豆瓣图书数据采集与可视化分析(一)- 豆瓣图书数据爬取
文章目录
- 前言
- 一、数据爬取步骤
- 二、豆瓣图书页面分析
- 1. 图书分类标签页面分析
- 2. 图书页面分析
- 三、数据采集实现
- 1. 图书分类标签数据采集
- 2. 图书数据采集
- 3. 把多个分类的CSV数据文件整合到一个CSV文件中
前言
在当今大数据时代,数据的获取与整理对于各个领域的研究和决策都具有至关重要的意义。图书领域也不例外,丰富且精准的图书数据能够为读者提供更优质的阅读推荐,助力图书行业从业者洞察市场趋势,还能为相关学术研究提供坚实的数据基础。
豆瓣作为国内知名的文化社区,汇聚了海量的图书信息,其分类体系清晰且涵盖面广,为我们采集图书数据提供了绝佳的数据源。本次项目聚焦于豆瓣图书数据,旨在构建一个全面、系统的图书数据集,以满足多方面对于图书信息分析的需求。
本项目将通过数据爬取技术,深入挖掘豆瓣图书分类标签页面以及各分类下的图书详细页面,采集关键信息,并运用合理的数据处理手段对采集到的数据进行清洗、整合,最终形成高质量的数据集。希望通过此次实践,不仅能为后续针对图书数据的分析与应用搭建良好的数据基石,也能为对数据采集与处理感兴趣的同行提供有价值的参考与借鉴,共同探索数据背后的无限可能,进一步推动图书相关领域在数据驱动下的创新发展。
一、数据爬取步骤
- 分析豆瓣图书分类标签页面
- 爬取豆瓣图书分类标签及地址
- 根据分类地址爬取每个分类的图书数据
- 每个分类的图书数据保存为一个CSV文件
- 整合所有的CSV文件为一个CSV文件
二、豆瓣图书页面分析
1. 图书分类标签页面分析
豆瓣图书分类标签地址:https://book.douban.com/tag/
豆瓣图书分类标签页面如下图所示:
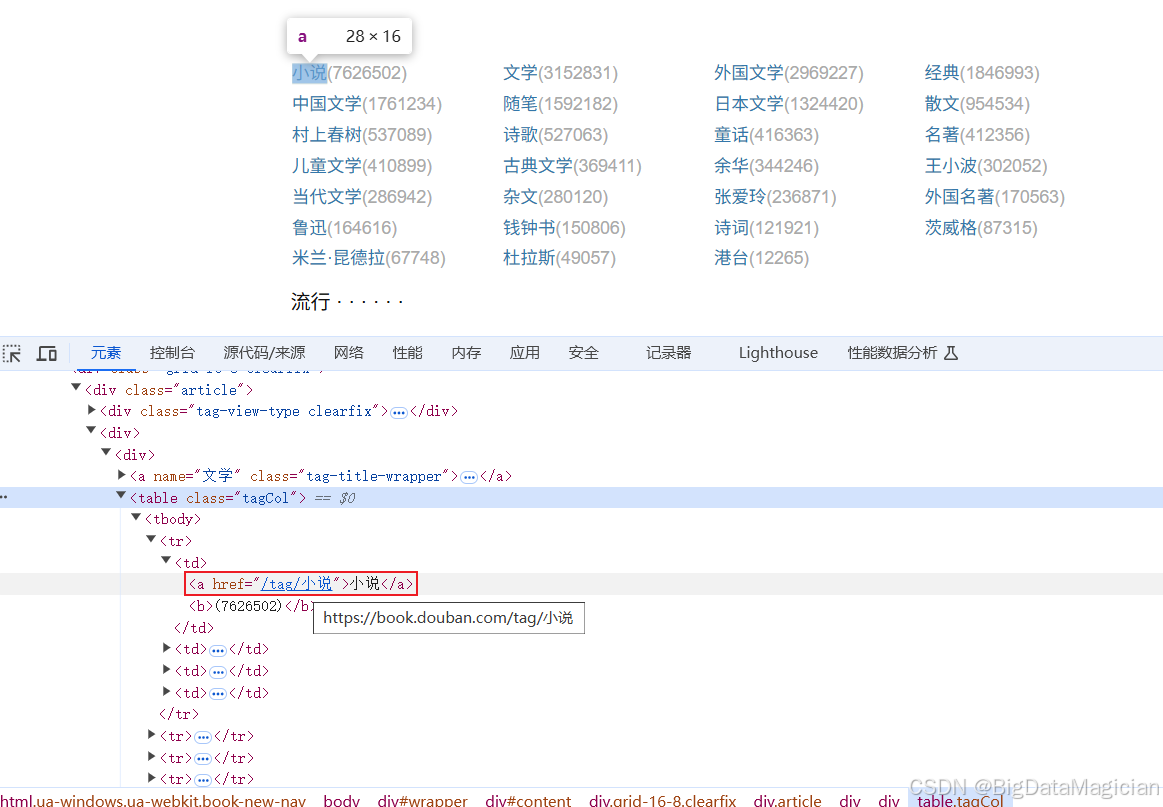
可以在每个<a>标签中获取分类标签连接和标签名,如下图所示:
2. 图书页面分析
进入分类之后,可以看到每个页面中有多个图书数据,包含图书图片、标题、作者、出版社、出版日期、价格、评分、评价人数、情节、纸质版价格这些字段,这些就是需要爬取的字段数据。
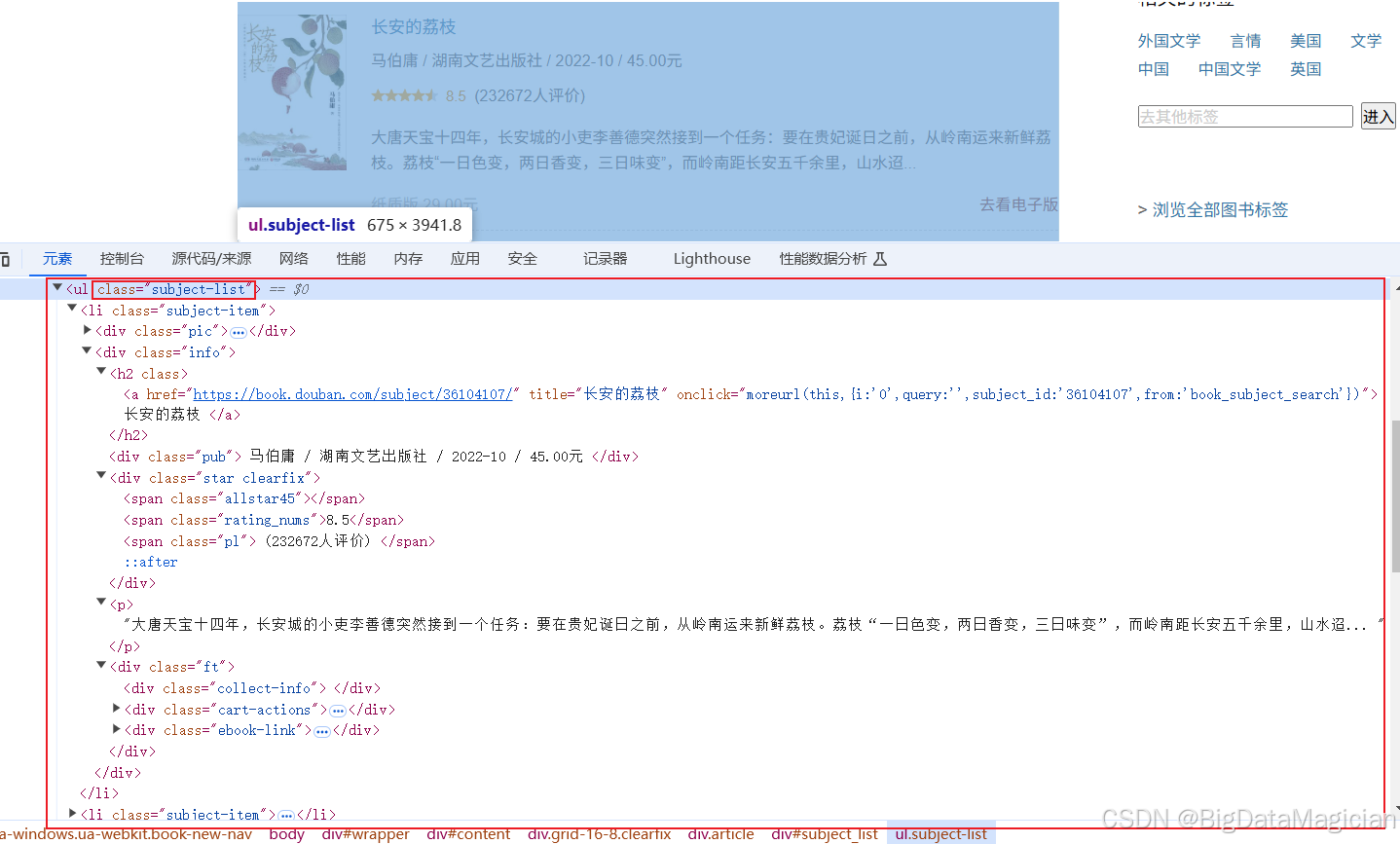
查看源码发现每项图书的数据在列表标签<ul class="subject-list">中,如下图所示:
在每个页面的最底部可以看到图书是分页显示的,如下图所示:
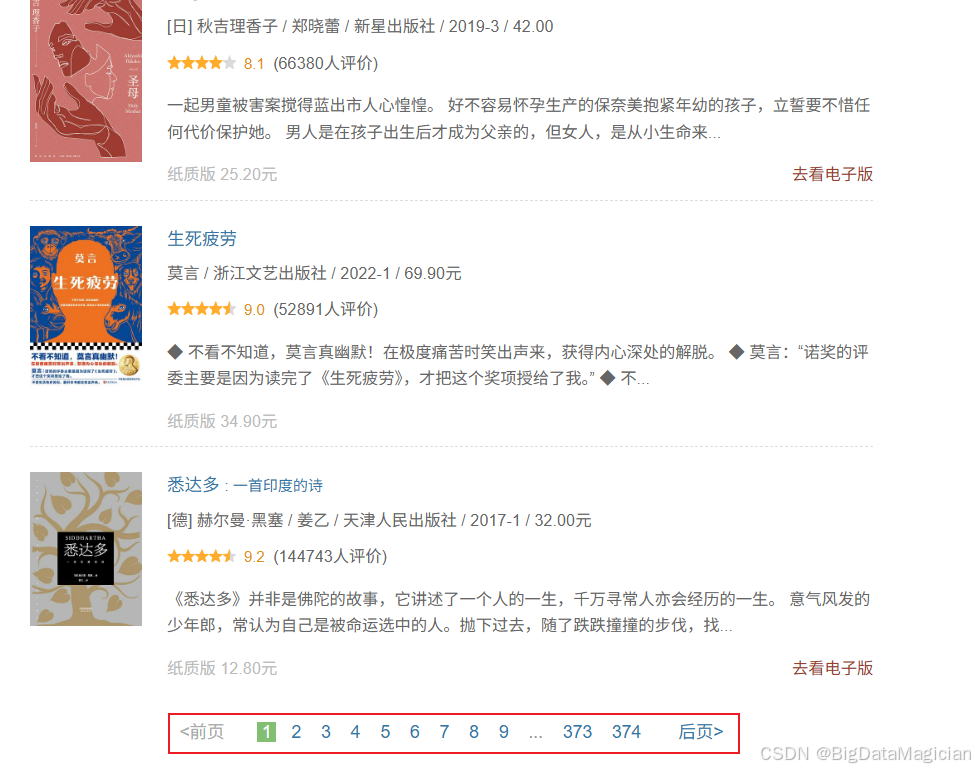
查看源码后可以看到每页的连接地址是有规律的,如下图所示:
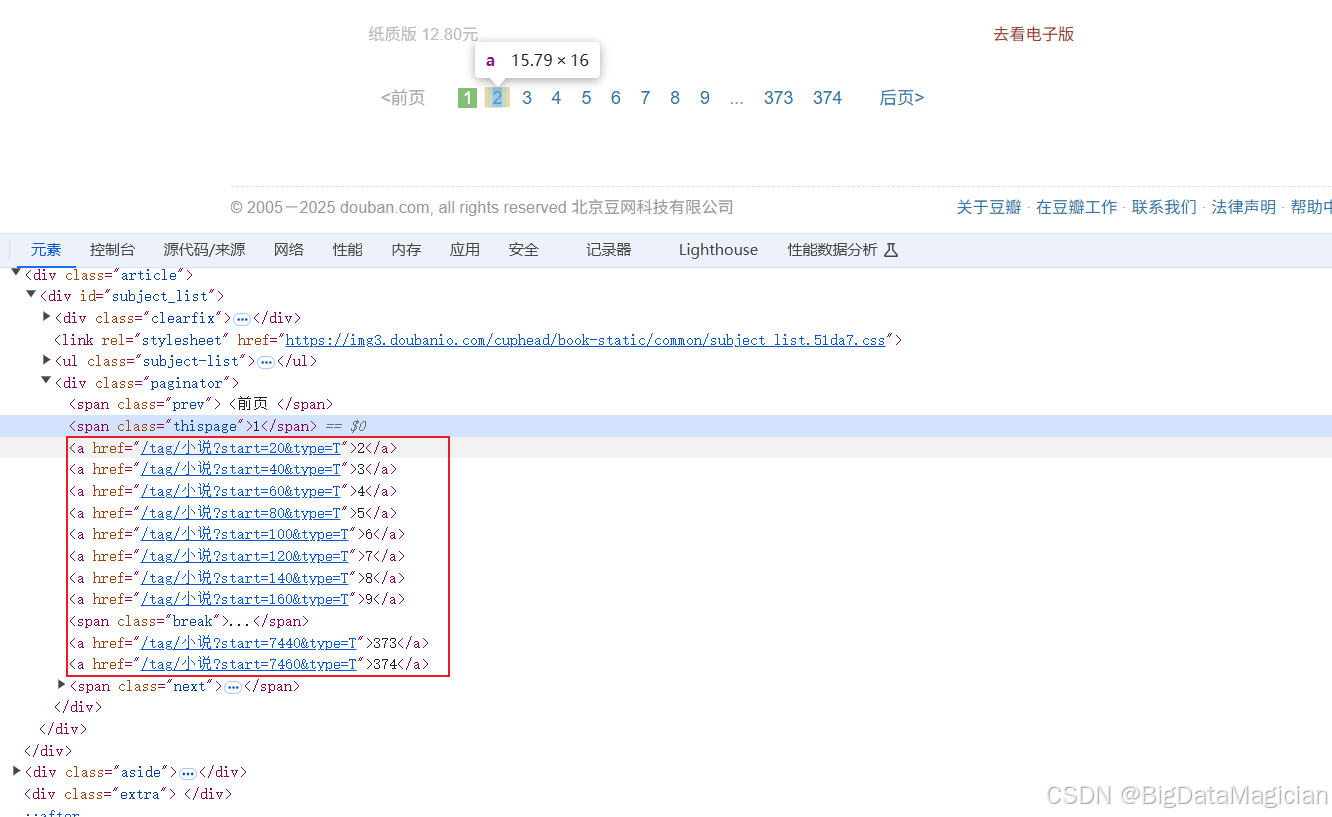
总结后得出地址构成为:
url = 'https://book.douban.com/tag/' + 图书分类标签 + '?start=' + 页数*20 + '&type=T'
三、数据采集实现
1. 图书分类标签数据采集
图书分类标签数据采集实现代码如下:
import pandas as pd
import requests
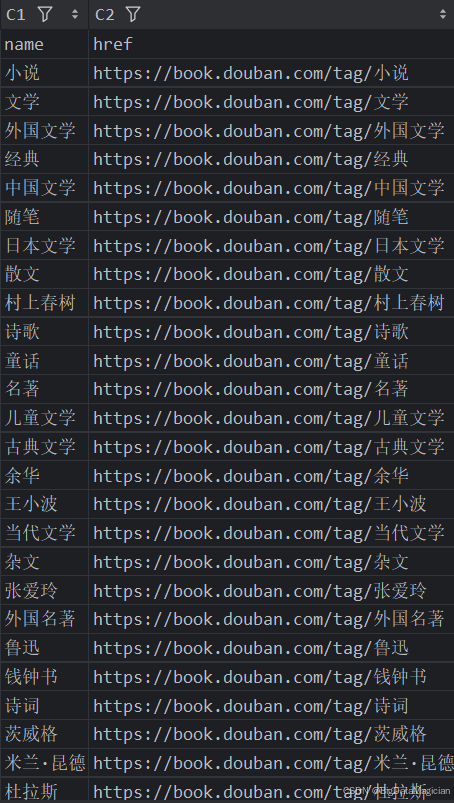
from bs4 import BeautifulSoupdef get_page_content(url):"""该函数用于获取指定URL页面的内容。:param url: 要请求的页面的URL:return: 页面的文本内容"""# 设置请求头,模拟浏览器访问headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'}try:# 发送请求,设置超时时间为10秒response = requests.get(url=url, timeout=10, headers=headers)# 检查响应状态码,若不是200则抛出异常response.raise_for_status()return response.textexcept requests.RequestException as e:print(f"请求出错: {e}")return Nonedef parse_page_content(content):"""该函数用于解析页面内容,提取图书分类标签的名称和链接。:param content: 页面的文本内容:return: 包含图书分类标签信息的列表"""# 使用BeautifulSoup解析页面内容soup = BeautifulSoup(content, 'lxml')# 选择所有图书分类标签的链接a_list = soup.select('.tagCol a')data_list = []for a in a_list:# 获取标签名称name = a.string# 构建完整的链接href = 'https://book.douban.com' + a.attrs.get('href')print(name, href)# 构建包含标签名称和链接的字典data_dict = {'name': name, 'href': href}data_list.append(data_dict)return data_listdef save_to_csv(data_list, file_path):"""该函数用于将数据保存到CSV文件中。:param data_list: 包含图书分类标签信息的列表:param file_path: 要保存的CSV文件的路径"""# 将数据列表转换为DataFramedf = pd.DataFrame(data_list)# 将DataFrame保存为CSV文件,不保存行索引,使用utf-8-sig编码df.to_csv(file_path, index=False, encoding='utf-8-sig')def main():"""主函数,负责调用其他函数完成整个数据爬取和保存的流程。"""url = 'https://book.douban.com/tag/'# 获取页面内容content = get_page_content(url)if content:# 解析页面内容,提取数据data_list = parse_page_content(content)if data_list:# 保存数据到CSV文件save_to_csv(data_list, './原始数据层/图书分类标签.csv')if __name__ == "__main__":main()
采集后的部分数据如下图所示:
2. 图书数据采集
图书数据采集代码实现如下:
import random
import time
from pathlib import Pathimport pandas as pd
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
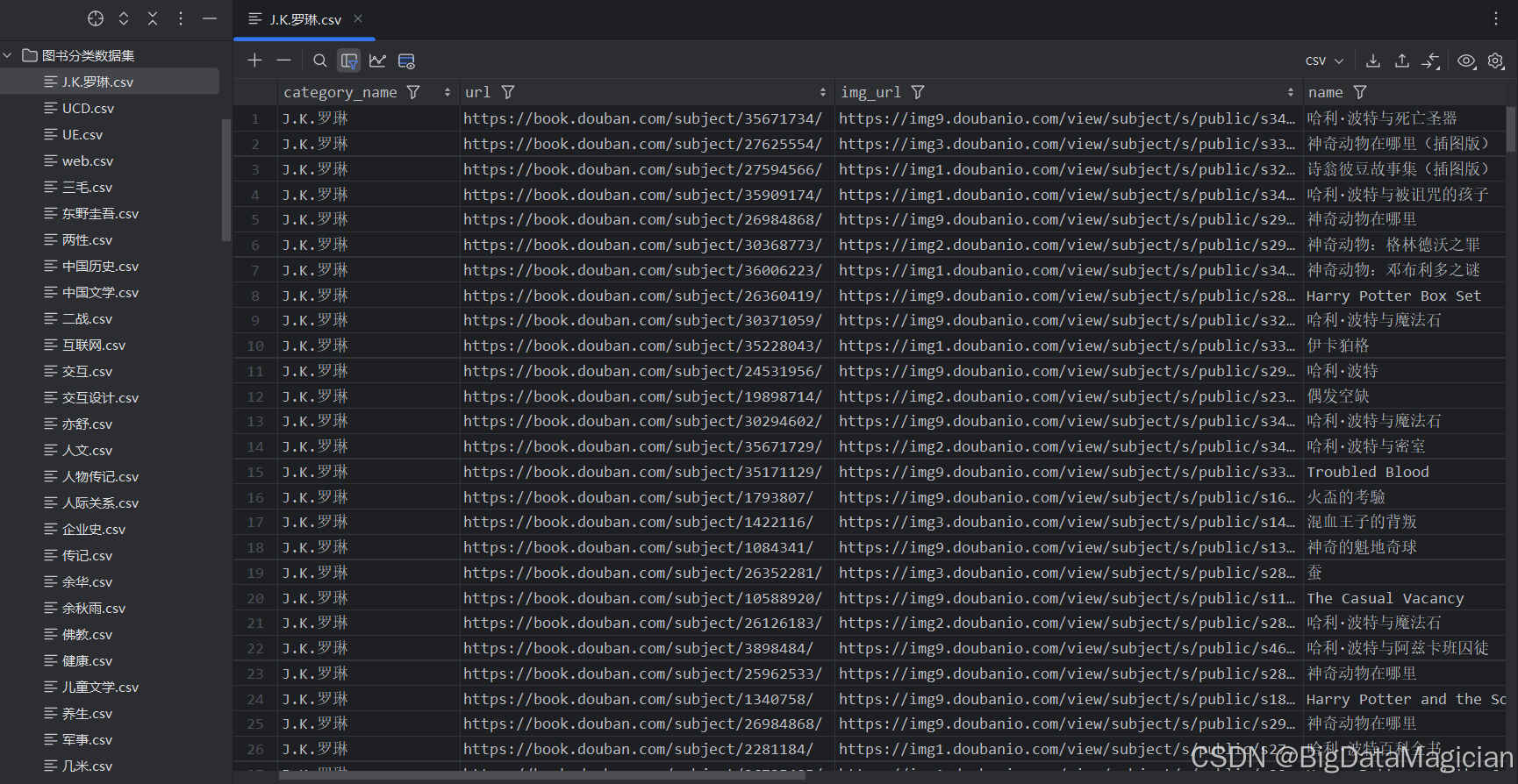
from selenium.webdriver.support.ui import WebDriverWaitdef get_element_text(element, css_selector):"""尝试查找元素并返回其文本内容,如果找不到则返回 None:param element: 要查找元素的父元素:param css_selector: CSS 选择器:return: 元素的文本内容或 None"""try:return element.find_element(By.CSS_SELECTOR, css_selector).text.strip()except NoSuchElementException:return Nonedef get_element_attribute(element, css_selector, attribute):"""尝试查找元素并返回其指定属性的值,如果找不到则返回 None:param element: 要查找元素的父元素:param css_selector: CSS 选择器:param attribute: 要获取的属性名:return: 元素的属性值或 None"""try:return element.find_element(By.CSS_SELECTOR, css_selector).get_attribute(attribute)except NoSuchElementException:return Nonedef process_subject(subject, category_name):"""处理单个图书条目,提取相关信息:param subject: 图书条目元素:param category_name: 图书分类名称:return: 包含图书信息的字典"""url = get_element_attribute(subject, '.pic > .nbg', 'href')img_url = get_element_attribute(subject, '.pic > .nbg > img', 'src')name = get_element_attribute(subject, '.info > h2 > a', 'title')pub = get_element_text(subject, '.info > .pub')rating = get_element_text(subject, '.info > .star > .rating_nums')rating_count = get_element_text(subject, '.info > .star > .pl')plot = get_element_text(subject, '.info > p')buy_info = get_element_text(subject, '.info > .ft .buy-info > a')data_dict = {'category_name': category_name,'url': url,'img_url': img_url,'name': name,'pub': pub,'rating': rating,'rating_count': rating_count,'plot': plot,'buy_info': buy_info,}return data_dictdef process_category(driver, category_name, category_href):"""处理单个图书分类,遍历该分类下的所有页面并提取图书信息:param driver: 浏览器驱动:param category_name: 图书分类名称:param category_href: 图书分类链接"""print(f"开始处理分类: {category_name},链接: {category_href}")page = 0while True:file_dir = f'./原始数据层/图书分类数据集/'file_name = f'{category_name}.csv'file_path = Path(file_dir + file_name)file_path.parent.mkdir(parents=True, exist_ok=True)# 构建当前页面的 URLurl = category_href + f'?start={page * 20}&type=T'print(f"正在访问页面: {url}")driver.get(url)time.sleep(random.uniform(1, 3))try:driver.find_element(By.CLASS_NAME, "subject-item")except NoSuchElementException:print(f"分类 {category_name} 页面加载完成,共处理 {page} 页")break# 等待所有图书条目元素加载完成subject_list = WebDriverWait(driver, random.uniform(10, 20)).until(EC.presence_of_all_elements_located((By.CLASS_NAME, "subject-item")))data_list = []for subject in subject_list:data_dict = process_subject(subject, category_name)data_list.append(data_dict)page += 1df1 = pd.DataFrame(data_list)if file_path.exists():df1.to_csv(file_path, mode='a', header=False, index=False)else:df1.to_csv(file_path, mode='w', header=True, index=False)time.sleep(random.uniform(1, 3))def main():# 读取图书分类标签 CSV 文件df = pd.read_csv('./原始数据层/图书分类标签.csv')# 初始化浏览器驱动driver = webdriver.Edge()time.sleep(random.uniform(1, 3))driver.get('https://book.douban.com/tag/小说')time.sleep(60)for _, category in df.iterrows():category_name = category['name']category_href = category['href']file_dir = f'./原始数据层/图书分类数据集/'file_name = f'{category_name}.csv'file_path = Path(file_dir + file_name)file_path.parent.mkdir(parents=True, exist_ok=True)if file_path.exists():print(f"文件已存在,跳过:{file_dir + file_name}")continueprocess_category(driver, category_name, category_href)# 关闭浏览器驱动driver.quit()if __name__ == '__main__':main()
采集后的多个CSV文件及部分数据如下图所示:
3. 把多个分类的CSV数据文件整合到一个CSV文件中
把多个分类的CSV数据文件整合到一个CSV文件中的代码实现如下:
from pathlib import Pathimport pandas as pddef get_all_csv_files(source_dir):"""获取指定目录下所有的 CSV 文件路径:param source_dir: 源目录路径:return: 包含所有 CSV 文件路径的列表"""print(f"正在查找 {source_dir} 目录下的所有 CSV 文件...")all_files = list(source_dir.glob('*.csv'))print(f"共找到 {len(all_files)} 个 CSV 文件。")return all_filesdef read_csv_files(file_paths):"""读取所有 CSV 文件并将其转换为 DataFrame 对象:param file_paths: 包含所有 CSV 文件路径的列表:return: 包含所有 DataFrame 对象的列表"""print("开始读取 CSV 文件...")dfs = []for file in file_paths:try:df = pd.read_csv(file, index_col=None, header=0)dfs.append(df)print(f"成功读取文件: {file}")except Exception as e:print(f"读取文件 {file} 时出错: {e}")return dfsdef combine_dataframes(dfs):"""合并所有 DataFrame 对象:param dfs: 包含所有 DataFrame 对象的列表:return: 合并后的 DataFrame 对象"""print("开始合并所有 DataFrame...")combined_df = pd.concat(dfs, axis=0, ignore_index=True)print("DataFrame 合并完成。")return combined_dfdef save_combined_dataframe(combined_df, output_file_path):"""将合并后的 DataFrame 对象保存为 CSV 文件:param combined_df: 合并后的 DataFrame 对象:param output_file_path: 输出文件的路径"""print(f"开始将合并后的数据保存到 {output_file_path}...")try:combined_df.to_csv(output_file_path, index=False, encoding='utf-8-sig')print(f"所有 CSV 文件已成功合并,并保存至 {output_file_path}")except Exception as e:print(f"保存文件时出错: {e}")def main():# 设置源目录和目标文件路径source_dir = Path("./原始数据层/图书分类数据集")output_dir = Path("./原始数据层")output_file_path = output_dir / '豆瓣图书数据集.csv'# 创建输出目录(如果不存在)output_dir.mkdir(parents=True, exist_ok=True)# 获取所有 CSV 文件all_files = get_all_csv_files(source_dir)# 读取所有 CSV 文件dfs = read_csv_files(all_files)# 合并所有 DataFramecombined_df = combine_dataframes(dfs)# 保存合并后的 DataFramesave_combined_dataframe(combined_df, output_file_path)if __name__ == "__main__":main()
整合后的数据集有12万多条数据,部分数据如下图所示:

相关文章:
- 豆瓣图书数据爬取)
豆瓣图书数据采集与可视化分析(一)- 豆瓣图书数据爬取
文章目录 前言一、数据爬取步骤二、豆瓣图书页面分析1. 图书分类标签页面分析2. 图书页面分析 三、数据采集实现1. 图书分类标签数据采集2. 图书数据采集3. 把多个分类的CSV数据文件整合到一个CSV文件中 前言 在当今大数据时代,数据的获取与整理对于各个领域的研…...
)
车载诊断新架构--- SOVD初入门(上)
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 周末洗了一个澡,换了一身衣服,出了门却不知道去哪儿,不知道去找谁,漫无目的走着,大概这就是成年人最深的孤独吧! 旧人不知我近况,新人不知我过…...

test——自动化测试
目录 一概念 1自动化 2回归测试 3自动化分类 3.1接口自动化 3.2UI自动化 4自动化测试金字塔 5web自动化测试 6工作原理 二函数 1元素定位 1.1cssSelector 编辑1.2xpath 语法 2操作对象 2.1click() 2.2send_keys() 2.3clear() 2.4text 2.5get_attribu…...
)
Kubernetes相关的名词解释CoreDNS插件(2)
为什么需要DNS服务? service发现是k8s中的一个重要机制,其基本功能为:在集群内通过服务名对服务进行访问,即需要完成从服务名到ClusterIP的解析。 k8s主要有两种service发现机制:环境变量和DNS。没有DNS服务的时候&am…...

【记录】服务器用命令开启端口号
这里记录下如何在服务器上开启适用于外界访问的端口号。 方法 1 使用防火墙 1 su ,命令 输入密码 切换到root节点 2 开启防火墙 systemctl start firewalld3 配置开放端口 firewall-cmd --zonepublic --add-port8282/tcp --permanent4 重启防火墙 firewall-cmd…...

代码审计入门 原生态sql注入篇
前置知识: 漏洞形成的原因: 1、可控的参数 2、函数缺陷 代码审计的步骤: 1、全局使用正则搜索 漏洞函数 ,然后根据函数看变量是否可控,再看函数是否有过滤 2、根据web的功能点寻找函数,然后根据函数看…...

数据结构0基础学习堆
文章目录 简介公式建立堆函数解释 堆排序O(n logn)topk问题 简介 堆是一种重要的数据结构,是一种完全二叉树,(二叉树的内容后面会出), 堆分为大小堆,大堆,左右结点都小于根节点,&am…...

分析虚幻引擎编辑器中使用 TAA 或 TSR 时角色眨眼导致的眼睛模糊问题
1. 引言 用户反馈在使用虚幻引擎编辑器时,当抗锯齿方法设置为时间性抗锯齿 (TAA) 或时间性超级分辨率 (TSR) 时,角色的眼睛在眨眼时会出现模糊现象。时间性抗锯齿和时间性超级分辨率是现代游戏引擎(包括虚幻引擎)中常用的抗锯齿和…...

捋一遍Leetcode【hot100】的二叉树专题
二叉树专题 除了后面两个,都挺简单 二叉树的中序遍历 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int …...

【java实现+4种变体完整例子】排序算法中【堆排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
以下是堆排序的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格: 一、堆排序基础实现 原理 基于二叉堆结构(最大堆),通过以下步骤实现排序: 构建最大堆:将…...
策略研究 - 源码)
量化交易 - RSRS(阻力支撑相对强度)策略研究 - 源码
一、介绍 RSRS(阻力支撑相对强度)是一种基于价格阻力位与支撑位动态变化的市场择时技术指标,由光大证券在2017年提出。其核心原理是通过量化最高价与最低价之间的线性关系,预测市场趋势变化。 原理: 线性回归建模&a…...

从FPGA实现角度介绍DP_Main_link主通道原理
DisplayPort(简称DP)是一个标准化的数字式视频接口标准,具有三大基本架构包含影音传输的主要通道(Main Link)、辅助通道(AUX)、与热插拔(HPD)。 Main Link:用…...

数据库备份-docker配置主从数据库
创建 Docker Compose 文件 创建一个 docker-compose.yml 文件,定义两个 MySQL 容器(一个主库,一个从库) services:mysql:image: mysql:8.0.27container_name: mysqlports:- "3306:3306"environment:TZ: Asia/ShanghaiM…...

YOLO11改进-Backbone-使用MobileMamba替换YOLO backbone 提高检测精度
轻量化模型的技术瓶颈 CNN 的局限性:传统 CNN(如 MobileNet)依赖局部感受野,难以捕捉长距离依赖关系,在高分辨率任务(如语义分割)中需通过增加计算量提升性能,效率低下。 Transforme…...
)
JavaScript学习教程,从入门到精通,DOM 操作语法知识点及案例代码(20)
DOM 操作语法知识点及案例代码 一、DOM 介绍 1. 什么是 DOM DOM (Document Object Model,文档对象模型) 是 HTML 和 XML 文档的编程接口。它提供了对文档的结构化的表示,并定义了一种方式可以使从程序中对该结构进行访问,从而改变文档的结…...

Vue3 + TypeScript中defineEmits 类型定义解析
TypeScript 中 Vue 3 的 defineEmits 函数的类型定义,用于声明组件可以触发的事件。以下是分步解释: 1. 泛型定义 ts <"closeDialog" | "getApplySampleAndItemX"> 作用:定义允许的事件名称集合,即组…...

Git命令归纳
初始化git git config --global user.name xxx:设置全局用户名,信息记录在~/.gitconfig文件中git config --global user.email xxxxxx.com:设置全局邮箱地址,信息记录在~/.gitconfig文件中git init:先创建一个目录&am…...

Oracle Recovery Tools修复ORA-600 6101/kdxlin:psno out of range故障
数据库异常断电,然后启动异常,我接手该库,尝试recover恢复 SQL> recover database; ORA-10562: Error occurred while applying redo to data block (file# 2, block# 63710) ORA-10564: tablespace SYSAUX ORA-01110: ???????? 2: H:\TEMP\GDLISNET\SYSAUX01.DBF O…...

ISO26262-浅谈用例导出方法和测试方法
目录 1 摘要2 测试方法3 测试用例导出方法4 测试方法与用例导出方法的差异和联系5 结论 1 摘要 ISO26262定义了测试方法和用例导出方法,共同保证产品的开发质量。但在刚开始学习ISO26262的时候,又不是非常清晰地理解它俩的区别和联系。本文主要对它俩的…...

小测验——已经能利用数据集里面的相机外参调整后看到渲染图像
文章目录 .1 外try——牛的显示.2 try——衣服的显示.3 原生R,T但是部分显示.4 在.3的基础上加上可视化界面.5 调参后能看到东西的.6 能看一点东西+可视化(pytorch3d).7 自己的代码可视化——需要调整.1 外try——牛的显示 import numpy as np import matplotlib.pyplot as …...

2024期刊综述论文 Knowledge Graphs and Semantic Web Tools in Cyber Threat Intelligence
发表在期刊Journal of Cybersecurity and Privacy上,专门讲知识图谱技术和语义Web工具在网络威胁情报领域的作用,还把本体和知识图谱放在相同的地位上讨论。 此处可以明确一点:本体和知识图谱都可以用于网络威胁情报的应用,当然也…...

文件上传及验证绕过漏洞
目录 一、文件上传常见点 二、客户端--JS绕过--PASS-01 1、环境安装 2、禁用JS 3、后缀名绕过 4、修改前端代码 三、服务端黑名单绕过 1、特殊可解析后缀--PASS-03 2、大小写绕过--PASS-06 3、点绕过--PASS-08 4、空格绕过--PASS-07 5、::$DATA绕过--PASS-09 6、配…...

stack和queue的使用和模拟实现
1:stack文档 stack文档 stack的使用 2:queue文档 queue文档 queue的使用 1:队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素。 2:队列作…...

基于Ubuntu2504部署OpenStack E版
OpenStack 初始化环境安装数据库、memcahe、rabbitmq等服务安装keystone服务安装glance服务安装placement服务安装nova服务安装neutron服务安装horizon服务 官网 OpenStack Epoxy 巩固了作为 VMware 替代方案的地位,增强了安全性,并改进了硬件支持 第 3…...

Jsp技术入门指南【七】JSP动作讲解
Jsp技术入门指南【七】JSP动作讲解 前言一、什么是JSP动作?二、核心JSP动作详解1. jsp:include:动态包含其他页面与<% include %>的区别 2. jsp:forward:请求转发到另一个页面3. jsp:param:为动作传递参数4. jsp:useBean&am…...

电脑 访问 github提示 找不到网页,处理方案
1、找到 本机的 host文件 例如 windows 的 一般在 C:\Windows\System32\drivers\etc\hosts 用管理员身份打开 hosts 文件 如果文件中没有 github的配置,需要自己手动添加上去; 如果有,则需要 检查 github.com 与 github.global.ssl.fastly.…...

性能比拼: Elixir vs Go
本内容是对知名性能评测博主 Anton Putra Elixir vs Go (Golang) Performance (Latency - Throughput - Saturation - Availability) 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 对比 Elixir 和 Go 简介 许多人长期以来一直要求我对比 Elixir 和 Go。在本视频…...
动手实现文本生成模型:基于 Decoder-only Transformer (PyTorch)
1. 选择框架:PyTorch 我们选择 PyTorch 作为实现框架。PyTorch 提供了灵活的动态图,并且拥有功能强大的 nn.Transformer 模块,方便我们快速构建模型。其社区活跃,资源丰富,是进行深度学习研究和开发的优秀选择。 确保你已经安装了 PyTorch 和其他必要的库: Bash pip i…...

WSL+Ubuntu+miniconda环境配置
安装到指定目录 bash Miniconda3-latest-Linux-x86_64.sh -b -p /usr/local/miniconda3添加环境变量 echo export PATH"/usr/local/miniconda3/bin:$PATH" >> /etc/profile echo export PATH"/usr/local/miniconda3/bin:$PATH" >> ~/.bashrc…...

linux学习 5 正则表达式及通配符
重心应该放在通配符的使用上 正则表达式 正则表达式是用于 文本匹配和替换 的强大工具 介绍两个交互式的网站来学习正则表达式 regexlearn 支持中文 regexone 还有一个在线测试的网址 regex101 基本规则 符号作用示例.匹配任何字符除了换行a.b -> axb/a,b[abc]匹配字符…...

【web服务_负载均衡Nginx】三、Nginx 实践应用与高级配置技巧
一、Nginx 在 Web 服务器场景中的深度应用 1.1 静态网站部署与优化 在 CentOS 7 系统中,使用 Nginx 部署静态网站是最基础也最常见的应用场景。首先,准备网站文件,在/var/www/html目录下创建index.html文件: sudo mkdir -p…...

详解与HTTP服务器相关操作
HTTP 服务器是一种遵循超文本传输协议(HTTP)的服务器,用于在网络上传输和处理网页及其他相关资源。以下是关于它的详细介绍: 工作原理 HTTP 服务器监听指定端口(通常是 80 端口用于 HTTP,443 端口用于 HT…...

LeetCode 2563.统计公平数对的数目:排序 + 二分查找
【LetMeFly】2563.统计公平数对的数目:排序 二分查找 力扣题目链接:https://leetcode.cn/problems/count-the-number-of-fair-pairs/ 给你一个下标从 0 开始、长度为 n 的整数数组 nums ,和两个整数 lower 和 upper ,返回 公平…...

Manus技术架构、实现内幕及分布式智能体项目实战
Manus技术架构、实现内幕及分布式智能体项目实战 模块一: 剖析Manus分布式多智能体全生命周期、九大核心模块及MCP协议,构建低幻觉、高效且具备动态失败处理能力的Manus系统。 模块二: 解析Manus大模型Agent操作电脑的原理与关键API…...

基于springboot的个人财务管理系统的设计与实现
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...

新能源汽车动力电池热管理方案全解析:开启电车续航与安全的密码
热管理:新能源汽车的隐形守护者 在新能源汽车飞速发展的今天,热管理系统作为保障车辆核心部件稳定运行的关键,正逐渐成为行业关注的焦点。据市场研究机构的数据显示,近年来新能源汽车的销量持续攀升,而与之相伴的是热…...

Ubuntu开启自启动PostgreSQL读取HDD失败处理思路
前置文章: windows通用网线连接ubuntu实现ssh登录、桌面控制、文件共享Ubuntu挂载HDD迁移存储PostgreSQL数据 背景: 启动实体Ubuntu机器后后很大的概率PostgreSQL不会成功启动,查看日志: Ubuntu启动时间: rootPine…...

损失函数总结
目录 回归问题L1损失 平均绝对值误差(MAE)Smooth L1 LossL2损失 均方误差损失MSE 分类问题交叉熵损失KL 散度损失 KLDivLoss负对数似然损失 NLLLoss 排序MarginRankingLoss 回归问题 L1损失 平均绝对值误差(MAE) 指模型预测值f(x…...

LeetCode 热题 100:回溯
46. 全排列 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]示例 2: 输入ÿ…...

Jetson Orin NX 部署YOLOv12笔记
步骤一.创建虚拟环境 conda create -n yolov12 python3.8.20 注意:YOLOv12/YOLOv11/YOLOv10/YOLOv9/YOLOv8/YOLOv7a/YOLOv5 环境通用 步骤二.激活虚拟环境 conda activate yolov12 #激活环境 步骤三.查询Jetpack出厂版本 Jetson系列平台各型号支持的最高Jetp…...

『Linux_网络』 第二章 UDP_Socket编程
学习了网络的概念了,接下来我们开始实践,本次我们会通过UDP来模拟实现UDP客户端和UDP服务器之间的通信,以及在此基础上扩展几个应用。 下面,我们将使用socket,bind,htons等接口实现UDP网络通信。 v1 版本 …...

【leetcode刷题日记】lc.322-零钱兑换
目录 1.题目 2.代码 1.题目 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认…...

从GET到POST:HTTP请求的攻防实战与CTF挑战解析
初探HTTP请求:当浏览器遇见服务器 基础协议差异可视化 # 典型GET请求 GET /login.php?username=admin&password=p@ssw0rd HTTP/1.1 Host: example.com User-Agent: Mozilla/5.0# 典型POST请求 POST /login.php HTTP/1.1 Host: example.com Content-Type: application/x…...

实现Azure Data Factory安全地请求企业内部API返回数据
需要配置一个Web Activity组件在Azure云上的Azure Data Factory运行,它需要访问企业内部的API获取JSON格式的数据,企业有网关和防火墙,API有公司的okta身份认证,通过公司的域账号来授权访问,现在需要创建一个专用的域账…...

JDOM处理XML:Java程序员的“乐高积木2.0版“
各位代码建筑师们!今天我们要玩一款比原生DOM更"Java友好"的XML积木套装——JDOM!它像乐高得宝系列(Duplo)一样简单易用,却能让你的XML工程稳如霍格沃茨城堡!(温馨提示:别…...
 PyTorch实现)
Grouped Query Attention (GQA) PyTorch实现
个人在网上看到的实现好像都长得奇奇怪怪的,没有简洁的感觉,因此在这里给出一种易读的GQA实现方法: import torch import torch.nn as nn import torch.nn.functional as Fclass GroupedQueryAttention(nn.Module):def __init__(self, embed…...

《AI大模型应知应会100篇》第27篇:模型温度参数调节:控制创造性与确定性
第27篇:模型温度参数调节:控制创造性与确定性 摘要 在大语言模型的使用中,“温度”(Temperature)是一个关键参数,它决定了模型输出的创造性和确定性之间的平衡。通过调整温度参数,您可以根据任…...

演讲比赛流程管理项目c++
对于一个基本项目,先分析基本的东西有哪些 1.类 演讲管理类:用于编写比赛流程用的功能 演讲者类:包含姓名,分数 创建比赛流程:创建选手12个人,分为两组,6人一组,每组进行两轮比赛࿰…...

在小米AX6000中通过米家控制tailscale
由于tailscale占用内存较大,AX6000中的可用内存非常有限,所以需要对AX6000的内存使用进行优化: 1.减小tmpfs内存占用的大小: #从150M -> 90M,由于tailscale下载安装包是27M作用, 解压后50M左右…...

REC: 引爆全球万亿级市场!Web3+消费革命重塑全球-东南亚-跨境商业未来
在全球数字经济浪潮下,东南亚已成为增长最快的互联网市场之一,其与全球之间蓬勃发展的跨境贸易更是蕴藏着巨大潜力。然而,传统模式下的效率瓶颈、信任壁垒和用户激励难题日益凸显。在此背景下,基于去中心化与消费相结合的 REC 颠覆…...