AI——神经网络以及TensorFlow使用
文章目录
- 一、TensorFlow安装
- 二、张量、变量及其操作
- 1、张量Tensor
- 2、变量
- 三、tf.keras介绍
- 1、使用tf.keras构建我们的模型
- 2、激活函数
- 1、sigmoid/logistics函数
- 2、tanh函数
- 3、RELU函数
- 4、LeakReLu
- 5、SoftMax
- 6、如何选择激活函数
- 3、参数初始化
- 1、bias偏置初始化
- 2、weight权重初始化
- 1、随机初始化
- 2、标准初始化
- 3、Xavier初始化
- 4、He初始化
- 4、神经网络构建
- 1、通过Sequential构建
- 2、function api方式构建
- 3、Model子类构建方式
- 5、神经网络的优缺点
一、TensorFlow安装
# 1、非GPU版本安装
pip3 install tensorflow==2.3.0# 2、GPU版本安装
pip3 install tensorflow-gpu==2.3.0
二、张量、变量及其操作
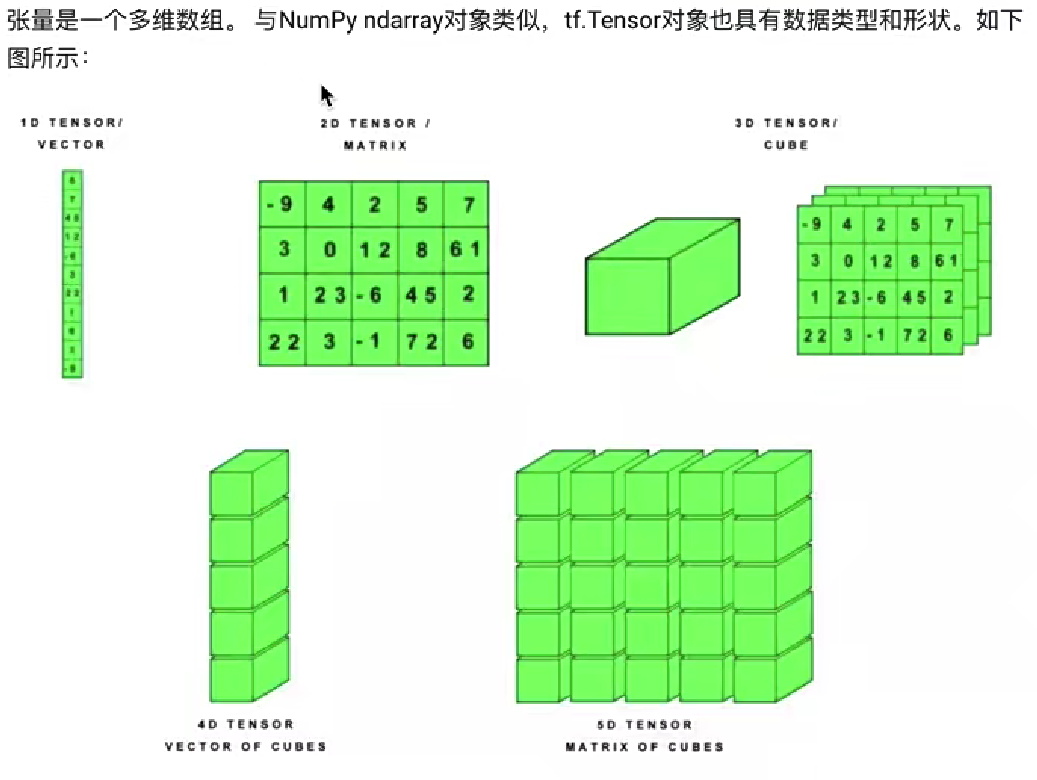
1、张量Tensor
import tensorflow as tf
import numpy as np# 创建基础的张量
## 1.创建int32类型的0维张量,即标量
rank_0_tensor = tf.constant(4)
print(rank_0_tensor)## 2.创建float32类型的1维张量
rank_1_tensor = tf.constant([2.0, 3.0, 4.0])
print(rank_1_tensor)## 3.创建float16类型的二维张量
rank_2_tensor = tf.constant([[1, 2],[3, 4],[5, 6]
], dtype=tf.float16)
print(rank_2_tensor)## 4.将张量转化为ndarray
np1 = np.array(rank_2_tensor)
print(np1)np2 = rank_2_tensor.numpy
print(np2)# 张量常用函数
a = tf.constant([[1, 2],[3, 4]
])
b = tf.constant([[1, 1],[1, 1]
])
print(tf.add(a, b)) # 计算张量元素的和
print(tf.multiply(a, b)) # 计算张量元素的乘积
print(tf.matmul(a, b)) # 计算张量矩阵的乘法# 聚合运算
c = tf.constant([[4.0, 5.0],[10.0, 1.0]
])
print(tf.reduce_max(c)) # 最大值
print(tf.reduce_mean(c)) # 平均值
print(tf.reduce_sum(c)) # 求和
print(tf.reduce_min(c)) # 最小值
print(tf.argmax(c)) # 最大值索引
print(tf.argmin(c)) # 最小值索引
2、变量

# 变量
var = tf.Variable([[1, 2],[3, 4]
])
print(var.shape) # 获取变量的形状
print(var.dtype) # 获取变量中数据类型
print(var.numpy) # 转化为ndarray
print(var.assign([[5, 6], [7, 8]])) # 修改变量值
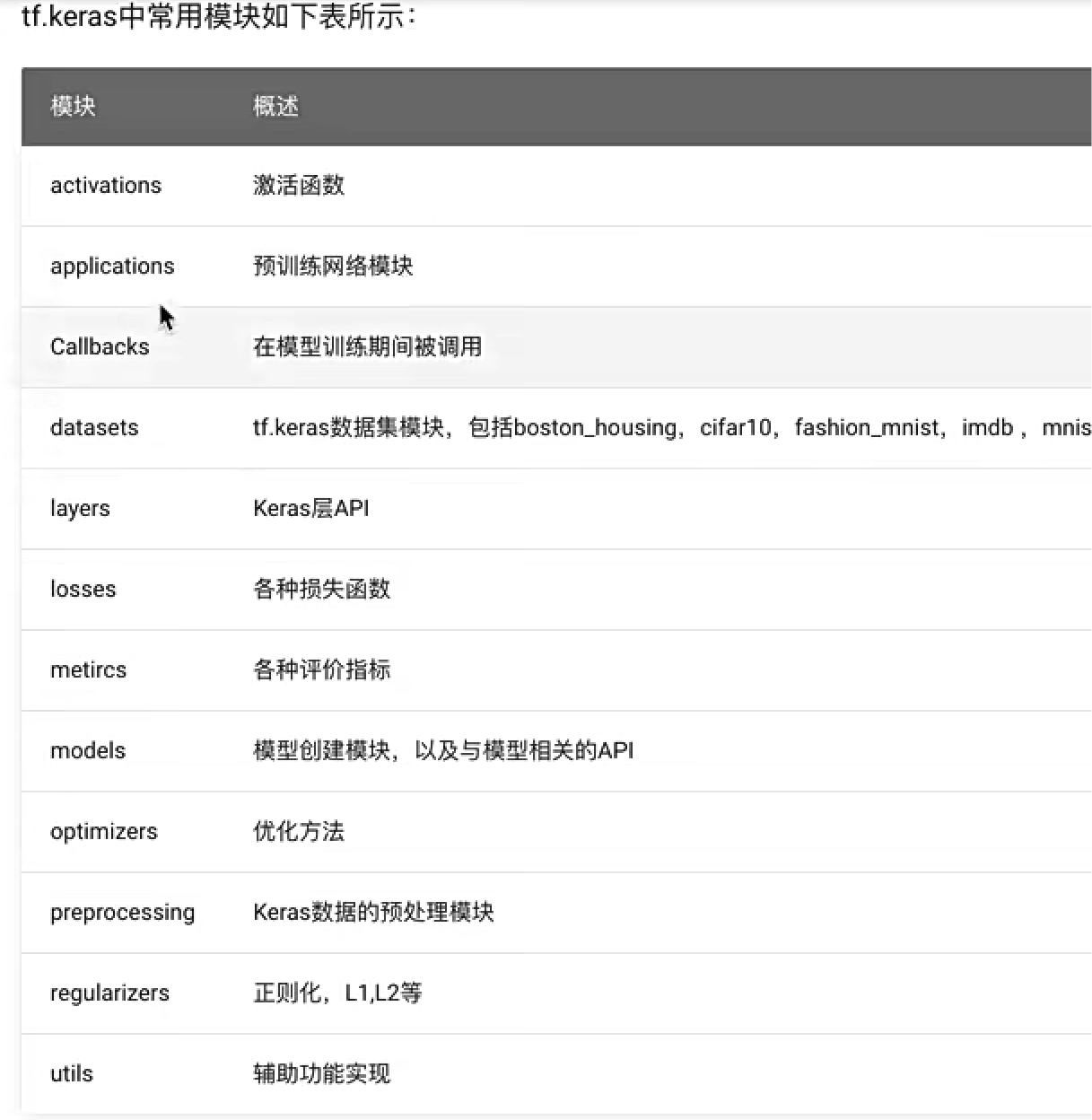
三、tf.keras介绍
1、使用tf.keras构建我们的模型
# 绘图工具
import seaborn as sns
# 数组计算
import numpy as np
# sklearn相关工具
from sklearn.datasets import load_iris
# 划分测试集和训练集
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 逻辑回归
from sklearn.linear_model import LogisticRegressionCV
# tf.keras中使用的相关工具
# 用于模型搭建
from tensorflow.keras.models import Sequential
# 构建模型的层和激活工具
from tensorflow.keras.layers import Dense, Activation
# 数据处理的辅助工具
from tensorflow.keras import utils
# pandas工具,让数据更好看
import pandas as pd# 1.使用sklearn获取鸢尾花数据
iris = load_iris()
iris_d = pd.DataFrame(data=iris.data, columns=['sepal_length', 'sepal_width', 'petal_length', 'petal_width'])
# 设置其目标值为target_names
iris_d['species'] = iris['target_names'][iris['target']]
# 使用seaborn中的pairplot函数探索数据特征间的关系
sns.pairplot(iris_d, hue="species")# 使用sklearn实现# 所有的特征值
x = iris_d.values[:, :4]# 所有的目标值
y = iris_d.values[:, 4]# 利用train_test_split完成数据集划分,测试集20%,训练集80%
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)# 特征预处理
# transfer = StandardScaler()
transfer = MinMaxScaler((0, 1))
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)## 模型调优 - 交叉验证、网格搜索
# 实例化估计器,CV这个估计器已经调过优了
lr = LogisticRegressionCV()
# 模型训练
lr.fit(x_train, y_train)
# 模型评估
lr.score(x_test, y_test)# 使用tf.keras实现
# 1.生成目标值的热编码
def one_hot_encode(arr):# 获取目标值中的所有类别进行热编码uniques, ids = np.unique(arr, return_inverse=True)return utils.to_categorical(ids, len(uniques))# 2.对目标值进行热编码
y_train_one = one_hot_encode(y_train)
y_test_one = one_hot_encode(y_test)# 3.模型构建
model = Sequential([# 隐藏层,输入层,input_shape表示我们有几个特征Dense(10, activation="relu", input_shape=(4,)),# 隐藏层Dense(10, activation="relu"),# 输出层,3表示我们有几种结果Dense(3, activation="softmax")
])# 4.模型预测与评估
## 4.1 模型编译
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])## 4.2 模型训练
# 类型转换
x_train = np.array(x_train, dtype=np.float32)
x_test = np.array(x_test, dtype=np.float32)
model.fit(x_train, y_train_one, epochs=10, batch_size=1, verbose=1)## 4.3模型评估
loss, accuracy = model.evaluate(x_test, y_test_one, verbose=1)
print("loss: ", loss)
print("准确率:", accuracy)
2、激活函数
1、sigmoid/logistics函数
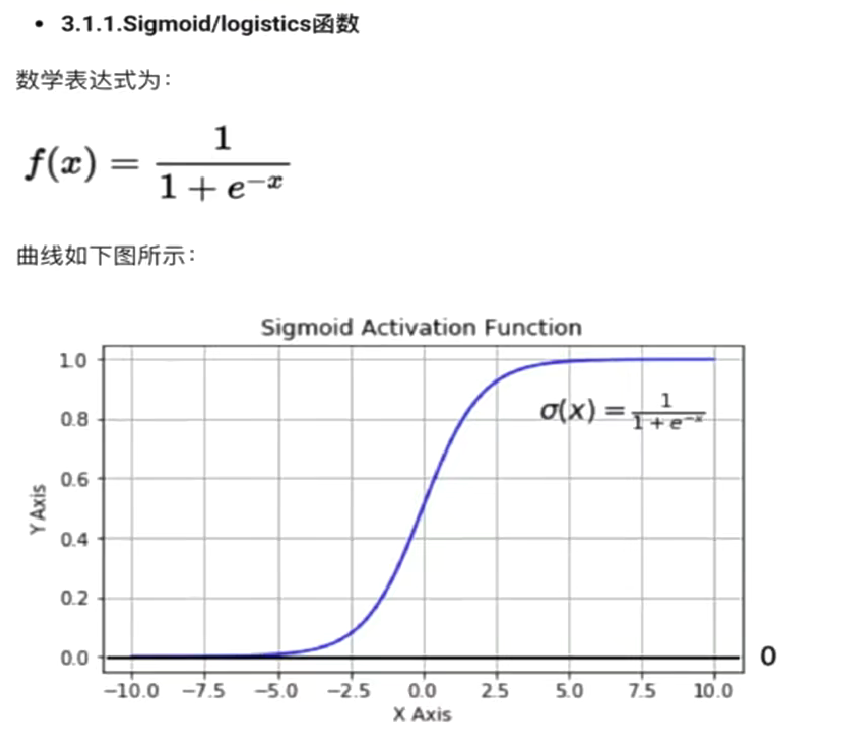

一般只用于输出层的二分类
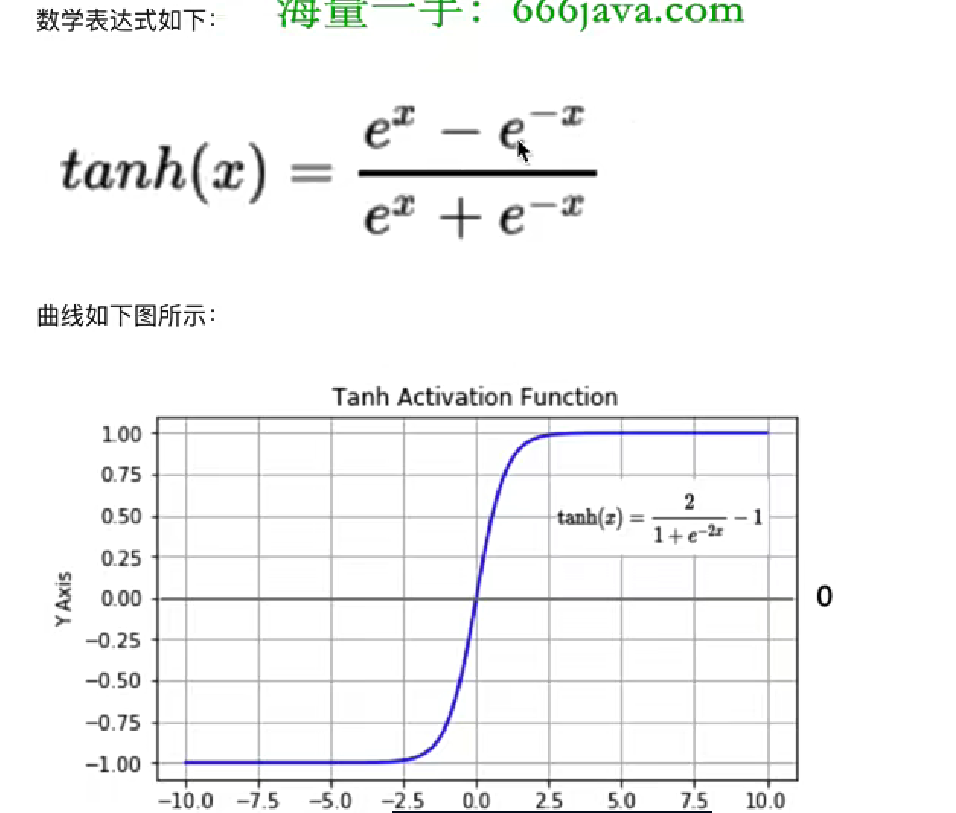
2、tanh函数

3、RELU函数
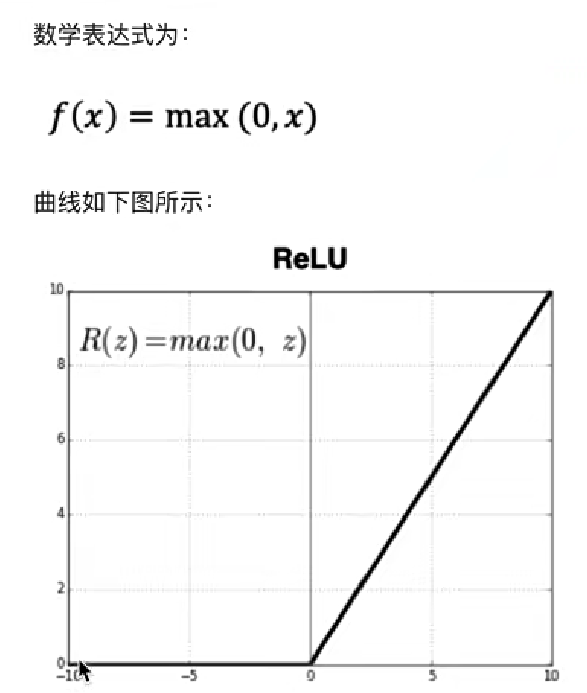


无脑使用RELU
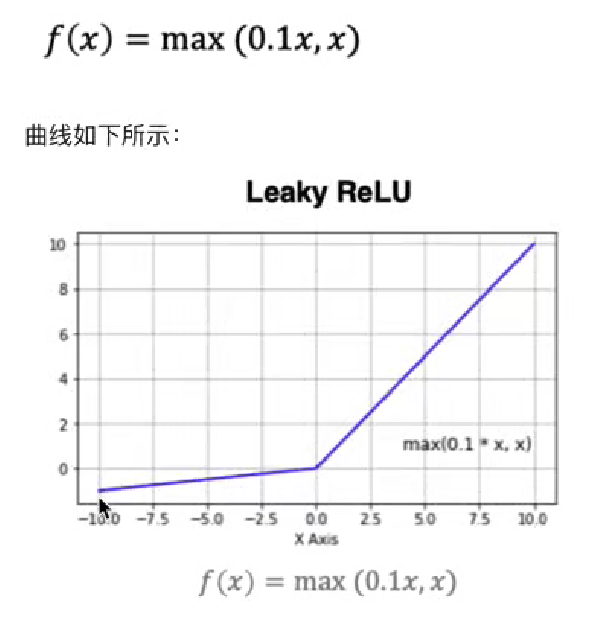
4、LeakReLu
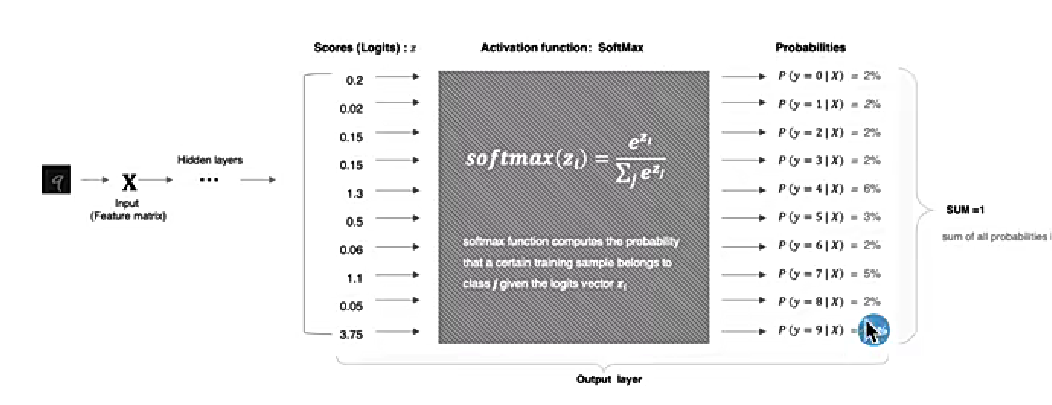
5、SoftMax
softmax用于多分类过程中,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展示出来。
6、如何选择激活函数

3、参数初始化
1、bias偏置初始化
直接初始化为0
2、weight权重初始化
1、随机初始化
随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数w进行初始化
2、标准初始化
权重参数初始化从区间均匀随机取值,即在(-1/根号d/,根号d/1)均匀分布中生成当前神经元的权重,其中d为每个神经元的输入数量
3、Xavier初始化
该方法的基本思想是各层的激活值和梯度的方差在传播过程中保持一致,也叫做Glorot初始化,在tf.keras中实现方法有两种:
- 正态化Xavier初始化

- 标准化Xavier初始化

4、He初始化
he初始化,也称为Kaiming初始化,他的基本思想是正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变
- 正太化的he初始化

- 标准化的he初始化

4、神经网络构建
1、通过Sequential构建
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers# 定义一个Sequential模型,包含3层
model = keras.Sequential([# 第一层:激活函数为relu,权重初始化为he_normallayers.Dense(3, activation="relu", kernel_initializer="he_normal", name="layer1", input_shape=(3, )),# 第二层:激活函数为relu,权重初始化为he_normallayers.Dense(2, activation="relu", kernel_initializer="he_normal", name="layer2"),# 第三次:激活函数为sigmoid,权重初始化和he_normallayers.Dense(2, activation="sigmoid", kernel_initializer="he_normal", name="layer3")
])model.summary()
2、function api方式构建

# 使用function api方式构建神经网络
import tensorflow as tf
# 定义模型的输入
inputs = tf.keras.Input(shape=(3,), name = 'input')
# 第一层:激活函数为relu,其他默认
x = tf.keras.layers.Dense(3, activation='relu', name='layer1')(inputs)
# 第二层:激活函数为relu,其他默认
x = tf.keras.layers.Dense(2, activation='relu', name='layer2')(x)
# 第三次:输出层,激活函数为sigmoid
outputs = tf.keras.layers.Dense(2, activation='sigmoid', name='layer3')(x)
# 使用Model创建模型
model = tf.keras.Model(inputs = inputs, outputs=outputs, name='my_model')
model.summary()
3、Model子类构建方式
# 使用Model子类的方式构建神经网络
import tensorflow as tfclass MyModel(tf.keras.Model):# 在init方法中定义网络的层结构def __init__(self):super(MyModel, self).__init__()# 第一层:激活函数为relu,权重初始化为he_normalself.layer1 = tf.keras.layers.Dense(3, activation='relu', kernel_initializer='he_normal', name='layer1', input_shape=(3,))# 第二层:激活函数为relu,权重初始化为he_normalself.layer2 = tf.keras.layers.Dense(2, activation='relu', kernel_initializer='he_normal', name='layer2')# 第三次:激活函数为sigmoid,权重初始化为he_normalself.layer3 = tf.keras.layers.Dense(2, activation='sigmoid', kernel_initializer='he_normal', name='layer3')# 在call方法中完成前向传播def call(self, inputs):x = self.layer1(inputs)x = self.layer2(x)return self.layer3(x)# 实例化model
model = MyModel()
# 设置一个输入调用模型(否则无法使用summary方法)
x = tf.ones((1, 3))
y = model(x)
model.summary()
5、神经网络的优缺点

相关文章:

AI——神经网络以及TensorFlow使用
文章目录 一、TensorFlow安装二、张量、变量及其操作1、张量Tensor2、变量 三、tf.keras介绍1、使用tf.keras构建我们的模型2、激活函数1、sigmoid/logistics函数2、tanh函数3、RELU函数4、LeakReLu5、SoftMax6、如何选择激活函数 3、参数初始化1、bias偏置初始化2、weight权重…...

实现对象之间的序列化和反序列化
1.什么是序列化? 在项目的开发中,为了让前端更好的分析后端返回的结果,我们一般会将返回的信息进行序列化,序列化就是将返回对象的状态信息转换为一种标准化的格式,方便在网络中传输也方便打印日志时号观察࿰…...

QML中日期处理类
在 QML 中处理日期和时间主要使用 JavaScript 的 Date 对象以及 Qt 提供的一些相关功能。以下是常用的日期处理方式: 1. JavaScript Date 对象 QML 可以直接使用 JavaScript 的 Date 对象: qml // 创建当前日期时间 var currentDate new Date()// 创…...

基于docker-java封装的工具类
基于docker-java封装的工具类 背景环境工具类 背景 写OJ系统时需要用docker作为代码沙箱使用,顺手封装了一个工具类,给自己做个笔记,如果可以的话也希望帮助到其他人。 环境 docker 26.1.4docker-java 3.4.2docker-java-transport-httpcli…...

windows docker desktop 无法访问容器端口映射
为什么使用docker desktop访问映射的端口失败,而其端口对应的服务是正常的? 常见问题,容器的防火墙没有关闭!!! 以centos7为例,默认情况下防火墙处于开启状态: 这下访问就OK了...

ReentrantReadWriteLock读写锁
一、锁的分类 这里不会对Java中大部分的分类都聊清楚,主要把 **互斥,共享** 这种分类聊清楚。 Java中的互斥锁,synchronized,ReentrantLock这种都是互斥锁。一个线程持有锁操作时,其他线程都需要等待前面的线程释放锁…...

Vue.js 入门教程
Vue.js 入门教程 Vue.js 是一款非常流行的前端 JavaScript 框架,适用于构建用户界面。它的设计思想是尽可能简单、灵活,易于与其他库或现有项目整合。本文将从最基础的概念开始,逐步引导你学习 Vue.js。 一、Vue.js 基础概念 1.1 什么是 V…...

解决Docker 配置 daemon.json文件后无法生效
vim /etc/docker/daemon.json 在daemon中配置一下dns {"registry-mirrors": ["https://docker.m.daocloud.io","https://hub-mirror.c.163.com","https://dockerproxy.com","https://docker.mirrors.ustc.edu.cn","ht…...

wpf stylet框架 关于View与viewmodel自动关联绑定的问题
1.1 命名规则 Aview 对应 AVIewModel, 文件夹 views 和 viewmodels 1.2 需要注册服务 //RootViewModel是主窗口 public class Bootstrapper : Bootstrapper<RootViewModel>{/// <summary>/// 配置IoC容器。为数据共享创建服务/// </summary…...

车载测试用例开发-如何平衡用例覆盖度和测试效率的方法论
1 摘要 在进行车载测试用例编写时,会遇到多个条件导致用例排列组合爆炸的情况,但是为了产品测试质量,我们又不得不保证用例设计的需求覆盖度,这样又会使得测试周期非常长。我们如何平衡效率和测试质量?本文进行了一些…...
森林中的兔子)
leetcode(01)森林中的兔子
今天开始记录刷题的过程,每天记录自己刷题的题目和自己的解法,欢迎朋友们给出更多更好的解法。 森林中的兔子 森林中有未知数量的兔子,提问其中若干只兔子“还有多少只兔子与你(被提问的兔子)颜色相同”。将答案收集到…...
)
人工智能-机器学习其他技术(决策树,异常检测,主成分分析)
决策树 一种对实例进行分类的树形结构,通过多层判断区分目标所属类别 本质:通过多层判断,从训练数据集中归纳出一组分类规则 优点: 计算量校,运算速度快 易于理解 缺点: 忽略属性间的相关性 样本分布不均时…...

AIGC通信架构深度优化指南
AIGC通信架构深度优化指南 标题:《百亿参数大模型如何高效通信?揭秘AIGC系统的协议层设计艺术》 副标题:从分布式训练到多模态推理,构建高可靠AI通信系统 1. AIGC典型通信场景 1.1 分布式模型训练参数同步 sequenceDiagram训练…...
:打破创业幻想,拥抱数据驱动)
精益数据分析(7/126):打破创业幻想,拥抱数据驱动
精益数据分析(7/126):打破创业幻想,拥抱数据驱动 在创业的道路上,我们都怀揣着梦想,但往往容易陷入自我编织的幻想中。我希望通过和大家一起学习《精益数据分析》,能帮助我们更清醒地认识创业过…...

Android Gradle多渠道打包
目录 1.多渠道打包是什么2.为什么需要多渠道打包3.多渠道配置VariantproductFlavorsbuildTypes 3.构建变体组合关于组合 4.渠道过滤5.渠道资源资源文件资源合并规则代码文件SourceSets 6. 渠道依赖项7.渠道统计meta-dataBuildConfig 8.管理渠道 1.多渠道打包是什么 多聚道打包…...

Day58 | 179. 最大数、316. 去除重复字母、334. 递增的三元子序列
179. 最大数 题目链接:179. 最大数 - 力扣(LeetCode) 题目难度:中等 代码: class Solution {public String largestNumber(int[] nums) {String[] strsnew String[nums.length];for(int i0;i<nums.length;i)str…...

LabVIEW发电机励磁系统远程诊断
变流器在风电系统中承担电能转换与控制的关键角色。它将发电机输出的低频、可变交流,通过整流、逆变等环节转为频率、电压稳定的交流,以满足电网接入要求;同时,根据实时风速调整发电机转速,实现最大功率追踪。 在某…...

性能比拼: Go vs Bun
本内容是对知名性能评测博主 Anton Putra Go (Golang) vs. Bun: Performance (Latency - Throughput - Saturation - Availability) 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 我对 Bun 在之前的基准测试中的出色表现感到惊讶,因此我决定将它与 Go …...
)
Kubernetes相关的名词解释Dashboard界面(6)
什么是Kubernetes Dashboard? Kubernetes Dashboard 是一个基于 Web 的用户界面,用于管理 Kubernetes 集群。它是 Kubernetes 官方提供的可视化工具,允许用户通过直观的图形界面而不是命令行来部署、管理和监控集群中的应用程序。 Dashboard…...

Linux网络编程 TCP---并发服务器:多进程架构与端口复用技术实战指南
知识点1【并发服务器—多进程版】 并发服务器:服务器可以同时服务多个客户端 首先复习一下服务器的创建过程(如下图) 1、监听套接字(套接字→绑定→监听(连接队列)) 2、利用accept从连接队列…...
 吴恩达版提示词工程 1. 引言)
(done) 吴恩达版提示词工程 1. 引言
url: https://www.bilibili.com/video/BV1Z14y1Z7LJ/?spm_id_from333.337.search-card.all.click&vd_source7a1a0bc74158c6993c7355c5490fc600 LLM 有两种: 1.基础 LLM,通过文本训练数据预测后面的内容。 这种 LLM 当你给它提问:What is…...

uniapp微信小程序实现sse
微信小程序实现sse 注:因为微信小程序不支持sse请求,因为后台给的是分包的流,所以我们就使用接受流的方式,一直接受,然后把接受的数据拿取使用。这里还是使用uniapp的原生请求。 上代码 //注意:一定要下…...
 深度应用指南)
【TeamFlow】3 Rust 与 WebAssembly (Wasm) 深度应用指南
WebAssembly 是一种低级的类汇编语言,能在现代浏览器中高效执行。Rust 因其无 GC、内存安全和卓越性能,成为编译到 Wasm 的理想语言。 一、为什么选择 Rust Wasm 性能优势:Rust 生成的 Wasm 代码执行效率接近原生 内存安全:避免…...

C 语言的未来:在变革中坚守与前行
C 语言,作为编程语言领域的一位 “老将”,自诞生以来就一直扮演着至关重要的角色。历经数十年的发展,它的影响力依然广泛而深远。在科技飞速发展的今天,新的编程语言如雨后春笋般不断涌现,C 语言的未来发展走向成为了众…...

SQL注入之information_schema表
1 information_schema表介绍: information_schema表是一个MySQL的系统数据库,他里面包含了所有数据库的表名 SQL注入中最常见利用的系统数据库,经常利用系统数据库配合union联合查询来获取数据库相关信息,因为系统数据库中所有信…...

android framework开发的技能要求
作为Android Framework开发工程师,需要具备深入的系统底层理解能力和对Android架构的全面认知。以下是核心技能要求,分为技术能力和软实力两大方向: 一、核心技术能力 Android系统架构深度掌握 Binder机制:理解Binder驱动、ServiceManager、AIDL跨进程通信原理,能分析Bind…...

AWS EC2完全指南:如何快速搭建高性能云服务器?
一、什么是AWS EC2?云时代的虚拟服务器革命 AWS Elastic Compute Cloud(EC2)作为全球领先的云服务器解决方案,正在重新定义虚拟服务器的可能性。与传统VPS相比,EC2提供: 秒级弹性扩展:CPU/RAM按…...

go环境安装mac
下载go安装包:https://golang.google.cn/dl/ 找到对应自己环境的版本下载。 注意有二进制的包,也有图形界面安装的包。图形界面直接傻瓜式点就行了。 二进制的按照下面操作: 1、下载二进制包。 2、将下载的二进制包解压至 /usr/local目录…...
)
Python实现对大批量Word文档进行批量自动化排版(15)
前言 本文是该专栏的第15篇,后面会持续分享Python办公自动化干货知识,记得关注。 在本专栏上一篇文章《Python实现对目标Word文档进行自动化排版【4万字精讲】(14)》中,笔者已经详细介绍“基于Python,实现对目标docx格式的word文档进行自动化排版”的实战教学(文章附带…...

嵌入式面试题解析:二维数组,内容与总线,存储格式
在嵌入式系统领域,扎实掌握基础概念是应对面试的关键。本文通过典型面试题,详细解析核心知识,梳理易错点,并补充常见面试题,助力新手快速入门。 一、二维数组元素地址计算 题目 若二维数组 arr[0..M-1][0..N-1] 的首…...

【iOS】alloc init new底层原理
目录 前言 alloc alloc核心操作 cls->instanceSize(extraBytes) calloc obj->initInstanceIsa init 类方法: 实例方法: new 前言 笔者最近在进行对OC语言源码的学习,学习源码的过程中经常会出现一些从来没有遇见过的函数&…...

解决vscode找不到Python自定义模块,报错No module named ‘xxx‘
1、 首先在.vscode下的launch.json中添加"env": {“PYTHONPATH”: “${workspaceRoot}”} {"version": "0.2.0","configurations": [{省略其他配置"env": {"PYTHONPATH": "${workspaceRoot}"}}] }2、 …...

【某比特币网址请求头部sign签名】RSA加密逆向分析
目标:aHR0cDovL21lZ2FiaXQudmlwL21hcmtldA 直接搜索sign不方便定位,可以换个思路搜asi_uuid或者user_info 为什么搜这个,因为都是请求头里面的参数,基本上会在一起 实际上就是Object(h.a)((new Date).getTime()) 直接在这里打断点…...

【Docker项目实战】使用Docker部署Jupyter Notebook服务
【Docker项目实战】使用Docker部署Jupyter Notebook服务 一、 Jupyter Notebook介绍1.1 Jupyter Notebook 简介1.2 主要特点1.3 主要使用场景二、本次实践规划2.1 本地环境规划2.2 本次实践介绍三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compos…...

Oracle高级语法篇 - 用户与角色关系
在Oracle数据库中,用户和角色是权限管理的核心概念。用户是数据库的使用者,而角色则是权限的集合。通过合理地分配角色给用户,可以简化权限管理,提高数据库的安全性和易用性。本文将详细讲解Oracle中用户和角色之间的关系…...

“小坝” 策略:始发站 buffer 控制与优化
端到端,这两个端是两个应用程序中的位置,第一个端指数据被产生处,第二个端指数据被消费处。更一般的,把数据发生的应用程序所在的主机视为数据始发站也是合理的。 网络中遍布 buffer,buffer 却是一把双刃剑的存在&…...

【esp32 点亮led】-解决不能闪烁问题
问题现象:将esp例程中的led例程下载到开发板中,led不能闪烁,串口查看,可以看到对应的led ON/led off 信息。 解决办法: 使用idf.py menuconfig 命令配置相应的引脚为GPIO模式,如下图所示,保存…...
—— 共现词矩阵及Python实现)
自然语言处理(9)—— 共现词矩阵及Python实现
共现词矩阵 1. 概述2. 构建步骤3. 代码实现(Python)结语 共现词矩阵(Co-occurrence Matrix)是自然语言处理(NLP)中用于捕捉词语间语义关系的重要工具。共现矩阵通过统计词语在特定上下文窗口内的共现频率&a…...

缓存 --- Redis的三种高可用模式
缓存 --- Redis的三种高可用模式 主从复制(Replication)哨兵模式(Sentinel)集群模式(Cluster)总结对比选择建议 Redis 的高可用架构模式主要有三种:主从复制(Replication)…...

飞帆中控件数据和 Vue 双向绑定
在 Vue 中,数据的双向绑定是指在视图和数据模型之间自动保持同步。Vue 实现双向绑定的核心特性是其 响应式系统,它能够追踪数据的变化并自动更新视图,反之亦然,视图的变化也可以影响数据。 Vue 提供了几种方式来实现数据双向绑定&…...

【外研在线-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

实现AWS Data Pipeline安全地请求企业内部API返回数据
需要编写一段Data Pipeline在AWS云上运行,它需要访问企业内部的API获取JSON格式的数据,企业有网关和防火墙,API有公司的okta身份认证,通过公司的域账号来授权访问,现在需要创建一个专用的域账号,让Data Pip…...

AI书籍大模型微调-基于亮数据获取垂直数据集
大模型的开源,使得每位小伙伴都能获得AI的加持,包括你可以通过AIGC完成工作总结,图片生成等。这种加持是通用性的,并不会对个人的工作带来定制的影响,因此各个行业都出现了垂直领域大模型。 垂直大模型是如何训练出来…...

cloudstudio学习笔记之openwebui
代码获取 git clone 参考资料 openwebui官网 https://docs.openwebui.com/getting-started/advanced-topics/development 后端启动 cd backend pip install -r requirements.txt -U sh dev.sh后端启动成功后的界面 在cloudstudio提供的vscode弹出的提示中打开浏览器并在末…...

Linux安装mysql_exporter
mysqld_exporter 是一个用于监控 MySQL 数据库的 Prometheus exporter。可以从 MySQL 数据库的 metrics_schema 收集指标,相关指标主要包括: MySQL 服务器指标:例如 uptime、version 等数据库指标:例如 schema_name、table_rows 等表指标:例如 table_name、engine、…...

Kubernetes控制平面组件:API Server代码基础概念
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

修改PointLIO项目
添加key_frame_info.msg消息 新建.msg文件,内容填写为: # Cloud Info Header header # cloud messages sensor_msgs/PointCloud2 key_frame_cloud_ori sensor_msgs/PointCloud2 key_frame_cloud_transed sensor_msgs/PointCloud2 key_frame_poses其中k…...
)
将 JSON 字符串转化为对象的详细笔记 (Java示例)
1. 主流 JSON 库的选择 在 Java 中,常用以下库进行 JSON 和对象之间的转换: Jackson:Spring 默认集成,性能优异,支持流式解析。FastJSON:阿里开发,速度快,但需注意版本安全性。Gso…...

基于Docker+k8s集群的web应用部署与监控
项目架构图 server ip master 192.168.140.130 node1 192.168.140.131 node2 192.168.140.132 ansible 192.168.140.166 jumpserver 192.168.100.133 firewall 192.168.1.86 nfs 192.168.140.157 harbor 192.168.140.159 Promethethus 192.168.140.130 Jen…...
)
Java(自用查看版)
目录 1.java的基本运行 2、基本格式 注释 标识名 关键字 常量 整型常量 浮点数: 字符常量: 字符串常量 布尔 null值 变量 整型变量: 浮点变量: 字符变量: 布尔变量: 类型转换 自动类型转换 强制类型转换 运算符 …...