深度学习-全连接神经网络
四、参数初始化
神经网络的参数初始化是训练深度学习模型的关键步骤之一。初始化参数(通常是权重和偏置)会对模型的训练速度、收敛性以及最终的性能产生重要影响。下面是关于神经网络参数初始化的一些常见方法及其相关知识点。
官方文档参考:torch.nn.init — PyTorch 2.6 documentation
1. 固定值初始化
固定值初始化是指在神经网络训练开始时,将所有权重或偏置初始化为一个特定的常数值。这种初始化方法虽然简单,但在实际深度学习应用中通常并不推荐。
1.1 全零初始化
将神经网络中的所有权重参数初始化为0。
方法:将所有权重初始化为零。
缺点:导致对称性破坏,每个神经元在每一层中都会执行相同的计算,模型无法学习。
应用场景:通常不用来初始化权重,但可以用来初始化偏置。
对称性问题
-
现象:同一层的所有神经元具有完全相同的初始权重和偏置。
-
后果:
-
在反向传播时,所有神经元会收到相同的梯度,导致权重更新完全一致。
-
无论训练多久,同一层的神经元本质上会保持相同的功能(相当于“一个神经元”的多个副本),极大降低模型的表达能力。
-
代码演示:
import torch import torch.nn as nn def test004():# 3. 全0参数初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化权重参数nn.init.zeros_(linear.weight)# 打印权重参数print(linear.weight) if __name__ == "__main__":test004()
打印结果:
Parameter containing: tensor([[0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0.]], requires_grad=True)
1.2 全1初始化
全1初始化会导致网络中每个神经元接收到相同的输入信号,进而输出相同的值,这就无法进行学习和收敛。所以全1初始化只是一个理论上的初始化方法,但在实际神经网络的训练中并不适用。
代码演示:
import torch import torch.nn as nn def test003():# 3. 全1参数初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化权重参数nn.init.ones_(linear.weight)# 打印权重参数print(linear.weight) if __name__ == "__main__":test003()
输出结果:
Parameter containing: tensor([[1., 1., 1., 1., 1., 1.],[1., 1., 1., 1., 1., 1.],[1., 1., 1., 1., 1., 1.],[1., 1., 1., 1., 1., 1.]], requires_grad=True)
1.3 任意常数初始化
将所有参数初始化为某个非零的常数(如 0.1,-1 等)。虽然不同于全0和全1,但这种方法依然不能避免对称性破坏的问题。
import torch import torch.nn as nn def test002():# 2. 固定值参数初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化权重参数nn.init.constant_(linear.weight, 0.63)# 打印权重参数print(linear.weight)pass if __name__ == "__main__":test002()
输出结果:
Parameter containing: tensor([[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300],[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300],[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300],[0.6300, 0.6300, 0.6300, 0.6300, 0.6300, 0.6300]], requires_grad=True)
参考2:
import torch import torch.nn as nn def test002():net = nn.Linear(2, 2, bias=True)# 假设一个数值x = torch.tensor([[0.1, 0.95]]) # 初始化权重参数net.weight.data = torch.tensor([[0.1, 0.2], [0.3, 0.4]]) # 输出什么:权重参数会转置output = net(x)print(output, net.bias)pass if __name__ == "__main__":test002()
2. 随机初始化
方法:将权重初始化为随机的小值,通常从正态分布或均匀分布中采样。
应用场景:这是最基本的初始化方法,通过随机初始化避免对称性破坏。
代码演示:随机分布之均匀初始化
import torch import torch.nn as nn def test001():# 1. 均匀分布随机初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化权重参数nn.init.uniform_(linear.weight)# 打印权重参数print(linear.weight) if __name__ == "__main__":test001()
打印结果:
Parameter containing: tensor([[0.4080, 0.7444, 0.7616, 0.0565, 0.2589, 0.0562],[0.1485, 0.9544, 0.3323, 0.9802, 0.1847, 0.6254],[0.6256, 0.2047, 0.5049, 0.3547, 0.9279, 0.8045],[0.1994, 0.7670, 0.8306, 0.1364, 0.4395, 0.0412]], requires_grad=True)
代码演示:正态分布初始化
import torch import torch.nn as nn def test005():# 5. 正太分布初始化linear = nn.Linear(in_features=6, out_features=4)# 初始化权重参数nn.init.normal_(linear.weight, mean=0, std=1)# 打印权重参数print(linear.weight) if __name__ == "__main__":test005()
打印结果:
Parameter containing: tensor([[ 1.5321, 0.2394, 0.0622, 0.4482, 0.0757, -0.6056],[ 1.0632, 1.8069, 1.1189, 0.2448, 0.8095, -0.3486],[-0.8975, 1.8253, -0.9931, 0.7488, 0.2736, -1.3892],[-0.3752, 0.0500, -0.1723, -0.4370, -1.5334, -0.5393]],requires_grad=True)
3. Xavier 初始化
前置知识:
均匀分布:
均匀分布的概率密度函数(PDF):
如果其他情况
计算期望值(均值):
计算方差(二阶矩减去均值的平方):
-
先计算 :
-
代入方差公式:
Xavier 初始化(由 Xavier Glorot 在 2010 年提出)是一种自适应权重初始化方法,专门为解决神经网络训练初期的梯度消失或爆炸问题而设计。Xavier 初始化也叫做Glorot初始化。Xavier 初始化的核心思想是根据输入和输出的维度来初始化权重,使得每一层的输出的方差保持一致。具体来说,权重的初始化范围取决于前一层的神经元数量(输入维度)和当前层的神经元数量(输出维度)。
方法:根据输入和输出神经元的数量来选择权重的初始值。
数学原理:
(1) 前向传播的方差一致性
假设输入 x 的均值为 0,方差为 ,权重 W的均值为 0,方差为 ,则输出 z=Wx的方差为:
为了使 Var(z)=Var(x),需要:
其中 是输入维度(fan_in)。这里乘以 nin 的原因是,输出 z 是由 nin 个输入 x 的线性组合得到的,每个输入 x 都与一个权重 W 相乘。因此,输出 z 的方差是 nin 个独立的 Wx 项的方差之和。
(2) 反向传播的梯度方差一致性
在反向传播过程中,梯度 是通过链式法则计算得到的,其中 L 是损失函数,x 是输入,z 是输出。梯度可以表示为:
假设 z=Wx,其中 W 是权重矩阵,那么 。因此,梯度 可以写为:
反向传播时梯度 的方差应与 相同,因此:
其中 是输出维度(fan_out)。为了保持梯度的方差一致性,我们需要确保每个输入维度 nin 的梯度方差与输出维度 nout 的梯度方差相同。因此,我们需要将 W 的方差乘以 nout,以确保梯度的方差在反向传播过程中保持一致。
(3) 综合考虑
为了同时平衡前向传播和反向传播,Xavier 采用:
权重从以下分布中采样:
均匀分布:
在Xavier初始化中,我们选择 和 ,这样方差为:
正态分布:
其中 是当前层的输入神经元数量,是输出神经元数量。
在前向传播中,输出的方差受 影响。在反向传播中,梯度的方差受 影响。
优点:平衡了输入和输出的方差,适合 和 激活函数。
应用场景:常用于浅层网络或使用 、 激活函数的网络。
代码演示:
import torch import torch.nn as nn def test007():# Xavier初始化:正态分布linear = nn.Linear(in_features=6, out_features=4)nn.init.xavier_normal_(linear.weight)print(linear.weight) # Xavier初始化:均匀分布linear = nn.Linear(in_features=6, out_features=4)nn.init.xavier_uniform_(linear.weight)print(linear.weight) if __name__ == "__main__":test007()
打印结果:
Parameter containing: tensor([[-0.4838, 0.4121, -0.3171, -0.2214, -0.8666, -0.4340],[ 0.1059, 0.6740, -0.1025, -0.1006, 0.5757, -0.1117],[ 0.7467, -0.0554, -0.5593, -0.1513, -0.5867, -0.1564],[-0.1058, 0.5266, 0.0243, -0.5646, -0.4982, -0.1844]],requires_grad=True) Parameter containing: tensor([[-0.5263, 0.3455, 0.6449, 0.2807, -0.3698, -0.6890],[ 0.1578, -0.3161, -0.1910, -0.4318, -0.5760, 0.3746],[ 0.2017, -0.6320, -0.4060, 0.3903, 0.3103, -0.5881],[ 0.6212, 0.3077, 0.0783, -0.6187, 0.3109, -0.6060]],requires_grad=True)
4. He初始化
也叫kaiming 初始化。He 初始化的核心思想是调整权重的初始化范围,使得每一层的输出的方差保持一致。与 Xavier 初始化不同,He 初始化专门针对 ReLU 激活函数的特性进行了优化。
数学推导
(1) 前向传播的方差一致性
对于 ReLU 激活函数,输出的方差为:
(因为 ReLU 使一半神经元输出为 0,方差减半) 为使 Var(z)=Var(x),需:
(2) 反向传播的梯度一致性
类似地,反向传播时梯度方差需满足:
因此:
(3) 两种模式
-
fan_in模式(默认):优先保证前向传播稳定,方差 。 -
fan_out模式:优先保证反向传播稳定,方差。
方法:专门为 ReLU 激活函数设计。权重从以下分布中采样:
均匀分布:
正态分布:
其中 是当前层的输入神经元数量。
优点:适用于 和 激活函数。
应用场景:深度网络,尤其是使用 ReLU 激活函数时。
代码演示:
import torch import torch.nn as nn def test006():# He初始化:正态分布linear = nn.Linear(in_features=6, out_features=4)nn.init.kaiming_normal_(linear.weight, nonlinearity="relu", mode='fan_in')print(linear.weight) # He初始化:均匀分布linear = nn.Linear(in_features=6, out_features=4)nn.init.kaiming_uniform_(linear.weight, nonlinearity="relu", mode='fan_out')print(linear.weight) if __name__ == "__main__":test006()
输出结果:
Parameter containing: tensor([[ 1.4020, 0.2030, 0.3585, -0.7419, 0.6077, 0.0178],[-0.2860, -1.2135, 0.0773, -0.3750, -0.5725, 0.9756],[ 0.2938, -0.6159, -1.1721, 0.2093, 0.4212, 0.9079],[ 0.2050, 0.3866, -0.3129, -0.3009, -0.6659, -0.2261]],requires_grad=True) Parameter containing: tensor([[-0.1924, -0.6155, -0.7438, -0.2796, -0.1671, -0.2979],[ 0.7609, 0.9836, -0.0961, 0.7139, -0.8044, -0.3827],[ 0.1416, 0.6636, 0.9539, 0.4735, -0.2384, -0.1330],[ 0.7254, -0.4056, -0.7621, -0.6139, -0.6093, -0.2577]],requires_grad=True)
5. 总结
在使用Torch构建网络模型时,每个网络层的参数都有默认的初始化方法,同时还可以通过以上方法来对网络参数进行初始化。
五、损失函数
1. 线性回归损失函数
1.1 MAE损失
MAE(Mean Absolute Error,平均绝对误差)通常也被称为 L1-Loss,通过对预测值和真实值之间的绝对差取平均值来衡量他们之间的差异。。
MAE的公式如下:
其中:
-
是样本的总数。
-
是第 个样本的真实值。
-
是第 个样本的预测值。
-
是真实值和预测值之间的绝对误差。
特点:
-
鲁棒性:与均方误差(MSE)相比,MAE对异常值(outliers)更为鲁棒,因为它不会像MSE那样对较大误差平方敏感。
-
物理意义直观:MAE以与原始数据相同的单位度量误差,使其易于解释。
应用场景: MAE通常用于需要对误差进行线性度量的情况,尤其是当数据中可能存在异常值时,MAE可以避免对异常值的过度惩罚。
使用torch.nn.L1Loss即可计算MAE:
import torch
import torch.nn as nn
# 初始化MAE损失函数
mae_loss = nn.L1Loss()
# 假设 y_true 是真实值, y_pred 是预测值
y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([2.5, 5.0, 3.0])
# 计算MAE
loss = mae_loss(y_pred, y_true)
print(f'MAE Loss: {loss.item()}')
1.2 MSE损失
均方差损失,也叫L2Loss。
MSE(Mean Squared Error,均方误差)通过对预测值和真实值之间的误差平方取平均值,来衡量预测值与真实值之间的差异。
MSE的公式如下:
其中:
-
是样本的总数。
-
是第 个样本的真实值。
-
是第 个样本的预测值。
-
是真实值和预测值之间的误差平方。
特点:
-
平方惩罚:因为误差平方,MSE 对较大误差施加更大惩罚,所以 MSE 对异常值更为敏感。
-
凸性:MSE 是一个凸函数(国际的叫法,国内叫凹函数),这意味着它具有一个唯一的全局最小值,有助于优化问题的求解。
应用场景:
MSE被广泛应用在神经网络中。
使用 torch.nn.MSELoss 可以实现:
import torch
import torch.nn as nn
# 初始化MSE损失函数
mse_loss = nn.MSELoss()
# 假设 y_true 是真实值, y_pred 是预测值
y_true = torch.tensor([3.0, 5.0, 2.5])
y_pred = torch.tensor([2.5, 5.0, 3.0])
# 计算MSE
loss = mse_loss(y_pred, y_true)
print(f'MSE Loss: {loss.item()}')
2. CrossEntropyLoss
2.1 信息量
信息量用于衡量一个事件所包含的信息的多少。信息量的定义基于事件发生的概率:事件发生的概率越低,其信息量越大。其量化公式:
对于一个事件x,其发生的概率为 P(x),信息量I(x) 定义为:
性质
-
非负性:I(x)≥0。
-
单调性:P(x)越小,I(x)越大。
2.2 信息熵
信息熵是信息量的期望值。熵越高,表示随机变量的不确定性越大;熵越低,表示随机变量的不确定性越小。
公式由数学中的期望推导而来:
其中:
是信息量,是信息量对应的概率
2.3 KL散度
KL散度用于衡量两个概率分布之间的差异。它描述的是用一个分布 Q来近似另一个分布 P时,所损失的信息量。KL散度越小,表示两个分布越接近。
对于两个离散概率分布 P和 Q,KL散度定义为:
其中:P 是真实分布,Q是近似分布。
2.4 交叉熵
对KL散度公式展开:
由上述公式可知,P是真实分布,H(P)是常数,所以KL散度可以用H(P,Q)来表示;H(P,Q)叫做交叉熵。
如果将P换成y,Q换成,则交叉熵公式为:
其中:
-
是类别的总数。
-
是真实标签的one-hot编码向量,表示真实类别。
-
是模型的输出(经过 softmax 后的概率分布)。
-
是真实类别的第 个元素(0 或 1)。
-
是预测的类别概率分布中对应类别 的概率。
函数曲线图:
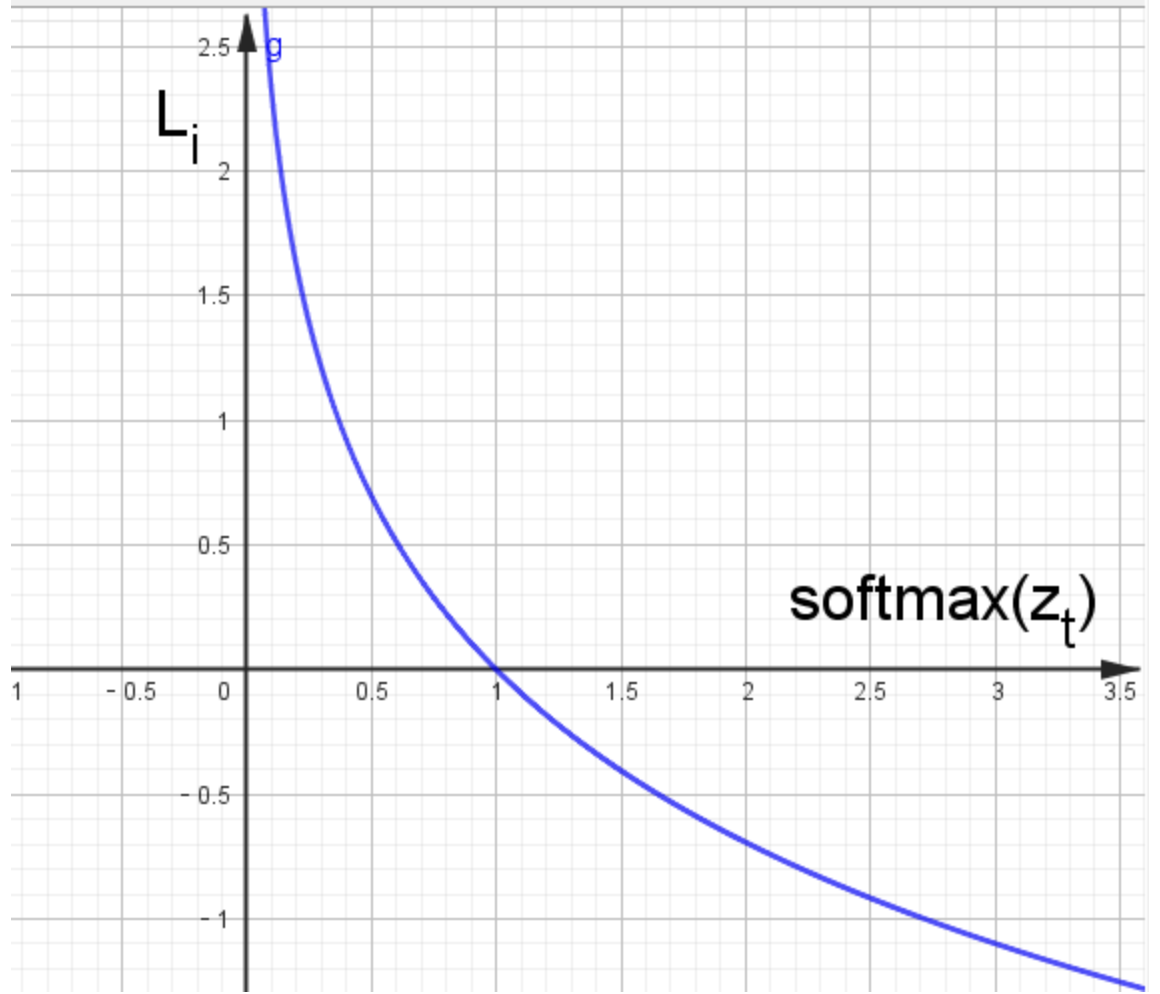 特点:
特点:
-
概率输出:CrossEntropyLoss 通常与 softmax 函数一起使用,使得模型的输出表示为一个概率分布(即所有类别的概率和为 1)。PyTorch 的 nn.CrossEntropyLoss 已经内置了 Softmax 操作。如果我们在输出层显式地添加 Softmax,会导致重复应用 Softmax,从而影响模型的训练效果。
-
惩罚错误分类:该损失函数在真实类别的预测概率较低时,会施加较大的惩罚,这样模型在训练时更注重提升正确类别的预测概率。
-
多分类问题中的标准选择:在大多数多分类问题中,CrossEntropyLoss 是首选的损失函数。
应用场景:
CrossEntropyLoss 广泛应用于各种分类任务,包括图像分类、文本分类等,尤其是在神经网络模型中。
nn.CrossEntropyLoss基本原理:
由交叉熵公式可知:
因为是one-hot编码,其值不是1便是0,又是乘法,所以只要知道1对应的index就可以了,展开后:
其中,m表示真实类别。
因为神经网络最后一层分类总是接softmax,所以可以把直接看为是softmax后的结果。
所以,CrossEntropyLoss 实质上是两步的组合:Cross Entropy = Log-Softmax + NLLLoss
-
Log-Softmax:对输入 logits 先计算对数 softmax:
log(softmax(x))。 -
NLLLoss(Negative Log-Likelihood):对 log-softmax 的结果计算负对数似然损失。简单理解就是求负数。原因是概率值通常在 0 到 1 之间,取对数后会变成负数。为了使损失值为正数,需要取负数。
对于,在softmax介绍中了解到,需要减去最大值以确保数值稳定。
则:
所以:
总的交叉熵损失函数是所有样本的平均值:
示例代码如下:
import torch
import torch.nn as nn
# 假设有三个类别,模型输出是未经softmax的logits
logits = torch.tensor([[1.5, 2.0, 0.5], [0.5, 1.0, 1.5]])
# 真实的标签
labels = torch.tensor([1, 2]) # 第一个样本的真实类别为1,第二个样本的真实类别为2
# 初始化CrossEntropyLoss
# 参数:reduction:mean-平均值,sum-总和
criterion = nn.CrossEntropyLoss()
# 计算损失
loss = criterion(logits, labels)
print(f'Cross Entropy Loss: {loss.item()}')
在这个例子中,CrossEntropyLoss 直接作用于未经 softmax 处理的 logits 输出和真实标签,PyTorch 内部会自动应用 softmax 激活函数,并计算交叉熵损失。
分析示例中的代码:
logits = torch.tensor([[1.5, 2.0, 0.5], [0.5, 1.0, 1.5]])
第一个样本的得分是 [1.5, 2.0, 0.5],分别对应类别 0、1 和 2 的得分。
第二个样本的得分是 [0.5, 1.0, 1.5],分别对应类别 0、1 和 2 的得分
labels = torch.tensor([1, 2])
第一个样本的真实类别是 1。
第二个样本的真实类别是 2。
CrossEntropyLoss 的计算过程可以分为以下几个步骤:
(1) LogSoftmax 操作
首先,对每个样本的 logits 应用 LogSoftmax 函数,将 logits 转换为概率分布。LogSoftmax 函数的公式是:
对于第一个样本 [1.5, 2.0, 0.5]:
减去最大值:
计算:
求和并取对数:
计算 log_softmax:
对于第二个样本 [0.5, 1.0, 1.5]:
减去最大值:
计算:
求和并取对数:
计算 log_softmax:
(2) 计算每个样本的损失
接下来,根据真实标签 计算每个样本的交叉熵损失。交叉熵损失的公式是:
对于第一个样本:
-
真实类别是 1,对应的 softmax 值是 -0.6041。
对于第二个样本:
-
真实类别是 2,对应的 softmax 值是 -0.6803。
(3) 计算平均损失
最后,计算所有样本的平均损失: 平均损失
3. BCELoss
二分类交叉熵损失函数,使用在输出层使用sigmoid激活函数进行二分类时。
由交叉熵公式:
对于二分类问题,真实标签 y的值为(0 或 1),假设模型预测为正类的概率为 ,则:
如果如果
所以:
示例:
import torch import torch.nn as nn # y 是模型的输出,已经被sigmoid处理过,确保其值域在(0,1) y = torch.tensor([[0.7], [0.2], [0.9], [0.7]]) # targets 是真实的标签,0或1 t = torch.tensor([[1], [0], [1], [0]], dtype=torch.float) # 计算损失方式一: bceLoss = nn.BCELoss() loss1 = bceLoss(y, t) #计算损失方式二: 两种方式结果相同 loss2 = nn.functional.binary_cross_entropy(y, t) print(loss1, loss2)
逐样本计算
| 样本 | y_i | t_i | 计算项 |
|---|---|---|---|
| 1 | 0.7 | 1 | 1*log(0.7) + 0*log(0.3) ≈ -0.3567 |
| 2 | 0.2 | 0 | 0*log(0.2) + 1*log(0.8) ≈ -0.2231 |
| 3 | 0.9 | 1 | 1*log(0.9) + 0*log(0.1) ≈ -0.1054 |
| 4 | 0.7 | 0 | 0*log(0.7) + 1*log(0.3) ≈ -1.2040 |
计算最终损失
4. 总结
-
当输出层使用softmax多分类时,使用交叉熵损失函数;
-
当输出层使用sigmoid二分类时,使用二分类交叉熵损失函数, 比如在逻辑回归中使用;
-
当功能为线性回归时,使用均方差损失-L2 loss;
六、反向传播算法
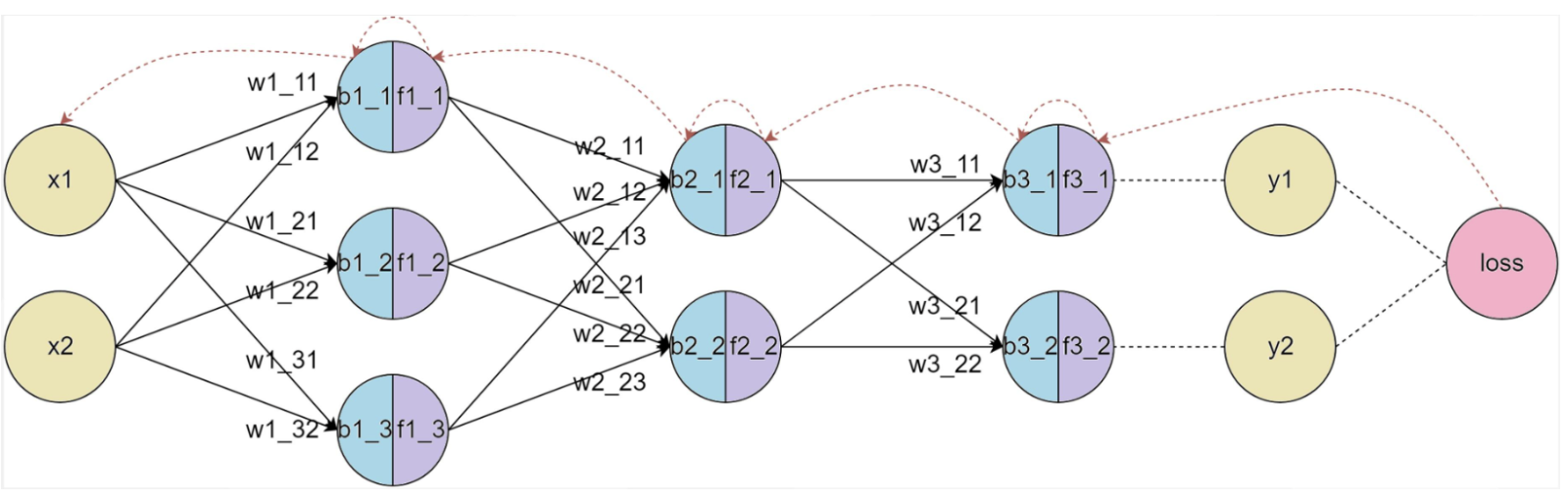 反向传播(Back Propagation,简称BP)算法是用于训练神经网络的核心算法之一,它通过计算损失函数(如均方误差或交叉熵)相对于每个权重参数的梯度,来优化神经网络的权重。
反向传播(Back Propagation,简称BP)算法是用于训练神经网络的核心算法之一,它通过计算损失函数(如均方误差或交叉熵)相对于每个权重参数的梯度,来优化神经网络的权重。
1. 前向传播
前向传播(Forward Propagation)把输入数据经过各层神经元的运算并逐层向前传输,一直到输出层为止。
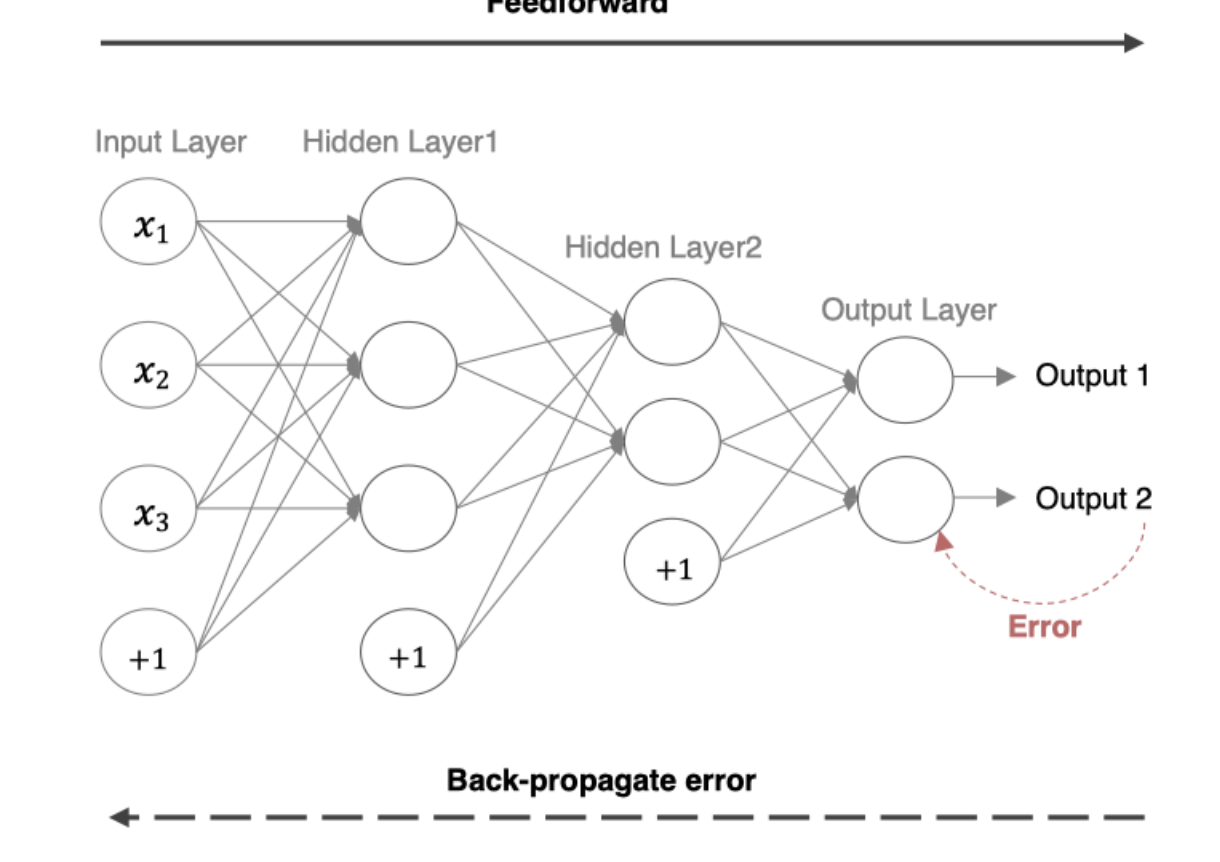 1.1 数学表达
1.1 数学表达
下面是一个简单的三层神经网络(输入层、隐藏层、输出层)前向传播的基本步骤分析。
1.1.1 输入层到隐藏层
给定输入 和权重矩阵 及偏置向量 ,隐藏层的输出(激活值)计算如下:
将 通过激活函数 进行激活:
1.1.2 隐藏层到输出层
隐藏层的输出 通过输出层的权重矩阵 和偏置 生成最终的输出:
输出层的激活值 是最终的预测结果:
1.2 作用
前向传播的主要作用是:
-
计算神经网络的输出结果,用于预测或计算损失。
-
在反向传播中使用,通过计算损失函数相对于每个参数的梯度来优化网络。
2. BP基础之梯度下降算法
梯度下降算法的目标是找到使损失函数 最小的参数 ,其核心是沿着损失函数梯度的负方向更新参数,以逐步逼近局部或全局最优解,从而使模型更好地拟合训练数据。
2.1 数学描述
简单回顾下数学知识。
2.1.1 数学公式
其中,是学习率:
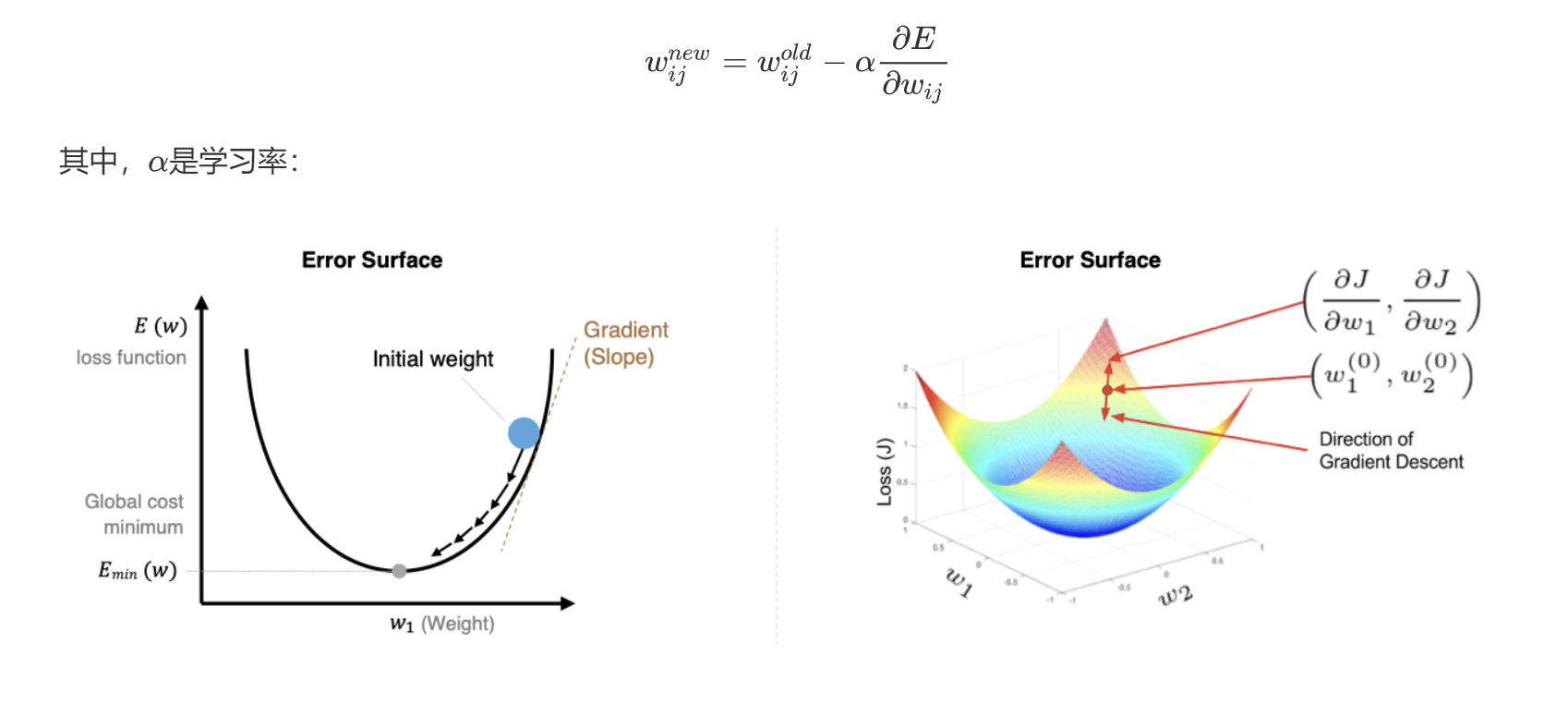
-
学习率太小,每次训练之后的效果太小,增加时间和算力成本。
-
学习率太大,大概率会跳过最优解,进入无限的训练和震荡中。
-
解决的方法就是,学习率也需要随着训练的进行而变化。
2.1.2 过程阐述
-
初始化参数:随机初始化模型的参数 ,如权重 和偏置 。
-
计算梯度:损失函数 对参数 的梯度 ,表示损失函数在参数空间的变化率。
-
更新参数:按照梯度下降公式更新参数:,其中, 是学习率,用于控制更新步长。
-
迭代更新:重复【计算梯度和更新参数】步骤,直到某个终止条件(如梯度接近0、不再收敛、完成迭代次数等)。
2.2 传统下降方式
根据计算梯度时数据量不同,常见的方式有:
2. 2.1 批量梯度下降
Batch Gradient Descent BGD
-
特点:
-
每次更新参数时,使用整个训练集来计算梯度。
-
-
优点:
-
收敛稳定,能准确地沿着损失函数的真实梯度方向下降。
-
适用于小型数据集。
-
-
缺点:
-
对于大型数据集,计算量巨大,更新速度慢。
-
需要大量内存来存储整个数据集。
-
-
公式:
其中, 是训练集样本总数,是第 个样本及其标签,是第 个样本预测值。
例如,在训练集中有100个样本,迭代50轮。
那么在每一轮迭代中,都会一起使用这100个样本,计算整个训练集的梯度,并对模型更新。
所以总共会更新50次梯度。
因为每次迭代都会使用整个训练集计算梯度,所以这种方法可以得到准确的梯度方向。
但如果数据集非常大,那么就导致每次迭代都很慢,计算成本就会很高。
示例:
x = torch.randn(1000, 10)y = torch.randn(1000, 1)
dataset = TensorDataset(x, y)dataloader = DataLoader(dataset, batch_size=len(dataset))
model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 100
for epoch in range(epochs):for b_x, b_y in dataloader:optimizer.zero_grad()output = model(b_x)loss = criterion(output, b_y)loss.backward()optimizer.step()
print('Epoch %d, Loss: %f' % (epoch, loss.item()))
2.2.2 随机梯度下降
Stochastic Gradient Descent, SGD
-
特点:
-
每次更新参数时,仅使用一个样本来计算梯度。
-
-
优点:
-
更新频率高,计算快,适合大规模数据集。
-
能够跳出局部最小值,有助于找到全局最优解。
-
-
缺点:
-
收敛不稳定,容易震荡,因为每个样本的梯度可能都不完全代表整体方向。
-
需要较小的学习率来缓解震荡。
-
-
公式:
其中, 是当前随机抽取的样本及其标签。
例如,如果训练集有100个样本,迭代50轮,那么每一轮迭代,会遍历这100个样本,每次会计算某一个样本的梯度,然后更新模型参数。
换句话说,100个样本,迭代50轮,那么就会更新100*50=5000次梯度。
因为每次只用一个样本训练,所以迭代速度会非常快。
但更新的方向会不稳定,这也导致随机梯度下降,可能永远都不会收敛。
不过也因为这种震荡属性,使得随机梯度下降,可以跳出局部最优解。
这在某些情况下,是非常有用的。
示例:
x = torch.randn(1000, 10)y = torch.randn(1000, 1)
dataset = TensorDataset(x, y)dataloader = DataLoader(dataset, batch_size=1)
model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 100
for epoch in range(epochs):for b_x, b_y in dataloader:optimizer.zero_grad()output = model(b_x)loss = criterion(output, b_y)loss.backward()optimizer.step()
print('Epoch %d, Loss: %f' % (epoch, loss.item()))
2.2.3 小批量梯度下降
Mini-batch Gradient Descent MGBD
-
特点:
-
每次更新参数时,使用一小部分训练集(小批量)来计算梯度。
-
-
优点:
-
在计算效率和收敛稳定性之间取得平衡。
-
能够利用向量化加速计算,适合现代硬件(如GPU)。
-
-
缺点:
-
选择适当的批量大小比较困难;批量太小则接近SGD,批量太大则接近批量梯度下降。
-
通常会根据硬件算力设置为32\64\128\256等2的次方。
-
-
公式:
其中, 是小批量的样本数量,也就是 。
例如,如果训练集中有100个样本,迭代50轮。
如果设置小批量的数量是20,那么在每一轮迭代中,会有5次小批量迭代。
换句话说,就是将100个样本分成5个小批量,每个小批量20个数据,每次迭代用一个小批量。
因此,按照这样的方式,会对梯度,进行50轮*5个小批量=250次更新。
示例:
x = torch.randn(1000, 10)y = torch.randn(1000, 1)
dataset = TensorDataset(x, y)# 小批量梯度下降,每批次100个样本dataloader = DataLoader(dataset, batch_size=100, shuffle=True)
model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 100
for epoch in range(epochs):for b_x, b_y in dataloader:optimizer.zero_grad()output = model(b_x)loss = criterion(output, b_y)loss.backward()optimizer.step()
print('Epoch %d, Loss: %f' % (epoch, loss.item()))
2.3 存在的问题
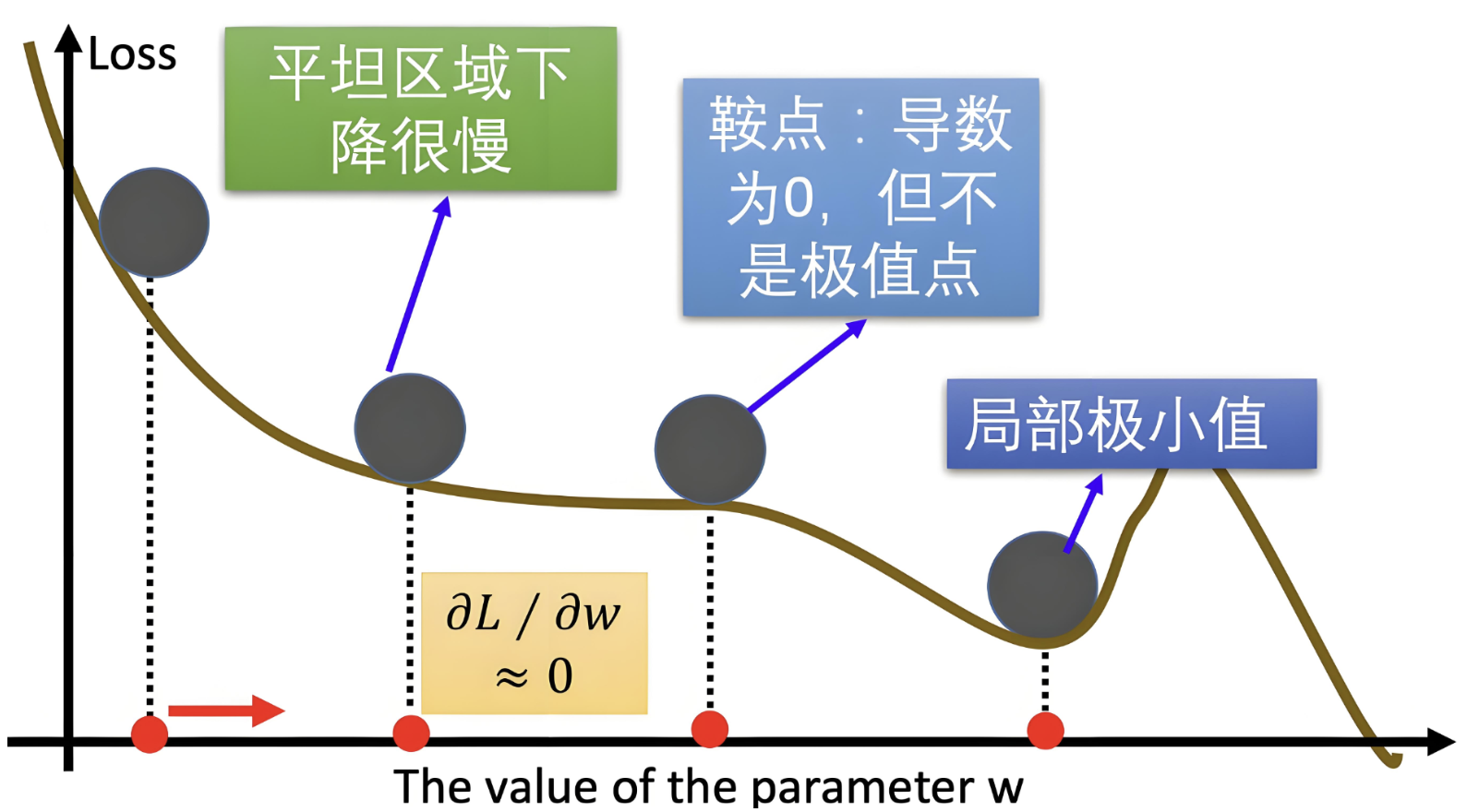
-
收敛速度慢:BGD和MBGD使用固定学习率,太大会导致震荡,太小又收敛缓慢。
-
局部最小值和鞍点问题:SGD在遇到局部最小值或鞍点时容易停滞,导致模型难以达到全局最优。
-
训练不稳定:SGD中的噪声容易导致训练过程中不稳定,使得训练陷入震荡或不收敛。
2.4 优化下降方式
通过对标准的梯度下降进行改进,来提高收敛速度或稳定性。
2.4.1 指数加权平均
我们平时说的平均指的是将所有数加起来除以数的个数,很单纯的数学。再一个是移动平均数,指的是计算最近邻的个数来获得平均数,感觉比纯粹的直接全部求均值高级一点。
指数加权平均:Exponential Moving Average,简称EMA,是一种平滑时间序列数据的技术,它通过对过去的值赋予不同的权重来计算平均值。与简单移动平均不同,EMA赋予最近的数据更高的权重,较远的数据则权重较低,这样可以更敏感地反映最新的变化趋势。
比如今天股市的走势,和昨天发生的国际事件关系很大,和6个月前发生的事件关系相对肯定小一些。
给定时间序列,EMA在每个时刻 的值可以通过以下递推公式计算:
当时:
当时:
其中:
-
是第 时刻的EMA值;
-
是第 时刻的观测值;
-
是平滑系数,取值范围为 。 越接近 ,表示对历史数据依赖性越高;越接近 则越依赖当前数据。
公式推导:
那么:
从上述公式可知:
-
当 β接近 1 时,衰减较慢,因此历史数据的权重较高。
-
当 β接近 0 时,衰减较快,因此历史数据的权重较低。
示例
假设我们有一组数据 x=[1,2,3,4,5],我们选择 β=0.1和β=0.9 来计算 EMA。
(1)β=0.1
-
初始化:
-
计算后续值:
最终,EMA 的值为 [1,1.9,2.89,3.889,4.8889]。
(2)β=0.9
-
初始化:
-
计算后续值:
最终,EMA 的值为 [1,1.1,1.29,1.561,1.9049]。
可以看到:
-
当 β=0.9 时,历史数据的权重较高,平滑效果较强。EMA值变化缓慢(新数据仅占10%权重),滞后明显。
-
当 β=0.1时,近期数据的权重较高,平滑效果较弱。EMA值快速逼近最新数据(每次新数据占90%权重)。
2.4.2 Momentum
动量(Momentum)是对梯度下降的优化方法,可以更好地应对梯度变化和梯度消失问题,从而提高训练模型的效率和稳定性。它通过引入 指数加权平均 来积累历史梯度信息,从而在更新参数时形成“动量”,帮助优化算法更快地越过局部最优或鞍点。
梯度更新算法包括两个步骤:
a. 更新动量项
首先计算当前的动量项 : 其中:
-
是之前的动量项;
-
是动量系数(通常为 0.9);
-
是当前的梯度;
b. 更新参数
利用动量项更新参数:
特点:
-
惯性效应: 该方法加入前面梯度的累积,这种惯性使得算法沿着当前的方向继续更新。如遇到鞍点,也不会因梯度逼近零而停滞。
-
减少震荡: 该方法平滑了梯度更新,减少在鞍点附近的震荡,帮助优化过程稳定向前推进。
-
加速收敛: 该方法在优化过程中持续沿着某个方向前进,能够更快地穿越鞍点区域,避免在鞍点附近长时间停留。
在方向上的作用:
(1)梯度方向一致时
-
如果梯度在多个连续时刻方向一致(例如,一直指向某个方向),Momentum 会逐渐积累动量,使更新速度加快。
-
例如,假设梯度在多个时刻都是正向的,动量 会逐渐增大,从而加速参数更新。
(2)梯度方向不一致时
-
如果梯度方向在不同时刻不一致(例如,来回震荡),Momentum 会通过积累的历史梯度信息部分抵消这些震荡。
-
例如,假设梯度在一个时刻是正向的,下一个时刻是负向的,动量 会平滑这些变化,使更新路径更加稳定。
(3)局部最优或鞍点附近
-
在局部最优或鞍点附近,梯度可能会变得很小,导致标准梯度下降法停滞。
-
Momentum 通过积累历史梯度信息,可以帮助参数更新越过这些平坦区域。
动量方向与梯度方向一致
(1)梯度方向一致时
-
如果梯度在多个连续时刻方向一致(例如,一直指向某个方向),动量会逐渐积累,动量方向与梯度方向一致。
-
例如,假设梯度在多个时刻都是正向的,动量 会逐渐增大,从而加速参数更新。
(2)几何意义
-
在优化问题中,如果损失函数的几何形状是 平滑且单调 的(例如,一个狭长的山谷),梯度方向会保持一致。
-
在这种情况下,动量方向与梯度方向一致,Momentum 会加速参数更新,帮助算法更快地收敛。
动量方向与梯度方向不一致
(1)梯度方向不一致时
-
如果梯度方向在不同时刻不一致(例如,来回震荡),动量方向可能会与当前梯度方向不一致。
-
例如,假设梯度在一个时刻是正向的,下一个时刻是负向的,动量 会平滑这些变化,使更新路径更加稳定。
(2)几何意义
-
在优化问题中,如果损失函数的几何形状是 复杂且非凸 的(例如,存在多个局部最优或鞍点),梯度方向可能会在不同时刻发生剧烈变化。
-
在这种情况下,动量方向与梯度方向可能不一致,Momentum 会通过积累的历史梯度信息部分抵消这些震荡,使更新路径更加平滑。
总结:
-
动量项更新:利用当前梯度和历史动量来计算新的动量项。
-
权重参数更新:利用更新后的动量项来调整权重参数。
-
梯度计算:在每个时间步计算当前的梯度,用于更新动量项和权重参数。
Momentum 算法是对梯度值的平滑调整,但是并没有对梯度下降中的学习率进行优化。
示例:
# 定义模型和损失函数
model = nn.Linear(10, 1)
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # PyTorch 中 momentum 直接作为参数
# 模拟数据
X = torch.randn(100, 10)
y = torch.randn(100, 1)
# 训练循环
for epoch in range(100):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
2.4.3 AdaGrad
AdaGrad(Adaptive Gradient Algorithm)为每个参数引入独立的学习率,它根据历史梯度的平方和来调整这些学习率。具体来说,对于频繁更新的参数,其学习率会逐渐减小;而对于更新频率较低的参数,学习率会相对较大。AdaGrad避免了统一学习率的不足,更多用于处理稀疏数据和梯度变化较大的问题。
AdaGrad流程:
-
初始化:
-
初始化参数 和学习率 。
-
将梯度累积平方的向量 初始化为零向量。
-
-
梯度计算:
-
在每个时间步 ,计算损失函数对参数 的梯度。
-
-
累积梯度的平方:
-
对每个参数 累积梯度的平方:
其中 是累积的梯度平方和, 是第个参数在时间步 的梯度。
推导:
-
-
参数更新:
-
利用累积的梯度平方来更新参数:
-
其中:
-
是全局的初始学习率。
-
是一个非常小的常数,用于避免除零操作(通常取)。
-
是自适应调整后的学习率。
-
-
AdaGrad 为每个参数分配不同的学习率:
-
对于梯度较大的参数,Gt较大,学习率较小,从而避免更新过快。
-
对于梯度较小的参数,Gt较小,学习率较大,从而加快更新速度。
可以将 AdaGrad 类比为:
-
梯度较大的参数:类似于陡峭的山坡,需要较小的步长(学习率)以避免跨度过大。
-
梯度较小的参数:类似于平缓的山坡,可以采取较大的步长(学习率)以加快收敛。
优点:
-
自适应学习率:由于每个参数的学习率是基于其梯度的累积平方和 来动态调整的,这意味着学习率会随着时间步的增加而减少,对梯度较大且变化频繁的方向非常有用,防止了梯度过大导致的震荡。
-
适合稀疏数据:AdaGrad 在处理稀疏数据时表现很好,因为它能够自适应地为那些较少更新的参数保持较大的学习率。
缺点:
-
学习率过度衰减:随着时间的推移,累积的时间步梯度平方值越来越大,导致学习率逐渐接近零,模型会停止学习。
-
不适合非稀疏数据:在非稀疏数据的情况下,学习率过快衰减可能导致优化过程早期停滞。
AdaGrad是一种有效的自适应学习率算法,然而由于学习率衰减问题,我们会使用改 RMSProp 或 Adam 来替代。
示例:
# 定义模型和损失函数model = torch.nn.Linear(10, 1)criterion = torch.nn.MSELoss()optimizer = torch.optim.Adagrad(model.parameters(), lr=0.01)
# 模拟数据X = torch.randn(100, 10)y = torch.randn(100, 1)
# 训练循环for epoch in range(100):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item()}')
2.4.4 RMSProp
虽然 AdaGrad 能够自适应地调整学习率,但随着训练进行,累积梯度平方 会不断增大,导致学习率逐渐减小,最终可能变得过小,导致训练停滞。
RMSProp(Root Mean Square Propagation)是一种自适应学习率的优化算法,在时间步中,不是简单地累积所有梯度平方和,而是使用指数加权平均来逐步衰减过时的梯度信息。旨在解决 AdaGrad 学习率单调递减的问题。它通过引入 指数加权平均 来累积历史梯度的平方,从而动态调整学习率。
公式为:
其中:
-
是当前时刻的指数加权平均梯度平方。
-
β是衰减因子,通常取 0.9。
-
η是初始学习率。
-
ϵ是一个小常数(通常取 ),用于防止除零。
-
是当前时刻的梯度。
优点
-
适应性强:RMSProp自适应调整每个参数的学习率,对于梯度变化较大的情况非常有效,使得优化过程更加平稳。
-
适合非稀疏数据:相比于AdaGrad,RMSProp更加适合处理非稀疏数据,因为它不会让学习率减小到几乎为零。
-
解决过度衰减问题:通过引入指数加权平均,RMSProp避免了AdaGrad中学习率过快衰减的问题,保持了学习率的稳定性
缺点
依赖于超参数的选择:RMSProp的效果对衰减率 和学习率 的选择比较敏感,需要一些调参工作。
示例:
# 定义模型和损失函数model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01, alpha=0.9, eps=1e-8)
# 模拟数据X = torch.randn(100, 10)y = torch.randn(100, 1)
# 训练循环for epoch in range(100):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
2.4.5 Adam
Adam(Adaptive Moment Estimation)算法将动量法和RMSProp的优点结合在一起:
-
动量法:通过一阶动量(即梯度的指数加权平均)来加速收敛,尤其是在有噪声或梯度稀疏的情况下。
-
RMSProp:通过二阶动量(即梯度平方的指数加权平均)来调整学习率,使得每个参数的学习率适应其梯度的变化。
Adam过程
-
初始化:
-
初始化参数 和学习率。
-
初始化一阶动量估计 和二阶动量估计。
-
设定动量项的衰减率 和二阶动量项的衰减率,通常 ,。
-
设定一个小常数(通常取),用于防止除零错误。
-
-
梯度计算:
-
在每个时间步 ,计算损失函数 对参数 的梯度。
-
-
一阶动量估计(梯度的指数加权平均):
-
更新一阶动量估计:
其中, 是当前时间步 的一阶动量估计,表示梯度的指数加权平均。
-
-
二阶动量估计(梯度平方的指数加权平均):
-
更新二阶动量估计:
其中, 是当前时间步 的二阶动量估计,表示梯度平方的指数加权平均。
-
-
偏差校正:
由于一阶动量和二阶动量在初始阶段可能会有偏差,以二阶动量为例:
在计算指数加权移动平均时,初始化 ,那么,得到,显然得到的 会小很多,导致估计的不准确,以此类推:
根据:,把 带入后, 得到:,导致 远小于 和 ,所以 并不能很好的估计出前两次训练的梯度。
所以这个估计是有偏差的。
使用以下公式进行偏差校正:
其中, 和 是校正后的一阶和二阶动量估计。
-
参数更新:
-
使用校正后的动量估计更新参数:
-
优点
-
高效稳健:Adam结合了动量法和RMSProp的优势,在处理非静态、稀疏梯度和噪声数据时表现出色,能够快速稳定地收敛。
-
自适应学习率:Adam通过一阶和二阶动量的估计,自适应调整每个参数的学习率,避免了全局学习率设定不合适的问题。
-
适用大多数问题:Adam几乎可以在不调整超参数的情况下应用于各种深度学习模型,表现良好。
缺点
-
超参数敏感:尽管Adam通常能很好地工作,但它对初始超参数(如 、 和 )仍然较为敏感,有时需要仔细调参。
-
过拟合风险:由于Adam会在初始阶段快速收敛,可能导致模型陷入局部最优甚至过拟合。因此,有时会结合其他优化算法(如SGD)使用。
2.5 总结
梯度下降算法通过不断更新参数来最小化损失函数,是反向传播算法中计算权重调整的基础。在实际应用中,根据数据的规模和计算资源的情况,选择合适的梯度下降方式(批量、随机、小批量)及其变种(如动量法、Adam等)可以显著提高模型训练的效率和效果。
Adam是目前最为流行的优化算法之一,因其稳定性和高效性,广泛应用于各种深度学习模型的训练中。Adam结合了动量法和RMSProp的优点,能够在不同情况下自适应调整学习率,并提供快速且稳定的收敛表现。
示例:
# 定义模型和损失函数model = nn.Linear(10, 1)criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01, betas=(0.9, 0.999), eps=1e-8)
# 模拟数据X = torch.randn(100, 10)y = torch.randn(100, 1)
# 训练循环for epoch in range(100):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item():.4f}')
相关文章:

深度学习-全连接神经网络
四、参数初始化 神经网络的参数初始化是训练深度学习模型的关键步骤之一。初始化参数(通常是权重和偏置)会对模型的训练速度、收敛性以及最终的性能产生重要影响。下面是关于神经网络参数初始化的一些常见方法及其相关知识点。 官方文档参考࿱…...

n2n 搭建虚拟局域网,实现内网穿透
一、ubuntu linux系统上通过源码安装 1、下载源码 git clone https://github.com/ntop/n2n 2、 进入源码目录n2n,依次执行下列命令 ./autogen.sh # 如果提示命令不存在,需要运行命令:apt-get update && apt-get install autoconf…...

SystemVerilog语法之定宽数组
1.2定宽数组 1.2.1定宽数组的声明和初始化 Verilog要求在声明中必须给出数组的上下界。因为几乎所有数组都使用0作为索引下界,所以SystemVerilog允许只给出数组宽度的便捷声明方式。SystemVerilog的$clog2()函数可以计算以2为底的对数向上舍入值。你可以通过在变量…...

SQL 使用 UPDATE FROM 语法进行更新
UPDATE FROM 是一种常见的 SQL 语法模式,允许你基于其他表的数据来更新目标表。这种语法在不同数据库系统中有所不同,下面我将介绍几种主要数据库的实现方式。 PostgreSQL/SQL Server 语法 UPDATE target_table SET target_column source_table.source…...

如何在LangChain中构建并使用自定义向量数据库
1. 自定义向量数据库对接 向量数据库的发展非常迅速,几乎每隔几天就会出现新的向量数据库产品。LangChain 不可能集成所有的向量数据库,此外,一些封装好的数据库可能存在 bug 或者其他问题。这种情况下,我们需要考虑创建自定义向…...

极狐GitLab Git LFS 速率限制如何设置?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 Git LFS 速率限制 (BASIC SELF) Git LFS (Large File Storage) 是一个用于处理大文件的Git扩展。如果您在仓库中使用 Git LF…...

如何查询IP地址是否被占用?
IP地址占用查询的重要性 在当前高度发达的网络环境下,IP地址作为网络设备间通信的基础,其管理显得尤为重要。IP地址占用查询作为网络管理的一个重要环节,具有以下几点重要性: 预防IP冲突:当两个或多个设备使用相同的I…...

数字后端实现教程 | 时钟树综合IMPCCOPT-1304错误Debug思路和解决方案
今天上午有学员在做公司自己项目CTS时发现跑不下去,报了如下所示的错误IMPCCOPT-4375。 复杂时钟设计时钟树综合(clock tree synthesis)常见20个典型案例 第一次遇到这种错误,其实可以从提示信息上入手。 Term CLK_AVDD_SS is power /ground ÿ…...

AI 大模型在教育革命中的角色重塑:从知识传递者到认知伙伴
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:从“教”与“学”到“共知”时代的开启 教育的本质是什么?是教师传授知识,学生被动接受?还是引导思维、激发潜能、陪伴成长? 在过去数百年里,教育形式经历了从口述、印刷、广播到互…...

Spring如何通过XML注册Bean
在上一篇当中我们完成了对三种资源文件的读写 上篇内容:Spring是如何实现资源文件的加载 Test public void testClassPathResource() throws IOException { DefaultResourceLoader defaultResourceLoader new DefaultResourceLoader(); Resource resource …...

Compose Multiplatform Android Logcat工具
一、通过adb发送指令,收集设备日志并保存 二、UI 三、代码 /*** 获取设备列表*/fun getDevices(): List<String> {val process ProcessBuilder("adb", "devices").redirectErrorStream(true).start()val output process.inputStream.…...

智能照明系统:照亮智慧生活的多重价值
在当今科技飞速发展的时代,智能照明系统正以其独特的优势改变着人们的生活和工作方式。这套集成了物联网、人工智能等先进技术的照明解决方案,不仅实现了基本的照明功能,更在节能环保、健康舒适、安全防护等多个维度展现出卓越价值。 从能源管…...

XMC4800 芯片深度解读:架构、特性、应用与开发指南
一、芯片定位与核心优势 XMC4800是英飞凌(Infineon)推出的高性能微控制器(MCU),属于 XMC4000系列,基于 ARM Cortex-M4内核,主打 工业控制、电机驱动、物联网(IoT) 和 嵌入式系统 应用。其核心优势在于: 多核异构处理:集成Cortex-M4(144MHz,带FPU和DSP指令集)与专…...

class com.alibaba.fastjson.JSONObject cannot be cast to class
class com.alibaba.fastjson.JSONObject cannot be cast to class 在做接口测试的时候,携带一个可用的token,打算debug看看代码的执行过程,由于Redis配置类的不完整导致报错 这是原本的Redis配置类 Configuration public class RedisConfig {BeanSuppressWarnings(value {&…...

二叉树操作与遍历实现
二叉树操作与遍历实现 二叉树操作与遍历实现树的相关概念1.树的相关术语2.二叉树的概念3.二叉树的存储结构1.顺序结构2.链式结构 1. 二叉树的创建树的表示1.1 创建节点1.2 构建二叉树 2. 二叉树的销毁3. 二叉树的遍历3.1 前序遍历3.2 中序遍历3.3 后序遍历3.4 层序遍历 4. 二叉…...
)
VSCode连接服务器跑深度学习代码相关问题(研0大模型学习第八天)
VS Code 远程连接服务器:从环境配置到代码运行与常见问题解决实录 在使用 VS Code 通过 Remote-SSH 连接到远程服务器进行 Python 开发,特别是涉及 Anaconda 环境和深度学习项目时,可能会遇到各种各样的问题。本文记录并解答了我在配置和运行…...

软件工程中的维护类型
目录 前言1. 排错性维护1.1 排错性维护的定义与重要性1.2 排错性维护的实践与挑战 2. 适应性维护2.1 适应性维护的定义与背景2.2 适应性维护的实施策略 3. 完善性维护3.1 完善性维护的定义与目标3.2 完善性维护的实施挑战与技巧 4. 预防性维护4.1 预防性维护的定义与作用4.2 预…...
)
软件工程(1)
#灵感# 记录一下软件工程的相关基础知识。 按马哲的说法,不能光有实践,也需要相关理论。 定义:软件工程涉及软件开发、维护、管理等多方面的原理、方法、工具和环境。此篇主要讲软件开发中的基本方法。 已知问题:旧的软件开发主要…...
)
递归的模板 (以反转链表为例)
我们再来回顾一下递归的模板,终止条件,递归调用,逻辑处理。 func reverseList(head *ListNode) *ListNode {// 终止条件if head nil || head.Next nil {return head}// 逻辑处理(可能有,也可能没有,具体…...

02-HTML结构
一、URL 1.1.URL的格式 1.2.URL和URI的区别 URI指逻辑或资源的标识符,URL是地址,URL是URI的子集 二、HTML文件结构 2.1.文档声明 默认告诉浏览器是html5页面,必须放在文档最前面 <!DOCTYPE html>2.2.HTML各元素结构 是根元素&…...

C++ vector 核心功能解析与实现
目录 整体结构概述 赋值运算符重载 下标运算符重载 内存管理函数 元素访问函数 插入和删除操作 完整代码 在C标准库中, vector 是一个非常常用的动态数组容器,它能够自动管理内存,并且提供了丰富的操作接口。本文将通过分析一段手写 …...

【Linux网络】构建UDP服务器与字典翻译系统
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

DeepSeek 大模型 + LlamaIndex + MySQL 数据库 + 知识文档 实现简单 RAG 系统
DeepSeek 大模型 LlamaIndex MySQL 数据库 知识文档 实现简单 RAG 系统 以下是一个使用 DeepSeek 大模型(假设为一个高性能的中文大模型)、LlamaIndex、MySQL 数据库 和 知识文档 实现简单 RAG(检索增强生成)系统的完整示例。该…...

【FFmpeg从入门到精通】第四章-FFmpeg转码
1 FFmpeg 软编码H.264与H.265 当前网络中常见的视频编码格式要数H.264最为火热,支持H.264的封装格式有很多,如FLV、MP4、HLS(M3U8)、MKV、TS等格式;FFmpeg本身并不支持H.264的编码器,而是由FFmpeg的第三方模块对其进行支持,例如x…...

爱普生RX8130CE实时时钟成为智能家居系统的理想解决方案
智能家居的本质是让生活更便捷、舒适与智能,而精准的时间管理是实现这一目标的重要基础。爱普生 RX8130CE 实时时钟(RTC)以其卓越的性能和丰富的功能,成为智能家居系统的理想时间解决方案,为用户打造更加智能化、人性化…...

Discuz!与DeepSeek的深度融合:打造智能网址导航新标杆
引言 在数字化信息爆炸的时代,网址导航网站作为用户获取优质资源、高效浏览互联网的重要入口,其信息筛选能力、用户体验和商业化潜力成为了决定其竞争力的核心要素。Discuz!作为国内应用广泛的社区论坛系统,以其强大的功能扩展性和用户管理能…...
)
23种设计模式-结构型模式之代理模式(Java版本)
Java 代理模式(Proxy Pattern)详解 🧭 什么是代理模式? 代理模式是结构型设计模式之一,为其他对象提供一个代理以控制对这个对象的访问。 就像生活中的“经纪人”,你无法直接联系明星,但可以…...

网络不可达network unreachable问题解决过程
问题:访问一个环境中的路由器172.16.1.1,发现ssh无法访问,ping发现回网络不可达 C:\Windows\System32>ping 172.16.1.1 正在 Ping 172.16.1.1 具有 32 字节的数据: 来自 172.16.81.1 的回复: 无法访问目标网。 来自 172.16.81.1 的回复:…...

@RefreshScope 和@nacosvalue 的区别
文章目录 1. RefreshScope定义与作用工作原理适用场景示例代码 2. NacosValue定义与作用工作原理适用场景示例代码 3. 主要区别4. 如何选择?5. 注意事项 在 Spring 框架中, RefreshScope 和 NacosValue 是两个不同的注解,分别用于不同的场景…...

Oracle EBS R12.2 安装 -- Step by Step
一、引言 在计算机应用已经非常普及的今天,对于绝大部分个人来说,学习并掌握ORACLE ERP系统是一件“实践性”很强的事情,仅仅“纸上谈兵”而不在系统中进行具体的操作,犹如捧着一本“驾驶手册”苦读,但却没有一辆车进行上路演练,是肯定无法学会开车的道理一样,能够为自…...

【JavaEE】计算机的工作原理
计算机系统的组成 一台完整的计算机包含硬件和软件两部分,另外还有一部分固化的软件称为固件(兼具软件和硬件的特性),硬件和软件结合才能使计算机正常运行并发挥作用,所以对计算机的理解应该把它看作一个包含软件系统…...

DAY8:Oracle高可用架构深度解析与Data Guard单节点搭建实战
引言 在数据库领域,高可用性(High Availability)是保障业务连续性的核心要求。Oracle作为企业级数据库的领导者,提供了RAC、Data Guard、GoldenGate三大核心方案。本文将深入剖析这些技术的实现原理,并手把手指导搭建…...
+链接)
程序的编译(预处理操作)+链接
程序的编译环境和执行环境 翻译环境:在这个环境中源代码被转换成可执行的机器指令 执行环境:用于实际执行代码 详解编译链接 翻译环境 注意: 1.组成一个程序的每个源文件通过编译过程分别转换成目标代码。 2.每个目标文件由链接器捆绑在一…...

Java 实现桌面共享-简单案例
服务器端(共享桌面) import java.awt.AWTException; import java.awt.Rectangle; import java.awt.Robot; import java.awt.Toolkit; import java.awt.image.BufferedImage; import java.io.DataOutputStream; import java.io.IOException; import java…...

Idea中实用设置和插件
目录 一、Idea使用插件 1.Fitten Code智能提示 2.MyBatisCodeHelperPro 3.HighlightBracketPair 4.Rainbow Brackets Lite 5.GitToolBox(存在付费) 6.MavenHelperPro 7.Search In Repository 8.VisualGC(存在付费) 9.vo2dto 10.Key Promoter X 11.CodeGlance…...
)
获取电脑信息(登录电脑的进程、C盘文件信息、浏览器信息、IP)
电脑的进程信息 // 获取登录电脑的进程信息String os System.getProperty("os.name").toLowerCase();String command;if (os.contains("win")) {command "tasklist";} else {command "ps -ef";}try {Process process new ProcessB…...
)
单例模式(线程安全)
1.什么是单例模式 单例模式(Singleton Pattern)是一种创建型设计模式,旨在确保一个类只有一个实例,并提供一个全局访问点来访问该实例。这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单…...

Sentinel源码—7.参数限流和注解的实现二
大纲 1.参数限流的原理和源码 2.SentinelResource注解的使用和实现 2.SentinelResource注解的使用和实现 (1)SentinelResource注解的使用 (2)SentinelResource注解和实现 (1)SentinelResource注解的使用 一.引入Sentinel Spring Boot Starter依赖 <dependency><…...
)
【单片机 C语言】单片机学习过程中常见C库函数(学习笔记)
memset() C 标准库 - <string.h> string .h 头文件定义了一个变量类型、一个宏和各种操作字符数组的函数。 <string.h> 是 C 标准库中的一个头文件,提供了一组用于处理字符串和内存块的函数。这些函数涵盖了字符串复制、连接、比较、搜索和内存操作…...
)
聚类算法(K-means、DBSCAN)
聚类算法 K-means 算法 算法原理 K-means 是一种基于类内距离最小化的划分式聚类算法,其核心思想是通过迭代优化将数据划分为 K 个簇。目标函数为最小化平方误差(SSE): S S E ∑ i 1 K ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2…...

Spring AI Alibaba Graph基于 ReAct Agent 的天气预报查询系统
1、在本示例中,我们仅为 Agent 绑定了一个天气查询服务,接收到用户的天气查询服务后,流程会在 AgentNode 和 ToolNode 之间循环执行,直到完成用户指令。示例中判断指令完成的条件(即 ReAct 结束条件)也很简…...

C++初阶——模板
C初阶——模板 一、概念引入 1.如何实现一个通用的交换函数,使它既可以用来交换各种类型的数据呢? 通过前面的学习,我们知道函数重载可以帮我们实现这一功能,代码如下: 运行结果如图: 使用函数重载虽然…...

【技术派后端篇】技术派中基于 Redis 的缓存实践
在互联网应用追求高并发和高可用的背景下,缓存对于提升程序性能至关重要。相较于本地缓存 Guava Cache 和 Caffeine,Redis 具有显著优势。Redis 支持集群和分布式部署,能横向扩展缓存容量和负载能力,适应大型分布式系统的缓存需求…...

系统安装及应用
重点 账号安全控制 系统引导和登陆控制 弱口令检测 端口扫描 前言 随着信息技术的快速发展,系统安全成为我们日常生活和工作中不可或缺的一部分。本章节主要探讨系统安全及应用,涵盖了账号安全控制、系统引导和登录控制、弱口令检测以及端口扫描等多个方面,为我们提供了一…...

发布事件和Insert数据库先后顺序
代码解释 csharp await PublishCreatedAsync(entity).ConfigureAwait(false); await Repository.InsertAsync(entity).ConfigureAwait(false);PublishCreatedAsync(entity):这是一个异步方法,其功能是发布与实体创建相关的事件。此方法或许会通知其他组…...

【英语语法】词法---冠词
目录 冠词一、不定冠词:a / an1. 基本用法2. 主要使用场景3. 特殊情况 二、定冠词:the1. 基本用法2. 主要使用场景3. 特殊情况 三、零冠词1. 基本规则2. 特殊情况 四、冠词对比五、常见错误总结 冠词 冠词是英语中用于限定名词的一类虚词,分…...

android的 framework 有哪些知识点和应用场景
Android Framework 知识点 1. 四大组件 Activity(活动) 是 Android 应用中最基本的组件,用于实现用户界面。一个 Activity 通常对应一个屏幕的内容。有自己的生命周期,包括 onCreate、onStart、onResume、onPause、onStop、onDe…...

Prompt 攻击与防范:大语言模型安全的新挑战
随着大语言模型(LLM)在企业服务、智能助手、搜索增强等领域的广泛应用,围绕其"Prompt"机制的安全问题也逐渐引起关注。其中最具代表性的,就是所谓的 Prompt Injection(提示词注入)攻击。 本文将…...

Ubuntu20.04安装Pangolin遇到的几种报错的解决方案
1.添加两个编译选项 /usr/include/OpenEXR/half.h:121:13: note: because ‘half’ has user-provided ‘half& half::operator(half)’121 | half & operator (half h);| ^~~~~~~~ 解决方案: 在CMakeList中添加以下两句: …...

软考 中级软件设计师 考点知识点笔记总结 day14 关系代数 数据库完整性约束
文章目录 6.5 关系代数6.5.1 关系代数—七种基本运算 6.6 数据库完整性约束6.7 关系型数据库SQL简介 6.5 关系代数 候选码(键):若关系中的某一属性或属性组的值能唯一标识一个元组,则称该属性或属性组为候选码。 主码࿰…...