spring-batch批处理框架(1)
学习链接
SpringBatch高效批处理框架详解及实战演练
spring-batch批处理框架(1)
spring-batch批处理框架(2)
spring batch官方文档
spring batch官方示例代码 - github
文章目录
- 学习链接
- 一、课程目标
- 课程目标
- 课程内容
- 前置知识
- 适合人群
- 二、Spring Batch简介
- 2.1 何为批处理?
- 2.2 Spring Batch了解
- 2.3 Spring Batch 优势
- 2.4 Spring Batch 架构
- 三、入门案例
- 3.1 批量处理流程
- 3.2 入门案例-H2版(内存)
- 3.3 入门案例-MySQL版
- 四、入门案例解析
- 五、作业对象 Job
- 5.1 作业介绍
- 5.1.1 作业定义
- 5.1.2 作业代码设计
- 5.2 作业配置
- 5.3 作业参数
- 5.3.1 JobParameters
- 5.3.2 作业参数设置
- 5.3.3 作业参数获取
- 方案1:使用ChunkContext类
- 方案2:==使用@Value 延时获取==
- 5.3.4 作业参数校验
- 定制参数校验器
- 默认参数校验器
- 组合参数校验器
- 5.3.5 作业增量参数
- 作业递增run.id参数
- 作业时间戳参数
- 5.4 作业监听器
- 5.5 执行上下文
- 5.5.1 作业上下文与步骤上下文
- 5.5.2 执行上下文
- 5.5.3 作业与步骤执行链
- 5.5.4 作业与步骤引用链
- 5.5.5 作业上下文API
- 5.5.6 步骤上下文API
- 5.5.7 执行上下文API
- 5.5.8 API综合小案例
- 六、步骤对象 Step
- 6.1 步骤介绍
- 6.2 基于简单Tasklet
- 6.3 基于块Tasklet
- **ChunkTasklet 泛型**
- 异常测试
- 6.4 步骤监听器
- 6.5 多步骤执行
- 6.6 步骤控制
- 6.6.1 条件分支控制-使用默认返回状态
- 6.6.2 条件分支控制-使用自定义状态值
- 6.7 步骤状态
- 6.8 流式步骤
- 七、批处理数据表
- 7.1 batch_job_instance表
- 7.2 batch_job_execution表
- 7.3 batch_job_execution_context表
- 7.4 batch_job_execution_params表
- 7.5 btch_step_execution表
- 7.6 batch_step_execution_context表
- 7.7 H2内存数据库
一、课程目标
课程目标
-
系统了解Spring Batch批处理
-
项目中能熟练使用Spring Batch批处理
课程内容
前置知识
-
Java基础
-
Maven
-
Spring SpringMVC SpringBoot
-
MyBatis
适合人群
- 想学习的所有人
二、Spring Batch简介
2.1 何为批处理?
何为批处理,大白话:就是将数据分批次进行处理的过程。比如:银行对账逻辑,跨系统数据同步等。
常规的批处理操作步骤:系统A从数据库中导出数据到文件,系统B读取文件数据并写入到数据库
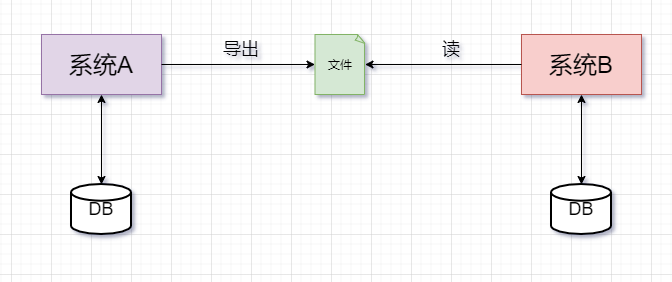
典型批处理特点:
-
自动执行,根据系统设定的工作步骤自动完成
-
数据量大,少则百万,多则上千万甚至上亿。(如果是10亿,100亿那只能上大数据了)
-
定时执行,比如:每天,每周,每月执行。
2.2 Spring Batch了解
官网介绍:https://docs.spring.io/spring-batch/docs/current/reference/html/spring-batch-intro.html#spring-batch-intro
这里挑重点讲下:
-
Sping Batch 是一个轻量级的、完善的的批处理框架,旨在帮助企业建立健壮、高效的批处理应用。
-
Spring Batch 是Spring的一个子项目,基于Spring框架为基础的开发的框架
-
Spring Batch 提供大量可重用的组件,比如:日志,追踪,事务,任务作业统计,任务重启,跳过,重复,资源管理等
-
Spring Batch 是一个批处理应用框架,不提供调度框架,如果需要定时处理需要额外引入-调度框架,比如: Quartz
2.3 Spring Batch 优势
Spring Batch 框架通过提供丰富的开箱即用的组件和高可靠性、高扩展性的能力,使得开发批处理应用的人员专注于业务处理,提高处理应用的开发能力。下面就是使用Spring Batch后能获取到优势:
-
丰富的开箱即用组件
-
面向Chunk的处理
-
事务管理能力
-
元数据管理
-
易监控的批处理应用
-
丰富的流程定义
-
健壮的批处理应用
-
易扩展的批处理应用
-
复用企业现有的IT代码
2.4 Spring Batch 架构
Spring Batch 核心架构分三层:应用层,核心层,基础架构层。
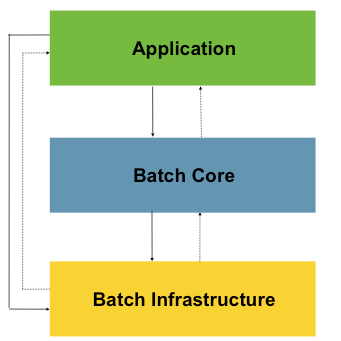
Application:应用层,包含所有的批处理作业,程序员自定义代码实现逻辑。
Batch Core:核心层,包含Spring Batch启动和控制所需要的核心类,比如:JobLauncher, Job,Step等。
Batch Infrastructure:基础架构层,提供通用的读,写与服务处理。
三层体系使得Spring Batch 架构可以在不同层面进行扩展,避免影响,实现高内聚低耦合设计。
三、入门案例
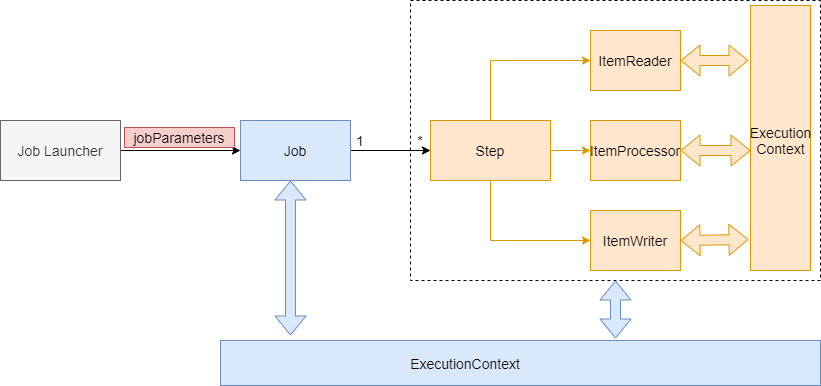
3.1 批量处理流程
前面对Spring Batch 有大体了解之后,那么开始写个案例玩一下。
开始前,先了解一下Spring Batch程序运行大纲:
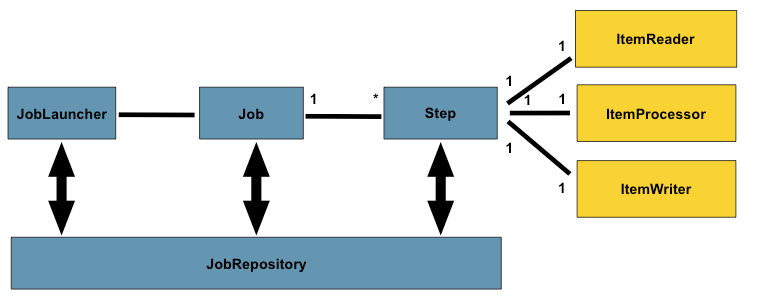
JobLauncher:作业调度器,作业启动主要入口。
Job:作业,需要执行的任务逻辑,
Step:作业步骤,一个Job作业由1个或者多个Step组成,完成所有Step操作,一个完整Job才算执行结束。
ItemReader:Step步骤执行过程中数据输入。可以从数据源(文件系统,数据库,队列等)中读取Item(数据记录)。
ItemWriter:Step步骤执行过程中数据输出,将Item(数据记录)写入数据源(文件系统,数据库,队列等)。
ItemProcessor:Item数据加工逻辑(输入),比如:数据清洗,数据转换,数据过滤,数据校验等
JobRepository: 保存Job或者检索Job的信息。SpringBatch需要持久化Job(可以选择数据库/内存),JobRepository就是持久化的接口
3.2 入门案例-H2版(内存)
需求:打印一个hello spring batch!不带读/写/处理
步骤1:导入依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.3</version><relativePath/>
</parent>
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-batch</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!--内存版--><dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency></dependencies>
其中的h2是一个嵌入式内存数据库,后续可以使用MySQL替换
步骤2:创建测试方法
package com.langfeiyes.batch._01_hello;import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;@SpringBootApplication
@EnableBatchProcessing
public class HelloJob {//job调度器@Autowiredprivate JobLauncher jobLauncher;//job构造器工厂@Autowiredprivate JobBuilderFactory jobBuilderFactory;//step构造器工厂@Autowiredprivate StepBuilderFactory stepBuilderFactory;//任务-step执行逻辑由tasklet完成@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("Hello SpringBatch....");return RepeatStatus.FINISHED;}};}//作业步骤-不带读/写/处理@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}//定义作业@Beanpublic Job job(){return jobBuilderFactory.get("hello-job").start(step1()).build();}public static void main(String[] args) {SpringApplication.run(HelloJob.class, args);}}步骤3:分析
例子是一个简单的SpringBatch 入门案例,使用了最简单的一种步骤处理模型:Tasklet模型,step1中没有带上读/写/处理逻辑,只有简单打印操作,后续随学习深入,我们再讲解更复杂化模型。
3.3 入门案例-MySQL版
MySQL跟上面的h2一样,区别在连接数据库不一致。
步骤1:在H2版本基础上导入MySQL依赖
<!-- <dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId><scope>runtime</scope>
</dependency> --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.12</version>
</dependency>
步骤2:配置数据库四要素与初始化SQL脚本
spring:datasource:username: rootpassword: adminurl: jdbc:mysql://127.0.0.1:3306/springbatch?serverTimezone=GMT%2B8&useSSL=false&allowPublicKeyRetrieval=truedriver-class-name: com.mysql.cj.jdbc.Driver# 初始化数据库,文件在依赖jar包中sql:init:schema-locations: classpath:org/springframework/batch/core/schema-mysql.sqlmode: always#mode: never
这里要注意, sql.init.model 第一次启动为always, 后面启动需要改为never,否则每次执行SQL都会异常。
第一次启动会自动执行指定的脚本,后续不需要再初始化
步骤3:测试
跟H2版一样。
(注意:当启动1次后,job会执行1次,当再次重启应用后,由于该job已经执行成功过了,所以不会再执行,如果需要再次执行,可以修改job名)
/* 方便删除sprign-batch库, 用于测试 */
drop database if exists `spring-batch`;
create database `spring-batch` character set 'utf8mb4' collate 'utf8mb4_general_ci';
四、入门案例解析
1>@EnableBatchProcessing
批处理启动注解,要求贴配置类或者启动类上
@SpringBootApplication
@EnableBatchProcessing
public class HelloJob {...
}
贴上@EnableBatchProcessing注解后,SpringBoot会自动加载JobLauncher JobBuilderFactory StepBuilderFactory 类并创建对象交给容器管理,要使用时,直接@Autowired即可
//job调度器
@Autowired
private JobLauncher jobLauncher;
//job构造器工厂
@Autowired
private JobBuilderFactory jobBuilderFactory;
//step构造器工厂
@Autowired
private StepBuilderFactory stepBuilderFactory;
2>配置数据库四要素
批处理允许重复执行,异常重试,此时需要保存批处理状态与数据,Spring Batch 将数据缓存在H2内存中或者缓存在指定数据库中。入门案例如果要保存在MySQL中,所以需要配置数据库四要素。
3>创建Tasklet对象
//任务-step执行逻辑由tasklet完成
@Bean
public Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("Hello SpringBatch....");return RepeatStatus.FINISHED;}};
}
Tasklet负责批处理step步骤中具体业务执行,它是一个接口,有且只有一个execute方法,用于定制step执行逻辑。
public interface Tasklet {RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception;
}
execute方法返回值是一个状态枚举类:RepeatStatus,里面有可继续执行态与已经完成态
public enum RepeatStatus {/*** 可继续执行的-tasklet返回这个状态会进入死循环*/CONTINUABLE(true), /*** 已经完成态*/FINISHED(false);....
}
4>创建Step对象
//作业步骤-不带读/写/处理
@Bean
public Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();
}
Job作业执行靠Step步骤执行,入门案例选用最简单的Tasklet模式,后续再讲Chunk块处理模式。
5>创建Job并执行Job
//定义作业
@Bean
public Job job(){return jobBuilderFactory.get("hello-job").start(step1()).build();
}
创建Job对象交给容器管理,当springboot启动之后,会自动去从容器中加载Job对象,并将Job对象交给JobLauncherApplicationRunner类,再借助JobLauncher类实现job执行。
验证过程;
打断点,debug模式启动

SpringApplication类run方法



JobLauncherApplicationRunner类


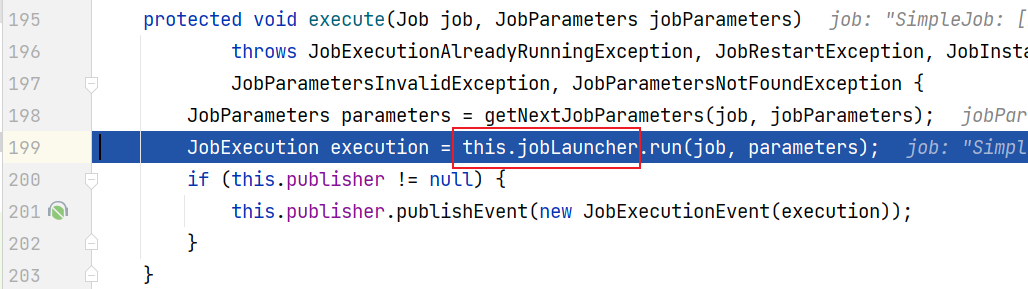

JobLauncher接口–实现类:SimpleJobLauncher
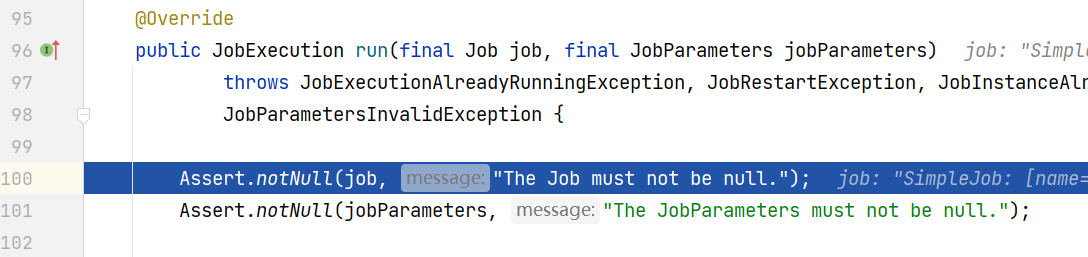
(注意:调用入口是JobLauncherApplicationRunner会找到容器中的Job实例,然后使用jobLauncher启动这些job实例)
五、作业对象 Job
5.1 作业介绍
5.1.1 作业定义
Job作业可以简单理解为一段业务流程的实现,可以根据业务逻辑拆分一个或者多个逻辑块(step),然后业务逻辑顺序,逐一执行。
所以作业可以定义为:能从头到尾独立执行的有序的步骤(Step)列表。
-
有序的步骤列表一次作业由不同的步骤组成,这些步骤顺序是有意义的,如果不按照顺序执行,会引起逻辑混乱,比如购物结算,先点结算,再支付,最后物流,如果反过来那就乱套了,作业也是这么一回事。
-
从头到尾
一次作业步骤固定了,在没有外部交互情况下,会从头到尾执行,前一个步骤做完才会到后一个步骤执行,不允许随意跳转,但是可以按照一定逻辑跳转。
-
独立每一个批处理作业都应该不受外部依赖影响情况下执行。
看回这幅图,批处理作业Job是由一组步骤Step对象组成,每一个作业都有自己名称,可以定义Step执行顺序。
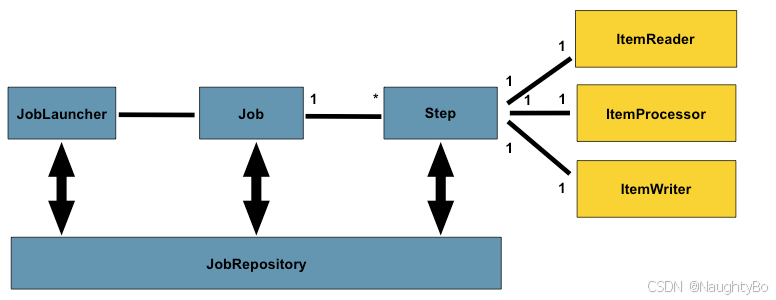
5.1.2 作业代码设计
前面定义讲了作业执行是相互独立的,代码该怎么设计才能保证每次作业独立的性呢?
答案是:Job instance(作业实例) 与 Job Execution(作业执行对象)
Job instance(作业实例)
当作业运行时,会创建一个Job Instance(作业实例),它代表作业的一次逻辑运行,可通过作业名称与作业标识参数进行区分。
比如一个业务需求: 每天定期数据同步,作业名称-daily-sync-job 作业标记参数-当天时间
Job Execution(作业执行对象)
当作业运行时,也会创建一个Job Execution(作业执行器),负责记录Job执行情况(比如:开始执行时间,结束时间,处理状态等)。
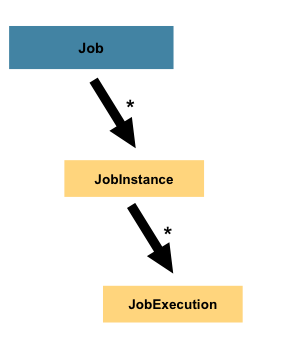
那为啥会出现上面架构设计呢?原因:批处理执行过程中可能出现两种情况:
-
一种是一次成功
仅一次就成从头到尾正常执行完毕,在数据库中会记录一条Job Instance 信息, 跟一条 Job Execution 信息
-
另外一种异常执行
在执行过程因异常导致作业结束,在数据库中会记录一条Job Instance 信息, 跟一条Job Execution 信息。如果此时使用相同识别参数再次启动作业,那么数据库中不会多一条Job Instance 信息, 但是会多了一条Job Execution 信息,这就意味中任务重复执行了。刚刚说每天批处理任务案例,如果当天执行出异常,那么人工干预修复之后,可以再次执行。
最后来个总结:
Job Instance = Job名称 + 识别参数
Job Instance 一次执行创建一个 Job Execution对象
完整的一次Job Instance 执行可能创建一个Job Execution对象,也可能创建多个Job Execution对象
(注意:第一次执行会在batch_job_instance中创建1条数据,在batch_job_execution中也创建1条数据,当第二次执行,不会在batch_job_instance中创建数据,而会在batch_job_execution表中创建1条数据,但这条数据会记录该job所对应step不会执行。经过后面学习,发现是因为启动的时候没有指定作业参数,所以第二次启动该job并没有报错,而是增加了1条记录在batch_job_execution中,然而,如果加了启动参数,后面第二次启动就会报错)
5.2 作业配置
再看回入门案例
package com.langfeiyes.batch._01_hello;import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;@SpringBootApplication
@EnableBatchProcessing
public class HelloJob {//job构造器工厂@Autowiredprivate JobBuilderFactory jobBuilderFactory;//step构造器工厂@Autowiredprivate StepBuilderFactory stepBuilderFactory;//任务-step执行逻辑由tasklet完成@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("Hello SpringBatch....");return RepeatStatus.FINISHED;}};}//作业步骤-不带读/写/处理@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}//定义作业@Beanpublic Job job(){return jobBuilderFactory.get("hello-job").start(step1()).build();}public static void main(String[] args) {SpringApplication.run(HelloJob.class, args);}}在启动类中贴上@EnableBatchProcessing注解,SpringBoot会自动听JobLauncher JobBuilderFactory StepBuilderFactory 对象,分别用于执行Jog,创建Job,创建Step逻辑。有了这些逻辑,Job批处理就剩下组装了。
5.3 作业参数
5.3.1 JobParameters
前面提到,作业的启动条件是作业名称 + 识别参数,Spring Batch使用JobParameters类来封装了所有传给作业参数。
我们看下JobParameters 源码
public class JobParameters implements Serializable {private final Map<String,JobParameter> parameters;public JobParameters() {this.parameters = new LinkedHashMap<>();}public JobParameters(Map<String,JobParameter> parameters) {this.parameters = new LinkedHashMap<>(parameters);}.....
}
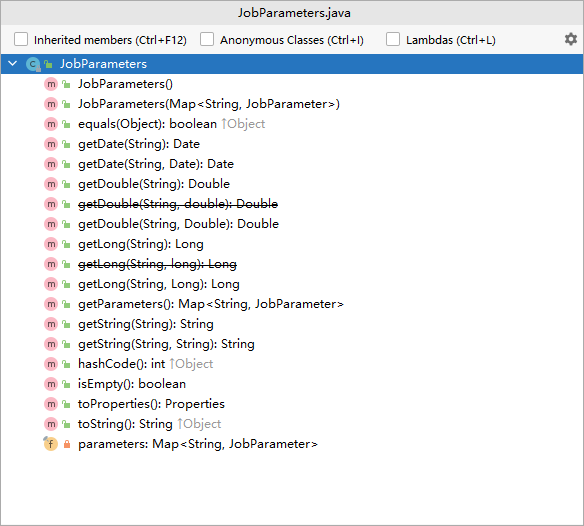
从上面代码/截图来看,JobParameters 类底层维护了Map<String,JobParameter>,是一个Map集合的封装器,提供了不同类型的get操作。
5.3.2 作业参数设置
还记得Spring Batch 入门案例吗,当初debug时候看到Job作业最终是调用时 **JobLauncher **(job启动器)接口run方法启动。
看下源码:JobLauncher
public interface JobLauncher {public JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException,JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException;}
在JobLauncher 启动器执行run方法时,直接传入即可。
jobLauncher.run(job, params);
那我们使用SpringBoot 方式启动Spring Batch该怎么传值呢?
1>定义ParamJob类,准备好要执行的job
package com.langfeiyes.batch._02_params;import org.springframework.batch.core.*;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;@SpringBootApplication
@EnableBatchProcessing
public class ParamJob {//job构造器工厂@Autowiredprivate JobBuilderFactory jobBuilderFactory;//step构造器工厂@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("param SpringBatch....");return RepeatStatus.FINISHED;}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}@Beanpublic Job job(){return jobBuilderFactory.get("param-job").start(step1()).build();}public static void main(String[] args) {SpringApplication.run(ParamJob.class, args);}
}
2>使用idea的命令传值的方式设置job作业参数
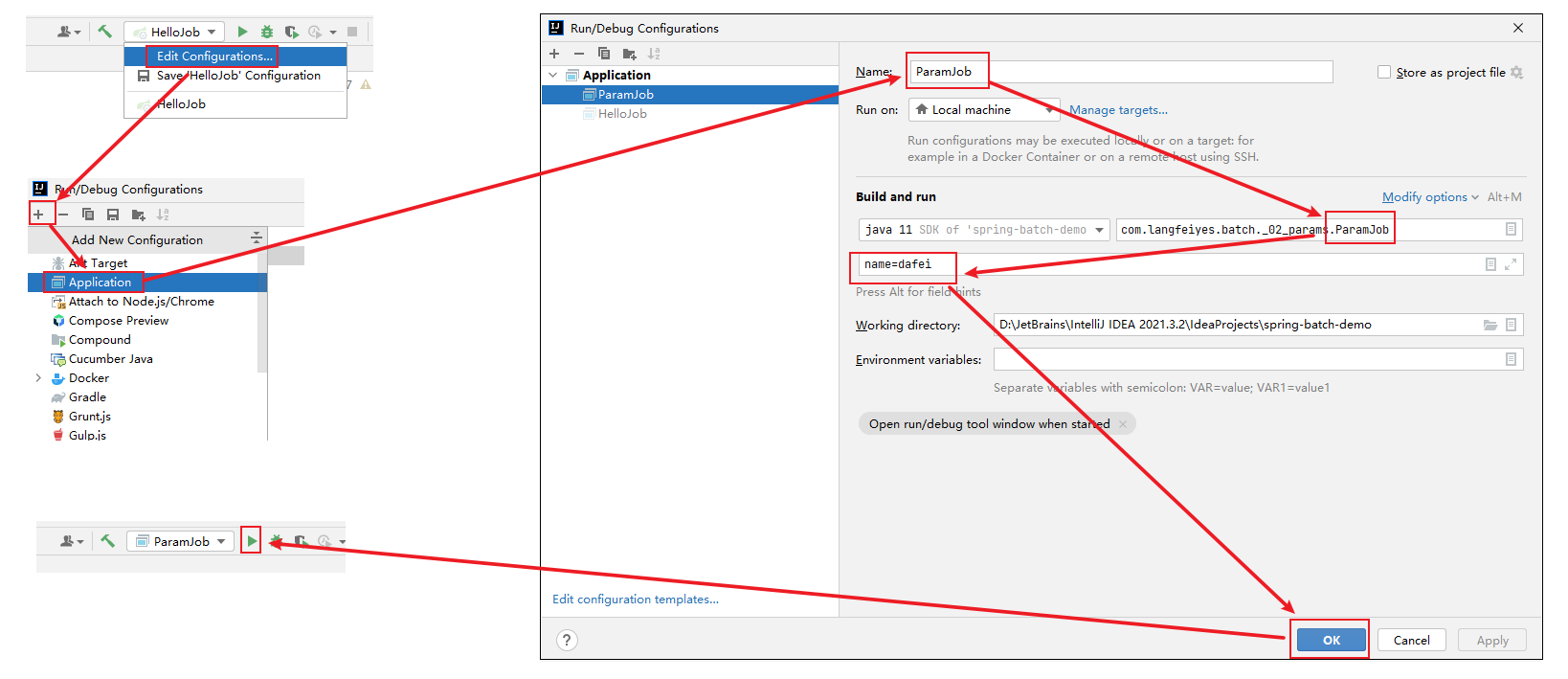
(其实就是JobLauncherApplicationRunner会将启动参数,在JobLauncherApplicationRunner中使用jobLauncher启动job时,会把启动参数给设置到作业参数中)可参考:idea设置Java程序运行参数
注意:如果不想这么麻烦,其实也可以,先空参数执行一次,然后指定参数后再执行。
点击绿色按钮,启动SpringBoot程序,作业运行之后,会在batch_job_execution_params 增加一条记录,用于区分唯一的Job Instance实例

注意:如果不改动JobParameters 参数内容,再执行一次批处理,会直接报错。

Caused by: org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException: A job instance already exists and is complete for parameters={name=dafei}. If you want to run this job again, change the parameters.
原因:Spring Batch 相同Job名与相同标识参数只能成功执行一次。
5.3.3 作业参数获取
当将作业参数传入到作业流程,该如何获取呢?
Spring Batch 提供了2种方案:
方案1:使用ChunkContext类
ParamJob类中tasklet写法
@Bean
public Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {Map<String, Object> parameters = chunkContext.getStepContext().getJobParameters();System.out.println("params---name:" + parameters.get("name"));return RepeatStatus.FINISHED;}};
}
注意:job名:param-job job参数:name=dafei 已经执行了,再执行会报错
所以要么改名字,要么改参数,这里选择改job名字(拷贝一份job实例方法,然后注释掉,修改Job名称)
// @Bean
// public Job job(){
// return jobBuilderFactory.get("param-job")
// .start(step1())
// .build();
// }@Beanpublic Job job(){return jobBuilderFactory.get("param-chunk-job").start(step1()).build();}
当然,也可以直接修改启动参数,完整代码如下
package com.zzhua.demo03;import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;@Slf4j
@EnableBatchProcessing
@SpringBootApplication
public class HelloJobParam {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Autowiredprivate JobRepository jobRepository;@Beanpublic Step step01() {return stepBuilderFactory.get("step01").tasklet(new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) {log.info("execute ...................");// 也就是说:在步骤里面可以获取到使用JobLauncher启动该job时,// 所传入的启动参数log.info("params: {}", chunkContext.getStepContext().getStepExecution().getJobParameters());return null;}}).build();}@Beanpublic Job job() {return jobBuilderFactory.get("job-01").start(step01()).build();}public static void main(String[] args) {SpringApplication.run(HelloJobParam.class, args);}}
方案2:使用@Value 延时获取
@StepScope
@Bean
public Tasklet tasklet(@Value("#{jobParameters['name']}")String name){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("params---name:" + name);return RepeatStatus.FINISHED;}};
}@Bean
public Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet(null)) // 注意这里传的是null.build();
}
step1调用tasklet实例方法时不需要传任何参数,Spring Boot 在加载Tasklet Bean实例时会自动注入。
// @Bean
// public Job job(){
// return jobBuilderFactory.get("param-chunk-job")
// .start(step1())
// .build();
// }@Bean
public Job job(){return jobBuilderFactory.get("param-value-job").start(step1()).build();
}
这里要注意,必须贴上@StepScope ,表示在启动项目的时候,不加载该Step步骤bean,等step1()被调用时才加载。这就是所谓延时获取。
完整代码如下(注意设置一下启动参数,如:name=ls)
@Slf4j
@EnableBatchProcessing
@SpringBootApplication
public class HelloJobValueParam {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Autowiredprivate JobRepository jobRepository;@StepScope // 这个注解只能加在tasklet上面,如果加在下面的Step上面,则会报错哦!@Beanpublic Tasklet tasklet(@Value("#{jobParameters['name']}")String name){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {log.info("execute ...................");log.info("param: {}", name); // 访问到了启动参数return null;}};}@Beanpublic Step step01() {return stepBuilderFactory.get("step01").tasklet(tasklet(null)).build();}@Beanpublic Job job() {return jobBuilderFactory.get("job-01").start(step01()).build();}public static void main(String[] args) {SpringApplication.run(HelloJobValueParam.class, args);}}
5.3.4 作业参数校验
当外部传入的参数进入作业时,如何确保参数符合期望呢?使用Spring Batch 的参数校验器:JobParametersValidator 接口。
先来看下JobParametersValidator 接口源码:
public interface JobParametersValidator {void validate(@Nullable JobParameters parameters) throws JobParametersInvalidException;
}
JobParametersValidator 接口有且仅有唯一的validate方法,参数为JobParameters,没有返回值。这就意味着不符合参数要求,需要抛出异常来结束步骤。
定制参数校验器
Spring Batch 提供JobParametersValidator参数校验接口,其目的就是让我们通过实现接口方式定制参数校验逻辑。
需求:如果传入作业的参数name值 为null 或者 “” 时报错
public class NameParamValidator implements JobParametersValidator {@Overridepublic void validate(JobParameters parameters) throws JobParametersInvalidException {String name = parameters.getString("name");if(!StringUtils.hasText(name)){throw new JobParametersInvalidException("name 参数不能为空");}}
}
其中的JobParametersInvalidException 异常是Spring Batch 专门提供参数校验失败异常,当然我们也可以自定义或使用其他异常。
@SpringBootApplication
@EnableBatchProcessing
public class ParamValidatorJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution,ChunkContext chunkContext) throws Exception {Map<String, Object> parameters = chunkContext.getStepContext().getJobParameters();System.out.println("params---name:" + parameters.get("name"));return RepeatStatus.FINISHED;}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}//配置name参数校验器@Beanpublic NameParamValidator validator(){return new NameParamValidator();}@Beanpublic Job job(){return jobBuilderFactory.get("name-param-validator-job").start(step1()).validator(validator()) //参数校验器.build();}public static void main(String[] args) {SpringApplication.run(ParamValidatorJob.class, args);}
}
新定义validator()实例方法,将定制的参数解析器加到Spring容器中,修改job()实例方法,加上.validator(validator()) 校验逻辑。
第一次启动时,没有传任何参数
String name = parameters.getString("name");
name为null,直接报错

加上name=dafei参数之后,正常执行

完整代码
由于启动参数中未指定name,导致jobLauncher启动该job时没有任务参数,所以会报错。因此,必须指定name参数。
@Slf4j
@EnableBatchProcessing
@SpringBootApplication
public class HelloJobParamValidate {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Step step01() {return stepBuilderFactory.get("step01").tasklet(new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) {log.info("execute ...................");// 也就是说:在步骤里面可以获取到使用JobLauncher启动该job时,// 所传入的启动参数log.info("params: {}", chunkContext.getStepContext().getStepExecution().getJobParameters());return null;}}).build();}@Beanpublic Job job() {return jobBuilderFactory.get("job-01").start(step01()).validator(validator()).build();}@Beanpublic JobParametersValidator validator() {return new JobParametersValidator() {@Overridepublic void validate(JobParameters parameters) throws JobParametersInvalidException {String name = parameters.getString("name");// 校验name不为空if (name == null || "".equals(name)) {throw new JobParametersInvalidException("name is null");}}};}public static void main(String[] args) {SpringApplication.run(HelloJobParamValidate.class, args);}}
默认参数校验器
除去上面的定制参数校验器外,Spring Batch 也提供2个默认参数校验器:DefaultJobParametersValidator(默认参数校验器) 跟 CompositeJobParametersValidator(组合参数校验器)。
DefaultJobParametersValidator参数校验器
public class DefaultJobParametersValidator implements JobParametersValidator, InitializingBean {private Collection<String> requiredKeys;private Collection<String> optionalKeys;....
}
默认的参数校验器它功能相对简单,维护2个key集合requiredKeys 跟 optionalKeys
- requiredKeys 是一个集合,表示作业参数jobParameters中必须包含集合中指定的keys
- optionalKeys 也是一个集合,该集合中的key 是可选参数
需求:如果作业参数没有name参数报错,age参数可有可无
package com.langfeiyes.batch._03_param_validator;import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.job.DefaultJobParametersValidator;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;import java.util.Map;@SpringBootApplication
@EnableBatchProcessing
public class ParamValidatorJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {Map<String, Object> parameters = chunkContext.getStepContext().getJobParameters();System.out.println("params---name:" + parameters.get("name"));System.out.println("params---age:" + parameters.get("age"));return RepeatStatus.FINISHED;}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}//配置默认参数校验器@Beanpublic DefaultJobParametersValidator defaultValidator(){DefaultJobParametersValidator defaultValidator = new DefaultJobParametersValidator();defaultValidator.setRequiredKeys(new String[]{"name"}); //必填defaultValidator.setOptionalKeys(new String[]{"age"}); //可选return defaultValidator;}@Beanpublic Job job(){return jobBuilderFactory.get("default-param-validator-job").start(step1()).validator(defaultValidator()) //默认参数校验器.build();}public static void main(String[] args) {SpringApplication.run(ParamValidatorJob.class, args);}
}新定义defaultValidator() 实例方法,将默认参数解析器加到Spring容器中,修改job实例方法,加上**.validator(defaultValidator())。**
右键启动,不填name 跟 age 参数,直接报错

如果填上name参数,即使不填age参数,可以通过,原因是age是可选的。

组合参数校验器
CompositeJobParametersValidator 组合参数校验器,顾名思义就是将多个参数校验器组合在一起。
看源码,大体能看出该校验器逻辑
public class CompositeJobParametersValidator implements JobParametersValidator, InitializingBean {private List<JobParametersValidator> validators;@Overridepublic void validate(@Nullable JobParameters parameters) throws JobParametersInvalidException {for (JobParametersValidator validator : validators) {validator.validate(parameters);}}public void setValidators(List<JobParametersValidator> validators) {this.validators = validators;}@Overridepublic void afterPropertiesSet() throws Exception {Assert.notNull(validators, "The 'validators' may not be null");Assert.notEmpty(validators, "The 'validators' may not be empty");}
}
底层维护一个validators 集合,校验时调用validate 方法,依次执行校验器集合中校验器方法。另外,多了一个afterPropertiesSet方法,用于校验validators 集合中的校验器是否为null。
需求:要求步骤中必须有name属性,并且不能为空
分析:必须有,使用DefaultJobParametersValidator 参数校验器, 不能为null,使用指定定义的NameParamValidator参数校验器
package com.langfeiyes.batch._03_param_validator;import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.job.CompositeJobParametersValidator;
import org.springframework.batch.core.job.DefaultJobParametersValidator;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;import java.util.Arrays;
import java.util.Map;@SpringBootApplication
@EnableBatchProcessing
public class ParamValidatorJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {Map<String, Object> parameters = chunkContext.getStepContext().getJobParameters();System.out.println("params---name:" + parameters.get("name"));System.out.println("params---age:" + parameters.get("age"));return RepeatStatus.FINISHED;}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}//配置name参数校验器@Beanpublic NameParamValidator validator(){return new NameParamValidator();}//配置默认参数校验器@Beanpublic DefaultJobParametersValidator defaultValidator(){DefaultJobParametersValidator defaultValidator = new DefaultJobParametersValidator();defaultValidator.setRequiredKeys(new String[]{"name"}); //必填defaultValidator.setOptionalKeys(new String[]{"age"}); //可选return defaultValidator;}//配置组合参数校验器@Beanpublic CompositeJobParametersValidator compositeValidator(){DefaultJobParametersValidator defaultValidator = new DefaultJobParametersValidator();defaultValidator.setRequiredKeys(new String[]{"name"}); //name必填defaultValidator.setOptionalKeys(new String[]{"age"}); //age可选NameParamValidator nameParamValidator = new NameParamValidator(); //name 不能为空CompositeJobParametersValidator compositeValidator = new CompositeJobParametersValidator();//按照传入的顺序,先执行defaultValidator 后执行nameParamValidatorcompositeValidator.setValidators(Arrays.asList(defaultValidator, nameParamValidator));try {compositeValidator.afterPropertiesSet(); //判断校验器是否为null} catch (Exception e) {e.printStackTrace();}return compositeValidator;}@Beanpublic Job job(){return jobBuilderFactory.get("composite-param-validator-job").start(step1())//.validator(validator()) //参数校验器//.validator(defaultValidator()) //默认参数校验器.validator(compositeValidator()) //组合参数校验器.build();}public static void main(String[] args) {SpringApplication.run(ParamValidatorJob.class, args);}
}新定义compositeValidator() 实例方法,将组合参数解析器加到spring容器中,修改job()实例方法,加上**.validator(compositeValidator())。**
右键启动,不填name参数,测试报错。如果放开name参数,传null值,一样报错。

5.3.5 作业增量参数
不知道大家发现了没有,每次运行作业时,都改动作业名字,或者改动作业的参数,原因是作业启动有限制:相同标识参数与相同作业名的作业,只能成功运行一次。那如果想每次启动,又不想改动标识参数跟作业名怎么办呢?答案是:使用JobParametersIncrementer (作业参数增量器)
看下源码,了解一下原理
public interface JobParametersIncrementer {JobParameters getNext(@Nullable JobParameters parameters);}
JobParametersIncrementer 增量器是一个接口,里面只有getNext方法,参数是JobParameters 返回值也是JobParameters。通过这个getNext方法,在作业启动时我们可以给JobParameters 添加或者修改参数。简单理解就是让标识参数每次都变动
作业递增run.id参数
Spring Batch 提供一个run.id自增参数增量器:RunIdIncrementer,每次启动时,里面维护名为run.id 标识参数,每次启动让其自增 1。
看下源码:
public class RunIdIncrementer implements JobParametersIncrementer {private static String RUN_ID_KEY = "run.id";private String key = RUN_ID_KEY;public void setKey(String key) {this.key = key;}@Overridepublic JobParameters getNext(@Nullable JobParameters parameters) {JobParameters params = (parameters == null) ? new JobParameters() : parameters;JobParameter runIdParameter = params.getParameters().get(this.key);long id = 1;if (runIdParameter != null) {try {id = Long.parseLong(runIdParameter.getValue().toString()) + 1;}catch (NumberFormatException exception) {throw new IllegalArgumentException("Invalid value for parameter "+ this.key, exception);}}return new JobParametersBuilder(params).addLong(this.key, id).toJobParameters();}}
核心getNext方法,在JobParameters 对象维护一个run.id,每次作业启动时,都调用getNext方法获取JobParameters,保证其 run.id 参数能自增1
具体用法:
@SpringBootApplication
@EnableBatchProcessing
public class IncrementParamJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {Map<String, Object> parameters = chunkContext.getStepContext().getJobParameters();System.out.println("params---run.id:" + parameters.get("run.id"));return RepeatStatus.FINISHED;}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}@Beanpublic Job job(){return jobBuilderFactory.get("incr-params-job").start(step1()).incrementer(new RunIdIncrementer()) //参数增量器(run.id自增).build();}public static void main(String[] args) {SpringApplication.run(IncrementParamJob.class, args);}
}修改tasklet()方法,获取run.id参数,修改job实例方法,加上**.incrementer(new RunIdIncrementer())** ,保证参数能自增。
连续执行3次,观察:batch_job_execution_params 表

其中的run.id参数值一直增加,其中再多遍也没啥问题。
(注意如果是这种情况下执行,是会报错的:给启动类运行参数加上a=b(始终保持这个条件),先给job配置上RunIdIncrementer,然后运行一遍,然后注释掉RunIdIncrementer,再运行一遍,最后再配置上RunIdIncrementer,执行时会报错。也请注意:这个是在JobLauncherApplicationRunner中)
作业时间戳参数
run.id 作为标识参数貌似没有具体业务意义,如果将时间戳作为标识参数那就不一样了,比如这种运用场景:每日任务批处理,这时就需要记录每天的执行时间了。那该怎么实现呢?
Spring Batch 中没有现成时间戳增量器,需要自己定义
//时间戳作业参数增量器
public class DailyTimestampParamIncrementer implements JobParametersIncrementer {@Overridepublic JobParameters getNext(JobParameters parameters) {return new JobParametersBuilder(parameters).addLong("daily", new Date().getTime()) //添加时间戳.toJobParameters();}
}
定义一个标识参数:daily,记录当前时间戳
@SpringBootApplication
@EnableBatchProcessing
public class IncrementParamJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {Map<String, Object> parameters = chunkContext.getStepContext().getJobParameters();System.out.println("params---daily:" + parameters.get("daily"));return RepeatStatus.FINISHED;}};}//时间戳增量器@Beanpublic DailyTimestampParamIncrementer dailyTimestampParamIncrementer(){return new DailyTimestampParamIncrementer();}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}@Beanpublic Job job(){return jobBuilderFactory.get("incr-params-job").start(step1()).incrementer(dailyTimestampParamIncrementer()) //时间戳增量器.build();}public static void main(String[] args) {SpringApplication.run(IncrementParamJob.class, args);}
}定义实例方法dailyTimestampParamIncrementer()将自定义时间戳增量器添加Spring容器中,修改job()实例方法,添加.incrementer(dailyTimestampParamIncrementer()) 增量器,修改tasklet() 方法,获取 daily参数。
连续执行3次,查看batch_job_execution_params 表

很明显可以看出daily在变化,而run.id 没有动,是3,为啥?因为**.incrementer(new RunIdIncrementer())** 被注释掉了。
5.4 作业监听器
作业监听器:用于监听作业的执行过程逻辑。在作业执行前,执行后2个时间点嵌入业务逻辑。
- 执行前:一般用于初始化操作, 作业执行前需要着手准备工作,比如:各种连接建立,线程池初始化等。
- 执行后:业务执行完后,需要做各种清理动作,比如释放资源等。
Spring Batch 使用JobExecutionListener 接口 实现作业监听。
public interface JobExecutionListener {//作业执行前void beforeJob(JobExecution jobExecution);//作业执行后void afterJob(JobExecution jobExecution);
}
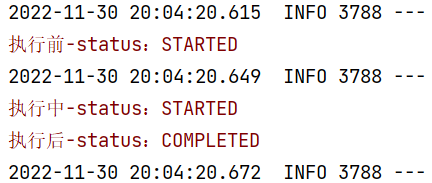
需求:记录作业执行前,执行中,与执行后的状态
方式一:接口方式
定义JobStateListener 实现JobExecutionListener 接口,重写beforeJob,afterJob 2个方法。
//作业状态--接口方式
public class JobStateListener implements JobExecutionListener {//作业执行前@Overridepublic void beforeJob(JobExecution jobExecution) {System.err.println("执行前-status:" + jobExecution.getStatus());}//作业执行后@Overridepublic void afterJob(JobExecution jobExecution) {System.err.println("执行后-status:" + jobExecution.getStatus());}
}
将jobStateListener设置给job
@SpringBootApplication
@EnableBatchProcessing
public class StatusListenerJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {JobExecution jobExecution = contribution.getStepExecution().getJobExecution();System.err.println("执行中-status:" + jobExecution.getStatus());return RepeatStatus.FINISHED;}};}//状态监听器@Beanpublic JobStateListener jobStateListener(){return new JobStateListener();}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}@Beanpublic Job job(){return jobBuilderFactory.get("status-listener-job").start(step1()).listener(jobStateListener()) //设置状态监听器.build();}public static void main(String[] args) {SpringApplication.run(StatusListenerJob.class, args);}
}
新加jobStateListener()实例方法创建对象交个Spring容器管理,修改job()方法,添加.listener(jobStateListener()) 状态监听器,直接执行,观察结果
方式二:注解方式
除去上面通过实现接口方式实现监听之外,也可以使用**@BeforeJob @AfterJob** 2个注解实现
//作业状态--注解方式
public class JobStateAnnoListener {@BeforeJobpublic void beforeJob(JobExecution jobExecution) {System.err.println("执行前-anno-status:" + jobExecution.getStatus());}@AfterJobpublic void afterJob(JobExecution jobExecution) {System.err.println("执行后-anno-status:" + jobExecution.getStatus());}
}
@SpringBootApplication
@EnableBatchProcessing
public class StatusListenerJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {JobExecution jobExecution = contribution.getStepExecution().getJobExecution();System.err.println("执行中-anno-status:" + jobExecution.getStatus());return RepeatStatus.FINISHED;}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}@Beanpublic Job job(){return jobBuilderFactory.get("status-listener-job1").start(step1()).incrementer(new RunIdIncrementer())// 这样设置,JobStateAnnoListener中的注解可以生效/*.listener(JobListenerFactoryBean.getListener(new JobStateAnnoListener()))*/// 这样设置,JobStateAnnoListener中的注解可以生效.listener(new JobStateListener()) //设置状态监听器.build();}public static void main(String[] args) {SpringApplication.run(StatusListenerJob.class, args);}
}
修改job()方法,添加**.listener(JobListenerFactoryBean.getListener(new JobStateAnnoListener()))**状态监听器,直接执行,观察结果
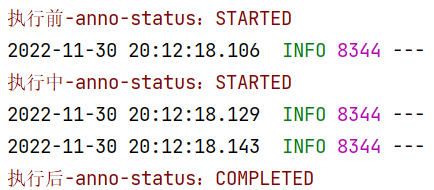
不需要纠结那一长串方法是啥逻辑,只需要知道它能将指定监听器对象加载到spring容器中。
5.5 执行上下文
5.5.1 作业上下文与步骤上下文
语文中有个词叫上下文,比如:联系上下文解读一下作者所有表达意思。从这看上下文有环境,语境,氛围的意思。类比到编程,业内也喜欢使用Context表示上下文。比如Spring容器: SpringApplicationContext 。有上下文这个铺垫之后,我们来看下Spring Batch的上下文。
Spring Batch 有2个比较重要的上下文:
-
JobContext
JobContext 绑定 JobExecution 执行对象,为Job作业执行提供执行环境(上下文)。
作用:维护JobExecution 对象,实现作业收尾工作,与处理各种作业回调逻辑
-
StepContext
StepContext 绑定 StepExecution 执行对象,为Step步骤执行提供执行环境(上下文)。
作用:维护StepExecution 对象,实现步骤收尾工作,与处理各种步骤回调逻辑
5.5.2 执行上下文
除了上面讲的JobContext 作业上下文, StepContext 步骤上线下文外,还有Spring Batch还维护另外一个上下文:ExecutionContext 执行上下文,作用是:数据共享
Spring Batch 中 ExecutionContext 分2大类
-
Job ExecutionContext
作用域:一次作业运行,所有Step步骤间数据共享。
-
Step ExecutionContext:
作用域:一次步骤运行,单个Step步骤间(ItemReader/ItemProcessor/ItemWrite组件间)数据共享。
5.5.3 作业与步骤执行链
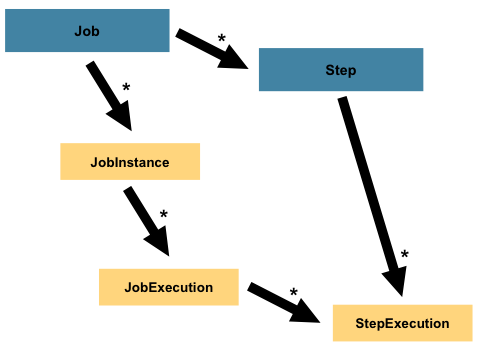
5.5.4 作业与步骤引用链
-
作业线
Job—JobInstance—JobContext—JobExecution–ExecutionContext
-
步骤线
Step–StepContext –StepExecution–ExecutionContext
5.5.5 作业上下文API
JobContext context = JobSynchronizationManager.getContext();JobExecution jobExecution = context.getJobExecution();
// 这个只能从map中获取,不能修改,如果要修改,要获取到对应的上下文对象
Map<String, Object> jobParameters = context.getJobParameters();
Map<String, Object> jobExecutionContext = context.getJobExecutionContext();
5.5.6 步骤上下文API
ChunkContext chunkContext = xxx;
StepContext stepContext = chunkContext.getStepContext();StepExecution stepExecution = stepContext.getStepExecution();
// 这个只能从map中获取,不能修改,如果要修改,要获取到对应的上下文对象
Map<String, Object> stepExecutionContext = stepContext.getStepExecutionContext();
Map<String, Object> jobExecutionContext = stepContext.getJobExecutionContext();
5.5.7 执行上下文API
ChunkContext chunkContext = xxx;
//步骤
StepContext stepContext = chunkContext.getStepContext();
StepExecution stepExecution = stepContext.getStepExecution();
// 获取到对应的上下文对象,就可以修改了
ExecutionContext executionContext = stepExecution.getExecutionContext();
executionContext.put("key", "value");//-------------------------------------------------------------------------//作业
JobExecution jobExecution = stepExecution.getJobExecution();
// 获取到对应的上下文对象,就可以修改了
ExecutionContext executionContext = jobExecution.getExecutionContext();
executionContext.put("key", "value");
5.5.8 API综合小案例
需求:观察作业ExecutionContext与 步骤ExecutionContext数据共享
分析:
1>定义step1 与step2 2个步骤
2>在step1中设置数据
作业-ExecutionContext 添加: key-step1-job value-step1-job
步骤-ExecutionContext 添加: key-step1-step value-step1-step
3>在step2中打印观察
作业-ExecutionContext 步骤-ExecutionContext
package com.langfeiyes.batch._06_context;import com.langfeiyes.batch._04_param_incr.DailyTimestampParamIncrementer;
import org.springframework.batch.core.*;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.listener.JobListenerFactoryBean;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.scope.context.JobContext;
import org.springframework.batch.core.scope.context.JobSynchronizationManager;
import org.springframework.batch.core.scope.context.StepContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ExecutionContext;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
@EnableBatchProcessing
public class ExecutionContextJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet1(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {//步骤ExecutionContext stepEC = chunkContext.getStepContext().getStepExecution().getExecutionContext();stepEC.put("key-step1-step","value-step1-step");System.out.println("------------------1---------------------------");//作业ExecutionContext jobEC = chunkContext.getStepContext().getStepExecution().getJobExecution().getExecutionContext();jobEC.put("key-step1-job","value-step1-job");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet tasklet2(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {//步骤ExecutionContext stepEC = chunkContext.getStepContext().getStepExecution().getExecutionContext();System.err.println(stepEC.get("key-step1-step"));System.out.println("------------------2---------------------------");//作业ExecutionContext jobEC = chunkContext.getStepContext().getStepExecution().getJobExecution().getExecutionContext();System.err.println(jobEC.get("key-step1-job"));return RepeatStatus.FINISHED;}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet1()).build();}@Beanpublic Step step2(){return stepBuilderFactory.get("step2").tasklet(tasklet2()).build();}@Beanpublic Job job(){return jobBuilderFactory.get("execution-context-job").start(step1()).next(step2()).incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(ExecutionContextJob.class, args);}
}运行结果:
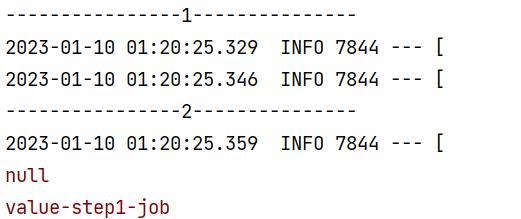
可以看出,在stepContext 设置的参数作用域仅在StepExecution 执行范围有效,而JobContext 设置参数作用与在所有StepExcution 有效,有点局部与全局 的意思。
打开数据库观察表:batch_job_execution_context 跟 batch_step_execution_context 表
JobContext数据保存到:batch_job_execution_context
StepContext数据保存到:batch_step_execution_context
总结:
步骤数据保存在Step ExecutionContext,只能在Step中使用,作业数据保存在Job ExecutionContext,可以在所有Step中共享
六、步骤对象 Step
前面一章节讲完了作业的相关介绍,本章节重点讲解步骤。
6.1 步骤介绍
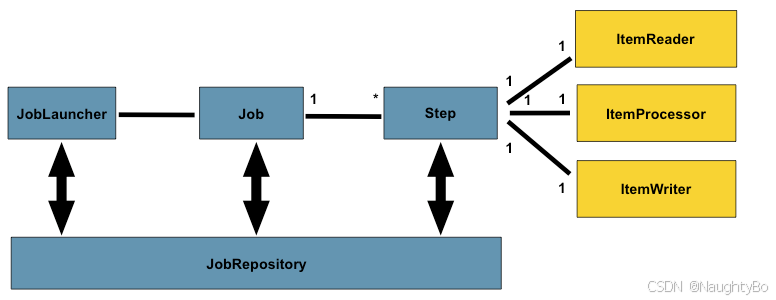
一般认为步骤是一个独立功能组件,因为它包含了一个工作单元需要的所有内容,比如:输入模块,输出模块,数据处理模块等。这种设计好处在哪?给开发者带来更自由的操作空间。
目前Spring Batch 支持2种步骤处理模式:
-
简单基于
Tasklet 处理模式这种模式相对简单,前面讲的都是居于这个模式批处理
@Bean public Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("Hello SpringBatch....");return RepeatStatus.FINISHED;}}; }只需要实现Tasklet接口,就可以构建一个step代码块。循环执行step逻辑,直到tasklet.execute方法返回RepeatStatus.FINISHED
-
基于块(chunk)的处理模式
基于块的步骤一般包含2个或者3个组件:1>ItemReader 2>ItemProcessor(可选) 3>ItemWriter 。 当用上这些组件之后,Spring Batch 会按块处理数据。
6.2 基于简单Tasklet
学到这,我们写过很多简单Tasklet模式步骤,但是都没有深入了解过,这节就细致分析一下具有Tasklet 步骤使用。
先看下Tasklet源码
public interface Tasklet {@NullableRepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception;
}
Tasklet 接口有且仅有一个方法:execute,
参数有2个:
StepContribution:步骤信息对象,用于保存当前步骤执行情况信息,核心用法:设置步骤结果状态contribution.setExitStatus(ExitStatus status)
contribution.setExitStatus(ExitStatus.COMPLETED);
ChunkContext:chunk上下文,跟之前学的StepContext,JobContext一样,区别是它用于记录chunk块执行场景。通过它可以获取前面2个对象。
返回值1个:
RepeatStatus:当前步骤状态, 它是枚举类,有2个值,一个表示execute方法可以循环执行,一个表示已经执行结束。
public enum RepeatStatus {/*** 当前步骤依然可以执行,如果步骤返回该值,会一直循环执行*/CONTINUABLE(true), /*** 当前步骤结束,可以为成功也可以表示不成,仅代表当前step执行结束了*/FINISHED(false);
}
需求:练习上面RepeatStatus状态
@SpringBootApplication
@EnableBatchProcessing
public class SimpleTaskletJob {@Autowiredprivate JobLauncher jobLauncher;@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {private int times = 10;@Overridepublic RepeatStatus execute(StepContribution contribution,ChunkContext chunkContext) throws Exception {System.out.println("------>" + System.currentTimeMillis());if(times-- > 0){return RepeatStatus.CONTINUABLE; //循环执行}return RepeatStatus.FINISHED;}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).build();}//定义作业@Beanpublic Job job(){return jobBuilderFactory.get("step-simple-tasklet-job").start(step1()).build();}public static void main(String[] args) {SpringApplication.run(SimpleTaskletJob.class, args);}}
/*
2025-04-13 11:56:23.665 INFO 14108 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=step-simple-tasklet-job]] launched with the following parameters: [{}]
2025-04-13 11:56:23.719 INFO 14108 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [step1]
------>1744516583737
------>1744516583744
------>1744516583750
------>1744516583755
------>1744516583760
------>1744516583766
------>1744516583772
------>1744516583778
------>1744516583784
------>1744516583790
------>1744516583795
2025-04-13 11:56:23.806 INFO 14108 --- [ main] o.s.batch.core.step.AbstractStep : Step: [step1] executed in 86ms
2025-04-13 11:56:23.819 INFO 14108 --- [ main] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=step-simple-tasklet-job]] completed with the following parameters: [{}] and the following status: [COMPLETED] in 126ms
*/
6.3 基于块Tasklet
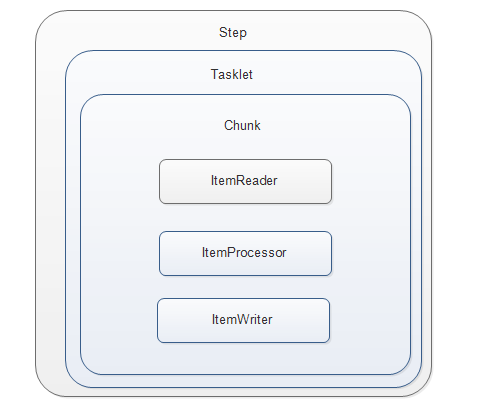
居于块的Tasklet相对简单Tasklet来说,多了3个模块:ItemReader( 读模块), ItemProcessor(处理模块),ItemWriter(写模块), 跟它们名字一样, 一个负责数据读, 一个负责数据加工,一个负责数据写。
结构图:
时序图(这时序图有问题,参考下面示例的输出):
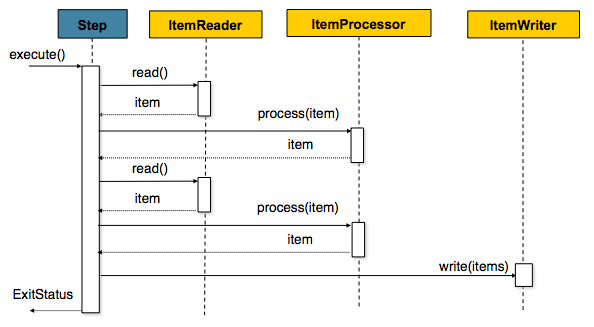
需求:简单演示chunk Tasklet使用
ItemReader ItemProcessor ItemWriter 都接口,直接使用匿名内部类方式方便创建
@SpringBootApplication
@EnableBatchProcessing
public class ChunkTaskletJob {@Autowiredprivate JobLauncher jobLauncher;@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic ItemReader itemReader(){return new ItemReader() {@Overridepublic Object read() {System.out.println("-------------read------------");return "read-ret";}};}@Beanpublic ItemProcessor itemProcessor(){return new ItemProcessor() {@Overridepublic Object process(Object item) throws Exception {System.out.println("-------------process------------>" + item);return "process-ret->" + item;}};}@Beanpublic ItemWriter itemWriter(){return new ItemWriter() {@Overridepublic void write(List items) throws Exception {System.out.println(items);}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").chunk(3) //设置块的size为3次.reader(itemReader()).processor(itemProcessor()).writer(itemWriter()).build();}//定义作业@Beanpublic Job job(){return jobBuilderFactory.get("step-chunk-tasklet-job").start(step1()).incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(ChunkTaskletJob.class, args);}
}
执行完了之后结果
-------------read------------
-------------read------------
-------------read------------
-------------process------------>read-ret
-------------process------------>read-ret
-------------process------------>read-ret
[process-ret->read-ret, process-ret->read-ret, process-ret->read-ret]
-------------read------------
-------------read------------
-------------read------------
-------------process------------>read-ret
-------------process------------>read-ret
-------------process------------>read-ret
[process-ret->read-ret, process-ret->read-ret, process-ret->read-ret]
-------------read------------
-------------read------------
-------------read------------
-------------process------------>read-ret
-------------process------------>read-ret
-------------process------------>read-ret
[process-ret->read-ret, process-ret->read-ret, process-ret->read-ret]
....
观察上面打印结果,得出2个得出。
1>程序一直在循环打印,先循环打印3次reader, 再循环打印3次processor,最后一次性输出3个值。
2>死循环重复上面步骤
问题来了,为啥会出现这种效果,该怎么改进?
其实这个是ChunkTasklet 执行特点,ItemReader会一直循环读,直到返回null,才停止。而processor也是一样,itemReader读多少次,它处理多少次, itemWriter 一次性输出当前次输入的所有数据。
我们改进一下上面案例,要求只读3次, 只需要改动itemReader方法就行
int timer = 3;
@Bean
public ItemReader itemReader(){return new ItemReader() {@Overridepublic Object read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException {if(timer > 0){System.out.println("-------------read------------");return "read-ret-" + timer--;}else{return null;}}};
}
结果不在死循环了
-------------read------------
-------------read------------
-------------read------------
-------------process------------>read-ret-3
-------------process------------>read-ret-2
-------------process------------>read-ret-1
[process-ret->read-ret-3, process-ret->read-ret-2, process-ret->read-ret-1]
思考一个问题, 如果将timer改为 10,而 .chunk(3) 不变结果会怎样?
-------------read------------
-------------read------------
-------------read------------
-------------process------------>read-ret-10
-------------process------------>read-ret-9
-------------process------------>read-ret-8
[process-ret->read-ret-10, process-ret->read-ret-9, process-ret->read-ret-8]
-------------read------------
-------------read------------
-------------read------------
-------------process------------>read-ret-7
-------------process------------>read-ret-6
-------------process------------>read-ret-5
[process-ret->read-ret-7, process-ret->read-ret-6, process-ret->read-ret-5]
-------------read------------
-------------read------------
-------------read------------
-------------process------------>read-ret-4
-------------process------------>read-ret-3
-------------process------------>read-ret-2
[process-ret->read-ret-4, process-ret->read-ret-3, process-ret->read-ret-2]
-------------read------------
-------------process------------>read-ret-1
[process-ret->read-ret-1]
找出规律了嘛?
当chunkSize = 3 表示 reader 先读3次,提交给processor处理3次,最后由writer输出3个值
timer =10, 表示数据有10条,一个批次(趟)只能处理3条数据,需要4个批次(趟)来处理。
是不是有批处理味道出来
结论:chunkSize 表示: 一趟需要ItemReader读多少次,ItemProcessor要处理多少次。
ChunkTasklet 泛型
上面案例默认的是使用Object类型读、写、处理数据,如果明确了Item的数据类型,可以明确指定具体操作泛型。
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.*;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;import java.util.List;//开启 spring batch 注解--可以让spring容器创建springbatch操作相关类对象
@EnableBatchProcessing
//springboot 项目,启动注解, 保证当前为为启动类
@SpringBootApplication
public class ChunkTaskletJob {//作业启动器@Autowiredprivate JobLauncher jobLauncher;//job构造工厂---用于构建job对象@Autowiredprivate JobBuilderFactory jobBuilderFactory;//step 构造工厂--用于构造step对象@Autowiredprivate StepBuilderFactory stepBuilderFactory;int timer = 10;//读操作@Beanpublic ItemReader<String> itemReader(){return new ItemReader<String>() {@Overridepublic String read() throws Exception {if(timer > 0){System.out.println("-------------read------------");return "read-ret-->" + timer--;}else{return null; // 返回null就会停止}}};}//处理操作@Beanpublic ItemProcessor<String, String> itemProcessor(){return new ItemProcessor<String, String>() {@Overridepublic String process(String item) throws Exception {System.out.println("-------------process------------>" + item);return "process-ret->" + item;}};}//写操作@Beanpublic ItemWriter<String> itemWriter(){return new ItemWriter<String>() {@Overridepublic void write(List<? extends String> items) throws Exception {System.out.println(items);}};}//构造一个step对象--chunk@Beanpublic Step step1(){//tasklet 执行step逻辑, 类似 Thread()--->可以执行runable接口return stepBuilderFactory.get("step1").<String, String>chunk(3) //暂时为3.reader(itemReader()).processor(itemProcessor()).writer(itemWriter()).build();}@Beanpublic Job job(){return jobBuilderFactory.get("chunk-tasklet-job").start(step1()).incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(ChunkTaskletJob.class, args);}}异常测试
如果在reader或是processor或是writer中抛出异常会怎么样呢?
@SpringBootApplication
@EnableBatchProcessing
public class ChunkTaskletJob {@Autowiredprivate JobLauncher jobLauncher;@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic ItemReader<String> itemReader() {return new ItemReader<String>() {private int times = 1;@Overridepublic String read() {int count = times++;System.out.println("-------------read------------" + count);if (count == 5) {// throw new RuntimeException("reader报错会怎么样?"); // 后面的都不会再执行了}if (count > 10) {return null;} else {return "read-ret" + count;}}};}@Beanpublic ItemProcessor<String, String> itemProcessor() {return new ItemProcessor<String, String>() {@Overridepublic String process(String item) throws Exception {System.out.println("-------------process------------>" + item);if (Integer.valueOf(item.substring("read-ret".length())) == 5) {// throw new RuntimeException("process报错会怎么样?"); // 后面的都不会再执行了}return "process-ret->" + item;}};}@Beanpublic ItemWriter<String> itemWriter() {return new ItemWriter<String>() {int count = 0;@Overridepublic void write(List<? extends String> items) throws Exception {System.out.println(items);count++;if (count == 2) {throw new RuntimeException("writer报错会怎么样?"); // 后面的都不会再执行了}}};}@Beanpublic Step step1() {return stepBuilderFactory.get("step1").<String, String>chunk(3) //设置块的size为3次.reader(itemReader()).processor(itemProcessor()).writer(itemWriter()).build();}//定义作业@Beanpublic Job job() {return jobBuilderFactory.get("step-chunk-tasklet-job").start(step1()).incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(ChunkTaskletJob.class, args);}
}
6.4 步骤监听器
前面我们讲了作业的监听器,步骤也有监听器,也是执行步骤执行前监听,步骤执行后监听。
步骤监听器有2个分别是:StepExecutionListener ChunkListener 意义很明显,就是step前后,chunk块执行前后监听。
先看下StepExecutionListener接口
public interface StepExecutionListener extends StepListener {void beforeStep(StepExecution stepExecution);@NullableExitStatus afterStep(StepExecution stepExecution);
}
需求:演示StepExecutionListener 用法
自定义监听接口
public class MyStepListener implements StepExecutionListener {@Overridepublic void beforeStep(StepExecution stepExecution) {System.out.println("-----------beforeStep--------->");}@Overridepublic ExitStatus afterStep(StepExecution stepExecution) {System.out.println("-----------afterStep--------->");return stepExecution.getExitStatus(); //不改动返回状态}
}
@SpringBootApplication
@EnableBatchProcessing
public class StepListenerJob {@Autowiredprivate JobLauncher jobLauncher;@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("------>" + System.currentTimeMillis());return RepeatStatus.FINISHED;}};}@Beanpublic MyStepListener stepListener(){return new MyStepListener();}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet()).listener(stepListener()) // 将步骤监听器设置在这里.build();}//定义作业@Beanpublic Job job(){return jobBuilderFactory.get("step-listener-job1").start(step1()).incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(StepListenerJob.class, args);}}在step1方法中,加入:.listener(stepListener()) 即可
同理ChunkListener 操作跟上面一样
public interface ChunkListener extends StepListener {static final String ROLLBACK_EXCEPTION_KEY = "sb_rollback_exception";void beforeChunk(ChunkContext context);void afterChunk(ChunkContext context);void afterChunkError(ChunkContext context);
}唯一的区别是多了一个afterChunkError 方法,表示当chunk执行失败后回调。
6.5 多步骤执行
到目前为止,我们演示的案例基本上都是一个作业, 一个步骤,那如果有多个步骤会怎样?Spring Batch 支持多步骤执行,以应对复杂业务需要多步骤配合执行的场景。
需求:定义2个步骤,然后依次执行
@SpringBootApplication
@EnableBatchProcessing
public class MultiStepJob {@Autowiredprivate JobLauncher jobLauncher;@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet tasklet1(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("--------------tasklet1---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet tasklet2(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("--------------tasklet2---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Step step1(){return stepBuilderFactory.get("step1").tasklet(tasklet1()).build();}@Beanpublic Step step2(){return stepBuilderFactory.get("step2").tasklet(tasklet2()).build();}//定义作业@Beanpublic Job job(){return jobBuilderFactory.get("step-multi-job1").start(step1()).next(step2()) //job 使用next 执行下一步骤.incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(MultiStepJob.class, args);}
}定义2个tasklet: tasklet1 tasklet2, 定义2个step: step1 step2 修改 job方法,从.start(step1()) 然后执行到 .next(step2())
Spring Batch 使用next 执行下一步步骤,如果还有第三个step,再加一个next(step3)即可
6.6 步骤控制
上面多个步骤操作,先执行step1 然后是step2,如果有step3, step4,那执行顺序也是从step1到step4。此时爱思考的小伙伴肯定会想,步骤的执行能不能进行条件控制呢?比如:step1执行结束根据业务条件选择执行step2或者执行step3,亦或者直接结束呢?答案是yes:设置步骤执行条件即可
Spring Batch 使用 start next on from to end 不同的api 改变步骤执行顺序。
6.6.1 条件分支控制-使用默认返回状态
需求:作业执行firstStep步骤,如果处理成功执行sucessStep,如果处理失败执行failStep
@SpringBootApplication
@EnableBatchProcessing
public class ConditionStepJob {@Autowiredprivate JobLauncher jobLauncher;@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet firstTasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("--------------firstTasklet---------------");return RepeatStatus.FINISHED;//throw new RuntimeException("测试fail结果");}};}@Beanpublic Tasklet successTasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("--------------successTasklet---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet failTasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("--------------failTasklet---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Step firstStep(){return stepBuilderFactory.get("step1").tasklet(firstTasklet()).build();}@Beanpublic Step successStep(){return stepBuilderFactory.get("successStep").tasklet(successTasklet()).build();}@Beanpublic Step failStep(){return stepBuilderFactory.get("failStep").tasklet(failTasklet()).build();}//定义作业@Beanpublic Job job(){return jobBuilderFactory.get("condition-multi-job").start(firstStep()).on("FAILED").to(failStep()).from(firstStep()).on("*").to(successStep()).end().incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(ConditionStepJob.class, args);}
}观察给出的案例,job方法以 .start(firstStep()) 开始作业,执行完成之后, 使用on 与from 2个方法实现流程转向。
.on(“FAILED”).to(failStep()) 表示当**firstStep()**返回FAILED时执行。
.from(firstStep()).on(“*”).to(successStep()) 另外一个分支,表示当**firstStep()**返回 * 时执行。
上面逻辑有点像 if / else 语法
if("FAILED".equals(firstStep())){failStep();
}else{successStep();
}
几个注意点:
1> on 方法表示条件, 上一个步骤返回值,匹配指定的字符串,满足后执行后续 to 步骤
2> * 为通配符,表示能匹配任意返回值
3> from 表示从某个步骤开始进行条件判断
4> 分支判断结束,流程以end方法结束,表示if/else逻辑结束
5> on 方法中字符串取值于 ExitStatus 类常量,当然也可以自定义。
6.6.2 条件分支控制-使用自定义状态值
前面也说了,on条件的值取值于ExitStatus 类常量,具体值有:UNKNOWN,EXECUTING,COMPLETED,NOOP,FAILED,STOPPED等,如果此时我想自定义返回值呢,是否可行?
答案还是yes:Spring Batch 提供JobExecutionDecider 接口实现状态值定制。
需求:先执行firstStep,如果返回值为A,执行stepA, 返回值为B,执行stepB, 其他执行defaultStep
分析:先定义一个决策器,随机决定返回A / B / C
public class MyStatusDecider implements JobExecutionDecider {@Overridepublic FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {long ret = new Random().nextInt(3);if(ret == 0){return new FlowExecutionStatus("A");}else if(ret == 1){return new FlowExecutionStatus("B");}else{return new FlowExecutionStatus("C");}}
}
@SpringBootApplication
@EnableBatchProcessing
public class CustomizeStatusStepJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet taskletFirst(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("--------------taskletFirst---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet taskletA(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("--------------taskletA---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet taskletB(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("--------------taskletB---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet taskletDefault(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("--------------taskletDefault---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Step firstStep(){return stepBuilderFactory.get("firstStep").tasklet(taskletFirst()).build();}@Beanpublic Step stepA(){return stepBuilderFactory.get("stepA").tasklet(taskletA()).build();}@Beanpublic Step stepB(){return stepBuilderFactory.get("stepB").tasklet(taskletB()).build();}@Beanpublic Step defaultStep(){return stepBuilderFactory.get("defaultStep").tasklet(taskletDefault()).build();}//决策器@Beanpublic MyStatusDecider statusDecider(){return new MyStatusDecider();}//定义作业@Beanpublic Job job(){return jobBuilderFactory.get("customize-step-job")// 由后面.next(statusDecider()) 决策器决定分支走向.start(firstStep()).next(statusDecider()) //决策器.from(statusDecider()).on("A").to(stepA()).from(statusDecider()).on("B").to(stepB()).from(statusDecider()).on("*").to(defaultStep()).end().incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(CustomizeStepJob.class, args);}}
反复执行,会返回打印的值有
--------------taskletA---------------
--------------taskletB---------------
--------------taskletDefault---------------
它们随机切换,为啥能做到这样?注意,并不是firstStep() 执行返回值为A/B/C控制流程跳转,而是由后面**.next(statusDecider())** 决策器。
6.7 步骤状态
Spring Batch 使用ExitStatus 类表示步骤、块、作业执行状态,大体上有以下几种:
public class ExitStatus implements Serializable, Comparable<ExitStatus> {//未知状态public static final ExitStatus UNKNOWN = new ExitStatus("UNKNOWN");//执行中public static final ExitStatus EXECUTING = new ExitStatus("EXECUTING");//执行完成public static final ExitStatus COMPLETED = new ExitStatus("COMPLETED");//无效执行public static final ExitStatus NOOP = new ExitStatus("NOOP");//执行失败public static final ExitStatus FAILED = new ExitStatus("FAILED");//执行中断public static final ExitStatus STOPPED = new ExitStatus("STOPPED");...
}
一般来说,作业启动之后,这些状态皆为流程自行控制。顺利结束返回:COMPLETED, 异常结束返回:FAILED,无效执行返回:NOOP, 这是肯定有小伙伴说,能不能编程控制呢?答案是可以的。
Spring Batch 提供 3个方法决定作业流程走向:
end():作业流程直接成功结束,返回状态为:COMPLETED
fail():作业流程直接失败结束,返回状态为:FAILED
stopAndRestart(step) :作业流程中断结束,返回状态:STOPPED 再次启动时,从step位置开始执行 (注意:前提是参数与Job Name一样)
**需求:当步骤firstStep执行抛出异常时,通过end, fail,stopAndRestart改变步骤执行状态 **
//开启 spring batch 注解--可以让spring容器创建springbatch操作相关类对象
@EnableBatchProcessing
//springboot 项目,启动注解, 保证当前为为启动类
@SpringBootApplication
public class StatusStepJob {//作业启动器@Autowiredprivate JobLauncher jobLauncher;//job构造工厂---用于构建job对象@Autowiredprivate JobBuilderFactory jobBuilderFactory;//step 构造工厂--用于构造step对象@Autowiredprivate StepBuilderFactory stepBuilderFactory;//构造一个step对象执行的任务(逻辑对象)@Beanpublic Tasklet firstTasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("----------------firstTasklet---------------");throw new RuntimeException("假装失败了");//return RepeatStatus.FINISHED; //执行完了}};}@Beanpublic Tasklet successTasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("----------------successTasklet--------------");return RepeatStatus.FINISHED; //执行完了}};}@Beanpublic Tasklet failTasklet(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("----------------failTasklet---------------");return RepeatStatus.FINISHED; //执行完了}};}//构造一个step对象@Beanpublic Step firstStep(){//tasklet 执行step逻辑, 类似 Thread()--->可以执行runable接口return stepBuilderFactory.get("firstStep").tasklet(firstTasklet()).build();}//构造一个step对象@Beanpublic Step successStep(){//tasklet 执行step逻辑, 类似 Thread()--->可以执行runable接口return stepBuilderFactory.get("successStep").tasklet(successTasklet()).build();}//构造一个step对象@Beanpublic Step failStep(){//tasklet 执行step逻辑, 类似 Thread()--->可以执行runable接口return stepBuilderFactory.get("failStep").tasklet(failTasklet()).build();}//如果firstStep 执行成功:下一步执行successStep 否则是failStep@Beanpublic Job job(){return jobBuilderFactory.get("status-step-job").start(firstStep())//表示将当前本应该是失败结束的步骤直接转成正常结束--COMPLETED//.on("FAILED").end() //表示将当前本应该是失败结束的步骤直接转成失败结束:FAILED//.on("FAILED").fail() //表示将当前本应该是失败结束的步骤直接转成停止结束:STOPPED 里面参数表示后续要重启时, 从successStep位置开始.on("FAILED").stopAndRestart(successStep()).from(firstStep()).on("*").to(successStep()).end().incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(StatusStepJob.class, args);}}6.8 流式步骤
FlowStep 流式步骤,也可以理解为步骤集合,由多个子步骤组成。作业执行时,将它当做一个普通步骤执行。一般用于较为复杂的业务,比如:一个业务逻辑需要拆分成按顺序执行的子步骤。
需求:先后执行stepA,stepB,stepC, 其中stepB中包含stepB1, stepB2,stepB3。
@SpringBootApplication
@EnableBatchProcessing
public class FlowStepJob {@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Beanpublic Tasklet taskletA(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("------------stepA--taskletA---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet taskletB1(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("------------stepB--taskletB1---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet taskletB2(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("------------stepB--taskletB2---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet taskletB3(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("------------stepB--taskletB3---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Tasklet taskletC(){return new Tasklet() {@Overridepublic RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {System.out.println("------------stepC--taskletC---------------");return RepeatStatus.FINISHED;}};}@Beanpublic Step stepA(){return stepBuilderFactory.get("stepA").tasklet(taskletA()).build();}@Beanpublic Step stepB1(){return stepBuilderFactory.get("stepB1").tasklet(taskletB1()).build();}@Beanpublic Step stepB2(){return stepBuilderFactory.get("stepB2").tasklet(taskletB2()).build();}@Beanpublic Step stepB3(){return stepBuilderFactory.get("stepB3").tasklet(taskletB3()).build();}@Beanpublic Flow flowB(){return new FlowBuilder<Flow>("flowB").start(stepB1()).next(stepB2()).next(stepB3()).build();}@Beanpublic Step stepB(){return stepBuilderFactory.get("stepB").flow(flowB()) // 将flowB包一下,到step中.build();}@Beanpublic Step stepC(){return stepBuilderFactory.get("stepC").tasklet(taskletC()).build();}//定义作业@Beanpublic Job job(){return jobBuilderFactory.get("flow-step-job").start(stepA()).next(stepB()).next(stepC()).incrementer(new RunIdIncrementer()).build();}public static void main(String[] args) {SpringApplication.run(FlowStepJob.class, args);}}此时的flowB()就是一个FlowStep,包含了stepB1, stepB2, stepB3 3个子step,他们全部执行完后, stepB才能算执行完成。下面执行结果也验证了这点。
2022-12-03 14:54:16.644 INFO 19116 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [stepA]
------------stepA--taskletA---------------
2022-12-03 14:54:16.699 INFO 19116 --- [ main] o.s.batch.core.step.AbstractStep : Step: [stepA] executed in 55ms
2022-12-03 14:54:16.738 INFO 19116 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [stepB]
2022-12-03 14:54:16.788 INFO 19116 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [stepB1]
------------stepB--taskletB1---------------
2022-12-03 14:54:16.844 INFO 19116 --- [ main] o.s.batch.core.step.AbstractStep : Step: [stepB1] executed in 56ms
2022-12-03 14:54:16.922 INFO 19116 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [stepB2]
------------stepB--taskletB2---------------
2022-12-03 14:54:16.952 INFO 19116 --- [ main] o.s.batch.core.step.AbstractStep : Step: [stepB2] executed in 30ms
2022-12-03 14:54:16.996 INFO 19116 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [stepB3]
------------stepB--taskletB3---------------
2022-12-03 14:54:17.032 INFO 19116 --- [ main] o.s.batch.core.step.AbstractStep : Step: [stepB3] executed in 36ms
2022-12-03 14:54:17.057 INFO 19116 --- [ main] o.s.batch.core.step.AbstractStep : Step: [stepB] executed in 318ms
2022-12-03 14:54:17.165 INFO 19116 --- [ main] o.s.batch.core.job.SimpleStepHandler : Executing step: [stepC]
------------stepC--taskletC---------------
2022-12-03 14:54:17.215 INFO 19116 --- [ main] o.s.batch.core.step.AbstractStep : Step: [stepC] executed in 50ms
使用FlowStep的好处在于,在处理复杂额批处理逻辑中,flowStep可以单独实现一个子步骤流程,为批处理提供更高的灵活性。
七、批处理数据表
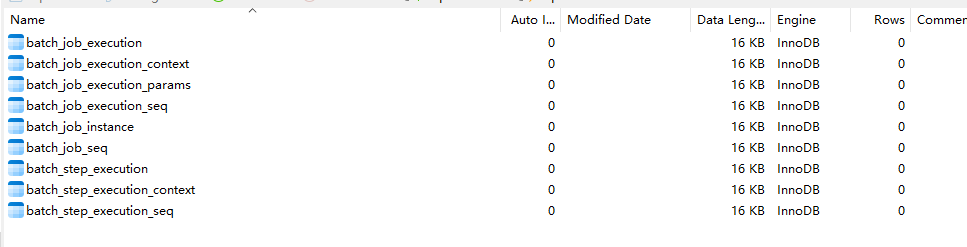
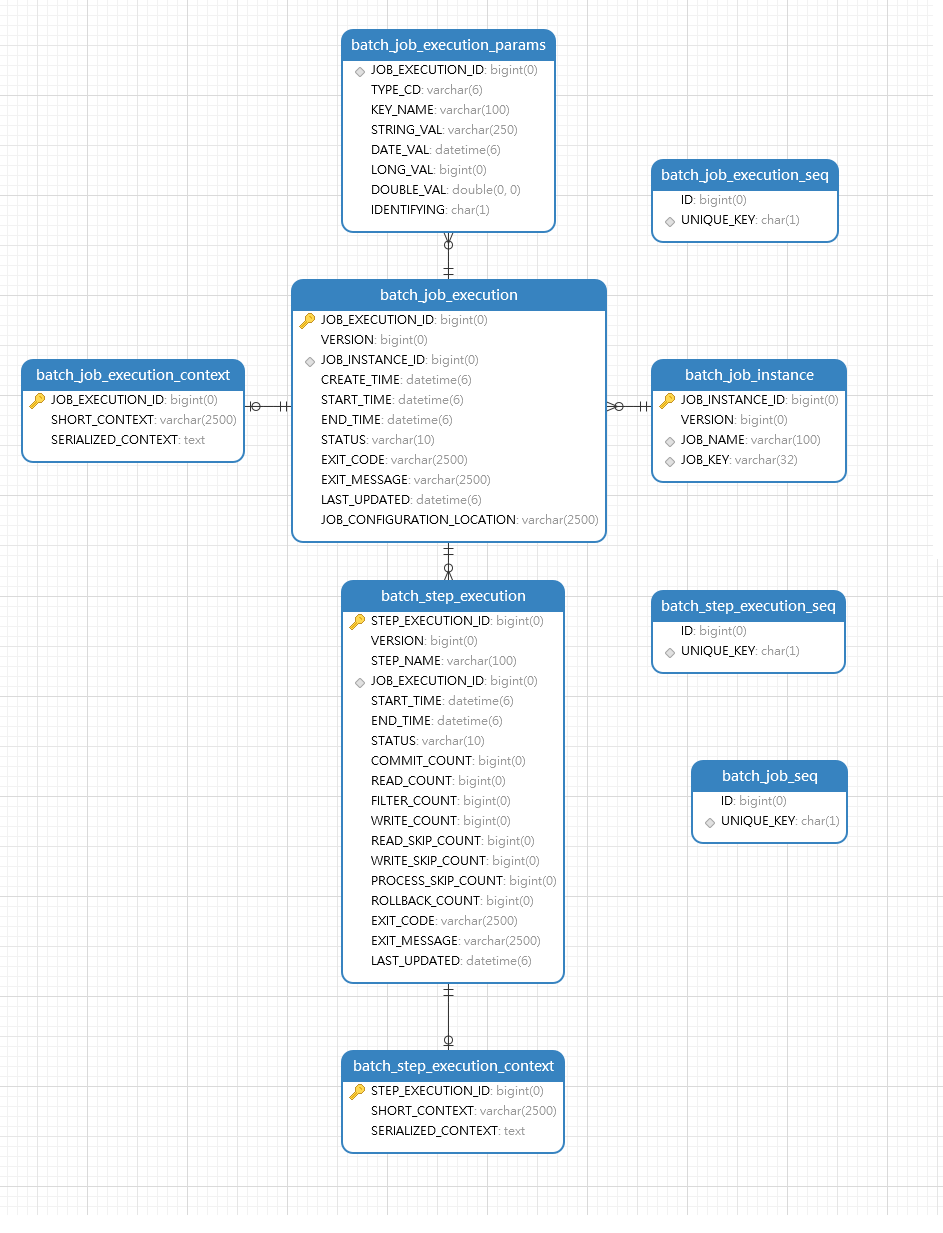
如果选择数据库方式存储批处理数据,Spring Batch 在启动时会自动创建9张表,分别存储: JobExecution、JobContext、JobParameters、JobInstance、JobExecution id序列、Job id序列、StepExecution、StepContext/ChunkContext、StepExecution id序列 等对象。Spring Batch 提供 JobRepository 组件来实现这些表的CRUD操作,并且这些操作基本上封装在步骤,块,作业api操作中,并不需要我们太多干预,所以这章内容了解即可。
7.1 batch_job_instance表
当作业第一次执行时,会根据作业名,标识参数生成一个唯一JobInstance对象,batch_job_instance表会记录一条信息代表这个作业实例。

| 字段 | 描述 |
|---|---|
| JOB_INSTANCE_ID | 作业实例主键 |
| VERSION | 乐观锁控制的版本号 |
| JOB_NAME | 作业名称 |
| JOB_KEY | 作业名与标识性参数的哈希值,能唯一标识一个job实例 |
7.2 batch_job_execution表
每次启动作业时,都会创建一个JobExecution对象,代表一次作业执行,该对象记录存放于batch_job_execution 表。

| 字段 | 描述 |
|---|---|
| JOB_EXECUTION_ID | job执行对象主键 |
| VERSION | 乐观锁控制的版本号 |
| JOB_INSTANCE_ID | JobInstanceId(归属于哪个JobInstance) |
| CREATE_TIME | 记录创建时间 |
| START_TIME | 作业执行开始时间 |
| END_TIME | 作业执行结束时间 |
| STATUS | 作业执行的批处理状态 |
| EXIT_CODE | 作业执行的退出码 |
| EXIT_MESSAGE | 作业执行的退出信息 |
| LAST_UPDATED | 最后一次更新记录的时间 |
(如果第一次执行job就成功了,那么jobinstance实例数和jobexecution数量是一样的;如果第一次执行job失败了,那么第二次执行(job名和参数不变),那么jobinstance不会再次创建,而jobexecution会创建1个新的)
7.3 batch_job_execution_context表
batch_job_execution_context用于保存JobContext对应的ExecutionContext对象数据。

| 字段 | 描述 |
|---|---|
| JOB_EXECUTION_ID | job执行对象主键 |
| SHORT_CONTEXT | ExecutionContext系列化后字符串缩减版 |
| SERIALIZED_CONTEXT | ExecutionContext系列化后字符串 |
7.4 batch_job_execution_params表
作业启动时使用标识性参数保存的位置:batch_job_execution_params, 一个参数一个记录

| 字段 | 描述 |
|---|---|
| JOB_EXECUTION_ID | job执行对象主键 |
| TYPE_CODE | 标记参数类型 |
| KEY_NAME | 参数名 |
| STRING_VALUE | 当参数类型为String时有值 |
| DATE_VALUE | 当参数类型为Date时有值 |
| LONG_VAL | 当参数类型为LONG时有值 |
| DOUBLE_VAL | 当参数类型为DOUBLE时有值 |
| IDENTIFYING | 用于标记该参数是否为标识性参数 |
7.5 btch_step_execution表
作业启动,执行步骤,每个步骤执行信息保存在batch_step_execution表中

| 字段 | 描述 |
|---|---|
| STEP_EXECUTION_ID | 步骤执行对象id |
| VERSION | 乐观锁控制版本号 |
| STEP_NAME | 步骤名称 |
| JOB_EXECUTION_ID | 作业执行对象id |
| START_TIME | 步骤执行的开始时间 |
| END_TIME | 步骤执行的结束时间 |
| STATUS | 步骤批处理状态 |
| COMMIT_COUNT | 在步骤执行中提交的事务次数 |
| READ_COUNT | 读入的条目数量 |
| FILTER_COUNT | 由于ItemProcessor返回null而过滤掉的条目数 |
| WRITE_COUNT | 写入条目数量 |
| READ_SKIP_COUNT | 由于ItemReader中抛出异常而跳过的条目数量 |
| PROCESS_SKIP_COUNT | 由于ItemProcessor中抛出异常而跳过的条目数量 |
| WRITE_SKIP_COUNT | 由于ItemWriter中抛出异常而跳过的条目数量 |
| ROLLBACK_COUNT | 在步骤执行中被回滚的事务数量 |
| EXIT_CODE | 步骤的退出码 |
| EXT_MESSAGE | 步骤执行返回的信息 |
| LAST_UPDATE | 最后一次更新记录时间 |
7.6 batch_step_execution_context表
StepContext对象对应的ExecutionContext 保存的数据表:batch_step_execution_context

| 字段 | 描述 |
|---|---|
| STEP_EXECUTION_ID | 步骤执行对象id |
| SHORT_CONTEXT | ExecutionContext系列化后字符串缩减版 |
| SERIALIZED_CONTEXT | ExecutionContext系列化后字符串 |
7.7 H2内存数据库
除了关系型数据库保存的数据外,Spring Batch 也执行内存数据库,比如H2,HSQLDB,这些数据库将数据缓存在内存中,当批处理结束后,数据会被清除,一般用于进行单元测试,不建议在生产环境中使用。
相关文章:
)
spring-batch批处理框架(1)
学习链接 SpringBatch高效批处理框架详解及实战演练 spring-batch批处理框架(1) spring-batch批处理框架(2) spring batch官方文档 spring batch官方示例代码 - github 文章目录 学习链接一、课程目标课程目标课程内容前置知识适合人群 二、Spring Batch简介2.1 何为批处理…...

MCP系列:权限管理与隐私保护
前言 随着模型上下文协议(MCP)的广泛应用,安全性问题也逐步突显。在前几篇文章中,我们已经探讨了MCP的基本概念、技术架构、实践应用以及工具调用机制。本篇文章将聚焦于MCP的安全性考量,包括权限管理、隐私保护以及风险缓解策略。 对于企业和开发者而言,了解如何保障M…...
多路复用技术)
【25软考网工笔记】第二章(7)多路复用技术
目录 一、多路复用技术 1. 频分复用FDM 1)频分复用的基本概念 2)频分复用与相关技术 3)注意事项与扩展 2. 时分复用 1)同步时分复用 2)统计时分复用 3)同步时分复用与统计时分复用的对比 4&#…...

任意文字+即梦3.0的海报设计Prompt
即梦3.0版本发布后,对文字的呈现能力得到了极大的提升,网上也出现了各种文章教大家怎么写提示词。 但是你有没有发现一个问题,好的提示词是需要艺术细胞的,只有那些浸淫设计领域的专家总结的提示词才算上乘。 就像是给你一个主题…...

自动化测试相关协议深度剖析及A2A、MCP协议自动化测试应用展望
一、不同协议底层逻辑关联分析 1. OPENAPI协议 OPENAPI 协议核心在于定义 API 的规范结构,它使用 YAML 或 JSON 格式来描述 API 的端点、请求参数、响应格式等信息。其底层逻辑是构建一个清晰、标准化的 API 描述文档,方便不同的客户端和服务端进行对接…...
:Matplotlib 基础绘图 - 让数据“开口说话”)
零基础上手Python数据分析 (18):Matplotlib 基础绘图 - 让数据“开口说话”
写在前面 —— 告别枯燥数字,拥抱可视化力量,掌握 Matplotlib 绘图基础 欢迎来到 “高效数据分析实战指南:Python零基础入门” 专栏! 经过前面 Pandas 模块的学习和实战演练,我们已经掌握了使用 Python 和 Pandas 进行数据处理、清洗、整合、分析的核心技能。 我们能够从…...

[特殊字符] AI 大模型的 Prompt Engineering 原理:从基础到源码实践
🌟 引言:Prompt Engineering - AI 大模型的"魔法咒语" 在 AI 大模型蓬勃发展的当下,它们展现出令人惊叹的语言处理能力,从文本生成到智能问答,从机器翻译到代码编写,几乎涵盖了自然语言处理的各…...

C++ 基于多设计模式下的同步异步⽇志系统-1准备工作
一.项目介绍 项⽬介绍 本项⽬主要实现⼀个⽇志系统, 其主要⽀持以下功能: • ⽀持多级别⽇志消息 • ⽀持同步⽇志和异步⽇志 • ⽀持可靠写⼊⽇志到控制台、⽂件以及滚动⽂件中 • ⽀持多线程程序并发写⽇志 • ⽀持扩展不同的⽇志落地⽬标地 二.日志系统的三种实现…...

c# MES生产进度看板,报警看板 热流道行业可用实时看生产进度
MES生产进度看板,报警看板 热流道行业可用实时看生产进度 背景 本软件是给宁波热流道行业客户开发的生产电子看板软件系统 功能 1.录入工艺流程图(途程图)由多个站别组成。可以手动设置每个工艺站点完成百分比。 2.可以看生成到哪个工…...

C语言学习之预处理指令
目录 预定义符号 #define的应用 #define定义常量 #define定义宏 带有副作用的宏参数 宏替换的规则 函数和宏定义的区别 #和## #运算符 ##运算符 命名约定 #undef 编辑 命令行定义 条件编译 头文件包含 头文件被包含的方式 1.本地头文件包含 2.库文件包含 …...

腾讯wxg企业微信 后端开发一面
UDP安全吗,怎么修改让其安全? packet header QUIC FrameHeader TCP的三个窗口 滑动 发送 拥塞, 怎么用UDP使用类似的功能 怎么确认消息是否收到? TCP的拥塞控制是怎么样的 HTTPS的握手流程 MySQL为什么用B树 红黑树等结构也能在叶子节点实现…...

【Hot100】 73. 矩阵置零
目录 引言矩阵置零我的解题优化优化思路分步解决思路为什么必须按照这个顺序处理?完整示例演示总结 🙋♂️ 作者:海码007📜 专栏:算法专栏💥 标题:【Hot100】 73. 矩阵置零❣️ 寄语ÿ…...
)
c++_csp-j算法 (2)
目录 BFS搜索(广度优先搜索) 讲解 BFS搜索算法原理 BFS搜索算法实现 BFS搜索算法的应用 例题(1) P1032 [NOIP 2002 提高组] 字串变换 例题(2) P1443 马的遍历 BFS搜索(广度优先搜索) 讲解 BFS搜索算法原理 广度优先搜索(BFS)算法是一种图的搜索算法,用于遍历…...

学习笔记: Mach-O 文件
“结构决定性质,性质决定用途”。如果不了解结构,是很难真正理解的。 通过一个示例的可执行文件了解Mach-O文件的结构 Mach-O基本结构 Header: :文件类型、目标架构类型等Load Commands:描述文件在虚拟内存中的逻辑结构、布局Data: 在Load commands中…...

基于GRPO将QWEN训练为和deepseek一样的推理模型!
GRPO 群体相对策略优化(GRPO)算法最初由deepseek团队提出,是近端策略优化(PPO)的一个变体。 GRPO 是一种在线学习算法,它通过使用训练过程中已训练模型自身生成的数据进行迭代改进。GRPO 目标背后的逻辑是在确保模型与参考策略保…...

STM32 外部中断EXTI
目录 外部中断基础知识 STM32外部中断框架 STM32外部中断机制框架 复用功能 重映射 中断嵌套控制器NVIC 外部中断按键控制LED灯 外部中断基础知识 STM32外部中断框架 中断的概念:在主程序运行过程中,出现了特点的中断触发条件,使得…...

Codex CLI - 自然语言命令行界面
本文翻译整理自:https://github.com/microsoft/Codex-CLI 文章目录 一、关于 Codex CLI相关链接资源 二、安装系统要求安装步骤 三、基本使用1、基础操作2、多轮模式 四、命令参考五、提示工程与上下文文件自定义上下文 六、故障排查七、FAQ如何查询可用OpenAI引擎&…...
含运行文档)
健身会员管理系统(ssh+jsp+mysql8.x)含运行文档
健身会员管理系统(sshjspmysql8.x) 对健身房的健身器材、会员、教练、办卡、会员健身情况进行管理,可根据会员号或器材进行搜索,查看会员健身情况或器材使用情况。...
)
数据结构——快排和归并排序(非递归)
快速排序和归并排序一般都是用递归来实现的,但是掌握非递归也是很重要的,说不定在面试的时候面试官突然问你快排或者归并非递归实现,递归有时候并不好,在数据量非常大的时候效率就不好,但是使用非递归结果就不一样了&a…...

Trae,字节跳动推出的 AI 编程助手插件
Trae 插件是 Trae 旗下全新一代的人工智能编程助手(前身为 MarsCode 编程助手),以插件形式集成在本地开发环境中,具备极高的兼容性和灵活性,旨在提升开发效率和代码质量。它支持超过100种编程语言,兼容主流…...

Qt项目——Tcp网络调试助手服务端与客户端
目录 前言结果预览工程文件源代码一、开发流程二、Tcp协议三、Socket四、Tcp服务器的关键流程五、Tcp客户端的关键流程六、Tcp服务端核心代码七、客户端核心代码总结 前言 这期要运用到计算机网络的知识,要搞清楚Tcp协议,学习QTcpServer ,学…...

2021-11-10 C++蜗牛爬井进3退1求天数
缘由C大一编程题目。-编程语言-CSDN问答 int n 0, t 0;cin >> n;while ((n - 3)>0)n, t;cout << t << endl;...

玛哈特整平机:工业制造中的关键设备
在现代工业制造中,平整度是衡量材料加工质量的核心指标之一。无论是金属板材、塑料片材还是复合材料,若存在弯曲、翘曲或波浪形缺陷,将直接影响后续加工效率和成品质量。整平机(又称校平机、矫平机)作为解决这一问题的…...
find命令)
LINUX419 更换仓库(没换成)find命令
NAT模式下虚拟机需与网卡处在同一个网段中吗 和VM1同个网段 会不会影响 这个很重要 是2 改成点2 倒是Ping通了 为啥ping百度 ping到别的地方 4399 倒是ping通了 准备下载httpd包 下不下来 正在替换为新版本仓库 报错 failure: repodata/repomd.xml from local: [Er…...

C# 预定义类型全解析
在 C# 编程中,预定义类型是基础且重要的概念。下面我们来详细了解 C# 的预定义类型。 预定义类型概述 C# 提供了 16 种预定义类型,包含 13 种简单类型和 3 种非简单类型。所有预定义类型的名称都由全小写字母组成。 预定义简单类型 预定义简单类型表…...
:ReactExecutor)
【仓颉 + 鸿蒙 + AI Agent】CangjieMagic框架(16):ReactExecutor
CangjieMagic框架:使用华为仓颉编程语言编写,专门用于开发AI Agent,支持鸿蒙、Windows、macOS、Linux等系统。 这篇文章剖析一下 CangjieMagic 框架中的 ReactExecutor。 这个执行器名字中的"React"代表"Reasoning and Acti…...

13.第二阶段x64游戏实战-分析人物等级和升级经验
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:12.第二阶段x64游戏实战-远程调试 效果图: 如下图红框,…...

Linux疑难杂惑 | 云服务器重装系统后vscode无法远程连接的问题
报错原因:本地的known_hosts文件记录服务器信息与现服务器的信息冲突了,导致连接失败。 解决方法:找到本地的known_hosts文件,把里面的所有东西删除后保存就好了。 该文件的路径可以在报错中寻找:比如我的路径就是&a…...

使用EXCEL绘制平滑曲线
播主播主,你都多少天没更新了!!!泥在干什么?你还做这个账号麻?!!! 做的做的(哭唧唧),就是最近有些忙,以及…… 前言&…...

你的电脑在开“外卖平台”?——作业管理全解析
你的电脑在开“外卖平台”?——作业管理全解析 操作系统系列文章导航(点击跳转) 程序员必看:揭开操作系统的神秘面纱 :从进程、内存到设备管理,全面解析操作系统的核心机制与日常应用。告别电脑卡顿&#x…...
)
平均池化(Average Pooling)
1. 定义与作用 平均池化是一种下采样操作,通过对输入区域的数值取平均值来压缩数据空间维度。其核心作用包括: 降低计算量:减少特征图尺寸,提升模型效率。保留整体特征:平滑局部…...

JavaScript中的Event事件对象详解
一、事件对象(Event)概述 1. 事件对象的定义 event 对象是浏览器自动生成的对象,当用户与页面进行交互时(如点击、键盘输入、鼠标移动等),事件触发时就会自动传递给事件处理函数。event 对象包含了与事件…...
)
OSPF综合实验(HCIP)
1,R5为ISP,其上只能配置Ip地址;R4作为企业边界路由器, 出口公网地址需要通过ppp协议获取,并进行chap认证 2,整个OSPF环境IP基于172.16.0.0/16划分; 3,所有设备均可访问R5的环回&…...

Unreal 从入门到精通之如何接入MQTT
文章目录 前言MQTT 核心特性MQTT 在 UE5 中的应用场景在 UE5 中集成 MQTTMqtt Client 的APIMqtt Client 使用示例最后前言 MQTT(Message Queuing Telemetry Transport)是一种专为物联网(IoT)和低带宽、高延迟网络环境设计的轻量级消息传输协议。它采用发布/订阅(Pub/Sub)…...

数据结构实验6.2:稀疏矩阵的基本运算
文章目录 一,实验目的二,问题描述三,基本要求四、算法分析(一)稀疏矩阵三元组表示法存储结构(二)插入算法(三)创建算法(四)输出算法(五…...

BDO分厂积极开展“五个一”安全活动
BDO分厂为规范化学习“五个一”活动主题,按照“上下联动、分头准备 、差异管理、资源共享”的原则,全面激活班组安全活动管理新模式,正在积极开展班组安全活动,以单元班组形式对每个班组每周组织一次“五个一”安全活动。 丁二醇单…...

那就聊一聊mysql的锁
MySQL 的锁机制是数据库并发控制的核心,作为 Java 架构师需要深入理解其实现原理和适用场景。以下是 MySQL 锁机制的详细解析: 一、锁的分类维度 1. 按锁粒度划分 锁粒度特点适用场景全局锁锁定整个数据库(FLUSH TABLES WITH READ LOC…...

Python番外——常用的包功能讲解和分类组合
目录 1. Web开发框架与工具 2. 数据处理与分析 3. 网络请求与爬虫 4. 异步编程 5. 数据库操作 6. 图像与多媒体处理 7. 语言模型与NLP 8. 安全与加密 9. 配置与工具 10. 其他工具库 11.典型组合场景 此章节主要是记录我所使用的包,以及模块。方便供自己方…...

【mongodb】数据库操作
目录 1. 查看所有数据库2. 切换到指定数据库(若数据库不存在,则创建)3. 查看当前使用的数据库4. 删除当前数据库5.默认数据库 1. 查看所有数据库 1.show dbs2.show databases 2. 切换到指定数据库(若数据库不存在,则…...

四月下旬系列
CUHKSZ 校赛 期中考试 DAY -1。 省流:前 1h 切 6 题,后 3h 过 1 题,读错一个本来很【】的题,被大模拟构造创【】了。 本地除了 VSCode 没有 Extensions,别的和省选差不多。使用 DEVC。 前 6 题难度 < 绿&#x…...
)
计算机网络 3-4 数据链路层(局域网)
4.1 局域网LAN 特点 1.覆盖较小的地理范围 2.较低的时延和误码率 3.局域网内的各节点之间 4.支持单播、广播、多播 分类 关注三要素 (出题点) ①拓扑结构 ②传输介质 ③介质访问控制方式 硬件架构 4.2 以太网 4.2.1 层次划分 4.2.2 物理层标准…...

WebSocket介绍
在网页聊天项目中,为了实现消息的发送和及时接收,我们使用了WebSocket,接下来就简单介绍一下这个WebSocket。 了解消息的转发逻辑 当两个不同客户端在不同的局域网中互相发送消息时,假如这两个客户端分别是a和b,因为…...

rpcrt4!COMMON_AddressManager函数分析之和全局变量rpcrt4!AddressList的关系
第一部分: 1: kd> x rpcrt4!addresslist 77c839dc RPCRT4!AddressList 0x00000000 1: kd> g Breakpoint 2 hit RPCRT4!OSF_ADDRESS::CompleteListen: 001b:77c0c973 55 push ebp 1: kd> g Breakpoint 11 hit RPCRT4!COMMON_Addr…...

Java Web 之 Tomcat 100问
Tomcat 是什么? Tomcat 是一个开源的 Java Servlet 容器和 Web 容器。 Tomcat 的主要功能有哪些? 三大主要功能: 运行 Java Web 应用。处理 HTTP 请求。管理 Web 应用。 如何安装 Tomcat ? 下载 Tomcat 安装包(A…...

ESB —— 企业集成架构的基石:功能、架构与应用全解析
企业服务总线(Enterprise Service Bus,ESB)是一种重要的企业级集成架构,以下为你详细介绍: 一、概念与定义 ESB 是一种基于面向服务架构(SOA)的中间件技术,它充当了企业内部不同应…...

wordpress SMTP配置qq邮箱发送邮件,新版QQ邮箱授权码获取方法
新版的QQ邮箱界面不同了,以下是新版的设置方法: 1. 进入邮箱后,点右上角的设置图标: 2. 左下角的菜单里,选择“账号与安全” : 3. 然后如下图,开启SMTP 服务: 4. 按提示验证短信&am…...

【操作系统原理04】进程同步
文章目录 大纲一.进程同步与进程互斥0.大纲1.同步2.互斥 二.进程互斥的软件实现方法0.大纲1.单标志法2.双标志先检查法3.双标志后检查法4.Peterson算法 三.进程互斥的硬件实现方法0.大纲1.中断屏蔽方法2.TestAndSet指令3.Swap指令 四.互斥锁五.信号量机制0.大纲1.概念2.整形信号…...

Java ThreadPoolExecutor 深度解析:从原理到实战
在 Java 的多线程编程领域,ThreadPoolExecutor是一个至关重要的工具类,它为开发者提供了强大且灵活的线程池管理能力。合理使用ThreadPoolExecutor,不仅能够提升应用程序的性能和响应速度,还能有效控制资源消耗,避免因…...

MCP 协议——AI 世界的“USB-C 接口”:解锁智能协作的新时代
在过去十年中,科技的进步已经改变了我们日常生活的方方面面。从智能手机的普及到物联网的快速发展,人们的生活被各种创新的技术重新定义。今天,我们即将迎来另一个里程碑式的转折点——MCP 协议的推出,它将为人工智能世界的协作与…...

知识就是力量——一些硬件的使用方式
硬件平台 正点原子ATK-MD0430 V2.0(4.3寸TFT LCD电容触摸屏/使用cc2530控制)1.硬件连接2. 软件驱动实现3. 优化与注意事项4. 示例工程参考5. 常见问题 正点原子ATK-MD0430 V2.0(4.3寸TFT LCD电容触摸屏/使用cc2530控制) 1.硬件连…...