使用 TensorFlow 和 Keras 构建 U-Net
U-Net是图像分割领域中最为著名的架构之一。U-Net 因其形状而得名,它是一种全卷积架构,首先将图像收缩,然后将其扩展为输出结果。虽然这种收缩路径构建了一个学习特征的层次结构,但跳过连接有助于在扩展路径中将这些特征转换回相关的模型输出。
点击此链接,您可以了解更多关于 U-Net 架构的信息。同时,本文将重点介绍实际实现。今天,我们将学习从零开始构建一个 U-Net 架构。我们将使用 TensorFlow 和 Keras 来完成此操作。首先,我们将简要回顾一下 U-Net 的组成。然后,我们将逐步讲解如何自己实现 U-Net。最后,我们将在 Oxford-IIIT Pet 数据集上从零开始训练网络,向您展示可以实现的目标以及如何进一步改进!
因此,阅读本教程后,您将了解……
- U-Net 架构是什么以及它的组件是什么。
- 如何使用 TensorFlow 和 Keras 自己构建 U-Net。
- 通过实施您可以实现什么样的性能以及如何进一步改进。
你准备好了吗?一起来看看吧!
什么是 U-Net?
当你向计算机视觉工程师询问图像分割时,他们的解释中很可能会提到 U-Net 这个术语。
U-Net 因其形状而得名,它是一种卷积架构,最初由 Ronneberger 等人(2015 年)提出,用于生物医学领域。更具体地说,它用于细胞分割,并且与该领域之前使用的方法相比,效果非常好。
U-Nets由三个组件组成:
- 收缩路径。如下图左侧所示,卷积层和池化层组用于对图像进行下采样,有时甚至会将图像大小减半。收缩路径学习不同粒度的层次结构特征。
- 一条扩张的路径。在右侧,你可以看到一组组上采样层(无论是简单的插值层还是转置卷积),它们对输入图像的分辨率进行上采样。换句话说,网络试图从收缩的输入构建更高分辨率的输出。
- 跳过连接。U-Net 除了将低层特征图作为上采样过程的输入外,还接收来自收缩路径同层的信息。这是为了缓解 U 网络中最低层存在的信息瓶颈,如果未通过跳过连接使用,则有效地“丢弃”来自高层特征的信号。
请注意,在原始 U-Net 架构中,输出的宽度和高度低于输入的宽度和高度(572x572 像素 vs 388x388 像素)。这是由架构本身引起的,可以通过使用其他默认架构(例如 ResNet)作为主干架构来避免。这将在另一篇文章中介绍。
借助 U-Net 这样的架构,我们可以学习特定图像的重要特征,并利用这些信息生成更高分辨率的输出。像素级的类别索引图可以作为此类输出。继续阅读,您将学习如何构建一个 U-Net 来实现这一目标!
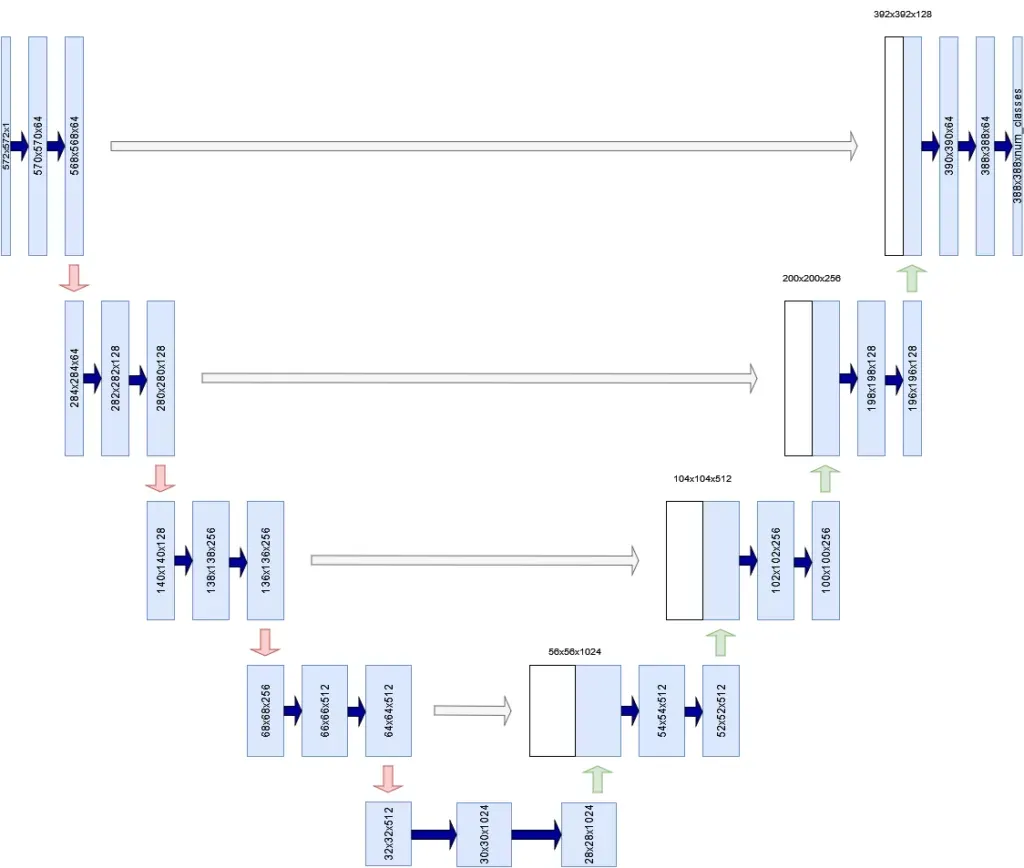
使用 TensorFlow 和 Keras 构建 U-Net
现在你已经了解了 U-Net 的工作原理,是时候构建一个了。打开你的 IDE 并创建一个 Python 文件(例如unet.py)或打开一个 Jupyter Notebook。同时确保你已安装接下来需要的先决条件。然后我们就可以开始编写代码了!
先决条件
为了运行今天的代码,在您的环境中安装一些依赖项非常重要。
首先,您需要一个最新版本的 Python — 最好是 3.12+。
此外,您还需要tensorflow和matplotlib。这些可以通过包管理器安装pip。安装完成后,您就可以开始了。
当今的结构
除了指定模型导入外,构建 U-Net 模型可以分为三个独立的任务:
- 定义 U-Net 模型的配置,以便可以在整个代码中重复使用。
- 定义 U-Net 的构建块。
- 定义流程函数来训练和评估您的 U-Net 模型。
之后,您将把所有内容合并成一个可工作的整体。
让我们从模型配置开始。
导入库
您的第一行代码将涵盖其余代码中需要的导入。让我们简要地介绍一下它们:
- Python
os表示操作系统函数,例如构建文件路径。加载数据集时会用到它。 - TensorFlow 本身就说明了一切,不是吗?:)
- 您的模型中将使用各种层。由于我们使用 Keras 构建您的神经网络,因此必须从 导入这些层
tensorflow.keras.layers。您将使用二维卷积层 (Conv2D)、二维最大池化层 (MaxPool2D)、转置卷积层 (Conv2DTranspose) 以及更通用的层,例如Input层(表示输入批次)、 层Activation(表示非线性激活函数),Concatenate用于张量连接以及CenterCrop裁剪跳过连接以匹配形状(稍后将讨论)。 - 此外,您还需要导入
Model用于构建 U-Net 的类,通过进行正常初始化HeNormal,Adam以进行优化,包括学习率调度功能(schedules),以及稀疏分类交叉熵(SparseCategoricalCrossentropy)作为您的损失函数。 - 回想一下,TensorFlow 有各种各样的回调函数,可以让你更轻松地进行建模。TensorBoard 回调就是其中一个例子,它允许你将训练进度导出到一个强大的可视化工具中。最后,你将导入一个 Keras
util函数plot_model来绘制模型结构。 - 其余的是其他导入。我们的数据集在 中表示
tensorflow_datasets,最后您还需要 Matplotlibpyplot库来实现可视化。
导入操作系统从tensorflow.keras.layers
导入Conv2D、\ MaxPool2D、Conv2DTranspose、Input、Activation、\ Concatenate、CenterCrop从tensorflow.keras导入模型从tensorflow.keras.initializers导入HeNormal从tensorflow.keras.optimizers导入时间表、Adam从tensorflow.keras.losses导入SparseCategoricalCrossentropy从tensorflow.keras.callbacks导入TensorBoard从tensorflow.keras.utils导入plot_model导入tensorflow_datasets作为tfds导入matplotlib.pyplot作为plt
U-Net配置定义
在我看来,在整个模型中分散各种配置选项是一种不好的做法。我更喜欢将它们定义在一个定义中,以便在整个模型中重复使用它们(如果我需要将模型部署到生产环境中,例如,我可以通过 JSON 环境变量提供我的配置,该变量可以轻松地以 的形式读入 Python dict)。配置定义如下所示。下面,我们将讨论各个组件:
'''
U-NET 配置
'''
def configuration (): ''' 获取配置。 '''返回 dict(data_train_prc = 80,data_val_prc = 90,data_test_prc = 100,num_filters_start = 64,num_unet_blocks = 3,num_filters_end = 3,input_width = 100,input_height = 100,mask_width = 60,mask_height = 60,input_dim = 3,优化器 = Adam,损失 = SparseCategoricalCrossentropy,初始化程序 = HeNormal(),batch_size = 50,buffer_size = 50,num_epochs = 50,metrics = [ 'accuracy' ],dataset_path = os.path.join(os.getcwd(),'data' ),class_weights = tensorflow.constant([ 1.0 , 1.0 , 2.0 ]), validation_sub_splits = 5 , lr_schedule_percentages = [ 0.2 , 0.5 , 0.8 ], lr_schedule_values = [ 3e-4 , 1e-4 , 1e-5 , 1e-6 ], lr_schedule_class = schedules.PiecewiseConstantDecay
)
- 回想一下,数据集必须分为训练集、验证集和测试集。训练集是最大的数据集,也是主要的数据集,它允许你在训练过程中进行前向传播、后向传播和优化。但是,由于你已经见过这个数据集,所以在训练过程中会使用验证集来评估每个迭代周期后的性能。最后,由于模型最终也可能在这个验证集上过拟合,所以有一个测试集,它在训练过程中根本不使用。相反,它会在模型评估过程中使用,以检验你的模型是否能够处理它以前从未见过的数据。如果模型能够处理,那么它在现实世界中也更有可能有效。
- 在您的模型配置中,
data_train_prc、data_val_prc和data_test_prc分别用于表示特定分割结束的百分比。在上面的配置中,80、90 和 100 表示数据集的 0-80% 将用于训练,80-90%(即总共 10%)用于验证,90-100%(也为 10%)用于测试。稍后您将看到以这种方式指定它们非常有效,因为这tfds.load使我们能够重新合并两个数据集(训练/测试),并将其拆分为三个!
2. 第一个 U-Net 卷积块生成的特征图数量为 64。您的网络总共包含 3 个 U-Net 块(上图所示为 5 个,但我们发现 3 个 U-Net 块在此数据集上效果更佳),并且在最后的 1x1 卷积层中将包含 3 个特征图。之所以设置为 3,是因为我们的数据集中每个像素有三种可能的类别——换句话说,它应该等于您的数据集中的类别数量。
3. 输入图像的宽和高均为 100 像素。输入图像的维度为 3 个通道(RGB 图像)。
4. 输出掩码的宽度和高度均为 60 像素。事实上,在原始 U-Net 架构中,输入和输出大小并不相等!
5. 模型方面,我们使用 Adam 优化器、稀疏分类交叉熵和 He 正态初始化。对于 Adam 优化器,我们使用名为 的学习率调度方案PiecewiseConstantDecay。该调度方案确保在预定的训练时间后将学习率设置为预设值。我们从3e-4(即 0.0003)的学习率开始,并在训练进行到 20%、50% 和 80% 时分别降低到1e-4、1e-5和1e-6。降低学习率将有助于您以更好的方式接近最优值。
6. 训练方面,我们生成 50 个像素的批次,并使用 50 个缓冲区大小进行混洗,并对模型进行 50 个时期的训练。
7. 作为附加指标,我们使用accuracy。
8. 我们的数据集将位于当前工作目录的data子文件夹中。5 个子分割用于验证目的。
9. 当你使用不平衡的数据集进行训练时,为目标预测分配类别权重是一个好主意。这将使那些代表性不足的权重更加重要。
好了,这是最重要的部分,但相对来说比较无聊。现在我们来构建一些 U-Net 模块吧!:)
U-Net构建块
回想一下,U-Net 由一条收缩路径(其本身由卷积块构成)和一条扩展路径(由上采样块构成)组成。在每一层(收缩路径的最后一层除外,它连接到扩展路径的头部),卷积块的输出都通过跳跃连接连接到上采样块。
你将首先构建一个卷积块,并在收缩路径中创建多个卷积块。然后,你将对上采样块和扩展路径执行相同的操作。
卷积块
这是您的结构conv_block:
'''
U-NET 构建模块
''' def conv_block ( x, filters, last_block ): ''' U-Net 卷积块。用于在收缩路径中进行下采样。
'''config = configuration() # 第一个 Conv 段
x = Conv2D(filters, ( 3 , 3 ),\ kernel_initializer=config.get( "initializer" ))(x)
x = Activation( "relu" )(x) # 第二个 Conv 段
x = Conv2D(filters, ( 3 , 3 ),\ kernel_initializer=config.get( "initializer" ))(x)
x = Activation( "relu" )(x) # 保留 Conv 输出以跳过输入
skip_input = x # 如果不是最后一个块,则应用池化if not last_block: x = MaxPool2D(( 2 , 2 ), strides=( 2 , 2 ))(x) return x, skip_input根据 Ronneberger 等人 (2015) 的论文,每个卷积块由两个 3x3 卷积块组成,每个卷积块的输出均经过 ReLU 激活。根据配置,我们使用 He 初始化,因为我们使用 ReLU 激活。
它由重复应用两个 3x3 卷积(无填充卷积)组成,每个卷积后跟一个整流线性单元(ReLU)和一个步幅为 2 的 2x2 最大池化操作,用于下采样。
回想一下上图,在每个级别,卷积块中的卷积的输出作为跳过连接传递到相应级别的上采样块中的第一个上采样层。
最大池化应用于相同的输出,以便下一个卷积块可以使用该输出。

在上面的代码中,您可以看到卷积层的输出被赋值给skip_input。随后,如果这不是最后一个卷积块,您将看到MaxPool2D被应用了 2x2 的池大小和步长 2。
处理后的张量x和跳过连接skip_input都会被返回。请注意,这也发生在最后一层。只有我们对返回值的操作才有意义,并且您会发现,在创建完整收缩路径的最后一层,我们没有使用跳过连接。
收缩路径和跳过连接
仿佛命中注定,现在就是这样!:)
让我们创建另一个名为 的函数contracting_path。在其中,你将构建属于收缩路径的卷积块。根据上面的代码,这些卷积块将在其层级上执行特征学习,然后执行最大池化,以使张量为下一个卷积块做好准备。
在原始的 U-Net 中,在每个“下采样步骤”(即最大池化,尽管严格来说常规卷积也是下采样步骤)中,特征通道的数量都会加倍。
在每个下采样步骤中,我们将特征通道的数量加倍。
在创建收缩路径时,你需要考虑到这一点。这就是为什么你需要使用效用函数compute_number_of_filters(你将在下文定义它)来计算每个卷积块中使用的滤波器数量。假设起始数量为 64,那么对于你今天构建的 3 块 U-Net(根据你的模型配置),滤波器的数量将是 64、128 和 256。对于 Ronneberger 等人(2014 年)提出的原始 5 块 U-Net,滤波器的数量将是 64、128、256、512 和 1024。
接下来,创建一个列表,用于存储卷积提供的张量。它用作跳过连接的容器。
现在,是时候创建实际的块了。通过使用,enumerate您可以创建一个输出 的枚举器(index, value),并创建一个for循环,该循环提供块编号(index)和该特定块中的过滤器数量(block_num_filters)。在循环中,检查它是否是最后一个块,并让输入通过卷积块,并根据卷积块的层级设置过滤器的数量。
然后,如果它不是最后一个块,您将把它添加skip_input到skip_inputs容器中。
最后,返回两者x(现在已经通过了整个收缩路径)以及skip_inputs执行此操作时产生的跳过连接张量。
def contracting_path ( x ): ''' U-Net 收缩路径。初始化多个卷积块以进行下采样。
'''config = configuration() # 计算每个块的特征图滤波器数量
num_filters = [compute_number_of_filters(index)\ for index in range (config.get( "num_unet_blocks" ))] # 为跳过输入张量创建容器
skip_inputs = [] # 将输入 x 传递到所有卷积块 #如果不是最后一个块,则将跳过输入张量添加到 skip_inputs for index, block_num_filters in enumerate (num_filters): last_block = index == len (num_filters)- 1x, skip_input = conv_block(x, block_num_filters,\ last_block) if not last_block: skip_inputs.append(skip_input) return x, skip_inputs
效用函数:计算特征图的数量
在contracting_path定义中,您使用它来compute_number_of_filters计算必须在特定卷积块中生成的必须使用的过滤器的数量/特征图的数量。
这个效用函数其实很简单:取第一个卷积块中滤波器的数量(根据你的模型配置,数量为 64),然后乘以 2^level。例如,在第三层(索引 = 2),你的卷积块有 64 x 2² = 256 个滤波器。
def compute_number_of_filters ( block_number ): ''' 根据特定 U-Net 块在收缩路径中的位置,计算其过滤器数量。 ''' return configuration().get( "num_filters_start" ) * ( 2 ** block_number)上采样块
到目前为止,您已经创建了用于对输入数据进行下采样的代码。现在是时候构建扩展路径的构建块了。让我们添加另一个函数,您将调用它upconv_block。它需要一些输入、预期的滤波器数量、与上采样块的层级相对应的跳过输入张量,以及有关它是否是最后一个块的信息。
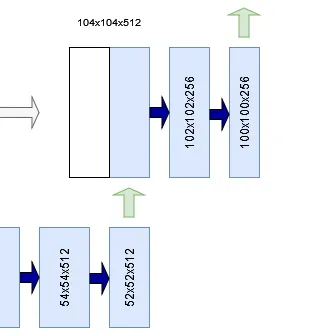
按照 U-Net 的设计,第一步是进行上采样。例如,在右图中,一个 52x52x512 的张量被上采样为 104x104x512 的张量。
在计算机视觉模型中,执行上采样主要有两种方式:
- 通过插值。这是经典方法,由 Ronneberger 等人 (2015) 使用。使用插值函数(例如双三次插值)来计算缺失像素。在 TensorFlow 和 Keras 中,此功能由上采样模块提供。
- 通过学习转置卷积进行上采样(我们将在另一篇文章中介绍)。另一种方法是使用转置卷积,即反向工作的卷积。它们不是使用学习到的核/滤波器对较大的图像进行“下采样”,而是对图像进行“上采样”,同时也使用学习到的核/滤波器。在 TensorFlow 中,这些表示为
ConvXDTranspose。您将使用这种类型的上采样,因为 (1) 它如今更为常见,并且 (2) 它使整个模型尽可能使用可训练的参数。
因此,对输入张量进行的第一个处理x是通过进行上采样Conv2DTranspose。
然后是时候讨论以下重要细节了——应用于跳过连接的裁剪。
请注意,任意层级L下卷积块输出的前两个维度的形状都大于相应上采样块中这些维度的形状。例如,在下面的示例中,您会看到形状为 136x136 像素的跳跃连接必须与 104x104 像素的张量连接。
扩展路径中的每一步都包括对特征图进行上采样,然后进行 2x2 卷积(“上卷积”),将特征通道数量减半,与收缩路径中相应裁剪的特征图连接,以及两个 3x3 卷积,每个卷积后跟一个 ReLU。
这是不可能的。Ronneberger 等人(2015)在其 U-Net 的原始实现中,通过从卷积块生成的特征图中截取一个中心裁剪区域来缓解这个问题。该中心裁剪区域的宽度和高度与上采样后的张量相同;在我们的例子中,该区域为 104x104 像素。现在,两个张量可以连接起来了。

为了进行此裁剪,您可以使用 TensorFlow 的CenterCrop层,使用上采样 Tensor 指定的目标宽度和高度从跳过输入中进行中心裁剪。
然后,使用该Concatenate层将裁剪后的跳过输入与上采样后的张量连接起来,之后就可以继续处理整体了。根据 Ronneberger 等人 (2015) 的论文和上述引文,该过程使用两个 3x3 卷积,每个卷积后都使用 ReLU 激活函数。
在最后一层,使用 1x1 卷积将每个 64 个分量的特征向量映射到所需数量的类别。
最后,在最后一层,应用一个 1x1 卷积(保留宽度和高度维度),输出一个张量,其第三维为 C。这里的 C 代表所需的类别数——在我们的模型配置中num_filters_end,该数字为 ,而今天的数据集确实有三类!:)
以下是创建上采样块的代码:
def upconv_block ( x, filters, skip_input, last_block = False ): ''' U-Net 上采样块。用于在扩展路径中进行上采样。
'''config = configuration() # 执行上采样
x = Conv2DTranspose(filters// 2 , ( 2 , 2 ), strides=( 2 , 2 ),\ kernel_initializer=config.get( "initializer" ))(x)
shp = x.shape # 裁剪跳过输入,保留中心
cropped_skip_input = CenterCrop(height = x.shape[ 1 ],\ width = x.shape[ 2 ])(skip_input) # 将跳过输入与 x
连接 concat_input = Concatenate(axis=- 1 )([cropped_skip_input, x]) # 第一个 Conv 段
x = Conv2D(filters// 2 , ( 3 , 3 ), kernel_initializer=config.get( "initializer" ))(concat_input)
x = Activation( "relu" )(x) # 第二个 Conv 段
x = Conv2D(过滤器// 2,(3,3), kernel_initializer = config.get(“initializer”))(x)x = Activation(“relu”)(x) # 如果是最后一个块,则准备输出如果last_block:x = Conv2D(config.get( “num_filters_end”),(1,1),kernel_initializer = config.get (“ initializer ”)) (x)返回x
使用跳跃连接的扩展路径
与收缩路径一样,您还需要在扩展路径中组合上采样层。
与收缩路径类似,你也需要计算扩展路径中各个区块的过滤器数量。不过,这次你从末尾开始计数——也就是区块数量减一,因为你是从过滤器数量较多到较少的顺序计算的。
然后,迭代过滤器的数量,计算它是否是最后一个块并计算从中获取跳过输入的级别,并将张量传递到上采样块。
现在,如果你将你的张量输入到所有组合块中,它们将完整地穿过收缩路径和扩张路径。是时候将你的 U-Net 组件拼接起来了!
def expansive_path ( x, skip_inputs ): ''' U-Net 扩展路径。初始化多个上采样块以进行上采样。
'''num_filters = [compute_number_of_filters(index)\ for index in range (configuration()\ .get( "num_unet_blocks" )- 1 , 0 , - 1 )] skip_max_index = len (skip_inputs) - 1 for index, block_num_filters in enumerate (num_filters): skip_index = skip_max_index - index last_block = index == len (num_filters)- 1x = upconv_block(x, block_num_filters,\ skip_inputs[skip_index], last_block) return x
U-Net构建器
build_unet...我们可以用您现在创建的函数来实现这一点。
这是一个相对简单的函数。它根据输入数据配置的高度、宽度和维度构建输入形状,然后将其传递给某个Input层——这是 TensorFlow 表示输入数据的方式。
然后,您的输入将通过contracting_path,从而产生收缩数据和用于跳过连接的每个卷积块的输出。
然后将它们输入到 ,expansive_path生成扩展数据。请注意,我们选择明确不建模 Softmax 激活函数,因为我们将其推送到损失函数,这是TensorFlow的规定,最后,我们Model以输入数据为起点,以扩展数据为终点初始化类。该模型名为U-Net。
def build_unet (): ''' 构建 U-Net。 '''config = configuration()
input_shape = (config.get( "input_height" ),\ config.get( "input_width" ), config.get( "input_dim" )) # 构建输入层
input_data = Input(shape=input_shape) # 构建收缩路径
contracted_data, skip_inputs = contracting_path(input_data) # 构建扩张路径
expanded_data = expansive_path(contracted_data, skip_inputs) # 定义模型
model = Model(input_data, expanded_data, name= "U-Net" ) return model
U-Net训练过程函数
现在您已经创建了模型构建块,是时候开始创建用于训练 U-Net 的函数了。您将要创建的函数如下:
- 初始化模型。
- 加载数据集。
- 数据预处理。
- 训练回调。
- 数据可视化。
初始化模型
你有一个创建模型的函数。然而,这只是一个框架——因为模型需要用损失函数进行初始化,还需要配置优化器等等。
因此,让我们创建一个名为的函数init_model来实现这一点。它接受每个epoch的步数,这些步数来自稍后将添加的数据集配置。
在此定义中会发生以下情况:
- 配置已加载,模型骨架已构建。
- 损失函数以及其他指标和训练周期数均已初始化。请注意
from_logits=True,使用 可指示 TensorFlow 模型的输出为对数函数 (logits),而非 Softmax 输出。配置完成后,损失函数会在计算损失之前执行 Softmax 激活函数。 - 学习率方案是通过计算边界值(即必须完成的迭代次数)由百分比构建而成的。需要注意的是,这里的一次迭代是指输入网络的一批数据;样本数量除以批次大小即可得出一个迭代周期的迭代次数。因此,为了计算边界值,我们需要输入迭代周期数、特定百分比以及每个迭代周期的步数(批次)。然后,使用边界值和相应的学习率值(将在模型配置部分讨论)初始化学习率方案。
- 然后,使用学习率计划初始化优化器。
- 现在,您可以按照 TensorFlow 模型的标准来编译您的模型。
- 一些实用程序现在将以视觉和摘要的方式描述您的模型。
- 最后,返回已初始化的
model。
'''
U-NET 训练过程构建模块
''' def init_model ( steps_per_epoch ): '''初始化 U-Net 模型。
'''config = configuration()
model = build_unet() # 检索编译输入
loss_init = config.get( "loss" )(from_logits= True )
metrics = config.get( "metrics" )
num_epochs = config.get( "num_epochs" ) # 构建 LR 调度
boundaries = [ int (num_epochs * percentage * steps_per_epoch)\ for percentage in config.get( "lr_schedule_percentages" )]
lr_schedule = config.get( "lr_schedule_class" )(boundaries, config.get( "lr_schedule_values" )) # 初始化优化器
optimizer_init = config.get( "optimizer" )(learning_rate = lr_schedule) # 编译模型
model. compile(loss=loss_init,optimizer=optimizer_init,metrics=metrics)# 绘制模型
plot_model(model,to_file= “unet.png”)# 打印模型摘要
model.summary()返回模型你的模型看起来是这样的。确实,呈U形!:)
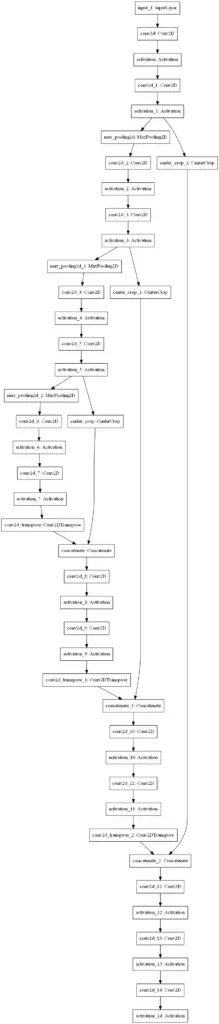
加载数据集
在今天的教程中,为了训练你的模型,你将使用 Parkhi 等人在 2012 年发表的 Oxford-IIT Pets 数据集:
我们创建了一个包含 37 个类别的宠物数据集,每个类别约有 200 张图片。这些图片在比例、姿势和光照方面差异很大。所有图片均附有品种、头部 ROI 和像素级三元图分割的地面实况标注。
我们使用它是因为它在TensorFlow数据集中可用,这使得加载更加容易,并且它具有开箱即用的分割最大值。例如,这是一张带有相应分割蒙版的输入图像:
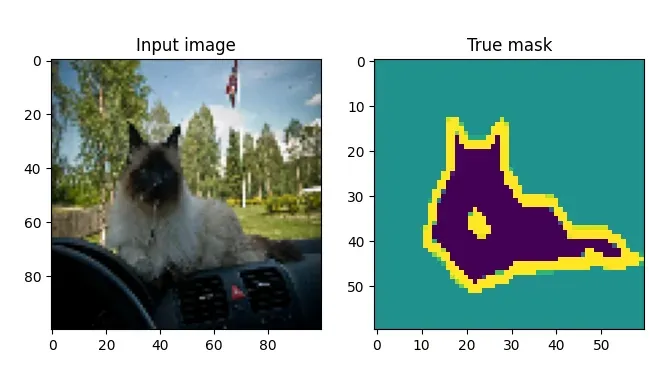
加载数据集非常简单。由于 TensorFlow 数据集仅包含训练和测试数据,并且您需要三个拆分(训练、验证和测试),因此您需要根据模型配置重新定义拆分,并将其传递给tfds.load。通过返回 info( with_info=True),您稍后将能够读取一些有趣的元数据。
def load_dataset (): ''' 返回带有信息的数据集。 '''config = configuration() # 检索百分比
train = config.get( "data_train_prc" )
val = config.get( "data_val_prc" )
test = config.get( "data_test_prc" ) # 重新定义对完整数据集的分割
splits = [ f'train[: {train} %]+test[: {train} %]' ,\ f'train[ {train} %: {val} %]+test[ {train} %: {val} %]' ,\ f'train[ {val} %: {test} %]+test[ {val} %: {test} %]' ] # 返回数据return tfds.load( 'oxford_iiit_pet:3.*.*' , split=splits, data_dir=configuration()\ .get( "dataset_path" ), with_info= True )
数据预处理
数据集在用于深度学习模型之前需要进行预处理。因此,今天的教程还需要你编写一些预处理代码。更准确地说,你将执行以下预处理:
- 样本级别的预处理,包括图像标准化。
- 数据增强可以人为地增加数据集的大小。
- 计算样本权重来平衡分割蒙版中过度代表的类别和代表不足的类别。
- 在数据集级别进行预处理,结合所有先前的要点。
现在让我们为每个要点编写代码。
执行图像规范化只需将张量转换为float32格式并除以255.0。除此之外,还要从掩码的类别中减去 1,因为它们的范围是 1-3,而我们希望它们的范围是 0-2:
def normalize_sample ( input_image, input_mask ): ''' 规范化输入图像和掩码类。 ''' # 将图像转换为 float32 并除以 255input_image = tensorflow.cast(input_image, tensorflow.float32) / 255.0 # 将类带入范围 [0, 2]input_mask -= 1 return input_image, input_mask接下来,在样本级 预处理的定义中实现这一点。输入图像会被调整为模型配置中指定的大小,蒙版也同样如此。最后,输入图像和蒙版都会被归一化并返回。
def preprocess_sample ( data_sample ): ''' 调整数据集样本的大小并进行归一化。 '''config = configuration() # 调整图像
大小 input_image = tensorflow.image.resize(data_sample[ 'image' ],\ (config.get( "input_width" ), config.get( "input_height" ))) # 调整掩码大小
input_mask = tensorflow.image.resize(data_sample[ 'segmentation_mask' ],\ (config.get( "mask_width" ), config.get( "mask_height" ))) # 归一化输入图像和掩码
input_image, input_mask = normalize_sample(input_image, input_mask) return input_image, input_mask数据增强允许 TensorFlow 对输入张量执行任意图像操作。在今天的教程中,您将通过随机水平和垂直翻转样本来实现数据增强。我们在所有调用中使用相同的种子,以确保您的输入和标签以相同的方式进行操作。
def data_augmentation ( inputs, labeles ): ''' 执行数据增强。 ''' # 对输入和标签使用相同的种子来实现确定性随机性。seed = 36 # 通过层输入数据
input = tensorflow.image.random_flip_left_right(inputs, seed=seed) input
= tensorflow.image.random_flip_up_down(inputs, seed=seed)
tags = tensorflow.image.random_flip_left_right(labels, seed=seed) tags = tensorflow.image.random_flip_left_right(labels, seed=seed)
tags = tensorflow.image.random_flip_up_down(labels, seed=seed) return inputs, labeles接下来是计算样本权重。给定每个类的权重,通过计算这些类权重的相对权重reduce_sum。随后,计算每个类的样本权重,并将其作为额外的数组返回,用于计算model.fit。
def compute_sample_weights ( image, mask ): ''' 为给定类的图像计算样本权重。 ''' # 计算类的相对权重
class_weights = configuration().get( "class_weights" )
class_weights = class_weights/tensorflow.reduce_sum(class_weights) # 使用每个mask 元素的样本权重计算与 mask 相同形状的张量。 sample_weights = tensorflow.gather(class_weights,indices=\ tensorflow.cast(mask, tensorflow.int32)) return image, mask, sample_weights
最后,你可以在数据集级别的预处理中组合以上所有定义。根据数据集类型的不同,执行方式也有所不同:
- 在预处理训练数据或验证数据时,会执行预处理、数据增强和类别加权,包括一些实用处理以改进训练过程。
- 在预处理测试数据时,效用函数和类权重被省略,因为它们不是必需的,因为在测试期间模型没有经过训练。
def preprocess_dataset ( data, dataset_type, dataset_info ): ''' 根据给定的数据集类型对数据集进行完全预处理。 '''config = configuration()
batch_size = config.get( "batch_size" )
buffer_size = config.get( "buffer_size" ) # 根据给定的数据集类型预处理数据。if dataset_type == "train" or dataset_type == "val" : # 1. 执行预处理# 2. 缓存数据集以提高性能# 3. 打乱数据集# 4. 生成批次# 5.重复# 6. 执行数据增强# 7. 添加样本权重# 8. 在需要之前预取新数据。return (data . map (preprocess_sample) .cache() .shuffle(buffer_size) .batch(batch_size) .repeat() . map (data_augmentation) . map (compute_sample_weights) .prefetch(buffer_size=tensorflow.data.AUTOTUNE)) else : # 1. 执行预处理# 2. 生成批次return (data . map (preprocess_sample) .batch(batch_size))
训练回调
剩下的就是编写一些实用函数。如果您熟悉 TensorFlow,那么您可能了解 Keras 回调函数。这些回调函数可用于在训练过程中的特定步骤执行某些操作。
今天,我们将使用这些回调将 TensorBoard 日志记录集成到您的模型中。这样,您就可以在训练过程中和训练结束后评估进度和模型训练效果。
def training_callbacks (): ''' 检索 model.fit 的初始化回调 ''' return [ TensorBoard( log_dir=os.path.join(os.getcwd(), "unet_logs" ), histogram_freq= 1 , write_images= True)
]数据可视化
最后一个效用函数与数据可视化相关。我们想了解模型的性能,因此我们将构建一个可视化实用程序,显示源图像、实际蒙版、预测蒙版以及叠加在源图像上的预测蒙版。为此,我们需要创建一个函数,根据模型预测生成蒙版:
def probs_to_mask ( probs ): ''' 将 Softmax 输出转换为 mask。 '''pred_mask = tensorflow.argmax(probs, axis= 2 ) return pred_mask
在第三个维度上,它只是取最大值的类索引并返回它。实际上,这相当于选择一个类。
您将其集成到 中generate_plot,它使用 Matplotlib 生成四个图,包括源图像、实际蒙版、预测蒙版和覆盖图:
def generate_plot ( img_input, mask_truth, mask_probs ): ''' 生成输入、真值掩码和概率掩码的图。 '''fig, axs = plt.subplots( 1 , 4 )
fig.set_size_inches( 16 , 6 ) # 绘制输入图像
axs[ 0 ].imshow(img_input)
axs[ 0 ].set_title( "输入图像" ) # 绘制真实掩码
axs[ 1 ].imshow(mask_truth)
axs[ 1 ].set_title( "真实掩码" ) # 绘制预测掩码
predicted_mask = probs_to_mask(mask_probs)
axs[ 2 ].imshow(predicted_mask)
axs[ 2 ].set_title( "预测掩码" ) # 绘制覆盖图
config = configuration()
img_input_resized = tensorflow.image.resize(img_input, (config.get( "mask_width" ), config.get( "mask_height" )))
axs[ 3 ].imshow(img_input_resized)
axs[ 3 ].imshow(predicted_mask, alpha= 0.5 )
axs[ 3 ].set_title( "Overlay" ) # 显示图表
plt.show()
将所有内容合并成一个可运行的示例
最后一步是将所有内容合并成一个可以运行的示例:
def main (): ''' 运行完整的训练程序。 ''' # 加载配置
config = configuration()
batch_size = config.get( "batch_size" )
validation_sub_splits = config.get( "validation_sub_splits" )
num_epochs = config.get( "num_epochs" ) # 加载数据
(training_data, validation_data, Testing_data), info = load_dataset() # 为 model.fit 和 model.evaluate 准备好训练数据
train_batches = preprocess_dataset(training_data, "train" , info)
val_batches = preprocess_dataset(validation_data, "val" , info)
test_batches = preprocess_dataset(testing_data, "test" , info) # 计算数据相关变量
train_num_samples = tensorflow.data.experimental.cardinality(training_data).numpy()
val_num_samples = tensorflow.data.experimental.cardinality(validation_data).numpy()
steps_per_epoch = train_num_samples // batch_size
val_steps_per_epoch = val_num_samples // batch_size // validation_sub_splits # 初始化模型
model = init_model(steps_per_epoch) # 训练模型
model.fit(train_batches, epochs=num_epochs, batch_size=batch_size,\ steps_per_epoch=steps_per_epoch, verbose= 1 , validation_steps=val_steps_per_epoch, callbacks=training_callbacks(),\ validation_data=val_batches) # 测试模型
score = model.evaluate(test_batches, verbose= 0 ) print ( f'Test loss: {score[ 0 ]} / Test accuracy: {score[ 1 ]} ' ) # 从测试中取出第一个批次图像并绘制它们for images, mask in test_batches.take( 1 ): # 为每个图像生成预测predicted_masks = model.predict(images) # 批量绘制每个图像和掩码for index, (image, mask) in enumerate ( zip (images, mask)): generate_plot(image, mask, predicted_masks[index]) if index > 4 : break if __name__ == '__main__' :
main()
完整型号代码
如果您想立即开始,也是可以的。完整的模型代码可以看我个人简介处或↓

训练我们的 U-Net
现在,让我们训练模型!打开终端,导航到你的 Python 脚本所在的位置,然后运行它。你应该会看到训练过程快速启动 :)
当我们从头开始训练我们的 U-Net 时,即使用 He 初始化的权重,它为我带来了这样的性能:
 训练准确度(橙色)和验证准确度(蓝色)。
训练准确度(橙色)和验证准确度(蓝色)。
 各个时期的学习率。学习率变化图清晰可见。
各个时期的学习率。学习率变化图清晰可见。
使用我们的模型生成的图像分割示例
回想一下,训练结束后,模型会从测试集中获取一些样本并输出结果。U-Net 的输出结果如下:
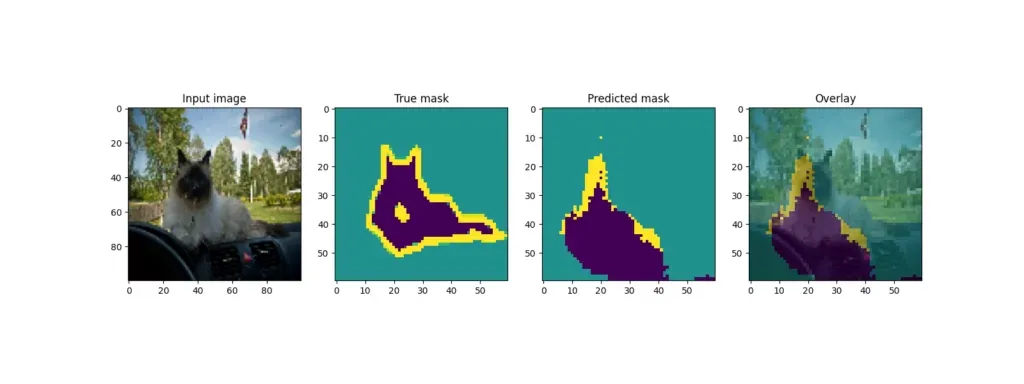
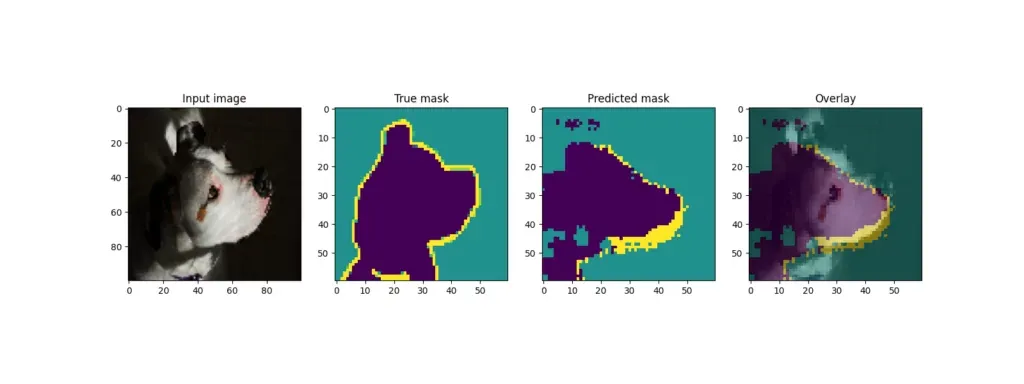
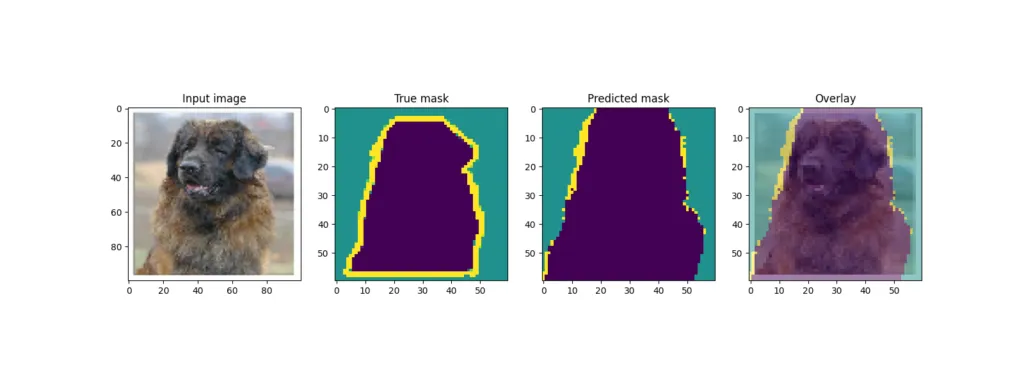
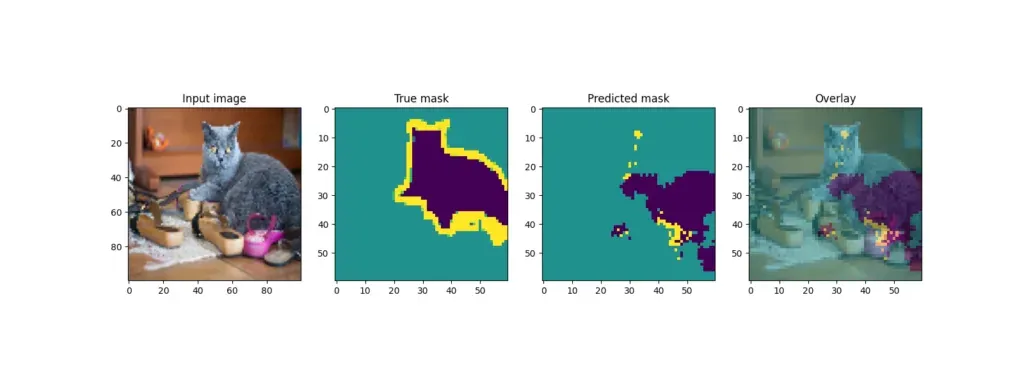
通过模型预训练提高模型性能
虽然一些例子(狗)产生了相当好的叠加效果,但其他例子(其中一只猫)的预测效果却差得多。
造成这种情况的一个关键原因是数据集的大小——尽管宠物数据集相对较大,但与其他更真实的数据集相比,它确实很小。虽然数据增强可能改善了结果,但它并不是一个可以解决所有问题的灵丹妙药。
除了增加数据集的大小之外,还有一种方法也行得通——也就是说,不要一开始就随机初始化权重。相反,预训练模型是个好主意,例如使用 ImageNet 数据集。这样,你的模型就已经学会了检测特定的模式,并允许你用它来初始化模型。
有许多软件包可以让你使用现有的卷积神经网络(例如 ResNet)作为骨干网络,为 TensorFlow 和 Keras 构建 U-Net。更棒的是,它们还能为这些骨干网络生成权重,让你从更佳的起点出发!
其他文章将介绍如何使用预训练的主干网络创建基于 U-Net 的图像分割模型。
最后,我们可以说你成功了:你从零开始创建了一个 U-Net!希望你从这些关于 U-Net 的文章以及我的其他文章中有所收获。欢迎提出任何意见、建议或问题。感谢你的阅读,如果你想了解更多类似的内容,请点击关注。祝你拥有美好的一天!
相关文章:

使用 TensorFlow 和 Keras 构建 U-Net
U-Net是图像分割领域中最为著名的架构之一。U-Net 因其形状而得名,它是一种全卷积架构,首先将图像收缩,然后将其扩展为输出结果。虽然这种收缩路径构建了一个学习特征的层次结构,但跳过连接有助于在扩展路径中将这些特征转换回相关…...

【网络篇】TCP vs UDP底层区别+网络编程概念
大家好呀 我是浪前 今天讲解的是网络篇的第三章:网络编程概念和TCP&UDP的区别 网络编程概念TCP和UDP的区别 跨主机通信:网络编程插座:网络编程的本质: 网络编程的重要概念:客户端和服务器: 客户端和服务器的交互模…...

如何保存服务器mysql数据库的数据到本地文件
打开mysql命令行如图1 图1 mysql命令行 修改文件保存路径。 在mysql安装目录下,找到my.ini文件,找到secure-file-priv变量配置的地方,修改对应的值,然后重启mysql,此时把文件放到指定路径,再执行导入导出…...
:ListView进阶使用)
Flutter学习 滚动组件(2):ListView进阶使用
目录 前言:一、实现复杂的ListView列表:1.1 Item布局封装1.2 ListView的使用1.3 增加分割线 二、实现ListView下拉刷新:三、实现上拉加载更多:四、实现下拉刷新、上拉加载更多:五、ListView滚动方向和控制:…...

linux oracle 19c 静默安装
oracle数据库有个比较很抓瞎的事情,不同的版本搭建的大致流程是一样的,但是在实操细节上会有不同,比如操作的脚本位置和配置项等等,这些会变,所以需要时常积累不同版本的文档 这里有一点要说明,之所以使用…...
)
中间件--ClickHouse-11--部署示例(Linux宿主机部署,Docker容器部署)
一、Linux宿主机部署 1、环境准备 操作系统:推荐使用 CentOS 7/8 或 Ubuntu 18.04/20.04。硬件要求: 至少 2 核 CPU 和 4GB 内存。足够的磁盘空间(根据数据量评估)。CPU需支持SSE4.2指令集(可通过以下命令检查&#…...

AI调试工具有哪些?
一、深度学习框架专用调试工具 TensorBoard • 功能:实时监控训练指标(损失值、准确率)、可视化神经网络结构、分析参数分布和梯度信息 • 适用框架:TensorFlow、PyTorch(通过插件) • 特点:支持…...

Warcraft Logs [Classic] [WCL] BOSS ID query
Warcraft Logs [Classic] [WCL] BOSS ID query 所有副本BOSSID查询 https://wowpedia.fandom.com/wiki/DungeonEncounterID#Retail IDNameMapInstanceIDPatch227High Interrogator GerstahnBlackrock Depths230228Lord RoccorBlackrock Depths230229Houndmaster GrebmarBlackro…...

MySQL——事务
一、什么是事务? 事务(Transaction) 是数据库操作的最小逻辑单元,它由一组不可分割的SQL操作组成。事务的核心目标是确保多个操作要么全部成功,要么全部失败,从而维护数据的完整性。例如,银行转…...
)
spring Ai---向量知识库(一)
在一些垂直领域以及公司内部信息相关或者实时性相关的大模型应用,就无法直接使用chatGPT。 这个时候,向量知识库就进入了。 通过坐标向量最接近的即为匹配相关答案。 向量模型定义:将文档向量化,保证内容越相似的文本,…...

MACOS 上的 快捷指令怎么用,有哪些分享资源可以用
一、快捷指令的基本概念与历史 快捷指令(Shortcuts)是苹果生态中的自动化工具,最初以第三方应用Workflow(2014年推出)的形式出现,2017年被苹果收购后更名为Shortcuts,并深度集成到iOS、iPadOS和macOS系统中。从macOS Mojave(10.14)开始,快捷指令正式登陆Mac平台,并…...
--个数遍历的二分+贪心优化)
最长子序列长度(LIS)--个数遍历的二分+贪心优化
B3637 最长上升子序列 - 洛谷 #include<bits/stdc.h> #include<string> using namespace std; #define N 100011 typedef long long ll; typedef pair<int,int> pii; int n; int g[N]; int dp[N]; int ma0; int main() { cin>>n; memset(g,0x3f,sizeo…...

RenderStage::runCameraSetUp
文章目录 RTTosg::Camera::_bufferAttachmentMapRenderStage::BufferComponent和RenderStage::_bufferAttachmentMapCamera::attach(BufferComponent buffer, GLenum internalFormat)Camera::attach(BufferComponent buffer, osg::Texture* texture.....Camera::attach(BufferC…...

突破速率瓶颈:毫米波技术如何推动 5G 网络迈向极限?
突破速率瓶颈:毫米波技术如何推动 5G 网络迈向极限? 引言 5G 网络的普及,已经让我们告别了“加载中”时代,实现了更快的数据传输、更低的延迟和更高的设备连接密度。而在 5G 技术的核心中,毫米波(mmWave&…...
)
前端面试真题集合(一)
一、Vue的响应式原理 Vue的响应式系统通过数据劫持和依赖追踪实现,核心流程如下: 数据劫持 • Vue 2.x:使用Object.defineProperty递归遍历数据对象,将属性转换为getter/setter,拦截属性的读取和修改操作。 • Vue 3.x:改用Proxy代理对象,支持动态属性添加和数组变化监听…...

聊聊Spring AI Alibaba的ElasticsearchDocumentReader
序 本文主要研究一下Spring AI Alibaba的ElasticsearchDocumentReader ElasticsearchDocumentReader community/document-readers/spring-ai-alibaba-starter-document-reader-elasticsearch/src/main/java/com/alibaba/cloud/ai/document/reader/es/ElasticsearchDocumentR…...

【网络技术_域名解析DNS】三、DNS 中间件实践应用与优化策略
一、DNS 中间件在典型行业的实践应用 1.1 金融行业:保障交易安全与服务稳定 金融行业对网络服务的安全性和稳定性要求极高,DNS 中间件在此领域发挥着不可替代的作用。以某银行线上支付系统为例,在 CentOS 7 环境下部署 DNS 中间件时&…...

Node.js 异步I/O与事件循环深度优化
Node.js 的核心魅力在于其异步、非阻塞I/O模型,这使得它在处理高并发、I/O密集型应用(如Web服务器、API网关、实时通信服务)时表现出色。然而,这种强大的能力并非凭空而来,它深深植根于其独特的**事件循环(…...

npm 常用操作和配置
一、npm 核心操作 1. 初始化项目 npm init # 交互式创建 package.json npm init -y # 跳过提问,直接生成默认 package.json2. 安装依赖 npm install <package> # 安装包到本地 node_modules(生产依赖) npm in…...

嵌入式芯片中的 低功耗模式 内容细讲
电源域与运行级别概述 电源域(Power Domain) 核心域(Core Domain):包括 CPU 核心和关键架构模块(如 NVIC、CPU 内核寄存器)。 外设域(Peripheral Domain):…...

React-请勿在循环或者条件语句中使用hooks
这是React Hooks的首要规则,这是因为React Hooks 是以单向循环链表的形式存储,即是有序的。循环是为了从最后一个节点移到一个节点的时候,只需通过next一步就可以拿到第一个节点,而不需要一层层回溯。React Hooks的执行࿰…...
)
React-memo (useMemo, useCallback)
在react中,当我们setState之后,若值发生变化,则会重新render当前组件以及其子组件 (默认情况下),在必要的时候,我可使用memo (class组件则对应shouldComponentUpdate、PureComponent)进行优化,来减少无效渲…...

点云数据处理开源C++方案
一、主流开源库对比 库名称特点适用场景开源协议活跃度PCL功能最全,算法丰富科研、工业级应用BSD★★★★★Open3D现代API,支持Python绑定快速开发、深度学习MIT★★★★☆CGAL计算几何算法强大网格处理、高级几何运算GPL/LGPL★★★☆☆PDAL专注于点云…...

android测试依赖
Android 项目中常用的测试相关库 1. androidx.arch.core:core-testing:2.2.0 作用: 提供与 Android Architecture Components(如 LiveData、ViewModel)相关的测试工具。主要用于测试基于 LiveData 的异步操作。 常见功能: 即时…...

Gradle与Idea整合
文章目录 1. Groovy 简介2. Groovy 安装[非必须]3. 在idea中创建java工程 1. Groovy 简介 在某种程度上,Groovy可以被视为Java的一种脚本化改良版,Groovy也是运行在JVM上,它可以很好地与Java代码及其相关库进行交互操作。它是一种成熟的面向对象编程语言…...
单链表)
【数据结构】励志大厂版·初阶(复习+刷题)单链表
前引:此篇文章作为小编复习的记录,将快速回忆单链表的知识点,讲解单链表增删查找的实现,每个细节之处要注意的地方,解释为何这样设计。文章末尾包含了单链表算法题, 同样解释详细,借助题目再次巩…...

前端面试宝典---参数解构+默认值的面试题
重点要义 对于函数参数要解构,且参数有默认值的,一律用Object.assign的思路去合并参。 看不懂这句话没关系,看下面的例子\ 例子1 function fn ({ x 1, y } { y: 10 }) {console.log(x, y) } fn() // 1 10没有传递实参,你就把{ …...
)
【开发心得】筑梦上海:项目风云录(16)
目录 代码反面案例 李青与诺基亚的兴衰 并行项目下的利益纠葛与团队协作 未完待续。。。 今天分享的是一个反面案例,也算是一个避坑指南了。 代码反面案例 今天分享的代码是一个反面案例,当时由于项目人员变动频繁,经常是新人看不太懂旧…...

Neovim插件深度解析:mcphub.nvim如何用MCP协议重构开发体验
在AI与工具链深度融合的今天,Neovim 作为现代开发者的生产力工具,正通过插件生态不断突破边界。mcphub.nvim 作为一款基于 MCP(Model Context Protocol) 协议的插件,重新定义了Neovim与智能工具的交互方式。它不仅简化了MCP服务器的集成与管理,更通过直观的UI和生态整合,…...

Qt UDP 通信的详细实现步骤和示例代码
在 Qt 中实现 UDP 通信主要使用 QUdpSocket 类。以下是 UDP 通信的详细实现步骤和示例代码: 一、UDP 通信基础 无连接协议:不需要建立持久连接数据报模式:以独立数据包(datagram)形式发送适用场景:实时性要…...
Trae 配置C++ 编译)
(二)Trae 配置C++ 编译
Trae配置c编译 零 CMake 编译C0.1 下载安装0.2 安装设置0.3 三种编译方式(见 下文 一 二 三)0.4 调试 (见 下文四) 一 使用MSVC方式编译1.1 安装编译环境1.2安装插件1.3 设置文件 二 使用GCC方式2.1 安装编译环境2.1.1下载:[MinGw](https://gcc-mcf.lhmouse.com/)2.1.2安装:(以…...
:斐波那契数模型)
动态规划算法的欢乐密码(一):斐波那契数模型
专栏:算法的魔法世界 个人主页:手握风云 目录 一、动态规划 二、例题讲解 2.1. 第 N 个泰波那契数 2.2. 三步问题 2.3. 使用最小花费爬楼梯 2.4. 解码方法 一、动态规划 动态规划是一种将复杂问题分解为更小的子问题,并利用子问题的解来…...

【FreeRTOS进阶】优先级翻转现象详解及解决方案
【FreeRTOS进阶】优先级翻转现象详解及解决方案 接下来我们聊聊优先级翻转这个经典问题。这个问题在实时系统中经常出现,尤其是在任务较多的场景下,而且问题定位起来比较麻烦。 什么是优先级翻转? 优先级翻转的核心定义很简单:…...

解决 IntelliJ IDEA 项目启动时端口冲突问题
1.问题 Description: The Tomcat connector configured to listen on port 8082 failed to start. The port may already be in use or the connector may be misconfigured. Action: Verify the connectors configuration, identify and stop any process thats listening…...
)
笔试专题(十一)
文章目录 添加字符(暴力枚举)题解代码 城市群数量(dfs)题解代码 判断是不是平衡二叉树(递归)题解代码 最大子矩阵(二维前缀和)题解代码 小葱的01串 (固定区间大小的滑动窗…...

C++11新增语法:列表初始化
前言: 接下来我们将要讲解,相较于c98,c11中新增的语法以及如何使用~。我们首先来讲解:列表初始化。 下文预告:右值引用和移动语义 C98中传统的{} 在c98中的{},仅能初始化数组和结构体 #include<iostrea…...

Linux:基础IO---动静态库
文章目录 1. 动静态库前置知识1.1 动静态库知识回顾1.2 什么是动静态库 2. 动静态库2.1 站在库的制作者的角度2.2 站在库的使用者的角度2.3 动态库是怎么被加载的(原理) 序:上一篇文章我们从认识到理解,从理解到实现场景ÿ…...

从裸仓库到GitLab全解析
Git服务器搭建与使用指南:从裸仓库到GitLab全解析 前言 在团队协作开发中,版本控制系统是必不可少的工具。虽然GitHub提供了优秀的代码托管服务,但企业级项目往往需要更安全的私有化部署方案。本文将手把手教你两种主流的Git服务器搭建方式…...

OzGIS:地理信息分析与处理软件
大家好,今天为大家介绍的软件是OzGIS:一款地理信息分析与处理软件。下面,我们将从软件的主要功能、支持的系统、软件官网等方面对其进行简单的介绍。 OzGIS官网网址为:https://ozgis.sourceforge.io/。 OzGIS是一款开源软件&#…...

PHP异常处理__Throwable
在 PHP 里,Throwable 是一个极为关键的接口,自 PHP 7 起被引入。它为错误和异常处理构建了一个统一的框架。下面会详细介绍 Throwable 的相关内容。 1. 基本概念 Throwable 是 Exception 和 Error 的父接口。在 PHP 7 之前,异常(…...

PHP异常处理__Exception类
以下是对 PHP 中 Exception 类的详细解释: 一、Exception 类概述 Exception 是 PHP 中所有异常类的基类。它提供了一个通用的异常处理机制,用于处理程序执行过程中可能出现的错误情况。当程序中出现异常时,可以创建 Exception 的实例并将其…...

C++中动态多态类别浅析
非抽象类继承和虚函数 #include <iostream> using namespace std;class Base { public:virtual void func() { // 虚函数,支持动态绑定cout << "Base::func()" << endl;} };class Derived : public Base { public:void func() overrid…...

游戏引擎学习第234天:实现基数排序
回顾并为今天的内容设定背景 我们今天继续进行排序的相关,虽然基本已经完成了,但还是想收尾一下,让整个流程更完整。其实这次排序只是个借口,主要是想顺便聊一聊一些计算机科学的知识点,这些内容在我们项目中平时不会…...

系分架构论文《论高并发场景的架构设计和开发方法》
系统分析师论文范文系列 【摘要】 2022年8月,我司承接了某知名电商平台“秒杀系统架构优化”项目,我作为系统分析师主导了整体架构设计与技术选型工作。该平台在促销活动中面临瞬时流量超过50万QPS的挑战,原有架构存在数据库崩溃、服务响应延…...

最新得物小程序sign签名加密,请求参数解密,响应数据解密逆向分析
点击精选,出现https://app.dewu.com/api/v1/h5/index/fire/index 这个请求 直接搜索sign的话不容易定位 直接搜newAdvForH5就一个,进去再搜sign,打上断点 可以看到t.params就是没有sign的请求参数, 经过Object(a.default)该函数…...
)
jangow靶机笔记(Vulnhub)
环境准备: 靶机下载地址: https://download.vulnhub.com/jangow/jangow-01-1.0.1.ova kali地址:192.168.144.128 靶机(jangow)地址:192.168.144.180 一.信息收集 1.主机探测 使用arp-scan进行主机探…...

Spring Boot + Caffeine:打造高性能缓存解决方案
1. 引言 1.1 缓存的重要性 缓存是提升系统性能的关键技术之一,通过将频繁访问的数据存储在内存中,减少对数据库或其他外部系统的访问次数,从而降低延迟并提高吞吐量。 缓存的基本概念:缓存是一种临时存储机制,用于快速访问常用数据。缓存在提升系统性能中的作用:减少数…...

C++入门小馆: 深入string类
嘿,各位技术潮人!好久不见甚是想念。生活就像一场奇妙冒险,而编程就是那把超酷的万能钥匙。此刻,阳光洒在键盘上,灵感在指尖跳跃,让我们抛开一切束缚,给平淡日子加点料,注入满满的pa…...

命令行基础
学习目标 掌握VRP命令行的基础知识 利用VRP命令行进行基本的配置 VRP命令行的基础知识 一、VRP 命令行基本架构 1. 用户视图(User View) 进入方式:设备启动后默认进入,提示符为 <HUAWEI>。功能&#…...

10-DevOps-Jenkins参数化构建实现多版本发布
在之前的Jenkins配置中,固定写死了程序的版本号,实际情况是随着版本的不断迭代,版本号也是不断变化的,版本号由代码仓库(GitLab)设置。 当前Jenkins配置是固定写的1.0,本节我们要把它改成动态的…...