高并发内存池项目
高并发内存池项目
- 一、项目介绍
- 二、什么是内存池
- 2.1池化技术
- 2.2内存池
- 2.3内存池主要解决的问题
- 2.3.1外部碎片
- 2.3.2内部碎片
- 2.4malloc的了解
- 三、定长内存池的实现
- 3.1 通过类型模板参数表示定长内存池
- 3.2定长内存池的实现原理
- 四、高并发内存池的框架设计
- 4.1ThreadCache的实现
- 4.2 CentralCache的实现
- 4.3 PageCache的实现
- 五、申请释放过程内存联调
- 六、性能瓶颈的分析与优化
一、项目介绍
该项⽬是实现⼀个高并发的内存池,他的原型是google的⼀个开源项目tcmalloc,tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free)
tcmalloc 的源码内容非常多,有非常复杂的细节设计,在这里不可能全部实现,因此只是学习和理解 tcmalloc 最核心的框架设计,并模拟实现一个 mini 版的高并发内存池。
项目所需知识:
这个项目会用到C/C++、数据结构(链表、哈希桶)、操作系统内存管理、单例模式、多线程、互斥锁等等方面的知识
二、什么是内存池
2.1池化技术
池化技术是一种资源管理策略,旨在提高资源的利用效率。 池化技术的核心思想是在需要时动态地分配和重用资源,而不是频繁地创建和销毁它们。这些资源可以是线程、数据库连接、对象实例或缓存数据,具体取决于使用场景。
池化技术通过维护一组预先准备好的资源实例(即“池”),当系统需要这些资源时,不是每次都创建新的实例,而是从池中获取一个已有的实例来使用,使用完毕后再归还到池中,以便后续的请求重复利用。这种技术主要解决的问题包括资源节约、提高响应速度、控制资源使用量以及增强系统性能和稳定性。
池化技术的应用非常广泛,常见的应用场景包括线程池、数据库连接池和内存池等。线程池用于并发任务计算、异步执行、定时任务调度等;数据库连接池用于优化数据库访问,减少连接创建和销毁的开销;内存池则用于管理程序的内存分配和释放,提高效率。
2.2内存池
内存池是指程序预先从操作系统申请⼀块足够大内存,此后,当程序中需要申请内存的时候,不是直接向操作系统申请,而是直接从内存池中获取;同理,当程序释放内存的时候,并不真正将内存返回给操作系统,而是返回内存池。当程序退出(或者特定时间)时,内存池才将之前申请的内存真正释放。
2.3内存池主要解决的问题
内存池主要解决申请内存时的效率问题和内存碎片的问题。
2.3.1外部碎片
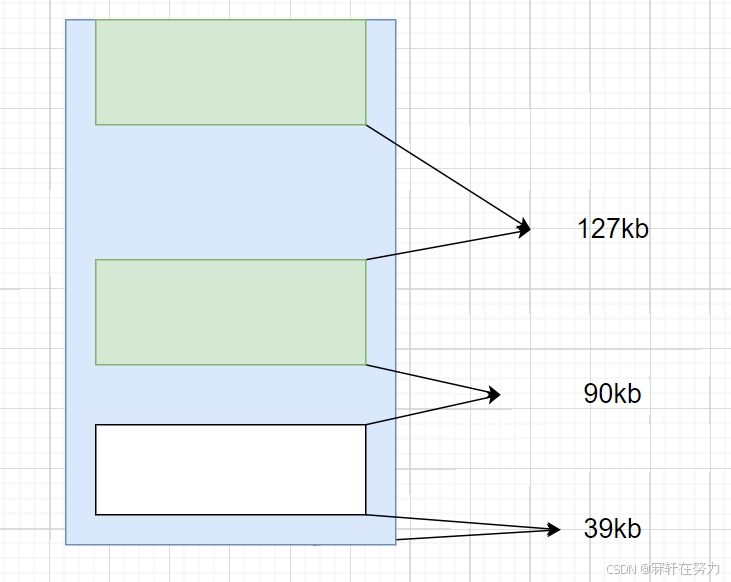
假设此时系统中剩余256kb的内存大小,但是这些内存空间是零散分布的,此时我们想申请一块128kb的内存空间,却申请不出来
2.3.2内部碎片
某个执行流要申请 7 字节 的空间,但由于内存池中某个规则,内存池返回了一个 8字节的内存空间,此时,这种情况就属于一种内碎片,因为这个执行流不会使用最后一个 字节的空间,即这个 字节 的空间就被浪费了, 如下:

内存池不仅要解决效率问题,对于碎片问题也需要处理,处理方案:
- 对于内碎片而言,不能完全避免,我们只能将内碎片中浪费空间的比率控制在一个范围中;
- 对于外碎片而言,我们需要提供一种策略,将零散分布的内存合并成为一个更大的内存块。
具体细节,后面在项目的实现中详谈
2.4malloc的了解
在 C/C++ 中,都是通过 malloc 向堆申请动态资源,但是malloc 并不是直接向系统申请资源的,而是调用相关系统接口实现的。
实际上, malloc 本身也是一个内存池,其通过系统接口会向系统申请一段大空间,然后再将这段空间分配给程序使用。
三、定长内存池的实现
在模拟实现tcmalloc之前先实现一个简单的定长内存池,让我们对内存池有一个简单的了解。
接下来,我们就来先设计一个定长的内存池,其目的有两个:
- 其一:让我们来了解一下内存池是如何管理内存对象的;
- 其二:这里的定长内存池是项目中的一个基础组件。
这里实现的定长内存池有两个功能:
- New,程序申请空间,从内存池中弹出一个内存对象;
- Delete,程序释放空间,将一个内存对象添加到内存池中。
3.1 通过类型模板参数表示定长内存池
template<class T>
class ObjectPool{};
每次申请和释放内存时,都是一个 sizeof(T) 大小的内存对象。
3.2定长内存池的实现原理
假设此时内存池中有一大块空闲的空间:

当我们向内存池中申请空间时,内存池会给我们分配固定大小sizeof(T)的内存对象

当这些内存对象被释放时,并不会直接被释放给系统,而是重新放回内存池中,这时这些内存对象在内存池中不一定是连续的,且此时_memory也不会往前移,要是再想使用它们,就需要把这些内存对象管理起来,然后待用户申请时再分配给用户。这时就可以使用链表将这些内存对象管理起来,因为链表的头删头插都是O(1)的,效率高。

为了能让他们连接起来,可以让每一个内存对象的前4/8字节的内容为下一个内存对象的起始地址,这样,就可以将所有还回来的内存对象组织起来,这个结构,我们称之为自由链表,它不存储任何额外的数据,只需要维持这些内存对象的关系即可,这个成员我们用 _freeList 表示
如果申请量非常大的时候,内存池中的内存空间不够分配了,那么就需要开辟一块新的内存空间,来给用户提供内存。
通过上面的阐述,我们就可以知道了该内存池需要一个_memory变量来指向内存池的首地址,需要一个_remainbytes变量来保存内存池中剩余空间大小,还需要一个管理这些被切分后释放了的内存对象的链表_freelist.
内存池对象的成员变量:
template<class T>
class ObjectPool{
private://使用char*是为了方便内存池切割时,_memory的移动。char* _memory = nullptr;//可用内存池地址size_t _remainbytes = 0;//内存池剩余空间void* _freelist = nullptr;//自由链表,管理被切分的内存对象
};
内存池成员函数New的实现:
首先分析自由链表中是否有可用的内存对象,如果有,那么直接从自由链表中获取内存对象即可,如果没有,那么就向内存池中申请内存,当内存池的内存不够时,就向系统申请另一块内存。
T* New() {T* obj = nullptr;//自由链表不为空if (_freelist) {//*(void**)为了获取前四或八字节的大小空间//因为32位系统和64位系统指针大小是不一样的void* next = *(void**)_freelist;obj = (T*)_freelist;_freelist = next;}else {if (_remain < sizeof(T)) {_remain = 128 * 1024;//调用系统接口_memory = (char*)SystemAlloc(_remain >> 13);if (_memory == nullptr)throw std::bad_alloc();}//因为需要将内存对象用自由链表连接起来,所以一个内存对象最少需要4/8字节的大小。size_t objsize = sizeof(void*) > sizeof(T) ? sizeof(void*) : sizeof(T);obj = (T*)_memory;_memory += objsize;_remain -= objsize;}//使用定位new调用T的构造函数初始化new(obj)T;return obj;
}
内存池成员函数Delete的实现:
Delete, 当程序使用完内存时,要归还内存对象,即将内存对象添加到内存池中。
我们说过,内存池需要通过 _freeList 将归还的内存对象组织起来,当一个内存对象归还给内存池时,就可以使用头插的方式将内存对象管理起来。
void Delete(T* obj) {//显示调用析构函数,释放对象obj->~T();//将内存对象头插入自由链表_freelist中*(void**)obj = _freelist;_freelist = obj;}
这样我们的定长内存池就实现好了,现在进行一个简单的测试吧:
先自定义一个树形结构,然后进行多轮次的申请释放,在此期间通过clock函数进行记录所需的时间,然后比较malloc/free所花的时间和定长数组所花的时间。
struct TreeNode
{int _val;TreeNode* _left;TreeNode* _right;TreeNode():_val(0), _left(nullptr), _right(nullptr){}
};void TestObjectPool()
{// 申请释放的轮次const size_t Rounds = 5;// 每轮申请释放多少次const size_t N = 100000;std::vector<TreeNode*> v1;v1.reserve(N);size_t begin1 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v1.push_back(new TreeNode);}for (int i = 0; i < N; ++i){delete v1[i];}v1.clear();}size_t end1 = clock();std::vector<TreeNode*> v2;v2.reserve(N);ObjectPool<TreeNode> TNPool;size_t begin2 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v2.push_back(TNPool.New());}for (int i = 0; i < N; ++i){TNPool.Delete(v2[i]);}v2.clear();}size_t end2 = clock();std::cout << "new cost time:" << end1 -begin1 << std::endl;std::cout << "object pool cost time:" << end2 - begin2 << std::endl;
}
release模式下:

Debug模式下:

可以发现定长内存池申请释放内存对象比malloc/free快。
四、高并发内存池的框架设计
当今的很多开发环境都是多核多线程,在申请/释放内存时,存在着线程安全问题,为了保证线程安全,需要加锁保证线程安全,故存在着激烈的锁竞争,这对性能的开销是非常大的,而 malloc 本身已经足够优秀,但在高并发场景下,高并发内存池有着更好的效率。
而这次我们所要实现的高并发内存池项目所要考虑的问题:
- 性能问题;
- 内存碎片问题;
- 在多执行流场景下,锁竞争所带来的性能消耗问题。
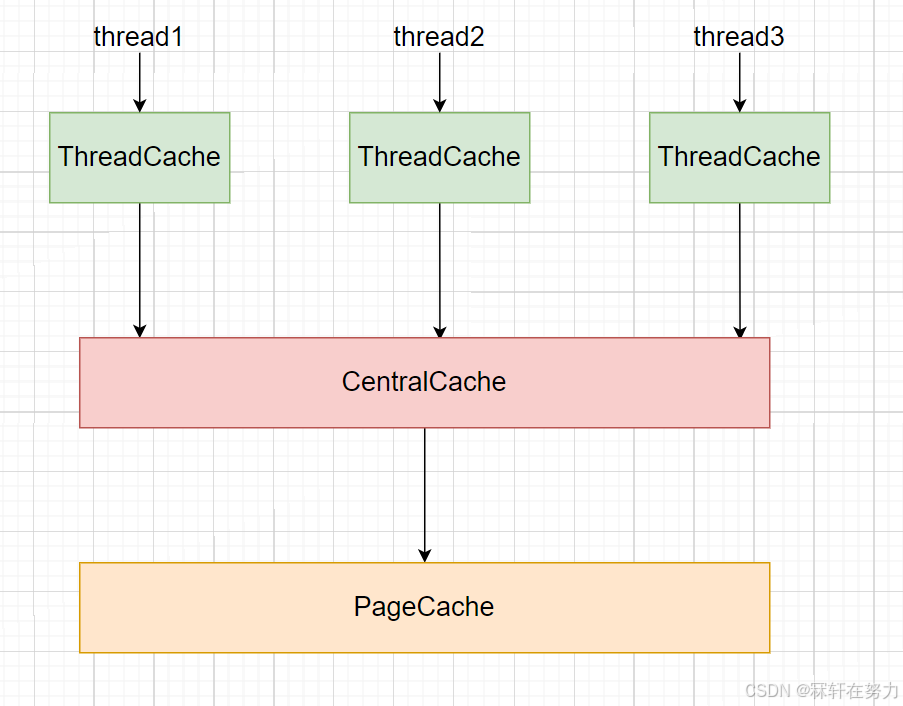
高并发内存池项目大致可以分为三层框架,如图所示:
Thread Cache
每个线程都有一个独属于自己的 Thread Cache (TLS - Thread Local Storage),其用于小于等于256kb的内存申请/释放,因为 Thread Cache 是线程私有的,故不存在竞争,也就不存在线程安全问题,因此,线程从 Thread Cache 申请/释放内存不需要加锁,故并发能力高,这也就是高并发线程池高效的原因之一。
但 Thread Cache 并不能满足所有的内存申请和释放,情况有两种:
- 对于大于 256kb 的内存申请和释放,Thread Cache 无法满足,需要直接访问 Page Cache 获取内存对象或者通过 system call 直接访问系统堆 ;
- 如果当前执行流的 Thread Cache 已经没有内存了,此时就需要访问下一层,也就是 Central Cache 获取内存对象。
Central Cache
当执行流自己私有的 Thread Cache 没有内存了,那么就会访问 Central Cache,Central Cache 会返回一批的内存对象插入到当前执行流的 Thread Cache 中,Thread Cache 再返回一个内存对象。
同时,假如某个 Thread Cache 在程序运行中,堆积了大量的内存对象 (未使用的内存对象),那么 Central Cache 也会对这些对象进行回收,防止一个执行流占用太多内存,且不使用,导致其他执行流的内存吃紧,这样可以使多个线程尽可能均衡的按需调度的使用内存。
其次,Central Cache 是多个执行流共享的,那么在多线程场景下,多个执行流可能会因为自己私有的 Thread Cache 没有对象或者 Thread Cache 中的没有使用的对象太多,导致多个执行流同时访问 Central Cache,很显然,这里的 Central Cache 存在着竞争,即存在线程安全问题,因此需要加锁保护,但是,这里所用的锁是桶锁 (Central Cache 是一个哈希桶结构),只有当多个执行流访问同一个桶时,才会竞争锁资源,因此,这里的竞争不会太激烈,对性能消耗不高。
Page Cache
当执行流因为自己私有的 Thread Cache 没有内存时,会去访问 Central Cache,假如此时的 Central Cache 也没有内存呢? 那么这个执行流就需要在向下一层访问,也就是访问 Page Cache,Page Cache 会返回一个 Span 对象给 Central Cache,这个 Span 对象是由若干个连续页组成的内存块,Central Cache 获取这个 Span 对象后,会将其切割为若干个内存对象,并链入到 Central Cache 对应的桶中,在返回给 Thread Cache 一批的内存对象,再由 Thread Cache 返回一个内存对象给程序。
当 Thread Cache 把从 Central Cache 获取的内存对象全部归还给了 Central Cache,那么此时这个 Span 对象就是一个完整的由若干个页组成的大块内存,继而 Central Cache 会将这个 Span 对象返回给 Page Cache,让 Page Cache 对这个 Span 对象进行前后页的合并,进而组成更大的页,以缓解外碎片问题。
同时,与 Central Cache 一样,这里也存在着多个执行流同时访问 Page Cache 的情况,因此也存在着竞争,即有线程安全问题,因此也需要进行加锁保护,但是这里用什么锁,我们后续到了实现在讨论。
可以看到,高并发内存池本质上就是两个逻辑:申请和释放逻辑。
我们的实现思路是:先理解和实现申请逻辑,只要把申请内存的链路理解通透,释放逻辑就是水到渠成了。
4.1ThreadCache的实现
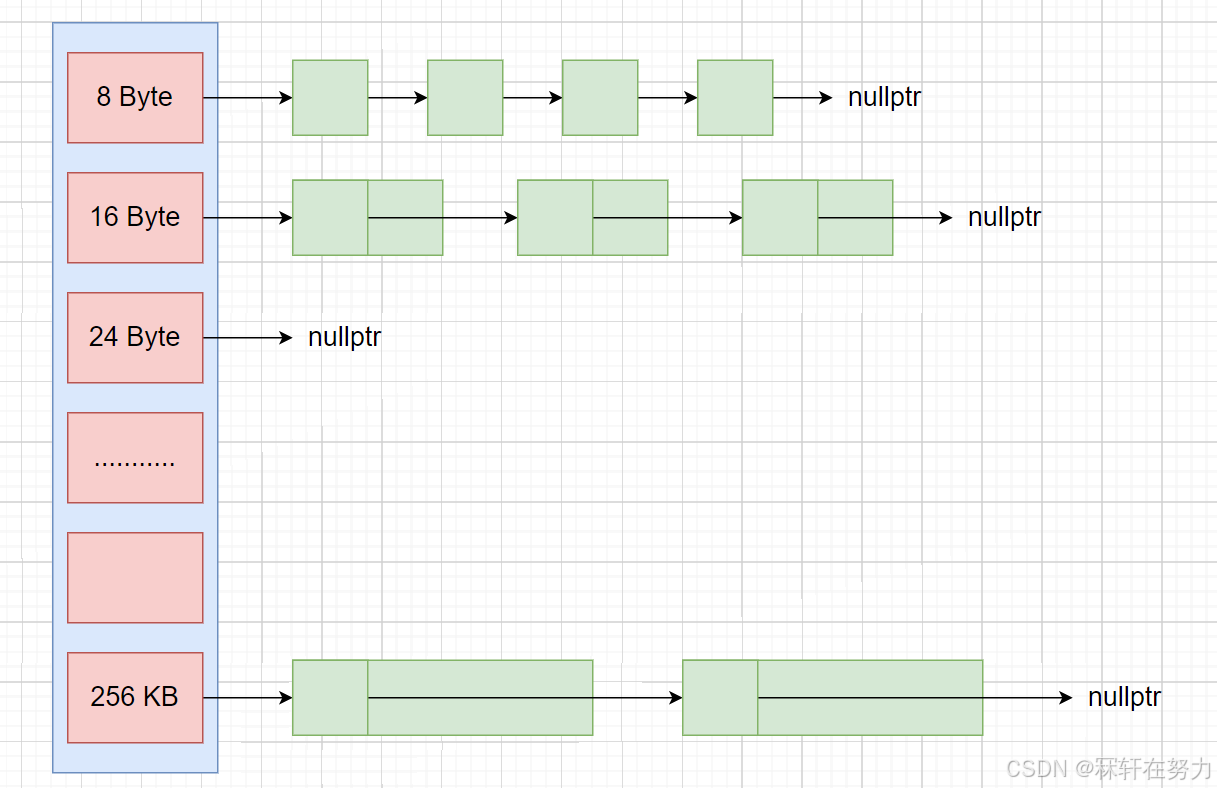
在实现ThreadCache之前需要先分析,线程每次申请的内存大小可能都是不一样的,在上面的定长内存池中使用一个自由链表来管理被被切分后的大小相同的内存,但是如果一个线程分别申请不同大小的内存后释放回来,那么一个自由链表就满足不了需求了,此时就需要多个管理不同大小内存的自由链表对这些小块内存进行管理。
在创建多个自由链表前需要考虑到底需要多少个自由链表,如果每个字节大小的内存都创建一个自由链表,那么就需要4*256KB or 8 * 256KB,通过计算就可得出光申请自由链表就需要那么多的内存,这就有点浪费内存了。所以可以采用内存对齐的方式,给线程申请对应的内存,如:线程申请7B的内存,那就给他申请8B的内存,申请14B的内存就给他16B,申请24B就给24B。
虽然这样就极大的减少了创建自由链表的所消耗的内存大小,但是会产生一些碎片化的内存无法被利用(内部碎片),这种内存碎片问题是无法避免的,因此确保内存浪费率保持在10%左右即可,如下为对齐规则:
| 数据范围 | 对齐数 | 自由链表数 | 浪费率 |
|---|---|---|---|
| 0 ~ 128 | 2^3 = 8 | 16 | 1/8 = 12.5% |
| 129 ~ 1024 | 2^4 = 16 | 56 | 15/144 = 10% |
| 1024+1 ~ 8*1024 | 2^7 = 16*8 | 56 | 127/1152 = 10% |
| 8*1024+1 ~ 64**1024+1 | 2^10 =16*8**8 | 56 | 1023/9216=10% |
| 64*1024+1 ~ 256**1024 | 2^13 | 56 | 8191/73728=10% |
说明:计算空间浪费率 = 没使用空间 / 总空间,对于1~128字节的,这里浪费率会比较高,比如1B的,开8B,浪费了7/8的空间,不过这里是小空间,问题不大。每个范围中浪费率最高的是第一个,也就是1B、128+1B、1024+1B、81024+1B、641024+1B,这些浪费率是最高的,因为每个范围中的size,越往后,分母(分配的空间)越大,而浪费的空间是不变的。
所以可以把ThreadCache定义为哈希桶结构:
为了方便计算内存对齐后的内存大小,创建一个common.h头文件将自由链表类和计算内存对齐的方法写在该头文件中,以便后面使用。
创建自由链表类
- 提供获取内存对象的前4/8个字节的大小内容
- 线程申请内存时,从自由链表中头删一个内存对象给线程
- 线程释放内存时,头插一个内存对象到自由链表中
- 插入一批的内存对象到自由链表中
- 从自由链表中头删一批的内存对象
//返回内存对象的前4/8个字节的大小内容
static void*& NextObj(void* obj) {return *(void**)obj;
}
//自由链表,管理切分内存对象
class FreeList {
public:// 头插一个数据void push(void* obj) {assert(obj);NextObj(obj) = _freelist;_freelist = obj;++_actualNum;}//头插一批的内存对象void pushRange(void* start, void* end, size_t size) {NextObj(end) = _freelist;_freelist = start;_actualNum += size;}//头删一个数据void* pop() {assert(_freelist);void* obj = _freelist;_freelist = NextObj(obj);--_actualNum;return obj;}//头删一批的内存对象void popRange(void*& start, void*& end, size_t size) {assert(size <= _actualNum);start = _freelist;end = start;for (size_t i = 1; i < size; ++i) {end = NextObj(end);}_freelist = NextObj(end);NextObj(end) = nullptr;_actualNum -= size;}//判断自由链表是否为空bool empty() {return _freelist == nullptr;}//获取当前数据个数size_t actualNum() {return _actualNum;}
private:void* _freelist = nullptr;size_t _maxsize = 1;//最大数量size_t _actualNum = 0;//自由链表当前剩余内存对象数量
};
创建SizeClass类
该类主要用来计算内存对齐后的内存大小和该内存应该存储在哪一个自由链表中(桶中)
- 根据传入的字节大小,返回对齐后的大小
- 根据传入的字节大小,返回其所存储的桶对应的下标
- 计算最大可申请内存大小除于需要申请内存大小的值,该值主要用于慢开始算法
class SizeClass {// 整体控制在最多10%左右的内碎片浪费// [1,128] 8byte对齐 freelist[0,16)// [128+1,1024] 16byte对齐 freelist[16,72)// [1024+1,8*1024] 128byte对齐 freelist[72,128)// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)/*size_t _RoundUp(size_t size, size_t alignNum) {if (size / alignNum != 0)return (size / alignNum + 1) * alignNum;else return size;}*///返回对齐数static inline size_t _RoundUp(size_t bytes, size_t alignNum) {return (bytes + alignNum - 1) & ~(alignNum - 1);}
public://返回通过对齐规则对齐后的字节数static inline size_t RoundUp(size_t size) {if (size <= 128) {return _RoundUp(size, 8);}else if (size <= 1024) {return _RoundUp(size, 16);}else if (size <= 8 * 1024) {return _RoundUp(size, 128);}else if (size <= 64 * 1024) {return _RoundUp(size, 1024);}else if (size <= 256 * 1024) {return _RoundUp(size, 8 * 1024);}else {//assert(false);return _RoundUp(size, 1 << PAGE_SHIFT);}}
private:static inline size_t _Index(size_t bytes, size_t align_shift) {return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}
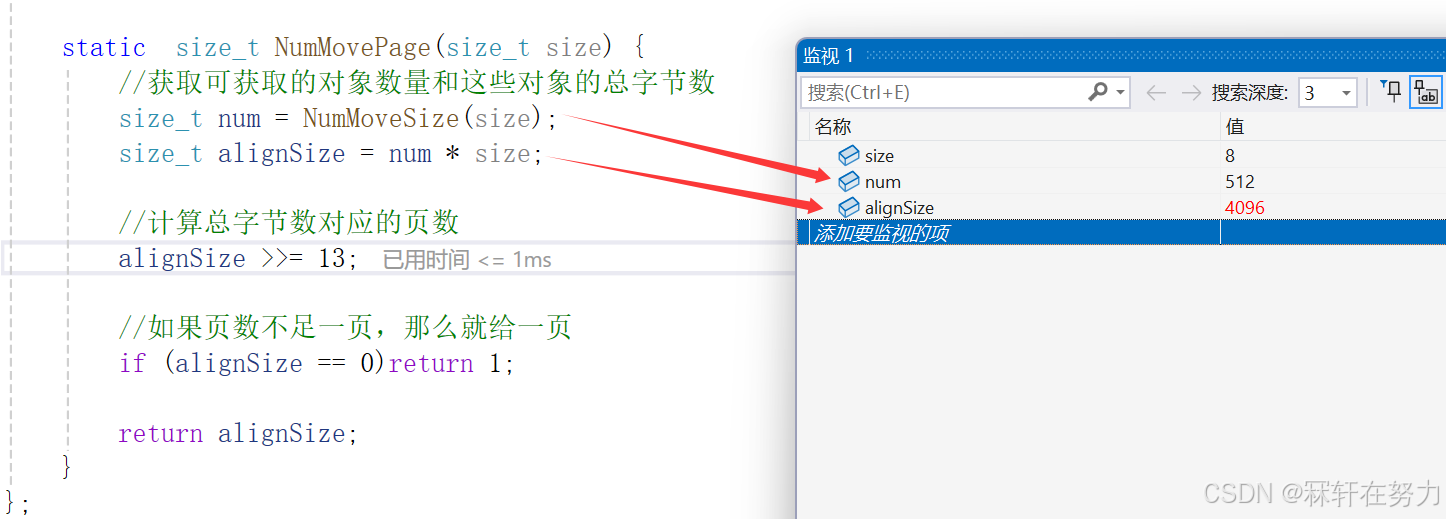
public://映射哪一个自由链表桶static inline size_t Index(size_t size) {assert(size <= MAX_BYTES);static int group_array[4] = { 16, 56, 56, 56 };if (size <= 128) {return _Index(size, 3);}else if (size < 1024) {return _Index(size - 128, 4) + group_array[0];}else if (size < 8 * 1024) {return _Index(size - 1024, 7) + group_array[0] + group_array[1];}else if (size < 64 * 1024) {return _Index(size - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2];}else if (size < 256 * 1024) {return _Index(size - 64 * 1024, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3];}else {assert(false);return -1;}}static inline size_t NumMoveSize(size_t size) {assert(size > 0);//不能申请0大小的内存空间,也避免除零错误size_t num = MAX_BYTES / size;if (num < 2) {//当申请256KB内存大小的时候,相除等于1,但是后面线程可能会需要申请4个256KB的内存,那么一次 //申请两个就能少申请几次。num也不能太大,因为太大会导致太多的内存没被使用,而其他线程又申请 //不到return 2;}else if (num > 512) {//如果申请8B大小的内存,那么就num将会非常的大,这显然一个线程一般是使用不完的,所以固定一次 //最多申请512个内存对象,避免大量的内存浪费。return 512;}return num;}
};
ThreadCache的申请逻辑实现
准备工作做完了,那么现在就可以开始实现ThreadCache了
- 当内存申请小于256KB时,先获取到线程本地存储的ThreadCache对象,然后通过传入的字节数计算哈希桶自由链表的下标
- 如果自由链表中有对象,那么就直接返回一个对象给线程使用
- 如果自由链表中没有对象,那么就向CentralCache申请一定数量的内存对象,并返回一个内存对象给线程使用
class ThreadCache {
public://申请和释放内存void* Allocate(size_t bytes);void DeAllocate(void* ptr, size_t bytes);//向中心缓存池中申请内存对象void* FetchFromCentralCache(size_t index, size_t bytes);
private://哈希桶FreeList _freelists[NFREELIST];
};
//TLS thread local storage //线程本地存储
static _declspec(thread) ThreadCache * pTLSThreadCache = nullptr;//申请内存
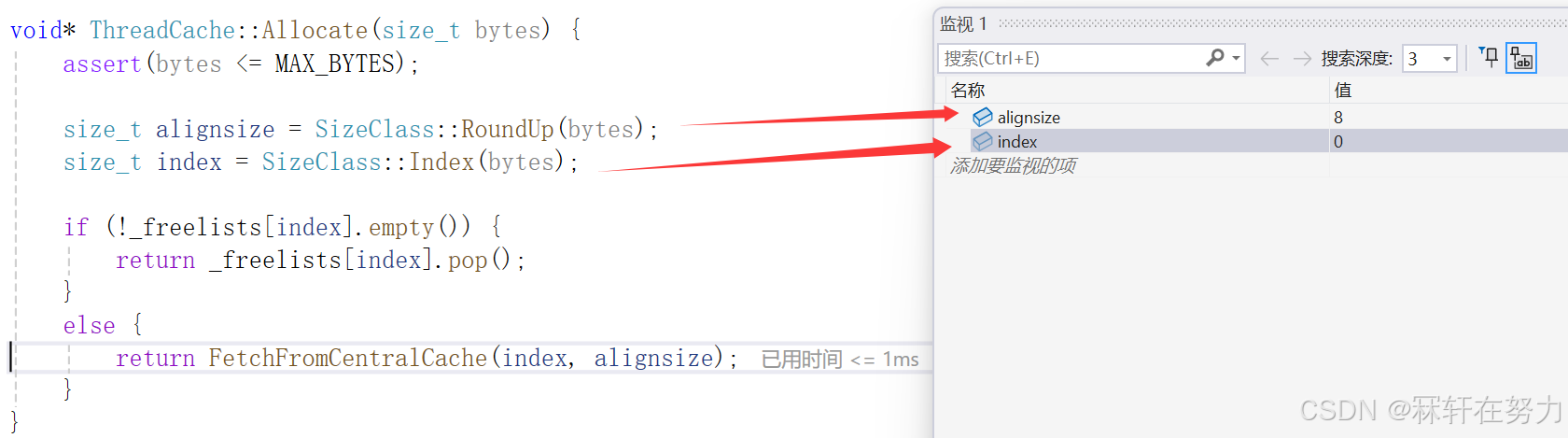
void* ThreadCache::Allocate(size_t bytes) {assert(bytes <= MAX_BYTES);size_t alignsize = SizeClass::RoundUp(bytes);size_t index = SizeClass::Index(bytes);if (!_freelists[index].empty()) {return _freelists[index].pop();}else {//没有内存了,向中心缓存申请内存return FetchFromCentralCache(index, alignsize);}
}
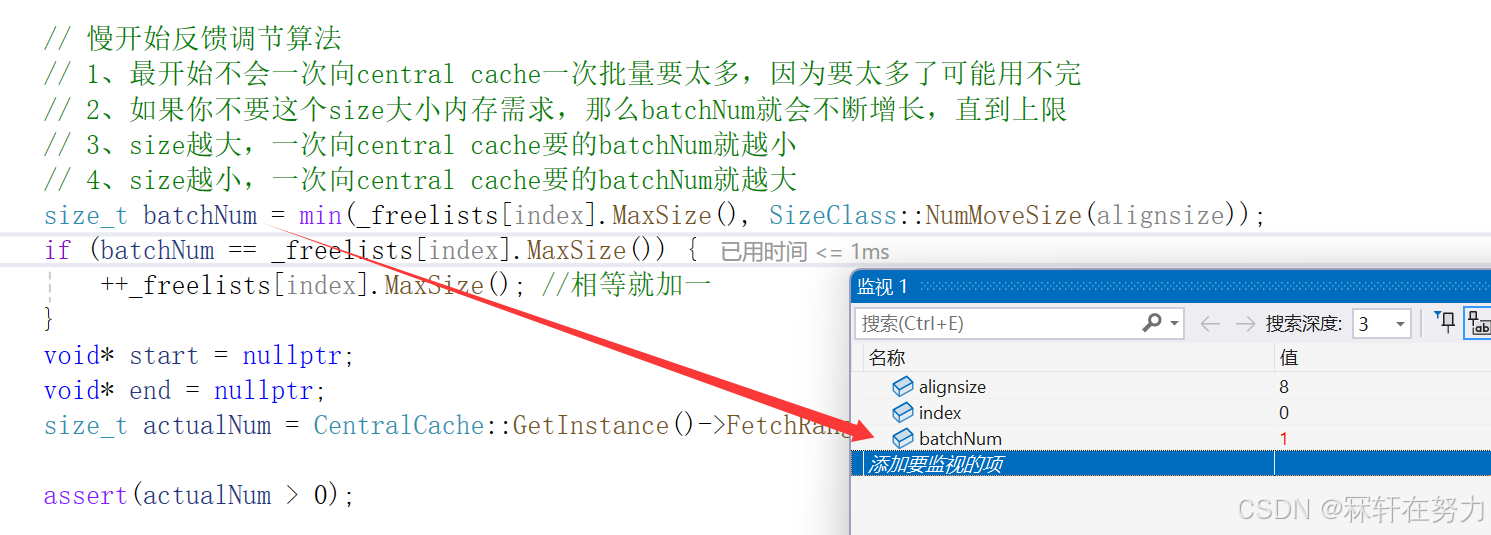
先通过慢开始算法计算出,预期要申请内存对象的个数,然后向CentralCache申请。实际申请到的内存对象个数可能比预期申请到的要少,因为CenralCache中也不一定有那么多内存对象,所以如果不足,那么有多少CentralCache就返回多少个内存对象回来。
void* ThreadCache::FetchFromCentralCache(size_t index, size_t alignsize) {assert(alignsize <= MAX_BYTES);// 慢开始反馈调节算法// 1、最开始不会一次向central cache一次批量要太多,因为要太多了可能用不完// 2、如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限// 3、size越大,一次向central cache要的batchNum就越小// 4、size越小,一次向central cache要的batchNum就越大size_t batchNum = min(_freelists[index].MaxSize(), SizeClass::NumMoveSize(alignsize));if (batchNum == _freelists[index].MaxSize()) {++_freelists[index].MaxSize(); //相等就加一}void* start = nullptr;void* end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, alignsize);assert(actualNum > 0);if (actualNum == 1) {assert(start == end);return start;}//插入的首地址是下一个连接的对象的地址//因为我们这时是需要取出一个对象给thread使用的_freelists[index].pushRange(NextObj(start), end, actualNum - 1);return start;
}
ThreadCache释放内存逻辑的实现
- 线程将内存对象释放给ThreadCache,ThreadCache通过传入的字节大小计算对应的桶的下标,然后将内存对象插入到桶中
- 如果此时桶中的内存对象个数和桶最大申请内存对象个数相同的话,就将该桶中的内存对象返还给CentralCache
//线程释放内存
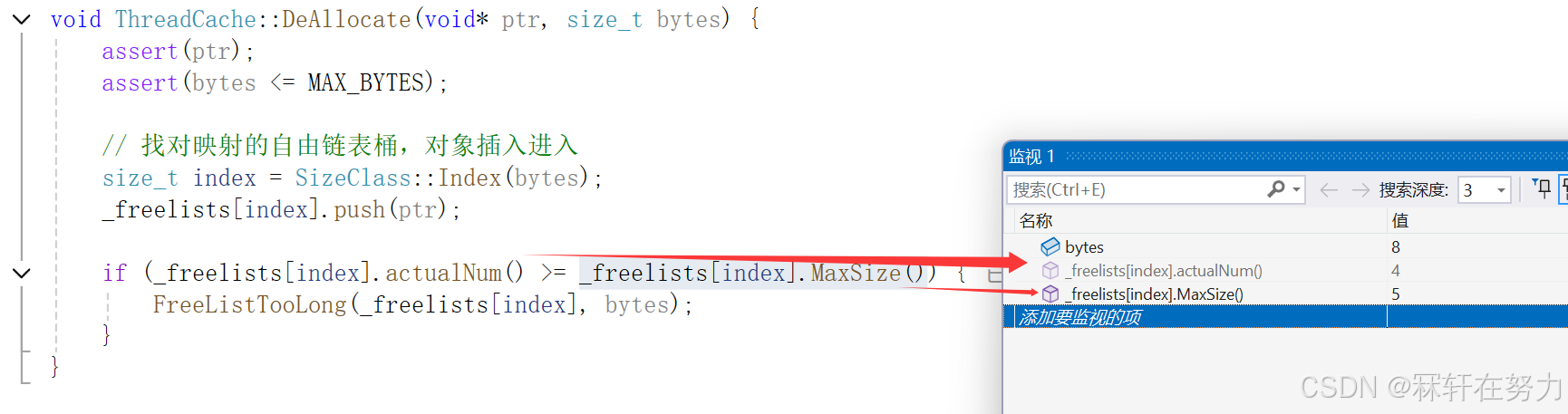
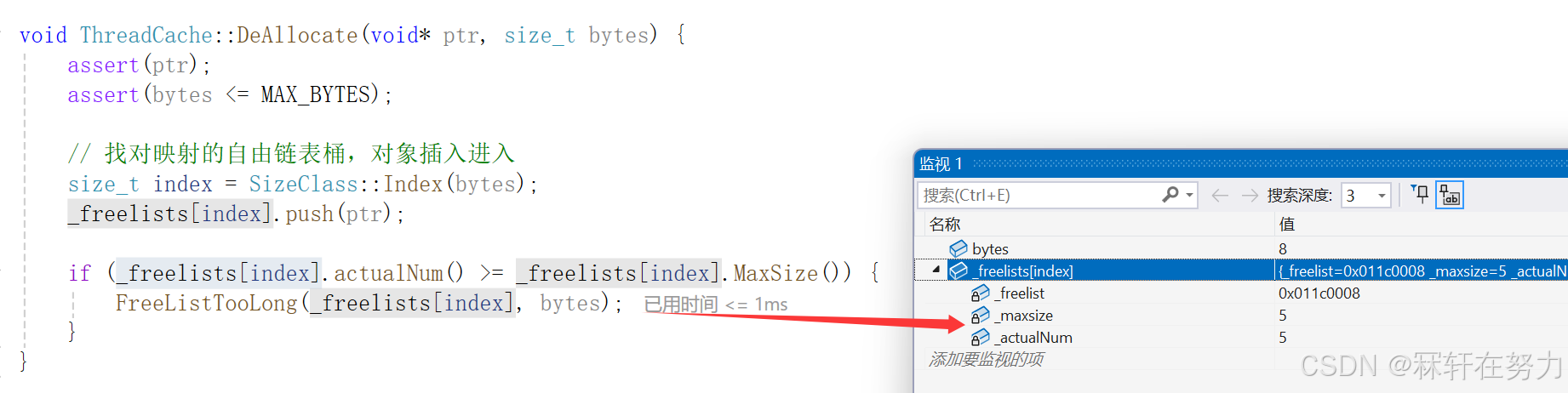
void ThreadCache::DeAllocate(void* ptr, size_t bytes) {assert(ptr);assert(bytes <= MAX_BYTES);// 找对映射的自由链表桶,对象插入进入size_t index = SizeClass::Index(bytes);_freelists[index].push(ptr);//实际个数等于最大申请个数,那么就返还该桶中的内存对象给CentralCacheif (_freelists[index].actualNum() >= _freelists[index].MaxSize()) {FreeListTooLong(_freelists[index], bytes);}
}//将桶中的内存对象返还给CentralCache
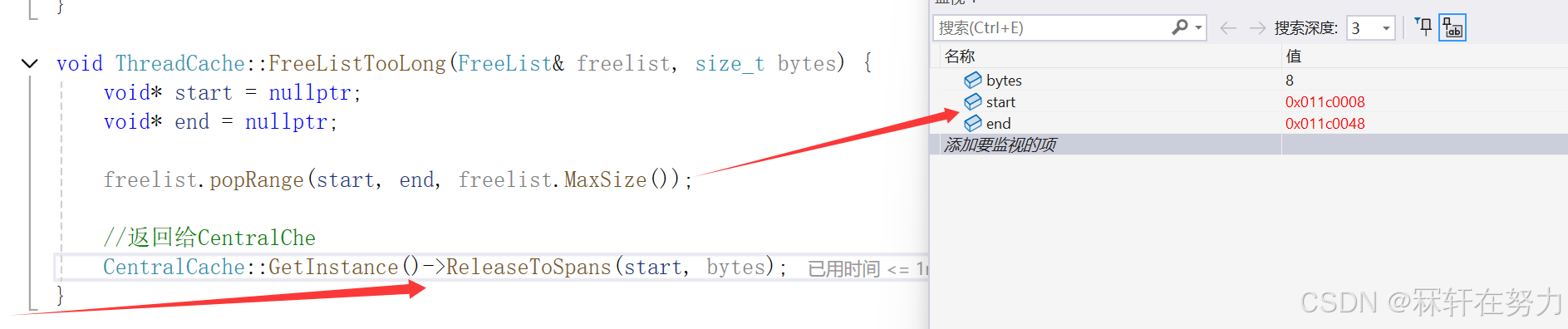
void ThreadCache::FreeListTooLong(FreeList& freelist, size_t bytes) {void* start = nullptr;void* end = nullptr;//弹出桶中的所有内存对象freelist.popRange(start, end, freelist.MaxSize());//返回给CentralCheCentralCache::GetInstance()->ReleaseToSpans(start, bytes);
}
4.2 CentralCache的实现
CentralCache和ThreadCache的结构是类似的,都是采用哈希桶的结构来存储内存对象。只是CentralCache上挂的是以页为单位的Span,Span下面挂的是对应大小的自由链表,如下图:
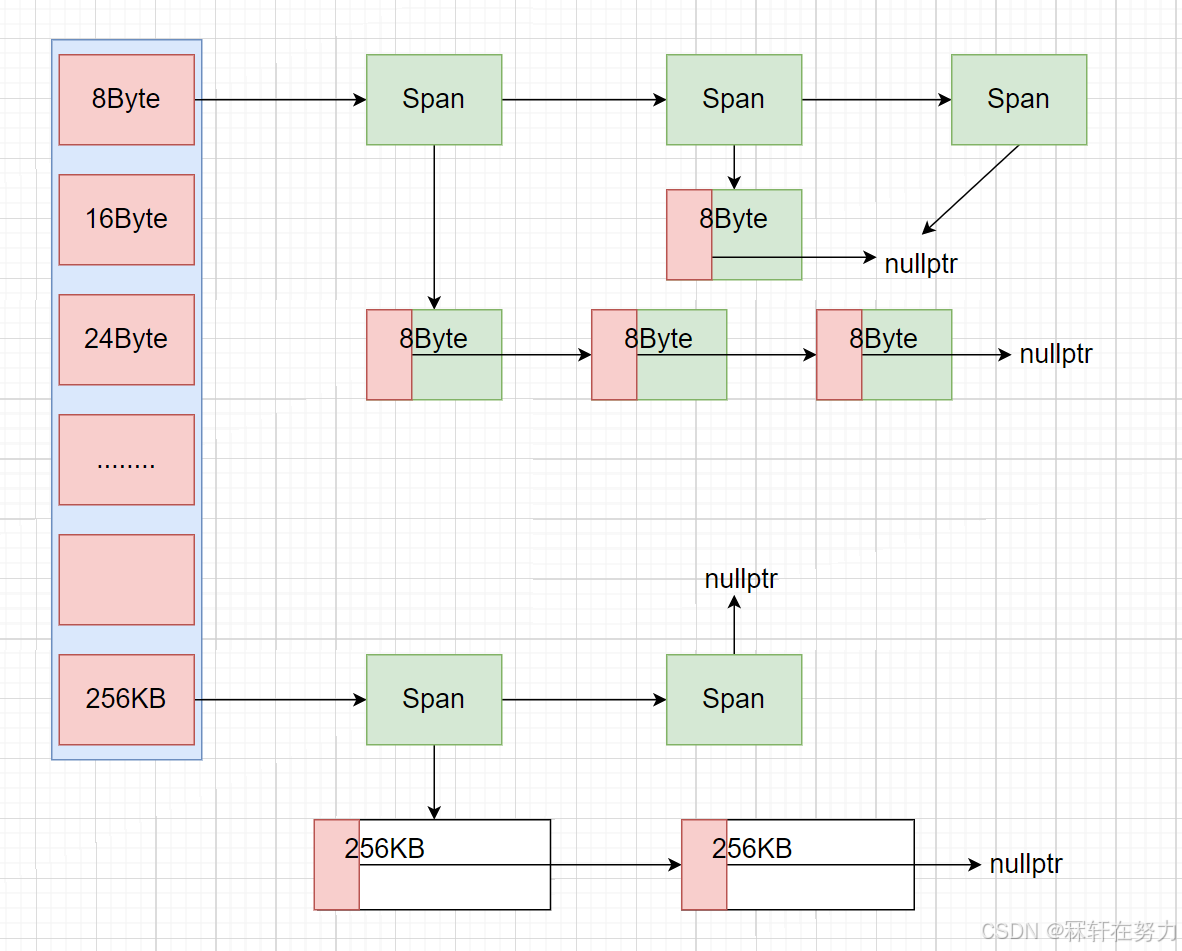
CentralCache和ThreadCache的映射规则相同,当ThreadCache对应的哈希桶没有空间时可以直接找CentralCache中相同下标的哈希桶申请空间,如ThreadCache的1号桶(16B)不够了就可以直接从CentralCache中1号桶拿,这样一一对应的关系,寻找起来比较方便
该项目使用8K大小的内存来表示一个页,在不同位数的操作系统下,那么就可以得到不同数量的页,在WIN32中可以得到:2^32 / 2^13 = 2^19个页, WIN64中可以得到:2^64 / 2^13 = 2^51个页。显然在64位系统下,使用int类型来存储页的数量是不行的,所以可以使用long long来进行存储。此时就可以使用条件编译来实现,不同的操作系统使用不同的类型来存储数据
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef unsigned int PAGE_ID;
#endif
注意:在32位下,_WIN32有定义,_WIN64没有定义;而在64位下,_WIN32和_WIN64都有定义。因此在条件编译时,我们应该先判断_WIN64是否有定义,再判断_WIN32是否有定义。
CentralCache的结构定义
因为CentralCache的结构挂着的是一个一个的Span对象,所以可以定义一个Span对象
实现Span类:
- 页号:当归还内存给PageCache的时候,能够知道该Span能否进行前后页的合并
- 对象被使用的状态:当该Span中的内存对象没有被使用时,那么就还给PageCache
- 自由链表:每个Span都会被切分成多个内存对象,挂在该自由链表中
- 前后指针:让SpanList定义成双向链表,便于后续的删除,因为单链表删除时得知道前一个元素
class Span {
public:PAGE_ID _pageId = 0; //页号size_t _pageNum = 0; //span中有多少页size_t _useCount = 0; //被切分的内存对象使用个数void* _freeList = nullptr;//自由链表,管理被切分的对象Span* _prev = nullptr;//前继指针Span* _next = nullptr;//后继指针bool _isUse = false; //是否正在被使用size_t _objSize = 0; //该span的自由链表中挂着的内存对象的大小};
实现SpanList类:
class SpanList {
public:SpanList() {_head = _spanPool.New();//_head = new Span;_head->_prev = _head;_head->_next = _head;}Span* Begin() {return _head->_next;}Span* End() {return _head;}bool Empty() {return _head->_next == _head;}void PushFront(Span* span) {assert(span);Insert(Begin(), span);}Span* PopFront() {Span* front = Begin();erase(front);return front;}void Insert(Span* pos, Span* newspan) {assert(newspan);assert(pos);Span* pre = pos->_prev;pre->_next = newspan;newspan->_prev = pre;newspan->_next = pos;pos->_prev = newspan;}void erase(Span* pos) {assert(pos);assert(pos != _head);Span* pre = pos->_prev;Span* next = pos->_next;pre->_next = next;next->_prev = pre;}
private:Span* _head; //哨兵位头节点
public:std::mutex _mtx;//桶锁static ObjectPool<Span> _spanPool;
};
CentralCache的结构:
通过上面的说明可以知道,CentralCache和ThreadCache结构类似,都包含208个桶,只是CentralCache每个桶是一个Span类型的双向链表。
使用单例模式,先创建一个CentralCache对象,然后通过静态成员函数进行获取到该对象。(饿汉模式)
//单例模式,全局只有一个CentralChe对象
class CentralCache {
public://获取CentralCache对象static CentralCache* GetInstance() {return &_centralChe;}//获取一个非空的spanSpan* GetOneSpan(SpanList& list, size_t bytes);//获取一定数量的内存对象size_t FetchRangeObj(void*& start, void*& end, size_t betchNum, size_t bytes);//将内存对象还给CentralCachevoid ReleaseToSpans(void* start, size_t bytes);
private:CentralCache() {}CentralCache(CentralCache&) = delete;SpanList _spanLists[NFREELIST];static CentralCache _centralChe;
};
CentralCache的内存申请逻辑
- 通过传入的字节大小,计算需要在哪个桶中申请内存对象
- 在对应桶中获取一个非空的Span对象
- 通过传入的期望数量进行申请对应数量的内存对象,如果该Span中不够,那么有多少就拿多少
- 更新该Span中的useCount
//从中心缓存获取一定数量的对象给ThreadCache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t bytes) {size_t index = SizeClass::Index(bytes);_spanLists[index]._mtx.lock();//获取一个非空的spanSpan* span = GetOneSpan(_spanLists[index], bytes);assert(span);assert(span->_freeList);//获取批量个内存对象start = span->_freeList;end = start;size_t actualNum = 1;size_t i = 1;while (i < batchNum && NextObj(end) != nullptr) {end = NextObj(end);++i;++actualNum;}span->_freeList = NextObj(end);NextObj(end) = nullptr;span->_useCount += actualNum;_spanLists[index]._mtx.unlock();return actualNum;}
获取非空的Span对象的函数实现:
- 在对应的桶中寻找一个满足条件的Span对象。
- 如果没有,那么就向PageCache中申请一个对应页数量的Span对象
- 将获取到的Span对象切分成多个内存对象,挂在自由链表上
- 将该Span插入CentralCache的桶中
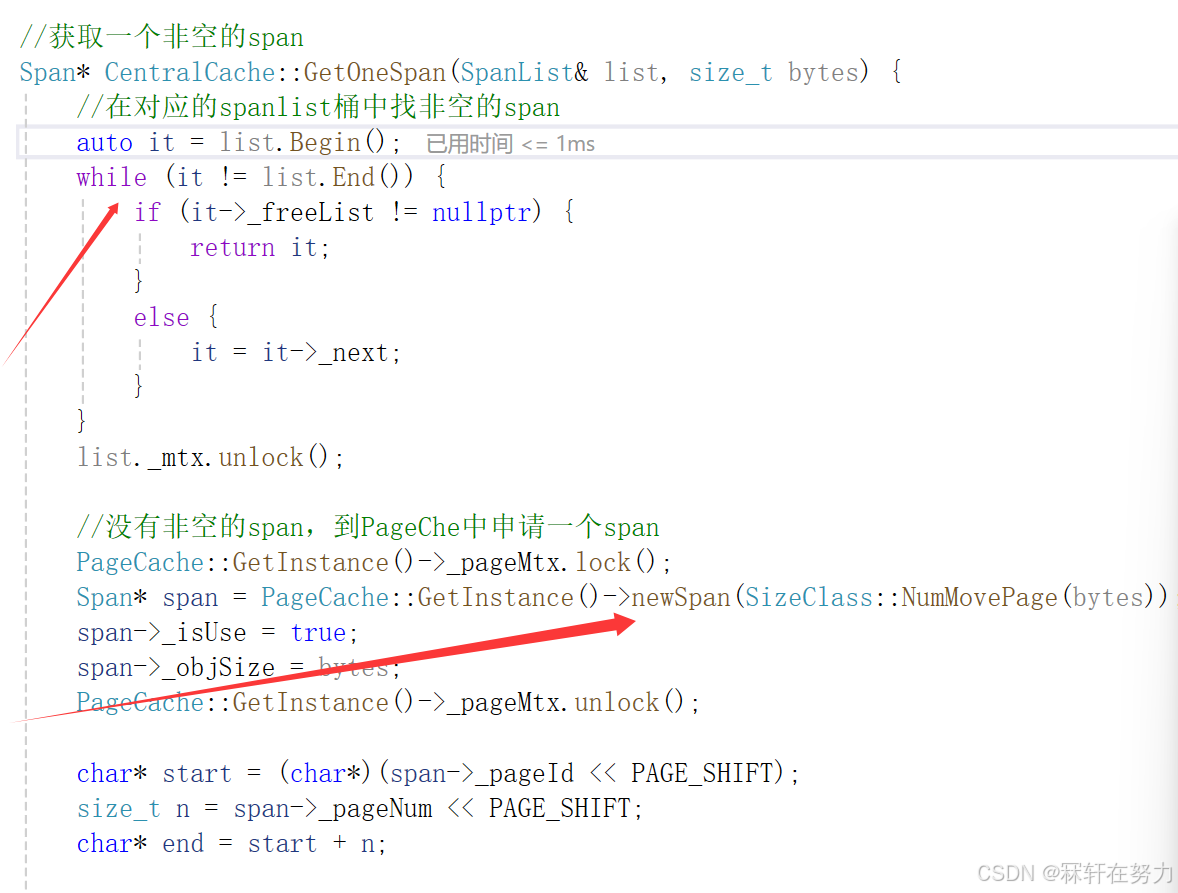
//获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t bytes) {//在对应的spanlist桶中找非空的spanauto it = list.Begin();while (it != list.End()) {if (it->_freeList != nullptr) {return it;}else {it = it->_next;}}//解锁,因为该线程要去访问PageCache了,此时可能其他线程归还内存对象到该桶中list._mtx.unlock();//没有非空的span,到PageChe中申请一个spanPageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->newSpan(SizeClass::NumMovePage(bytes));span->_isUse = true;span->_objSize = bytes;PageCache::GetInstance()->_pageMtx.unlock();char* start = (char*)(span->_pageId << PAGE_SHIFT);size_t n = span->_pageNum << PAGE_SHIFT;char* end = start + n;//把span切分连接到自由链表中char* tail = start + bytes;void* cur = start;while (tail < end) {NextObj(cur) = tail;cur = tail;tail += bytes;}NextObj(cur) = nullptr;span->_freeList = start;//加锁插入spanlist中list._mtx.lock();list.PushFront(span);return span;
}
CentralCache的释放内存逻辑
- 通过传入的字节大小,计算对应桶的下标
- 将该自由链表中的内存对象归还给对应的Span对象
- 如果该Span对象中的内存对象此时都没有被使用,那么就将该Span归还给PageCache
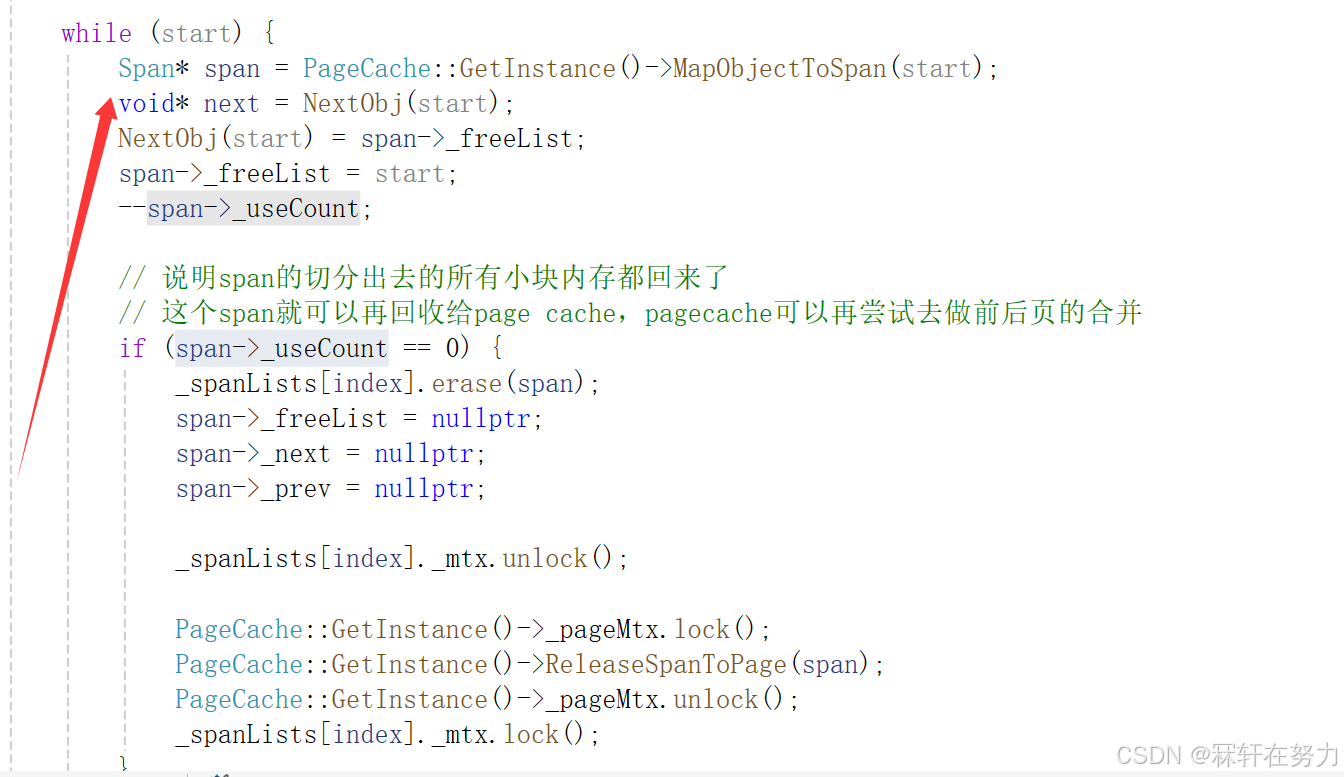
void CentralCache::ReleaseToSpans(void* start, size_t bytes) {size_t index = SizeClass::Index(bytes);_spanLists[index]._mtx.lock();while (start) {Span* span = PageCache::GetInstance()->MapObjectToSpan(start);void* next = NextObj(start);NextObj(start) = span->_freeList;span->_freeList = start;--span->_useCount;// 说明span的切分出去的所有小块内存都回来了// 这个span就可以再回收给page cache,pagecache可以再尝试去做前后页的合并if (span->_useCount == 0) {_spanLists[index].erase(span);span->_freeList = nullptr;span->_next = nullptr;span->_prev = nullptr;_spanLists[index]._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPage(span);PageCache::GetInstance()->_pageMtx.unlock();_spanLists[index]._mtx.lock();}start = next;}_spanLists[index]._mtx.unlock();
}
4.3 PageCache的实现
PageCache和ThreadCache、CentralCache的映射规则都不一样,它采用的是直接定址法。该结构上挂着的是一个个对应页数的Span,如:一号下标挂的是一页大小的Span,二号下标挂的是两页大小的Span,以此类推,最多128页大小的Span,因为128 * 8K = 4 * 256K,一个128页的Span可以分为4个256K大小的内存对象,是足够的。
static const size_t NPAGE = 129;
PageCache的结构定义
因为全局只有一个,且申请内存时,如果没有对应页大小的Span,会寻找更大的Span进行切分成对应页大小的Span和另一个Span,此时,然后将另一个Span插入到对应的桶中。释放内存时,当CentralCahce归还回来了一个Span后,如果该Span能够进行前后页的合并,那么就将两个或多个Span进行合并。上面的操作都涉及到多个桶,所以使用桶锁不是很方便。这里使用一把普通的锁就可以了。
class PageCache {
public:static PageCache* GetInstance() {return &_instance;}//返回一个新的spanSpan* newSpan(size_t kpage);//通过哈希表找到对应的spanSpan* MapObjectToSpan(void* obj);//将span对象归还给pagechevoid ReleaseSpanToPage(Span* span);std::mutex _pageMtx;//锁
private:SpanList _spanLists[NPAGE];PageCache() {}PageCache(const PageCache&) = delete;std::unordered_map<PAGE_ID, Span*> _idSpanMap;//通过id查找对应的SpanObjectPool<Span> _spanPool;//通过定长内存池来申请内存static PageCache _instance;
};
CentralCache中Span都是PageCache分配给它的,在分配的时候就实现了对应的映射,所以将该哈希表定义在PageCache中。
PageCache的内存申请逻辑
- 根据传入的页数大小,进行判断,如果大于128页那么直接向系统申请内存,如果小于128页向PageCache申请内存
- 根据传入的页数大小,在对应的桶中寻找Span,如果找到就将该Span中的页与该Span建立映射
- 没找到,就找更大的Span,然后将该Span切分成两个Span,其中一个满足要找的Span,将另一个Span插入对应的桶中
- 将切分下来满足条件的Span和它内部的页建立映射关系
Span* PageCache::newSpan(size_t kpage) {assert(kpage > 0);if (kpage > NPAGE - 1) {void* ptr = SystemAlloc(kpage);Span* span = _spanPool.New();span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;span->_pageNum = kpage;_idSpanMap[span->_pageId] = span;return span;}if (!_spanLists[kpage].Empty()) {//将该Span中的页都与该Span进行隐射Span* kspan = _spanLists[kpage].PopFront();for (PAGE_ID i = 0; i < kspan->_pageNum; ++i) {_idSpanMap[kspan->_pageId + i] = kspan;}return kspan;}for (size_t i = kpage + 1; i < NPAGE; ++i) {//如果不为空,就将span进行切分if (!_spanLists[i].Empty()) {Span* nspan = _spanLists[i].PopFront();Span* kspan = _spanPool.New();kspan->_pageId = nspan->_pageId;kspan->_pageNum = kpage;nspan->_pageId += kpage;nspan->_pageNum -= kpage;_spanLists[nspan->_pageNum].PushFront(nspan);//对span进行映射_idSpanMap[nspan->_pageId] = nspan;_idSpanMap[nspan->_pageId + nspan->_pageNum - 1] = nspan;//因为kspan给CentralChe以后,会被切分。所以对kspan被切分的span进行映射for (PAGE_ID i = 0; i < kspan->_pageNum; ++i) {_idSpanMap[kspan->_pageId + i] = kspan;}return kspan;}}Span* newspan = _spanPool.New();void* ptr = SystemAlloc(NPAGE - 1);newspan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;newspan->_pageNum = NPAGE - 1;//将申请的128页的span插入对应的桶中_spanLists[newspan->_pageNum].PushFront(newspan);return newSpan(kpage);
}
查找对应Span的函数实现:
- 传入要查找对象的首地址,将该地址右移PAGE_SHIFT个单位,得到页号
- 通过页号在哈希表中进行查找,存在就返回对应的Span对象,不存在就返回空
Span* PageCache::MapObjectToSpan(void* obj) {PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT;//获取页号std::unique_lock<std::mutex>(_pageMtx);auto ret = _idSpanMap.find(id);if (ret != _idSpanMap.end()) {return ret->second;}else {assert(false);return nullptr;}
}
PageCache的内存释放逻辑
- 要释放的Span的页大小大于128页,那么就直接释放给系统(因为直接向系统申请的)
- 判断该归还回来的Span能否进行前后页的合并,能合并就合并成更大的页,然后插入到对应的桶中
void PageCache::ReleaseSpanToPage(Span* span) {if (span->_pageNum > NPAGE - 1) {void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);_spanPool.Delete(span);return;}//将span进行前后页的合并while (1) {PAGE_ID id = span->_pageId - 1;auto ret = _idSpanMap.find(id);if (ret == _idSpanMap.end()) {break;}Span* prevSpan = ret->second;if (prevSpan->_isUse == true) {break;}if (prevSpan->_pageNum + span->_pageNum > NPAGE - 1) {break;}span->_pageId = prevSpan->_pageId;span->_pageNum += prevSpan->_pageNum;_spanLists[prevSpan->_pageNum].erase(prevSpan);_spanPool.Delete(prevSpan);}//将span进行向后合并while (1) {PAGE_ID id = span->_pageId + span->_pageNum;auto ret = _idSpanMap.find(id);if (ret == _idSpanMap.end()) {break;}Span* nextSpan = ret->second;if (nextSpan->_isUse == true) {break;}if (nextSpan->_pageNum + span->_pageNum > NPAGE - 1) {break;}span->_pageNum += nextSpan->_pageNum;_spanLists[nextSpan->_pageNum].erase(nextSpan);_spanPool.Delete(nextSpan);}//将span插入到对应的哈希桶中_spanLists[span->_pageNum].PushFront(span);span->_isUse = false;_idSpanMap[span->_pageId] = span;_idSpanMap[span->_pageId + span->_pageNum - 1] = span;
}
SystemFree函数实现
inline static void SystemFree(void* ptr) {
#ifdef _WIN32bool status = VirtualFree(ptr, 0, MEM_RELEASE);
#else// linux下brk mmap等
#endifif (status == false)throw std::bad_alloc();
}
五、申请释放过程内存联调
ConcurrentAlloc函数实现
- 大于256KB的内存直接向PageCache申请
- 判断ThreadCache是否已经初始化,如果初始化了就直接通过Allocate函数申请内存,没初始化先初始化再申请内存
void* ConcurrentAlloc(size_t bytes) {//大于256k的申请直接向PageChe申请if (bytes >= MAX_BYTES) {size_t alignSize = SizeClass::RoundUp(bytes);size_t kpage = alignSize >> PAGE_SHIFT;PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->newSpan(kpage);PageCache::GetInstance()->_pageMtx.unlock();void* ptr = (void*)(span->_pageId << PAGE_SHIFT);return ptr;}else{//通过TLS,每个线程无锁的获取自己专属的ThreadCache对象if (pTLSThreadCache == nullptr) {static std::mutex mtx;static ObjectPool<ThreadCache> tcPool;mtx.lock();pTLSThreadCache = tcPool.New();mtx.unlock();}//std::cout << std::this_thread::get_id() << ':' << pTLSThreadCache << std::endl;return pTLSThreadCache->Allocate(bytes);}
}
申请内存过程测试1
在多线程环境下调试程序是非常麻烦的事情,所以这里在单线程的环境下来观察申请内存逻辑是否和预期的一样。
void TestConcurrentAlloc1()
{void* p1 = ConcurrentAlloc(6);void* p2 = ConcurrentAlloc(8);void* p3 = ConcurrentAlloc(1);void* p4 = ConcurrentAlloc(7);void* p5 = ConcurrentAlloc(8);cout << p1 << endl;cout << p2 << endl;cout << p3 << endl;cout << p4 << endl;cout << p5 << endl;
}
每个线程(申请内存小于256KB)刚开始申请内存时,都会初始化一个TLS存储的ThreadCache对象,然后通过这个对象申请内存

申请内存时,传入的字节大小为7是小于8字节的,所以定位到0号桶,但此时ThreadCache中还没有对象,需要向CentralCache申请内存对象
通过NumMoveSize函数计算得出,thread cache一次最多可向central cache申请8字节大小对象的个数是512,但由于采用的是慢开始算法,因此还需要将上限值与对应自由链表的_maxSize的值进行比较,而此时对应自由链表_maxSize的值是1,所以最终得出本次thread cache向central cache申请8字节对象的个数是1个
访问CentralCache是需要加锁的,然后遍历0号桶中的Span,查找是否有满足条件的Span对象,此时肯定是没有的,直接向PageCache申请内存
在向PageCache申请内存时,需要先计算Span中的页数,然后再申请,此时申请的字节数为8字节,且最大数量为512,所以最大字节数是4096,小于一页的内存大小,那么就给一页
但此时PageCache是没有Span的,所以PageCache直接向堆申请128页的Span

通过调试窗口查看申请到的Span的信息,并通过计算可以发现实际起始地址和页号是可以相互转换的
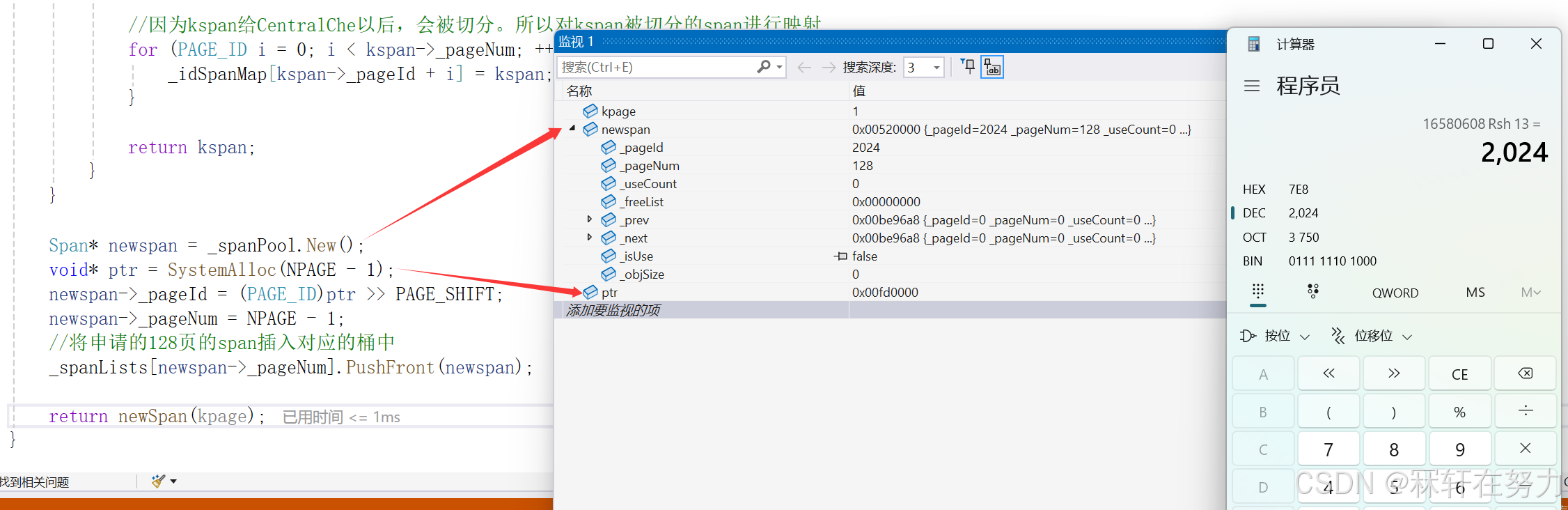
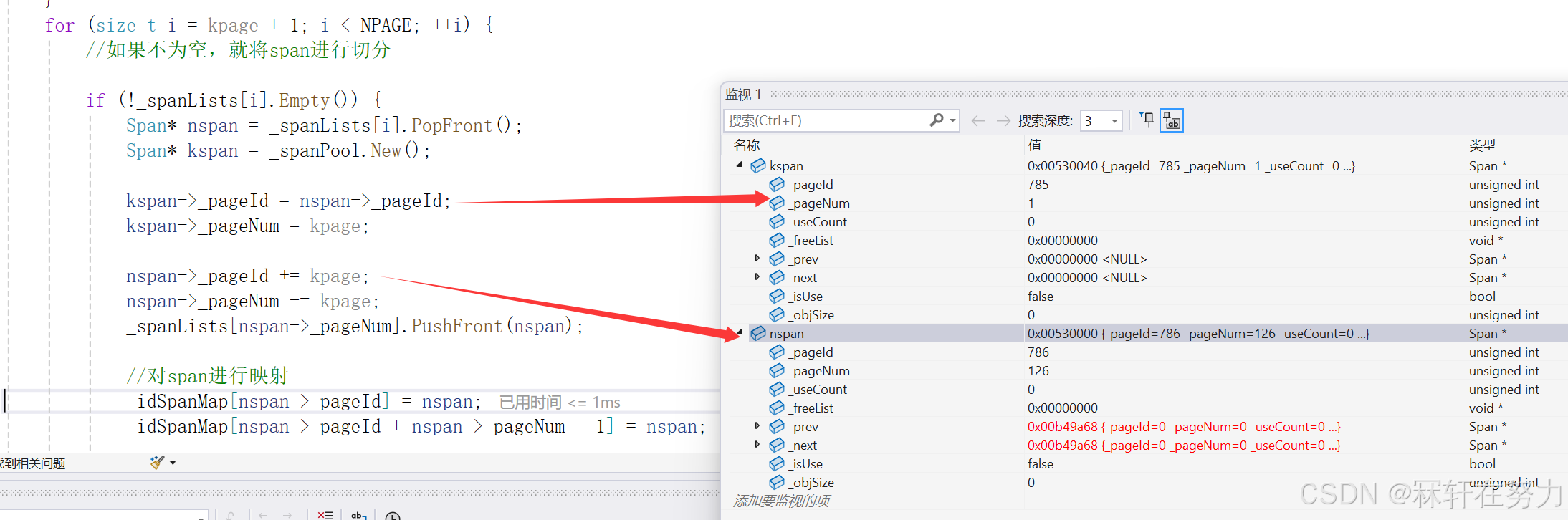
现在将申请到的128页的span插入到page cache的第128号桶当中,然后再调用一次NewSpan,在这次调用的时候,虽然在1号桶当中没有span,但是在往后找的过程中就一定会在第128号桶找到一个span。此时我们就可以把这个128页的span拿出来,切分成1页的span和127页的span,将1页的span返回给central cache并将该Span中的页和Span建立映射,把127页的span挂到page cache的第127号桶
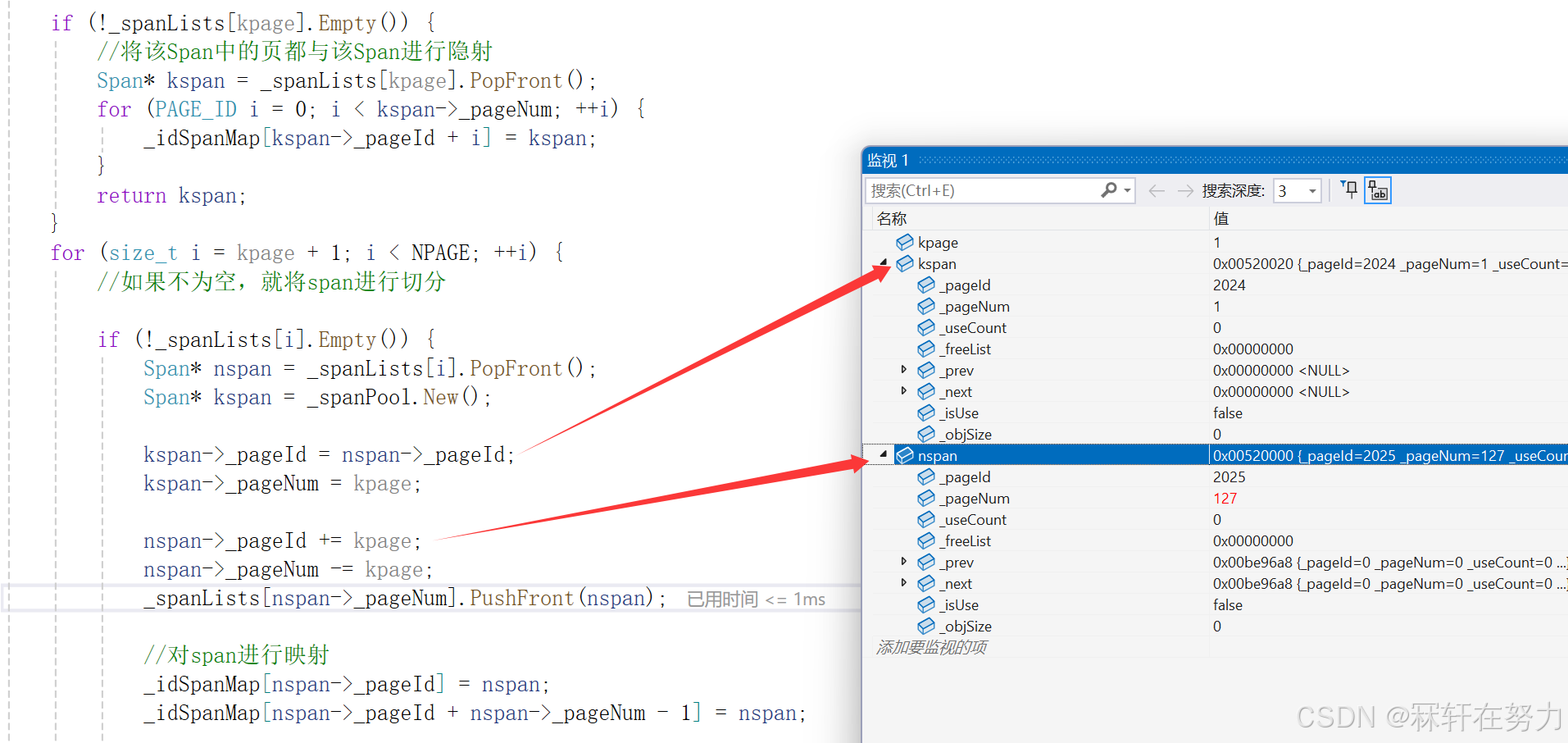
获取到一个span以后,不需要立即对CentralCache中的0号桶加锁,因为此时还需要将该span进行切分并挂到其自由链表上。等操作完以后再加锁,将该span插入到CentralCache的0号桶中
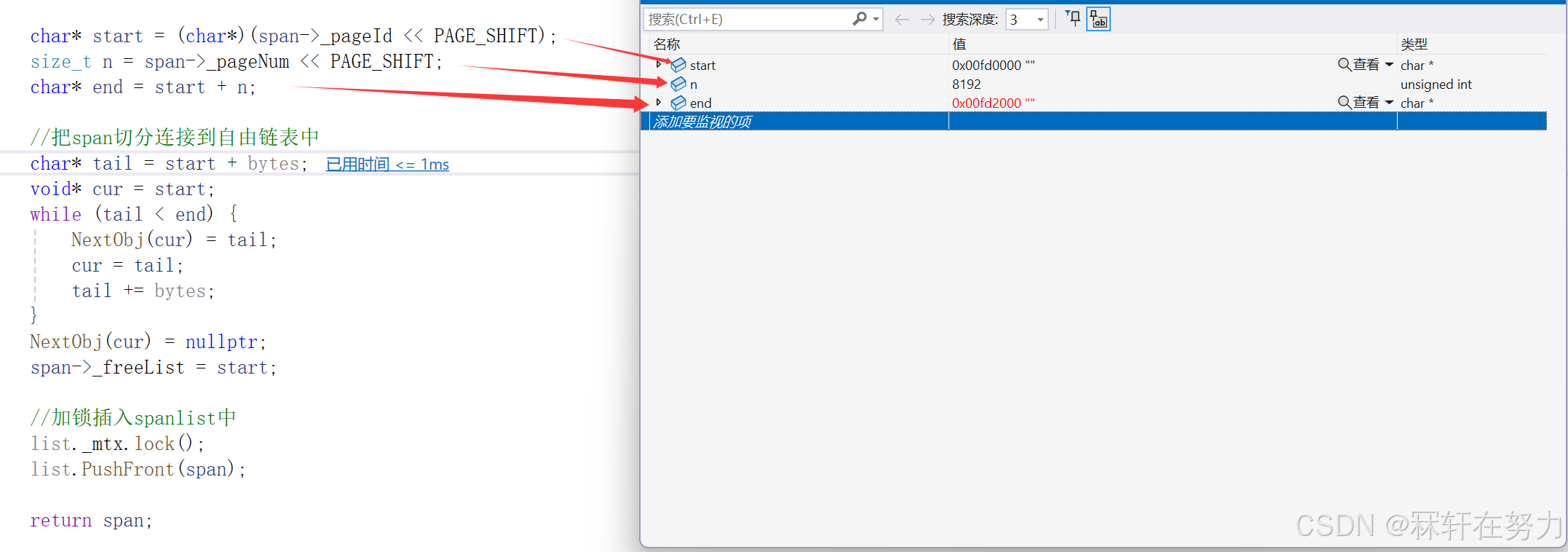
由于thread cache只向central cache申请了一个对象,因此拿到这个非空的span后,直接从这个span里面取出一个对象即可,此时该span的_useCount也由0变成了1
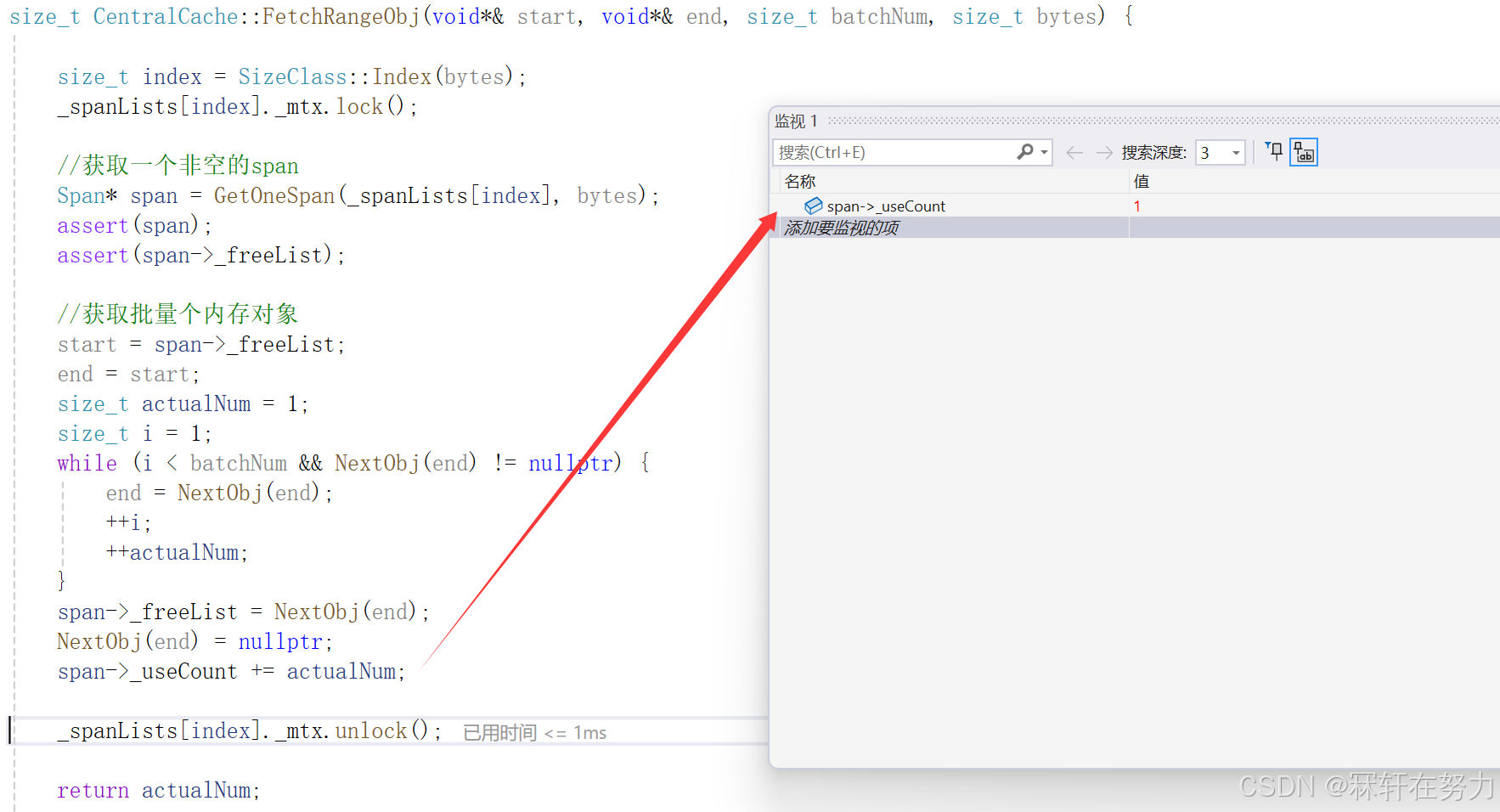
此时thread cache实际只向central cache申请到了一个对象,因此直接将这个对象返回给线程即可

当线程第二次申请内存块时就不会再创建thread cache了,因为第一次申请时就已经创建好了,此时该线程直接获取到对应的thread cache进行内存块申请,当该线程第二次申请8字节大小的对象时,此时thread cache的0号桶中还是没有对象的,因为第一次thread cache只向central cache申请了一个8字节对象,因此这次申请时还需要再向central cache申请对象
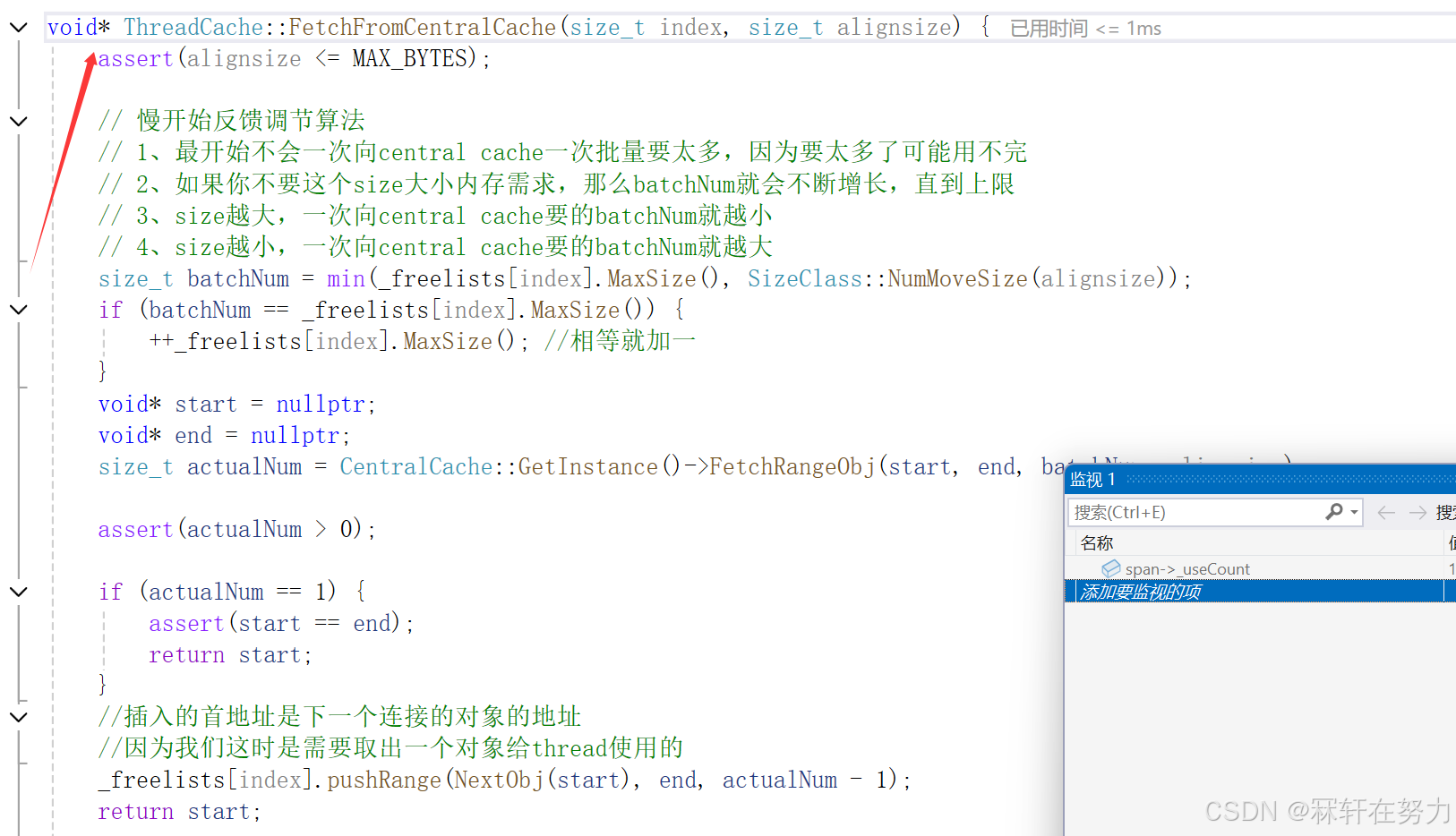
这时thread cache向central cache申请对象时,thread cache第0号桶中自由链表的MaxSize已经慢增长到2了,所以这次在向central cache申请对象时就会申请2个。如果下一次thread cache再向central cache申请8字节大小的对象,那么central cache会一次性给thread cache3个,这就是所谓的慢增长。
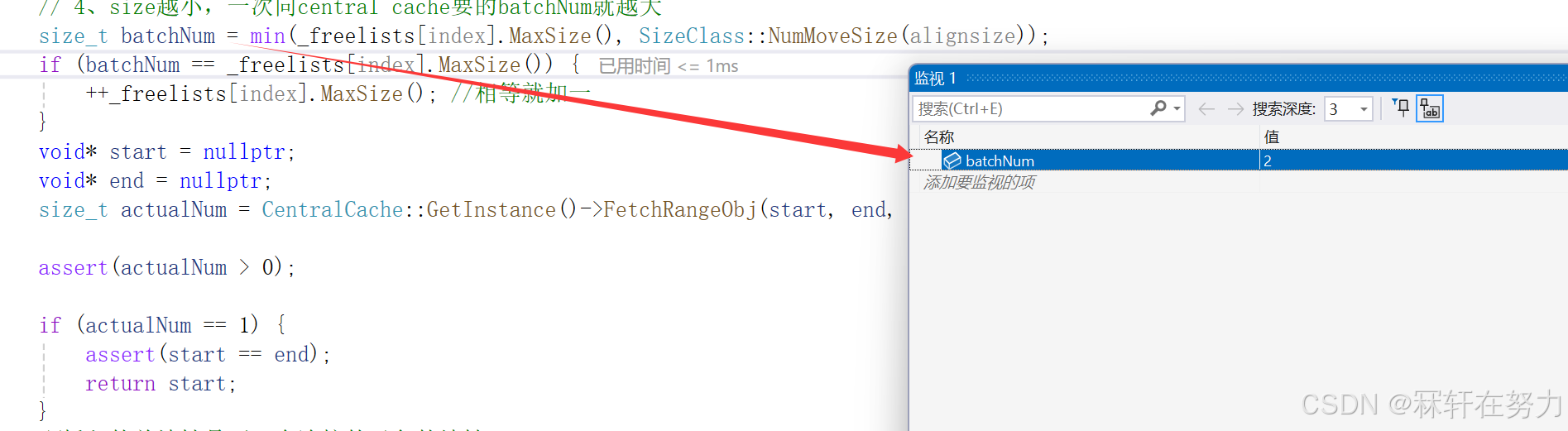
此时CentralCache中的0号桶中是有满足条件的span的,所以直接给ThreadCache返回两个8字节的内存对象,此时返回一个给线程使用,一个挂在ThreadCache中的0号桶中,等线程下次再访问时,可直接在ThreadCache中获取到该内存对象

当线程第三次申请1字节的内存时,由于1字节对齐后也是8字节,此时thread cache也就不需要再向central cache申请内存块了,直接将第0号桶当中之前剩下的一个8字节对象返回即可

申请内存过程测试2
为了进一步测试代码的正确性,我们可以做这样一个测试:让线程申请1024次8字节的对象,然后通过调试观察在第1025次申请时,central cache是否会再向page cache申请内存块
void TestConcurrentAlloc2()
{for (size_t i = 0; i < 1024; ++i){void* p1 = ConcurrentAlloc(6);cout << p1 << endl;}void* p2 = ConcurrentAlloc(8);cout << p2 << endl;
}
根据预期,当CentralCache中0号桶的1024个内存对象被申请完以后,再次向其申请,那么就需要向PageCache申请一个一页的span然后进行切分了。
第1025次申请,可以发现batchNum的值变为了46
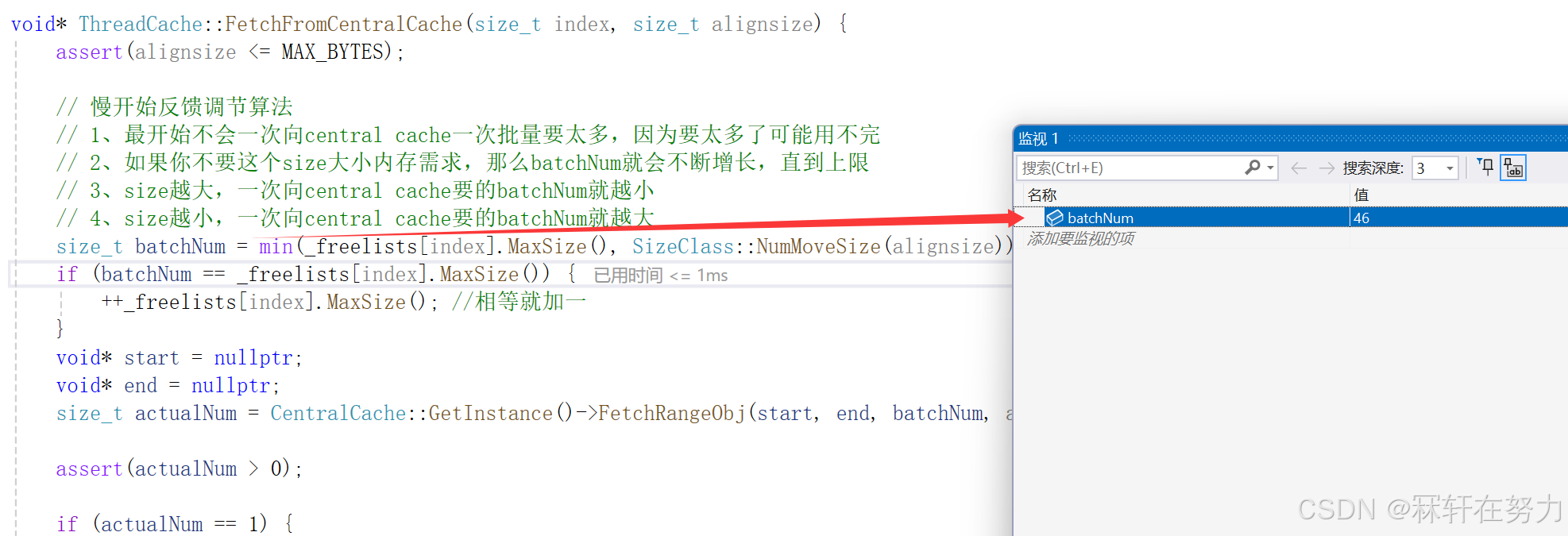
此时申请,找不到满足条件的span,向PageCache申请一页的Span
ConcurrentFree函数的实现
- 先获取到对应内存对象的Span,然后得到对齐后的字节数,通过字节数比较
- 释放的内存对象大于256KB,就直接调用PageCache的释放函数,释放给操作系统
- 小于等于256KB,调用ThreadCache的释放逻辑
void ConcurrentFree(void* ptr) {Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);size_t bytes = span->_objSize;if (bytes > MAX_BYTES) {PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPage(span);PageCache::GetInstance()->_pageMtx.unlock();}else {assert(pTLSThreadCache);pTLSThreadCache->DeAllocate(ptr, bytes);}
}
释放内存的过程测试1
先申请七个内存对象,然后逐渐将他们释放,观察现象
void MultiThreadAlloc1()
{std::vector<void*> v;for (size_t i = 0; i < 7; ++i){void* ptr = ConcurrentAlloc(6);v.push_back(ptr);}for (auto e : v){ConcurrentFree(e);}
}
释放第一个内存对象,将该内存对象插入到ThreadCache对应桶中的自由链表中,此时自由链表中的实际数目小于一次申请内存对象的最大数目,此时不会还给CentralCache
释放第二个内存对象时,自由链表中的实际数目等于一次申请内存对象的最大数目,此时将该桶中的内存对象还给CentralCache
ThreadCache先是将第0号桶当中的对象弹出MaxSize个,在这里实际上就是全部弹出,此时该自由链表_size的值变为0,然后继续调用CentralCache当中的ReleaseToSpans函数,将这三个对象还给CentralCache当中对应的span
此时span中的useCount并不等于0,所以不将该span归还给PageCache。
当七个内存对象都还给该span以后,此时该span中的useCount值为0,就需要归还给PageCache了
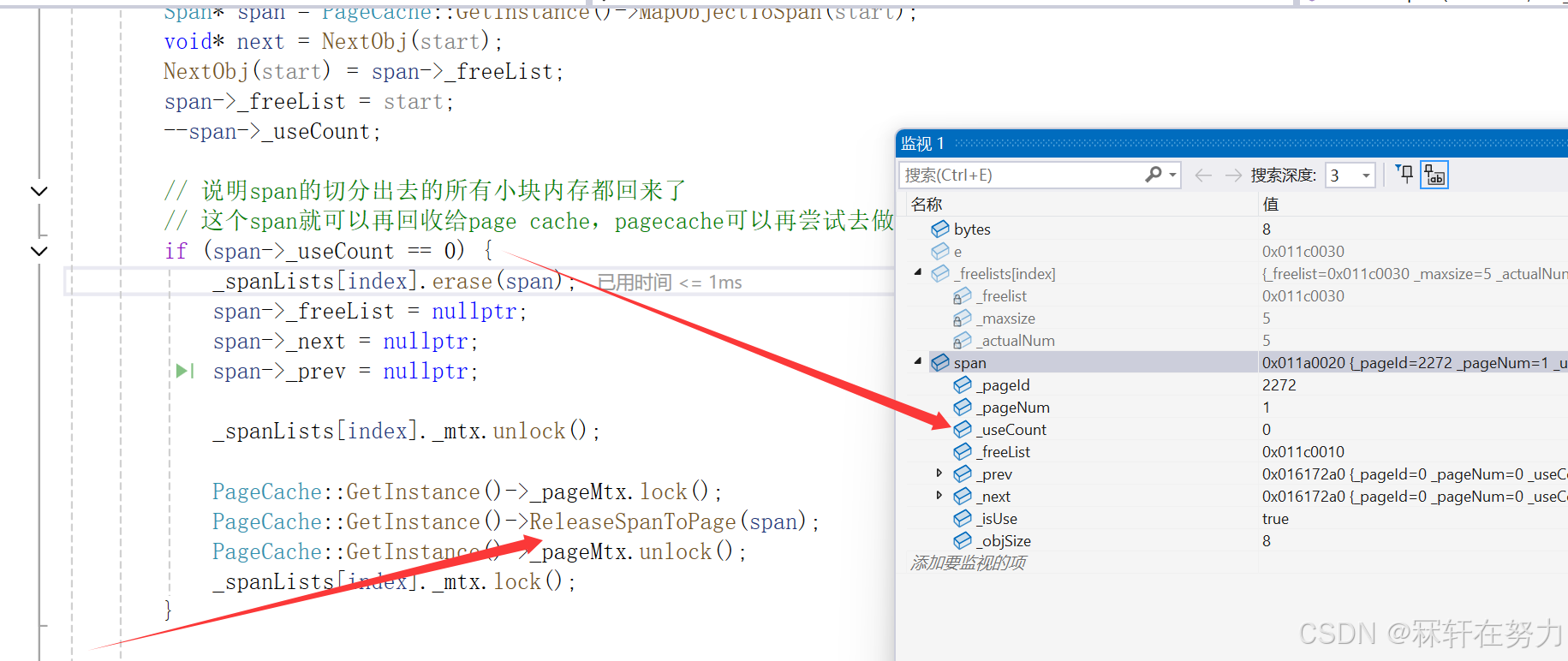
归还给PageCache,需要进行前后页的合并,如果能够与前后页合并,那么就合并,不能就直接插入到对应的桶中。因为此时的span是通过128页的span切分出来的,所以能够进行与后面页的合并为一个128页的span
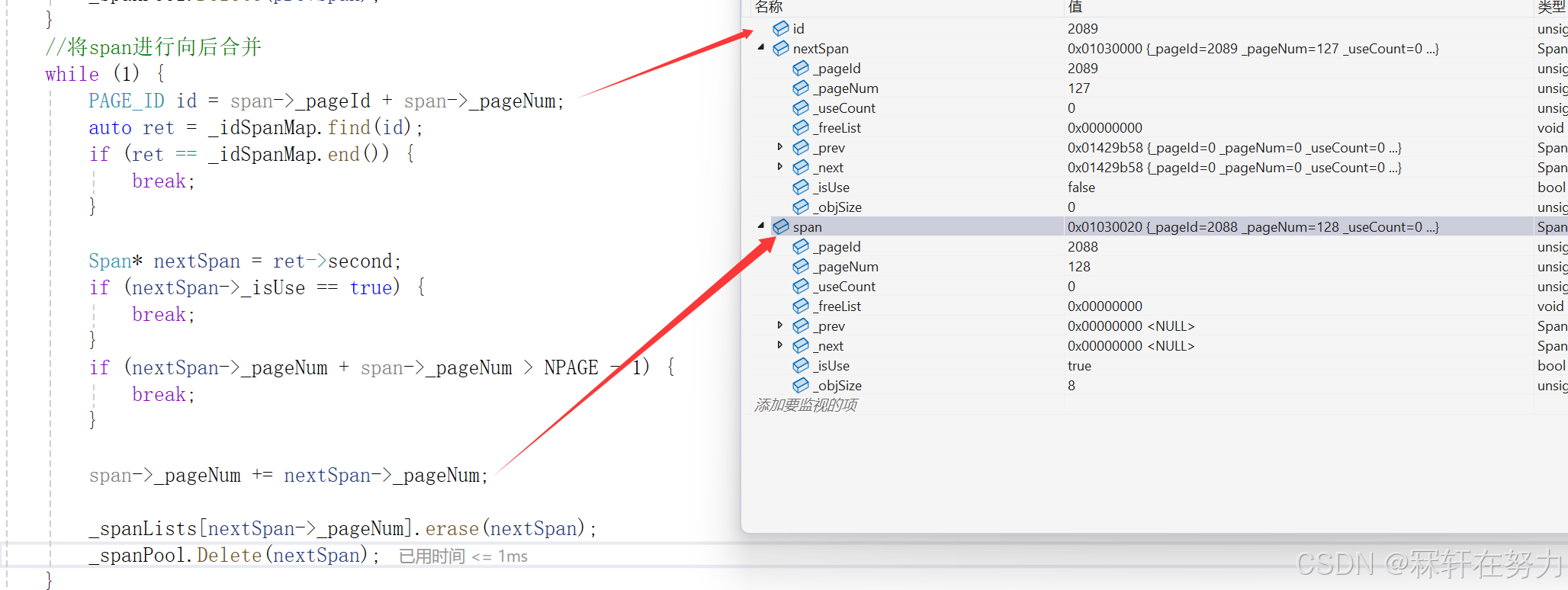
合并完以后,将该span的isUse设置为false,然后插入到128号桶中
测试大内存的申请释放
//测试大内存的申请释放
void* p1 = ConcurrentAlloc(257 * 1024); //257KB
ConcurrentFree(p1, 257 * 1024);测试超大内存的申请释放
void* p2 = ConcurrentAlloc(129 * 8 * 1024); //129页大小
ConcurrentFree(p2, 129 * 8 * 1024);
六、性能瓶颈的分析与优化
性能测试
// ntimes 一轮申请和释放内存的次数
// rounds 轮次
// nwors表示创建多少个线程
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(malloc(16));//v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime.load());printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime.load());printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(ConcurrentAlloc(16));//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime.load());printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime.load());printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}
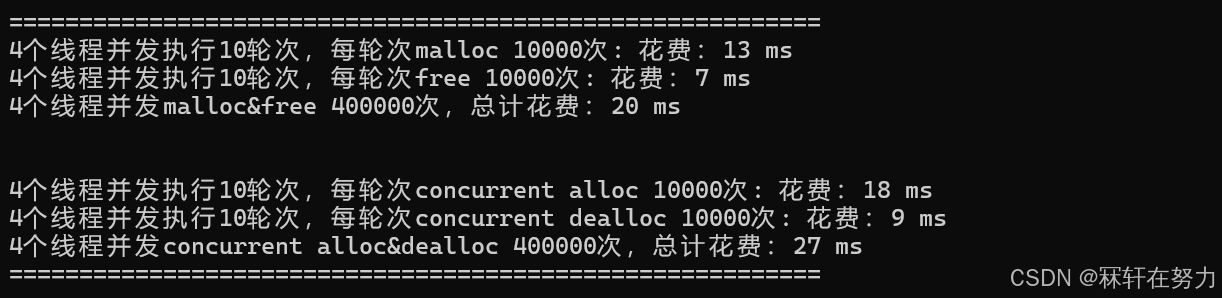
测试4个线程,每个线程申请10万次,且在同一个桶中申请:
测试4个线程,每个线程申请10万次,不在同一个桶中申请内存:

测试4个线程,每个线程申请1万次,且在同一个桶中申请:
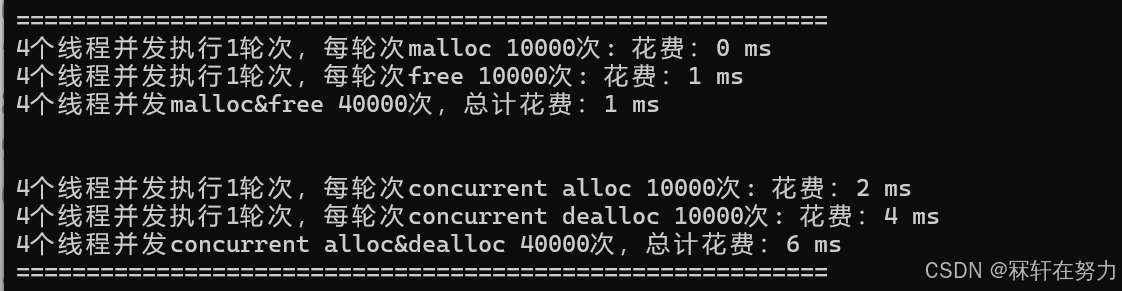
测试4个线程,每个线程申请1万次,不在同一个桶中申请内存:
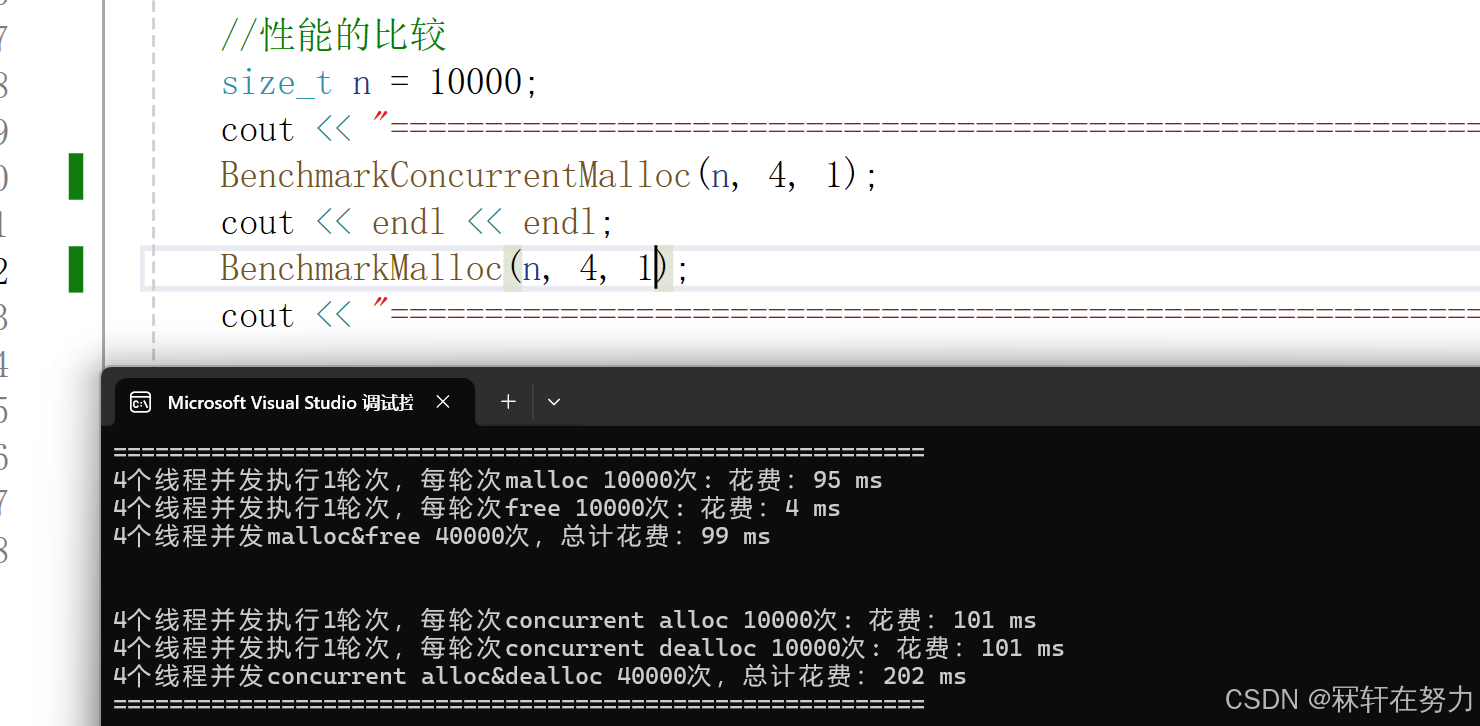
可以发现,当前的内存池和malloc还是有一些差距的
vs中测试性能的工具
本人使用的是vs2022,首先点击调试按钮,然后可以看到性能探测器
点击性能探测器,将检测勾上,点击开始:
选择需要测试的项目:
等它分析完以后,就可以看到哪些函数使用的时间比较长了:
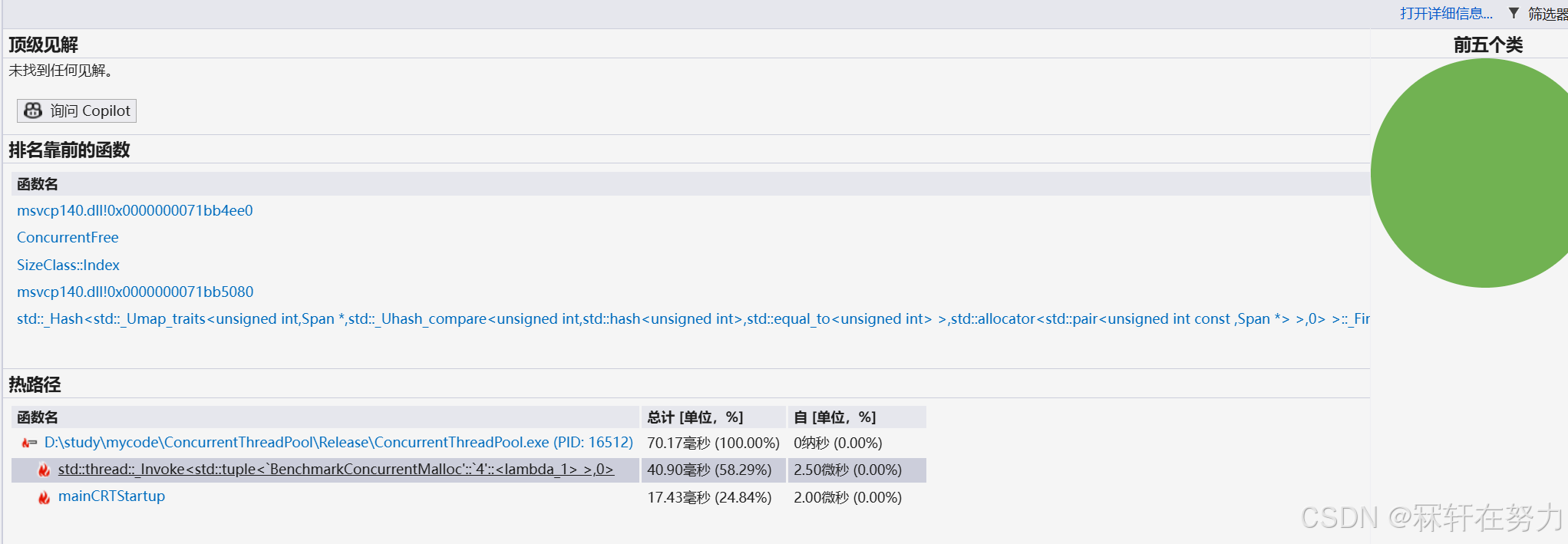
然后可以看到,其中releasetoSpans函数使用的时间最多,然后可以看到哈希表的查找也很耗时
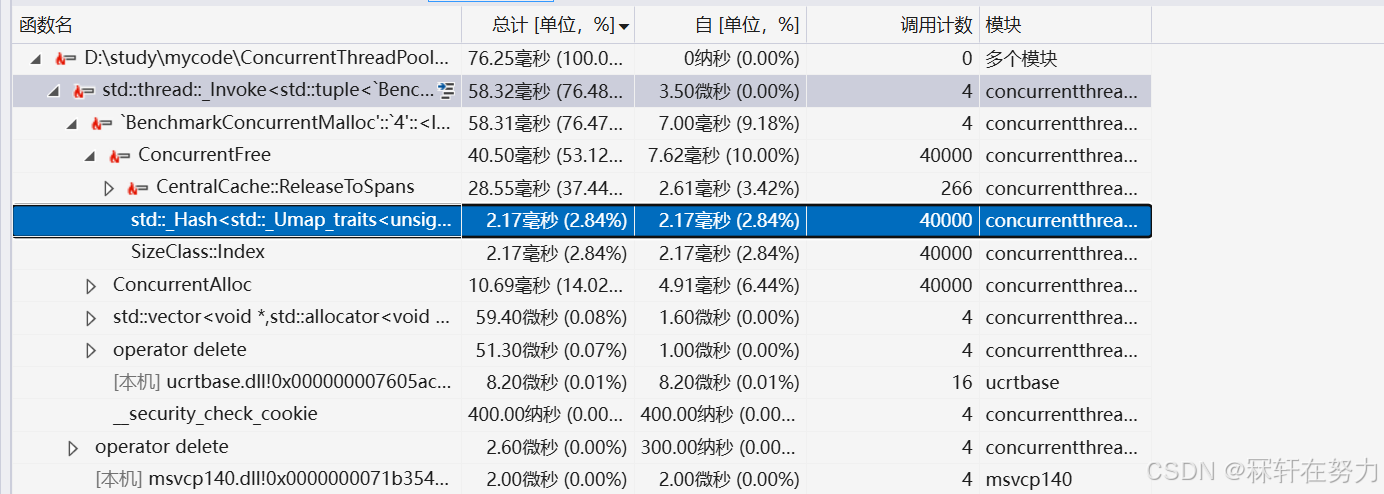
归结原因可以分析出,主要是归还内存对象的时候,查找对应的span,每一次都需要加锁和解锁,这是非常消耗性能资源的
针对性能瓶颈使用基数树进行优化
上面性能问题一方面是数据量大了之后unordered_map查找消耗比较大,还有一个就是锁竞争的消耗比较大,而如果说查的越慢那么锁竞争就会越激烈,所以说上面的实现中,随着数据量的增大,会导致性能越来越不行。
在tcmalloc中使用了基数树来替代上面代码中的哈希表,这里就来简单介绍一下基数树:
在tcmalloc中给出了三颗基数树,分别为1层的、2层的和3层的,它们使用于不同的场景,基数树实际就是一颗多叉树。
一层基数树
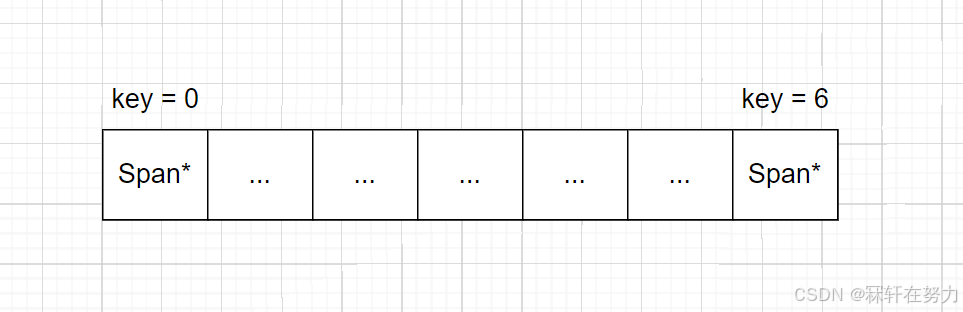
一层基数树,实际就是一个通过直接定址法得到的哈希表,其key值就是一个数组的下标,val存在对应数组下标的位置中。当把key的值看成页号,val看成对应的span对象,那么就可以直接通过随机访问数组的形式,直接得到对应的span,如:arr[key]
template <int BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS; // 数组要开的长度void** array_; // 底层存放指针的数组public:typedef uintptr_t Number;explicit TCMalloc_PageMap1() {// 开空间size_t size = sizeof(void*) << BITS;size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT);array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);memset(array_, 0, sizeof(void*) << BITS);}// Return the current value for KEY. Returns NULL if not yet set,// or if k is out of range.void* get(Number k) const { // 通过k来获取对应的指针if ((k >> BITS) > 0) {return NULL;}return array_[k];}// REQUIRES "k" is in range "[0,2^BITS-1]".// REQUIRES "k" has been ensured before.//// Sets the value 'v' for key 'k'.void set(Number k, void* v) { // 将v设置到k下标array_[k] = v;}
};代码说明:
- BITS表示存储所有的页号至少需要多少比特位
- 对于32位系统下,按一页8KB来算,页内偏移就是13位(8KB = 2^13),所以页号能占32 - 13 = 19位,那么就是32 - PAGE_SHFIT,上面PAGE_SHFIT定义的是13,所以这里BITS就是19,而对于64位下,需要的空间就非常的大了,一层基数树满足不了,需要三层基数树
- get函数通过k来获取对应的指针,set函数将v设置到k下标
二层基数树
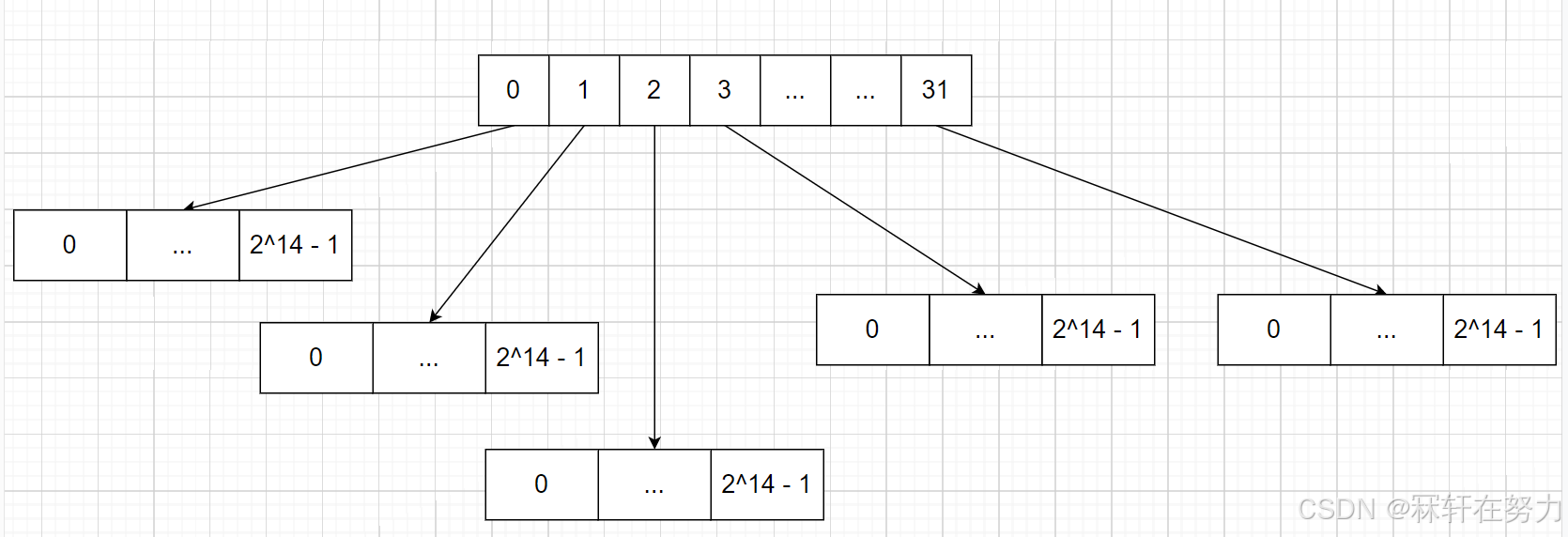
二层基数树,和1层基数树差不多,都是使用的直接定址法,进行存储和访问。不同的是,二层基数树将key值进行了拆分,如:
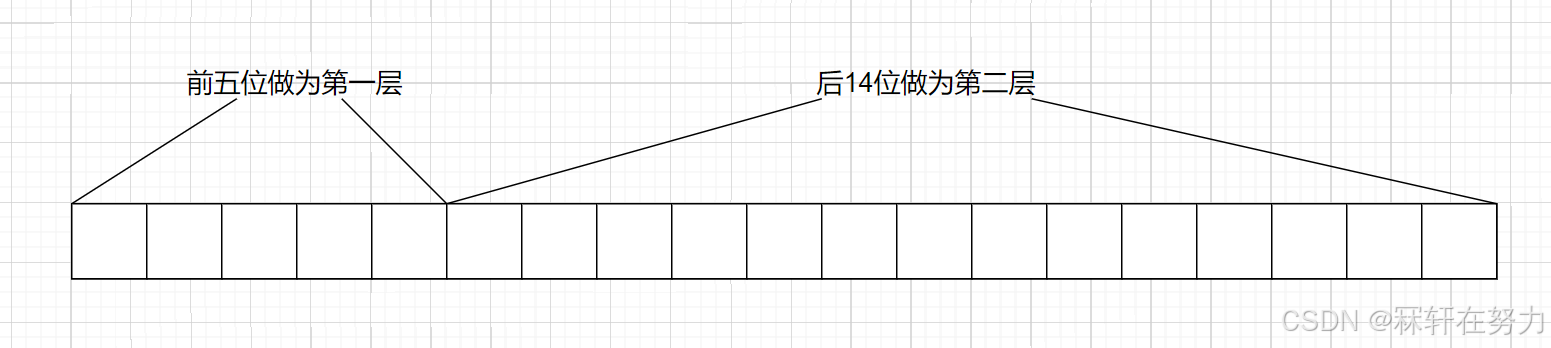
二层基数树的结构:
前五位作为第一层,那么第一层数组大小就有2^5 = 32, 后14位作为第二层(叶子层)那么数组大小就有2^14
// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.static const int ROOT_BITS = 5; // 32位下前5位搞一个第一层的数组static const int ROOT_LENGTH = 1 << ROOT_BITS;static const int LEAF_BITS = BITS - ROOT_BITS; // 32位下后14位搞成第二层的数组static const int LEAF_LENGTH = 1 << LEAF_BITS;// Leaf nodestruct Leaf { // 叶子就是后14位的数组void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; // 根就是前5位的数组
public:typedef uintptr_t Number;//explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap2() { // 直接把所有的空间都开好memset(root_, 0, sizeof(root_));PreallocateMoreMemory(); // 直接开2M的span*全开出来}void* get(Number k) const {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 || root_[i1] == NULL) {return NULL;}return root_[i1]->values[i2];}void set(Number k, void* v) {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);ASSERT(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v;}// 确保从start开始往后的n页空间开好了bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> LEAF_BITS;// Check for overflowif (i1 >= ROOT_LENGTH)return false;// 如果没开好就开空间if (root_[i1] == NULL) {static ObjectPool<Leaf> leafPool;Leaf* leaf = (Leaf*)leafPool.New();memset(leaf, 0, sizeof(*leaf));root_[i1] = leaf;}// Advance key past whatever is covered by this leaf nodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}// 提前开好空间,这里就把2M的直接开好void PreallocateMoreMemory() {// Allocate enough to keep track of all possible pagesEnsure(0, 1 << BITS);}
};
三层基数树
同样的逻辑,再多第一层就行,这个主要是给64位下用的,对应的结构就是这样:
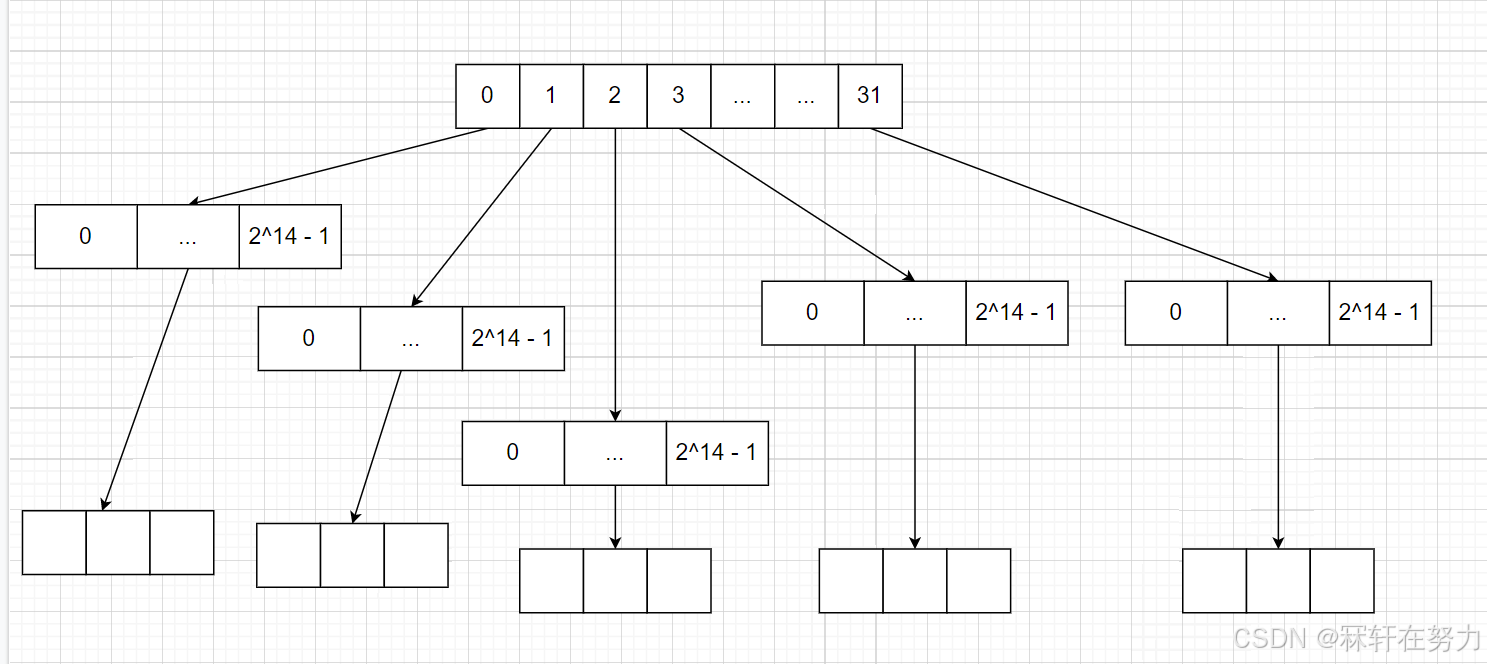
三层基数树和上面的基数树一样,都是只有叶子层才放值,其他都是作为映射。
代码优化
这里只是优化了32位下的,所以使用的是一层基数树,64位如果感兴趣可自行优化
使用到_idSpanMap的地方主要是在PageCache中,只需要将PageCache.cpp中调用该对象的地方进行修改即可。
说明一下:
为什么这里使用基数树可以不用加锁:
-
对基数树进行读操作,进行读操作的地方只有两个,分别是ConcurrentFree、ReleaseToSpans,二者都存在于回收的逻辑当中
-
对于基数树的写操作也是只有两个函数会走到,一个是NewSpan、一个是ReleaseSpanToPage
-
上述读操作中,都是将span释放,表示此时该span中的内存对象已经全部归还回来了,没有其他线程在访问该span,所以是线程安全的。写操作中,一个是申请内存,此时建立映射关系并没有其他线程可以访问到;一个是释放操作,此时该span已经从CentralCache中的对应桶中移除,其他线程也访问不到,可以将其和PageCache中的span进行前后页的合并,并重新建立映射。
-
基数树中的数组都是提前开好的,不会出现扩容时使得存储在该结构中的元素重新映射的情况。其结构是不会发生改变的,是线程安全的
使用基数树优化后的性能测试
测试4个线程,每个线程申请10万次,且在同一个桶中申请:
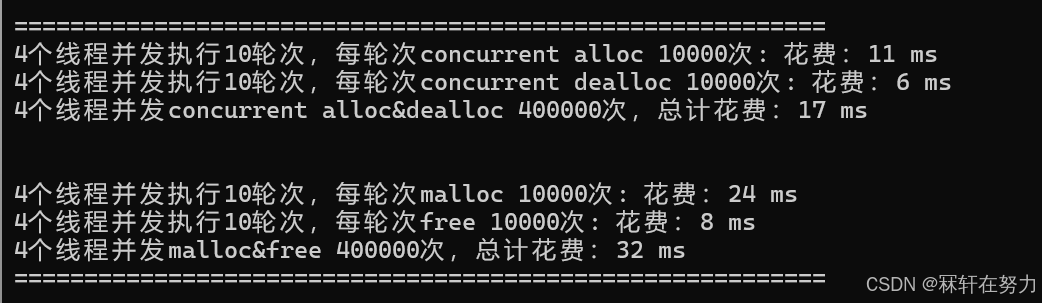
测试4个线程,每个线程申请1万次,且在同一个桶中申请:
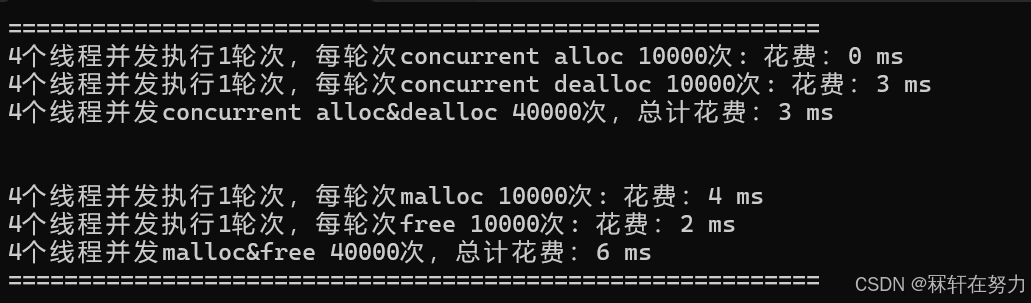
测试4个线程,每个线程申请10万次,不在同一个桶中申请内存:
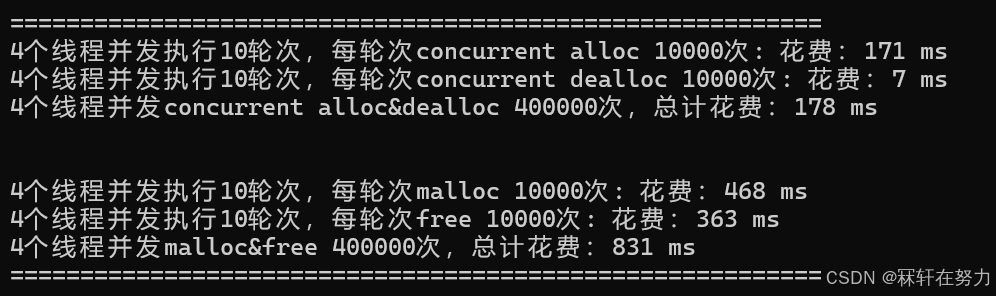
测试4个线程,每个线程申请1万次,不在同一个桶中申请内存:
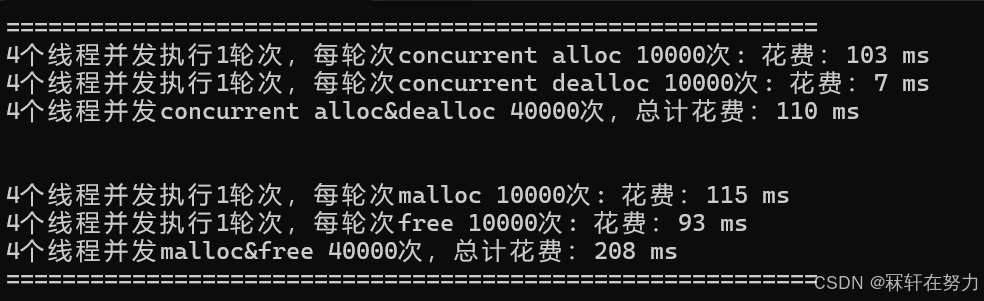
可以发现,现在的内存池比malloc快了不少。
该项目到这就结束了
项目源代码:https://github.com/lx467/ConcurrentThreadPool
相关文章:

高并发内存池项目
高并发内存池项目 一、项目介绍二、什么是内存池2.1池化技术2.2内存池2.3内存池主要解决的问题2.3.1外部碎片2.3.2内部碎片 2.4malloc的了解 三、定长内存池的实现3.1 通过类型模板参数表示定长内存池3.2定长内存池的实现原理 四、高并发内存池的框架设计4.1ThreadCache的实现4…...

你学会了些什么211201?--http基础知识
概念 HTTP–Hyper Text Transfer Protocol,超文本传输协议;是一种建立在TCP上的无状态连接(短连接)。 整个基本的工作流程是:客户端发送一个HTTP请求(Request ),这个请求说明了客户端…...
)
储能集装箱电池簇安装支架结构设计(大纲)
储能集装箱电池簇安装支架结构设计 第一章 绪论 1.1 研究背景与意义 储能技术在能源转型中的战略地位电池簇在储能系统中的核心作用支架结构对电池安全稳定运行的重要性研究电池簇安装支架的工程价值与应用前景 1.2 国内外研究现状 国际先进储能集装箱支架设计技术概述国内…...

解决Chrome浏览器访问https提示“您的连接不是私密连接”的问题
如何绕过Chrome的“您的连接不是私密连接”证书警告页面 在使用Chrome浏览器访问一些自签名或测试用的HTTPS网站时,常常会遇到这样一个拦截页面: “您的连接不是私密连接” 虽然这是Chrome出于安全考虑的设计,但对于开发者或测试人员来说&am…...

前端笔记-AJAX
什么是AJAX? AJAX(Asynchronous JavaScript and XML)就是异步的JS和XML, 是一种无需刷新页面即可与服务器交换数据并更新部分网页内容的技术。它的核心是通过 JavaScript 在后台发送 HTTP 请求,接收服务器返回的…...

单片机可以用来做机器人吗?
不少同学心里都有个疑问:学了单片机到底能不能用来制作机器人呢?答案是毋庸置疑的,能!但具体该如何操作,又得掌握哪些知识呢?今天,咱们就用通俗易懂的话语,详细地为大家一步步剖析清楚。 一、单片机 —— 机器人的 “智慧大脑” 单片机就如同机器人的大脑一般,通过编…...

VS Code + GitHub:高效开发工作流指南
目录 一、安装 & 基本配置 1.下载 VS Code 2.安装推荐插件(打开侧边栏 Extensions) 3.设置中文界面(可选) 二、使用 VS Code 操作 Git/GitHub 1.基本 Git 操作(不输命令行!) 2.连接 GitHub(第一次使用) 三、克隆远程仓库到 VS Code 方法一(推荐): 方…...
)
Linux系统编程 day7、8 信号(周日划水了)
信号相关概念 信号这章难就难在其抽象。 信号共性:简单、不能携带大量数据、满足条件才发送。 信号的特质:信号是软件层面上的“中断”,一旦信号产生,无论程序执行到什么位置,必须立即停止,处理信号&…...

.NET WPF 三维模型
文章目录 .NET WPF 三维模型1 Viewport3D1.1 3D 坐标系1.2 核心组件1.2.1 相机 (Camera)1.2.2 光源 (Light)1.2.3 3D 模型(Model3D) 1.3 模型纹理(Material)1.4 完整示例:创建坐标轴与立方体1.5 转换模型1.6 性能1.6.1…...
)
iOS 中的虚拟内存 (理解为什么需要虚拟内存)
什么叫“虚拟地址空间”? 一句话:它是 CPU 看得见、App 以为自己独享,但实际上会被内核和硬件(MMU)动态翻译到真实 物理内存 的一整块“虚拟地图”。 1. 背景:为什么要“虚拟”? 需求虚拟地址空…...

算法之动态规划
动态规划 动态规划1. 核心思想2. 基本步骤3. 关键概念3.1 基本概念3.2 优化技巧 4. 常见应用场景5. 典型案例5.1 斐波那契数列5.2 背包问题5.2.1 0-1背包问题5.2.2 完全背包问题 5.3 最短路径——Floyd算法5.4 最长公共子序列(LCS)5.5 最长递增子序列&am…...

leetcode0130. 被围绕的区域- medium
1 题目:被围绕的区域 官方标定难度:中 给你一个 m x n 的矩阵 board ,由若干字符 ‘X’ 和 ‘O’ 组成,捕获 所有 被围绕的区域: 连接:一个单元格与水平或垂直方向上相邻的单元格连接。 区域:…...
)
衡石科技ChatBI--飞书数据问答机器人配置详解(附具体操作路径和截图)
先决条件 需要在衡石系统认证方式中配置好飞书认证方式,具体步骤详见认证方式中关于飞书的部分。先完成这部分配置后,再进行以下步骤。 飞书中创建机器人应用 1. 创建飞书应用 在飞书企业自建应用管理中创建应用,设置logoÿ…...

25.解决中医知识问答删除历史对话功能后端处理请求时抛出异常
ChatTest.vue:176 DELETE http://localhost:8080/api/chat/conversations/20 500 (Internal Server Error) deleteConversation ChatTest.vue:176 onClick ChatTest.vue:22 ChatTest.vue:185 删除失败 AxiosError {message: Request failed with status code 500, name: Axio…...

【解决方法】关于解决QGC地面站4.4.3中文BUG,无法标注航点的问题
GC以中文启动时无法标记航点,只有在英文状态下启动然后转换为中文才能标记航点。这个BUG源于中文翻译脚本里面以中文逗号作为多个选项的分隔符,导致编译器认为这个只是一个整体。所以翻译时数量不匹配,导致BUG。 解决方法:将所有…...

Flowith AI,解锁下一代「知识交易市场」
前言 最近几周自媒体号都在疯狂推Manus,看了几篇测评后,突然在某个时间节点,在特工的文章下,发现了很小众的Flowith。 被这段评论给心动到,于是先去注册了下账号。一翻探索过后,发现比我想象中要有趣的多&…...

【AI实战】基于DeepSeek构建个性化AI对话代理:从提示词工程到完整实现
作为开发者,我们经常需要与AI进行各种交互。本文将详细介绍如何通过提示词工程(prompt engineering)构建个性化的AI对话代理,并使用DeepSeek的API实现完整解决方案。 一、个性化AI代理的核心要素 1.1 角色设定(Role Setting) 角色设定是构建个性化AI的…...

基于ueditor编辑器的功能开发之重写ueditor的查找和替换功能,支持滚动定位
百度编辑器的查找和替换无法随着页面滚动定位,找到searchreplace.js,重写里面的方法 效果展示: 20250421173735 思路: 找到查找和替换的输入框,发现id名分别为findtxt和findtxt1,分别绑定change事件&…...
)
分布式数据库TiDB:架构、核心特性与生产实践(分库分表)
在云计算与大数据时代,传统单机数据库面临三大挑战:海量数据存储、高并发访问和实时分析需求。MySQL分库分表方案复杂、NoSQL缺乏ACID支持、MPP数仓难以处理OLTP... 在这样的背景下,TiDB应运而生。作为一款开源的分布式NewSQL数据库ÿ…...

用自然语言指令构建机器学习可视化编程流程:InstructPipe 的创新探索
想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。 1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其…...

利用WSL2的镜像功能访问Windows下的所有网卡
目录 引言 镜像功能 如何设置 自动代理 结语 引言 我通常用PC上的LAN口去连接开发板,但是在WSL2中要访问LAN口连接的开发板有点麻烦。WSL2默认的网络模式为NAT,如果要访问Windows中网口需要设置桥接,比较繁琐。今天尝试了一下Windows 1…...

AI助理iOS开发:Copilot for Xcode 下载与安装全指南
引言 借助 Copilot for Xcode 也有两年了,如今已经变成了日常开发中的“默契搭档”。它能根据上下文补全代码,快速生成常用逻辑,甚至有时候在我还在思考怎么写的时候,它就已经给出了不错的建议。特别是在写一些重复性较高的代码&…...

Hadoop+Spark 笔记 2025/4/21
定义 1. 大数据(Big Data) - 指传统数据处理工具难以处理的海量、高速、多样的数据集合,通常具备3V特性(Volume体量大、Velocity速度快、Variety多样性)。扩展后还包括Veracity(真实性)和Va…...

模拟车辆变道 python 可视化
目录 车头朝向一起变化 车头朝向不变化,矩形框 车头朝向一起变化 import cv2 import numpy as npdef world_to_pixel(world_x, world_y, img_w=800, img_h=800):scale_x = img_w / 120 # 横向范围:0~120米scale_y = img_h / 80 # 纵向范围:0~80米pixel_x = int(world_x …...

国产仪器进化论:“鲁般号”基于无人机的天线测试系统
2025年4月14日,成都玖锦科技有限公司正式发布了新品:“鲁般号会飞的系统”系列,这是玖锦科技首款基于无人机的天线方向图测试系统。 在“振兴民族产业,打造民族品牌”的征途中,“鲁般号”系列是继“墨子”、“孔明”、…...
:SPI FLASH设备驱动)
Linux学习笔记协议篇(六):SPI FLASH设备驱动
目录 一、设备树解析 二、SPI设备驱动代码分析 1、spi_nor_probe 2、spi_nor_scan (1)协议配置 (2)初始化Flash参数(核心步骤) (3)MTD子系统集成 (3)配置 SPI 通信参数 spi…...

Spring Boot 核心模块全解析:12 个模块详解及作用说明
在当今的微服务与云原生时代,Spring Boot 已成为构建现代 Java 应用的事实标准。它通过“约定优于配置”的理念,大大降低了 Spring 应用的开发门槛,帮助开发者快速启动和部署独立的、生产级别的项目。 本篇文章将系统梳理 Spring Boot 框架中…...

【无人机】无人机方向的设置,PX4飞控方向,QGC中设置飞控的方向/旋转角度。PX4使用手册飞行控制器/传感器方向
目录 #1、基本概念:计算方向 #2、详细步骤:设置方向 #3、微调 默认情况下,飞行控制器(和外部指南针,如果有)应放置在框架顶部朝上,方向应使箭头指向飞机前部。 如果板或外部指南针安装在任何…...

【Spring Boot基础】MyBatis的基础操作:日志、增删查改、列名和属性名匹配 -- 注解实现
MyBatis的基础操作 1.打印日志2. 参数传递2.1不传参2.2 固定参数 3. 增(Insert)3.1 用对象接参3.2 用param注解接收参数3.3 返回主键 4. 删(Delete)4.1 用Integer接参4.2 用对象接参 5. 改(Update)6. 查(Select)6.1 查6.2 拼接SQL语句6.3 列名和属性名匹配6.3.1 起别名 as6.3.2…...

泰迪智能科技大模型应用平台功能特色优势
1.平台概述 大模型应用平台是一款专为高校在大模型应用场景下的教学和科研需求设计的知识库问答系统。平台具备便捷性,支持上传常见格式的数据文件,如txt、doc、pdf、md等,并提供简洁明了的操作配置界面,使用户能够轻松搭建和训练…...

【NLP 69、KG - BERT】
人们总是在无能为力的时候喜欢说顺其自然 —— 25.4.21 一、KG-BERT:基于BERT的知识图谱补全模型 1.模型结构与设计 Ⅰ、核心思想: 将知识图谱中的三元组(头实体-关系-尾实体)转化为文本序列,利用BERT的上下文理解能…...

Spring解决循环依赖
Spring 通过 三级缓存机制 解决循环依赖问题,其核心思想是 提前暴露未完全初始化的 Bean,允许依赖方在 Bean 完全初始化前引用其早期版本。以下是详细解析: 一、三级缓存机制 Spring 在单例 Bean 的创建过程中维护了三级缓存,用于…...
)
深入解析 Spring 中的 @Value 注解(含源码级剖析 + 自定义实现)
深入解析 Spring 中的 Value 注解(含源码级剖析 自定义实现) 在 Spring 开发中,我们经常使用 Value 注解将配置文件中的值注入到 Bean 的属性中。本文将深入探讨 Value 的使用方式、默认值支持、底层原理以及自定义实现方式。 一、Value 的…...

【Flink SQL实战】 UTC 时区格式的 ISO 时间转东八区时间
文章目录 一、原始数据格式二、解决方案三、其他要求 在实际开发中,我们常常会遇到此类情况:数据源里的时间格式是类似 2025-04-21T09:23:16.025Z 这种带 TimeZone 标识的 ISO 8601 格式,而我们需要在 Flink SQL 中将其转换成北京时间显示。 …...
)
【论文阅读23】-地下水预测-TCN-LSTM-Attention(2024-11)
这篇论文主要围绕利用深度学习模型检测地下水位异常以识别地震前兆展开。 [1] Chen X, Yang L, Liao X, et al. Groundwater level prediction and earthquake precursor anomaly analysis based on TCN-LSTM-attention network[J]. IEEE Access, 2024, 12: 176696-176718. 期刊…...

/proc/sys/vm/下各参数含义
/proc/sys/vm/下各参数含义 admin_reserve_kbytes如何计算最小有效预留? compact_memorycompaction_proactivenesscompact_unevictable_alloweddirty_background_bytesdirty_background_ratiodirty_bytesdirty_expire_centisecsdirty_ratiodirtytime_expire_seconds…...

算法分析与设计——动态规划复习题(待更新
检测题: 组合优化问题的目标函数通常不包括以下哪种形式? A. 需最小化的代价函数 B. 需最大化的回报函数 C. 需满足的硬约束条件 D. 需最小化的能量函数 答案:C 关于约束条件的说法,以下哪项是正确的? A. 硬约束可以通…...
)
【EasyPan】项目常见问题解答(自用持续更新中…)
EasyPan 网盘项目介绍 一、项目概述 EasyPan 是一个基于 Vue3 SpringBoot 的网盘系统,支持文件存储、在线预览、分享协作及后台管理,技术栈涵盖主流前后端框架及中间件(MySQL、Redis、FFmpeg)。 二、核心功能模块 用户认证 注册…...

基于Java的不固定长度字符集在指定宽度和自适应模型下图片绘制生成实战
目录 前言 一、需求介绍 1、指定宽度生成 2、指定列自适应生成 二、Java生成实现 1、公共方法 2、指定宽度生成 3、指定列自适应生成 三、总结 前言 在当今数字化与信息化飞速发展的时代,图像的生成与处理技术正日益成为众多领域关注的焦点。从创意设计到数…...
架构)
电子电器架构 ---软件定义汽车的电子/电气(E/E)架构
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

Stable Diffusion 制作角色三视图
对于漫画创作,DPM 2M Karras和UniPC是高效且稳定的首选采样方法,结合Karras噪声调度可显著提升画面质量。若需进一步优化,可参考具体场景调整步数并辅以ControlNet等工具。避免使用随机性强的采样器(如Euler a)&#x…...

C++--负载均衡在线OJ
这是本人写的第二个项目,相比第一个代码量更少一些,但是此项目涉及linux中的内容更多,同样是干货满满,实现了 类似 leetcode 的题⽬列表在线编程功能,地址仓库:xwy/C学习项目 1. 所用技术与开发环境 C11和…...
)
【数字图像处理】彩色图像处理(1)
研究彩色图像处理的原因 1:利用颜色信息,可以简化目标物的区分,以及从场景中提取出目标物 2:人眼对颜色非常敏感,可以分辨出来几千种颜色色调和亮度,却只能分别出几十种灰度 彩色图像分类 伪彩色图像处理&…...

【Easylive】consumes = MediaType.MULTIPART_FORM_DATA_VALUE 与 @RequestPart
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 consumes MediaType.MULTIPART_FORM_DATA_VALUE 的作用 1. 定义请求的数据格式 • 作用:告诉 Feign 和 HTTP 客户端,这个接口 接收的是 multipart/form-data 格式的…...

【python】copy deepcopy 赋值= 对比
上结论 写法是否独立是否安全修改copy() (用于一维列表)✅ 是独立副本✅ 安全deepcopy() (多层结构时用)✅ 是完全副本✅ 安全直接赋值()❌ 是引用❌ 改一个会影响另一个 一、.copy() 和 deepcopy() 有什…...

环形缓冲区容量耗尽解决方案
以下是针对环形缓冲区在时间窗口统计场景中容量耗尽问题的解决方案设计及优劣分析,结合搜索结果中的技术原理和工程实践: 一、核心问题定位 当环形缓冲区容量耗尽时,新数据覆盖旧数据会导致: 时间窗口统计失真:无法准…...

蓝桥杯 17.发现环
发现环 原题目链接 题目描述 小明的实验室有 N 台电脑,编号 1 ⋯ N。 原本这 N 台电脑之间有 N−1 条数据链接相连,恰好构成一个树形网络。 在树形网络上,任意两台电脑之间有唯一的路径相连。 不过在最近一次维护网络时,管理…...

数据库服务器架构
ORM ORM(Object Relational Mapping):对象与关系数据之间的映射 映射关系表: 类(class)—— 数据库的表(table) 对象(object)——记录(record…...

Netty前置基础知识之BIO、NIO以及AIO理论详细解析和实战案例
前言 Netty是什么? Netty 是一个基于 Java 的 高性能异步事件驱动网络应用框架,主要用于快速开发可维护的协议服务器和客户端。它简化了网络编程的复杂性,特别适合构建需要处理海量并发连接、低延迟和高吞吐量的分布式系统。 1)Netty 是…...

职坐标IT培训:人工智能职业跃迁路径
随着人工智能时代全面来临,职业发展格局正经历颠覆性重构。政策端,《新一代人工智能发展规划》与《生成式AI服务管理办法》双轨并行,既为行业注入动能,也划定了技术应用的合规边界。在此背景下,从业者需构建覆盖基础理…...