【JavaWeb后端开发03】MySQL入门
文章目录
- 1. 前言
- 1.1 引言
- 1.2 相关概念
- 2. MySQL概述
- 2.1 安装
- 2.2 连接
- 2.2.1 介绍
- 2.2.2 企业使用方式(了解)
- 2.3 数据模型
- 2.3.1 **关系型数据库(RDBMS)**
- 2.3.2 数据模型
- 3. SQL语句
- 3.1 DDL语句
- 3.1.1 数据库操作
- 3.1.1.1 查询数据库
- 3.1.1.2 创建数据库
- 3.1.1.3 使用数据库
- 3.1.1.4 删除数据库
- 3.1.2 图形化工具
- 3.1.2.1 介绍
- 3.1.2.2 安装
- 3.1.2.3 连接数据库
- 3.1.3 表操作
- 3.1.3.1 创建
- 3.1.3.2 约束
- 3.1.3.3 数据类型
- 3.1.3.4 表结构设计-案例
- 3.1.3.5 表操作-其他操作
- 3.2 DML语句
- 3.2.1 增加(insert)
- 3.2.1.1 **语法**
- 3.2.1.2 案例演示
- 3.2.2 修改(update)
- 3.2.2.1 语法
- 3.2.2.2 案例演示
- 3.2.3 删除(delete)
- 3.2.3.1 语法
- 3.2.3.2 案例演示
- 3.3 DQL语句
- 3.3.1 介绍
- 3.3.2 语法
- 3.3.3 基本查询
- 3.3.4 条件查询
- 3.3.5 聚合函数
- 3.3.6 分组查询
- 3.3.7 排查查询
- 3.3.8 分页查询
1. 前言
1.1 引言
在我们讲解SpringBootWeb基础知识(IOC、DI等)的时候,我们讲到在web开发中,为了应用程序职责单一,方便维护,我们一般将web应用程序分为三层,即:Controller、Service、Dao 。
之前我们的案例中,是这样子的请求流程:浏览器发起请求,先请求Controller;Controller接收到请求之后,调用Service进行业务逻辑处理;Service再调用Dao,Dao再解析user.txt中所存储的数据。
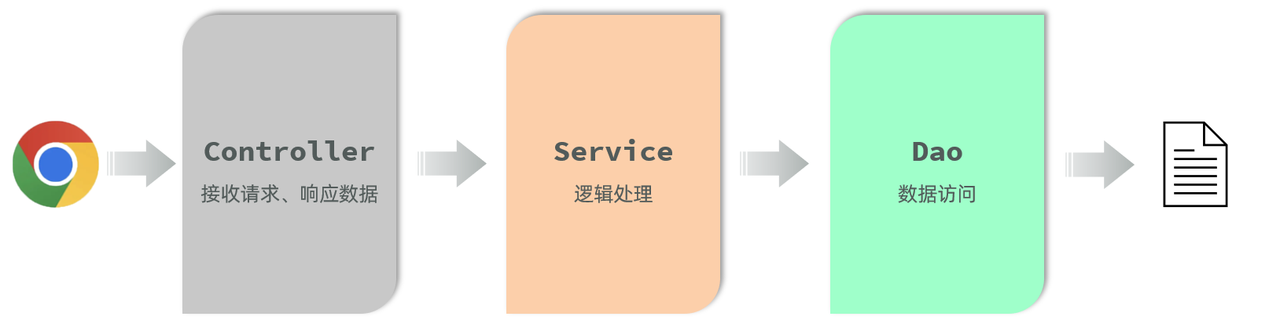
txt文件中可以存储数据,但是在企业项目开发中一般不会使用文本文件存储项目数据,因为不便管理维护,操作难度大。
在真实的企业开发中呢,都会采用数据库来存储和管理数据,那此时,web开发调用流程图如下所示:
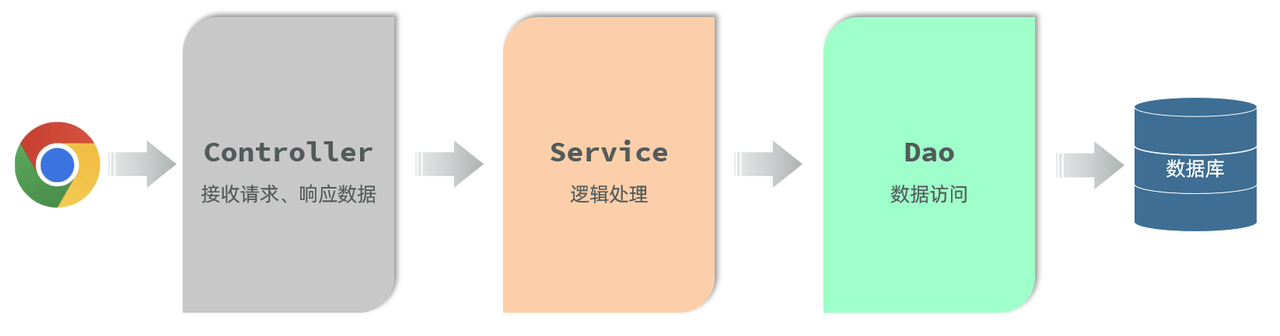
那么今天我们就要来学习数据库技术。
1.2 相关概念
首先来了解一下什么是数据库。
- 数据库:英文为 DataBase,简称DB,它是存储和管理数据的仓库。
像我们日常访问的电商网站京东,企业内部的管理系统OA、ERP、CRM这类的系统,以及大家每天都会刷的头条、抖音类的app,那这些大家所看到的数据,其实都是存储在数据库中的。最终这些数据,只是在浏览器或app中展示出来而已,最终数据的存储和管理都是数据库负责的。
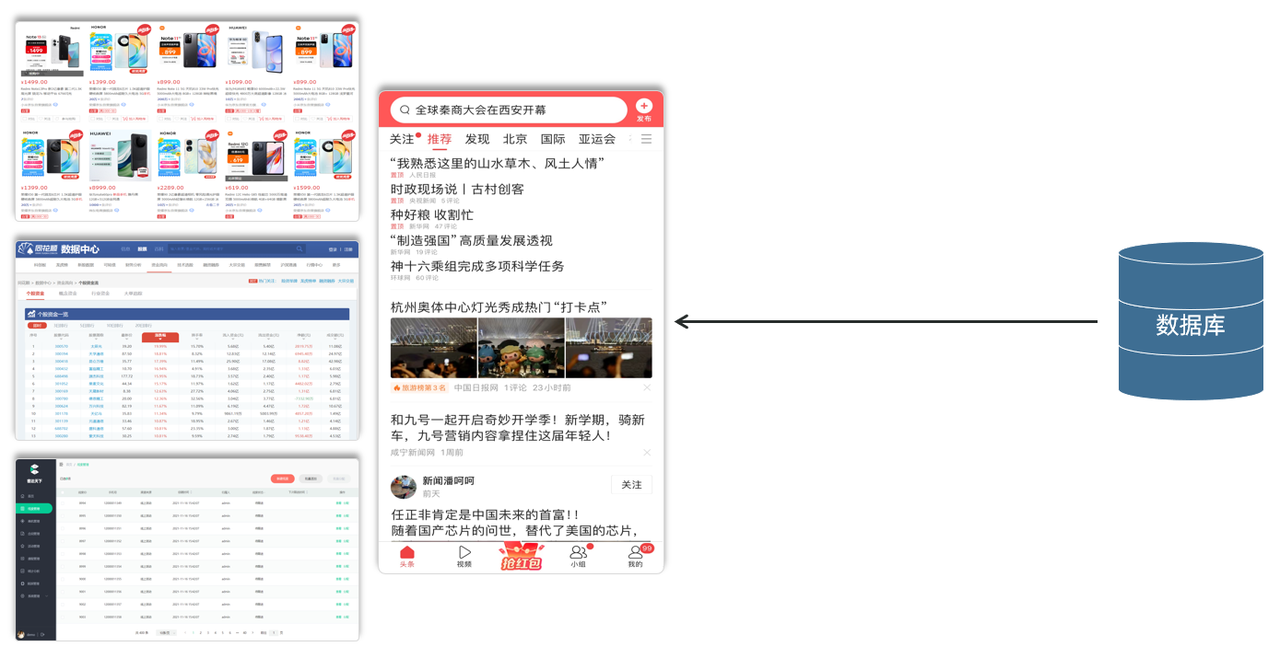
数据是存储在数据库中的,那我们要如何来操作数据库以及数据库中所存放的数据呢?
那这里呢,会涉及到一个软件,那就是数据库管理系统。
- 数据库管理系统(DataBase Management System,简称DBMS),是操作和管理数据库的大型软件。
将来我们只需要操作这个软件,就可以通过这个软件来操纵和管理数据库了。
此时又出现一个问题:DBMS这个软件怎么知道要操作的是哪个数据库、哪个数据呢?是对数据做修改还是查询呢?
需要给DBMS软件发送一条指令,告诉这个软件我们要执行的是什么样的操作,要对哪个数据进行操作。而这个指令就是SQL语句。
- SQL(Structured Query Language,简称SQL):结构化查询语言,它是操作关系型数据库的编程语言,定义了一套操作关系型数据库的统一标准。
我们学习数据库开发,最为重要的就是学习SQL语句 。
关系型数据库:我们后面会详细讲解,现在大家只需要知道我们学习的数据库属于关系型数据库即可。
结论:程序员给数据库管理系统(DBMS)发送SQL语句,再由数据库管理系统操作数据库当中的数据。
了解了数据库的一些简单概念之后,接下来我们再来介绍下目前主流的数据库,这里截取了排名前十的数据库:
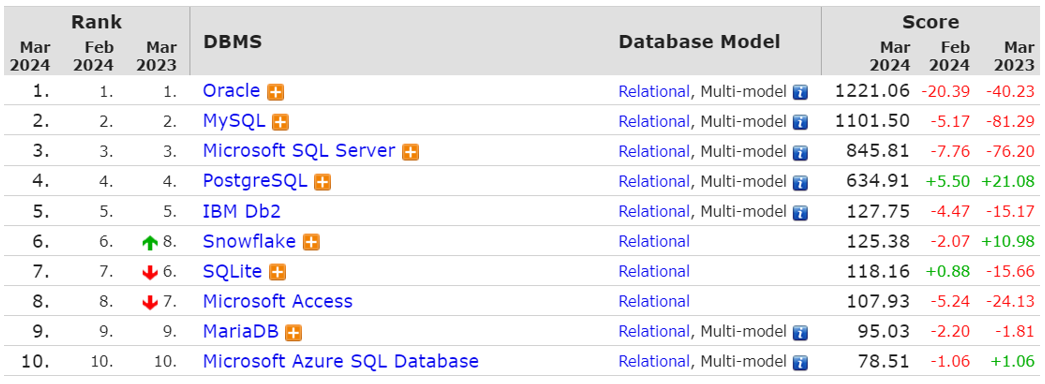
Oracle:大型的收费数据库,Oracle公司产品,价格昂贵。(通常是不差钱的公司会选择使用这个数据库)
MySQL:开源免费的中小型数据库,后来Sun公司收购了MySQL,而Oracle又收购了Sun公司。目前Oracle推出两个版本的Mysql:社区版(开源免费)、商业版(收费)。
SQL Server:Microsoft 公司推出的收费的中型数据库,C#、.net等语言常用。
PostgreSQL:开源免费的中小型数据库。
DB2:IBM公司的大型收费数据库产品。
SQLLite:嵌入式的微型数据库。Android内置的数据库采用的就是该数据库。
MariaDB:开源免费的中小型数据库。是MySQL数据库的另外一个分支、另外一个衍生产品,与MySQL数据库有很好的兼容性。
那这么多数据库,我们全部都需要学习吗,其实并不用,我们只需要学习其中的一个就可以了,我们此次课程中学习的数据库是现在互联网公司开发使用最为流行的MySQL数据库。
此时大家可能会有一个疑问,我们现在学习的是Mysql数据库,我们以后去公司做开发,如果用到的是Oracle数据库或SQL Server数据库该怎么办?其实大家完全不用担心这个问题,因为这些数据库都是属于关系型数据库,要操作关系型数据库都是通过 SQL语句来实现的,而SQL语句又是操作关系型数据库的统一标准。
结论:只要我们学会了SQL语句,就可以通过SQL语句来操作Mysql,也可以通过SQL语句来操作Oracle或SQL Server
课程内容安排:
-
MySQL概述
-
SQL语句(DDL、DML、DQL)
-
多表设计
-
多表查询
-
事务
-
索引
2. MySQL概述

官网:https://dev.mysql.com/
MySQL官方提供了两个版本:
-
商业版本(MySQL Enterprise Edition)
- 该版本是收费的,我们可以使用30天。 官方会提供对应的技术支持。
-
社区版本(MySQL Community Server)
- 该版本是免费的,但是MySQL不会提供任何的技术支持。
本课采用的是MySQL的社区版本(8.0.34)
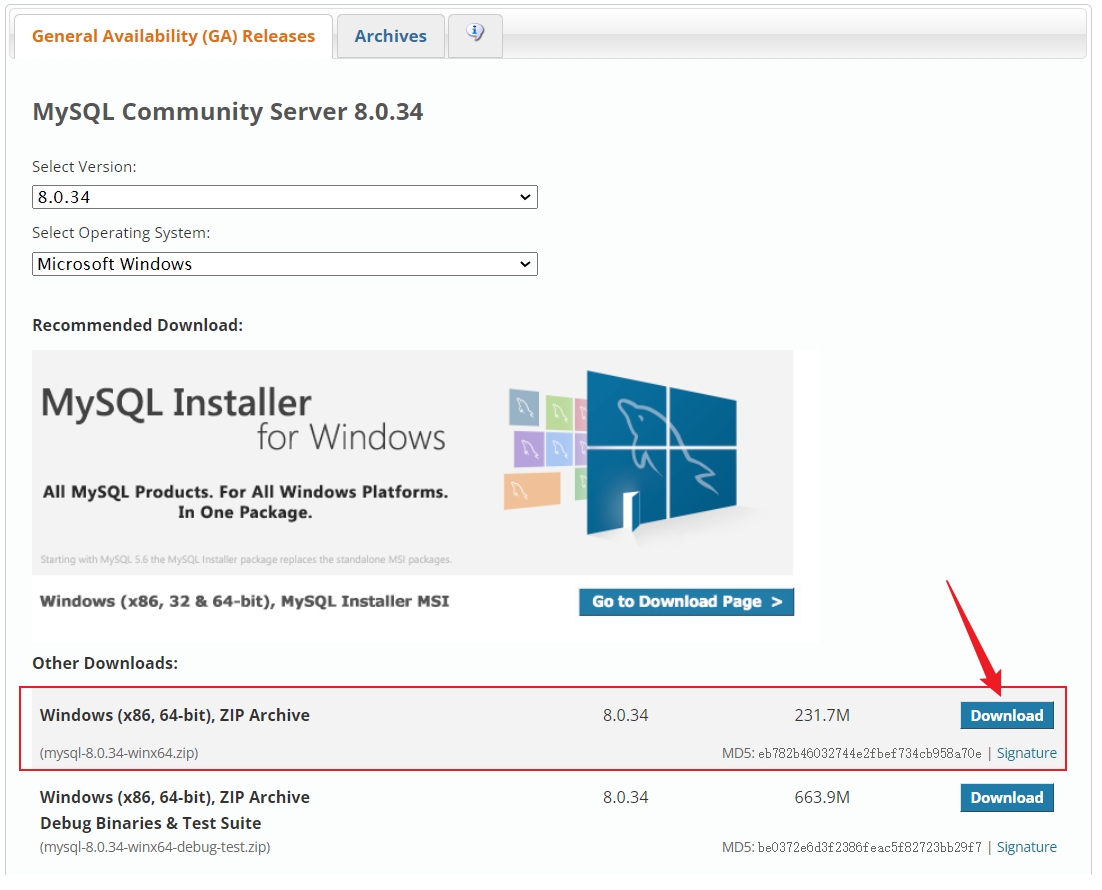
2.1 安装
官网下载地址:https://downloads.mysql.com/archives/community/
2.2 连接
2.2.1 介绍
MySQL服务器启动完毕后,然后再使用如下指令,来连接MySQL服务器:
-
-h 参数不加,默认连接的是本地 127.0.0.1 的MySQL服务器
-
-P 参数不加,默认连接的端口号是 3306
上述指令,可以有两种形式:
- 密码直接在-p参数之后直接指定 (这种方式不安全,密码直接以明文形式出现在命令行)
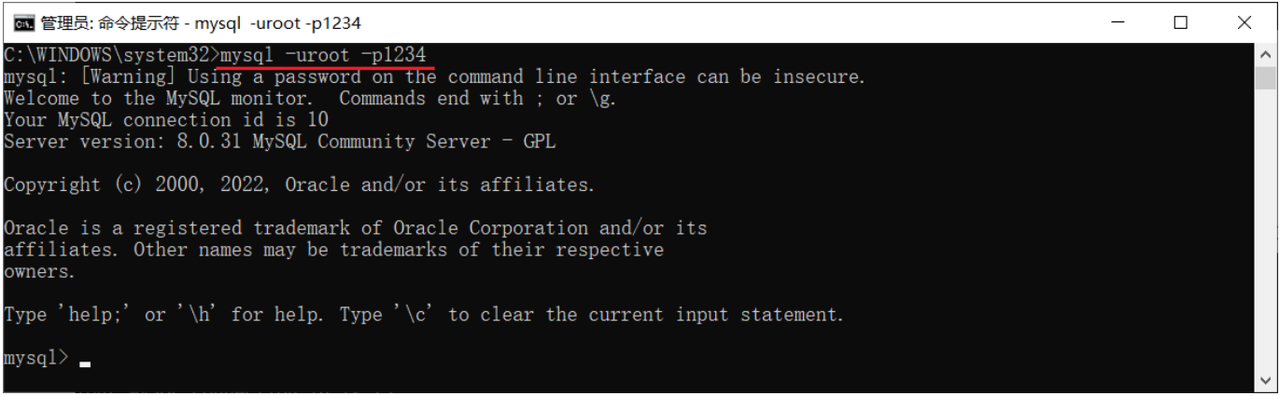
- 密码在-p回车之后,在命令行中输入密码,然后回车
2.2.2 企业使用方式(了解)
上述的MySQL服务器我们是安装在本地的,这个仅仅是在我们学习阶段,在真实的企业开发中,MySQL数据库服务器是不会在我们本地安装的,是在公司的服务器上安装的,而服务器还需要放置在专门的IDC机房中的,IDC机房呢,就需要保证恒温、恒湿、恒压,而且还要保证网络、电源的可靠性(备用电源及网络)。
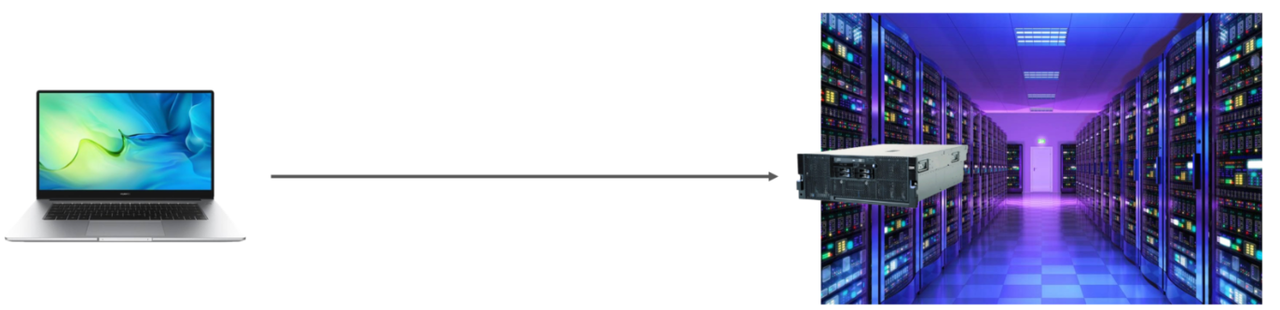
那我们要想使用服务器上的这台MySQL服务器,就需要在我们的电脑上去远程连接这台MySQL 。 而服务器上安装的MySQL数据库呢,并不是你一个人在访问,我们项目组的其他开发人员也是需要访问这台MySQL的。
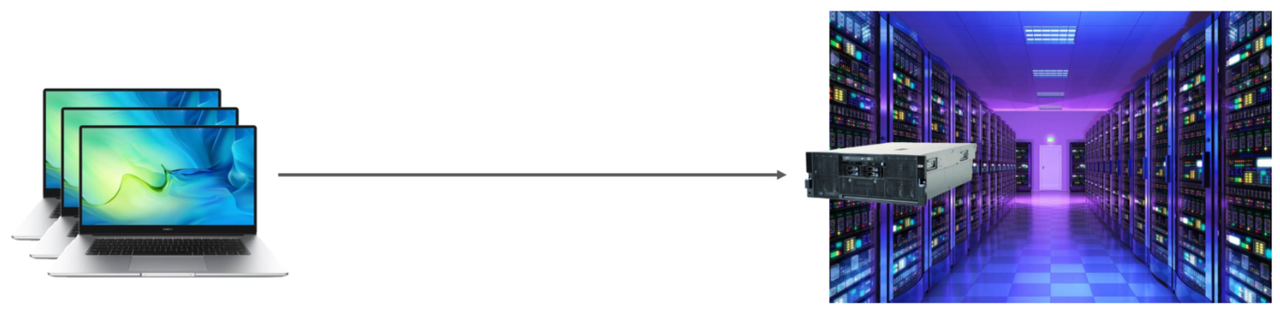
接下来,就来演示一下,通过MySQL的客户端命令行,如何来连接服务器上部署的MySQL :
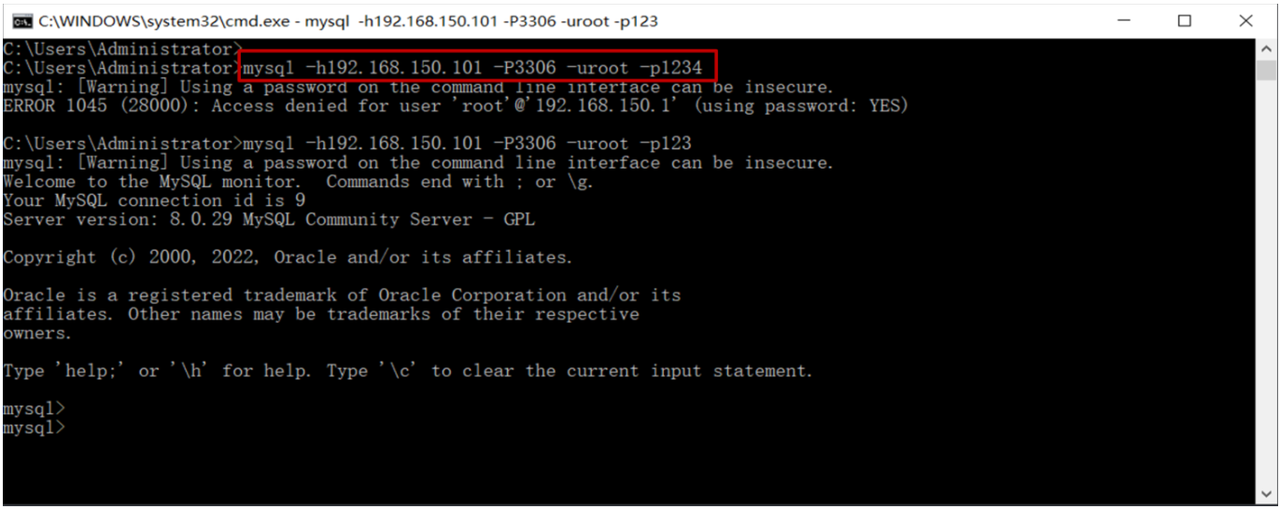
mysql -u用户名 -p密码 -h要连接的mysql服务器的ip地址(默认127.0.0.1) -P端口号(默认3306)

2.3 数据模型
介绍完了Mysql数据库的安装配置之后,接下来我们再来聊一聊Mysql当中的数据模型。学完了这一小节之后,我们就能够知道在Mysql数据库当中到底是如何来存储和管理数据的。
在介绍 Mysql的数据模型之前,需要先了解一个概念:关系型数据库。
2.3.1 关系型数据库(RDBMS)
概念:建立在关系模型基础上,由多张相互连接的二维表组成的数据库。而所谓二维表,指的是由行和列组成的表,如下图:
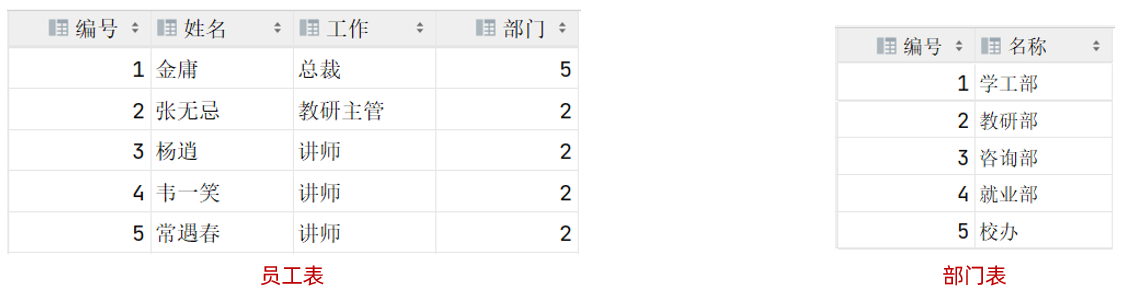
二维表的优点:
-
使用表存储数据,格式统一,便于维护
-
使用SQL语言操作,标准统一,使用方便,可用于复杂查询
我们之前提到的MySQL、Oracle、DB2、SQLServer这些都是属于关系型数据库,里面都是基于二维表存储数据的。
结论:基于二维表存储数据的数据库就成为关系型数据库,不是基于二维表存储数据的数据库,就是非关系型数据库(比如大家后面要学习的Redis,就属于非关系型数据库)。
2.3.2 数据模型
介绍完了关系型数据库之后,接下来我们再来看一看在Mysql数据库当中到底是如何来存储数据的,也就是Mysql 的数据模型。
MySQL是关系型数据库,是基于二维表进行数据存储的,具体的结构图下:
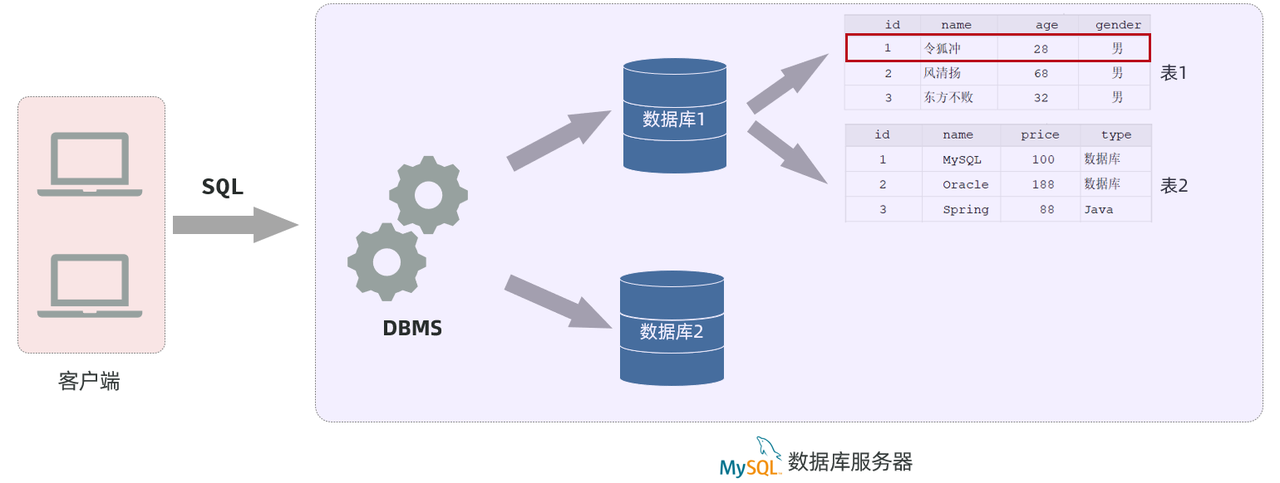
-
通过MySQL客户端连接数据库管理系统DBMS,然后通过DBMS操作数据库。
-
使用MySQL客户端,向数据库管理系统发送一条SQL语句,由数据库管理系统根据SQL语句指令去操作数据库中的表结构及数据。
-
一个数据库服务器中可以创建多个数据库,一个数据库中也可以包含多张表,而一张表中又可以包含多行记录。
在Mysql数据库服务器当中存储数据,你需要:
先去创建数据库(可以创建多个数据库,之间是相互独立的)
在数据库下再去创建数据表(一个数据库下可以创建多张表)
再将数据存放在数据表中(一张表可以存储多行数据)
3. SQL语句
SQL:结构化查询语言。一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。SQL语句根据其功能被分为四大类:DDL、DML、DQL、DCL 。
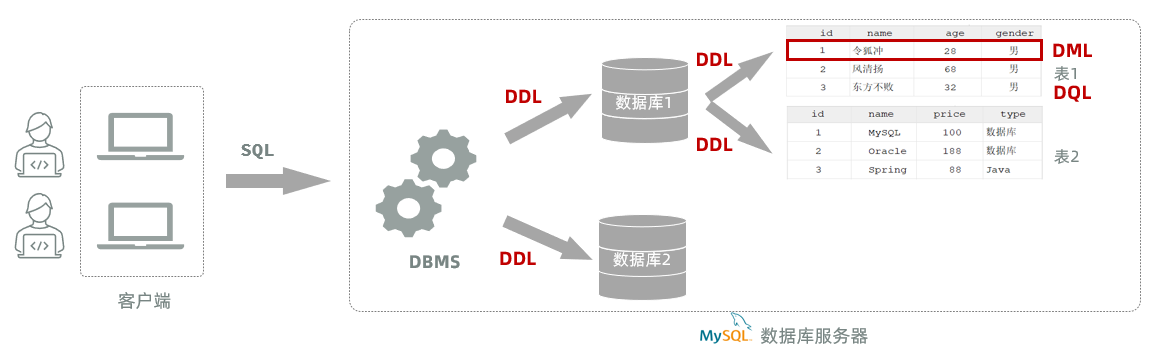
分类
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库、表、字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增、删、改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
3.1 DDL语句
3.1.1 数据库操作
我们在进行数据库设计,需要使用到刚才所介绍SQL分类中的DDL语句。
DDL英文全称是Data Definition Language(数据定义语言),用来定义数据库对象(数据库、表、表中字段)。
DDL中数据库的常见操作:查询、创建、使用、删除。
3.1.1.1 查询数据库
- 查询所有数据库
命令行中执行效果如下:


- 查询当前数据库
命令行中执行效果如果:

我们要操作某一个数据库,必须要切换到对应的数据库中。
通过指令:select database() ,就可以查询到当前所处的数据库
3.1.1.2 创建数据库
- 语法:
创建数据库时,可以不指定字符集。 因为在MySQL8版本之后,默认的字符集就是 utf8mb4。
- 案例: 创建一个itcast数据库。
命令行执行效果如下:

注意:在同一个数据库服务器中,不能创建两个名称相同的数据库,否则将会报错。

可以使用if not exists来避免这个问题
命令行执行效果如下:

3.1.1.3 使用数据库
- 语法:
我们要操作某一个数据库下的表时,就需要通过该指令,切换到对应的数据库下,否则不能操作。
- 案例:切换到itcast数据
命令执行效果如下:

3.1.1.4 删除数据库
-
语法:
-
如果删除一个不存在的数据库,将会报错。
-
可以加上参数 if exists ,如果数据库存在,再执行删除,否则不执行删除。
-
-
案例:删除itcast数据库
命令执行效果如下:

说明:上述语法中的database,也可以替换成 schema
如:create schema db01;
如:show schemas;
3.1.2 图形化工具
3.1.2.1 介绍
前面我们讲解了DDL中关于数据库操作的SQL语句,在我们编写这些SQL时,都是在命令行当中完成的。大家在练习的时候应该也感受到了,在命令行当中来敲这些SQL语句很不方便,主要的原因有以下 3 点:
-
没有任何代码提示。(全靠记忆,容易敲错字母造成执行报错)
-
操作繁琐,影响开发效率。(所有的功能操作都是通过SQL语句来完成的)
-
编写过的SQL代码无法保存。
在项目开发当中,通常为了提高开发效率,都会借助于现成的图形化管理工具来操作数据库。
目前MySQL主流的图形化界面工具有以下几种:

DataGrip是JetBrains旗下的一款数据库管理工具,是管理和开发MySQL、Oracle、PostgreSQL的理想解决方案。
官网: https://www.jetbrains.com/zh-cn/datagrip/
3.1.2.2 安装
安装: 参考资料中提供的《DataGrip安装手册》
说明:DataGrip这款工具可以不用安装,因为Jetbrains公司已经将DataGrip这款工具的功能已经集成到了 IDEA当中,所以我们就可以使用IDEA来作为一款图形化界面工具来操作Mysql数据库。
3.1.2.3 连接数据库
1). 创建Project
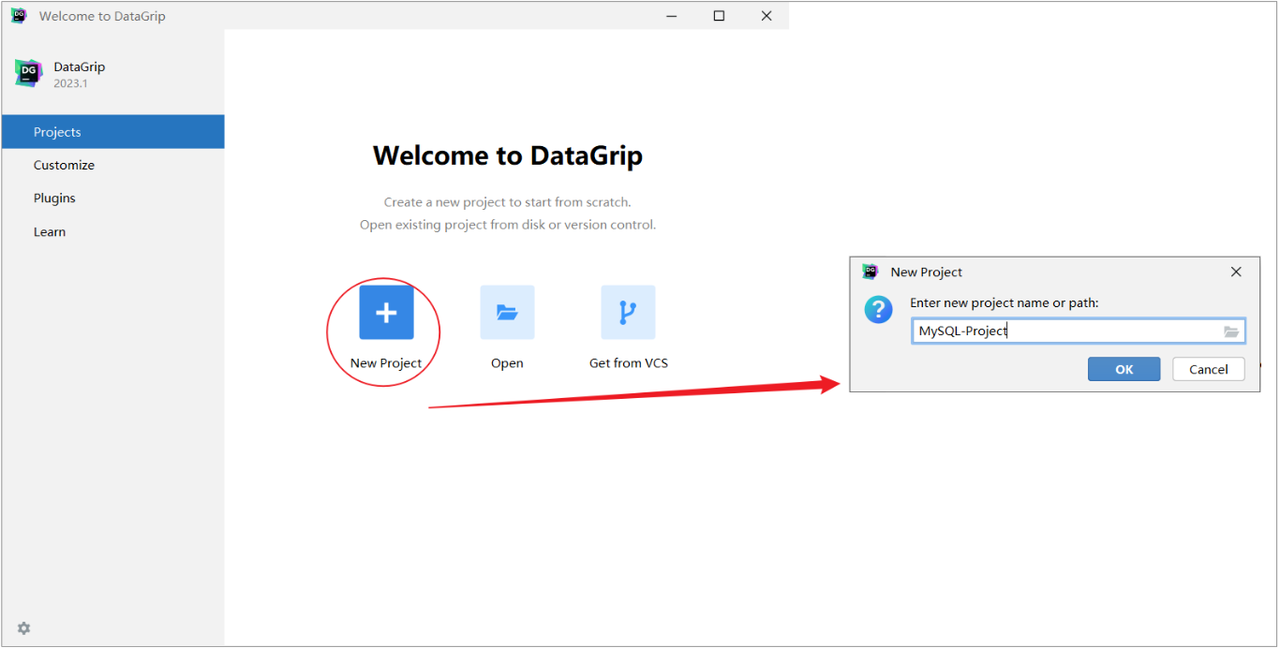
2). 创建连接
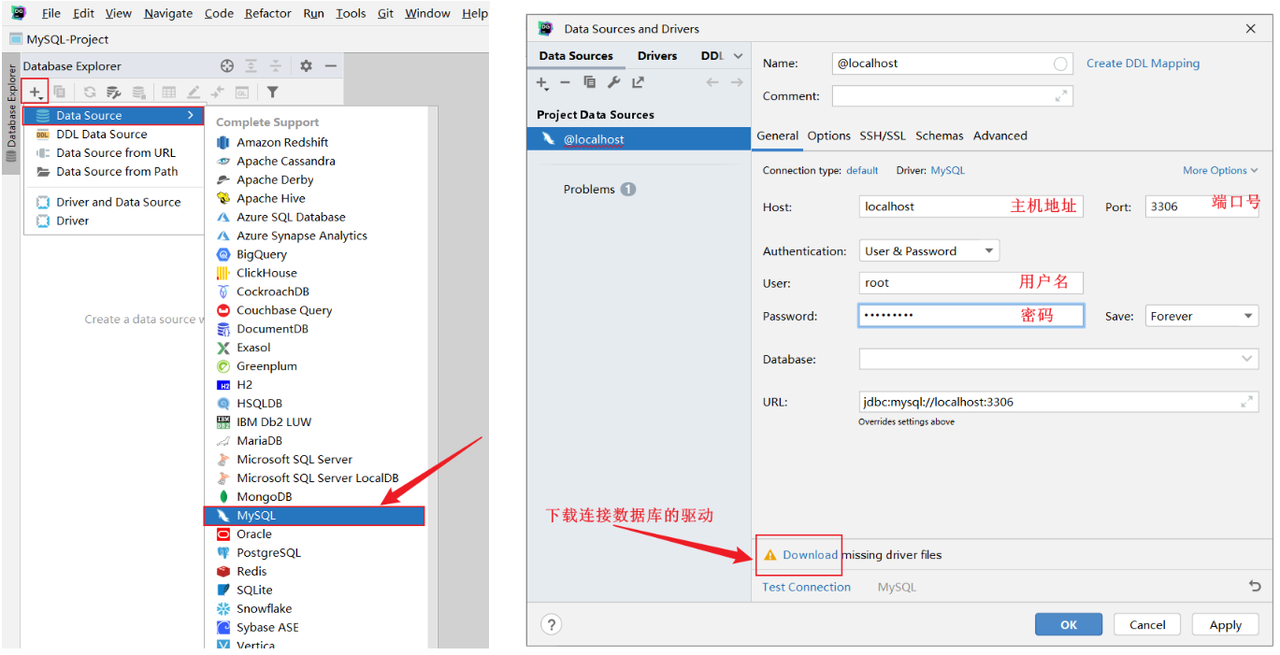

下载驱动, 可能会比较耗时, 耐心等待一会儿。
3). 测试连接
下载完驱动之后,可以点击 Test Connection 来测试一下是否可以正常的连接数据库。
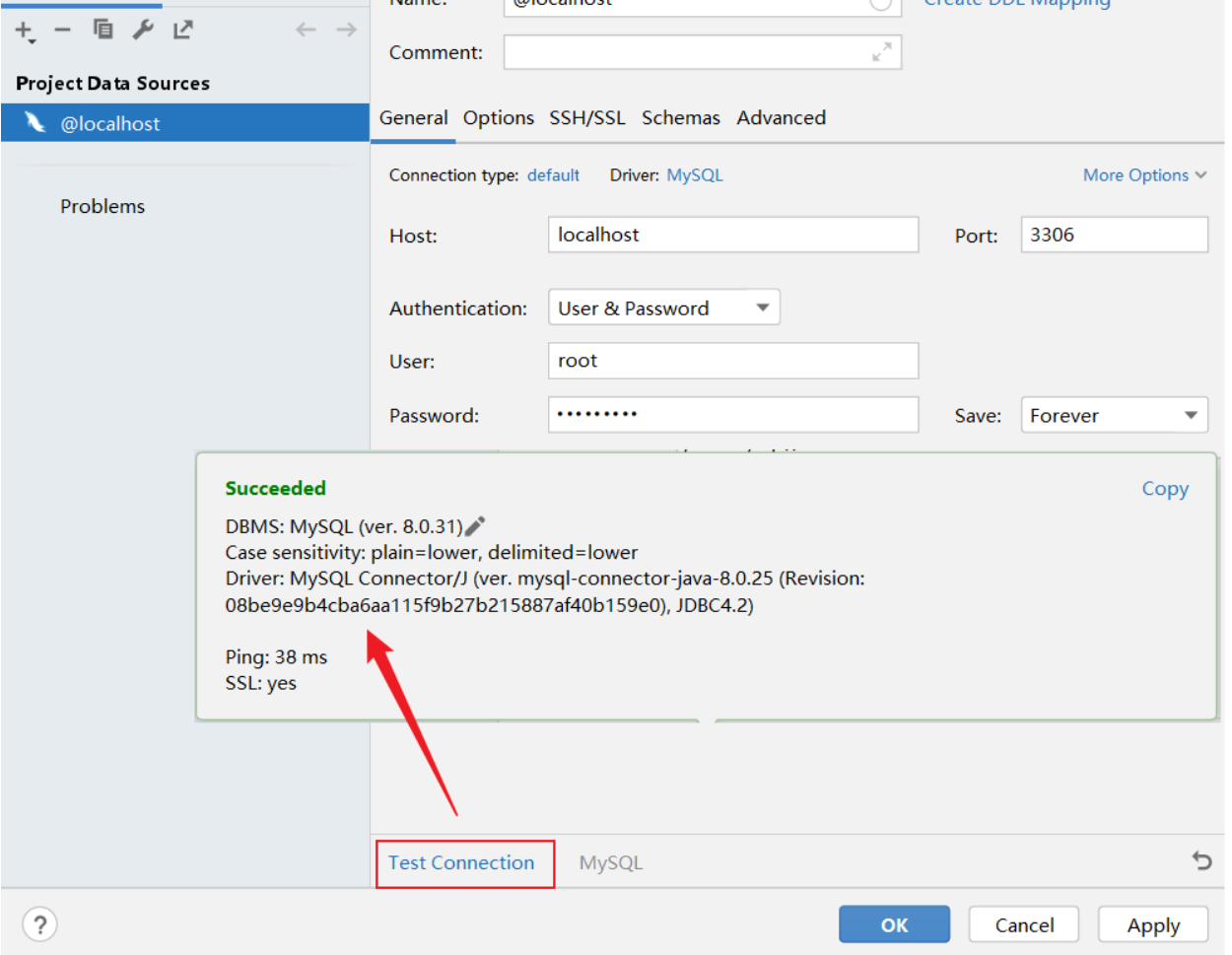
然后点击 OK , 就已经连接上了MySQL数据库了。
默认情况下,连接上了MySQL数据库之后, 数据库并没有全部展示出来。 需要选择要展示哪些数据库。具体操作如下:
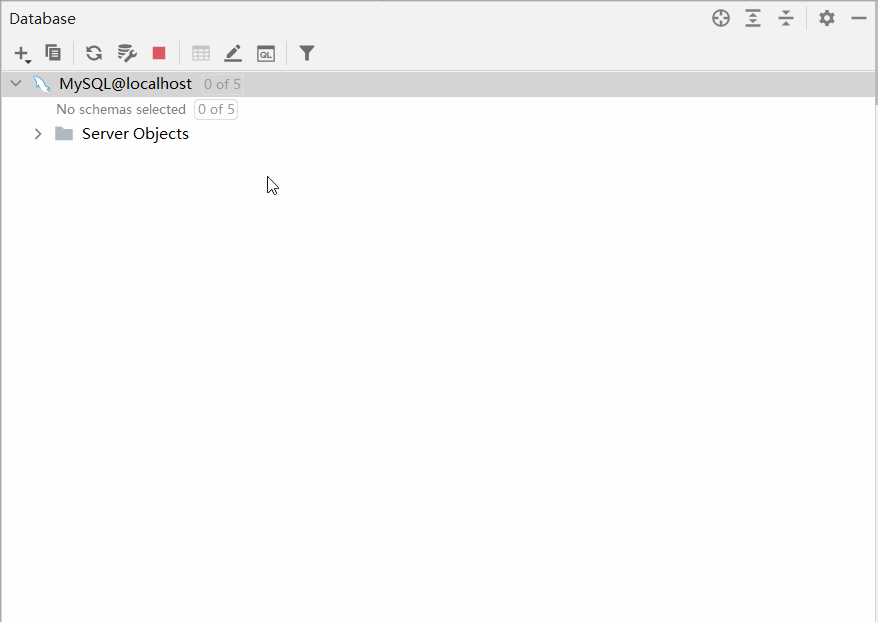
3.1.3 表操作
学习完了DDL语句当中关于数据库的操作之后,接下来我们继续学习DDL语句当中关于表结构的操作。
关于表结构的操作也是包含四个部分:创建表、查询表、修改表、删除表。
3.1.3.1 创建
-
语法:
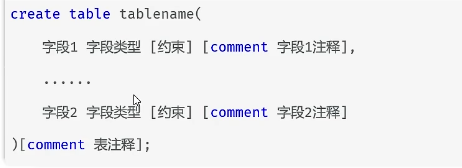
- 注意: [ ] 中的内容为可选参数; 最后一个字段后面没有逗号
-
案例:创建tb_user表
- 对应的结构如下:
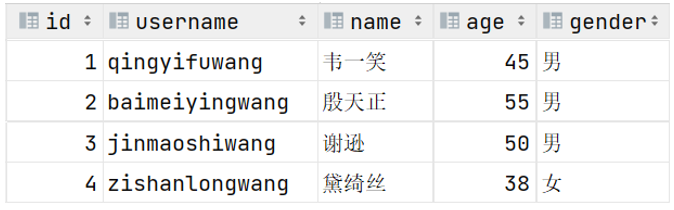
-
建表语句:
create table user(id int comment 'ID,唯一标识',username varchar(50) comment '用户名',name varchar(10) comment '姓名',age int comment '年龄',gender char(1) comment '性别' ) comment '用户信息表'; -
数据表创建完成,接下来我们还需要测试一下是否可以往这张表结构当中来存储数据。
双击打开tb_user表结构,大家会发现里面没有数据:
添加数据:
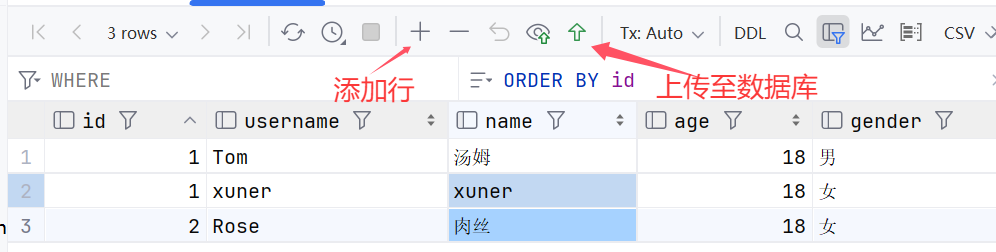
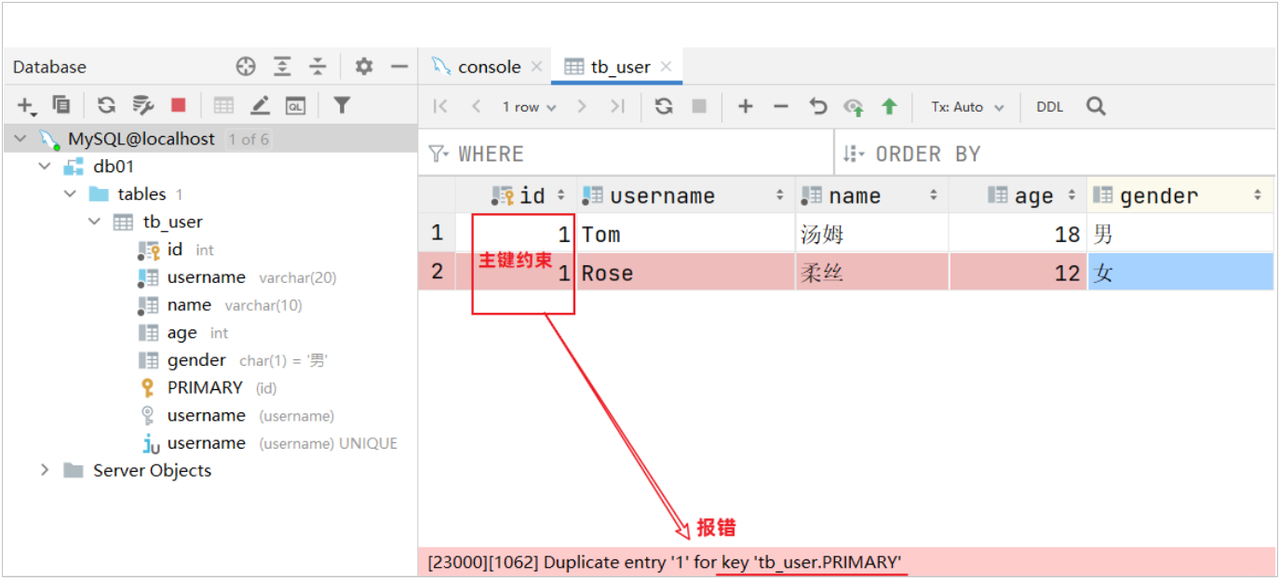
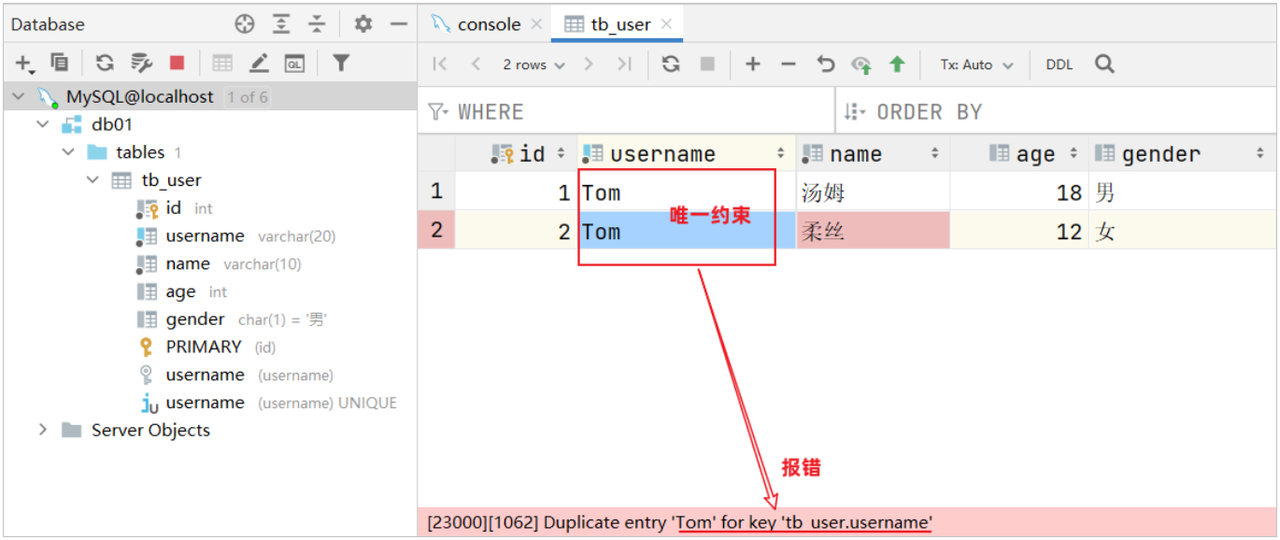
我们之前提到过:id字段是一行数据的唯一标识,不能有重复值。但是现在数据表中有两个相同的id值,这是为什么呢?
- 其实我们现在创建表结构的时候, id这个字段我们只加了一个备注信息说明它是一个唯一标识,但是在数据库层面呢,并没有去限制字段存储的数据。所以id这个字段没有起到唯一标识的作用。
想要限制字段所存储的数据,就需要用到数据库中的约束。
3.1.3.2 约束
-
概念:所谓约束就是作用在表中字段上的规则,用于限制存储在表中的数据。
-
作用:就是来保证数据库当中数据的正确性、有效性和完整性。(后面的学习会验证这些)
-
在MySQL数据库当中,提供了以下5种约束:
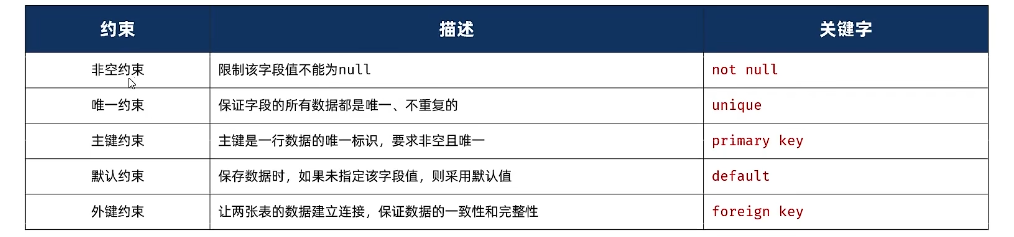
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
- 案例:创建tb_user表,对应的结构如下:
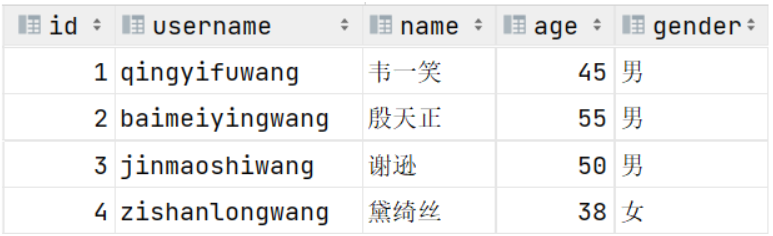
在上述的表结构中:现在我们加上一些限制
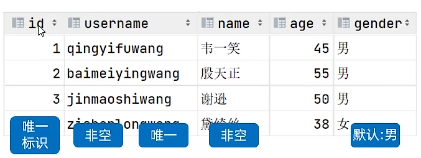
建表语句:
-- 创建表(+约束)
create table user(id int primary key comment 'ID,唯一标识', -- 主键约束username varchar(50) not null unique comment '用户名', -- 非空且唯一name varchar(10) not null comment '姓名', -- 非空age int comment '年龄',gender char(1) default '男' comment '性别' -- 默认
) comment '用户信息表';
数据表创建完成,接下来测试一下表中字段上的约束是否生效
大家有没有发现一个问题:id字段下存储的值,如果由我们自己来维护会比较麻烦(必须保证值的唯一性)。MySQL数据库为了解决这个问题,给我们提供了一个关键字:auto_increment(自动增长)
主键自增:auto_increment
每次插入新的行记录时,数据库自动生成id字段(主键)下的值
具有auto_increment的数据列是一个正数序列开始增长(从1开始自增)
测试主键自增:
-- 创建表(+约束)
create table user(id int primary key auto_increment comment 'ID,唯一标识', -- 主键约束且自动增长username varchar(50) not null unique comment '用户名', -- 非空且唯一name varchar(10) not null comment '姓名', -- 非空age int comment '年龄',gender char(1) default '男' comment '性别' -- 默认
) comment '用户信息表';

3.1.3.3 数据类型
在上面建表语句中,我们在指定字段的数据类型时,用到了int 、varchar、char,那么在MySQL中除了以上的数据类型,还有哪些常见的数据类型呢? 接下来,我们就来详细介绍一下MySQL的数据类型。
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。
1). 数值类型

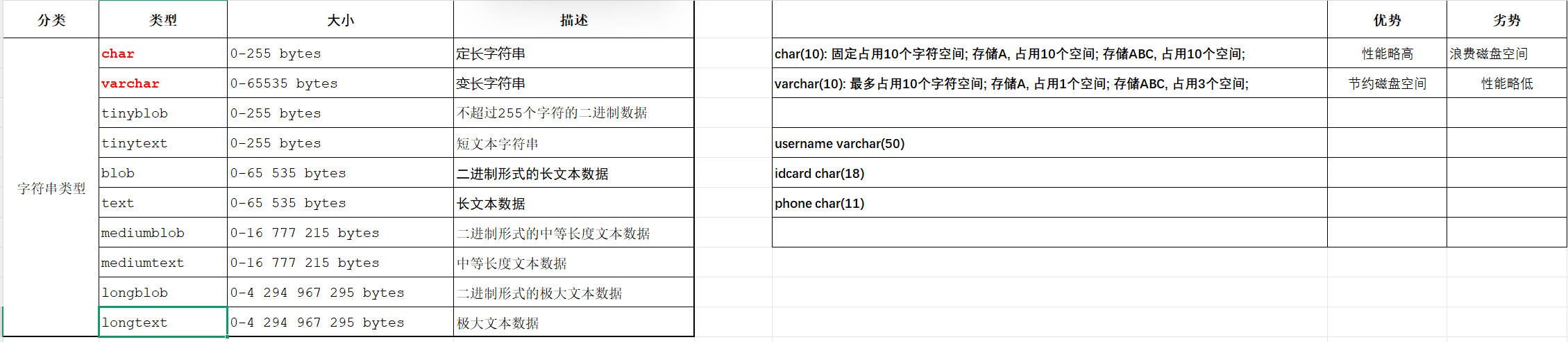
2). 字符串类型
char 与 varchar 都可以描述字符串,char是定长字符串,指定长度多长,就占用多少个字符,和字段值的长度无关 。而varchar是变长字符串,指定的长度为最大占用长度 。相对来说,char的性能会更高些。
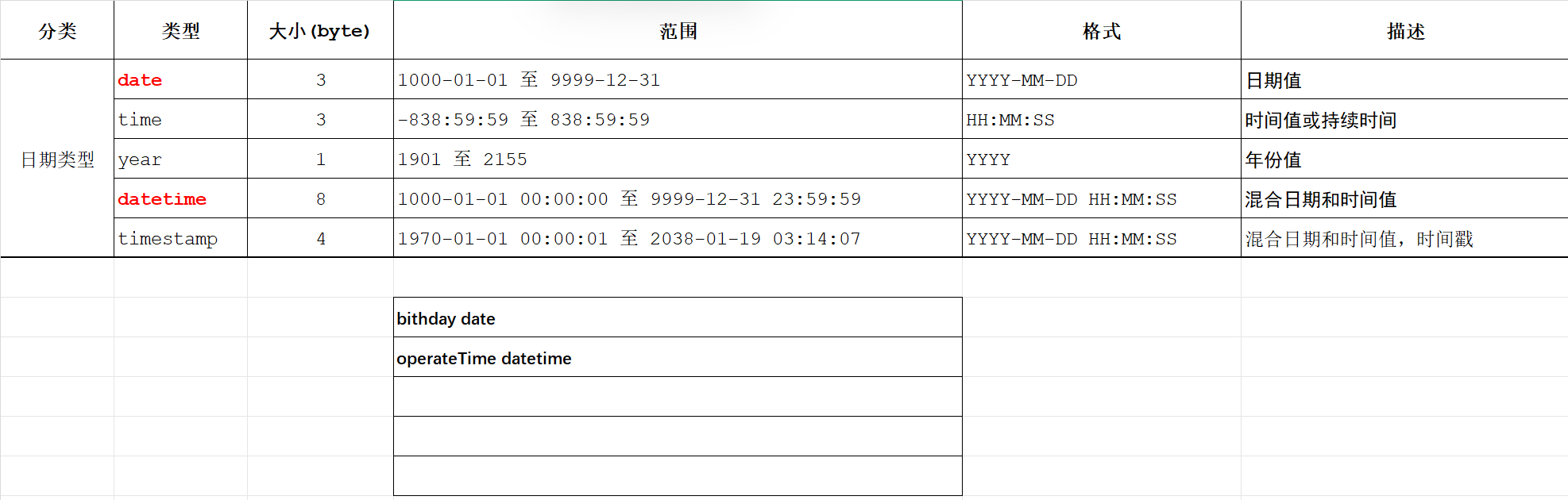
3). 日期时间类型

3.1.3.4 表结构设计-案例
需求:根据产品原型/需求创建表((设计合理的数据类型、长度、约束)
产品原型及需求如下:
1). 列表展示
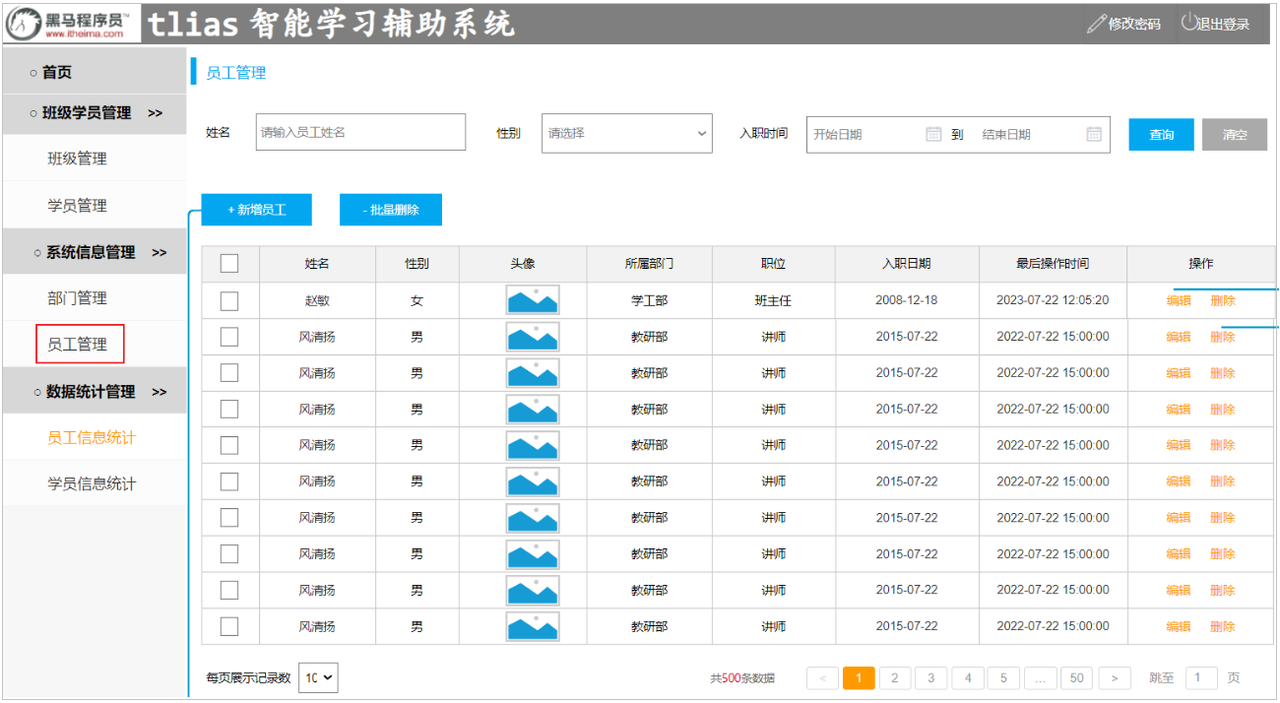
2). 新增员工
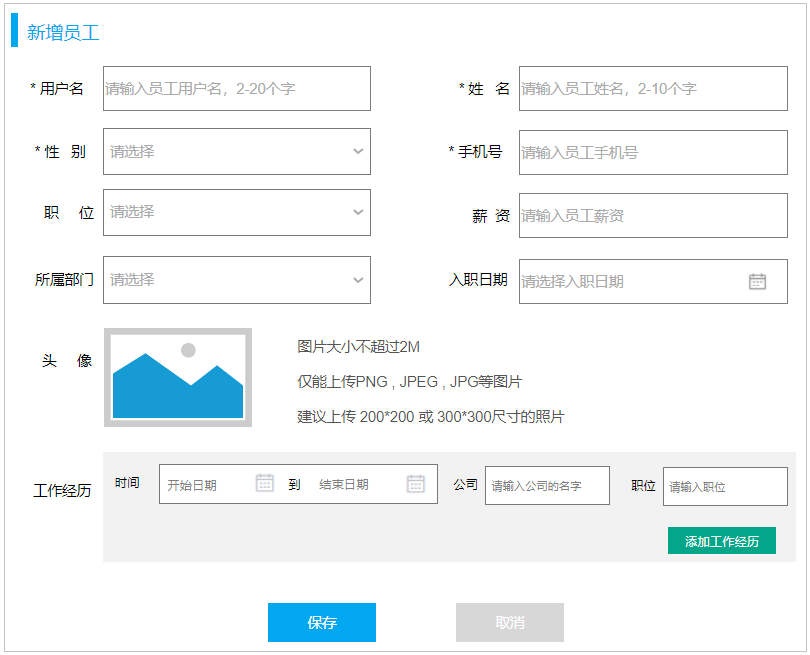
3). 需求说明及字段限制
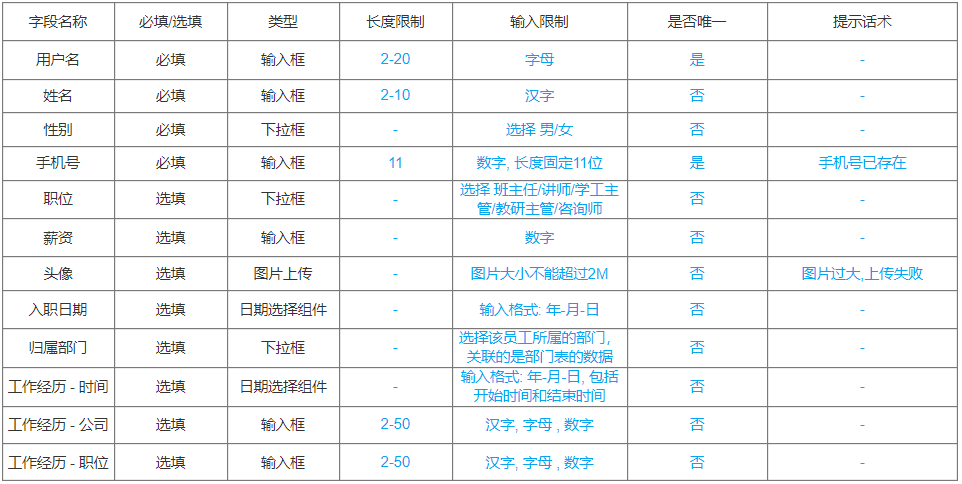
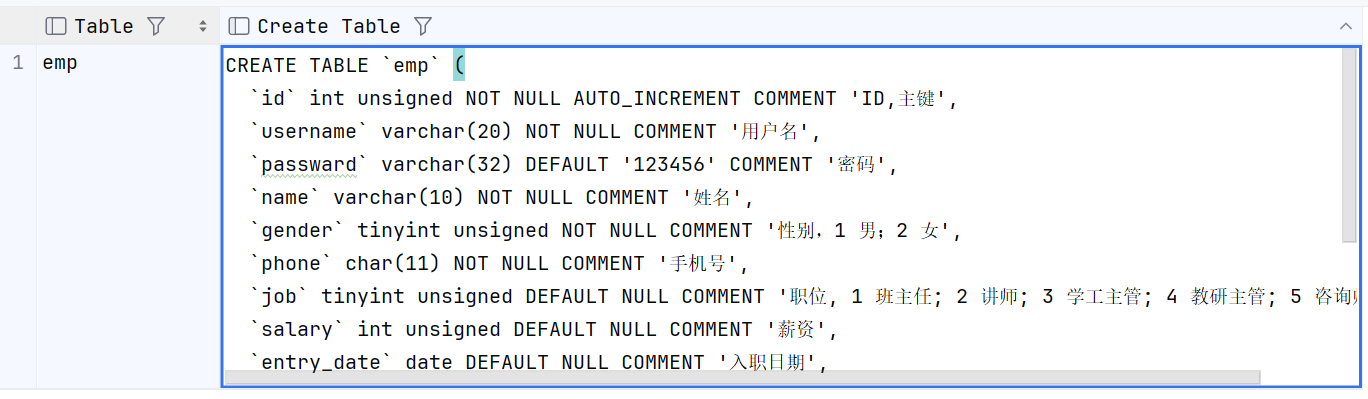
-- 案例 :员工表单emp
-- 设计表基础字段:id 主键; create_time 创建时间; update_time 修改时间;
create table emp(id int unsigned primary key auto_increment comment 'ID,主键',username varchar(20) not null unique comment '用户名',password varchar(32) default '123456' comment '密码',name varchar(10) not null comment '姓名',gender tinyint unsigned not null comment '性别,1 男;2 女', -- 在企业中性别一般用编号存储phone char(11) not null unique comment '手机号' ,job tinyint unsigned comment '职位, 1 班主任; 2 讲师; 3 学工主管; 4 教研主管; 5 咨询师', -- 这里的职位也用编号存储salary int unsigned comment '薪资',entry_date date comment '入职日期',image varchar(255) comment '图像',-- 存储图片的访问路径create_time datetime comment '创建时间',update_time datetime comment '修改时间'
) comment '员工表';
步骤:
-
阅读产品原型及需求文档,看看里面涉及到哪些字段。不仅要考虑页面展示字段,也要考虑录入员工需要哪些信息
-
查看需求文档说明,确认各个字段的类型以及字段存储数据的长度限制。
- 在页面原型中描述的基础字段的基础上,再增加额外的基础字段。
使用SQL创建表:
除了使用SQL语句创建表外,我们还可以借助于图形化界面来创建表结构,这种创建方式会更加直观、更加方便。
设计表流程:
阅读页面原型及需求文档
基于页面原则和需求文档,确定原型字段(类型、长度限制、约束)
再增加表设计所需要的业务基础字段(id(主键,唯一标识一条数据)、create_time、update_time)
create_time:记录的是当前这条数据插入的时间。
update_time:记录当前这条数据最后更新的时间。
3.1.3.5 表操作-其他操作
上面讲解了表结构的创建、数据类型、设计表的流程,接下来,再来讲解表结构的查询、修改、删除操作 。
查询、修改、删除数据库表的具体的语法:
-- 查询当前数据库所有表
show tables;-- 查看表结构
desc emp;-- 查询建表语句
show create table emp;-- 字段:添加字段qq varchar(13)
alter table emp add qq varchar(13) comment 'QQ'; -- 默认加在最后-- 字段:修改字段类型qq varchar(15)
alter table emp modify qq varchar(15) comment 'QQ'; -- 不加注释默认删除注释-- 字段:修改字段名 qq -> qq_num varchar(15)
alter table emp change qq qq_num varchar(15) comment 'QQ';-- 字段:删除字段 qq_num4
alter table emp drop column qq_num;-- 修改表名
alter table emp rename to employee;-- 删除表
drop table employee;
查询表结构
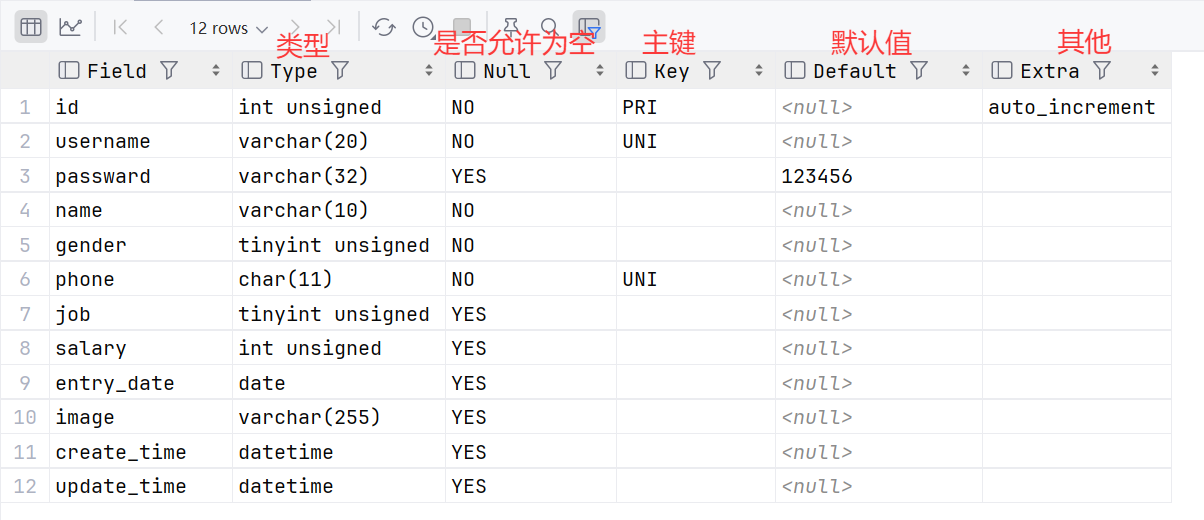
查询建表语句
关于表结构的查看、修改、删除操作,工作中一般都是直接基于图形化界面操作。在删除表时,表中的数据也会被全部删除
3.2 DML语句
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
-
添加数据(INSERT)
-
修改数据(UPDATE)
-
删除数据(DELETE),即删除某一条数据
3.2.1 增加(insert)
3.2.1.1 语法

3.2.1.2 案例演示
-- DML : 数据操作语言
-- DML : 插入数据 - insert
-- 1. 为 emp 表的 username, password, name, gender, phone 字段插入值
insert into emp (username, password, name, gender, phone) values('xuner','12345678','寻而',1,'15545679999');-- 2. 为 emp 表的 所有字段插入值
-- 方式一
insert into emp (id, username, password, name, gender, phone, job, salary, entry_date, image, create_time, update_time)values (null,'xiaomi','12345678','小米',1,'15578971114',1,6000,'2020-01-01','1.jpg',now(),now());-- null自动增长
-- 函数now,可以获取当前系统时间
-- 方式二 : 简化方式一
insert into emp values(null,'xiaomi2','12345678','小米2',1,'15578971116',1,6000,'2020-01-01','1.jpg',now(),now());-- 3. 批量为 emp 表的 username, password, name, gender, phone 字段插入数据
insert into emp (username, password, name, gender, phone) values('xuner2','12345678','寻2',1,'15545619999'),('xuner1','12345678','寻而1',1,'15545669999');
insert操作的注意事项:
- 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
- 字符串和日期型数据应该包含在引号中,会报警告但可执行。
- 插入的数据大小,应该在字段的规定范围内。
3.2.2 修改(update)
3.2.2.1 语法

3.2.2.2 案例演示
-- DML : 更新数据 - update
-- 1. 将 emp 表的ID为1员工 用户名更新为 'zhangsan', 姓名name字段更新为 '张三'
update emp set username = 'zhangsan',name = '张三' where id = 1;-- 2. 将 emp 表的所有员工的入职日期更新为 '2010-01-01'
update emp set entry_date = '2010-01-01';
注意事项:
修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
在修改数据时,一般需要同时修改公共字段update_time,将其修改为当前操作时间。
3.2.3 删除(delete)
3.2.3.1 语法

3.2.3.2 案例演示
-- DML : 删除数据 - delete
-- 1. 删除 emp 表中 ID为1的员工
delete from emp where id = 1;-- 2. 删除 emp 表中的所有员工
delete from emp;
注意事项:
DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。
当进行删除全部数据操作时,会提示询问是否确认删除所有数据,直接点击Execute即可。
3.3 DQL语句
3.3.1 介绍
DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。
查询关键字:SELECT
查询操作是所有SQL语句当中最为常见,也是最为重要的操作。在一个正常的业务系统中,查询操作的使用频次是要远高于增删改操作的。当我们打开某个网站或APP所看到的展示信息,都是通过从数据库中查询得到的,而在这个查询过程中,还会涉及到条件、排序、分页等操作。
3.3.2 语法
DQL查询语句,语法结构如下:

我们今天会将上面的完整语法拆分为以下几个部分学习:
-
基本查询(不带任何条件)
-
条件查询(where)
-
分组查询(group by)
-
排序查询(order by)
-
分页查询(limit)
准备一些测试数据用于查询操作:
3.3.3 基本查询
在基本查询的DQL语句中,不带任何的查询条件。
语法如下:
-
查询多个字段
-
查询所有字段(通配符)
-
设置别名
-
去除重复记录

案例演示:
-
案例1:查询指定字段 name,entry_date并返回
-
案例2:查询返回所有字段
* 号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)
-
案例3:查询所有员工的 name, entry_date,并起别名(姓名、入职日期)
-
案例4:查询已有的员工关联了哪几种职位(不要重复)
-- =================== DQL: 基本查询 ======================
-- 1. 查询指定字段 name,entry_date 并返回
select name,entry_date from emp;-- 2. 查询返回所有字段
-- 方式一:推荐
select id, username, password, name, gender, phone, job, salary, entry_date, image, create_time, update_time from emp
-- 方式二:不推荐
select * from emp;-- 3. 查询所有员工的 name,entry_date, 并起别名(姓名、入职日期)
select name as 姓名,entry_date as 入职日期 from emp;
-- 别名中间有空格,就必须要加引号
select name as '姓 名',entry_date as 入职日期 from emp;
-- as也可省略
select name '姓 名',entry_date 入职日期 from emp;-- 4. 查询已有的员工关联了哪几种职位(不要重复)
select distinct job from emp;

3.3.4 条件查询
语法:

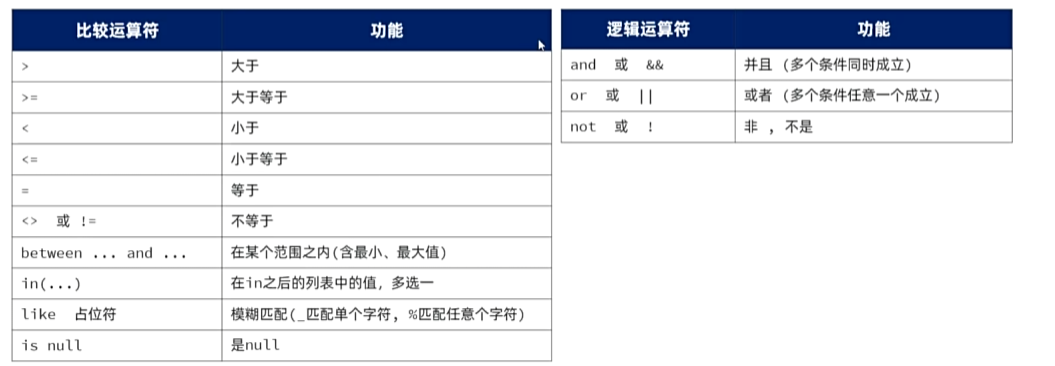
学习条件查询就是学习条件的构建方式,而在SQL语句当中构造条件的运算符分为两类:
-
比较运算符
-
逻辑运算符
-
案例1:查询 姓名 为 ‘杨逍’ 的员工
-
案例2:查询 薪资小于等于 5000 的员工信息
-
案例3:查询 没有分配职位 的员工信息
注意:查询为NULL的数据时,不能使用
= null或!=null。得使用is null或is not null。
-
案例4:查询 有职位 的员工信息
-
案例5:查询 密码不等于 ‘123456’ 的员工信息
-
案例6:查询 入职日期 在 ‘2000-01-01’ (包含) 到 ‘2010-01-01’(包含) 之间的员工信息
-
案例7:查询 入职时间 在 ‘2000-01-01’ (包含) 到 ‘2010-01-01’(包含) 之间 且 性别为女 的员工信息
-
案例8:查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息
-
案例9:查询 姓名 为两个字的员工信息
-
案例10:查询 姓 ‘张’ 的员工信息
-
案例11:查询 姓名中包含 ‘二’ 的员工信息
-- =================== DQL: 条件查询 ======================
-- 1. 查询 姓名 为 柴进 的员工
select * from emp where name = '柴进';-- 2. 查询 薪资小于等于5000 的员工信息
select * from emp where salary<=5000;-- 3. 查询 没有分配职位 的员工信息
select * from emp where job is null;-- 4. 查询 有职位 的员工信息
select * from emp where job is not null;-- 5. 查询 密码不等于 '123456' 的员工信息
select * from emp where password != '123456';
select * from emp where password <> '123456';-- 6. 查询 入职日期 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间的员工信息
select * from emp where entry_date between '2000-01-01' and '2010-01-01'; -- between必须由小到大-- 7. 查询 入职时间 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间 且 性别为女 的员工信息
select * from emp where entry_date between '2000-01-01' and '2010-01-01' && gender = 2;select * from emp where (entry_date between '2000-01-01' and '2010-01-01') and gender = 2;-- 8. 查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息
select * from emp where job = 2 or job = 3 or job = 4;
select * from emp where job between 2 and 4;
select * from emp where job in (2,3,4);-- 9. 查询 姓名 为两个字的员工信息(_:单个字符;%:任意字符)
select * from emp where name like '__';-- 10. 查询 姓 '李' 的员工信息
select * from emp where name like '李%';-- 11. 查询 姓名中包含 '二' 的员工信息
select * from emp where name like '%二%';
3.3.5 聚合函数
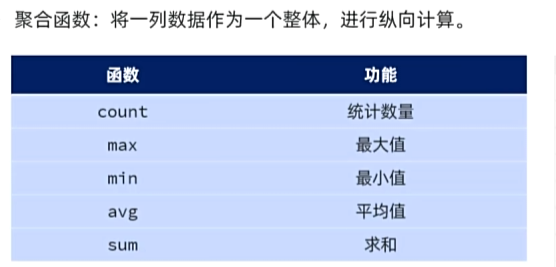
之前我们做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)
常用聚合函数:
注意 : 聚合函数会忽略空值,对NULL值不作为统计。
-
count :按照列去统计有多少行数据。
- 在根据指定的列统计的时候,如果这一列中有null的行,该行不会被统计在其中。
-
sum :计算指定列的数值和,如果不是数值类型,那么计算结果为0
-
max :计算指定列的最大值
-
min :计算指定列的最小值
-
avg :计算指定列的平均值
案例演示:
- 案例1:统计该企业员工数量
- 案例2:统计该企业员工的平均薪资
- 案例3:统计该企业员工的最低薪资
- 案例4:统计该企业员工的最高薪资
- 案例5:统计该企业每月要给员工发放的薪资总额(薪资之和)
-- 聚合函数
-- 注意:所有聚合函数不参与null的统计-- 1. 统计该企业员工数量,优先使用count(*),效率最高,常量性能最低
-- count(字段)
select count(id) from emp;
-- count(*)
select count(*) from emp;
-- count(常量)
select count(0) from emp; -- 任意常量,会去扫描行,把每一行标记成常量,最后统计常量的个数-- 2. 统计该企业员工的平均薪资
select avg(salary) from emp;-- 3. 统计该企业员工的最低薪资
select min(salary) from emp;-- 4. 统计该企业员工的最高薪资
select max(salary) from emp;-- 5. 统计该企业每月要给员工发放的薪资总额(薪资之和)
select sum(salary) from emp;
3.3.6 分组查询
-
分组: 按照某一列或者某几列,把相同的数据进行合并输出。
-
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。
-
分组查询通常会使用聚合函数进行计算。
-
语法:

案例演示:
-
案例1:根据性别分组 , 统计男性和女性员工的数量
-
案例2:查询入职时间在 ‘2015-01-01’ (包含) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于2的职位
-- =================== DQL: 分组查询 ======================
-- 分组
-- 注意:分组之后,select后的字段列表不能随意书写,能写的一般是分组字段 + 聚合函数
-- 1. 根据性别分组 , 统计男性和女性员工的数量
select gender,count(*) from emp group by gender ;-- 2. 先查询入职时间在 '2015-01-01' (包含) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于2的职位
select job,count(*) from emp where entry_date <= '2015-01-01' group by job having count(*)>=2;
注意事项:
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
执行顺序:where > 聚合函数 > having;
where与having区别(面试题)
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以。

3.3.7 排查查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
语法:

-
排序方式:
-
ASC :升序(默认值)
-
DESC:降序
-
案例演示:
- 案例1:根据入职时间, 对员工进行升序排序
注意事项:如果是升序, 可以不指定排序方式ASC
-
案例2:根据入职时间,对员工进行降序排序
-
案例3:根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序
注意事项:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
-- =================== 排序查询 ======================
-- 1. 根据入职时间, 对员工进行升序排序
select * from emp order by entry_date asc;-- 2. 根据入职时间, 对员工进行降序排序
select * from emp order by entry_date desc;-- 3. 根据 入职时间 对公司的员工进行 升序排序 , 入职时间相同 , 再按照 更新时间 进行降序排序
select * from emp order by entry_date asc,update_time desc ;
3.3.8 分页查询
分页操作在业务系统开发时,也是非常常见的一个功能,日常我们在网站中看到的各种各样的分页条,后台也都需要借助于数据库的分页操作。
分页查询语法:

- 案例1:从起始索引0开始查询员工数据, 每页展示5条记录
- 案例2:查询 第1页 员工数据, 每页展示5条记录
- 案例3:查询 第2页 员工数据, 每页展示5条记录
- 案例4:查询 第3页 员工数据, 每页展示5条记录
-- =================== 分页查询 ======================
-- 起始索引 = (页码减一) * 每页展示记录数
-- 1. 从起始索引0开始查询员工数据, 每页展示5条记录
select * from emp limit 0,5;
select * from emp limit 5;-- 2. 查询 第1页 员工数据, 每页展示5条记录
select * from emp limit 0,5; -- 起始索引0就是第一页-- 3. 查询 第2页 员工数据, 每页展示5条记录 0-4第一页 5-9 第二页
select * from emp limit 5,5;-- 4. 查询 第3页 员工数据, 每页展示5条记录
select * from emp limit 10,5;
注意事项:
起始索引从0开始。
计算公式 :起始索引 = (查询页码 - 1)* 每页显示记录数
分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT
如果查询的是第一页数据(0),起始索引可以省略,直接简写为 limit 条数


相关文章:

【JavaWeb后端开发03】MySQL入门
文章目录 1. 前言1.1 引言1.2 相关概念 2. MySQL概述2.1 安装2.2 连接2.2.1 介绍2.2.2 企业使用方式(了解) 2.3 数据模型2.3.1 **关系型数据库(RDBMS)**2.3.2 数据模型 3. SQL语句3.1 DDL语句3.1.1 数据库操作3.1.1.1 查询数据库3.1.1.2 创建数据库3.1.1…...

使用纯前端技术html+css+js实现一个蔬果商城的前端模板!
当我们刚开始学习前端的时候,我们都会先学习一些基础的编程知识点。对于网站开发前端学习,我们就会学习 html css js 等基础的前端技术,我们学习了基础编程知识后,肯定是需要一些项目,或者一些练习题,巩固一…...

SAP系统生产跟踪报表入库数异常
生产跟踪报表入库数异常 交库21820,入库43588是不可能的 原因排查: 报表的入库数取值,是取移动类型321 (即系检验合格后过账到非限制使用)的数. 查凭证,101过账2次21807,321过账了2次21794,然后用102退1次21794.就是说这批物料重复交库了. 解决: 方案一:开发增强设…...

mac 本地 docker 部署 nacos
标题查看 docker 的 nacos 版本 查看可用的Nacos版本,以最新版为例. 指定版本 自己修改即可. 访问Nacos镜像库地址:https://hub.docker.com/r/nacos/nacos-server/tags?page1&orderinglast_updated 标题二、挂载目录配置步骤 标题创建本地目录 按用户要…...

cgroup threaded功能例子
一、背景 cgroup在如今的系统里基本都是默认打开的一个功能。对于cgroup的cpu子系统,默认的颗粒度是进程为维度进行cgroup的cpu及cpuset的控制。而对于一些复杂进程,可能的需求是进程里一些个别线程要绑定在X1-Xn这些cpu核上,而除了这些个别…...

Elasticsearch插件:IDEA中的Elasticsearch开发利器
Elasticsearch插件:IDEA中的Elasticsearch开发利器 一、插件概述 Elasticsearch插件是为IntelliJ IDEA设计的专业工具,它让开发者能在IDE内直接与Elasticsearch集群交互,提供了查询编写、索引管理、数据分析等全方位支持。 核心价值&#…...

electron从安装到启动再到打包全教程
目录 介绍 安装 修改npm包配置 执行安装命令 源代码 运行 打包 先安装git, 安装打包工具 导入打包工具 执行打包命令 总结 介绍 electron确实好用,但安装是真的要耗费半条命。每次安装都会遇到各种问题,然后解决了之后。后面就不需要安装了,但有时候比如电脑重装…...

【Linux】轻量级命令解释器minishell
Minishell 一、项目背景 在linux操作系统中,用户对操作系统进行的一系列操作都不能直接操作内核,而是通过shell间接对内核进行操作。 Shell 是操作系统中的一种程序,它为用户提供了一种与操作系统内核和计算机硬件进行交互的界面。用户可以通…...

KEIL报错解决方案:No Algorithm found for: 08001000H - 080012EBH?
改这里: Cortex JLink/JTrace Target Drive - Flash Download - Size: 配好你这款芯片应该用的空间大小...

用银河麒麟 LiveCD 快速查看原系统 IP 和打印机配置
原文链接:用银河麒麟 LiveCD 快速查看原系统 IP 和打印机配置 Hello,大家好啊!今天给大家带来一篇在银河麒麟操作系统的 LiveCD 或系统试用镜像环境下,如何查看原系统中电脑的 IP 地址与网络打印机 IP 地址的实用教程。在系统损坏…...

DeepseekV3MLP 模块
目录 代码代码解释导入和激活函数配置类初始化方法前向传播方法计算流程 代码可视化 代码 import torch import torch.nn as nn import torch.nn.functional as F# 定义激活函数字典 ACT2FN {"relu": F.relu,"gelu": F.gelu,"silu": F.silu,&q…...

Ubuntu 系统下安装和使用性能分析工具 perf
在 Ubuntu 系统下安装和使用性能分析工具 perf 的步骤如下: 1. 安装 perf perf 是 Linux 内核的一部分,通常通过安装 linux-tools 包获取: # 更新软件包列表 sudo apt update# 安装 perf(根据当前内核版本自动匹配) …...

安恒Web安全面试题
《网安面试指南》https://mp.weixin.qq.com/s/RIVYDmxI9g_TgGrpbdDKtA?token1860256701&langzh_CN 5000篇网安资料库https://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247486065&idx2&snb30ade8200e842743339d428f414475e&chksmc0e4732df793fa3bf39…...

OSPF --- LSA
文章目录 一、OSPF LSA(链路状态通告)详解1. LSA通用头部2. OSPFv2 主要LSA类型a. Type 1 - Router LSAb. Type 2 - Network LSAc. Type 3 - Summary LSAd. Type 4 - ASBR Summary LSAe. Type 5 - AS External LSAf. Type 7 - NSSA External LSA 3. LSA泛…...

IDEA/WebStorm中Git操作缓慢的解决方案
问题描述 在WebStorm中进行前端开发时,发现Git操作(如push、checkout、pull等)特别缓慢,而在命令行(cmd)中执行相同的Git命令却很快,排除了网络问题。 解决方案 通过修改WebStorm安装目录下的runnerw.exe文件名可以…...

网络威胁情报 | Yara
Yara 是一个在威胁情报、数字取证和威胁猎取方面较为常用的语言。本文并非是Yara语言的教程,更多的是希望可以让大家知道这个语言的神奇之处及其在当今信息安全领域的重要性。 Yara 是什么? “恶意软件研究人员(以及其他所有人)…...
)
12.QT-Combo Box|Spin Box|模拟点餐|从文件中加载选项|调整点餐份数(C++)
Combo Box QComboBox 表⽰下拉框 核⼼属性 属性说明currentText当前选中的⽂本currentIndex当前选中的条⽬下标.从0开始计算.如果当前没有条⽬被选中,值为-1editable是否允许修改设为true时, QComboBox 的⾏为就⾮常接近 QLineEdit ,也可以 设置 validatoriconSize下拉框图标…...

FTTR 全屋光纤架构分享
随着光纤网络技术的发展,FTTR 技术逐步普及到千家万户,为了战未来,从现在开始构建并铺设 FTTR 全屋光纤是非常有必要的。 在前期 FTTR 全屋光纤网络的载荷搭建,可以额定为千兆网络或者2.5GE光纤网络,万兆光网最大的成本…...

内网穿透快解析免费开放硬件集成SDK
一、行业问题 随着物联网技术的发展,符合用户需求的智能硬件设备被广泛的应用到各个领域,而智能设备的远程运维管理也是企业用户遇到的问题 二、快解析内网穿透解决方案 快解析是一款内网穿透产品,可以实现内网资源在外网访问,…...

实验八 版本控制
实验八 版本控制 一、实验目的 掌握Git基本命令的使用。 二、实验内容 1.理解版本控制工具的意义。 2.安装Windows和Linux下的git工具。 3.利用git bash结合常用Linux命令管理文件和目录。 4.利用git创建本地仓库并进行简单的版本控制实验。 三、主要实验步骤 1.下载并安…...

《马尼拉》桌游期望计算器
《马尼拉》桌游期望计算器:做出最明智的决策 注:本项目仍在开发验证中,计算结果可能不够准确,欢迎游戏爱好者提供协助! 在线使用 | GitHub 项目简介 马尼拉期望计算器是一个基于 Vue 3 Vite 开发的网页应用ÿ…...

VLAN间通讯技术
多臂路由 路由器使用多条物理线路,每条物理线路充当一个 VLAN 的网管 注意:路由器对端的交换机接口,需要设定 Access 类型,因为路由器的物理接口无法处理 VLAN 标签 。 单臂路由 使用 以太网子接口 (sub-interface) 实现。 …...

linux基础学习--linux文件与目录管理
linux文件与目录管理 1. 目录与路径 1.1 相对路径与绝对路径 绝对路径:路径写法一定从根目录/写起。 绝对路径的正确度要高。 相对路径:路径写法不是由/写起。 1.2 目录的相关操作 切换目录的命令是cd,下面是比较特殊的目录:…...
)
云原生--基础篇-2--云计算概述(云计算是云原生的基础,IaaS、PaaS和SaaS服务模型)
1、云计算概念 云计算是一种通过互联网提供计算资源(包括服务器、存储、数据库、网络、软件等)和服务的技术模式。用户无需拥有和维护物理硬件,而是可以根据需要租用这些资源,并按使用量付费。 2、云计算特点 (1&am…...

存储器综合:内存条
一、RW 1000题刷题 1、计算Cache缺失率 2、 二、前提回顾 1、CPU从单个DRAM芯片中取地址 注意:Cache与主存的交互以“主存块”为单位,当出现Cache Miss时,主存以“主存块”为单位传输至Cache中。 2、内存条编址 多个DRAM芯片组成内存条&a…...
config.txt视频配置)
树莓派超全系列教程文档--(38)config.txt视频配置
config.txt视频配置 视频选项HDMI模式树莓派4-系列的HDMI树莓派5-系列的HDMI 复合视频模式enable_tvout LCD显示器和触摸屏ignore_lcddisable_touchscreen 通用显示选项disable_fw_kms_setup 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 视频选…...

pytest-项目结构
项目结构 api_test_project/ ├── config/ │ └── config.py # 配置文件,存储接口的基本信息,如 URL、请求头、认证信息等 ├── data/ │ └── test_data.json # 测试数据文件,存储接口的请求参数、预期结果等 ├── tests/…...

几何编码:启用矢量模式地理空间机器学习
在 ML 模型中使用点、线和多边形,将它们编码为捕捉其空间属性的向量。 自地理信息系统 (GIS) 诞生之初,“栅格模式”和“矢量模式”之间就存在着显著的区别。在栅格模式下,数据以值的形式呈现在规则的网格上。这包括任何形式的图像࿰…...

什么是SPA,SPA与MAP区别
什么是SPA,SPA与MAP区别 文章目录 什么是SPA,SPA与MAP区别一、什么是SPA二、SPA和MPA的区别一、单页应用与多页应用的区别**二、SPA 的优缺点对比**三、WPA的优缺点 **三、SPA 实现关键技术**hash 模式模式history模式 四、SPA 的适用场景与原因**适用场…...

计算机前沿技术课程论文 K-means算法在图像处理的应用
K-means算法在图像处理的应用 这是本人在计算机前沿技术课程中的课程论文文章,为了方便大家参考学习,我把完整的论文word文档发到了我的资源里,有需要的可以自取。 点击完整资源链接 目录 K-means算法在图像处理的应用摘要:引言1…...

第十四届蓝桥杯 2023 C/C++组 平方差
目录 题目: 题目描述: 题目链接: 思路: 核心思路: 第一种思路: 第二种思路: 坑点: 代码: 数学找规律 O(n) 50分代码详解: O(1)满分代码详解&#x…...

【数学建模】随机森林算法详解:原理、优缺点及应用
随机森林算法详解:原理、优缺点及应用 文章目录 随机森林算法详解:原理、优缺点及应用引言随机森林的基本原理随机森林算法步骤随机森林的优点随机森林的缺点随机森林的应用场景Python实现示例超参数调优结论参考文献 引言 随机森林是机器学习领域中一种…...
)
计算机组成与体系结构:存储器(Memory)
目录 📁 当你打开一个文件,计算机会做什么? ⚡ 越大的 memory,访问速度越快吗? 🧠 那么,我们是怎么设计存储器的呢? Primary Memory(主存)登场ÿ…...

MyBatis框架—xml映射
目录 一.为什么需要进行手动映射? 二.关联查询 1.使用resultMap进行映射 2.使用Connection进行映射 一.为什么需要进行手动映射? 当我们设计多表查询或关联查询时,表中含有相同的字段名或要进行关联查询时,MyBatis无法智能识别如何处理映射结果&…...

Vue接口平台学习十——接口用例页面2
效果图及简单说明 左边选择用例,右侧就显示该用例的详细信息。 使用el-collapse折叠组件,将请求到的用例详情数据展示到页面中。 所有数据内容,绑定到caseData中 // 页面绑定的用例编辑数据 const caseData reactive({title: "",…...

Visual Studio 2022 运行一个后台程序而不显示控制台窗口
在 Visual Studio 2022 中,希望运行一个后台程序而不显示控制台窗口(黑色命令框),可以通过以下方法实现: 修改项目输出类型为 Windows 应用程序 右键项目 → 选择 属性 (Properties)在 配置属性 → 链接器 → 系统 (…...
C++版——day17)
剑指Offer(数据结构与算法面试题精讲)C++版——day17
剑指Offer(数据结构与算法面试题精讲)C版——day17 题目一:节点值之和最大的路径题目二:展平二叉搜索树题目三:二叉搜索树的下一个节点附录:源码gitee仓库 题目一:节点值之和最大的路径 题目&am…...

opencv函数展示4
一、形态学操作函数 1.基本形态学操作 (1)cv2.getStructuringElement() (2)cv2.erode() (3)cv2.dilate() 2.高级形态学操作 (1)cv2.morphologyEx() 二、直方图处理函数 1.直方图…...

10天学会嵌入式技术之51单片机-day-3
第九章 独立按键 按键的作用相当于一个开关,按下时接通(或断开),松开后断开(或接通)。实物图、原理图、封装 9.2 需求描述 通过 SW1、SW2、SW3、SW4 四个独立按键分别控制 LED1、LED2、LED3、LED4 的亮…...
:3秒对话式搞定“等时圈”绘制)
DeepSeek智能时空数据分析(二):3秒对话式搞定“等时圈”绘制
序言:时空数据分析很有用,但是GIS/时空数据库技术门槛太高 时空数据分析在优化业务运营中至关重要,然而,三大挑战仍制约其发展:技术门槛高,需融合GIS理论、SQL开发与时空数据库等多领域知识;空…...

第 7 篇:总结与展望 - 时间序列学习的下一步
第 7 篇:总结与展望 - 时间序列学习的下一步 (图片来源: Guillaume Hankenne on Pexels) 恭喜你!如果你一路跟随这个系列走到了这里,那么你已经成功地完成了时间序列分析的入门之旅。我们从零开始,一起探索了时间数据的基本概念、…...

计算机视觉中的正则化:从理论到实践的全面解析
🌟 计算机视觉中的正则化:从理论到实践的全面解析🌟 大家好!今天要和大家分享的是在计算机视觉(CV)领域中非常重要的一个概念——正则化(Regularization)。无论你是刚开始接触深度学…...

解决使用hc595驱动LED数码管亮度低的问题
不知道大家在做项目的时候有没有遇到使用hc595驱动LED数码管亮度低的问题(数码管位数较多),如果大佬们有好的方法的可以评论区留言 当时我们解决是换成了天微的驱动芯片,现在还在寻找新的解决办法(主要软件不花钱&…...

Allegro23.1新功能之4K显示器页面显示不全如何解决操作指导
Allegro23.1新功能之4K显示器页面显示不全如何解决操作指导 Allegro升级到了23.1的时候,可能会出现界面显示不全的情况,如下图 是因为4K高清显示器的原因导致的 如何解决,具体操作如下 我的电脑,右键选择属性 点击高级系统设置 …...
,适配器——stack,queue,priority_queue)
C++——STL——容器deque(简单介绍),适配器——stack,queue,priority_queue
目录 1.deque(简单介绍) 1.1 deque介绍: 1.2 deque迭代器底层 1.2.1 那么比如说用迭代器实现元素的遍历,是如何实现的呢? 1.2.2 头插 1.2.3 尾插 1.2.4 实现 编辑 1.2.5 总结 2.stack 2.1 函数介绍 2.2 模…...

网络原理——UDP
1、 与TCP的关键区别 特性UDPTCP连接方式无连接面向连接可靠性不可靠可靠数据顺序不保证顺序保证顺序传输速度更快相对较慢头部开销8字节20-60字节流量控制无有拥塞控制无有适用场景实时应用、广播/多播可靠性要求高的应用 2、UDP 报文结构 报文结构大致可以分为首部和载荷&a…...

下载pycharm遇到的问题及解决方法
下载和安装 PyCharm 时可能会遇到一些具体问题,以下是一些常见问题及其解决方法: 常见问题及解决方法 下载速度慢或下载中断 解决方法: 检查你的互联网连接,并重启路由器。尝试使用不同的网络连接(如使用移动热点&…...

微硕WSP4407A MOS管在智能晾衣架中的应用与市场分析
微硕WSP4407A MOS管在智能晾衣架中的应用与市场分析 一、引言 智能晾衣架作为一种现代化的家居设备,其核心部件之一是驱动电路,而MOS管作为驱动电路中的关键元件,其性能直接影响到智能晾衣架的运行效率和稳定性。微硕半导体推出的WSP4407A …...

Java 性能优化:如何利用 APM 工具提升系统性能?
Java 性能优化:如何利用 APM 工具提升系统性能? 在当今竞争激烈的软件开发领域,系统性能至关重要。随着应用规模的扩大和用户需求的增加,性能问题逐渐凸显,这不仅影响用户体验,还可能导致业务损失。而 APM…...

FPGA 中 XSA、BIT 和 DCP 文件的区别
在 FPGA(现场可编程门阵列)开发中,XSA、BIT 和 DCP 文件是常见的文件类型,它们在功能、用途、文件内容等方面存在明显区别,以下是详细介绍: 1. XSA 文件 定义与功能 XSA(Xilinx Shell Archiv…...