即插即用模块(1) -MAFM特征融合
(即插即用模块-特征处理部分) 一、(2024) MAFM&MCM 特征融合+特征解码

paper:MAGNet: Multi-scale Awareness and Global fusion Network for RGB-D salient object detection
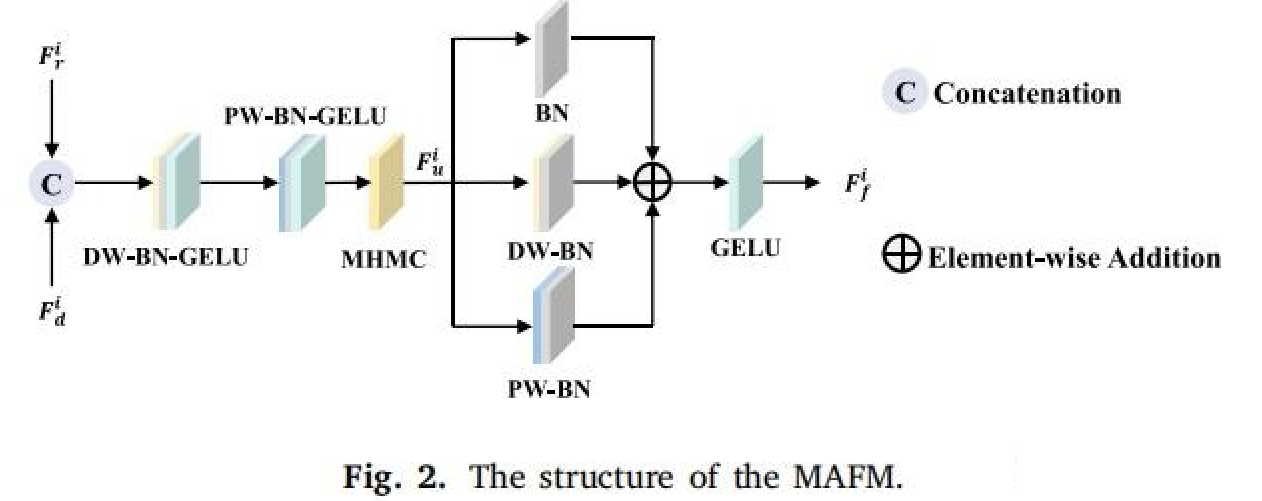
1. 多尺度感知融合模块 (MAFM)
多尺度感知融合模块 (MAFM) 旨在高效融合 RGB 和深度模态的互补信息,充分利用 RGB 图像的丰富纹理细节和深度图像的空间结构特性,同时克服 RGB 对光照变化的敏感性以及深度图像细节不足的局限性。通过多尺度特征整合和非线性变换,MAFM 实现高效的特征融合,同时降低计算复杂度。
实现流程:
- 特征拼接:将 RGB 和深度特征图沿通道维度拼接,形成统一的多模态特征表示,保留各模态的独特信息。
- 深度可分离卷积 (DW 层):应用深度可分离卷积高效提取空间局部特征,随后进行批归一化 (BN) 以稳定训练,并通过 GELU 激活函数引入非线性,提升特征表达能力。
- 点卷积 (PW 层):通过点卷积优化通道间交互,再次应用 BN 和 GELU 激活,确保特征的有效 recalibration。
- 多头多尺度卷积 (MHMC):将融合特征输入 MHMC 模块,通过多尺度卷积捕捉不同尺度的上下文信息,进一步增强特征融合效果。
- 残差融合:通过残差结构和元素级求和,整合不同分支的特征图,保留全局和局部信息。
- 非线性变换:最终通过 GELU 激活函数进行非线性变换,生成融合特征图。
Multi-scale Awareness Fusion Module 结构图:
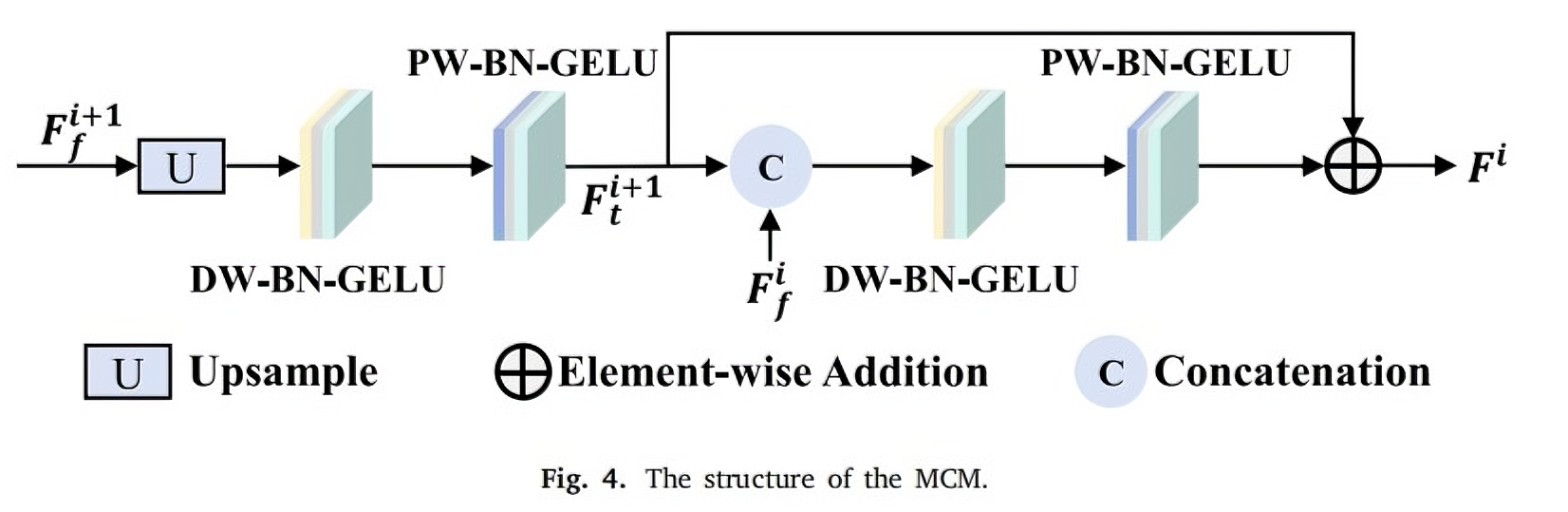
2. 多级卷积模块 (MCM)
多级卷积模块 (MCM) 旨在通过多尺度特征融合,逐步生成包含丰富细节的噪声目标预测图。MCM 采用残差结构,包含多个卷积块,通过整合不同尺度的特征图显著提升解码器的学习能力和泛化性能。
实现流程:
- 特征上采样与拼接:对高级特征图进行上采样,并与下一级特征图沿通道维度拼接,构建多尺度特征表示。
- 深度可分离卷积 (DW 层):使用深度可分离卷积提取空间特征,随后进行 BN 和 GELU 激活,以高效处理多尺度信息。
- 点卷积 (PW 层):通过点卷积优化通道间特征交互,再次应用 BN 和 GELU 激活,确保特征鲁棒性。
- 残差连接:将融合特征图与残差连接的结果进行元素级求和,生成最终输出,保留细节并增强稳定性。
Multi-level Convolution Module 结构图:
3、代码实现
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
from timm.models.layers import trunc_normal_# Conv_One_Identity
class COI(nn.Module):def __init__(self, inc, k=3, p=1):super().__init__()self.outc = incself.dw = nn.Conv2d(inc, self.outc, kernel_size=k, padding=p, groups=inc)self.conv1_1 = nn.Conv2d(inc, self.outc, kernel_size=1, stride=1)self.bn1 = nn.BatchNorm2d(self.outc)self.bn2 = nn.BatchNorm2d(self.outc)self.bn3 = nn.BatchNorm2d(self.outc)self.act = nn.GELU()self.apply(self._init_weights)def forward(self, x):shortcut = self.bn1(x)x_dw = self.bn2(self.dw(x))x_conv1_1 = self.bn3(self.conv1_1(x))return self.act(shortcut + x_dw + x_conv1_1)def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)elif isinstance(m, nn.Conv2d):fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsfan_out //= m.groupsm.weight.data.normal_(0, math.sqrt(2.0 / fan_out))if m.bias is not None:m.bias.data.zero_()class MHMC(nn.Module):def __init__(self, dim, ca_num_heads=4, qkv_bias=True, proj_drop=0., ca_attention=1, expand_ratio=2):super().__init__()self.ca_attention = ca_attentionself.dim = dimself.ca_num_heads = ca_num_headsassert dim % ca_num_heads == 0, f"dim {dim} should be divided by num_heads {ca_num_heads}."self.act = nn.GELU()self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.split_groups = self.dim // ca_num_headsself.v = nn.Linear(dim, dim, bias=qkv_bias)self.s = nn.Linear(dim, dim, bias=qkv_bias)for i in range(self.ca_num_heads):local_conv = nn.Conv2d(dim // self.ca_num_heads, dim // self.ca_num_heads, kernel_size=(3 + i * 2),padding=(1 + i), stride=1,groups=dim // self.ca_num_heads) # kernel_size 3,5,7,9 大核dw卷积,padding 1,2,3,4setattr(self, f"local_conv_{i + 1}", local_conv)self.proj0 = nn.Conv2d(dim, dim * expand_ratio, kernel_size=1, padding=0, stride=1,groups=self.split_groups)self.bn = nn.BatchNorm2d(dim * expand_ratio)self.proj1 = nn.Conv2d(dim * expand_ratio, dim, kernel_size=1, padding=0, stride=1)self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)elif isinstance(m, nn.Conv2d):fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsfan_out //= m.groupsm.weight.data.normal_(0, math.sqrt(2.0 / fan_out))if m.bias is not None:m.bias.data.zero_()def forward(self, x, H, W):B, N, C = x.shapev = self.v(x)s = self.s(x).reshape(B, H, W, self.ca_num_heads, C // self.ca_num_heads).permute(3, 0, 4, 1,2) # num_heads,B,C,H,Wfor i in range(self.ca_num_heads):local_conv = getattr(self, f"local_conv_{i + 1}")s_i = s[i] # B,C,H,Ws_i = local_conv(s_i).reshape(B, self.split_groups, -1, H, W)if i == 0:s_out = s_ielse:s_out = torch.cat([s_out, s_i], 2)s_out = s_out.reshape(B, C, H, W)s_out = self.proj1(self.act(self.bn(self.proj0(s_out))))self.modulator = s_outs_out = s_out.reshape(B, C, N).permute(0, 2, 1)x = s_out * vx = self.proj(x)x = self.proj_drop(x)return x# Multi-scale Awareness Fusion Module
class MAFM(nn.Module):def __init__(self, inc):super().__init__()self.outc = incself.attention = MHMC(dim=inc)self.coi = COI(inc)self.pw = nn.Sequential(nn.Conv2d(in_channels=inc, out_channels=inc, kernel_size=1, stride=1),nn.BatchNorm2d(inc),nn.GELU())self.pre_att = nn.Sequential(nn.Conv2d(inc * 2, inc * 2, kernel_size=3, padding=1, groups=inc * 2),nn.BatchNorm2d(inc * 2),nn.GELU(),nn.Conv2d(inc * 2, inc, kernel_size=1),nn.BatchNorm2d(inc),nn.GELU())self.apply(self._init_weights)def forward(self, x, d):B, C, H, W = x.shapex_cat = torch.cat((x, d), dim=1)x_pre = self.pre_att(x_cat)# Attentionx_reshape = x_pre.flatten(2).permute(0, 2, 1) # B,C,H,W to B,N,Cattention = self.attention(x_reshape, H, W) # attentionattention = attention.permute(0, 2, 1).reshape(B, C, H, W) # B,N,C to B,C,H,W# COIx_conv = self.coi(attention) # dw3*3,1*1,identityx_conv = self.pw(x_conv) # pwreturn x_convdef _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)elif isinstance(m, nn.Conv2d):fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsfan_out //= m.groupsm.weight.data.normal_(0, math.sqrt(2.0 / fan_out))if m.bias is not None:m.bias.data.zero_()# Decoder
class MCM(nn.Module):def __init__(self, inc, outc):super().__init__()self.upsample2 = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)self.rc = nn.Sequential(nn.Conv2d(in_channels=inc, out_channels=inc, kernel_size=3, padding=1, stride=1, groups=inc),nn.BatchNorm2d(inc),nn.GELU(),nn.Conv2d(in_channels=inc, out_channels=outc, kernel_size=1, stride=1),nn.BatchNorm2d(outc),nn.GELU())self.predtrans = nn.Sequential(nn.Conv2d(in_channels=outc, out_channels=outc, kernel_size=3, padding=1, groups=outc),nn.BatchNorm2d(outc),nn.GELU(),nn.Conv2d(in_channels=outc, out_channels=1, kernel_size=1))self.rc2 = nn.Sequential(nn.Conv2d(in_channels=outc * 2, out_channels=outc * 2, kernel_size=3, padding=1, groups=outc * 2),nn.BatchNorm2d(outc * 2),nn.GELU(),nn.Conv2d(in_channels=outc * 2, out_channels=outc, kernel_size=1, stride=1),nn.BatchNorm2d(outc),nn.GELU())self.apply(self._init_weights)def forward(self, x1, x2):x2_upsample = self.upsample2(x2) # 上采样x2_rc = self.rc(x2_upsample) # 减少通道数shortcut = x2_rcx_cat = torch.cat((x1, x2_rc), dim=1) # 拼接x_forward = self.rc2(x_cat) # 减少通道数2x_forward = x_forward + shortcutpred = F.interpolate(self.predtrans(x_forward), 384, mode="bilinear", align_corners=True) # 预测图return pred, x_forwarddef _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)elif isinstance(m, nn.Conv2d):fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsfan_out //= m.groupsm.weight.data.normal_(0, math.sqrt(2.0 / fan_out))if m.bias is not None:m.bias.data.zero_()if __name__ == '__main__':x = torch.randn(4, 16, 128, 128).cuda()y = torch.randn(4, 16, 128, 128).cuda()z = torch.randn(4, 32, 64, 64).cuda()model = MAFM(16).cuda()out = model(x, y)# model = MCM(32, 16).cuda()# _, out = model(x, z)# print(out.shape)
':x = torch.randn(4, 16, 128, 128).cuda()y = torch.randn(4, 16, 128, 128).cuda()z = torch.randn(4, 32, 64, 64).cuda()model = MAFM(16).cuda()out = model(x, y)# model = MCM(32, 16).cuda()# _, out = model(x, z)# print(out.shape)
相关文章:
 -MAFM特征融合)
即插即用模块(1) -MAFM特征融合
(即插即用模块-特征处理部分) 一、(2024) MAFM&MCM 特征融合特征解码 paper:MAGNet: Multi-scale Awareness and Global fusion Network for RGB-D salient object detection 1. 多尺度感知融合模块 (MAFM) 多尺度感知融合模块 (MAFM) 旨在高效融合 RGB 和深度…...

Linux学习——TCP
一.TCP编程API 1.socket函数 1.socket函数 include include int socket(int domain,int type,int protocol); 参数 domain AF_INET AF_INET6 AF_UNIX,AF_LOCAL AF_NETLINK AF_PACKET type SOCK_STREAM: 流式…...
)
Kubernetes控制平面组件:调度器Scheduler(二)
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

数据通信学习笔记之OSPF其他内容2
OSPF 与 BFD 联动 网络上的链路故障或拓扑变化都会导致设备重新进行路由计算,所以缩短路由协议的收敛时间对于提高网络的性能是非常重要的。 OSPF 与 BFD 联动就是将 BFD 和 OSPF 关联起来,一旦与邻居之间的链路出现故障,BFD 对完品以&…...

数据通信学习笔记之OSPF的区域
OSPFArea 用于标识一个 OSPF 的区域 区域是从逻辑上将设备划分为不同的组,每个组用区域号 (Area ID)来标识 OSPF 的区域 ID 是一个 32bit 的非负整数,按点分十进制的形式(与 IPV4 地址的格式一样)呈现,例如 Area0.0.0.1。 为了简便起见&#…...
)
css3新特性第四章(渐变)
渐变 线性渐变 径向渐变 重复渐变 使用: background-image: xx 渐变 background-image: linear-gradient(red,yellow,green); 公共代码 .box {width: 300px;height: 200px;border: 1px solid black;float: left;margin-left: 30px;margin-top: 30px;text-align:…...

玩机搞机基本常识-------小米OLED屏幕机型怎么设置为永不休眠_手机不息屏_保持亮屏功能 拒绝“烧屏” ?
前面在帮一位粉丝解决小米OLED机型在设置----锁屏下没有永不休眠的问题。在这里,大家要明白为什么有些小米机型有这个设置有的没有的原因。区分OLED 屏幕和 LCD屏幕的不同。从根本上拒绝烧屏问题。 OLED 屏幕的一些优缺点💝💝💝 …...

深拷贝和浅拷贝的区别
浅拷贝: 只复制原对象的基本数据类型字段,拥有相对独立的副本数据,修改时不会影响到原对象的字段值。对于原对象的引用数据类型字段,直接共享原对象字段的引用,修改自己的字段时会同时影响原对象。 深拷贝:…...

RabbitMQ和Seata冲突吗?Seata与Spring中的事务管理冲突吗
1. GlobalTransactional 和 Transactional 是否冲突? 答:不冲突,它们可以协同工作,但作用域不同。 Transactional: 这是 Spring 提供的注解,用于管理单个数据源内的本地事务。在你当前的 register 方法中,…...

[安全实战]逆向工程核心名词详解
逆向工程核心名词详解 一、调试与执行类 1. 断点(Breakpoint) 定义:在代码中设置标记,使程序执行到此处时暂停类型: 普通断点:通过INT3指令实现条件断点:满足特定条件时触发内存断点…...

用键盘实现控制小球上下移动——java的事件控制
本文分享Java的一个有趣小项目,实现用键盘控制小球的移动 涉及java知识点:Swing GUI框架,绘图机制,事件处理,焦点控制 1.编写窗口和面板 (1.)定义面板类 Panel 继承自Java 自带类JPanel (2.)定义窗口类 window 继承…...
——Mcu模块配置及代码详解(上))
AutoSAR从概念到实践系列之MCAL篇(二)——Mcu模块配置及代码详解(上)
欢迎大家学习我的《AutoSAR从概念到实践系列之MCAL篇》系列课程,我是分享人M哥,目前从事车载控制器的软件开发及测试工作。 学习过程中如有任何疑问,可底下评论! 如果觉得文章内容在工作学习中有帮助到你,麻烦点赞收藏评论+关注走一波!感谢各位的支持! 根据上一篇内容中…...

BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View
背景 在自动驾驶场景下,以往工作是目标检测任务用图像视角做,语义分割用BEV视角做。本文提出了BEVDet,实现了一个统一的框架,它模块化设计分为图像编码器,视角转换器,BEV编码器以及BEV空间的3D检测头。然而…...

高效获取淘宝实时商品数据:API 接口开发与数据采集实战指南
在电商行业竞争白热化的当下,实时且准确的商品数据是企业制定营销策略、优化产品布局的重要依据。淘宝作为国内头部电商平台,其海量的商品数据蕴含着巨大价值。通过 API 接口高效获取淘宝实时商品数据,成为电商从业者和开发者的必备技能。本文…...
 : Flow核心概念与与操作符指南)
kotlin知识体系(六) : Flow核心概念与与操作符指南
1. Flow基础概念 1.1 冷流(Cold Stream) 冷流是Flow的默认形式,其核心特点如下: • 按需触发:仅在消费者调用 collect 时开始发射数据,且每次收集都会重新执行流的逻辑(类似“单播”࿰…...

【CentOs】构建云服务器部署环境
(一) 服务器采购 2 CPU4G 内存40G 系统盘 80G 数据盘 (二) 服务器安全组和端口配置 (三) 磁盘挂载 1 登录 root 2 查看目前磁盘使用情况 df -h 3 查看磁盘挂载情况 识别哪些磁盘没挂载 fdisk -l 4 对未挂载磁盘做分区 fdisk /dev/vdb 输入m࿰…...

【AI论文】对人工智能生成文本的稳健和细粒度检测
摘要:机器生成内容的理想检测系统应该能够在任何生成器上很好地工作,因为越来越多的高级LLM每天都在出现。 现有的系统往往难以准确识别人工智能生成的短文本内容。 此外,并非所有文本都完全由人类或LLM创作,因此我们更关注部分案…...

MyFamilyTree:专业家谱族谱制作工具
MyFamilyTree 是一款专业级家谱族谱制作工具,支持 Windows 7 至 11 系统(含服务器版本)。该软件以直观的拖拽式操作为核心,支持构建多维家族树结构,并提供丰富的多媒体集成功能,便于用户记录家族成员的生…...

【统计分析120】统计分析120题分享
1-30 判断题 数学模型 指的是通过抽象、简化现实世界的某些现象,利用数学语言来描述他们的结构和行为,做出一些必要的假设,运用适当的数学工具,得到一个数学结论 数学模型:指的是通过抽象、简化现实世界的某些现象&am…...

【Windows10下PP-OCRv4部署指南】
Windows10下PP-OCRv4部署指南 一、环境准备 安装Visual Studio 2022 下载并安装 C桌面开发组件,确保支持MSVC编译环境。 配置系统环境变量,确保cl.exe等编译工具可用。 Python环境配置 推荐使用Conda创建虚拟环境: bash Co…...

Matlab PID参数整定和设计
1、内容简介 Matlab 206-PID参数整定和设计 可以交流、咨询、答疑 2、内容说明 略 某流量控制系统整定方法仿真(3) 摘 要:本次设计针对一个给定的流量控制系统进行仿真,已经确认该系统为简单控制系统,并且控制策略…...
)
【Linux系统】Linux基础指令(详解Linux命令行常用指令,每一个指令都有示例演示)
文章目录 一、与文件路径相关的指令0.补充知识:路径的认识1.pwd 指令2.cd 指令(含家目录的介绍) 二、创建和删除文件的指令0.补充知识:普通文件和目录文件1.touch 指令(可以修改文件的时间戳)2.mkdir 指令3…...

LLM基础-什么是Token?
LLM基础-什么是Token? 概述 Token 是大语言模型(LLM, Large Language Model)中最基本的输入单元,它是语言被模型“理解”的方式。不同于人类可以直接看懂一段自然语言文本,LLM 只能处理数字,而这些数字就…...

Few-shot medical image segmentation with high-fidelity prototypes 论文总结
题目:Few-shot medical image segmentation with high-fidelity prototypes(高精确原型) 论文:Few-shot medical image segmentation with high-fidelity prototypes - ScienceDirect 源码:https://github.com/tntek/D…...
)
大模型之路(day 1)
这段时间以来,全身心的投入了研究大模型,虽然还是入门,但比之前已经好了非常多了,不得不说,计算机的学习特别需要强大的自驱力和耐心,以及检索能力。知乎确实在这些知识的分享上做的比csdn好太多了 万事开…...

996引擎-拓展变量:物品变量
996引擎-拓展变量:物品变量 测试代码参考资料对于Lua来说,只有能保存数据库的变量才有意义。 至于临时变量,不像TXT那么束手束脚,通常使用Lua变量就能完成。 测试代码 -- 存:物品拓展strfunction (player)local where =...
)
集合框架(重点)
1. 什么是集合框架 List有序插入对象,对象可重复 Set无序插入对象,对象不可重复(重复对象插入只会算一个) Map无序插入键值对象,键只唯一,值可多样 (这里的有序无序指的是下标,可…...

IDEA在Git提交时添加.ignore忽略文件,解决为什么Git中有时候使用.gitignore也无法忽略一些文件
文章目录 一、为什么需要.gitignore文件?二、如何在IntelliJ IDEA中高效管理.gitignore文件?1:先下载这个.ignore插件2. 创建或编辑.gitignore文件3. 使用IDEA内置模板快速生成忽略规则4. 实时预览忽略效果5. 检查忽略规则是否生效6.但是一般我们更多时候…...

如何将自己封装的组件发布到npm上:详细教程
如何将自己封装的组件发布到npm上:详细教程 作为前端开发者,我们经常从npm(Node Package Manager)上下载并使用各种第三方库和组件。然而,有时候我们可能会发现自己需要的功能在npm上并不存在,或者我们希望…...
)
位运算,状态压缩dp(算法竞赛进阶指南学习笔记)
目录 移位运算一些位运算的操作最短 Hamilton 路径(状态压缩dp模板,位运算) 0x是十六进制常数的开头;本身是声明进制,后面是对应具体的数; 数组初始化最大值时用0x3f赋值; 移位运算 左移 把二…...

node.js|环境部署|源码编译高版本的node.js
一、 前言 本文就如何二进制部署和源码编译安装部署node.js环境做一个简单的介绍 node的版本大体是以18版本为界限,也就是说18版本之前对glibc版本没有要求,其后的版本都对glibc版本有要求,node的版本越高,glibc需要的版本也越…...

通信安全员ABC证的考试内容包括哪些?
通信安全员 ABC 证的考试内容整体上围绕通信安全相关的法律法规、安全技术、安全管理等方面展开,但在具体侧重点上有所不同,以下是详细介绍: 通信安全基础知识 通信原理:包含模拟通信和数字通信的基本原理,如调制、解…...

Oracle--SQL基本语法
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 1、SQL语句介绍 在Oracle开发中,客户端把SQL语句发送给服务器,服务器对SQL语句进行编译、执行,把执行的结果返回给…...
)
windows服务器及网络:论如何安装(虚拟机)
今天我要介绍的是:在Windows中对于安装系统(虚拟机的步骤以及相关的安装事宜),事不宜迟,让我们来看看系统安装(虚拟机)是怎么操作的: 对现在来说,安装电脑系统已经是非常…...

【网络篇】从零写UDP客户端/服务器:回显程序源码解析
大家好呀 我是浪前 今天讲解的是网络篇的第四章:从零写UDP客户端/服务器:回显程序源码解析 从零写UDP客户端/服务器:回显程序源码解析 UDP 协议特性核心类介绍 UDP的socket应该如何使用:1: DatagramSocket2: DatagramPacket回…...
)
学习笔记:黑马程序员JavaWeb开发教程(2025.3.23)
11.2 案例-文件上传-简介 文件上传的前端页面的代码需要放到springboot项目的static里面,也就是resource文件夹下面的static文件夹里面 服务端接收前端上传的数据,再服务端定义一个controller来接收数据,再controller中定义一个…...

提示词构成要素对大语言模型跨模态内容生成质量的影响
提示词构成要素对大语言模型跨模态内容生成质量的影响 提示词清晰度、具象性与质量正相关 限定指向性要素优于引导指向性要素 大语言模型生成内容保真度偏差 以讯飞星火大模型为实验平台,选取100名具备技术素养的人员,从提示词分类、构成要素和实践原则归纳出7种提示词组…...

浅聊docker的联合文件系统
前言: 在我们pull镜像的时候,就会发现一个神奇的地方,在将镜像pull到本地的时候它是分层下载的,如下图: 这时候我就有一个疑问,为什么是分层下载的?怎么和我们平时下载软件的时候不一样呢? 联…...
)
计算机视觉cv入门之Haarcascade的基本使用方法(人脸识别为例)
Haar CascadeXML特征分类器,是一种基于机器学习的方法,它利用了积分图像(或总面积)的概念有效地提取特征(例如,边缘、线条等)的数值。“级联分类器”即意味着不是一次就为图像中的许多特征应用数百个分类器,而是一对一地应用分类器…...

【NLP 62、实践 ⑮、基于RAG + 智谱语言模型的Dota2英雄故事与技能介绍系统】
羁绊由我而起,痛苦也由我承担 —— 25.4.14 英雄介绍文件: 通过网盘分享的文件:RAG 智谱语言模型的Dota2英雄故事与技能介绍系统 链接: https://pan.baidu.com/s/1G7Xo5TRvFl2BzUnE0NFaBA?pwd4d4j 提取码: 4d4j --来自百度网盘超级会员v3的…...

Keil MDK 编译问题:function “HAL_IncTick“ declared implicitly
问题与处理策略 问题描述 ..\..\User\stm32f1xx_it.c(141): warning: #223-D: function "HAL_IncTick" declared implicitlyHAL_IncTick(); ..\..\User\stm32f1xx_it.c: 1 warning, 0 errors问题原因 在 stm32f1xx_it.c 文件中调用了 HAL_IncTick(),但…...

OpenCV基础01-图像文件的读取与保存
介绍: OpenCV是 Open Souce C omputer V sion Library的简称。要使用OpenCV需要安装OpenCV包,使用前需要导入OpenCV模块 安装 命令 pip install opencv-python 导入 模块 import cv2 1. 图像的读取 import cv2 img cv2.imread(path, flag)这里的flag 是可选参数&…...

IP数据报
IP数据报组成 IP数据报(IP Datagram)是网络中传输数据的基本单位。 IP数据报头部 版本(Version) 4bit 告诉我们使用的是哪种IP协议。IPv4版本是“4”,IPv6版本是“6”。 头部长度(IHL,Intern…...

视频联网平台与AI识别技术在电力行业的创新应用
一、电力行业智能化转型的迫切需求 在能源革命与数字化转型的双重推动下,电力行业正面临着前所未有的智能化升级需求。随着特高压电网的大规模建设和新能源占比的不断提高,传统的电力运维管理模式已经难以满足现代电网安全、高效运行的要求。据统计&…...

Apache Parquet 文件组织结构
简要概述 Apache Parquet 是一个开源、列式存储文件格式,最初由 Twitter 与 Cloudera 联合开发,旨在提供高效的压缩与编码方案以支持大规模复杂数据的快速分析与处理。Parquet 文件采用分离式元数据设计 —— 在数据写入完成后,再追加文件级…...

深度学习方向急出成果,是先广泛调研还是边做实验边优化?
目录 有限资源下本科生快速发表深度学习顶会论文的实战策略 1.短周期内可出成果的研究路径 2.论文阅读与复现的优先顺序 3.无一对一指导时的调研与实验组织 4.成功案例:本科生顶会论文经验 5.快速上手的研究子方向推荐 大家好这里是AIWritePaper官方账号&…...
实例)
Python 深度学习实战 第11章 自然语言处理(NLP)实例
Python 深度学习实战 第11章 自然语言处理(NLP)实例 内容概要 第11章深入探讨了自然语言处理(NLP)的深度学习应用,涵盖了从文本预处理到序列到序列学习的多种技术。本章通过IMDB电影评论情感分类和英西翻译任务,详细介绍了如何使…...

9、Hooks:现代魔法咒语集——React 19 核心Hooks
一、魔法咒语的本质革新 "类组件如同古老的魔杖挥舞仪式,而Hooks是新时代的无杖施法!"霍格沃茨魔法研究院的魔杖动力学教授惊叹道。React Hooks通过函数式能量场重构了魔法运作模式,让组件能量流转如尼可勒梅的炼金术。 ——以《国…...

FutureTask底层实现
一、FutureTask的基本使用 平时一些业务需要做并行处理,正常如果你没有返回结果的需求,直接上Runnable。 很多时候咱们是需要开启一个新的线程执行任务后,给我一个返回结果。此时咱们需要使用Callable。 在使用Callable的时候,…...

深入浅出:LDAP 协议全面解析
在网络安全和系统管理的世界中,LDAP(轻量级目录访问协议,Lightweight Directory Access Protocol)是一个不可忽视的核心技术。它广泛应用于身份管理、认证授权以及目录服务,尤其在企业级环境中占据重要地位。本文将从基…...