sin ( x ) \sin(x) sin(x) 的导数。
让我们进行更多的计算:
c = 2 * b
print(c)d = c + 1
print(d)
# 输出
tensor([ 0.0000e+00, 5.1764e-01, 1.0000e+00, 1.4142e+00, 1.7321e+00,1.9319e+00, 2.0000e+00, 1.9319e+00, 1.7321e+00, 1.4142e+00,1.0000e+00, 5.1764e-01, -1.7485e-07, -5.1764e-01, -1.0000e+00,-1.4142e+00, -1.7321e+00, -1.9319e+00, -2.0000e+00, -1.9319e+00,-1.7321e+00, -1.4142e+00, -1.0000e+00, -5.1764e-01, 3.4969e-07],grad_fn=<MulBackward0>)
tensor([ 1.0000e+00, 1.5176e+00, 2.0000e+00, 2.4142e+00, 2.7321e+00,2.9319e+00, 3.0000e+00, 2.9319e+00, 2.7321e+00, 2.4142e+00,2.0000e+00, 1.5176e+00, 1.0000e+00, 4.8236e-01, -3.5763e-07,-4.1421e-01, -7.3205e-01, -9.3185e-01, -1.0000e+00, -9.3185e-01,-7.3205e-01, -4.1421e-01, 4.7684e-07, 4.8236e-01, 1.0000e+00],grad_fn=<AddBackward0>)
最后,让我们计算一个单元素输出。当你在一个张量上不带参数调用.backward() 时,它要求调用的这个张量只包含一个元素,这和计算损失函数时的情况一样。
out = d.sum()
print(out)
# 输出
tensor(25., grad_fn=<SumBackward0>)
存储在我们张量中的每个grad_fn 都允许你通过其next_functions 属性一路追溯计算过程,直至其输入。下面我们可以看到,深入查看张量d 的这个属性,会向我们展示所有先前张量的梯度函数。请注意,a.grad_fn 显示为None ,这表明它是该函数的一个输入,自身没有计算历史记录。
print('d:')
print(d.grad_fn)
print(d.grad_fn.next_functions)
print(d.grad_fn.next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions[0][0].next_functions)
print('\nc:')
print(c.grad_fn)
print('\nb:')
print(b.grad_fn)
print('\na:')
print(a.grad_fn)
# 输出
d:
<AddBackward0 object at 0x7fb08c130e20>
((<MulBackward0 object at 0x7fb08c132230>, 0), (None, 0))
((<SinBackward0 object at 0x7fb08c132230>, 0), (None, 0))
((<AccumulateGrad object at 0x7fb08c130e20>, 0),)
()c:
<MulBackward0 object at 0x7fb08c132230>b:
<SinBackward0 object at 0x7fb08c132230>a:
None
有了这一整套机制后,我们要如何得到导数呢?你可以在输出张量上调用backward() 方法,然后检查输入张量的grad 属性来查看梯度:
out.backward()
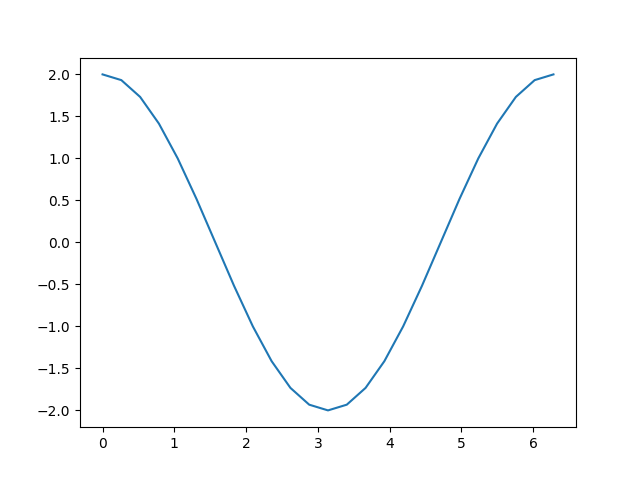
print(a.grad)
plt.plot(a.detach(), a.grad.detach())
# 输出
tensor([ 2.0000e+00, 1.9319e+00, 1.7321e+00, 1.4142e+00, 1.0000e+00,5.1764e-01, -8.7423e-08, -5.1764e-01, -1.0000e+00, -1.4142e+00,-1.7321e+00, -1.9319e+00, -2.0000e+00, -1.9319e+00, -1.7321e+00,-1.4142e+00, -1.0000e+00, -5.1764e-01, 2.3850e-08, 5.1764e-01,1.0000e+00, 1.4142e+00, 1.7321e+00, 1.9319e+00, 2.0000e+00])[<matplotlib.lines.Line2D object at 0x7fb03055a050>]
回想一下我们为得到当前结果所采取的计算步骤:
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
b = torch.sin(a)
c = 2 * b
d = c + 1
out = d.sum()
就像我们计算d 时那样,加上一个常数并不会改变导数。这样就剩下 c = 2 ∗ b = 2 ∗ sin ( a ) c = 2 * b = 2 * \sin(a) c=2∗b=2∗sin(a) ,其导数应该是 2 ∗ cos ( a ) 2 * \cos(a) 2∗cos(a) 。从上面的图中可以看到,结果正是如此。
需要注意的是,只有计算图中的叶节点会计算梯度。例如,如果你尝试print(c.grad) ,得到的结果会是None 。在这个简单例子中,只有输入是叶节点,所以只有它的梯度会被计算。
训练中的自动求导
我们已经简要了解了自动求导(Autograd)的工作原理,但它在实际用于其既定目的时是什么样的呢?让我们定义一个小型模型,并研究它在单个训练批次后是如何变化的。首先,定义一些常量、我们的模型以及一些输入和输出的替代值:
BATCH_SIZE = 16
DIM_IN = 1000
HIDDEN_SIZE = 100
DIM_OUT = 10class TinyModel(torch.nn.Module):def __init__(self):super(TinyModel, self).__init__()self.layer1 = torch.nn.Linear(DIM_IN, HIDDEN_SIZE)self.relu = torch.nn.ReLU()self.layer2 = torch.nn.Linear(HIDDEN_SIZE, DIM_OUT)def forward(self, x):x = self.layer1(x)x = self.relu(x)x = self.layer2(x)return xsome_input = torch.randn(BATCH_SIZE, DIM_IN, requires_grad=False)
ideal_output = torch.randn(BATCH_SIZE, DIM_OUT, requires_grad=False)model = TinyModel()
你可能会注意到,我们从未为模型的各层指定requires_grad = True。在torch.nn.Module的子类中,默认认为我们希望跟踪各层权重的梯度以用于学习。
如果查看模型的各层,我们可以检查权重的值,并确认此时尚未计算梯度:
print(model.layer2.weight[0][0:10]) # just a small slice
print(model.layer2.weight.grad)
# 输出
tensor([ 0.0920, 0.0916, 0.0121, 0.0083, -0.0055, 0.0367, 0.0221, -0.0276,-0.0086, 0.0157], grad_fn=<SliceBackward0>)
None
让我们看看在完成一个训练批次后情况会有怎样的变化。对于损失函数,我们将采用预测值与理想输出之间欧几里得距离的平方。并且,我们会使用一个基础的随机梯度下降优化器。
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)prediction = model(some_input)loss = (ideal_output - prediction).pow(2).sum()
print(loss)
# 输出
tensor(211.2634, grad_fn=<SumBackward0>)
现在,让我们调用loss.backward() 方法,看看会发生什么:
loss.backward()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])
# 输出
tensor([ 0.0920, 0.0916, 0.0121, 0.0083, -0.0055, 0.0367, 0.0221, -0.0276,-0.0086, 0.0157], grad_fn=<SliceBackward0>)
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,0.1732, -5.3835])
我们可以看到,针对每个学习权重的梯度都已经计算出来了,但权重本身并未改变,这是因为我们还没有运行优化器。优化器的作用就是根据计算得到的梯度来更新模型的权重。
optimizer.step()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])
# 输出
tensor([ 0.0791, 0.0886, 0.0098, 0.0064, -0.0106, 0.0293, 0.0186, -0.0300,-0.0088, 0.0211], grad_fn=<SliceBackward0>)
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,0.1732, -5.3835])
你应该会看到第二层(layer2)的权重已经发生了变化。
关于这个过程有一点很重要:在调用optimizer.step()之后,你需要调用optimizer.zero_grad(),否则每次你调用loss.backward()时,学习权重上的梯度就会累积起来。
print(model.layer2.weight.grad[0][0:10])for i in range(0, 5):prediction = model(some_input)loss = (ideal_output - prediction).pow(2).sum()loss.backward()print(model.layer2.weight.grad[0][0:10])optimizer.zero_grad(set_to_none=False)print(model.layer2.weight.grad[0][0:10])
# 输出
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,0.1732, -5.3835])
tensor([ 19.2095, -15.9459, 8.3306, 11.5096, 9.5471, 0.5391, -0.3370,8.6386, -2.5141, -30.1419])
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
在运行完上述代码块后,你应该会发现,在多次运行loss.backward() 之后,大多数梯度的量级会大得多。如果在运行下一个训练批次之前没有将梯度清零,就会导致梯度以这种方式激增,从而产生错误且不可预测的学习结果。
开启和关闭自动求导
在某些情况下,你需要对自动求导(Autograd)是否启用进行精细控制。根据不同的情况,有多种方法可以做到这一点。
最简单的方法是直接更改张量上的requires_grad 标志:
a = torch.ones(2, 3, requires_grad=True)
print(a)b1 = 2 * a
print(b1)a.requires_grad = False
b2 = 2 * a
print(b2)
# 输出
tensor([[1., 1., 1.],[1., 1., 1.]], requires_grad=True)
tensor([[2., 2., 2.],[2., 2., 2.]], grad_fn=<MulBackward0>)
tensor([[2., 2., 2.],[2., 2., 2.]])
在上面的代码单元中,我们看到b1 有一个grad_fn(即一个被追踪的计算历史记录),这正是我们所预期的,因为它是从一个开启了自动求导功能的张量a 推导而来的。当我们通过a.requires_grad = False 显式地关闭自动求导时,计算历史记录就不再被追踪了,正如我们在计算b2 时所看到的那样。
如果你只是需要暂时关闭自动求导功能,一个更好的方法是使用torch.no_grad():
a = torch.ones(2, 3, requires_grad=True) * 2
b = torch.ones(2, 3, requires_grad=True) * 3c1 = a + b
print(c1)with torch.no_grad():c2 = a + bprint(c2)c3 = a * b
print(c3)
# 输出
tensor([[5., 5., 5.],[5., 5., 5.]], grad_fn=<AddBackward0>)
tensor([[5., 5., 5.],[5., 5., 5.]])
tensor([[6., 6., 6.],[6., 6., 6.]], grad_fn=<MulBackward0>)
torch.no_grad() 也可以用作函数或方法的装饰器:
def add_tensors1(x, y):return x + y@torch.no_grad()
def add_tensors2(x, y):return x + ya = torch.ones(2, 3, requires_grad=True) * 2
b = torch.ones(2, 3, requires_grad=True) * 3c1 = add_tensors1(a, b)
print(c1)c2 = add_tensors2(a, b)
print(c2)
# tensor([[5., 5., 5.],[5., 5., 5.]], grad_fn=<AddBackward0>)
tensor([[5., 5., 5.],[5., 5., 5.]])
有一个对应的上下文管理器torch.enable_grad(),用于在自动求导未开启时将其开启。它也可以用作装饰器。
最后,你可能有一个需要进行梯度跟踪的张量,但你想要一个不需要梯度跟踪的副本。为此,我们可以使用张量对象的detach()方法,它会创建一个与计算历史分离的张量副本。
x = torch.rand(5, requires_grad=True)
y = x.detach()print(x)
print(y)
# 输出
tensor([0.0670, 0.3890, 0.7264, 0.3559, 0.6584], requires_grad=True)
tensor([0.0670, 0.3890, 0.7264, 0.3559, 0.6584])
我们在上面想要绘制某些张量的图像时就进行了这样的操作。这是因为matplotlib期望输入为NumPy数组,而对于requires_grad=True的PyTorch张量,并未启用从PyTorch张量到NumPy数组的隐式转换。创建一个分离的副本能让我们继续进行操作。
自动求导与原地操作
到目前为止,在本笔记本的每个示例中,我们都使用变量来保存计算的中间值。自动求导需要这些中间值来进行梯度计算。因此,在使用自动求导时,你必须谨慎使用原地操作。因为这样做可能会破坏在backward()调用中计算导数所需的信息。如下所示,如果尝试对需要自动求导的叶子变量进行原地操作,PyTorch甚至会阻止你这么做。
注意
下面的代码单元会抛出一个运行时错误。这是预期的情况。
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
torch.sin_(a)
自动求导分析器
自动求导会详细追踪你计算的每一步。这样的计算历史记录,再结合时间信息,就可以成为一个实用的分析器——而自动求导已经内置了这个功能。以下是一个简单的使用示例:
device = torch.device('cpu')
run_on_gpu = False
if torch.cuda.is_available():device = torch.device('cuda')run_on_gpu = Truex = torch.randn(2, 3, requires_grad=True)
y = torch.rand(2, 3, requires_grad=True)
z = torch.ones(2, 3, requires_grad=True)with torch.autograd.profiler.profile(use_cuda=run_on_gpu) as prf:for _ in range(1000):z = (z / x) * yprint(prf.key_averages().table(sort_by='self_cpu_time_total'))# 输出
/var/lib/workspace/beginner_source/introyt/autogradyt_tutorial.py:485: FutureWarning:The attribute `use_cuda` will be deprecated soon, please use ``use_device = 'cuda'`` instead.------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------cudaEventRecord 53.91% 7.718ms 53.91% 7.718ms 1.929us 0.000us 0.00% 0.000us 0.000us 4000aten::mul 23.35% 3.344ms 23.35% 3.344ms 3.344us 6.782ms 50.51% 6.782ms 6.782us 1000aten::div 22.65% 3.242ms 22.65% 3.242ms 3.242us 6.646ms 49.49% 6.646ms 6.646us 1000cudaDeviceSynchronize 0.09% 12.581us 0.09% 12.581us 12.581us 0.000us 0.00% 0.000us 0.000us 1
------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 14.317ms
Self CUDA time total: 13.428ms
分析器还能够为各个代码子模块添加标签,依据输入张量的形状拆分数据,并将数据导出为Chrome追踪工具文件。有关该API的完整详细信息,请查阅文档。
高级主题:自动求导的更多细节与高级API
若有一个具有 n n n维输入和 m m m维输出的函数, y ⃗ = f ( x ⃗ ) \vec{y} = f(\vec{x}) y=f(x) ,其完整梯度是一个矩阵,矩阵中的元素是每个输出相对于每个输入的导数,此矩阵被称为雅可比矩阵:
J = ( ∂ y 1 ∂ x 1 ⋯ ∂ y n ∂ x 1 ⋮ ⋱ ⋮ ∂ y 1 ∂ x m ⋯ ∂ y m ∂ x n ) J = \begin{pmatrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_n}{\partial x_1} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_1}{\partial x_m} & \cdots & \frac{\partial y_m}{\partial x_n} \end{pmatrix} J= ∂x1∂y1⋮∂xm∂y1⋯⋱⋯∂x1∂yn⋮∂xn∂ym
若存在第二个函数, l = g ( y ⃗ ) l = g(\vec{y}) l=g(y) ,它接收 m m m维输入(即与上述输出维度相同)并返回标量输出,那么它相对于 y ⃗ \vec{y} y 的梯度可表示为列向量, v = ( ∂ l ∂ y 1 ⋯ ∂ l ∂ y m ) T v = \begin{pmatrix} \frac{\partial l}{\partial y_1} & \cdots & \frac{\partial l}{\partial y_m} \end{pmatrix}^T v=(∂y1∂l⋯∂ym∂l)T ,这其实就是一个单列的雅可比矩阵。
更具体来讲,可将第一个函数视为你的PyTorch模型(可能存在多个输入和多个输出),将第二个函数视为损失函数(以模型的输出作为输入,损失值作为标量输出)。
如果我们将第一个函数的雅可比矩阵与第二个函数的梯度相乘,并应用链式法则,可得:
J T ⋅ v = ( ∂ y 1 ∂ x 1 ⋯ ∂ y m ∂ x 1 ⋮ ⋱ ⋮ ∂ y 1 ∂ x n ⋯ ∂ y m ∂ x n ) ( ∂ l ∂ y 1 ⋮ ∂ l ∂ y m ) = ( ∂ l ∂ x 1 ⋮ ∂ l ∂ x n ) J^T \cdot v = \begin{pmatrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_m}{\partial x_1} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_1}{\partial x_n} & \cdots & \frac{\partial y_m}{\partial x_n} \end{pmatrix} \begin{pmatrix} \frac{\partial l}{\partial y_1} \\ \vdots \\ \frac{\partial l}{\partial y_m} \end{pmatrix}= \begin{pmatrix} \frac{\partial l}{\partial x_1} \\ \vdots \\ \frac{\partial l}{\partial x_n} \end{pmatrix} JT⋅v= ∂x1∂y1⋮∂xn∂y1⋯⋱⋯∂x1∂ym⋮∂xn∂ym ∂y1∂l⋮∂ym∂l = ∂x1∂l⋮∂xn∂l
注意:也可使用等效操作 v T ⋅ J v^T \cdot J vT⋅J ,会得到一个行向量。
所得的列向量是第二个函数相对于第一个函数输入的梯度——在模型与损失函数的情境下,就是损失相对于模型输入的梯度。
torch.autograd 是用于计算这些乘积的引擎。这就是我们在反向传播过程中累积学习权重梯度的方式。
基于这个原因,backward() 调用也可以接受一个可选的向量输入。这个向量表示张量上的一组梯度,它们会与在其之前的由自动求导所追踪的张量的雅可比矩阵相乘。让我们用一个小向量来尝试一个具体的例子:
x = torch.randn(3, requires_grad=True)y = x * 2
while y.data.norm() < 1000:y = y * 2print(y)
# 结果
tensor([ 299.4868, 425.4009, -1082.9885], grad_fn=<MulBackward0>)
如果我们现在尝试调用y.backward(),会得到一个运行时错误,提示信息为只能对标量输出隐式计算梯度。对于多维输出,自动求导要求我们为这三个输出提供梯度,以便它能将这些梯度与雅可比矩阵相乘。
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float) # stand-in for gradients
y.backward(v)print(x.grad)
# 输出
tensor([1.0240e+02, 1.0240e+03, 1.0240e-01])
(请注意,输出梯度都与 2 的幂次相关——这正是我们对重复加倍操作所预期的结果。)
高级 API
自动求导(Autograd)有一个 API,可让你直接访问重要的微分矩阵和向量运算。具体而言,它允许你针对特定输入计算特定函数的雅可比矩阵和海森矩阵。(海森矩阵与雅可比矩阵类似,但它表示的是所有的二阶偏导数。)它还提供了用这些矩阵进行向量乘积运算的方法。
让我们来计算一个简单函数的雅可比矩阵,该函数针对两个单元素输入进行求值:
def exp_adder(x, y):return 2 * x.exp() + 3 * yinputs = (torch.rand(1), torch.rand(1)) # arguments for the function
print(inputs)
torch.autograd.functional.jacobian(exp_adder, inputs)
# 输出
(tensor([0.7212]), tensor([0.2079]))(tensor([[4.1137]]), tensor([[3.]]))
如果你仔细观察,第一个输出应该等于(2ex)(因为(ex) 的导数是(e^x) ),并且第二个值应该是(3)。
当然,你也可以对更高阶的张量进行这样的操作:
inputs = (torch.rand(3), torch.rand(3)) # arguments for the function
print(inputs)
torch.autograd.functional.jacobian(exp_adder, inputs)
# 输出
(tensor([0.2080, 0.2604, 0.4415]), tensor([0.5220, 0.9867, 0.4288]))(tensor([[2.4623, 0.0000, 0.0000],[0.0000, 2.5950, 0.0000],[0.0000, 0.0000, 3.1102]]), tensor([[3., 0., 0.],[0., 3., 0.],[0., 0., 3.]]))
torch.autograd.functional.hessian()方法的工作原理完全相同(前提是你的函数是二阶可微的),但它会返回一个包含所有二阶导数的矩阵。
如果你提供一个向量,还有一个函数可以直接计算向量与雅可比矩阵的乘积:
def do_some_doubling(x):y = x * 2while y.data.norm() < 1000:y = y * 2return yinputs = torch.randn(3)
my_gradients = torch.tensor([0.1, 1.0, 0.0001])
torch.autograd.functional.vjp(do_some_doubling, inputs, v=my_gradients)
# 输出
(tensor([-665.7186, -866.7054, -58.4194]), tensor([1.0240e+02, 1.0240e+03, 1.0240e-01]))
torch.autograd.functional.jvp() 方法执行的矩阵乘法操作与 vjp() 相同,只是操作数的顺序相反。vhp() 和 hvp() 方法对于向量与海森矩阵的乘积也做了类似的事情(只是操作数顺序有所不同)。
如需了解更多信息,请查阅包括关于函数式 API 文档中的性能说明 。
相关文章:
YouTube系列——自动求导基础)
深度学习框架PyTorch——从入门到精通(3.3)YouTube系列——自动求导基础
这部分是 PyTorch介绍——YouTube系列的内容,每一节都对应一个youtube视频。(可能跟之前的有一定的重复) 我们需要Autograd做什么?一个简单示例训练中的自动求导开启和关闭自动求导自动求导与原地操作 自动求导分析器高级主题&…...

永磁同步电机控制算法-VF控制
一、原理介绍 V/F 控制又称为恒压频比控制,给定VF 控制曲线 电压是频率的tt例函数 即控制电压跟随频率变化而变化以保持磁通恒定不变。 二、仿真模型 在MATLAB/simulink里面验证所提算法,搭建仿真。采用和实验中一致的控制周期1e-4,电机部分计算周期为…...

【Docker 运维】Java 应用在 Docker 容器中启动报错:`unable to allocate file descriptor table`
文章目录 一、根本原因二、判断与排查方法三、解决方法1、限制 Docker 容器的文件描述符上限2、在执行脚本中动态设置ulimit的值3、升级至 Java 11 四、总结 容器内执行脚本时报错如下,Java 进程异常退出: library initialization failed - unable to a…...
)
SpringBoot + Vue 实现云端图片上传与回显(基于OSS等云存储)
前言 在实际生产环境中,我们通常会将图片等静态资源存储在云端对象存储服务(如阿里云OSS、七牛云、腾讯云COS等)上。本文将介绍如何改造之前的本地存储方案,实现基于云端存储的图片上传与回显功能。 一、技术选型 云存储服务&a…...

Session与Cookie的核心机制、用法及区别
Python中Session与Cookie的核心机制、用法及区别 在Web开发中,Session和Cookie是两种常用的用于跟踪用户状态的技术。它们在实现机制、用途和安全性方面都有显著区别。本文将详细介绍它们的核心机制、用法以及它们之间的主要区别。 一、Cookie的核心机制与用法 1…...

离线安装rabbitmq全流程
在麒麟系统(如银河麒麟)上离线安装 RabbitMQ 的具体操作步骤如下: 一、准备工作 确认系统版本:确认麒麟系统的版本,例如银河麒麟高级服务器 V10。确定 RabbitMQ 及依赖版本:根据系统版本确定兼容的 Rabbi…...

llama-webui docker实现界面部署
1. 启动ollama服务 [nlp server]$ ollama serve 2025/04/21 14:18:23 routes.go:1007: INFO server config env"map[OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST: OLLAMA_KEEP_ALIVE:24h OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:4 OLLAMA_MAX_…...

第1 篇:你好,时间序列!—— 开启时间数据探索之旅
第 1 篇:你好,时间序列!—— 开启时间数据探索之旅 (图片来源: Stephen Dawson on Unsplash) 你有没有想过: 明天的天气会是怎样?天气预报是怎么做出来的?某支股票未来的价格走势如何预测?购物…...
:vector作为函数参数的三种传递方式详解)
C++算法(11):vector作为函数参数的三种传递方式详解
在C中,std::vector是最常用的动态数组容器之一。当我们需要将vector传递给函数时,不同的传递方式会对性能和功能产生显著影响。本文将详细介绍三种常见的传递方式及其适用场景,帮助开发者根据需求选择最合适的方法。 1. 按值传递(…...

版本控制利器——SVN简介
版本控制利器——SVN简介 在软件开发和项目管理的领域中,版本控制是一项至关重要的工作。它能帮助团队成员高效协作,确保代码的安全性和可追溯性。今天,我们就来详细介绍一款经典的版本控制系统——SVN(Subversion)。…...

链式栈和线性栈
1. 线性栈(顺序栈) 结构定义: #include <iostream> using namespace std;#define MAX_SIZE 100 // 预定义最大容量// 线性栈结构体 typedef struct {int* data; // 存储数据的数组int top; // 栈顶指针&…...

消息中间件RabbitMQ:简要介绍及其Windows安装流程
一、简要介绍 定义:RabbitMQ 是一个开源消息中间件,用于实现消息队列和异步通信。 场景:适用于分布式系统、异步任务处理、消息解耦、负载均衡等场景。 比喻:RabbitMQ 就像是快递公司,负责在不同系统间安全快速地传递…...

足球 AI 智能体技术解析:从数据采集到比赛预测的全链路架构
一、引言 在足球运动数字化转型的浪潮中,AI 智能体正成为理解比赛、预测赛果的核心技术引擎。本文从工程实现角度,深度解析足球 AI 的技术架构,涵盖数据采集、特征工程、模型构建、实时计算到决策支持的全链路技术方案,揭示其背后…...
- 交互与Widget(四))
VTK知识学习(53)- 交互与Widget(四)
1、测量类Widget 1)概述 与测量相关的主要 Widget如下: vtkDistanceWidget:用于在二维平面上测量两点之间的距离。vtkAngleWidget:用于二维平面的角度测量。vtkBiDimensionalWidget:用于测量二维平面上任意两个正交方向的轴长。 按照前面提到的步骤创…...

基础服务系列-Windows10 安装AnacondaJupyter
下载 https://www.anaconda.com/products/individual 安装 安装Jupyter 完成安装 启动Jupyter 浏览器访问 默认浏览器打开,IE不兼容,可以换个浏览器 修改密码 运行脚本...
)
使用c++调用deepseek的api(附带源码)
可以给服务器添加deepseek这样就相当于多了一个智能ai助手 deepseek的api申请地址使用格式测试效果源码 deepseek的api申请地址 这边使用硅基流动的api,注册就有免费额度 硅基流动: link 使用格式 api的调用格式,ds的api调用就是用固定协议然后发送到…...

HarmonyOS-ArkUI: animateTo 显式动画
什么是显式动画 啊, 尽管有点糙,但还是解释一下吧, 显式动画里面的“显式”二字, 是程序员在代码调用的时候,就三令五申,明明白白调用动画API而创建的动画。 这个API的名字就是: animateTo。这就是显式动画。说白了您可以大致理解为,显式动画,就是调用animateTo来完成…...

Spring AI MCP
MCP是什么 MCP是模型上下文协议(Model Context Protocol)的简称,是一个开源协议,由Anthropic(Claude开发公司)开发,旨在让大型语言模型(LLM)能够以标准化的方式连接到外…...

Kubernetes 创建 Jenkins 实现 CICD 配置指南
Kubernetes 创建 Jenkins 实现 CICD 配置指南 拉取 Jenkins 镜像并推送到本地仓库 # 从官方仓库拉取镜像(若网络不通畅可使用国内镜像源) docker pull jenkins/jenkins:lts-jdk11# 国内用户可去下面地址寻找镜像源并拉取: https://docker.a…...

01_Flask快速入门教程介绍
一、课程视频 01_Flask快速入门教程介绍 二、课程特点 讲课风格通俗易懂,理论与实战相结合 教程:视频 配套文档 配套的代码 最新本版,Python版本是3.12,Flask版本是3.10 即使是从没接触过Flsk的小白也看得懂学得会 三、适用人…...

SSH反向代理
SSH反向代理 一、过程 1、 确保树莓派和阿里云服务器的 SSH 服务正常运行 检查树莓派的ssh服务 sudo systemctl status ssh如果未启用,请启动并设置开机自启: sudo systemctl enable ssh sudo systemctl start ssh检查阿里云服务器的SSH服务 sudo …...

第 5 篇:初试牛刀 - 简单的预测方法
第 5 篇:初试牛刀 - 简单的预测方法 经过前面四篇的学习,我们已经具备了处理时间序列数据的基本功:加载、可视化、分解以及处理平稳性。现在,激动人心的时刻到来了——我们要开始尝试预测 (Forecasting) 未来! 预测是…...

深度学习中的归一化技术:从原理到实战全解析
摘要:本文系统解析深度学习中的归一化技术,涵盖批量归一化(BN)、层归一化(LN)、实例归一化(IN)、组归一化(GN)等核心方法。通过数学原理、适用场景、优缺点对…...
)
流量抓取工具(wireshark)
协议 TCP/IP协议簇 网络接口层(没有特定的协议)PPPOE 物理层数据链路层 网络层: IP(v4/v6) ARP(地址解析协议) RARP ICMP(Internet控制报文协议) IGMP传输层:TCP(传输控制协议)UDP(用户数据报协议)应用层…...

【原创】Ubuntu20.04 安装 Isaac Gym 仿真器
Isaac Gym 是 NVIDIA 开发的一个基于GPU的机器人仿真平台。其高效的 GPU 加速能力和大规模并行仿真性能,成为强化学习训练和机器人控制研究的重要选择。 本文将介绍 Isaac Gym 的安装过程【简易】。 1.配置环境 Ubuntu20.04 安装 NVIDIA 显卡驱动 Ubuntu20.04 安…...

AI 速读 SpecReason:让思考又快又准!
在大模型推理的世界里,速度与精度往往难以兼得。但今天要介绍的这篇论文带来了名为SpecReason的创新系统,它打破常规,能让大模型推理既快速又准确,大幅提升性能。想知道它是如何做到的吗?快来一探究竟! 论…...

从“堆料竞赛”到“体验深耕”,X200 Ultra和X200s打响手机价值升维战
出品 | 何玺 排版 | 叶媛 vivo双旗舰来袭! 4月21日,vivo X系列春季新品发布会盛大开启,带来了一场科技与创新的盛宴。会上,消费者期待已久的X200 Ultra及X200s两款旗舰新品正式发布。 vivo两款旗舰新品发布后,其打破…...

Macbook IntelliJ IDEA终端无法运行mvn命令
一、背景 idea工具里执行Maven命令mvn package,报错提示 zsh: command not found: mvn。 macOS,默认使用的是zsh,环境变量通常配置在 ~/.zshrc 文件中。 而我之前一直是配置在~/.bash_profile文件中。 二、环境变量 vi ~/.zshrc设置MAVE…...

CentOS 7进入救援模式——VirtualBox虚拟机
目录 1. 在`VirtualBox`环境下,开机按F12,进入`VirtualBox temporary boot device selection `界面,按`c`键,选中`CD-ROM `回车。2. 选中`Troubleshooting`(故障排除),进入`Troubleshooting`界面3. 接下来会显示救援模式菜单,通常选择`"1) Continue"`(除非您…...
)
AI软件栈:LLVM分析(六)
LLVM后端代码生成的关键步骤 文章目录 指令选择指令调度寄存器分配 指令选择 完成从基于LLVM IR的DAG转换为基于特定目标平台的DAG(注意,此时描述格式依然是DAG形态)基于TabGen完成指令重映射(典型的处理包括:指令拆散…...

【第十六届 蓝桥杯 省 C/Python A/Java C 登山】题解
题目链接:P12169 [蓝桥杯 2025 省 C/Python A/Java C] 登山 思路来源 一开始想的其实是记搜,但是发现还有先找更小的再找更大的这种路径,所以这样可能错过某些最优决策,这样不行。 于是我又想能不能从最大值出发往回搜…...

Github 热点项目 Jumpserver开源堡垒机让服务器管理效率翻倍
Jumpserver今日喜提160星,总星飙至2.6万!这个开源堡垒机有三大亮点:① 像哆啦A梦的口袋,支持多云服务器一站式管理;② 安全审计功能超硬核,操作记录随时可回放;③ 网页终端无需装插件࿰…...

5V 1A充电标准的由来与技术演进——从USB诞生到智能手机时代的电力革命
点击下面图片带您领略全新的嵌入式学习路线 🔥爆款热榜 88万阅读 1.6万收藏 一、起源:USB标准与早期电力传输需求 1. USB的诞生背景 1996年,由英特尔、微软、IBM等公司组成的USB-IF(USB Implementers Forum)发布了…...

驱动开发硬核特训 · Day 16:字符设备驱动模型与实战注册流程
🎥 视频教程请关注 B 站:“嵌入式 Jerry” 一、为什么要学习字符设备驱动? 在 Linux 驱动开发中,字符设备(Character Device)驱动 是最基础也是最常见的一类驱动类型。很多设备(如 LED、按键、…...

外网如何连接内网中的mysql数据库服务器
一、MySQL 产品简介 mysql是一款数据库产品,它主要用于存储、管理和检索数据,对用户的数据进行存储管理 二、运维人员遇到的问题 当内网服务器部署好mysql数据库后,外网如何安全的访问数据库进行增删改查,是运维人员遇到的一个…...

你的大模型服务如何压测:首 Token 延迟、并发与 QPS
写在前面 大型语言模型(LLM)API,特别是遵循 OpenAI 规范的接口(无论是 OpenAI 官方、Azure OpenAI,还是 DeepSeek、Moonshot 等众多兼容服务),已成为驱动下一代 AI 应用的核心引擎。然而,随着应用规模的扩大和用户量的增长,仅仅关注模型的功能是不够的,API 的性能表…...

4月谷歌新政 | Google Play今年对“数据安全”的管控将全面升级!
大家好,我是牢鹅!每年的Q2季度是Google Play重要政策更新的时间节点,一般都伴随着重磅政策的更新,今年也不例外。4月10日,谷歌政策迎来2025年第二次更新,本次政策更新内容相较3月政策更新,不管是…...

第十四届蓝桥杯 2023 C/C++组 有奖问答
目录 题目: 题目描述: 题目链接: 思路: 核心思路: 思路详解: 代码: 代码详解: 题目: 题目描述: 题目链接: 蓝桥云课 有奖问答 思路&…...

【Redis】SpringDataRedis
Spring Data Redis 使得开发者能够更容易地与 Redis 数据库进行交互,并且支持不同的 Redis 客户端实现,如 Jedis 和 Lettuce。Spring Data Redis 会自动选择一个客户端,通常情况下,Spring Boot 默认使用 Lettuce 作为 Redis 客户端…...

XAttention
XAttention: Block Sparse Attention with Antidiagonal Scoring 革新Transformer推理的高效注意力机制资源 论文链接:XAttention: Block Sparse Attention with Antidiagonal Scoring 代码开源:GitHub仓库 XAttention是韩松团队提…...

07.Python代码NumPy-排序sort,argsort,lexsort
07.Python代码NumPy-排序sort,argsort,lexsort 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是NumPy的使用语法。前后每一小节的内容是存在的有:学习and理解的关联性,希望…...

无人机飞控运行在stm32上的RTOS实时操作系统上,而不是linux这种非实时操作系统的必要性
飞控程序需要运行在STM32等微控制器(MCU)的实时操作系统(RTOS)而非Linux等非实时操作系统(如通用Linux内核),主要原因在于实时性、资源占用、硬件适配性以及系统可靠性等方面的实质性差异。以下…...

Leetcode - 周赛446
目录 一、3522. 执行指令后的得分二、3523. 非递减数组的最大长度三、3524. 求出数组的 X 值 I四、3525. 求出数组的 X 值 II 一、3522. 执行指令后的得分 题目链接 本题就是一道模拟题,代码如下: class Solution {public long calculateScore(String…...

Linux——系统安全及应用
目录 一:账号安全控制 1,基本安全措施 系统账号清理 密码安全控制 命令历史,自动注销 2,用户切换与提权 su命令的用法 PAM认证 3,sudo命令——提升执行权限 在配置文件/etc/sudoers中添加授权 通过sudo执行…...

随机面试--<二>
编译安装软件的流程 1-安装所需源代码 2-配置安装环境 3-进行相关设置 4-编译 5-安装 nginx安装新模块的流程 1-准备与原nginx版本相同的源码包,准备模块安装包 2-准备编译安装环境 3-配置参数 来源于nginx -V配置原模块 以及--add-module 增加模块 4-mak…...
)
LeetCode面试经典 150 题(Java题解)
一、数组、字符串 1、合并两个有序数组 从后往前比较,这样就不需要使用额外的空间 class Solution {public void merge(int[] nums1, int m, int[] nums2, int n) {int l mn-1, i m-1, j n-1;while(i > 0 && j > 0){if(nums1[i] > nums2[j])…...
【技术追踪】Differential Transformer(ICLR-2025)
Differential Transformer:大语言模型新架构, 提出了 differential attention mechanism,Transformer 又多了一个小 trick~ 论文:Differential Transformer 代码:https://github.com/microsoft/unilm/tree/master/Diff…...
)
报告系统状态的连续日期 mysql + pandas(连续值判断)
本题用到知识点:row_number(), union, date_sub(), to_timedelta()…… 目录 思路 pandas Mysql 思路 链接:报告系统状态的连续日期 思路: 判断连续性常用的一个方法,增量相同的两个列的差值是固定的。 让日期与行号 * 天数…...

【C++类和数据抽象】类的作用域
目录 一、类的作用域基本概念 1.1 什么是类的作用域 1.2 作用域层次体系 1.3 类作用域的特点 1.4 基本访问规则 二、访问控制三剑客 2.1 public:开放接口 2.2 private:数据封装 2.3 protected:继承通道 2.4 跨作用域访问示例 三…...

【区块链技术解析】从原理到实践的全链路指南
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块技术选型对比 二、实战演示环境配置要求核心代码实现(10个案例)案例1:创建简单区块链案例2:工作…...